
Overzicht verschillende analyse methodes - gast-ouder.nl verschillende analyse... · 3. het...
13
Overzicht verschillende analyse methodes: Variantie analyse Dependent (afhankelijkheid tussen variabele) Doel: is om te achterhalen of groepen verschillen in hun score op de afhankelijke variabele. Je kunt hierbij denken aan een experimentele setting. Een onderzoeker wil weten of zijn manipulaties, zijn treatments, invloed hebben op de afhankelijke variabele. Variantieanalyse wordt niet alleen gebruikt bij experimenteel onderzoek. Het wordt ook gebruikt bij sociaal- wetenschappelijk onderzoek, waarbij je bijvoorbeeld wilt weten of mannen en vrouwen in hun inkomen. Het draait uiteindelijk allemaal om de verschillen tussen groepen in hun score op de afhankelijke variabele. Kan verklarend en beschrijvend Analyse van gegevens Spreiding rondom gemiddelde Opzoek naar verschillen. 1. Anova eenweg veriantie analyse 1 factor 1 afhankelijk variabele 2. Factorial Anova tweeweg variantie analyse meer factoren, 1 afhankelijke variabele 3. Ancova covariantie variantie analyse 1 of meer factoren 1 of meer afhankelijk variabele. Deze gaat voor deze cursus te ver. Over de onafhankelijk variabele heeft de onderzoeker controle over niveaus van ordinaal of nominaal. heten treatment variabele of factoren De afhankelijk variabele interval of ratio meetniveau. Binnen 1 toets twee verschillende meetniveaus bruikbaar. Toetsen van verschillen in meerdere groepen. 1. Ho= alles gelijk u1 = u2 = u3 2. H1 = minstens 1 wijkt af Variantie analyse bestaat uit grofweg drie stappen: 1. het controleren van de assumpties a. Er is een afhankelijke variabele en deze moet van metrisch meetniveau zijn (interval of ratio). Als er sprake is van meerdere afhankelijke variabelen, dan spreken van MANOVA en niet meer van ANOVA. b. Een of meerdere onafhankelijke variabelen (factoren noemen we die) die van ofwel nominaal ofwel ordinaal meetniveau zijn (categorische variabelen). c. In geval van een experiment geldt ook dat we te maken moeten hebben met onafhankelijke en aselect gekozen experimentele eenheden. d. De populaties zijn normaal verdeeld. e. De varianties binnen categorieen van de factoren zijn homogeen. 2. het analyseren van de hoof- en interactie effecten. a. H0: μ1= μ2 = μ3 = μk Ha: minstens een μ wijkt af van de andere Daarbij gebruik je de toetsingsgrootheid van F. Je stelt een α vast, die bepaalt wanneer je de H0 verwerpt en wanneer niet. Vervolgens kun je in de ANOVA tabel gaan kijken wat de resultaten zijn. Welke factoren hebben een significante F en wat zegt dat jou? Het is vaak ook zo dat je een factor hebt die meer dan twee categorieën bevat. Bij opleidingsniveau zien we vaak dat een indeling in drie categorieën wordt gehanteerd. Als dat het geval is, wil je meestal ook weten welke categorieën van je factor er nu voor zorgen dat je een significant effect hebt. Om dit te achterhalen, voeren we een post hoc analyse uit. In een post hoc analyse kun je namelijk zien welke groepen nu van elkaar verschillen en welke niet. Dan gebruik je de Levene’s test om te bepalen welke post hoc test je moet gebruiken. Als de assumptie niet geschonden is, gebruik je de Tukey. Als deze niet geschonden, maar je hebt geen gelijke groepsgroottes, dan gebruik je de Hochberg. Wanneer je assumptie van homogeniteit geschonden is, gebruik je de Games Howell. In deze analyse kun je dan zien welke groepen significant van elkaar verschillen. Als je meerdere onafhankelijke variabelen hebt (vanaf two-way omhoog), dan vraag je ook altijd de interacties tussen deze variabelen op. Meestal heb je daar ook theoretisch hypothesen over opgesteld en ben je juist geïnteresseerd in de interactie-effecten. In het geval van meerdere onafhankelijke variabelen en interacties kijk je altijd eerst naar de interactie-effecten. Zijn ze significant? Daarna kijk je pas naar de hoofdeffecten.
Transcript of Overzicht verschillende analyse methodes - gast-ouder.nl verschillende analyse... · 3. het...

Overzicht verschillende analyse methodes: Variantie analyse
Dependent (afhankelijkheid tussen variabele) Doel: is om te achterhalen of groepen verschillen in hun score op de afhankelijke variabele. Je
kunt hierbij denken aan een experimentele setting. Een onderzoeker wil weten of zijn manipulaties, zijn treatments, invloed hebben op de afhankelijke variabele. Variantieanalyse wordt niet alleen gebruikt bij experimenteel onderzoek. Het wordt ook gebruikt bij sociaal-wetenschappelijk onderzoek, waarbij je bijvoorbeeld wilt weten of mannen en vrouwen in hun inkomen. Het draait uiteindelijk allemaal om de verschillen tussen groepen in hun score op de afhankelijke variabele.
Kan verklarend en beschrijvend
Analyse van gegevens
Spreiding rondom gemiddelde
Opzoek naar verschillen. 1. Anova eenweg veriantie analyse 1 factor 1 afhankelijk variabele 2. Factorial Anova tweeweg variantie analyse meer factoren, 1 afhankelijke
variabele 3. Ancova covariantie variantie analyse 1 of meer factoren 1 of meer afhankelijk
variabele. Deze gaat voor deze cursus te ver.
Over de onafhankelijk variabele heeft de onderzoeker controle over niveaus van ordinaal of nominaal. heten treatment variabele of factoren
De afhankelijk variabele interval of ratio meetniveau. Binnen 1 toets twee verschillende meetniveaus bruikbaar.
Toetsen van verschillen in meerdere groepen. 1. Ho= alles gelijk u1 = u2 = u3 2. H1 = minstens 1 wijkt af
Variantie analyse bestaat uit grofweg drie stappen:
1. het controleren van de assumpties a. Er is een afhankelijke variabele en deze moet van metrisch meetniveau zijn
(interval of ratio). Als er sprake is van meerdere afhankelijke variabelen, dan spreken van MANOVA en niet meer van ANOVA.
b. Een of meerdere onafhankelijke variabelen (factoren noemen we die) die van ofwel nominaal ofwel ordinaal meetniveau zijn (categorische variabelen).
c. In geval van een experiment geldt ook dat we te maken moeten hebben met onafhankelijke en aselect gekozen experimentele eenheden.
d. De populaties zijn normaal verdeeld. e. De varianties binnen categorieen van de factoren zijn homogeen.
2. het analyseren van de hoof- en interactie effecten. a. H0: μ1= μ2 = μ3 = μk Ha: minstens een μ wijkt af van de andere
Daarbij gebruik je de toetsingsgrootheid van F. Je stelt een α vast, die bepaalt wanneer je de H0 verwerpt en wanneer niet. Vervolgens kun je in de ANOVA tabel gaan kijken wat de resultaten zijn. Welke factoren hebben een significante F en wat zegt dat jou? Het is vaak ook zo dat je een factor hebt die meer dan twee categorieën bevat. Bij opleidingsniveau zien we vaak dat een indeling in drie categorieën wordt gehanteerd. Als dat het geval is, wil je meestal ook weten welke categorieën van je factor er nu voor zorgen dat je een significant effect hebt. Om dit te achterhalen, voeren we een post hoc analyse uit. In een post hoc analyse kun je namelijk zien welke groepen nu van elkaar verschillen en welke niet. Dan gebruik je de Levene’s test om te bepalen welke post hoc test je moet gebruiken. Als de assumptie niet geschonden is, gebruik je de Tukey. Als deze niet geschonden, maar je hebt geen gelijke groepsgroottes, dan gebruik je de Hochberg. Wanneer je assumptie van homogeniteit geschonden is, gebruik je de Games Howell. In deze analyse kun je dan zien welke groepen significant van elkaar verschillen. Als je meerdere onafhankelijke variabelen hebt (vanaf two-way omhoog), dan vraag je ook altijd de interacties tussen deze variabelen op. Meestal heb je daar ook theoretisch hypothesen over opgesteld en ben je juist geïnteresseerd in de interactie-effecten. In het geval van meerdere onafhankelijke variabelen en interacties kijk je altijd eerst naar de interactie-effecten. Zijn ze significant? Daarna kijk je pas naar de hoofdeffecten.

3. het analyseren van de richting van de significant bevonden verschillen. a. Bij het bepalen de richting van de effecten, kijk je naar je sum of squares en
naar je post hoc analyse. Zeker met ordinale variabele, zoals opleidingsniveau, kun je dan snel zien wat de richting van het verband is. Is het ‘hoe hoger, hoe meer’ of ‘hoe lager, hoe meer’. Wanneer alle stappen zijn gezet, rapporteer je hierover op een correcte wijze. Zo wordt meestal de “hypothese is bevestigd (F(2,15) = 16.88, p < .001)” formulering gehanteerd.
T-toetsen uitvoeren mag niet, want gaat te snel dingen als significant beschouwen. Je krijgt dan een te grote alfa. Zie sheet.
Je gaat kijken naar de spreiding tussen de groepen (groepsgemiddelde) wordt vergeleken met de spreiding binnen de groepen. Spreiding binnen de groepen NL elftal hockey kunnen allemaal ongeveer even ver slaan. Spreiding buiten groepen verschil NL elftal en Nijmegen hockey club m.b.t. verslaan. Als de spreiding tussen de groepen klein is in verhouding tot de spreiding binnen de groepen, concluderen we dat de groepen wat het gemiddelde betreft niet significant van elkaar verschillen. Als de spreiding tussen de groepen groot is in verhouding tot de spreiding binnen de groepen, concluderen we dat de groepen wat het gemiddelde betreft wel significant van elkaar verschillen, dat wil zeggen dat er minstens één gemiddelde afwijkt.
SS= sum of squares in de aantekeningen lezen.
Heilkelpunt is een grote groep heeft meer invloed dan een kleine groep. Daarom moeten de groepen ongeveer even groot zijn.
F < 0.05 dan significant en H0 verwerpen rekensom zie aantekeningen
Levene test: 1. Siginificantie van < 0.05 dan h0 verwerpen. 2. Met Levene kijk je of de test homogeen of hetrogeen is.
H0 is homogeen = geen verschil in variantie H1 is hetrogeen = wel verschil in variantie
3. Levene static is een soort F
Post hoc: 4. Verschil tussen gemiddelde toetsen, welke groepen schelen van elkaar.
Tukey homogeen; gelijke groepsgroottes (kolom N) Hockberg Homogen; ongelijke groepsgroottes Games Howell heterogeen. Dan Levene test doen.
5. Uit tabel komt mean differens en significantie. Bij sig. < 0.05 verschilt de groep van elkaar.
In het hoorcollege en het boek van Hair is gesproken over covariaten. Leg in je eigen woorden uit wat covariaten zijn en waarom het belangrijk kan zijn om deze bij het uitvoeren van variantieanalyse mee te nemen. Tot nu toe hebben we gesproken over onafhankelijke variabelen die categorisch zijn. Soms is het echter zo dat je als onderzoeker wilt controleren voor metrische onafhankelijke variabele. Je wilt er namelijk zeker van zijn dat je gevonden effecten ‘echt’ zijn en niet eigenlijk worden veroorzaakt door een andere variabele. Leeftijd is bijvoorbeeld een variabele die veel variantie van de afhankelijke variabele kan ‘wegnemen’. Door deze variabele als covariaat mee te nemen in je analyse, zorg je ervoor dat de hoofdeffecten in je model zo veel mogelijk van de variantie verklaren die over blijft na controle voor je covariaat. De covariaten zijn daarbij altijd van metrische (interval of ratio) meetniveau. Het is daarbij van belang dat het covariaat wel samenhangt met de afhankelijke variabele, maar niet met de onafhankelijke! Je wilt dat het covariaat variantie in de afhankelijke variabele verklaart, maar niks te maken heeft met de onafhankelijke factoren.
Factor analyse Opdracht 3 vraag 5 nog een keer bekijken.
Statistisch, beschrijvend
Doel: Latente structuur vinden die ten grondslag ligt aan meerdere items. Data reductie en analyse van gegevens
Opzoek naar achterliggend aspect
Interdependent
Multi dimensionaal, het heeft betrekking op meerdere constructen/dimensies
Compositioneel geen vrije keus, maar expliciete vragen met antwoordcategorieën.
Komt voor betrouwbaarheidsanalyse
Beginnen met correlatie analyse

1 analyse, meerdere dimensies onderscheiden
Idee is hetzelfde als bij betrouwbaarheidsanalyse: je bent opzoek naar latent kenmerk en bezig met data reductie en interpretatie.
Variabele minimaal interval niveau
Factoren = componenten= dimensies
Hoeft niet te hercoderen, mag wel
Stappen plan: 1. Uitgangspunt is correlatiematrix
Je moet genoeg waarnemingen hebben per variabele en in elk geval 5 keer zoveel als dat je variabelen hebt. Ideaal is als je 10 waarnemingen per variabele hebt. Je moet er ook zeker van zijn dat factoranalyse de geschikte techniek is. Daarvoor moet je kijken naar de Bartlett’s test of sphericity. In het hoorcollege zagen we al dat ook de KMO test hierbij hoort
2. Kies benadering Principale componenten analyse/component analysisalles wordt bij deze
vorm verklaard, door de andere variabele in het model. Meer wiskunde/natuurkunde. Alle variatie wordt algemeen of gedeeld verondersteld. Dit model voor factor analyse is het meest geschikt indien:
Datareductie een primair belang is, waarbij de nadruk wordt gelegd op het minimaliseren van het aantal factoren dat nodig is om de maximale hoeveelheid totale variantie te verklaren.
Aan de hand van kennis die op voorhand bekend is, blijkt dat specifieke en ‘error’ variantie een geringe hoeveelheid is van de
totale variantie. Pricipale factor analyse/Common factor Analysis altijd gedeelde variantie,
kies je meestal voor. De variantie van elke variabelen kan niet volledig worden verklaard door de andere variabelen in het model; elke variabele heeft een uniek deel. Deze methode is van toepassing als:
Het hoofddoel het herkennen van de latente dimensies of constructen in de originele variabelen is.
De onderzoeker weinig kennis heeft van de hoeveelheid specifieke en ‘error’ variantie in de totale variantie en daarom deze variantie wil elimineren.
3. Factor analyse geschikt check op stap 1 KMO -test
vergelijkt de correlaties uit de correlatiematrix met de partiële correlaties. Factoranalyse is geschikt indien waarde > 0.50
Bartlett's test of sphericity nulhypothese: alle correlaties zijn 0 factoranalyse is geschikt indien
H0 verworpen kan worden, ofwel een significante waarde voor 2 Barlett’s test moet significant zijn (p < .05 of .01).
4. Initiële factoren berekenen. Componenten worden zodanig getrokken dat:
1e component extraheert zoveel mogelijk variantie van de oorspronkelijke variabelen (bevat zoveel mogelijk informatie van de oorspronkelijke variabelen)
2e component verklaart zoveel mogelijk van de overgebleven variantie, enzovoort
vandaar de term Principale Componenten Analyse of Principal Axis Factoring (principaal=belangrijkst/voornaamst)
Componenten staan (in deze fase) loodrecht op elkaar (orthogonaliteit) 5. Bepaal aantal factoren totale verklaarde variantie moet rond de 0.60 liggen. Maar
minst belangrijkste eis. De eigenwaarde moet hoger zijn dat 1, dit is de belangrijkste eis.
Dubbellader laat hoog op meerdere factoren, verschil < 0.20 de kleinste dubbellader als eerste eruit halen. Maar houdt de theorie in de gaten…
6. Roteer de initiële oplossing blz 123 t/m 125 Doel: verhogen interpreteerbaarheid van factoren. 2 vormen:

Orthogonaal: (varimaxx) onafhankelijk factoren loodrecht op elkaar
Obliqueroteren: altijd doen om te kijkn naar factoren samenhang. Dit moet je doen als 1 waarde boven de 0.3 zit in de factor correlatie matrix. Als het niet tussen de…. En de….. zit dan nog een keer orthogonaal roteren.
7. Benoemen factoren Bepaal voor elke factor welke variabelen het hoogst laden (het gezicht van de
factor bepalen) en geef op basis van deze variabelen een label aan de dimensie.
8. score per respondent
Iteratief proces, je kijkt of het goed gaat aan de hand van de volgende vragen 1. Scoren KMO en Bartlett voldoende? 2. Aantal factoren: De keuze voor het aantal factoren kan op meerdere statistieken
worden gebaseerd, namelijk eigenwaarde/ eigenvalue, scree plot en verklaarde variantie. De eis aan de eigenvalue is dat deze groter is dan 1 (eigenvalue > 1). De scree plot stelt dat de plek waarop de knik zit de laatste factor is die je nog meeneemt (meestal levert deze techniek een factor meer op). Tot slot de verklaarde variantie; deze zou rond de 60% moeten zitten (of hoger uiteraard). Maar dit is niet de meest belangrijke methode, de andere twee zijn belangrijker. Wanneer de keuze meer conceptueel is, zijn er geen duidelijke statistieken. Je laat je dan in elk geval adviseren door bovenstaande criteria.
3. Type rotatie; door Oblique te roteren bij je oplossing krijg je een factor correlatie matrix. Wanneer correlaties hoger dan .30 of lager dan -.30 zijn, is Oblique roteren gerechtvaardigd. Wanneer dat niet zo is, wordt Varimax gebruikt, Orthogonaal rotatie.
4. Zijn er items met communaliteiten onder de .20? Zo ja, dan verwijderen. Dit gebeurt één voor één (na verwijdering telkens eerst opnieuw analyseren)
5. Zijn er (in de factor matrix na rotatie) dubbelladers (verschil van minder dan .20)? Zo ja, dan mogelijk verwijderen.
6. Interpretatie van de factoren: zijn de factoren te interpreteren en komt deze interpretatie in de buurt van de vooraf bedachte interpretatie?
Verschil tussen betrouwbaarheidsanalyse en factor analyse: betrouwbaarheidsanalyse een unidimensionele schaaltechniek. De verschillende items worden teruggebracht tot een schaal. Factoranalyse is echter (meestal) multidimensioneel. Verschillende items worden op een bepaalde manier samengebracht, zodat er (mogelijk) meerdere factoren (schalen) ontstaan. Daarnaast kun je nog zeggen dat hoewel beide technieken de correlatiematrix als uitgangspunt hebben, ze beide andere manieren (formules) gebruiken om tot een oplossing te komen. Bij betrouwbaarheidsanalyse kijk je naar de mate van interne consistentie en bij factoranalyse naar factorladingen.
Betrouwbaarheids analyse
Uni dimensionaal, het heeft betrekking op 1 construct/dimensie
Doel: Latente structuur vinden die ten grondslag ligt aan meerdere items. Data reductie en analyse van gegevens
Interdependent
Komt na factor analyse
Kan maar voor 1 latent kenmerk
Respons set voorkomen
Hoge score betekent hoge latent kenmerk, dus iedere vraag moet met neus dezelfde kant op staan.
Combrachs alfa = maat interne consistentie
Hoe meer items, hoe hoger alfa
Op grond van welke criteria beslis je bij betrouwbaarheidsanalyse of een schaal voldoende betrouwbaar is? Bij betrouwbaarheidsanalyse kijken we naar de Cronbachs alfa. Een alfa van boven de .85 wordt als een goede (betrouwbare) schaal gezien. Een alfa van minder dan .60 wordt als onvoldoende betrouwbaar gezien. Alle waarden ertussen zijn redelijk tot goed. Deels is de interpretatie van de alfa afhankelijk van de hoeveelheid items. Wanneer we maar weinig items hebben (<10), mag de alfa wat lager zijn (in principe niet onder de .60). Wanneer je veel items hebt (>10), moet de alfa hoog zijn (boven de .80 of .85).
Iteratief: schakel tussen data en theorie, en 1 voor 1 verwijderen

In spss is een functie waar staat alfa stijgt als dit item wordt verwijderd. Wanneer item verwijderen? Als stijging hoger is dan 0.05. Stijging lager dan 0.01 dan nooit verwijderen
Hoe hoger alfa, hoe beter het klopt
Beginnen met correlatie analyse
Sheet 13 hc6
Vervolgens meetschalen maken
Item niet verwijderen als theorie zegt dat het erbij hoort. Je kunt de keuze voor somscores of factorscores baseren op meerdere criteria (zie bv. Rules
of Thumb 3-8 op p140 van Hair). In het hoorcollege is aangegeven dat factorscores worden gebruikt bij Oblique rotatie en somscores bij Orthogonale rotatie. We voegen daar hier aan toe dat somscores vaak makkelijker te interpreteren zijn (vooral als je weinig items hebt) maar in ieder geval dichter bij de oorspronkelijke scores blijven. Gemiddelde scores zijn het makkelijkst te interpreteren, aangezien je op die manier de range van de oorspronkelijke antwoordcategorieën terugkrijgt en bij Likert items, waar 5 antwoordalternatieven mogelijk waren, een gemiddelde score van 3 terug verwijst naar de (meestal) neutrale categorie in de antwoordmogelijkheden. Om die reden kiezen we hier voor somscores of gemiddelde scores.
Correspondentie analyse
Multidimensionale techniek
Interndependent
Analyse van gegevens Doel: het inzicht te verkrijgen in de samenhang (‘correspondentie’) tussen kolom- en
rijcategorieen van een kruistabel door deze samen af te beelden in een visuele presentatie. Aan de hand van deze visuele presentatie kunnen eventuele dimensies die de samenhang tussen kolommen en rijen verklaren, worden geïnterpreteerd. Hierbij wordt gestreefd naar een zo interpreteerbaar en zuinig (= klein aantal dimensies) mogelijk interpretatie.
Kruistabellen, contigentie tabellen
Explorerende techniek, dus geen hypothese toetsing
Compositioneel Geen vrije keuks, maar expliciete antwoord categorieën.
Zo min mogelijk dimensies, complexen tabellen reduceren
Bourdieu ff goed bekijken, lang over gegaan in college.
Gebruik maken van chi-kwardraat toets. o Hoe hoger (Fe-Fo)2 hoe meer het brijdraagt aan chi-kwardraat toets. o Fe < Fe = veel correspondenten = + teken ??? 1. Actual sales lower than expected negatieve samenhang o Fe> Fo = weinig correspondenten = - teken ??? 2. Actual sales higher than expected positieve samenhang. o Fe = rijtotaal x kolomtotaal / totaal = verwachte totaal o Fo = ?? geobserveerde??
Samenhang in categorieën weergeven.
6 stappenplan 1. doel
Welk doel voor ogen?
datareductie
Relatie tussen rij- of kolomcategorieën
Relatie tussen rij- en kolomcategorieën Vooraf bedenken
welke objecten je nodig hebt
benadering: compositionele methode; vgl. factoranalyse
welke dataverzameling 2. onderzoeksontwerp 3. assumpties
Heel weinig, maar wel
vergelijkbare objecten
alle attributen let op: CA biedt géén significantietoetsen, het is een explorerende analyse,
geen toetsende soms kun je door exploratie gevonden verbanden gaan ‘na-toetsen’ Chi
kwardraat toets. Om de samenhang in een kruistabel te toetsen, gebruiken

we een χ2-toets. Deze toetst de nulhypothese dat er geen samenhang bestaat tussen de twee variabelen in de kruistabel tegen de alternatieve hypothese dat er wel samenhang bestaat. We verwerpen de nulhypothese als de overschrijdingskans bij een berekende χ2-waarde kleiner is dan het vastgestelde significantieniveau (p < α).
4. analyse uitvoeren en fit beoordelen Fit beoordelen aan de hand van wortel inertia en eigenwaarde
5. interpretatie resultaten 6. validering resultaten
Geen likert schalen etc. maar kruistabellen.
Singel value: hoger dan 0.20. wortel inertia = singervaleu 2 = > 0.04 De goede dimensie is degene waar de puntjes het grootste/meeste stuk innemen.
Verschil met factor analyse: o Factor analyse werkt met antwoordschalen en CA met frequenties o Factor analyse meer vuistregels o CA zelf dimensie interpreteren.
Correspondentieanalyse is gebaseerd op een kruistabel. Beschrijf op welke vier manieren je variabelen kunt combineren om een kruistabel voor correspondentieanalyse te maken. Om correspondentieanalyse te kunnen gebruiken, moeten de data op een bepaalde manier worden geprepareerd. Het bestand muziek_tabel2.sav is hier een voorbeeld van. Een dergelijk bestand is op vier manieren samen te stellen:
1. Je neemt een eenvoudige, bivariate kruistabel als uitgangspunt en zet deze om naar het format zoals omschreven in het hoorcollege en gedaan in muziek_tabel2.sav. De rijen bevatten dan categorieën van de ene variabele en de kolommen van de andere variabelen (bv. opleidingsniveau tegenover een muzieksoort).
2. De vergelijkt een set objecten niet op een kenmerk, maar op meerdere kenmerken. De rijen bevatten dan de objecten (bv. laag opgeleiden, middelbare opgeleiden, hoog opgeleiden) en de kolommen meerdere muzieksoorten. In de rijen staat dus een variabele, in de kolommen staan meerdere variabelen.
3. Een variant op optie 2 is dat je meerdere objecten vergelijkt op een kenmerk. Je neemt naast opleidingsniveau bv. ook inkomen mee en vergelijkt deze objecten op een muzieksoort. De rijen bevatten nu dus categorieën van meerdere variabelen en de kolommen van een variabelen.
4. De laatste mogelijkheid is een combinatie van 2 en 3: je vergelijkt meerdere objecten op meerdere kenmerken (ook wel multipele correspondentieanalyse genoemd), bv. opleidingsniveau en inkomen op meerdere muzieksoorten.
Bij het uitvoeren en interpreteren van correspondentieanalyse let je op de volgende zaken: a. De fit van de oplossing. De totale inertia is een maat voor de verklaarde variantie van de
oplossing. Dit is een indicatie van de verklaringskracht van de dimensies die getrokken zijn.
b. Het aantal dimensies. Je bepaalt het aantal dimensies aan de hand van een combinatie van statistische en inhoudelijke criteria. In principe neem je dimensies met een singular value > 2 mee. Deze moeten echter wel inhoudelijk te interpreteren te zijn (ondersteuning vanuit theorie?). Het kan ook voorkomen dat je een dimensies die statistisch (net) niet bijdraagt aan de oplossing toch inhoudelijk erg sterk is en dat je deze daarom meeneemt. Verder neem je bij voorkeur zo min mogelijk dimensies mee (maximaal 2 a 3).
c. Interpretatie. Je kunt inzicht verkrijgen in de correspondentie tussen de rijen en kolommen door naar de afstanden tussen de categorieën te kijken: hoe kleiner de afstand, hoe groter de correspondentie. Hetzelfde principe kun je toepassen bij het interpreteren van de dimensies. Over een twee-dimensioneel plaatje mag je een loodrecht assenstelsel leggen. Categorieën of combinaties van categorieën die bij de extremen van de assen liggen, geven inzicht in de betekenis van die assen (= dimensies). Verschillende cijfermatige uitkomsten uit de analyse kunnen ook helpen bij het benoemen van de dimensies. De massa geeft het gewicht c.q. het belang van een categorie in de oplossing aan. De overzichten van de ‘row points’ en ‘column points’ geven aan hoe de dimensies en de categorieën aan elkaar gerelateerd zijn. Zo geeft de kolom ‘contribution of point to inertia of dimension’ aan hoe zwaar een categorie meetelt in een dimensie. Deze waarden zijn vergelijkbaar met factorladingen in factoranalyse en maken interpretatie van de dimensies makkelijker.

Multiple regressie analyse
Interval meetniveau
Analyse van gegevens
dependent
Statisch verklarend
Stappenplan: 1. Hypothetiseren regressie coëfficiënt 2. Schat basismodel
Doel: na gaan in hoeverre aanpassingen door schendingen van assumpties substantiële verbeteringen opleveren.
3. Check verdeling variabele
Scheefheid van variabele o Maten van symmetrie bepalend voor onderschatting van werkelijke
correlatie o Gewenste situatie bij benadering symmetrisch verdeeld. (klokvorm) o Symmetrisch heeft twee eigenschappen
Scheefheid Skewness > 2 keer standaard error dan scheef Steilheid Kurtosis> 2x standaard error dan steil/plat. Als het afwijkt dan heb je vier mogelijkheden om het op te lossen.
Inverse, worteltrekken, logaritme en kwadraten. Deze vier vormen zorgen voor meer symmetrie.
4. Check model assumpties
Interval meetniveau Afhankelijk variabele niet repareerbaar Onafhankelijke variabele wel repareerbaar Dichomtome variabele is interval. Want tussen de twee
afhankelijke zit evenveel ruimte en rangorde. Wanneer je van een variabele een dichtome variabele maakt, noem je dat een dummy variabele.
Lineariteit is strikte eis! Nog niet helemaal duidelijk… Relatie tussen on- en af- hanekelijke lineir anders onzuivere
schatting. Eerst kijken naar de scheefheid van de afhankelijke variabele.
Polynome termen variable in kwardraat. Polynome is ander woord voor kwardraat. De macht min 1 is het aantal knikken waarvoor gecorrigeerd wordt. Je moet de hoogste macht bepalen die significant is. En alles wat daaronder zit neem je mee. Dus X3 = significant, dan neem je ook X2 en X mee.
Multicollineariteit wil je niet Relatie tussen onafhankelijke Correlatie tussen onafhankelijke variabele re hoog slecht Gevolg schending standaard error, een misschatting van
standaard error = misschatting van significantie. Kijken naar tolerantie waarden
1. Zegt niet proportie verklaarde variantie, maar 1- proportie verklaarde variantie.
2. < 0.25 alert worden; < 0,10 serieus probleem. Van oorspronkelijke x- xgem en xgem = 0. Die moet je gaan
kwadrateren. Dus oorspronkelijke x centreren rondom gemiddelde 0. Dan haal je multicollineariteit eruit.
Oplossing: het verwijderen of samenvoegen van onafhankelijke variabele.
Homoscedasticiteit wil je wel Spreiding tussen groepjes ongeveer gelijk.
1. Levene test, anders geen eerlijk vergelijk mogelijk Plotjes bekijken of er structuur inzit Geschatte regressiewaarden / SE = t- waarde Oplossen: Transformeren van scheve/platte/steile variabelen (vooral
de afhankelijke variabele) OF Toepassen van Weighted Least Squares (WLS) (behoort niet tot de stof)

5. Schat definitieve model 6. Evalueer het model
Bruikbaarheid hele model (F-toets)
Significantietest regressiecoëfficiënten
Determinatie coëfficiënt R2 7. Interpreteer bevindingen
Gebruik methodes ordinaire least square. o Schatting van coëfficiënt o Recht lijn o BLEU Best Linear Unbiases Estimated
Zuiverheid Efficientie standaard error rondom significantie (om significantie te
bepalen)
Dummy variabelen zijn hercoderingen van een nominale of ordinale variabele die je als onafhankelijke variabele in een regressieanalyse wilt meenemen. Door voor iedere categorie van een nominale of ordinale variabele een dummy aan te maken met codering 0/1 kun je die variabele als het ware een interval karakter geven en toch meenemen in een regressieanalyse.
o Interpreteren van dummy variabele? Het opnemen van dummy variabelen geeft inzicht in de verschillen in groepsgemiddelden. De t-toets (t-waarde en bijbehorende p-waarde) geeft aan of de b-waarde van een dummy variabele significant van 0 afwijkt. De b-waarde geeft aan wat het verschil in gemiddelde is van de categorie waar die dummy voor staat ten opzichte van de referentiecategorie, onder controle van de overige variabelen in het model (voorbeeld hoorcollege: het verschil in gemiddelde omzet tussen de clothing en de electronics branche, onder controle van het aantal werknemers en de veranderingen die het bedrijf heeft ondergaan).
o Waarom is gestandaardiseerde regressiecoëfficiënt van dummyvariabele en polynome termen niet goed interpreteerbaar? Gestandaardiseerde regressiecoefficienten (symbool β) geven aan met hoeveel standaarddeviaties de afhankelijke variabele toe- of afneemt als de betreffende onafhankelijke variabele met een standaarddeviatie toeneemt, onder controle van de overige variabelen. De gestandaardiseerde regressiecoefficienten van dummy variabelen en polynome termen zijn niet te interpreteren, omdat deze variabelen samen verwijzen naar een onderliggende variabele. Daarmee is het niet mogelijk om bv. de β van variabele x te interpreteren onder controle van variabele x2. x en x2 zijn immers aan elkaar gerelateerd. Eenzelfde redenering geldt voor dummy variabelen. OPLOSSING: Door een compound variabele aan te maken voeg je een set dummy variabelen of polynome termen weer samen tot een variabele. Die sets vervang je in een nieuwe regressieanalyse door de compound. De β die bij de compound hoort, geeft nu wel het relatieve belang weer van de onderliggende variabele, omdat je het effect nu wel onder controle van de andere variabelen kunt interpreteren.
Compoun variabele: Vanuit het hoorcollege kennen we enkele checks voor de analyse met compounds, zodat we weten of het goed is gegaan of niet. o De b-waarden van de compound moeten 1 zijn. o De b-waarden van de andere variabelen en de R2 moeten gelijk blijven.
Wat is representativiteit en waarom is representativiteit belangrijk? Een steekproef is representatief op het moment dat dezelfde kenmerken worden vertoond als de populatie waar de steekproef uit getrokken is. Meer concreet houdt representativiteit in dat de verdeling van de onderzochte variabelen in de steekproef hetzelfde is als in de populatie. Representativiteit is van groot belang voor de generaliseerbaarheid van de onderzoeksresultaten. Als bepaalde groepen in de steekproef onder- of oververtegenwoordigd zijn in de steekproef, dan mogen de onderzoeksresultaten niet zonder meer van toepassing worden verklaard op de populatie. De representativiteit van de steekproef heeft dus consequenties voor de externe validiteit van het onderzoek. Welke analysetechnieken kun je gebruiken om de representativiteit na te gaan? Maak hierbij onderscheid tussen beschrijvende en toetsende technieken en geef aan met welke SPSS procedures je deze technieken kunt uitvoeren.

Om een uitspraak te kunnen doen over de representativiteit moeten we de verdelingen van variabelen in de steekproef vergelijken met de populatieverdelingen. Dat betekent dus dat we moeten beschikken over populatiegegevens. De meest basale manier om een verdeling in steekproef te bestuderen, is het analyseren van een frequentietabel. Voor variabelen van interval en ratio meetniveau wordt een frequentietabel snel onoverzichtelijk. Dan kan ook worden gekozen voor grafische weergavemethoden als het histogram of een stam-en-blad diagram. De verdelingen van de variabelen in de steekproef zijn dan ‘op het oog’ te vergelijken met de populatieverdelingen. In SPSS is het een en ander op te vragen via Analyze _ Frequencies. Als we met meer zekerheid uitspraken willen doen over de representativiteit van een steekproef, dan moeten we specifiek toetsen op representativiteit. Die zekerheid drukken we bij toetsing uit met α (het significantieniveau). Of een verdeling van een nominale of ordinale variabele (bv. geslacht of opleidingsniveau) overeenkomt met de populatieverdeling is te toetsen met behulp van een unidimensionele chi2-toets. Deze procedure is te benaderen via Analyze _ Nonparametric Tests _ Chi-Square. Voor variabelen van interval of ratio niveau (bv. leeftijd of gewicht) kan gebruik worden gemaakt van een z- of t-toets (Analyze _ Compare Means _ One Sample T-Test). Bij het uitvoeren van de toets op representativiteit die je bij vraag 5 hebt uitgevoerd, heb je waarschijnlijk een significantieniveau gehanteerd van 30%, zoals dat in het hoorcollege is aangegeven. Soms wordt bij een toets op representativiteit uitgegaan van een nog hoger significantieniveau van bv. 85%. Bij de meeste andere statistische toetsen kies je je alfa zo laag mogelijk, bv. 1% of 5%. Leg uit waarin de uitgevoerde representativiteitstoets verschilt van andere statistische toetsen en waarom een hoger significantieniveau hierbij gerechtvaardigd is. Betrek in je antwoord het onderscheid tussen de type I en type II fout. Een type I fout treedt op wanneer H0 wordt verworpen, terwijl H0 feitelijk waar is. De keuze om H0 te verwerpen wordt beïnvloed door het gestelde significantieniveau (alfa). In veel gevallen heeft deze een waarde van .05. Hoe lager de alfa waarde wordt gesteld, hoe moeilijker het wordt om H0 te verwerpen. De kans dat H0 foutief wordt verworpen, wordt dus kleiner wanneer de gestelde alfa zo klein mogelijk is. Een type II fout vindt plaats wanneer H0 wordt aangehouden, terwijl deze eigenlijk onwaar is. De kans op deze fout kan niet door middel van een zelf gestelde grens worden bepaald. De kans op een type II fout drukken we uit met beta waarde en hangt samen met de gestelde alfa: hoe hoger de gekozen alfa, hoe lager de beta. Bij de meeste statistische toetsen wil je de kans op een type I fout zo klein mogelijk houden. Doorgaans heb je immers hypothesen die gaan over een verschil, een verandering of een correlatie. Je wilt niet te snel de nulhypothese dat er geen verschil, geen verandering of geen correlatie is verwerpen en het risico lopen dat de nulhypothese toch waar is (= de definitie van een type I fout). Bij de uitgevoerde representativiteitstoetsen wil je juist dat de nulhypothese opgaat. Je wilt te snel de nulhypothese behouden, terwijl deze eigenlijk niet waar is. Ofwel, je wil de kans op een type II fout minimaliseren. De kans op een type II fout (beta) hangt van verschillende zaken af (zie Hair, 2006, pp. 9-13), waaronder van de gekozen alfa. Hoe hoger de gekozen alfa, hoe lager de waarde voor beta. Om die reden kiezen we hier voor de hogere alfa waarde van 30% en wordt soms gewerkt met nog hogere waarden, bv. 85%. Dit sluit beter aan bij het doel dat we nastreven bij het toetsen van representativiteit. Wat verstaan we onder datacleaning? Welke specifieke activiteiten verricht je daarbij? Geef tevens aan met welke analysetechnieken en procedures je die activiteiten kunt realiseren in SPSS. Nadat er enquêtes afgenomen zijn bij de respondenten moet de onderzoeker de verkregen data overzetten in SPSS. Tijdens het overzetten van de gegevens kunnen er allerlei fouten optreden. Wanneer de data in SPSS staat moet de onderzoeker zich ervan vergewissen dat de data goed is. Hij zal de data moeten bekijken en eventuele fouten of slordigheden moeten corrigeren. Allereerst kijkt de onderzoeker of alle gegevens in de datamatrix kloppen. Dat doet hij door middel van vier stappen: • Codes • Missings declareren • Routings • Response set (zie bijlage 1) Daarna zal hij een missing value analyse uitvoeren. Om de data nader te bekijken, kun je een aantal stappen doen. Je kunt frequentietabellen draaien van je variabelen en kijken of je fouten of slordigheden zit. Je zou ook kruistabellen kunnen draaien en kijken of je daar opmerkelijke zaken ziet.

Een andere manier is te kijken naar je meta-data (data over je data). Dit doe je door te kijken in net tabblad Variable View. Hier kun je de meta-data aanpassen bij geconstateerde fouten en slordigheden. Kortom, datacleaning wordt gebruikt om de verkregen data op te schonen, te controleren en goed weer te geven in een statistisch programma, waarna begonnen kan worden aan statistische procedures. Wat verstaan we onder response set? Licht toe wat de consequenties van response set kunnen zijn en hoe je hiermee kunt omgaan. Wanneer respondenten op een bepaalde systematische manier de vragen niet serieus invult, zodanig dat dit ten koste gaat van de validiteit van de meting. Wanneer bijvoorbeeld een aantal Likert-items vragen achter elkaar gevraagd worden, kan het zijn dat respondenten een patroon laten zien zonder dat het inhoudelijk (meet je wat je wil meten) logisch is. Er zijn verschillende oorzaken die kunnen leiden tot response set, een voorbeeld is dat de respondent geen zin heeft of geïrriteerd is geraakt door de lang durende enquête dat hij snel overal “sterk ja” invoert zonder de vraag te lezen. Wanneer je als onderzoeker te maken hebt met respondenten met een verdacht response set moet je maatregelen treffen. Een response set beïnvloedt namelijk je validiteit, meet ik wat ik wil meten. Wanneer je een response set hebt waargenomen moet je kijken of het inhoudelijk (kijken naar de vragen) inconsistent is. Hierna zal je als onderzoeker moeten kijken naar wat de omvang is van het aantal respondenten, is deze laag zou je ze bijvoorbeeld kunnen verwijderen of de betreffende variabelen missing maken. Wat verstaan we onder missing value analyse en waarom is missing value analyse van belang? Met missing value analyse gaat de onderzoeker kijken of er in de ontbrekende scores op variabelen samenhang te vinden is. Het is van belang om te onderzoeken welke processen hebben geleid tot missing data, zodat de juiste stappen kunnen worden ondernomen om om te gaan met missing data. Een onderscheid kan gemaakt worden tussen random en non-random missing data. Random betekent dat de missing scores willekeurig over de respondenten en vragen voorkomen. Non-random betekent dat er onderliggende patronen aanwezig zijn tussen missing data en andere vragen. Missing data heeft praktische consequenties, namelijk dat de steekproefgrootte kan worden aangetast en dus ook de statistische power. Ook de geldigheid van uitspraken die over de onderzoekseenheden worden gedaan kan worden aangetast. Welke stappen zet je bij het uitvoeren van missing value analyse? Geef voor elke stap welke keuzes je bij die stap maakt en waar je die keuzes op baseert. Hair beschrijft zeer gedetailleerd welke stappen er genomen dienen te worden bij Missing Value Analysis (MVA). De stappen die hij beschrijft zijn (Hair p. 53): Stap 1: type missing data vaststellen Bij deze stap onderzoek je of je de missing data negeerbaar is. Hair geeft drie voorbeelden van negeerbare missing data, namelijk: non-response/steekproef; routings en censored data/ontwerp. Naast negeerbare missing data heeft de onderzoeker ook vaak te maken met data dat niet te negeren is. Hair onderscheidt twee categorieen niet negeerbare data; te verklaren missing processen en onverklaarbaar missing processen. Met de niet negeerbare missing data zal de onderzoeker aan de slag moeten. De volgende stappen zijn nodig om accurate remedies te kiezen om met de missing data om te gaan. Stap 2: omvang van de missing data vaststellen Hoeveel respondenten blijven erover voor de analyse van je data? Hier dien je te kijken naar het percentage van variabelen met missing data voor elke respondent en naar het aantal respondenten met missing data voor elke variabele. Missing data lager dan 10% is te verwaarlozen mits de data random is (zie ook Hair p.55). Hair geeft aan dat de onderzoeker moet kijken of respondenten dan wel variabelen verwijderd kunnen worden wanneer deze buitensporig hoge missings hebben. Stap 3: nagaan of de missing data random zijn Nadat de onderzoeker heeft vastgesteld dat de omvang van missing data groot is moet er gekeken worden of de missing data randorm is. Er zijn twee soorten van random data, namelijk: MCAR: missing completely at random. MAR: missing at random. Het soort van random data geeft straks aan welke substitutiemethodes je kan gebruiken. Met andere woorden welke methoden je mag gebruiken om de missing data te vervangen door een gekozen score.
De volgende tests in SPSS moeten gedaan worden om MCAR dan wel MAR vast te stellen: MAR: hierbij ga je voor elke variabele die je wilt onderzoeken verdelen in twee groepen. Een groep met alle respondenten die een geldige score hebben en een groep met respondenten met een missing op die variabele. SPSS draait een tabel uit met in de rijen de variabelen met de twee groepen en in de kolommen de variabelen met in de cellen een aantal gegevens. Voor elke combinatie van variabelen wordt een t-toets uitgevoerd. Hair geeft aan dat wanneer een t-toets significant is dit een teken kan zijn voor MAR (let op: metrische data). De onderzoeker moet in de tabel zoeken naar consistente patronen om aan te kunnen geven dat de data MAR is (Hair, p.57). Voor niet metrische data kunnen kruistabellen worden bestudeerd om te zoeken naar patronen in missing data. MCAR: de tweede manier is om een algehele chi2-toets uit te voeren om te kijken of het MCAR is. Wanneer deze toets niet significant is, dan hebben we te maken met MCAR. Om een uitspraak te kunnen doen of de missing data MAR dan wel MCAR is, gebruik je alle informatie die je voorhanden hebt. Het antwoord wordt gebaseerd op de volgende drie informatiebronnen: • Is het aantal missing groter dan 10%? (stap 2) • Is er een systematisch patroon te herkennen in de tabel? (stap 3: MAR test) • Is de toets voor MCAR significant of niet? (stap 3: MCAR test) Stap 4: substitutie methode kiezen en uitvoeren MAR: Modelling Based Approaches MCAR: Missing data vervangen en Missing data niet vervangen. (zie verder Hair p.58) Validiteit: De mate waarin de gemeten kenmerken daadwerkelijk de kenmerken zijn van de ondezochte objecten (systematische of random error). Betrouwbaarheid: De mate waarin de metingen van de kenmerken dezelfde resultaten oplevert als het onderzoek onder dezelfde omstandigheden zou worden herhaald. Bruikbaarheid: De mate waarin de onderzoeksresultaten goed aansluiten bij het probleem van de opdrachtgever, ofwel die daadwerkelijk kunnen bijdragen aan de oplossing van een praktijkprobleem.
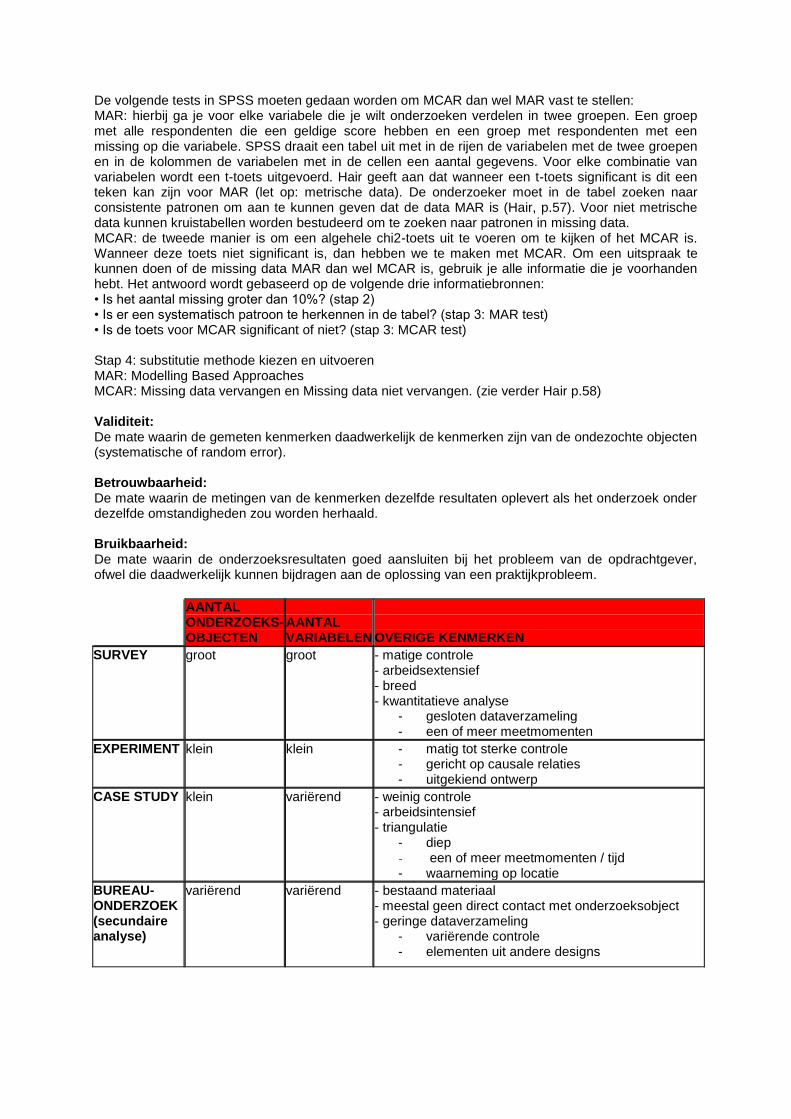
AANTAL ONDERZOEKS- OBJECTEN
AANTAL VARIABELEN
OVERIGE KENMERKEN
SURVEY groot groot - matige controle - arbeidsextensief - breed - kwantitatieve analyse
- gesloten dataverzameling - een of meer meetmomenten
EXPERIMENT klein klein - matig tot sterke controle - gericht op causale relaties - uitgekiend ontwerp
CASE STUDY klein variërend - weinig controle - arbeidsintensief - triangulatie
- diep - een of meer meetmomenten / tijd - waarneming op locatie
BUREAU-ONDERZOEK (secundaire analyse)
variërend variërend - bestaand materiaal - meestal geen direct contact met onderzoeksobject - geringe dataverzameling
- variërende controle - elementen uit andere designs

DESIGN ANALYSEMODEL
PRE-EXPERIMENT
• one shot case study • one group pretest-posttest • static group
Zie sheet 15
ECHT-EXPERIMENT
• pretest-posttest control group • posttest only control group • solomon four group design
QUASI- EXPERIMENT
• timeseries • multiple time series
Opstellen vragenlijst: stappen
1. Specificeer de benodigde informatie 1. De variabelen die nodig zijn om de onderzoeksvraag te beantwoorden.
2. Kies een adequate dataverzamelingstechniek. 1. Observatie participerend / niet- participerend 2. Inhoudsanalyse kwantitatief / kwalitatief 3. Enquête/Interview schriftelijk (post, email, web) persoonlijk (traditioneel, CAPI)
telefonisch (traditioneel, CATI, gsm) 3. Kies de inhoud van de vragen
1. Is de vraag noodzakelijk? 2. Is er meer dan 1 vraag nodig?
4. Bedenk of de respondent de vragen kan beantwoorden 1. Is de respondent geïnformeerd? 2. Kan de respondent het zich herinneren? 3. Kan de respondent de vraag beantwoorden?
5. Bedenk of de respondent de vragen wil beantwoorden 1. Inspanning voor de respondent 2. Context 3. Legitimatie van het doel 4. Gevoelige informatie 5. Verhoog bereidheid (incentive)
6. Kies adequate structuren voor de vragen 1. Open vragen 2. Gesloten vragen 3. Single/multiple respons 4. Dichotome vragen 5. Schaal items (bijvoorbeeld Likert)
7. Kies adequete formuleringen (inclusief verbingsteksten) 1. Gebruik gewone woorden 2. Gebruik eenduidige woorden 3. Vermijd impliciete veronderstellingen 4. Vermijd generalisaties en schattingen 5. Gebruik positieve en negatieve stellingen
8. Kies een adequate volgorde voor de vragen en 9. adequate lay out. 1. Openingsvragen 2. Type informatie 3. Moeilijke vragen 4. Effect op volgende vragen 5. Logische volgorde 6. Routings 7. Rustige en overzichtelijke vormgeving
9. Test de vragenlijst 1. Test je vragenlijst altijd bij een of enkele personen die tot de beoogde populatie
behoren en/of laat de vragenlijst checken bij experts

non-respons:
dat deel van de onderzoekseenheden in de steekproef van wie uiteindelijk geen bruikbare gegevens beschikbaar zijn, onder meer door weigeringen
populatie: het totaal van objecten waarop een onderzoek betrekking heeft en waarover een uitspraak
wordt gedaan representativiteit:
de mate waarin de onderzochte steekproef beschouwd kan worden als een adequate vertegenwoordiging van de populatie waarover het onderzoek handelt
selectiviteit: de steekproef vormt geen representatieve afspiegeling van de beoogde populatie
steekproef: gedeelte uit een (operationele) populatie op basis waarvan uitspraken kunnen worden gedaan
over de populatie waaruit de steekproef is getrokken aselect:
steekproef waarbij de objecten zijn gekozen volgens een toevalsprocedure validiteit:
de mate waarin gemeten wordt wat je beoogt te meten. externe:
reikwijdte of generaliseerbaarheid van conclusies naar populaties (en andere omstandigheden)
interne: kwaliteit van de conclusies van een onderzoek
weging: representativiteit van een steekproef verbeteren om die zo meer op de populatie te laten
lijken. Onderzoekseenheden worden gewogen als in een steekproef groepen over- of ondervertegenwoordigd zijn t.o.v. de populatie.
Nog doen:
we mogen de missing data beschouwen als MCAR (Hair, p.53 en 55). o MAR (modeling approach erg pittig):
maximum likelihood estimation (EM) missing data gezien als subset van de steekproef
o MCAR: listwise deletion pairwise deletion mean substitution voor het geheel voor subgroepen regression techniques
Eventueel bijlage opdracht 2 bekijken. Wat is power precies; aantal respondenten bij analyses nog meer?? Rules of thump???


















