

Correspondentie Analyse
19
-
Upload
data-insights-inzicht-in-data -
Category
Business
-
view
3.814 -
download
2
description
applications of correspondence analysis in market research
Transcript of Correspondentie Analyse

Correspondentie-analyse in Marktonderzoek - 2 __________________________________________________________________________________________________
J. Blomme – [email protected]
1. Situering en kernbegrippen
Hoewel correspondentie-analyse een reeds lang bestaande techniek is, neemt de belangstelling ervoor de laatste jaren gestadig toe. Dit houdt verband met de toegenomen populariteit van exploratieve gegevensanalyse, waarvoor correspondentie-analyse zich goed leent. Correspondentie-analyse kan in het algemeen beschouwd worden als een techniek om de samenhang tussen categorische variabelen te exploreren. Traditioneel worden daartoe kruistabellen gehanteerd. Grote kruistabellen en meerdere kruistabellen maken het evenwel vlug lastig om samenhangen op te sporen. Correspondentie-analyse (CA) maakt het mogelijk samenhangen grafisch voor te stellen. Meestal wordt gekozen voor een tweedimensionele plot waarin de categorieën van variabelen als punten voorkomen en waarbij het nulpunt (de oorsprong van het assenstelsel) staat voor de totale populatie. De techniek zorgt ervoor dat de onderlinge afstanden tussen deze punten zoveel mogelijk de samenhang in de tabel(len) reflecteren. De technieken en procedures die onder CA sorteren, kunnen als een deelverzameling van schaaltechnieken beschouwd worden. Zo hebben de in de SPSS-module “Categories” opgenomen technieken zoals ANACOR, HOMALS, PRINCALS en OVERALS (ook “ALS”-technieken genoemd omdat ze werken overeenkomstig het principe van “alternating least squares”)1 als gezamenlijk kenmerk dat op een of andere manier schaalwaarden worden berekend voor de categorieën van de in de analyse betrokken variabelen. Ter verduidelijking hiervan dienen een aantal kernbegrippen van naderbij beschouwd te worden.
1.1. Niet-lineariteit
CA is een geheel van technieken die voorzien in de niet-lineaire analyse van categorische variabelen. Als zodanig zijn de “ALS”-technieken de tegenhangers van de klassieke multivariate lineaire technieken zoals factoranalyse, regressie-analyse, discriminantanalyse, e.a. Niet-lineariteit heeft betrekking op het feit dat bij CA geen voorafgaande eisen aan het meetniveau van de te behandelen variabelen worden gesteld. Dit is eveneens het geval bij log-lineaire analyse. Deze laatste techniek heeft echter als nadeel dat het vinden van een spaarzaam (“parsimonious”) model moeilijk wordt bij een grote steekproefomvang. CA fungeert hier als een te overwegen alternatief. Zoals dit het geval is bij log-lineaire analyse, worden de variabelen die
betrokken worden in een correspondentie-analyse categorische variabelen genoemd. Dit zijn variabelen die de te onderzoeken objecten sorteren in een betrekkelijk klein aantal groepen, welke als categorieën worden aangeduid. Er worden dus gegevens geanalyseerd van een aantal objecten met betrekking tot een aantal variabelen. Een variabele wordt gedefinieerd door de mogelijkheid om objecten in te delen in onderscheiden en elkaar uitsluitende categorieën.
Een onderscheid wordt gemaakt tussen drie soorten variabelen. In het geval van een nominale variabele zijn de categorieën niet volgens een van tevoren vastgelegde volgorde ingedeeld. Bij de verwerking van ordinale variabelen dient er rekening mee gehouden te worden dat de categorieën in een voorafbepaalde volgorde staan. De derde mogelijkheid is dat de categorieën van tevoren een bepaalde getalwaarde krijgen met de bedoeling dat (anders dan bij ordinale variabelen) verschillen tussen die getallen geïnterpreteerd mogen worden als verschillen tussen objecten in die categorieën. Zo’n variabelen noemen we numerieke variabelen (bv. het verschil tussen 25 jaar en 20 jaar is even groot als het verschil tussen 55 jaar en 50 jaar).
Het is van belang om in te zien dat het onderscheid tussen nominale, ordinale en numerieke variabelen niet voortvloeit uit de eigenschappen van de variabelen zelf, maar dat het gaat om eigenschappen die door een onderzoeker aan deze variabelen worden opgelegd. Zo kan de variabele ‘leeftijd’ door een onderzoeker ook als een ordinale variabele worden gehanteerd. De onderzoeker gaat er dan van uit dat de categorieën wel op een bepaalde volgorde staan, maar niet dat afstanden tussen opeenvolgende categorieën gelijk zijn. Anderzijds kan een variabele als politieke voorkeur (nominaal) door een onderzoeker ook als een ordinale variabele behandeld worden (o.m. door politieke partijen op een schaal van ‘links’ naar ‘rechts’ te rangordenen). Kortom, of een variabele nominaal, ordinaal of numeriek behandeld moet worden, wordt niet voorgeschreven door intrinsieke eigenschappen van de variabele zelf, maar wordt bepaald door de eisen die de onderzoeker aan de variabele stelt.
In tal van onderzoeken komt het voor dat gegevens ontbreken. De oorzaken hiervan zijn velerlei. Wat te doen als er ontbrekende gegevens zijn ? Er zijn drie mogelijkheden. Voor de ontbrekende gegevens van een variabele voeren we één nieuwe, afzonderlijke categorie in. Alle objecten met ontbrekende gegevens op de variabele worden aan de aparte categorie toegewezen. Deze aanpak veronderstelt uiteraard, dat objecten waarvan de gegevens ontbreken, om deze reden op elkaar lijken en dat het hierom gewettigd is de ontbrekende

Correspondentie-analyse in Marktonderzoek - 3 __________________________________________________________________________________________________
J. Blomme – [email protected]
gegevens als één categorie op te vatten. Het is natuurlijk de vraag of deze veronderstelling realistisch is. Deze aanpak krijgt de naam : ontbrekende gegevens actief enkelvoudig behandelen. ‘Enkelvoudig’ betekent : de ontbrekende gegevens worden in één categorie ondergebracht ; ‘actief’ betekent dat deze categorie in de verdere verwerking volwaardig meetelt. De tweede aanpak is dat aan elke variabele net zoveel nieuwe categorieën worden toegevoegd als er objecten met ontbrekende gegevens zijn. Dit houdt in dat in elke nieuwe categorie slechts één object voorkomt. In dit geval worden ontbrekende gegevens actief meervoudig behandeld. Een belangrijk nadeel van deze aanpak is dat de toegevoegde categorieën een zeer lage marginale frequentie hebben (immers, ze bevatten slechts één object). De derde aanpak laat alle ontbrekende gegevens buiten beschouwing in de verdere analyse. Ontbrekende gegevens worden passief behandeld.
Het begrip ‘ontbrekende gegevens’ is afhankelijk van de interpretatie door de onderzoeker. Nemen we als voorbeeld een enquête naar leesgewoonten van kranten. Nu kan men stellen dat respondenten die niet regelmatig Het Nieuwsblad lezen in één categorie vallen, nl. de categorie niet-regelmatige Het Nieuwsblad-lezers (actief enkelvoudig). Het is echter de vraag of deze laatste groep respondenten op elkaar lijken, louter en alleen op grond van de vaststelling dat ze iets niet doen. Mensen die Het Nieuwsblad wel lezen, hebben iets met elkaar gemeen, maar geldt daarom dat zij die Het Nieuwsblad niet lezen iets met elkaar gemeen hebben ? Dit laatste kan betwijfeld worden, en om deze reden kan de onderzoeker besluiten om ervan uit te gaan dat voor de niet-lezers de gegevens ontbreken (passieve behandeling). Meervoudig actieve behandeling houdt daarentegen in dat elke niet-lezer een uniek exemplaar wordt in zijn eigen categorie. Passieve behandeling houdt duidelijke voordelen in. Er wordt dan bij de verdere bewerking wel gelet op het feit dat lezers van eenzelfde krant iets gemeenschappelijks hebben, maar daaraan wordt niet de conclusie verbonden dat niet-lezers iets met elkaar gemeen hebben.
Het voorgaande leidt tot de conclusie dat er een element van willekeur bestaat. Het is aan de onderzoeker om te bepalen of een variabele nominaal, ordinaal of numeriek is terwijl er geen stricte regels bestaan over de vraag hoe ontbrekende gegevens behandeld moeten worden. Die willekeur kan worden ingeperkt doordat de onderzoeker niet slechts één keuze uit de opties doet, maar een aantal analyses doet onder verschillende opties en dan de resultaten van die verschillende analyses met elkaar vergelijkt. Dan
kan blijken dat de resultaten in hoofdzaak hetzelfde zijn, ook al werden verschillende opties gekozen. Ook kan blijken dat de resultaten verschillend zijn, al naar gelang welke optie genomen werd. In dit laatste geval moet de onderzoeker er zich rekenschap van geven waar zulke verschillen vandaan kunnen komen : de onderzoeker moet proberen te achterhalen wat er met de gegevens aan de hand is waardoor zulke verschillen kunnen optreden. Bij exploratieve gegevensanalyse is het zo dat de onderzoeker nog niet overal duidelijke vragen heeft. Vergelijking van verschillende analyses van dezelfde data kan ertoe bijdragen dat de onderzoeker ontdekt wat de zinnige vragen zijn. In dit opzicht is CA een techniek die het verdere analyseverloop in goede banen kan helpen leiden.
1.2. “Optimal scaling”
Bij klassieke multivariate analyses wordt het meetniveau van de variabelen als gegeven beschouwd. Op basis van het meetniveau van de variabelen wordt een geschikte analysetechniek gekozen. Bij de “ALS”-technieken wordt niet a priori een bepaald meetniveau verondersteld, maar worden in de analyse zogenaamde optimale schaalwaarden (optimale kwantificatie, “optimal scaling”) berekend voor de categorieën van de in de analyse betrokken variabelen. Optimale schaalwaarden zijn nieuwe waarden voor de oorspronkelijke waarden van één of meer variabelen. Deze optimale schaalwaarden zijn in een of meer opzichten ‘beter’ dan de oorspronkelijke waarden van de variabelen, o.m. omdat ze de correlatie tussen twee variabelen maximaliseren. Optimale schaalwaarden kunnen dan ook dienen om de oorspronkelijke waarden van variabelen te vervangen. Omdat optimale schaalwaarden worden berekend voor variabelen ongeacht het a priori toegedachte meetniveau leidt het gebruik van optimale schaalprocedures ertoe dat variabelen van ongelijk meetniveau in eenzelfde analyse kunnen betrokken worden. Voor de praktijk van het marktonderzoek is dit een belangrijke aanvulling op het arsenaal van analysemogelijkheden.
Relaties tussen variabelen komen slechts tot hun recht indien de categorieën van variabelen optimaal gekwantificeerd worden. Wat ‘optimaal’ betekent, hangt af van de onderzoekscontext. De optimale kwantificatie van een variabele is daarom relatief. Dit betekent dat de kwantificatie van een variabele moet beschouwd worden in de context van andere variabelen die in de analyse betrokken worden.

Correspondentie-analyse in Marktonderzoek - 4 __________________________________________________________________________________________________
J. Blomme – [email protected]
Naargelang van deze laatste kan blijken dat een variabele anders gekwantificeerd moet worden.
Stel dat er een a priori-kwantificatie bestaat voor een variabele. Er kan dan een transformatiegrafiek getekend worden. In dergelijke grafiek staan de a priori- kwantificaties op de horizontale as en op de verticale as staan de optimale kwantificaties. Elke categorie van een variabele wordt dus afgebeeld als een punt van de grafiek. Dit geeft de mogelijkheid opnieuw te definiëren wat we verstaan onder numerieke, ordinale en nominale variabelen. Numerieke behandeling eist dat de punten in de transformatiegrafiek op een rechte lijn liggen.
Ordinale behandeling stelt de minder strenge eis dat de punten op een monotoon stijgende curve liggen. Dit betekent dat als de a priori-kwantificatie van categorie j groter is dan die van categorie i, de optimale kwantificatie van categorie j niet kleiner mag zijn dan die van kategorie i (wel is toegestaan dat de optimale kwantificaties gelijk aan elkaar worden). Wordt een variabele nominaal behandeld, dan worden aan de transformatiegrafiek geen eisen gesteld. De curve mag dus op meerdere plaatsen een knik vertonen. Het kan blijken dat de transformatiegrafiek toch monotoon stijgend is, wat er dan op wijst dat hetzelfde resultaat gevonden zal worden als de variabele ordinaal behandeld zou zijn. Terloops dient erop gewezen te worden dat als een variabele slechts twee categorieën heeft (een binaire variabele) de transformatiegrafiek slechts twee punten bevat die altijd op een rechte lijn liggen. De gevolgtrekking is dat het voor een binaire variabele niets uitmaakt of deze numeriek, ordinaal of nominaal wordt behandeld.
Transformatiegrafieken hebben alleen zin als er een a priori-kwantificatie van de categorieën van een variabele bestaat. Uit de transformatiegrafiek kan dan bv. blijken dat deze een logaritmisch of kwadratisch verloop kent, hetgeen inhoudt dat de a priori-kwantificatie dient vervangen te worden door algebraïsche functie van de oorspronkelijke waarden.
In klassieke multivariate analyse wordt ervan uitgegaan dat elke variabele een a priori-kwantificatie heeft en dat elke variabele numeriek moet worden behandeld. In dit geval vertonen de transformatiegrafieken alle de vorm van rechte lijnen. Men spreekt daarom van lineaire multivariate analyse. Worden echter één of meer variabelen ordinaal of nominaal behandeld (aangenomen dat er een a priori- kwantificatie is), dan geldt de lineaire restrictie niet en kan men spreken van niet-lineaire multivariate analyse. Indien er geen a priori-kwantificatie is, dan
betekent dit hetzelfde als dat er een willekeurige a priori-kwantificatie is (in dit geval wordt aan de categorieën van een variabele een etiket gegeven onder de vorm van cijfers, in een of andere volgorde). Wordt de variabele vervolgens nominaal behandeld, dan speelt de getalwaarde die aan de categorieën is toegekend geen enkele rol. Een transformatiegrafiek heeft in dit geval m.a.w. geen zin. Om na te gaan of voldaan wordt aan de assumpties van multivariate analyse-technieken kan op de variabelen een correspondentie-analyse worden toegepast. Met behulp van een eenvoudig voorbeeld kan dit geadstrueerd worden. In het geval van factoranalyse wordt verondersteld dat de variabelen numeriek geschaald zijn. Stel dat uitgegaan wordt van Likert-items (5-punts items) waarbij de code 1 staat voor zeer oneens en de code 5 staat voor zeer eens. De veronderstelling bij dit soort items is dat de afstanden tussen de schaalwaarden 1,2,3,4 en 5 gelijk zijn, dus dat er sprake is van een intervalschaal. Het is echter goed mogelijk dat in werkelijkheid de schaalwaarden voor de verschillende items deze veronderstelling tegenspreken. Een voorbeeld ter verduidelijking. Veronderstel dat we optimale kwantificaties berekenen voor een reeks Likert-items. Uit tabel 1 blijkt o.m. dat voor item 1 de afstand tussen “eens” (code 4) en “zeer eens” (code 5) 1,25 bedraagt. Voor item 2 is de afstand slechts 0,10.
Tabel 1 : Schaalwaarden voor (5 punts-) antwoordcategorieën na optimale kwantificatie
(1)
(2)
(3)
(4)
(5)
Item 1
-1,30
-1,29
0,03
0,70
1,95
Item 2
-1,15
-1,11
-0,02
1,10
1,20
De items in dit voorbeeld vormen dus duidelijk geen intervalschalen. Optimale kwantificatie kan derhalve leiden tot schaalwaarden die beter voldoen dan de oorspronkelijke waarden. Dit zou bv. kunnen blijken door eerst een factoranalyse toe te passen op de oorspronkelijke variabelen en daarna de resultaten te vergelijken met die verkregen bij factoranalyse na optimale kwantificatie.
Zelfs indien er sprake is van nominaal meetniveau, kunnen optimale schaalwaarden worden berekend die toelaten de correlatie tussen variabelen te

Correspondentie-analyse in Marktonderzoek - 5 __________________________________________________________________________________________________
J. Blomme – [email protected]
maximaliseren. Wat optimaal is, hangt af van de betrokken analysetechniek en de in de analyse betrokken variabelen. Er is dus niet zoiets als een soort absolute optimale schaling van categorieën van variabelen. Voor de procedures ANACOR en HOMALS wordt slechts een nominaal meetniveau van de variabelen verondersteld (cfr. infra). Door de optimale schalingsresultaten uit deze analyses te vergelijken met de oorspronkelijke scores van de categorieën kan men nagaan of bv. een intervalschaal aanwezig is. In dit geval zouden de afstanden tussen opeenvolgende schaalwaarden gelijk moeten zijn. Bij de procedures PRINCALS en OVERALS kan het meetniveau van de variabelen nominaal, ordinaal of interval zijn.
1.3. Dimensie-reductietechnieken
De zojuist genoemde “ALS”-technieken kunnen beschouwd worden als dimensie-reductietechnieken. Dit betekent dat de samenhang tussen de categorieën van variabelen door middel van de berekening van optimale schaalwaarden in beeld wordt gebracht in een zo klein mogelijk aantal dimensies. De dimensies geven elk bepaalde aspecten weer van de samenhang of verschillen tussen categorieën van variabelen.
2. Transformatie en optimale kwantificatie In voorgaand punt werd er reeds op gewezen dat relaties tussen variabelen beter tot hun recht komen als de categorieën van variabelen optimaal gekwantificeerd zijn. Nemen we als voorbeeld de variabele ‘leeftijd’. Uit een onderzoek naar eetgewoonten kan blijken dat de optimale kwantificatie van de leeftijdscategorieën de verschillen tussen de oudere groepen kleiner neemt dan die tussen de jongere groepen. De optimale kwantificatie zou zelfs kunnen laten zien dat de oudere groepen samengevoegd kunnen worden ; alleen de verschillen in leeftijd tussen jongeren enerzijds en die tussen jongeren en ouderen anderzijds spelen een rol. Een dergelijke kwantificatie is optimaal in relatieve zin, d.w.z. met betrekking tot de andere variabelen in het onderzoek. Het is best mogelijk dat in een onderzoek naar politiek komt vast te staan dat leeftijdscategorieën anders moeten gekwantificeerd worden.
Met betrekking tot optimale kwantificatie kan een onderscheid gemaakt worden tussen enkelvoudige en meervoudige kwantificatie. Enkelvoudige kwantificatie komt er op neer dat voor elke categorie van een variabele een kwantificatie wordt gezocht die geldig blijft in alle dimensies van de analyse. Meervoudige kwantificatie houdt in dat de kwantificatie van de categorieën voor elke dimensie van de oplossing verschillend mag zijn. Aangenomen dat er een a priori-kwantificatie bestaat, betekent enkelvoudige kwantificatie dat er een transformatiegrafiek is die de a priori-kwantificatie omzet in een optimale kwantificatie. Die grafiek blijft geldig voor alle dimensies van de oplossing. Daar staat tegenover dat bij meervoudige kwantificatie elke dimensie van de oplossing een eigen transformatiegrafiek heeft. Is er geen a priori-kwantificatie, dan kunnen we desondanks een willekeurige a priori-kwantificatie kiezen en de variabele vervolgens nominaal behandelen. Nominale behandeling betekent immers : de kwantificatie van de categorieën trekt zich niets aan van de a priori-kwantificatie. Dan blijft het verschil bestaan dat enkelvoudige kwantificatie van zo’n variabele zal gelden voor alle dimensies van de oplossing, terwijl meervoudige kwantificatie voor elke dimensie afzonderlijk een optimale kwantificatie van de categorieën kiest. Een techniek die zich goed leent voor optimale kwantificatie van variabelen is PRINCALS (“PRINciple Components analysis by Alternating Least Squares”). De PRINCALS-opties berusten op twee uitgangspunten. Het eerste is dat de gebruiker kan kiezen of variabelen numeriek, ordinaal of nominaal behandeld worden. Het tweede uitgangspunt is dat gekozen kan worden tussen enkelvoudige of meervoudige kwantificatie. De combinatie van deze twee uitgangspunten leidt tot de vier mogelijkheden in tabel 2.
Tabel 2 : PRINCALS-opties
kwantificatie
variabelen enkelvoudig meervoudig
numeriek X niet van toepassing
ordinal X niet van toepassing
nominaal X X
Uit tabel 2 kan afgelezen worden dat twee combinaties niet voorkomen. De eerste is die van

Correspondentie-analyse in Marktonderzoek - 6 __________________________________________________________________________________________________
J. Blomme – [email protected]
meervoudige kwantificatie van numerieke variabelen. De reden hiervoor is dat de numerieke behandeling van een variabele inhoudt dat de kwantificatie van de variabele op verschillende dimensies steeds een lineaire functie moet zijn van de a priori-kwantificatie. Dit uitgangspunt staat haaks op het principe van meervoudige kwantificatie, dat in dit geval zou inhouden dat de kwantificaties van de categorieën van een numerieke variabele op meerdere dimensies onderling verschillen. Ook de combinatie ordinaal/meervoudig komt niet voor, maar dit om een andere reden. Meervoudige ordinale kwantificatie van een variabele impliceert dat de kwantificaties op achtereenvolgende dimensies allemaal dezelfde rangorde hebben als de a priori-kwantificatie. Ze hebben dus ook onderling een rangcorrelatie van 1 zodat de meervoudig ordinale kwantificatie maar weinig zal verschillen van de enkelvoudig ordinale oplossing. De enkelvoudig nominale behandeling van een variabele houdt ook iets tegenstrijdigs in. De behandeling veronderstelt immers dat de onderzoeker geen rekening kan of wil houden met een a priori-kwantificatie maar desondanks toch verlangt dat de categoriekwantificaties op elke dimensies van de oplossing evenredig met elkaar zijn. Ligt het dan niet voor de hand dat de onderzoeker die enkelvoudige kwantificatie wil omdat gehoopt wordt dat de categoriekwantificatie overeenkomt met een bepaalde van tevoren bestaande verwachting omtrent die kwantificaties ? Zou het dan niet beter zijn om die verwachting meteen vast te leggen als een ordinale a priori-ordening waarmee in de oplossing rekening wordt gehouden ? Tegenover die redenering staat dat de onderzoeker soms wel een a priori-verwachting heeft over een aantal categorieën van een variabele, maar dat sommige categorieën in die reeks niet goed te plaatsen zijn. We zullen de toepassing van optimale schaalanalyse illustreren aan de hand van een onderzoek van Novak en Hoffman (1999) over het navigatiegedrag van gebruikers van het World Wide Web. Bij de ontwikkeling van een conceptueel model ter verklaring van het navigatiegedrag van WWW-gebruikers maken Novak en Hoffman gebruik van het begrip “flow”, dat zij omschrijven als de intrinsieke amusement dat gebruikers ervaren. Trevino en Webster (1992 : 542) geven volgende operationele omschrijving van “flow” : “Flow represents the extent to which (a) the user perceives a sense of control over the computer interaction, (b) the user perceives that his or her
attention is focused on the interaction, (c) the user’s curiosity is aroused during the interaction, and (d) the user finds the interaction intrinsically interesting”. Het door Novak en Hoffman ontwikkelde conceptueel model voorziet o.m. in een verklaring van “flow” in termen van de antecedenten ervan. In het bijzonder schrijven de beide onderzoekers de ervaring van intrinsiek amusement toe aan het bestaan van een congruentie tussen enerzijds de (navigatie)vaardigheden van de gebruiker en de uitdagingen die uitgaan van het navigeren op het World Wide Web. Meer in het bijzonder omschrijven Novak en Hofmann “flow” als “a cognitive state experienced during online navigation that is determined by : 1) high levels of skill and control ; 2) high levels of challenge and arousal ; 3) focused attention ; and is 4) enhanced by interactivity and telepresence” (Novak & Hofmann, 1999 : 6). In hetgeen volgt zullen we de constructie van de antecedente variabele ‘vaardigheden’ (“skills”) van naderbij analyseren aan de hand van een subset van respondenten die participeerden aan het door Novak en Hoffman uitgevoerde onderzoek. Uit een aanvankelijk uitgevoerde factoranalyse op een zestal items waarmee het begrip ‘vaardigheden’ geïndiceerd werd, bleken twee factoren met een eigenwaarde groter dan één gezamenlijk 69,1 % van de variantie in de oorspronkelijke items te verklaren. In tabel 3 zijn deze items vermeld met de antwoordfrequenties ervan op de 9-punten schalen die gebruikt werden in het onderzoek. Op de vier items is een optimale schaalanalyse verricht door gebruikmaking van PRINCALS. In het voorbeeld worden alle variabelen enkelvoudig ordinaal behandeld. Hiervoor zijn twee argumenten. Het eerste is dat de categorieën van elke variabele (de getallen 1 tot 9) kennelijk in een bepaalde volgorde staan. Het tweede argument is dat een numerieke analyse ervan uitgaat dat de afstand tussen opeenvolgende categoriewaarden steeds gelijk is. De juistheid van deze veronderstelling is erg betwistbaar. Ordinale kwantificatie zal laten zien of er reden is de categorieën zodanig te kwantificeren dat hun onderlinge afstanden niet meer gelijk zijn. Uit tabel 3 kan afgeleid worden dat een afzonderlijke analyse van categoriekwantificaties op zijn plaats is. De frequentieverdeling ziet er immers niet uit als een normale verdeling. Bij elk van de vier items is de frequentieverdeling zelfs extreem scheef te noemen. De resultaten van de PRINCALS-analyse

Correspondentie-analyse in Marktonderzoek - 7 __________________________________________________________________________________________________
J. Blomme – [email protected]
onderschrijven in de eerste plaats de resultaten van de factoranalyse. De PRINCALS-eigenwaarden hebben een waarde van 0,558 op de eerste dimensie en 0,172 op de tweede dimensie. Als we als vuistregel hanteren dat een eigenwaarde groter moet zijn dan (1/aantal variabelen), dan kan uit de itemanalyse afgeleid worden dat de tweede dimensie (eigenwaarde 0,172 > 0,167) nog net kan weerhouden worden maar op zichzelf weinig toevoegt aan de eendimensionele oplossing.
Tabel 3 : Antwoordfrequenties voor “skills”-items
Item
1
2
3
4
5
6
7
8
9
I am extremely skilled at using the Web (skilled)(*)
5
4 18 12 45 56 110 126 124
I know how to find what I am looking for on the Web (find)(*)
3 3 9 12 13 46 125 174 115
I consider myself knowledgeable about good search techniques on the Web (searchtech)(*)
2 12 9 18 17
56 125 138 123
I know somewhat less about the Web than most users (knowless)(*)(***)
4 9 8 11 20 30 57 122 239
How would you rate your skill at using the Web, compared to other things you do on the computer ? (rate1)(**)
1 1 4 11 147 84 130 96 26
How would you rate your skill at using the Web, compared to the sport or game you are best at ? (rate2)(**)
9 10 22 11 105 67 102 74 100
(*) 1 = volledig akkoord ; 9 = helemaal niet akkoord (**) 1 = veel minder goed ; 9 = veel beter (***) omscoring itemcategorieën
Bekijken we nu de categoriekwantificaties zelf in tabel 4. Wat uit de tabel onmiddellijk kan opgemaakt worden is dat de afstand tussen de verschillende categorieën voor geen van de items gelijk is. Met uitzondering van één item worden twee of meerdere categorieën van de items
samengevoegd (in rood weergegeven categoriekwantificaties). De PRINCALS-analyse geeft eveneens een bevestiging voor de ordinale kwantificatie van de categorieën van de variabelen : de getransformeerde waarden (categoriekwantificaties) vertonen voor elk van de items een monotoon stijgend verloop.
Tabel 4 : Categoriekwantificaties voor “skills”-items
item
1
2
3
4
5
6
7
8
9
skilled
-2.56 -1.93 -1.93 -1.90 -1.31 -0.82 -0.23 0.40 1.27
Find -1.49 -1.49 -1.49 -1.49 -1.49 -1.47 -0.71 0.29 1.43
searchtech
-1.62 -1.62 -1.62 -1.62 -1.41 -0.96 -0.65 0.41 1.37
knowless
-1.58 -1.58 -1.58 -1.58 -1.58 -1.58 -1.04 -0.33 0.96
rate1 -7.54 -6.63 -5.65 -1.77 -0.76 -0.16 0.54 0.76 1.47
rate2 -3.06 -3.06 -2.29 -2.29 -0.25 -0.03 0.27 0.27 1.14
3. Werkwijze CA
Bij de klassieke multivariate analysetechnieken zoals factoranalyse en meervoudige regressie-analyse wordt als regel de analyse uitgevoerd op een correlatiematrix. Bij de “ALS”-technieken wordt uitgegaan van een zogenaamde indicatormatrix. Zo’n indicatormatrix wordt verkregen door de categorieën van de variabelen om te coderen tot dummy-variabelen. Stel dat we een datamatrix hebben met drie variabelen en vijf respondenten. De variabelen zijn geslacht (man, vrouw), opleiding (hoog, middelbaar, laag) en type krantengebruiker (light user, medium user, heavy user). De indicatormatrix ziet er dan uit zoals voorgesteld in tabel 5. Intuïtief zal duidelijk zijn dat wanneer analyses worden uitgevoerd op de categorieën van variabelen en niet op de variabelen zelf, de resultaten ook betrekking zullen hebben op wat categorieën van variabelen met elkaar gemeen hebben. Terwijl in het geval van HOMALS vertrokken wordt van een indicatormatrix, vindt de analyse bij ANACOR plaats op gegevens die
Correspondentie-analyse in Marktonderzoek - 8 __________________________________________________________________________________________________
J. Blomme – [email protected]
georganiseerd zijn in kruistabelformaat.
Tabel 5 : Indicatormatrix bij correspondentie-analyse
geslacht opleiding user
resp.nr
M V L M H L M H
1 1 0 1 0 0 1 0 0
2 1 0 0 1 0 1 0 0
3 0 1 0 0 1 0 0 1
4 1 0 1 0 0 0 1 0
5 1 0 1 0 0 1 0 0
6 1 0 0 0 0 0 1 0
7 1 0 0 0 1 0 0 1
3.1. CA toegepast op gegevens georganiseerd in
kruistabelformaat
In hetgeen voorafging werden enkele kernbegrippen van de “ALS”-technieken uiteengezet. Deze begrippen krijgen meer betekenis wanneer ze worden gedemonstreerd aan de hand van een voorbeeld. In hetgeen volgt worden de zojuist behandelde kernbegrippen geadstrueerd en wordt eveneens het begrip ‘chikwadraatafstand’ toegelicht. Wat de techniek van correspondentie-analyse doet kan als volgt worden samengevat : correspondentie-analyse tracht de samenhang in een of meer tabellen zo goed mogelijk grafisch weer te geven. Meestal kiest men voor een tweedimensionele plot. In de plot komen de categorieën van de variabelen als punten terug en staat de oorsprong (het nulpunt) voor de totale populatie. De techniek zorgt ervoor, dat de onderlinge afstanden tussen deze punten zoveel mogelijk de samenhang in de tabel(len) reflecteren. Een dergelijke afbeelding is evenwel meestal niet mogelijk zonder enig verlies aan informatie. Het is aan de onderzoeker om te beoordelen of dit een belangrijk deel vormt of tot een klein en verwaarloosbaar deel beperkt blijft. We zullen hierop nader ingaan aan de hand van drie vragen, die voor een toepassing van correspondentie-analyse relevant zijn :
∇ wat wordt er van de samenhang in een tabel afgebeeld in een plot ?
∇ hoe is, wanneer de plot eenmaal tot stand is gekomen, het verlies aan tabelinformatie te bepalen ?
∇ hoe moet de plot geïnterpreteerd worden ? 1. Wat wordt er van de samenhang in een tabel afgebeeld in een plot ?
Als in een kruistabel de rijpercentages en kolompercentages worden berekend, kan de overeenkomst tussen rijen en kolommen onderling en met betrekking tot de randverdelingen worden bepaald. Nemen we als voorbeeld het verband tussen opleidingsniveau en Internetgebruik. In onderstaande tabel worden deze beide variabelen tegen elkaar afgezet.
Tabel 6 : Internetgebruik naar opleidingsniveau (Bron : Hoffman & Novak, 1999)2
Opleidingsniveau
Internet gebruik
less than high
school
high school graduate
some college
college graduate
totaal
no access
408
701
349
172
1630
access only
27
108
111
39
285
Web user
201
283
453
585
1522
totaal
636
1092
913
796
3437
In correspondentie-analyse wordt de proportionele verdeling binnen een rijcategorie van een tabel een rijprofiel genoemd. In het gegeven voorbeeld zouden we kunnen spreken van het profiel van hoog opgeleiden (‘’college graduate’’), het profiel van middelbaar opgeleiden (‘’some college’’ en ‘’high school graduate’’) en het profiel van laag opgeleiden (‘’less than high school”). In plaats van rijprofielen onderling te vergelijken, kan men ze ook relateren aan de proportionele verdeling van de totale populatie, het zogenaamde gemiddelde rijprofiel (d.i. het profiel van de marginale distributie van de kolomvariabele). Gemiddelde rijprofielen zijn te omschrijven als het gewogen gemiddelde van de afzonderlijke rijprofielen en worden vaak omschreven als ‘’centroids’’ omdat ze de totale onderzoeksgroep representeren en in het centrum (de oorsprong) van het assenstelsel geplaatst worden. Ten slotte kunnen rijprofielen
Correspondentie-analyse in Marktonderzoek - 9 __________________________________________________________________________________________________
J. Blomme – [email protected]
vergeleken worden met de marginale rijprofielen. Aangezien rijprofielen onafhankelijk zijn van het aantal in elke rij, leveren marginale rijprofielen informatie over het aantal in elke rijcategorie. Op dezelfde wijze kunnen kolomprofielen berekend worden, kunnen kolomprofielen onderling vergeleken worden en kunnen kolomprofielen vergeleken worden met het gemiddelde kolomprofiel en met de marginale kolomprofielen.
Tabel 7 : Rij- en kolomprofielen voor het voorbeeld van het
verband tussen opleidingsniveau en Internetgebruik
Opleidingsniveau Internet gebruik less than
high school
high school graduate
some college
College graduate
marginale rij-profielen
no access 0,250 0,430 0,214 0,106 0,474
access only 0,095 0,379 0,389 0,137 0,083
Web user 0,132 0,186 0,298 0,384 0,443
gem. rij- profielen
0,185 0,318 0,266 0,232 1,000
Opleidingsniveau Internet gebruik less than
high school
high school
graduate
some college
college graduate
gem. kolom- profielen
no access 0,642 0,642 0,382 0,216 0,474
access only
0,042 0,099 0,122 0,049 0,083
Web user 0,316 0,259 0,496 0,735 0,443
marginale kolom- profielen
0,185 0,318 0,266 0,232 1,000
Behalve de rij- en kolomprofielen en het gemiddelde rij- en kolomprofiel is in tabel 7 ook het marginale rijprofiel en het marginale kolomprofiel opgenomen. Zoals vermeld, kunnen verschillen bepaald worden tussen rijen (kolommen) onderling en tussen rijen (kolommen) en het gemiddelde
rijprofiel (kolomprofiel). Gemiddelde rij- en kolomprofielen (‘’centroids’’) worden in correspondentie-analyse in de oorsprong van het assenstelsel geplaatst. Het is duidelijk dat naarmate de samenhang in een tabel sterker is, de profielen van de rij- en kolomcategorieën sterker zullen verschillen, zowel onderling als t.o.v. het profiel van de totale populatie.
Vooraleer evenwel verschillen tussen rijen (kolommen) onderling en verschillen tussen rijen (kolommen) en het gemiddelde rijprofiel (kolomprofiel) worden berekend, is het noodzakelijk na te gaan of er in de tabel sprake is van een statistisch significant verband. In het voorbeeld van het verband tussen opleidingsniveau en Internetgebruik blijkt dit inderdaad het geval te zijn : de berekende chikwadraatwaarde (539,365) is bij 6 vrijheidsgraden significant op het .001-niveau. Indien geen statistisch significant verband wordt gevonden in een tabel is toepassing van correspondentie-analyse niet relevant. De afwijkingen van rijen of kolommen in een kruistabel ten opzichte van elkaar en ten opzichte van het gemiddelde (rij- of kolom)profiel worden berekend met behulp van de zgn. chikwadraatafstand. De chikwadraatafstand heeft een analoge betekenis als de (dis)similariteit bij multidimensionele schaalanalyse. Indien een rij of kolom precies gelijk is aan de randverdeling (het gemiddelde rij- of kolomprofiel) is de chikwadraatafstand gelijk aan 0. Bijgevolg zal zo’n rij of kolom ook precies in de oorsprong van het assenstelsel vallen. De oorsprong van het assenstelsel (het nulpunt) representeert immers de totale steekproef. Ook voor het bepalen in hoeverre rijen en kolommen onderling van elkaar verschillen wordt gebruik gemaakt van de chikwadraatafstand. Hoe groter de chikwadraatafstand tussen twee rijen of kolommen, hoe meer de verdelingen van die twee rijen of kolommen van elkaar zullen verschillen. Eveneens geldt hoe groter de chikwadraatafstand tussen rijen of kolommen, hoe verder die van elkaar verwijderd zijn in een grafische weergave. In tabel 8 vermelden we de chikwadraatafstanden tussen rijen en kolommen voor het voorbeeld van het verband tussen opleidingsniveau en Internetgebruik.
In het voorgaande is uiteengezet dat voor twee variabelen kan worden nagegaan of er al dan niet een samenhang bestaat. Bij een significante chikwadraatwaarde weten we dan dat twee variabelen niet onafhankelijk van elkaar zijn. Als we echter meer gedetailleerde informatie willen hebben over die afhankelijkheid, dan kunnen we nagaan in hoeverre de categorieën van de ene variabele, bijvoorbeeld de rijen, onderling nog
Correspondentie-analyse in Marktonderzoek - 10 __________________________________________________________________________________________________
J. Blomme – [email protected]
gelijkenis vertonen met betrekking tot de categorieën van de andere variabele, de kolommen. Om die gelijkenis (of afstand) tussen rijen of kolommen onderling te bepalen, wordt gebruik gemaakt van de chikwadraatafstand. Met behulp van de chikwadraatafstand kan dus worden nagegaan in hoeverre rijen van elkaar verschillen. De overeenkomsten of verschillen hebben altijd betrekking op de kolomcategorieeën. Omgekeerd kan worden nagegaan of de kolomcategorieën verschillen met betrekking tot de rijen.
Tabel 8 : Chikwadraatafstanden tussen rijen en kolommen voor
het voorbeeld van het verband tussen opleidingsniveau en Internetgebruik
chikwadraatafstanden tussen rijen
R1
R2
R3
R1
.
0,561
0,924
R2
0,561
.
0,764
R3
0,924
0,764
.
chikwadraatafstanden tussen kolommen
K1
K2
K3
K4
K1
.
0,495
0,493
0,426
K2
0,495
.
0,354
0,654
K3
0,493
0,354
.
0,417
K4
0,426
0,654
0,417
.
2. Hoe is het verlies aan tabelinformatie te bepalen ?
Wanneer uitgaande van de hiervoor besproken principes, de kruistabel met de gegevens van opleidingsniveau en Internetgebruik wordt onderworpen aan een correspondentie-analyse worden de volgende resultaten verkregen zoals vermeld in tabel 9.
In de tabel worden in de eerste plaats de ‘’singular value’’ vermeld van de dimensies. In het voorbeeld van de samenhang tussen opleidingsniveau (4 categorieën) en Internetgebruik
(3 categorieën) is het maximaal aantal dimensies 2. Er kunnen namelijk nooit meer zinvolle dimensies worden gevonden dan het minimum van het aantal rijen (3) en kolommen (4), verminderd met 1, dus min(3-1),(4-1) = 2. De samenhang tussen beide variabelen op de eerste dimensie wordt weergegeven door de ‘’singular value’’ van de eerste dimensie, nl. 0,379. De samenhang tussen opleidingsniveau en Internetgebruik op de tweede dimensie daalt naar 0,115.
Tabel 9 : : Anacor-oplossing voor het voorbeeld van het verband tussen opleiding en beroepsstatus
dimensie
singular value
inertia
proportie verklaarde variantie
cumulatieve proportie
verklaarde variantie
1
0,37923
0,14381
0,916
0,916
2
0,11452
0,01311
0,084
1,000
Totaal
0,15693
1,000
Chi2 = 539,365
Een belangrijke waarde in tabel 9 is de ‘’inertia’’-waarde die berekend wordt als het quotiënt van de deling van de totale chi2-waarde (539,365) door het aantal onderzoekseenheden (3437). CA kan opgevat worden als een methode voor de decompositie (in een zo gering mogelijk aantal dimensies) van de variantie (‘’inertia’’) in een tabel, waarbij de variantie wordt aangegeven door de chi2-waarde. In dit opzicht vertoont CA een gelijkenis met factoranalyse, aangezien het ook de bedoeling is van factoranalyse om de totale variantie in een set variabelen weer te geven in een zo gering mogelijk aantal dimensies.
Samenhang in een kruistabel blijkt in eerste instantie uit de mate waarin afwijkingen voorkomen tussen geobserveerde en verwachte frequenties. Als de waargenomen en verwachte celfrequenties in een tabel nauwelijks van elkaar verschillen en de rijen en kolommen derhalve onafhankelijk van elkaar zijn, dan hebben we genoeg aan de rij- en kolomprofielen om de ‘’samenhang’’ tussen variabelen te beschrijven. Naarmate de verschillen tussen waargenomen en verwachte celfrequenties toenemen, stijgt ook de chi2-waarde.
Correspondentie-analyse in Marktonderzoek - 11 __________________________________________________________________________________________________
J. Blomme – [email protected]
In het voorbeeld van het verband tussen opleidingsniveau en Internetgebruik wordt 91,6 % van de chikwadraat afgesplitst door de eerste dimensie. Op grond van deze resultaten kan geconcludeerd worden dat de eerste dimensie het meest van de samenhang tussen opleiding en Internetgebruik in beeld brengt. Anderzijds blijkt de tweedimensionele oplossing te resulteren in een volledige verklaring van de variantie.
De rijscores onder dimensie 1 en 2 (zie tabel 10) zijn optimale scores voor categorieën van Internetgebruik op de eerste en tweede dimensie. De kolomscores onder dimensie 1 en 2 zijn de optimale scores voor de opleidingscategorieën op de eerste en de tweede dimensie. Het marginaal profiel bevat de relatieve frequenties.
Tabel 10 : Optimale scores voor rij- en kolomcategorieëen in het voorbeeld van het verband tussen opleidingsniveau en
Internetgebruik rijscores
marginaal profiel
dimensie 1
Dimensie 2
no access
.474
-.607
.126
access only
.083
-.146
-1.123
Web user kolomscores
.443
.677
.075
less than high school
.185
-.478
.497
high school
.318
-.602
-.093
some college
.266
.228
-.445
college graduate
.232
.947
.241
Het is eveneens mogelijk meer specifiek de fit van de oplossing te controleren. De output van een correspondentie-analyse geeft de procentuele bijdrage weer van de dimensies aan de verklaring van de verschillen tussen de categorieën en de totale groep. In tabel 11 worden deze procentuele bijdragen weergegeven voor de rijcategorieën. Uit bovenstaande proporties valt o.m. af te leiden dat verschillen in Internetgebruik tussen hoger opgeleiden (‘’college’’) en de totale groep voor 98,1% verklaard worden door de eerste dimensie. Dit is nog meer het geval voor verschillen in
Internetgebruik voor de categorie ‘’high school’’ (99,3%). In de plot (zie pag. 12) betekent dit dat deze beide categorieën, gezien als vectoren vanuit de oorsprong, veel meer in de richting van de eerste dan de tweede dimensie liggen.
Tabel 11 : Procentuele bijdrage van dimensies aan de verklaring van de verschillen in Interne gebruik naar opleidingsniveau
dimensie 1 dimensie 2
rijcategorie no access
.987
.013 access only
.053
.947
Web user kolomcategorie less than high school high school some college college graduate
.996
0,754
0,993
0,464
0,981
.004
0,246
0,007
0,536
0,019
3. Hoe moet de plot geïnterpreteerd worden ? Wanneer de fit van de oplossing redelijk voldoet, komen we toe aan de beantwoording van de derde vraag, nl. hoe de plot geïnterpreteerd moet worden. In de praktijk zal correspondentie-analyse vaak worden aangewend vanwege de mogelijkheden tot grafische weergave van de resultaten. Rij- en kolomcategorieëen kunnen via correspondentie-analyse grafisch worden weergegeven omdat coördinaten worden berekend, waarmee de plaats van een rij-of kolomcategorie vastligt. De coördinaten hebben als eigenschap dat het zoals eerder vermeld optimale schaalwaarden zijn. Dit betekent dat de correlatie tussen de rij- en kolomvariabele zal maximaal zijn, ongeacht het meetniveau van de rij- en kolomvariabele in de kruistabel. De kruistabel die met behulp van correspondentie-analyse wordt geanalyseerd, wordt zodanig getransformeerd dat de gemiddelde rij- en kolomproefielen in de oorsprong van de grafische weergave vallen. Bij de interpretatie van een plot dienen de volgende vuistregels in acht genomen te worden.
In de eerste plaats dient gelet te worden op de afstanden van de rij- en kolompunten ten opzichte van de oorsprong. Naarmate deze afstand groter is, is de afwijking van het betreffende rij- of kolomprofiel ten opzichte van het profiel van de totale groep groter. Rijen of kolommen met een klein randtotaal worden verder weggeplaatst van
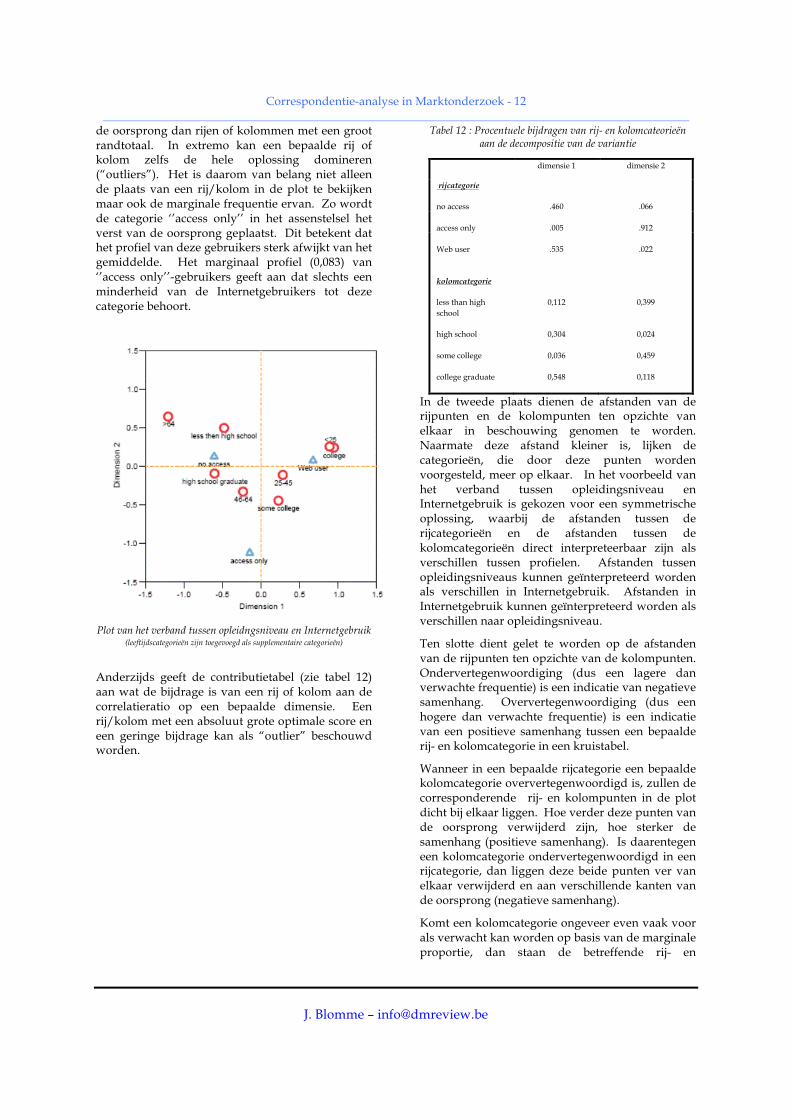
Correspondentie-analyse in Marktonderzoek - 12 __________________________________________________________________________________________________
J. Blomme – [email protected]
de oorsprong dan rijen of kolommen met een groot randtotaal. In extremo kan een bepaalde rij of kolom zelfs de hele oplossing domineren (“outliers”). Het is daarom van belang niet alleen de plaats van een rij/kolom in de plot te bekijken maar ook de marginale frequentie ervan. Zo wordt de categorie ‘’access only’’ in het assenstelsel het verst van de oorsprong geplaatst. Dit betekent dat het profiel van deze gebruikers sterk afwijkt van het gemiddelde. Het marginaal profiel (0,083) van ‘’access only’’-gebruikers geeft aan dat slechts een minderheid van de Internetgebruikers tot deze categorie behoort.
Plot van het verband tussen opleidngsniveau en Internetgebruik
(leeftijdscategorieën zijn toegevoegd als supplementaire categorieën)
Anderzijds geeft de contributietabel (zie tabel 12) aan wat de bijdrage is van een rij of kolom aan de correlatieratio op een bepaalde dimensie. Een rij/kolom met een absoluut grote optimale score en een geringe bijdrage kan als “outlier” beschouwd worden.
Tabel 12 : Procentuele bijdragen van rij- en kolomcateorieën aan de decompositie van de variantie
dimensie 1 dimensie 2
rijcategorie no access
.460
.066 access only
.005
.912
Web user kolomcategorie less than high school high school some college college graduate
.535
0,112
0,304
0,036
0,548
.022
0,399
0,024
0,459
0,118
In de tweede plaats dienen de afstanden van de rijpunten en de kolompunten ten opzichte van elkaar in beschouwing genomen te worden. Naarmate deze afstand kleiner is, lijken de categorieën, die door deze punten worden voorgesteld, meer op elkaar. In het voorbeeld van het verband tussen opleidingsniveau en Internetgebruik is gekozen voor een symmetrische oplossing, waarbij de afstanden tussen de rijcategorieën en de afstanden tussen de kolomcategorieën direct interpreteerbaar zijn als verschillen tussen profielen. Afstanden tussen opleidingsniveaus kunnen geïnterpreteerd worden als verschillen in Internetgebruik. Afstanden in Internetgebruik kunnen geïnterpreteerd worden als verschillen naar opleidingsniveau.
Ten slotte dient gelet te worden op de afstanden van de rijpunten ten opzichte van de kolompunten. Ondervertegenwoordiging (dus een lagere dan verwachte frequentie) is een indicatie van negatieve samenhang. Oververtegenwoordiging (dus een hogere dan verwachte frequentie) is een indicatie van een positieve samenhang tussen een bepaalde rij- en kolomcategorie in een kruistabel.
Wanneer in een bepaalde rijcategorie een bepaalde kolomcategorie oververtegenwoordigd is, zullen de corresponderende rij- en kolompunten in de plot dicht bij elkaar liggen. Hoe verder deze punten van de oorsprong verwijderd zijn, hoe sterker de samenhang (positieve samenhang). Is daarentegen een kolomcategorie ondervertegenwoordigd in een rijcategorie, dan liggen deze beide punten ver van elkaar verwijderd en aan verschillende kanten van de oorsprong (negatieve samenhang).
Komt een kolomcategorie ongeveer even vaak voor als verwacht kan worden op basis van de marginale proportie, dan staan de betreffende rij- en

Correspondentie-analyse in Marktonderzoek - 13 __________________________________________________________________________________________________
J. Blomme – [email protected]
kolompunten, gezien als vectoren vanuit de oorsprong, ongeveer loodrecht op elkaar. Rij- en kolompunten hangen dan niet samen.
Wanneer de verschillen tussen geobserveerde en verwachte frequenties worden gedeeld door de wortel uit de verwachte frequenties krijgen we een beeld van de mate waarin tussen rijen en kolommen positieve of negatieve samenhangen bestaan. In tabel 13 vermelden we de resultaten van deze berekening voor het voorbeeld van het verband tussen opleidingsniveau en Internetgebruik.
We nemen als voorbeeld de categorie ‘’less than high school’’. Voor deze opleidingscategorie is de kans op ‘’no access’’ groter dan verwacht (6.13). De kans op ‘’no access’’ voor hoog opgeleiden (‘’college’’) is veel lager dan verwacht (-14.33). De plot laat zien dat correspondentie-analyse de afstanden tussen verwachte en geobserveerde frequenties in een kruistabel in beeld brengt.
Bij een correspondentie-analyse is de hoek tussen de lijn middelpunt-rijcategorie en de lijn middelpunt-kolomcategorie van groot belang. Als die hoek nul is en een rijcategorie en een kolomcategorie staan op eenzelfde lijn, dan betekent dit dat de kolomcategorie uniek is voor de rijcategorie. Als de hoek tussen de twee lijnen groter wordt, neemt de samenhang af. Als de hoek 90 graden is, is de correlatie afwezig en als de hoek nog groter is, wil dat zeggen dat de samenhang negatief is.
Tabel 13 : De samenhang tussen rijen en kolommen voor het
voorbeeld van het verband tussen opleiding en Internetgebruik (geobserveerde-verwachte frequentie) /√ (verwachte frequentie)
no access
access only
Web user
less than
high school
6.13
-3.54
-4.80
high
school graduate
8.04
1.84
-9.12
some
college
-4.04
4.07
2.42
college
-14.33
-3.33
12.39
.
Categorieën die ver buiten het middelpunt staan,
zijn bepalender voor een groep dan categorieën die meer in het middelpunt staan. Om die sterkte van de verbanden meer inzichtelijk te maken kan men rondom het middelpunt een onregelmatige cirkel tekenen die de groepen (bv. rijcategorieën) in de plot met elkaar verbindt. Op die manier ontstaat een polygoon of veelhoek (waarvan de hoeken worden afgerond). Op basis hiervan kunnen we stellen dat categorieën die binnen de cirkel staan, weinig groepsonderscheidend zijn terwijl de categorieën die buiten de cirkel staan het meest groepsspecifiek en dus het meest interessant zijn.
3.2. Uitbreidingen van ANACOR
De kruistabel die we in voorgaand punt analyseerden, had als voornaamste eigenschap dat beide randverdelingen sommeren tot het aantal observaties. De randtotalen bevatten de verdeling per variabele. Beide variabelen habben betrekking op eigenschappen van respondenten binnen eenzelfde steekproef. Elke respondent kwam maar in 1 rij en 1 kolom voor. De kruistabellen die hierna vernoemd worden, wijken alle in meer of mindere mate af van deze eigenschappen van een “gewone” kruistabel. Andere soorten kruistabellen, die met behulp van correspondentie-analyse, i.c. ANACOR, kunnen worden geanalyseerd, zijn bijvoorbeeld :
• kruistabellen, die zowel over rijen als kolommen niet sommeren tot het aantal objecten in de steekproef ;
• tijdreeksgegevens ; • respondenten x variabelen ; • produkten x eigenschappen ; • dissimilariteiten, enz.
Bij de analyse van dergelijke data, dienen een aantal regels in acht genomen te worden.
• In het geval van de analyse van “non-frequency”-data is het niet zinvol om interpretaties te verbinden aan chikwadraat- afstanden. De toepassing van ANACOR op “non-frequency”-data heeft in eerste instantie tot doel een visuele voorstelling van de structuur van de data te bekomen3.
• Indien ANACOR wordt toegepast op rangorde-data (e.g. bekomen door toepassing van de methode van de paarsgewijze vergelijking) dan

Correspondentie-analyse in Marktonderzoek - 14 __________________________________________________________________________________________________
J. Blomme – [email protected]
dient de meest geprefereerde keuze de hoogste waarde te krijgen in de te analyseren matrix van rangorden.
• Indien de data die met behulp van ANACOR geanalyseerd worden, georganiseerd zijn onder de vorm van ongelijkheden (“dissimilarities”), dan dienen alle ongelijkheden in de matrix afgetrokken te worden van een getal groter dan de grootste ongelijkheid (meestal wordt bij dit laatste gekozen voor een getal dat 1 groter is dan de grootste dissimilariteit).
• In het geval van de analyse van symmetrische relaties dienen de diagonaalwaarden gelijkgesteld te worden aan de grootste waarde +1.
3.3. HOMALS : Meervoudige correspondentie-analyse
Om de relatie met het voorgaande te benadrukken zij opgemerkt dat HOMALS ook bekend staat als meervoudige correspondentie-analyse. Het belangrijkste verschil met ANACOR is dat nu meer dan twee variabelen in de analyse worden betrokken. Waar bij ANACOR de datamatrix een kruistabel is, is bij HOMALS de datamatrix de eerder vermelde indicatormatrix. Dus de matrix van dummy-variabelen per respondent. De respondenten staan doorgaans in rijen en de categorieën van de variabelen in kolommen. Bij HOMALS houdt optimale schaling in dat per variabele zodanige categoriekwantificaties (optimale scores) worden berekend dat de categorieën van een variabele zover mogelijk uit elkaar liggen. Naar analogie met ANACOR krijgen ook de rijen, bij HOMALS de respondenten, een score, de zogenaamde objectscores. De objectscores worden zodanig berekend dat de categoriekwantificaties het gemiddelde vormen van de objecten (respondenten) die in die categorie vallen. HOMALS tracht respondenten die in dezelfde categorie vallen zo dicht mogelijk bij elkaar te plaatsen en respondenten die in verschillende categorieën vallen ver van elkaar te plaatsen. Idealiter verdelen de categorieën de respondenten in homogene groepen. Variabelen worden homogeen genoemd als ze de respondenten in nagenoeg dezelfde subgroepen opsplitsen. HOMALS kan krachtens het voorgaande in marktonderzoektermen dan ook gezien worden als een techniek waarmee men segmentatie-analyses kan verrichten. Met het bijkomend voordeel, dat variabelen van
verschillend meetniveau in eenzelfde analyse kunnen betrokken worden.
Omdat HOMALS betrekking heeft op meer dan twee variabelen zijn er ook belangrijke verschillen in uitvoer en resultaten in vergelijking met gewone correspondentie-analyse. Een van de meest wezenlijke verschillen is dat bij correspondentie-analyse (ANACOR) de eta of correlatieratio aangeeft wat de correlatie is op een bepaalde dimensie tussen twee optimaal geschaalde variabelen. Bij HOMALS geeft de eta aan wat de gemiddelde bijdrage is van alle betrokken analysevariabelen aan een bepaalde dimensie. Per dimensie wordt per variabele een zogenaamde discriminatiemaat berekend. Deze discriminatiemaat geeft o.m. aan hoe goed de categorieën van een variabele ruimtelijk gespreid zullen worden bij een grafische weergave. De discriminatiemaat geeft in feite dus de variantie weer van een optimaal geschaalde variabele.
Hoe hoger de discriminatiemaat van een variabele, hoe verder de categorieën van die variabele uit elkaar en van de oorsprong liggen. Als we alle discriminatiematen op een bepaalde dimensie optellen en delen door het aantal variabelen krijgen we een beeld van de “fit” (de gemiddelde discriminatiemaat). Indien de gemiddelde discriminatiemaat laag is, kan dit een gevolg zijn van het feit dat enkele variabelen een zeer hoge discriminatiemaat hebben en sommige een zeer lage, zodat vaak meer dimensies nodig zijn om een compleet beeld te krijgen. Een lage gemiddelde discriminatiemaat kan ook betekenen dat geen enkele variabele een grote bijdrage levert aan een bepaalde dimensie.
Bij de interpretatie van de resultaten van een HOMALS-analyse dient rekening te worden gehouden met een aantal “eigenaardigheden”.
Net zoals bij ANACOR worden categorieën met een klein randtotaal verder van de oorsprong gelegd dan categorieën met een groot randtotaal.
HOMALS rekent per dimensie aparte categoriekwantificaties uit per variabele. Het aantal onafhankelijke kwantificaties kan nooit groter zijn dan het aantal categorieën minus 1. Dus als bv. 10 variabelen met elk drie categorieën onderworpen worden aan een HOMALS-analyse dan zullen er maximaal (3-1) = 2 dimensies mogelijk zijn met onafhankelijke kwantificaties.
Indien de variabelen die aan een HOMALS-analyse onderworpen worden een “goede” schaal vormen (d.w.z. een ééndimensionele schaal vormen), dan zal de tweede dimensie lineair afhankelijk zijn van de eerste dimensie. Dit kan grafisch gevisualiseerd

Correspondentie-analyse in Marktonderzoek - 15 __________________________________________________________________________________________________
J. Blomme – [email protected]
worden. Indien een aantal variabelen een ééndimensionele schaal vormen, dan zal een plot van de categoriekwantificaties op de eerste en tweede dimensie een hoefijzerpatroon te zien geven. Zo’n hoefijzerpatroon kan onder bepaalde voorwaarden gezien worden als een signaal dat de dimensie alle relevante informatie bevat.
Als bij een gegeven oplossing, zeg in twee dimensies, een derde dimensie wordt berekend, dan blijven de eerste (twee) dimensies onveranderd. Net zoals in het geval van ANACOR zijn de verschillende dimensies bij HOMALS “genest”.
Als alle dimensies worden berekend dan zal de som van de discriminatiewaarden per variabele gelijk zijn aan het aantal categorieën per variabele minus 1. Dit betekent dat een variabele met veel categorieën een potentieel hogere discriminatiemaat kan hebben dan een dichotome variabele. Een gevolgtrekking is dan ook dat indien er grote verschillen zijn in het aantal categorieën van de variabelen die aan een HOMALS-analyse worden onderworpen, dit ook de interpretatie van de bekomen resultaten zal bemoeilijken. Het verdient daarom aanbeveling om na te gaan of via hercodering er voor gezorgd kan worden dat de variabelen die in een HOMALS-analyse betrokken worden, zoveel mogelijk een gelijk aantal categorieën hebben.
HOMALS is gevoelig voor “outliers” : respondenten met een unieke score. Het niet opmerken van “outliers” kan tot gevolg hebben dat men oplossingen inspecteert die volledig bepaald worden door één of enkele respondenten. Het is dus van belang ook (en vooral) bij grotere databases de objectscores te inspecteren op extreme (absolute waarde) objectscores. Indien zo’n situatie zich voordoet zijn er enkele strategieën mogelijk, w.o.
• de desbetreffende respondenten elimineren ; • de waarde(n) voor de desbetreffende
respondenten op de betrokken variabele(n) op “missing” zetten ;
• hercodering ; • indien alleen de eerste en tweede dimensie
enkele “outliers” bevatten deze dimensies negeren en alleen de derde en volgende dimensies gebruiken.
Indien er hoge discriminatiewaarden (bijna 1.0) worden gevonden, hoeft dit niet altijd een bruikbaar resultaat op te leveren. Het is goed mogelijk dat een hoge discriminatiemaat een gevolg is van een categorie met een laag randtotaal. Het is daarom aan te bevelen om de bijdrage van de
categorieën van variabelen aan de discriminatiematen per dimensie te berekenen. De bijdrage is de categoriekwantificatie in het kwadraat vermenigvuldigd met de relatieve frequentie van de desbetreffende categorie. Een categorie met een geringe bijdrage kan als “outlier” beschouwd worden (mogelijke oplossingen : hercodering, categorie op “missing” zetten).
Zowel HOMALS als ANACOR zijn dimensiereductietechnieken. HOMALS en ANACOR zullen trachten de chikwadraatafstanden tussen rijen en kolommen in een zo klein mogelijk aantal dimensies weer te geven. Het weglaten van dimensies leidt tot verlies aan informatie. In een aantal gevallen zal een tweedimensionele grafische weergave van de HOMALS-resultaten tot een verkeerd beeld van de afstand tussen categorieën van variabelen leiden.
4. Toepassingen van correspondentie-analyse in marktonderzoek
We zullen in hetgeen volgt de toepassing van correspondentie-analyse in marktonderzoek illustreren aan de hand van een tweetal voorbeelden. In een eerste voorbeeld wordt de bruikbaarheid van correspondentie-analyse aangetoond voor het analyseren van (dis)similariteitsgegevens. Voor deze toepassing maken we gebruik van een onderzoek van Bouts en Mackor (1991) over merkassociaties bij banken. In een tweede toepassing wordt aangetoond hoe via een indicatormatrix inzicht kan verkregen worden in gebruikspatronen van frisdranken. De gegevens voor deze analyse ontlenen we aan Kuylen (1990). In beide gevallen werden de gegevens van voornoemde auteurs door onszelf geanalyseerd door gebruikmaking van de ANACOR, resp. HOMALS-procedure zoals opgenomen in de SPSS-module “Categories”.
4.1. Merkassociaties bij banken
Het beeld van de bank als merk bestaat, zoals bij alle merken, uit een veelheid van associaties. Door deze associaties van de consument krijgt het onvatbare merk voor hem/haar gestalte. Het psychologische merk (het merk in hoofde van de consument) kan worden onderverdeeld in drie categorieën : zintuiglijk, emotioneel en rationeel. Zintuiglijk roepen banken weinig associaties op.
Correspondentie-analyse in Marktonderzoek - 16 __________________________________________________________________________________________________
J. Blomme – [email protected]
Dat heeft te maken met het feit dat de dienstverlening van een bank voor een belangrijk deel onzichtbaar en ongrijpbaar is. Emotionele en vooral rationele associaties bestaan daarentegen wel bij banken. Het beeld dat mensen van een bank hebben, wordt echter sterk opgehangen aan de eigen bank. Het gevolg hiervan is dat bij imago-onderzoek naar banken heel sterk het profiel van de eigen bank wordt teruggespeeld. Dat wil echter niet zeggen dat consumenten geen beeld hebben van andere banken dan hun eigen bank. Dagelijks zien ze advertenties van banken en worden zij geconfronteerd met verhalen over de dienstverlening van banken. Alleen rijst de vraag : hoe krijgen we die beelden boven water ? Hoe brengen we die meerdimensionele beeldvorming nu tevoorschijn ?
In de eerste plaats is er kwalitatief onderzoek naar het imago van banken. Imago-onderzoek bij banken in een kwalitatieve opzet wordt uitgevoerd door middel van groepsdiscussies en diepte-interviews. Hierbij wordt o.m. gebruik gemaakt van projectieve technieken (bv. foto-sort). Kwalitatief onderzoek kan een heel levendig beeld van banken naar voren brengen, maar kwantificering ontbreekt. Uiteindelijk willen we immers te weten komen hoe banken zich positioneren in hoofde van consumenten en welke dimensies die positionering kunnen verklaren.
In sommige kwantitatieve studies moeten respondenten aangeven of een bepaalde eigenschap al of niet past bij een bank. Deze methode geeft vrij vlakke beelden. Het is daarom minder aangewezen mensen te vragen ‘wat past bij wat’, maar ze te confronteren met groepen (sets) van banken en daartussen overeenkomsten en verschillen laten aangeven. Respondenten zijn immers in staat om banken in groepen in te delen en vanuit deze vergelijking associaties te formuleren. Een voorbeeld hiervan is de “natural grouping”-techniek die zeer geschikt is om associatieve netwerken in kaart te brengen. Een andere methode is het gebruik van triade-technieken, waarbij de respondent bij groepjes van drie (triade) moet aangeven welke van de drie hij/zij het meest bij elkaar vindt passen en welke twee het minst bij elkaar passen. In het onderzoek van Bouts en Mackor (1991) is gebruik gemaakt van deze methode. Het onderzoek is uitgevoerd met behulp van een telepanel dat een representatief staal is van de Nederlandse bevolking. De leden van het telepanel hebben thuis een homecomputer staan. Het gaat dus om computergestuurde enquêtering. Aan de respondenten werd een lijst van zes banken voorgelegd : ABN, AMRO, NMB, Postbank, RABO en Spaarbank. Vooraleer de respondenten de
eigenlijke vragenlijst te zien kregen, werd gevraagd welke van deze banken zij niet kenden. Respondenten die één of meerdere banken niet kenden werden niet in het onderzoek opgenomen. Respondenten die de banken wel kenden, kregen alle mogelijke (10) combinaties van deze (6) banken op het beeldscherm te zien. De vraagstelling was als volgt : Welke van deze banken vindt u het meest bij elkaar passen ? Vervolgens werd gevraagd waarom ze een bepaalde combinatie van banken als het meest bij elkaar passend vonden. Hierbij konden de respondenten kiezen uit een lijst met associaties. Om de bruikbaarheid van correspondentie-analyse aan te tonen voor het analyseren van (dis)similariteitsgegevens, beperken we ons in hetgeen volgt tot de combinaties van banken die door de respondenten werden naar voren geschoven als meest passend. Om de ‘afstand’ tussen banken te bepalen, is in het onderzoek gebruik gemaakt van het aantal keren dat een combinatie van banken wordt genoemd als meest passend.
In tabel 14 is voor elke combinatie tussen banken aangegeven hoeveel keer deze door de respondenten als meest passend naar voren werd geschoven. Zoals eerder aangestipt, dienen “non frequency”-data in het geval van correspondentie-analyse (ANACOR) behandeld te worden als similariteiten. In het door ons gekozen voorbeeld van combinaties tussen banken , geven de frequenties waarmee banken als meest passend worden gepercipieerd een aanduiding van de gelijkenis of similariteit tussen banken. De gegevens dienen derhalve niet aangepast te worden4. Aangezien we een symmetrische matrix invoeren, worden de diagonaalwaarden gelijkgesteld aan de grootste gelijkenis + 1 (59 +1 = 60).
Tabel 14 : Aantal keren dat combinaties van banken als meest passend worden genoemd (Bouts & Mackor, 1991 : 55 ; eigen
bewerking)
ABN AMRO NMB POST BANK
RABO SPAAR BANK
ABN 60 59 43 24 25 16
AMRO 59 60 34 17 43 19
NMB 43 34 60 44 26 21
POSTBANK 24 17 44 60 25 55
RABO 25 43 26 25 60 48
SPAAR BANK
16 19 21 55 48 60
Hoewel de interpretatie van het begrip “chikwadraatafstand” in het geval van “non-frequency”-data met de nodige voorzichtigheid

Correspondentie-analyse in Marktonderzoek - 17 __________________________________________________________________________________________________
J. Blomme – [email protected]
dient te gebeuren (cfr. supra), kunnen de resultaten m.b.t. de chikwadraat-decompositie wel meer duidelijkheid verschaffen aangaande het belang van onderscheiden dimensies ter verklaring van verschillen tussen banken. In onderstaande tabel zijn de resultaten van deze decompositie opgenomen. Hieruit blijkt dat de eerste en twee dimensie samen 95,6% van de variantie afsplitsen. Hieraan kan de conclusie verbonden worden dat de bijdrage van de derde dimensie verwaarloosbaar laag is. Een oplossing in twee dimensies volstaat. Afgaand op de correlatieratio’s voor beide dimensies (dimensie 1 en 2), constateren we dat de sterkste verschillen tussen banken zich aftekenen op de eerste dimensie.
Tabel 15 : Uitsplitsing van de bijdragen per dimensie
dim singular
value inertia
proportion explained
cumulative proportion
1 .356 .127 .699 .699
2 .219 .048 .266 .965
3 .068 .005 .026 .991
4 .039 .002 .008 .999
5 .013 .000 .001 1.000
Total .181 1.000
Een nog duidelijker indicatie van de verschillen tussen banken kan opgemaakt worden uit de mapping en de bijdragen van de kolom- en rijpunten aan de « inertia » van de eerste twee dimensies (aangezien we een symmetrische matrix analyseren, valt het onderscheid tussen kolom- en rijpunten weg). Op de eerste (horizontale) dimensie tekenen zich visueel twee groepen af, nl. ABN-AMRO enerzijds en POSTBANK-SPAARBANK anderzijds. Op de tweede (verticale) dimensie zijn de verschillen visueel het sterkst tussen NMB enerzijds en RABO anderzijds. Een verdere aanduiding van de verschillen tussen banken wordt verkregen door de bijdragen van de kolom- en rijpunten (banken) aan de eerste en tweede dimensie. Voor de eerste dimensie zijn de contributies de volgende : ABN (.248), AMRO (.218), NMB (.018), POSTBANK (.188), RABO (.015) en SPAARBANK (.314). Voor de verticale dimensie vinden we volgende bijdragen : ABN (.014), AMRO (.078), NMB (.296), POSTBANK (.189), RABO (.381) en SPAARBANK (.041). Vergelijken we per bank de bijdragen aan beide dimensies dan dienen de zojuist genoemde (visuele) verschillen tussen banken enigszins genuanceerd te worden. Op de
eerste dimensie blijken ABN (.248 vs .014) en AMRO (.218 vs .078) enerzijds zich te differentiëren van SPAARBANK (.314 vs .041) anderzijds. Op de tweede dimensie tekenen zich de sterkste verschillen af tussen NMB (.018 vs .296) en RABO (.015 vs .381). De POSTBANK blijkt een tussenpositie in te nemen (.188 op de eerste dimensie en .189 op de tweede dimensie).
Perceptuele mapping van combinaties tussen banken
Hoe moeten we deze afstanden tussen banken nu verklaren ? We kunnen een poging wagen de horizontale as en de verticale as te benoemen maar eigenlijk hebben we daar meer gegevens voor nodig. Bouts en Mackor (1991) onderwierpen in dit opzicht de associaties die respondenten vermeldden bij de keuze van een combinatie van banken aan een correnpondentie-analyse. Op die manier werden de associaties tussen banken ruimtelijk vertaald waardoor het mogelijk werd de genoemde verschillen tussen banken te interpreteren. Hoewel het interpreteren van merkassociaties tussen banken op grond van een vooraf geconstrueerde lijst van associaties niet zonder gevaren is (in welke mate stemmen vooraf opgestelde associaties overeen met de percepties van banken door respondenten ?)5, konden Bouts en Mackor aan de hand van hun methode en analysetechniek aantonen dat de fusie tussen AMRO en ABN een juiste keuze is aangezien beide banken bij de ondervraagden grotendeels dezelfde associaties opriepen. In een tijd waarin fusies aan de orde van de dag zijn, kan correspondentie-analyse derhalve een hulpmiddel zijn om na te gaan in hoeverre imago’s van fuserende ondernemingen onderling overeenstemmen.
4.2. Gebruikspatronen van frisdranken
In het volgende voorbeeld illustreren we de toepassing van meervoudige correspondentie-
Correspondentie-analyse in Marktonderzoek - 18 __________________________________________________________________________________________________
J. Blomme – [email protected]
analyse (HOMALS). Meer in het bijzonder zullen we aan de hand van gegevens van Kuylen (1990) aantonen dat correspondentie-analyse een aangewezen analysetechniek is om inzicht te verkrijgen in gebruikspatronen van produkten (in dit geval frisdranken). Zoals eerder uiteengezet wordt in het geval van meervoudige correspondentie-analyse vertrokkken van een indicatormatrix waarbij de categorieën van variabelen worden omgezet in dummy-variabelen. Het hierna te bespreken voorbeeld vormt een variant op dit uitgangspunt omdat de datamatrix die wordt gebruikt voor het analyseren van gebruikspatronen afwijkt van de gebruikelijke indicatormatrix.
Veronderstel dat we geïnteresseerd zijn in de gebruikspatronen van een zevental frisdranken (COLA, dieet-COLA, PEPSI-COLA, dieet-PEPSI, SPRITE, 7UP en dieet-7UP) onder 34 respondenten. De rijen van de datamatrix (indicatormatrix) bestaan uit de respondenten en de kolommen zijn de frisdranken. In tegenstelling tot een gebruikelijke indicatormatrix waarbij voor 7 variabelen met 2 categorieën (gebruiken en niet-gebruiken) 14 kolommen worden voorzien, worden voor de respondenten slechts 8 kolommen voorzien. Elke variabele heeft slechts één categorie, die één is als men een bepaalde frisdrank gebruikt en anders als « missing » wordt beschouwd en dus op 0 wordt gesteld. Deze ogenschijnlijk merkwaardige benadering leidt er toe dat we een beeld krijgen van de combinaties van gebruikspatronen van frisdranken. Door alleen “gebruik” te analyseren en “niet gebruik” als “missing” te beschouwen, wordt voorkomen dat niet gebruik de oplossing gaat domineren. In marktonderzoek komt het immers vaak voor dat vragen worden gesteld over onderwerpen als merkentrouw, cross-selling, substitutie, e.d. Een vraag “Welke produkten van welke merken gebruikt een consument”, kan met behulp van meervoudige correspondentie-analyse (HOMALS) geanalyseerd worden door het gebruik van dummy-variabelen, waarbij – zoals zojuist vermeld – de categorie “niet gebruik” op “missing” wordt gezet. De analyse richt zich vervolgens op de vraag welke combinaties van produkten en/of merken voorkomen.
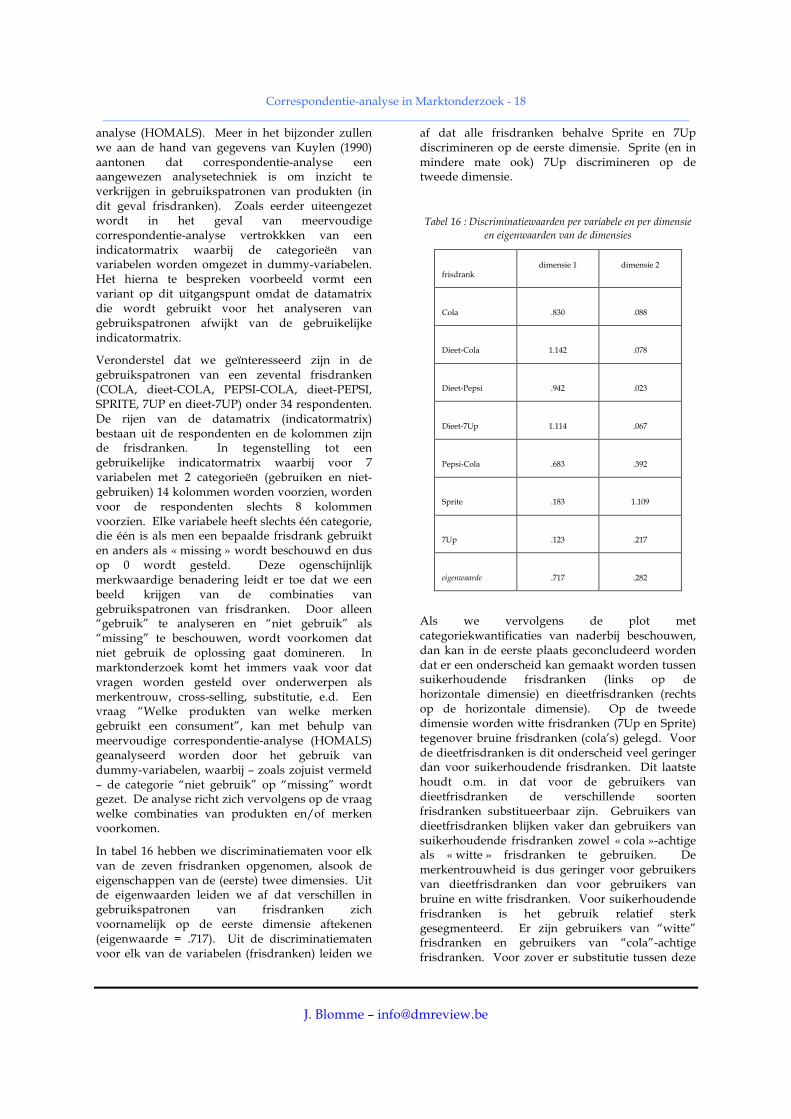
In tabel 16 hebben we discriminatiematen voor elk van de zeven frisdranken opgenomen, alsook de eigenschappen van de (eerste) twee dimensies. Uit de eigenwaarden leiden we af dat verschillen in gebruikspatronen van frisdranken zich voornamelijk op de eerste dimensie aftekenen (eigenwaarde = .717). Uit de discriminatiematen voor elk van de variabelen (frisdranken) leiden we
af dat alle frisdranken behalve Sprite en 7Up discrimineren op de eerste dimensie. Sprite (en in mindere mate ook) 7Up discrimineren op de tweede dimensie.
Tabel 16 : Discriminatiewaarden per variabele en per dimensie en eigenwaarden van de dimensies
frisdrank dimensie 1 dimensie 2
Cola
.830
.088
Dieet-Cola
1.142
.078
Dieet-Pepsi
.942
.023
Dieet-7Up
1.114
.067
Pepsi-Cola
.683
.392
Sprite
.183
1.109
7Up
.123
.217
eigenwaarde
.717
.282
Als we vervolgens de plot met categoriekwantificaties van naderbij beschouwen, dan kan in de eerste plaats geconcludeerd worden dat er een onderscheid kan gemaakt worden tussen suikerhoudende frisdranken (links op de horizontale dimensie) en dieetfrisdranken (rechts op de horizontale dimensie). Op de tweede dimensie worden witte frisdranken (7Up en Sprite) tegenover bruine frisdranken (cola’s) gelegd. Voor de dieetfrisdranken is dit onderscheid veel geringer dan voor suikerhoudende frisdranken. Dit laatste houdt o.m. in dat voor de gebruikers van dieetfrisdranken de verschillende soorten frisdranken substitueerbaar zijn. Gebruikers van dieetfrisdranken blijken vaker dan gebruikers van suikerhoudende frisdranken zowel « cola »-achtige als « witte » frisdranken te gebruiken. De merkentrouwheid is dus geringer voor gebruikers van dieetfrisdranken dan voor gebruikers van bruine en witte frisdranken. Voor suikerhoudende frisdranken is het gebruik relatief sterk gesegmenteerd. Er zijn gebruikers van “witte” frisdranken en gebruikers van “cola”-achtige frisdranken. Voor zover er substitutie tussen deze

Correspondentie-analyse in Marktonderzoek - 19 __________________________________________________________________________________________________
J. Blomme – [email protected]
twee categorieën voorkomt, betreft dit Cola en 7Up.
Gebruikspatronen van frisdranken
Noten
1 Zie hierover o.m. SPSS Categories, SPSS Inc., Chicago, 1998.
2 De gegevens in tabel 6 hebben betrekking op Internetgebruik onder blanke respondenten.
3 Zie voor enkele interessante uitwerkingen hiervan o.m. Sikkel, 1981 ; Javalgi, 1992 ; Bendixen, 1996.
4 Dissimilariteitsgegevens dienen aangepast te worden : op de diagonaal staat de waarde van de grootste ongelijkenis ; de overige waarden worden afgetrokken van deze diagonaalwaarde (zie o.m. WELLER & ROMNEY, A.K., 1990 : 70 e.v.).
5 Een min of meer realiteitsgetrouwe lijst van associaties kan o.m. worden opgesteld aan de hand van voorafgaand kwalitatief onderzoek (groepsdiscussies en individuele diepte-interviews).
Geraadpleegde literatuur
BENDIXEN, M., A practical guide to the use of correspondence analysis in marketing research, Marketing Research On-Line, 1996.
BOUTS, J.M. & MACKOR, O., Merkassociaties bij banken, Tijdschrift voor Marketing, maart 1991, 52-57.
CLAUSEN, S.E., Applied correspondence analysis, London, Sage, Quantitative Applications in the Social Sciences 121, 1998.
GREENACRE, M.J., Theory and applications of correspondence analysis, London, Academic Press, 1989.
HOFFMAN, D.L. & NOVAK, Th.P., The evolution of the digital divide : Examining the relationship of race to Internet access and usage over time, Vanderbilt University, may 1999.
JAVALGI, R., Whipple, Th., McManamon, M. & Edick, V., Hospital image : A correspondence analysis approach, Journal of Health Care Marketing, 1992, pp. 34-41.
KUYLEN, A.A., Schaalmethoden en toepassingen, Hand-out Marktonderzoekseminar SPSS-Benelux, Zeist, 4 juni 1990.
NOVAK, Th.P. & HOFFMAN, D.L., Measuring the customer experience in online environments : A structural modeling approach, Owen Graduate School of Management, Vanderbilt University, 1999.
SIKKEL, D., Grafische weergave van tabellen met correspondentieanalyse, Jaarboek Nederlandse Vereniging voor Marktonderzoek en Informatiemanagement, 1981, pp. 19-29.
TREVINO, L.K. & WEBSTER, J., Flow in computer-mediated communication, Communication Research, 1992, 19(5), 539-573.
VAN DE GEER, J.P., Analyse van kategorische gegevens, Deventer, Van Loghum Slaterus, 1988.
WELLER, S.C. & ROMNEY, A.K., Metric Scaling. Correspondence analysis, London, Sage, Quantitative Applications in the Social Sciences 75, 1990.


















