
Les 10: Geheugenhi ërarchie
130
ca10-1 Les 10: Geheugenhiërarchie Parkinson's laws: "Work expands so as to fill the time available for its completion“ "Expenditure rises to meet income“ “Programs expand to fill all available memory”
-
Upload
deirdre-davenport -
Category
Documents
-
view
26 -
download
0
description
Les 10: Geheugenhi ërarchie. Parkinson's laws: "Work expands so as to fill the time available for its completion“ "Expenditure rises to meet income“ “Programs expand to fill all available memory”. Doelstelling. - PowerPoint PPT Presentation
Transcript of Les 10: Geheugenhi ërarchie

ca10-1
Les 10: Geheugenhiërarchie
Parkinson's laws:"Work expands so as to fill the time available for its completion“
"Expenditure rises to meet income“ “Programs expand to fill all available memory”

ca10-2
Doelstelling
Aanbieden van de illusie van een zeer groot, parallel toegankelijk, goedkoop en snel geheugen, opgebouwd uit
•Kleine snelle geheugens (duur)
•Grote trage geheugens (goedkoop)

ca10-3
Inhoud
• Soorten geheugens
• Lokaliteit
• Caches
• Impact op prestatie
• Ingebedde systemen
• Eindbeschouwingen
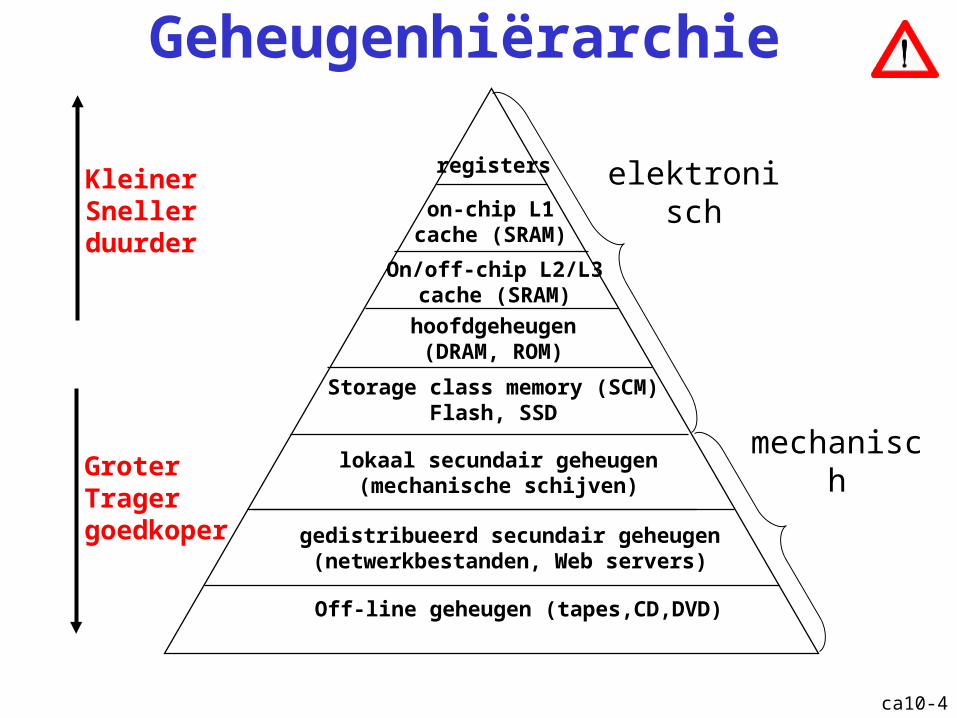
ca10-4
Geheugenhiërarchie
registers
on-chip L1cache (SRAM)
hoofdgeheugen(DRAM, ROM)
lokaal secundair geheugen(mechanische schijven)
GroterTragergoedkoper gedistribueerd secundair geheugen
(netwerkbestanden, Web servers)
On/off-chip L2/L3cache (SRAM)
KleinerSnellerduurder
elektronisch
mechanisch
Off-line geheugen (tapes,CD,DVD)
Storage class memory (SCM)Flash, SSD
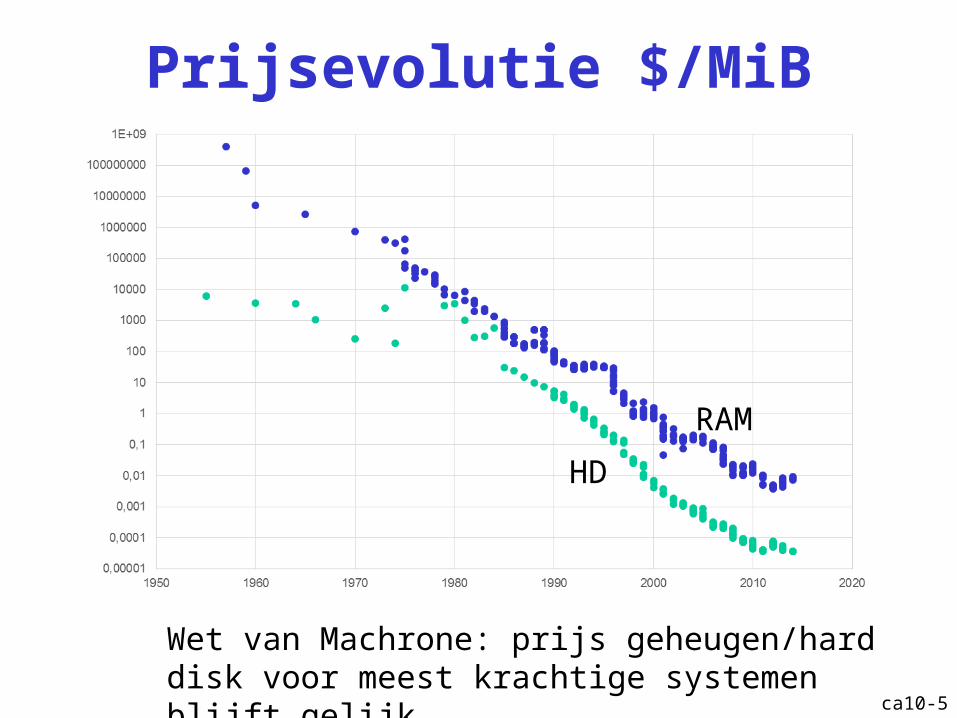
Prijsevolutie $/MiB
ca10-5
Wet van Machrone: prijs geheugen/hard disk voor meest krachtige systemen blijft gelijk
RAM
HD
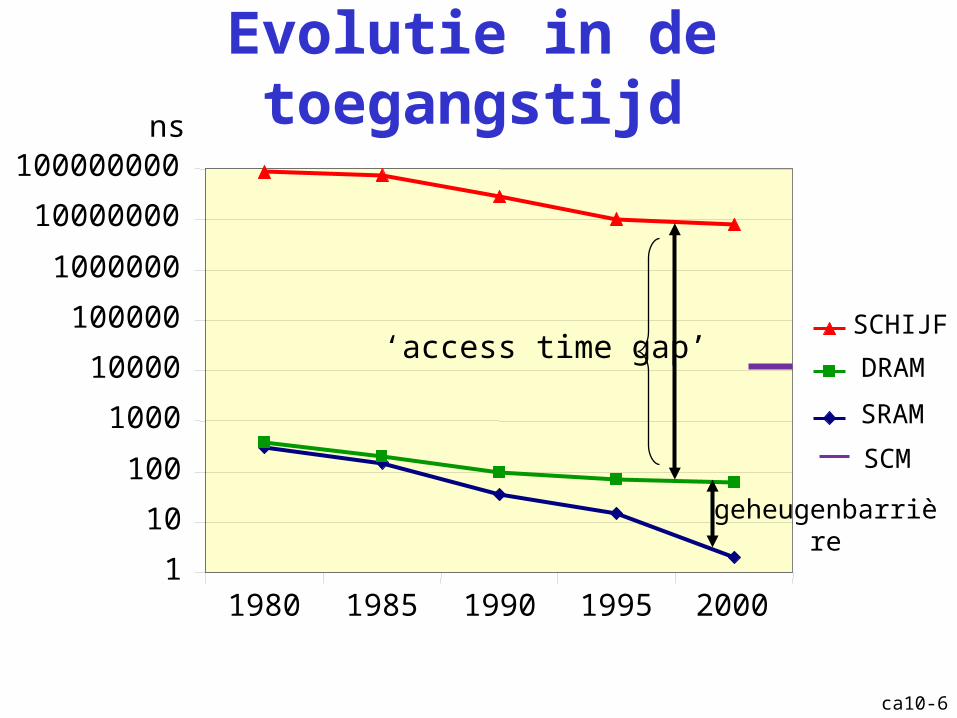
ca10-6
Evolutie in de toegangstijd
1
10
100
1000
10000
100000
1000000
10000000
100000000
1980 1985 1990 1995 2000
SRAM
DRAM
SCHIJF
ns
‘access time gap’
geheugenbarrière
SCM

ca10-7
Registers
• Aantal 8 256 • Grootte: 2-8 bytes• Parallel toegankelijk. Tegelijk lezen en
schrijven mogelijk (meerdere lees- en schrijfpoorten).
• Extreem snel, parallel toegankelijk, zeer duur
• Tijdens uitvoering moeten alle gegevens in registers zitten (IR, data- en adresregisters)

ca10-8
Hoofdgeheugen of RAM:Random Access Memory
Twee technologieën:
• statisch geheugen: gebaseerd op latches.
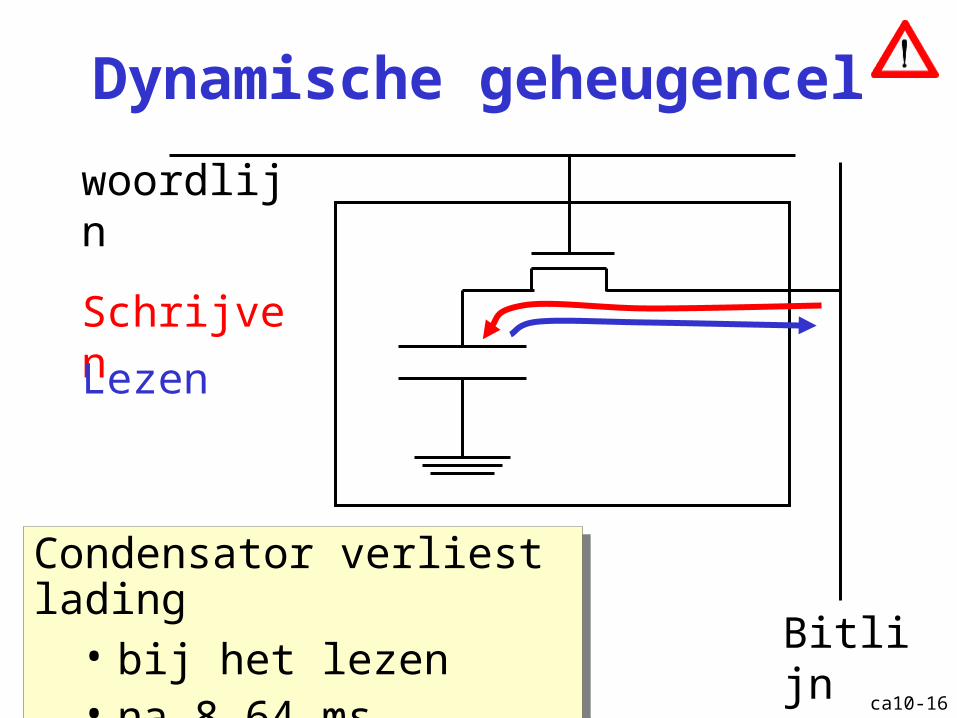
• dynamisch geheugen: gebaseerd op een lading in een condensator
Niet parallel toegankelijk: ofwel lezen ofwel schrijven.
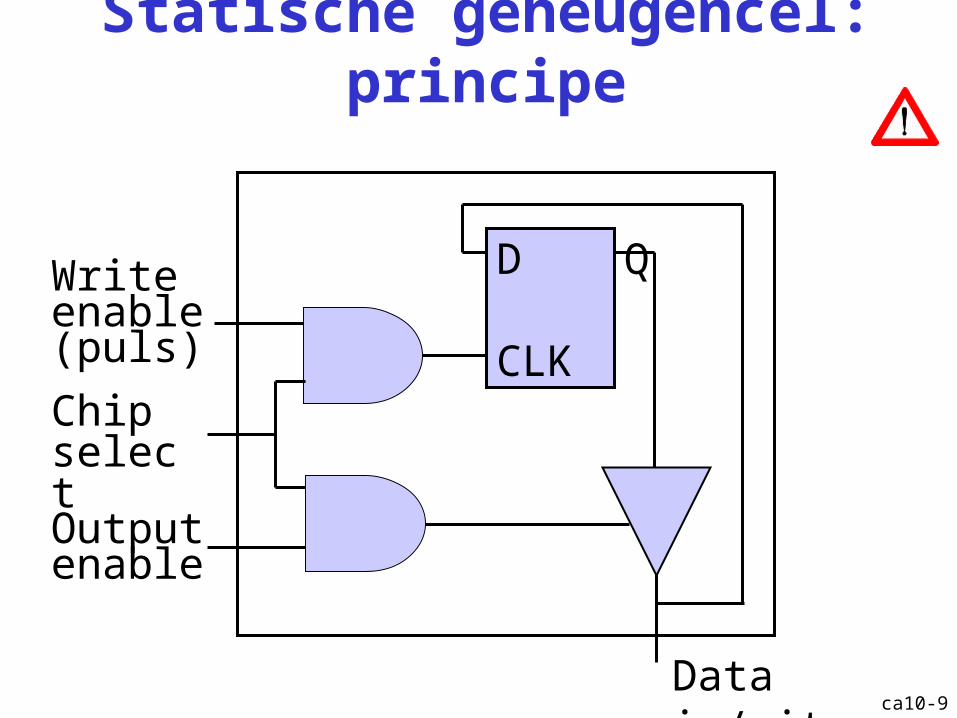
ca10-9
Statische geheugencel: principe
D Q
CLK
Write enable (puls)
Output enable
Data in/uit
Chip select
ca10-10
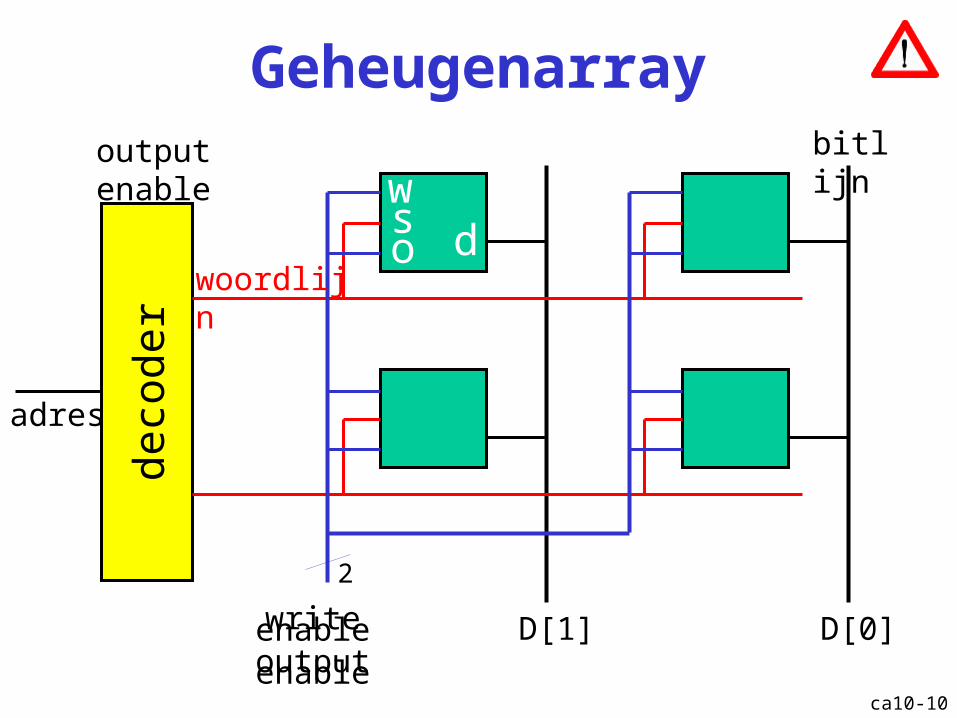
Geheugenarrayde
code
r
write enableoutput enable
adres
D[1] D[0]
ws d
woordlijn
bitlijnoutput enable
o
2
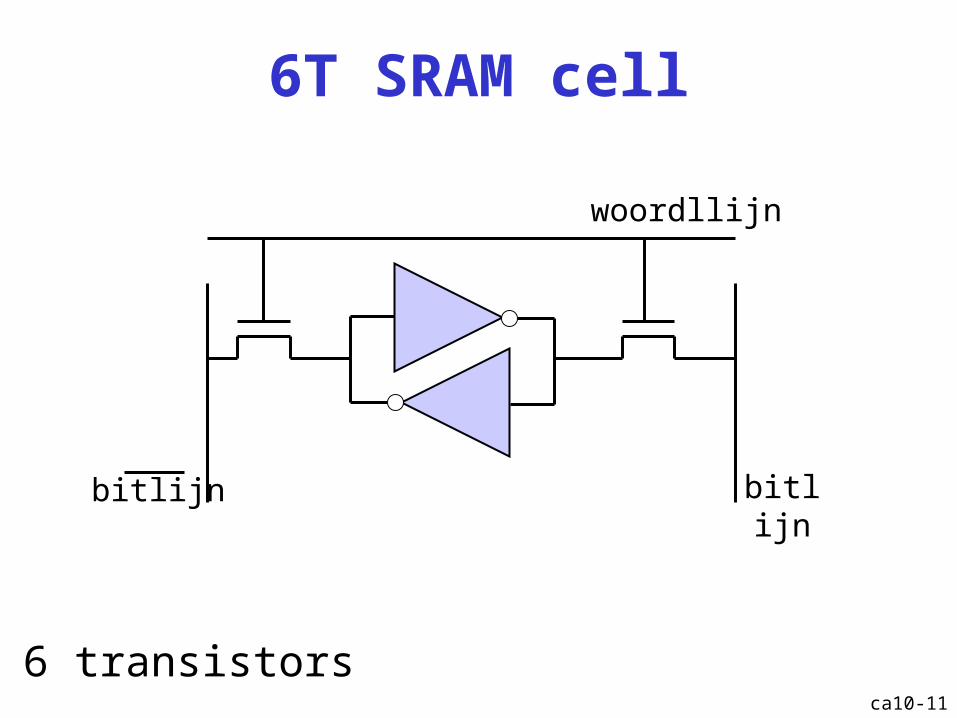
6T SRAM cell
ca10-11
woordllijn
bitlijnbitlijn
6 transistors
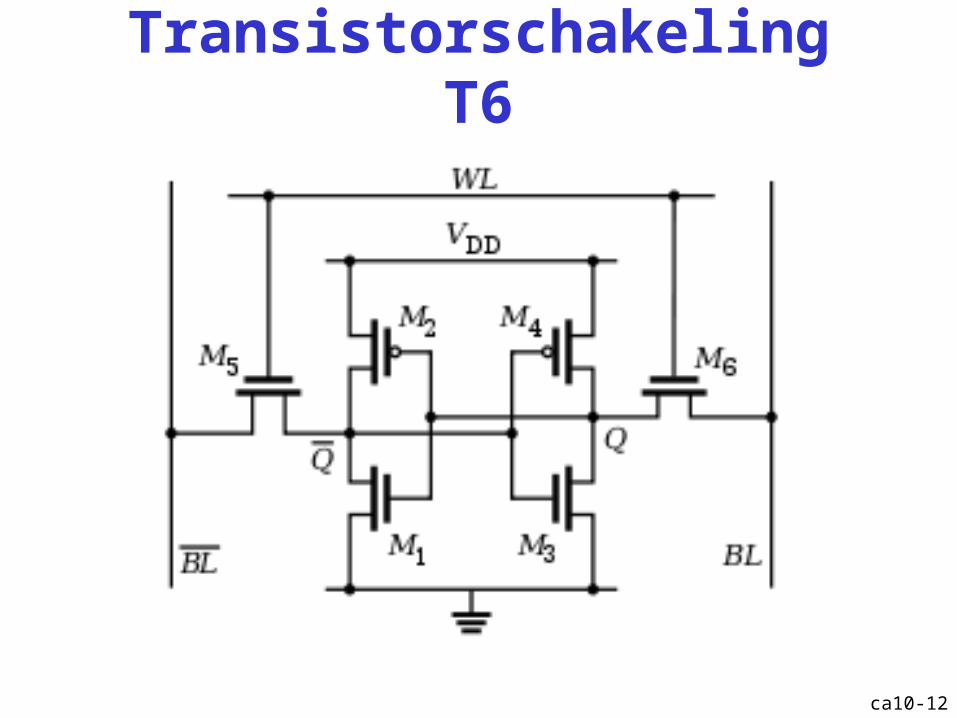
Transistorschakeling T6
ca10-12
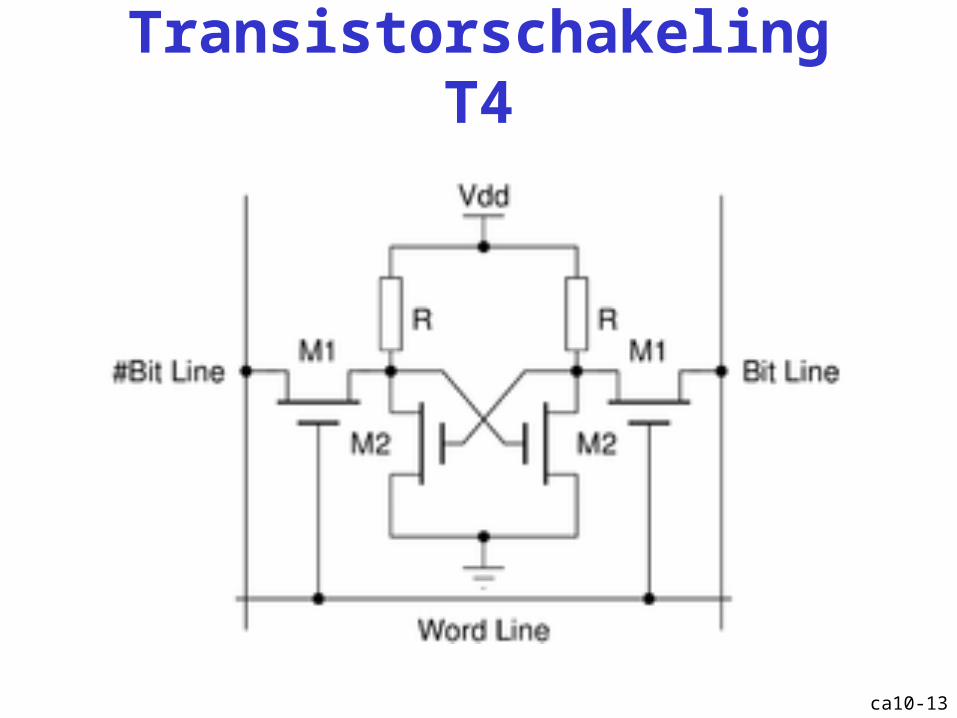
Transistorschakeling T4
ca10-13
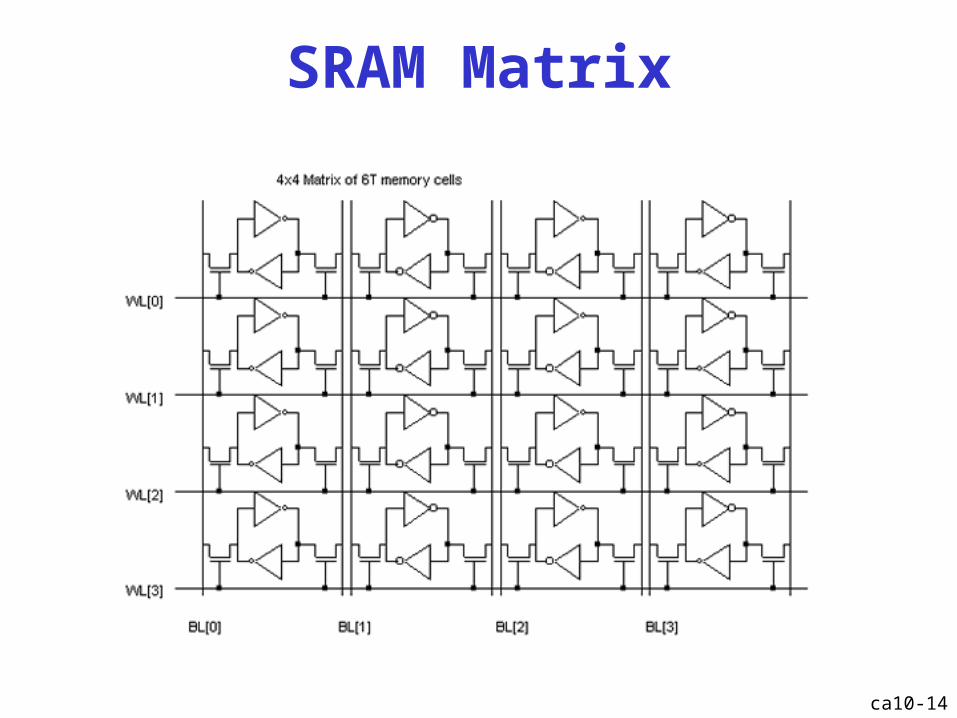
SRAM Matrix
ca10-14
ca10-15
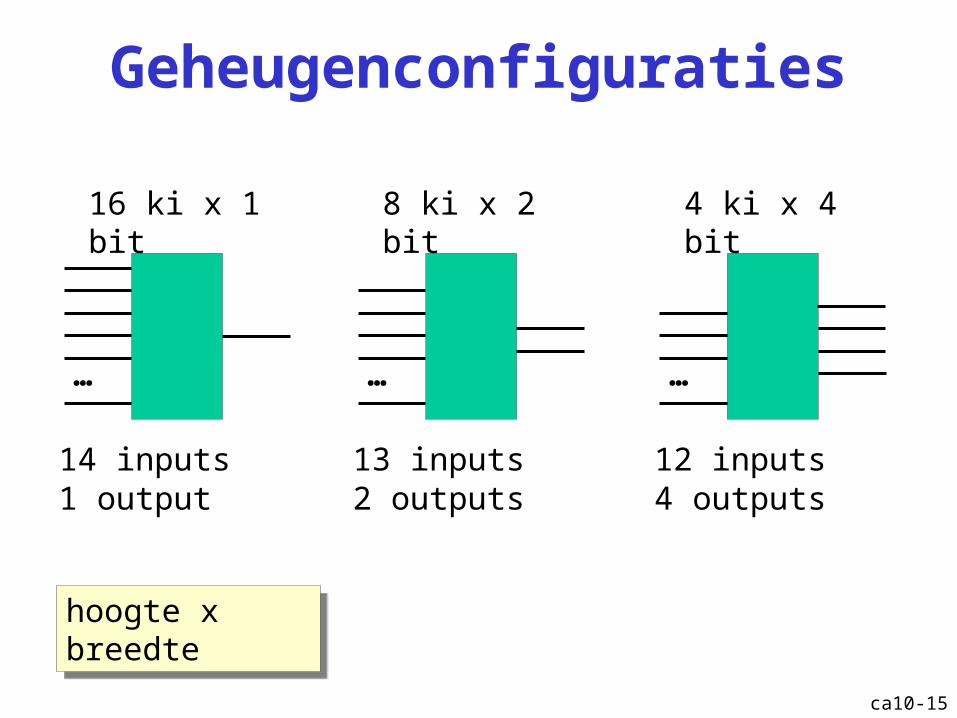
Geheugenconfiguraties
16 ki x 1 bit
14 inputs1 output
8 ki x 2 bit
13 inputs2 outputs
4 ki x 4 bit
12 inputs4 outputs
hoogte x breedtehoogte x breedte
… … …
ca10-16
Dynamische geheugencel
Schrijven
Lezen
Condensator verliest lading • bij het lezen• na 8-64 ms
Condensator verliest lading • bij het lezen• na 8-64 ms
Bitlijn
woordlijn
ca10-17
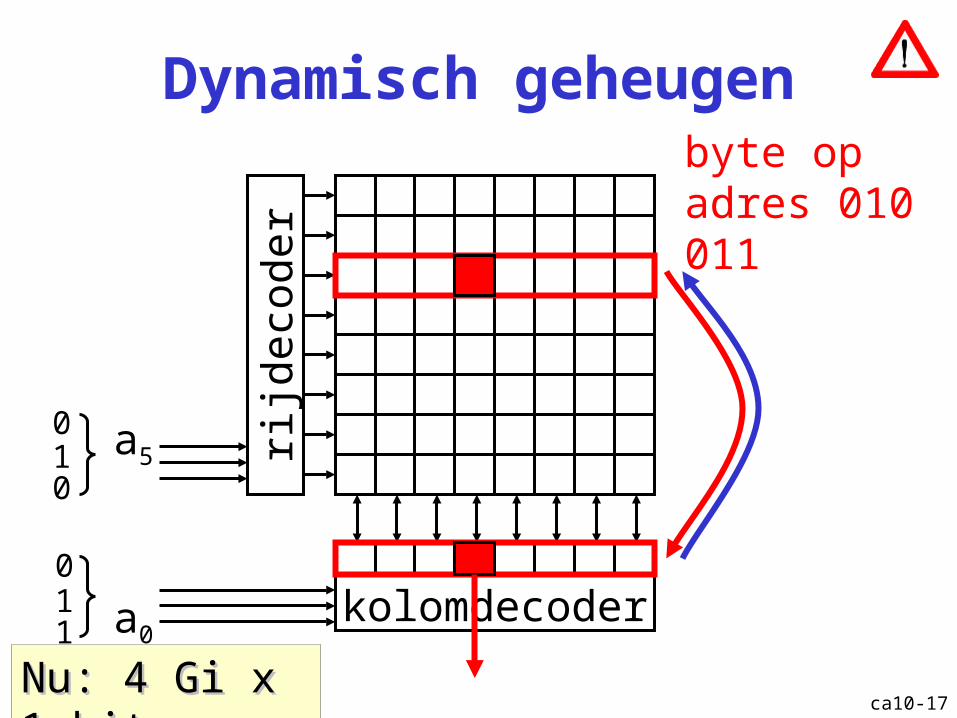
Dynamisch geheugen
rijde
code
r
kolomdecodera0
a5
byte op adres 010 011
011
010
Nu: 4 Gi x 1 bitNu: 4 Gi x 1 bit

ca10-18
Refresh
• Geheugen 32 Mib = 225
– Rij-adres = 12 bit– Kolomadres = 13 bit
• Eerst rij-adres aanleggen, en dan kolomadres• Per 64 ms moeten 4096 rijen gerefresht
worden (lezen + schrijven), d.i. 1 rij per 15 s (64 kHz).
• Een refresh-cyclus duurt 100 ns per rij en tijdens een refresh is de geheugenmodule inactief. De overhead is dus <1%

ca10-19
Kenparameters
Latentie: tijd die verstrijkt tussen het aanleggen van een adres en het verschijnen van het eerste byte.
Bandbreedte: aantal byte/s dat maximaal kan getransfereerd worden (van opeenvolgende locaties).
Effectieve snelheid van het geheugen wordt door deze twee parameters bepaald. Hoe lager in de hiërarchie, des te groter de discrepantie tussen latentie en bandbreedte
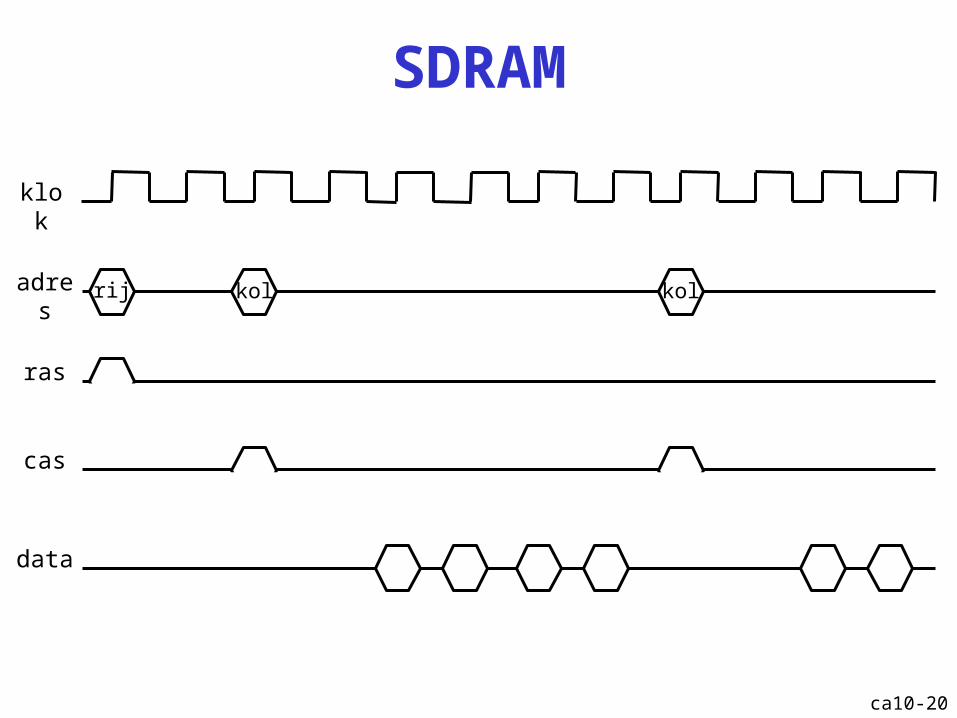
SDRAM
ca10-20
klok
adres
ras
cas
data
rij kol kol
ca10-21
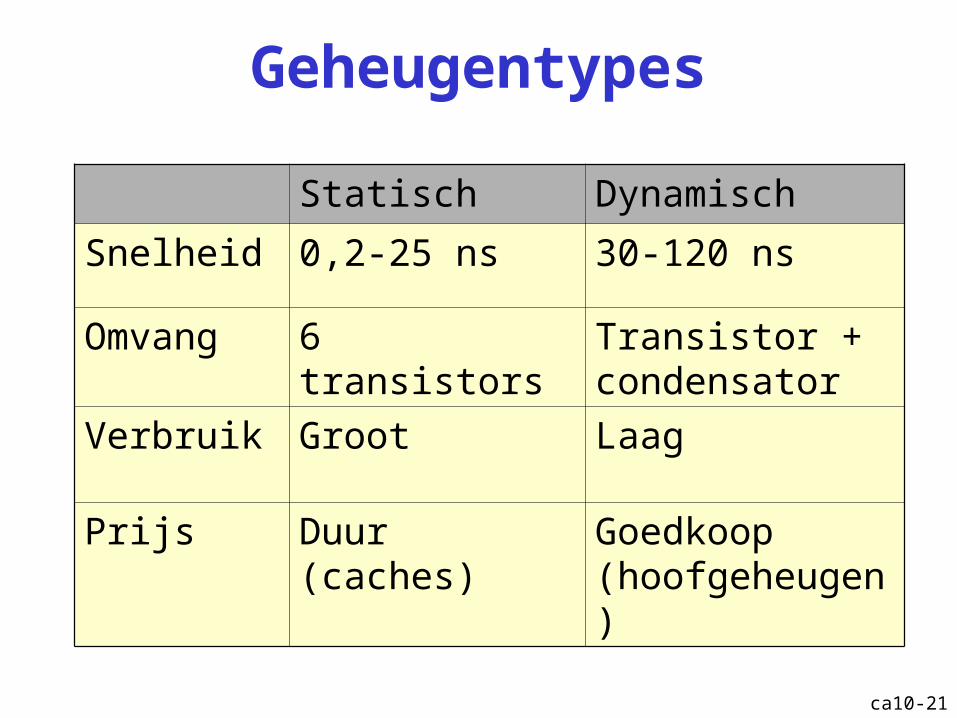
Geheugentypes
Statisch Dynamisch
Snelheid 0,2-25 ns 30-120 ns
Omvang 6 transistors Transistor + condensator
Verbruik Groot Laag
Prijs Duur (caches) Goedkoop (hoofgeheugen)

ca10-22
Permanente geheugentypes
• ROM: Read Only Memory, eigenlijk geen geheugen, maar een combinatorisch circuit.
• PROM: Programmable ROM (1 x)

ca10-23
Permanente geheugentypes
• EPROM: Erasable PROM (n x), wissen met UV licht
• EEPROM: Electrically Erasable PROM, elektrisch te wissen via speciale pin
• FLASH: snelle versie van EEPROM – Compactflash– USB sticks– Solid State Disks
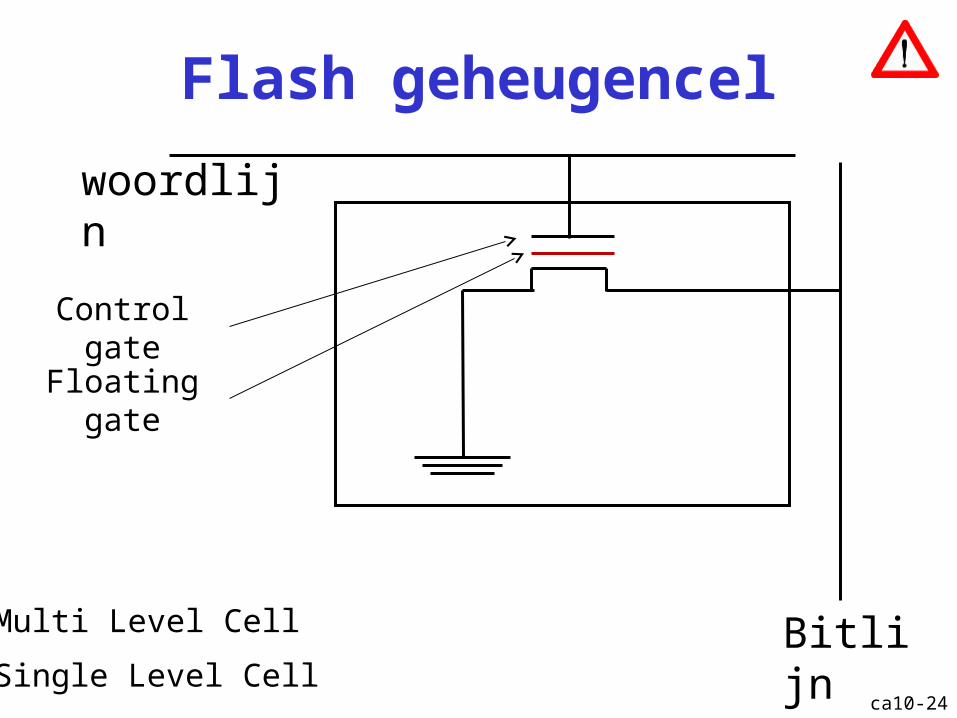
ca10-24
Flash geheugencel
Bitlijn
woordlijn
Control gate
Floating gate
Multi Level Cell
Single Level Cell

ca10-25
Secundair geheugen• Hard disk >100 GB• CD-ROM, CD-RW 650 MB• DVD-ROM, DVD-RAM 4,7-17 GB• Zip-Drive 100-250-750 MB = 95,7-238-714MiB• Floppy disk 1,44 MB = 1,38 MiB• Jaz drive 2 GB• HD-DVD (20 GB) Blu-Ray (27 GB) – in meerdere
lagen reeds to 200 GB (één highres film is ongeveer 12 GB)
• Solid State Drive (SSD)
ca10-26
Magnetische opslag
8.5 nm partikels
100 nm

ca10-27
Inhoud
• Soorten geheugens
• Lokaliteit
• Caches
• Impact op prestatie
• Ingebedde systemen
• Eindbeschouwingen
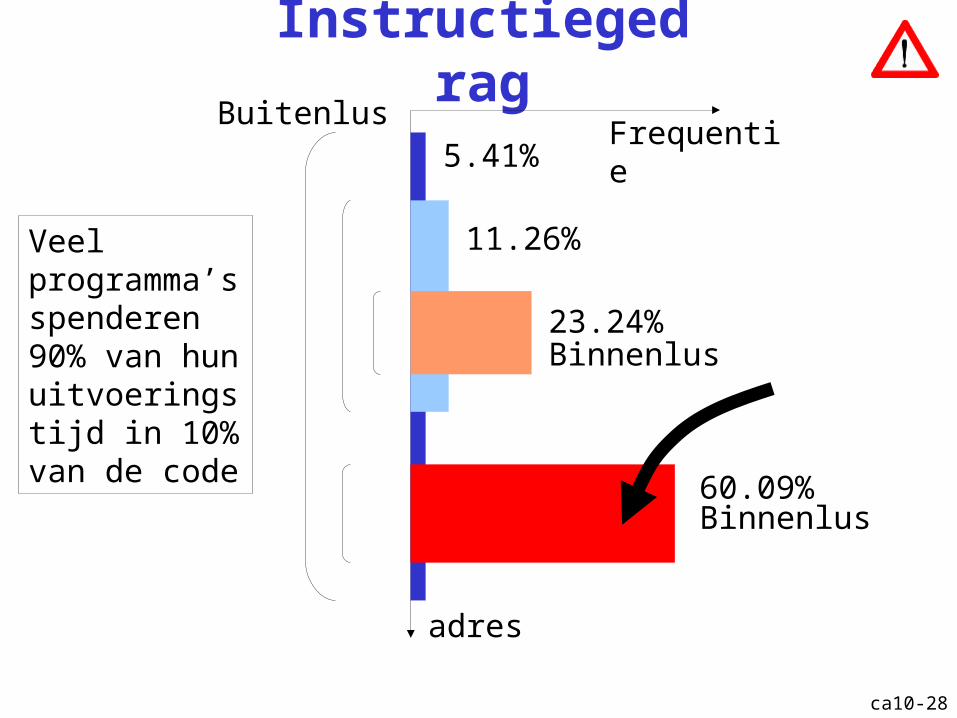
ca10-28
InstructiegedragBuitenlus
Binnenlus
Frequentie
adres
5.41%
11.26%
23.24%
60.09%Binnenlus
Veel programma’s spenderen 90% van hun uitvoeringstijd in 10% van de code

ca10-29
Lokaliteit
• Temporele lokaliteit: sommige geheugenlocaties komen vaak terug in in de adresstroom
• Spatiale lokaliteit: geheugenlocaties in een adresstroom liggen niet ver uit elkaar (b.v. volgen elkaar op).
Lokaliteit: temporeel
Lokaliteit: spatiaal
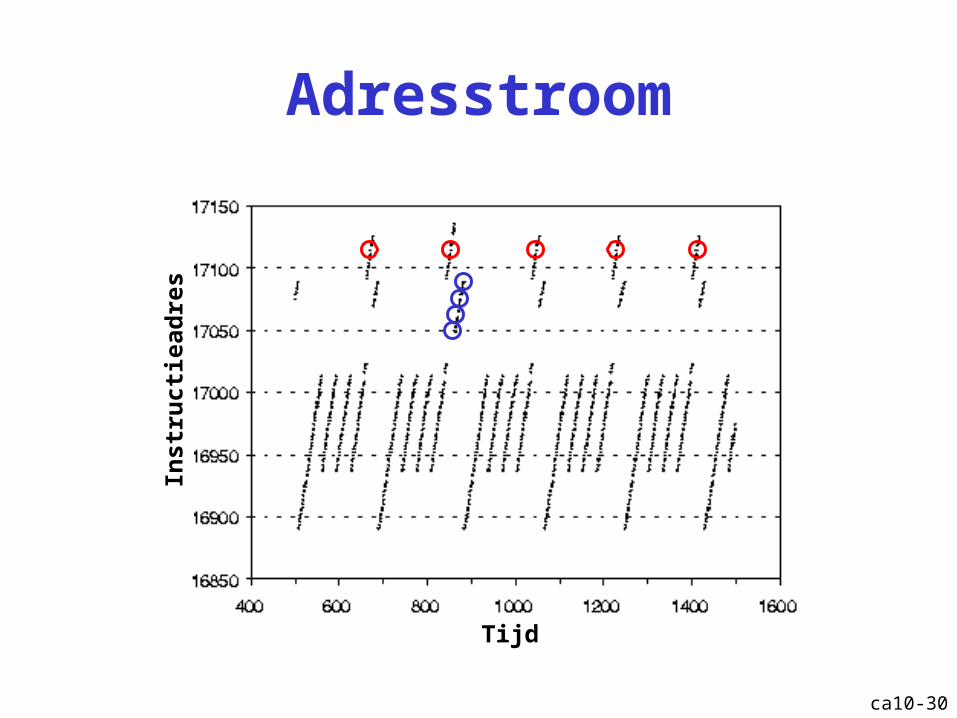
ca10-30
Adresstroom
Tijd
Inst
ruct
iead
res
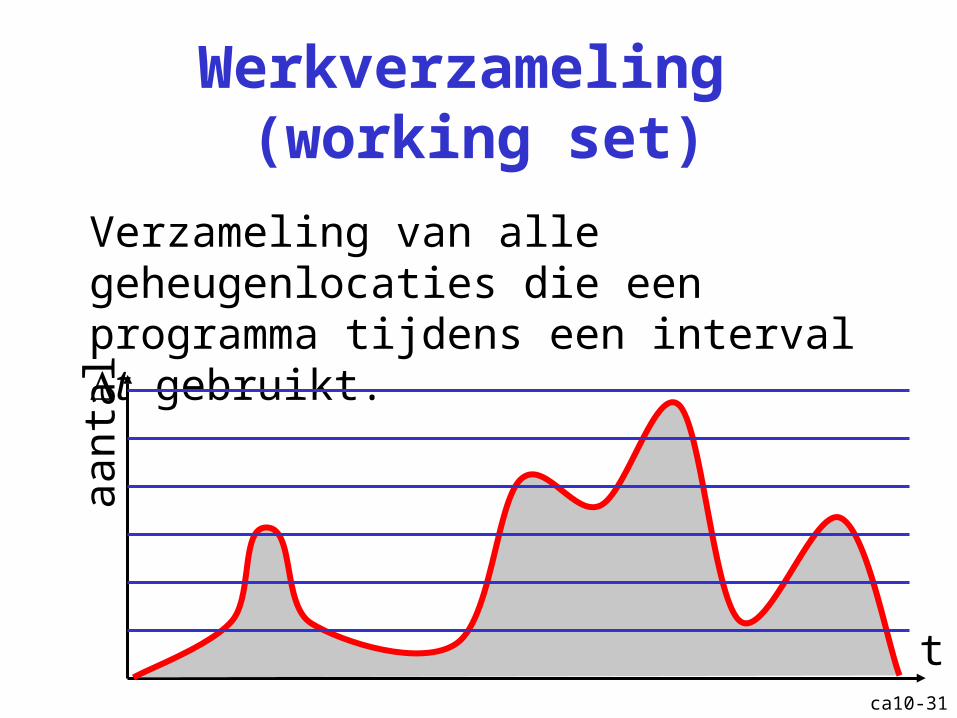
ca10-31
Werkverzameling (working set)
Verzameling van alle geheugenlocaties die een programma tijdens een interval t gebruikt.
t
aant
al

ca10-32
Inhoud• Soorten geheugens• Lokaliteit• Caches
– Werking– Indexering– Vervangingsstrategie– Lees/schrijf strategie– Prestatieverbetering
• Impact op prestatie• Ingebedde systemen• Eindbeschouwingen
Cache keeps intruders away from backcountry supplies
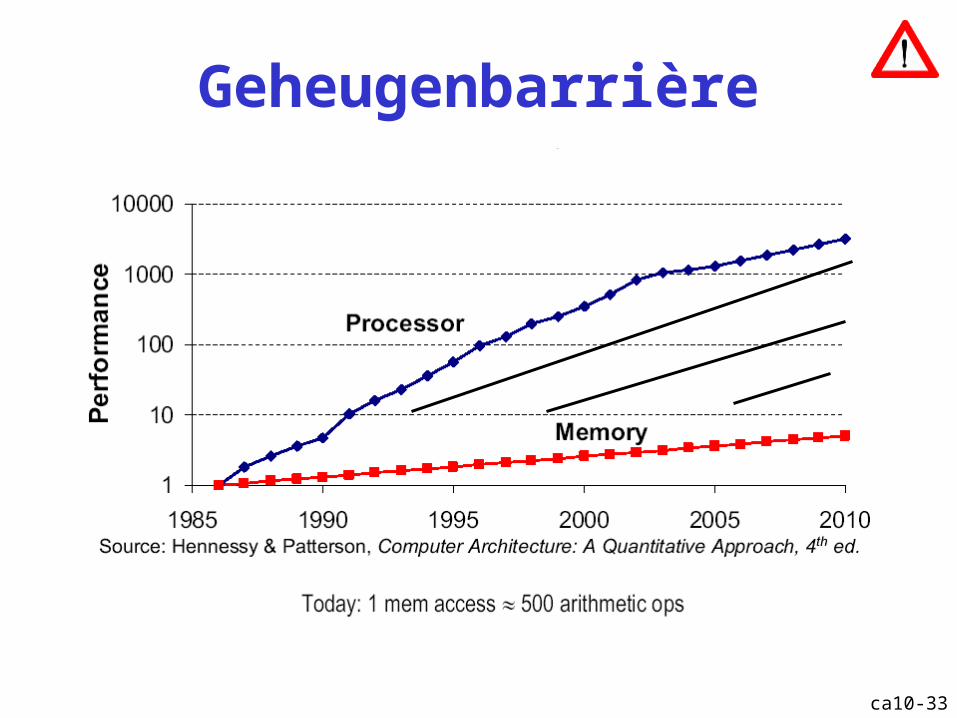
ca10-33
Geheugenbarrière
ca10-34
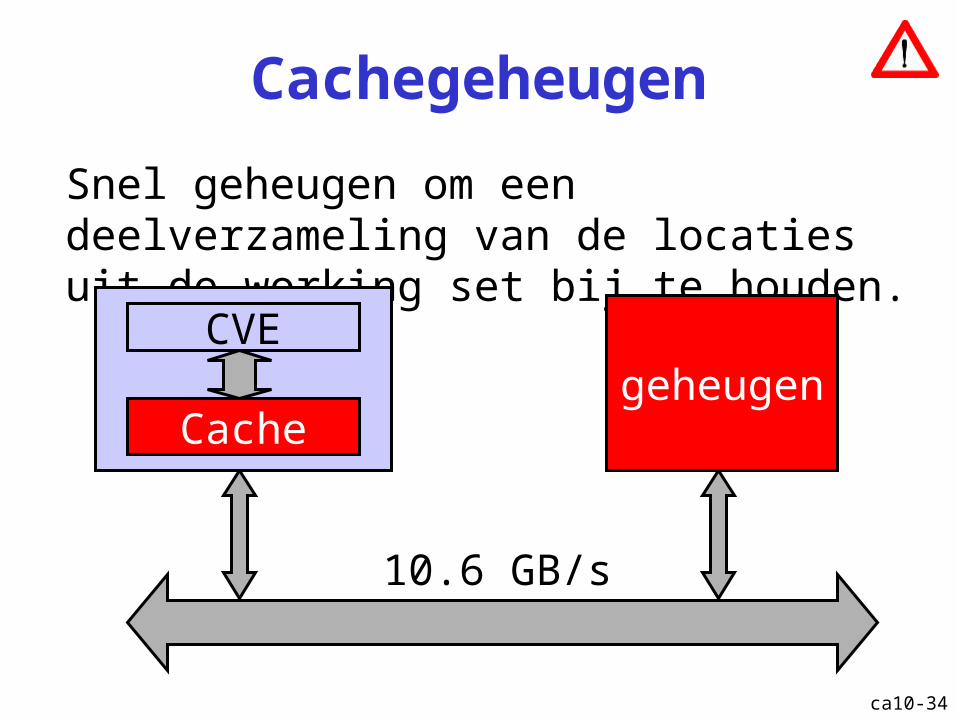
Cachegeheugen
Snel geheugen om een deelverzameling van de locaties uit de working set bij te houden.
geheugenCVE
Cache
10.6 GB/s
ca10-35
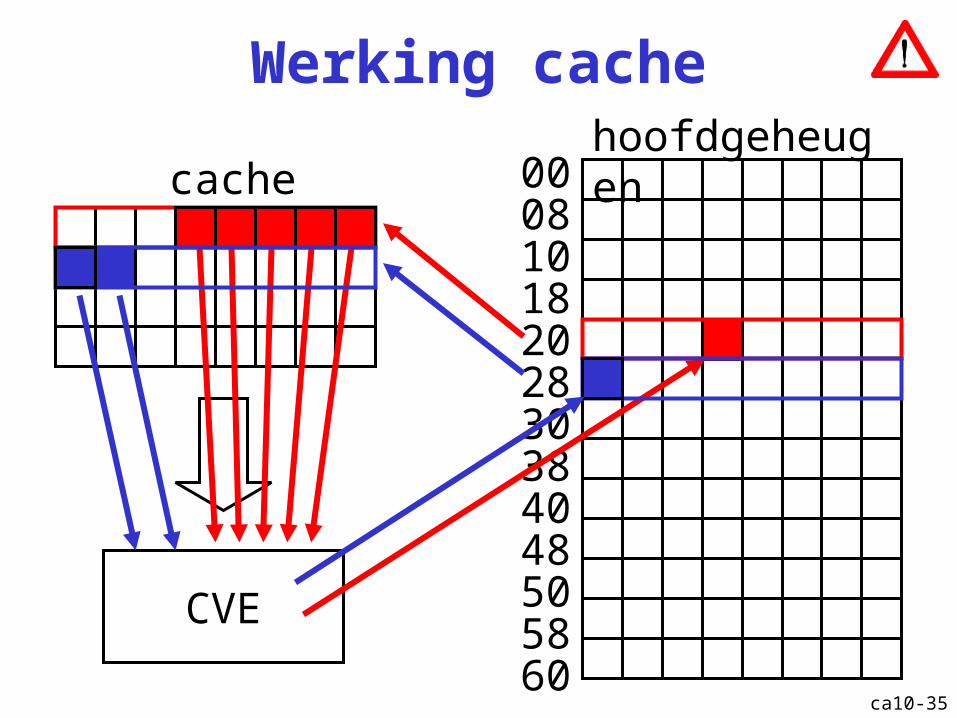
Werking cache
00081018202830384048505860
CVE
cachehoofdgeheugen

ca10-36
Indexering
• Direct-mapped caches
• Set-associatieve caches
• Volledig associatieve caches
ca10-37
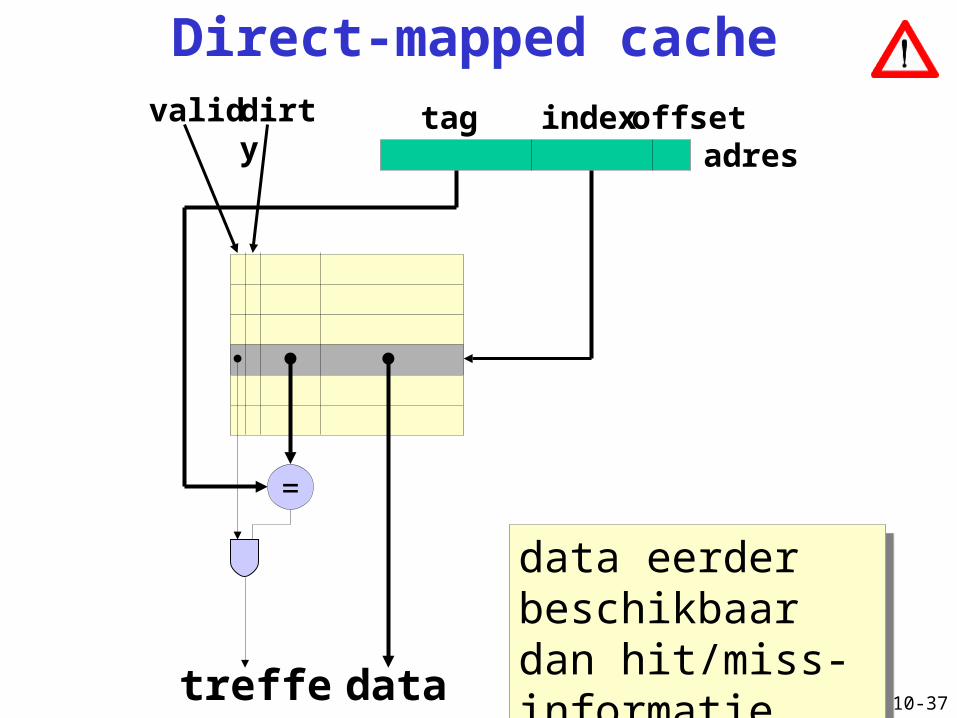
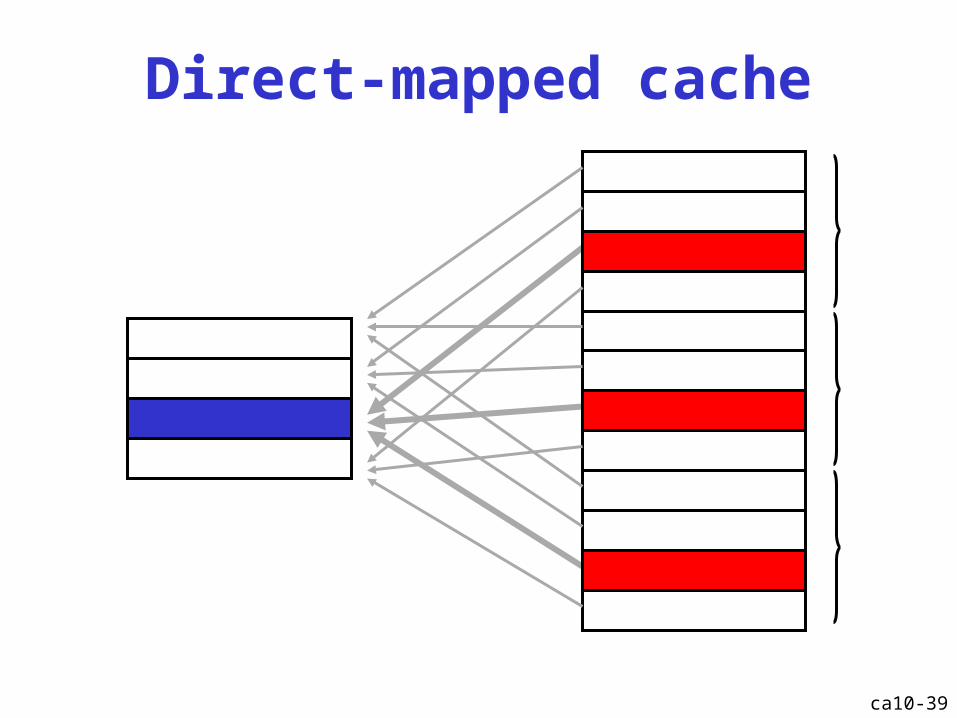
Direct-mapped cache
=
datatreffer
tag index offsetvalid dirty
adres
data eerder beschikbaar dan hit/miss-informatie
data eerder beschikbaar dan hit/miss-informatie
Cache: direct mapped
ca10-38
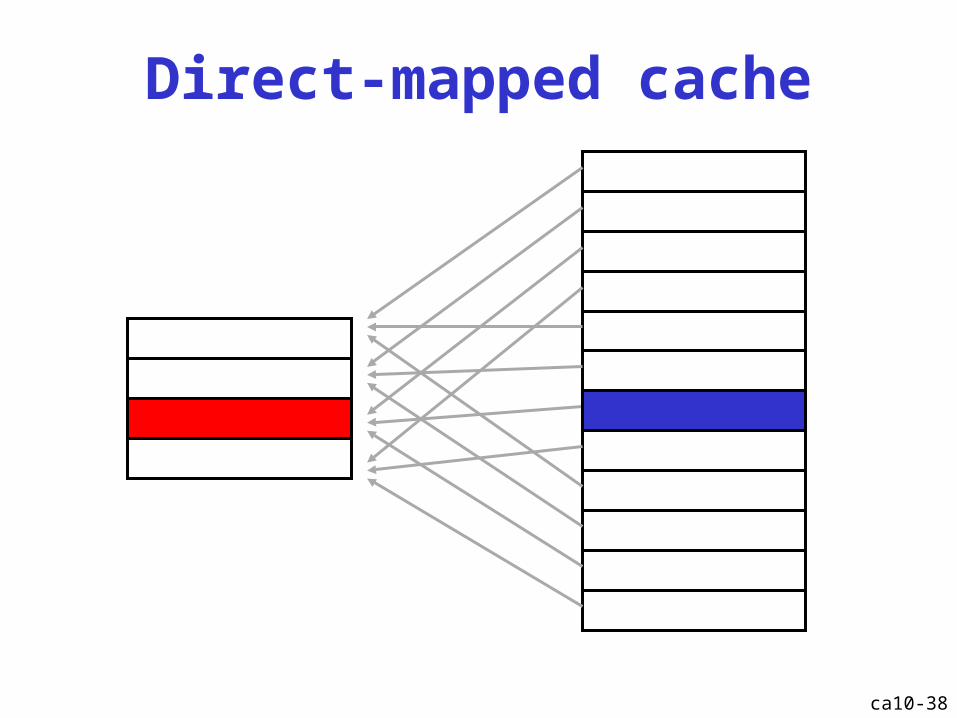
Direct-mapped cache
ca10-39
Direct-mapped cache
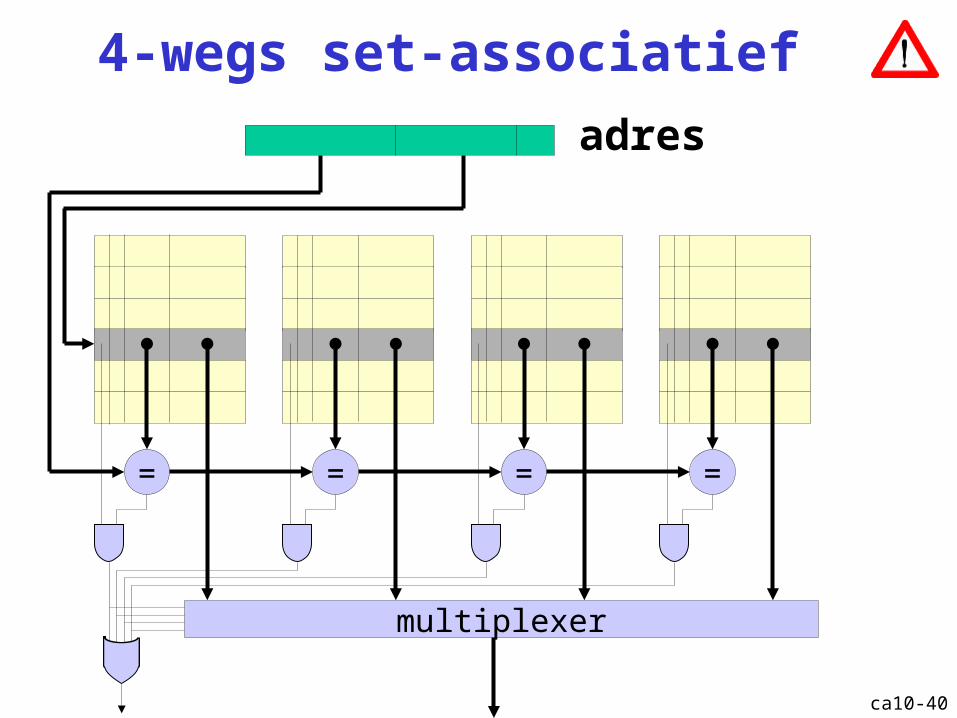
ca10-40
4-wegs set-associatief
= = = =
multiplexer
adres
Cache: set-associatief
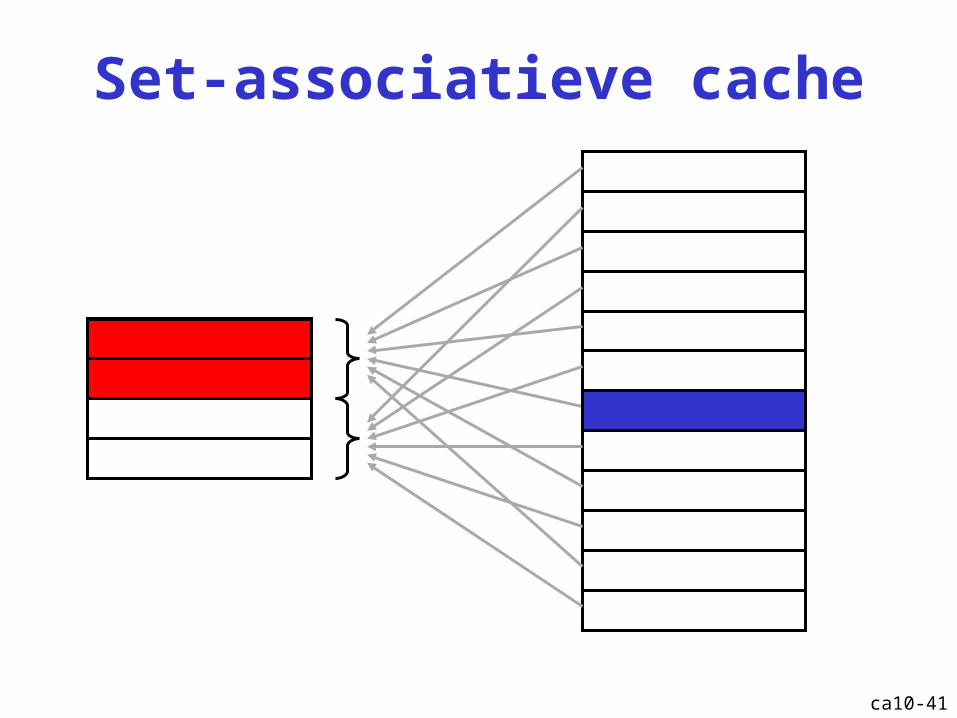
ca10-41
Set-associatieve cache
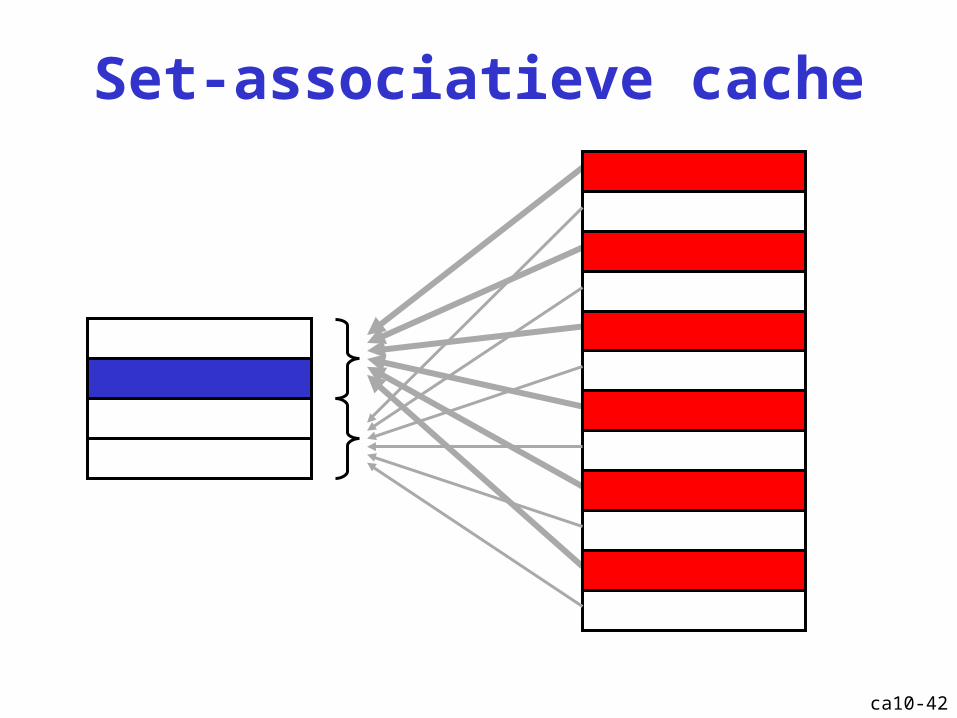
ca10-42
Set-associatieve cache
ca10-43
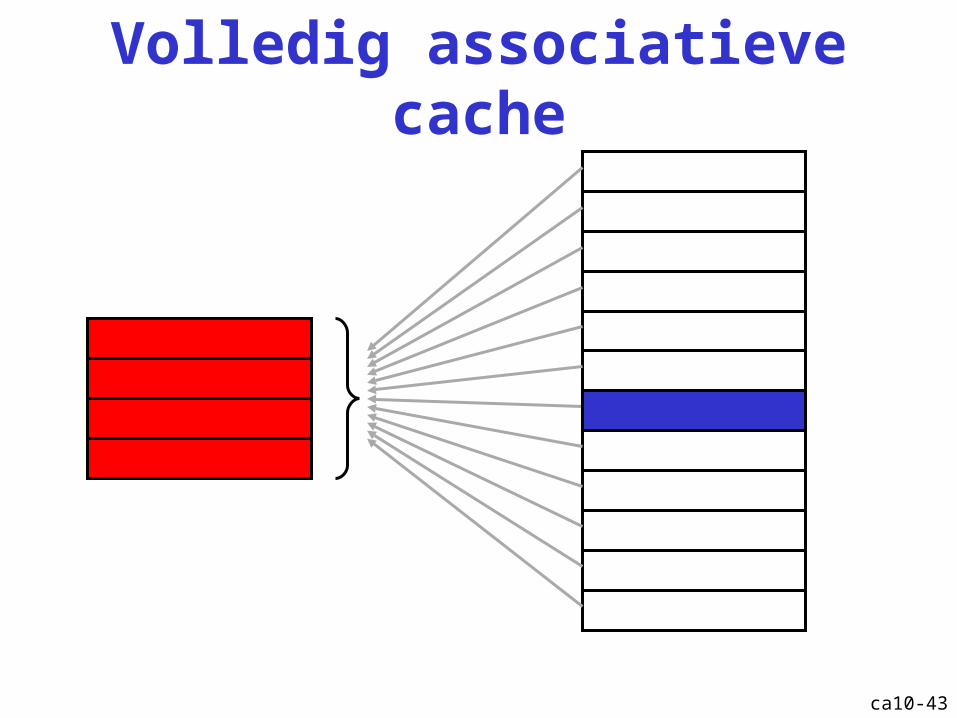
Volledig associatieve cache
Cache: volledig associatief
ca10-44
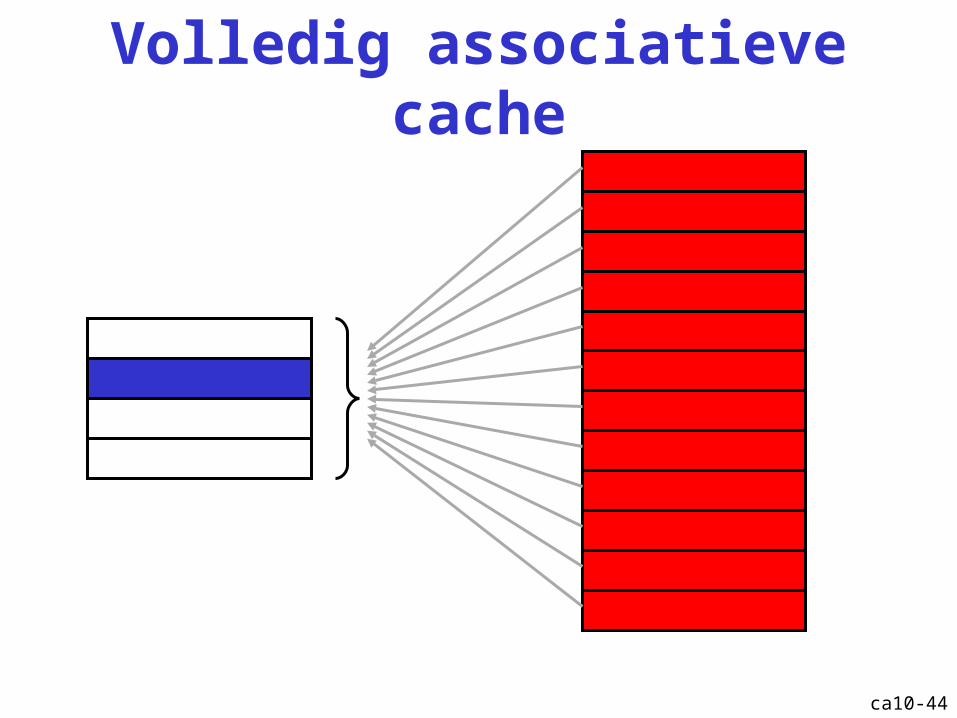
Volledig associatieve cache
ca10-45
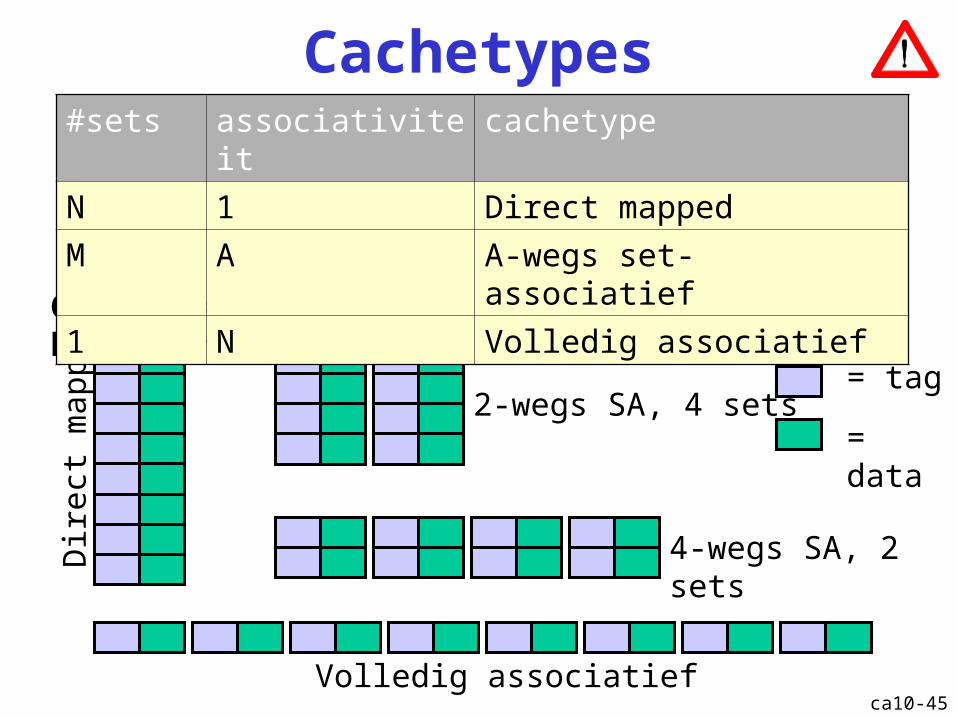
Cachetypes
Grootte = #sets x associativiteit x blokgrootte
Dire
ct m
appe
d
2-wegs SA, 4 sets
4-wegs SA, 2 sets
Volledig associatief
= tag
= data
#sets associativiteit cachetype
N 1 Direct mapped
M A A-wegs set-associatief
1 N Volledig associatief
ca10-46
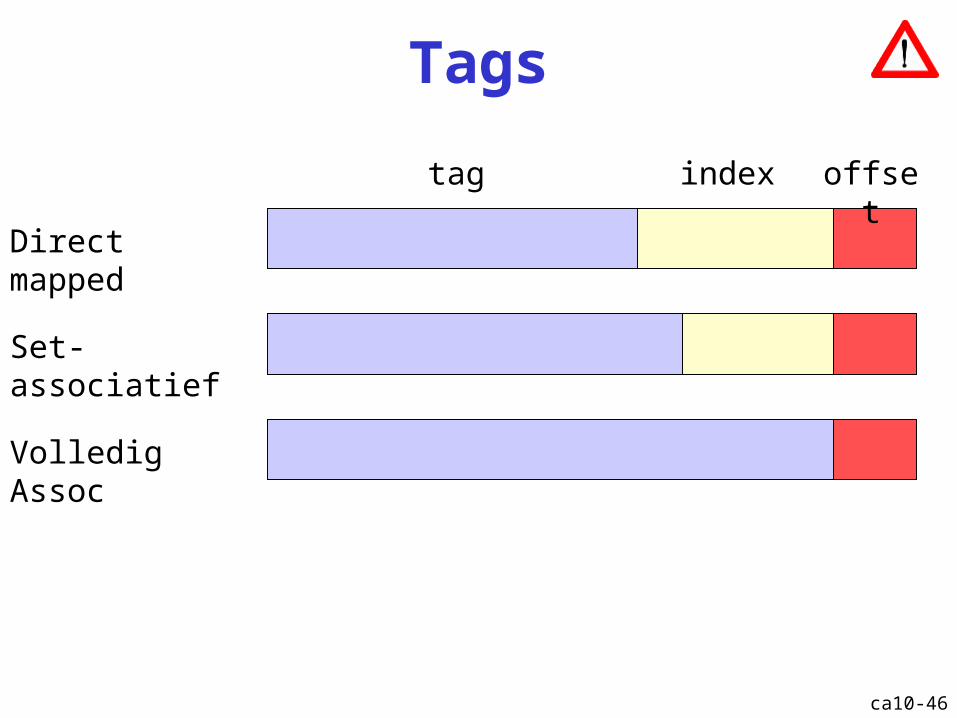
Tags
offsetindextag
Direct mapped
Set-associatief
Volledig Assoc
Cache: tags

ca10-47
Vervangingsstrategie• Als de set volzet is, dan moet er een
blok uit de set verwijderd worden.
• Keuze– LRU: least recently used (langst niet
gebruikt geweest)– FIFO: first-in first-out (oudste blok)– Random: willekeurig blok– Opt: blok dat het langst niet gebruikt zal
worden
Cache: vervangingsstrategie

ca10-48
Miss rates ifv vervangingsstrategie
Associativiteit 2-wegs SA 4-wegs SA
grootte LRU RND FIFO LRU RND FIFO
16 kiB 11.41 11.73 11.55 11.17 11.51 11.33
64 kiB 10.34 10.43 10.39 10.24 10.23 10.31
256 kiB 9.22 9.21 9.25 9.21 9.21 9.25
[Data cache, Spec 2000, 64 byte blokken (alpha)]
Associativiteit 2-wegs SA 4-wegs SA 8-wegs SA
grootte LRU RND LRU RND LRU RND
16 KiB 5.18% 5.69% 4.67% 5.29% 4.39% 4.96%
64 KiB 1.88% 2.01% 1.54% 1.66% 1.39% 1.53%
256 KiB 1.15% 1.17% 1.13% 1.13% 1.12% 1.12%
[instructiecache]
ca10-49
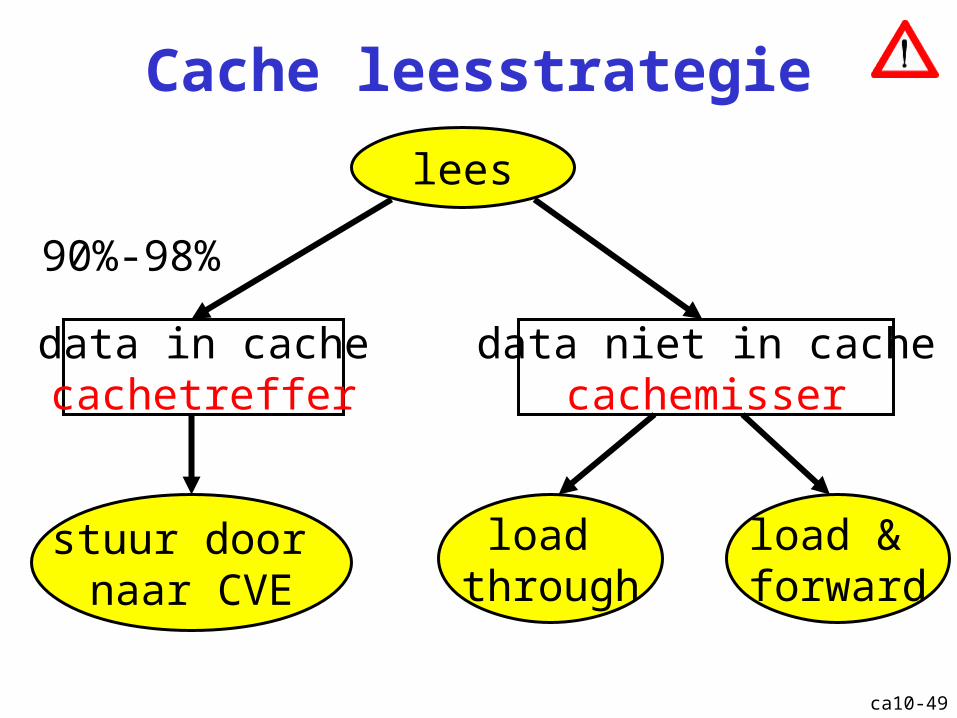
Cache leesstrategie
lees
data in cachecachetreffer
data niet in cachecachemisser
stuur door naar CVE
load through
load & forward
90%-98%
Cache: leesstrategie
ca10-50
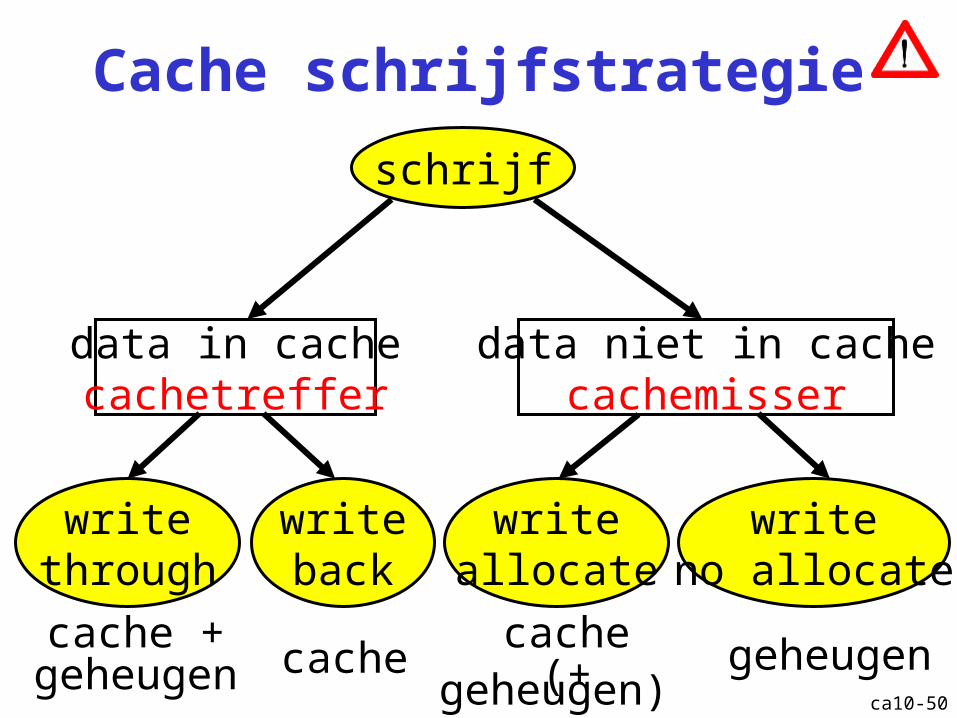
Cache schrijfstrategie
schrijf
data in cachecachetreffer
data niet in cachecachemisser
writeallocate
writeno allocate
writethrough
writeback
cache +geheugen cache
cache(+ geheugen) geheugen
Cache: schrijfstrategie

ca10-51
Gemiddelde toegangstijd
Gemiddelde toegangstijd (AMAT)
= Hit Time + (Miss Rate x Miss Penalty)
= (Hit Rate x Hit Time) + (Miss Rate x Miss Time)
Gemiddelde toegangstijd (AMAT)
= Hit Time + (Miss Rate x Miss Penalty)
= (Hit Rate x Hit Time) + (Miss Rate x Miss Time)
3 + 0.02 x 100 = 5
0.98 x 3 + 0.02 x 103 = 5
[AMAT: Average Memory Access Time]
Miss rate ↓ Miss penalty ↓ Hit time ↓
AMAT ↓
ca10-52
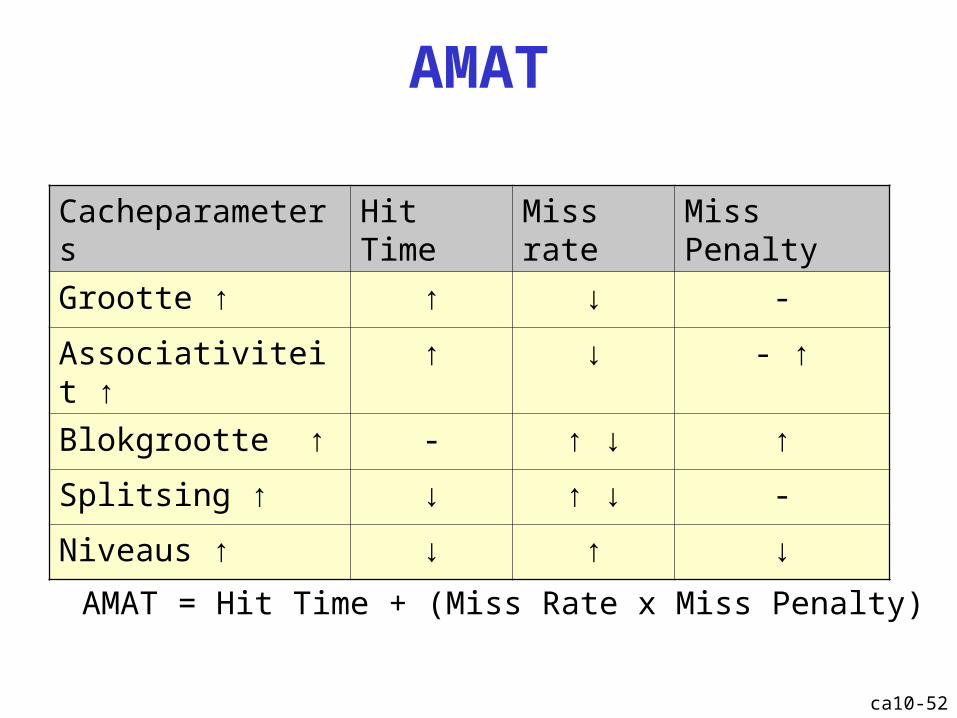
AMAT
Cacheparameters Hit Time Miss rate Miss Penalty
Grootte ↑ ↑ ↓ -
Associativiteit ↑ ↑ ↓ - ↑
Blokgrootte ↑ - ↑ ↓ ↑
Splitsing ↑ ↓ ↑ ↓ -
Niveaus ↑ ↓ ↑ ↓
AMAT = Hit Time + (Miss Rate x Miss Penalty)

ca10-53
Misserclassificatie: 3C model
• Compulsory (cold) of koude missers: nodig om een blok de eerste keer in de cache te brengen.– INF = oneindig grote cache– koude missers = missers(INF)
• Capaciteitsmissers: cache is te klein om de werkverzameling te bevatten.– VA = volledig associatieve cache, LRU vervanging– capaciteitsmissers
= missers(VA) - missers(INF)
Cache: koude misser Cache: capaciteitsmisser

ca10-54
Misserclassificatie: 3C model• Conflict (collision) missers: het blok had
in de cache kunnen zitten maar werd verdrongen door een ander blok.– C = te onderzoeken cache met bepaald
vervangingsalgoritme – Conflictmissers = missers(C) - missers(VA)
Cache: conflictmisser
ca10-55
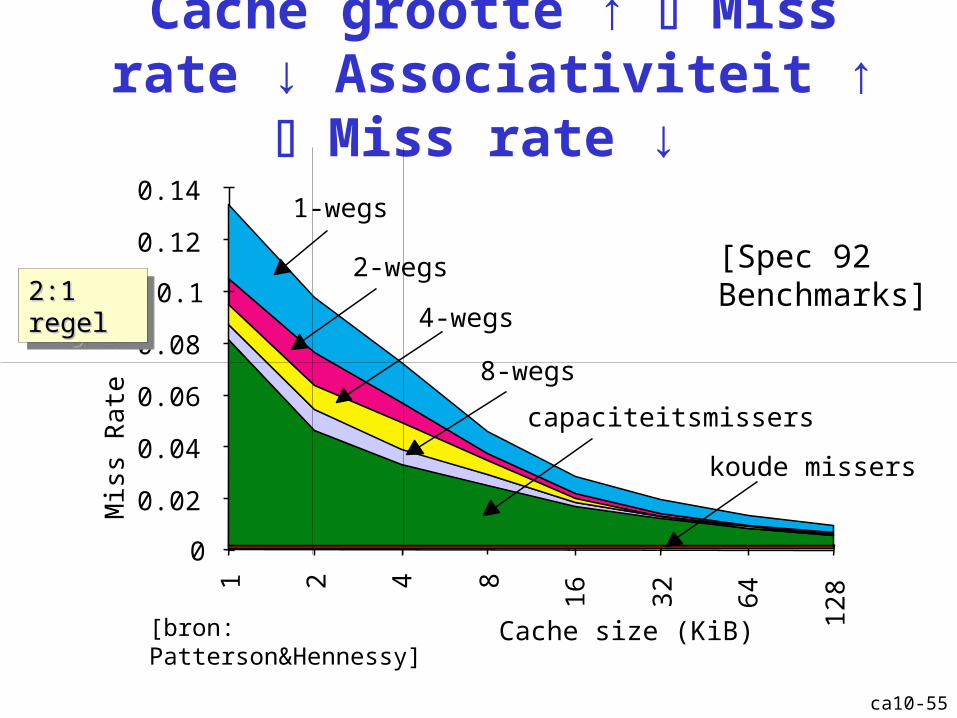
Cache grootte ↑ Miss rate ↓ Associativiteit ↑ Miss rate ↓
Cache size (KiB)
Mis
s R
ate
0
0.02
0.04
0.06
0.08
0.1
0.12
0.14
1 2 4 8
16
32
64
128
1-wegs
2-wegs
4-wegs
8-wegs
capaciteitsmissers
2:1 regel2:1 regel2:1 regel2:1 regel[Spec 92Benchmarks]
[bron: Patterson&Hennessy]
koude missers
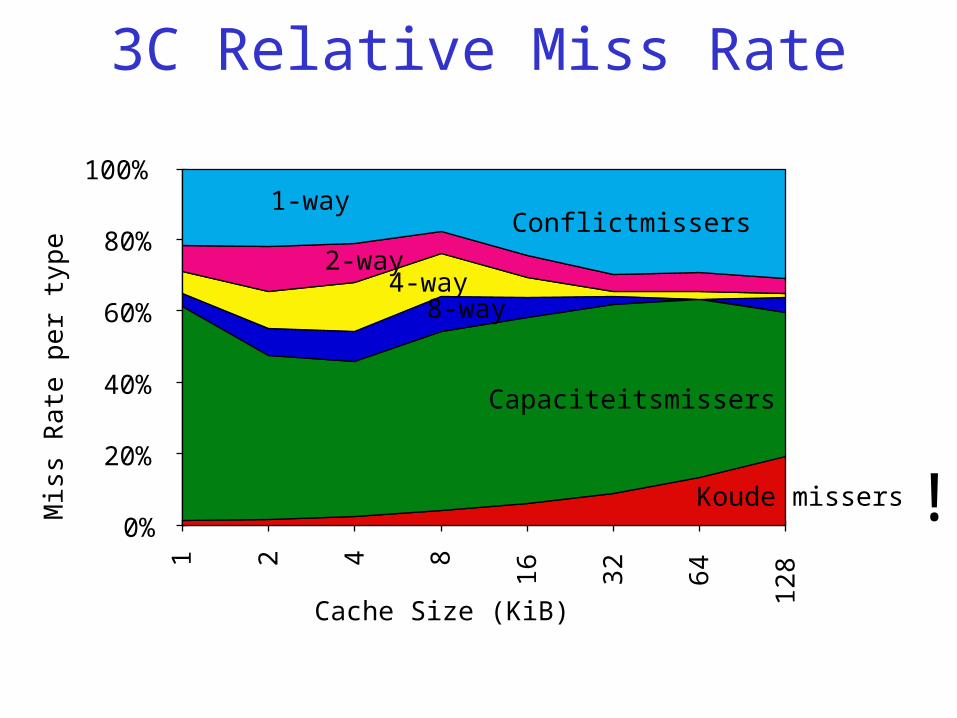
3C Relative Miss Rate
Cache Size (KiB)
Mis
s R
ate
pe
r ty
pe
0%
20%
40%
60%
80%
100%1 2 4 8
16
32
64
128
1-way
2-way4-way
8-way
Capaciteitsmissers
Koude missers
Conflictmissers
!
ca10-57
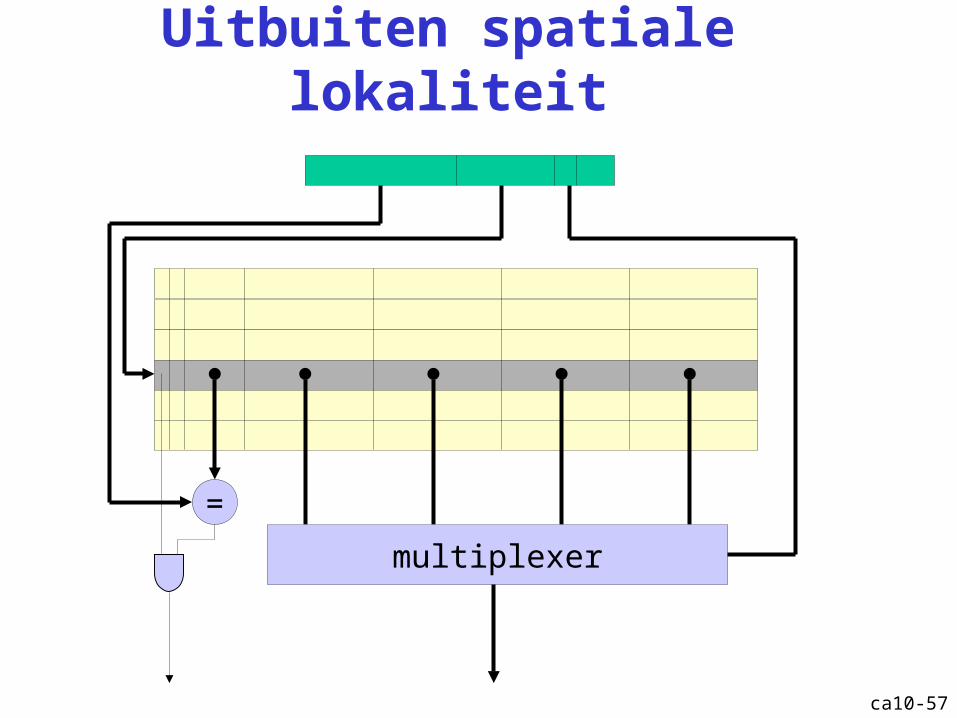
Uitbuiten spatiale lokaliteit
=
multiplexer
ca10-58
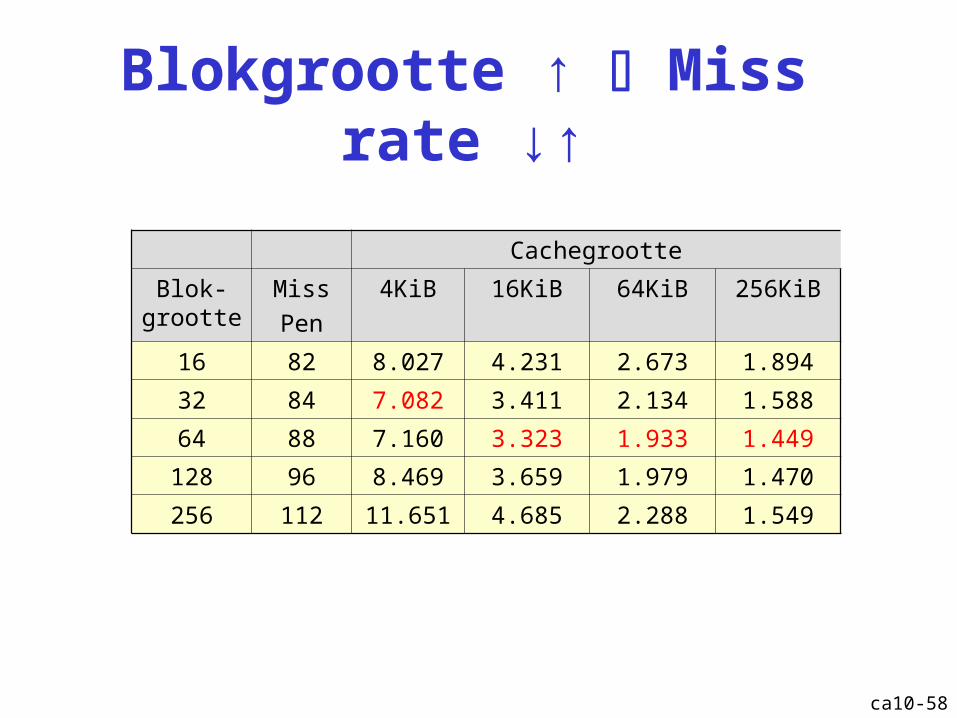
Blokgrootte ↑ Miss rate ↓↑
Cachegrootte
Blok- grootte
Miss
Pen
4KiB 16KiB 64KiB 256KiB
16 82 8.027 4.231 2.673 1.894
32 84 7.082 3.411 2.134 1.588
64 88 7.160 3.323 1.933 1.449
128 96 8.469 3.659 1.979 1.470
256 112 11.651 4.685 2.288 1.549
ca10-59
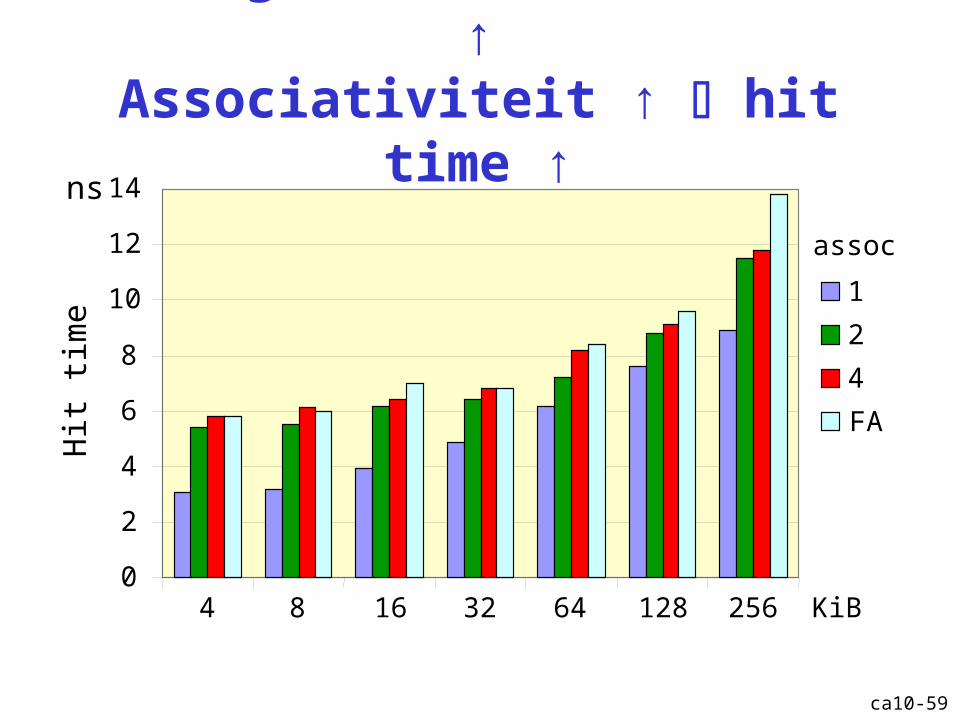
Cachegrootte ↑ hit time ↑Associativiteit ↑ hit time ↑
0
2
4
6
8
10
12
14
4 8 16 32 64 128 256 KiB
1
2
4
FA
assoc
ns
Hit
time
ca10-60
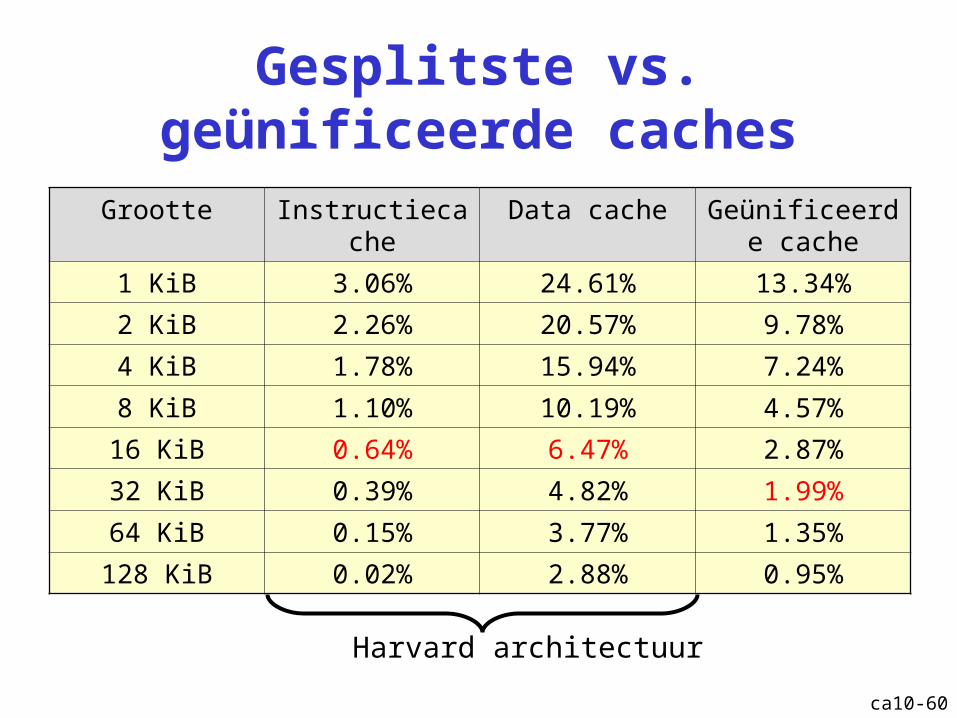
Gesplitste vs. geünificeerde caches
Grootte Instructiecache Data cache Geünificeerde cache
1 KiB 3.06% 24.61% 13.34%
2 KiB 2.26% 20.57% 9.78%
4 KiB 1.78% 15.94% 7.24%
8 KiB 1.10% 10.19% 4.57%
16 KiB 0.64% 6.47% 2.87%
32 KiB 0.39% 4.82% 1.99%
64 KiB 0.15% 3.77% 1.35%
128 KiB 0.02% 2.88% 0.95%
Harvard architectuur

ca10-61
Voorbeeld[20% data cache; 80% instructiecache; 16 KiB
miss penalty = 50 cycli; hit time = 1 cyclus]
Gesplitste cache
AMAT = 80% x (1 + 0.64% x 50) +
20% x (1 + 6.47% x 50) = 1.903
Geünificeerde cache
AMAT = 80% x (1 + 1.99% x 50) +
20% x (2 + 1.99% x 50) = 2.195Extra cyclus: Cache met 1 toegangspoort
Maak het vaak voorkomende geval snel!
Maak het vaak voorkomende geval snel!
ca10-62
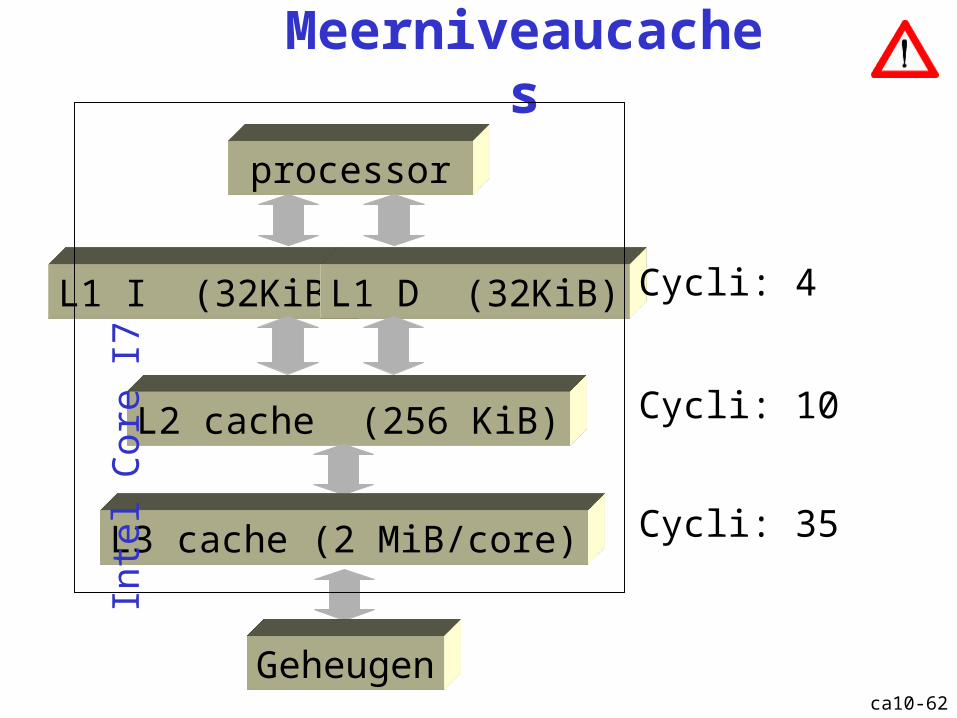
Meerniveaucaches
processor
L1 I (32KiB) L1 D (32KiB)
L2 cache (256 KiB)
L3 cache (2 MiB/core)
Cycli: 4
Cycli: 10
Cycli: 35
Geheugen
Inte
l Cor
e I7
Cache: hiërarchie
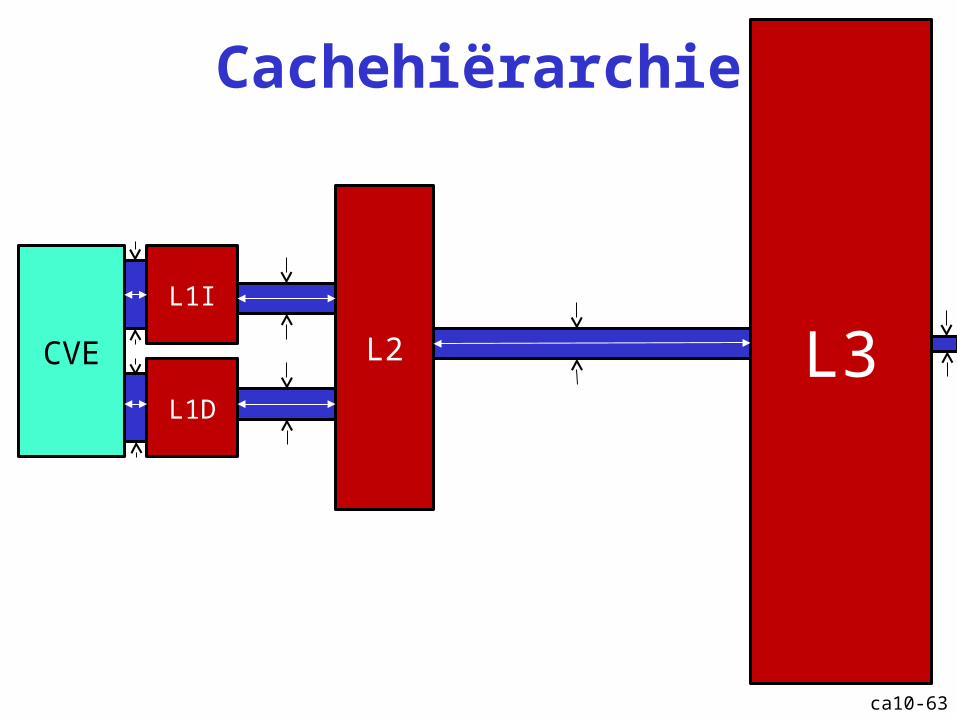
Cachehiërarchie
ca10-63
CVE
L1I
L2 L3L1D

ca10-64
VoorbeeldProcessor Pentium 4 Ultrasparc III
Clock (2001) 2000 Mhz 900 Mhz
L1 I cache 96 KiB TC 32 KiB, 4WSA
Latency 4 2
L1 D cache 8 KiB 4WSA 64 KiB, 4WSA
Latency 2 2
TLB 128 128
L2 cache 256 KiB 8WSA 8 MiB DM (off chip)
Latency 6 15
Block size 64 bytes 32 bytes
Bus width 64 bits 128 bits
Bus clock 400 Mhz 150 Mhz
Processor Pentium 4 Ultrasparc III
Clock (2001) 2000 Mhz 900 Mhz
L1 I cache 96 KiB TC 32 KiB, 4WSA
Latency 4 2
L1 D cache 8 KiB 4WSA 64 KiB, 4WSA
Latency 2 2
TLB 128 128
L2 cache 256 KiB 8WSA 8 MiB DM (off chip)
Latency 6 15
Block size 64 bytes 32 bytes
Bus width 64 bits 128 bits
Bus clock 400 Mhz 150 Mhz

ca10-65
Inhoud
• Soorten geheugens
• Lokaliteit
• Caches
• Impact op prestatie
• Ingebedde systemen
• Eindbeschouwingen
bca10-66
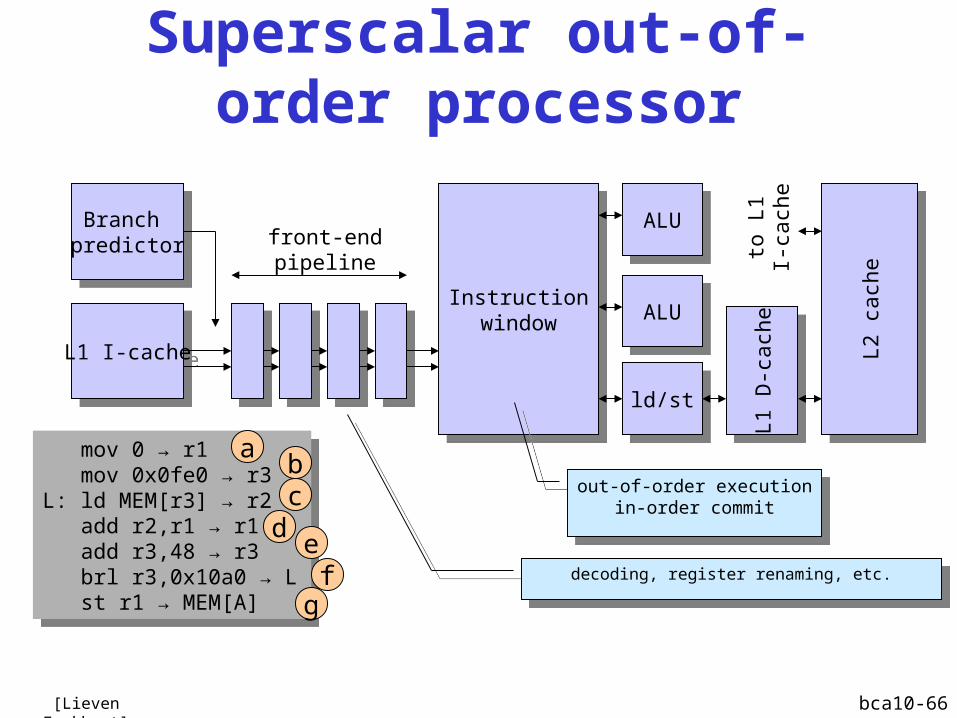
Superscalar out-of-order processor
L1 I-cacheL1 I-cache
Branch predictor
Branch predictor
Instructionwindow
Instructionwindow
ALUALU
ld/stld/st
L1 D
-cach
eL1
D-c
ach
e
L2 c
ach
eL2
cach
e
to L
1I-
cach
e
mov 0 → r1 mov 0x0fe0 → r3L: ld MEM[r3] → r2 add r2,r1 → r1 add r3,48 → r3 brl r3,0x10a0 → L st r1 → MEM[A]
mov 0 → r1 mov 0x0fe0 → r3L: ld MEM[r3] → r2 add r2,r1 → r1 add r3,48 → r3 brl r3,0x10a0 → L st r1 → MEM[A]
ab
dc
ef
g
ALUALU
front-endpipeline
out-of-order executionin-order commit
out-of-order executionin-order commit
decoding, register renaming, etc.decoding, register renaming, etc.
[Lieven Eeckhout]
bca10-67
Cycle 1
L1 I-cacheL1 I-cache
Branch predictor
Branch predictor
Instructionwindow
Instructionwindow
ALUALU
ld/stld/st
L1 D
-cach
eL1
D-c
ach
e
L2 c
ach
eL2
cach
e
a
b
ALUALU
mov 0 → r1 mov 0x0fe0 → r3L: ld MEM[r3] → r2 add r2,r1 → r1 add r3,48 → r3 brl r3,0x10a0 → L st r1 → MEM[A]
mov 0 → r1 mov 0x0fe0 → r3L: ld MEM[r3] → r2 add r2,r1 → r1 add r3,48 → r3 brl r3,0x10a0 → L st r1 → MEM[A]
ab
dc
ef
g
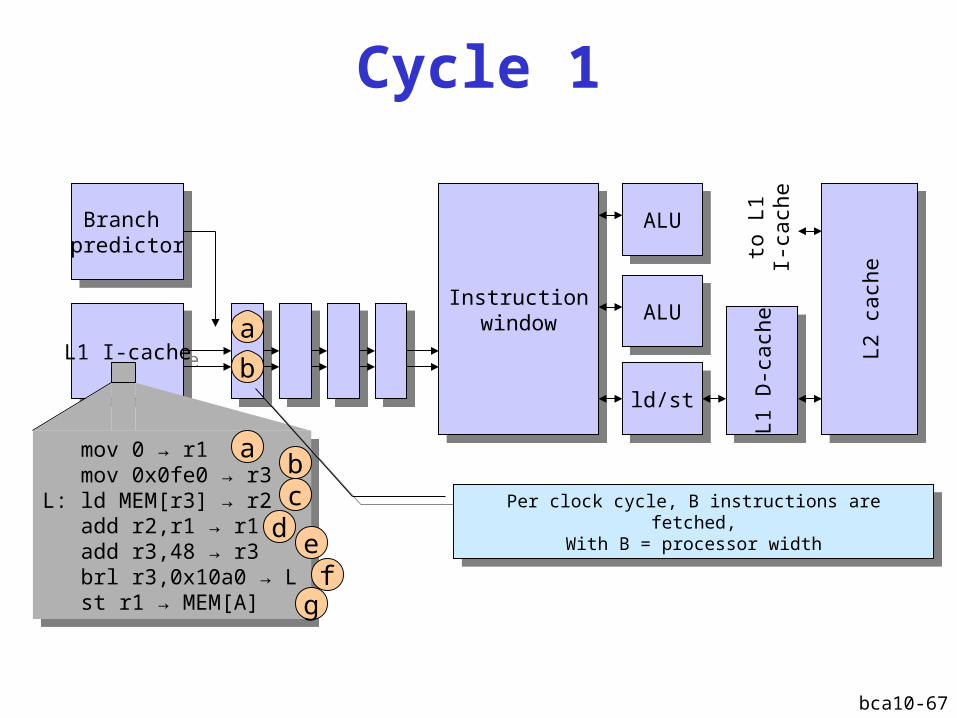
Per clock cycle, B instructions are fetched,With B = processor width
Per clock cycle, B instructions are fetched,With B = processor width
to L
1I-
cach
e
bca10-68
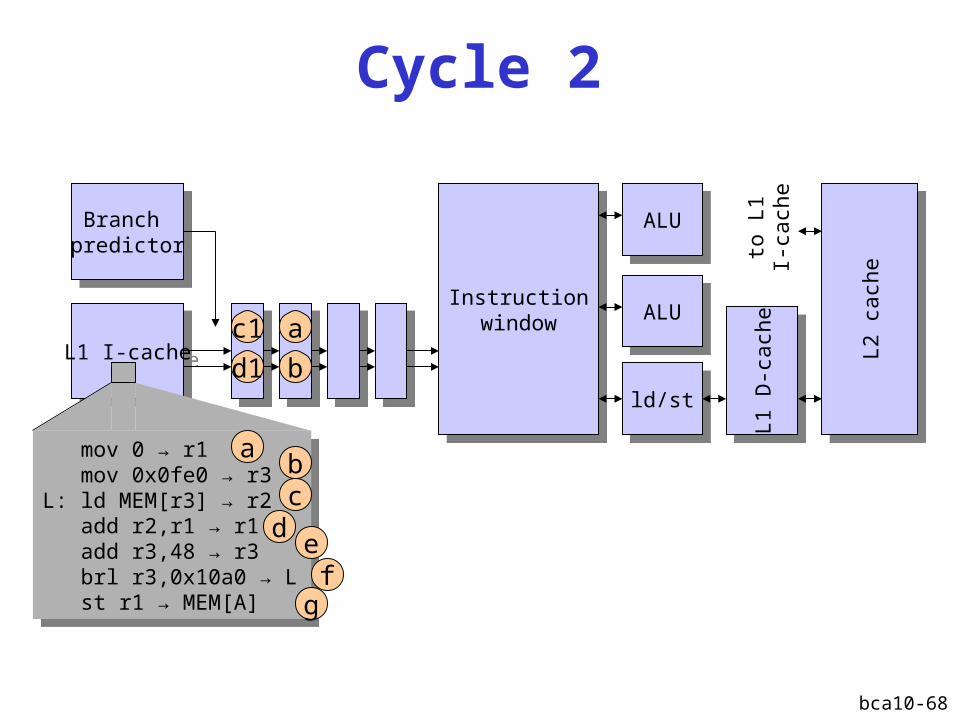
Cycle 2
L1 I-cacheL1 I-cache
Branch predictor
Branch predictor
Instructionwindow
Instructionwindow
ALUALU
ld/stld/st
L1 D
-cach
eL1
D-c
ach
e
L2 c
ach
eL2
cach
e
a
bd1
c1 ALUALU
mov 0 → r1 mov 0x0fe0 → r3L: ld MEM[r3] → r2 add r2,r1 → r1 add r3,48 → r3 brl r3,0x10a0 → L st r1 → MEM[A]
mov 0 → r1 mov 0x0fe0 → r3L: ld MEM[r3] → r2 add r2,r1 → r1 add r3,48 → r3 brl r3,0x10a0 → L st r1 → MEM[A]
ab
dc
ef
g
to L
1I-
cach
e
bca10-69
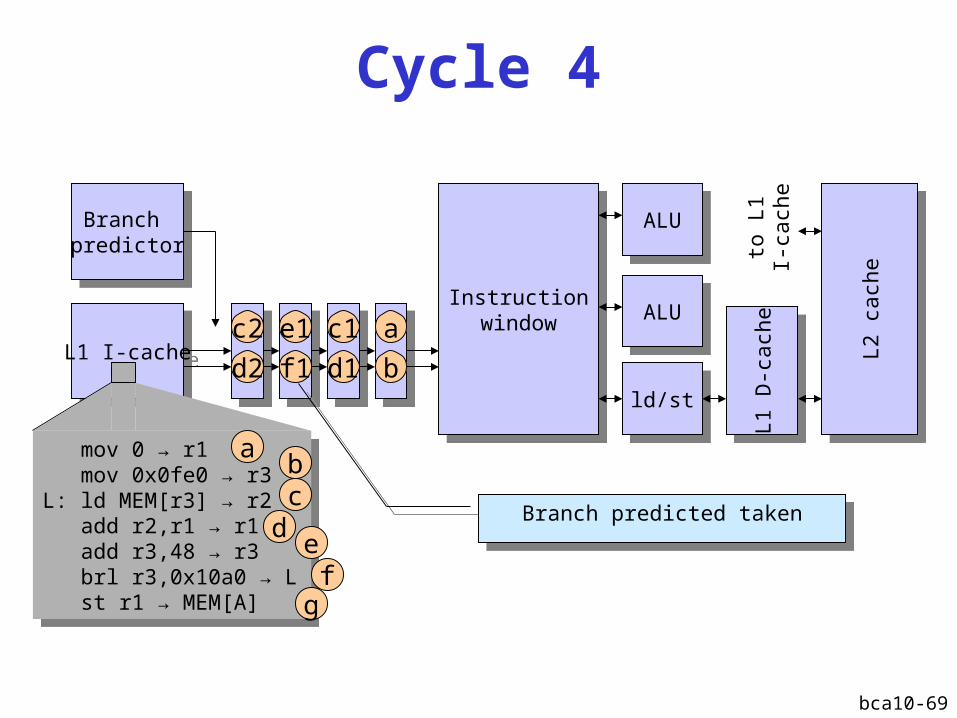
Cycle 4
L1 I-cacheL1 I-cache
Branch predictor
Branch predictor
Instructionwindow
Instructionwindow
ALUALU
ld/stld/st
L1 D
-cach
eL1
D-c
ach
e
L2 c
ach
eL2
cach
e
a
bd1
c1e1
f1d2
c2 ALUALU
mov 0 → r1 mov 0x0fe0 → r3L: ld MEM[r3] → r2 add r2,r1 → r1 add r3,48 → r3 brl r3,0x10a0 → L st r1 → MEM[A]
mov 0 → r1 mov 0x0fe0 → r3L: ld MEM[r3] → r2 add r2,r1 → r1 add r3,48 → r3 brl r3,0x10a0 → L st r1 → MEM[A]
ab
dc
ef
g
Branch predicted takenBranch predicted taken
to L
1I-
cach
e
bca10-70
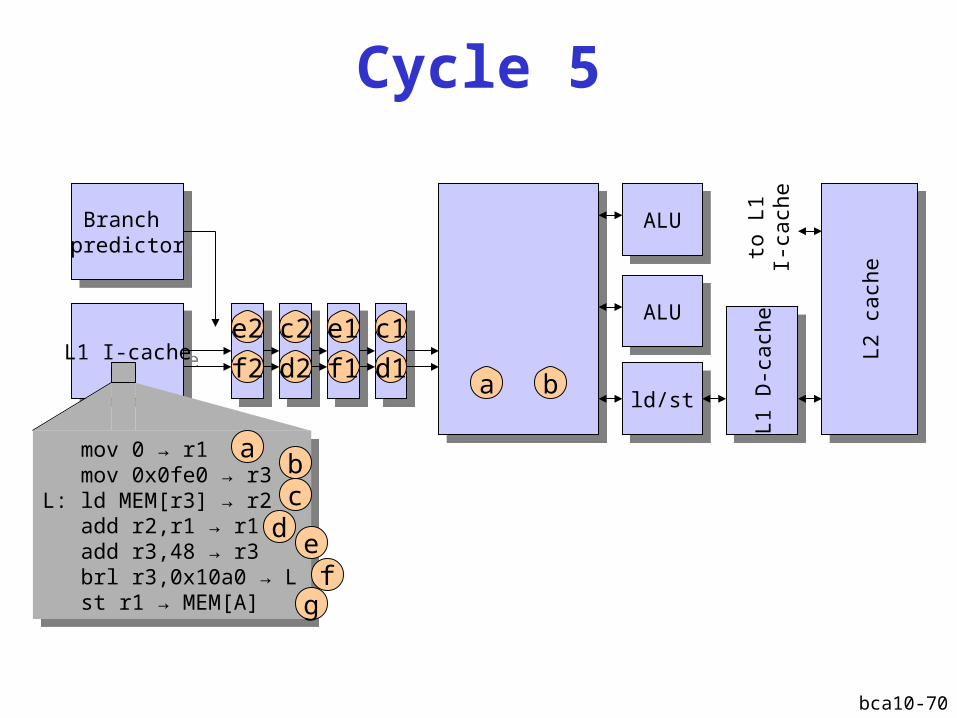
Cycle 5
L1 I-cacheL1 I-cache
Branch predictor
Branch predictor
ALUALU
ld/stld/st
L1 D
-cach
eL1
D-c
ach
e
L2 c
ach
eL2
cach
e
a b
ALUALU
mov 0 → r1 mov 0x0fe0 → r3L: ld MEM[r3] → r2 add r2,r1 → r1 add r3,48 → r3 brl r3,0x10a0 → L st r1 → MEM[A]
mov 0 → r1 mov 0x0fe0 → r3L: ld MEM[r3] → r2 add r2,r1 → r1 add r3,48 → r3 brl r3,0x10a0 → L st r1 → MEM[A]
ab
dc
ef
g
d1
c1e1
f1d2
c2e2
f2
to L
1I-
cach
e
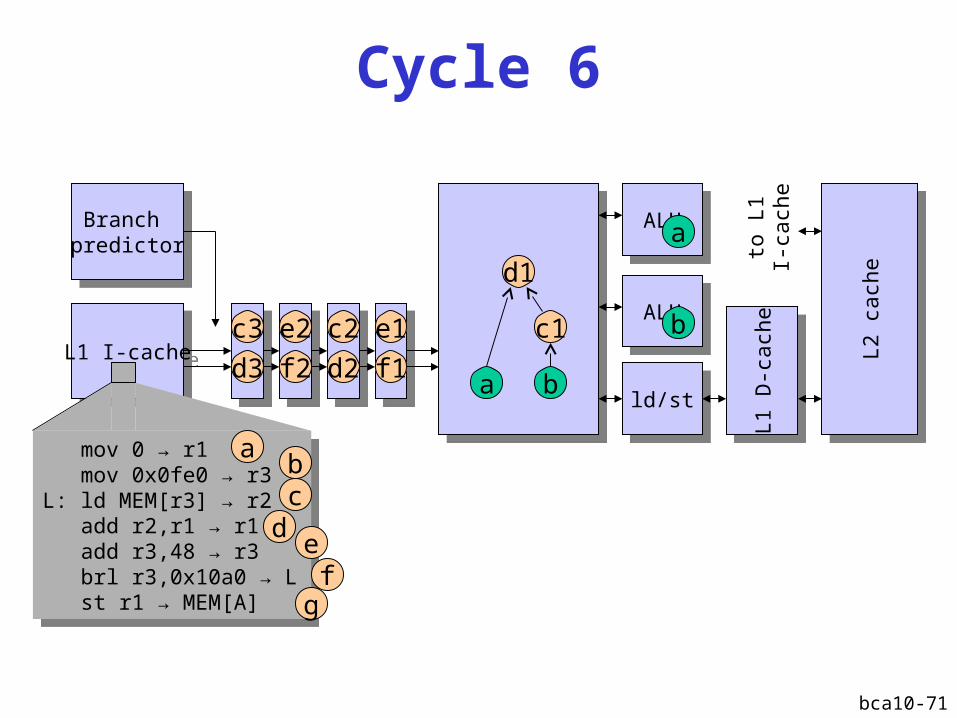
bca10-71
ALUALU
Cycle 6
L1 I-cacheL1 I-cache
Branch predictor
Branch predictor
ALUALU
ld/stld/st
L1 D
-cach
eL1
D-c
ach
e
L2 c
ach
eL2
cach
e
a b
d1
c1
a
b
mov 0 → r1 mov 0x0fe0 → r3L: ld MEM[r3] → r2 add r2,r1 → r1 add r3,48 → r3 brl r3,0x10a0 → L st r1 → MEM[A]
mov 0 → r1 mov 0x0fe0 → r3L: ld MEM[r3] → r2 add r2,r1 → r1 add r3,48 → r3 brl r3,0x10a0 → L st r1 → MEM[A]
ab
dc
ef
g
d3
c3 e1
f1d2
c2e2
f2
to L
1I-
cach
e
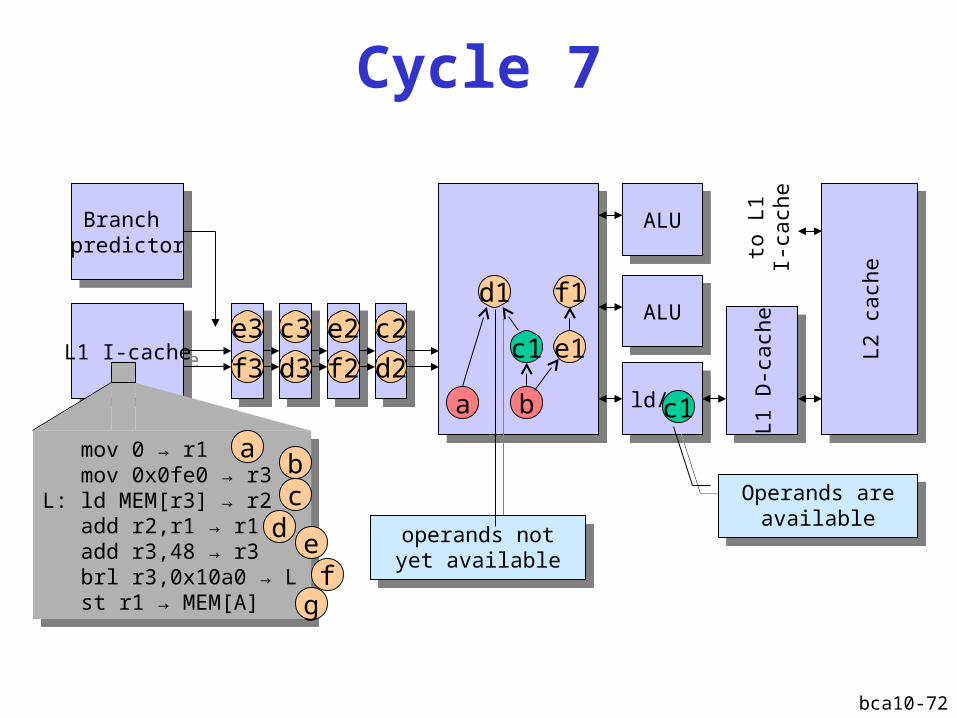
bca10-72
Cycle 7
L1 I-cacheL1 I-cache
Branch predictor
Branch predictor
ALUALU
ld/stld/st
L1 D
-cach
eL1
D-c
ach
e
L2 c
ach
eL2
cach
e
a b
d1
c1 e1
f1
c1
ALUALU
mov 0 → r1 mov 0x0fe0 → r3L: ld MEM[r3] → r2 add r2,r1 → r1 add r3,48 → r3 brl r3,0x10a0 → L st r1 → MEM[A]
mov 0 → r1 mov 0x0fe0 → r3L: ld MEM[r3] → r2 add r2,r1 → r1 add r3,48 → r3 brl r3,0x10a0 → L st r1 → MEM[A]
ab
dc
ef
g
d2
c2e2
f2d3
c3e3
f3
Operands are available
Operands are available
operands not yet available
operands not yet available
to L
1I-
cach
e
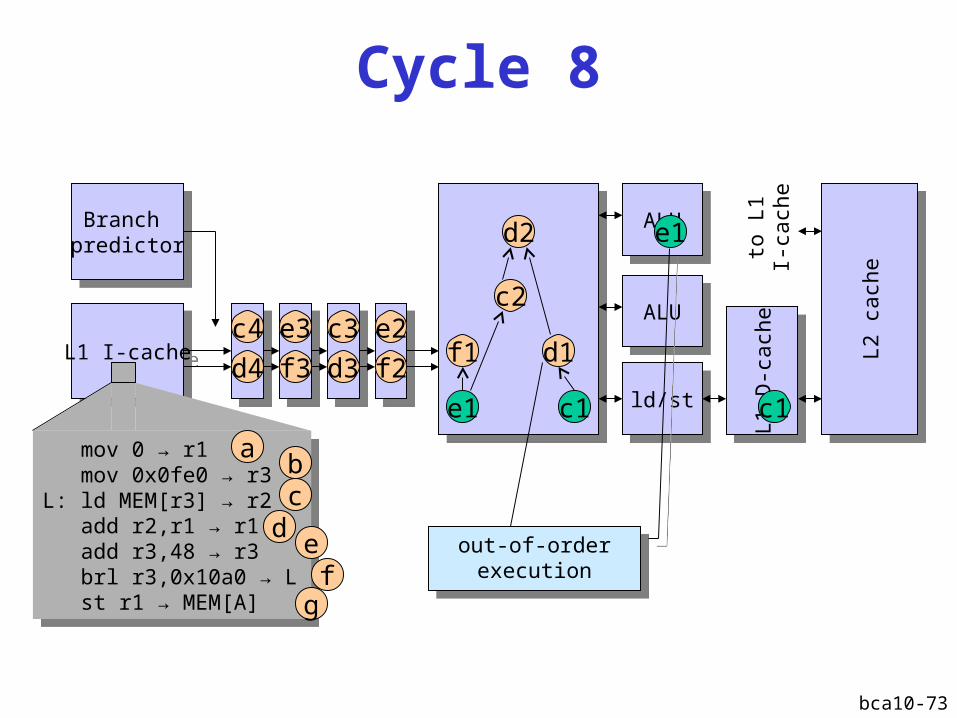
bca10-73
Cycle 8
L1 I-cacheL1 I-cache
Branch predictor
Branch predictor
ALUALU
ld/stld/st
L1 D
-cach
eL1
D-c
ach
e
L2 c
ach
eL2
cach
e
d1
c1e1
f1
d2
c2
e1
c1
ALUALU
mov 0 → r1 mov 0x0fe0 → r3L: ld MEM[r3] → r2 add r2,r1 → r1 add r3,48 → r3 brl r3,0x10a0 → L st r1 → MEM[A]
mov 0 → r1 mov 0x0fe0 → r3L: ld MEM[r3] → r2 add r2,r1 → r1 add r3,48 → r3 brl r3,0x10a0 → L st r1 → MEM[A]
ab
dc
ef
g
d4
c4 e2
f2d3
c3e3
f3
out-of-order execution
out-of-order execution
to L
1I-
cach
e
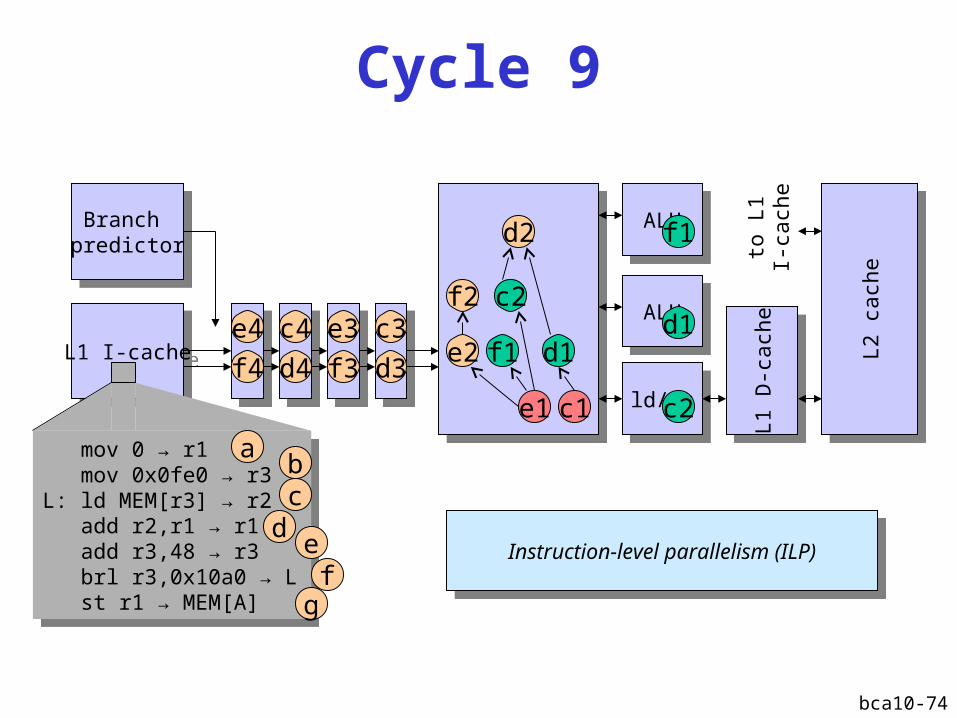
bca10-74
Cycle 9
L1 I-cacheL1 I-cache
Branch predictor
Branch predictor
ALUALU
ld/stld/st
L1 D
-cach
eL1
D-c
ach
e
L2 c
ach
eL2
cach
e
d1
c1e1
f1
d2
c2
e2
f2
f1
c2
ALUALUd1
mov 0 → r1 mov 0x0fe0 → r3L: ld MEM[r3] → r2 add r2,r1 → r1 add r3,48 → r3 brl r3,0x10a0 → L st r1 → MEM[A]
mov 0 → r1 mov 0x0fe0 → r3L: ld MEM[r3] → r2 add r2,r1 → r1 add r3,48 → r3 brl r3,0x10a0 → L st r1 → MEM[A]
ab
dc
ef
g
d3
c3e3
f3d4
c4e4
f4
Instruction-level parallelism (ILP)Instruction-level parallelism (ILP)
to L
1I-
cach
e
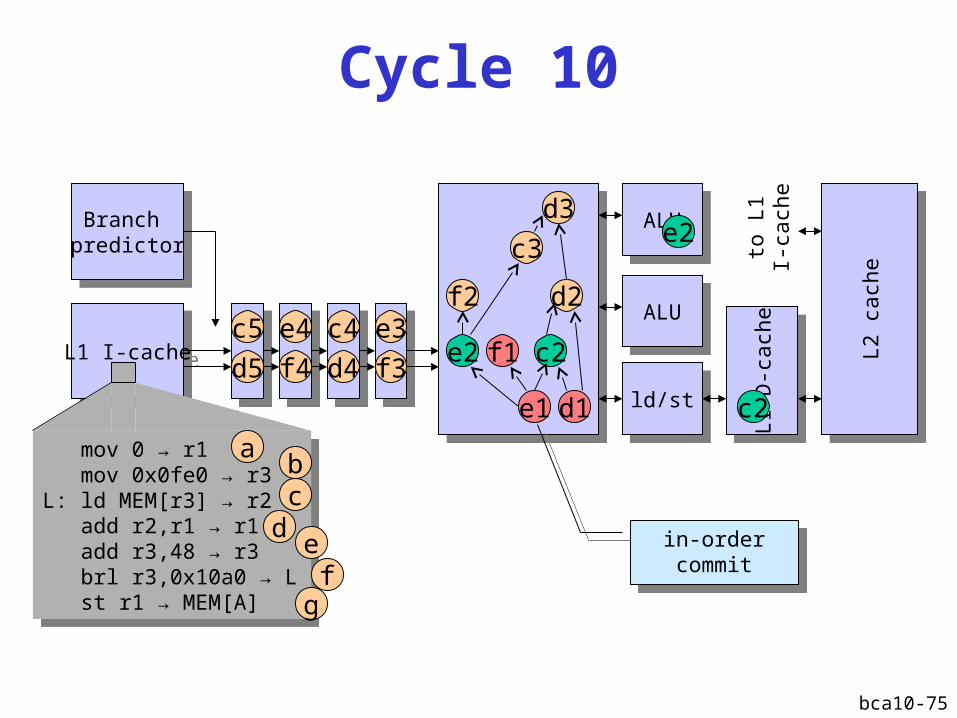
bca10-75
Cycle 10
L1 I-cacheL1 I-cache
Branch predictor
Branch predictor
ALUALU
ld/stld/st
L1 D
-cach
eL1
D-c
ach
e
L2 c
ach
eL2
cach
e
d1e1
f1
d2
c2e2
f2
d3
c3e2
c2
ALUALU
mov 0 → r1 mov 0x0fe0 → r3L: ld MEM[r3] → r2 add r2,r1 → r1 add r3,48 → r3 brl r3,0x10a0 → L st r1 → MEM[A]
mov 0 → r1 mov 0x0fe0 → r3L: ld MEM[r3] → r2 add r2,r1 → r1 add r3,48 → r3 brl r3,0x10a0 → L st r1 → MEM[A]
ab
dc
ef
g
d5
c5 e3
f3d4
c4e4
f4
in-order commit
in-order commit
to L
1I-
cach
e
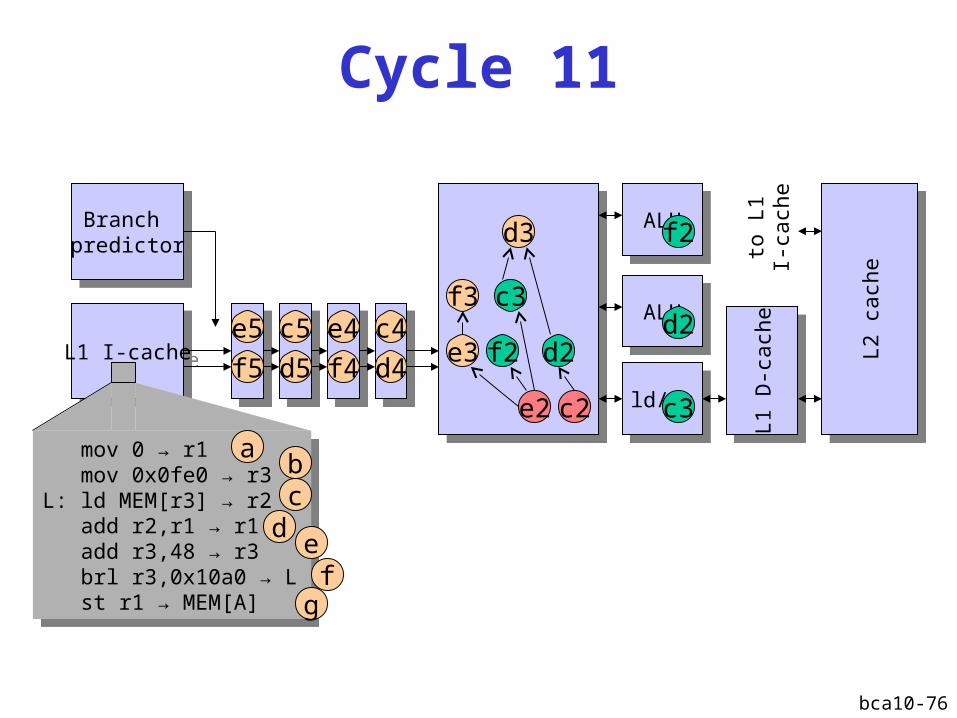
bca10-76
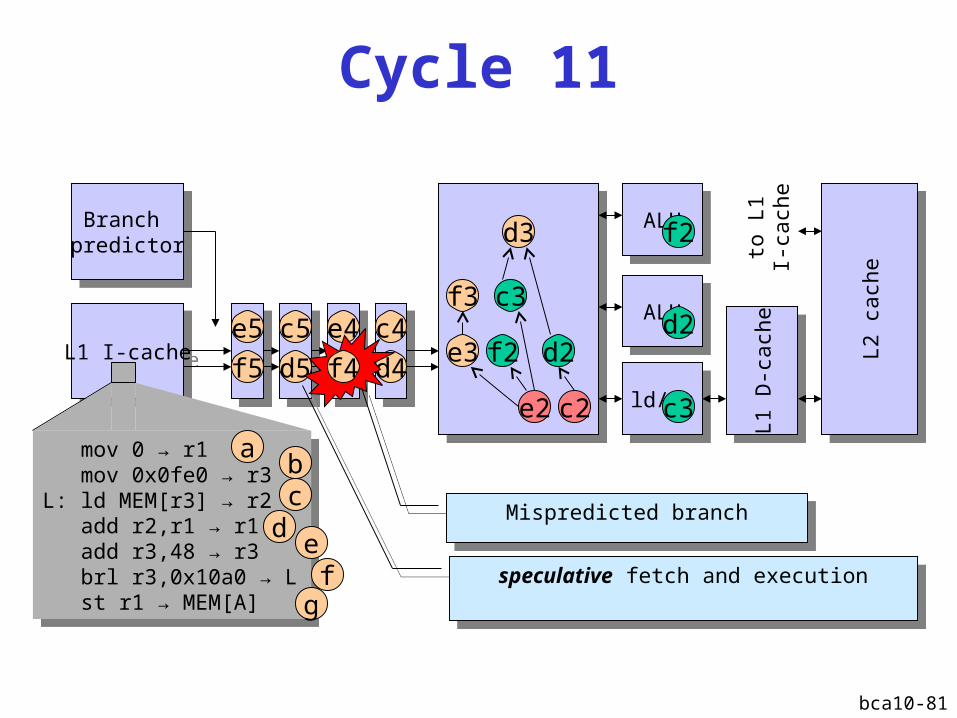
Cycle 11
L1 I-cacheL1 I-cache
Branch predictor
Branch predictor
ALUALU
ld/stld/st
L1 D
-cach
eL1
D-c
ach
e
L2 c
ach
eL2
cach
e
d2
c2e2
f2
d3
c3
e3
f3
f2
c3
ALUALUd2
mov 0 → r1 mov 0x0fe0 → r3L: ld MEM[r3] → r2 add r2,r1 → r1 add r3,48 → r3 brl r3,0x10a0 → L st r1 → MEM[A]
mov 0 → r1 mov 0x0fe0 → r3L: ld MEM[r3] → r2 add r2,r1 → r1 add r3,48 → r3 brl r3,0x10a0 → L st r1 → MEM[A]
ab
dc
ef
g
d4
c4e4
f4d5
c5e5
f5
to L
1I-
cach
e
bca10-77
Instruction Level Parallelism
[Starting from full trace, SpecInt 2000]
0
20
40
60
80
100
120
140
160
180
200
bzip2 crafty eon gcc gzip parser perlbmk twolf vortex vpr
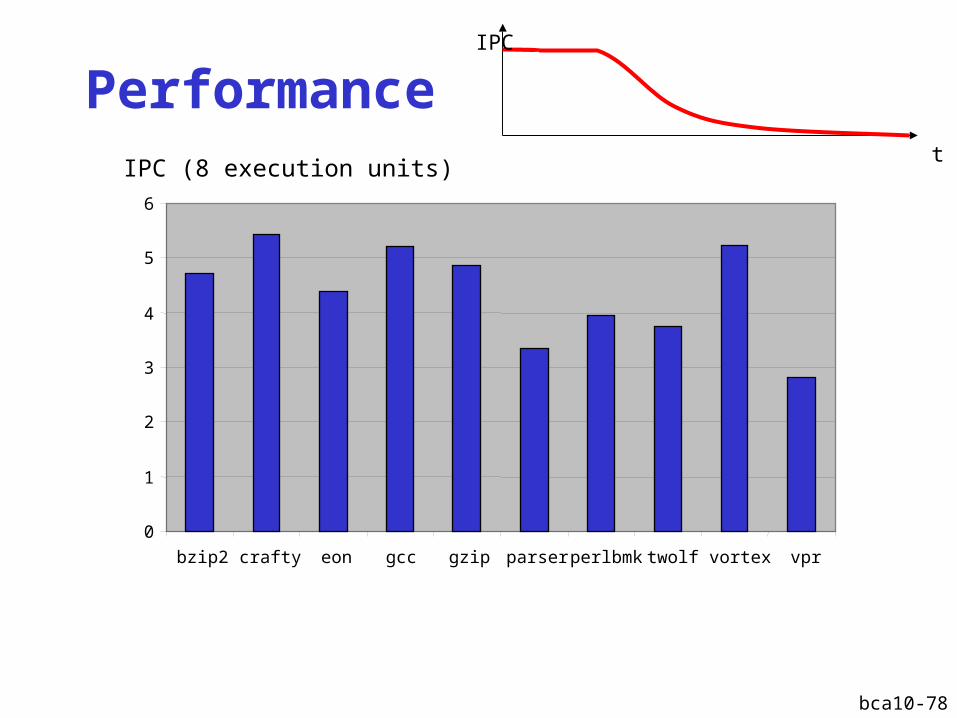
bca10-78
Performance
0
1
2
3
4
5
6
bzip2 crafty eon gcc gzip parser perlbmk twolf vortex vpr
IPC (8 execution units)
IPC
t
bca10-79
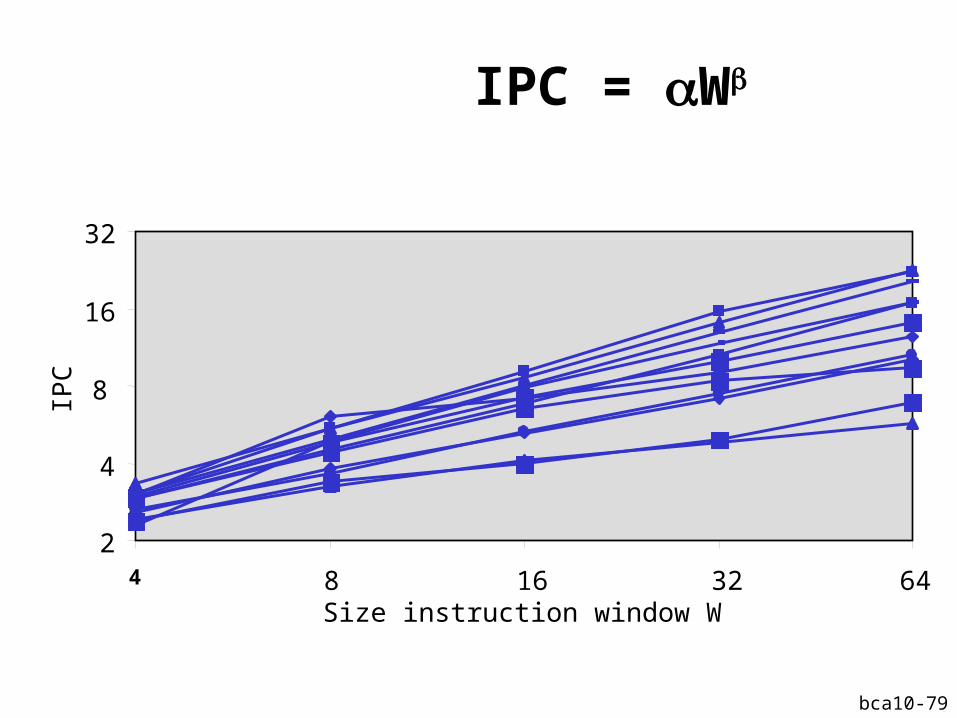
IPC = W
2
4
8
16
32
4 8 16 32 64 Size instruction window W
IPC
bca10-80
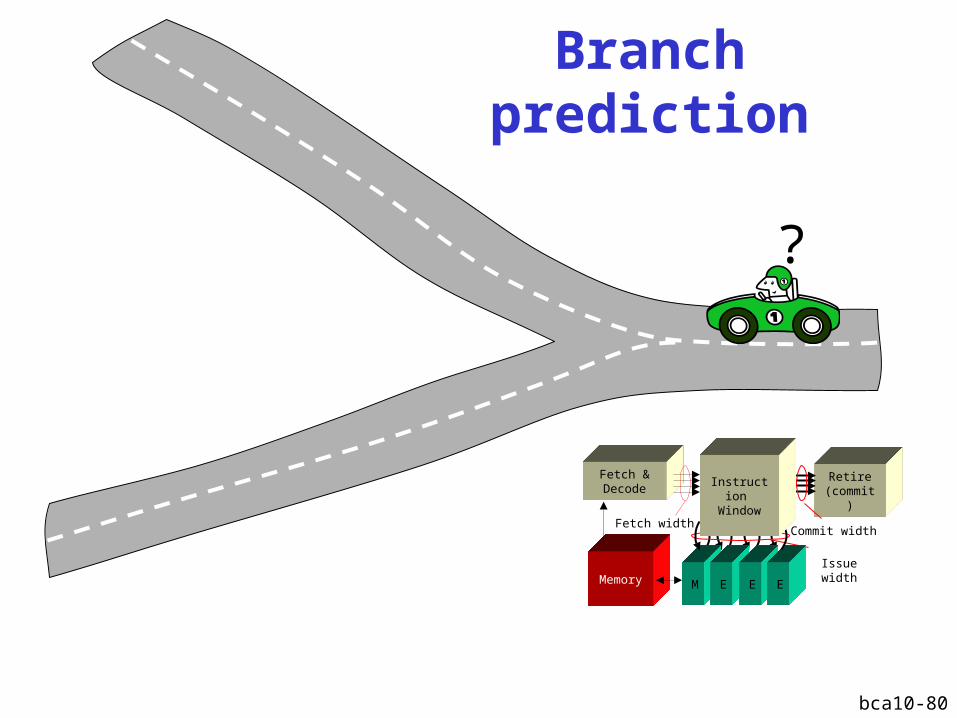
Branch prediction
?
Retire(commit)
Fetch &Decode
Fetch widthCommit width
Issue width
M E E EMemory
Instruction Window
bca10-81
Cycle 11
L1 I-cacheL1 I-cache
Branch predictor
Branch predictor
ALUALU
ld/stld/st
L1 D
-cach
eL1
D-c
ach
e
L2 c
ach
eL2
cach
e
d2
c2e2
f2
d3
c3
e3
f3
f2
c3
ALUALUd2
mov 0 → r1 mov 0x0fe0 → r3L: ld MEM[r3] → r2 add r2,r1 → r1 add r3,48 → r3 brl r3,0x10a0 → L st r1 → MEM[A]
mov 0 → r1 mov 0x0fe0 → r3L: ld MEM[r3] → r2 add r2,r1 → r1 add r3,48 → r3 brl r3,0x10a0 → L st r1 → MEM[A]
ab
dc
ef
g
d4
c4e4
d5
c5e5
f5 f4
Mispredicted branchMispredicted branch
speculative fetch and executionspeculative fetch and execution
to L
1I-
cach
e
bca10-82
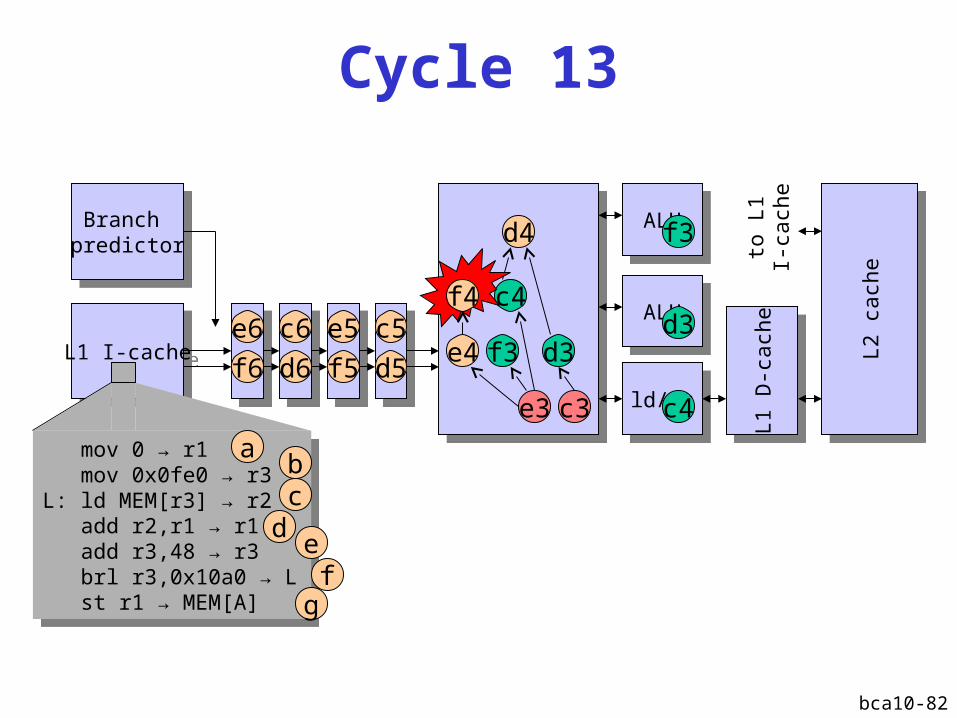
Cycle 13
L1 I-cacheL1 I-cache
Branch predictor
Branch predictor
ALUALU
ld/stld/st
L1 D
-cach
eL1
D-c
ach
e
L2 c
ach
eL2
cach
e
d3
c3e3
f3
d4
c4
e4
f3
c4
ALUALUd3
mov 0 → r1 mov 0x0fe0 → r3L: ld MEM[r3] → r2 add r2,r1 → r1 add r3,48 → r3 brl r3,0x10a0 → L st r1 → MEM[A]
mov 0 → r1 mov 0x0fe0 → r3L: ld MEM[r3] → r2 add r2,r1 → r1 add r3,48 → r3 brl r3,0x10a0 → L st r1 → MEM[A]
ab
dc
ef
g
d5
c5e5
d6
c6e6
f6 f5
f4
to L
1I-
cach
e
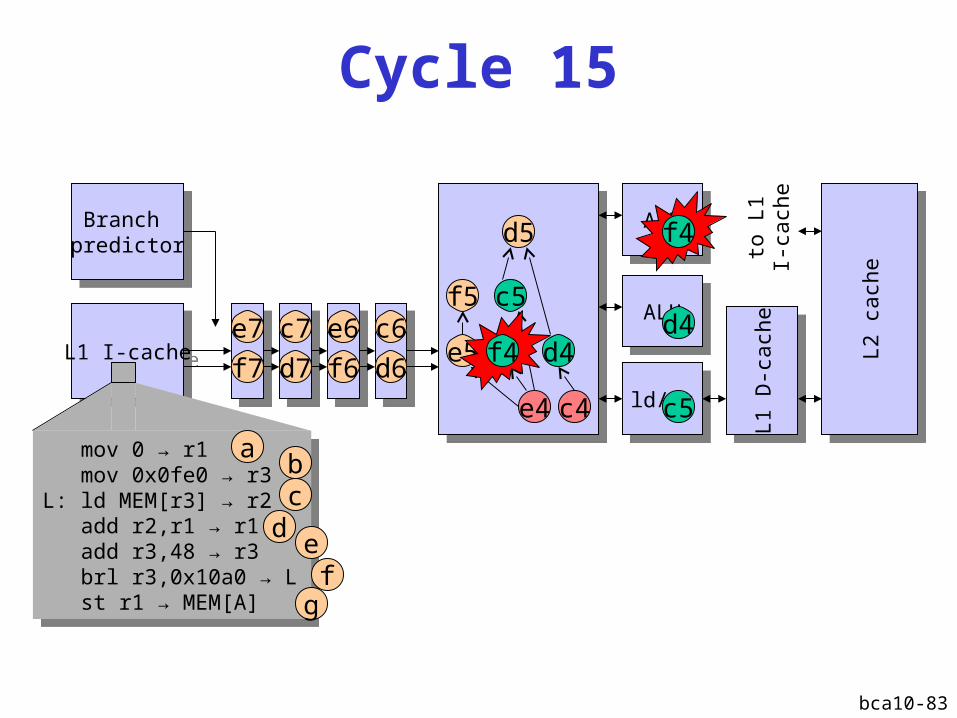
bca10-83
ALUALU
Cycle 15
L1 I-cacheL1 I-cache
Branch predictor
Branch predictor
ld/stld/st
L1 D
-cach
eL1
D-c
ach
e
L2 c
ach
eL2
cach
e
d4
c4e4
d5
c5
e5
c5
ALUALUd4
mov 0 → r1 mov 0x0fe0 → r3L: ld MEM[r3] → r2 add r2,r1 → r1 add r3,48 → r3 brl r3,0x10a0 → L st r1 → MEM[A]
mov 0 → r1 mov 0x0fe0 → r3L: ld MEM[r3] → r2 add r2,r1 → r1 add r3,48 → r3 brl r3,0x10a0 → L st r1 → MEM[A]
ab
dc
ef
g
d6
c6e6
d7
c7e7
f7 f6
f5
f4
f4
to L
1I-
cach
e
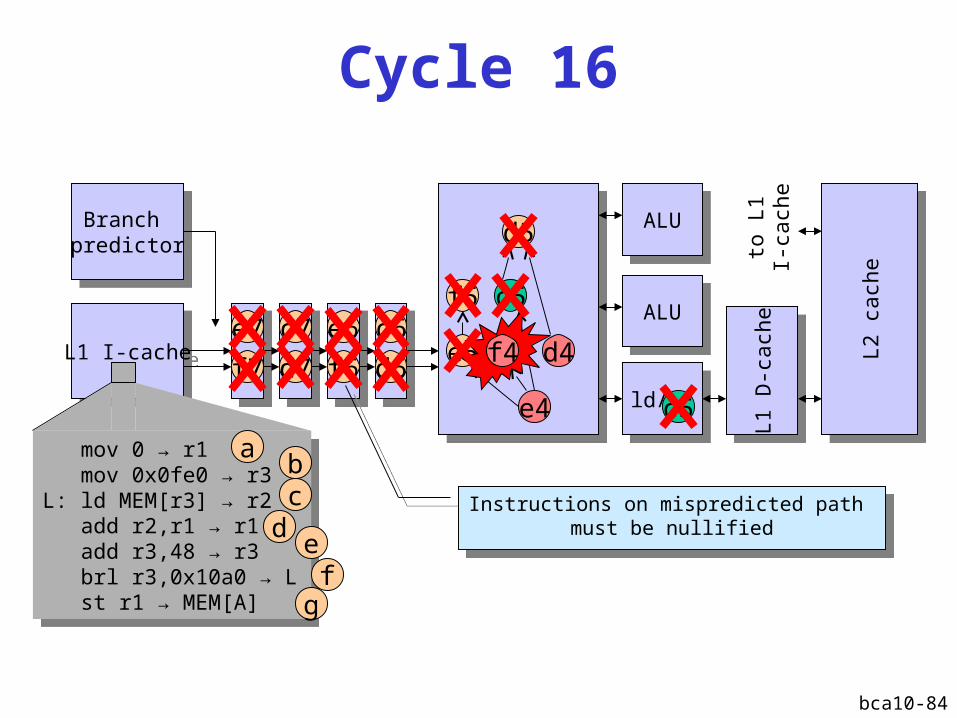
bca10-84
Cycle 16
ALUALU
L1 I-cacheL1 I-cache
Branch predictor
Branch predictor
ld/stld/st
L1 D
-cach
eL1
D-c
ach
e
L2 c
ach
eL2
cach
e
d4
e4
d5
c5
e5
c5
ALUALU
mov 0 → r1 mov 0x0fe0 → r3L: ld MEM[r3] → r2 add r2,r1 → r1 add r3,48 → r3 brl r3,0x10a0 → L st r1 → MEM[A]
mov 0 → r1 mov 0x0fe0 → r3L: ld MEM[r3] → r2 add r2,r1 → r1 add r3,48 → r3 brl r3,0x10a0 → L st r1 → MEM[A]
ab
dc
ef
g
d6
c6e6
d7
c7e7
f7 f6
f5
f4
Instructions on mispredicted path must be nullified
Instructions on mispredicted path must be nullified
to L
1I-
cach
e
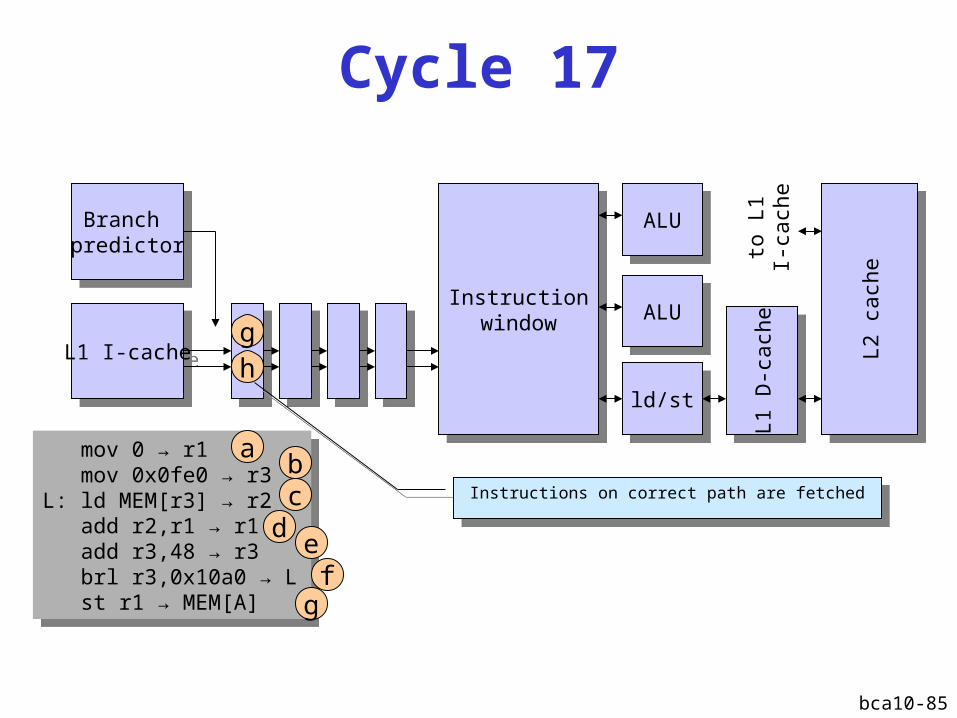
bca10-85
Cycle 17
L1 I-cacheL1 I-cache
Branch predictor
Branch predictor
Instructionwindow
Instructionwindow
ALUALU
ld/stld/st
L1 D
-cach
eL1
D-c
ach
e
L2 c
ach
eL2
cach
e
mov 0 → r1 mov 0x0fe0 → r3L: ld MEM[r3] → r2 add r2,r1 → r1 add r3,48 → r3 brl r3,0x10a0 → L st r1 → MEM[A]
mov 0 → r1 mov 0x0fe0 → r3L: ld MEM[r3] → r2 add r2,r1 → r1 add r3,48 → r3 brl r3,0x10a0 → L st r1 → MEM[A]
ab
dc
ef
g
ALUALUgh
Instructions on correct path are fetchedInstructions on correct path are fetched
to L
1I-
cach
e
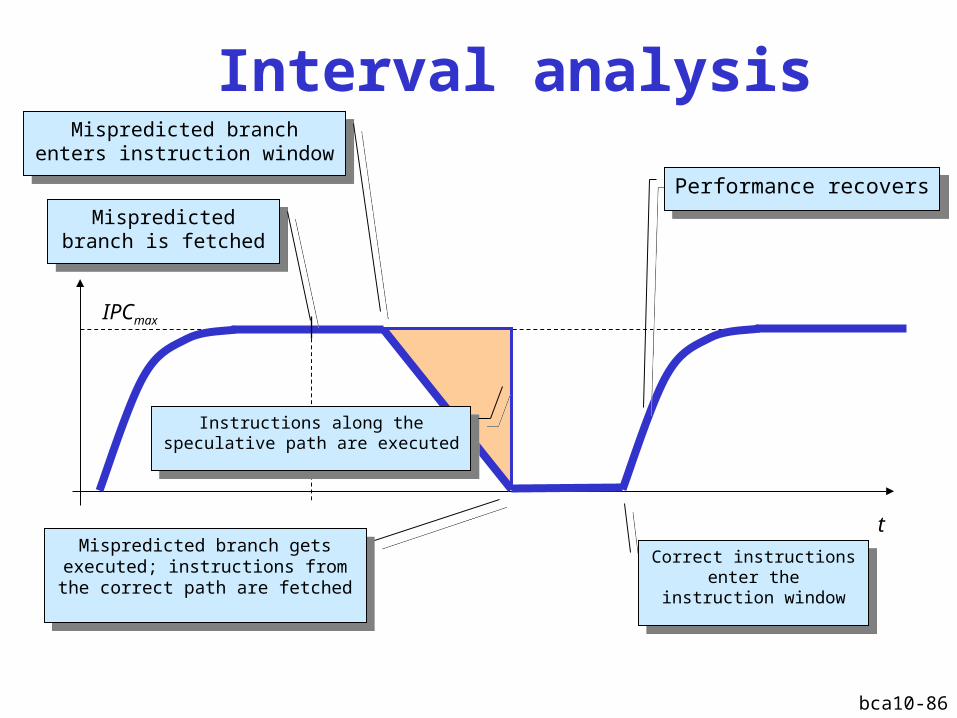
bca10-86
Interval analysis
IPC
t
Mispredicted branch enters instruction window
Mispredicted branch enters instruction window
Mispredicted branch gets executed; instructions from the correct path are fetched
Mispredicted branch gets executed; instructions from the correct path are fetched
Correct instructions enter the
instruction window
Correct instructions enter the
instruction window
Performance recoversPerformance recovers
IPCmax
Mispredicted branch is fetched
Mispredicted branch is fetched
Instructions along the speculative path are executed
Instructions along the speculative path are executed
Intervalanalyse
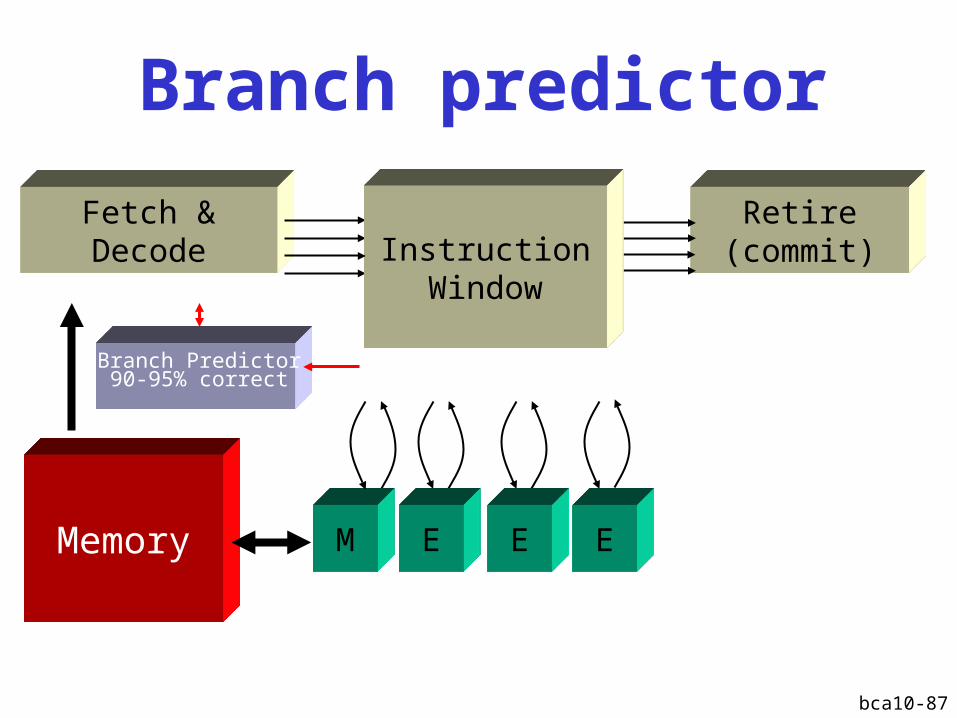
bca10-87
Retire(commit)
Branch predictor
Fetch &Decode Instruction
Window
M E E EMemory
Branch Predictor90-95% correct
bca10-88
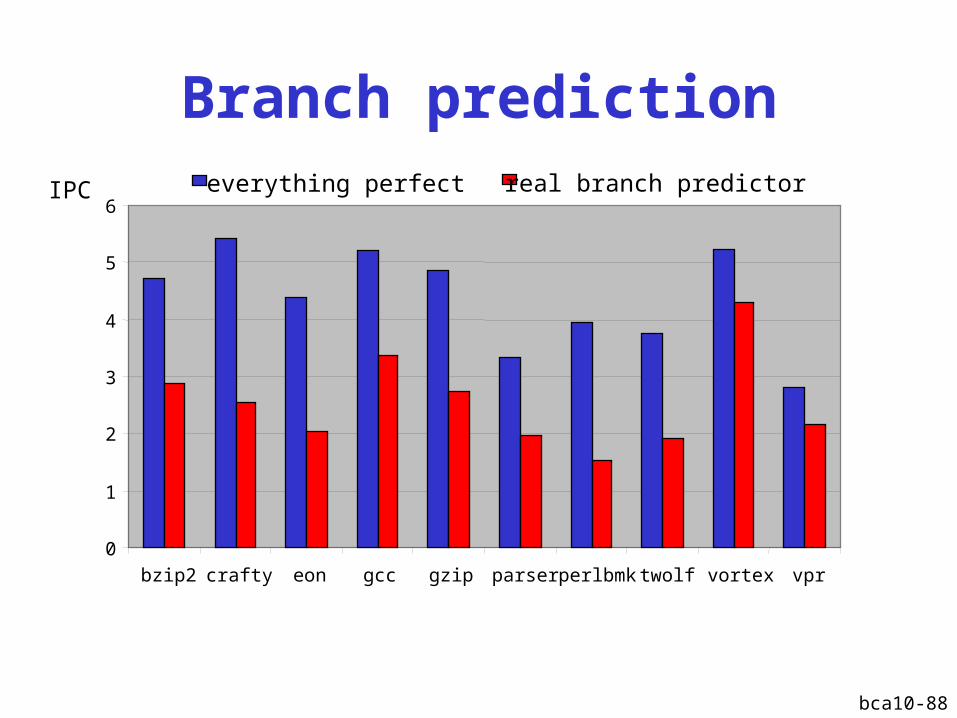
Branch prediction
0
1
2
3
4
5
6
bzip2 crafty eon gcc gzip parser perlbmk twolf vortex vpr
everything perfect real branch predictorIPC
Sprongvoorspeller
bca10-89
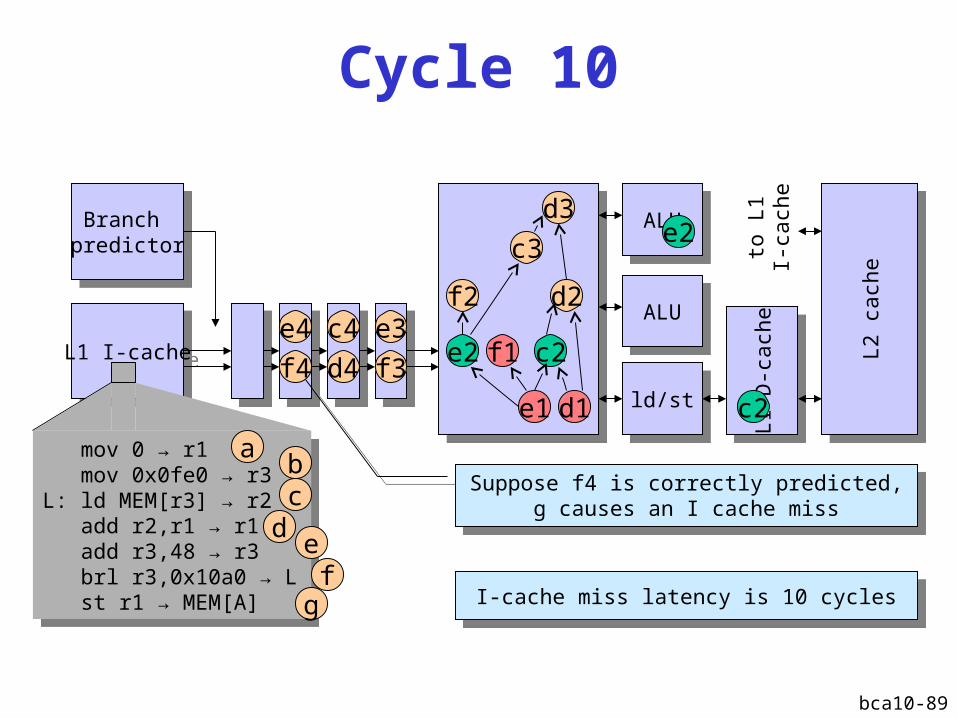
Cycle 10
L1 I-cacheL1 I-cache
Branch predictor
Branch predictor
ALUALU
ld/stld/st
L1 D
-cach
eL1
D-c
ach
e
L2 c
ach
eL2
cach
e
d1e1
f1
d2
c2e2
f2
d3
c3e2
c2
ALUALU
mov 0 → r1 mov 0x0fe0 → r3L: ld MEM[r3] → r2 add r2,r1 → r1 add r3,48 → r3 brl r3,0x10a0 → L st r1 → MEM[A]
mov 0 → r1 mov 0x0fe0 → r3L: ld MEM[r3] → r2 add r2,r1 → r1 add r3,48 → r3 brl r3,0x10a0 → L st r1 → MEM[A]
ab
dc
ef
g
e3
f3d4
c4e4
f4
Suppose f4 is correctly predicted, g causes an I cache miss
Suppose f4 is correctly predicted, g causes an I cache miss
I-cache miss latency is 10 cyclesI-cache miss latency is 10 cycles
to L
1I-
cach
e
Cache: misser
bca10-90
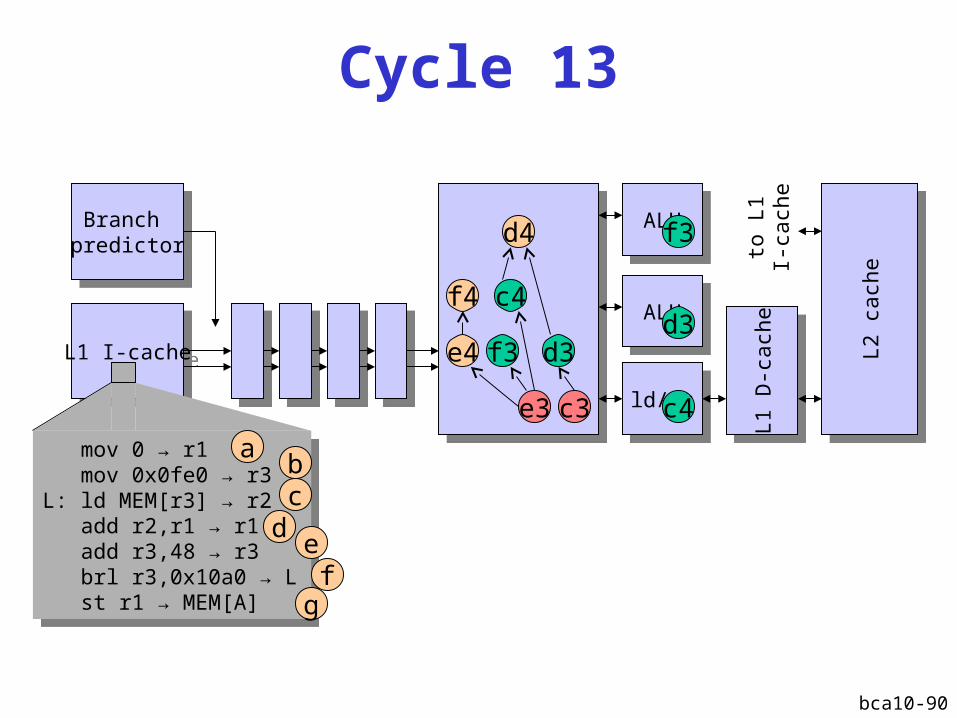
Cycle 13
L1 I-cacheL1 I-cache
Branch predictor
Branch predictor
ALUALU
ld/stld/st
L1 D
-cach
eL1
D-c
ach
e
L2 c
ach
eL2
cach
e
d3
c3e3
f3
d4
c4
e4
f3
c4
ALUALUd3
mov 0 → r1 mov 0x0fe0 → r3L: ld MEM[r3] → r2 add r2,r1 → r1 add r3,48 → r3 brl r3,0x10a0 → L st r1 → MEM[A]
mov 0 → r1 mov 0x0fe0 → r3L: ld MEM[r3] → r2 add r2,r1 → r1 add r3,48 → r3 brl r3,0x10a0 → L st r1 → MEM[A]
ab
dc
ef
g
f4
to L
1I-
cach
e
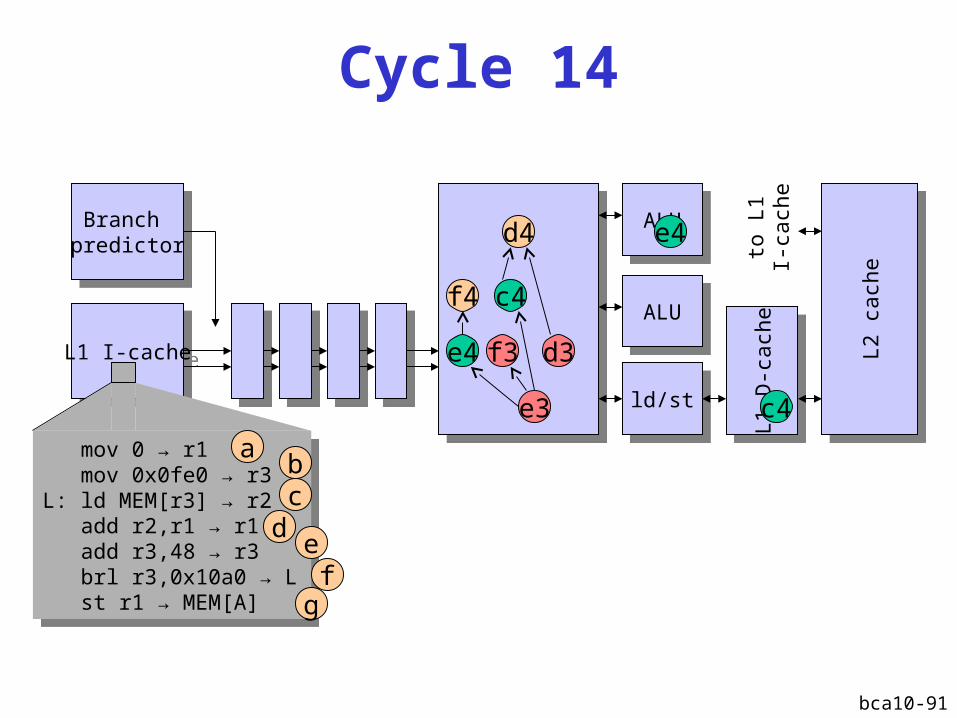
bca10-91
Cycle 14
L1 I-cacheL1 I-cache
Branch predictor
Branch predictor
ALUALU
ld/stld/st
L1 D
-cach
eL1
D-c
ach
e
L2 c
ach
eL2
cach
e
d3
e3
f3
d4
c4
e4
c4
ALUALU
mov 0 → r1 mov 0x0fe0 → r3L: ld MEM[r3] → r2 add r2,r1 → r1 add r3,48 → r3 brl r3,0x10a0 → L st r1 → MEM[A]
mov 0 → r1 mov 0x0fe0 → r3L: ld MEM[r3] → r2 add r2,r1 → r1 add r3,48 → r3 brl r3,0x10a0 → L st r1 → MEM[A]
ab
dc
ef
g
f4
e4
to L
1I-
cach
e
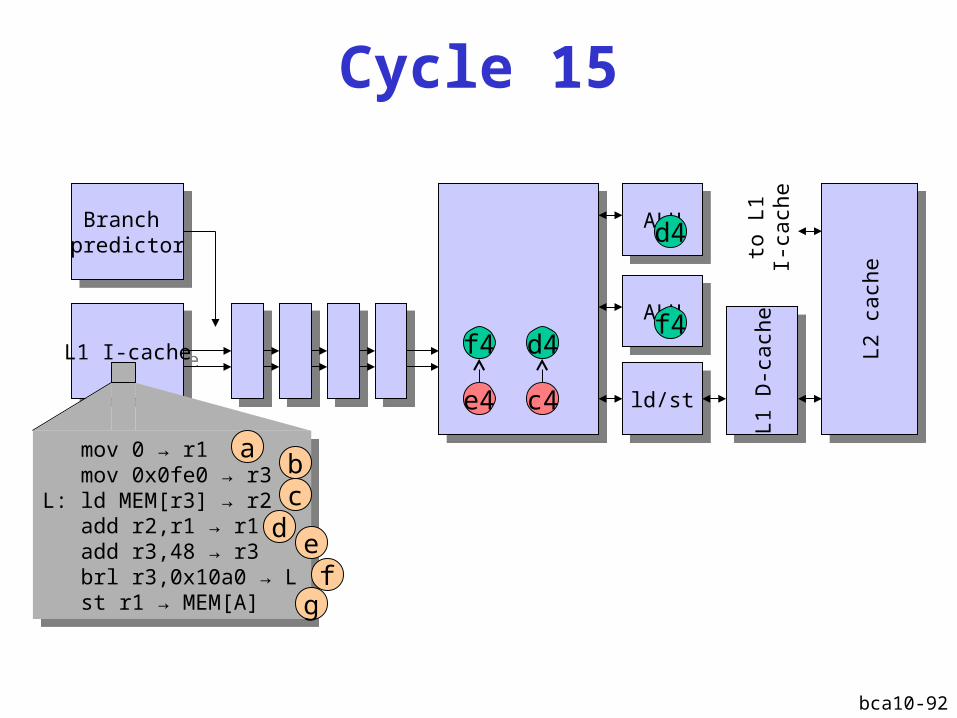
bca10-92
Cycle 15
L1 I-cacheL1 I-cache
Branch predictor
Branch predictor
ALUALU
ld/stld/st
L1 D
-cach
eL1
D-c
ach
e
L2 c
ach
eL2
cach
e
d4
c4e4
ALUALU
mov 0 → r1 mov 0x0fe0 → r3L: ld MEM[r3] → r2 add r2,r1 → r1 add r3,48 → r3 brl r3,0x10a0 → L st r1 → MEM[A]
mov 0 → r1 mov 0x0fe0 → r3L: ld MEM[r3] → r2 add r2,r1 → r1 add r3,48 → r3 brl r3,0x10a0 → L st r1 → MEM[A]
ab
dc
ef
g
f4
d4
f4
to L
1I-
cach
e
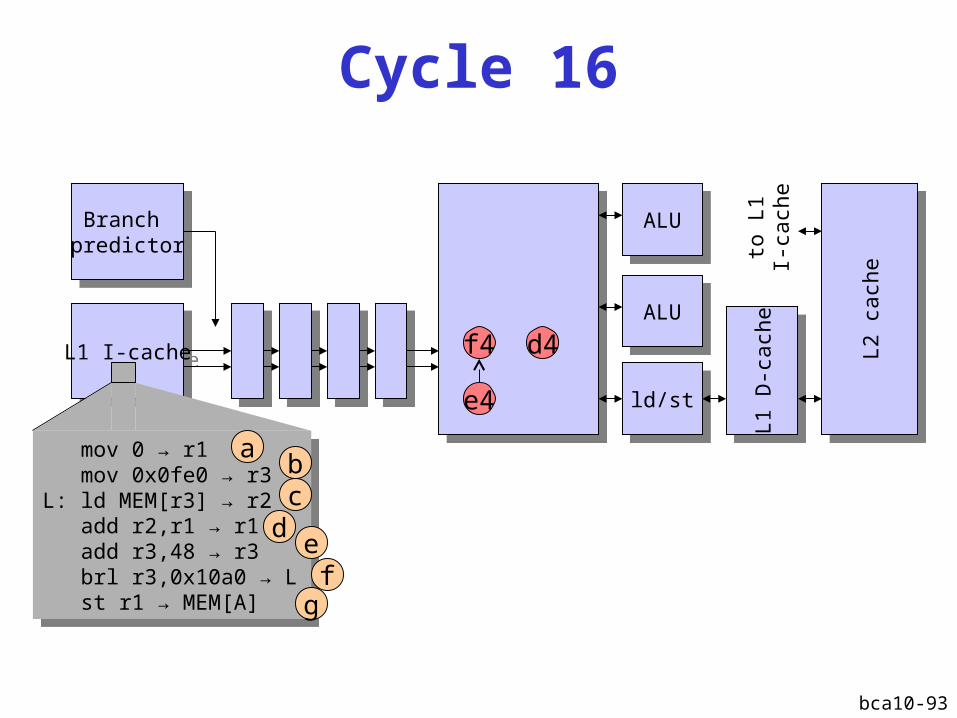
bca10-93
Cycle 16
L1 I-cacheL1 I-cache
Branch predictor
Branch predictor
ALUALU
ld/stld/st
L1 D
-cach
eL1
D-c
ach
e
L2 c
ach
eL2
cach
e
d4
e4
ALUALU
mov 0 → r1 mov 0x0fe0 → r3L: ld MEM[r3] → r2 add r2,r1 → r1 add r3,48 → r3 brl r3,0x10a0 → L st r1 → MEM[A]
mov 0 → r1 mov 0x0fe0 → r3L: ld MEM[r3] → r2 add r2,r1 → r1 add r3,48 → r3 brl r3,0x10a0 → L st r1 → MEM[A]
ab
dc
ef
g
f4
to L
1I-
cach
e
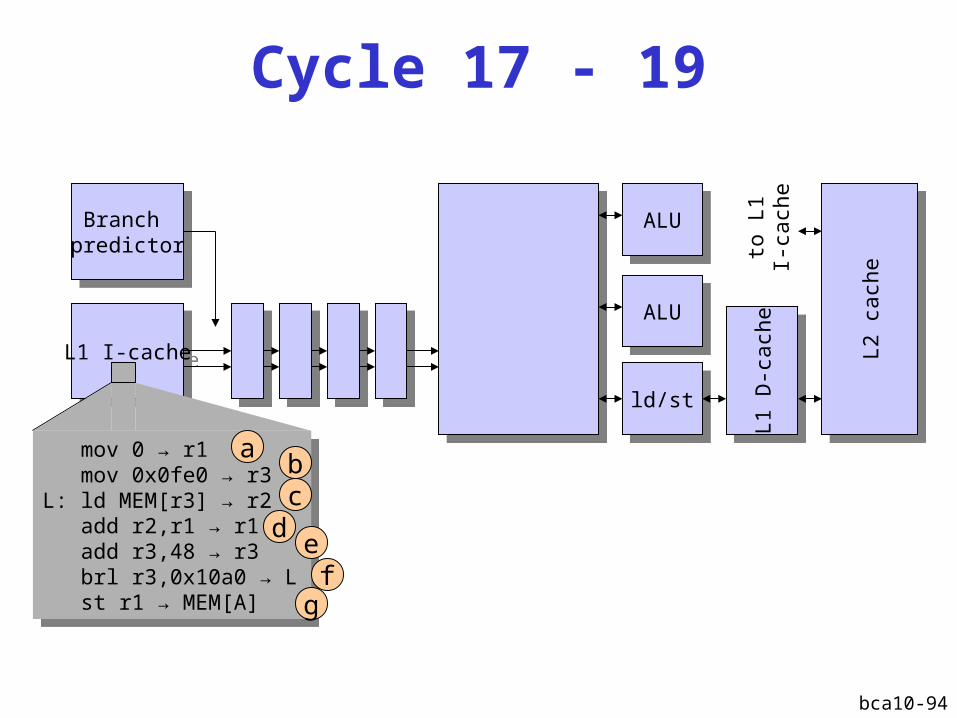
bca10-94
Cycle 17 - 19
L1 I-cacheL1 I-cache
Branch predictor
Branch predictor
ALUALU
ld/stld/st
L1 D
-cach
eL1
D-c
ach
e
L2 c
ach
eL2
cach
e
ALUALU
mov 0 → r1 mov 0x0fe0 → r3L: ld MEM[r3] → r2 add r2,r1 → r1 add r3,48 → r3 brl r3,0x10a0 → L st r1 → MEM[A]
mov 0 → r1 mov 0x0fe0 → r3L: ld MEM[r3] → r2 add r2,r1 → r1 add r3,48 → r3 brl r3,0x10a0 → L st r1 → MEM[A]
ab
dc
ef
g
to L
1I-
cach
e
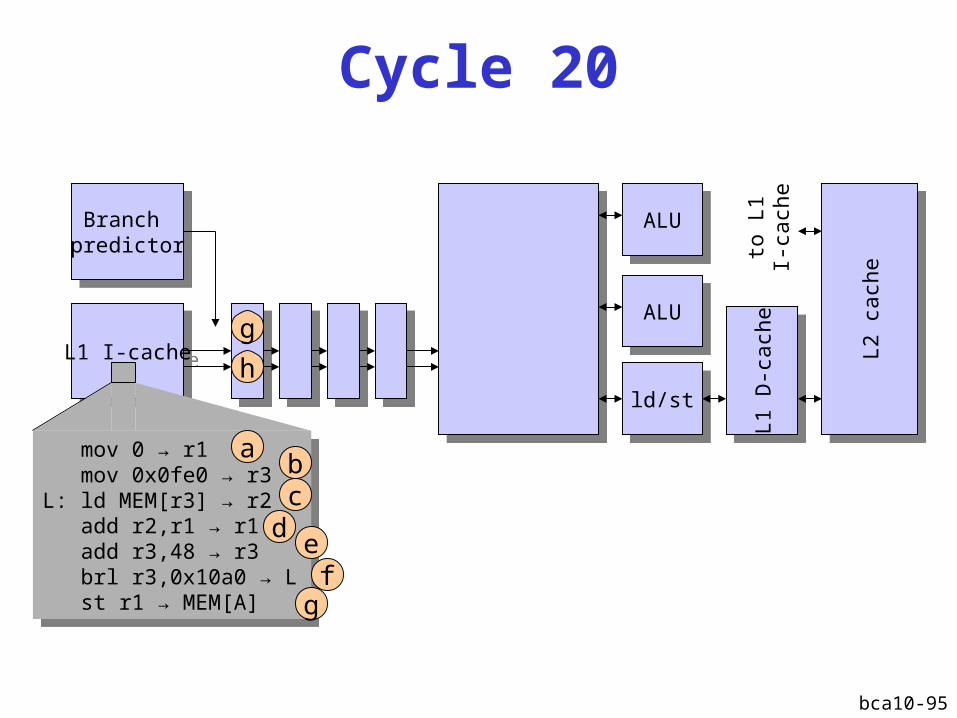
bca10-95
Cycle 20
L1 I-cacheL1 I-cache
Branch predictor
Branch predictor
ALUALU
ld/stld/st
L1 D
-cach
eL1
D-c
ach
e
L2 c
ach
eL2
cach
e
ALUALU
mov 0 → r1 mov 0x0fe0 → r3L: ld MEM[r3] → r2 add r2,r1 → r1 add r3,48 → r3 brl r3,0x10a0 → L st r1 → MEM[A]
mov 0 → r1 mov 0x0fe0 → r3L: ld MEM[r3] → r2 add r2,r1 → r1 add r3,48 → r3 brl r3,0x10a0 → L st r1 → MEM[A]
ab
dc
ef
g
g
h
to L
1I-
cach
e
bca10-96
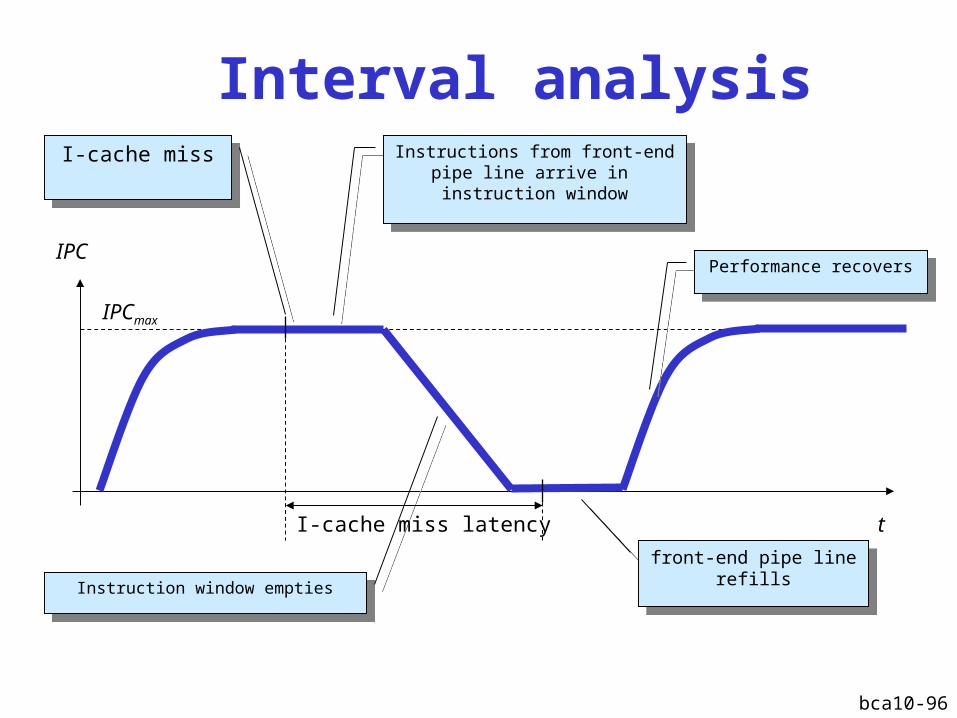
Interval analysis
IPC
t
I-cache missI-cache miss Instructions from front-endpipe line arrive in instruction window
Instructions from front-endpipe line arrive in instruction window
Instruction window emptiesInstruction window emptiesfront-end pipe line
refills
front-end pipe linerefills
Performance recoversPerformance recovers
IPCmax
I-cache miss latency
bca10-97
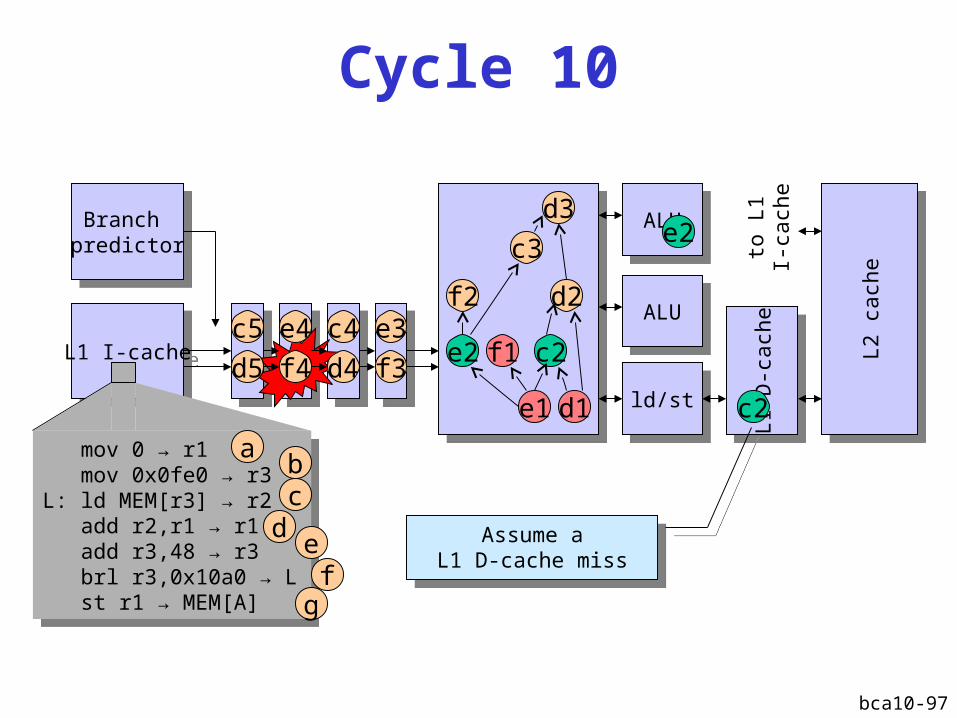
Cycle 10
L1 I-cacheL1 I-cache
Branch predictor
Branch predictor
ALUALU
ld/stld/st
L1 D
-cach
eL1
D-c
ach
e
L2 c
ach
eL2
cach
e
d1e1
f1
d2
c2e2
f2
d3
c3e2
c2
ALUALU
mov 0 → r1 mov 0x0fe0 → r3L: ld MEM[r3] → r2 add r2,r1 → r1 add r3,48 → r3 brl r3,0x10a0 → L st r1 → MEM[A]
mov 0 → r1 mov 0x0fe0 → r3L: ld MEM[r3] → r2 add r2,r1 → r1 add r3,48 → r3 brl r3,0x10a0 → L st r1 → MEM[A]
ab
dc
ef
g
e3
f3d4
c4e4
f4d5
c5
Assume aL1 D-cache miss
Assume aL1 D-cache miss
to L
1I-
cach
e
Cache: misser
bca10-98
Cycle 11
L1 I-cacheL1 I-cache
Branch predictor
Branch predictor
ALUALU
ld/stld/st
L1 D
-cach
eL1
D-c
ach
e
L2 c
ach
eL2
cach
e
d2
c2e2
f2
d3
c3
c2ALUALU
mov 0 → r1 mov 0x0fe0 → r3L: ld MEM[r3] → r2 add r2,r1 → r1 add r3,48 → r3 brl r3,0x10a0 → L st r1 → MEM[A]
mov 0 → r1 mov 0x0fe0 → r3L: ld MEM[r3] → r2 add r2,r1 → r1 add r3,48 → r3 brl r3,0x10a0 → L st r1 → MEM[A]
ab
dc
ef
g
e3
f3
d4
c4e4
f4d5
c5
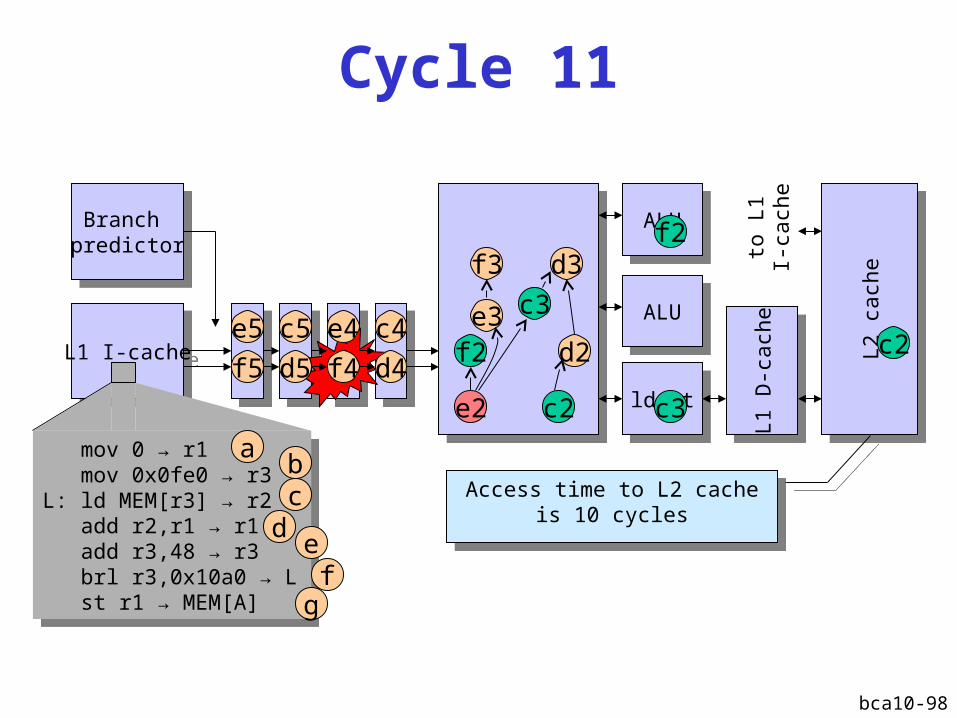
Access time to L2 cache is 10 cycles
Access time to L2 cache is 10 cycles
f2
c3
e5
f5
to L
1I-
cach
e
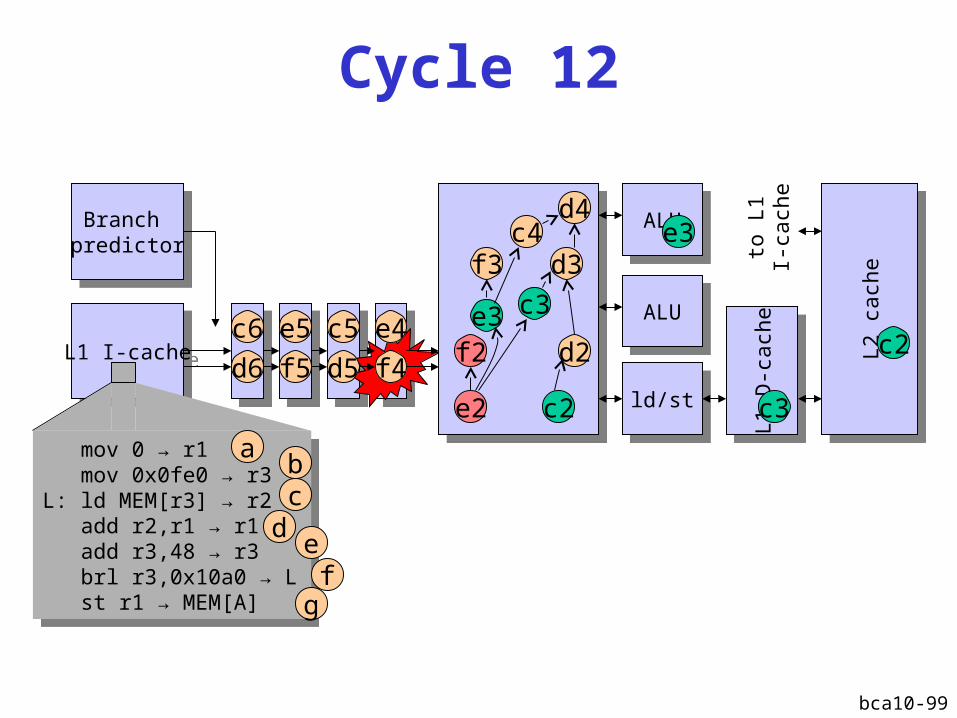
bca10-99
Cycle 12
L1 I-cacheL1 I-cache
Branch predictor
Branch predictor
ALUALU
ld/stld/st
L1 D
-cach
eL1
D-c
ach
e
L2 c
ach
eL2
cach
e
d2
c2e2
f2
d3
c3
c2ALUALU
mov 0 → r1 mov 0x0fe0 → r3L: ld MEM[r3] → r2 add r2,r1 → r1 add r3,48 → r3 brl r3,0x10a0 → L st r1 → MEM[A]
mov 0 → r1 mov 0x0fe0 → r3L: ld MEM[r3] → r2 add r2,r1 → r1 add r3,48 → r3 brl r3,0x10a0 → L st r1 → MEM[A]
ab
dc
ef
g
e3
f3
d4c4
e4
f4d5
c5
c3
e5
f5
e3
d6
c6
to L
1I-
cach
e
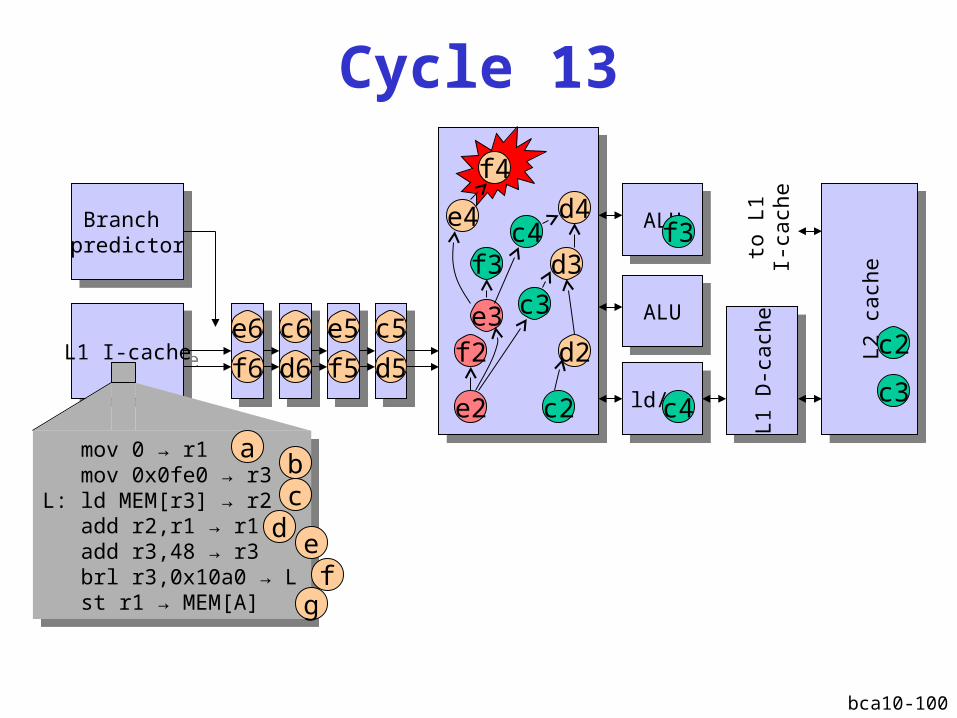
bca10-100
Cycle 13
L1 I-cacheL1 I-cache
Branch predictor
Branch predictor
ALUALU
ld/stld/st
L1 D
-cach
eL1
D-c
ach
e
L2 c
ach
eL2
cach
e
d2
c2e2
f2
d3
c3
c2ALUALU
mov 0 → r1 mov 0x0fe0 → r3L: ld MEM[r3] → r2 add r2,r1 → r1 add r3,48 → r3 brl r3,0x10a0 → L st r1 → MEM[A]
mov 0 → r1 mov 0x0fe0 → r3L: ld MEM[r3] → r2 add r2,r1 → r1 add r3,48 → r3 brl r3,0x10a0 → L st r1 → MEM[A]
ab
dc
ef
g
e3
f3
d4c4
e4
f4
d5
c5
c4
e5
f5
f3
d6
c6e6
f6
to L
1I-
cach
e
c3
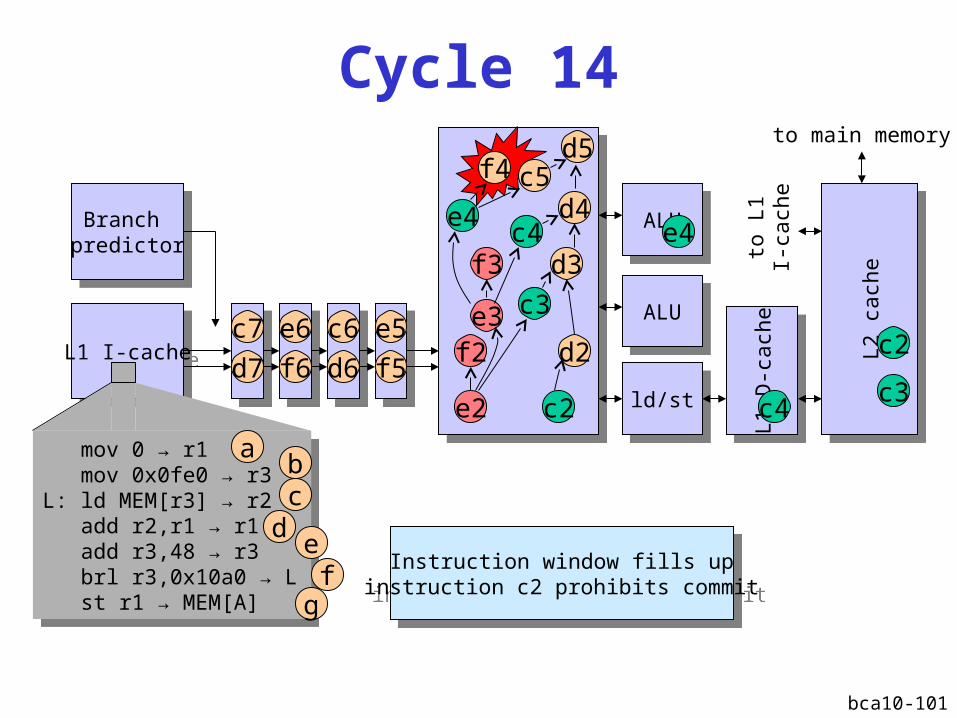
bca10-101
Cycle 14
L1 I-cacheL1 I-cache
Branch predictor
Branch predictor
ALUALU
ld/stld/st
L1 D
-cach
eL1
D-c
ach
e
L2 c
ach
eL2
cach
e
d2
c2e2
f2
d3
c3ALUALU
mov 0 → r1 mov 0x0fe0 → r3L: ld MEM[r3] → r2 add r2,r1 → r1 add r3,48 → r3 brl r3,0x10a0 → L st r1 → MEM[A]
mov 0 → r1 mov 0x0fe0 → r3L: ld MEM[r3] → r2 add r2,r1 → r1 add r3,48 → r3 brl r3,0x10a0 → L st r1 → MEM[A]
ab
dc
ef
g
e3
f3
d4c4
e4
f4d5
c5
c4
e5
f5
e4
d6
c6e6
f6d7
c7
to main memory
to L
1I-
cach
e
c2
c3
Instruction window fills upinstruction c2 prohibits commit
Instruction window fills upinstruction c2 prohibits commit
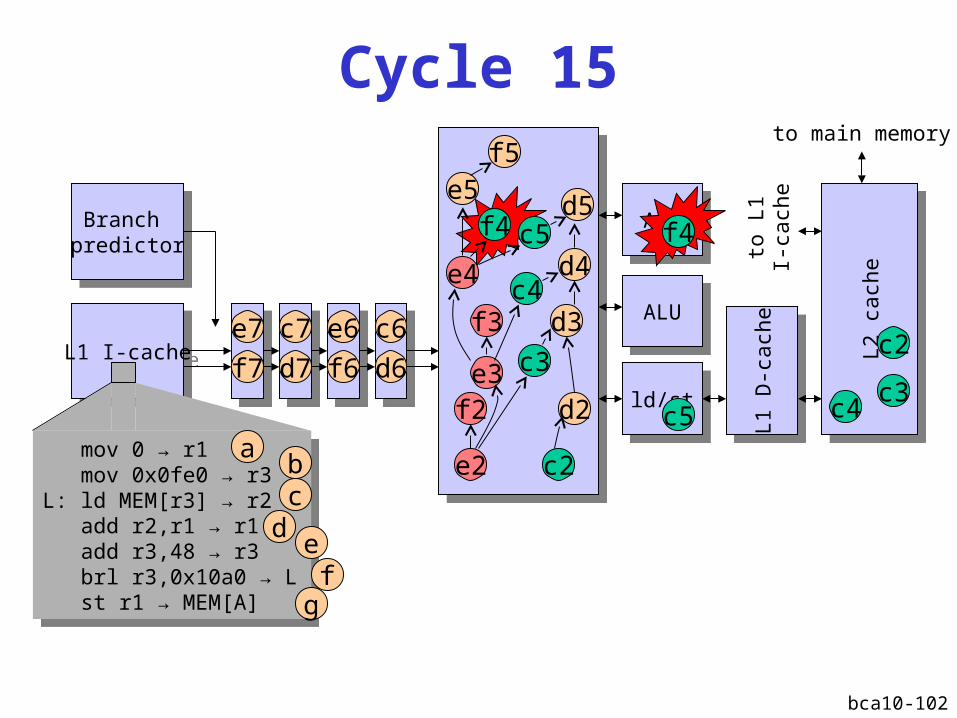
ALUALU
bca10-102
Cycle 15
L1 I-cacheL1 I-cache
Branch predictor
Branch predictor
ld/stld/st
L1 D
-cach
eL1
D-c
ach
e
L2 c
ach
eL2
cach
e
d2
c2e2
f2
d3
c3
ALUALU
mov 0 → r1 mov 0x0fe0 → r3L: ld MEM[r3] → r2 add r2,r1 → r1 add r3,48 → r3 brl r3,0x10a0 → L st r1 → MEM[A]
mov 0 → r1 mov 0x0fe0 → r3L: ld MEM[r3] → r2 add r2,r1 → r1 add r3,48 → r3 brl r3,0x10a0 → L st r1 → MEM[A]
ab
dc
ef
g
e3
f3
d4c4
e4
f4d5
c5
e5f5
f4
d6
c6e6
f6d7
c7e7
f7
c5
to main memory
to L
1I-
cach
e
c4
c2
c3
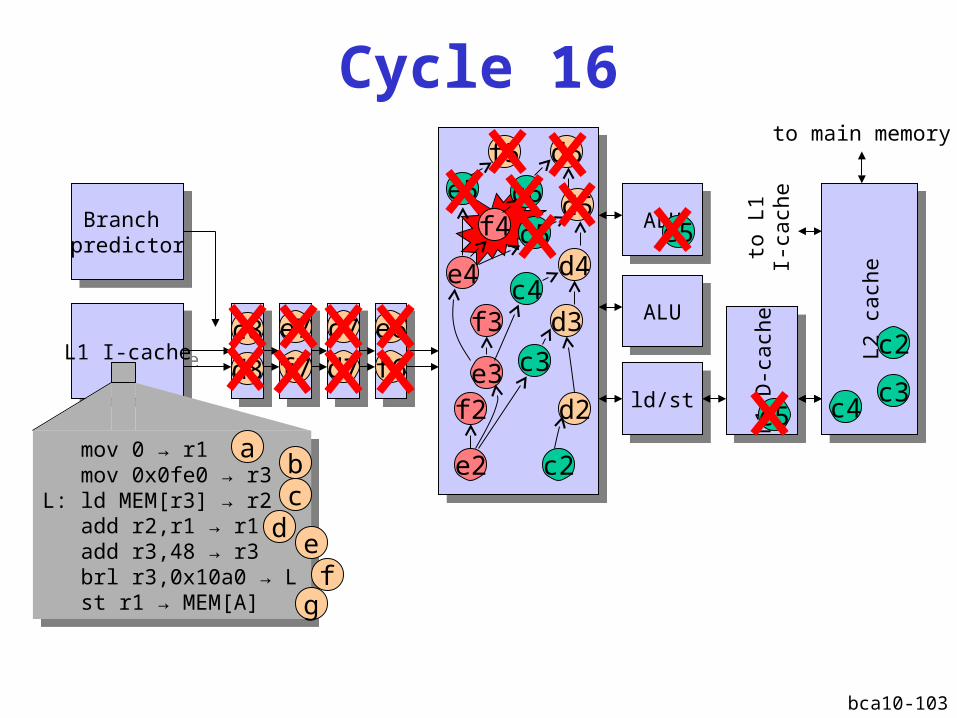
bca10-103
Cycle 16
L1 I-cacheL1 I-cache
Branch predictor
Branch predictor
ALUALU
ld/stld/st
L1 D
-cach
eL1
D-c
ach
e
L2 c
ach
eL2
cach
e
d2
c2e2
f2
d3
c3
ALUALU
mov 0 → r1 mov 0x0fe0 → r3L: ld MEM[r3] → r2 add r2,r1 → r1 add r3,48 → r3 brl r3,0x10a0 → L st r1 → MEM[A]
mov 0 → r1 mov 0x0fe0 → r3L: ld MEM[r3] → r2 add r2,r1 → r1 add r3,48 → r3 brl r3,0x10a0 → L st r1 → MEM[A]
ab
dc
ef
g
e3
f3
d4c4
e4
f4d5
c5
e5f5
e5
d6
c6
e6
f6d7
c7e7
f7
c5
d8
c8
to main memory
to L
1I-
cach
e
c4
c2
c3
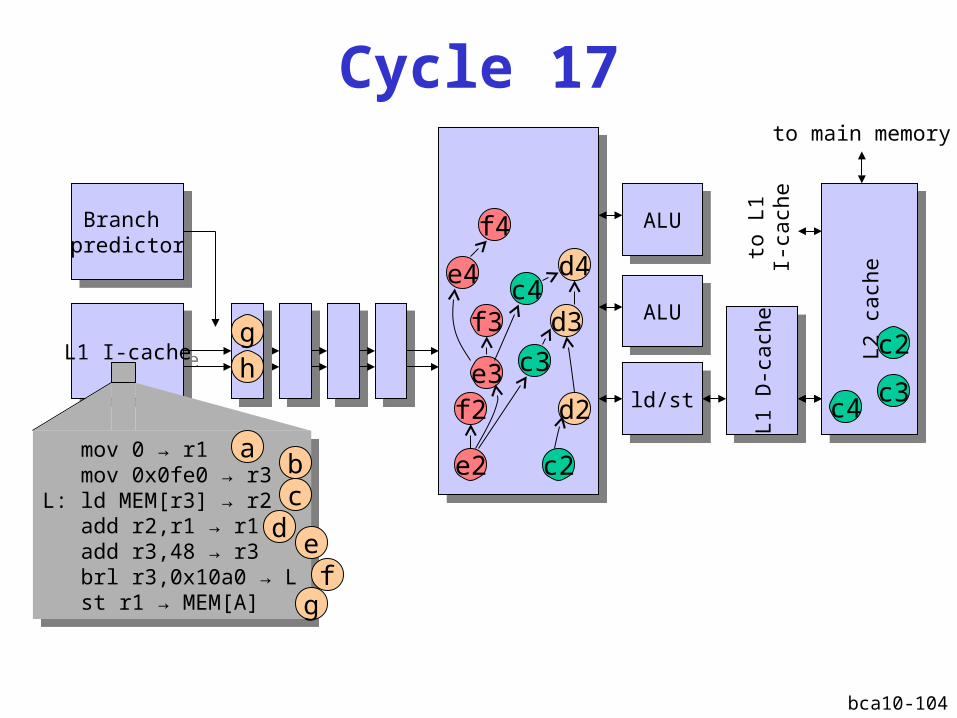
bca10-104
Cycle 17
L1 I-cacheL1 I-cache
Branch predictor
Branch predictor
ALUALU
ld/stld/st
L1 D
-cach
eL1
D-c
ach
e
L2 c
ach
eL2
cach
e
d2
c2e2
f2
d3
c3
ALUALU
mov 0 → r1 mov 0x0fe0 → r3L: ld MEM[r3] → r2 add r2,r1 → r1 add r3,48 → r3 brl r3,0x10a0 → L st r1 → MEM[A]
mov 0 → r1 mov 0x0fe0 → r3L: ld MEM[r3] → r2 add r2,r1 → r1 add r3,48 → r3 brl r3,0x10a0 → L st r1 → MEM[A]
ab
dc
ef
g
e3
f3
d4c4
e4
f4
to main memory
to L
1I-
cach
e
c4
c2
c3
gh
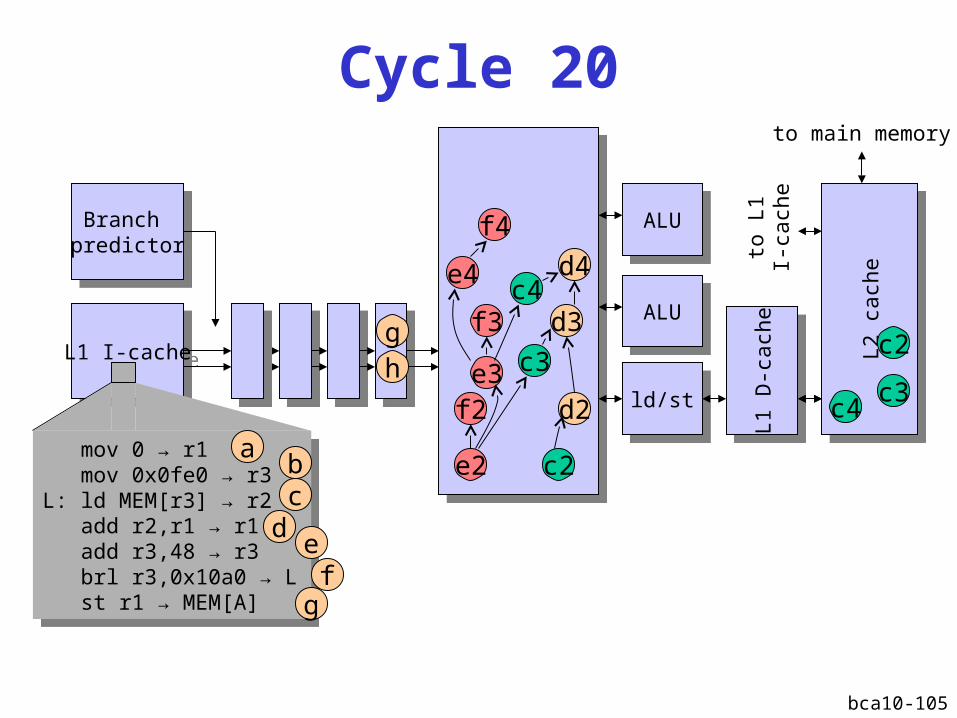
bca10-105
Cycle 20
L1 I-cacheL1 I-cache
Branch predictor
Branch predictor
ALUALU
ld/stld/st
L1 D
-cach
eL1
D-c
ach
e
L2 c
ach
eL2
cach
e
d2
c2e2
f2
d3
c3
ALUALU
mov 0 → r1 mov 0x0fe0 → r3L: ld MEM[r3] → r2 add r2,r1 → r1 add r3,48 → r3 brl r3,0x10a0 → L st r1 → MEM[A]
mov 0 → r1 mov 0x0fe0 → r3L: ld MEM[r3] → r2 add r2,r1 → r1 add r3,48 → r3 brl r3,0x10a0 → L st r1 → MEM[A]
ab
dc
ef
g
e3
f3
d4c4
e4
f4
to main memory
to L
1I-
cach
e
c4
c2
c3
gh
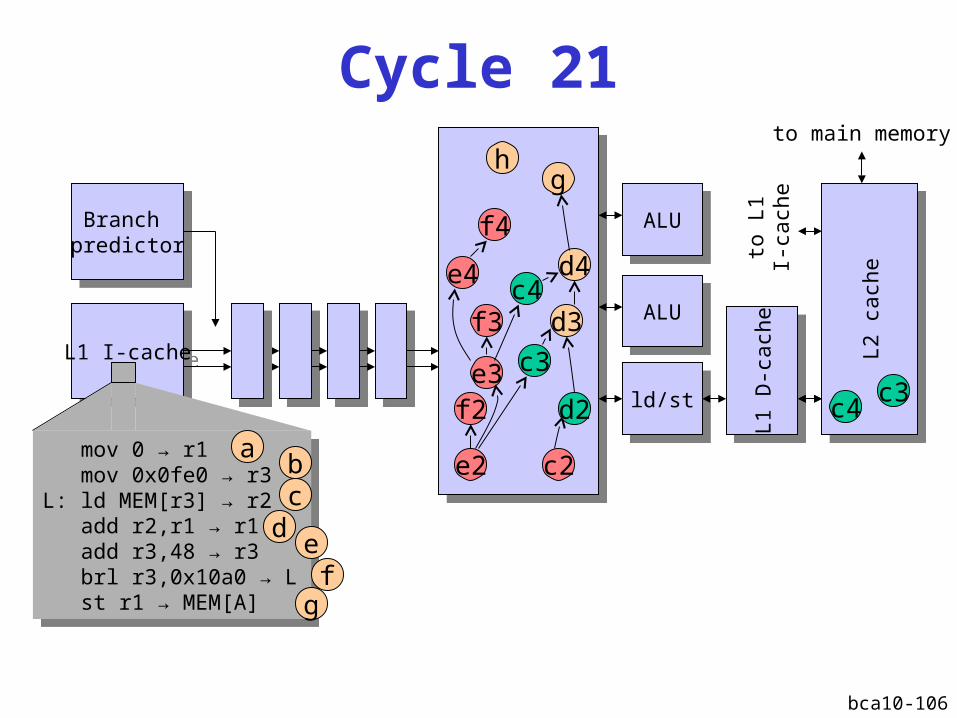
bca10-106
Cycle 21
L1 I-cacheL1 I-cache
Branch predictor
Branch predictor
ALUALU
ld/stld/st
L1 D
-cach
eL1
D-c
ach
e
L2 c
ach
eL2
cach
e
e2
f2
d3
c3
ALUALU
mov 0 → r1 mov 0x0fe0 → r3L: ld MEM[r3] → r2 add r2,r1 → r1 add r3,48 → r3 brl r3,0x10a0 → L st r1 → MEM[A]
mov 0 → r1 mov 0x0fe0 → r3L: ld MEM[r3] → r2 add r2,r1 → r1 add r3,48 → r3 brl r3,0x10a0 → L st r1 → MEM[A]
ab
dc
ef
g
e3
f3
d4c4
e4
f4
to main memory
to L
1I-
cach
e
c4c3
c2
d2
gh
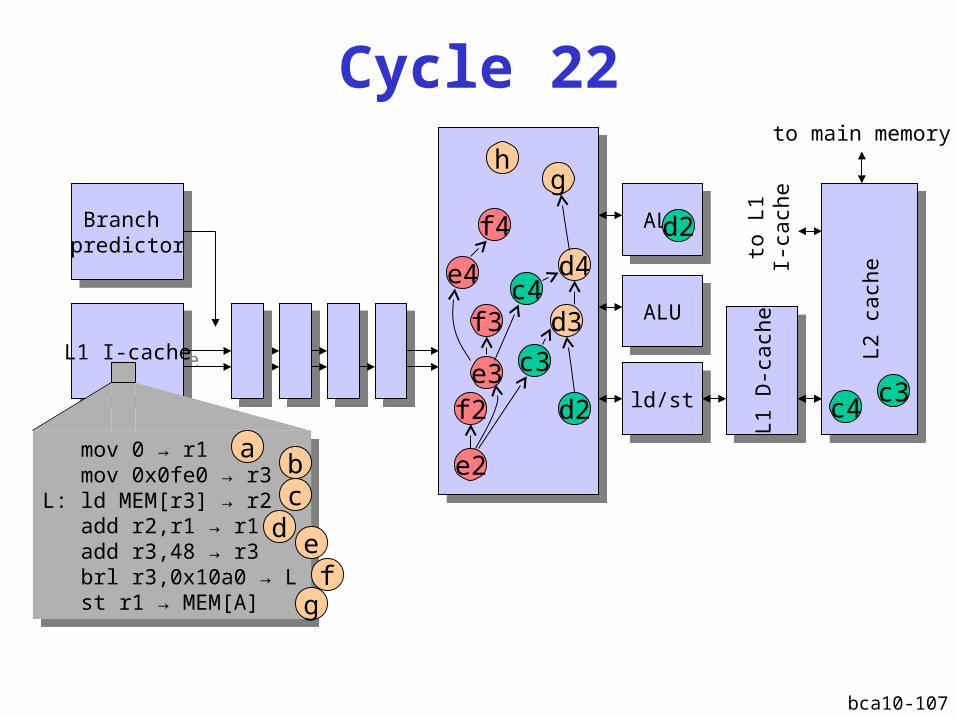
bca10-107
Cycle 22
L1 I-cacheL1 I-cache
Branch predictor
Branch predictor
ALUALU
ld/stld/st
L1 D
-cach
eL1
D-c
ach
e
L2 c
ach
eL2
cach
e
e2
f2
d3
c3
ALUALU
mov 0 → r1 mov 0x0fe0 → r3L: ld MEM[r3] → r2 add r2,r1 → r1 add r3,48 → r3 brl r3,0x10a0 → L st r1 → MEM[A]
mov 0 → r1 mov 0x0fe0 → r3L: ld MEM[r3] → r2 add r2,r1 → r1 add r3,48 → r3 brl r3,0x10a0 → L st r1 → MEM[A]
ab
dc
ef
g
e3
f3
d4c4
e4
f4
to main memory
to L
1I-
cach
e
c4c3
d2
d2
gh
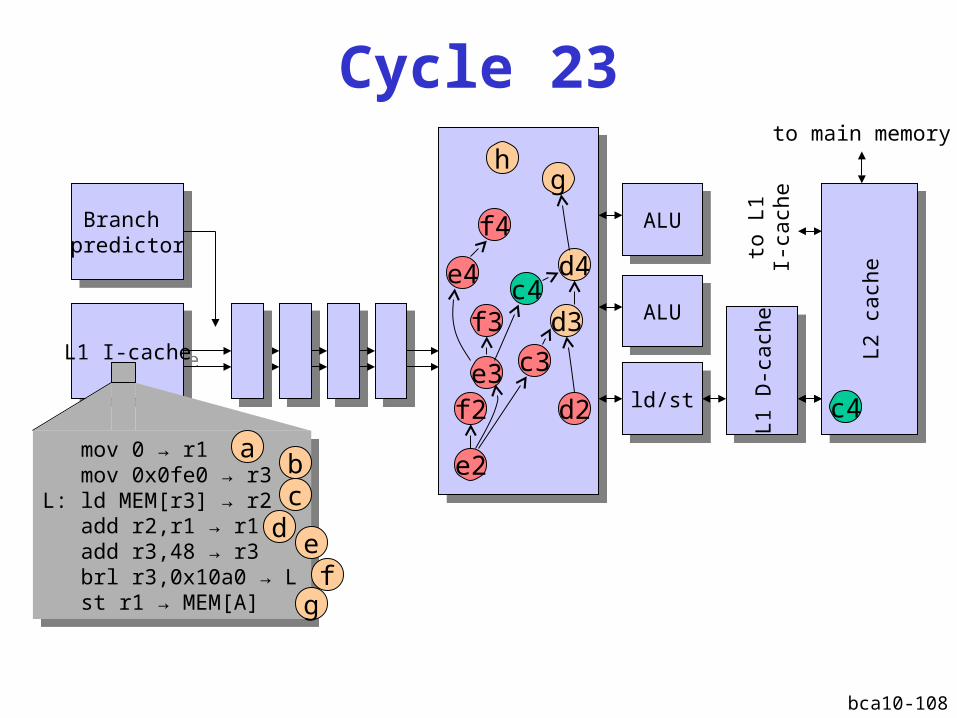
bca10-108
Cycle 23
L1 I-cacheL1 I-cache
Branch predictor
Branch predictor
ALUALU
ld/stld/st
L1 D
-cach
eL1
D-c
ach
e
L2 c
ach
eL2
cach
e
e2
f2
d3 ALUALU
mov 0 → r1 mov 0x0fe0 → r3L: ld MEM[r3] → r2 add r2,r1 → r1 add r3,48 → r3 brl r3,0x10a0 → L st r1 → MEM[A]
mov 0 → r1 mov 0x0fe0 → r3L: ld MEM[r3] → r2 add r2,r1 → r1 add r3,48 → r3 brl r3,0x10a0 → L st r1 → MEM[A]
ab
dc
ef
g
e3
f3
d4c4
e4
f4
to main memory
to L
1I-
cach
e
c4
c3
d2
gh
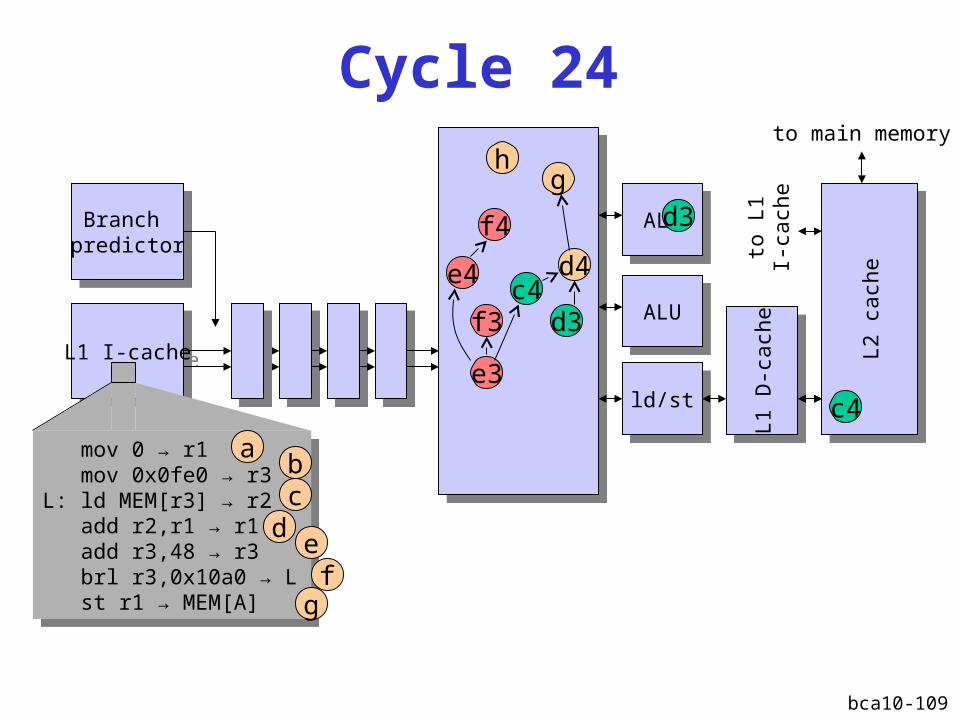
bca10-109
Cycle 24
L1 I-cacheL1 I-cache
Branch predictor
Branch predictor
ALUALU
ld/stld/st
L1 D
-cach
eL1
D-c
ach
e
L2 c
ach
eL2
cach
e
ALUALU
mov 0 → r1 mov 0x0fe0 → r3L: ld MEM[r3] → r2 add r2,r1 → r1 add r3,48 → r3 brl r3,0x10a0 → L st r1 → MEM[A]
mov 0 → r1 mov 0x0fe0 → r3L: ld MEM[r3] → r2 add r2,r1 → r1 add r3,48 → r3 brl r3,0x10a0 → L st r1 → MEM[A]
ab
dc
ef
g
e3
f3
d4c4
e4
f4
to main memory
to L
1I-
cach
e
c4
d3
d3
gh
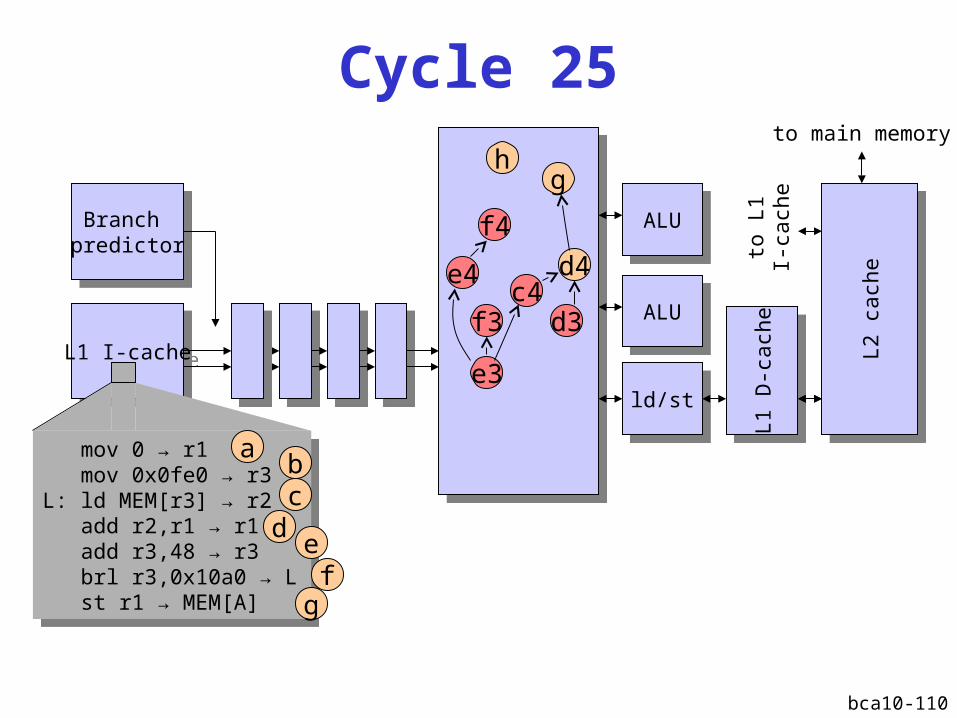
bca10-110
Cycle 25
L1 I-cacheL1 I-cache
Branch predictor
Branch predictor
ALUALU
ld/stld/st
L1 D
-cach
eL1
D-c
ach
e
L2 c
ach
eL2
cach
e
ALUALU
mov 0 → r1 mov 0x0fe0 → r3L: ld MEM[r3] → r2 add r2,r1 → r1 add r3,48 → r3 brl r3,0x10a0 → L st r1 → MEM[A]
mov 0 → r1 mov 0x0fe0 → r3L: ld MEM[r3] → r2 add r2,r1 → r1 add r3,48 → r3 brl r3,0x10a0 → L st r1 → MEM[A]
ab
dc
ef
g
e3
f3
d4e4
f4
to main memory
to L
1I-
cach
e
c4d3
gh
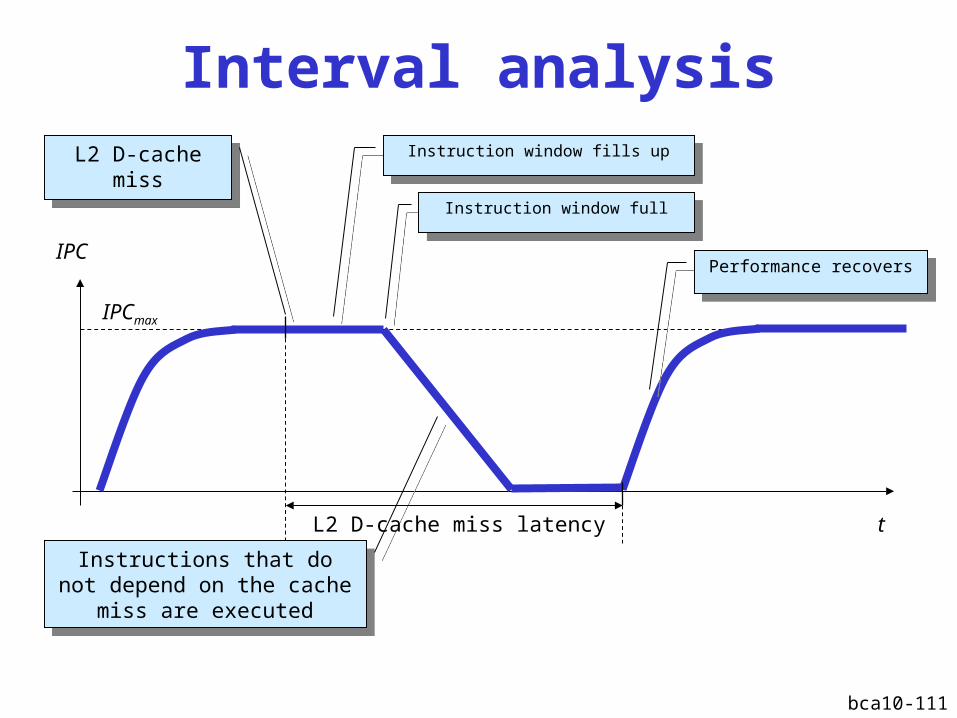
bca10-111
Interval analysis
IPC
t
L2 D-cache miss
L2 D-cache miss
Instruction window fills upInstruction window fills up
Instructions that do not depend on the cache miss
are executed
Instructions that do not depend on the cache miss
are executed
Performance recoversPerformance recovers
IPCmax
L2 D-cache miss latency
Instruction window fullInstruction window full
ca10-112
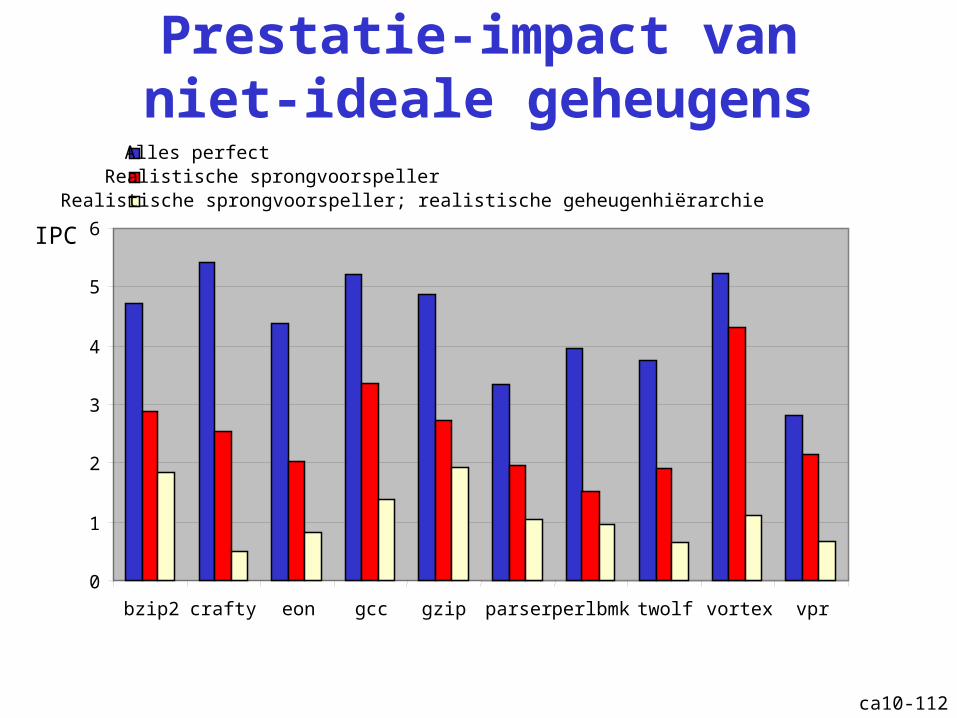
Prestatie-impact van niet-ideale geheugens
0
1
2
3
4
5
6
bzip2 crafty eon gcc gzip parser perlbmk twolf vortex vpr
Alles perfectRealistische sprongvoorspeller
IPC
Realistische sprongvoorspeller; realistische geheugenhiërarchie
ca10-113
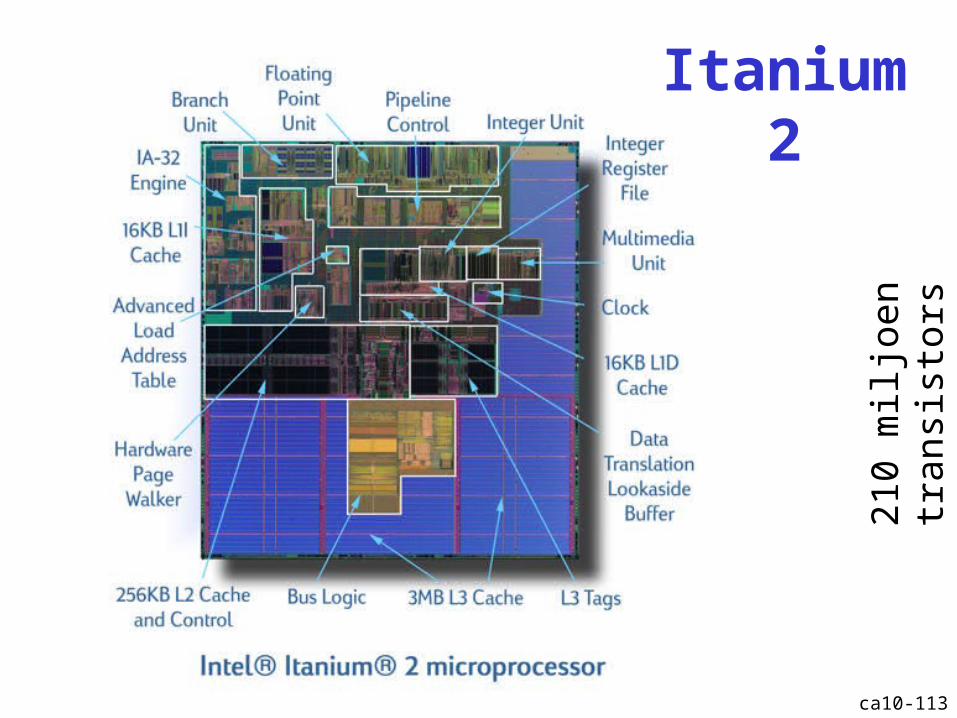
Itanium 2
210
milj
oen
tran
sist
ors

ca10-114
Inhoud
• Soorten geheugens
• Lokaliteit
• Caches
• Impact op prestatie
• Ingebedde systemen
• Eindbeschouwingen
ca10-115
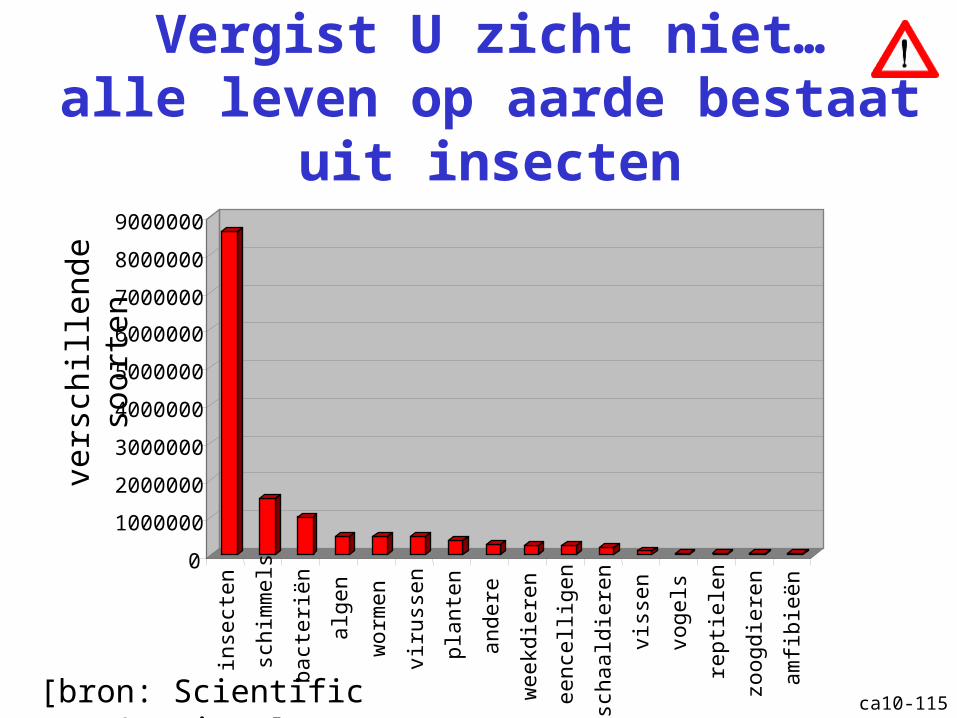
Vergist U zicht niet…alle leven op aarde bestaat uit
insecten
0
1000000
2000000
3000000
4000000
5000000
6000000
7000000
8000000
9000000in
sect
en
schi
mm
els
bact
erië
n
alge
n
wor
men
viru
ssen
plan
ten
ande
re
wee
kdie
ren
eenc
ellig
en
scha
aldi
eren
viss
en
voge
ls
rept
iele
n
zoog
dier
en
amfib
ieën
[bron: Scientific American]
vers
chill
ende
soo
rten
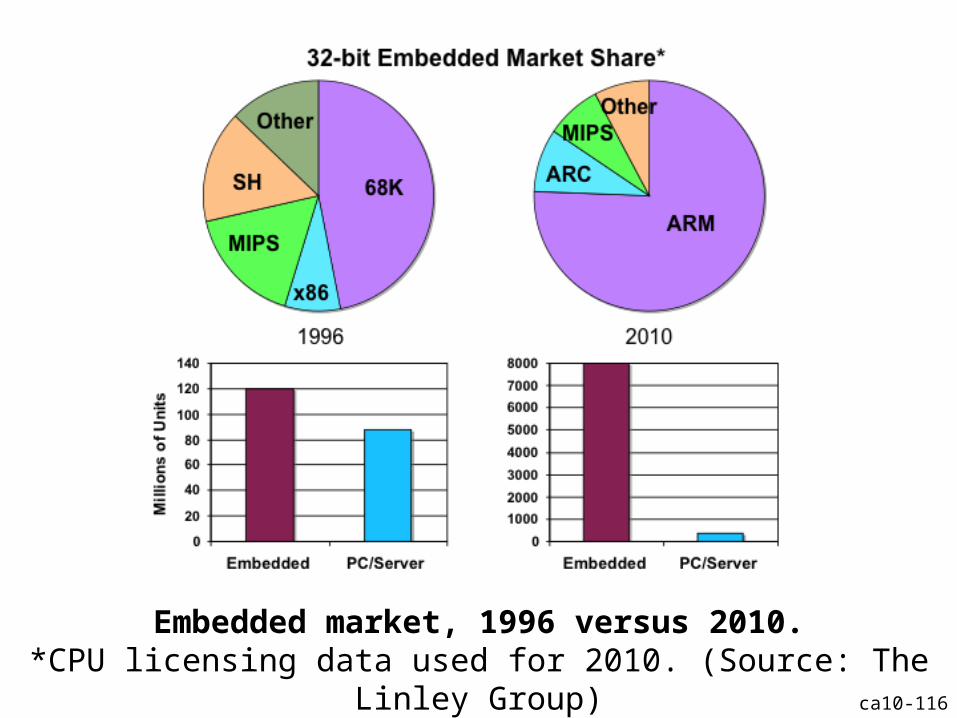
ca10-116
Embedded market, 1996 versus 2010.*CPU licensing data used for 2010. (Source: The Linley Group)

Enkele recente cijfers
• # verkochte PC’s in 2008: 300 miljoen
• # ingebedde processors in 2008– Automotive: 1,2 miljard (90 miljoen 32 bit)– GSM’s: 1 miljard– …
• ARM verkocht in 2012: 8 miljard processors
ca10-117
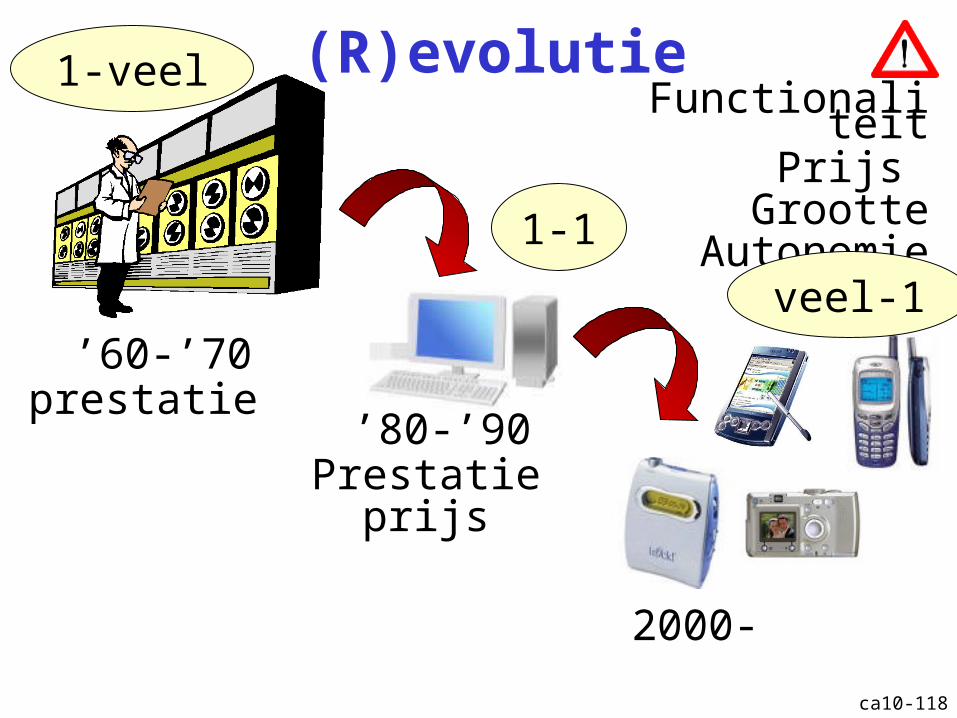
ca10-118
(R)evolutie
’60-’70
’80-’90
2000-
prestatie
Prestatieprijs
FunctionaliteitPrijs
GrootteAutonomie
1-veel
1-1
veel-1

ca10-119
“The computer revolution hasn't happened yet”
• De alomtegenwoordige computer (ubiquitous computing, pervasive computing)
• Intelligente omgeving (Ambient Intelligence)
Alan Kay, HP

ca10-120
Modern ingebed systeem
63 processors
BMW serie-7

ca10-121
Ingebedde systemen• “Embedded system” of “Dedicated
system”• Processorchip ingebouwd in een
apparaat• Voert steeds hetzelfde programma uit
(uit ROM of Flash)• Vaak met beperkte hardware: geen
cache, geen virtueel geheugen,…• Vaak in ware tijd (real-time)
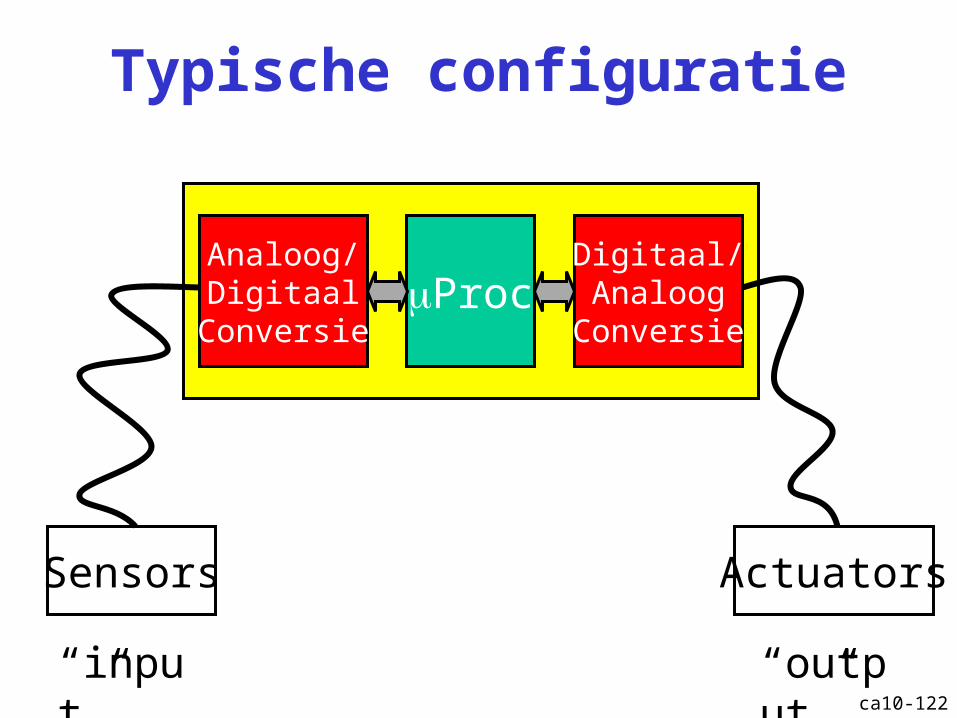
ca10-122
Typische configuratie
Sensors Actuators
Analoog/Digitaal
Conversie
Digitaal/Analoog
ConversieProc
“input” “output”

ca10-123
Voorbeelden• Digitale camera
• Alarmsystemen
• CD-spelers
• Digitale tuners
• Domoticasystemen
• Afstandsbediening
• Microgolfoven
• Digitale uurwerken
• Telefooncentrale
• Netwerkapparatuur, modem• Displaysystemen
• Printers• DVD-spelers• Elektronische agenda’s• Synthesizers• Scanners• GSM Satellieten• Auto’s • Treinen• Vliegtuigen• Raketten• Wapensystemen

ca10-124
Kenmerken• Klein en licht (draagbare toepassingen)
• Vermogenverbruik minimaal: autonomie > 8 uur, warmteproductie aanvaardbaar.
• Robuust tegen vocht, hitte, vorst, schokken, straling, enz.
• Interactie is met de buitenwereld: “tijdigheid” is onderdeel van “correctheid”.
• Betrouwbaar: vliegtuigen, auto’s
• Zeer kostgevoelig: 1 cent x 1 miljoen = …

ca10-125
Ingebedde processors
• Vaak microcontrollers van 4,8 of 16 bit (computersysteem op 1 chip: geheugen, input/ouput, enz.)
• Vaak ook gewone processors
• Vermogenverbruik is cruciaal voor mobiele toepassingen

ca10-126
Digitale-signaalprocessors
• DSP: Digital Signal Processor
• Gespecialiseerde processor om digitale signalen (b.v. audiosignalen) te verwerken.
• CD-spelers, telefooncentrales, elektronische muziekinstrumenten, enz.
• Vaak zeer complex en gespecialiseerd voor het uitvoeren van signaalverwerkingsalgoritmen: b.v. fast Fourier transformatie (som van producten)

ca10-127
Inhoud
• Soorten geheugens
• Lokaliteit
• Caches
• Impact op prestatie
• Ingebedde systemen
• Eindbeschouwingen
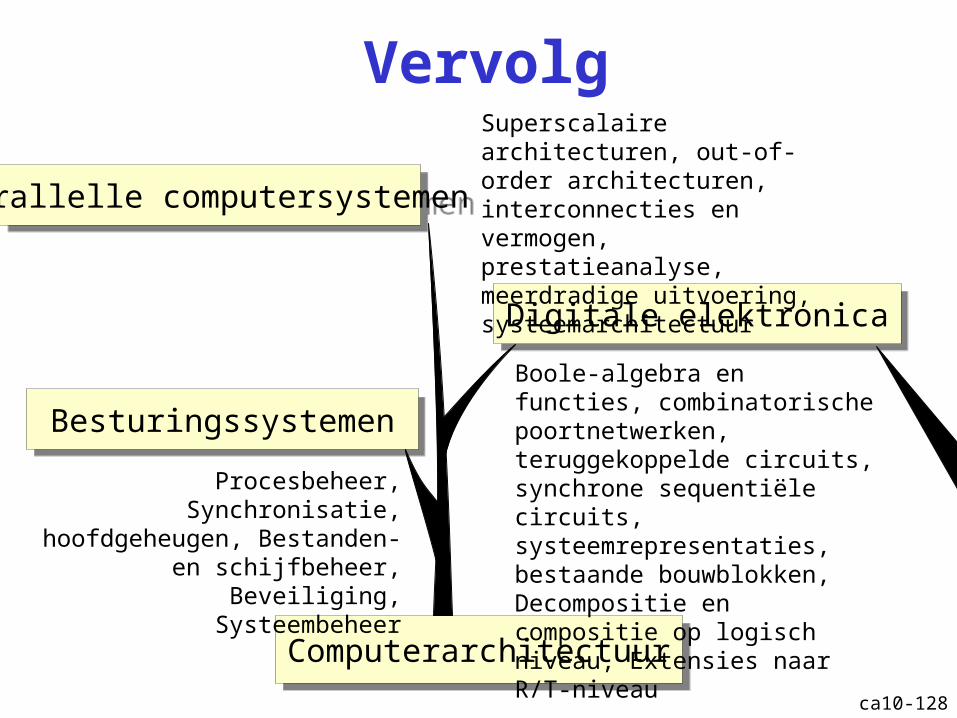
ca10-128
Vervolg
ComputerarchitectuurComputerarchitectuur
Boole-algebra en functies, combinatorische poortnetwerken, teruggekoppelde circuits, synchrone sequentiële circuits, systeemrepresentaties, bestaande bouwblokken, Decompositie en compositie op logisch niveau, Extensies naar R/T-niveau
Procesbeheer, Synchronisatie, hoofdgeheugen, Bestanden- en
schijfbeheer, Beveiliging, Systeembeheer
Digitale elektronicaDigitale elektronica
BesturingssystemenBesturingssystemen
Parallelle computersystemenParallelle computersystemen
Superscalaire architecturen, out-of-order architecturen, interconnecties en vermogen, prestatieanalyse, meerdradige uitvoering, systeemarchitectuur

ca10-129
Pauze

ca10-130
http://www.eetimes.com/document.asp?doc_id=1326377&_mc=NL_EET_EDT_EET_review_20150418&cid=NL_EET_EDT_EET_review_20150418&elq=ffa1b73023664da4bccb7e28d21b2003&elqCampaignId=22619&elqaid=25441&elqat=1&elqTrackId=dae6c67ea56d4963ba0fedcae4bdaaf6


















