
EEN SYSTEEM VOOR HET VISUALISEREN VAN FINANCIËLE … · beter te laten aansluiten bij de...
41
EEN SYSTEEM VOOR HET VISUALISEREN VAN FINANCIËLE RELATIES Mark Jansen, MA-Thesis, University of Groningen 2008
Transcript of EEN SYSTEEM VOOR HET VISUALISEREN VAN FINANCIËLE … · beter te laten aansluiten bij de...

EEN SYSTEEM VOOR HET VISUALISEREN VAN FINANCIËLE RELATIES
Mark Jansen, MA-Thesis, University of Groningen 2008

1 Inleiding 3 1.1 Achtergrond 3 1.2 Doel van de afstudeeropdracht 3 1.3 Over FINAN Financial Analysis 4
2 Semantisch web 6 2.1 Ontologieën en het Semantische Web 6 2.2 Resource Description Framework (RDF) 6 2.3 Web Ontology Language (OWL) 7 2.4 EXtensible Business Reporting Language (XBRL) 9
3 Het systeem 11
4 Informatiebeheer 14 4.1 Domein 14 4.2 Knowledgebase 16 4.3 Populated ontology 19 4.4 Informatieverrijking door machine-interpretatie 22
5 Visualisatie 23 5.1 Visuele structuur – network graph 23 5.2 De opbouw van de visuele structuur 24 5.3 Realisatie van views 26
6 Conclusie 29 6.1 Future work 29
7 References 30
Appendix A: Voorbeeld Ontologie-instantie 32
Appendix B: Screenshots Visualisatie-demo 38
2

1 INLEIDING
1.1 ACHTERGROND
De Bank for International Settlements (BIS) is een internationale organisatie die toezicht houdt op internationale monetaire en financiële samenwerking en dient als bank voor centrale banken. Ze doet dit onder andere door op te treden als forum voor discussie en beleidsanalyse tussen centrale banken en binnen de internationale financiële gemeenschap, en door te dienen als economisch en monetair onderzoekscentrum. Het hoofdkantoor bevindt zich in Basel, Zwitserland. In 1996 heeft de Bank for International Settlements (BIS) een begin gemaakt aan wijziging van de tot dan toe gehanteerde regels voor kapitaalvereisten van banken. [1] De bestaande richtlijnen, beter bekend als Basel-1, zijn indertijd opgesteld om internationale vergelijkingen tussen banken mogelijk te maken en hoewel deze in eerste instantie bedoeld waren voor grote internationaal opererende banken werden de richtlijnen al snel overgenomen door nationale toezichthouders en ook aan kleine banken voorgeschreven. De belangrijkste regel van Basel-1 stelt dat banken voor normale leningen een garantievermogen van tenminste 8 procent moeten hanteren. Hoewel er uitzonderingen en ‘kortingen’ bestaan voor verschillende soorten krediet dient deze BIS-ratio zeer frequent bewaakt te worden. Banken hanteren over het algemeen ook nog een veiligheidsmarge waardoor het garantiepercentage zo tussen de 11% en 13% zal liggen. De nieuwe richtlijnen, ook wel het Revised International Capital Framework of Basel II genoemd, zijn een poging om de bestaande richtlijnen voor garantievermogen te verfijnen en beter te laten aansluiten bij de werkelijke risico’s die banken lopen. Daarnaast moedigt het banken aan om bestaande en toekomstige risico’s te identificeren en manieren te ontwikkelen om dit beter te beheersen. Op die manier zijn ze flexibeler en beter in staat te ontwikkelen met de vooruitgang op de markt en met risicomanagement. Basel II stelt instellingen in staat om te kiezen tussen twee methodes voor het berekenen van kapitaalvereisten in kredietrisico. Zo is er de standardized approach (SA) en een methode gebaseerd op interne waarderingen (IRB). De standardized approach is een verfijnde variant van de Basel I methode. In plaats van het uniforme percentage wordt er nu ook gekeken naar de rating die van toepassing is. Over het algemeen zal een rating een verlagend effect hebben op de kapitaaleis. Daarnaast zal ook de looptijd een rol spelen bij het bepalen van de kapitaaleis. Het idee bij de Internal-Based Ratings (IRB) methode is dat er bij banken intern veel kennis is van kredietrisico. Deze kennis kan worden gebruikt bij het houden van toezicht. Als de toezichthouder ermee akkoord gaat, mogen de gegevens gebruikt worden als basis voor de berekening van de vermogenseis voor de kredietverstrekker. Het is in het eigen belang van de banken om continu een juist inzicht te hebben in de risico’s die zij lopen. Twijfel over de solvabiliteit en liquiditeit op de financiële markten kunnen dramatische gevolgen hebben. Het effect van het hanteren van interne waarderingen kan betekenen dat de berekeningen voor kapitaaleisen nauwkeuriger plaatsvinden dan de standardized approach. [1]
1.2 DOEL VAN DE AFSTUDEEROPDRACHT
Banken kunnen over veel gegevens beschikken en hebben de kennis om die gegevens te gebruiken om tot een inschatting te komen wat betreft kredietrisico en kunnen dus gebruik maken van de IRB-methode zoals beschreven in het Basel II verdrag. De manier om tot een dergelijk inschatting te komen staat echter niet vast en dit kan dus van bank tot bank verschillen. Er worden geen uitspraken gedaan over hoe banken precies tot hun inschattingen komen, maar het is gebleken dat er geen goede structuur zit in dit proces. Er zijn signalen die aangeven dat er behoefte is aan om een manier om de beschikbare gegevens beter toegankelijk te maken. Zoals
3

aangegeven in sectie 1.1 is het in het belang van de bank om een goede inschatting te maken van het risico dat ze lopen. Accountmanagers maken nu op een onoverzichtelijke manier beslissingen aan de hand van gegevens van verschillende bronnen. Een belangrijk aspect bij het inschatten van de kredietwaardigheid van een bedrijf is het nagaan van factoren die van invloed zijn op dat bedrijf. Een voorbeeld van een grote invloedsfactor is bijvoorbeeld de verhouding met betrekking tot eigendom van een bedrijf. Het spreekt voor zich dat een moederbedrijf van een kredietaanvrager een grote invloedsfactor is en daarmee een risico kan vormen voor de kredietwaardigheid. Een dergelijke relatie zal over het algemeen niet onopgemerkt blijven. Ontdekken wie de eigenaar is van het moederbedrijf kan al een stuk moeilijker zijn. Als er daarnaast nog een dozijn invloedsfactoren zijn, is het niet moeilijk voor te stellen dat het overzicht lastig te behouden is. Het inschatten van kredietrisico kan dus onoverzichtelijk zijn door de hoeveelheid invloedsfactoren. Deze onoverzichtelijkheid is de aanleiding voor dit project. Het idee is dat er een manier moet zijn om de informatie zo te structureren en weer te geven dat het niet alleen duidelijker wordt, maar dat er ook informatie naar voren komt die anders niet gemakkelijk te ontdekken valt. Denk daarbij aan risicovolle constructies waarbij een aandeelhouder van het ene bedrijf een belangrijke functie vervult bij een ander bedrijf, en dat die onderling ook weer een relatie hebben. Deze cirkelconstructie komt lang niet altijd direct uit documenten naar voren, zeker niet als deze gegevens ook nog eens van verschillende bronnen komen. Een betere structurering van de gegevens gecombineerd met een visuele weergave van de onderlinge relaties zou de inzichtelijkheid moeten kunnen vergroten. Het doel van deze scriptie is om antwoord te geven op vragen die naar voren komen bij de ontwikkeling van een systeem voor het inschatten van kredietrisico. Om welke gegevens gaat het? Waar letten analisten op als het gaat om kredietverstrekking? Waar komen de gegevens vandaan? Op welke manier moeten ze gestructureerd worden? Hoe kunnen de gegevens het beste weergegeven worden? Door deze vragen te behandelen wordt een basis gelegd voor het ontwikkelen van een systeem dat beter risicomanagement voor kredietverstrekkers mogelijk maakt. De onderzoeksvraag zou dan als volgt geformuleerd kunnen worden om deze aspecten te behandelen: In hoeverre en op welke wijze is het mogelijk extractie en visualisatie van relevante bedrijfsfinanciële gegevens te realiseren om de inzichtelijkheid hiervan te vergroten? Om de onderzoeksvraag te kunnen beantwoorden en uit te werken is veel gebruik gemaakt van bestaande kennis in de verschillende vakgebieden. De uitwerking van dit verslag vond mede daarom plaats bij het bedrijf FINAN Financial Analysis. Naast de interesse die daar bestaat voor een dergelijke systeem is er ook de kennis op het gebied van financiële analyse die nodig is voor dit project. Met hulp van de economen bij Finan is bijvoorbeeld de ontologie van de kredietrisico tot stand gekomen. Naast de financiële kennis van Finan is ook veel gebruik gemaakt van bronnen met betrekking tot het Semantic Web en visualisatie. In dit verslag zullen eerst enkele technieken worden besproken die relevant zijn voor de ontwikkeling van dit systeem, zoals de Resource Description Framework en de Web Ontology Language (hoofdstuk 2). Vervolgens zal aan de hand van een schematische weergave het systeem en de verschillende onderdelen van dat systeem worden besproken (hoofdstuk 3). Daarna zal er dieper worden ingegaan op twee onderdelen van het systeem: het informatiebeheer (hoofdstuk 4) en de visualisatie van de gegevens (hoofdstuk 5).
1.3 OVER FINAN FINANCIAL ANALYSIS
FINAN Financial Analysis is een organisatie die oplossingen biedt voor de ondersteuning van financiële analyses. Bij de ontwikkeling worden financieel-economische principes gecombineerd met praktische ervaringen die door medewerkers en gebruikers zijn opgedaan. In de ontwikkelfase wordt nauw samengewerkt met o.a. de Faculteit Economie en Bedrijfskunde van de Rijksuniversiteit Groningen. Het resultaat is een verzameling van gereedschappen die
4

financiële analyse op een gedegen, theoretisch goed onderbouwde manier ondersteunen, maar ook in de alledaagse praktijk van financiële dienstverleners toepasbaar zijn. Onder de gebruikers van de producten van FINAN Financial Analysis bevinden zich dan ook banken, accountantskantoren, financiële adviseurs, grote ondernemingen en onderwijsinstellingen. [4]
5

2 SEMANTISCH WEB
In deze sectie zullen verschillende aspecten behandeld worden van verschillende technieken die verderop in deze scriptie aan de orde zullen komen. Het gaat dan vooral om verschillende datamodellen en technieken die met het semantische web te maken hebben.
2.1 ONTOLOGIEËN EN HET SEMANTISCHE WEB
Het Semantische Web is een uitbreiding op het World Wide Web waar de semantische eigenschappen van informatie en diensten op het web gedefinieerd staan, waardoor het mogelijk wordt voor het web om verzoeken van gebruikers en machines te begrijpen en eraan te voldoen met behulp van web content. Dit is afgeleid van de visie van Sir Tim Berners-Lee met het Web als universeel medium voor de uitwisseling van data, informatie en kennis. [7] Het Semantische Web bestaat uit een set ontwerprichtlijnen, werkgroepen en een variatie aan technologieën die het geheel mogelijk moeten maken. Sommige elementen van het Semantische Web zijn slechts bedacht als toekomstige mogelijkheden die nog gerealiseerd of geïmplementeerd dienen te worden. Andere elementen zijn tot uitdrukking gekomen in formele specificaties, waaronder het Resource Description Framework en de Web Ontology Language (OWL), die allemaal bedoeld zijn om een formele omschrijving te geven van concepten, termen en relaties binnen een gegeven domein. [8] Een ontology language is een taal waarin het mogelijk is om informatie over verschillende soorten objecten in het interessegebied uit te kunnen drukken. Verzamelingen van dergelijke informatie worden ontologieën genoemd. Een ontologie is dan ook een manier om de wereld te beschrijven. Er zijn vele verschillende voorstellen voor ontologieën die variëren van het beschrijven van objecten tot het vormen van een basis voor grote kennisgebieden of ontologieën voor specifieke applicaties. Er zijn ook verschillende soorten talen voorgesteld als ontologietalen. Deze voorstellen varieerden van zeer krachtige talen waarin vrijwel alles uitgedrukt kan worden, zoals hoogste orde logica, tot minder expressieve talen of zelfs talen die alleen een simpele taxonomie kunnen beschrijven.
2.2 RESOURCE DESCRIPTION FRAMEWORK (RDF)
Het World Wide Web Consortium (W3C) ontwikkelde het Resource Description Framework (RDF) als een reeks specificaties voor het modeleren van metadata. Inmiddels heeft RDF zich ontwikkeld als een algemene methode voor het modeleren van informatie met behulp van verschillende syntax-vormen. [14] Het modeleren van metadata met RDF gebeurt door het maken van statements in de subject-predicate-object vorm. In deze triples vormt het subject de bron en stelt het predicate een relatie voor tussen het subject en het object, waarbij het predicate een eigenschap of aspect van het subject weergeeft. Zo zou de zin ‘Jan is een persoon’ als volgt uitgedrukt kunnen worden: Jan – is een – persoon. Bovenstaande manier van uitdrukken is handig omdat RDF toestaat dat subjects en objects uitgewisseld kunnen worden. Dus een object in een triple kan een subject zijn in een ander triple. RDF maakt het ook mogelijk om statements zelf als subject of object van een triple te gebruiken. Op deze manieren zijn zowel geketende statements als ook geneste statements mogelijk. Via het web is het dan mogelijk deze uitdrukkingen te combineren met statements van anderen. Voorbeelden: Jan is een persoon. Een persoon heeft een naam. -> Jan heeft een naam.
6

-> Jan is een persoon met een naam. De RDF model and syntax specification stelt ook een XML syntax voor RDF data modellen voor. Een mogelijke invulling voor dergelijke syntax ziet er als volgt uit: <rdf:Description rdf:about="http://www.famouswriters.org/twain/mark"> <s:hasName>Mark Twain</s:hasName> <s:hasWritten rdf:resource="http://www.books.org/ISBN0001047582"/> </rdf:Description> <rdf:Description rdf:about="http://www.books.org/ISBN0001047582"> <s:title>The Adventures of Tom Sawyer</s:title> <rdf:type rdf:resource="http://www.description.org/schema#Book"/> </rdf:Description> Aangezien de voorgestelde XML syntax vele alternatieve manieren toestaat om informatie te noteren, is bovenstaande voorbeeld slechts één van vele mogelijke notaties voor een RDF model. RDF is grofweg beperkt tot binaire predicates en RDF Schema is grofweg beperkt tot een subclass hiërarchie en property hiërarchie, met domein- en bereikdefinities van deze properties. De Web Ontology Working Group van het W3C kwam echter met een aantal karakteristieke use-cases voor ontologieën op het web welke meer uitdrukkingskracht vereisten dan alleen RDF en RDFSchema. Een aantal onderzoeksgroepen in zowel Amerika als Europa had de noodzaak voor een krachtigere modelling language al onderkend, wat leidde tot een gezamenlijk initiatief om dit voor elkaar te krijgen. Het initiatief leverde DAML+OIL op (van het Amerikaanse DAML en het Europese OIL). De W3C Web Ontology Working Group heeft deze modelling language gebruikt als uitgangspunt voor het definiëren van Web Ontology Language, de taal die bedoeld is als standaard en als algemeen geaccepteerde ontologietaal van het Semantische Web.[12]
2.3 WEB ONTOLOGY LANGUAGE (OWL)
OWL ondersteunt meer mogelijkheden voor systemen om Web content te interpreteren dan bijvoorbeeld XML, RDF en RDF Schema door het gebruik van formele semantiek. [12] De Web Ontology Language (OWL) is ontwikkeld voor het gebruik bij applicaties die de inhoud van informatie moeten verwerken in plaats van deze alleen maar aan gebruikers te tonen. Met behulp van een reasoner kunnen systemen redeneren over in OWL gestructureerde documenten. OWL is nauw verwant aan Description Logics 1 en heeft veel kenmerken die komen van deze manier van kennisweergave. Description Logics voorzien vooral de manier waarop OWL kennis structureert. Bovendien komt de semantiek van de kennisstructuren direct van Description Logics. OWL is ook beïnvloed door andere methodes die zorgen voor de verschillen met Description Logic, vooral de mogelijkheid van OWL om informatie over een bepaalde eigenschap te groeperen binnen een declaratie, zoals subproperties, bereik en domein. In Description Logic moet deze informatie dan over verschillende declaraties verdeeld worden. Het toestaan van dergelijke groeperingen in OWL is bedoeld om het begrijpelijker te maken voor mensen en makkelijker te maken voor user interfaces om ze aan mensen te tonen. Omdat OWL moet passen in de Semantic Web-visie van het W3C is de officiële syntaxis die van RDF/XML. Dit wordt echter gezien als een moeilijk te begrijpen voor mensen en daarom is OWL voorzien van een tweede, op mensen georiënteerde syntaxis. [12]
1 Description logics (DL) zijn een groep talen voor het weergeven van kennis welke kunnen worden gebruikt om specifieke kennis van een applicatiedomein weer te geven op een gestructureerde, duidelijke en formele manier.
7

Korte uitleg van een OWL-ontologie Hieronder zullen kort de basiskenmerken van een OWL-ontologie worden besproken, zoals classes, individuals en properties. Dit is om een indruk te geven wat wordt bedoeld wanneer het gaat over OWL en het maken van een ontologie. Verschillende zaken die hier worden besproken komen ook terug in sectie 4.1 over het maken van de ontologie die hoort bij dit project. De voorbeelden in dit stukje komen van de website van het W3C over OWL. Veel toepassingen van een ontologie hangen af van de mogelijkheid om te redeneren over individuals. Om dit op een goede manier te kunnen doen, moeten we een mechanisme hebben om classes te beschrijven waar individuals toe behoren en de eigenschappen die zij krijgen als lid van die class. Individuals kunnen altijd specifieke eigenschappen krijgen, maar veel van de kracht van ontologieën is afhankelijk van het redeneren over classes. De basisconcepten van een domein zouden overeen moeten komen met classes die de bladeren vormen van verschillende taxonomische bomen. Elke individual in de OWL-wereld is een lid van de class owl:Thing, dus elke daaronder gedefinieerde class is automatisch een subclass van owl:Thing. Domeinspecifieke classes worden gedefinieerd door een named class te introduceren. Een voorbeeld over wijnen: <owl:Class rdf:ID="Winery"/> <owl:Class rdf:ID="Region"/> <owl:Class rdf:ID="ConsumableThing"/> De fundamentele taxonomische constructie voor classes is rdfs:subClassOf. Dit koppelt een meer specifieke class aan een meer algemene class. Als X een subclass is van Y, dan is elke instantie van X ook een instantie van Y. Bovendien is de subClassOf-relatie transitief. Als X een subclass is van Y en Y is een subclass van Z dan is X ook een subclass van Z. We definiëren PotableLiquid (vloeistof geschikt voor drinken) als een subclass van ConsumableThing: <owl:Class rdf:ID="PotableLiquid"> <rdfs:subClassOf rdf:resource="#ConsumableThing" /> </owl:Class> Naast classes willen we ook hun leden kunnen beschrijven. We hebben het dan over individuals. Een individual wordt simpelweg geïntroduceerd door een declaratie als een lid van de class: <Region rdf:ID="CentralCoastRegion" /> Deze declaratie zegt precies hetzelfde als het volgende: <owl:Thing rdf:ID="CentralCoastRegion" /> <owl:Thing rdf:about="#CentralCoastRegion"> <rdf:type rdf:resource="#Region"/> </owl:Thing> Rdf:type is een RDF property dat een individual bindt aan de class waar het een lid van is. Een property is een binaire relatie. Er wordt onderscheid gemaakt tussen properties tussen twee individuals (object properties) en properties tussen individuals en datatypes (datatype properties). Datatype properties kunnen van toepassing zijn op RDF literals of simple types in overeenstemming met XML Schema datatypes. Wanneer een property gedefinieerd wordt, zijn er een aantal manieren om de relatie te beperken. Zo kunnen bijvoorbeeld het domein en het bereik aangegeven worden. Verder is het onder andere nog mogelijk een specialisatie (subproperty) van een bestaande property te definiëren. Voorbeeld van een object property met domein en bereik:
8

<owl:ObjectProperty rdf:ID="madeFromGrape"> <rdfs:domain rdf:resource="#Wine"/> <rdfs:range rdf:resource="#WineGrape"/> </owl:ObjectProperty> Voorbeeld van een datatype property: <owl:DatatypeProperty rdf:ID="hasZipCode"> <rdfs:range rdf:resource="http://www.w3.org/2001/XMLSchema#int"/> </owl:DatatypeProperty> Voorbeeld van een definitie van een subproperty: <owl:ObjectProperty rdf:ID="isToppingOf"> <rdfs:subPropertyOf rdf:resource="#isIngredientOf"/> </owl:ObjectProperty>
2.4 EXTENSIBLE BUSINESS REPORTING LANGUAGE (XBRL)
eXtensible Business Reporting Language (XBRL) is een taal voor de elektronische communicatie van bedrijfsgegevens en financiële gegevens, en is een variant van XML. Het wordt ontwikkeld door een internationaal non-profit consortium van ongeveer 450 grote bedrijven, organisaties en overheidsinstellingen. Het is een open standaard zonder licentiekosten. Verschillende landen, waaronder Nederland, hebben het al in gebruik genomen of zijn bezig met de ontwikkeling ervan. Het idee achter XBRL is dat het financiële informatie niet langer als een blok tekst beschouwd, zoals een internetpagina of een geprint document, maar dat het ieder stukje data van een tag voorziet om het leesbaar te maken voor machines. De introductie van XBRL tags maakt het mogelijk om bedrijfsinformatie automatisch te laten verwerken waardoor handmatig invoeren en vergelijken overbodig wordt. Informatie in een XBRL kan worden herkend, geselecteerd, geanalyseerd, opgeslagen en op verschillende manieren aan gebruikers worden gepresenteerd. Bovendien kan het gemakkelijk worden uitgewisseld met andere systemen. Dit versnelt het behandelen van financiële gegevens, vermindert de kans op fouten en maakt automatische controle mogelijk. [20] XBRL definieert een syntaxis waarin een feit gerapporteerd kan worden als de waarde van een concept binnen een bepaalde context. De syntaxis stelt software in staat om die feiten op een betrouwbare en efficiënte manier te vinden en te interpreteren. Het XBRL framework splitst de informatie van bedrijfsrapportage op in twee componenten: XBRL-instanties en taxonomieën. De instanties bevatten de feiten die gerapporteerd zijn terwijl de taxonomieën de concepten definiëren die worden uitgedrukt in de feiten. De combinatie van een XBRL-instantie en de onderliggende taxonomieën vormen samen een XBRL-bedrijfsrapportage. Een taxonomie bestaat uit een XML Schema en alle linkbases binnen dat schema of waarnaar direct verwezen wordt vanuit dat schema. In XBRL-terminologie is een concept een definitie van een rapportageterm, welke terugkomen als XML Schema elementdefinitie. In een taxonomieschema krijgt een concept een concrete naam en een type. Het type bepaalt welke soort datatypes zijn toegestaan. Zo zal bijvoorbeeld het concept ‘kas’ over het algemeen een monetair type hebben, en zal de waarde die wordt gerapporteerd voor ‘kas’ monetair zijn. Een linkbase is een collectie van uitbreidende links. Er worden vijf verschillende soorten uitbreidende links gebruikt in taxonomieën om concepten te documenteren: definitie, berekening, presentatie, label en referentie. De linkbases in een taxonomie breiden de betekenis van concepten verder uit door relaties tussen concepten uit te drukken en door concepten te koppelen aan hun documentatie. De eerste drie soorten drukken relaties tussen concepten uit, de
9

laatste twee koppelen concepten aan hun documentatie. Linkbases kunnen ook in een apart document voorkomen. [20] Het Nederlandse Taxonomie Project De Nederlandse taxonomie is een gezamenlijk ontwikkeling van de overheid en het bedrijfsleven op initiatief van de ministeries van Justitie en Financiën om te komen tot een administratieve lastenverlichting voor ondernemers. De Nederlandse Taxonomie is gebaseerd op de wereldwijde open standaard XBRL. Sinds 1 januari 2007 kunnen ondernemers en intermediairs een groot deel van hun financiële verantwoordingsrapportages aan de overheid opstellen met behulp van de Nederlandse taxonomie. Bovendien is een grootschalige berichtenuitwisseling met de Kamer van Koophandel, de Belastingdienst en het CBS mogelijk. Hiermee is het mogelijk om effectief en efficiënt te rapporteren aan de overheid. Meer dan tachtig marktpartijen en overheidsorganisaties hebben in een convenant afspraken gemaakt over het gebruik en beheer van de Nederlandse taxonomie en Procesinfrastructuur. Samen met de convenantpartijen is het Nederlandse Taxonomie Project (NTP) bezig om deze partijen aan te sluiten, zodat ze de voordelen van de Nederlandse taxonomie ook echt kunnen benutten en kunnen doorgeven aan hun klanten. Een deel van deze partijen is al ‘XBRL-enabled’. Ook andere partijen kunnen nog steeds aansluiten. [11]
10
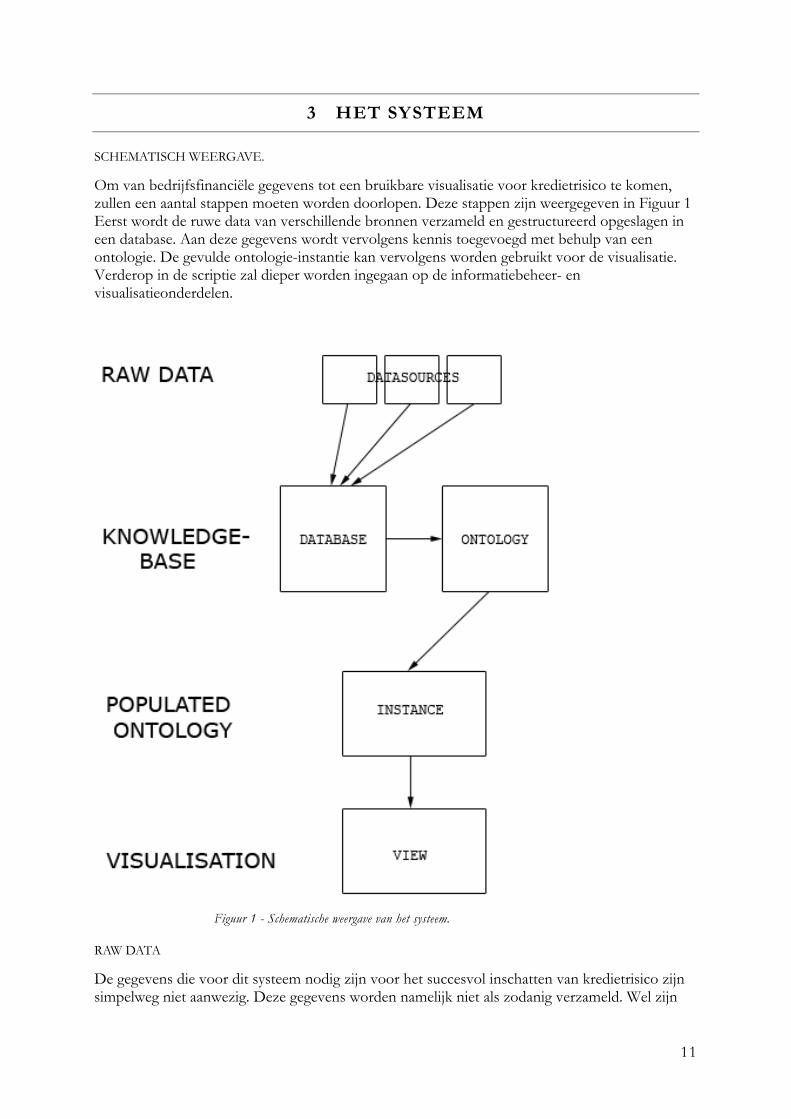
3 HET SYSTEEM
SCHEMATISCH WEERGAVE.
Om van bedrijfsfinanciële gegevens tot een bruikbare visualisatie voor kredietrisico te komen, zullen een aantal stappen moeten worden doorlopen. Deze stappen zijn weergegeven in Figuur 1 Eerst wordt de ruwe data van verschillende bronnen verzameld en gestructureerd opgeslagen in een database. Aan deze gegevens wordt vervolgens kennis toegevoegd met behulp van een ontologie. De gevulde ontologie-instantie kan vervolgens worden gebruikt voor de visualisatie. Verderop in de scriptie zal dieper worden ingegaan op de informatiebeheer- en visualisatieonderdelen.
Figuur 1 - Schematische weergave van het systeem.
RAW DATA
De gegevens die voor dit systeem nodig zijn voor het succesvol inschatten van kredietrisico zijn simpelweg niet aanwezig. Deze gegevens worden namelijk niet als zodanig verzameld. Wel zijn
11

ze aanwezig als onderdeel van andere gegevensbronnen: kredietverstrekkers beschikken over het algemeen over klantgegevens die ze kunnen raadplegen, en ook publieke bronnen, zoals de Kamer van Koophandel, worden geraadpleegd. De benodigde gegevens bevinden zich daarom meestal tussen andere gegevens, met name numerieke financiële gegevens zoals jaarverslagen. Bovendien zijn de gegevens niet op dezelfde manier gestructureerd. De ruwe gegevens moeten uit verschillende bronnen verzameld worden. Het systeem moet kunnen omgaan met een variatie aan gegevensbronnen. Dat wil zeggen dat er een manier moet komen om gegevens die van verschillende kanten wordt aangeleverd te verwerken. De juiste gegevens moeten geselecteerd worden, waarna deze op een goed gestructureerde manier opgeslagen kunnen worden. Er moet een extractietool komen dat de gebruikte datamodellen kan verwerken en deze kan vertalen naar een eenduidig datamodel. Het idee is dat de ruwe gegevens niet continue verzameld en omgezet hoeven te worden. Op welke manier de gegevens worden aangeleverd en worden omgezet, valt buiten de scoop van dit project aangezien we hiervoor van derden afhankelijk zijn. Als de gegevens eenmaal omgezet zijn, kunnen deze worden opgeslagen in een knowledgebase waarna deze dient als gegevensbron voor de rest van het systeem.
KNOWLEDGEBASE
De knowledgebase dient als centrale opslagplaats voor informatie. Zoals hierboven al werd beschreven, kan de informatie van verschillende bronnen komen. Daarnaast moet het mogelijk zijn om verschillende applicaties er gebruik van te laten maken. De gegevens moeten daarom eenduidig en gestructureerd opgezet worden. Het bevat dan niet alleen gegevens, maar ook informatie over wat de gegevens voorstellen. Als een applicatie vervolgens beschikt over regels die aangeven hoe gegevens gebruikt kunnen worden, is het mogelijk om deze automatisch te laten interpreteren. Een combinatie van de regels van de ontologie met de gegevens uit de knowledgebase moet dit mogelijk maken. Door het zo op te zetten dat het door machines geïnterpreteerd kan worden, kan de verzameling, organisatie en verspreiding geoptimaliseerd worden.
ONTOLOGIE
In de ontologie wordt het domein van het kredietrisico gedefinieerd. De ontologie bevat de kennis over de benodigde gegevens en bevat regels die vertellen hoe het systeem de gegevens moet interpreteren. Het geeft aan welke concepten in het domein voor kunnen komen en hoe deze zich tot elkaar kunnen verhouden. In het kredietrisico gaat het onder andere over de concepten ‘person’ en ‘company’ en de relaties tussen deze concepten, zoals ‘has_shareholder’ en ‘has_manager’. Daarnaast worden er ook nog eigenschappen van deze concepten en relaties gedefinieerd. Samen met de gegevens uit de knowledgebase vormt de ontologie de populated ontologie. De domeinkennis van de ontologie is dan gecombineerd met de objecten in de knowledgebase. Hoewel het idee van een ontologie is dat het een algemeen aanvaardbare omschrijving is van het interessedomein, kan het natuurlijk voorkomen dat er wijzigingen gemaakt dienen te worden in de ontologie. Ze kunnen verschillende risicoanalisten verschillende definities hebben voor risicofactoren en dus een andere ontologie willen dan degene die bij dit project is gebruikt. Daarom is het noodzakelijk dat de ontologie gemakkelijk aanpasbaar wordt. Als de knowledgebase correct is opgesteld zal het een wijziging in de ontologie geen problemen moeten opleveren met de extractie van de juiste gegevens. Het is belangrijk dat de ontologie als het definitiepunt van het visualiseren van kredietrisico kan dienen, zodat aanpassing en onderhoud van het systeem geen ingewikkeld proces wordt.
12

POPULATED ONTOLOGIE
Wanneer de ontologie gecombineerd wordt met de knowledgebase heb je een populated ontologie. De populated ontologie is de domeinkennis gecombineerd met de feiten in een formaat dat leesbaar is voor machines. Het systeem kan vervolgens deze informatie gaan interpreteren met behulp van een reasoner, waarbij het mogelijk is dat nieuwe feiten worden afgeleid aan de hand van de bestaande feiten. Hoe meer feiten de populated ontologie bevat, hoe waarschijnlijker het wordt dat de reasoner nieuwe feiten zal kunnen afleiden. Door het gebruik van een reasoner kan de populated ontologie dus automatisch uitgebreid worden met nieuwe gegevens.
INSTANTIE
Als een gebruik een zoekopdracht uitvoert om meer informatie op te vragen zal er een instantie worden gemaakt van de ontologie met daarin de informatie die voor de gebruiker relevant is. Met een zoekopdracht wordt in dit geval bedoelt dat de gebruiker een bedrijfs- of persoonsnaam als zoekterm invoert in een zoekveld bijvoorbeeld na aanleiding van een kredietaanvraag. Die zoekterm is dan de basis voor het creëren van de instantie. De gebruiker heeft nu een ontologie-instantie van de populated ontologie gebaseerd op de zoekopdracht en een vooraf vastgesteld bereik. Het bereik is in dit geval het aantal stappen de applicatie over relaties mag doen om meer gegevens op te halen. Deze informatie kan gebruikt worden voor bewerkingen en visualisatie. Een volledige populated ontology kan een behoorlijke omvang hebben. Om capaciteitsproblemen te voorkomen is het noodzakelijk dat de informatie die een gebruiker per zoekopdracht kan vinden wordt beperkt. Er is een compromis nodig wat betreft het aantal stappen dat er gedaan mag worden over relaties om de instantie te maken. Dat wil zeggen: hoeveel tussenstappen wil je toestaan om een relatie te vinden tussen de zoekopdracht en een willekeurige andere individual. Hoewel het voor de visualisatie verstandig is dit aantal niet te hoog te maken, hoeven niet alle gegevens van de instantie ineens getoond te worden. De omvang van de instantie is daarom een balans tussen het nut van de informatie en de capaciteit van het systeem. Het is de bedoeling dat een gebruiker over de getoonde informatie kan navigeren. Het is dan mogelijk dat de gebruiker verder wil navigeren dan de gegevens die zijn getoond of geladen. Met getoonde gegevens zal dit in principe geen probleem zijn moeten zijn, aangezien er meer gegevens worden geladen dan er worden getoond. Dit wordt anders als een gebruiker zeer ver wil navigeren. Om te voorkomen dat een gebruiker tegen een grens aanloopt waar die er niet zou moeten zijn, moet het mogelijk zijn om de instantie opnieuw te kunnen laden afhankelijk van de positie van de gebruiker.
VISUALISATIE
Voor het visualiseren van de relaties tussen de individuals wordt gebruikt gemaakt van een netwerkvisualisatie, waarbij de nodes de classes voorstellen en de edges de relaties. Onderscheid tussen verschillende classes en verschillende relaties wordt duidelijk gemaakt door een combinatie van kleurgebruik en het gebruik van iconen. Door gebruikersacties op bepaalde elementen (hover, click) is het mogelijk om extra informatie op te vragen over die elementen. De focus ligt op het individual dat door de gebruiker is opgevraagd door middel van een zoekopdracht, maar het is mogelijk andere classes in focus te brengen en zo over relaties te navigeren. Daarnaast moet het voor de gebruiker gemakkelijk zijn om een selectie te maken van relaties en classes door deze gemakkelijk te kunnen uitschakelen. Er wordt dieper ingegaan op de verschillende onderdelen van de visualisatie verderop in deze scriptie.
13

4 INFORMATIEBEHEER
Deelvraag 1: Op welke wijze zijn de gegevens vormgegeven en hoe zetten we dit om zodat ze geschikt zijn voor ons doel? De aanleiding van dit project is dat het geheel aan gegevens die nodig voor risicomanagement van kredietverstrekkers zo onoverzichtelijk is. Deze gegevens zijn niet gestandaardiseerd, niet op een zelfde manier opgeslagen of simpelweg afwezig. Financiële instellingen hebben in veel gevallen niet eens de gegevens beschikbaar voor dit doeleinde. Er is geen representatieve dataset waar vanuit gegaan kan worden voor het maken van een extractietool. Aangezien een goede dataset cruciaal is voor zowel het gedeelte van de applicatie voor informatiebewerking als de uiteindelijke evaluatie van het visuele gedeelte, zal het beheer van de dataset hier behandeld worden. Het doel van het project dat deze scriptie probeert te behandelen is het inzichtelijker maken van de invloeden van bedrijfsrelaties op het kredietrisico. In de ontologie is vastgelegd welke gegevens nodig zijn om deze bedrijfsrelaties te visualiseren. De visualisatie zelf is dan een instantie van de ontologie met de beschikbare gegevens. Hoe de visualisatie tot stand is gekomen zal verderop in dit verslag worden besproken. Deze sectie zal zich beperken tot de theoretische en praktische aspecten van de invoerzijde van het project. Wat is het domein? Welke gegevens zijn noodzakelijk en hoe zijn deze gegevens vormgegeven? In welke vorm zijn de gegevens geschikt voor visualisatie?
4.1 DOMEIN
Hoewel de onderzoeksvraag dit niet als zodanig reflecteert, beperkt het project zich tot het domein van het kredietrisico, zoals in de inleiding al werd aangegeven. Relevante bedrijfsfinanciële gegevens zijn dus de gegevens die hiervoor van belang zijn. Het domein van het kredietrisico beperkt zich voor dit project tot bedrijven en instellingen, maar ook personen zullen betrokken worden bij de relevante gegevens omdat deze ook invloed uitoefenen. Een kredietverstrekker wil inzicht krijgen in de situatie van een klant en dan vooral factoren die van invloed kunnen zijn op de kredietpositie van die klant.
4.1.1 ONTOLOGIE
In samenwerking met de economen van Finan is gewerkt aan de ontologie die dient als basis voor de verwerking en visualisatie van de betreffende gegevens. Uitgangspunt van de ontologie is een bedrijf waar relaties van uitgaan. Dit voorkomt onnodig complexe netwerken omdat deze in veel gevallen relaties in twee richtingen gedefinieerd kunnen worden. Zo kan voor bedrijf B een relatie shareholder (aandeelhouder) met persoon P gedefinieerd worden als B has_shareholder P of als P is_shareholder_of B. Er is besloten om in deze gevallen uit te gaan van X has (heeft) relaties waarbij X een bedrijf is. Dit is een logisch gevolg van het definiëren van relaties als subproperties van de is_influenced_by (wordt beïnvloed door) relatie.
14

Door alle relaties als subproperties van is_influenced_by te definiëren ontstaat er een probleem met betrekking tot transitiviteit. Sommige relaties kunnen invloed overdragen aan gerelateerde individuals als gevolg van het soort relatie. Zo is bijvoorbeeld de eerder genoemde has_shareholder (aandeelhouder-)relatie transitief, maar niet op de gebruikelijke manier. Transitief op de gebruikelijke manier zou als volgt gaan: A heeft_aandeelhouder B, B heeft_aandeelhouder C, dan A heeft_aandeelhouder C. Dit is echter niet juist. Het is de bedoeling dat invloed gemodelleerd wordt op de volgende manier: A heeft_aandeelhouder B, B heeft_aandeelhouder C, dan A wordt_beïnvloed_door C Het bleek echter niet mogelijk te zijn de ontologie op die manier te definiëren. Om toch een ontologie te kunnen definiëren in OWL is besloten het gebruikelijk resultaat te accepteren. Er zal echter toch een meer expressieve manier gevonden moeten worden om dit alsnog te kunnen definiëren in een ontologie.
4.1.2 CONCEPTEN
Eerste stap was het creëren van de concepten die onze ontologie gaat bevatten. Aangezien dit project uitgaat van het modelleren van bedrijven en de invloeden op deze bedrijven is het logisch dat het concept Company (‘bedrijf’) centraal staat in de ontologie. Daarnaast was het duidelijk dat er relaties bestaan die personen een belangrijke rol geven in onze ontologie. Voor het grootste deel van de relaties is het genoeg om alleen deze concepten te definiëren. Accountants en banken vallen buiten de Company en Person concepten door de manier waarop ze gerelateerd zijn. Daarom zijn ook de concepten Advisor (o.a. accountant, fiscalist, tussenpersoon) en Financial Organisation (o.a. bank) aan de ontologie toegevoegd. Verder is er nog de uitzonderlijke situatie waar een invloedsrelatie kan bestaan met een overheidsinstelling. Voor een dergelijke instelling gelden weer andere relaties, dus ook hiervoor is een concept toegevoegd: Public Sector Organisation (publieksrechterlijke organisatie, of overheidsinstelling).
4.1.3 RELATIES
Relaties in deze ontologie zijn allemaal invloedsrelaties. Dat betekent dat het allemaal subproperties zijn van de is_influenced_by (wordt beïnvloed door) property. De relaties die zijn gedefinieerd zijn van belang voor kredietrisico en oefenen invloed uit op het betreffende bedrijf. Hoewel sommige relaties tegengestelde richtingen lijken te hebben, zijn ze gedefinieerd met het oog op de invloed die ze uitoefenen op het individu. Zo kan een bedrijf beïnvloed worden door een afnemer (client) als deze een groot deel van de omzet vertegenwoordigd of door een leverancier (supplier) die een cruciaal onderdeel levert. Dit betekent echter niet automatisch dat het tegenovergestelde ook geldt. Een voorbeeld: Bedrijf A levert aan bedrijf B. De omzet van A komt voor 75% van B. Bedrijf B maakt echter een product waarvoor het product van bedrijf A niet noodzakelijk is. Bedrijf B is dan een belangrijke invloedsfactor voor bedrijf A, wat wordt gedefinieerd in de vorm: A has_important_client B. Bedrijf A is echter geen belangrijke invloedsfactor voor bedrijf B, dus de relatie B has_essential_supplier A hoeft niet gedefinieerd te worden. Bij elk van de relaties is aangegeven met welke concepten deze kunnen bestaan. Zo kan een shareholder relatie met zowel personen als bedrijven bestaan, omdat zowel personen als
15

bedrijven aandelen kunnen hebben. Bovendien zijn voor een aantal relaties vastgesteld dat ze transitief kunnen zijn. Dat wil zeggen dat de influence (invloed) van een dergelijke relatie overdraagbaar is via eenzelfde relatie. Zo kan bijvoorbeeld een aandeelhouder van een bedrijf A invloed uitoefenen op bedrijf B als bedrijf A zelf aandeelhouder is van bedrijf B. De volgende relaties zijn gedefinieerd: shareholder (aandeelhouder), manager (bestuurder), accountant (accountant), parent company (moederbedrijf), subsidiairy (dochterbedrijf), authorized legal entity (tekeningsbevoegd), important cliënt (grote afnemer), essential supplier (essentiële leverancier), director (commissaris), agent (tussenpersoon), tax advisor (fiscalist), lends from (lenen van), lends to (lenen aan), rents from (huren van), pensionfund with (pensioenregeling bij). Bronconcept Relatie Doelconcepten B Has shareholder P / B B Has manager P B Has accountant A B Has parent company B B Has subsidiairy B B Has authorized legal entity P / B B Has important client P / B B Has essential supplier B B Has director P B Has agent A B Has tax advisor A B Lends from B / P / F B Lends to B / P B Rents from B / P B Has pensionfund with B / F Tabel 1 B –Company, P – Person, A – Advisor, F – Financial Organisation, O – Public Sector Organisation
4.2 KNOWLEDGEBASE
Er is geen gegevensverzameling beschikbaar die direct voor ons doel geschikt is. Als al één of meerdere van de benodigde gegevens aanwezig zijn, dan is het goed mogelijk dat deze niet gestructureerd zijn of op een manier die voor ons doeleinde niet geschikt is. Het is dus zaak dat er een knowledgebase wordt opgezet waar deze gegevens eenduidig en gestructureerd aanwezig zijn. Dit kan bijvoorbeeld een database zijn waar de gegevens van de verschillende bronnen verzameld worden door bijvoorbeeld het inlezen van de verschillende soorten files of door middel van menselijke input. Er zijn verschillende datamodellen mogelijk voor de knowledgebase. Eén daarvan, eXtensible Business Reporting Language (XBRL) kwam al snel naar voren. XBRL is een op XML gebaseerde open standaard voor het samenstellen en elektronisch uitwisselen van business rapportages en gegevens via het internet. Het ontbreken van een algemene standaard voor het uitwisselen van deze gegevens beperkt de mogelijkheden om deze gegevens op eenvoudige wijze te verzamelen, elektronisch uit te wisselen, te analyseren en nader te bewerken. XBRL moet dit mogelijk maken voor gegevens die op basis van dezelfde taxonomie zijn geselecteerd en gerapporteerd. Zie hoofdstuk 2 voor meer informatie over XBRL. Hoewel het Nederlandse Taxonomie project zich nu nog amper met de gegevens bezighoudt die voor dit project van belang zijn, is het niet ondenkbaar dat deze op een later tijdstip nog aan de taxonomie zullen worden toegevoegd. Kenmerken van XBRL komen al wel veelal overeen met de vereisten van dit project, en zal daarom ook niet zonder meer opzij gezet moeten worden. Zeker niet als er in de komende tijd steeds meer gebruik van gemaakt gaat worden in het Nederlandse bedrijfsleven.
16

4.2.1 DE KEUZE VOOR XML
De knowledgebase zal de gegevens bevatten die de kredietverstrekker beschikbaar heeft. Dit wil niet zeggen dat alle gegevens die de knowledgebase kan bevatten ook gebruikt zullen worden voor ons doel. De informatie in de knowledgebase kan door vele applicaties gedeeld worden. Belangrijk is dan wel dat de informatie zo is gedefinieerd dat deze en andere applicaties daar ook mee om kunnen gaan. Een belangrijke standaard voor het representeren van data is XML. XML is een gestructureerd en voorspelbaar opslagformaat en prima geschikt voor het doel binnen dit project. Bovendien is er goede bekendheid met XML en daarmee ook veel support. Door XML te gebruiken is het mogelijk de knowledgebase goed te structureren en is het bovendien mogelijk de gegevens ook voor andere applicaties te gebruiken dan in deze paper worden voorgesteld. Voor het doel van deze opdracht is XML echter niet direct geschikt. Daarvoor moet er aan de gegevens nog domeinkennis worden toegevoegd met behulp van de ontologie. Dit is het doel van de Web Ontology Language (OWL) beschreven in paragraaf 2.1. OWL stelt de applicatie in staat de gegevens te gebruiken en erover te redeneren om tot nieuwe inzichten te komen. De structuur van OWL is een vorm van XML en kan daarom ook dienen als datamodel voor de gegevens van kredietverstrekkers. Het is ook mogelijk om gegevens direct te structureren en op te slaan in het OWL formaat. Als het mogelijk is om de benodigde gegevens direct om te zetten en op te slaan in de Web Ontology Language, waarom is er dan gekozen om de gegevens eerst in XML te verzamelen en deze in een database op te slaan en deze vervolgens om te zetten naar OWL wanneer deze nodig zijn? Om deze vraag te beantwoorden zullen de voordelen en nadelen van beide methodes behandeld worden zodat duidelijk wordt dat het in dit geval beter is om ervoor te kiezen de gegevens in XML op te slaan. XML is een algemeen ondersteund formaat dat veel toepassingen kent. Het is daardoor gemakkelijker te implementeren in combinatie met andere systemen. Dit is vooral van belang voor het aanleveren van de gegevens door derden en voor de verspreiding van de gegevens naar verschillende onderdelen van het systeem. Voor het omgaan met de gegevens is er dan geen bijzondere kennis nodig. Dit in tegenstelling tot OWL dat een meer gespecialiseerd formaat is. OWL kent veel minder toepassingen en wordt daarom niet algemeen ondersteund. Om de gegevens te kunnen gebruiken in combinatie met dit systeem moeten ze worden omgezet in formaat waarmee systemen kunnen redeneren, in dit geval OWL. Wanneer er sprake is van een XML database zal een XML Schema met OWL-kennis aanwezig moeten zijn die aangeeft waar de benodigde gegevens gevonden kunnen worden, zodat deze op de juiste manier omgezet worden. Het is echter ook mogelijk om de gegevens direct in OWL op te slaan zodat een transformatie niet nodig is. Door de gegevens in OWL te structureren en op te slaan, kun je een transformatiestap overslaan wanneer de gegevens worden opgevraagd voor visualisatie. De knowledgebase voor dit systeem kan ook voor andere applicaties nuttig zijn, zoals een Customer Relations Management systeem of Financial Reporting systeem. Dit maakt het noodzakelijk om de knowledgebase zo te structureren dat zulke andere applicaties ermee om kunnen gaan. Bovendien zullen de gegevens voor de knowledgebase van verschillende bronnen komen. Om aanlevering makkelijker te maken, is het een goed idee om gebruik te maken van een goede standaard voor opslag en verspreiding van gegevens. Deze argumenten maken duidelijk waarom XML beter geschikt is als datamodel voor de knowledgebase dan OWL. De noodzaak van een algemeen opslagformaat weegt op tegen de extra bewerking die gemaakt moet worden om de gegevens voor dit systeem geschikt te maken. Figuur 2 illustreert de verschillende stappen binnen het systeem bij het gebruik van een XML database als knowledgebase.
17
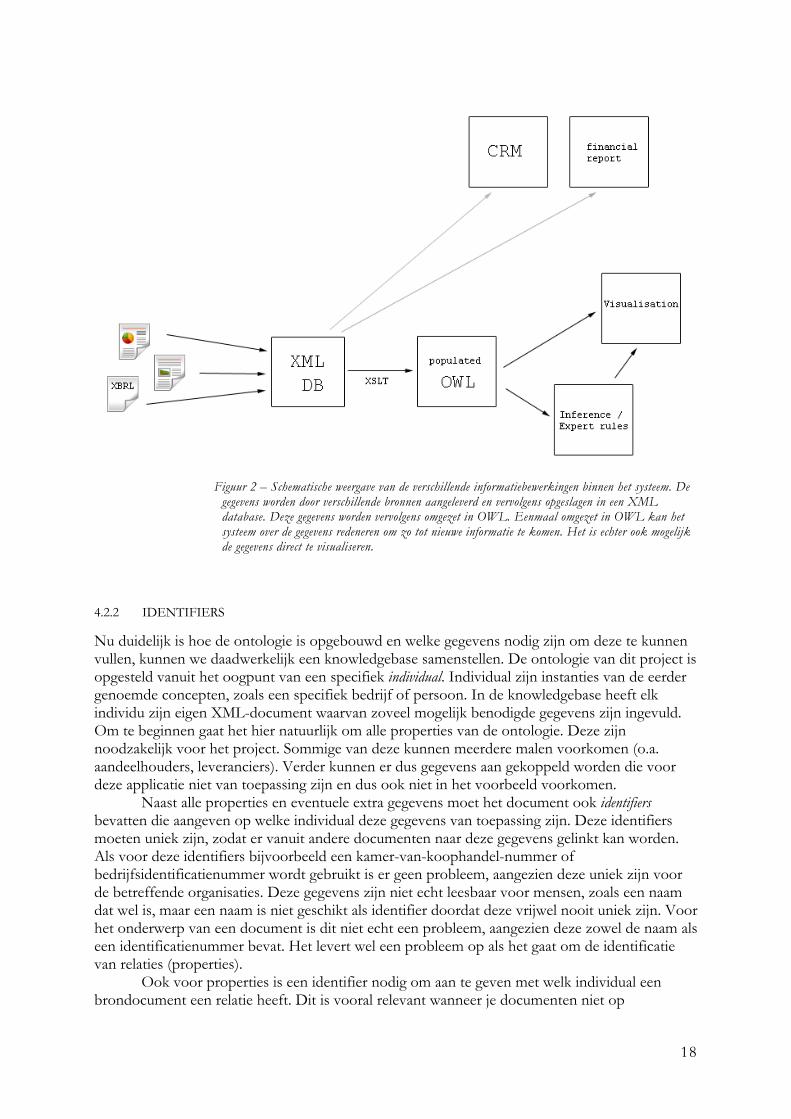
Figuur 2 – Schematische weergave van de verschillende informatiebewerkingen binnen het systeem. De
gegevens worden door verschillende bronnen aangeleverd en vervolgens opgeslagen in een XML database. Deze gegevens worden vervolgens omgezet in OWL. Eenmaal omgezet in OWL kan het systeem over de gegevens redeneren om zo tot nieuwe informatie te komen. Het is echter ook mogelijk de gegevens direct te visualiseren.
4.2.2 IDENTIFIERS
Nu duidelijk is hoe de ontologie is opgebouwd en welke gegevens nodig zijn om deze te kunnen vullen, kunnen we daadwerkelijk een knowledgebase samenstellen. De ontologie van dit project is opgesteld vanuit het oogpunt van een specifiek individual. Individual zijn instanties van de eerder genoemde concepten, zoals een specifiek bedrijf of persoon. In de knowledgebase heeft elk individu zijn eigen XML-document waarvan zoveel mogelijk benodigde gegevens zijn ingevuld. Om te beginnen gaat het hier natuurlijk om alle properties van de ontologie. Deze zijn noodzakelijk voor het project. Sommige van deze kunnen meerdere malen voorkomen (o.a. aandeelhouders, leveranciers). Verder kunnen er dus gegevens aan gekoppeld worden die voor deze applicatie niet van toepassing zijn en dus ook niet in het voorbeeld voorkomen. Naast alle properties en eventuele extra gegevens moet het document ook identifiers bevatten die aangeven op welke individual deze gegevens van toepassing zijn. Deze identifiers moeten uniek zijn, zodat er vanuit andere documenten naar deze gegevens gelinkt kan worden. Als voor deze identifiers bijvoorbeeld een kamer-van-koophandel-nummer of bedrijfsidentificatienummer wordt gebruikt is er geen probleem, aangezien deze uniek zijn voor de betreffende organisaties. Deze gegevens zijn niet echt leesbaar voor mensen, zoals een naam dat wel is, maar een naam is niet geschikt als identifier doordat deze vrijwel nooit uniek zijn. Voor het onderwerp van een document is dit niet echt een probleem, aangezien deze zowel de naam als een identificatienummer bevat. Het levert wel een probleem op als het gaat om de identificatie van relaties (properties). Ook voor properties is een identifier nodig om aan te geven met welk individual een brondocument een relatie heeft. Dit is vooral relevant wanneer je documenten niet op
18

individuele basis wilt bekijken, maar gekoppeld aan (deel van) de documentcollectie. Door gebruik te maken van een deel van de collectie, of de collectie als geheel, is informatie eenvoudig aan elkaar te koppelen. Wanneer je bijvoorbeeld een document hebt over een bedrijf met gegevens over de aandeelhouders, en je hebt vervolgens ook weer een document over één of meer van die aandeelhouders, dan weet je indirect weer meer van het eerste bedrijf. Unieke identifiers zijn dan cruciaal om de juiste documenten aan elkaar te koppelen. Voor de visualisatie is het dan nodig dat de identifiers worden gekoppeld aan de gegevens die leesbaar zijn voor mensen, zoals namen. Als er op documentbasis naar een bedrijf gekeken wordt dan kan het invullen van namen als identifiers misschien volstaan, omdat deze in de meeste gevallen wel uniek zal zijn. Toch is het wenselijk om ook hier gebruik te maken van unieke identifiers, aangezien men over het algemeen toch zal willen navigeren tussen documenten en deze daar dus voor gebruikt kunnen worden. Om deze gegevens toch voor mensen leesbaar te maken zonder gegevens van andere documenten te laden zullen deze zich dus ook in het brondocument moeten bevinden. Dit scheelt een vertaalslag naar iets dat voor mensen leesbaar is.
4.2.3 DE DOCUMENTSTRUCTUUR.
De opzet van de brongegevens met bovenstaande elementen in gedachten is verder niet complex. Het document zal zowel de naam als de identifier van het individu in kwestie bevatten. Daarnaast bevat het nog de elementen die de relaties van dit individu definiëren: het concepttype en de properties. Het concepttype moet aanwezig zijn om onderscheid te kunnen maken bij de conversie en de visualisatie. De properties moeten zoals gezegd aanwezig zijn om het type relatie en het gerelateerde individu vast te leggen. Hieronder een voorbeeld van deze structuur: <document xmlns ....> <id>uniek123</id> <name>Bakker Inc</name> <concept>Bedrijf</concept> <properties> <has_shareholder> <propertyid>12341234</propertyid> <propertyname>De Bruin</propertyname> <propertyconcept>Person</propertyconcept> </has_shareholder> <has_manager> <propertyid>89089089</propertyid> <propertyname>Jan Bakker</propertyname> <propertyconcept>Person</propertyconcept> </has_manager> .... .... </properties> </document> In een aantal gevallen kunnen de geneste property-elementen ook meer dan eens voorkomen. Zo zal een bedrijf over het algemeen meer dan één aandeelhouder hebben.
4.3 POPULATED ONTOLOGY
Wanneer een gebruiker een bedrijf zoekt, dan worden de relevante gegevens verzameld uit de knowledgebase. De gegevens in de knowledgebase zijn prima bruikbaar voor mensen, maar hebben op zichzelf nog geen betekenis. Het systeem kan er zelf geen waarde aan toekennen. Deze betekenis wordt eraan gegeven door de ontologie die het domein beschrijft. Door de gegevens aan de ontologie toe te voegen laat je het systeem weten wat de gegevens betekenen
19

en hoe het deze moet laten zien. Bij het laden van een zoekopdracht gebeurt dan ook niet meer dan het invullen van een ontologie-instantie met de gegevens die horen bij het resultaat van die zoekopdracht. De populated ontology maakt het vervolgens mogelijk om semantische zoekopdrachten uit te voeren, of om nieuwe informatie af te leiden met behulp van een inferentiesysteem. Voor dit systeem is ervoor gekozen om de ontologie-instantie in te vullen met gegevens aan de hand van een zoekopdracht. Dit is echter niet vanzelfsprekend. Bij het redeneren over de gegevens om te proberen nieuwe feiten af te leiden, is het wenselijk alle gegevens te gebruiken. Dit voorkomt dat dingen worden overgeslagen en er dus geen nieuwe relaties voor worden ontdekt. Om duidelijk te maken dat het voor dit systeem toch verstandig is om de ontologie-instantie per zoekopdracht in te vullen, zullen de verschillende aspecten van beide methodes worden besproken. Door alle gegevens te gebruiken om de ontologie in te vullen, kun je alle gegevens gebruiken om nieuwe feiten mee af te leiden. Dit zou betekenen dat je veel extra informatie naar boven kunt halen, die anders niet direct duidelijk zou zijn. Dit in tegenstelling tot de selectie die gemaakt bij een zoekopdracht. Daarbij is het mogelijk dat een feit niet wordt ontdekt omdat niet alle gegevens zijn meegenomen. Een ontologie die gevuld is met alle beschikbare gegevens heeft daarom meer kans nieuwe gegevens af te leiden dan een ontologie die alleen selectief is gevuld. Het is echter de vraag of alle gegevens die je zou kunnen afleiden binnen het domein van dit project wel zo interessant zijn. Als er genoeg gegevens beschikbaar zijn, zou je vast kunnen afleiden dat de president van de Verenigde Staten indirect een risicofactor is voor de bakker op de hoek, maar dit is niet van wezenlijk belang voor een kredietverstrekker vanwege het aantal stappen dat daar tussen zit. Hoewel veel nieuwe invloedsrelaties ontdekt zouden kunnen worden door alle gegevens te gebruiken, zal bij veel van deze relaties de gevonden invloed zeer klein zijn en daarom niet van belang voor de gebruiker. Een ander aspect dat van invloed is op de beslissing om slechts een selectie te gebruiken bij het invullen van de ontologie heeft te maken met de ‘kosten’ van de informatiebewerkingen. Met ‘kosten’ wordt in dit geval de tijd en capaciteit bedoeld dat ervoor nodig is om bijvoorbeeld inferentie toe te passen op de gegevens. Als alle gegevens gebruikt moeten worden, dan zullen deze periodiek bijgewerkt moeten worden. De hoeveelheid gegevens maakt het onmogelijk dit per wijziging of zoekopdracht te doen. Door inferentie op slechts een selectie van de gegevens toe te passen is het mogelijk om dit pas te doen wanneer de gebruiker gegevens opvraagt. Dit voorkomt de noodzaak om de status van de gegevens bij te houden, omdat je altijd de laatste gegevens gebruikt voor bewerkingen. Voor het doel van ons systeem is het beter om per zoekopdracht een gerelateerde selectie gegevens te gebruiken om de ontologie mee te vullen. Aangezien het onwaarschijnlijk is dat relaties die ver uit elkaar liggen van belang zijn voor de gebruiker, is het niet erg om slechts een kleiner gedeelte te gebruiken. Bovendien is het op die manier gemakkelijker om de gegevens te beheren. De toegevoegde waarde van een populated ontology met alle gegevens weegt daarom niet op tegen de kosten die daaraan verbonden zijn.
4.3.1 DE ONTOLOGIE INVULLEN
Eerder in dit verslag werd uitgelegd hoe de knowledgebase wordt samengesteld, omdat deze nog niet of nauwelijks bestaat. Deze brongegevens zijn in dit geval dus een theoretische situatie waar de rest van het project mee werkt. De volgende stap is het verwerken van de gegevens door deze om te zetten naar een formaat dat bruikbaar is. In deze sectie zal worden gesproken over het maken van de populated ontologie met de gegevens uit het document en alles wat daarbij komt kijken. Ieder document maakt gebruik van standaardkenmerken van de ontologie, zoals de classes. Deze regels staan vast en hoeven maar éénmaal gedefinieerd te worden per populated ontologie.
20

Daarnaast zijn er de regels die kenmerkend zijn voor de geladen gegevens. Dit zijn de gegevens die worden ingevuld aan de hand van de eerder gedefinieerde knowledgebase. Hieronder zal eerst ingegaan worden op de standaardregels van de ontologie en daarna wordt het invullen van de ontologie besproken. Hierbij moet worden opgemerkt dat de standaardregels afhankelijk zijn de definitie van de ontologie: als de ontologie wordt gewijzigd, dan moeten onderstaande regels ook aanpast worden. Net als andere xml-bestanden heeft ook rdf/xml een xml-declaratie op de eerste regel. Voor een geldig owl-bestand is een minimale declaratie voldoende: <?xml version="1.0"?> Voordat we een verzameling termen kunnen gaan gebruiken, moeten we precies aangeven welke regels we daarvoor gaan gebruiken. Een standaard component van een ontologie is dan ook een aantal xml-namespace declaraties, omsloten in de rdf:RDF openingstag. Deze zorgen ervoor dat identifiers daadwerkelijk een uniek zijn zonder de leesbaarheid van de ontologie daarvoor op te offeren. De ‘xmlns’ en ‘xml:base’ declaraties maken in het voorbeeld gebruik van een willekeurig gegenereerde URL. <rdf:RDF xmlns="http://www.owl-ontologies.com/Ontology1213860762.owl#" xml:base="http://www.owl-ontologies.com/Ontology1213860762.owl" xmlns:rdfs="http://www.w3.org/2000/01/rdf-schema#" xmlns:xsd="http://www.w3.org/2001/XMLSchema#" xmlns:owl="http://www.w3.org/2002/07/owl#" xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"> De volgende stap is het aanmaken van de ontologie. Dit zijn de tags en attributen die specifiek zijn voor ons model, maar wel hetzelfde zijn voor alle populated ontologieën. Het gaat dan vooral om het definiëren van classes en properties. Voor classes en de omschrijving van de ontologie is dit als volgt: <owl:Ontology rdf:about=""/> <owl:Class rdf:ID="Advisor"/> Voor properties ligt dit iets anders, omdat daar ook een domein voor gedefinieerd moet worden. Als een property transitief is wordt dat ook hier aangegeven. Deze eigenschappen zijn in de xml-structuur dochters van de ObjectProperty tag. De transitieve property shareholder (aandeelhouder) ziet er dan als volgt uit: <owl:ObjectProperty rdf:ID="has_shareholder"> <rdf:type rdf:resource="...#TransitiveProperty"/> <rdfs:domain rdf:resource="#Company"/> </owl:ObjectProperty> En de niet-transitieve property ‘accountant’ als volgt: <owl:ObjectProperty rdf:ID="has_accountant"> <rdfs:domain rdf:resource="#Company"/> </owl:ObjectProperty> De overige properties hebben voorlopig één van deze vormen. De laatste standaard tag van een document is het afsluitende rdf:RDF element. </rdf:RDF>
21

Al de standaardelementen staan extern gedefinieerd zodat de ontologie gemakkelijk gewijzigd kan worden. Deze definitiefile moet ook de gegevens bevatten die nodig zijn voor het aanmaken van de variabele onderdelen van populated ontologieën. Bij het invullen van een ontologie met de variabele gegevens van de knowledgebase komt iets meer kijken. Zo moeten er voor het onderwerp van het document alle relaties gedefinieerd worden met unieke identifiers. Daarna moeten alle individuals die in dat document voorkomen worden gedefinieerd, en alle relaties die daar aan gerelateerd. Hieronder een voorbeeld van een resulterende owl, waarbij de gebruikte namen en cijfers de unique identifiers voorstellen: <Company rdf:ID=Bakker Inc> <has_shareholder rdf:resource="#12341234"/> <has_shareholder rdf:resource="#56785678"/> <has_manager rdf:resource="#De Bruin"/> ... </Company> <Person rdf:ID="De Bruin"/> <Company rdf:ID="Dokwerkers BV."/>
4.4 INFORMATIEVERRIJKING DOOR MACHINE-INTERPRETATIE
De combinatie van gegevens uit de knowledgebase met de regels uit de ontologie levert een populated ontologie op die machine-understandable is. Dat wil zeggen dat de gegevens zo gestructureerd zijn dat een machine erover kan redeneren. In een goed gedefinieerde en goed gevulde ontologie is het mogelijk om automatische nieuwe statements af te leiden uit bestaande relaties met behulp van een reasoner. De relaties in de kredietrisico-ontologie zijn allemaal verschillend, maar ze zijn subproperties van de is_influenced_by (heeft invloed op) relatie. Dat wil zeggen dat voor het statement A has_manager B (A heeft_manager B) ook het statement A is_influenced_by B geldt. In een aantal van de relaties komt influence (invloed) naar voren als een indirect risico. Door de relatie manager (bestuurder) dan transitief te maken, kun je de reasoner duidelijk maken dat de invloeden op de manager ook invloeden zijn op het bedrijf waar die persoon manager van is. Op deze manier kan de knowledgebase door het systeem zelf aangevuld worden met nieuwe informatie. Een goed gedefinieerd datamodel alleen is niet genoeg voor het redeneren over informatie. Er zijn ook applicaties nodig die met dergelijke datamodellen kan omgaan. Met behulp van een inference engine, of reasoner, is het mogelijk om impliciete relaties uit de gestructureerde relaties van ons datamodel expliciet te maken. Er zijn verschillende projecten die werken aan inference engines, zoals F-OWL [5], Protégé [21] of SWOOP [18]. F-OWL is een inference engine voor de semantische webtaal OWL, gebaseerd op F-Logic [10]. Protégé en SWOOP zijn tools voor het maken, wijzigen en debuggen van OWL ontologieën. Het werd ontwikkeld door het MIND lab van de Universiteit van Maryland, maar het is ondertussen een open source project met deelnemers wereldwijd. Voor het begrijpen en ontdekken van nieuwe gegevens in de knowledgebase is een inference engine nodig. Naast een reasoner moet er een regelset komen die aangeeft wanneer relaties risicovol zijn. Aan de hand van deze regelset kan het systeem opvallende relatieconstructies ontdekken en de gebruiker daarvan op de hoogte stellen. Cirkelverhoudingen zijn opvallende constructies en brengen in veel gevallen extra risico met zich mee. Een kleine cirkelverhouding kan bijvoorbeeld op de volgende manier bestaan: Persoon A is bestuurder bij bedrijf B en aandeelhouder bij bedrijf C. Als bedrijf B dan ook nog eens aandeelhouder van bedrijf C blijkt te zijn, is er een onoverzichtelijke situatie waar Persoon A minder invloed lijkt te hebben dan hij daadwerkelijk heeft. Een dergelijke risicovolle constructie is niet lastig te ontdekken als er regels voor gedefinieerd zijn. Een mededeling bij de visualisatie kan de gebruiker hier dan van op de hoogte stellen zodat deze er een beslissing over kan nemen.
22

VISUALISATIE
Deelvraag 2: Hoe moet de data worden gevisualiseerd om de inzichtelijkheid te vergroten? In dit hoofdstuk zal worden ingegaan op het visualisatiegedeelte van het systeem. Er wordt ingegaan op het gebruik van een visuele structuur en de keuzes die zijn gemaakt bij de verschillende aspecten die daarbij naar voren komen. Het gaat dan vooral over het moment waarop een gebruiker een zoekopdracht heeft ingevoerd en waarbij het resultaat op het scherm getoond moet worden. Het doel van de visualisatie van deze informatie is om de inzichtelijkheid ervan te vergroten en daarmee de besluitvorming van de gebruiker te ondersteunen. Is de visualisatie in staat om de gangbare vragen die de gebruiker ten aanzien van kredietrisico te beantwoorden? Welke aspecten zijn hiervoor nodig en hoe worden deze gevisualiseerd? Hoe kunnen we bepalen of de visualisatie de gebruiker beter ondersteunt dan bestaande methodes? Een visualisatie is een weergave van informatie dat op een zinnige manier gebruikt maakt van ruimte en lay-out. De keuze om bepaalde informatie te visualiseren is een makkelijke wanneer men beseft dat dit waarneming kan versterken. Door een juiste visualisatie kan men abstracte informatie op een intuïtieve manier overbrengen. Plaatjes maken het mogelijk een idee of concept in een oogopslag te begrijpen. Een goed ontwikkelde visualisatie:
• zorgt ervoor dat grote hoeveelheden gegevens op zowel kleine schaal als grote schaal begrijpelijk zijn. Denk daarbij zowel aan details van een enkel bedrijf als een overzicht van vele bedrijfsrelaties.
• vergemakkelijkt het zoeken naar informatie door herkenbare elementen te gebruiken. • maakt een complexe dataset begrijpelijker, o.a. door het gebruiken van domeinmetaforen. • maakt verborgen relaties zichtbaar. • maakt het mogelijk om een dataset tegelijkertijd vanuit verschillende perspectieven te
bekijken. • maak het formuleren van hypotheses makkelijker. • is goede manier van communiceren.
Het nut van visualisaties hangt echter af van het verband tussen de gekozen visuele structuur en het applicatiedomein. Visualisaties dienen zo te worden ontwikkeld dat ze intuïtief te begrijpen zijn en effectief en nauwkeurig geïnterpreteerd kunnen worden.
4.5 VISUELE STRUCTUUR – NETWORK GRAPH
Voor het weergeven van relationele gegevens zoals in de ontologie wordt gebruik gemaakt van een network graph of domain map, netwerkstructuur waarbij entiteiten als knopen worden weergegeven en de relaties van de entiteiten als lijnen tussen de knopen. Dezelfde visuele structuur wordt onder andere ook gebruikt voor het visualiseren van relationele database modellen [9] en het weergeven van sociale netwerken [6]. Een network graph is een simpele manier om relaties overzichtelijk weer te geven. Hoewel domain maps zoekfunctionaliteit kunnen ondersteunen (bijv. door het highlighten van zoektermen) is één van de belangrijkste doelen het ondersteunen van verkennend browsen in een informatiedomein om er bekend mee te worden en interessante informatie te vinden. Daarom is het noodzakelijk te kunnen navigeren binnen de visuele structuur. Het moet dus mogelijk zijn om op eenvoudige wijze te wisselen tussen perspectieven om optimaal gebruik te kunnen maken van de visuele structuur. De visuele structuur moet aangekleed worden om alle verschillende aspecten van de informatie uit het domein voldoende tot uitdrukking te brengen. Entiteiten behoren niet allemaal
23

tot dezelfde klasse. Er zijn verschillende soorten relaties welk onderscheid wel degelijk belangrijk is. Bovendien kunnen er eigenschappen zijn van zowel relaties als entiteiten die ook weer andere informatie uitdrukken. De uitwerking van de visuele structuur met de genoemde aspecten worden hierna besproken.
4.6 DE OPBOUW VAN DE VISUELE STRUCTUUR
Een network graph is een simpele structuur waarbij entiteiten worden getoond als knopen en de relaties tussen de entiteiten worden weergegeven als lijnen tussen de knopen. In het voorgestelde systeem zal er een enkel individu (een entiteit van onze ontologie) de focus hebben. Dit is het bedrijf of de persoon die door de gebruiker is opgevraagd. Aan de hand van dit individu zal het netwerk opgebouwd worden. Alle entiteiten waar het individu in focus direct mee gerelateerd is zullen er omheen verschijnen met daarbij lijnen die de relaties voorstellen. Deze zullen over het algemeen ook weer relaties hebben met elkaar of andere entiteiten en ook deze zullen verschijnen. Zo wordt er een web getoond aan de hand van de gebruikte informatie.
Figuur 3 - Deel van een network graph
Het is cruciaal dat de visualisatie wordt voorzien van kenmerken die het mogelijk maken de verschillen tussen de individuals weer te geven. Een vereiste van de ontologie is namelijk dat individuals uniek zijn. De meest simpele methode om dit onderscheid duidelijk te maken is door de waarde van het individu als label van de knoop te gebruiken. De individuals van de ontologie van dit project hebben in alle gevallen een unieke identifier en in vrijwel alle gevallen een naam. Hoewel de naam niet in alle gevallen uniek is, en dus niet volledig onderscheidend, is het wel zeer leesbaar voor mensen en bovendien zeer intuïtief om verschillende individuals uit elkaar te houden. Naast labels zijn er nog andere kenmerken die verschillen tussen individuals duidelijk moeten maken.
Figuur 4 - Gebruik van labels
Het gebruik van kleuren speelt op twee manieren een belangrijke rol bij het vereenvoudigen van complexe gegevens. Een individu is in feite een instantie van een abstracte class. Die class brengt een aantal kenmerken met zich mee die het onderscheidt van andere classes. Om dit in de visualisatie tot uitdrukking te brengen worden knopen voorzien van verschillende kleuren. Op deze manier is eenvoudig te zien welke individuals tot dezelfde class behoren. Hetzelfde geldt voor relaties tussen individuals. Niet alle lijnen drukken dezelfde relaties uit en daarom wordt gebruik gemaakt van kleuren om aan te geven welke lijnen een specifieke
24

relatie uitdrukt. Kleuren zijn belangrijk om onderscheid te kunnen maken tussen verschillende individuals en verschillende relaties. Een belangrijk punt bij het gebruik van kleuren is het onderscheidend vermogen tussen de kleuren.[19] Niet alle kleurcombinaties zijn voor dit doel geschikt. Voor de ontologie van dit project werden 15 relaties gedefinieerd. Om elke relatie van zijn eigen kleur te voorzien moeten er dus 15 kleuren gekozen worden. Hoewel er studies zijn die aangeven dat dit aantal kleuren voldoende onderscheidend vermogen kan geven [2][17], wordt over het algemeen aangeraden niet meer dan vijf of zes verschillende kleuren te gebruiken [3][15]. Door het gebruik van verschillende lijnstijlen (bv. stippellijn, plus-min-lijnen) is het mogelijk dit aantal noodzakelijke kleuren te verminderen, omdat kleuren opnieuw gebruikt kunnen worden bij een andere lijnstijl. Om aan te geven welke relatie door welke lijn wordt aangegeven zijn deze opgenomen in de legenda. Het onderscheidend vermogen van kleuren gecombineerd met lijnstijlen en een legenda zorgen voor een duidelijkere visualisatie.
Figuur 5 - Gebruik van kleuren ter onderscheiding
Voor de individuals in de visualisatie is onderscheid door middel van kleuren en de legenda wellicht niet voldoende. De prominente plaats die ze innemen op het scherm maakt het wenselijk om in één oogopslag te kunnen zien wat de individuals voorstellen. In enkele keer kan de label een indicatie geven, maar vaak niet. Daarom is besloten icoontjes toe te voegen aan de weergave van individuals, bijvoorbeeld voor personen een icoon van een mannetje en voor banken een dollarteken. Door gebruik te maken van iconen die symbolisch zijn voor hun overeenkomstige classes kunnen gebruikers dus snel herkennen tot welke klasse desbetreffende individual behoort.
Figuur 6 - Gebruik van iconen
Een legenda is een noodzakelijk onderdeel van vrijwel iedere visualisatie. Zonder het gebruik van deze toelichting is het gebruik van kleuren en tekens overbodig, omdat de gebruiker dan nog niet weet waartussen nu onderscheid gemaakt wordt. De legenda is weergegeven onder de visualisatie op een grijs vlak. Aan de linkerkant worden de classes getoond naast met de bijbehorende iconen. Rechts daarvan staan alle relaties met de bijbehorende lijnstijl en –kleur. De gebruiker kan zo eenvoudig de lijnen koppelen aan de relaties en de individuals aan de classes. Naast de toelichting dient de legenda in dit systeem nog een tweede functie, namelijk het realiseren van verschillende views. Naast alle classes en relaties bevindt zich een checkbox. Bij het laden van een zoekopdracht staan deze aangevinkt. De gebruiker kan dan bepalen welke individuals en relaties zichtbaar blijven. Als de gebruiker er bijvoorbeeld voor kiest om alle personen uit de visualisatie te halen, dan zullen ook alle relaties met deze individuals uit de visualisatie verdwijnen. Het wordt dan in feite een visualisatie van bedrijven. Door gebruik te maken van de checkboxes in de legenda kan de gebruiker de visualisatie aanpassen om tot betere
25

inzichten te komen.
Figuur 7 - De legenda
Er is veel meer informatie beschikbaar dan direct kan worden getoond met bovenstaande hulpmiddelen. Aangezien het doel van een visualisatie is om gegevens duidelijker te maken, moet ervoor gezorgd worden dat het scherm niet te complex wordt en daarmee aan het doel voorbij gaat. Daarom zijn bepaalde gegevens in eerste instantie niet zichtbaar voor de gebruiker. Na wat rondvragen bleek dat vooral extra informatie over de individuals gewenst was. Denk hierbij aan informatie zoals relatienummer, adres en andere klantgegevens. Om deze informatie toch beschikbaar te maken is besloten om gebruik te maken van een popup die wordt getoond wanneer de gebruiker de cursor over de schermelementen beweegt. Bij individuals wordt de gewenste extra informatie getoond in de popup en bij relaties de omschrijving van die relatie.
Figuur 8 - Een popup
4.7 REALISATIE VAN VIEWS
Ben Shneiderman van de Universiteit van Maryland karakteriseerde hoe gebruikers omgaan met de visualisatie van grote hoeveelheden informatie op de volgende manier: Overview, Zoom-in (of Filter) en Details on Demand [16]. Gebruikers starten met een overzicht van het informatiegebied en kunnen vervolgens inzoomen op delen die van belang lijken, meer
26

informatie opvragen enzovoorts. Theorieën zoals Information foraging [13] kunnen een interessante manier zijn om te bepalen waar men inzoomt. Niet iedere gebruiker zal hetzelfde doel voor ogen hebben bij het gebruik van het systeem. Verschillende gebruikers zullen verschillende vragen hebben. Dit zal leiden tot een ander idee over hoe ze tot het inzicht kunnen komen om hun vragen te beantwoorden. Door het toepassen van itemselectie, niveaus en navigatie kan de visualisatie aangepast worden aan de wensen van de gebruiker voor het beantwoorden van vragen. In deze sectie zal een aantal views worden besproken die met het systeem mogelijk zijn om gebruikers te ondersteunen. Daarnaast wordt er ingegaan op navigatie van de visual space.
4.7.1 VIEWS: RISICO-WAARSCHUWING
Bij het managen van kredietrisico maken experts inschattingen op basis van beschikbare gegevens. Het is mogelijk een deel van de richtlijnen die deze experts hanteren om te zetten in expert rules en die vervolgens in het systeem te integreren. Het systeem kan aan de hand van deze expert rules mogelijke risico’s detecteren en aan de gebruiker melden. Hoewel de visualisatie slechts een beperkte hoeveelheid elementen tegelijkertijd zal tonen, kan het systeem over een groter bereik redeneren. Daardoor zal het niet alleen in staat zijn risico’s te ontdekken die zichtbaar zijn, maar ook risico’s die niet direct zichtbaar zullen zijn. Het systeem kan de experts ondersteunen door visuele waarschuwingen te geven als het een situatie tegenkomt die risicovol kan zijn.
4.7.2 VIEWS: INVLOEDNIVEAUS
Enkele van de relaties die voor dit project zijn gedefinieerd hebben kwantitatieve factoren die van invloed zijn bij het bepalen van risico. Zo is er de shareholder-relatie (aandeelhouders). Bij hele grote bedrijven kunnen dit er vele tientallen zijn wat de inzichtelijkheid uiteraard niet ten goede komt. Bovendien kan een enkele aandeelhouder veel aandelen bezitten ten opzichte van anderen. De invloed van een aandeelhouder is gekoppeld aan het aantal aandelen van die aandeelhouder. Daarom kan de visualisatie gekoppeld worden aan de hoeveelheid aandelen. Als een aandeelhouder zich onder een kritische grens bevindt, wordt deze niet getoond in de visualisatie. Daarnaast kan de dikte van een lijn gebruikt worden om de invloed van verschillende aandeelhouders weer te geven.
4.7.3 VIEWS: PARENT – SUBSIDIARY RELATIES
Bij het onderzoeken van relaties tussen individuals zijn de hiërarchische relaties niet te vermijden. In veel gevallen is dit de belangrijkste relatie die de beoogde gebruiker zou willen ontdekken. De hiërarchische relatie is al in gebruik bij het bepalen van kredietrisico en dat zal bij dit systeem niet anders zijn. Voor dit doel zijn de ‘has parent company’ en ‘has subsidiary’ relaties gedefinieerd. Daarnaast moet het systeem hiërarchische ordening ondersteunen, waarbij de relaties hun real world analogies volgen. De visualisatie moet hiërarchische ordening ondersteunen waarbij moederbedrijven (parent company) boven worden geplaatst en dochterbedrijf (subsidiaries) onder. De gebruikelijke manier om hiërarchische verhoudingen te visualiseren is door middel van een boomstructuur. Hoewel het met dit systeem al mogelijk is om alleen subsidiaries en parent companies te bekijken, is het wenselijker om de visuele structuur van deze view aan te passen aan de informatie die getoond wordt. Door een boomstructuur te gebruiken komen de hiërarchische relaties beter tot hun recht en dit komt de inzichtelijkheid van deze relaties ten goede. Daarom moet het systeem een optie hebben om de subsidiary en parent company relaties op deze manier te visualiseren.
27

4.7.4 NAVIGATIE
De focus van een visualisatie, en alle relaties die daar bijhoren, wordt bepaald door de oorspronkelijke zoekopdracht. De hoeveelheid informatie die beschikbaar is, zorgt ervoor dat de visualisatie beperkt moet worden tot een paar niveaus vanaf de individual in focus. Dat wil zeggen: het aantal relaties van gerelateerde individuals dat wordt getoond is maar beperkt. In veel gevallen zal dit genoeg zijn om de gebruiker van de gewenste informatie te voorzien, maar het kan voorkomen dat de gebruiker meer wil zien. De gebruiker moet door een simpele actie de focus van de visualisatie kunnen veranderen naar een andere individual op het scherm. Een andere manier om meer informatie op het scherm te tonen is door uit te zoomen op het netwerk. De focus blijft daarbij op het resultaat van de zoekopdracht, maar er worden meer relatieniveaus getoond. Afhankelijk van het gekozen niveau kan dit wel ten koste gaan van de overzichtelijkheid. Op een hoger niveau worden er immers meer elementen getoond en teveel elementen zorgen voor onnodige clutter. Net als het veranderen van focus kan het creëren van een overzichtspositie leiden tot een beter inzicht. Door van individual naar individual te navigeren kan een gebruiker zich een beter beeld vormen van de manier waarop relaties in elkaar zitten. Dit betekent dat de gebruiker niet langer de focus heeft op de oorspronkelijke zoekopdracht. Om te voorkomen dat een gebruiker ‘de weg kwijtraakt’ en dus de zoekopdracht opnieuw moet uitvoeren om weer terug te keren, moet er navigatieondersteuning aanwezig zijn. Navigatieondersteuning zal in de vorm van een browsegeheugen aanwezig zijn. Dit is niet meer dan een lijst met bezochte individuals, die aangeklikt kunnen worden om deze weer in focus te brengen.
28

5 CONCLUSIE
In deze scriptie werd een beschrijving gegeven voor het ontwikkelen van een systeem voor het management van kredietrisico. De ontwikkeling van een dergelijk systeem is gewenst door de onoverzichtelijkheid van de gegevens binnen dit domein. Om het risico bij kredietverstrekking te verkleinen is een beter inzicht nodig in de beschikbare gegevens. Door het bespreken van bruikbare technieken en het behandelen van problemen die er op dat vlak zijn, wordt aangetoond op welke wijze het mogelijk is om de inzichtelijkheid van bedrijfsfinanciële gegevens te vergroten. De onoverzichtelijkheid was te wijten aan de verscheidenheid van gegevens die bovendien afkomstig waren van verschillende bronnen. Dit probleem wordt opgelost door de gegevens te verzamelen in een knowledgebase, waar er betekenis en structuur aan gegeven wordt. Hoewel er verschillende oplossingen mogelijk zijn, is er gekozen voor een algemeen bekende en goed ondersteunde structuur. Door XML te gebruiken wordt het aanleveren, beheren en uitlezen van gegevens vereenvoudigd. Er is echter meer nodig dan de gegevens alleen. Er moest kennis over het domein van het kredietrisico worden toegevoegd. Er is een ontologie opgesteld dat de regels bevat over dit domein. Door de gegevens uit de knowledgebase te combineren met de ontologie ontstaat er een ingevulde ontologie, die door machines te interpreteren is. Een inference engine kan dan over de gegevens redeneren en impliciete feiten expliciet maken, waarmee nieuwe feiten naar boven komen. In veel gevallen is het wenselijk om direct alle gegevens te gebruiken voor het invullen van de ontologie, maar in dit geval bleek het een beter idee om alleen een selectie van de gegevens te gebruiken. Aan de gegevens wordt nu extra kennis toegevoegd wanneer de gebruiker deze opvraagt. De visualisatie van kredietrisico is een netwerkgraaf met daarin het resultaat van de zoekopdracht en gerelateerde elementen. Dit stelt de gebruiker in staat om in een oogopslag te zien hoe de verhouding liggen om daarmee een inschatting van het risico te kunnen doen. De visualisatie maakt gebruik van verschillende visuele elementen om de informatie te verduidelijken: kleuren, vormen, icoontjes, een legenda en lay-out. Het stelt de gebruiker in staat om zowel te verkennen als het overzicht te behouden. Extra informatie is op te vragen met popups. Op deze manier wordt de inzichtelijkheid van de gegevens vergroot.
5.1 FUTURE WORK
Nu de beschrijving en een gedeelte van de implementatie van het systeem voor het visualiseren van kredietrisico is gegeven, is de volgende stap de daadwerkelijke uitwerking ervan. Hoewel aardig nauwkeurig wordt beschreven hoe het systeem ontwikkeld moet worden, is niet alles tot in detail voorgeschreven. Bij verdere implementatie is het interessant om te zien hoe deze richtlijnen stand zullen houden en hoe het systeem presteert met betrekking tot onder andere capaciteit en het ontdekken van nieuwe statements. Ook de beschrijving van de visualisatie is veelzijdig en maakt veelvuldig gebruik van bestaande wijsheden op dit gebied. Interessant zal zijn hoe de visualisatie gaat presteren bij tests op het gebied van usability, welke door de aard van dit project nog niet hebben plaatsgevonden. Verder zal er nagedacht moeten worden over een manier om de ontologie expressiever te maken dan nu mogelijk is met OWL. Het is nu niet mogelijk om een subproperty transitief te maken voor de ‘parent’ property, waardoor het niet mogelijk is om invloed te beredeneren over verschillende subproperties. Dit is wel iets dat wenselijk is voor het domein en daarom zal er dus een oplossing voor gevonden moeten worden.
29

6 REFERENCES
[1] Basel Committee on Banking Supervision, International Convergence of Capital Measurement and
Capital Standards: A Revised Framework Comprehensive Version, June 2006
[16] B Shneiderman, The eyes have it: a task by data type taxonomy for information visualizations. In: Visual Languages, 1996. Proceedings., IEEE Symposium on, pp. 336-343. 1996
[14] Broeksta, Kampman en Van Harmelen, Sesame: An Architecture for Storing and Querying RDF Data and Schema Information, In: Semantics for the WWW, MIT Press, 2001, D. Fensel, J. Hendler, H. Lieberman and W. Wahlster (eds).
[2] Cahill, Mary-Carol, and Carter, Robert. C., Jr. Color code size for searching displays of different density. Human Factors, 18(3), 273-280. 1976
[3] Carter, R. C. Visual search with color. Journal of Experimental Psychology: Human Perception and Performance, 8(1), 127-136. 1982
[8] Herman, Ivan, Design Issues, W3C. 2008
[7] Herman, Ivan, Semantic Web Activity Statement, W3C. 2008
[21] http://protege.stanford.edu (correct op 13-09-2008) [4] http://www.finan.nl (correct op 29-08-2008)
[20] http://www.xbrl-nederland.nl (correct op 29-08-2008)
[11] http://www.xbrl-ntp.nl (correct op 29-08-2008)
[18] Kalyanpur et al., SWOOP: a web ontology editing browser, University of Maryland. 2005
[10] Kifen, Lausen en Wu, Logical Foundations of Object-Oriented and Frame-based languages, In:
Journal of the Association for Computing Machinery. May 1995
[6] Linton C. Freeman,Visualizing Social Networks, Journal of. Social Structure, 1, 2000,
[9] Mao Lin Huang, Information Visualization of Attributed Relational Data. In: ACM Internation Conference Proceedings vol 16. Sydney, Australia 2001.
[12] Patel-Schneider, Peter F., What is OWL (and why should I care)? In: Ninth International Conference on the Principles of Knowledge Representation and Reasoning, Whistler, Canada, June 2004.
[13] Pirolli, P. L.; Card, S. K. Information foraging. Psychological Review. 106 (4): 643-675. 1999
[15] Shneiderman, Ben. Designing the User Interface. Reading, Massachusetts: Addison- Wesley Publishing Company. 1987
30

[17] Smallman, H. S. and Boynton, R. M. Segregation of basic colors in an information Display (1990). Journal of the Optical Society of America, 7(102), 1985-1994.
[19] Tufte, Edward R. Envisioning Information. Cheshire, CT: Graphics Press. 1990
[5] Zou, Finin en Chen, F-OWL: an inference engine for the semantic web, University of Maryland. 2005
31

APPENDIX A: VOORBEELD ONTOLOGIE-INSTANTIE
<?xml version="1.0"?> <rdf:RDF xmlns="http://www.owl-ontologies.com/Ontology1221402220.owl#" xml:base="http://www.owl-ontologies.com/Ontology1221402220.owl" xmlns:xsd="http://www.w3.org/2001/XMLSchema#" xmlns:rdfs="http://www.w3.org/2000/01/rdf-schema#" xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#" xmlns:owl="http://www.w3.org/2002/07/owl#"> <owl:Ontology rdf:about=""/> <owl:Class rdf:ID="Advisor"/> <Financial_Organisation rdf:ID="Bank_Snoras"> <has_manager rdf:resource="#Vladimir_Antonov"/> <has_shareholder rdf:resource="#Vladimir_Antonov"/> </Financial_Organisation> <Company rdf:ID="Cape_NV"/> <owl:Class rdf:ID="Company"/> <Financial_Organisation rdf:ID="Conversbank"> <has_manager rdf:resource="#Vladimir_Antonov"/> <has_shareholder rdf:resource="#Vladimir_Antonov"/> </Financial_Organisation> <Person rdf:ID="Dick_Bosch"/> <owl:Class rdf:ID="Financial_Organisation"/> <Company rdf:ID="Gemini_Investment_Fund_Ltd"/> <owl:ObjectProperty rdf:ID="has_accountant"> <rdfs:domain> <owl:Class> <owl:unionOf rdf:parseType="Collection"> <owl:Class rdf:about="#Advisor"/> <owl:Class rdf:about="#Company"/> <owl:Class rdf:about="#Financial_Organisation"/> </owl:unionOf> </owl:Class> </rdfs:domain> <rdfs:range rdf:resource="#Advisor"/> <rdfs:subPropertyOf rdf:resource="#is_influenced_by"/> </owl:ObjectProperty> <owl:ObjectProperty rdf:ID="has_agent"> <rdfs:domain> <owl:Class> <owl:unionOf rdf:parseType="Collection"> <owl:Class rdf:about="#Advisor"/> <owl:Class rdf:about="#Company"/> <owl:Class rdf:about="#Financial_Organisation"/> </owl:unionOf> </owl:Class> </rdfs:domain> <rdfs:range rdf:resource="#Advisor"/> <rdfs:subPropertyOf rdf:resource="#is_influenced_by"/> </owl:ObjectProperty> <owl:ObjectProperty rdf:ID="has_authorized_legal_entity"> <rdf:type rdf:resource="http://www.w3.org/2002/07/owl#TransitiveProperty"/> <rdfs:domain> <owl:Class>
32

<owl:unionOf rdf:parseType="Collection"> <owl:Class rdf:about="#Advisor"/> <owl:Class rdf:about="#Company"/> <owl:Class rdf:about="#Financial_Organisation"/> </owl:unionOf> </owl:Class> </rdfs:domain> <rdfs:range> <owl:Class> <owl:unionOf rdf:parseType="Collection"> <owl:Class rdf:about="#Company"/> <owl:Class rdf:about="#Person"/> </owl:unionOf> </owl:Class> </rdfs:range> <rdfs:subPropertyOf rdf:resource="#is_influenced_by"/> </owl:ObjectProperty> <owl:ObjectProperty rdf:ID="has_director"> <rdfs:domain> <owl:Class> <owl:unionOf rdf:parseType="Collection"> <owl:Class rdf:about="#Advisor"/> <owl:Class rdf:about="#Company"/> <owl:Class rdf:about="#Financial_Organisation"/> </owl:unionOf> </owl:Class> </rdfs:domain> <rdfs:range rdf:resource="#Person"/> <rdfs:subPropertyOf rdf:resource="#is_influenced_by"/> </owl:ObjectProperty> <owl:ObjectProperty rdf:ID="has_essential_supplier"> <rdf:type rdf:resource="http://www.w3.org/2002/07/owl#TransitiveProperty"/> <rdfs:domain> <owl:Class> <owl:unionOf rdf:parseType="Collection"> <owl:Class rdf:about="#Advisor"/> <owl:Class rdf:about="#Company"/> <owl:Class rdf:about="#Financial_Organisation"/> </owl:unionOf> </owl:Class> </rdfs:domain> <rdfs:range rdf:resource="#Company"/> <rdfs:subPropertyOf rdf:resource="#is_influenced_by"/> </owl:ObjectProperty> <owl:ObjectProperty rdf:ID="has_important_client"> <rdf:type rdf:resource="http://www.w3.org/2002/07/owl#TransitiveProperty"/> <rdfs:domain> <owl:Class> <owl:unionOf rdf:parseType="Collection"> <owl:Class rdf:about="#Advisor"/> <owl:Class rdf:about="#Company"/> <owl:Class rdf:about="#Financial_Organisation"/> </owl:unionOf> </owl:Class> </rdfs:domain>
33

<rdfs:range> <owl:Class> <owl:unionOf rdf:parseType="Collection"> <owl:Class rdf:about="#Company"/> <owl:Class rdf:about="#Person"/> </owl:unionOf> </owl:Class> </rdfs:range> <rdfs:subPropertyOf rdf:resource="#is_influenced_by"/> </owl:ObjectProperty> <owl:ObjectProperty rdf:ID="has_manager"> <rdf:type rdf:resource="http://www.w3.org/2002/07/owl#TransitiveProperty"/> <rdfs:domain> <owl:Class> <owl:unionOf rdf:parseType="Collection"> <owl:Class rdf:about="#Advisor"/> <owl:Class rdf:about="#Company"/> <owl:Class rdf:about="#Financial_Organisation"/> </owl:unionOf> </owl:Class> </rdfs:domain> <rdfs:range rdf:resource="#Person"/> <rdfs:subPropertyOf rdf:resource="#is_influenced_by"/> </owl:ObjectProperty> <owl:ObjectProperty rdf:ID="has_parent_company"> <rdf:type rdf:resource="http://www.w3.org/2002/07/owl#TransitiveProperty"/> <rdfs:domain> <owl:Class> <owl:unionOf rdf:parseType="Collection"> <owl:Class rdf:about="#Advisor"/> <owl:Class rdf:about="#Company"/> <owl:Class rdf:about="#Financial_Organisation"/> </owl:unionOf> </owl:Class> </rdfs:domain> <rdfs:range> <owl:Class> <owl:unionOf rdf:parseType="Collection"> <owl:Class rdf:about="#Advisor"/> <owl:Class rdf:about="#Company"/> <owl:Class rdf:about="#Financial_Organisation"/> <owl:Class rdf:about="#Public_Sector_Organisation"/> </owl:unionOf> </owl:Class> </rdfs:range> <rdfs:subPropertyOf rdf:resource="#is_influenced_by"/> </owl:ObjectProperty> <owl:ObjectProperty rdf:ID="has_pensionfund_with"> <rdfs:domain> <owl:Class> <owl:unionOf rdf:parseType="Collection"> <owl:Class rdf:about="#Advisor"/> <owl:Class rdf:about="#Company"/> <owl:Class rdf:about="#Financial_Organisation"/> </owl:unionOf>
34

</owl:Class> </rdfs:domain> <rdfs:range> <owl:Class> <owl:unionOf rdf:parseType="Collection"> <owl:Class rdf:about="#Company"/> <owl:Class rdf:about="#Financial_Organisation"/> </owl:unionOf> </owl:Class> </rdfs:range> <rdfs:subPropertyOf rdf:resource="#is_influenced_by"/> </owl:ObjectProperty> <owl:ObjectProperty rdf:ID="has_shareholder"> <rdf:type rdf:resource="http://www.w3.org/2002/07/owl#TransitiveProperty"/> <rdfs:domain> <owl:Class> <owl:unionOf rdf:parseType="Collection"> <owl:Class rdf:about="#Advisor"/> <owl:Class rdf:about="#Company"/> <owl:Class rdf:about="#Financial_Organisation"/> </owl:unionOf> </owl:Class> </rdfs:domain> <rdfs:range> <owl:Class> <owl:unionOf rdf:parseType="Collection"> <owl:Class rdf:about="#Company"/> <owl:Class rdf:about="#Financial_Organisation"/> <owl:Class rdf:about="#Person"/> </owl:unionOf> </owl:Class> </rdfs:range> <rdfs:subPropertyOf rdf:resource="#is_influenced_by"/> </owl:ObjectProperty> <owl:ObjectProperty rdf:ID="has_subsidiary"> <rdf:type rdf:resource="http://www.w3.org/2002/07/owl#TransitiveProperty"/> <rdfs:domain> <owl:Class> <owl:unionOf rdf:parseType="Collection"> <owl:Class rdf:about="#Advisor"/> <owl:Class rdf:about="#Company"/> <owl:Class rdf:about="#Financial_Organisation"/> </owl:unionOf> </owl:Class> </rdfs:domain> <rdfs:range> <owl:Class> <owl:unionOf rdf:parseType="Collection"> <owl:Class rdf:about="#Advisor"/> <owl:Class rdf:about="#Company"/> <owl:Class rdf:about="#Financial_Organisation"/> </owl:unionOf> </owl:Class> </rdfs:range> <rdfs:subPropertyOf rdf:resource="#is_influenced_by"/>
35

</owl:ObjectProperty> <owl:ObjectProperty rdf:ID="has_taxadvisor"> <rdfs:domain> <owl:Class> <owl:unionOf rdf:parseType="Collection"> <owl:Class rdf:about="#Advisor"/> <owl:Class rdf:about="#Company"/> <owl:Class rdf:about="#Financial_Organisation"/> </owl:unionOf> </owl:Class> </rdfs:domain> <rdfs:range rdf:resource="#Advisor"/> <rdfs:subPropertyOf rdf:resource="#is_influenced_by"/> </owl:ObjectProperty> <Company rdf:ID="Helvetia_BV"> <has_manager rdf:resource="#Victor_R_Muller"/> <has_manager rdf:resource="#Jan_de_Vries"/> <has_shareholder rdf:resource="#Victor_R_Muller"/> <has_shareholder rdf:resource="#Cape_NV"/> <has_shareholder rdf:resource="#Dick_Bosch"/> <has_important_client rdf:resource="#Landzaat_Group"/> <has_authorized_legal_entity rdf:resource="#Ruben_van_Tam"/> </Company> <owl:ObjectProperty rdf:ID="is_influenced_by"/> <Person rdf:ID="Jan_de_Vries"/> <Person rdf:ID="Klaas_Stuijfzand"/> <Company rdf:ID="Landzaat_Group"/> <owl:ObjectProperty rdf:ID="lends_from"> <rdfs:domain> <owl:Class> <owl:unionOf rdf:parseType="Collection"> <owl:Class rdf:about="#Advisor"/> <owl:Class rdf:about="#Company"/> <owl:Class rdf:about="#Financial_Organisation"/> </owl:unionOf> </owl:Class> </rdfs:domain> <rdfs:range> <owl:Class> <owl:unionOf rdf:parseType="Collection"> <owl:Class rdf:about="#Company"/> <owl:Class rdf:about="#Financial_Organisation"/> <owl:Class rdf:about="#Person"/> </owl:unionOf> </owl:Class> </rdfs:range> <rdfs:subPropertyOf rdf:resource="#is_influenced_by"/> </owl:ObjectProperty> <owl:ObjectProperty rdf:ID="lends_to"> <rdfs:domain> <owl:Class> <owl:unionOf rdf:parseType="Collection"> <owl:Class rdf:about="#Advisor"/> <owl:Class rdf:about="#Company"/> <owl:Class rdf:about="#Financial_Organisation"/>
36

</owl:unionOf> </owl:Class> </rdfs:domain> <rdfs:range> <owl:Class> <owl:unionOf rdf:parseType="Collection"> <owl:Class rdf:about="#Company"/> <owl:Class rdf:about="#Person"/> </owl:unionOf> </owl:Class> </rdfs:range> <rdfs:subPropertyOf rdf:resource="#is_influenced_by"/> </owl:ObjectProperty> <owl:Class rdf:ID="Person"/> <owl:Class rdf:ID="Public_Sector_Organisation"/> <owl:ObjectProperty rdf:ID="rents_from"> <rdfs:domain> <owl:Class> <owl:unionOf rdf:parseType="Collection"> <owl:Class rdf:about="#Advisor"/> <owl:Class rdf:about="#Company"/> <owl:Class rdf:about="#Financial_Organisation"/> </owl:unionOf> </owl:Class> </rdfs:domain> <rdfs:range> <owl:Class> <owl:unionOf rdf:parseType="Collection"> <owl:Class rdf:about="#Company"/> <owl:Class rdf:about="#Person"/> </owl:unionOf> </owl:Class> </rdfs:range> <rdfs:subPropertyOf rdf:resource="#is_influenced_by"/> </owl:ObjectProperty> <Person rdf:ID="Ruben_van_Tam"/> <Company rdf:ID="Spyker_Cars_BV"> <has_director rdf:resource="#Vladimir_Antonov"/> <has_shareholder rdf:resource="#Helvetia_BV"/> <has_shareholder rdf:resource="#Gemini_Investment_Fund_Ltd"/> <has_shareholder rdf:resource="#Bank_Snoras"/> <lends_from rdf:resource="#Bank_Snoras"/> </Company> <Person rdf:ID="Victor_R_Muller"/> <Person rdf:ID="Vladimir_Antonov"/> </rdf:RDF>
37
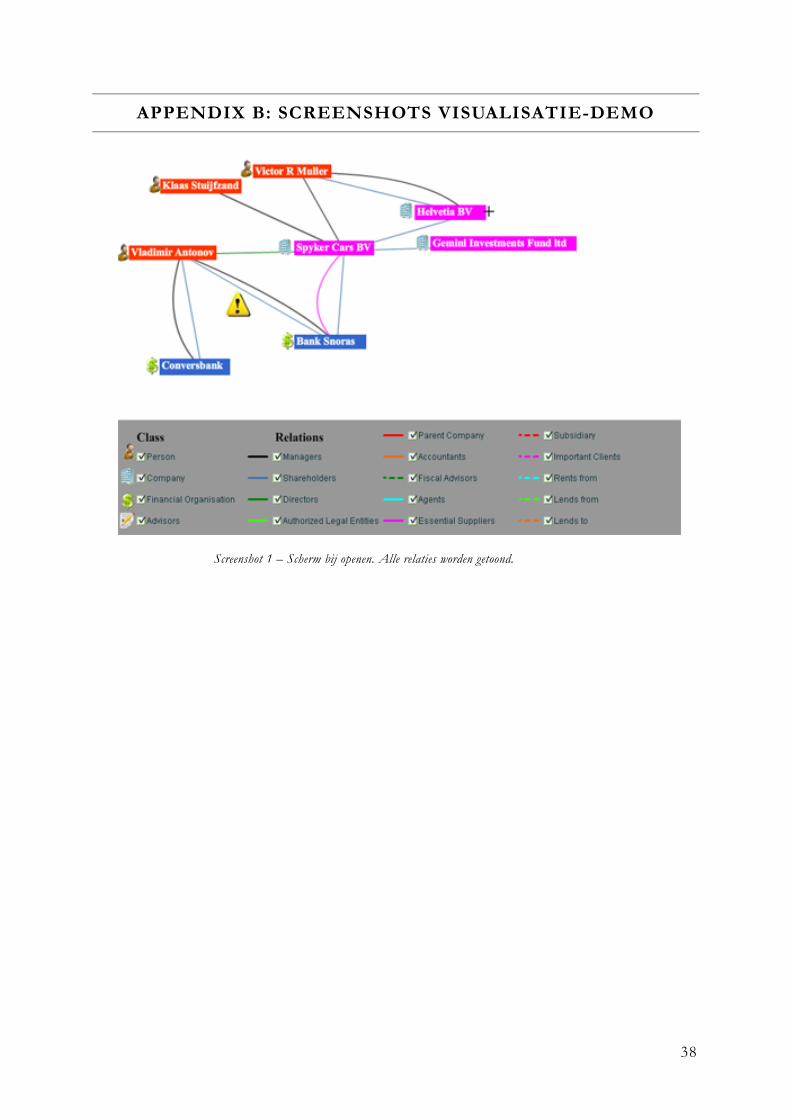
APPENDIX B: SCREENSHOTS VISUALISATIE-DEMO
Screenshot 1 – Scherm bij openen. Alle relaties worden getoond.
38
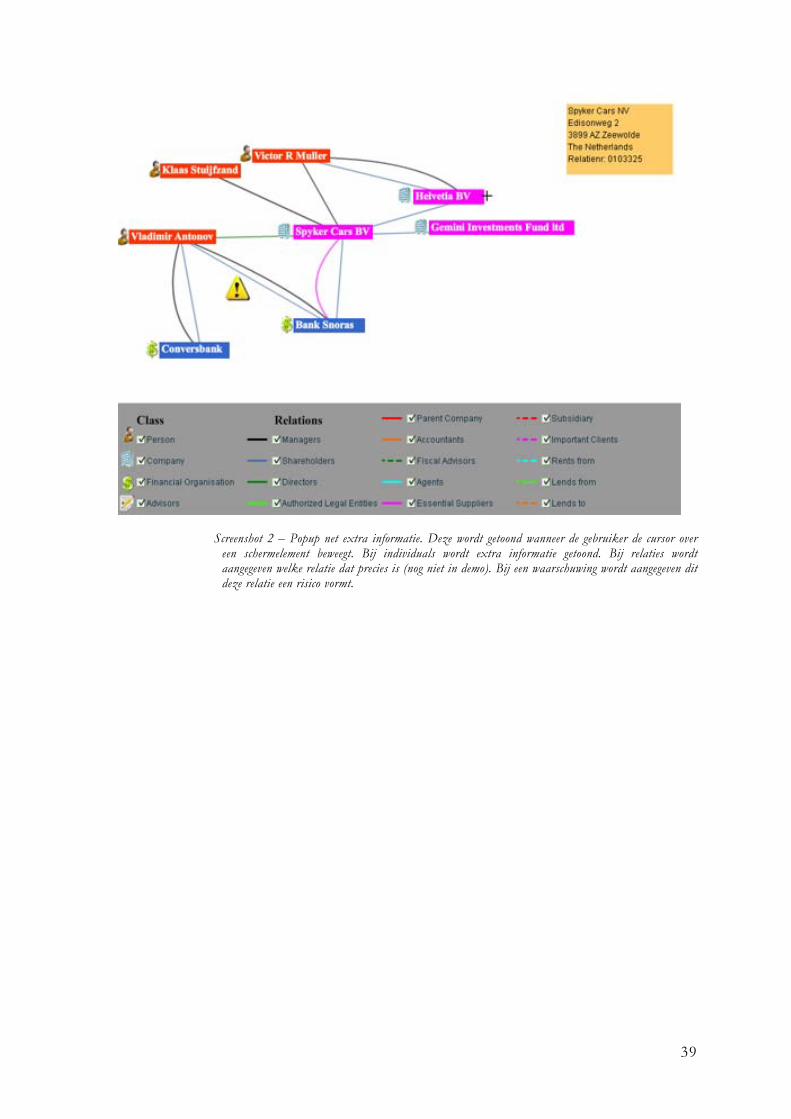
Screenshot 2 – Popup net extra informatie. Deze wordt getoond wanneer de gebruiker de cursor over een schermelement beweegt. Bij individuals wordt extra informatie getoond. Bij relaties wordt aangegeven welke relatie dat precies is (nog niet in demo). Bij een waarschuwing wordt aangegeven dit deze relatie een risico vormt.
39
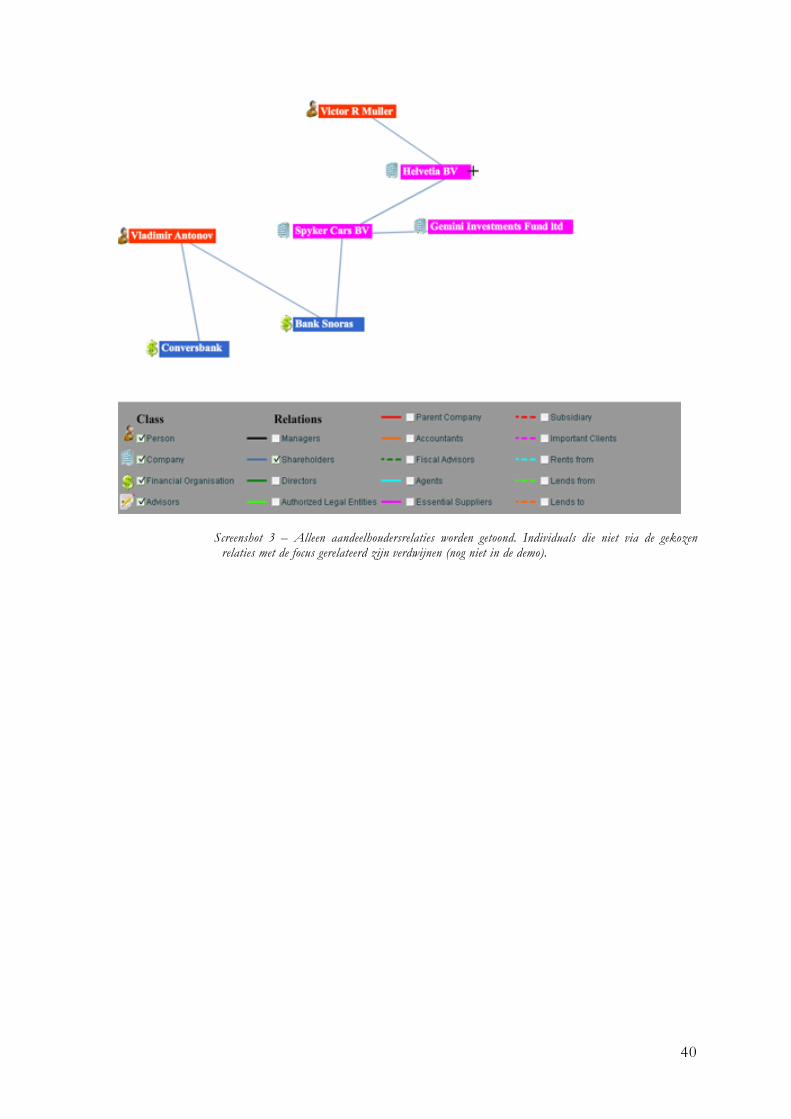
Screenshot 3 – Alleen aandeelhoudersrelaties worden getoond. Individuals die niet via de gekozen relaties met de focus gerelateerd zijn verdwijnen (nog niet in de demo).
40
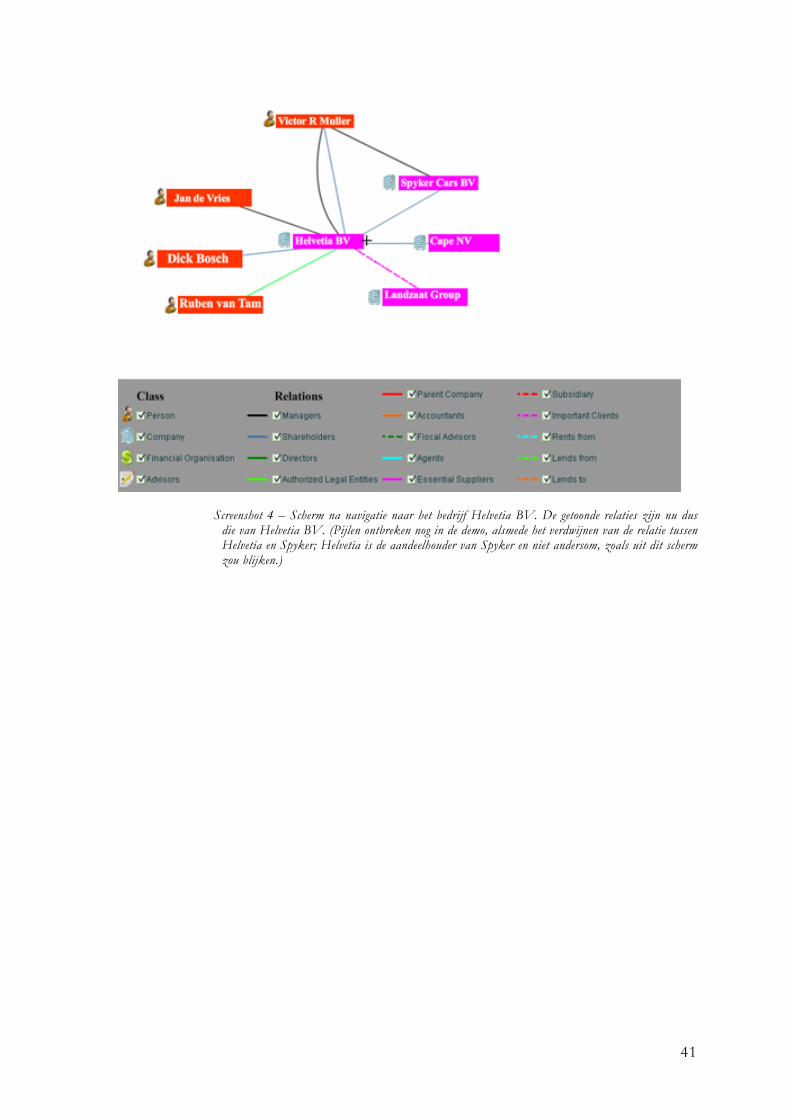
Screenshot 4 – Scherm na navigatie naar het bedrijf Helvetia BV. De getoonde relaties zijn nu dus die van Helvetia BV. (Pijlen ontbreken nog in de demo, alsmede het verdwijnen van de relatie tussen Helvetia en Spyker; Helvetia is de aandeelhouder van Spyker en niet andersom, zoals uit dit scherm zou blijken.)
41


















