
Amerikaanse handboeken boekhouden uit de 20 eeuw: een...
53
UNIVERSITEIT GENT FACULTEIT ECONOMIE EN BEDRIJFSKUNDE ACADEMIEJAAR 2008 – 2009 Amerikaanse handboeken boekhouden uit de 20 ste eeuw: een taalkundige studie van de complexiteit Masterproef voorgedragen tot het bekomen van de graad van Master in de bedrijfseconomie Katrien Persoons onder leiding van Prof. Ignace De Beelde + Prof. Anne-Marie Vandenbergen
-
Upload
duongkhanh -
Category
Documents
-
view
213 -
download
0
Transcript of Amerikaanse handboeken boekhouden uit de 20 eeuw: een...

UNIVERSITEIT GENT
FACULTEIT ECONOMIE EN BEDRIJFSKUNDE
ACADEMIEJAAR 2008 – 2009
Amerikaanse handboeken boekhouden uit de 20
ste eeuw: een taalkundige studie van de complexiteit
Masterproef voorgedragen tot het bekomen van de graad van
Master in de bedrijfseconomie
Katrien Persoons
onder leiding van
Prof. Ignace De Beelde + Prof. Anne-Marie Vandenbergen


UNIVERSITEIT GENT
FACULTEIT ECONOMIE EN BEDRIJFSKUNDE
ACADEMIEJAAR 2008 – 2009
Amerikaanse handboeken boekhouden uit de 20
ste eeuw: een taalkundige studie van de complexiteit
Masterproef voorgedragen tot het bekomen van de graad van
Master in de bedrijfseconomie
Katrien Persoons
onder leiding van
Prof. Ignace De Beelde + Prof. Anne-Marie Vandenbergen

Vertrouwelijkheidsclausule
PERMISSION Ondergetekende verklaart dat de inhoud van deze masterproef mag geraadpleegd en/of
gereproduceerd worden, mits bronvermelding.
Katrien Persoons

I
Woord vooraf
Vooraleer het eigenlijke onderzoek aan te vatten zal ik jullie geduld nog even op de proef stellen
door kort de mensen en instituten te bedanken die bijgedragen hebben tot de verwezenlijking van
dit werkstuk. Vooreerst wil ik mijn beide promotoren bedanken omdat ze het mij mogelijk gemaakt
hebben een vakoverschrijdend onderwerp te kiezen dat een interessante combinatie is van mijn
vorige en huidige studie. Verder gaat mijn appreciatie uit naar mijn familie en vrienden voor de
morele steun, en naar Dr. Bart Larivière voor het bijbrengen van de nodige SPSS-kennis. Tot slot zou
ik ook Google en de Universiteit van Michigan willen vermelden voor het inscannen en ter
beschikking stellen van vijf van de tien handboeken, waardoor mij heel wat bezoeken aan de
bibliotheek bespaard bleven.

II
Inhoudsopgave
1 Inleiding 1
2 Theoretische achtergrond 3
2.1 Complexiteit 3
2.2 Systemisch-Functionele Grammatica 6
3 Onderzoeksopzet 8
3.1 Onderzoeksvraag en hypothese 8
3.2 Fragmenten 9
3.3 Analyse 10
4 Experiëntiële Metafunctie 11
4.1 Zinslengte 11
4.2 Lexicale densiteit 14
4.3 Nominalisatie 19
5 Tekstuele Metafunctie 23
5.1 Conjuncties 23
5.2 Bladspiegel 25
6 Interpersoonlijke Metafunctie 28
7 Algemeen Besluit 34
8 Lijst van geraadpleegde werken IV
8.1 Primaire Literatuur IV
8.2 Secundaire Literatuur IV
9 Bijlagen

III
Lijst van tabellen
Tabel 1: Gemiddeld aantal woorden per zin 12
Tabel 2: Percentage korte zinnen per fragment 13
Tabel 3: Percentage lange zinnen per fragment 14
Tabel 4: Lexicale densiteit per fragment 17
Tabel 5: Type/Token ratio: lexicale densiteit 18
Tabel 6: Aantal nominalisaties per fragment 21
Tabel 7: Type/Token ratio: nominalisatie 22
Tabel 8: Aantal conjuncties per fragment 24
Tabel 9: Soorten conjuncties 25
Tabel 10: Gemiddeld aantal woorden per pagina 26
Tabel 11: Gemiddelde paragraaflengte (# woorden/paragraaf) 27
Tabel 12: (Herleid) aantal persoonlijke voornaamwoorden per fragment 29

1
1 Inleiding
De taal gebruikt in accountinghandboeken is sinds een 25-tal jaar een bron van ongerustheid bij
accountants. Een te hoge moeilijkheidsgraad kan immers belangrijke gevolgen hebben voor degenen
die zich deze discipline eigen willen maken (Adelberg & Razek 1984). Studenten kunnen bijvoorbeeld
gefrustreerd geraken doordat ze proportioneel gezien te veel tijd besteden aan het begrijpen van de
informatie, hetgeen dan weer kan leiden tot de ontwikkeling van een negatieve houding ten opzichte
van de materie. Wanneer het om inleidende handboeken gaat, die de studenten een eerste
kennismaking met het onderwerp boekhouden bieden, kan dit tot gevolg hebben dat ze zich er niet
verder in specialiseren of veranderen van studierichting1. Bovendien zijn de leerkrachten in een
dergelijke situatie bijna verplicht om meer tijd te spenderen aan het verduidelijken van wat er in de
handboeken staat, waardoor er minder uren overblijven om informatie bij te brengen die de
handboeken aanvult. Dit zou dan weer tot slechtere examenresultaten kunnen leiden. Tot slot zou
een te complex taalgebruik studenten kunnen ontmoedigen om het boekhoudproces grondig te
begrijpen. Men probeert de tekst uit het hoofd te leren zonder inzicht te hebben in waarom
bepaalde handelingen gesteld worden.
De bezorgdheid dat de taal gebruikt in accountinghandboeken te complex was heeft er volgens
Davidson (2005) in de Verenigde Staten toe geleid dat men deze handboeken in de twintigste eeuw
herzien heeft. Op die manier moesten ze toegankelijker worden voor studenten, zowel wat
woordenschat als grammatica betreft. Hoewel dit enerzijds als een positieve evolutie kan beschouwd
worden, heeft Davidson (2005) er toch zijn bedenkingen bij. Deze aanpassingen gingen volgens hem
immers gepaard met een achteruitgang in het lees- en verbale vermogen van de studenten. Het is
onduidelijk welke evolutie het eerst plaatsvond, maar Davidson (2005) speculeert dat de
handboeken werden aangepast aan het niveau van de studenten, en niet omgekeerd. Hij
argumenteert bovendien dat als een uiteenzetting een te lage moeilijkheidsgraad heeft, de
studenten naderhand minder vertrouwd zijn met technische termen en abstracte redeneringen,
hetgeen later problemen kan veroorzaken. Volgens hem is het ook onmogelijk complex materiaal
over te brengen in een vereenvoudigde taal, en zullen studenten later zelf deze vereenvoudigde stijl
hanteren omdat het hen zo aangeleerd is. Chiang, Englebrecht, Phillips & Wang (2008) voegen eraan
toe het leren omgaan met complexe problemen onontbeerlijk is voor studenten.
1 Geiger & Ogilby (2000) geven echter wel aan dat deze beslissing ook afhangt van de leerkracht en hoe nuttig
en interessant men het onderwerp vindt.

2
Davidson (2005) maakte in zijn studie van twintigste-eeuwse accountinghandboeken gebruik van
klassieke leesbaarheidsformules om de gemiddelde woordlengte, zinslengte, lengte van de
paragrafen, complexiteit van de zinnen, etc. te berekenen. Het probleem is echter dat deze
meetinstrumenten en variabelen reeds lang bekritiseerd zijn, waardoor de resultaten van zijn
onderzoek eveneens in vraag kunnen gesteld worden. Om deze redenen werd er in de huidige studie
dan ook voor geopteerd het onderzoek te herhalen met meetinstrumenten die gekaderd worden
binnen Hallidays Systemisch-Functionele Grammatica. Er werden echter uitsluitend inleidende
handboeken behandeld, en dus geen geavanceerde of handboeken van tussenniveau. Ook bleef het
aantal handboeken beperkt tot tien (vijf uit het begin en vijf uit het einde van de twintigste eeuw). Er
werd onderzocht of de complexiteit van de daarin gebruikte taal inderdaad is verminderd, en dit aan
de hand van zes variabelen: gemiddelde zinslengte (met de subvariabelen aantal lange en korte
zinnen), lexicale densiteit, nominalisaties, conjuncties, bladspiegel en aanspreking van de lezer.
Aangezien de analyse betrekking heeft op de leesbaarheid van de teksten worden enkel tekstuele
kenmerken behandeld, en dus geen persoonlijke kenmerken van de lezer. Schema’s, grafieken,
diagrammen, etc. worden eveneens buiten beschouwing gelaten.
Het onderzoek is als volgt opgebouwd: Eerst zal verduidelijkt worden waarom de klassieke
meetinstrumenten bekritiseerd worden, en waarom Systemisch-Functionele Grammatica uitgekozen
werd als nieuw referentiekader. Nadien wordt de eigenlijke analyse, die zowel kwantitatief als
kwalitatief zal zijn, verduidelijkt. Volgens Hallidays recept vindt de analyse plaats op drie niveaus:
experiëntieel, tekstueel en interpersoonlijk. Per niveau worden de fragmenten onderzocht op de
relevante variabelen, waarna in een algemene conclusie zal worden samengevat hoe de bevindingen
zich verhouden tot Davidsons studie en waar er nog werkpunten liggen voor latere analyses.

3
2 Theoretische achtergrond
2.1 Complexiteit
Om te kunnen achterhalen of de complexiteit van bepaalde teksten verschilt, is het uiteraard nodig
te weten welke elementen de complexiteit van een tekst beïnvloeden. Het feit dat hierover geen
eensgezindheid bestaat onder wetenschappers duidt reeds aan dat we te maken hebben met een
ingewikkelde materie. Davidson (2005) stelt dat er ten minste drie grote componenten zijn die de
complexiteit van een tekst mee bepalen, namelijk de syntactische , semantische en lexicale. Ondanks
de problemen die het definiëren van de complexiteit van een tekst met zich meebrengt, is het aantal
instrumenten dat ontwikkeld werd om deze complexiteit te meten relatief beperkt. Strikt genomen
kunnen deze meetinstrumenten opgedeeld worden in twee groepen, namelijk de
leesbaarheidsformules enerzijds en de Cloze-procedure anderzijds.
Leesbaarheidsformules benaderen de problematiek op een kwantitatieve manier. Davison & Green
(1988: 1):
“Research began in the 1920s on the problem of how language is processed and effectively
comprehended. Rather than build psychological models of language comprehension,
researchers instead looked for statistical correlations between objectively observable
features of texts and the reading level of readers, as measured by standardized tests. This
research led to a number of readability formulas *…+.”
Deze formules2 meten meestal de gemiddelde zinslengte en de complexiteit van de daarin gebruikte
woorden. Men meent namelijk dat de lengte van de zinnen gerelateerd is met het herinneren en
opslaan van woorden in het kortetermijngeheugen. De moeilijkheid van de woorden - uitgedrukt in
lengte in aantal lettergrepen of letters en hoe frequent de woorden voorkomen in het normale
taalgebruik– zou dan weer verband houden met de snelheid van herkenning van het woord en
herinnering van de betekenis. Het gewogen gemiddelde van deze resultaten leidt dan tot een totale
score per tekst die geldt voor de gemiddelde lezer (Bruce & Rubin 1988).
Uit deze korte omschrijving blijkt dat deze leesbaarheidsformules relatief snel en gemakkelijk te
hanteren zijn. Daarom worden ze ook veelvuldig gebruikt om de complexiteit van teksten te ‘meten’.
2 Klare (2000) schat dat er 31 leesbaarheidsformules zijn met hun varianten, waaronder de Flesch Reading Ease
formule, Dale-Chall en Gunnings Fog Index.

4
Daarnaast hebben ze echter ook belangrijke nadelen. Eerst en vooral zijn ze te eenvoudig, aangezien
ze bijlange niet alle factoren meten die de verstaanbaarheid van een tekst beïnvloeden. Zo worden
de schrijfstijl en de organisatie van de tekst buiten beschouwing gelaten (Anderson & Davison 1988).
Daarenboven hangt de moeilijkheid ook af van de kenmerken van de lezer, en niet louter van die van
de tekst (Davison & Green 1988, Bruce & Rubin 1988). Tot slot beweert Selzer (1981) dat
leesbaarheidsformules oorspronkelijke bedoeld waren om auteurs van leerboeken te helpen deze
aan te passen aan het leesniveau van de kinderen die ze zouden gebruiken. Hoe nuttig ze zijn voor
het beoordelen van boeken voor volwassenen zou twijfelachtig zijn en het resultaat zelfs misleidend.
Daarbij komt nog dat men zich de vraag kan stellen of langere woorden en zinnen wel degelijk
complexer zijn dan kortere. Anderson & Davison (1988) merken bijvoorbeeld op dat de meerderheid
van de lange woorden samengestelde woorden en afgeleide woorden zijn. Hun betekenis is dan vaak
op te maken uit de samenstellende delen (cf. bijvoorbeeld unladylike, girlish, helplessness), waardoor
de woordlengte geen oorzaak van moeilijkheid is voor de meeste lezers3. Hetzelfde geldt voor lange
zinnen. Deze bestaan meestal uit twee of meer kortere zinnen die verbonden worden door een
voegwoord. Deze verbindingselementen maken duidelijk wat het verband is tussen de kortere zinnen
en vereenvoudigen bijgevolg de verstaanbaarheid, ook al verlengen ze de zin. Wanneer diezelfde
lange zin vervangen zou worden door een aantal korte zinnen zonder voegwoord, kan het zijn dat het
verband ertussen moeilijk af te leiden is. Op deze manier gezien is een lange zin vaak gemakkelijker
te begrijpen dan een aantal kortere. Ter illustratie volgt een voorbeeld uit één van de onderzochte
handboeken:
(1) “Before a firm can earn a return on capital (as measured by accounting profits), it must
recover all costs.” (Stickney & Weil 1997: 462)
Wanneer (1) zou vervangen door twee korte zinnen zonder voegwoord, zou het veel minder duidelijk
zijn wat men precies bedoelt:
(2) A firm can earn a return on capital (as measured by accounting profits). It must recover all
costs.
Er zijn immers verschillende manieren waarop je deze zinnen met elkaar zou kunnen verbinden (zoals
bijvoorbeeld door middel van because, unless of even if), zeker als je niet vertrouwd bent met deze
materie. Desondanks zal (2) een hogere leesbaarheidsscore behalen dan (1).
3 Tenzij voor die lezers die problemen hebben met het decoderen van woorden in basiswoord, prefix, suffix,
etc.

5
Anderson & Davison (1988) en Selzer (1981) wijzen bovendien op het belang van het woord
“correlatie” in bovenstaande quote van Davison & Green (cf. supra p.3). De formules houden dus niet
in dat de zinslengte en woordlengte complexiteit veroorzaken. Wanneer men een tekst aanpast door
de zinnen in te korten en kortere en vaker voorkomende woorden te gebruiken, verbetert de
leesbaarheid volgens de formule wel, maar men stelt dikwijls vast dat dit niet hetzelfde effect heeft
op de lezer.
Naast de leesbaarheidsformules is ook de Cloze-methode een vaak gehanteerd systeem om de
complexiteit te meten. Deze methode houdt in dat men een aantal woorden weglaat uit de tekst
(meestal elk vijfde woord), om deze opnieuw te laten invullen. Naargelang het woord dat weggelaten
wordt zal men de verstaanbaarheid van de semantische of syntactische aspecten van de betekenis
meten, zodat beide componenten getest worden (Adelberg & Razek 1984). Een maatstaf voor de
leesbaarheid van de tekst wordt dan afgeleid van het percentage correct ingevulde woorden. De
norm hierbij is 57%. Met andere woorden, als de proefpersoon 57% van de weggelaten woorden
correct invult, zal deze persoon erin slagen zonder hulp 90% van de tekst verstaan (Stevens, Stevens
& Stevens 1992). De voordelen van deze methode zijn eveneens haar eenvoud en het feit dat ze
rekening houdt met de kenmerken van de lezer. Men kan de in te vullen woorden immers deels
afleiden uit de context, maar men heeft daarnaast ook al enige voorkennis nodig. Tot slot is de Cloze-
procedure meer aangepast aan het doelpubliek (in plaats van aan “de gemiddelde lezer” in de
leesbaarheidsformules).
Ook deze meettechniek heeft al wat tegenkanting ondergaan, zij het in mindere mate dan de
leesbaarheidsformules. Zo vinden sommigen dat het herstellen van een verminkte tekst een totaal
andere opgave is dan het proberen begrijpen van diezelfde tekst. Anderen vinden dan weer dat het
onduidelijk is wat men juist meet aan de hand van een Cloze-test. Wanneer een lidwoord of een
ander functiewoord wordt weggelaten, kan men dit met een elementaire kennis van de taal afleiden
uit de context. Een belangrijk inhoudswoord daarentegen kan bijna enkel door specialisten ‘geraden’
worden (Boogaerd 1997).
Leesbaarheidsformules en de Cloze-procedure worden vaak als alternatieven gezien voor het
analyseren van de moeilijkheidsgraad van teksten, maar strikt genomen meten ze beiden iets anders.
De leesbaarheidsformules beperken zich tot tekstuele kenmerken, terwijl de Cloze-methode ook
rekening houdt met de persoonlijke kenmerken – in het bijzonder voorkennis - van de lezer.
Wetenschappers maken hierbij dan ook het onderscheid tussen leesbaarheid (“readability”) en
verstaanbaarheid (“understandability”). Zoals Davidson (2005) en Chiang et al. (2008) aangeven

6
verwijst de term leesbaarheid louter naar de kenmerken van de tekst. Deze is dus constant voor alle
lezers. Verstaanbaarheid ontstaat dan weer als gevolg van de interactie tussen tekst, taak en lezer.
De inhoud van deze thesis zal zich beperken tot de kenmerken van de tekst – juist omdat deze
identiek is voor alle lezers-, en er zal dus getracht worden de leesbaarheid van de betrokken teksten
te vergelijken. Omwille van de nadelen van de leesbaarheidsformules zullen deze echter niet
aangewend worden. Vele wetenschappers hebben deze problemen reeds aan de kaak gesteld, maar
tot op heden is er geen aanvaardbaar alternatief voorgesteld dat beter voor de dag komt (Anderson
& Davison 1988). In deze thesis werd er dan ook voor geopteerd de problematiek op een andere
manier te benaderen, meer bepaald via de Systemisch-Functionele Grammatica van Halliday. Deze
theorie zal kort worden behandeld in de volgende paragrafen.
2.2 Systemisch-Functionele Grammatica
In Systemisch-Functionele Grammatica wordt taal niet louter gezien als een mechanisme om
gedachten of een deel van de werkelijkheid over te brengen, maar als iets dat zelf betekenis creëert:
“It is simultaneously a part of reality, a shaper of reality, and a metaphor for reality” (Halliday 1993:
84). Naargelang de omstandigheden zal men dus keuzes maken in het soort taal dat men gebruikt.
Dat is dan ook de reden waarom teksten geproduceerd in verschillende contexten andere
kenmerken vertonen en andere functies realiseren. De taal gebruikt in accountinghandboeken, met
als doel het overbrengen van boekhoudkundige informatie, zal in deze optiek verschillend zijn van
andere genres. Het unieke lexicon, en de unieke grammatica en structuur van het genre maken het
voor de gebruiker gemakkelijker om kennis over te brengen en een bepaalde argumentatie te
ontwikkelen, iets wat niet mogelijk is via het dagelijkse taalgebruik (Fang 2004). Dit voordeel heeft
echter ook een prijs, want tegelijkertijd maakt dit de variëteit abstracter, technischer en compacter,
zodat ze moeilijker verstaanbaar wordt voor de lezer dan zijn alledaagse taal. Dit betekent echter
niet dat academisch taalgebruik niet toegankelijker kan gemaakt worden voor de lezer, maar de
auteur van academische werken kan nooit de conventies verlaten omdat deze een bepaalde functie
hebben (Schleppegrell 2001). Je kan dus niet zomaar accountinghandboeken schrijven in dezelfde
variëteit als deze die je in de plaatselijke supermarkt hanteert.
Halliday argumenteert verder nog dat een taalgebruiker om een bepaalde betekenis te genereren
keuzes moet maken op drie verschillende niveaus, die hij “metafuncties” noemt. Op het
experiëntiële niveau gebruikt de mens taal om te praten over de wereld, zowel extern (met

7
betrekking tot gebeurtenissen, toestanden, dingen, kwaliteiten), als intern (zoals gevoelens,
gedachten, emoties). Op het tekstuele niveau organiseert men de boodschap op zo’n manier dat het
duidelijk wordt hoe deze past binnen de boodschappen errond én in de bredere context. Op het
interpersoonlijke niveau ten slotte gebruikt men taal om te communiceren met anderen en
bijvoorbeeld hun gedrag te beïnvloeden en gedachten uit te wisselen (in Thompson 1996). In feite is
er ook nog een vierde, logische, metafunctie, die te maken heeft met de connecties tussen
boodschappen en de manier waarop men deze signaleert. Al deze metafuncties dragen volgens
Halliday evenveel bij tot de betekenis van de hele boodschap. De lezer moet dus deze drie niveaus
begrijpen om de volledige inhoud te doorgronden. De uiteindelijke boodschap is dan het resultaat
van een keuze die de spreker of schrijver onbewust maakt in elk van deze metafuncties.

8
3 Onderzoeksopzet
3.1 Onderzoeksvraag en hypothese
De vraag die dit onderzoek zal trachten te beantwoorden is de volgende: Is de complexiteit van de
taal gebruikt in accountinghandboeken uit het begin van de twintigste eeuw groter dan deze van de
handboeken uit het einde van de twintigste eeuw? Wanneer deze problematiek vertaald wordt naar
Hallidays Systemisch-Functionele Grammatica luidt de vraag als volgt: Bevorderen de auteurs aan het
eind van de twintigste eeuw - binnen de conventies van het accountinggenre - de toegankelijkheid
van hun teksten meer dan hun collega’s een kleine eeuw vroeger?
Ondanks het feit dat er hier andere meetinstrumenten gebruikt worden, wordt er toch van uit
gegaan dat de resultaten gelijkaardig zullen zijn aan deze van vroeger onderzoek. Het probleem is
echter dat deze onderzoeken niet zo talrijk zijn en niet altijd betrekking hebben op hetzelfde soort
handboeken of dezelfde periode. Indien dit wel zo is spreken de resultaten elkaar vaak tegen,
misschien ook omdat ze niet allemaal dezelfde leesbaarheidsformule hanteren (Davidson 2005: 8).
Het is dus moeilijk op deze manier een eenduidige hypothese te formuleren.
Davidsons (2005) analyse van inleidende accountinghandboeken (naast gevorderde handboeken en
boeken op tussenniveau) had als resultaat dat de grammaticale complexiteit gedurende de twintigste
eeuw langzaam verminderde, maar dat de complexiteit van de woordenschat juist toenam. Traugh et
al. (in Chiang et al. 2008) ontdekten dan weer geen verschil in het leesbaarheidsniveau van
accountinghandboeken voor beginners tussen 1957 en 1986. Hayes, Wolfer & Wolfe (in Davidson
2005) concludeerden op basis van hun onderzoek dat het aantal gebruikte verschillende woorden, de
gemiddelde zins- en woordlengte, en het gebruik van ongewone woorden significant daalde tussen
1919 en 1991 in Amerikaanse handboeken accounting.
Bovenstaande informatie leidt tot de hypothese dat de syntactische elementen die onderzocht
worden aan complexiteit zullen inboeten. Het woordenschatniveau zal dezelfde beweging maken als
we Hayes et al. (in Davidson 2005) geloven, maar de omgekeerde volgens Davidson (2005).

9
3.2 Fragmenten
Wat de selectie van de te onderzoeken materie betreft werd er geopteerd voor een corpus van tien
tekstfragmenten afkomstig uit eenzelfde aantal accountinghandboeken. Vijf van deze werken
werden gepubliceerd in het begin van de twintigste eeuw (meer bepaald tussen 1908 en 1917), de
vijf andere op het einde van de twintigste eeuw (tussen 1992 en 1997). De handboeken uit de oudste
en deze uit de nieuwste periode zullen tegen elkaar worden afgewogen. Bij de selectie van de
handboeken werd er zoveel mogelijk gezocht naar een vergelijkbare basis. Zo zijn de gekozen
handboeken allemaal Amerikaans, zodat de verschillen die eventueel vastgesteld worden niet te
wijten zijn aan de variant van het Engels die de auteurs gebruiken. Het gaat daarbij ook uitsluitend
om inleidende handboeken, en dus geen gevorderde of boeken op tussenniveau, aangezien
Davidsons studie (2005) een verschillende evolutie vaststelt wat deze drie niveaus betreft. Tot slot
werd zoveel mogelijk getracht fragmenten met een gelijkaardige inhoud te bespreken. Dit is echter
niet zo eenvoudig als het lijkt.
Sullivan & Benke (1997) beweren dat er drie mogelijke manieren zijn om deze fragmenten te
selecteren. Een eerste optie is willekeurig een aantal pagina’s uit elk handboek te kiezen. Deze wordt
door hen verworpen omdat de delen zo verschillend kunnen zijn dat ze nog moeilijk kunnen
vergeleken worden. Een tweede mogelijkheid bestaat erin passages te selecteren die hetzelfde
beschrijven. Sullivan & Benke (1997) verwerpen dit alternatief eveneens omdat de handboeken
dezelfde materie op zo’n verschillende manier aanpakken dat er opnieuw weinig basis voor vergelijk
is. Om die reden opteren zij ervoor hele hoofdstukken te vergelijken die hetzelfde of gelijkaardig
materiaal bevatten.
De ervaring leert echter dat het boekhouden zo’n uitgebreide discipline is dat veel auteurs hun
werken op een andere manier indelen. Hierdoor is het zelden zo dat hoofdstukken exact hetzelfde
materiaal bevatten. Bovendien zijn er wel degelijk thema’s die op een gelijkaardige manier benaderd
worden. Dit is bijvoorbeeld het geval bij “afschrijvingen”, en dit werd hier dan ook gekozen als
gemeenschappelijk thema. Wat de lengte van de fragmenten betreft werd er voor geopteerd om
telkens de eerste drie pagina’s van het deel van het hoofdstuk dat afschrijvingen behandelt te
analyseren. Dit heeft als voordeel dat de selectie qua lengte van de fragmenten zeer vlot verloopt.
Nadeel is wel dat de lengte van de fragmenten in woorden nogal kan verschillen4. Dit aspect vormt
echter een wezenlijk deel van de leesbaarheid en complexiteit van de tekst (hoe compact staat alles
4 Het langste fragment dat hier behandeld wordt heeft bijvoorbeeld een lengte van 1263 woorden, terwijl het
kortste fragment slechts 666 woorden bevat.

10
op elkaar?), zodat het nuttig is er eveneens rekening mee te houden. Aangaande de eigenlijke
analyse dient nog opgemerkt te worden dat zinnen die niet eindigen op de derde pagina van het
hoofdstuk maar doorlopen tot het begin van de vierde pagina niet in rekening worden gebracht. Dit
is het geval bij de handboeken van Danos & Imhoff (1994), Meigs & Meigs (1992), Hatfield (1909),
Gilman (1916), Racine (1913) en Mitchell (1917). Voetnoten en woorden die voorkomen in tabellen
en balansen worden eveneens buiten beschouwing gelaten.
3.3 Analyse
Voor de analyse van de gekozen fragmenten wordt er verder gewerkt met de drie functionele
niveaus van betekenis die Halliday onderscheidt. Wat het experiëntiële niveau betreft worden de
fragmenten onderzocht op zinslengte, lexicale dichtheid en nominalisaties. Op tekstueel vlak
bestuderen we de aanwezigheid van conjuncties en de bladspiegel. De analyse van de persoonlijke
voornaamwoorden is dan weer verbonden met het interpersoonlijke niveau. De resultaten van het
onderzoek zullen zowel kwantitatief als kwalitatief besproken worden. In wat volgt zal ook worden
verduidelijkt wat het verband is tussen deze variabelen, de metafuncties waartoe ze behoren en de
complexiteit van de gekozen fragmenten.
Het is duidelijk dat deze bespreking taalkundig van aard zal zijn. Handboeken accounting bestaan
naast tekst echter ook uit balansen, T-rekeningen, enz. Deze elementen kunnen geanalyseerd
worden volgens de zogeheten multimodal discourse analysis, maar zullen hier buiten beschouwing
worden gelaten.
Waarom is dit nu een betere methode dan de klassieke leesbaarheidsformules? Ten eerste wordt er
met veel meer variabelen gewerkt dan enkel zinslengte en moeilijkheid van de woorden. Ten tweede
zullen de kwantitatieve benadering van de leesbaarheidsformules aangevuld worden met een
kwalitatieve analyse. Uiteraard heeft ook deze benadering zijn nadelen. Deze komen aan bod in de
conclusie van deze thesis.

11
4 Experiëntiële Metafunctie
Het eerste niveau van betekenis dat hier zal behandeld worden is het experiëntiële niveau. Zoals de
term aangeeft gebruikt men taal om te praten over ervaringen die men heeft in de buitenwereld.
Naargelang de manier waarop deze ervaringen geformuleerd worden zal het gemakkelijker of juist
moeilijker zijn voor de toehoorder om te begrijpen wat men precies wil zeggen. In dit kader zal voor
de betrokken fragmenten nagegaan worden hoe lang de gebruikte zinnen gemiddeld zijn en hoeveel
(verschillende) lexicale items en nominalisaties ze bevatten.
4.1 Zinslengte
Zoals reeds gezegd bij de bespreking van de leesbaarheidsformules wordt de lengte van de zinnen
gemeten omdat men veronderstelt dat deze correleert met de hoeveelheid informatie die men
vasthoudt in het kortetermijngeheugen. Ook al werd vooraf kritiek geuit op het nut van het meten
van deze variabele (cf. supra p. 3-5), toch heeft het berekenen van de zinslengte ook zijn plaats in
deze bespreking. Deze variabele maakt immers een wezenlijk deel uit van de experiëntiële
metafunctie, zij het op een indirecte manier. Hoeveel woorden een zin bevat hangt immers samen
met het aantal delen waaruit de zin bestaat. Het aantal zinsdelen maakt op zijn beurt deel uit van de
logische metafunctie, die samen met de experiëntiële metafunctie de ideationele metafunctie vormt.
Een andere reden die de aanwezigheid van deze variabele rechtvaardigt is dat in wat volgt eveneens
de voegwoorden zullen behandeld worden. Het resultaat van deze analyse kan dan gebruikt worden
om de resultaten van de analyse van de zinslengte te verfijnen. Simplistisch uitgedrukt: Hoe langer de
zinnen, hoe moeilijker voor de lezer. Hoe meer voegwoorden, hoe gemakkelijker. Op deze manier
kunnen de bedenkingen bij dit meetinstrument deels opgeborgen worden.
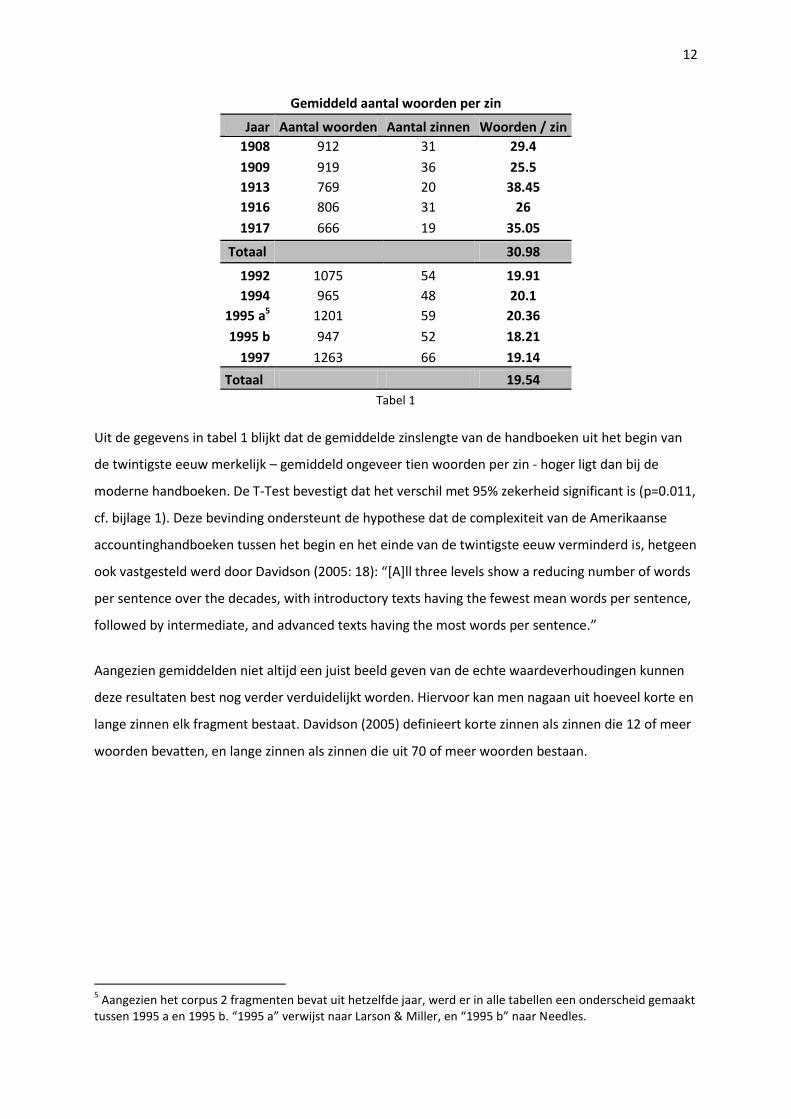
12
Gemiddeld aantal woorden per zin
Jaar Aantal woorden Aantal zinnen Woorden / zin
1908 912 31 29.4
1909 919 36 25.5
1913 769 20 38.45
1916 806 31 26
1917 666 19 35.05
Totaal
30.98
1992 1075 54 19.91
1994 965 48 20.1
1995 a5 1201 59 20.36
1995 b 947 52 18.21
1997 1263 66 19.14
Totaal 19.54
Tabel 1
Uit de gegevens in tabel 1 blijkt dat de gemiddelde zinslengte van de handboeken uit het begin van
de twintigste eeuw merkelijk – gemiddeld ongeveer tien woorden per zin - hoger ligt dan bij de
moderne handboeken. De T-Test bevestigt dat het verschil met 95% zekerheid significant is (p=0.011,
cf. bijlage 1). Deze bevinding ondersteunt de hypothese dat de complexiteit van de Amerikaanse
accountinghandboeken tussen het begin en het einde van de twintigste eeuw verminderd is, hetgeen
ook vastgesteld werd door Davidson (2005: 18): “[A]ll three levels show a reducing number of words
per sentence over the decades, with introductory texts having the fewest mean words per sentence,
followed by intermediate, and advanced texts having the most words per sentence.”
Aangezien gemiddelden niet altijd een juist beeld geven van de echte waardeverhoudingen kunnen
deze resultaten best nog verder verduidelijkt worden. Hiervoor kan men nagaan uit hoeveel korte en
lange zinnen elk fragment bestaat. Davidson (2005) definieert korte zinnen als zinnen die 12 of meer
woorden bevatten, en lange zinnen als zinnen die uit 70 of meer woorden bestaan.
5 Aangezien het corpus 2 fragmenten bevat uit hetzelfde jaar, werd er in alle tabellen een onderscheid gemaakt
tussen 1995 a en 1995 b. “1995 a” verwijst naar Larson & Miller, en “1995 b” naar Needles.
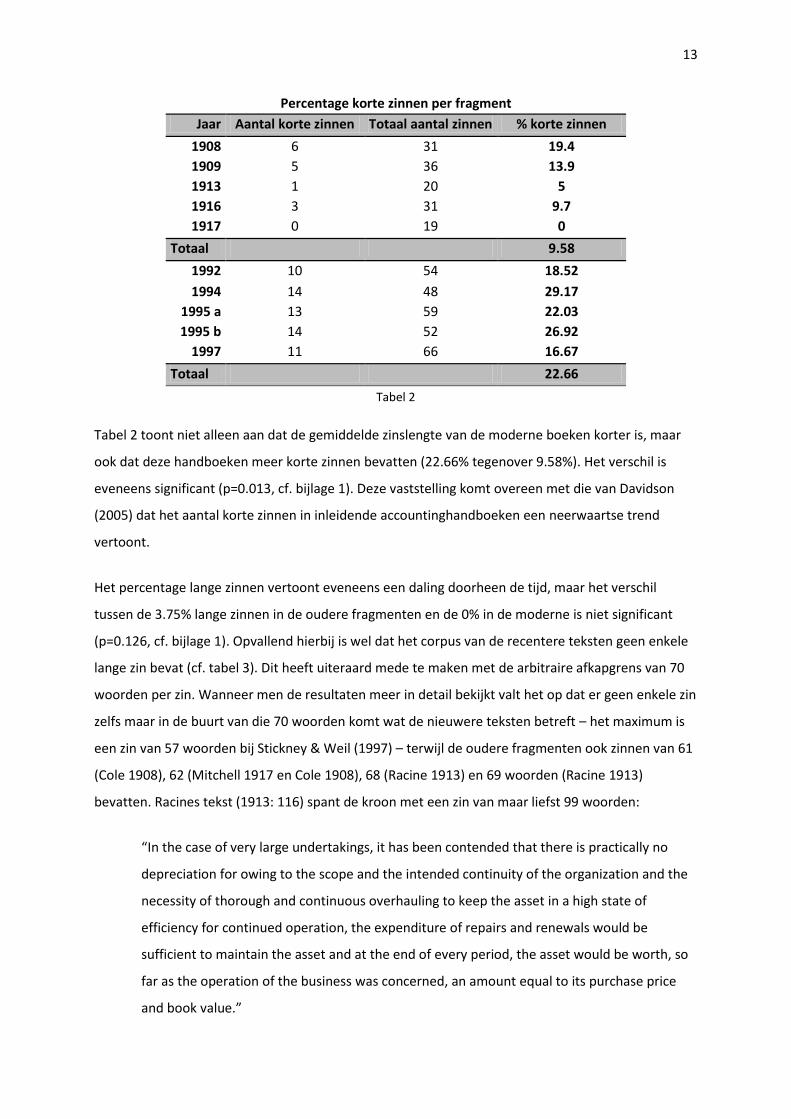
13
Percentage korte zinnen per fragment
Jaar Aantal korte zinnen Totaal aantal zinnen % korte zinnen
1908 6 31 19.4
1909 5 36 13.9
1913 1 20 5
1916 3 31 9.7
1917 0 19 0
Totaal 9.58
1992 10 54 18.52
1994 14 48 29.17
1995 a 13 59 22.03
1995 b 14 52 26.92
1997 11 66 16.67
Totaal 22.66
Tabel 2
Tabel 2 toont niet alleen aan dat de gemiddelde zinslengte van de moderne boeken korter is, maar
ook dat deze handboeken meer korte zinnen bevatten (22.66% tegenover 9.58%). Het verschil is
eveneens significant (p=0.013, cf. bijlage 1). Deze vaststelling komt overeen met die van Davidson
(2005) dat het aantal korte zinnen in inleidende accountinghandboeken een neerwaartse trend
vertoont.
Het percentage lange zinnen vertoont eveneens een daling doorheen de tijd, maar het verschil
tussen de 3.75% lange zinnen in de oudere fragmenten en de 0% in de moderne is niet significant
(p=0.126, cf. bijlage 1). Opvallend hierbij is wel dat het corpus van de recentere teksten geen enkele
lange zin bevat (cf. tabel 3). Dit heeft uiteraard mede te maken met de arbitraire afkapgrens van 70
woorden per zin. Wanneer men de resultaten meer in detail bekijkt valt het op dat er geen enkele zin
zelfs maar in de buurt van die 70 woorden komt wat de nieuwere teksten betreft – het maximum is
een zin van 57 woorden bij Stickney & Weil (1997) – terwijl de oudere fragmenten ook zinnen van 61
(Cole 1908), 62 (Mitchell 1917 en Cole 1908), 68 (Racine 1913) en 69 woorden (Racine 1913)
bevatten. Racines tekst (1913: 116) spant de kroon met een zin van maar liefst 99 woorden:
“In the case of very large undertakings, it has been contended that there is practically no
depreciation for owing to the scope and the intended continuity of the organization and the
necessity of thorough and continuous overhauling to keep the asset in a high state of
efficiency for continued operation, the expenditure of repairs and renewals would be
sufficient to maintain the asset and at the end of every period, the asset would be worth, so
far as the operation of the business was concerned, an amount equal to its purchase price
and book value.”
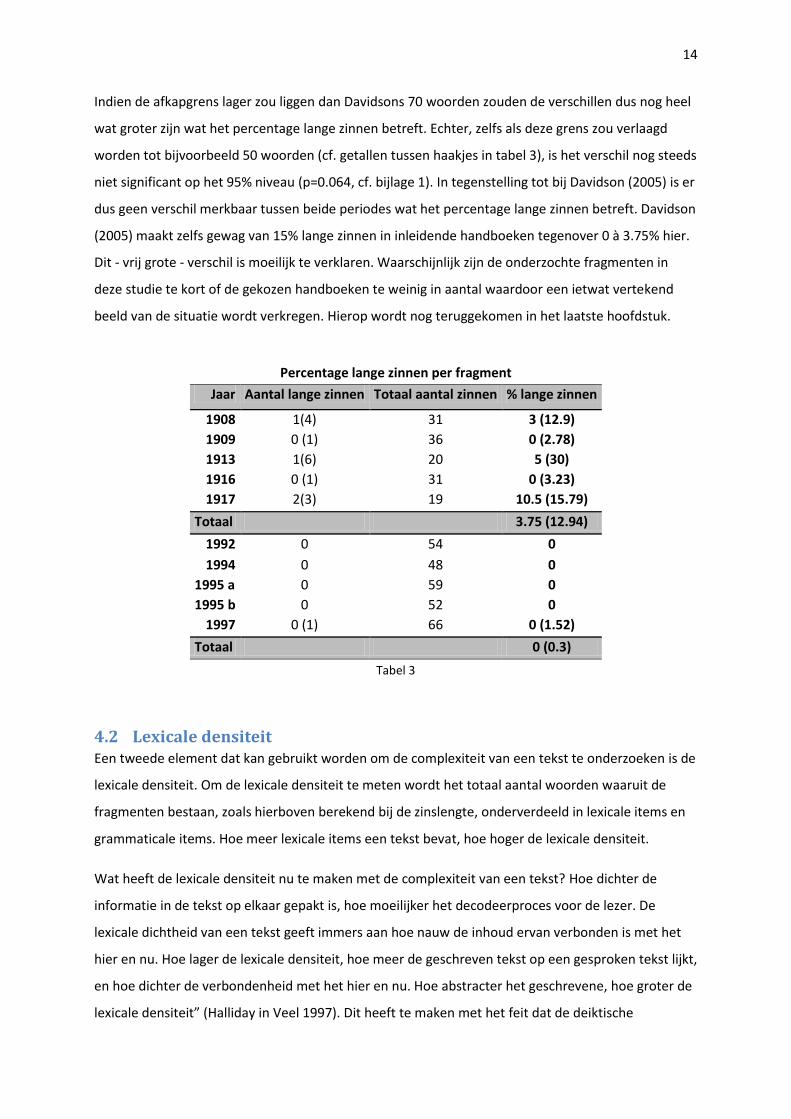
14
Indien de afkapgrens lager zou liggen dan Davidsons 70 woorden zouden de verschillen dus nog heel
wat groter zijn wat het percentage lange zinnen betreft. Echter, zelfs als deze grens zou verlaagd
worden tot bijvoorbeeld 50 woorden (cf. getallen tussen haakjes in tabel 3), is het verschil nog steeds
niet significant op het 95% niveau (p=0.064, cf. bijlage 1). In tegenstelling tot bij Davidson (2005) is er
dus geen verschil merkbaar tussen beide periodes wat het percentage lange zinnen betreft. Davidson
(2005) maakt zelfs gewag van 15% lange zinnen in inleidende handboeken tegenover 0 à 3.75% hier.
Dit - vrij grote - verschil is moeilijk te verklaren. Waarschijnlijk zijn de onderzochte fragmenten in
deze studie te kort of de gekozen handboeken te weinig in aantal waardoor een ietwat vertekend
beeld van de situatie wordt verkregen. Hierop wordt nog teruggekomen in het laatste hoofdstuk.
Percentage lange zinnen per fragment
Jaar Aantal lange zinnen Totaal aantal zinnen % lange zinnen
1908 1(4) 31 3 (12.9)
1909 0 (1) 36 0 (2.78)
1913 1(6) 20 5 (30)
1916 0 (1) 31 0 (3.23)
1917 2(3) 19 10.5 (15.79)
Totaal 3.75 (12.94)
1992 0 54 0
1994 0 48 0
1995 a 0 59 0
1995 b 0 52 0
1997 0 (1) 66 0 (1.52)
Totaal 0 (0.3)
Tabel 3
4.2 Lexicale densiteit Een tweede element dat kan gebruikt worden om de complexiteit van een tekst te onderzoeken is de
lexicale densiteit. Om de lexicale densiteit te meten wordt het totaal aantal woorden waaruit de
fragmenten bestaan, zoals hierboven berekend bij de zinslengte, onderverdeeld in lexicale items en
grammaticale items. Hoe meer lexicale items een tekst bevat, hoe hoger de lexicale densiteit.
Wat heeft de lexicale densiteit nu te maken met de complexiteit van een tekst? Hoe dichter de
informatie in de tekst op elkaar gepakt is, hoe moeilijker het decodeerproces voor de lezer. De
lexicale dichtheid van een tekst geeft immers aan hoe nauw de inhoud ervan verbonden is met het
hier en nu. Hoe lager de lexicale densiteit, hoe meer de geschreven tekst op een gesproken tekst lijkt,
en hoe dichter de verbondenheid met het hier en nu. Hoe abstracter het geschrevene, hoe groter de
lexicale densiteit” (Halliday in Veel 1997). Dit heeft te maken met het feit dat de deiktische

15
elementen, die betrekking hebben op de uitgangssituatie, allemaal tot de grammaticale items
behoren.
Wells (1984: 1) wijst er terecht op dat wetenschappelijke teksten inherent abstracter zijn dan teksten
over alledaagse dingen omdat men verplicht is te generaliseren: “ Whereas everyday concepts are
related to the world of experience in a direct but relatively ad hoc manner, scientific concepts are
both more abstract and more general; their primary relationship is to other concepts within the
relevant system and only indirectly to the particular objects and events that they subsume”.
Uiteraard zijn er gradaties in dit “decontextualized thinking” (Wells 1984: 2) – hoe abstracter, hoe
moeilijker voor de lezer.
Halliday (1993) geeft aan dat de complexiteit uiteraard ook beïnvloed wordt door de inhoud van de
lexicale items en hoe ze verdeeld zijn over de grammaticale structuur, maar dat de lexicale densiteit
op zich eveneens een bepalende rol speelt. Het moeilijkst zijn die passages waarin lexicale items
elkaar opvolgen zonder onderbroken te worden door grammaticale items, zelfs indien de individuele
lexicale items waaruit deze reeks bestaat perfect begrijpbaar zijn. Hieronder volgt een voorbeeld van
een zin met een hoge en één met een lage lexicale densiteit om te verduidelijken waar de
moeilijkheid ligt:
(3) “The depreciation process assigns periodic charges that reflect systematic calculations.”
(Stickney & Weil 1997: 462)
(3) wordt gekenmerkt door een hoge lexicale densiteit aangezien de zin 8 lexicale items bevat en
slechts 2 grammaticale items (the en that). Dit betekent dat de lezer veel informatie te verwerken
heeft op een korte ruimte. Deze compactheid wordt onder andere veroorzaakt door de aanwezigheid
van de uitgebreide en complexe nominale groep “periodic charges that reflect systematic
calculations”. In het dagdagelijkse spontane taalgebruik zou deze informatie een andere zin of
zinsdeel bevolken, waardoor het menselijk geheugen minder belast wordt (Fang 2004). Het volgende
voorbeeld, dat nochtans evenveel woorden bevat, is veel gemakkelijker te interpreteren:
(4) “The rate of depreciation is the same in each year.” (Needles 1995: 397)
Zin (4) bevat immers 4 lexicale items (rate, depreciation, same en year) en maar liefst 6
grammaticale items. Er is dus een kleinere hoeveelheid lexicale informatie vervat in dezelfde
oppervlakte, hetgeen de verwerking voor de lezer vergemakkelijkt. Bovendien leggen de
grammaticale items de relaties tussen de lexicale items bloot. Hoe minder grammaticale items er zijn

16
in verhouding tot de lexicale items, hoe onduidelijker het dus wordt op welke manier ze met elkaar
verbonden zijn.
Om een woord onder te kunnen brengen bij de lexicale of grammaticale items is het nodig criteria
definiëren die het onderscheid duidelijk maken. (Halliday 1989) geeft een helder beeld van wat nu
juist het verschil tussen beide is. Lexicale items of inhoudswoorden behoren tot een open systeem,
aangezien men tot in het oneindige nieuwe lexicale items kan toevoegen. Grammaticale items zijn
dan weer functiewoorden, die de relaties tussen de inhoudswoorden uitdrukken. Ze behoren tot een
gesloten systeem, hetgeen betekent dat het veel moeilijker is nieuwe elementen toe te voegen.
Toch is het onderscheid tussen de twee niet steeds zo duidelijk te maken. Dit is bijvoorbeeld het
geval bij voorzetsels en sommige bijwoorden in het Engels. Wetenschappers maken dan ook niet
altijd gebruik van dezelfde criteria bij het berekenen van de lexicale densiteit van een tekst. Welke
onderverdeling men kiest bepaalt uiteraard in sterke mate het eindresultaat, maar zolang men
consequent de regels toepast op alle fragmenten zal het verschil tussen de verschillende
mogelijkheden normaal gezien niet al te groot zijn.
De huidige analyse is gebaseerd op de onderverdeling van O’Loughlin (in Prebianca & D’Ely 2008).
Hierbij bestaan de lexicale items uit zelfstandige naamwoorden, werkwoorden, adjectieven en
bijwoorden van plaats, tijd en manier. De grammaticale items worden dan gevormd door de
werkwoorden be en have, hulpwerkwoorden, lidwoorden, voornaamwoorden, hoofd- en
rangtelwoorden, vragende en negatieve bijwoorden, voorzetsels en conjuncties.
Hoe compact een tekst werkelijk is kan onder andere worden nagegaan door het aantal lexicale
items in een tekst te vergelijken met het totaal aantal items waaruit de tekst bestaat.
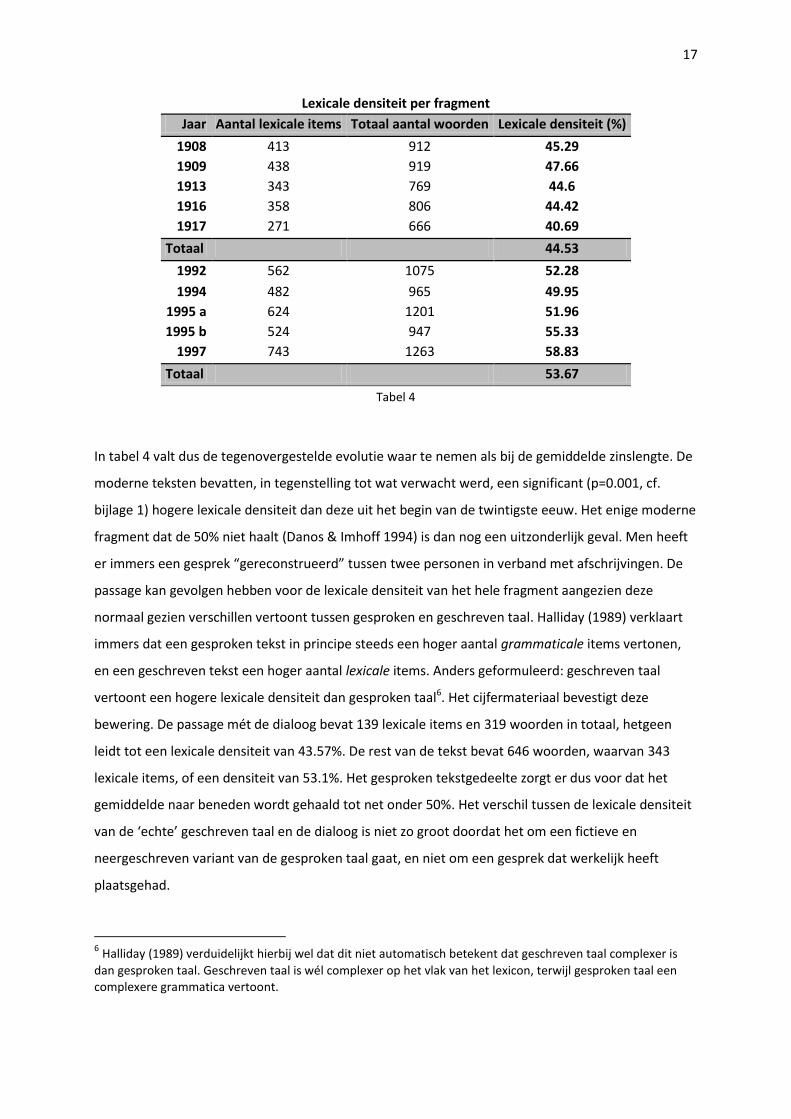
17
Lexicale densiteit per fragment
Jaar Aantal lexicale items Totaal aantal woorden Lexicale densiteit (%)
1908 413 912 45.29
1909 438 919 47.66
1913 343 769 44.6
1916 358 806 44.42
1917 271 666 40.69
Totaal 44.53
1992 562 1075 52.28
1994 482 965 49.95
1995 a 624 1201 51.96
1995 b 524 947 55.33
1997 743 1263 58.83
Totaal 53.67
Tabel 4
In tabel 4 valt dus de tegenovergestelde evolutie waar te nemen als bij de gemiddelde zinslengte. De
moderne teksten bevatten, in tegenstelling tot wat verwacht werd, een significant (p=0.001, cf.
bijlage 1) hogere lexicale densiteit dan deze uit het begin van de twintigste eeuw. Het enige moderne
fragment dat de 50% niet haalt (Danos & Imhoff 1994) is dan nog een uitzonderlijk geval. Men heeft
er immers een gesprek “gereconstrueerd” tussen twee personen in verband met afschrijvingen. De
passage kan gevolgen hebben voor de lexicale densiteit van het hele fragment aangezien deze
normaal gezien verschillen vertoont tussen gesproken en geschreven taal. Halliday (1989) verklaart
immers dat een gesproken tekst in principe steeds een hoger aantal grammaticale items vertonen,
en een geschreven tekst een hoger aantal lexicale items. Anders geformuleerd: geschreven taal
vertoont een hogere lexicale densiteit dan gesproken taal6. Het cijfermateriaal bevestigt deze
bewering. De passage mét de dialoog bevat 139 lexicale items en 319 woorden in totaal, hetgeen
leidt tot een lexicale densiteit van 43.57%. De rest van de tekst bevat 646 woorden, waarvan 343
lexicale items, of een densiteit van 53.1%. Het gesproken tekstgedeelte zorgt er dus voor dat het
gemiddelde naar beneden wordt gehaald tot net onder 50%. Het verschil tussen de lexicale densiteit
van de ‘echte’ geschreven taal en de dialoog is niet zo groot doordat het om een fictieve en
neergeschreven variant van de gesproken taal gaat, en niet om een gesprek dat werkelijk heeft
plaatsgehad.
6 Halliday (1989) verduidelijkt hierbij wel dat dit niet automatisch betekent dat geschreven taal complexer is
dan gesproken taal. Geschreven taal is wél complexer op het vlak van het lexicon, terwijl gesproken taal een complexere grammatica vertoont.
18
Het berekenen van de lexicale densiteit op zich volstaat niet om een goed beeld van de situatie te
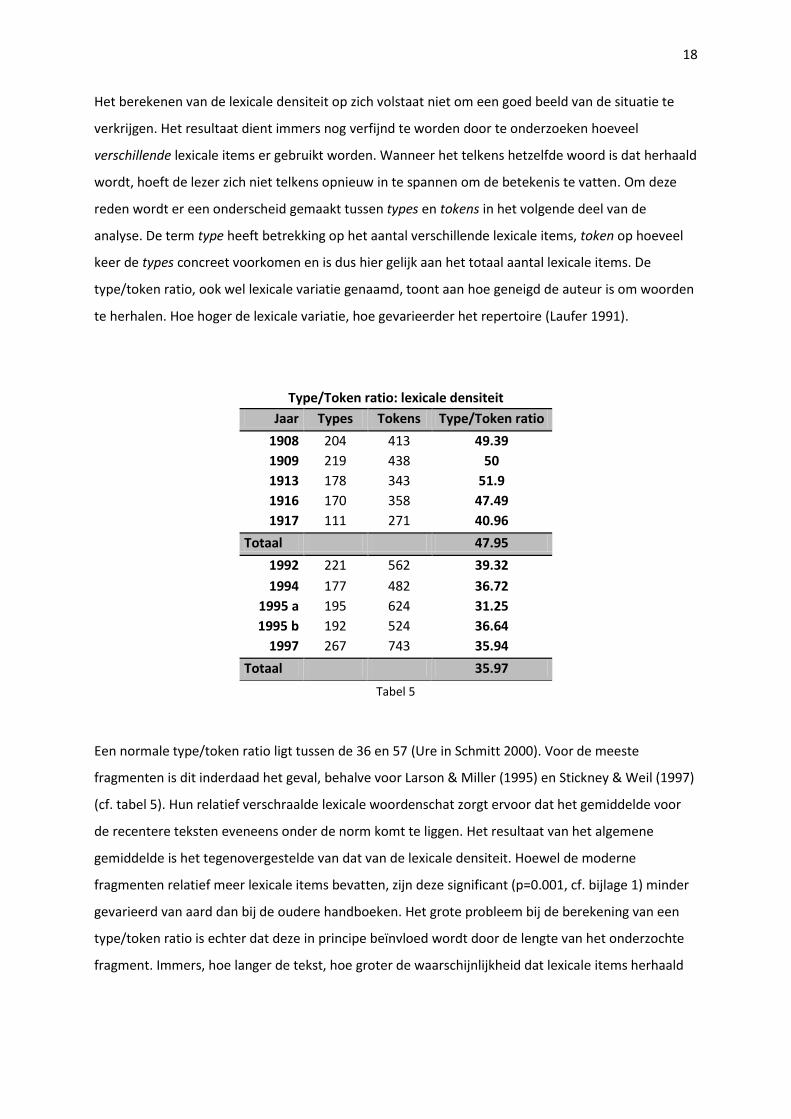
verkrijgen. Het resultaat dient immers nog verfijnd te worden door te onderzoeken hoeveel
verschillende lexicale items er gebruikt worden. Wanneer het telkens hetzelfde woord is dat herhaald
wordt, hoeft de lezer zich niet telkens opnieuw in te spannen om de betekenis te vatten. Om deze
reden wordt er een onderscheid gemaakt tussen types en tokens in het volgende deel van de
analyse. De term type heeft betrekking op het aantal verschillende lexicale items, token op hoeveel
keer de types concreet voorkomen en is dus hier gelijk aan het totaal aantal lexicale items. De
type/token ratio, ook wel lexicale variatie genaamd, toont aan hoe geneigd de auteur is om woorden
te herhalen. Hoe hoger de lexicale variatie, hoe gevarieerder het repertoire (Laufer 1991).
Type/Token ratio: lexicale densiteit
Jaar Types Tokens Type/Token ratio
1908 204 413 49.39
1909 219 438 50
1913 178 343 51.9
1916 170 358 47.49
1917 111 271 40.96
Totaal 47.95
1992 221 562 39.32
1994 177 482 36.72
1995 a 195 624 31.25
1995 b 192 524 36.64
1997 267 743 35.94
Totaal 35.97
Tabel 5
Een normale type/token ratio ligt tussen de 36 en 57 (Ure in Schmitt 2000). Voor de meeste
fragmenten is dit inderdaad het geval, behalve voor Larson & Miller (1995) en Stickney & Weil (1997)
(cf. tabel 5). Hun relatief verschraalde lexicale woordenschat zorgt ervoor dat het gemiddelde voor
de recentere teksten eveneens onder de norm komt te liggen. Het resultaat van het algemene
gemiddelde is het tegenovergestelde van dat van de lexicale densiteit. Hoewel de moderne
fragmenten relatief meer lexicale items bevatten, zijn deze significant (p=0.001, cf. bijlage 1) minder
gevarieerd van aard dan bij de oudere handboeken. Het grote probleem bij de berekening van een
type/token ratio is echter dat deze in principe beïnvloed wordt door de lengte van het onderzochte
fragment. Immers, hoe langer de tekst, hoe groter de waarschijnlijkheid dat lexicale items herhaald

19
zullen worden. Dit zou dan ook kunnen verklaren waarom de lexicale variatie in de nieuwere
fragmenten – die individueel telkens langer zijn (cf. aantal woorden in tabel 1) – lager ligt.
De Pearson Correlatiecoëfficiënt maakt inderdaad duidelijk dat er hier een matig tot sterke negatieve
correlatie is (r=-0.648, cf. bijlage 2) tussen de lengte en lexicale variatie van een tekstfragment. Met
andere woorden, hoe langer het fragment, hoe kleiner de lexicale variatie. Bij fragmenten met gelijke
lengte zou het verschil tussen beide periodes dus zeker kleiner zijn.
4.3 Nominalisatie
Wanneer men de zelfstandige naamwoorden, die deel uitmaken van de lexicale items, verder
analyseert, valt het op dat sommige van hen – zoals depreciation, impairment en renewal - afgeleid
zijn van werkwoorden. Ook dit proces, nominalisatie genaamd, is een potentiële bron van
moeilijkheid voor een lezer. In het normale patroon verwijzen werkwoorden immers naar processen,
adjectieven naar eigenschappen en zelfstandige naamwoorden naar personen of dingen. Halliday
(1993, 82) synthetiseert de problematiek als volgt:
“It seems likely that part of the difficulty arises, however, because these metaphorical
expressions are not just another way of saying the same thing. In a certain sense, they
present a different view of the world. As we grew up, using our language to learn with and
think with, we have come to expect *…+ that nouns were for people and things, verbs for
actions and events. Now we find that almost everything has turned into a noun. We have to
reconstruct our mental image of the world so that it becomes a world made out of things,
rather than the world of happening – events with things taking part in them – that we were
accustomed to.”
Gill Francis (in Moss 2000: 47-8) formuleert dit op een andere manier:
“Nominalisation is a synoptic interpretation of reality: it freezes the processes and makes
them static so that they can be talked about and evaluated. *…+ Statements about actions,
which might more easily be questioned, are replaced by simple presentations of
"things/facts" which must be either memorised for future repetition or simply passed over.
*…+ Again, this puts the phenomenon at a distance and makes it more difficult for the learner
to identify with his/her personal experience.”

20
Beide vormen van moeilijkheid komen dus eigenlijk op hetzelfde neer. Nominalisatie zorgt ervoor dat
de lezer weggehaald worden uit het hier en nu en met een andere manier van voorstellen dient leren
om te gaan. Opnieuw zal dit geïllustreerd worden met een voorbeeld uit de onderzochte
fragmenten:
(5) “Yet, new inventions and improvements may cause a company to discard an obsolete
asset long before it wears out.” (Larson & Miller 1995: 323, nadruk toegevoegd)
‘Uitvinden’ en ‘verbeteren’ zijn processen die logischerwijze uitgedrukt worden door een werkwoord.
Door er een zelfstandig naamwoord van te maken gaan ze echter het resultaat van het proces, zijnde
het product, vertegenwoordigen. Het probleem is echter dat men zich hier moeilijk een concreet
object bij kan voorstellen, zodat het moeilijk is voor een lezer om zich in te leven in de inhoud van de
tekst. Daarbij komt nog dat een proces steeds een uitvoerder nodig heeft. Door er een nominalisatie
op toe te passen is het echter niet meer nodig deze te vermelden. Een werkwoord heeft immers
verplicht een onderwerp nodig, terwijl een zelfstandig naamwoord gerust zonder bepaling kan
voorkomen. Ook de tijd waarin het werkwoord staat - en die duidelijk maakt waar het proces zich
situeert ten opzichte van het hier en nu - gaat verloren. Het proces lijkt hierdoor algemeen geldig en
niet enkel in een bepaalde situatie. Thompson (1996) concludeert hieruit dat nominalisatie een
objectificatie (of dehumanisatie) en een inherente generalisatie met zich meebrengt. Hij vergelijkt dit
met algemene waarheden, die eveneens los van tijd en persoon worden geformuleerd.
Nominalisaties komen vaak voor in academische teksten omdat ze een auteur in staat stellen om
technische termen te creëren en voordien vermelde informatie in één woord samen te vatten (Veel
1997). Banks (1996) heeft een onderzoek gedaan naar de evolutie van nominalisatie in
wetenschappelijke teksten. Dit waren enerzijds descriptieve teksten in verband met biologie en
anderzijds experimentele geschriften over fysica, chemie, aardrijkskunde en astronomie. Daarbij
kwam hij tot de vaststelling dat er in het begin van de twintigste eeuw evenveel nominalisaties
voorkwamen in beide soorten teksten, ongeveer 1 per 23 woorden. Tegen de late twintigste eeuw
was dit gebruik bij beide zelfs nog gegroeid tot 1 per 12 à 15 woorden. Zou hetzelfde gelden voor
economische teksten in verband met boekhouden?
21
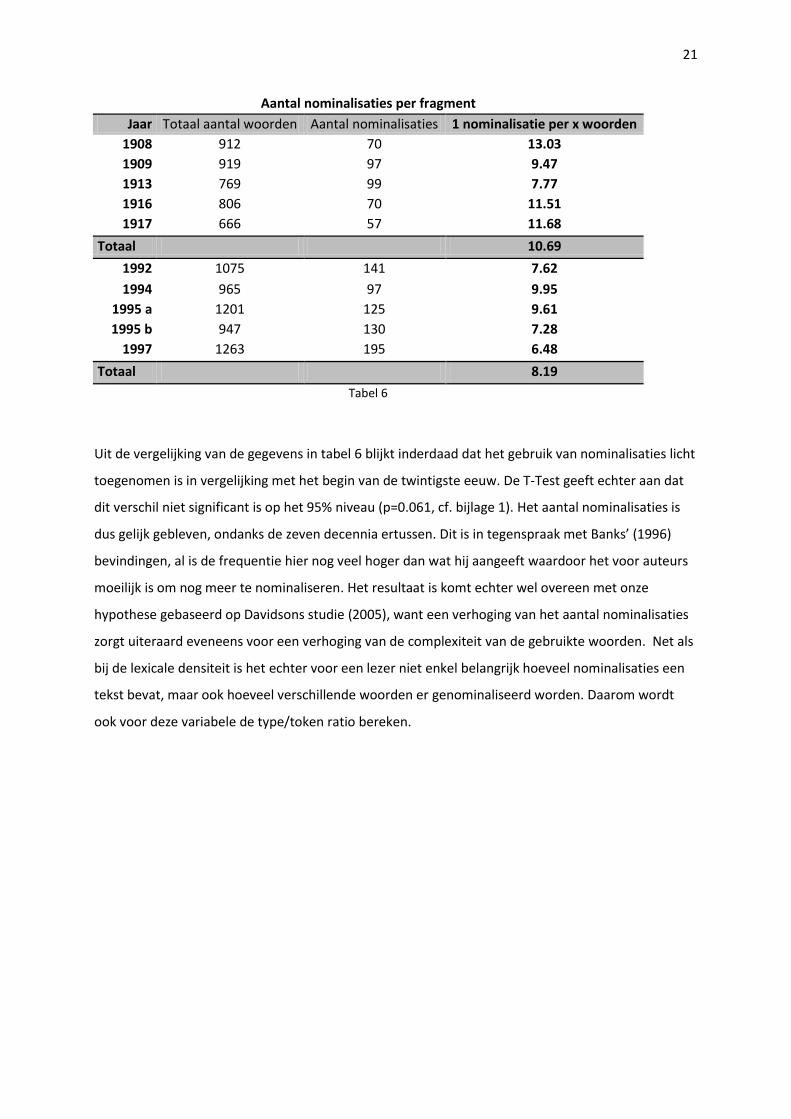
Aantal nominalisaties per fragment
Jaar Totaal aantal woorden Aantal nominalisaties 1 nominalisatie per x woorden
1908 912 70 13.03
1909 919 97 9.47
1913 769 99 7.77
1916 806 70 11.51
1917 666 57 11.68
Totaal 10.69
1992 1075 141 7.62
1994 965 97 9.95
1995 a 1201 125 9.61
1995 b 947 130 7.28
1997 1263 195 6.48
Totaal 8.19
Tabel 6
Uit de vergelijking van de gegevens in tabel 6 blijkt inderdaad dat het gebruik van nominalisaties licht
toegenomen is in vergelijking met het begin van de twintigste eeuw. De T-Test geeft echter aan dat
dit verschil niet significant is op het 95% niveau (p=0.061, cf. bijlage 1). Het aantal nominalisaties is
dus gelijk gebleven, ondanks de zeven decennia ertussen. Dit is in tegenspraak met Banks’ (1996)
bevindingen, al is de frequentie hier nog veel hoger dan wat hij aangeeft waardoor het voor auteurs
moeilijk is om nog meer te nominaliseren. Het resultaat is komt echter wel overeen met onze
hypothese gebaseerd op Davidsons studie (2005), want een verhoging van het aantal nominalisaties
zorgt uiteraard eveneens voor een verhoging van de complexiteit van de gebruikte woorden. Net als
bij de lexicale densiteit is het echter voor een lezer niet enkel belangrijk hoeveel nominalisaties een
tekst bevat, maar ook hoeveel verschillende woorden er genominaliseerd worden. Daarom wordt
ook voor deze variabele de type/token ratio bereken.
22
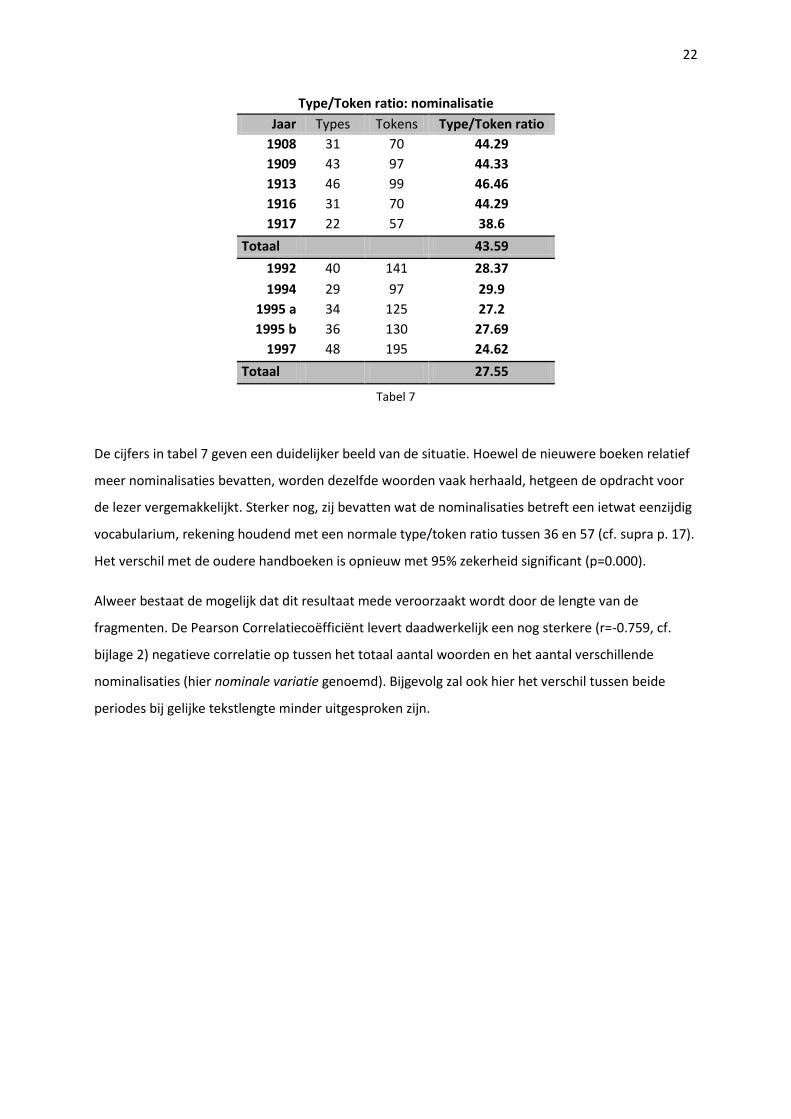
Type/Token ratio: nominalisatie
Jaar Types Tokens Type/Token ratio
1908 31 70 44.29
1909 43 97 44.33
1913 46 99 46.46
1916 31 70 44.29
1917 22 57 38.6
Totaal 43.59
1992 40 141 28.37
1994 29 97 29.9
1995 a 34 125 27.2
1995 b 36 130 27.69
1997 48 195 24.62
Totaal 27.55
Tabel 7
De cijfers in tabel 7 geven een duidelijker beeld van de situatie. Hoewel de nieuwere boeken relatief
meer nominalisaties bevatten, worden dezelfde woorden vaak herhaald, hetgeen de opdracht voor
de lezer vergemakkelijkt. Sterker nog, zij bevatten wat de nominalisaties betreft een ietwat eenzijdig
vocabularium, rekening houdend met een normale type/token ratio tussen 36 en 57 (cf. supra p. 17).
Het verschil met de oudere handboeken is opnieuw met 95% zekerheid significant (p=0.000).
Alweer bestaat de mogelijk dat dit resultaat mede veroorzaakt wordt door de lengte van de
fragmenten. De Pearson Correlatiecoëfficiënt levert daadwerkelijk een nog sterkere (r=-0.759, cf.
bijlage 2) negatieve correlatie op tussen het totaal aantal woorden en het aantal verschillende
nominalisaties (hier nominale variatie genoemd). Bijgevolg zal ook hier het verschil tussen beide
periodes bij gelijke tekstlengte minder uitgesproken zijn.

23
5 Tekstuele Metafunctie
De tekstuele metafunctie houdt verband met hoe boodschappen een plaats krijgen binnen een tekst,
en op die manier een begrijpbaar en samenhangend geheel vormen. Deze samenhang kan echter op
twee niveaus bekeken worden. Men maakt daarom een onderscheid tussen coherentie enerzijds en
cohesie anderzijds. Het begrip coherentie heeft te maken met de interactie tussen tekst en lezer.
Men kijkt na of de tekst als geheel betekenisvol voor de lezer, en of er een logische argumentatie
wordt gevolgd. Cohesie verwijst exclusief naar tekstuele kenmerken, en meer bepaald naar lexicale
en grammaticale verbanden tussen zinnen (Crane 2006). Het onderscheid tussen cohesie en
coherentie is dus vergelijkbaar met het verschil tussen understandability en readability zoals dat
behandeld werd in hoofdstuk 2. Toen werd gezegd dat deze studie zich beperkt tot tekstuele
kenmerken of de leesbaarheid van de fragmenten. Om die reden zal dan ook enkel cohesie aan bod
komen bij de analyse, en dit aan de hand van de variabelen ‘aantal conjuncties’ en ‘bladspiegel’.
5.1 Conjuncties
Halliday en Hasan (1976) stellen dat er vijf elementen zijn die de cohesie van een tekst bevorderen,
namelijk verwijzingen, weglatingen, substituties, lexicale cohesie en conjuncties. Conjuncties nemen
een bijzondere plaats in binnen dit geheel omdat ze slechts op een indirecte manier cohesief zijn. In
tegenstelling tot de andere componenten verwijzen ze immers niet rechtstreeks naar een ander deel
van de tekst, maar hun specifieke betekenis verondersteld wel de aanwezigheid van andere
elementen in de tekst.
Zoals reeds gezegd werd bij de bespreking van de leesbaarheidsformules (cf. supra p.4) beweren
Anderson en Davison (1988) dat de aanwezigheid van conjuncties het begrijpen van de tekst
vergemakkelijkt, vooral wanneer het anders niet duidelijk is hoe de zinnen of zinsdelen met elkaar
verbonden zijn. Hoe meer ze voorkomen, hoe gemakkelijker de lezer dus de verbanden tussen de
zinnen kan achterhalen én hoe minder kans op een verkeerde interpretatie. Deze variabele vertoont
bijgevolg een omgekeerd evenredige relatie in vergelijking met de vorige. Men dient als schrijver
echter ook rekening houden met het doelpubliek. Een overdaad aan cohesiebevorderende
elementen kan de lezer het gevoel geven dat hij niet intelligent genoeg is om zelf de connecties te
achterhalen, en dus maar één zin tegelijkertijd kan verstaan. Dit is aan te raden als men voor
24
kinderen schrijft (Thompson 1996: 159), maar niet bij boekhoudkundige teksten voor volwassenen.
Het is aan de auteur om hierin een goed evenwicht te vinden.
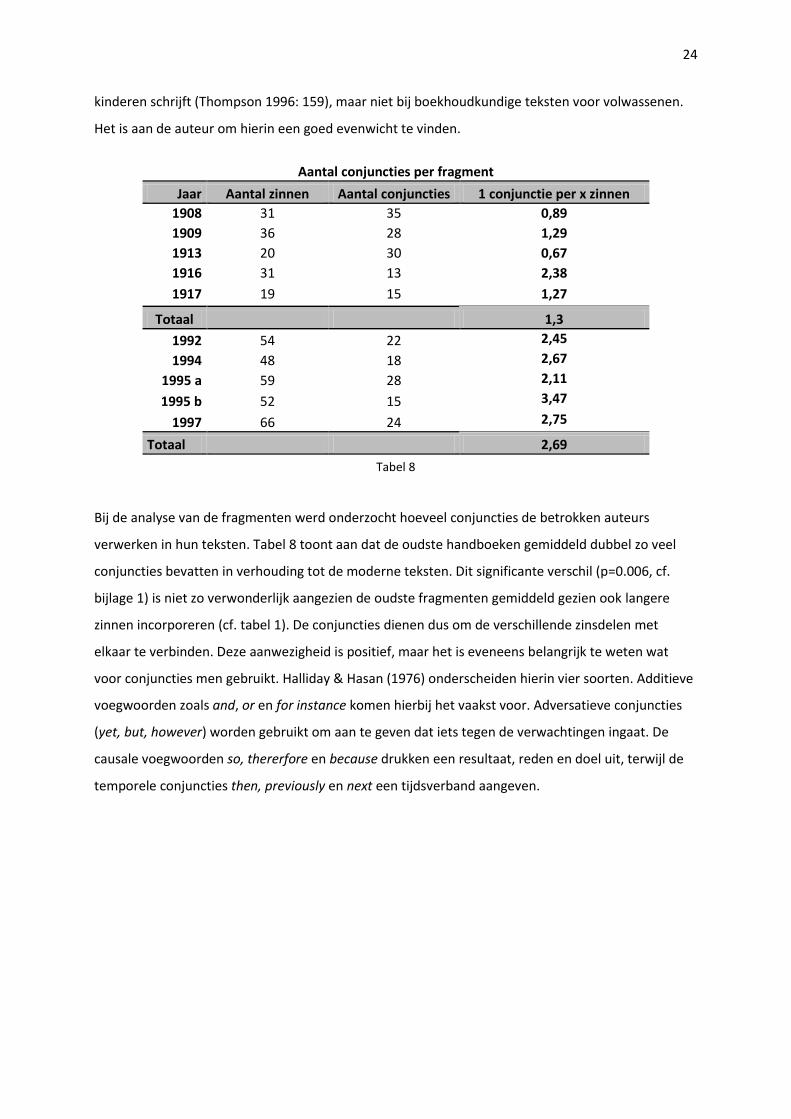
Aantal conjuncties per fragment
Jaar Aantal zinnen Aantal conjuncties 1 conjunctie per x zinnen
1908 31 35 0,89
1909 36 28 1,29
1913 20 30 0,67
1916 31 13 2,38
1917 19 15 1,27
Totaal 1,3
1992 54 22 2,45
1994 48 18 2,67
1995 a 59 28 2,11
1995 b 52 15 3,47
1997 66 24 2,75
Totaal 2,69
Tabel 8
Bij de analyse van de fragmenten werd onderzocht hoeveel conjuncties de betrokken auteurs
verwerken in hun teksten. Tabel 8 toont aan dat de oudste handboeken gemiddeld dubbel zo veel
conjuncties bevatten in verhouding tot de moderne teksten. Dit significante verschil (p=0.006, cf.
bijlage 1) is niet zo verwonderlijk aangezien de oudste fragmenten gemiddeld gezien ook langere
zinnen incorporeren (cf. tabel 1). De conjuncties dienen dus om de verschillende zinsdelen met
elkaar te verbinden. Deze aanwezigheid is positief, maar het is eveneens belangrijk te weten wat
voor conjuncties men gebruikt. Halliday & Hasan (1976) onderscheiden hierin vier soorten. Additieve
voegwoorden zoals and, or en for instance komen hierbij het vaakst voor. Adversatieve conjuncties
(yet, but, however) worden gebruikt om aan te geven dat iets tegen de verwachtingen ingaat. De
causale voegwoorden so, thererfore en because drukken een resultaat, reden en doel uit, terwijl de
temporele conjuncties then, previously en next een tijdsverband aangeven.
25
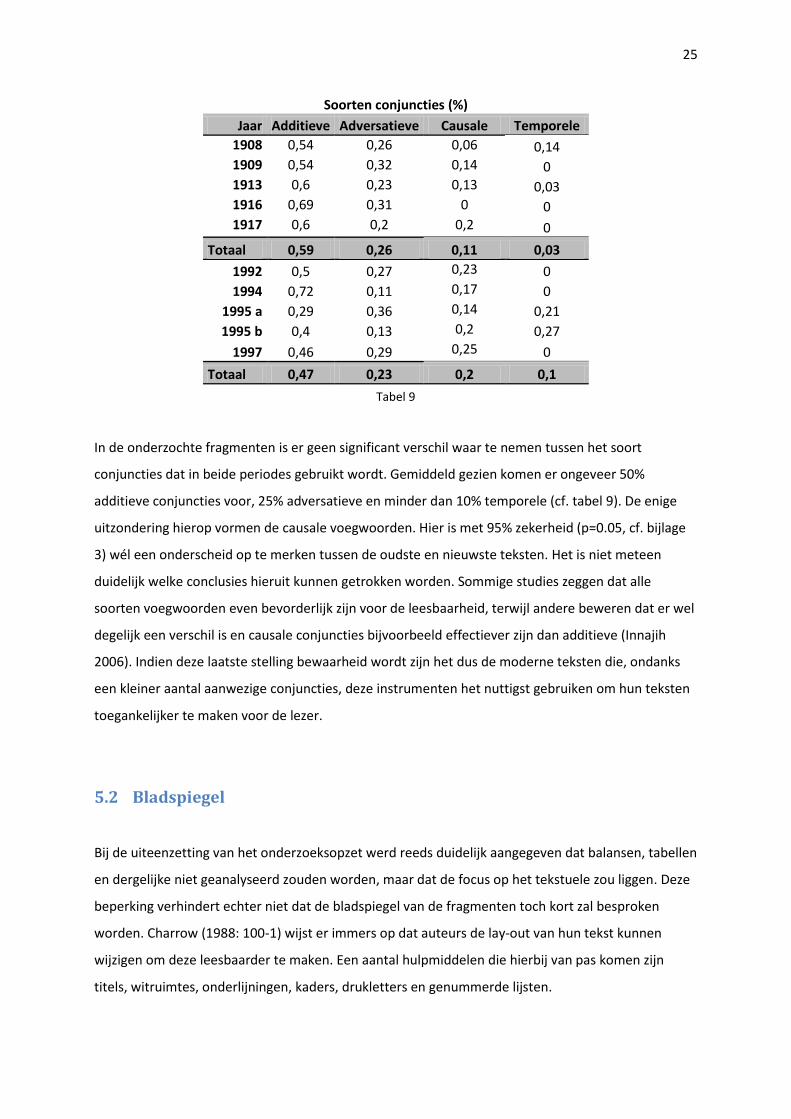
Soorten conjuncties (%)
Jaar Additieve Adversatieve Causale Temporele
1908 0,54 0,26 0,06 0,14 1909 0,54 0,32 0,14 0 1913 0,6 0,23 0,13 0,03 1916 0,69 0,31 0 0 1917 0,6 0,2 0,2 0
Totaal 0,59 0,26 0,11 0,03
1992 0,5 0,27 0,23 0
1994 0,72 0,11 0,17 0
1995 a 0,29 0,36 0,14 0,21
1995 b 0,4 0,13 0,2 0,27
1997 0,46 0,29 0,25 0
Totaal 0,47 0,23 0,2 0,1
Tabel 9
In de onderzochte fragmenten is er geen significant verschil waar te nemen tussen het soort
conjuncties dat in beide periodes gebruikt wordt. Gemiddeld gezien komen er ongeveer 50%
additieve conjuncties voor, 25% adversatieve en minder dan 10% temporele (cf. tabel 9). De enige
uitzondering hierop vormen de causale voegwoorden. Hier is met 95% zekerheid (p=0.05, cf. bijlage
3) wél een onderscheid op te merken tussen de oudste en nieuwste teksten. Het is niet meteen
duidelijk welke conclusies hieruit kunnen getrokken worden. Sommige studies zeggen dat alle
soorten voegwoorden even bevorderlijk zijn voor de leesbaarheid, terwijl andere beweren dat er wel
degelijk een verschil is en causale conjuncties bijvoorbeeld effectiever zijn dan additieve (Innajih
2006). Indien deze laatste stelling bewaarheid wordt zijn het dus de moderne teksten die, ondanks
een kleiner aantal aanwezige conjuncties, deze instrumenten het nuttigst gebruiken om hun teksten
toegankelijker te maken voor de lezer.
5.2 Bladspiegel
Bij de uiteenzetting van het onderzoeksopzet werd reeds duidelijk aangegeven dat balansen, tabellen
en dergelijke niet geanalyseerd zouden worden, maar dat de focus op het tekstuele zou liggen. Deze
beperking verhindert echter niet dat de bladspiegel van de fragmenten toch kort zal besproken
worden. Charrow (1988: 100-1) wijst er immers op dat auteurs de lay-out van hun tekst kunnen
wijzigen om deze leesbaarder te maken. Een aantal hulpmiddelen die hierbij van pas komen zijn
titels, witruimtes, onderlijningen, kaders, drukletters en genummerde lijsten.

26
Wanneer een dergelijke analyse toegepast wordt op de handboeken valt het op dat de vroegste
teksten relatief weinig gebruik maken van dit soort instrumenten. Alle fragmenten bevatten wel
tussentitels, maar er wordt niks omkaderd of in drukletters gezet. Sommige woorden zijn wel
schuingedrukt in Gilman (1916), terwijl bij Mitchell (1917) de tussentitels cursief en genummerd zijn.
Illustraties zijn eveneens schaars. Uitzonderingen hierop zijn een afschrijvingsschema in Mitchell
(1917) en een balans in Cole (1908).
In de jaren negentig wordt veel meer aandacht besteed aan deze leesbaarheidscomponent. Bij alle
auteurs zijn belangrijke begrippen vetgedrukt, en ook de marge wordt vaak benut om de lezer extra
bij te staan. Zo gebruiken Meigs & Meigs (1992), Danos & Imhoff (1994) en Needles (1995) de kantlijn
om doelstellingen te vermelden, terwijl Larson & Miller (1995) de ruimte gebruiken om er
tussentitels te plaatsen. De inhoud wordt eveneens verduidelijkt via balansen (Needles 1995 en
Larson & Miller 1995), afschrijvingsschema’s (Meigs & Meigs 1992 en Danos & Imhoff 1994),
grafieken (Danos & Imhoff 1994 en Larson & Miller 1995) en een diagram (Meigs & Meigs 1992).
De soberheid bij de visuele opbouw van de oudere handboeken wordt uiteraard deels veroorzaakt
door de mindere technische mogelijkheden van die tijd. Men kon uiteraard wel variëren qua
witruimtes en lettertype. Het gemiddeld aantal woorden per pagina ligt voor de moderne boeken
volgens tabel 10 significant hoger (p=0.009, cf. bijlage 1).
Gemiddeld aantal woorden per pagina7
1908 1909 1913 1916 1917 1992 1994 1995 1995 1997 304 307 274.67 272.67 223.67 363.33 322 400.33 315.67 421
Totaal: 276.4 Totaal: 364.47 Tabel 10
Het feit dat de oudere handboeken gemiddeld minder aantal woorden per pagina bevatten heeft
echter vooral te maken met het kleinere formaat van deze boeken en het grotere lettertype dat
gehanteerd wordt. Dat verklaart ook hoe het komt dat de nieuwe boeken, ondanks de ruime
aanwezigheid van visuele elementen -die niet in rekening worden gebracht maar wel veel plaats
innemen-, toch nog meer woorden per pagina groeperen. De hoeveelheid witruimte lijkt op het
eerste zicht zelfs kleiner te zijn dan bij de modernere teksten. Deze intuïtie wordt echter niet
bewaarheid wanneer men de gemiddelde lengte van de paragrafen nagaat, uitgedrukt in gemiddeld
aantal woorden per paragraaf:
7 Om een beeld te verkrijgen dat conform de werkelijkheid is, werden woorden van zinnen die niet eindigden
op de derde pagina hier wel meegerekend bij de berekening van het totaal aantal woorden per fragment. Wat Hatfield (1909), Mitchell (1917), Danos (1994), Gilman (1916) en Meigs (1992) betreft gaat het om 15 woorden of minder, maar bij Racine (1913) worden maar liefst 55 woorden op deze manier in rekening gebracht.

27
Gemiddelde paragraaflengte (# woorden/paragraaf)
1908 1909 1913 1916 1917 1992 1994 1995 1995 1997 152 153,17 69,91 115,14 74 67,19 87,73 80,07 67,64 66,47
Totaal: 112.84 Totaal: 73.82 Tabel 11
Uit tabel 11 blijkt dat moderne auteurs sneller een nieuwe paragraaf beginnen. De extra witruimte
die hierdoor gecreëerd wordt zou de bladspiegel overzichtelijker kunnen maken, hetgeen ook
bevorderlijk is voor de leesbaarheid. Het verschil is volgens de T-Test echter niet significant (p=0.096,
cf. bijlage 1).

28
6 Interpersoonlijke Metafunctie
Naast communiceren over de interne en externe wereld en logische samenhang creëren met andere
boodschappen dient taal ook om te interageren met anderen. Zoals Thompson (37-8) aangeeft
gebeurt dit in geschreven taal op een andere manier dan bij gesproken taal, omdat er geen face-to-
face interactie is. Het is dus heel moeilijk om in te spelen op reacties van de toehoorder. Hyland (in
Breeze 2007: 15) formuleert de interpersoonlijke component van geschreven taal als volgt:
“Writers can choose to engineer a feeling of complicity, by using expressions such as “as is
well known” or “it is natural to suppose that”. On the other hand, they can address readers
directly, by using rhetorical questions like “where does that leave Canada?”. Finally, on the
most basic level, writers can raise the interpersonal temperature of a text by using first or
second person pronouns; conversely, they can cool the text down by recourse to passives,
impersonal it-cleft constructions and grammatical metaphor.”
Hoe kan deze functie nu in verband worden gebracht met de taalkundige complexiteit van de tekst?
Via bepaalde hulpmiddelen zoals vragen, directieven en persoonlijke voornaamwoorden kan de
auteur de lezers bij de tekst betrekken, om zo te anticiperen op eventuele vragen en de interpretatie
in een bepaalde richting te leiden. Persoonlijke voornaamwoorden worden dus in feite gebruikt als
tegengewicht voor lexicale densiteit en nominalisatie. Ze vergemakkelijken het begrijpen in plaats
van de lezer te vervreemden van diens normale wereldbeeld. Door hun introductie lijkt de tekst
meer op de familiaire en interactieve taal waarmee men vertrouwd is uit het dagelijkse leven (Fang
2004).
Breeze (2007) beweert dat een kwantitatieve benadering van deze problematiek mogelijk is door het
aantal keer te tellen dat de auteur de lezer expliciet aanspreekt – met we, you of een bezittelijk
voornaamwoord in de eerste of tweede persoon. Dit werd dan ook toegepast op alle fragmenten,
maar zoals te zien is in tabel 12 kwamen deze aansprekingen niet frequent genoeg voor om er
duidelijke conclusies uit af te leiden8. De bespreking van de resultaten zal dan ook kwalitatief
gebeuren. Aangezien de lengte van de fragmenten varieert, geven de absolute cijfers een ietwat
vertekend beeld. Alles werd dan ook herleid naar aantal persoonlijke voornaamwoorden per 1000
woorden tekst. Deze aantallen bevinden zich tussen haakjes. Het getal ervoor is dan het absolute
8 I en de bezittelijke voornaamwoorden kwamen nergens voor en werden dus ook niet vermeld in de tabel. De
(bijna) afwezigheid van expliciete verwijzingen is echter niet zo verwonderlijk aangezien de fragmenten relatief beperkt in lengte zijn én persoonlijke voornaamwoorden zoveel mogelijk vermeden worden in academische geschriften. Dit heeft te maken met het feit dat men zo objectief mogelijk wil overkomen en dus verwijzingen naar een expliciete persoonlijke aanwezigheid binnen de perken tracht te houden (Biber 1998).
29
cijfer. Door de kleine aantallen is er echter nauwelijks een verschil tussen de absolute en herleide
resultaten.
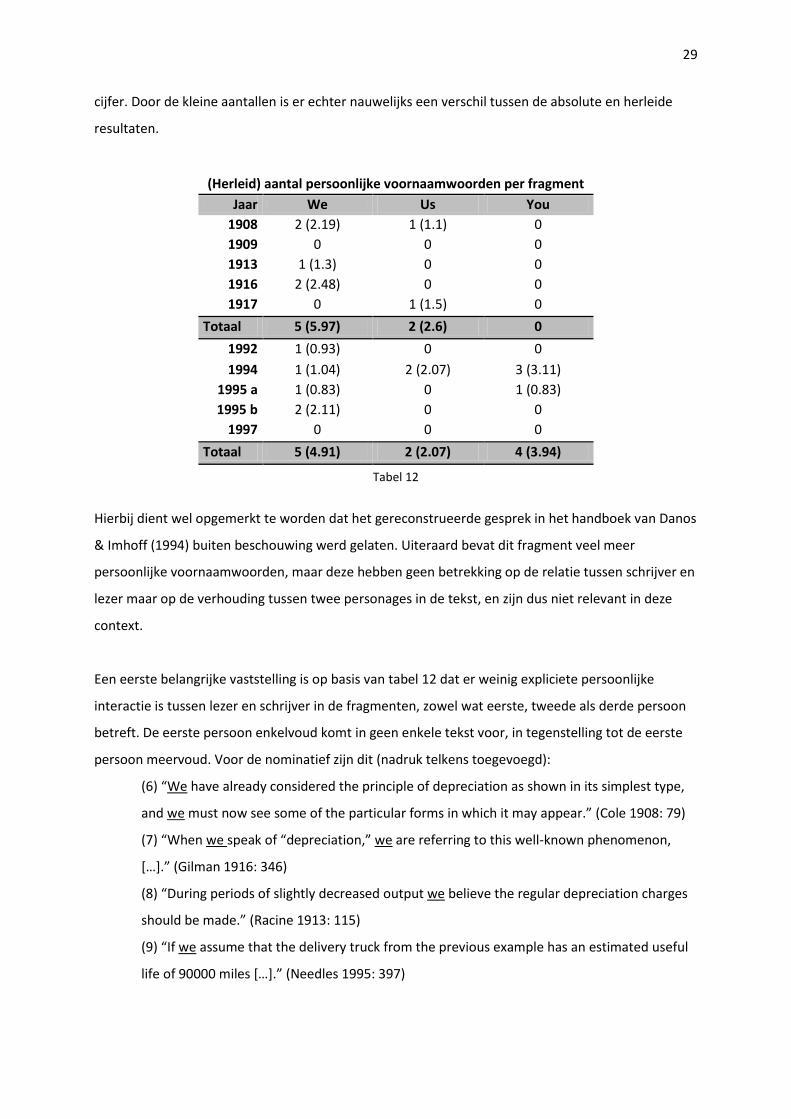
(Herleid) aantal persoonlijke voornaamwoorden per fragment
Jaar We Us You
1908 2 (2.19) 1 (1.1) 0
1909 0 0 0
1913 1 (1.3) 0 0
1916 2 (2.48) 0 0
1917 0 1 (1.5) 0
Totaal 5 (5.97) 2 (2.6) 0
1992 1 (0.93) 0 0
1994 1 (1.04) 2 (2.07) 3 (3.11)
1995 a 1 (0.83) 0 1 (0.83)
1995 b 2 (2.11) 0 0
1997 0 0 0
Totaal 5 (4.91) 2 (2.07) 4 (3.94)
Tabel 12
Hierbij dient wel opgemerkt te worden dat het gereconstrueerde gesprek in het handboek van Danos
& Imhoff (1994) buiten beschouwing werd gelaten. Uiteraard bevat dit fragment veel meer
persoonlijke voornaamwoorden, maar deze hebben geen betrekking op de relatie tussen schrijver en
lezer maar op de verhouding tussen twee personages in de tekst, en zijn dus niet relevant in deze
context.
Een eerste belangrijke vaststelling is op basis van tabel 12 dat er weinig expliciete persoonlijke
interactie is tussen lezer en schrijver in de fragmenten, zowel wat eerste, tweede als derde persoon
betreft. De eerste persoon enkelvoud komt in geen enkele tekst voor, in tegenstelling tot de eerste
persoon meervoud. Voor de nominatief zijn dit (nadruk telkens toegevoegd):
(6) “We have already considered the principle of depreciation as shown in its simplest type,
and we must now see some of the particular forms in which it may appear.” (Cole 1908: 79)
(7) “When we speak of “depreciation,” we are referring to this well-known phenomenon,
*…+.” (Gilman 1916: 346)
(8) “During periods of slightly decreased output we believe the regular depreciation charges
should be made.” (Racine 1913: 115)
(9) “If we assume that the delivery truck from the previous example has an estimated useful
life of 90000 miles *…+.” (Needles 1995: 397)

30
(10) “If we assume that the use of the truck was 20000 miles for the first year […+.” (Needles
1995: 397)
(11) “We explain these two methods next, and then consider some accelerated depreciation
methods.” (Larson & Miller 1995: 323)
(12) “Before we consider these issues in more detail *…+.” (Danos & Imhoff 1994: 391)
(13) “Earlier in this chapter, we described a delivery truck *…+.” (Meigs & Meigs 1992: 419)
Het probleem hierbij is echter dat deze “wij” drie soorten referenten kan hebben. Een inclusieve we
verwijst naar schrijver en lezer samen, terwijl een exclusieve we - die bij Kuo (1999) het vaakst
voorkomt om aan te kondigen wat er te gebeuren staat- enkel betrekking heeft op de auteur.
Het is niet altijd even duidelijk, maar de we van voorbeelden (6) tot en met (13) lijkt uitsluitend
exclusief te zijn, waardoor dit niet echt als een aanspreking van de lezer kan beschouwd worden. Dit
vermoeden wordt nog versterkt door de vaststelling dat sommige werken twee auteurs hebben,
zoals in het geval van Meigs & Meigs (1992), Danos & Imhoff (1994), Larson & Miller (1995), en
Stickney & Weil (1997). In deze situatie lijkt het logisch dat de eerste persoon meervoud exclusief
naar de schrijvers verwijst. (7) is het enige voorbeeld dat misschien niet onder de exclusieve we valt.
Hier lijkt we te verwijzen naar “wij boekhouders”, de derde mogelijke en meest zeldzame referent
van de eerste persoon meervoud.
Een tweede uitzondering op de afwezigheid van persoonlijke voornaamwoorden is de eerste persoon
accusatief, zij het steeds in combinatie met let (nadruk telkens toegevoegd):
(14) “Let us see how these three forms will appear in accounting.” (Cole 1908: 80)
(15) “Let us assume the purchase of a certain instrument whose service life will be exactly
five years *…+.” (Mitchell 1917: 298)
(16) “To illustrate how this selection might be made, let’s listen in on a conversation between
Brad and Mary *…+.” (Danos & Imhoff 1994: 390)
(17) “*L+et us consider an example of each of the following types of depreciation methods
allowed within GAAP.” (Danos & Imhoff 1994: 391)
Zinnen (14) tot en met (17) lijken op het eerste zicht een inclusieve us – met de betekenis “laten we
samen …”- te bevatten. Kuo (1999) beweert echter dat de combinatie let + us vaak gebruikt wordt
door de schrijver om naar zichzelf te verwijzen, en zo uit te leggen welk onderwerp er nadien
behandeld zal worden. Dit is opnieuw de functie waarin us hier voorkomt. Op die manier bekeken
wordt het persoonlijk voornaamwoord opnieuw niet gebruikt om de lezer te betrekken bij de
redenering.

31
Een derde uitzondering is het gebruik van de tweede persoon nominatief. Opvallend hierbij is dat dit
enkel in de moderne teksten gebeurt (nadruk telkens toegevoegd):
(18) “If you expect an asset to be traded in on a new asset, the salvage value is the expected
trade-in value.” (Larson & Miller 1995: 323)
(19) “Because plant assets are purchased for use, you can think of a plant asset as a quantity
of usefulness *…+.” (Danos & Imhoff 1994: 389)
(20) “Because depreciation represents the cost of using a plant asset, you should not begin
recording depreciation charges until the asset is actually put to use *…+.” (Danos & Imhoff
1994: 389)
(21) “You can use the following formula to measure straight-line annual depreciation.”
(Danos & Imhoff 1994: 391)
Deze situatie is gelijkaardig aan de vorige twee gevallen. Hoewel you nooit kan verwijzen naar de
schrijver zelf kan het, naast het rechtstreeks aanspreken van de lezer, ook gebruikt worden met
dezelfde betekenis als “men”. Dit lijkt nogmaals het geval wat voorbeelden (18)-(21) betreft. De
“exclusieve” you onderscheidt de lezers immers als een aparte groep (Kuo 1999). In dat geval zouden
de beweringen enkel voor hen gelden, terwijl de instructies die hier uit de doeken worden gedaan op
iedereen van toepassing zijn. Men heeft dus te maken met een interactieve en inclusieve you.
De derde persoon enkelvoud wordt vertegenwoordigd door one. Opnieuw zijn er verschillende
soorten referenten mogelijk. Naast het meest congruente gebruik om de betekenis “men” uit te
drukken, kan one eveneens verwijzen naar de schrijver(s) zelf of naar schrijver(s) en lezer(s) samen.
Desondanks blijft one een uiterst onpersoonlijke voornaamwoord, waar vooral gebruik van wordt
gemaakt om te suggereren dat een bepaalde mening algemeen aanvaard is (Kuo 1999). Zelfs als zou
one in (22) en (23) dus naar de lezer verwijzen, dan nog is dit een heel indirecte aanspreking.
(22) “The last illustration in the preceding chapter showed that in treating depreciation one is
concerned not chiefly with a choice between different accounts when an entry is originally
made, but with the length of time the value shall remain charged to the capital account.”
(Cole 1908: 79)
(23) “It is hardly likely to be done through the medium of another account, unless one wishes
to open an account called “Appreciation,” and it is, therefore, managed simply by bringing
down a new valuation, as shown in Chapter V.” (Cole 1908: 79)
Een andere, meer impliciete techniek die de vroegste auteurs gebruiken om de lezer te betrekken bij
het verhaal is het formuleren van vragen. Op deze manier nodigt men de lezer uit om zich in te leven

32
in de redenering en op zoek te gaan naar het antwoord alvorens verder te lezen. Cole (1908) is de
enige die hiervan gebruik maakt (nadruk telkens toegevoegd):
(24) “What shall the corporation do with these assets?” (Cole 1908: 81)
(25) “What, then, will the books show to the man familiar with accounts?” (Cole 1908: 81)
Hyland (2005: 185) meent dat het stellen van vragen “de strategie par excellence is om dialogische
betrokkenheid te creëren”. Volgens hem stimuleert dit de interesse bij de lezer, en wordt deze
hierdoor als een gelijke behandeld. Wanneer het echter om vragen gaat die vervolgens door de
auteur zelf worden beantwoord, wordt de dialoog geopend en onmiddellijk daarna terug gesloten.
Dit is ook in fragmenten (24) en (25) het geval, zodat men kan stellen dat er wel rechtstreeks
aandacht geschonken wordt aan de lezer, maar dat dit niet zo lang duurt.
Een laatste manier om de lezer aan te spreken is het gebruik van de imperatief. Hierbij beveelt de
schrijver de lezer om een bepaalde handeling te stellen. Ook dit is een techniek die, op (26) na,
uitsluitend door moderne auteurs wordt gehanteerd (nadruk telkens toegevoegd):
(26) “Assume that instead of buying coal the company had bought a machine which was of
such a nature that it would wear out in about two years.” (Gilman 1916: 347)
(27) “Consider, for example, the cost of dismantling a nuclear electricity-generating plant.”
(Stickney & Weil 1997: 464)
(28) “When calculating depreciation in problems in this text, take the entire salvage value
into account unless the problem gives explicit contrary instructions, such as for declining-
balance depreciation methods.” (Stickney & Weil 1997: 464)
(29) “Suppose, for example, that a delivery truck costs $10000 and has an estimated residual
value of $1000 at the end of its estimated useful life of five years.” (Needles 1995: 397)
(30) “Note that the depreciation process does not measure the decline in the car’s market
value each period.” (Danos & Imhoff 1994: 389)
(31) “For example, assume a machine costs $50000, has a $10000 residual value, and has an
estimated useful life of 10000 hours running time.” (Danos & Imhoff 1994: 391)
(32) “Bear in mind, however, that ‘payment’ of many years’ depreciation expense may be
made in advance when the plant asset is purchased.” (Meigs & Meigs 1992: 420)
De bevelen in (26)-(32)zetten de lezer hier telkens aan tot dezelfde, cognitieve, taak. Hyland (2005:
185) onderscheidt daarnaast ook nog directieven die aanzetten tot een fysieke taak en directieven
die de lezer leiden naar een ander deel van de tekst. Dit soort imperatieven komen echter niet voor
in het behandelde corpus.

33
Uit deze analyse kan worden geconcludeerd dat er in beide periodes sowieso weinig middelen
gebruikt worden om de lezer te betrekken bij de tekst. Als deze al worden gebruikt (in de vorm van
persoonlijke voornaamwoorden, vragen, of bevelen) is het vaak onduidelijk of men de lezer hier wel
echt mee wil aanspreken9. Er valt hierbij weinig onderscheid te maken tussen de oudste en nieuwste
teksten. Het enige echte verschil tussen de twee ligt in het soort van aanspreking. You komt in geen
enkele oudere tekst voor, en ook de imperatief wordt met uitzondering van Gilman (1916) enkel
door moderne auteurs gehanteerd. Cole (1908) is dan weer de enige die vragen formuleert.
9 Het hangt er natuurlijk ook van af hoe de lezer dit zelf aanvoelt. Dit hoeft immers niet altijd overeen te komen
met wat de auteur voor ogen had.

34
7 Algemeen Besluit
De vorige paragrafen hebben getracht een antwoord te geven op de vraag in hoeverre de
complexiteit van de taal gebruikt in accountinghandboeken uit de jaren negentig van de vorige eeuw
verschilt van de taal gebruikt in hetzelfde soort handboeken uit het begin van diezelfde eeuw. In
tegenstelling tot vorige onderzoeken die zich met deze problematiek bezighielden (cf. Davidson
2005, Adelberg & Razek 1984, Chiang et al. 2008, Sullivan & Benke 1997), gebeurde de analyse van
de betrokken teksten niet aan de hand van leesbaarheidsformules of de Cloze-procedure. Deze
meetinstrumenten werden in het verleden immers reeds veelvuldig in vraag gesteld (cf. Boogaerd
1997, Klare 2000, Selzer 1981). Als alternatief werd een meer taalkundige aanpak voorgesteld, door
het onderwerp te kaderen binnen de Systemisch-Functionele Grammatica.
Halliday maakt hierin een onderscheid tussen drie niveaus waarop een tekst betekenis creëert. De
lezer dient bijgevolg elk van deze niveaus of metafuncties te doorgronden om de inhoud volledig te
verstaan. Om die reden werden per metafunctie een aantal variabelen geselecteerd, op basis
waarvan de tekstanalyse plaatsvond. Deze aanpak heeft als verdienste dat een groter aantal
tekstuele elementen aan bod komt, en dat deze zowel kwantitatief als kwalitatief behandeld worden.
Het onderzoek is bijgevolg veel gedetailleerder van aard. Deze nieuwe benadering heeft geleid tot de
volgende resultaten:
- De gemiddelde zinslengte is significant korter in de modernere handboeken, en ze bevatten
procentueel gezien ook meer korte zinnen. Wat het aantal lange zinnen betreft kon er geen
significant verschil vastgesteld worden tussen beide periodes, zelfs al zou de afkapgrens
verlaagd worden tot 50 woorden.
- Lexicale densiteit en nominalisatie vertonen de omgekeerde trend. De oudere boeken
bevatten verhoudingsgewijs minder lexicale items en nominalisaties en zijn bijgevolg minder
complex. Dit wordt echter in beide gevallen deels gecompenseerd door een lagere
type/token ratio.
- De oudste teksten bevatten twee keer meer conjuncties, maar het soort voegwoorden
vertoont bijna geen verschil. Enkel de causale conjuncties zijn meer aanwezig in de moderne
handboeken, hetgeen waarschijnlijk de toegankelijkheid verhoogt.
- De bladspiegel is meer gesofisticeerd in de moderne handboeken. De talrijk aanwezige
visuele elementen maken het de lezer gemakkelijker om alles te begrijpen.

35
- De lezer wordt in beide periodes weinig betrokken bij de tekst door middel van persoonlijke
voornaamwoorden. Opvallend is wel dat you uitsluitend en de imperatief bijna uitsluitend in
de moderne teksten voorkomen. Het formuleren van vragen komt dan weer enkel bij de
vroegste handboeken voor, net als het gebruik van one.
De complexiteit van de gebruikte taal is dus inderdaad op bepaalde vlakken gedaald, maar op andere
vlakken gelijk gebleven of zelfs gestegen. Op basis van dit onderzoek lijkt het moeilijk te geloven dat
een sterke vereenvoudiging van de complexiteit van de gebruikte taal aan de basis zou liggen van een
achteruitgang in het lees- en verbale vermogen van (aspirant-) boekhouders (cf. supra p. 1). Het
aantal nominalisaties, die onder andere dienen om technische termen te creëren, is zelfs
toegenomen, zodat Davidsons vrees dat studenten hier minder vertrouwd mee zouden geraken
ongegrond lijkt. De vaststelling dat de verschillen tussen beide periodes relatief beperkt zijn is niet
zo verwonderlijk als men ze kadert binnen Systemisch-Functionele Grammatica. Deze theorie
poneert immers dat de auteurs wel variaties kunnen aanbrengen om hun teksten toegankelijker te
maken, maar dat dit enkel mogelijk is binnen de conventies van het genre. Indien deze conventies
genegeerd worden en er bijvoorbeeld geen nominalisaties of veel persoonlijke voornaamwoorden
gebruikt worden, kunnen de accountinghandboeken hun functie van “het bijbrengen van
boekhoudkundige kennis” niet vervullen. Wanneer deze redenering verder doorgetrokken wordt
valt het dus te verwachten dat de complexiteit van de taal gebruikt in accountinghandboeken ook in
de toekomst slechts beperkt zal evolueren.
Bij het formuleren van deze conclusie mag echter uiteraard niet voorbij gegaan worden aan de
beperkingen van dit onderzoek. Ten eerste kunnen vragen worden gesteld bij de selectie van de
fragmenten. Zo beweren Bruce & Rubin (1988) dat het analyseren van een deel van een tekst de
complexiteit significant kan wijzigen. Dit heeft te maken met de vaststelling van sommige
onderzoekers dat de leesbaarheid van de hoofdstukken van eenzelfde boek kan verschillen
naargelang het behandelde onderwerp. Sullivan & Benke (1997) bijvoorbeeld ondervonden
(paradoxaal genoeg) dat de inleidende hoofdstukken van de door hen geanalyseerde
accountinghandboeken moeilijker te begrijpen waren dan de kapittels die afschrijvingen
behandelden. De grootte van de discrepantie hangt echter ook af van hoe groot het verschil is tussen
de lengte van de geselecteerde passage en de totale lengte van het boek. In dit onderzoek is dit
verschil enorm groot. Zoals gezegd werden telkens 3 pagina’s gekozen, terwijl het handboek van
Danos & Imhoff (1994) bijvoorbeeld 911 pagina’s (inclusief bijlagen) telt. De geanalyseerde passage
maakt dus iets meer dan 0.3% uit van het gehele werk. Het corpus van ongeveer 10000 woorden kan
dus bezwaarlijk representatief genoemd worden voor de tien handboeken, maar om praktische
redenen was het onmogelijk om grotere delen of zelfs hele boeken onder de loep te nemen.

36
Een tweede soort bedenking die men zich zou kunnen maken is dat de analyse verre van exhaustief
is. Hoewel de passages bestudeerd werden aan de hand van een tiental variabelen, zullen zij
waarschijnlijk niet de totale groep van elementen vormen die de complexiteit van een tekst kunnen
beïnvloeden. Bij de analyse van lexicale densiteit en nominalisatie bijvoorbeeld wegen frequente en
minder frequente woorden even zwaar door, terwijl een veel voorkomende nominalisatie als
information toch een andere moeilijkheidsgraad heeft dan obsolescence. Onder andere Mota (2003)
en Prebianca & D’Ely (2008) lossen dit probleem op door een gewogen lexicale densiteit te
berekenen, waarbij minder frequente woorden half zo zwaar doorwegen. Ook hier kunnen vragen bij
gesteld worden, want vanaf wanneer wordt een woord als ‘frequent’ beschouwd, en waarom slechts
een onderverdeling in twee groepen van frequentie? Een tweede handicap van deze analyse bestaat
erin dat hetzelfde woord verschillende betekenissen kan hebben. Deze situatie komt hier niet echt
voor omdat alle fragmenten hetzelfde onderwerp behandelen, zodat de context gelijkaardig is. Toch
dient eveneens met dit aspect rekening gehouden te worden, zodat het verschil tussen congruente
en minder congruente betekenissen beter tot uiting komt.
De belangrijkste onvolledigheid is echter dat er – op de conjuncties na – bijna uitsluitend gefocust
werd op het niveau van de zin, terwijl voor de lezer het tekstniveau van uiterst groot belang is. Dit
brengt ons onmiddellijk bij een volgende punt van mogelijk kritiek: de keuze om het onderzoek te
beperken tot tekstuele kenmerken gaat volledig voorbij aan hoe deze interageren met de kenmerken
van de lezer. Onder andere Bruce & Rubin (1988) en Anderson & Davison (1988) wijzen op het
belangrijke aandeel dat de eigenschappen van de lezer, zoals diens motivatie en interessesfeer,
hebben in de totstandkoming van de complexiteit van een werk. Een element dat echter vaak
vergeten wordt in deze context is de manier waarop lezers omgaan met een tekst. Een verkeerde
behandelwijze van het handboek zou immers eveneens de oorzaak kunnen zijn dat bepaalde kennis
niet overgebracht wordt. Phillips (2007) is de eerste die dit onontgonnen terrein op een diepgaande
manier verkend heeft, en zijn empirische studie in verband met inleidende accountinghandboeken
levert interessante resultaten op. Zo komt er in het onderzoek naar voor dat de meeste studenten
geen vooraf bepaalde leesstrategie hebben maar louter experimenteren en zich laten leiden door de
omstandigheden. Het leesgedrag is dan ook zeer gevarieerd. Hoofdstukken worden in één of
meerdere keren doorgenomen, op een vluchtige of grondige manier, reeds voor de lessen of pas
erna, etc. De tijd die er nog rest tot het examen speelt hierin ook een belangrijke rol. Er is echter nog
meer onderzoek nodig om duidelijkheid te scheppen in welke strategie de meest effectieve is.
Behalve de persoonlijke kenmerken van de lezer gaat onze studie nog voorbij aan een ander
fundamenteel onderdeel van accountinghandboeken, namelijk de balansen, T-rekeningen,
afschrijvingsschema’s, grafieken, etc. Hoewel deze elementen niet behoren tot de tekst, dragen ze

37
door hun aanwezigheid toch bij tot de moeilijkheidsgraad van de tekst die ze begeleiden. Sullivan &
Benke (1997) halen dit dan ook aan als een mogelijke verklaring voor hun afwijkende conclusie in
verband met de leesbaarheid van inleidende hoofdstukken en hoofdstukken die afschrijven
behandelen (cf. supra). Zo zou het bijvoorbeeld kunnen dat de verschillende aspecten van het
afschrijven beschreven worden met behulp van schema’s en grafieken, terwijl dit soort uitleg in de
inleiding vervangen wordt door complexere taal. Sullivan & Benke (1997) maken weliswaar gebruik
van leesbaarheidsformules en niet van de analysemethode die hier wordt toegepast, maar beide
manieren van werken negeren inderdaad deze visuele elementen.
Een laatste bedenking die kan gemaakt worden is deze over de oorsprong van het resultaat. Het is
niet omdat men bepaalde verschillen vaststelt tussen de accountinghandboeken uit het de eerste
twee decennia van de 20e eeuw en deze uit het laatste decennium van de 20e eeuw, dat dit eigen is
aan economisch academisch proza of een bewuste keuze van de betrokken auteurs was. In feite zou
men best andere – liefst academische - boeken bij het onderzoek betrekken, om te onderzoeken of
de observaties niet veroorzaakt worden door een algemene evolutie binnen het geschreven Engels
(Goldschmidt & Szmrecsanyi 2007).
Dit is dan ook een eerste tip voor onderzoekers die zich verder met dit thema willen bezighouden.
Daarnaast zou men dezelfde analysetechnieken kunnen toepassen op een aantal inleidende
handboeken uit de jaren twintig tot en met tachtig, om na te gaan of er een evolutie merkbaar is van
het begin tot het einde van de twintigste eeuw. Een andere mogelijkheid is om, net als Davidson,
gevorderde handboeken en boeken op tussenniveau aan het corpus toe te voegen. De methode van
analyseren zou bovendien kunnen aangevuld worden met een multimodal discourse analyse om de
effecten van visuele hulpmiddelen te achterhalen. Men zou eveneens lezers kunnen ondervragen of
testen om te zien of de onderzochte variabelen inderdaad ook door hen als bronnen van
complexiteit worden beschouwd.
Hoe uitgebreid men toekomstig onderzoek echter ook maakt, het zal auteurs nooit een handleiding
kunnen bezorgen over hoe ze een leesbaar handboek kunnen produceren dat aangepast is aan hun
doelpubliek. Of om met Klares woorden (2000: 18) af te sluiten: “Writing is a complex bit of human
behavior, and therefore a definition of good or satisfactory writing is hard to develop. There are rules
for specific purposes, to be sure, but careful adherence to them does not guarantee good writing. In
short, writing is an art and not a science.”

IV
8 Lijst van geraadpleegde werken
8.1 Primaire Literatuur
Cole, W.M., 1908, Accounts, their Construction and Interpretation, for Businessmen and Students of
Affairs, Boston: Houghton Mifflin Company, pp. 79-81.
Danos, P. en E.A. Imhoff, 1994, Introduction to Financial Accounting, Burr Ridge: Irwin, pp. 389-391.
Gilman, S., 1916, Principles of Accounting, Chicago: La Salle Extension University, pp. 346-348.
Hatfield, H.R., 1909, Modern Accounting, Its Principles and Some of Its Problems,
New York: D. Appleton and Company, pp. 121-123.
Larson, K.D. en P.B.W. Miller, 1995, Financial Accounting, Chicago: Irwin, pp. 322-324.
Meigs, R.F. en W.B. Meigs, 1992, Financial Accounting, New York: McGraw-Hill. Pp. 418-420.
Mitchell, T.W., 1917, Accounting Principles, Ramsey: Alexander Hamilton Institute, pp. 297-299.
Needles, B.E., 1995, Financial Accounting, Boston: Houghton Mifflin Company, pp. 395-397.
Racine, S.F., 1913, Accounting Principles, Seattle: The Western Institute of Accountancy, Commerce
and Finance, pp. 114-116.
Stickney, C.P. en R.L. Weil, 1997, Financial Accounting. An Introduction to Concepts, Methods, and
Uses. Fort Worth: The Dryden Press, pp. 462-464.
8.2 Secundaire Literatuur
Adelberg, A.H. en J.R. Razek, 1984, The Cloze Procedure: A Methodology for Determining the
Understandability of Accounting Textbooks, The Accounting Review, LIX.1, pp. 109-122.
Anderson, R.C. en A. Davison (1988). Conceptual and Empirical Bases of Readability Formulas. In A.
Davison & G.M. Green (Eds.), Linguistic Complexity and Text Comprehension. Readability
Issues Reconsidered. New Jersey: Lawrence Erlbaum Associates, Publishers.
Banks, D., 1996, The Passive and Metaphor in Scientific Writing, Cuadernos de Filología Inglesa, 5.2,
pp. 13-22.
Biber, D., 1998, Variation across Speech and Writing. Cambridge: Cambridge University Press.
Boogaerd, M., 1997, Van Buiten, Geleerd: Allochtone en Buitenlandse Studenten in het Nederlandse
Hoger Onderwijs, Amsterdam: Het Spinhuis.

V
Breeze, R., 2007, How Personal is this Text? Researching Writer and Reader Presence in Student
Writing Using Wordsmith Tools. CORELL: Computer Resources for Language Learning, 1, pp.
14-21.
Bruce, B. en A. Rubin, 1988, Readability Formulas: Matching Tool and Task. In A. Davison & G.M.
Green (Eds.), Linguistic Complexity and Text Comprehension. Readability Issues Reconsidered.
New Jersey: Lawrence Erlbaum Associates, Publishers.
Charrow, V., 1988, Readability vs. Comprehensibility: A Case Study in Improving a Real Document. In
A. Davison & G.M. Green (Eds.), Linguistic Complexity and Text Comprehension. Readability
Issues Reconsidered. New Jersey: Lawrence Erlbaum Associates, Publishers.
Chiang, W. en T.D. Englebrecht en T.J. Phillips en Y. Wang, 2008, Readability of Financial Accounting
Textbooks, The Accounting Educator’s Journal, XVIII, pp. 47-80.
Crane, P.A., 2006, Texture in Text: A Discourse Analysis of a News Article Using Halliday and Hasan’s
Model of Cohesion, Journal of School of Foreign Languages, 30, pp. 131-156.
Davison, A. en G.M. Greene, 1988, Linguistic Complexity and Text Comprehension. Readability Issues
Reconsidered, New Jersey: Lawrence Erlbaum Associates, Publishers.
Davidson, R.A., 2005, Analysis of the Complexity of Writing Used in Accounting Textbooks Over the
Past 100 Years, Accounting Education, 14.1, pp. 53-74.
Fang, Z., 2004, Scientific Literacy: A Functional Linguistics Perspective, Science Education, 89.2, pp.
335-347.
Geiger, M.A. en S.M. Ogilby, 2000, The First Course in Accounting: Students’ Perceptions and their
Effect on the Decision to Major in Accounting, Journal of Accounting Education, 18, pp. 63-78.
Goldschmidt, N. en B. Szmrecsanyi, 2007, What Do Economists Talk About? A Linguistic Analysis of
Published Writing in Economic Journals, American Journal of Economics and Sociology, 66.2,
pp. 335-378.
Halliday, M.A.K., 1989, Spoken and Written Language, Oxford: Oxford University Press.
Halliday, M.A.K., 1993, Writing Science: Literacy and Discursive Power, London: Falmer Press.
Halliday, M.A.K. en R. Hasan, 1976, Cohesion in English, London: Longman.
Hyland, K., 2005, Stance and Engagement: A Model of Interaction in Academic Discourse, Discourse
Studies, 7.2, pp. 173-192.
Innajih, A.A., 2006, The Impact of Textual Cohesive Conjunctions on the Reading Comprehension of
Foreign Language Students. ARECLS e-journal, 3, pp. 1-20.
Klare, G.R., 2000, The Measurement of Readability: Useful Information for Communicators, ACM
Journal of Computer Documentation, 24.3, pp. 11-25.
Kuo, C., 1999, The Use of Personal Pronouns: Role Relationships in Scientific Journal Articles, English
for Specific Purposes, 18.2, pp. 121-138.

VI
Laufer, B, 1991, The Development of L2 Lexis in the Expression of the Advanced Learner, The Modern
Language Journal, 75.4, pp. 440-448.
Moss, M.G., 2000, The Language of School Textbooks and the Ideology of Science, Zona Próxima, 1,
pp. 44-55.
Mota, M.B., 2003, Working Memory Capacity and Fluency, Accuracy, Complexity and Lexical Density
in L2 Speech Production, Fragmentos, 24, pp. 69-104.
Phillips, B.J. en F. Phillips, 2007, Sink or Skim: Textbook Reading Behaviors of Introductory Accounting
Students, Issues in Accounting Education, 22.1, pp. 21-44.
Prebianca, G.V. en R. D’Ely, 2008, EFL Speaking and Individual Differences in Working Memory
Capacity: Grammatical Complexity and Weighted Lexical Density in the Oral Production of
Beginners, Signótica, 20.2, p. 335-366.
Schleppegrell, M.J., 2001, Linguistic Features of the Language of Schooling, Linguistics and Education,
12.4, pp. 431-459.
Schmitt, N., 2000, Vocabulary in Language Teaching, Cambridge: Cambridge University Press.
Selzer, J., 1981, Readability is a Four-Letter Word, The Journal of Business Communication. 18:4, pp
23-34.
Stevens, K.T., en K.C. Stevens en W.P. Stevens, 1992, Measuring the Readability of Business Writing:
The Cloze Procedure versus Readability Formulas, The Journal of Business Communication,
29:4, pp. 367-382.
Sullivan, C.M.en R.L. Benke, 1997, Comparing Introductory Financial Accounting Handbooks, Journal
of Accounting Education, 15.2, pp. 181-220.
Thompson, G.,1996, Introducing Functional Grammar, London: Arnold.
Veel, R.,1997, Learning How to Mean – Scientifically Speaking: Apprenticeship into Scientific
Discourse in the Secondary School”. In F. Christie en J.R. Martin (Eds.), Genre and Institutions:
Social Processes in the Workplace and School. London: Cassell.
Wells, G., 1984, Learning and Teaching Scientific Concepts: Vygotsky’s Ideas Revisited, Toronto:
Ontario Institute For Studies In Education.
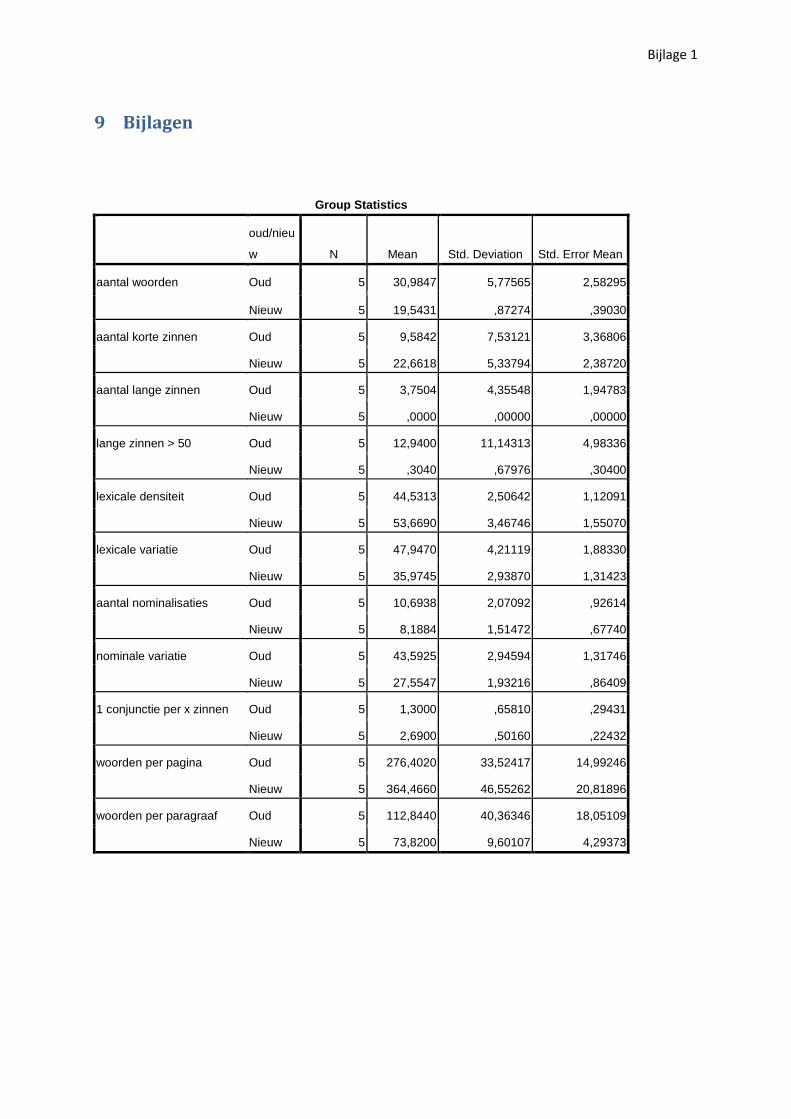
Bijlage 1
9 Bijlagen
Group Statistics
oud/nieu
w N Mean Std. Deviation Std. Error Mean
aantal woorden Oud 5 30,9847 5,77565 2,58295
Nieuw 5 19,5431 ,87274 ,39030
aantal korte zinnen Oud 5 9,5842 7,53121 3,36806
Nieuw 5 22,6618 5,33794 2,38720
aantal lange zinnen Oud 5 3,7504 4,35548 1,94783
Nieuw 5 ,0000 ,00000 ,00000
lange zinnen > 50 Oud 5 12,9400 11,14313 4,98336
Nieuw 5 ,3040 ,67976 ,30400
lexicale densiteit Oud 5 44,5313 2,50642 1,12091
Nieuw 5 53,6690 3,46746 1,55070
lexicale variatie Oud 5 47,9470 4,21119 1,88330
Nieuw 5 35,9745 2,93870 1,31423
aantal nominalisaties Oud 5 10,6938 2,07092 ,92614
Nieuw 5 8,1884 1,51472 ,67740
nominale variatie Oud 5 43,5925 2,94594 1,31746
Nieuw 5 27,5547 1,93216 ,86409
1 conjunctie per x zinnen Oud 5 1,3000 ,65810 ,29431
Nieuw 5 2,6900 ,50160 ,22432
woorden per pagina Oud 5 276,4020 33,52417 14,99246
Nieuw 5 364,4660 46,55262 20,81896
woorden per paragraaf Oud 5 112,8440 40,36346 18,05109
Nieuw 5 73,8200 9,60107 4,29373
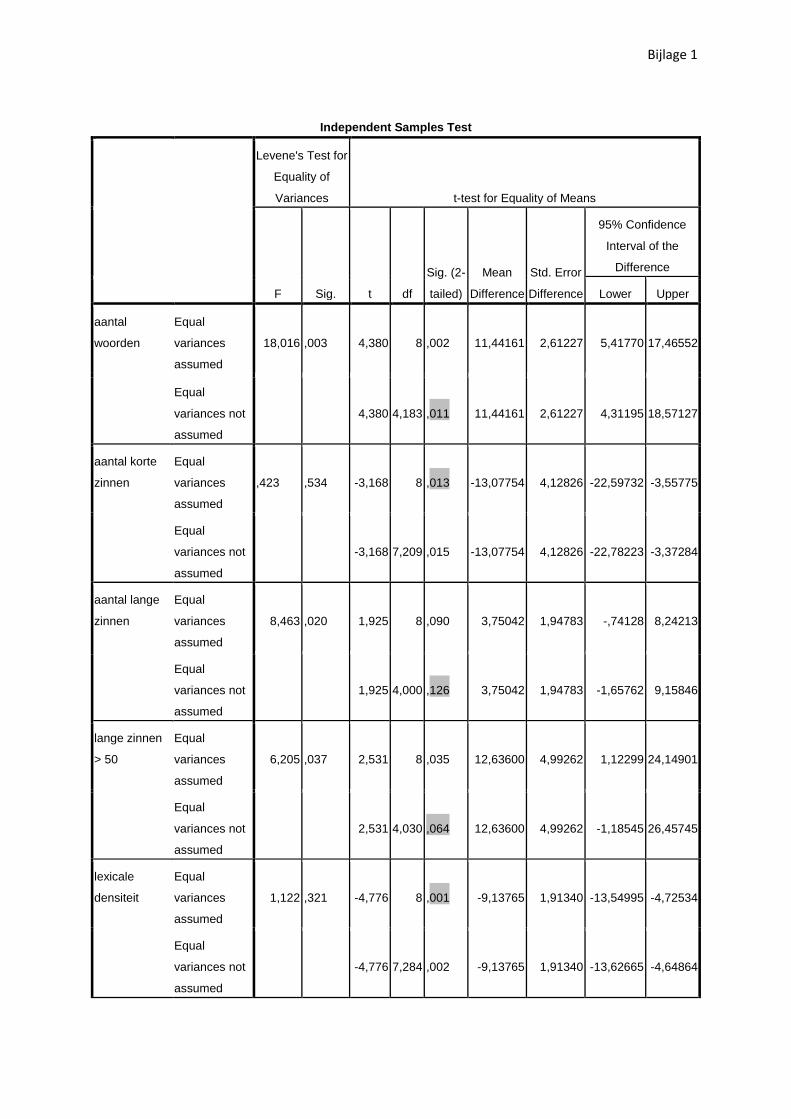
Bijlage 1
Independent Samples Test
Levene's Test for
Equality of
Variances t-test for Equality of Means
F Sig. t df
Sig. (2-
tailed)
Mean
Difference
Std. Error
Difference
95% Confidence
Interval of the
Difference
Lower Upper
aantal
woorden
Equal
variances
assumed
18,016 ,003 4,380 8 ,002 11,44161 2,61227 5,41770 17,46552
Equal
variances not
assumed
4,380 4,183 ,011 11,44161 2,61227 4,31195 18,57127
aantal korte
zinnen
Equal
variances
assumed
,423 ,534 -3,168 8 ,013 -13,07754 4,12826 -22,59732 -3,55775
Equal
variances not
assumed
-3,168 7,209 ,015 -13,07754 4,12826 -22,78223 -3,37284
aantal lange
zinnen
Equal
variances
assumed
8,463 ,020 1,925 8 ,090 3,75042 1,94783 -,74128 8,24213
Equal
variances not
assumed
1,925 4,000 ,126 3,75042 1,94783 -1,65762 9,15846
lange zinnen
> 50
Equal
variances
assumed
6,205 ,037 2,531 8 ,035 12,63600 4,99262 1,12299 24,14901
Equal
variances not
assumed
2,531 4,030 ,064 12,63600 4,99262 -1,18545 26,45745
lexicale
densiteit
Equal
variances
assumed
1,122 ,321 -4,776 8 ,001 -9,13765 1,91340 -13,54995 -4,72534
Equal
variances not
assumed
-4,776 7,284 ,002 -9,13765 1,91340 -13,62665 -4,64864
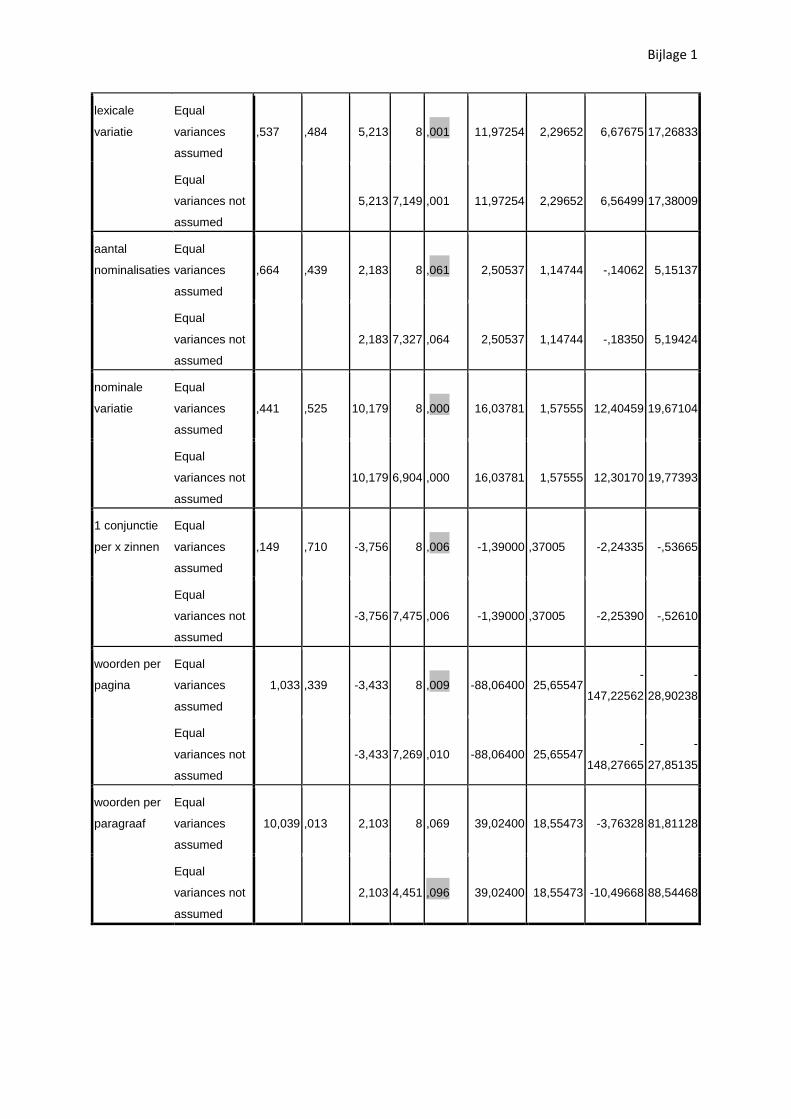
Bijlage 1
lexicale
variatie
Equal
variances
assumed
,537 ,484 5,213 8 ,001 11,97254 2,29652 6,67675 17,26833
Equal
variances not
assumed
5,213 7,149 ,001 11,97254 2,29652 6,56499 17,38009
aantal
nominalisaties
Equal
variances
assumed
,664 ,439 2,183 8 ,061 2,50537 1,14744 -,14062 5,15137
Equal
variances not
assumed
2,183 7,327 ,064 2,50537 1,14744 -,18350 5,19424
nominale
variatie
Equal
variances
assumed
,441 ,525 10,179 8 ,000 16,03781 1,57555 12,40459 19,67104
Equal
variances not
assumed
10,179 6,904 ,000 16,03781 1,57555 12,30170 19,77393
1 conjunctie
per x zinnen
Equal
variances
assumed
,149 ,710 -3,756 8 ,006 -1,39000 ,37005 -2,24335 -,53665
Equal
variances not
assumed
-3,756 7,475 ,006 -1,39000 ,37005 -2,25390 -,52610
woorden per
pagina
Equal
variances
assumed
1,033 ,339 -3,433 8 ,009 -88,06400 25,65547 -
147,22562
-
28,90238
Equal
variances not
assumed
-3,433 7,269 ,010 -88,06400 25,65547 -
148,27665
-
27,85135
woorden per
paragraaf
Equal
variances
assumed
10,039 ,013 2,103 8 ,069 39,02400 18,55473 -3,76328 81,81128
Equal
variances not
assumed
2,103 4,451 ,096 39,02400 18,55473 -10,49668 88,54468
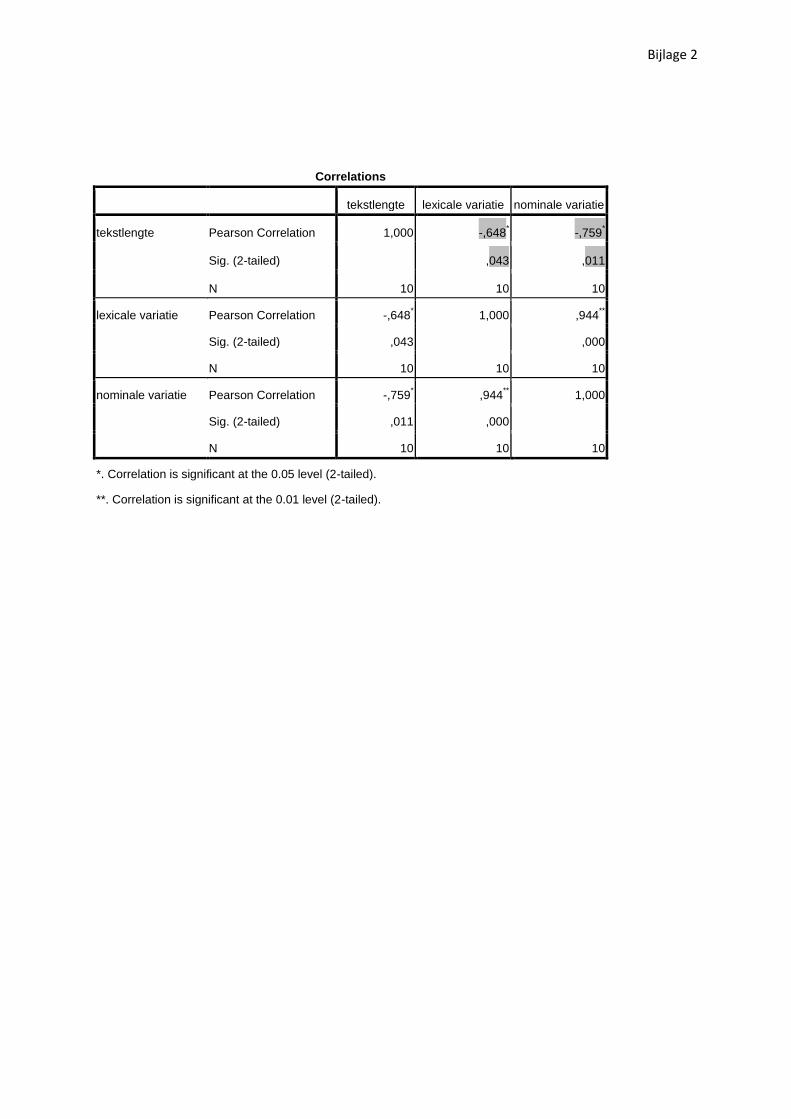
Bijlage 2
Correlations
tekstlengte lexicale variatie nominale variatie
tekstlengte Pearson Correlation 1,000 -,648* -,759
*
Sig. (2-tailed) ,043 ,011
N 10 10 10
lexicale variatie Pearson Correlation -,648* 1,000 ,944
**
Sig. (2-tailed) ,043 ,000
N 10 10 10
nominale variatie Pearson Correlation -,759* ,944
** 1,000
Sig. (2-tailed) ,011 ,000
N 10 10 10
*. Correlation is significant at the 0.05 level (2-tailed).
**. Correlation is significant at the 0.01 level (2-tailed).
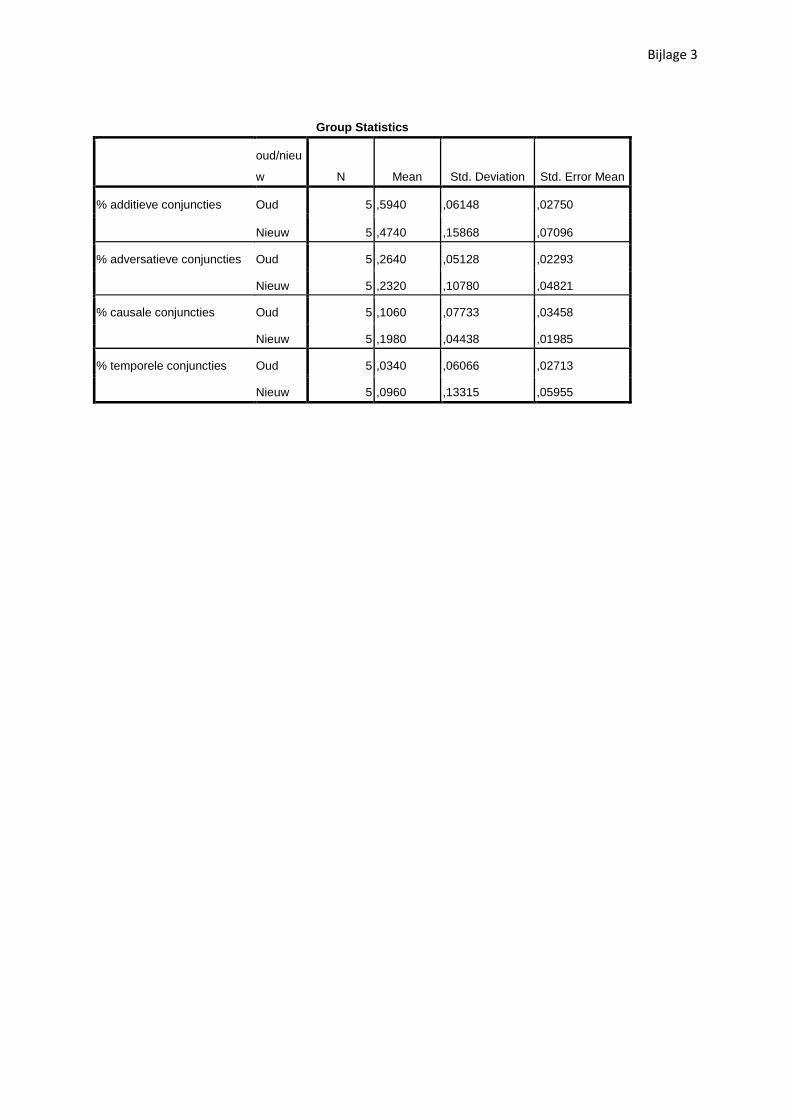
Bijlage 3
Group Statistics
oud/nieu
w N Mean Std. Deviation Std. Error Mean
% additieve conjuncties Oud 5 ,5940 ,06148 ,02750
Nieuw 5 ,4740 ,15868 ,07096
% adversatieve conjuncties Oud 5 ,2640 ,05128 ,02293
Nieuw 5 ,2320 ,10780 ,04821
% causale conjuncties Oud 5 ,1060 ,07733 ,03458
Nieuw 5 ,1980 ,04438 ,01985
% temporele conjuncties Oud 5 ,0340 ,06066 ,02713
Nieuw 5 ,0960 ,13315 ,05955
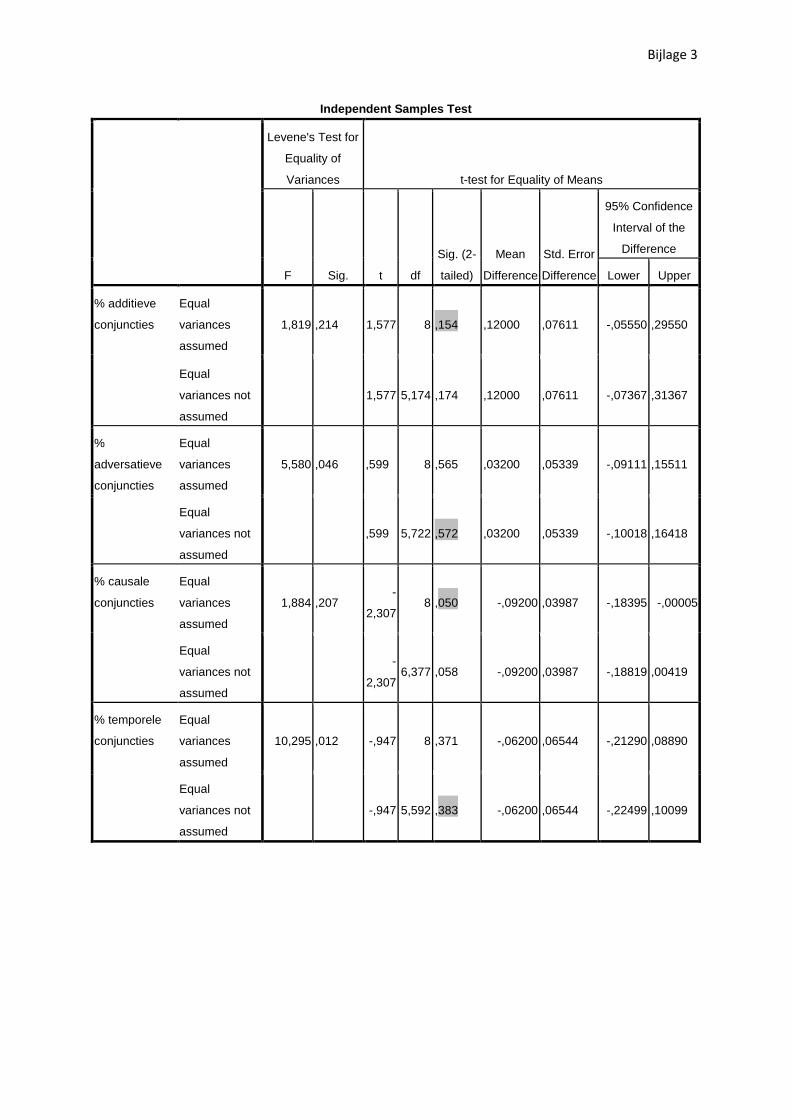
Bijlage 3
Independent Samples Test
Levene's Test for
Equality of
Variances t-test for Equality of Means
F Sig. t df
Sig. (2-
tailed)
Mean
Difference
Std. Error
Difference
95% Confidence
Interval of the
Difference
Lower Upper
% additieve
conjuncties
Equal
variances
assumed
1,819 ,214 1,577 8 ,154 ,12000 ,07611 -,05550 ,29550
Equal
variances not
assumed
1,577 5,174 ,174 ,12000 ,07611 -,07367 ,31367
%
adversatieve
conjuncties
Equal
variances
assumed
5,580 ,046 ,599 8 ,565 ,03200 ,05339 -,09111 ,15511
Equal
variances not
assumed
,599 5,722 ,572 ,03200 ,05339 -,10018 ,16418
% causale
conjuncties
Equal
variances
assumed
1,884 ,207 -
2,307 8 ,050 -,09200 ,03987 -,18395 -,00005
Equal
variances not
assumed
-
2,307 6,377 ,058 -,09200 ,03987 -,18819 ,00419
% temporele
conjuncties
Equal
variances
assumed
10,295 ,012 -,947 8 ,371 -,06200 ,06544 -,21290 ,08890
Equal
variances not
assumed
-,947 5,592 ,383 -,06200 ,06544 -,22499 ,10099


















