1. Inleiding - RUG
78
1. Inleiding De laatste jaren wordt over de westerse landen steeds minder gesproken als productiemaatschappijen, en steeds meer als kenniseconomieën. De taken en problemen van onze maatschappij liggen niet langer hoofdzakelijk bij de productie van goederen en diensten. Onze maatschappij vereist een snelle en accurate toevoer en doorstroom van informatie over onder andere de voorkeuren, behoeften, meningen en gedragingen van verschillende bevolkingsgroepen. In antwoord op deze behoefte aan informatie van de overheid, het bedrijfsleven en verscheidene sociale instanties wordt veelvuldig gebruik gemaakt van de onderzoeksmethode van de enquête. Enquêtes kunnen voor veel onderzoeksdoelen gebruikt worden en kunnen op meerdere manieren uitgevoerd worden. Vaak wordt een enquête uitgevoerd als aanvulling op, of als basis van een groter onderzoek. Een online enquête kan dan een goede uitkomst bieden. Belangrijke voordelen van een online enquête boven andere enquêtestrategieën zijn de snelheid waarmee de enquête opgezet, uitgevoerd en verwerkt kan worden, en het feit dat redelijk eenvoudig een grote populatie bereikt kan worden. Een dergelijke onderzoeksstrategie wordt dan ook vaak toegepast voor het uitvoeren van marktonderzoeken of politieke peilingen. Voor een onderzoek met als thema ‘computervirussen’ wilde ik meer weten over de manier waarop verschillende groepen computergebruikers omgaan met computervirussen. Om dit te onderzoeken heb ik een enquête opgesteld en uitgevoerd op papier en het World Wide Web, waarbij de respondenten gevraagd worden naar hun mening over en hun gedragingen ten opzichte van computervirussen. Ondanks de vele adviezen en waarschuwingen die in de literatuur over het opzetten en uitvoeren van een enquête te vinden zijn, zijn de problemen die het uitvoeren van een enquête met zich mee kan brengen moeilijk te voorzien. Om zoveel mogelijk moeilijkheden te voorkomen, zijn de adviezen van verschillende onderzoekers voor het bewoorden van de vragen en het opstellen van vragenlijsten nauwkeurig opgevolgd, en zijn de meeste vragen gesloten geformuleerd. Zowel het opzetten van de enquête voor het ‘Computer Virus Onderzoek’ (in het vervolg aangeduid met ‘CVO’), als het uitvoeren van de enquête onder 135 deelnemers leverden geen problemen op. Het verwerken van de verzamelde gegevens is dan de volgende stap. Hier liep ik tegen een tweetal moeilijkheden op: 1. De antwoorden die op de papieren versie ingevuld waren, zijn handmatig in MS Access ingevoerd. De antwoorden die verzameld zijn door de online versie van de enquête zijn verstuurd via e-mail. Deze e-mailberichten waren niet gestructureerd opgezet, waardoor het nodig was ook deze antwoorden handmatig in te voeren in de database: respondent 1
Transcript of 1. Inleiding - RUG

1. Inleiding
De laatste jaren wordt over de westerse landen steeds minder gesproken als
productiemaatschappijen, en steeds meer als kenniseconomieën. De taken en problemen van
onze maatschappij liggen niet langer hoofdzakelijk bij de productie van goederen en
diensten. Onze maatschappij vereist een snelle en accurate toevoer en doorstroom van
informatie over onder andere de voorkeuren, behoeften, meningen en gedragingen van
verschillende bevolkingsgroepen. In antwoord op deze behoefte aan informatie van de
overheid, het bedrijfsleven en verscheidene sociale instanties wordt veelvuldig gebruik
gemaakt van de onderzoeksmethode van de enquête.
Enquêtes kunnen voor veel onderzoeksdoelen gebruikt worden en kunnen op meerdere
manieren uitgevoerd worden. Vaak wordt een enquête uitgevoerd als aanvulling op, of als
basis van een groter onderzoek. Een online enquête kan dan een goede uitkomst bieden.
Belangrijke voordelen van een online enquête boven andere enquêtestrategieën zijn de
snelheid waarmee de enquête opgezet, uitgevoerd en verwerkt kan worden, en het feit dat
redelijk eenvoudig een grote populatie bereikt kan worden. Een dergelijke
onderzoeksstrategie wordt dan ook vaak toegepast voor het uitvoeren van marktonderzoeken
of politieke peilingen. Voor een onderzoek met als thema ‘computervirussen’ wilde ik meer
weten over de manier waarop verschillende groepen computergebruikers omgaan met
computervirussen. Om dit te onderzoeken heb ik een enquête opgesteld en uitgevoerd op
papier en het World Wide Web, waarbij de respondenten gevraagd worden naar hun mening
over en hun gedragingen ten opzichte van computervirussen. Ondanks de vele adviezen en
waarschuwingen die in de literatuur over het opzetten en uitvoeren van een enquête te vinden
zijn, zijn de problemen die het uitvoeren van een enquête met zich mee kan brengen moeilijk
te voorzien. Om zoveel mogelijk moeilijkheden te voorkomen, zijn de adviezen van
verschillende onderzoekers voor het bewoorden van de vragen en het opstellen van
vragenlijsten nauwkeurig opgevolgd, en zijn de meeste vragen gesloten geformuleerd.
Zowel het opzetten van de enquête voor het ‘Computer Virus Onderzoek’ (in het vervolg
aangeduid met ‘CVO’), als het uitvoeren van de enquête onder 135 deelnemers leverden
geen problemen op. Het verwerken van de verzamelde gegevens is dan de volgende stap.
Hier liep ik tegen een tweetal moeilijkheden op:
1. De antwoorden die op de papieren versie ingevuld waren, zijn handmatig in MS Access
ingevoerd. De antwoorden die verzameld zijn door de online versie van de enquête zijn
verstuurd via e-mail. Deze e-mailberichten waren niet gestructureerd opgezet, waardoor
het nodig was ook deze antwoorden handmatig in te voeren in de database: respondent
1

voor respondent en antwoord voor antwoord: 135 x 58 = 7830 antwoorden. Het risico
om fouten te maken door antwoorden over te slaan, of foutieve waarden in te voeren, is
bij een dergelijke invoermethode te groot.
2. De antwoorden op de gesloten vragen konden rechtstreeks overgenomen worden in de
database. De verwerking van deze antwoorden leverde geen moeilijkheden op. Om de
antwoorden op de open vragen te kunnen verwerken zijn categorieën aangemaakt,
waarbij ieder antwoord in maximaal één categorie ingedeeld is. De categorieën kregen
een karakter toegekend (bijvoorbeeld ‘A’, ‘B’ of ‘C’), welke gebruikt is om als antwoord
op de betreffende vraag in de database op te slaan. Op deze manier zijn de antwoorden
dus ‘gekwantificeerd’ en behandeld als zijnde antwoorden op gesloten vragen. Een vraag
als “Wat is volgens u een passende straf voor virusmakers en anderen die bewust
virussen verspreiden?” leverde antwoorden op als “geldboete en gevangenisstraf”,
“actief inzetten bij gedupeerde bedrijven en een geldboete betalen”, “geldboete die
betaald moet worden aan degenen die schade hebben geleden”, en kortweg “geldboete”.
Al deze antwoorden zijn ingedeeld in de categorie “geldboete”. Echter, op deze manier
gaat te veel van de oorspronkelijke informatie verloren.
Het eerste probleemgebied, dat van de gegevensinvoer en de gegevensopslag, is te
verwachten bij een enquête die op papier uitgedeeld wordt. De antwoorden die via een
online enquête verzameld worden staan reeds in elektronische vorm opgeslagen en zouden
dus voor minder problemen op dit gebied moeten zorgen. Doordat de antwoorden op een
ongestructureerde manier via e-mail verzonden werden, kon nauwelijks van dit voordeel
gebruik gemaakt worden.
De verwerking van de antwoorden op de open vragen, het tweede probleemgebied, geeft bij
beide enquêtestrategieën problemen.
Er is dus behoefte aan één, eenvoudig en snel te gebruiken ‘tool’ voor het opzetten, het
uitvoeren en het verwerken van een enquête, en bij voorkeur een enquête die op het World
Wide Web uitgevoerd wordt. Daarbij dient het verwerkingssysteem dermate uitgebreid te
zijn dat het mogelijkheden biedt voor de invoer en opslag van de verzamelde antwoorden,
een analyse van de antwoorden op zowel de open als de gesloten vragen, en tenslotte een
presentatie van de uiteindelijke resultaten.
Aan de hand van deze systeemeisen kunnen de volgende vragen gesteld worden:
1. Hoe ziet een dergelijke ‘tool’ er idealiter uit?
2. Bestaat een dergelijke tool? En, zo ja: welke functies worden geboden?
3. Zo nee: is het mogelijk een dergelijke ‘tool’ te ontwikkelen en op welke manier kan
dit gebeuren?
2

Deze vragen hebben geleid tot de volgende onderzoeksvraag
“In hoeverre is het mogelijk antwoorden op zowel open als gesloten vragen in online
enquêtes zoveel mogelijk geautomatiseerd en in één systeem op te slaan, te analyseren en te
presenteren?”
Om een antwoord op deze onderzoeksvraag te kunnen geven, wordt in de volgende
hoofdstukken aandacht besteed aan de volgende tien deelvragen:
1. Wat zijn de voor- en nadelen van het uitvoeren van een online enquête, naast andere
enquêtestrategieën?
2. Wat zijn open vragen en gesloten vragen?
3. Welk vraagtype is het meest geschikt om te gebruiken in een enquête?
4. Op welke manieren kunnen de antwoorden op open vragen verwerkt worden?
5. Wat zijn de gewenste systeemfunctionaliteiten van een online enquêtesysteem?
6. Op welke manieren kunnen de antwoorden op zowel open als gesloten vragen tezamen
in één bestaand systeem opgeslagen, geanalyseerd en gepresenteerd worden?
7. Voldoen deze ‘totaal’-systemen aan de gewenste systeemfunctionaliteiten?
8. Op welke manier gaan bestaande online enquêtesystemen om met beide typen vragen en
antwoorden?
9. Voldoen deze online enquêtesystemen aan de gewenste systeemfunctionaliteiten?
10. Hoe kan een alternatief systeem, dat zoveel mogelijk tegemoet komt aan de gewenste
systeemfunctionaliteiten, eruit zien?
In hoofdstuk twee wordt een theoretisch kader geschetst waarbij een antwoord gegeven
wordt op de eerste drie deelvragen. Door te kijken naar verschillende methodologieën en
onderzoeksmethoden wordt uitgelegd wat de voor- en nadelen zijn van een enquête, in het
bijzonder van de online enquête. Verder behandelt dit theoretische hoofdstuk de begrippen
‘open vragen’ en ‘gesloten vragen’. Veel enquêtes zijn dusdanig opgesteld dat er zo min
mogelijk open vragen gesteld worden. Hoofdstuk twee sluit daarom af met het beantwoorden
van de derde deelvraag, welke vraagvorm het beste gekozen kan worden om te gebruiken in
een enquête.
Deelvraag vier wordt in hoofdstuk drie behandeld, waarbij wordt ingegaan op een methode
die een uitgebreide en verantwoorde analyse van open antwoorden mogelijk maakt: de op de
‘Grounded Theory’ methode gebaseerde ‘Computer Assisted Qualitative Data Analysis
Software’ of kortweg CAQDAS. Hoewel er wel computerprogramma’s als voorbeelden
3

genoemd worden, gaat het in dit hoofdstuk enkel om de theoretische mogelijkheden, niet om
specifieke software.
Deelvragen vijf, zes en zeven worden in het vierde hoofdstuk beantwoord. De verschillende
analysefuncties die in het derde hoofdstuk aan bod zijn gekomen, worden in dit hoofdstuk
afgezet tegen zowel de antwoorden op open vragen, als de antwoorden op gesloten vragen.
Aan de hand van deze koppeling en de bestudering van de mogelijkheden van twee
bestaande systemen, Kwalitan en MS Access, is gekeken wat de beste oplossing is en op
welke manier deze oplossing gekoppeld kan worden aan een online enquêtesysteem.
Om het onderzoek naar de verschillende mogelijkheden van bestaande ‘tools’ af te sluiten,
wordt een vergelijkend onderzoek gedaan naar bestaande online enquêtesystemen die de
onderzoeker begeleiden bij het aanmaken, uitvoeren en verwerken van een enquête. Op basis
van deze vergelijking en op basis van de in hoofdstuk drie opgedane kennis omtrent
verschillende CAQDAS functionaliteiten en de bruikbaarheid van deze functionaliteiten bij
de verwerking van antwoorden op zowel open als gesloten vragen, is het mogelijk een tool te
ontwerpen en te ontwikkelen die zoveel mogelijk voldoet aan de gewenste
systeemfunctionaliteiten. Deze realisatie en implementatie van een nieuwe online
enquêtesysteem wordt in hoofdstuk vijf uitgebreid besproken.
In hoofdstuk zes wordt bekeken op welke punten een vervolgonderzoek interessant kan zijn
en worden tussentijdse conclusies samengevoegd om een antwoord te geven op de
onderzoeksvraag.
Ter illustratie zijn regelmatig voorbeelden uit mijn eigen enquête gebruikt.
4

2. Theoretisch kader
2.1. Inleiding
De onderzoeksvraag suggereert een tweetal belangrijke thema’s, namelijk ‘online enquêtes’
en ‘antwoorden op open en gesloten vragen’.
Dit hoofdstuk is bedoeld om deze twee thema’s in de context van de onderzoeksvraag toe te
lichten, zodat deze in de volgende hoofdstukken, zonder verdere toelichting, gehanteerd
kunnen worden.
Het thema ‘online enquêtes’ wordt behandeld aan de hand van de termen
‘onderzoeksmethodologie’, ‘onderzoeksmethode’ en ‘onderzoeksstrategie’. Deze begrippen
worden kort uitgelegd en er worden van ieder begrip een aantal voorbeelden uitgewerkt.
Ook het tweede thema, ‘antwoorden op open en gesloten vragen’, komt in dit hoofdstuk aan
bod. Beide typen vragen, open en gesloten, worden gedefinieerd. Er wordt tevens bekeken
welke type het beste gebruikt kan worden aan de hand van een overzicht van voor- en
nadelen per vraagtype.
2.2. Enkele onderzoeksmethodologieën
Een methodologie kan beschouwd worden als het standpunt van waaruit een onderzoek
wordt uitgevoerd. Een methodologie kiezen heeft alles te maken met het type gegevens dat
gezocht wordt en het type onderzoek dat uitgevoerd moet worden. Er bestaan veel
verschillende methodologieën, zoals primair onderzoek, secundair onderzoek, inductief
onderzoek en deductief onderzoek (zie Skinner). Een andere opzet is die van het kwalitatieve
en kwantitatieve onderzoek. Voor deze scriptie zijn vooral de verschillen tussen deze twee
laatste onderzoeksmethodologieën interessant.
Het verschil tussen kwalitatief en kwantitatief onderzoek is niet zwart-wit. Kwantitatief
onderzoek zoekt naar aantallen, getallen en percentages. Kwantitatief onderzoek is
inventariserend. Dit type onderzoek wordt in de literatuur ook wel aangeduid met ‘hard
research’ (Silverman 2000). Voorbeelden van kwantitatief onderzoek zijn politieke peilingen
en marktonderzoek (voor bepaalde producten of diensten). Kwalitatief onderzoek is
explorerend. Dit type onderzoek zoekt naar (actieve) kennis, opvattingen, meningen en
gedragingen. Generaliserend kan gezegd worden dat kwalitatief onderzoek getallen vermijdt.
Dit type onderzoek wordt door Silverman (2000) ook wel ‘soft research’ genoemd.
5

De termen kwalitatief en kwantitatief worden in het vervolg met name gebruikt om twee
verschillende soorten gegevens aan te duiden, en niet zo zeer om twee verschillende
onderzoeksmethodologieën te omschrijven. Moore en McCabe (1997) beschouwen
kwantitatieve gegevens als numerieke waarden waarop rekenkundige bewerkingen en
statistische methoden toepasbaar zijn. Zij geven als voorbeelden van kwantitatieve gegevens
een lengte in centimeters of het inkomen in ecu per gezin. Kwalitatieve gegevens zijn
volgens hen de categorieën waartoe een persoon of ding behoort, zoals het geslacht van een
persoon. Deze waarden kunnen soms ook in getallen uitgedrukt worden zoals vrouwelijk = 1
en mannelijk = 0. Het is volgens hen niet zinvol om statistische methoden toe te passen op
een verzameling van nullen en enen en dat is de reden dat deze waarden kwalitatief zijn en
niet kwantitatief.
In deze scriptie worden de termen kwalitatief en kwantitatief op een iets andere manier
gehanteerd dan dat ze door Moore en McCabe gedefinieerd worden. Kwantitatieve gegevens
zijn in de context van deze scriptie alle gegevens die geteld of geturfd kunnen worden en die
snel en eenvoudig omgezet kunnen worden naar percentages. Kwalitatieve gegevens
daarentegen kunnen niet simpelweg geteld worden en dienen eerst geïnterpreteerd te worden
voordat analyse mogelijk is. Vanuit deze optiek is het voorbeeld dat Moore en McCabe
gaven, het geslacht van een persoon, een kwantitatief gegeven, immers er kan geteld worden
hoeveel respondenten mannelijk en hoeveel vrouwelijk zijn.
2.3. Enkele onderzoeksmethoden
Nadat een geschikte methodologie als invalshoek voor het onderzoek gekozen is, kan een
methode voor het uitvoeren van het onderzoek bepaald worden. Hierbij dient rekening
gehouden te worden met het type gegevens dat gezocht wordt en de methodologie die
gevolgd dient te worden.
Hier volgt allereerst een korte omschrijving van de meest gebruikte onderzoeksmethoden.
2.3.1. Experiment
Een experiment is een onderzoek dat geschiedt door middel van voor- en nametingen, rond
een uitgevoerde test. Het doel van een experiment is het bewijzen van een causale relatie
tussen te manipuleren onafhankelijke variabelen en te meten afhankelijke variabelen.
Hiervoor wordt gebruik gemaakt van proefpersonen of proefomgevingen in experimentele-
en controlegroepen, vaak in een laboratorium. Doordat in deze beperkte omgeving alle
variabelen onder controle gehouden kunnen worden, is er voor de verkregen resultaten geen
6

andere verklaring dan de ‘manipulatie door de onderzoeker’ als oorzaak mogelijk. Dit wordt
ook wel interpretatie-exclusiviteit genoemd. Bij een goed uitgevoerd experiment is er dus
sprake van een zeer nauwkeurige waarneming.
2.3.2. Enquête
Het doel van een enquête is het beschrijven en plausibel verklaren van verbanden tussen een
groot aantal kenmerken bij een groot aantal eenheden (individuen of groepen mensen). Het
gaat hierbij met name om gedragingen, opvattingen en meningen waarnaar gevraagd wordt.
Dit onderzoek kan door verschillende vraagtypen te gebruiken zowel kwalitatief als
kwantitatief zijn.1 Onderzoek geschiedt door ‘proefpersonen’ (respondenten) een vragenlijst
voor te leggen.
Hoewel een enquête op een redelijk eenvoudige en snelle manier veel informatie van veel
respondenten kan opleveren, kent het stellen van vragen aan respondenten ook vele
risicopunten die de resultaten ongemerkt sterk kunnen beïnvloeden. Babbie (2001) noemt als
voorbeelden hiervan: foutieve vraagstelling, foutieve vraagvolgorde en interpretatiefouten
door de respondent en / of de onderzoeker.
2.3.3. Veldonderzoek
Doel van het veldonderzoek is het observeren, beschrijven en interpreteren van gedragingen
van onderzoekseenheden (zoals mensen, planten of dieren) in een beperkte, natuurlijke
situatie. Middelen hierbij zijn ‘veldsubjecten’ in natuurlijke groepen. Doordat de
onderzoeker de natuurlijke situatie van een populatie bestudeert is hij / zij daarbij niet
afhankelijk van derden. Om betrouwbare resultaten te verkrijgen is het van belang dat de
natuurlijke situatie niet verstoord wordt door het onderzoek.
2.3.4. Bronnenonderzoek
Bronnenonderzoek, oftewel secundair onderzoek, is het raadplegen van bestaande bronnen.
Het kan hierbij bijvoorbeeld gaan om beschrijvingen van eerder gedaan onderzoek en de
resultaten daarvan, maar het kan ook gaan om beschreven feiten. Deze bronnen zijn onder
andere te vinden in archieven, databanken en bibliotheken. De middelen die gebruikt worden
zijn eenheden van beeld, geluid en tekst. Doordat het om bestaande bronnen gaat, die
opnieuw te raadplegen zijn, is het mogelijk goed vast te stellen welke invloed de interpretatie
van de onderzoeker heeft gehad op de resultaten van het onderzoek.
1 Voor de verschillende typen vragen, zie §2.5.
7

2.3.5. Vergelijking
Iedere onderzoeksmethode heeft zijn eigen voor- en nadelen. De meest kenmerkende van
deze voor- en nadelen zijn in tabel 1 kort nogmaals weergegeven.
Voordelen Nadelen Experiment - interpretatie-
exclusiviteit → zeer nauwkeurige waarneming
- alle condities dienen zoveel mogelijk hetzelfde te blijven
- kleinschalig onderzoek Enquête - grote
onderzoekspopulatie - eenvoudig om
meerdere kenmerken in één keer te bestuderen
- aantal resultaten afhankelijk van de medewerking van derden
- veel risicopunten Veldonderzoek - niet afhankelijk van
derden - flexibiliteit: het
onderzoek kan op ieder moment worden aangepast
- derden mogen zich niet bewust zijn van het onderzoek
- alle factoren die invloed kunnen hebben op de resultaten zijn variabel
- kleinschalig onderzoek Bronnenonderzoek - lage kosten
- exacte vaststelling van de interpretatie van de onderzoeker mogelijk
- geen gebruikmaking van nieuwe of vernieuwende gegevens
- eerder gedane onderzoek moet aansluiten bij eigen onderzoek
Tabel 1. Voor- en nadelen van verschillende onderzoeksmethoden.
2.4. Enkele enquêtestrategieën
Deze scriptie houdt zich bezig met de methode van de “enquête”. Nadat er gekozen is voor
deze onderzoeksmethode, volgt het kiezen van een onderzoeksstrategie om de enquête uit te
voeren. De drie meest gebruikte strategieën worden in deze paragraaf behandeld.
2.4.1. Mondeling
Mondelinge enquêtes zijn er in twee vormen, namelijk ‘face to face’ of via de telefoon. Uit
onderzoeken is gebleken dat interactie tussen de respondent en de enquêteur leidt tot een
betrouwbaarder resultaat van het onderzoek. Reden hiervoor is wellicht de mogelijkheid om
tussentijds toelichting te geven. Op deze manier kan meer duidelijkheid verschaft worden
8

omtrent de bedoeling van de vraag door de onderzoeker en de betekenis van het antwoord
door de respondent. Echter, juist door de aanwezigheid van de enquêteur is het ook mogelijk
dat de respondent niet een geheel eerlijk antwoord durft of wil geven. En een enquêteur die
niet neutraal is of die teveel in discussie treedt met de respondent kan het onderzoek sterk
beïnvloeden.
Mondelinge enquêtes kunnen ondersteund worden door het gebruik van een computer, er
wordt dan gesproken van de ‘Computer Assisted Personal Interviewing’ (CAPI) of
‘Computer Assisted Telephone Interviewing’ (CATI) methode. Door gebruikt te maken van
een computer is het mogelijk de bijzondere functionaliteiten van de computer aan te spreken.
Zo kan een door de computer ondersteunde enquête aan een database gekoppeld worden,
waardoor de gegevens direct elektronisch opgeslagen kunnen worden op een gestructureerde
manier, waarop meteen een analyse uitgevoerd kan worden. Ook de tijd die een respondent
nodig heeft gehad om een vraag te beantwoorden kan opgeslagen worden. Uit onderzoek is
gebleken dat de tijd die een respondent nodig heeft voor het beantwoorden van een vraag
samenhangt met het al dan niet ‘faken’ van een antwoord. Bij deze computerondersteunde
methode is het bovendien aantrekkelijk gebruik te maken van allerlei vormen van
multimedia, zoals bewegend beeld en geluiden. Door middel van hyperlinks kan de
respondent automatisch naar de volgende vraag geleid worden, afhankelijk van een eerder
gegeven antwoord.
Het aanwezig zijn van de enquêteur kost veel tijd (en geld) en daarom wordt een mondelinge
enquête vaak slechts op kleine schaal uitgevoerd. Door de aanwezigheid van de enquêteur
kunnen de respondenten niet anoniem antwoorden. Dit ligt vooral bij persoonlijke vragen
gevoelig.
2.4.2. Schriftelijk
Het werken met een (telefonische) enquêteur is niet altijd de meest ideale optie. Onder
andere bij gevoelige, persoonlijke en tijdrovende onderwerpen is de drempel tot openhartig
antwoorden hoger als er een interviewer in het spel is. Schriftelijk onderzoek kan dan een
uitkomst zijn.
Bij een schriftelijke enquête krijgt de respondent een formulier waarop de antwoorden
aangegeven of ingevuld kunnen worden. In de literatuur wordt deze methode ook wel ‘PAPI’
genoemd: ‘Paper And Pencil Interviewing’ (zie ook Vasu & Vasu 1999).
Voordelen van deze methode zijn het behoud van de privacy van de respondent en de
mogelijkheid voor de respondent de enquête op de voor hem / haar meest geschikte tijd en
op de meest geschikte plaats in te vullen. Ten opzichte van een mondelinge enquête, kent de
9

schriftelijke enquête als belangrijkste nadeel dat tussentijds ingrijpen door de enquêteur niet
mogelijk is. Bovendien is van tevoren nooit precies bekend hoeveel respondenten
uiteindelijk aan de enquête zullen meewerken, en de ingevulde enquête zullen retourneren.
2.4.3. Via het World Wide Web
Een methode die vergelijkbaar is met ‘PAPI’, is het afnemen van een enquête op Internet. De
respondent kan bij de onlinemethode in een formulier (‘online form’) de antwoorden
aanklikken of intypen. Deze methode wordt ook wel ‘Computer Assisted Survey Research’
(CASR), ‘Computerized Self-Administered Questionnaire’ (CSAQ) of ‘Computer Assisted
Web Interviewing’ (CAWI) genoemd (zie bijvoorbeeld Vasu & Vasu 1999, Nipo).
Kiesler en Sproull (1986) hebben een onderzoek gedaan naar de betrouwbaarheid van
antwoorden die gegeven zijn op enquêtes die op Internet uitgevoerd zijn, in vergelijking met
enquêtes die op papier uitgevoerd zijn. Zij kwamen tot de ontdekking dat elektronische
enquêtes waarschijnlijk betrouwbaarder waren dan de ‘PAPI’ methode. De respondenten
gaven eerlijkere antwoorden en namen een extremere positie in. Het artikel waarin dit
onderzoek kort wordt aangehaald vermeldt niet waarop deze conclusie is gebaseerd.
Waarschijnlijk is de online enquête betrouwbaarder dan de schriftelijke enquête doordat de
respondent er zelf voor kiest de website met de online enquête te bezoeken en aan de enquête
mee te werken. De motivatie om de enquête naar waarheid in te vullen zal daardoor wellicht
groter zijn dan bij een schriftelijke enquête.
De voordelen van de schriftelijke enquête en van de door een computer ondersteunde
mondelinge enquête gelden ook voor de online enquête. De enquête kan op een plaats en tijd
ingevuld worden die voor de respondent het meest geschikt is. Bovendien biedt de online
enquête de respondent meer privacy, doordat er geen enquêteur bij aanwezig is. De
technische mogelijkheden van het World Wide Web kunnen door een online enquête goed
benut worden: gebruik van multimedia, hyperlinks en een direct aan de enquête gekoppelde
database voor een gestructureerde opslag van de gegevens en een directe verwerking
(‘realtime’) van de verzamelde antwoorden.
Maar een enquête op het Internet kent nog meer voordelen. Allereerst heeft de online
enquête als voordeel boven de schriftelijke enquête dat er nauwelijks kosten voor de
verspreiding aan verbonden zijn: er hoeft niets geprint of gekopieerd te worden.
Het grootste voordeel is waarschijnlijk wel de eenvoud en de snelheid waarmee een
ongekend grote populatie bereikt kan worden. Coomber (1997) schrijft over zijn ervaringen
met een online uitgevoerde enquête: “A potentially vast population of all kinds of
10

individuals and groups may be more easily reached than ever before, across geographical
borders, and even continents.”
Coomber geeft toe dat het Internet ook nadelen kent. Via het Internet worden alleen
respondenten bereikt die van de computertechnologie gebruik (kunnen) maken. Dit heeft zijn
weerslag op de representativiteit wat betreft achtergrond, opleiding en geslacht van de
bereikte individuen.2 Ook Babbie (2001) geeft aan dat de representatie een probleem is voor
de meeste onderzoekers: zijn de mensen die deelnemen aan een online enquête wel
representatief voor de te onderzoeken populatie? Echter, in 1996 berichtte Nielsen al: “While
Internet users still tend to be upscale, their overall characteristics are coming more in line
with general population averages.” En: “Internet access and use are becoming increasingly
mainstream.” (zie hiervoor de website van CommerceNet). Tegenwoordig zijn er steeds
meer mensen uit allerlei bevolkingsgroepen die gebruik maken van het Internet, en die
daardoor bereikbaar zijn voor een enquête die via dit medium uitgevoerd wordt. Toch dient
er rekening gehouden te worden met het feit dat bepaalde groepen op deze manier niet
bereikt zullen worden en dat het ook mogelijk is dat een respondent de enquête meerdere
malen invult.
2.4.4. Vergelijking
In tabel 2 zijn de voor- en nadelen van de besproken enquêtestrategieën puntsgewijs
nogmaals naast elkaar gezet.
Voordelen Nadelen Mondeling - interactie leidt tot betere
uitkomsten - tussentijds toelichten of
ingrijpen mogelijk - aantal respondenten van
tevoren bekend - indien ondersteund door
computer: koppeling aan gestructureerde database, gebruik van hyperlinks en gebruik van multimedia
- aanwezigheid van enquêteur kost geld en tijd → kleinschalig onderzoek
- weinig anonimiteit - aanwezigheid van
enquêteur kan resultaten sterk beïnvloeden
Schriftelijk - veel anonimiteit - kan op eigen plaats en tijd
ingevuld worden
- aantal respondenten van tevoren niet bekend
- drukken en verspreiden van enquêtes kostbaar
- tussentijds toelichten of
2 In 1997 waren het voornamelijk nog de welgestelde, goedopgeleide jonge mannen die gebruik maakten van het World Wide Web en die dus via dit medium bereikbaar waren voor deelname aan een enquête.
11

12
ingrijpen niet mogelijk Online - veel anonimiteit
- kan op eigen plaats en tijd ingevuld worden
- koppeling aan gestructureerde database
- gebruikmaking van multimedia
- gebruikmaking van hyperlinks
- lage kosten - grote onderzoekspopulatie
- aantal respondenten van tevoren niet bekend
- tussentijds toelichten of ingrijpen niet mogelijk
- sommige respondenten niet bereikbaar door techniek
- enquête kan meerdere malen door dezelfde respondent ingevuld worden
Schema 2. Voor- en nadelen van verschillende enquêtestrategieën.
2.5. Twee vraagvormen
Een enquête kan zoals eerder gezegd uit twee soorten vragen bestaan: gesloten en open
vragen. In deze paragraaf worden de verschillen tussen deze twee vraagvormen aangegeven.
2.5.1. Gesloten vragen
Gesloten vragen zijn vragen waarbij de respondent een antwoord kan kiezen uit een set
vooraf gegeven alternatieven. Indien het gaat om toetsvragen (proefwerk, examen e.d.),
heten de foutieve alternatieven ‘afleiders’. (Zie ook Moelands e.a.) Om een set met
alternatieven te bedenken heeft de onderzoeker veel kennis nodig van het bevraagde
onderwerp en van de respondenten. De set dient ‘exclusive’ (exclusief) en ‘exhaustive’
(uitputtend) te zijn: de antwoorden mogen elkaar niet overlappen, en alle te bedenken
antwoorden moeten opgenomen zijn. Het antwoord dat de respondent zal kiezen is bij een
gesloten vraag sterk afhankelijk van de gepresenteerde set antwoordmogelijkheden. Bij een
kleiner aantal alternatieven is de kans dat het ‘goede’ antwoord geraden of gegokt wordt
groter. De combinatie van een vraag met gegeven antwoorden waaruit de respondent dient te
kiezen zorgt ervoor dat de kans op een verkeerde interpretatie door zowel de respondent als
de onderzoeker aanzienlijk verkleind wordt.
Een gesloten vraag kan in vele vormen voorkomen:
- meerkeuzevraag met alternatieven waarbij één antwoord aangekruist mag worden, in
een online formulier weergegeven met een zogenaamde radiobutton:
- meerkeuzevraag met alternatieven waarbij meerdere antwoorden aangekruist mogen
worden, in een online formulier aangegeven met een zogenaamde checkbox:

- likertschaal waarbij de ondervraagde op een schaalverdeling een mening aan kan
geven (schaal loopt bijvoorbeeld van “mee oneens – neutraal – mee eens”)
- meerkeuzevragen met, afhankelijk van het gekozen antwoord, een vervolgvraag.
De antwoorden op gesloten vragen zijn eenvoudig te tellen en te verwerken omdat er een
restrictie is gegeven aan het maximale aantal verschillende antwoorden, en omdat de
verschillende antwoordmogelijkheden van tevoren bekend zijn. De analyse van de
antwoorden op gesloten vragen is vergelijkbaar met de verwerking van kwantitatieve
gegevens, en daarom worden de antwoorden op de gesloten vragen in het vervolg ook wel
aangeduid met kwantitatieve gegevens.
2.5.2. Open vragen
Bij open vragen dient de respondent zelf een antwoord te bedenken en in te vullen. Een open
vraag kan de respondent vragen om een geheel eigen, open antwoord te geven, in volzinnen.
Dit levert vaak veel woorden op, die voor de analyse van de antwoorden overbodig zijn,
zoals lidwoorden, hulpwerkwoorden en voorzetsels. Daarom kan er ook gevraagd worden
om woordassociaties. Hierbij worden alleen de functiewerkwoorden en naamwoorden door
de respondent genoteerd, waardoor antwoord door de respondent zelf al teruggebracht wordt
tot de essentie.
In de meeste enquêtes wordt echter nauwelijks gebruik gemaakt van open vragen. Dit heeft
voornamelijk te maken met de tijdrovende en kostbare verwerking van open antwoorden. De
antwoorden zijn moeilijker te categoriseren en kunnen niet simpelweg geteld worden. De
onderzoeker moet meer tijd nemen voor het doornemen en interpreteren van de antwoorden.
Deze interpretatie levert het gevaar op van ‘misunderstanding’ en ‘researcher bias’: de
resultaten zijn afhankelijk van de interpretatie van de vraag door de respondent, en de
interpretatie van het antwoord door de onderzoeker (Babbie 2001). De uiteindelijke
resultaten kunnen door een verkeerde interpretatie de plank volledig misslaan.
Soms is het noodzakelijk een open vraag te stellen, bijvoorbeeld wanneer het niet mogelijk is
van tevoren alle mogelijke alternatieven voor een gesloten versie te bedenken, of wanneer de
onderzoeker wil voorkomen dat de respondent in een bepaalde richting geduwd wordt of een
bepaald antwoord moet kiezen. In sommige gevallen is het belangrijk de actieve kennis van
de respondent te testen (bijvoorbeeld in het geval van toetsen en examens). Een open
antwoord is vaak genuanceerder dan een gesloten antwoord en geeft een grote hoeveelheid
details.
Een open vraag kent ook meerdere gradaties. Een volledig open vraag is bijvoorbeeld:
“Heeft u verder nog vragen of opmerkingen?”. Het antwoord op deze vraag is van tevoren
13

volstrekt onbekend voor de onderzoeker. Een respondent kan een vraag stellen of een
opmerking maken over het doel van het onderzoek, de opzet van het onderzoek, de resultaten
van het onderzoek of over een specifieke vraag uit de enquête.
Een andere gradatie is een open vraag die wel vraagt om een geheel eigen antwoord in te
voeren, maar waarbij de respondent door de vraagstelling al wel in een bepaalde richting
geduwd wordt. Bijvoorbeeld: “Hoe bent u erachter gekomen dat uw computer geïnfecteerd
was met een computervirus?”. Hoewel het antwoord niet van tevoren bekend is, is bij een
dergelijke vraag wel bekend waar de respondent over zal schrijven, namelijk de manier
waarop hij / zij erachter is gekomen dat de computer geïnfecteerd was met een
computervirus.
Een derde mogelijkheid is een open vraag die net zo goed ook in gesloten vorm gesteld kan
worden en waarbij de vorm van het antwoord van tevoren bekend is: “Wat is uw leeftijd?”.
Een gesloten versie van deze vraag kan zijn: “Tot welke leeftijdscategorie behoort u?”. De
onderzoeker weet dat de respondent in het geval van de open vraag een getal zal invullen, en
in het geval van de gesloten vraag een categorie. Beide antwoorden zijn te behandelen als
een gesloten antwoord: eenvoudig te tellen (of te turven) en daardoor geschikt voor een
snelle statistische verwerking.
2.5.3. Gesloten vraag met open optie
Een bijzondere vorm van gesloten vraag is de gesloten vraag met een open optie.
Voorbeelden uit mijn eigen enquête zijn: “Anders, namelijk:…” en “Ja, omdat: …”. Door
een dergelijke optie op te nemen in de vraag wordt het voor de respondent mogelijk een
antwoord te geven, dat niet opgenomen is in de set vooraf gegeven alternatieven. Indien de
respondent er voor kiest hier een eigen antwoord in te vullen wordt de gesloten vraag opeens
een open vraag en dient het antwoord ook als dusdanig behandeld te worden.
2.5.4. Vergelijking
De manier waarop de vraag gesteld wordt, heeft grote invloed op het antwoord van de
respondent. Gendall en Hoek (1990) hebben een meervoudig onderzoek gedaan in hoeverre
het gegeven antwoord afhangt van de bewoording van de vraag (positief of negatief
bijvoorbeeld), de volgorde waarin de vragen gesteld worden en het type vraag dat gekozen
wordt, open of gesloten. Om te onderzoeken wat het verschil in resultaten kan zijn bij een
open of een gesloten vraag, hebben de onderzoekers een testenquête gehouden. Zij hebben
de ondervraagden telkens één van de volgende vragen voorgelegd:
14

Versie 1 – Open vraag:
“What do you think is the single most important problem facing New Zealand right now?”
Versie 2 – Gesloten vraag:
“Which of these is the single most important problem facing New Zealand right now?”
Aids Interest rates
Inflation Unemployment
High exchange rates Economy in general
Law and order Racial problems
Antwoorden op de open vraag zijn uiteindelijk (daar waar mogelijk) gecategoriseerd in
gesloten alternatieven zodat vergelijking met de gesloten vraag mogelijk werd. De
categorieën en de resultaten van beide vraagstellingen zijn in tabel 3 naast elkaar gezet.
Most important problem Gesloten vraag % Open vraag %
Unemployment 56 50
Economy in general 22 11
Law and order 9 5
Racial problems 7 10
Aids 6 -
Don’t know 1 -
Unstable government - 5
Declining moral standards - 3
Other * - 16
Total 100% 100%
* “Including: schooling, drugs, lack of Christian faith, laziness, David Lange, breakdown of
family”
Tabel 3. Resultaten van de testenquête van Gendall en Hoek (1990).
Zoals de onderzoekers verwachtten, en zoals in bovenstaande tabel duidelijk af te lezen is,
was het patroon van de gegeven antwoorden op de open en de gesloten vraag verschillend,
terwijl het algemene beeld dat van beiden ontstond hetzelfde was (bijvoorbeeld,
15

‘unemployment’ was in beide gevallen het belangrijkste issue volgens de respondenten).
Hieruit kan geconcludeerd worden dat de resultaten voor een deel wel degelijk afhangen van
de vraagvorm.
Beide vraagvormen hebben eigen voor- en nadelen. Deze zijn in tabel 4 kort opgesomd.3
Voordelen Nadelen Open vragen
- genuanceerde en informatieve antwoorden door gebruikmaking van jargon en creativiteit bij verwoorden van het antwoord
- respondent wordt niet in een richting geduwd of gedwongen een keuze te maken
- antwoord kan niet geraden of gegokt worden
- onderzoeker hoeft geen rekening te houden met set alternatieven
- verwerking van de verzamelde antwoorden is tijdrovend
- verkeerde interpretatie mogelijk door zowel respondent als onderzoeker
Gesloten vragen
- antwoorden makkelijk (statistisch) te verwerken
- resultaten betrouwbaar - kans op misinterpretatie
minimaal
- kennis nodig van onderwerp en respondenten voor maken van een alternatievenset
- resultaten afhankelijk van het alternatievenset
- minder informatief dan open antwoorden
Tabel 4. Voor- en nadelen van de verschillende vraagvormen.
2.6. Conclusie
In dit hoofdstuk zijn in het kort een aantal onderzoeksmethodologieën en
onderzoeksmethoden besproken. De onderzoeksmethode van de enquête is verder uitgewerkt
in een bespreking van de verschillende enquêtestrategieën, waarbij de nadruk lag op de
bespreking van de online enquête. Tenslotte zijn twee verschillende typen vragen die in een
enquête kunnen voorkomen kort vergeleken. Bij dergelijke vergelijkingen tussen open en
gesloten vragen in de literatuur wordt vaak aangeraden in enquêtes alleen gebruik te maken
3 Hierbij moet wederom vermeld worden dat de lijst niet uitputtend is, maar alleen ingaat op verschillen die voor het onderwerp van deze scriptie van belang zijn.
16

van gesloten vragen, vanwege de korte verwerkingstijd en de betrouwbaarheid van de
verzamelde antwoorden.
Een in de literatuur vaak genoemd advies is het uitvoeren van een ‘pilot test’, waarbij in een
testenquête een open versie van de vraag geformuleerd worden. Aan de hand van de
verkregen antwoorden op deze testvraag kan vervolgens een set alternatieven voor een
gesloten vraag geformuleerd worden, die gebruikt kan worden in de definitieve versie van de
enquête.
Welke vraagvorm het meest geschikt is, is sterk afhankelijk van de situatie en van het doel
van het onderzoek. Veel onderzoekers wegen het belang van een bepaald type vraag, open of
gesloten, af tegen het werk dat er voor nodig is om de antwoorden te verwerken. Op de
website van het online enquêtesysteem eXamine staat letterlijk: “Wilt u open vragen stellen?
Bedenk wel dat de antwoorden hierop lastig te analyseren zijn. Mogelijk bent u meer gebaat
bij voorgedefinieerde antwoorden…”.
Hoofdstuk 3 en 4 gaan verder in op de verschillen die er zijn bij de analyse van de
antwoorden op open vragen en de analyse van de antwoorden op gesloten vragen. In het
vervolg zullen deze twee antwoordtypen aangeduid worden met ‘open antwoorden’ en
‘gesloten antwoorden’.
17

3. Wat zijn de mogelijkheden voor analyse van kwalitatieve data?
3.1. Inleiding
In het vorige hoofdstuk zijn de globale verschillen tussen open en gesloten vragen
behandeld. Dit hoofdstuk en de volgende hoofdstukken richten zich voornamelijk op de
verschillen tussen de verwerking van ‘open antwoorden’ en de verwerking van ‘gesloten
antwoorden’.
De verwerking van de verkregen antwoorden kan in een drietal stappen opgesplitst worden:
1. Antwoorden op een gestructureerde wijze opslaan > invoer
2. Analyse uitvoeren op de antwoorden > analyse
3. Resultaten van de analyse presenteren > uitvoer
Gesloten vragen bestaan uit een set vooraf gegeven antwoorden. Hoewel van tevoren niet
bekend is welk antwoord de respondent zal kiezen, is de set van mogelijk te kiezen
antwoorden dus wel bekend. Veelal zijn de gesloten antwoorden geprecodeerd of bestaan ze
uit numerieke waarden. Dit maakt het eenvoudig de antwoorden in een database zoals MS
Access op te slaan. De gegevens zijn in een dergelijk programma dermate gestructureerd
opgeslagen dat ze geëxporteerd kunnen worden naar een ander computerprogramma voor
een toepassing van statistische methoden. Voorbeelden van dit soort statistische
programma’s zijn MS Excel en SPSS (Statistical Package for Social Science). Hoofdstukken
4 en 5 gaan nader in op het gebruik van enkele statistische functies en op het gebruik van MS
Access om de verzamelde gegevens op te slaan en te verwerken.
Open antwoorden kunnen zowel lang (bijvoorbeeld een antwoord op een essayvraag) als kort
zijn. Het is mogelijk deze antwoorden in een kwantitatieve database op te slaan, maar dan
ligt er vaak een restrictie op het maximaal aantal karakters dat in één veld opgeslagen kan
worden.4 Voor korte open antwoorden vormt deze restrictie vaak geen probleem. Langere
teksten hebben echter een andere aanpak nodig voor opslag en structurering.
De verwerking van gesloten antwoorden is voor de meeste onderzoekers een bekend proces
dat redelijk voor zich spreekt. De verwerking van de open antwoorden daarentegen kent
meer moeilijkheden. De antwoorden kunnen vaak niet simpelweg geteld en geturfd worden,
18

maar moeten eerst geïnterpreteerd worden. Een kwantitatieve database is niet ontworpen
voor een dergelijke interpretatie van de gegevens en kent geen speciale mogelijkheden om
de onderzoeker bij deze taak te ondersteunen.
In dit hoofdstuk worden enkele bestaande mogelijkheden om kwalitatieve data te analyseren
besproken. Dit gebeurt aan de hand van beschrijvingen en discussies in de literatuur en mijn
eigen bevindingen bij het werken met enkele computerprogramma’s die gebruikt kunnen
worden voor het analyseren van open antwoorden, zoals MS Word, MS Access, Wordsmith,
Kwalitan, MaxQDA en Form2Data.
3.2. Ontwikkeling van kwalitatieve data analyse
‘Qualitative data analysis’ is een term die gebruikt wordt voor een grote verzameling
methoden voor de analyse van kwalitatieve data. De analyse van kwalitatieve data, of meer
specifiek van open antwoorden kan op twee manieren gebeuren: handmatig en met behulp
van de computer
Tot een aantal jaren geleden maakten de meeste kwalitatieve onderzoekers voornamelijk
gebruik van pen en papier bij hun onderzoek. Bevindingen en observaties werden
opgeschreven, waarna ze overgenomen werden op indexkaartjes waarmee geschoven kon
worden om zo alle bij elkaar horende onderdelen (bijvoorbeeld segmenten van de tekst of
antwoorden op een specifieke vraag) te verzamelen. De computer werd hooguit gebruikt
voor het intypen van hun analyses (Weitzman 2000).
Tegenwoordig worden de meeste (grotere) kwalitatieve onderzoeken niet meer handmatig
uitgevoerd. Kwalitatieve onderzoekers maken nu veelal dankbaar gebruik van ‘Computer-
Assisted Qualitative Data Analysis Software’, oftewel CAQDAS. De term ‘computer-
assisted’ geeft reeds aan dat bij dergelijke software niet gedacht moet worden aan een
computerprogramma dat in staat is de kwalitatieve analyse voor de onderzoeker uit te voeren
(zoals de computer wel in staat is kwantitatieve analyses uit te voeren met programma’s als
SPSS en MS Excel). De software is in staat de data voor te bereiden op een interpretatie door
de onderzoeker, bijvoorbeeld door middel van ‘content analysis’5.
Miles en Huberman (1994: p44) omschrijven de rol van de computer bij het uitvoeren van
een kwalitatief onderzoek als volgt:
4 In MS Access kunnen in een veld van het datatype ‘char’ maximaal 255 karakters opgeslagen worden; in een veld van het datatype ‘memo’ maximaal 64.000 karakters.
19

1. Making notes in the field;
2. Writing up or transcribing field notes;
3. Editing: correcting, extending, or revising field notes;
4. Coding: attaching keywords or tags to segments of text to permit later retrieval;
5. Storage: keeping text in an organized database;
6. Search and retrieval: locating relevant segments of text and making them available for
inspection;
7. Data “linking”: connecting relevant data segments to each other to form categories,
clusters, or networks of information;
8. Memoing: writing reflective commentaries on some aspect of the data as a basis for
deeper analysis;
9. Content analysis: counting frequencies, sequences, or locations of words and phrases;
10. Data display: placing selected or reduced data in a condensed, organized format, such as
a matrix or network, for inspection;
11. Conclusion-drawing and verification: aiding the analyst to interpret displayed data and to
test or confirm hypotheses;
12. Theory-building: developing systematic, conceptually coherent explanations of findings
and testing hypotheses;
13. Graphic mapping: creating diagrams that depict findings or theories; and
14. Report-writing
Bovenstaande opsomming geeft in korte bewoordingen de mogelijke CAQDAS
functionaliteiten weer. Een aantal CAQDAS programma’s zijn op de aanwezigheid en
werking van deze functionaliteiten getest. Punten tien tot en met dertien in bovenstaande
lijst zijn functies die gebruikt kunnen worden voor de ontwikkeling van een nieuwe theorie.
Een enquête wordt veelal uitgevoerd om een bepaalde bestaande theorie te testen. Een
onderzoeker die snel een online enquête wil uitvoeren heeft wellicht weinig baat bij deze
uitgebreide functies. De beschouwing van de functionaliteiten van de geteste programma’s
beperkt zich daarom tot punten één tot en met negen in bovenstaande lijst van Miles en
Huberman.
Ryan en Bernard (2000) onderscheiden twee basismethoden voor CAQDAS om tekst te
analyseren: op woordniveau (‘content analysis’) en op segmentniveau (op basis van de
5 Voor meer informatie over ‘content analysis’ zie §3.3.
20

Grounded Theory methode). Aan de hand van deze twee niveaus worden in de volgende
paragrafen de belangrijkste en meest gebruikte CAQDAS technieken besproken.
3.3. CAQDAS functies op woordniveau: ‘content analysis’
De meest voor de hand liggende manier om een analyse op kwalitatieve data uit te voeren is
‘content analysis’. ‘Content analysis’ is een analysemethode die de inhoud van de tekst
analyseert op woordniveau. Dit kan op meerdere manieren gebeuren. ‘Words-in-context’
(WIC) en ‘words-out-of-context’ (WOC) reduceren de tekst tot de fundamentele betekenis
van specifieke woorden. Zo wordt het voor onderzoekers gemakkelijker patronen te
herkennen en teksten onderling te vergelijken. Het programma Wordsmith is gebruikt om te
kijken welke ‘content analysis’ functies bestaan en hoe ze gebruikt kunnen worden. Dit
programma kent onder andere de volgende mogelijkheden: maken van
woordfrequentielijsten, woord x woord matrices, lijsten met sleutelwoorden en
concordantielijsten.
3.3.1. Words-in-context
Bij WIC wordt een lijst gemaakt van alle voorkomens van een door de onderzoeker
opgegeven woord, waarbij het woord elke keer in de context van een vast aantal woorden
(bijvoorbeeld 30) wordt weergegeven. De lijst die hieruit ontstaat is een concordantielijst.
Een andere WIC functie is het maken van een collocatie-overzicht. De onderzoeker geeft bij
deze functie een woord op waarnaar door het programma gezocht moet worden. Vervolgens
worden alle woordcombinaties waarin het opgegeven woord voorkomt opgenomen in een
tabel. Daarbij wordt aangegeven hoe vaak het woord dat samen met het opgegeven woord
een woordcombinatie vormt, voor óf na het opgegeven woord in de tekst voorkomt.
Tenslotte is het in Wordsmith mogelijk een lijst te genereren met de meest voorkomende
woordparen en hun frequenties. De resultaten van deze laatste twee opdrachten kunnen in
een tabel gepresenteerd worden of in een woord x woord matrix, een tweedimensionale tabel
waarin aangeven wordt hoe vaak ieder woord samen met een ander woord voorkomt.
3.3.2. Words-out-of-context
Bij WOC analyse wordt een lijst gemaakt van alle voorkomende woorden en het aantal keren
dat de woorden in de tekst voorkomen, hun frequenties. Wanneer een woordfrequentielijst
gemaakt wordt, zullen in veel gevallen woorden als ‘de’, ‘het’ en ‘een’ hoog boven in de lijst
voorkomen. Vaak zijn dit echter niet de woorden die interessant zijn voor het onderzoek.
21

Wordsmith biedt daarom ook de mogelijkheid een woordenlijst te genereren die enkel de
woorden weergeeft die significant vaak voorkomen, de sleutelwoorden.
Nadeel van de WOC methode is dat de woorden uit de context gehaald worden. Wanneer
een woord meerdere betekenissen kan hebben (ambigue woorden), kan het na het uitvoeren
van een WOC analyse onduidelijk geworden zijn om welke betekenis van het woord het
gaat. Ook informatie over de manier waarop het woord in de tekst gebruikt is, positief of
negatief, gaat verloren. Door de woorden uit de context te halen, kunnen subtiele, doch
belangrijke, nuances verloren gaan.
3.4. CAQDAS functies op segmentniveau: Grounded Theory
CAQDAS kan diverse ‘content analysis’ functies uitvoeren. Daarnaast bieden de
computerprogramma’s ook andere mogelijkheden die speciaal voor de analyse van
kwalitatieve data ontwikkeld zijn en die nauwelijks handmatig uitvoerbaar zijn, zoals het
coderen van de tekst, het aanbrengen van connecties tussen de codes en het aanbrengen van
hyperlinks. In deze paragraaf worden de achterliggende gedachten en de belangrijkste
CAQDAS functies besproken aan de hand van gelezen literatuur en geteste software.6
3.4.1. Grounded Theory
De meeste CAQDAS programma’s werken op basis van een theorie-ontwikkelingsmethode
die ontwikkeld is door Glaser & Strauss: Grounded Theory.7 In hun centrale werk Discovery
of Grounded Theory (1967) opperen zij een nieuwe strategie om theorieën te ontwikkelen.
Zij stellen voor dat gefundeerde theorieën stap voor stap ontwikkeld worden op basis van
systematisch verkregen en geanalyseerde onderzoeksgegevens. De onderzoeker begint met
het lezen van een klein gedeelte van de verzamelde data, bijvoorbeeld een tekstsegment of
een antwoord op een open vraag. Daarna worden één of meerdere labels aan dit segment
toegekend, die in het kort informatie verschaffen over de inhoud van het segment.
6 Deze bespreking beperkt zich tot de punten één tot en met negen van de lijst van Miles en Huberman, zie §3.2. 7 Over het feit of CAQDAS programma’s wel of niet gebaseerd zijn op de Grounded Theory methode wordt al enige tijd fel gedebatteerd (zie bijvoorbeeld Lonkila 1995; Kelle 1997; Lee & Fielding 1996; Coffey, Holbrook & Atkinson 1996). Lonkila (1995: p46) schrijft hierover: “It seems clear that the development of CAQDAS programs has strongly been influenced by grounded theory. But it does not follow from this that they can only be used in an analysis in line with grounded methodology.” Kelle voegt daaraan toe dat de meeste ontwikkelaars van CAQDAS programma’s kwalitatieve onderzoekers zijn die een andere methodologie volgen dan de Grounded Theory methode. Hoewel de programma’s dus gebaseerd lijken te zijn op de Grounded Theory methode, zijn ze wel degelijk ook voor andere theorie-ontwikkelingsmethoden bruikbaar.
22

De tweede stap van de Grounded Theory methode is het vergelijken. Hierbij kunnen
meerdere soorten vergelijkingen onderscheiden worden (Charmaz 2000):
- vergelijken van verschillende personen (situaties, acties);
- vergelijken van gegevens van dezelfde persoon op verschillende tijden;
- vergelijken van verschillende incidenten;
- vergelijken van gegevens met categorieën;
- en tenslotte het vergelijken van een categorie met andere categorieën.
Tijdens de analyse schrijft de onderzoeker memo’s om zijn / haar ideeën over de labels, de
relaties tussen de labels en tussen de categorieën, en overige gedachten over de segmenten te
archiveren.
Bij zeer grote corpora bestaat het risico dat een segment over het hoofd gezien wordt en niet
gecodeerd wordt. Vanwege dit risico zijn enkele onderzoekers geneigd te zeggen dat een
grondige codering alleen mogelijk is door gebruikmaking van computerprogrammatuur
(onder andere Lonkila 1995: p45).
De principes van coderen (ook wel indexeren of labelen genoemd), vergelijken (ook wel
aangegeven met ‘search and retrieve’) en het bijhouden van memo’s worden veelvuldig
toegepast in software voor de analyse van kwalitatieve gegevens. In de volgende paragraaf
wordt de connectie tussen Grounded Theory en CAQDAS verder duidelijk door de
bespreking van analytische functies die bij beide een centrale rol spelen:
- coderen
- structureren van de codes
- memo’s toevoegen en annoteren
- links en hypertekst toevoegen
- zoeken en verzamelen
- weergeven van de gegevens en de resultaten
3.4.2. Coderen van de data
De eerste functie waarin CAQDAS de onderzoeker kan ondersteunen is het aanmaken en
toekennen van codes. Codes zijn een belangrijk instrument voor de onderzoeker die
materiaal aan een kwalitatieve analyse onderwerpt. Codes worden in de meeste
computerprogramma’s toegekend op het niveau van de segmenten, kleine delen van de tekst.
Door middel van codes kan de onderzoeker vastleggen waar het segment over gaat of wat
zijn / haar interpretatie is van hetgeen in het segment wordt aangetroffen.
23

In sommige gevallen moeten de codes handmatig toegekend worden, terwijl de onderzoeker
de tekst leest. Andere programma’s zijn in staat om de codes automatisch toe te voegen aan
de segmenten, door opgave van een te zoeken woord (of een combinatie van woorden), het
bereik waarbinnen gezocht moet worden en de code die toegekend moet worden. Het is
hierbij verstandig de automatisch toegekende codes te controleren, in verband met de
ambiguïteit van een groot aantal woorden.
Seidel en Kelle (1995: p57) omschrijven de functie van codes als ‘signposting’: het is een
noodzakelijke voorbereiding voor het verzamelen van alle relevante segmenten, en voor het
vergelijken van relevante segmenten. Na het coderen kan de tekst in stukken opgebroken
worden en is het mogelijk alle relevante delen te verzamelen, waarbij gezocht wordt naar
specifiek opgegeven codes.
Door een code aan een tekst te verbinden, heeft de onderzoeker besloten dat het betreffende
segment overeenkomt met alle andere segmenten met dezelfde code, en dat het segment niet
overeenkomt met segmenten die deze code niet hebben gekregen. De codes bevatten daarom
ook informatie over de overeenkomsten en verschillen tussen de segmenten.
Lonkila (1995) gaat uit van drie stappen in het coderingsproces, die elkaar niet perse hoeven
op te volgen, maar dat vaak wel doen. Allereerst noemt de auteur de methode van ‘open
coding’. Open coderen is bedoeld om het onderzoek op gang te krijgen. Strauss en Corbin
(1990) omschrijven open coderen als volgt:
“… the analytic process by which concepts are identified and developed in terms of their
properties and dimensions. The basic analytic procedures by which this is accomplished
are: the asking of questions about the data; and the making of comparisons for
similarities and differences between each incident, event or other instances of
phenomena. Similar events and incidents are labeled and grouped to form categories.”
Open coderen breekt een tekst in stukken, segmenten, en staat de onderzoeker toe nieuwe
codes toe te kennen en in categorieën onder te brengen.
Een volgende stap is volgens Lonkila het ‘axial coding’. Hierbij probeert de onderzoeker de
relaties tussen de verschillende codes en categorieën vast te leggen.8 Op deze manier worden
de datasegmenten weer bij elkaar terug gebracht door een meer hiërarchische structuur aan te
brengen in de vorm van categorieën.
Een laatste stap betreft het ‘selective coding’. Aan de hand van een basiscode of
basiscategorie die het meest relevant is voor het onderzoek kan selectief gecodeerd worden,
8 Voor meer informatie over het structureren van codes, zie de CAQDAS functie “structureren van de codes”, §3.4.3.
24

waarna er door middel van een search-and-retrieve opdracht gezocht kan worden naar
segmenten die aan deze basiscode voldoen.9
De werkbeschrijving van één van de populairste CAQDAS programma’s, Atlas.ti (zie voor
de ‘full manual’ de website van Atlas.ti), gaat ook uit van een coderingsproces waarbij
begonnen wordt met ‘open coding’. De beschrijving noemt echter ook nog andere methoden
om te coderen. Zo is het in Atlas.ti mogelijk een deel van de letterlijke tekst aan te wijzen als
code. Dit heet ‘in vivo coding’. Ook is het mogelijk om een lijst met vooraf gedefinieerde
codes te gebruiken, waaruit een code gekozen kan worden tijdens het coderen van een
segment. Op deze manier wordt een zo consistent mogelijk coderingssysteem bereikt waarbij
het maken van typefouten zo goed als onmogelijk is. Tenslotte is het programma in staat
automatisch te coderen, zonder tussenkomst van de onderzoeker.
Seidel en Kelle (1995), Silverman (2000) en Richards en Richards (1995) geven allen de
voorkeur aan een indeling in ‘feitelijk’ en ‘referentieel’ coderen.
Bij feitelijke codering is er sprake van het toekennen van codes die feiten over segmenten
bevatten. Dit kunnen feiten zijn over de respondent, maar in elk geval zijn het altijd feiten uit
de tekst zelf. Hierbij is geen sprake van interpretatie door de onderzoeker. Door gebruik te
maken van feitelijke codering kan alle informatie over een respondent in één hiërarchische
boom opgenomen worden. 10 Deze methode van coderen wordt ook wel ‘samenvattend’
genoemd.
Een andere manier van coderen is volgens de genoemde auteurs het toekennen van
referenties. Referentiele codering betreft niet zo zeer een feit over de respondent, maar geeft
aan waar de respondent over spreekt, of waar een bepaald tekst segment over gaat. Deze
manier is dus onderhevig aan de interpretatie van de onderzoeker. Deze methode van
coderen wordt ook wel ‘indexeren’ of ‘heuristisch coderen’ genoemd (zie ook Silverman
2000). Referentiele codes worden met name gebruikt bij geheel open teksten, zoals open
vragen in een enquête. Een voorbeeld van een dergelijke vraag is de afsluitende vraag “Heeft
u nog vragen of opmerkingen?”. Een antwoord op deze vraag geeft veelal geen informatie
over de respondent zelf en kan om deze reden vaak alleen referentieel gecodeerd worden.
9 Voor meer informatie over de werking van het zoeken naar bepaalde codes, zie de CAQDAS functie “zoeken en verzamelen (‘search and retrieve’), §3.4.6.
25

3.4.3. Structureren van de codes
Het structureren van de codes in categorieën is ook een vorm van coderen. Dit is het door
Lonkila (1995) genoemde ‘axial coding’; Prein, Kelle en Bird (1995: p63) noemen dit
‘second-order coding’. De codes worden in categorieën ingedeeld om generaliserend
(‘generalization’) over de data na te kunnen denken en om dimensies (‘dimensionalization’)
aan de data te geven. In Kwalitan, een kwalitatief analyseprogramma dat onder andere
ontwikkeld is door Vincent Peters, hoogleraar aan de Universiteit van Tilburg, kunnen codes
op twee manieren geordend worden in een overzichtelijke structuur: in categorieën van
samenhangende codes en in hiërarchische boomstructuren. Deze beide structuren worden
hieronder nader toegelicht.
Categorieën
Categorieën zijn overkoepelende begrippen of thema’s waar meerdere codes onder vallen op
basis van hun betekenis (afhankelijk van de interpretatie van de onderzoeker) of hun inhoud
(letterlijke tekst). In Kwalitan kan iedere code onder slechts één categorie genoemd worden.
Zo kunnen de begrippen ‘man’ en ‘vrouw’ ingedeeld worden in de categorie ‘geslacht’, en
kan de leeftijd van een respondent in een leeftijdscategorie ingedeeld worden. Een indeling
in categorieën betekent een structuur van maximaal 1 niveau diep, een code in een categorie.
Een complexere indeling in meerdere niveaus kan bereikt worden door een boomstructuur
aan te maken.
Boomstructuur
Om nog meer zicht te krijgen op de codes die gaandeweg in een onderzoek ontwikkeld
worden kunnen de categorieën verder gestructureerd worden tot een hiërarchische
boomstructuur. In deze boomstructuur kunnen de codes worden geordend op een zodanige
wijze dat er verschillende niveaus van codes worden onderscheiden. Een centraal begrip kan
op die manier worden uiteengelegd in meerdere begrippen, die op hun beurt weer een groep
sub-begrippen overkoepelen etc. Door het aanmaken van een boomstructuur is het mogelijk
om een complex pad van codes te volgen, dat gebruikt kan worden voor het verzamelen van
alle segmenten die van die min of meer specifieke code(s) zijn voorzien.
Richards en Richards (1995) zijn er van overtuigd dat codes alleen zin hebben indien ze
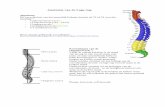
georganiseerd worden in hiërarchische categorieën (een boomstructuur). Figuur 1 is een
voorbeeld van een dergelijke boomstructuur die is gemaakt aan de hand van mijn eigen
enquête. In de boomstructuur zijn een klein aantal feitelijke coderingen, die gebruikt zouden
10 Voor een voorbeeld van een feitelijke boomstructuur, zie figuur 1.
26

kunnen worden om de antwoorden die de respondenten hebben gegeven te coderen,
samengevoegd tot een schematisch overzicht.
Figuur 1. Feitelijke categorieën weergegeven in een hiërarchische boomstructuur. Onder de
onderste categorieën vallen alle links naar de betreffende tekstsegmenten of naar de
betreffende respondenten.
In een dergelijke boomstructuur definieert de ‘root node’ wat het onderwerp van de boom is,
in bovenstaande afbeelding is dat ‘respondenten’. Het gaat in deze boom dus om feitelijke
informatie over de respondenten. De laatste knoop (‘node’) krijgt betekenis door het volgen
van alle takken (ook wel links of connecties genoemd) naar die knoop toe.
Hiërarchische structurering van de codes en de segmenten is daarmee niet alleen een vorm
van organisatie, maar ook een analysetechniek. Daarbij moet wel in de gaten gehouden
worden dat het altijd om een taxonomische structuur gaat, waarbij de meest generieke
categorie het begin van de boom is, en waarbij de meest specifieke categorieën de onderste
knopen vormen. Wanneer een boom op deze manier opgezet wordt, wordt de relatie tussen
de knopen alleen door de lijnen beschreven, en hoeft dit niet woordelijk gedaan te worden
met termen als “is onderdeel van…” en “is gevolg van…”. Bovendien is het noodzakelijk
dat alle ‘children’ van een ‘parent node’ dezelfde relaties hebben ten opzichte van deze
‘parent node’.
3.4.4. Memo’s toevoegen en annoteren
Het coderen en structureren van de tekstsegmenten is vaak voor een groot deel gebaseerd op
de interpretatie van de onderzoeker en het onderwerp waarop het onderzoek zich richt. Het
vastleggen van deze interpretaties gebeurt onder andere door het toekennen van codes. Deze
labels op zich zijn vaak gebonden aan een maximale lengte (in Kwalitan 50 tekens) en het
zal moeilijk zijn om alle gedachten achter een bepaald geconstateerd fenomeen of achter een
interpretatie vast te leggen in één of meerdere korte labels per segment. Veel kwalitatieve
27

analyseprogramma’s zijn daarom voorzien van een hulpmiddel om de gedachten die achter
een code liggen op één of andere manier vast te leggen. Om tijdens het proces de juiste
keuzes te maken en om deze keuze achteraf te kunnen verantwoorden is het van belang
regelmatig en uitvoerig vast te leggen welke overwegingen een rol hebben gespeeld en hoe
de keuzes in diverse situaties zijn uitgevallen. Dit vastleggen van ideeën, theorieën en
betekenissen van codes gebeurt door het schrijven van zogenaamde memo’s.
Glaser (1978: p83-84) geeft een klassieke definitie van memo’s: “[A memo is] the theorizing
write-up of ideas about codes and their relationshop as they strike the analyst while coding
… it can be a sentence, a paragraph, or a few pages … it exhausts the analyst’s momentary
ideation based on data with perhaps a little conceptual elaboration.”
Babbie (2001) geeft de voorkeur aan een driedeling van het memosysteem. Allereerst noemt
hij ‘code memo’s’. Dit zijn memo’s die meer informatie geven over de betekenis van de
labels. Indien de labels bestaan uit afkortingen, kunnen in de code memo’s de volledige
labels opgenomen worden. Daarnaast noemt hij de theoretische memo’s. Deze bestaan uit
ideeën over concepten, relaties en theorieën die de onderzoeker tijdens het coderen
ontwikkeld. Tenslotte bestaan er ‘operationele memo’s’, waarin notities opgenomen worden
over de voor de analyse gebruikte methodologieën en strategieën.
In sommige programma’s is het mogelijk naast memo’s ook annotaties aan de
onderzoeksdata toe te voegen. Deze worden net als memo’s aan segmenten gekoppeld en
bevatten additionele informatie over het segment, zoals non-verbale observaties,
samenvatting van de inhoud etc.
3.4.5. Links en hypertekst toevoegen
Bij het coderen worden de tekstsegmenten als afzonderlijke tekstdelen behandeld. Om te
voorkomen dat de segmenten uit hun context gehaald worden en de tekst gefragmenteerd
raakt, kunnen links aangebracht worden. De segmenten blijven zo onderdeel van de gehele
context (Prein, Kelle, Richards & Richards 1995; Silverman 2000).
Veel CAQDAS programma’s zijn sterk in het aanbrengen van links tussen verschillende
onderdelen, zoals de tekst, codes, annotaties, memo’s en externe bestanden (zoals audio- en /
of videobestanden, afbeeldingen, etc.). Dit type links wordt ook wel ‘conceptuele links’
genoemd. Er bestaat dan een denkbeeldige link tussen twee of meer onderdelen. Deze links
worden voor de onderzoeker niet zichtbaar gemaakt door middel van een woord, knop of
28

icoon in de lopende tekst waarop geklikt kan worden; de links zijn enkel opgeslagen in het
achterliggende databasesysteem. De links kunnen bijvoorbeeld gebruikt worden wanneer een
lijst met alle gebruikte codes opgevraagd wordt, waarbij op de codes geklikt kan worden om
de bijbehorende memo te lezen.
De nieuwste programma’s zijn tevens in staat ‘operationele links’ in de tekstuele data aan te
maken, welke vaak worden aangegeven met een icoontje waarop geklikt kan worden. Door
op de link te klikken gaat de gebruiker direct naar het gekoppelde item, zoals een code, een
memo of een tekst segment. Hierdoor is er dus niet alleen in gedachten een link aangebracht
(conceptueel), maar is de link ook daadwerkelijk te volgen. Een operationele link is vaak een
‘harde link’. Dit betekent dat de onderzoeker zelf een begin- en eindpunt moet aangeven. De
link wordt dan geplaatst bij het beginpunt en indien de onderzoeker op de link klikt, gaat hij /
zij direct naar het eindpunt van de link, de bestemming. Dit zijn permanente links tussen
gerelateerde delen van de kwalitatieve database. Een andere manier is het aanmaken van een
dynamische, intelligente link. De onderzoeker kan tijdens het lezen van de tekst een deel van
de tekst (bijvoorbeeld een woord of een woordcombinatie) markeren (ook wel ‘highlighten’),
waarna het programma zelf op zoek gaat naar andere segmenten, waar dezelfde tekst
voorkomt. Op deze manier kan de onderzoeker heen en weer navigeren tussen
tekstsegmenten die inhoudelijk letterlijk aan elkaar gerelateerd zijn.
Indien het mogelijk is om heen en weer (dus in twee richtingen) te bewegen (of te
navigeren), dan spreekt men van hypertext-links, of kortweg hyperlinks.
3.4.6. Zoeken en verzamelen
Figuur 2. Een voorbeeld van een zoekopdracht naar gecodeerde tekstsegmenten. De
onderzoeker geeft de opdracht te zoeken naar alle segmenten in alle teksten die gecodeerd
zijn met het label ‘A’. Het segment met code A uit tekst 1 en het segment met code A uit tekst
2 worden samen gevoegd in een nieuw overzicht met zoekresultaten.
29

Het coderen van de tekst heeft voornamelijk tot doel dat alle segmenten die voorzien zijn
van dezelfde code eenvoudig en snel teruggevonden kunnen worden. Het zoekproces op de
kwalitatieve data kan vergeleken worden met het uitvoeren van zogenaamde ‘queries’
(zoekopdrachten) op kwantitatieve data. De gegevens dienen zowel bij het zoeken en
verzamelen van kwalitatieve data, als bij de ‘queries’ op kwantitatieve data te voldoen aan
de in de opdracht gestelde voorwaarden (zie figuur 2). Weitzman en Miles (1995) zijn van
mening dat niet alleen de snelheid waarmee dit zoeken gebeurt van belang is, maar ook de
manieren waarop gezocht kan worden. Zij noemen een aantal van de meest gebruikte
methoden:
- ‘Boolean’
Bij een Boolse zoekopdracht kan gezocht worden naar een combinatie van termen, door
gebruik te maken van “AND”, “OR” en / of “NOT”. Op deze manier kunnen hele
precieze zoekopdrachten geformuleerd worden. Een uitgebreide Boolse zoekopdracht
zoekt tevens naar geneste segmenten, overlappende segmenten, of “tenminste drie van
de volgende vijf termen”.
Voorbeeld van een Boolse zoekopdracht is: “Toon alle respondenten die (1) gebruik
maken van MS Office EN die (2) wel eens een computervirus op hun computer gehad
hebben”.
- ‘Relational’
Segmenten die door codes met elkaar verbonden zijn kunnen eenvoudig gevonden
worden wanneer er gezocht wordt naar de betreffende code of naar een (hiërarchisch)
pad van codes. Hierbij wordt de hiërarchische boomstructuur betrokken bij de
zoekopdracht.
- ‘Sequence’
Dit is het zoeken naar het voorkomen van combinaties van bepaalde woorden of codes,
in een bepaalde volgorde voor of na elkaar.
- ‘Proximity’
Het voorkomen van bepaalde woorden of codes, die binnen een opgegeven bereik samen
voorkomen kan ook gezocht worden.11 Een ‘proximity’ opdracht zou bijvoorbeeld
kunnen zijn: “toon alle respondenten bij wie de woorden (1) emailbericht EN (2)
geïnfecteerd voorkomen binnen een afstand van vijf woorden”.
- ‘Fuzzy logic’
11 Dit wordt ook wel ‘co-occurrence’ genoemd.
30

De ‘fuzzy logic’ zoekmethode maakt het mogelijk te zoeken naar termen of codes die
qua spelling gelijk zijn aan of lijken op de gegeven zoekopdracht.
- ‘Wildcard’
Veel programma’s bieden een ‘wildcard’ zoekmethode aan. Hierbij wordt een
zoekopdracht gegeven waarbij gebruik gemaakt kan worden van karakters als het
sterretje of een vraagteken, die ieder ander karakter kunnen vervangen, een zogenaamde
‘joker’. Zo kan door middel van de opdracht “program*” gezocht worden naar
“programma”, “programmeren”, “programmeertaal”, etc.
- ‘Synonyms’
Om te kunnen zoeken naar een opgegeven woord en naar alle synoniemen en verbogen
vormen van dat woord, moet het computerprogramma voorzien zijn van een
woordenboek en een thesaurus. Voorbeelden zijn “virussen – virii” en “software –
computerprogramma”
Extra functionaliteit wordt bereikt wanneer het mogelijk is om één van bovenstaande
zoekopties te gebruiken in combinatie met een opgave van het bereik waarbinnen gezocht
dient te worden (bijvoorbeeld alleen de vrouwelijke computergebruikers of alleen de
vrouwelijke computergebruikers die dagelijks gebruik maken van het Internet). Dit wordt in
de meeste programma’s gerealiseerd door één of meerdere zoekmethodes te combineren met
een Boolse opdracht.
3.4.7. Weergeven van de data
De resultaten van een ‘search and retrieve’ opdracht kunnen op meerdere manieren worden
weergegeven:
- Het gevonden segment wordt ‘highlighted’ weergegeven in de oorspronkelijke tekst.
- Het gevonden segment wordt (samen met andere gevonden segmenten) weergegeven in
een nieuw bestand, omgeven door de directe context.
- Het gevonden segment wordt (samen met andere gevonden segmenten) weergegeven in
een nieuw bestand, zonder context.
Bij de laatste twee opties moet het programma de mogelijkheid bieden door middel van een
hyperlink direct terug te springen naar hetzelfde segment in de oorspronkelijke tekst. De
meeste kwalitatieve analyseprogramma’s geven ook informatie over de plek waar het
segment gevonden is, bijvoorbeeld bij welke respondent het segment (of het antwoord)
hoort, waar de informatie gevonden is, de inhoud van het segment, etc. Hierbij is het van
belang dat de links tussen de verschillende onderdelen (tussen tekst en tekst, tussen codes en
31

tekst, etc.) “intelligent” zijn. Wanneer een code (laatste knoop in de boom) verplaatst wordt,
dient de link mee te verplaatsen; wanneer een code hernoemd wordt, dient dit op alle
plaatsen waar deze code voorkomt te gebeuren.
De nieuwste generatie CAQDAS programma’s slaat de gevonden resultaten op in een
databasesysteem (wanneer dit gebeurt binnen hetzelfde programma wordt dit ook wel
‘systeem closure’ genoemd), zodat de resultaten later nog eens opnieuw geanalyseerd
kunnen worden, of verwerkt kunnen worden door een statistisch programma.
Frequentieresultaten kunnen direct naar een statistisch programma doorgestuurd worden
voor verdere analyse. Overige gegevens kunnen gepresenteerd worden in de vorm van een
tabel, een grafiek, een grafisch netwerk (boomstructuur), een vector (zie figuur 3) of een
matrix (zie figuur 4).
Figuur 3. Een vector: alle codes van één bepaalde categorie worden gekoppeld aan een
enkele andere code om te onderzoeken hoe vaak de verschillende combinaties voorkomen.
De resultaten worden weergegeven in tabelvorm, waarbij de velden gevuld zijn met het
aantal computergebruikers van iedere groep (vraag 2 in de ‘CVO’ enquête, zie bijlage II)
dat wel eens een virus gemaakt heeft (vraag 48, zie bijlage II).
32

Figuur 4.Een matrix: alle codes van één bepaalde categorie, in dit geval ‘straf virusmakers’
worden gekoppeld aan alle codes van een andere categorie, in dit geval ‘virusinfectie’.
Hierbij wordt een matrix (tweedimensionale tabel) verkregen met daarin het aantal
respondenten dat al dan niet een infectie met een computervirus heeft meegemaakt (vraag 10
in de ‘CVO’ enquête, zie bijlage II) en de straf die zij passend vinden voor virusmakers
(vraag 51, zie bijlage II).
3.5. CAQDAS gradaties
Niet ieder kwalitatief analyseprogramma kent dezelfde functionaliteiten. Voor het uitvoeren
van een analyse op kwalitatieve gegevens kan de onderzoeker gebruik maken van zeer
eenvoudige programma’s met weinig CAQDAS functionaliteiten, zoals tekstverwerkers, tot
zeer complexe programma’s zoals zogenaamde ‘theory builders’. De programma’s kunnen
ingedeeld worden naar de mate waarin ze beschikken over de functionaliteiten die besproken
zijn in de vorige paragraaf.
Een simpele vorm van kwalitatieve analyse kan uitgevoerd worden met een tekstverwerker,
zoals het programma MS Word. Tekstverwerkers zijn geprogrammeerd voor de creatie en
revisie van teksten. De meeste programma’s van dit type zijn ook in staat enkele eenvoudige
‘content analysis’ taken uit te voeren zoals het zoeken van woorden en het tellen van het
aantal woorden, het aantal regels en het aantal pagina’s. De nieuwste versies van MS Word
bieden ook de mogelijkheid commentaar en revisiesuggesties aan de tekst te koppelen.
Daarnaast is het mogelijk om gebruik te maken van macro’s. Dit zijn kleine programma’s,
geschreven in de taal Visual Basic, die in staat zijn allerlei taken automatisch uit te voeren
op één of meerdere documenten. Door de tekst in de documenten te voorzien van codes, kan
een macro in alle gecodeerde documenten zoeken naar een bepaalde code. Alle gevonden
33

resultaten kunnen vervolgens in een nieuw bestand opgeslagen worden. Eventueel is het
mogelijk ook op dit nieuwe bestand een macro los te laten met bepaalde taken. Echter, tegen
deze methode zijn een aantal bezwaren aan te dragen. Wordprocessors nemen voor
specifieke CAQDAS-taken meer tijd in beslag dan de daarvoor speciaal ontworpen software.
Bovendien zijn in CAQDAS deze taken reeds voorgeprogrammeerd in de software, zodat de
onderzoeker niet zelf aan de slag hoeft met het schrijven van ingewikkelde macro’s.
Tenslotte is het met speciale CAQDAS software mogelijk de analyse uitgebreider uit te
voeren (zoals het automatisch aanmaken van matrices, etc.).
‘Text receivers’ zijn programma’s die gespecialiseerd zijn in het zoeken en sorteren van alle
voorkomens van een bepaald woord, een bepaalde zin of combinaties hiervan. Dit type
programma’s gaat hierbij een stapje verder dan de tekstverwerkers. Sommige ‘text receivers’
zijn in staat enkele ‘content analysis’ functies uit te voeren zoals het geven van een
woordfrequentielijst, het tonen van woorden in hun context en het maken van woordenlijsten
en concordantielijsten.12 In deze categorie hoort ook het eerder behandelde programma
Wordsmith thuis.
Een volgende categorie wordt gevormd door de ‘textbase managers’. Deze
managementsoftware is bedoeld om de gegevens op een gestructureerde wijze op te slaan.
De programma’s zijn in staat de data te organiseren en te sorteren en daarbij subsets van de
gegevens te creëren. De tekst wordt daarbij opgedeeld in velden of ‘records’ die in een
databasestructuur worden opgeslagen. Sommige programma’s zijn in staat memo’s of
externe bestanden aan de gegevens te koppelen. Dit type kan beschouwd worden als een
kwalitatief databasesysteem, waarbij het enkel om de gestructureerde opslag van de
kwalitatieve gegevens gaat, en waarbij geen analysetaken door het programma uitgevoerd
kunnen worden.
De laatste softwarecategorie die verreweg het meest gebruik maakt van CAQDAS
functionaliteiten en die hiervoor ook speciaal ontwikkeld is, is de groep van de ‘code-and-
retrieve’ programma’s. Deze zijn veelal door kwalitatieve onderzoekers zelf ontworpen en
zijn meestal gebaseerd op de Grounded Theory onderzoeksmethode van Glaser en Strauss
(1967). De programma’s zijn in staat de tekst te verdelen in segmenten. Aan deze segmenten
kunnen codes toegekend worden, waarna er gezocht kan worden op alle segmenten met een
bepaalde codering. Behalve het bijhouden van codes en memo’s kennen deze programma’s
ook ‘content analysis’ functies, en bieden ze meestal ook de mogelijkheid om hyperlinks aan
de tekst toe te voegen.
12 Voor meer informatie over ‘content analysis’ zie §3.3
34

3.6. Voordelen en nadelen van CAQDAS
Voordat bekeken kan worden of CAQDAS een oplossing biedt voor het analyseren van open
antwoorden verkregen uit enquêtes, dient eerst gekeken te worden of het gebruik van
CAQDAS functies überhaupt wenselijk en zinvol is. Hiertoe worden hieronder de voor- en
nadelen van dit soort software tegen elkaar afgezet.
Veel van de nadelen van CAQDAS die in de literatuur besproken worden hebben te maken
met een overwaardering van het coderingsproces. Doordat het importeren van de gegevens
en vervolgens het coderen van de segmenten een tijdrovende zaak zijn, zijn veel auteurs
bang dat de onderzoekers verleid worden tot “quick and dirty research with its attendant
danger of premature theoretical closure” (Fielding & Lee 1991: p8). Het risico bestaat dat
een onderzoeker zich volledig en uitsluitend op het coderen van de tekst gaat richten en
hierbij de originele data uit het oog verliest. Het risico bestaat ook dat een onderzoeker de
betekenis van het coderen overschat en hierbij alle andere manieren om tekst te analyseren
negeert. Dey (1995: p77) noemt tenslotte nog het gevaar “of drowning in complexity” als de
onderzoeker zich enkel en alleen stort op het coderen van de data en dit zo ver doorvoert dat
er oneindig veel codes en categorieën aangemaakt worden.
Volgens Lee en Fielding (1995) wordt de onderzoeker in de richting geduwd van een
uiteindelijk kwantitatief analysemodel, door het aanmaken van matrices en vectoren en door
het doen van ‘content analysis’.
Bij kwantitatief onderzoek was al lange tijd duidelijk dat het geen zin heeft tijd te besteden
aan het invoeren van de antwoorden die vijf respondenten op vijf verschillende vragen
hebben gegeven. Datzelfde kan ook voor kwalitatief onderzoek gezegd worden. CAQDAS is
dus alleen nuttig indien de onderzoeker beschikt over een groot corpus van gegevens, vaak
tekst. Een geschikt tekstueel corpus is bijvoorbeeld één hele lange tekst (bijvoorbeeld een
boek), of vele korte stukjes tekst (bijvoorbeeld de antwoorden op een open vraag).
Fielding en Lee (1995) konden echter tijdens hun systematische veldonderzoek naar
gebruikerservaringen met CAQDAS geen substantieel, empirisch bewijs vinden voor
bovengenoemde bezorgdheden van enkele andere onderzoekers.
De voordelen die in de literatuur genoemd worden en die ikzelf door het gebruik van enkele
CAQDAS programma’s heb ervaren, hebben te maken met snelheid, volledigheid,
consistentie en gemak. Door tijdrovende taken van de onderzoeker over te nemen, zoals het
zoeken en kopiëren van tekstsegmenten, kan het gebruik van de computer leiden tot een
35

grotere efficiëntie. Eenmaal gecodeerde gegevens zijn eenvoudig en snel terug te vinden
door uitgebreide search-and-retrieve faciliteiten.
CAQDAS stimuleert bovendien de consistentie bij het coderen van de data. Het
onderzoeksproces kan systematischer en consistenter uitgevoerd worden, waardoor het
gehele onderzoek grondiger uitgevoerd wordt. Dit draagt bij tot een grotere betrouwbaarheid
van de onderzoeksresultaten. Wanneer het analyseren door een onderzoeksteam wordt
gedaan kan het coderen van de data eenvoudig gedaan worden aan de hand van een
coderingsframe, waarin alle codes en hun betekenis van tevoren zijn vastgelegd.
CAQDAS kan de onderzoeker aansporen met de gegevens te spelen en relaties te ontdekken
tussen verschillende categorieën, die met een handmatige methode wellicht niet ontdekt
waren. De kwalitatieve analyse software stimuleert bovendien de combinatie van kwalitatief
onderzoek en kwantitatief onderzoek door het mogelijk te maken de kwalitatieve data
enigszins te kwantificeren: woorden en woordcombinaties kunnen geteld worden, codes
kunnen aan elkaar gekoppeld worden, aan de hand waarvan een numeriek patroon ontdekt
kan worden; er kunnen woord x woord, codes x codes, woord x segment en codes x segment
matrices gemaakt worden die geëxporteerd kunnen worden naar statistische programma’s als
SPSS of MS Excel.
Tenslotte wordt secundaire analyse van de gegevens gemakkelijker gemaakt door gebruik te
maken van CAQDAS, doordat onderzoekers eenvoudig en snel de, al dan niet gecodeerde,
gegevens aan elkaar kunnen doorsturen. Door een tweede, blinde codering uit te voeren, kan
de validiteit en betrouwbaarheid van de onderzoeksresultaten getest worden. Bovendien
maakt een elektronische versie van de data het makkelijker de gegevens te gebruiken voor
een tweede onderzoek dat zich op een ander aspect van de gegevens richt.
3.7. Conclusie
“Software will not pull good work out of a poor researcher” (Weitzman 2000: p817)
De meeste auteurs zijn het er over eens: “Software will never ‘do’ theory building for you,
but it can explicitly support your intellectual efforts, making it easier for you to think
coherently about the meaning of your data” (Weitzman & Miles 1995: p330).
In een bijdrage aan het handboek van Denzin en Lincoln komt Weitzman (zie Denzin &
Lincoln 2000: p806) hier zelf op terug: “This situation may change in the coming years.
There are some current efforts to use artificial intelligence approaches to get computers to
interpret text.”
36

In de kwalitatieve databasepakketten zijn nauwelijks natuurlijke taalfuncties
geïmplementeerd die het mogelijk maken dat de computer zelfstandig leert teksten te
analyseren. Dit is opvallend omdat er momenteel veel aandacht geschonken wordt aan
technieken voor ‘natural language processing’ (NLP) en spraakherkenning. Wanneer de
computer in staat zou zijn het coderingsproces geheel van de onderzoeker over te nemen en
daarbij in staat zou zijn de tekst te begrijpen, kan dit de onderzoeker veel werk en tijd
besparen. Wellicht is de complexiteit van integratie van de NLP functies niet de enige reden
waarom CAQDAS niet over dergelijke functies beschikt. Een programma die van deze
functies gebruik wil maken dient te beschikken over een volledig woordenboek in minstens
één taal (het programma kan dan ook alleen voor teksten in die taal gebruikt worden), en een
volledige thesaurus. Bovendien moet de complete grammatica van de gekozen taal ingevoerd
zijn, wil het programma in staat zijn de tekst ook daadwerkelijk te begrijpen. Hoewel dit op
zich opgebouwd zou kunnen worden uit reeds bestaande onderdelen die gebruikt zijn in
programma’s die wel gebruik maken van NLP, maakt een dergelijke implementatie de
CAQDAS wellicht te kostbaar voor een onderzoeker die sporadisch van deze software
gebruik maakt.
De meeste kwalitatieve onderzoekers zijn van mening dat CAQDAS de onderzoeker wel
degelijk kan helpen bij het ontwikkelen en formuleren van ideeën en conclusies over het
onderwerp. CAQDAS biedt deze mogelijkheid door de gegevens op codes te doorzoeken en
door het tonen van de zoekresultaten, het coderingsschema en een eventuele indeling in
categorieën en een boomstructuur. Het is belangrijk dat onderzoekers inzien dat de computer
een heel handige ‘tool’ kan zijn, maar dat ze zich in hun analyses niet moeten beperken tot
de mogelijkheden van de computer. Idealiter worden alleen díe CAQDAS functies gebruikt,
die bruikbaar zijn voor het eigen onderzoek.
Hoewel in de literatuur vaak geschreven wordt dat CAQDAS niet geschikt zou zijn voor
korte teksten, zoals open antwoorden in (online) enquêtes, kunnen de meeste functies naar
mijn mening wel degelijk gebruikt worden voor een grondige en betrouwbare analyse van
open antwoorden die verkregen worden door een enquête. Het volgende hoofdstuk richt zich
dan ook op de mogelijkheden om de CAQDAS functies te gebruiken bij de analyse van
zowel open als gesloten antwoorden. Dit in antwoord op de vraag in hoeverre het gebruik
van de verschillende CAQDAS-functies mogelijk, zinvol en wenselijk is bij de twee
antwoordtypen. Na deze bespreking wordt gekeken welke functies open antwoorden en
37

gesloten antwoorden nodig hebben voor een goede analyse, en in hoeverre bestaande
databasesystemen over deze functies beschikken.
38

4. Voldoen bestaande systemen?
4.1. Inleiding
In het vorige hoofdstuk is er ingegaan op de hulpmiddelen en de programma’s die speciaal
ontwikkeld zijn voor de uitvoering van kwalitatief onderzoek met behulp van de computer.
In dit hoofdstuk worden de genoemde functies van CAQDAS programma’s nog eens
opgesomd en wordt er gekeken welke functies bruikbaar zijn voor de verwerking van
antwoorden op zowel open als gesloten vragen in een online enquête. Daarna wordt gekeken
op welke manier de open en gesloten antwoorden het beste opgeslagen, verwerkt en
gepresenteerd kunnen worden door gebruik te maken van twee bestaande
computerprogramma’s: Kwalitan voor de analyse van kwalitatieve gegevens; MS Access
voor de analyse van kwantitatieve gegevens. Hierbij is onderzocht of het mogelijk is de
kwalitatieve en kwantitatieve gegevens samen in één programma op te nemen. Ook is
gekeken of een alternatief systeem, dat het beste van beide bestaande programma’s
combineert, nog meer voordelen oplevert.
4.2. Zijn CAQDAS functies bruikbaar bij de verwerking van beide vraagvormen?
4.2.1. Coderen
Coderen is een methode die uitermate geschikt is voor een uitgebreide ‘labeling’ van de
antwoorden die verzameld worden door het uitvoeren van een enquête. Gesloten antwoorden
zijn vaak geprecodeerd. Achter een set met tekstuele alternatieven schuilt dan bijvoorbeeld
een serie karakters (bijvoorbeeld ‘A’, ‘B’, ‘C’ en ‘D’) of codes. Wanneer de respondent een
antwoord heeft gegeven, kan dit karakter, dat eigenlijk gebruikt wordt als afkorting van het
werkelijk gegeven antwoord, gebruikt worden in een verwerking van de antwoorden. Indien
het gesloten antwoord een eenvoudig te tellen waarde bevat, bijvoorbeeld het antwoord op
een ja / nee vraag, of indien het antwoord numeriek is, hoeft het antwoord niet geprecodeerd
te zijn voor een directe verwerking van de gegevens. Gesloten antwoorden hoeven niet
naderhand handmatig (al dan niet door een computerprogramma ondersteund) gecodeerd te
worden en zijn niet onderhevig aan de interpretatie van de onderzoeker.
Open antwoorden die door het uitvoeren van een enquête verzameld zijn, zijn vaak korte
stukjes tekst waarvan de inhoud en soms zelfs het onderwerp van tevoren niet bekend is. Om
deze antwoorden enigszins te kunnen analyseren en te gebruiken in een algemene analyse
van alle enquête-antwoorden tezamen, is het nodig dat de open antwoorden in zekere mate
39

gekwantificeerd worden. Indien de Grounded Theory onderzoeksmethode van Glaser &
Strauss (1967) gevolgd wordt, kan voor deze kwantificering gebruik gemaakt worden van
het coderingsprincipe, waarvan de werking is uitgelegd in het vorige hoofdstuk. Dit
coderingsprincipe staat toe dat een tekst zo veel labels krijgt toegekend, dat alle informatie
die van belang kan zijn voor het onderzoek erin ligt opgeslagen. Op deze manier kan het
antwoord teruggebracht worden tot wat de onderzoeker beschouwt als de essentie van het
antwoord. Het coderen van open antwoorden is daarmee onderhevig aan de interpretatie van
de onderzoeker. Een belangrijk voordeel van het coderen van open antwoorden is dat een
meervoudig open antwoord, bijvoorbeeld in de vorm van “Ik vind dat … en … ”, ook
meervoudig gecodeerd kan worden. Des te opener het antwoord, des te belangrijker is het dat
het antwoord gecodeerd wordt. Immers een antwoord op een open vraag als “Wat is uw
leeftijd?” kan eenvoudig opgeslagen worden zonder dat het eerst gecodeerd wordt. Een
antwoord op een open vraag als “Heeft u nog vragen of opmerkingen?” kan van tevoren niet
ingeschat worden en behoeft voor verdere verzameling en (statistische) analyse een
volledige en consistente codering. Ditzelfde geldt uiteraard ook voor opties bij gesloten
vragen als “Anders, namelijk…”. Zoals in hoofdstuk twee reeds uitgelegd is, levert een
dergelijke optie bij een gesloten vraag in feite een open antwoord op.
4.2.2. Structureren
Het structureren van codes in categorieën is vooral zinvol als er veel verschillende codes
gebruikt zijn en als meerdere codes qua betekenis samenhangen. Het kan zinvol zijn zowel
de codes die gebruikt zijn om de open antwoorden te coderen, als de codes die gebruikt zijn
bij de geprecodeerde antwoorden in te delen in categorieën. Vooral de codes die gebruikt
zijn voor de antwoorden op open vragen die heel open gesteld zijn dienen gestructureerd te
worden om de verschillende onderwerpen die door de respondenten zijn aangesneden van
elkaar te kunnen onderscheiden. Wederom kan de vraag “Heeft u nog vragen of
opmerkingen” hier als voorbeeld dienen. Deze vraag kan antwoorden in vele verschillende
richtingen opleveren. De antwoorden kunnen gecodeerd worden op inhoud, waarna de codes
gestructureerd kunnen worden naar onderwerp. In veel gevallen zal het echter voldoende zijn
de codes te categoriseren per vraag. Zo bevat bijvoorbeeld de categorie ‘vraag 4’ alle voor
vraag 4 gebruikte codes.
4.2.3. Annoteren
Bij ieder onderzoek is het van groot belang dat de onderzoeker tussentijds de mogelijkheid
heeft om aantekeningen te maken van gemaakte keuzes, achterliggende ideeën en theorieën
40

en de betekenis van de verschillende codes. Dit geldt ook voor de verwerking van de open en
gesloten antwoorden. Met name de interpretatie op basis waarvan een open antwoord
gecodeerd wordt, kan goed in een memo bewaard worden. De keuzes die de onderzoeker bij
deze interpretatie en de uiteindelijke codering maakt, en de aspecten waarop hij / zij zich
daarbij richt, dienen goed vastgelegd te worden. Memo’s kunnen ook gebruikt worden om
tijdens het coderen van de antwoorden alvast interessante koppelingen tussen twee of meer
vragen te noteren. Bij gesloten antwoorden is het verstandig ook de tekstuele set van
alternatieven in de vorm van een memo op te slaan in de database, zodat de betekenis van de
codes na verloop van tijd niet voor onduidelijkheden kan zorgen.
4.2.4. Hyperlinks toevoegen
Wanneer een onderzoeker gebruik wil maken van codes, categorieën en memo’s, is het
handig als de verschillende onderdelen en de antwoorden aan elkaar gelinkt kunnen worden.
De computer biedt twee systemen waarin het mogelijk is deze links aan te brengen. Het
eerste systeem is een relationele database, zoals het programma MS Access waarin velden
van meerdere tabellen aan elkaar gekoppeld kunnen worden. Een andere mogelijkheid maakt
gebruik van het World Wide Web, dat gebaseerd is op het linken van bestanden en ook
uitstekend gebruikt kan worden voor het linken tussen teksten, memo’s en codes. Het
aanbrengen van operationele hyperlinks zorgt er voor dat de onderzoeker eenvoudig door de
verschillende onderdelen kan navigeren.
4.2.5. Zoeken en verzamelen
Het coderen en structureren van de antwoorden heeft alleen zin als de codes en de
categorieën vervolgens gebruikt kunnen worden in zoekopdrachten. Op deze manier kunnen
alle respondenten die met dezelfde labels gecodeerd zijn en dus een antwoord van dezelfde
strekking hebben gegeven eenvoudig gezocht en verzameld worden. De onderzoeker hoeft,
door op de codes en de categorieën te zoeken, niet voor iedere zoekopdracht alle
afzonderlijke, volledige open antwoorden opnieuw door te nemen. Het coderen heeft de open
antwoorden dus enigszins gekwantificeerd zodat de open en de gesloten antwoorden nu
samen gebruikt kunnen worden in een ‘query’.
4.2.6. Weergeven van de data
Zonder een presentatie van de analyseresultaten heeft het uitvoeren van een onderzoek
weinig nut. De gegeven antwoorden kunnen op meerdere manieren gepresenteerd worden.
Eén manier is het tonen van een overzicht van alle volledige antwoorden. Dit is echter een
41

weinig overzichtelijke manier, die het trekken van conclusies niet vergemakkelijkt. Een
andere manier is het presenteren van de resultaten van een gerichte zoekopdracht. Een
zoekopdracht kan één of meerdere numerieke waarden of percentages opleveren, of een lijst
met alle respondenten die aan de opgegeven zoekvoorwaarde(n) voldoen. De numerieke
waarden of percentages kunnen getoond worden in een tabel, een grafiek, een matrix of een
vector. Indien een open vraag gebruikt is in de zoekopdracht, is het ook mogelijk de open
antwoorden van respondenten die voldoen aan de zoekvoorwaarde(n) te tonen.
4.2.7. ‘Content analysis’
‘Content analysis’ wordt in de literatuur meestal niet genoemd als één van de CAQDAS
functies, maar kan naar mijn mening wel degelijk als een CAQDAS functie beschouwd
worden. Het is immers een methode om met behulp van de computer kwalitatieve data te
analyseren. Het hangt van het doel van het onderzoek af in hoeverre ‘content analysis’
interessant is om toe te passen op de verzamelde kwalitatieve data. Vaak zijn de open
antwoorden in online enquêtes korte stukjes tekst, waarbij het coderen en structureren, en het
zoeken en verzamelen voldoen voor een analyse van de antwoorden. In sommige gevallen
kan ‘content analysis’ echter wel interessant zijn. Bij lange open antwoorden (denk hierbij
aan essayvragen), of wanneer het onderzoek gericht is op het woordgebruik van de
respondenten, kan een ‘content analysis’ naar de gebruikte woorden en frequentie waarmee
deze woorden gebruikt worden interessante resultaten opleveren.
‘Content analysis’ is niet interessant om te gebruiken bij gesloten antwoorden. Immers de
tekst van deze antwoorden bestaat uit woorden van de onderzoeker zelf.
4.2.8. Vergelijking
De bruikbaarheid van de verschillende CAQDAS functies in combinatie met open en
gesloten antwoorden is hierboven uitvoerig behandeld. In tabel 5 zijn de functies nogmaals
opgesomd, waarbij is aangegeven welke functies voor open antwoorden en welke functies
voor gesloten antwoorden zinvol en wenselijk zijn.
42

CAQDAS functie Open antwoorden Gesloten antwoorden
Coderen
Structureren van de codes Zoeken en verzamelen Memo’s en annotaties toevoegen Hyperlinks toevoegen Weergeven van de resultaten Content analyse
Tabel 5. CAQDAS functies die bruikbaar zijn voor open en gesloten antwoorden.
4.3. Bestaat er een databasesysteem dat beide vraagvormen kan verwerken?
Er bestaan voldoende programma’s die in staat zijn te werken met ofwel kwantitatieve ofwel
kwalitatieve gegevens. Dit hoofdstuk onderzoekt in hoeverre bestaande programma’s
gebruikt kunnen worden om zowel kwantitatieve als kwalitatieve gegevens op te slaan, te
analyseren en te presenteren. Daartoe is uit de categorie ‘kwantitatieve databases’ één
programma gekozen en getest op de mogelijkheden om zowel kwantitatieve gegevens als
kwalitatieve gegevens te verwerken, namelijk MS Access. Ook uit de categorie ‘kwalitatieve
analyse programma’s’ is één programma getest op de mogelijkheden om beide typen
gegevens te verwerken, namelijk Kwalitan.
Kunnen alle gegevens in één van deze twee programma’s opgeslagen, verwerkt en
gepresenteerd worden?
4.3.1. Kunnen alle gegevens verwerkt worden in een kwalitatieve database?
Kwalitan is een computerprogramma dat ontwikkeld is ter ondersteuning van de uitvoering
van een analyse van kwalitatieve data. In hoofdstuk drie is een opsomming gegeven van de
verschillende CAQDAS gradaties: Kwalitan behoort tot de categorie ‘code-and-retrieve’
programma’s.
Voordat met Kwalitan gewerkt kan worden moet de data op import in het programma
voorbereid worden. Het programma kan alleen tekstbestanden importeren, waarbij alle
opmaak van de tekst verloren gaat. De open antwoorden kunnen in hun oorspronkelijke,
43

onbewerkte vorm onder elkaar in een tekstbestand opgeslagen worden. Het te importeren
tekstbestand met de gesloten antwoorden kan op vier manieren opgesteld zijn:
1. Het tekstbestand bestaat uit de set met mogelijke antwoorden, die voor ieder gegeven
antwoord herhaald wordt en welke gecodeerd is met het gegeven antwoord.
2. Het tekstbestand bestaat uit de tekstuele gekozen antwoorden, welke gecodeerd zijn met
de bijbehorende code / afkorting.
3. Het tekstbestand bestaat uit de tekstueel gekozen antwoorden, zonder codering.
4. Het tekstbestand bestaat uit de tekstueel gekozen antwoorden, waarbij de antwoorden uit
slechts één woord bestaan (bijvoorbeeld “regelmatig”, “soms” of “nooit”), of enkel uit
de afgekorte versie van het antwoord (een karakter, code of getal).
Deze vier mogelijkheden zijn in figuur 5 weergegeven.
@ Ik gebruik de pc soms
Ik gebruik de pc vaak
Ik gebruik de pc soms
Ik gebruik de pc nooit
@ B
Ik gebruik de pc soms
Ik gebruik de pc soms Soms
Figuur 5. De vier mogelijkheden om gesloten antwoorden in een tekstbestand op te slaan dat
geïmporteerd kan worden in Kwalitan. In Kwalitan wordt het ‘@’ gebruikt om een code aan
te geven.
Na import van tenminste één tekstbestand met antwoorden biedt Kwalitan de volgende
CAQDAS functionaliteiten:
- coderen van de tekst
- structureren van de codes in categorieën en boomstructuren
- zoekopdrachten waarbij filters (voorwaarden) gedefinieerd kunnen worden
- memo’s en annotaties toevoegen
- hyperlinks toevoegen
- weergeven van de resultaten in de vorm van lijsten, tabellen en matrices; bovendien
kunnen de resultaten zo opgemaakt worden dat ze geëxporteerd kunnen worden naar het
statistische programma SPSS voor verdere analyse
- ‘content analysis’ uitvoeren dat een woordfrequentielijst oplevert
In de vorige paragraaf is bestudeerd in hoeverre deze functies bruikbaar zijn voor open en
gesloten antwoorden. Daar kwam uit dat alle bovenstaande functies toepasbaar zijn op open
44

antwoorden. Voor de gesloten antwoorden is daar geconcludeerd dat de functies coderen en
‘content analysis’ niet van toepassing zijn. Echter, wanneer de gesloten antwoorden
geïmporteerd worden in een tekstbestand van het derde of het vierde type, kunnen de
antwoorden alsnog wel voorzien worden van codes. Op een tekstbestand van type vier is het
tevens zinvol om een ‘content analysis’ uit te voeren. Deze analysefunctie telt namelijk het
aantal keren dat ieder woord voorkomt. Als ieder woord een antwoord representeert is het
met ‘content analysis’ mogelijk te tellen hoe vaak ieder antwoord gegeven is.
Kwalitan is onderzocht op een aantal belangrijke functionaliteiten zoals snelheid,
duidelijkheid en consistentie in gebruik, gebruik van een database, gebruik van CAQDAS
functionaliteiten, mogelijkheid om het programma te koppelen aan een online enquête en de
bruikbaarheid voor een onervaren onderzoeker. Tabel 6 geeft kort de belangrijkste plus- en
minpunten van Kwalitan weer.
Pluspunten van Kwalitan Minpunten van Kwalitan
- consistent coderen mogelijk gemaakt
door aanmaak van coderingsschema,
waaruit reeds aangemaakte codes
gekozen kunnen worden voor
hergebruik
- autocoding mogelijk
- ‘content analysis’ functies
- voorzien van een stap voor stap
interface en begeleiding
- codes kunnen ingedeeld worden in een
grafische boomstructuur
- onderzoeker hoeft niet zelf een
gegevensstructuur te bedenken
- gegevens worden op eigen schijfruimte
opgeslagen
- handmatige import van tekstbestanden
- geen weergave van de geïmporteerde
antwoorden in tabellen of grafieken
mogelijk
- resultaten van zoekopdrachten alleen
weergegeven in lijsten
- geen statistische methoden aanwezig
- geen ‘realtime’ analyse of directe
koppeling met een website mogelijk
- querymogelijkheden gaan niet verder
dan zoek- en verzamelopdrachten
waarbij alleen bepaalde codes
opgegeven kunnen worden als
zoekvoorwaarde
- platformafhankelijk: programma werkt
alleen onder MS Windows
Tabel 6. Plus- en minpunten van de opslag, verwerking en presentatie van de open en
gesloten antwoorden in Kwalitan.
45

Het programma Kwalitan is duidelijk geschikt voor de verwerking van open antwoorden. De
CAQDAS functionaliteiten zijn in dit programma goed geïmplementeerd en de onderzoeker
wordt in het verwerken van de gegevens stap voor stap begeleid en ondersteund. Echter, het
programma is niet sterk in een gestructureerde opslag van de gegevens, het uitvoeren van
zoekopdrachten en de weergave van de zoekresultaten. Wellicht dat een programma als MS
Access op dit vlak meer mogelijkheden kan bieden?!
4.3.2. Kunnen alle gegevens verwerkt worden in een kwantitatieve database?
MS Access is het programma dat ik bij de verwerking van mijn eigen enquête heb gebruikt.
Met het programma kan een relationele database gemaakt worden waarin grote
hoeveelheden gegevens in één of meerdere tabellen gestructureerd kunnen worden.
Vervolgens kunnen deze gegevens gebruikt worden in uitgebreide ‘queries’ en voor een
statistische verwerking. Het programma is daarmee uitermate geschikt voor een snelle
verwerking van de gesloten antwoorden. MS Access kan verschillende datatypen opnemen
in de velden van een tabel, zoals tekst, numeriek, datum en tijd, valuta, autonummering, ja /
nee en hyperlink. Gesloten antwoorden zijn vaak korte antwoorden of afgekorte antwoorden,
zoals een karakter, een code of een getal. Deze antwoorden worden daarom meestal
opgenomen in een tekstveld van het type ‘char’ of een numeriek veld van het type ‘int’.
Open antwoorden dienen vanzelfsprekend opgenomen te worden in een tekstueel veld. Een
tekstueel veld van het type ‘char’ kan slechts 255 karakters (‘characters’) bevatten; een
tekstueel veld van het type ‘memo’ kan 64.000 karakters bevatten. Open antwoorden dienen
dus in een memoveld bewaard te worden. Een andere mogelijkheid is het opslaan van het
open antwoord in een tekstbestand. In de tabel kan vervolgens in een veld van het type
‘hyperlink’ een link aangemaakt worden naar dit tekstbestand. Het antwoord wordt in dit
geval dus niet rechtstreeks opgeslagen in de database. De aangemaakte link is operationeel,
wat betekent dat als de onderzoeker erop klikt, het tekstbestand geopend wordt. Nadeel van
deze methode is dat voor ieder antwoord een apart tekstbestand aangemaakt dient te worden
en dat het antwoord in het tekstbestand niet inhoudelijk doorzocht kan worden, of gebruikt
kan worden in een ‘query’.
Wanneer de gegevens eenmaal geïmporteerd zijn in de database, kunnen de gesloten
antwoorden direct gebruikt worden voor statistische toepassingen en ‘queries’. De open
antwoorden moeten wederom eerst gecodeerd worden. Omdat van tevoren niet bekend is
hoeveel codes nodig zijn om een antwoord te coderen, is het niet verstandig de codes in
dezelfde tabel als de antwoorden op te nemen, want dan moet voor iedere code die aan een
46

antwoord gekoppeld wordt een nieuwe kolom aan de tabel toegevoegd worden. Een betere
methode is het aanmaken van een extra tabel waarin alle codes opgeslagen worden en
voorzien worden van een ‘codenummer’. Een derde tabel kan dan vervolgens als koppeltabel
dienen tussen het antwoord en de codes die aan dat antwoord toegekend zijn. Zie voor een
voorbeeld figuur 6.
# Antwoord # Code Antw. Code
1
2
3
Antwoord1
Antwoord2
Antwoord3
1
2
3
Code1
Code2
Code3
1
1
2
1
3
3
Figuur 6. Overzicht van drie tabellen die aangemaakt moeten worden om een code aan een
antwoord toe te kunnen kennen
.
Het voordeel van een relationele database is dat de gegevens in de derde tabel ook
daadwerkelijk gekoppeld kunnen worden aan de gegevens in de eerste en de tweede tabel,
zoals afgebeeld in figuur 7.
Figuur 7. De tabel met de antwoorden en de tabel met de codes zijn aan elkaar gekoppeld
via een derde tabel met de antwoord - code combinaties.
MS Access is op dezelfde functionaliteiten onderzocht als Kwalitan: snelheid, duidelijkheid
en consistentie in gebruik, gebruik van een database, gebruik van CAQDAS
functionaliteiten, mogelijkheid om het programma te koppelen aan een online enquête en de
bruikbaarheid voor een onervaren onderzoeker. Tabel 7 geeft kort een aantal belangrijke
plus- en minpunten van MS Access weer.
47

Pluspunten van MS Access Minpunten van MS Access
- uitgebreide querymogelijkheden door
koppelingen tussen tabellen en de
mogelijkheid om zowel codes als
letterlijke antwoorden te gebruiken als
zoekvoorwaarde
- weergave van antwoorden en
queryresultaten in tabellen en grafieken
mogelijk
- statistische methoden aanwezig
- overzichtelijke gegevensstructuur
doordat alle gegevens in afzonderlijke
records en velden kunnen worden
opgeslagen; tevens mogelijkheid om
meerdere tabellen aan te maken
- gegevens worden op eigen schijfruimte
opgeslagen
- gegevensstructuur moet door
onderzoeker zelf aangemaakt worden
- codes kunnen niet in een grafische
boomstructuur getoond worden
- handmatige import van tekstbestanden
- geen ‘content analysis’ functies
aanwezig
- autocoding alleen mogelijk door zelf een
uitgebreid SQL statement te maken:
hiervoor is kennis van SQL nodig
- geen stap voor stap analysetraject
- weinig consistente codering doordat drie
tabellen nodig zijn voor het koppelen
van een antwoord en een code
- geen ‘realtime’ analyse of directe
koppeling met een website mogelijk
- het is niet mogelijk gekoppelde
tekstbestanden te doorzoeken
- gebonden aan het MS Windows
besturingssysteem
Tabel 7. Plus- en minpunten van de opslag, verwerking en presentatie van de open en
gesloten antwoorden in MS Access.
MS Access kent een aantal sterke pluspunten, maar ook meerdere minpunten. MS Access
kan heel goed gebruikt worden voor de opslag van de gegevens, het uitvoeren van
zoekopdrachten en het presenteren van de resultaten. Echter, het programma is niet
eenvoudig in gebruik en vereist veel interactie met de onderzoeker. Hij / zij moet zelf een
gegevensstructuur opstellen en wordt niet ondersteund bij het analyseren van de open
antwoorden. Is het mogelijk een systeem te ontwerpen, die het beste van Kwalitan
combineert met het beste van MS Access?
48

4.4. Een alternatieve methode
Aan de hand van de bestudering van de mogelijkheden die Kwalitan en MS Access bieden is
het mogelijk een wensenpakket op te stellen waaraan een alternatief systeem zou moeten
voldoen:
- stap voor stap ondersteuning bij de codering en structurering van de open antwoorden;
hulp bij consistente codering en tonen van een grafische boomstructuur
- uitgebreide CAQDAS en ‘content analysis’ functionaliteiten
- uitgebreide querymogelijkheden en statistische methoden
- directe koppeling met een website zodat handmatige import en opzet van een eigen
gegevensstructuur niet nodig is en het systeem platform- en programma-onafhankelijk is
- ‘realtime’ weergave van de resultaten in tabellen en grafieken
Eén van de grootste nadelen van beide bestaande programma’s is dat ze niet direct
gekoppeld kunnen worden aan een online enquête. Dit betekent dat het niet mogelijk is de
antwoorden die een respondent geeft direct gestructureerd en overzichtelijk op te slaan in
een database die de onderzoeker niet zelf hoeft op te zetten. De gegevens zijn dan ook niet
beschikbaar voor een ‘realtime’ verwerking. Dit betekent dat de gegevens niet direct na
ontvangst gebruikt kunnen worden voor een tussentijdse analyse.
Een methode waarbij dit allemaal wel mogelijk is, is de koppeling van de online enquête met
een MySql database. Deze database is vergelijkbaar met een MS Access database. Alle
voordelen van een verwerking van de antwoorden in MS Access gelden ook voor een
verwerking van de antwoorden in MySql. Echter, ook in een MySql ontbreken de CAQDAS
functies die nodig zijn voor een analyse van de open antwoorden. Dit gebrek kan worden
opgevangen door de website die aan de database gekoppeld is. De website biedt de
onderzoeker een interface waarmee hij / zij een analyse op de gegevens kan uitvoeren zonder
daarbij kennis te hoeven hebben van specifieke software of programmeertalen zoals SQL.
Zonder dat de onderzoeker het door hoeft te hebben, worden de gegevens in de database
opgeslagen en kunnen de gegevens ook weer uit de database gelezen worden. Dit maakt het
mogelijk uitgebreide zoekopdrachten op te stellen waarbij ook de open antwoorden gebruikt
kunnen worden, die vervolgens door het systeem omgezet worden in SQL ‘queries’.
Op deze manier ontstaat één systeem dat zowel mogelijkheden biedt voor een
gestructureerde opslag van de verzamelde antwoorden, het uitvoeren van uitgebreide
zoekopdrachten, statistische methoden, en de belangrijkste CAQDAS functies. Bovendien
49

hoeft de onderzoeker niet zelf een geschikte databasestructuur te bedenken en op te zetten,
en hoeft hij / zij niet zelf de gegevens te importeren en te structureren. De website en de
achterliggende database zorgen voor een stap voor stap analyseproces met voldoende
begeleiding. De verschillende plus- en minpunten van dit alternatieve systeem zijn
opgesomd in tabel 8.
Pluspunten van de alternatieve methode Minpunten van de alternatieve methode
- alle pluspunten van Kwalitan
- alle pluspunten van MS Access
- systeem is platformonafhankelijk en de
onderzoeker hoeft zelf niet te
beschikken over speciale software
- geen import van gegevens nodig, deze
worden automatisch vanaf de website in
de database weggeschreven
- exportmogelijkheden voor MS Access,
MS Excel en SPSS
- gegevens zijn niet direct opgeslagen op
eigen computer
Tabel 8. Plus- en minpunten van de opslag, verwerking en presentatie van de open en
gesloten antwoorden in een alternatief systeem dat gebaseerd is op een website met een
daaraan gekoppelde MySql database.
4.5. Conclusie
In dit hoofdstuk is gekeken op welke manieren open en gesloten antwoorden in één systeem
opgeslagen, verwerkt en gepresenteerd kunnen worden. Hoewel Kwalitan en MS Access
voldoende mogelijkheden bieden om beide antwoordtypen te verwerken, zijn beide systemen
niet ideaal om te gebruiken wanneer een onderzoeker snel en eenvoudig een online enquête
wil uitvoeren. Vervolgens is gekeken op welke manier het beste van beide programma’s
gecombineerd kan worden in een alternatief systeem dat gebaseerd is op een website die een
duidelijk en eenvoudig te gebruiken interface biedt. Aan de website kan een MySql database
gekoppeld worden, die het mogelijk maakt de gegevens gestructureerd op te slaan en
‘realtime’ te verwerken. Dit levert een totaalpakket op waarin een enquête aangemaakt,
uitgevoerd en verwerkt kan worden. In het volgende hoofdstuk wordt in dit hoofdstuk
voorgestelde alternatieve systeem verder uitgewerkt en geïmplementeerd.
50

5. Ontwerp en implementatie van een alternatief
5.1. Inleiding
In hoofdstuk vier kwam een alternatieve methode, die gebruik maakt van een website en een
MySql database voor het uitvoeren van een online enquête, als beste uit de bus. Om deze
methode zo optimaal mogelijk uit te werken tot een goed werkend systeem, zijn eerst nog
een aantal bestaande online enquêtesystemen onderzocht op de mogelijkheden die zij
aanbieden en vooral ook op de aanwezige CAQDAS functies. De mogelijkheden blijken zeer
beperkt en CAQDAS functies ontbreken veelal.
Het enquêtesysteem dat in dit hoofdstuk voorgesteld wordt, is gebaseerd op de theorie
omtrent de mogelijkheden om open en gesloten antwoorden te gebruiken en te verwerken, en
op de bevindingen van het praktische, vergelijkende onderzoek van bestaande online
enquêtesystemen.
De in de algemene inleiding genoemde CVO enquête is als testenquête gebruikt. Door
middel van deze enquête heb ik onderzocht hoe verschillende gebruikersgroepen
maatregelen treffen tegen, en omgaan met computervirussen. De resultaten van deze CVO
enquête zijn gebruikt als invoer voor de testenquête en berusten dus op de werkelijkheid.13
De oorspronkelijke enquête bestond uit 58 vragen en is gehouden onder 135 respondenten,
zowel op papier als via Internet.14
5.2. Vergelijkend onderzoek
Voor het vergelijkende onderzoek naar de mogelijkheden die bestaande online
enquêtesystemen bieden zijn enkele toonaangevende systemen bestudeerd en getest: Enquête
Via Internet, Survey World, Online Enquête, eXamine, eQuest, Zoomerang, Quask,
Studentenenquete en Websurveyor. De vergelijkingen zijn opgezet aan de hand van de drie
taken die onderscheiden kunnen worden bij het houden van een enquête:
1. Het aanmaken van een enquête en het invoeren van de vragen.
2. Het publiceren en uitvoeren van de enquête.
3. Het verwerken van de verzamelde gegevens en het presenteren van de resultaten.
13 Zie voor de ‘CVO’ enquête bijlage II. 14 De op Internet ingevulde enquête werd door gebruik te maken van een kant-en-klaar ‘sendmail’ programma in Perl via e-mail naar mij opgestuurd; de gegevens moesten handmatig in de MS Access database ingevoerd worden.
51

Bij wijze van illustratie zijn de bevindingen die gedaan zijn bij twee van deze systemen,
“Enquête Via Internet” en “Survey World” hier kort samengevat.15
5.2.1. Enquête Via Internet
+ Eén onderzoeker kan meerdere enquêtes beheren. + Gegevens over enquête en beheerder kunnen gewijzigd worden. + Logboek houdt de belangrijkste ontwikkelingen bij, zoals het aanmaken van
een nieuwe enquête, toevoeging van nieuwe vragen en aangebrachte wijzigingen.
+ Keuze uit vijf vraagtypen.16 + Achtergrondkleur van de enquête kan aangepast worden; afbeelding kunnen
‘geupload’ worden. - Het is niet mogelijk ‘skips’ (vervolgvragen) te definiëren.
+ Duidelijke instructies voor versturen van uitnodigingen en inpassen van
enquête in eigen website. + Check op uiterlijke publicatiedatum.
+ Resultaten zijn realtime te volgen in een overzicht van alle gegeven
antwoorden, waarbij ook percentages berekend worden. + Export mogelijk naar XML, Access, Excel en Word. - Exportbestanden moeten via e-mail aangevraagd worden. - Het is niet mogelijk koppelingen tussen tabellen te definiëren of ‘queries’ uit te
voeren. - De verwerking van open antwoorden is niet bekend.
1
2
3
5.2.2. Survey World
+ Keuze uit meerdere talen. + Lay-out kan volledig aan huisstijl aangepast worden. + Keuze uit tien vraagtypen.17 - Het is niet mogelijk ‘skips’ (vervolgvragen) te definiëren. - Het is niet mogelijk externe bestanden (afbeeldingen) te ‘uploaden’ en toe te
voegen aan de vragen.
1
15 Zie http://www.enqueteviainternet.com en http://www.surveyworld.com. 16 Onder andere: open vragen, gesloten vragen met één of meerdere keuzes en een likertschaal. 17 Onder andere: ja / nee vraag, open vraag waarbij de respondent kan antwoorden in één regel of in meerdere regels, gesloten vraag met één of meerdere keuzes, en een matrixvraag. De overige vraagtypen zijn combinaties van de genoemde typen of typen die bedoeld zijn voor zeer specifieke marktonderzoeken.
52

+ Duidelijke instructies voor versturen van uitnodigingen en invoegen van
enquête in eigen website. + Deelnemers kunnen uit een bestaand adresboek geïmporteerd worden en
uitgenodigd worden via e-mail. + Er wordt bijgehouden wie gereageerd heeft en wie niet (en waarom niet) en er
kan een tweede e-mailbericht ter herinnering gestuurd worden. + Wanneer de uitnodiging verstuurd is kan de enquête niet meer gewijzigd
worden.
+ Resultaten zijn realtime te volgen in meerkleurige, 3D grafieken die voorzien
zijn van een duidelijke legenda. + Er kunnen koppelingen (kruisverbanden) gemaakt worden tussen meerdere
vragen. + Export van de resultaten is mogelijk naar Office software en SPSS. - De verwerking van open antwoorden is niet bekend.
2
3
Wat duidelijk ontbreekt in deze twee systemen, en ook in de andere bestudeerde systemen, is
de verwerking van de verzamelde antwoorden op de open vragen. Uit correspondentie met
verschillende ICT bedrijven die in online enquêtes gespecialiseerd zijn en met universiteiten
die een systeem hebben voor het uitvoeren van tentamens via het WWW, is duidelijk
geworden dat de open vragen bij deze organisaties handmatig verwerkt worden. Dit betekent
dat de gegeven antwoorden verzameld, geprint en handmatig gestructureerd worden, waarna
ze gelezen en geïnterpreteerd worden. De vragen worden op deze manier afzonderlijk van de
overige gestelde vragen behandeld, en worden door de genoemde bedrijven niet gekoppeld
aan andere gegeven antwoorden. De universiteiten geven aan de hand van de interpretatie
van het antwoord een waardering voor het antwoord, welke uiteindelijk wel gekoppeld wordt
aan de overige antwoorden om zo een totaal cijfer voor het tentamen te kunnen geven. Op
basis van de opgedane kennis van de verschillende CAQDAS functionaliteiten lijkt het mij
noodzakelijk enkele van deze functies te implementeren zodat het systeem ook wat betreft de
verwerking van de antwoorden op de open vragen de onderzoeker kan ondersteunen.
Aan de hand van deze bevindingen, de resultaten van de vergelijkingen en de kennis die
opgedaan is omtrent de verschillende verwerkingsfuncties heb ik een online enquêtesysteem
opgezet dat zoveel mogelijk gebruik maakt van de pluspunten van programma’s als Kwalitan
en MS Access en van de pluspunten van de bestaande online enquêtesystemen. De volgende
paragrafen beschrijven welke functies geïmplementeerd zijn en op welke manier dit gebeurd
is.
53

5.3. Gebruikte technieken
Voor het uitwerken van algoritmen voor een alternatief online enquêtesysteem is gebruik
gemaakt van de standaard webtaal HTML en van JavaScript. Uit de vergelijkingen van
bestaande online enquêtesystemen en uit de correspondentie met verschillende ICT bedrijven
die in online enquêtes gespecialiseerd zijn, bleek dat de meeste systemen gebruik maken van
het databasesysteem MySql. Deze database kan eenvoudig aan een website gekoppeld
worden en kan via deze website geraadpleegd worden door gebruikmaking van de
programmeertaal PHP.
De eerste stap die genomen is in het opzetten van het nieuwe enquêtesysteem is het
aanmaken van de MySql database. Bij het aanmaken van de database zijn ook direct twee
tabellen aangemaakt: ‘beheerders’ en ‘enquetes’. In tabel 9 worden de verschillende
onderdelen van deze tabellen opgesomd.
TABELLEN VELDEN OMSCHRIJVING
- beheerder naam van enquêtebeheerder (onderzoeker) - e-mail emailadres van enquêtebeheerder - inlognaam inlognaam voor enquêtesysteem
Beheerders
- inlogcode gegenereerde inlogcode voor enquêtesysteem - enquete naam van de enquête - inleiding tekst waarmee de enquête ingeleid wordt - afsluiting tekst waarmee de enquête afgesloten wordt - aanmaakdatum datum waarop enquête aangemaakt is - afsluitdatum uiterlijke publicatie datum - font lettertype van de enquête - fontcolor kleur van de tekst van de enquête - bgcolor achtergrondkleur van de enquête - balkcolor kleur van een balkje in de enquête - buttonbg kleur van de knoppen in de enquête
Enquetes
- bordercolor kleur van de knopranden in de enquête
Tabel 9. De onderdelen van de tabellen ‘beheerders’ en ‘enquêtes’.
De tweede stap is het bedenken van geschikte algoritmen om het systeem op te zetten. Dit
heb ik gedaan aan de hand van de eerder genoemde taken die bij het uitvoeren van een
enquête grofweg kunnen worden onderscheiden, namelijk:
1. Het aanmaken van een enquête en het invoeren van de vragen.
2. Het publiceren en uitvoeren van de enquête.
3. Het verwerken van de verzamelde gegevens en het presenteren van de resultaten.
54

De volgende paragrafen bespreken hoe iedere taak gerealiseerd is binnen het alternatieve
online enquêtesysteem.
5.4. Aanmaken van een enquête
5.4.1. Het eerste bezoek
Bij het oproepen van het enquêtesysteem, krijgt de onderzoeker in eerste instantie toegang
tot slechts drie mogelijkheden: het lezen van hulpbestanden, aanmelden als nieuwe
enquêtebeheerder of inloggen als reeds aangemelde enquêtebeheerder.
Een nieuwe gebruiker dient zich eerst kenbaar te maken bij het systeem. De onderzoeker
kiest hiertoe tijdens het eerste bezoek aan de website de optie “aanmelden als nieuwe
gebruiker”. Vervolgens geeft de onderzoeker een aantal persoonsgegevens op, die
opgeslagen worden in de tabel ‘beheerders’: naam van de beheerder, emailadres van de
beheerder en een zelf te kiezen inlognaam en inlogcode. Op het hierop volgende scherm
wordt om de zojuist opgegeven inlognaam en inlogcode gevraagd om voor het eerst in te
loggen in het nieuwe systeem. Een reeds aangemelde onderzoeker kan in het menu direct
kiezen voor ‘inloggen’ om van het systeem gebruik te maken.18
5.4.2. Een nieuwe enquête
Nadat de enquêtebeheerder is ingelogd wordt een uitgebreider navigatiemenu aangeboden
(zie figuur 10.2) en wordt een overzicht getoond van enquêtes die de ingelogde beheerder
reeds aangemaakt heeft. In dit overzicht zijn de enquêtenaam, de datum van aanmaak, de
uiterste publicatiedatum en het aantal deelnemers (respondenten) opgenomen.
Indien er nog geen enquête is aangemaakt, of indien de beheerder van een reeds bestaande
enquête een nieuw onderzoek wil starten, is de volgende stap het aanmaken van een nieuwe
enquête. De naam die de onderzoeker kiest voor de enquête dient in kleine letters opgegeven
te worden, mag niet beginnen met een getal en mag niet geheel numeriek zijn. Deze regels
zijn zo opgesteld omdat de naam van de enquête ook gebruikt wordt als onderdeel van
tabelnamen, waarbij MySql dezelfde regels hanteert.
18 Om het systeem te testen kan gebruik gemaakt worden van de inlognaam ‘beheerder’ en de inlogcode ‘test123’. Voor deze enquêtebeheerder is een complete enquête aangemaakt om het systeem te kunnen testen.
55

Bij het aanmaken van een nieuwe enquête kan verder een inleidende tekst en een afsluitende
tekst opgegeven worden. De inleidende tekst wordt aan de respondent getoond bij het
oproepen van de enquête; de afsluitende tekst wordt getoond wanneer de respondent de
enquête voltooid heeft. De opmaak van de inleidende en de afsluitende tekst kan volledig
aangepast worden aan de wensen van de onderzoeker, doordat gebruik gemaakt is van een
‘inline HTML editor’ die door een JavaScript gegenereerd wordt (zie figuur 8.).
Figuur 8. De ‘inline htmleditor’ die gegenereerd wordt door een JavaScript biedt veel
opmaakmogelijkheden.
Het script van deze ‘inline editor’ kan gratis van Internet ‘gedownload’ worden.19 Deze
editor is alleen te gebruiken door Internet Explorer 5.5 of hoger, maar indien een andere
browser gebruikt wordt, wordt een standaard ‘textarea’ getoond, zoals weergegeven is in
figuur 9.
Figuur 9. Een standaard ‘textarea’ waarin een tekst getypt kan worden.
Tenslotte wordt gevraagd om een uiterlijke datum van publicatie. Deze datum wordt
gebruikt door een functie die bij het oproepen van de enquête door de respondent controleert
of de ‘afsluitdatum’ reeds bereikt is. Indien dit het geval is wordt niet de enquête getoond,
maar een alternatieve tekst die aangeeft dat het onderzoek beëindigd is.
Nu de algemene enquêtegegevens door de onderzoeker opgegeven zijn, worden er twee
acties uitgevoerd. De eerste is het aanmaken van nieuwe tabellen die voor iedere nieuwe
enquête opnieuw aangemaakt worden, en waarbij de enquêtenaam deel van de tabelnaam is.
56
19 Zie hiervoor HTMLArea v2.03 op http://www.interactivetools.com.

Deze tabellen worden dus alleen door de zojuist aangemaakte enquête gebruikt. Het betreft
de tabellen en velden die opgenomen zijn in tabel 10 en die allen beginnen met de naam van
de enquête, gevolgd door een ‘underscore’ ( _ ), gevolgd door de eigenlijke naam van de
tabel. De tabelnamen zijn op deze manier opgebouwd om de tabellen die bij een specifieke
enquête horen te onderscheiden van de tabellen die bij een andere enquête horen. Idealiter
wordt voor iedere enquête een nieuwe database aangemaakt. Lokaal is dit mogelijk, maar bij
gebruikmaking van ruimte op een externe webserver, is slechts plaats voor één database (met
een onbeperkt aantal tabellen).
TABELLEN VELDEN OMSCHRIJVING
_antwoorden - resnummer nummer van respondent (uniek) - catnummer nummer van de categorie (uniek) _categorieen - categorie naam van de categorie - codenummer nummer van de code (uniek) - codetekst tekst van de code - codetype type van de code: feitelijk of referentieel
_codes
- codememo memo bij de code - resnummer nummer van gekoppelde respondent - vraagnummer nummer van gekoppelde vraag
_koppelingen1
- codenummer nummer van gekoppelde code - codenummer nummer van gekoppelde code _koppelingen2 - catnummer nummer van gekoppelde categorie - vraagnummer nummer van vraag - optie gekoppelde optie
_opties
- vervolg nummer van de vervolgvraag - resnummer nummer van respondent (uniek) - begin tijdstip en datum waarop respondent begint - eind tijdstip en datum waarop respondent eindigt
_respondenten
- email emailadres van respondent - vraagnummer nummer van de vraag - vraagtekst tekst van de vraag - vraagtype type van de vraag
_vragen
- vraagmemo memo bij de vraag
Tabel 10. Omschrijving van de tabellen en de velden die gedefinieerd worden bij het
aanmaken van een nieuwe enquête.
De vragen die de onderzoeker aanmaakt, komen in de tabel _vragen te staan. Hierbij is voor
iedere vraag ruimte opgenomen voor een vraagnummer, de tekst van de vraag, het type van
de vraag (zie voor deze typen pagina 60) en eventueel een memo bij de vraag. De “opties”
die per vraag meegegeven worden, zoals de set van gesloten antwoorden, de waarden van de
likertschaal en het aantal regels dat de respondent kan invoeren bij een open vraag, worden
57

opgeslagen in de tabel _opties. In deze tabel wordt iedere “optie” aan het bijbehorende
vraagnummer gekoppeld. De tabellen _vragen en _opties worden dus gevuld bij het
aanmaken van de enquête.
Wanneer een respondent deelneemt aan de enquête worden de tabellen _respondenten en
_antwoorden gebruikt. In de eerste tabel worden enkele gegevens over de respondent
opgeslagen, zoals het nummer van de respondent en het tijdstip en de datum waarop de
respondent aan de enquête begint. Voordat de eerste respondent een antwoord op een vraag
heeft gegeven bestaat de tabel _antwoorden enkel uit het veld ‘resnummer’. Elke keer als de
eerste respondent een antwoord op een vraag heeft gegeven wordt de tabel uitgebreid met
een veld met de naam ‘vraag$vraagnummer’, waarbij $vraagnummer een variabele is en
gelijk staat aan het nummer van de vraag die zojuist beantwoord is.
Als de onderzoeker toe is aan het verwerken van de verzamelde antwoorden, kunnen de open
antwoorden gecodeerd worden. In de tabel _codes wordt de informatie over iedere
aangemaakte code opgeslagen: nummer van de code, tekst van de code, type van de code en
eventueel een memo. De combinatie van vraagnummer en respondentnummer is de link naar
het gegeven antwoord en dient daarom uniek te zijn. De tabel _koppelingen1 geeft
vervolgens de koppelingen tussen de vraagnummers, de respondentnummers en de
codenummers. De codes kunnen vervolgens ingedeeld worden in categorieën. Deze
categorieën worden met naam en nummer opgeslagen in de tabel _categorieen. De tabel
_koppelingen2 is de tabel die het laatste gevuld wordt. In deze tabel worden koppelingen
gemaakt tussen de codes en de categorieën door categorienummer en het nummer van de
toegekende code op te slaan. De combinatie van een categorienummer met een codenummer
dient uniek te zijn, om dubbele koppelingen te voorkomen.
De aanmaak van nieuwe tabellen is voor de onderzoeker niet zichtbaar. De tweede actie die
plaats vindt, is wel zichtbaar: een nieuwe uitbreiding van het navigatiemenu. De drie
verschillende navigatiemenu’s zoals ze eerder in deze paragraaf genoemd zijn, zijn in figuur
10 weergegeven.
58

Figuur 10.1
Figuur 10.2
Figuur 10.3
Figuur 10. De verschillende navigatiemenu’s: 10.1. Wordt getoond als de gebruiker nog niet
ingelogd is op het systeem; 10.2. Wordt getoond wanneer de gebruiker ingelogd is op het
systeem maar nog geen enquête aangemaakt heeft, of nog niet een reeds aangemaakte
enquête geselecteerd heeft; 10.3. Wordt getoond wanneer de onderzoeker een enquête
geselecteerd heeft om mee te werken.
De volgende stap in het aanmaken van een enquête is het toevoegen van vragen aan de (lege)
enquête. Het systeem zoekt eerst of er in de tabel _vragen al vragen opgenomen zijn. Indien
dit niet het geval is, is het nummer van de vraag “1”. Indien er al vragen in de database zijn
opgeslagen wordt door middel van de SQL-functie MAX het laatste (hoogste) vraagnummer
geselecteerd. Vervolgens wordt dit getal verhoogd met één, en dit vormt het nummer van de
nieuwe vraag. De vraagnummers zijn van het type ‘int’ (‘integer’), maar niet van het type
‘autonummering’ (‘autoincrement’), omdat het dan later niet mogelijk zou zijn de vragen
van nummer te laten veranderen door ze naar boven of naar beneden te verschuiven in
59

volgorde. De onderzoeker voert nu eerst een vraagtekst in. 20 Vervolgens wordt gekozen voor
één van de volgende vraagtypen:
1. een gesloten ja / nee vraag met als extra optie “geen idee” of “geen mening”;
2. een gesloten vraag met een set van antwoorden, waarbij één antwoord gegeven kan
worden;
3. een gesloten vraag met een set van gradaties verdeeld over een likertschaal;
4. en tenslotte een open vraag met een tekstvak voor het open antwoord.
Een belangrijk alternatief type is de gesloten vraag met een set van antwoorden, waarbij de
respondent meerdere antwoorden aan kan geven. Voor de verzamelde antwoorden op een
dergelijke vraag is nog een tabel nodig, die het respondentnummer en het vraagnummer
koppelt en een tabel die vervolgens het nummer van deze koppeling koppelt aan het gegeven
antwoord. Deze oplossing is niet ingewikkeld om te begrijpen, maar is niet geïmplementeerd
vanwege het feit dat de realisatie op dit moment te arbeidsintensief is. Een ander belangrijk
type is de gesloten vraag met een open alternatief, zoals “anders, namelijk:…” of “ja, omdat:
…”. Om een dergelijke vraag te kunnen verwerken moet het enquêtesysteem enorm
uitgebreid worden. Het antwoord dat op een dergelijke vraag gegeven wordt, dient dan
namelijk ook voorzien te worden van een aanduiding van het antwoordtype: open of
gesloten. Indien het één van de vooraf gegeven gesloten antwoorden betreft, dan kan het
antwoord verwerkt worden zoals de overige gesloten antwoorden. Betreft het een alternatief,
open antwoord, dan dient het antwoord voor een analyse geïnterpreteerd en gecodeerd te
worden. Ook dit vraagtype vraagt dus om extra tabellen, en is om deze reden nog niet
geïmplementeerd.
Wanneer er gekozen is voor één van de vier aangeboden vraagtypen, worden, afhankelijk
van het vraagtype dat gekozen is, verschillende mogelijkheden getoond. Is er gekozen voor
type 1, dan kan er vervolgens gekozen worden om de optie “geen idee” of de optie “geen
mening” toe te voegen aan de antwoordenset die standaard bestaat uit de antwoorden “ja” en
“nee”. Is er gekozen voor type 2, dan worden er tien invoervelden getoond, waarin de
onderzoeker een set van maximaal tien gesloten antwoorden kan invoeren. Voor type 3 geldt
ongeveer hetzelfde: hierbij worden vijf invoervelden getoond, waarin de onderzoeker een set
van maximaal vijf gradaties voor een likertschaal kan opgeven. Wordt er gekozen voor het
20 Voor het aanmaken van de vragen wordt ook gebruik gemaakt van eerder beschreven JavaScript ‘inline editor’.
60

vierde type, de open vraag, dan kan het maximale aantal regels dat de respondent mag
intypen opgegeven worden.
Tenslotte kunnen alle vragen, ongeacht type, voorzien worden van een memo. Figuur 11
toont hoe een scherm voor het aanmaken van een nieuwe vraag eruit kan zien en figuur 12
laat zien hoe deze vraag er uiteindelijk uit ziet.
Figuur 11. Voorbeeld scherm waarin een gesloten vraag met een likertschaal aangemaakt
en toegevoegd wordt aan de enquête (vraag 53 in de ‘CVO’ enquête, zie bijlage II).
Figuur 12. Voorbeeld van een vraag met een likertschaal (vraag 53 in de ‘CVO’ enquête, zie
bijlage II).
61

Wanneer de optie “vragenoverzicht” in het navigatiemenu gekozen wordt (zie figuur 10),
worden alle aangemaakte vragen in volgorde onder elkaar getoond. Voor het lezen van de
memo bij een vraag, kan de onderzoeker gebruik maken van een link naast de vraag om een
kleiner browserscherm te openen met daarin de bijbehorende memo.
5.4.3. Een bestaande enquête
Wanneer een enquête aangemaakt is en vragen zijn toegevoegd biedt het systeem uitgebreide
mogelijkheden om wijzigingen aan te brengen in de vragen, de inleidende en de afsluitende
teksten en de lay-out van de uiteindelijke enquête. Van de inleiding en de afsluiting kunnen
alleen de letterlijke tekst en de opmaak gewijzigd worden. De vragen kunnen op meerdere
manieren aangepast worden. Zo kunnen verschillende onderdelen gewijzigd worden:
vraagtekst, opgegeven opties (bijvoorbeeld de gesloten antwoorden of de gradaties voor een
likertschaal) en de memo. Vragen kunnen ook verwijderd worden. Indien dit gebeurt met een
vraag die niet de laatste vraag is, schuiven alle volgende vragen op naar boven. Dit
verschuiven van vragen kan ook gedaan worden zonder een vraag te verwijderen. Met
uitzondering van de eerste vraag, kunnen alle vragen per keer één plaatsje omhoog
geschoven worden. Wanneer bijvoorbeeld de derde vraag één plaatsje omhoog geschoven
wordt, wordt deze vraag de tweede vraag; de voormalig tweede vraag wordt automatisch de
nieuwe derde vraag. Door dezelfde vraag nogmaals omhoog te schuiven kan van de
oorspronkelijk derde vraag de eerste vraag gemaakt worden, wordt de eerste vraag de tweede
vraag en wordt de tweede vraag de derde vraag. Terwijl in de achterliggende database de
vraagnummers van twee vragen omgewisseld worden, ziet de onderzoeker op het scherm dat
de geselecteerde vraag omhoog geschoven is. Op deze manier kan de gehele vragenlijst
gereorganiseerd worden.
Tenslotte is het nog mogelijk ‘skips’ (ook wel vervolgvragen genoemd) te definiëren. Op
deze manier kan aangegeven worden welke vraag aan de respondent getoond moet worden,
afhankelijk van het antwoord dat gegeven is op de vorige vraag. De ‘skips’ worden per
antwoordmogelijkheid (optie) gedefinieerd. Uiteraard hoeft de onderzoeker geen ‘skip’ aan
te geven als de volgende vraag de vervolgvraag is. Het is niet mogelijk een ‘skip’ aan te
geven voor open vragen, immers het antwoord van de open vraag is van tevoren niet bekend.
Een laatste stap in het aanmaken van een enquête is het aanpassen van de lay-out van de
enquête. De enquête kan aangepast worden aan de website van de onderzoeker door
bijvoorbeeld de achtergrondkleur van de enquête en van de knoppen te veranderen, de
randen van de knoppen en het lettertype (keuze uit vijf standaard lettertypen). Om te laten
zien hoe de nieuwe kleuren en / of het nieuwe lettertype eruit zien in de uiteindelijke enquête
62

wordt gebruik gemaakt van de HTML-tag <IFRAME>. Op deze manier kan een
voorbeeldscherm van de enquête getoond worden als onderdeel van het opmaakscherm.
5.5. Uitvoeren van de enquête
Nu de enquête ‘gevuld’ is met vragen en opgemaakt is naar eigen wens, kan de enquête
gepubliceerd worden. Dit houdt in dat aan de doelgroep bekend gemaakt kan worden dat de
enquête online staat en dat men uitgenodigd wordt aan het onderzoek deel te nemen. Deze
bekendmaking kan op verschillende manieren gebeuren. Door een e-mailbericht te versturen
met een aankondiging kunnen eenvoudig en snel veel respondenten tegelijk geattendeerd
worden op de enquête. Een link op de eigen website kan de respondenten ook naar de
enquête leiden. Het enquêtesysteem genereert hiervoor de benodigde HTML-code die
gekopieerd kan worden naar de eigen website, zoals bijvoorbeeld figuur 13.
Figuur 13. Voorbeeld HTML-code om op te nemen in de eigen website voor een verwijzing
naar de enquête. ‘ENQ’ is hierbij een variabele die door PHP automatisch gevuld wordt met
de naam van de enquête die de onderzoeker eerder geselecteerd heeft.
Een andere mogelijkheid is het tonen van de enquête binnen de eigen website door gebruik
te maken van de eerder genoemde <IFRAME> HTML-tag. Hiermee wordt de enquête in een
nieuw scherm binnen het actieve scherm geopend. Op deze manier kan de enquête
eenvoudig opgenomen worden in de lay-out van een bestaande website. Nadeel van deze
methode is dat de <IFRAME> tag niet ‘compatible’ met iedere browser is. Een voorbeeld
van de code zoals deze aan de onderzoeker aangeboden wordt, staat in figuur 14.
Figuur 14. Voorbeeld HTML-code om op te nemen in de eigen website om de enquête te
tonen als onderdeel van de webpagina.
Voordat de enquête aan de respondent getoond wordt, is het van belang dat de onderzoeker
de enquête zelf uitgebreid test of laat testen, door te kiezen voor de menu-optie “enquête
testen in definitieve vorm” (zie ook figuur 10.). De resultaten van deze testronde worden niet
63

in de database opgeslagen, zodat ze geen invloed hebben op de werkelijk verkregen
resultaten van het onderzoek.
Babbie (2001) schrijft dat het van belang is dat de respondent aan het begin van de enquête
niet lastig gevallen wordt met allerlei persoonlijke vragen die niet in direct verband staan
met het onderwerp van het onderzoek, zoals in het geval van de ‘CVO’ enquête bijvoorbeeld
vragen over adresgegevens, leeftijd, sociale status en geslacht.
Iedere keer als de enquête opgeroepen wordt en de inleidende tekst aan een respondent
getoond wordt, wordt daarom alleen het tijdstip en de datum waarop de respondent aan de
enquête is begonnen in de database opgeslagen. Door deze gegevens toe te voegen aan de
tabel _respondenten, wordt automatisch een nieuw respondentnummer aangemaakt.
‘Resnummer’ is namelijk van het type ‘autonummering’ en de waarde moet uniek zijn. Het
respondentnummer wordt gebruikt om in de tabel _antwoorden de antwoorden van de
verschillende respondenten van elkaar te kunnen onderscheiden. Het respondentnummer en
het antwoord dat de respondent op een vraag gegeven heeft worden elke keer meegegeven
naar de volgende vraag. Pas als de respondent op de knop voor de volgende vraag geklikt
heeft, wordt het antwoord op de vorige vraag weggeschreven naar de database. Daarna wordt
de volgende vraag getoond. Van het wegschrijven van het antwoord naar de database merkt
de respondent uiteraard niets.
Zowel open als gesloten antwoorden kunnen eenvoudig in de MySql database worden
opgeslagen. Gesloten antwoorden worden opgeslagen in een veld van het datatype
‘character’ (char: maximaal 255 tekens); open antwoorden worden opgeslagen in een veld
van het datatype ‘longtext’ (maximaal 4.294.967.295 tekens). Na de opslag kunnen de beide
soorten antwoorden ‘realtime’ bekeken worden. De gesloten antwoorden zijn dan ook direct
beschikbaar voor een statistische analyse. Analyse van de open antwoorden kan het beste
plaatsvinden wanneer eerst alle antwoorden gecodeerd worden. Daarna kunnen ‘queries’
uitgevoerd kunnen worden op de coderingen en de categorieën waarin de codes zijn
ingedeeld. De twee typen antwoorden vragen dus om een afzonderlijke aanpak wat betreft de
analyse van de antwoorden.
64

5.6. Verwerken van de verzamelde resultaten
5.6.1. ‘Realtime’ verwerking
Het enquêtesysteem biedt de mogelijkheid tussentijds de verzamelde resultaten te bekijken.
Direct nadat de eerste respondent aan de enquête heeft deelgenomen, zijn de resultaten voor
de onderzoeker zichtbaar. De gesloten antwoorden worden getoond in een tabel en een
eenvoudige grafiek, waarbij de gegeven antwoorden geteld worden en omgezet worden in
percentages. De tabel wordt simpelweg gevuld met de gegevens uit de tabel in de database;
de grafiek wordt opgebouwd met een afbeelding van 1x1 pixel, waarbij de hoogte van de
afbeelding een vaste waarde heeft, maar de breedte van de afbeelding afhankelijk is van het
aantal keren dat een bepaald antwoord gegeven is. Dit levert een zogenaamd staafdiagram
op.
Ook de gegeven open antwoorden kunnen direct bekeken worden. Deze worden in een tabel
getoond, waarbij alleen de laatste vijf antwoorden getoond worden, in verband met de lengte
die de open antwoorden kunnen hebben. Voor een diepgaande verwerking van de open
antwoorden dienen de antwoorden gecodeerd en gestructureerd te worden. Dit is dan ook de
volgende stap in de verwerking van de verzamelde resultaten.
5.6.2. Coderen en structureren
Om een doordachte, consistente en efficiënte manier van coderen te bereiken, kan de
onderzoeker de open antwoorden op drie manieren coderen:
- vooraf een set met codes aanmaken, waaruit bij het coderen van ieder open antwoord
een of meerdere codes gekozen kunnen worden;
- tijdens het coderen van een antwoord een nieuwe code aanmaken, het zogenaamde
‘open coding’;
- zoeken naar het voorkomen van een bepaald woord, een woordcombinatie of een
compleet antwoord en aan de zoekresultaten automatisch een code toe laten kennen:
‘auto coding’.
Het aanmaken van een nieuwe code is vergelijkbaar met het aanmaken van een nieuwe
vraag. Een code bestaat uit een codetekst, een codetype (feitelijk of referentieel, zie ook
paragraaf 3.4.2.) en een codememo. De codegegevens worden in de tabel _codes bewaard.
Wanneer de onderzoeker een open vraag geselecteerd heeft om te coderen wordt een
overzicht gegeven van alle antwoorden die op deze vraag gegeven zijn, en indien er reeds
antwoorden gecodeerd zijn, de toegekende codes. Bovendien staat achter ieder antwoord een
link om dat specifieke antwoord te voorzien van codes. Een code die uit het lijstje met codes
65

geselecteerd wordt en toegekend wordt aan een specifiek antwoord, wordt samen met het
nummer van de vraag en het nummer van de respondent die het antwoord gegeven heeft
opgeslagen in de tabel _koppelingen1.
Een andere mogelijkheid om de antwoorden op een bepaalde vraag te coderen is
‘autocoding’. De onderzoeker kan opgeven naar welke term in de antwoorden gezocht moet
worden. Voor de toe te kennen code kan de gebruikelijke informatie opgegeven worden:
codetekst, codetype en codememo. Het systeem zoekt in alle antwoorden die op de
geselecteerde vraag gegeven zijn naar de opgegeven zoekterm. Wanneer de zoekterm
gevonden wordt in één van de antwoorden, wordt er automatisch een koppeling gemaakt
tussen het antwoord (combinatie van respondentnummer en vraagnummer) en de code (het
nummer van de code) in de tabel _koppelingen1.
Indien dit gewenst is, kan in een later stadium een koppeling tussen een code en een
antwoord weer verwijderd worden. Doordat in de tabel _koppelingen1 alleen het nummer
van de code gebruikt wordt om een koppeling met een antwoord te maken, worden achteraf
gemaakte wijzigingen in de codetekst automatisch doorgevoerd op alle plaatsen waar de
code aan een antwoord is toegekend.
Als alle open antwoorden gecodeerd zijn, kunnen de codes in categorieën ingedeeld worden.
De methode om een code aan een categorie toe te kennen is vergelijkbaar met de methode
voor het toekennen van codes aan antwoorden. Het enige verschil is dat een code aan
meerdere antwoorden gekoppeld kan worden, maar aan slechts één categorie. De categorieën
zelf kunnen ook weer gekoppeld worden aan een overkoepelende categorie om op deze
manier een hiërarchie te ontwikkelen. Wanneer de hiërarchie voltooid is, kan deze getoond
worden in de vorm van een grafische boomstructuur. In deze boomstructuur worden de
categorieën en codes per open vraag getoond. De codes vormen operationele links naar een
overzicht van alle aan de betreffende code gekoppelde antwoorden.
5.6.3. Zoeken en verzamelen
Voor het zoeken naar respondenten die aan bepaalde zoekvoorwaarden voldoen, kan gebruik
gemaakt worden van de verzamelde gesloten antwoorden en de codes die toegekend zijn aan
de open antwoorden. Het is de bedoeling geweest de onderzoeker zoveel mogelijk te ontzien
van allerlei ingewikkelde programmeertaken en daarom worden de zoekopdrachten
opgesteld in het Webinterface, waarvoor de onderzoeker geen kennis hoeft te hebben van het
opstellen van ‘queries’ of de programmeertaal SQL (‘Structured Query Language’).21
21 In de MySql handleiding van Kulk (1999) wordt SQL als volgt omschreven: “De meeste relationele database management systemen hebben de taal SQL geïmplementeerd. SQL bevat mogelijkheden om
66

Er kunnen twee typen zoekopdrachten geformuleerd worden. Het eerste type vraagt om de
invoer van de nummers van twee gesloten vragen. Vervolgens worden de antwoorden op de
eerste vraag verticaal in een matrix geplaatst en afgezet tegen de antwoorden op de tweede
vraag, die horizontaal in de matrix worden geplaatst. Op deze manier kan gekeken worden
welke antwoorden in combinatie met elkaar gegeven zijn.
Een ander type zoekopdracht zoekt naar het aantal respondenten dat aan één, twee of drie
zoekvoorwaarden voldoet. Hierbij kunnen maximaal drie verschillende of drie dezelfde
vraagnummers opgegeven worden. Vervolgens dient de onderzoeker het gezochte
antwoord(en) of de gezochte code(s) op te geven. Ook is het mogelijk aan te geven of het om
een “EN” statement of een “OF” statement gaat. Zo kan een zoekopdracht er uiteindelijk
als volgt uitzien:
Zoek het aantal respondenten dat…
1. vraag 10 heeft beantwoord met [antwoord] “ja”
EN
2. vraag 12 heeft beantwoord met [code] “geïnfecteerd e-mailbericht”
OF
3. vraag 12 heeft beantwoord met [code] “geïnfecteerde download”
Zowel de zoekvoorwaarden die de onderzoeker formuleert, als de vragen die hij / zij opgeeft
voor de matrix, worden door PHP omgezet in SQL ‘queries’ die uitgevoerd worden op de
MySql database. Echter, de codes en de antwoorden zijn in afzonderlijke tabellen opgeslagen
(_codes en _antwoorden). Het is van tevoren net bekend of de onderzoeker gebruik zal
maken van de codes of de antwoorden in zijn / haar zoekopdracht. Dit heeft tot gevolg dat
het niet mogelijk is een enkele SQL ‘query’ op te stellen waarbij zowel een code als een
antwoord opgegeven wordt als zoekvoorwaarde. Om de open antwoorden en de gesloten
antwoorden toch samen in een zoekopdracht te kunnen gebruiken, worden meerdere
SELECT ‘queries’ opgegeven, waarbij de formulering afhankelijk is van het gekozen
vraagtype. Betreft de selectie een open vraag, dan wordt de ‘query’ uitgevoerd op de tabel
codes; betreft het een gesloten vraag, dan wordt de ‘query’ uitgevoerd op de tabel
antwoorden. De resultaten van de ‘queries’ worden in afzonderlijke ‘arrays’ weggeschreven.
Indien een “EN” statement geselecteerd is, worden de verschillende ‘arrays’ met elkaar
vergeleken en worden alleen de waarden die in beide ‘arrays’ voorkomen in een nieuwe
relatieschema’s te declareren, om vragen aan een database te stellen en om de toestand van het databasesysteem te wijzigen.”
67

‘array’ weggeschreven (functie array_intersect). Wanneer gekozen is voor een “OF”
statement, worden de ‘arrays’ samengevoegd in een nieuwe ‘array’ (functie array_diff).
Tenslotte wordt het aantal waarden in de ‘array’ geteld en wordt deze numerieke waarden
(het aantal respondenten dat aan de zoekvoorwaarde(n) voldoet) gepresenteerd.
5.6.4 Exporteren van de onderzoeksresultaten
De resultaten van de enquête kunnen geëxporteerd worden naar andere (statistische)
programma’s, zoals MS Access, MS Excel en SPSS. Hiertoe worden de gegevens die
opgeslagen zijn in de tabel _antwoorden opgeslagen in tekstbestanden die vervolgens van de
website ‘gedownload’ kunnen worden. De gegevens in deze tekstbestanden zijn opgeslagen
in CVS-formaat. Dit betekent dat ze van elkaar gescheiden zijn met een vast teken, namelijk
een tab, welke in de drie genoemde programma’s herkend kan worden als een
scheidingsteken voor de verschillende velden. De eerste regel in het tekstbestand geeft de
veldnamen, de volgende regels komen overeen met de rijen in de MySql-tabel. De resultaten
kunnen natuurlijk ook direct vanaf de website gekopieerd worden naar bijvoorbeeld een MS
Word bestand, een MS PowerPoint presentatie of een andere website.
5.6.5. ‘Content analysis’
Er is slechts één ‘content analysis’ functie geïmplementeerd, namelijk die van de
woordfrequentielijst. De onderzoeker geeft aan van welke vraag hij / zij een
woordfrequentielijst wil genereren. Het systeem doorloopt dan alle antwoorden die op die
specifieke vraag gegeven zijn. De antwoorden worden ontdaan van interpunctie en
afgebroken bij de spaties. Op deze manier kunnen alle afzonderlijke woorden opgenomen
worden in een lijst van woorden. Door middel van de functie array_count_values wordt
geteld hoe vaak ieder woord in de lijst is opgenomen. Door de resultaten van deze functie
weg te schrijven naar het scherm, ontstaat een overzicht van alle gebruikte woorden en het
aantal keren dat ze gebruikt zijn.
5.7. Toepassing van het systeem
Het systeem is getest door de 58 vragen uit de ‘CVO’ enquête in te voeren, evenals de
antwoorden van 30 respondenten. Tijdens het werken met het systeem valt op dat het
systeem zeer efficiënt werkt door de stap voor stap begeleiding bij het invoeren en wijzingen
van de vragen, maar ook bij de analyse van de ingevoerde antwoorden. Tijdens deze test zijn
echter ook een aantal gebreken aan het licht gekomen. Zo is het niet mogelijk in de tekst van
68

de vraag of in een antwoord een apostrof in te voeren. Dit teken wordt als speciaal karakter
behandeld, waardoor de vraag niet goed opgeslagen wordt in de database. Woorden als
‘programma’s’ en ‘macro’s’ zijn daarom ingevoerd als ‘programmas’ en ‘macros’.
Bij het invoeren van veel vragen zijn typefouten snel gemaakt. De vragen kunnen te allen
tijde nog gewijzigd worden, maar dat geldt niet voor de opties. Wanneer deze veranderd
worden nadat een respondent heeft deelgenomen aan de enquête, komen de antwoorden die
gegeven zijn voor de wijziging niet meer overeen met de antwoorden die na de wijziging
worden gegeven. Wellicht dient er in de toekomst een spellingscontrole ingebouwd te
worden, die zoveel de mogelijk voor de hand liggende fouten kan voorkomen. De volgende
paragraaf gaat dieper in op de mogelijkheden en functionaliteiten die in de toekomst aan het
systeem toegevoegd kunnen of moeten worden. Bij een aantal van deze beperkingen is
bewust gekozen om ze niet te implementeren, andere kwamen aan het licht tijdens het
toepassen van het systeem.
5.8. Voor de toekomst…
Er zijn een aantal functies in dit online enquêtesysteem die nog verder uitgewerkt zouden
kunnen worden. Deze paragraaf bespreekt enkele ‘gebreken’ in de achterliggende techniek,
de gebruiksvriendelijkheid voor de onderzoeker en de toegankelijkheid voor de respondent.
5.8.1 Achterliggende techniek
De database is op dit moment minimaal beveiligd. De onderzoeker kiest zelf een inlogcode
en inlognaam, welke opgeslagen worden in een tabel in de database. Bij het inloggen op het
systeem wordt de ingetypte inlogcode niet op het scherm getoond, maar verhuld door het
gebruik van ‘*’. Vervolgens wordt gecontroleerd of de inlognaam en de inlogcode samen
voorkomen. Echter, iedere hacker kan op dit moment eenvoudig in de database inbreken,
gegevens veranderen en de inlogcodes kopiëren.
Een ander risicovol punt is het doorgeven van de variabelen na het uitvoeren van een actie of
na het volgen van een link. De waarden van de door te geven variabelen worden nu in de
adresbalk van de browser getoond en zouden beter beveiligd kunnen worden door ze te
encrypten. Op deze manier kunnen de waarden niet door hackers onderschept worden. Het
encrypten van de variabelen en vooral ook het decrypten is een ingewikkelde taak. Indien er
voor gekozen wordt het enquêtesysteem daadwerkelijk online aan te bieden is het echter wel
een noodzakelijke taak.
69

Om te voorkomen dat er erg veel enquêtes aangemaakt worden die allemaal in de database
opgeslagen blijven staan, wordt de beheerder van een nieuwe enquête gevraagd een uiterlijke
datum van publicatie op te geven. Het systeem voert een check uit om te kijken of de
opgegeven datum reeds bereikt is. Indien dat het geval is, wordt momenteel alleen een
melding aan de respondent getoond, dat de enquête niet langer uitgevoerd wordt. Idealiter
blijft de enquête na deze datum nog twee weken in het systeem aanwezig, zodat de
onderzoeker de verzamelde gegevens in die tijd nog kan gebruiken voor het onderzoek en
eventueel de gegevens kan downloaden. Na deze twee weken zou de enquête dan definitief
uit de database verwijderd kunnen worden. Dit zal de database aanzienlijk opschonen.
Een extra functionaliteit die geboden kan worden om het aantal respondenten dat deelneemt
aan de enquête onder controle te houden is de onderzoeker de mogelijkheid te bieden een
‘IP-range’ op te geven. Iedere computer die verbinding maakt met het Internet is voorzien
van een IP adres. Door te definiëren welke IP adressen deel mogen nemen aan de enquête,
kan de onderzoeker een beperkte doelgroep opgeven, bijvoorbeeld alleen de studenten en
medewerkers van de eigen universiteit. Een andere methode is bijvoorbeeld het opgeven van
het minimale en / of maximale aantal te verzamelen antwoorden.
Wat niet getest is, is de snelheid waarmee de ‘queries’ uitgevoerd worden, en wat er gebeurt
als meerdere onderzoekers tegelijkertijd op het systeem in loggen, al dan niet op
verschillende enquêtes. Hiervoor zullen tests uitgevoerd moeten worden om te voorkomen
dat de maximale hoeveelheid dataverkeer, die ingesteld is door de webprovider,
overschreden wordt.
Tenslotte is het nodig hier een opmerking te maken over de programmeercodes. Het is
wellicht mogelijk het programmeren efficiënter uit te voeren, waardoor er minder
dataverkeer is en het systeem nog sneller te gebruiken is. Dit kan gerealiseerd worden door
meer gebruik te maken van algemene, externe bestanden voor codes die hergebruikt worden,
en door nog meer elementen op te nemen in de ‘cascading stylesheets’ waarin de stijl van de
website gedefinieerd is.
5.8.2 Gebruiksvriendelijkheid voor onderzoekers
Een systeem, dat vriendelijk in het gebruik is voor de onderzoeker die een enquête wil
aanmaken, uitvoeren en verwerken, is voorzien van duidelijke en overzichtelijk helpfunctie.
Op dit moment is op de welkomstpagina te lezen wat globaal de mogelijkheden van het
systeem zijn. Daarnaast is een samenvatting van Babbie’s (2001) voorwaarden voor een
goed opgezette enquête opgenomen: voorwaarden voor een goed opgezette vragenlijst,
voorwaarden voor goed verwoorde vragen en tenslotte een aantal adviezen voor het kiezen
70

van een geschikt vraagtype. De website zal echter ook nog voorzien moeten worden van een
uitgebreide handleiding, een ‘Frequently Asked Question’-sectie (FAQ) en de mogelijkheid
om vragen en opmerkingen op de site achter te laten (in de vorm van een forum of een
gastenboek) of via e-mail aan de ontwikkelaar te versturen.
Des te meer mogelijkheden het systeem biedt, des te vriendelijker wordt het systeem wellicht
ervaren, mits deze mogelijkheden helder, zinvol en functioneel zijn. Het is eenvoudig te
realiseren dat er meer gebruik gemaakt kan worden van de multimediamogelijkheden van het
Internet. Hierbij valt bijvoorbeeld te denken aan de mogelijkheid dat de onderzoeker een
afbeelding opgeeft, die dienst kan doen als enquêtelogo, en die bij iedere vraag zichtbaar
blijft. Op deze manier kan de onderzoeker de enquête een persoonlijk tintje geven. Naast het
opgeven van een logo zou ook de mogelijkheid geboden kunnen worden bij een vraag een
link naar een extern bestand op te nemen, zoals een afbeelding, een video- of audiobestand,
of naar een andere website. Deze bestanden krijgt de respondent bij het invullen van de
enquête dan bij de betreffende vraag te horen en / of te zien. Nadeel van het gebruik van
externe bestanden is dat ze eerst ‘geupload’ moeten worden naar de webserver. Wanneer hier
voor gekozen wordt, dient er een functie in het systeem ingebouwd te worden die bijhoudt
hoeveel ruimte de afbeeldingen per enquête op de server innemen, en die hier een maximum
aan stelt, bijvoorbeeld 1.000.000 bytes (1 MB).
Momenteel wordt het systeem alleen in het Nederlands aangeboden. Het is wellicht het
overwegen waard het systeem meertalig te maken, zowel voor de onderzoekers, als voor de
respondenten.
Ook wat betreft de mogelijkheden voor het opstellen van enquêtevragen zou nog het één en
ander uitgebreid kunnen worden. Het is nu alleen mogelijk een meerkeuzevraag met
alternatieven op te geven waarbij de respondent slechts één antwoord op de vraag kan geven;
de alternatieven worden vooraf gegaan door ‘radiobuttons’. Wellicht is het wenselijk ook
een meerkeuze vraag met alternatieven aan te kunnen bieden waarbij de respondent
meerdere antwoorden kan kiezen. De antwoorden worden dan vooraf gegaan door
‘checkboxes’. In verband met een lastige opslag in de database, is er voor gekozen deze
mogelijkheid nog niet te implementeren. Ook het vraagtype dat in paragraaf 2.5.3. besproken
is, de gesloten vraag met een open optie, zou toegevoegd moeten worden. Een laatste veel
gebruikte vraagvorm die ontbreekt, is de matrixvraag waarbij in een matrix meerdere
deelvragen opgenomen zijn met telkens dezelfde set alternatieven om uit te kiezen.
Het systeem is nu dusdanig geprogrammeerd dat alle vragen afzonderlijk getoond worden,
omdat dit voor de respondenten veelal overzichtelijker is dan alle vragen onder elkaar. Deze
tweede mogelijkheid zou echter wellicht wel als optie aangeboden kunnen worden. Het
71

tonen van meerdere vragen per pagina is vooral praktisch bij een klein aantal vragen, of
wanneer de vragen ingedeeld zijn in deelonderwerpen,, bijvoorbeeld ‘persoonsgegevens’. Bij
het vragen naar de persoonsgegevens zou de onderzoeker tevens moeten kunnen aangeven of
het ook toegestaan is anoniem aan de enquête deel te nemen.
Vooral ook de toepassing van ‘natural language processing’ kan een belangrijke stap
voorwaarts betekenen. Door de krachtige functies uit de natuurlijke taalverwerking te
implementeren in het enquêtesysteem, kan het mogelijk gemaakt worden de antwoorden
geheel automatisch te coderen (volledige ‘auto-coding’) en te analyseren. De onderzoeker
zal hierdoor steeds meer van zijn taken verlicht worden bij het uitvoeren van een enquête.
De open antwoorden kunnen momenteel gecodeerd worden met één of meerdere labels.
Deze coderingslabels kunnen vervolgens in een categorieën verdeeld worden, welke in een
grafische boomstructuur getoond kunnen worden. Wellicht is het wenselijk om ook de
geprecodeerde gesloten antwoorden in een dergelijke structuur te kunnen opnemen, met
name in het geval van vervolgvragen.
Tenslotte moeten de verkregen resultaten niet alleen op de website getoond worden in een
tabel, een grafiek, een boomstructuur of een matrix, maar is het ook belangrijk dat de
gegevens geëxporteerd kunnen worden naar andere, veel gebruikte computerprogramma’s
zoals SPSS, MS Access, MS Excel, MS PowerPoint, MS Word etc. De gegevens kunnen
direct vanaf de website gekopieerd worden naar een MS Word document of een MS
PowerPoint presentatie. Om de gegevens te importeren in de andere drie genoemde
programma’s wordt momenteel alleen een tekstbestand aangeboden. Het is in PHP ook
mogelijk een formaat op te stellen dat specifiek bedoeld is voor bijvoorbeeld MS Excel. Er
wordt dan niet een tekstbestand aangemaakt dat uiteindelijk 1 tabel oplevert, maar een
compleet ‘werkboek’ dat kan bestaan uit meerdere tabellen en zelfs grafieken. Het zou ook
mogelijk moeten zijn meerdere soorten grafieken en diagrammen te maken. In PHP kunnen
namelijk dynamische afbeeldingen en diagrammen gegenereerd worden. Echter, zowel voor
het maken van een MS Excel ‘werkboek’, als voor het gebruiken van dynamische
afbeeldingen dient een speciale PHP ‘library’ geïnstalleerd te zijn op de webserver. Niet
iedere webprovider biedt de mogelijkheid deze ‘libraries’ te gebruiken.
Het gehele systeem zou misschien nog meer ‘stap voor stap’ opgezet kunnen worden, om het
volgen van de juiste route door het systeem nog duidelijker te maken voor de onderzoeker.
5.8.3. Toegankelijkheid voor respondenten
Er wordt steeds meer onderzoek gedaan naar de gebruikersvriendelijkheid van websites. Ook
de gebruikersvriendelijkheid en de toegankelijkheid van het online enquêtesysteem zoals dat
72

in dit hoofdstuk gepresenteerd is, dient goed onderzocht te worden in de toekomst. De
toegankelijkheid voor de respondenten kan verhoogd worden door een vriendelijker
‘userinterface’. Hiervoor moet bijvoorbeeld onderzocht worden welke kleuren het beste
gebruikt kunnen worden (in verband met kleurenblindheid bijvoorbeeld), welke woorden het
beste gekozen kunnen worden voor het navigatiemenu en op welke manier de site het beste
ingedeeld en gestructureerd kan worden.
Een stapje verder gaat het invoeren van geluidsbestanden bij iedere vraag. Hierdoor is het
mogelijk dat ook slechtzienden mee kunnen doen aan de enquête doordat ze de vraag kunnen
horen. Echter, om de website daadwerkelijk laagdrempelig te maken voor respondenten met
een handicap dienen wellicht nog veel meer maatregelen genomen te worden (zoals namen
geven aan afbeelding, mogelijkheid bieden om vragen via spraak te beantwoorden etc.).
Daarnaast dient de interface enigszins bijgestuurd te worden om het systeem ook bruikbaar
te maken in de browsers Netscape, Mozilla en Opera. De website kan momenteel in deze
browsers geopend en gebruikt worden, maar ziet er enigszins anders uit dan in Internet
Explorer. Bij deze aanpassingen dient ook rekening gehouden te worden met andere
platformen zoals Unix en Macintosh en andere schermresoluties (de meest gebruikte zijn 15
inch en 17 inch monitoren, maar 19 inch en 21 inch komen ook steeds meer voor).
Een laatste extra ‘feature’ voor de respondenten die hier genoemd wordt, is de
progressiebalk. In een dergelijke balk kan worden bijgehouden hoe veel vragen de
respondent reeds beantwoord heeft, en hoe veel vragen nog onbeantwoord zijn.
5.9. Conclusie
In dit hoofdstuk is een mogelijk alternatief systeem gepresenteerd. Het systeem is onder
andere gebaseerd op de CAQDAS functionaliteiten uit hoofdstuk drie. In hoofdstuk vier zijn
de besproken CAQDAS functies in een schema opgenomen om aan te geven welke functies
voor antwoorden op open en gesloten vragen gebruikt kunnen worden. Dit schema is in tabel
11 opnieuw gebruikt om aan te geven welke functionaliteiten uiteindelijk in dit alternatieve
systeem geïmplementeerd zijn.
73

CAQDAS functie Open antwoorden Gesloten antwoorden
Coderen
Structureren van de codes
Zoeken en verzamelen Memo’s en annotaties toevoegen Hyperlinks toevoegen Weergeven van de resultaten Content analyse
Tabel 11. CAQDAS functies die in het gepresenteerde alternatieve systeem gerealiseerd zijn.
Uit de tabel valt af te lezen dat met uitzondering van het structureren van de codes van de
gesloten antwoorden alle genoemde CAQDAS functies in het alternatieve systeem
gerealiseerd zijn.
Vervolgens zijn in hoofdstuk vier een tweetal bestaande computerprogramma’s en een aantal
bestaande online enquêtesystemen bestudeerd op de mogelijkheden die zij bieden om zowel
open als gesloten antwoorden in een online enquête te verwerken. Hieruit is een lijst van
plus- en minpunten voortgekomen. In het in dit hoofdstuk gepresenteerde online
enquêtesysteem zijn zoveel mogelijk van deze pluspunten overgenomen. Dit levert een
systeem op dat een groot aantal voordelen kent boven bestaande computerprogramma’s en
bestaande online enquêtesystemen. Zo is het ontwikkelde systeem platform- en programma-
onafhankelijk en is een directe koppeling tussen website en database gemaakt. Daarnaast
biedt het systeem voldoende CAQDAS functionaliteiten om zowel open als gesloten
antwoorden te verwerken en maakt het systeem uitvoerig gebruik van de voordelen van het
Internet, zoals hyperlinks en allerlei grafische mogelijkheden. Bovendien worden al deze
functionaliteiten in één systeem aangeboden en is het systeem dermate uitgebreid opgezet
dat het mogelijkheden biedt voor het opzetten, het uitvoeren en het verwerken van een
enquête. De onderzoeker hoeft niet te beschikken over speciale software of kennis van
specifieke programma’s of programmeertalen (zoals SQL), en wordt in staat gesteld in korte
tijd een enquête uit te voeren, waarbij een grote populatie bereikt kan worden.
De bespreking van een alternatief systeem is afgesloten met een opsomming van de
beperkingen. Deze opsomming is uiteraard niet uitputtend. Het volgende hoofdstuk gaat
onder andere in op meer algemene onderwerpen voor vervolgonderzoeken.
74

6. Conclusie
Deze scriptie heeft geleid tot het zoeken naar een systeem, bestaand of nieuw, dat het
mogelijk maakt een online enquête met zowel gesloten als open vragen op te zetten, uit te
voeren en te verwerken. Aanleiding hiervoor waren de problemen waar ik tegenaan liep bij
de verwerking van een enquête die verschillende groepen computergebruikers vroeg om hun
mening over en gedragingen ten opzichte van computervirussen. Naar aanleiding van de
behoefte aan één eenvoudige en snel te gebruiken ‘tool’ voor het opzetten, het uitvoeren en
het verwerken van een online enquête, is in de inleiding de volgende onderzoeksvraag
gesteld:
“Is hoeverre is het mogelijk antwoorden op zowel open als gesloten vragen in online
enquêtes zoveel mogelijk geautomatiseerd en in één systeem op te slaan, te analyseren en te
presenteren?”
Om een antwoord te kunnen geven op deze onderzoeksvraag zijn meerdere aspecten van de
thema’s ‘online enquête’ en ‘open en gesloten vragen’ bekeken. In hoofdstuk twee wordt
allereerst een theoretisch kader geschetst, waarin de begrippen kwalitatief, kwantitatief,
online enquête, open vragen en gesloten vragen gedefinieerd worden. Een eerste conclusie
die uit dit theoretische kader getrokken kan worden heeft te maken met de online enquête in
vergelijking met andere enquêtestrategieën. Wanneer een onderzoeker een enquête wil
gebruiken als aanvulling op, of als basis van een groter onderzoek, is de online enquête bij
uitstek geschikt. De een online enquête is een snelle onderzoeksstrategie en via het World
Wide Web is het mogelijk een grote populatie te bereiken. Bovendien hoeven voor een
online enquête niet veel kosten gemaakt te worden, doordat er geen sprake is van
papiergebruik en enquêteurs. Een andere opmerking die aan de hand van het tweede
hoofdstuk gemaakt kan worden is het feit dat een enquête uit zowel open als gesloten vragen
kan bestaan, afhankelijk van het onderzoek en het onderwerp. Een onderzoeker moet zich bij
keuze voor het type vraag laten leiden door het onderwerp en het gewenste antwoord, niet
door het werk dat verricht moet worden om de antwoorden te verwerken.
Het derde hoofdstuk bespreekt een manier van verwerken van open antwoorden, die
gebaseerd is op de Grounded Theory methode van Glaser en Strauss (1967): CAQDAS. Dit
theoretische onderzoek heeft zich beperkt tot de functies coderen, structureren, zoeken en
verzamelen, het toevoegen van hyperlinks en memo’s, en het weergeven van de resultaten.
Daarbij is ook enige aandacht geschonken aan methoden voor ‘content analysis’. Uit dit
theoretisch onderzoek kan geconcludeerd worden dat open antwoorden wel degelijk
gestructureerd en geautomatiseerd verwerkt kunnen worden op een verantwoorde manier.
75

Hierbij moet opgemerkt worden dat CAQDAS de onderzoeker wel ondersteunt bij een
verwerking van de gegevens, maar deze analyse niet van de onderzoeker overneemt. De
analyse kan dus wel met gebruikmaking van de computer uitgevoerd worden, maar kan niet
volledig aan de computer overgelaten worden. Hiervoor dienen wellicht ‘natural language
processing’ functies geïmplementeerd te worden, die in staat zijn de tekst te ontleden en te
begrijpen. Programma’s die van deze functies voorzien zijn, zullen waarschijnlijk in staat
zijn een interpretatie van de gegevens te geven, die de interpretatie van de onderzoeker heel
dicht nadert.
In hoofdstuk vier wordt vervolgens onderzoek gedaan naar de bruikbaarheid van CAQDAS
functies bij de verwerking van zowel open als gesloten antwoorden. Hieruit blijkt dat de
meeste besproken CAQDAS functies heel goed gebruikt kunnen worden voor zowel open als
gesloten antwoorden. Vervolgens zijn twee bestaande programma’s getoetst op de
mogelijkheden om beide typen antwoorden op te slaan, te verwerken en te presenteren. Er is
hierbij gekozen voor twee gangbare systemen: het kwalitatieve databaseprogramma
Kwalitan en het kwantitatieve databaseprogramma MS Access. Hoewel zowel Kwalitan als
MS Access in staat blijken deze taken voor beide vraagvormen uit te kunnen voeren, zijn de
programma’s er duidelijk niet voor ontwikkeld. Er zijn dan ook meerdere minpunten op te
noemen, waardoor de programma’s minder geschikt zijn voor een verwerking van beide
typen antwoorden. Een voorbeeld hiervan is het feit dat het niet mogelijk is deze
programma’s direct te koppelen aan een online enquête. Omdat beide bestaande
programma’s belangrijke functionaliteiten missen is tenslotte gekeken op welke manier de
pluspunten van de programma’s samengevoegd kunnen worden in een alternatief, nieuw
systeem, dat gebaseerd is op een MySql database voor de opslag van de gegevens en een
website die dient als interface voor het opzetten, uitvoeren en verwerken van de enquête. De
voordelen van dit alternatieve systeem wegen zwaarder dan de nadelen, en om deze reden is
er voor gekozen dit systeem verder uit te werken.
Voordat het alternatieve systeem gerealiseerd is, zijn nog enkele bestaande online
enquêtesystemen bestudeerd. Uit deze vergelijking kan geconcludeerd worden dat deze
systemen sterk zijn in het begeleiden van de onderzoeker bij het opzetten en uitvoeren van
de enquête, maar dat te weinig functionaliteit geboden wordt voor de verwerking van de
gegevens en de presentatie van de resultaten. Zowel uit dit vergelijkende onderzoek als uit
correspondentie met verschillende ICT bedrijven die gespecialiseerd zijn in online enquêtes
blijkt dat er behoefte is aan een systeem dat in staat is ook de open antwoorden te verwerken.
De bevindingen van het vergelijkend onderzoek in hoofdstuk vier en van het vergelijkend
onderzoek naar bestaande online enquêtesystemen zijn gecombineerd met de besproken
76

CAQDAS functies uit hoofdstuk drie. Het functiepakket dat hieruit is voortgekomen, is
vervolgens gerealiseerd tot een systeem dat mogelijkheden biedt om een enquête op te
zetten, uit te voeren en te verwerken. Hierbij kunnen zowel de open antwoorden als de
gesloten antwoorden verwerkt worden, en gebruikt worden in zoekopdrachten. De resultaten
van deze zoekopdrachten kunnen tenslotte gepresenteerd worden of ‘gedownload’ worden
om op te slaan op de eigen computer en eventueel te gebruiken in andere (statistische)
programma’s. Het hoofdstuk sluit af met een bespreking van de mogelijkheden en functies
die in de toekomst nog geprogrammeerd zouden kunnen worden. Deze opsomming is niet
uitputtend en er kunnen nog een aantal onderzoeken verricht worden om het systeem te
perfectioneren. Een van de belangrijkste onderwerpen voor vervolgonderzoek is wellicht het
toepassen van ‘natural language processing’ taken.
Hoewel het alleen de bedoeling was een systeem te programmeren dat in staat is zowel open
als gesloten antwoorden te verwerken, is het systeem uiteindelijk veel uitgebreider
geworden. Het systeem kan bijvoorbeeld ook gebruikt worden voor het opzetten van een
nieuwe enquête en voor het uitvoeren en publiceren van de enquête. De programmeertaal
PHP bleek zeer goed gebruikt te kunnen worden voor de verschillende programmeertaken.
Met deze taal was het mogelijk de meer complexe functies van het categoriseren, het
opstellen van ‘queries’ en het uitvoeren van ‘content analysis’ te realiseren.
Het valt op te merken dat het onderzoek onderhevig is aan een aantal beperkingen. Zo is er
slecht één methode onderzocht om kwalitatieve data te analyseren, namelijk de op Grounded
Theory gebaseerde CAQDAS. Een andere beperking is de bespreking van slechts twee
bestaande programma’s. Voor deze beperking is gekozen, omdat dit de meest gangbare
systemen zijn. Voor een nog uitgebreider online enquêtesysteem dat alle mogelijke
onderzoekers moet kunnen ondersteunen bij het uitvoeren van een enquête, is het wellicht
noodzakelijk ook andere methoden en systemen te bestuderen op geboden functies en
mogelijkheden. Het ontwikkelde systeem is uiteraard niet de enige methode om een online
enquête op te zetten, uit te voeren en te verwerken. Het is bijvoorbeeld ook mogelijk het
programma Frontpage te gebruiken voor het opzetten van een enquête of in plaats van PHP
gebruik te maken van de programmeertalen Lite of ASP. Een laatste beperking van dit
onderzoek is het feit dat er geen onderzoek gedaan is naar de mogelijkheden die speciale
software voor het maken en verwerken van een online enquête bieden. De reden voor deze
beperking is de prijs van dergelijke software, die het onaantrekkelijk maakt de software voor
een eenmalig uit te voeren enquête aan te schaffen.
In de inleiding zijn een aantal vragen geformuleerd over de gewenste ‘tool’. Naar aanleiding
van alle conclusies die in de vorige hoofdstukken reeds getrokken zijn, is het mogelijk deze
77

vragen te beantwoorden. De gewenste ‘tool’ bestaat uit verschillende functionaliteiten die
het enerzijds mogelijk maken een online enquête op te stellen, uit te voeren en te verwerken;
en het anderzijds mogelijk maken de verzamelde antwoorden op zowel de open als de
gesloten vragen te analyseren. Het in hoofdstuk vijf gepresenteerde systeem is zoveel
mogelijk van deze functionaliteiten voorzien door de statistische methoden die de meeste
online enquêtesystemen gebruiken over te nemen en deze aan te vullen met de CAQDAS
mogelijkheden die in het derde hoofdstuk uitgebreid besproken zijn. Deze scriptie kan
afgesloten worden met een antwoord op de in de inleiding gestelde onderzoeksvraag. De
bestudeerde computerprogramma’s en online enquêtesystemen bleken allen op een aantal
belangrijke punten tekort te schieten. Het is vervolgens goed gelukt de pluspunten van deze
systemen te combineren tot een compleet online enquêtesysteem, dat gebaseerd is op
onderzoeken naar de regels voor het opstellen van enquêtes, naar de
verwerkingsmogelijkheden van antwoorden op open antwoorden en naar de functies en
mogelijkheden die reeds bestaande programma’s en online enquêtesystemen bieden.
78


















