Automatische plaatsbepaling van Wikipedia pagina's Chris De...
65
Chris De Rouck Automatische plaatsbepaling van Wikipedia pagina's Academiejaar 2010-2011 Faculteit Ingenieurswetenschappen en Architectuur Voorzitter: prof. dr. Willy Govaerts Vakgroep Vakgroep Toegepaste Wiskunde en Informatica Voorzitter: prof. dr. ir. Daniël De Zutter Vakgroep Informatietechnologie Master in de ingenieurswetenschappen: computerwetenschappen Masterproef ingediend tot het behalen van de academische graad van Begeleider: Olivier Van Laere Promotoren: prof. dr. ir. Bart Dhoedt, Steven Schockaert
Transcript of Automatische plaatsbepaling van Wikipedia pagina's Chris De...

Chris De Rouck
Automatische plaatsbepaling van Wikipedia pagina's
Academiejaar 2010-2011Faculteit Ingenieurswetenschappen en Architectuur
Voorzitter: prof. dr. Willy GovaertsVakgroep Vakgroep Toegepaste Wiskunde en Informatica
Voorzitter: prof. dr. ir. Daniël De ZutterVakgroep Informatietechnologie
Master in de ingenieurswetenschappen: computerwetenschappen Masterproef ingediend tot het behalen van de academische graad van
Begeleider: Olivier Van LaerePromotoren: prof. dr. ir. Bart Dhoedt, Steven Schockaert


Chris De Rouck
Automatische plaatsbepaling van Wikipedia pagina's
Academiejaar 2010-2011Faculteit Ingenieurswetenschappen en Architectuur
Voorzitter: prof. dr. Willy GovaertsVakgroep Vakgroep Toegepaste Wiskunde en Informatica
Voorzitter: prof. dr. ir. Daniël De ZutterVakgroep Informatietechnologie
Master in de ingenieurswetenschappen: computerwetenschappen Masterproef ingediend tot het behalen van de academische graad van
Begeleider: Olivier Van LaerePromotoren: prof. dr. ir. Bart Dhoedt, Steven Schockaert

Voorwoord
Ik wens hierbij uitdrukkelijk enkele mensen te bedanken die geholpen hebben bij het tot stand
komen van deze masterproef. In de eerste plaats zijn dit Steven Schockaert, Olivier Van Laere
en Bart Dhoedt voor het beantwoorden van vele vragen, de hulp doorheen het volledige jaar en
het nauwkeurige naleeswerk. Daarnaast wens ik ook mijn broers en Chirovrienden te danken
voor hun steun en vooral voor af en toe voor ontspanning te zorgen wanneer de nood het hoogst
was. Ook de vrienden waarmee ik samen de voorbije vijf jaar op school heb doorgebracht wens
ik nog even te danken voor de vele momenten die we samen beleefd hebben. Ten slotte wens ik
ook mijn ouders te bedanken die me de kans gegeven hebben om te studeren en me dit op mijn
eigen manier hebben laten doen.
Chris De Rouck, 2011

Toelating tot bruikleen
“De auteur geeft de toelating deze scriptie voor consultatie beschikbaar te stellen en delen van
de scriptie te kopieren voor persoonlijk gebruik.
Elk ander gebruik valt onder de beperkingen van het auteursrecht, in het bijzonder met betrek-
king tot de verplichting de bron uitdrukkelijk te vermelden bij het aanhalen van resultaten uit
deze scriptie.”
Chris De Rouck, mei 2011

Automatische plaatsbepaling
van Wikipedia pagina’s
door
Chris De Rouck
Masterproef ingediend tot het behalen van de academische graad van
Master in de ingenieurswetenschappen: computerwetenschappen
Promotoren: Prof. Dr. Ir. Bart Dhoedt, Dr. Steven Schockaert
Begeleider: ir. Olivier Van Laere
Vakgroep Informatietechnologie
Voorzitter: Prof. Dr. Ir. Daniel. De Zutter
Vakgroep Toegepaste Wiskunde en Informatica
Voorzitter: Prof. Dr. Willy. Govaerts
Faculteit Ingenieurswetenschappen en Architectuur
Academiejaar 2010–2011
Universiteit Gent
Samenvatting
Tegenwoordig duiken er als maar meer applicaties op die gebruik maken van geografische infor-matie. Dit komt doordat het nu ook mogelijk is het Internet te benaderen via mobiele toestellen.Via deze toestellen is het mogelijk om met behulp van GPS coordinaten enkel geografisch rele-vante inhoud en in het bijzonder artikels te tonen. Het grootste deel van de beshikbare bronnenop het web zijn echter nog niet voorzien van geografische coordinaten. Daarom gaan we probe-ren om automatisch geografische coordinaten te bepalen voor Wikipedia pagina’s. In dit werkbeperken we ons tot pagina’s die over specifieke locaties gaan zoals gebouwen en steden. Metbehulp van een Naive Bayes classifier gaan we die pagina’s proberen voorzien van geografischecoordinaten. Hiervoor worden taalmodellen gebruikt, die in eerder onderzoek gegenereerd zijnuit Flickr foto’s. We hebben experimenten uitgevoerd met verschillende vormen van smoothing,met verschillende taalmodellen en hebben vervolgens nog andere verbeteringen gezocht. Metonze beste resultaten doen we beter dan Yahoo! Placemaker, een gratis beschikbare state-of-the-art webservice die in staat is om documenten of webpagina’s te voorzien van geografischecoordinaten. We kunnen 16% (Placemaker: 4%) van de geteste pagina’s binnen een straal van1 kilometer lokaliseren en tot 77% (Placemaker: 67%) binnen een straal van 100 kilometer.
Trefwoorden
Georeferencing, Wikipedia, Taalmodellen, Naive Bayes, Web 2.0

Automatic location detection of Wikipedia pagesChris De Rouck
Supervisor(s): Bart Dhoedt, Steven Schockaert, Olivier Van Laere
Abstract— We describe a method for the automatic location detectionof Wikipedia pages. For achieving this goal, a Naive Bayes classifier withlanguage models trained with Flickr data is used. We experimented withdifferent kinds of smoothing, language models and enhanced the techniquewith our knowledge of the structure of Wikipedia. Our experimental re-sults show that the resulting method is able to outperform state-of-the-artmethods that are based on gazetteer look-up.
Keywords—Georeferencing, Wikipedia, Language models, Naive Bayes,Web 2.0
I. INTRODUCTION
THE geographic scope of a web resource plays an increas-ingly important role for assessing its relevance in a given
context, as can witnessed by the popularity of location-basedservices on mobile devices. When uploading a photo to Flickr,for instance, users can explicitly add geographical coordinatesto indicate where it has been taken. Similarly users can updatetheir Facebook status with their current location at that time.Nonetheless, such coordinates are currently only available fora minority of all relevant web resources, and techniques arebeing studied to estimate geographic location in an automatedway. In the domain of Flickr photos there is sufficient spatiallygrounded training data available which can be used to train lan-guage models. These are already successfully used [1] to obtainthe location of other photos. However, in other domains, like theWikipedia encyclopedy, there is not enough spatially groundedtraining data available. For some articles the coordinates are al-ready available, and for other articles they are not. But becauseof the nature of the encyclopedy there are not multiple articlesabout the same place, which implies they can not be used to pre-dict the location of other pages. As language models trained onFlickr data have already proven useful for georeferencing pho-tos, we may wonder whether they could be useful for findingthe coordinates of other web resources, for example Wikipediapages. This paper is structured as follows. In the next sectionwe describe our technique for the georeferencing of Wikipediapages. Section 3 contains our experimental results, after whichwe discuss related work and conclude.
II. GEOREFERENCING WIKIPEDIA
The idea of geographic scope can be interpreted in differentways for Wikipedia pages. A page about a person, for instance,might geographically be related to the places where this personhas lived throughout his life, but perhaps also to those parts ofthe world in which this person’s work has influences (e.g. lo-cations of buildings that were designed by some architect). Inthis article, however, we exclusively deal with finding the co-ordinates of Wikipedia pages about a specific place, such as alandmark or a city. It is then natural to assume that the geo-graphic scope of the page corresponds to a point.
A. Language Models
The language models used in this work have been generatedin previous research [1]. Flickr photos containing geographiccoordinates have been clustered and their tags have been re-trieved as well. Tags that are not specific enough for a givenregion are filtered using the χ2 feature selection technique. Thisresults in a list of clusters which have a geographic coordinate,the number of photos that are used to generate them and a list oftags from these photos with their number of occurences.
B. Extracting Tags
The next step consists of representing a Wikipedia page as alist of Flickr tags. This can be done by scanning the Wikipediapage and identifying occurrences of Flickr tags. As Flickr tagscannot contain spaces, however, it is important that concatena-tions of word sequences in Wikipedia pages are also considered.Moreover capitalization should be ignored. For example, an oc-currence of “Eiffel tower” on a page is mapped to the Flickr tags“eiffeltower”, “eiffel” and “tower”.
C. Naive Bayes classifier
The problem of georeferencing a Wikipedia page consists ofselecting the area a from the set of areas A that is most likely tocover the geographic scope of the Wikipedia page. This proba-bility can be estimated using a standard language modeling ap-proach. The important part here is obtaining a reliable estimateof the chance that tag t is in a cluster a. Some form of smoothingis needed, to avoid a zero probability when encountering a tagt that does not occur with any of the photos in area a. We firstbuilt our experiments with the Laplace smoothing technique.
D. Jelinek-Mercer smoothing and Bayesian smoothing withDirichlet Priors
Jelinek-Mercer smoothing calculates the interpolation be-tween two terms. The first term is the chance that when there isa tag occurence in a, it is tag t. This probability is then interpo-lated with the chance that when their is a tag occurence over allclusters inA, it is tag t. Bayesian smoothing using Dirichlet Pri-ors is similar to Laplace smoothing, but is generally consideredto be a better alternative. Bayesian smoothing uses the sameinformation, used by Jelinek-Mercer smoothing but combinatesthem in a different way.
E. Adaptations specific for Wikipedia
Wikipedia pages are not just articles, they have been markedup semantically using HTML tags, which contain valuable in-formation. The first idea is to only look at tags that occur insection titles (identified using HTML tags of the form <h1>),in anchor text (<a>) or in emphasized regions (<strong> and

<b>). The second idea is to only look at the abstract of theWikipedia page, which is defined as the part of the page beforethe first section heading. As this abstract is supposed to summa-rize its content, it is less likely to contain references to placesthat are outside the geographical scope of the page.
III. EXPERIMENTAL RESULTS
In our evaluation, the Geographic Coordinates dataset fromDBpedia 3.6 is used to determine an initial set of georeferencedWikipedia pages. To ensure that all articles refer to a specificlocation, we only retained those pages that are mentioned as a“spot” in the GeoNames gazetteer. This resulted in a set of 7537georeferenced Wikipedia pages, whose coordinates we used asour gold standard.
Using the techniques outlined in the previous section, for eachpage the most likely area from A is determined. To evaluate theperformance of our method, we calculate the accuracy, definedas the percentage of the test pages that were classified in the areaactually containing the location of page x. In addition, we alsolook at how many of the Wikipedia pages are correctly georef-erenced within a 1km radius, 5km radius, etc.
Our main interest is in comparing the methods proposed inthe previous section with the performance of Yahoo! Place-maker, a freely available state-of-the-art webservice capable ofgeoparsing entire documents and webpages. Provided with free-form text, Placemaker identifies places mentioned in text, dis-ambiguates those places and returns the corresponding loca-tions. It is important to note that this approach uses externalgeographical knowledge such as gazetteers and other undocu-mented sources of information.
Jelinek-Mercer and Bayesian smoothing obtained approxi-mately the same results when the optimal parameters were used.Table I shows the results for language models with the num-ber of clusters k varying from 50 to 20000 clusters, where weconsider the basic variant in which the entire Wikipedia page isscanned for tag occurrences. There is a trade-off to be found:finer-grained areas lead to more precise locations, while coarse-grained areas lead to a higher accuracy.
TABLE IJELINEK-MERCER SMOOTHING (λ = 0,3) FOR DIFFERENT NUMBERS OF
CLUSTERS K
k 1 km 5km 10km 50km 100km Acc50 20 159 269 762 1499 79,43
500 340 1077 1423 3146 4355 73,302500 774 1703 2230 4155 5163 61,655000 943 1956 2496 4366 5291 55,467500 1019 2032 2593 4493 5331 52,04
10000 1067 2119 2716 4595 5343 47,7912500 1114 2171 2747 4620 5358 47,9515000 1141 2187 2801 4645 5306 46,5817500 1180 2243 2846 4692 5326 45,6520000 1184 2260 2874 4673 5281 44,56
Subsequently we did tests with other methods from which theones that used only the text in the “keywords” or “abstract” ob-tained the best results. The results with these methods can be
found in Table II. This table shows a comparison with the re-sults from the Yahoo! Placemaker as well.
TABLE IIANALYSIS OF THE EFFECT OF RESTRICTING THE REGIONS OF A WIKIPEDIA
ARTICLE THAT ARE SCANNED FOR TAG OCCURENCES (CONSIDERING K =20000 CLUSTERS) AND COMPARISON WITH YAHOO! PLACEMAKER (P.M.)
k 1 km 5km 10km 50km 100kmarticle 1184 2260 2874 4673 5281
abstract 1246 2256 2820 4555 5151keywords 1242 2452 3128 5098 5766
P.M. 313 1583 2395 4257 5056
IV. RELATED WORK
The interest of calculating the geographic scope of web re-sources has been there since the rise of the search engines. In[2], it was tried to predict the location of web pages. In 70%of the cases a location in the correct city was found. In [3],something similar is done but even relations between web pagesare used under the assumption of topic locality. The researchthat best matches ours is [4], in which it was tried to predict thelocation of Wikipedia pages with a rule-based system to disam-biguate locations and link them to the right place in the TGN,which is a geographic semantic network. 80% of the pagescould be identified as corresponding to a place of which 80%could be linked to the right entry in the TGN. In [5], a methodbased on Wordnet and a Naive Bayes classifier was used for thesame task. To the best of our knowledge, approaches for geo-referencing Wikipedia pages, or web pages in general, withoutusing a gazetteer or other forms of structured geographic knowl-edge have not yet been proposed in the literature.
V. CONCLUSIONS
We discussed techniques for the automatic classification ofWikipedia pages. As language models can not be trained withother Wikipedia pages, we tested whether language modelstrained by different sources could be used for this task. By com-paring our results with the Yahoo! Placemaker we can confirmthis is possible. With our best method we can locate 16,48%(Y.P.: 4,14%) within a radius of 1 kilometer and 77% (Y.P.:67,08%) within a radius of 100 kilometer.
REFERENCES
[1] Olivier Van Laere, Steven Schockaert, Bart Dhoedt, Towards AutomatedGeoreferencing of Flickr Photos., Proc. of the 6th Workshop on GeographicInformation Retrieval, 2010
[2] Alvaro Zubizarreta, Pablo de la Fuente, Jose M. Cantera, Mario Arias, JorgeCabrero, Guido Garcıa, Cesar Llamas, and Jesus Vegas. A georeferencingmultistage method for locating geographic context in web search., Proc.of the 17th ACM conference on Information and knowledge management,pages 1485–1486, 2008.
[3] Maario J. Silva, Bruno Martins, Marcirio Chaves, Ana Paula Afonso, andNuno Cardoso. Adding geographic scopes to web resources., Computers,Environment and Urban Systems, 30:378–399, 2006.
[4] Simon E. Overell and Stefan Ruger. Identifying and grounding descrip-tions of places., Proc. of the SIGIR Workshop on Geographic InformationRetrieval, pages 2–4, 2006.
[5] D. Buscaldi and P. Rosso. A comparison of methods for the automatic iden-tification of locations in wikipedia., Proc. of the 4th ACM Workshop onGeographical Information Retrieval, pages 89–92, 2007.

INHOUDSOPGAVE i
Inhoudsopgave
1 Inleiding 1
1.1 Probleemstelling . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1
1.2 Doelstelling . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2
1.3 Overzicht . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3
2 Web 2.0 en het belang van georeferencing 4
2.1 Wikipedia en het nut van geografisch geannoteerde artikels . . . . . . . . . . . . 4
2.1.1 Wikipedia . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4
2.1.2 Domein van de locatie . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6
2.1.3 Geografisch geannoteerde artikels . . . . . . . . . . . . . . . . . . . . . . . 6
2.1.4 Toepassingen van geografisch geannoteerde artikels . . . . . . . . . . . . . 6
2.2 Relevante bronnen en mogelijke toepassingen . . . . . . . . . . . . . . . . . . . . 7
2.2.1 Flickr . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
2.2.2 Facebook . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
2.2.3 Netlog . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8
2.2.4 Foursquare en Gowalla . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9
2.2.5 Google Maps, Bing Maps, Panoramio . . . . . . . . . . . . . . . . . . . . 11
2.2.6 Groupon . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
2.2.7 Qwiki . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
2.3 Georeferencing . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15
2.3.1 Wat is georeferencing? . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15
2.3.2 Lengte- en breedteligging . . . . . . . . . . . . . . . . . . . . . . . . . . . 15
2.3.3 Geoparsing versus Geocoding . . . . . . . . . . . . . . . . . . . . . . . . . 16
2.3.4 Termclassificatie . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16
2.3.5 Geografisch bereik van pagina’s . . . . . . . . . . . . . . . . . . . . . . . . 17

INHOUDSOPGAVE ii
2.4 Gazetteers . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17
2.4.1 Geonames . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17
2.4.2 Getty Thesaurus of Geographical Names . . . . . . . . . . . . . . . . . . . 18
2.4.3 WordNet . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 18
2.4.4 YAGO2: Yet Another Geographical Ontology . . . . . . . . . . . . . . . . 20
2.5 Semantisch Web . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 20
2.5.1 Wat is het Semantisch Web . . . . . . . . . . . . . . . . . . . . . . . . . . 20
2.5.2 Resource Description Framework . . . . . . . . . . . . . . . . . . . . . . . 21
2.5.3 Open Graph Protocol . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21
2.5.4 DBpedia . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 22
2.6 Verwant onderzoek . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 23
2.6.1 Geografisch bereik van een pagina . . . . . . . . . . . . . . . . . . . . . . 23
2.6.2 Identificatie van locaties in Wikipedia . . . . . . . . . . . . . . . . . . . . 24
2.6.3 Wikipedia als bron voor classificatie . . . . . . . . . . . . . . . . . . . . . 26
3 Taalmodellen voor het georeferencen van Wikipedia pagina’s 27
3.1 Flickr taalmodellen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 27
3.2 Termselectie . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 29
3.2.1 Algemeen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 29
3.2.2 χ2 feature selection . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 29
3.3 Naive Bayes met Laplace smoothing . . . . . . . . . . . . . . . . . . . . . . . . . 30
3.4 Jelinek-Mercer en Bayesian smoothing . . . . . . . . . . . . . . . . . . . . . . . . 31
3.4.1 Jelinek-Mercer smoothing . . . . . . . . . . . . . . . . . . . . . . . . . . . 31
3.4.2 Bayesian smoothing met Dirichlet Priors . . . . . . . . . . . . . . . . . . . 32
3.5 Aanpassingen specifiek voor Wikipedia . . . . . . . . . . . . . . . . . . . . . . . . 32
3.5.1 Tekst vs Tags . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 32
3.5.2 Efficientie algoritme . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 33
3.5.3 Gebruik Wikipediastructuur . . . . . . . . . . . . . . . . . . . . . . . . . . 33
3.5.4 Combinatie van methodes . . . . . . . . . . . . . . . . . . . . . . . . . . . 34
3.5.5 Tag smoothing . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 35
4 Evaluatie 36
4.1 Dataset . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 36

INHOUDSOPGAVE iii
4.2 Evaluatiemethode . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 37
4.2.1 Accuraatheid en Mean Reciprocal Rank . . . . . . . . . . . . . . . . . . . 37
4.2.2 Afstand ten opzichte van de gevonden locatie . . . . . . . . . . . . . . . . 38
4.3 Baseline: Yahoo! Placemaker . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 38
4.3.1 Algemeen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 39
4.3.2 Werkwijze . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 39
4.4 Resultaten . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 40
4.4.1 Verschillende vormen van smoothing . . . . . . . . . . . . . . . . . . . . . 40
4.4.2 Variatie in aantal clusters . . . . . . . . . . . . . . . . . . . . . . . . . . . 41
4.4.3 Tag Smoothing . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 44
4.4.4 Gebruik Wikipediastructuur . . . . . . . . . . . . . . . . . . . . . . . . . . 44
4.4.5 Terugkoppeling resultaten en vergelijking met Yahoo! Placemaker . . . . 47
5 Conclusies 49
Bibliografie 52

INLEIDING 1
Hoofdstuk 1
Inleiding
1.1 Probleemstelling
Na de grote doorbraak van zoekmachines en online sociale netwerken zijn vele ontwikkelaars
op zoek naar “the next big thing”. Door de eenvoud waarmee ze ontwikkeld kunnen worden
ontstaan er dagelijks nieuwe webapplicaties. Iedereen probeert te voorspellen waarmee gescoord
zou kunnen worden en probeert zijn idee leven in te blazen met de hoop op een succesverhaal.
Vele applicaties bouwen verder op het succes van anderen. Bijvoorbeeld bij Twitter zien we een
aantal projecten die succes trachten te behalen door extra functies voor de betreffende dienst te
maken.
Er is echter nog een ander groot fenomeen dat zijn weg vindt naar de gewone man. Het
ziet er naar uit dat binnenkort iedereen er een zal hebben. Het begon met simpele telefoons
die dan uitgebreid werden met een aantal toepassingen, toegespitst op het kantoorleven. Tegen-
woordig zijn de smartphones echter echte alleskunners. Ze hebben een krachtige processor, de
mogelijkheid tot opname van foto’s en video’s, toegang tot dat reeds bejubelde Internet en nog
vele andere mogelijkheden. Aangezien er zoveel mogelijk is op die draagbare toestellen wordt
het tegelijkertijd ook interessanter om applicaties te ontwikkelen die rekening houden met de
locatie van de gebruiker.
De voorbije twintig jaar was iedereen die op het Internet ging ergens binnenshuis op een vaste
locatie en leek het dus weinig relevant om locatiegebaseerde applicaties te maken. Dankzij de
grote evolutie die het Internet enerzijds en de telecommarkt anderzijds gemaak hebben is het nu
wel interessant om dit te doen. Een aspect van locatiegebaseerde applicaties is het toegankelijk
maken van reeds beschikbare gegevens naar gelang van de locatie van de gebruiker. Hiervoor is

1.2 Doelstelling 2
het belangrijk om bij webpagina’s en artikels een geografische positie of een bereik te kunnen
bepalen. Het geografisch bereik van webpagina’s werd hierbij al het meest onderzocht. Dit is te
verklaren doordat het bij het ontwerp van zoekmachines wel al relevant was om een bereik te
hebben voor een pagina. Enkel met zo’n bereik kunnen plaatselijk relevante resultaten accuraat
gebruikt worden om de gebruikers de beste pagina’s te tonen. De webpagina van de viswinkel
twee straten verder is namelijk meer relevant dan die van viswinkels uit een ander land.
1.2 Doelstelling
In deze masterproef, gaan we ons echter richten op het lokaliseren van artikels. Wij willen
de plaats bepalen waarover een Wikipedia artikel gaat. In combinatie met mobiele toestellen
die met GPS uitgerust zijn, kan dan bijvoorbeeld wanneer je in een stad een bepaald gebouw
passeert, de informatie daarover op je scherm getoverd worden. Zo krijg je een heel interactief
platform, maar voor een dergelijke applicatie is het uitermate belangrijk om de juiste GPS
coordinaten van de artikels te kunnen bepalen. Om de coordinaten die we gevonden hebben op
te slaan zullen we gebruik gaan maken van de lengte- en breedteligging van de locatie.
Navigeren is momenteel nog steeds een van de belangrijkste mogelijkheden die gecreeerd
worden via geografische data. Naast de navigatie functies die GPS en zijn varianten bekend
hebben gemaakt zijn de “check-in” applicaties tegenwoordig het populairst. Op deze diensten
kan je locaties die je bezoekt toevoegen aan je profiel. Als je dan vervolgens op een van die
plaatsen aankomt kan je er “inchecken” waarmee je aangeeft dat je daar fysiek aanwezig bent.
Op die manier kunnen je vrienden weten waar je bent of waar je je de laatste tijd zoal mee bezig
gehouden hebt. Het belang van dergelijke services wordt ook geıllustreerd doordat Facebook en
Google met dergelijke diensten beginnen.
Aangezien geografische coordinaten maar recent nuttig zijn geworden in dit domein, is
de meeste informatie die beschikbaar is op het wereldwijde web nog niet geannoteerd met
coordinaten. Daarnaast gaan natuurlijk ook niet alle auteurs die nu een Wikipedia pagina
schrijven over een plaats er als eerste die coordinaten aan toevoegen, ofwel omdat ze niet weten
dat dit mogelijk is, ofwel omdat ze het nut ervan niet inzien. Aan alle beschikbare informatie
met de hand coordinaten toevoegen is een nogal arbeidsintensieve taak en daarom gaan we zoe-
ken naar methoden om de annotatie te automatiseren. Daarnaast is het mogelijk om, indien er
geen zekerheid is over de correctheid van de coordinaten, een applicatie te maken die de locatie
suggereert aan de auteurs van de pagina’s. Deze kunnen dan beslissen of ze die coordinaten

1.3 Overzicht 3
gaan aanvaarden, bijsturen of weigeren.
1.3 Overzicht
Na deze inleiding geeft Hoofdstuk 2 een overzicht van de belangrijkste locatiegebaseerde Web
2.0 applicaties. Daarnaast verklaren we ook enkele veelgebruikte termen in het domein van de
georeferencing, met andere woorden het toekennen van coordinaten aan (web)bronnen. We ver-
volgen ons onderzoek met een kijk op welke bronnen van geografische informatie nuttig zouden
kunnen zijn voor ons onderzoek. De meeste hiervan zullen gazetteers zijn, databanken waarin
plaatsnamen gekoppeld zijn aan coordinaten. Ook het semantisch web gaan we even bekijken
aangezien ook verbanden tussen verschillende webpagina’s belangrijke informatie kunnen bevat-
ten. Tevens kan iets zoals de Social Graph van Facebook er mogelijks voor zorgen dat auteurs
meer belang gaan hechten aan het semantisch annoteren van hun pagina’s of artikels, en we
dus ook mogelijks meer geografisch geannoteerde artikels zouden kunnen krijgen. We sluiten
Hoofdstuk 2 af met een literatuurstudie over verwante onderzoeken. Hierbij maken we een on-
derscheid tussen artikels waarbij men het geografisch bereik van een pagina heeft trachten te
bepalen, waarbij men de exacte locatie poogde te bepalen en waar men Wikipedia gebruikte om
(andere) bronnen te classificeren.
Vervolgens gaan we in Hoofdstuk 3 onze eigen methode bespreken. Hierin bespreken we
zowel de technieken die we effectief gebruikt hebben, als de technieken die nodig waren om
de taalmodellen te genereren waarop we ons gebaseerd hebben. Daarnaast bespreken we ook
hoe we de basistechnieken hebben proberen verbeteren door rekening te houden met de speciale
eigenschappen van Wikipedia. Dit is namelijk een grote graaf van verbonden artikels die allemaal
volgens een eenduidig geformuleerde structuur opgemaakt zijn. Met deze kennis zullen we ook
onze methode proberen te verfijnen.
In Hoofdstuk 4 beginnen we met onze evaluatiemethode uit te leggen. We bespreken de
manier van evalueren en we leggen de hierbij gebruikte metrieken uit. Vervolgens komt de
gehanteerde baseline, Yahoo! Placemaker, kort aan bod. Daarna volgt een uitvoerige bespreking
van de resultaten van de methode en de hierop gemaakte varianten. Verder vergelijken we nog
deze resultaten met die van onze baseline.
In een afsluitend hoofdstuk formuleren we onze conclusies.

WEB 2.0 EN HET BELANG VAN GEOREFERENCING 4
Hoofdstuk 2
Web 2.0 en het belang van
georeferencing
Dit hoofdstuk begint met een bespreking van relevante bronnen voor het onderzoek. Bij de
bronnen die effectief gebruikt worden zullen we dit ook hier al aangeven. We tonen ook toepas-
singen aan voor het resultaat van ons onderzoek en bekijken reeds gerealiseerde toepassingen.
Vervolgens worden enkele termen verduidelijkt en wordt er dieper ingegaan op het georeferen-
cen. Tenslotte volgt een bespreking van relevante onderzoeken waaruit sommige ideeen gebruikt
zullen worden.
2.1 Wikipedia en het nut van geografisch geannoteerde artikels
2.1.1 Wikipedia
Wikipedia1 is een vrije (gratis) online encyclopedie met meer dan 3.500.000 artikels. Er is reeds
een structuur aangebracht in de artikels, ze worden namelijk allemaal volgens een vast stramien
opgemaakt. Hiervoor zijn voor elk type pagina template pagina’s ontwikkeld. Zo is er rechts
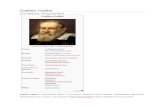
bovenaan bijvoorbeeld ook een plaats waar de geografische coordinaten kunnen aangegeven
worden zoals in Figuur 2.1. Daarnaast is er een speciale box met landinformatie voor pagina’s
over landen.
1http://www.wikipedia.org

2.1 Wikipedia en het nut van geografisch geannoteerde artikels 5
Figuur 2.1: Een artikel uit Wikipedia, rechts bovenaan zie je de geografische coordinaten

2.1 Wikipedia en het nut van geografisch geannoteerde artikels 6
2.1.2 Domein van de locatie
Voor een monument zoals de Eiffeltoren of het Atomium is er weinig ambiguıteit omtrent het
bepalen van de juiste coordinaten. Maar als we het over grotere geografische entiteiten hebben
zoals landen of staten wordt het al gauw minder duidelijk welke coordinaten het best zijn. Naast
de locatie van het geografisch middelpunt van het land, kan ook die van het centrum van de
hoofdstad gebruikt worden. Deze locaties kunnen soms meer dan 1000 kilometer uit elkaar
liggen, wat de resultaten van ons onderzoek zou kunnen beınvloeden. Dit probleem wordt in
deze masterproef niet verder behandeld. Daarom zullen grote gebieden uit de testverzameling
verwijderd worden.
2.1.3 Geografisch geannoteerde artikels
Hoewel de voorzieningen voor coordinaten aanwezig zijn, zijn er nog veel artikels waar deze
niet ingevuld zijn. Daarom zouden we dus graag een automatische methode ontwikkelen om
de Wikipedia artikels te geotaggen. Dit betekent: geografische coordinaten toevoegen aan het
artikel in kwestie en dit zodat de toegekende coordinaten de plaats weergeven waarover het
artikel gaat.
2.1.4 Toepassingen van geografisch geannoteerde artikels
De coordinaten van Wikipedia pagina’s kunnen gebruikt worden om deze op een kaart weer
te geven. Zo kunnen via mobiele toestellen gemakkelijk relevante artikels opgevraagd worden.
Daarnaast kunnen verbanden ontdekt worden tussen geografisch geannoteerde steden, gebouwen
en gebeurtenissen.
Momenteel wordt op het Internet vooral informatie gezocht via zoekmachines. Uit onder-
zoek is gebleken dat een groot deel van de zoektermen die hiervoor gebruikt worden geografische
termen bevatten. In 2004 al hebben Sanderson en Kohler [1] de zoektermen van de Excite
zoekmachine geanalyseerd. Daar konden ze uit opmaken dan maar liefst 18,6% van de zoekop-
drachten geografische woorden bevatten. Momenteel worden Internet gebruikers als maar meer
mobiel en daarmee zal nog meer gezocht worden naar geografisch relevante data. Daarom is het
belangrijk om ook onze encyclopedische gegevens en bij uitbreiding alle webbronnen geografisch
te kunnen duiden.
Een artikel kan dan nog voor meer mensen interessant zijn dan de inwoners van de streek
waarover het gaat. Bijvoorbeeld een artikel over de aanslagen op het World Trade Center heeft

2.2 Relevante bronnen en mogelijke toepassingen 7
een wereldwijde relevantie. Een pagina over een wijkfeest in het centrum van dezelfde stad heeft
daartegenover een meer regionaal bereik. Wij zullen ons concentreren op het bepalen van de
locatie van het artikel en niet zozeer rond het bereik van het artikel.
2.2 Relevante bronnen en mogelijke toepassingen
Deze sectie behandelt eerst enkele applicaties die gebruik maken van geografische informatie.
De veelheid aan toepassingen geeft duidelijk aan dat de markt van geografische applicaties sterk
groeit en dat het dus wel degelijk nuttig zou zijn als Wikipedia en bij uitbreiding het Internet
verder voorzien zouden worden van geografische coordinaten. Daarnaast kan data van sommige
van deze applicaties nuttig zijn in ons onderzoek.
2.2.1 Flickr
Flickr2 is een online fotoservice waar gebruikers via het Web 2.0 model hun eigen foto’s eenvoudig
kunnen opladen. Tegenwoordig kan dit niet enkel via de computer maar ook via mobiele devices.
Wanneer er met een smartphone een foto getrokken wordt kan die rechtstreeks opgeladen worden
zodat die enkele seconden later op Flickr verschijnt. Aangezien de smartphones vaak ook een
GPS module aan boord hebben, zijn ze in staat om de foto’s van een locatie te voorzien. Zo
kunnen de foto’s ook op een kaart weergegeven worden. Door dergelijke toepassingen worden
er nu zelfs al GPS modules gemaakt speciaal voor foto- en videotoestellen. Sommige toestellen
krijgen deze modules ingebouwd in het toestel zelf om de integratie nog naadlozer te laten
verlopen. Het is in ieder geval duidelijk dat de komende jaren, meer en meer mensen toegang
zullen hebben tot dergelijke toestellen en dat de markt voor toepassingen hierop nog exponentieel
zou kunnen toenemen. De taalmodellen waarvan we zullen vertrekken voor de locatiebepaling
van de Wikipedia pagina’s werden in voorgaand onderzoek [2] gecreeerd met behulp van gegevens
over Flickr foto’s.
2.2.2 Facebook
Facebook is een online sociaal netwerk3 dat de laatste jaren omnipresent geworden is op het
Internet. Iedereen kent het en op miljoenen sites zijn hun sociale widgets te vinden. Hiermee
kan je reageren op bepaalde artikels of die leuk vinden waardoor deze op je persoonlijk profiel
2http://www.flickr.com3http://www.facebook.com

2.2 Relevante bronnen en mogelijke toepassingen 8
geplaatst worden. Vervolgens kunnen je vrienden zien wat jou interesseert en kunnen de gedeelde
artikels gemakkelijk bereikt worden.
Dit laatste is een doorn in het oog van die andere grote speler op het Internet, Google4, die
het afgelopen decennium groot geworden is met hun zoekmachine. Aangezien een groot deel
van hun inkomsten vergaard wordt door de plaatsing van advertenties naast hun zoekresultaten
en deze dreigen namelijk fel te verminderen aangezien de mensen minder zoekmachines nodig
hebben (pull model). Daarentegen wordt die nu via diensten als Facebook rechtstreeks naar hen
toegeduwd en hebben de gebruikers dus de informatie al zonder de zoekmachines nog te moeten
passeren (push model). De sociale netwerken worden dus de nieuwe Internetportalen, waar dit
ontegensprekelijk de zoekmachines waren met Google voorop in de jaren 2000.
De zoekmachines worden nu dus geleidelijk, op hun beurt, vervangen door de sociale diensten,
die met behulp van de persoonlijke informatie en de gebruikersvoorkeuren enkel het voor de
gebruiker relevante nieuws tonen. Deze verandering in het Internetlandschap kan vergeleken
worden met de verandering die we eind de jaren ’90 van de vorige eeuw zagen toen de handmatig
samengestelde startpagina’s, die vele Internet providers aanboden, vervangen werden door de
zoekmachines. Dit soort portaalpagina’s zijn natuurlijk nog niet helemaal verdwenen, maar ze
zijn meer geevolueerd naar een soort van gespecialiseerd informatiekanaal voor gelijkgestemden.
Zo kan je bijvoorbeeld het succesvolle Seniorennet5 beschouwen dat zich specifiek richt op de
iets ouderen en voor hen relevante informatie aabiedt.
2.2.3 Netlog
Facebook is natuurlijk niet het enige sociale netwerk, maar wel veruit het populairste. We hebben
in Belgie echter ook een relatief grote speler op Europees niveau met Netlog6, wat zich echter
op een iets jonger publiek richt. In Nederland is Hyves7 dan weer alomtegenwoordig. LinkedIn8
daarentegen is meer gericht op de bedrijfswereld. Door het succes van Facebook duiken er nu
ook veel varianten op. Het Internet wordt door die sociale initiatieven voor mensen die op hun
privacy staan een beetje te sociaal. Een nieuw platform dat hier handig op inspeelt is Path9. Ze
noemen zichzelf het persoonlijk netwerk, dit weerspiegelt zich in het maximum van 50 vrienden
4http://www.google.com/5http://www.seniorennet.be/6http://nl.netlog.com7http://hyves.nl/8http://www.linkedin.com9http://www.path.com

2.2 Relevante bronnen en mogelijke toepassingen 9
Figuur 2.2: Een locatie op Foursquare, weergegeven met Google Maps, rechts ziet u de statis-
tieken en de “Mayor”.
dat je kan toevoegen. De vraag is natuurlijk of de massa zin heeft om tien verschillende sociale
netwerken te onderhouden. Bij Path kan je momenteel enkel je verhaal kwijt via de iPhone App.
Deze dienst staat dus nog in zijn kinderschoenen.
2.2.4 Foursquare en Gowalla
Foursquare10 en Gowalla11 gooien het dan weer over een andere boeg. Deze diensten zijn hier
nog maar met mondjesmaat in gebruik en het is zelfs niet duidelijk of dergelijke diensten ooit
zullen aanslaan bij het grote publiek.
Op Foursquare kan iedereen zelf locaties toevoegen, bijvoorbeeld: je huis, je werk, plaatsen
waar je hobby’s beoefent, restaurants,... De plaatsen (Figuur 2.2) kunnen zo gek niet bedacht
10http://www.foursquare.com11http://www.gowalla.com

2.2 Relevante bronnen en mogelijke toepassingen 10
worden, of ze zijn reeds toegevoegd. Dit kan heel eenvoudig via de applicatie die te downloaden is
voor alle gangbare smartphones. Als de gebruiker vervolgens ergens naartoe gaat, kan hij via die
locaties laten weten waar hij is. Foursquare vrienden kunnen, wanneer ze op de dienst inloggen,
van elkaar zien waar ze zijn. Daarnaast zijn er nog een aantal andere mogelijkheden, er kunnen
bijvoorbeeld tips en waarderingen bij een locatie achtergelaten worden. In een cocktailbar kan
dan de cocktail van het huis aanbevolen worden.
Om het gebruik van hun netwerk te promoten is er ook een extra spelelement toegevoegd.
Zo kunnen er “badges” verdiend worden door veel plaatsen op dezelfde dag te bezoeken of door
veel naar hetzelfde type van plaatsen te gaan. Zelfs door in te checken op een skioord kan er
een speciale skibadge verdiend worden. En als je voldoende vaak op dezelfde plaats komt, meer
dan alle anderen, kan je de mayor van die plaats worden. In principe betekent dit niet meer
dan een aanduiding van wie op een bepaalde plaats het meest komt. Tevens is er ook continu
een tussenstand onder vrienden: wie heeft de laatste zeven dagen het meeste incheckpunten
verdiend?
Dit spelelement dient er enkel toe om de instap naar het platform te verkleinen. Op deze
manier wordt er gepoogd om het platform te laten groeien zodanig dat er meer mensen actief
op worden. Want pas als er voldoende mensen een dergelijk platform gebruiken wordt het com-
mercieel interessant. Hiervoor werden al een aantal mogelijkheden ingebouwd in het platform.
De echte eigenaar van een bepaalde zaak kan namelijk claimen dat hij/zij de eigenaar is van
die locatie. Dit kan op verschillende manieren, bijvoorbeeld via de telefoon of door een kaartje
van Foursquare op te laten sturen met een code op. Vervolgens dient de eigenaar die code in te
geven via de website zodat de ontwikkelaars weten dat jij effectief de eigenaar van die zaak bent.
Vanaf dan kan de pagina door de eigenaar beheerd worden. Zo kan hij acties uitschrijven voor
zijn winkel, bijvoorbeeld: gratis consumpties voor de mayor in een horeca zaak of een cadeautje
voor iedereen die incheckt in ons restaurant. Op deze manier kunnen lokale handelaars het
gebruik van Foursquare stimuleren. Zij hebben hier ook baat bij, want elke check-in genereert
voor hen uiteindelijk reclame. Deze netwerken kunnen dus gezien worden als de moderne vorm
van mond-tot-mondreclame.
Gowalla is onder meer wat betreft het inchecken heel vergelijkbaar met Foursquare. Het
verschilt vooral in de extra’s en spelelementen die rond het platform gebouwd werden. Een
extra mogelijkheid in Gowalla is het toevoegen van “trips”: er kan een nieuwe trip aangemaakt
worden door gerelateerde plaatsen te bundelen, vervolgens kan je een “trip” volgen door de

2.2 Relevante bronnen en mogelijke toepassingen 11
plaatsen erin te bezoeken. Dit kan interessant zijn voor bijvoorbeeld stadsbezoeken waarbij
dan gewoon een veelgevolgde citytrip op Gowalla kan gevolgd worden. Deze ervaring kan dan
nog verbeterd worden door relevante informatie uit Wikipedia encyclopedie bij de “trip” te
tonen. Daarnaast kan je vanuit Gowalla inchecken op andere locatiegebaseerde diensten zoals
Foursquare en het recent gelanceerde Facebook Places. Tegenwoordig kan je via Gowalla zelfs
berichtjes achterlaten op een locatie zodat je vriend dat pas kan lezen als ze er eerst naartoe
gaan.
Voor onderzoek naar locatiegebaseerde toepassingen zou vooral de API van dergelijke dien-
sten interessant moeten zijn. Het grootste probleem dat hierbij optreedt is dat bij een zoek-
opdracht tot voor kort een locatie diende meegegeven te worden waarrond de plaats opgezocht
kon worden. Dit is voor de meeste mobiele applicaties interessant aangezien zo enkel locaties in
de buurt gevonden worden; maar om plaatsen te lokaliseren is dit niet nuttig. Hier is, althans
bij Foursquare, heel recent verandering in gekomen want ze bieden nu met hun Venues API12
de mogelijkheid om rechtstreeks plaatsen op te zoeken. Niet enkel in de buurt van bepaalde
coordinaten, maar er kunnen ook gewoon namen of adressen opgezocht worden in de Foursquare
databank. Gezien het grote aantal plaatsen dat toegevoegd wordt in dergelijke systemen kan
het een opportuniteit zijn om deze APIs te gebruiken voor onderzoeksdoeleinden. In ieder geval
zullen deze diensten nu of in de toekomst nog interessant worden voor onderzoek in het domein
van locatiebepaling.
2.2.5 Google Maps, Bing Maps, Panoramio
Google Maps is begonnen als een grote wereldkaart waarop je een route tussen twee punten kan
plannen. Je geeft vertrek- en aankomstplaats in en vervolgens krijg je de snelste of korstste
route uitgestippeld. Google Maps is zeker niet de enige die een dergelijke dienst aanbiedt, maar
het springt er wel uit door de vele extra functies die reeds ingebouwd zijn. De kaart bestaat
uit verschillende lagen. Zo kan je een gewoon stratenplan opvragen. Hierop kan je dan een laag
leggen met satellietbeelden van de betreffende plaatsen waardoor je een beter beeld krijgt van
het stratenplan. Meer recent is er Street View ingebouwd. Dit is 3D weergave van de straten
waarin er virtueel kan rondgewandeld worden. Via de Google Maps applicatie op Android13 is
12https://developer.foursquare.com/venues/13http://www.android.com/

2.2 Relevante bronnen en mogelijke toepassingen 12
Figuur 2.3: Google navigatie op Android met StreetView
ook turn-by-turn14 navigatie ingebouwd. De integratie van Street View in de navigatie applicatie
biedt Google een serieus competitief voordeel op de navigatiemarkt, zoals je kan zien in Figuur
2.3. Ook de kaarten van Google kan je in je eigen web applicaties integreren via een API.
Er kunnen markeringen op aangebracht worden zodat je de kaarten kan aanpassen voor jouw
doeleinde. Zo worden de plaatsen in de eerder besproken diensten Foursquare en Gowalla hierop
aangeduid. Panoramio gebruikt de dienst dan weer om geografisch geannoteerde foto’s via een
kaart toegangkelijk te maken.
Via Panoramio kunnen er dus foto’s geupload worden, zoals bij zovele andere online fotodien-
sten. Wat hen uniek maakt is dat er bij de foto’s kan aangegeven worden waar die gemaakt zijn.
Daardoor kunnen de beschikbare foto’s doorbladerd worden via de wereldkaart van Google.
14Met turn-by-turn navigatie wordt bedoeld dat het navigatietoestel bij elke afslag duidelijk aangeeft en even-
tueel ook zegt dat er dient afgeslaan te worden.

2.2 Relevante bronnen en mogelijke toepassingen 13
Figuur 2.4: Google Maps met een overlay van geografisch geannoteerde Wikipedia pagina’s.
Ondertussen is Panoramio reeds opgekocht door Google, en is deze dienst geıntegreerd in de
standaard Maps applicatie. Daarin kan je, naast de foto’s van Panoramio zelf, al een laag over
de kaart leggen met geografisch geannoteerde Wikipedia pagina’s zoals je kan zien in Figuur 2.4.
Bing Maps heeft in praktijk ook bijna alle mogelijkheden die Google Maps heeft ingebouwd.
Microsoft heeft echter alles een klein beetje anders geımplementeerd en een andere naam gegeven.
Zo wordt Google Streetview bij Microsoft bijvoorbeeld Bing StreetSide, maar dit haalt helemaal
niet het niveau van het origineel. Bing Maps kan net zoals Google Maps ook via een API
gebruikt worden in andere applicaties. Facebook maakt hiervan gebruik voor hun Places dienst.
Dit is logisch aangezien Facebook en Microsoft strategische partners zijn.
2.2.6 Groupon
Groupon15 bundelt de kracht van mensen door deals af te sluiten met lokale handelaars. De
gebruikers van Groupon kunnen dan deelnemen aan een deal en zo bijvoorbeeld: voordelig gaan
eten, iets kopen of iets bezoeken. Dit is een interessante speler omdat het als beginnend bedrijf
eigenlijk al direct een business model heeft. Iets waar veel van de hierboven besproken sociale
starters meer moeilijkheden mee hebben. Tevens is het mogelijk dat Groupon zijn krachten
bundelt met andere (locatiegebaseerde) sociale applicaties.
15http://www.groupon.be

2.2 Relevante bronnen en mogelijke toepassingen 14
Figuur 2.5: Qwiki, een mooi voorbeeld van data aggregatie.
2.2.7 Qwiki
Qwiki16 is een voorbeeld van wat nu al mogelijk is door informatie uit verschillende (web)bronnen
te extraheren en vervolgens samen te voegen. Qwiki’s zijn een soort van gesproken informatie-
berichten die op een korte en duidelijke manier een bepaald onderwerp verduidelijken. Een van
de belangrijkste bronnen voor de informatie is hierbij ook Wikipedia. Qwiki’s die over plaatsen
gaan gebruiken ook de coordinaten, als die beschikbaar zijn, om de plaats op een kaart te kun-
nen tonen zoals in Figuur 2.5 zichtbaar is. Het aantal Qwiki’s is momenteel nog beperkt en het
ontbreken van geografische informatie omtrent een heleboel plaatsen is hier mogelijk een deel
van de oorzaak.
Dit project toont ons dat door het samenbrengen van informatie uit verschillende bron-
nen, mooie dingen gemaakt kunnen worden. Zo zouden we dus op een Qwiki-achtige manier
in staat moeten zijn om gesproken interactieve stadsroutes met allerhande multimedia te gene-
reren. Wanneer de informatie uit Wikipedia met behulp van de coordinaten verbonden wordt
met foto’s en filmpjes die ermee verband houden, kan er bijvoorbeeld een interactieve digitale
16http://www.qwiki.com

2.3 Georeferencing 15
stadswandeling gemaakt worden. Een geografisch geannoteerd web heeft duidelijk heel wat
mogelijkheden.
2.3 Georeferencing
2.3.1 Wat is georeferencing?
Georeferencing is het bepalen van de locatie waarover een tekst of een collectie van voorwerpen
gaat. Er zijn meerdere manieren om een locatie uit te drukken. In het dagelijks leven worden
meestal beschrijvende termen zoals het land, de plaats, de straatnaam gebruikt om aan te geven
welke locatie bedoeld wordt. Om een plaats aan te geven die we niet gewoon met dergelijke
termen kunnen beschrijven hebben we in onze natuurlijke taal nog andere elementen. Zo kan je
bijvoorbeeld ook relatieve plaatsaanduidingen hebben zoals: hij woont tien kilometer ten zuiden
van Brussel. Als we dergelijke elementen uit de natuurlijke taal gaan gebruiken om de locatie
aan te geven wordt het moeilijk om deze gegevens met de computer te gebruiken. Daarom gaan
we in deze masterproef verder gebruik maken van de lengte- en breedteligging. Hiermee kan een
plaats exact aangeduid worden en zodoende zal er geen ambiguıteit zijn omtrent welke locatie
nu juist bedoeld wordt.
2.3.2 Lengte- en breedteligging
Geografische coordinaten kunnen op vele manieren uitgedrukt worden: decimale graden; graden,
minuten en seconden; graden, decimalen en minuten, UMT,... En ze kunnen gemakkelijk omge-
zet worden van het ene naar het andere systeem. We verkiezen verder om van decimale graden
gebruik te maken aangezien we zo een locatie met slechts twee getallen kunnen vastleggen: de
decimale lengteligging en decimale breedteligging. Met de Haversine formule kan ook de afstand
tussen twee geografische coordinaten eenvoudig bepaald worden.
De lengteligging17 is de hoek tussen het meridiaanvlak van Greenwich en het meridiaanvlak
van het meetpunt. Het is samen met de breedteligging een geografische positieaanduiding in
bolcoordinaten. Voor de coordinaten op aarde varieert de lengteligging van 0 tot 180 graden,
met de toevoeging O.L. (oosterlengte, ten oosten van de nulmeridiaan, op het oostelijk halfrond)
of W.L. (westerlengte, ten westen van de nulmeridiaan, op het westelijk halfrond).
De breedteligging18 van een plek op Aarde is de hoek die de verbindingslijn tussen die plek
17http://nl.wikipedia.org/wiki/Lengtegraad18http://nl.wikipedia.org/wiki/Breedtegraad

2.3 Georeferencing 16
en het middelpunt van de Aarde met het vlak van de evenaar maakt. De breedteligging varieert
van 0 tot 90 graden, met de toevoeging NB (noorderbreedte, ten noorden van de evenaar, op het
noordelijk halfrond) of ZB (zuiderbreedte, ten zuiden van de evenaar, op het zuidelijk halfrond).
2.3.3 Geoparsing versus Geocoding
Geoparsing is het proces waarbij aan textuele elementen die voorkomen in een ongestructureerde
tekst, zoals “tien kilometer ten zuiden van Gent”, geografische coordinaten of codes toegekend
worden. Dankzij het toevoegen van de geografische coordinaten kunnen de bronnen toege-
voegd worden aan geografische informatiesystemen. Niet enkel tekst kan geanalyseerd worden
met behulp van Geoparsing, maar ook media zoals foto’s en audiofragmenten waarin mogelijk
plaatsnamen uitgesproken worden. Voor het uitvoeren van Geoparsing operaties heeft Yahoo!19
reeds een API gebouwd: Yahoo! Placemaker20. Deze API zullen we later gebruiken als baseline
voor ons onderzoek.
Geocoding is een meer eenvoudige variant hiervan. Hierbij worden enkel eenduidig gestruc-
tureerde adressen, zoals postadressen, omgezet in geografische coordinaten. Voor het uitvoeren
van Geocoding opdrachten kan de Google Geocoding API21 gebruikt worden, maar ook Yahoo!
heeft een Geocoding API. Ook het omzetten van geografische coordinaten naar straatadressen
is mogelijk en dit wordt Inverse Geocoding genoemd.
2.3.4 Termclassificatie
Termclassificatie (Named Entity Recognition) is een onderdeel van het verwerken van natuurlijke
taal (NLP), namelijk het classificeren van namen in een bepaalde categorie. Zo kunnen we
bijvoorbeeld Brussel als stad classificeren. Maar FC Brussels is dan weer een voetbalploeg.
Met Brussels South wordt zelfs een luchthaven bedoeld die niet in de stad Brussel ligt, maar
in Charleroi te vinden is. Voor deze taken worden vaak geografisch georienteerde ontologieen
gebruikt [3, 4]. Ook encyclopedieen als Wikipedia blijken interessante bronnen om eventueel in
combinatie met andere ontologieen gebruikt te worden ter classificatie van entiteiten [5].
19http://www.yahoo.com20http://developer.yahoo.com/geo/placemaker/21http://code.google.com/intl/nl-NL/apis/maps/documentation/geocoding/

2.4 Gazetteers 17
2.3.5 Geografisch bereik van pagina’s
Het geografisch bereik van een pagina is het gebied waarbinnen mensen geınteresseerd zijn in de
pagina. Dit is voornamelijk interessant voor zoekmachines. Aangezien zoekmachines al lange
tijd in de belangstelling gestaan hebben is er, ook op het vlak van georeferencing, voornamelijk
onderzoek gedaan naar het bereik (scope) van webpagina’s, en dan nog eerder naar het doelbereik
(target scope) dan naar het bronbereik (source scope):
• Bronbereik Hiermee bedoelen we het gebied waarover de inhoud van een pagina gaat.
Bijvoorbeeld een pagina over de Verenigde Staten van Amerika heeft een bronbereik dat
volledig dit land betreft. Een pagina over de Eiffeltoren heeft een veel kleiner bronbereik
namelijk slechts het deel van Parijs waar deze IJzeren Dame geplaatst is en een klein
gebied daarrond.
• Doelbereik Dit is het bereik waarop de pagina relevantie heeft naar potentiele bezoekers
van de pagina. De hierboven beschreven pagina’s zullen allebei eigenlijk een wereldwijd
doelbereik hebben. Een pagina over de provinciale belastingen van Oost-Vlaanderen zal
slechts een bereik hebben dat zich beperkt tot die provincie. De sporthal van Wetteren is
dan weer slechts relevant voor Wetteraars en mensen uit enkele buurgemeentes.
Als we nu beiden vergelijken is het snel duidelijk dat voor de meeste toepassingen het doelbe-
reik het belangrijkst is. Zoekmachines proberen bijvoorbeeld door middel van het doelbereik van
een pagina meer relevante resultaten te tonen aan hun gebruikers. Hierdoor is er in het verleden
veel meer onderzoek gedaan naar het doelbereik van een pagina dan naar het bronbereik. Voor
de nieuwe geografisch gebonden toepassingen is echter vaak het bronbereik meer relevant. Wij
gaan ons dus hierop richten.
2.4 Gazetteers
2.4.1 Geonames
Geonames22 is een online geografische databank die meer dan 8 miljoen plaatsnamen bevat.
De Geonames databank is gratis te downloaden en dus handig om te gebruiken in onderzoek.
Je kan er niet alleen namen vinden maar ook de overeenkomstige geografische coordinaten.
22http://www.geonames.org

2.4 Gazetteers 18
Daarnaast worden nog een aantal andere functies aangeboden zoals het opzoeken van postcodes
en statistieken van landen raadplegen.
2.4.2 Getty Thesaurus of Geographical Names
De Getty Thesaurus of Geographical Names is een online geografisch semantisch netwerk dat
voor het eerst gepubliceerd werd in 1997. De TGN23 kan gebruikt worden om extra informatie
te verzamelen over plaatsen. De informatie die in de TGN zit kan ook gebruikt worden om
plaatsen te kunnen indentificeren of classificeren.
De TGN bevat plaatsen met informatie die daaraan geassocieerd is. Plaatsen kunnen ad-
ministratieve politieke entiteiten zijn (zoals steden en landen) en natuurlijke elementen (zoals
bergen en rivieren). Zowel hedendaagse plaatsen als geschiedkundige plaatsen zijn opgenomen
in de databank.
Naast een eerste belangrijkste naam worden er voor alle mensen, plaatsen en voorwerpen die
in de databank aanwezig zijn ook synoniemen bijgehouden. De TGN is niet zomaar een databank
die geografische zaken beschrijft, maar ook de relaties die bestaan tussen de verschillende items
in de databank zijn er in opgenomen. De TGN kan mede dankzij deze verbanden ook gebruikt
worden als zoekassistent bij het bevragen van andere databanken. Dit semantische netwerk
blijkt ook voor onderzoeksdoeleinden zeer interessant.
Alle plaatsen worden in een hierarchie opgenomen. Er wordt voor elke plaats begonnen op
wereldniveau en stap voor stap afgedaald tot we bij de locatie zelf komen. Voor de gemeente
Wetteren wordt dus de volgende hierarchie bekomen: het continent Europa, het land Belgie, de
Vlaamse gemeenschap, de provincie Oost-Vlaanderen en ten slotte de gemeente Wetteren zelf.
In Figuur 2.6 kan je duidelijk zien hoe de hierarchie van een plaats bijgehouden wordt.
2.4.3 WordNet
WordNet24 is een grote lexicale databank met Engelstalige woorden. Zelfstandige naamwoor-
den, werkwoorden, adjectieven en bijwoorden zijn allemaal gegroepeerd per betekenis (synset),
zondanig dat ze elk een specifiek concept vertegenwoordigen. Deze synsets zijn verbonden door
relaties tussen de verschillende concepten. Het resulterende netwerk kan gratis via een browser
interface doorzocht worden. De structuur van WordNet maakt het uitermate geschikt voor de
verwerking van natuurlijke taal.
23http://www.getty.edu/research/tools/vocabularies/tgn/index.html24http://wordnet.princeton.edu/

2.4 Gazetteers 19
Figuur 2.6: Een plaats uit de Getty Thesaurus of Geographical Names. Naast de beschrijvende
informatie is de hierarchie van de plaats duidelijk zichtbaar.

2.5 Semantisch Web 20
2.4.4 YAGO2: Yet Another Geographical Ontology
YAGO225 is een kennisdatabank met focus op temporele en ruimtelijke kennis. Het werd auto-
matisch gegenereerd uit Wikipedia, Geonames en WordNet en bevat bijna 10 miljoen entiteiten
(personen, organisaties, steden). Daarnaast bevat het 80 miljoen feiten die de algemene wereld-
kennis vertegenwoordigen.
YAGO2 is ondersteund door de Europese projecten LivingKnowledge en WebDam, en door
het Duitse ”Excellence Cluster on Multimodal Computing and Interaction”. YAGO2 is logi-
scherwijs een uitbreiding van de eerste versie, en hierbij is speciale aandacht gegaan naar tijd en
locatie. Zo werden de tijd en plaats bij alle entiteiten waarvoor die relevant waren toegevoegd,
indien ze beschikbaar waren op Wikipedia. Ook voor deze toepassing zou het automatisch
georeferencen van Wikipedia pagina’s een troef kunnen worden.
In tegenstelling tot vele andere automatisch samengestelde kennisbanken heeft YAGO2 een
gecontroleerde26 correctheid van 95%.
2.5 Semantisch Web
2.5.1 Wat is het Semantisch Web
Het Semantisch Web27 28 is een idee ondersteund door het World Wide Web Consortium29 om
het web te laten evolueren naar een web van data. Het is een poging om het web uit te breiden
met een extra laag die de data erin gestructureerd voorstelt. Tegenwoordig zijn webpagina’s
gelinkt doordat deze opgemaakt worden in de HTML webtaal. De informatie die beschikbaar
is op het web is momenteel gericht naar mensen. Om de beschikbare data toegankelijk te
maken voor machines worden er metadata toegevoegd over de pagina’s zelf en hoe ze in verband
staan met elkaar. Hierdoor kunnen geautomatiseerde systemen het web op een intelligentere
manier beschouwen en vragen van gebruikers beter beantwoorden. Om dit te realiseren zijn een
aantal technologieen ontwikkeld die bedoeld zijn om een beschrijving van concepten en termen
te kunnen geven, en relaties te kunnen aanduiden tussen verschillende bronnen. Met de term
Semantisch Web wordt ook vaak verwezen naar deze technologieen die dit mogelijk maken.
25http://www.mpi-inf.mpg.de/yago-naga/yago/26http://www.mpi-inf.mpg.de/yago-naga/yago/evaluation.html27http://www.w3.org/2001/sw/SW-FAQ28http://en.wikipedia.org/wiki/Semantic web29http://www.w3c.org

2.5 Semantisch Web 21
2.5.2 Resource Description Framework
RDF30 is een belangrijke bouwsteen binnen het Semantisch Web. Het wordt gezien als de
standaard manier om informatie uit te wisselen over verschillende bronnen op het web. Met het
Resource Description Framework of kortweg RDF kan men informatie op een eenduidige manier
opmaken. Dit wordt gedaan met behulp van een drieledige structuur: subject-predikaat-object.
Wegens de drieledige structuur wordt een RDF eenheid ook vaak aangeduid als een RDF triplet.
Het subject is hierin dan de webbron die beschreven wordt. Het predikaat duidt op de eigenschap
van de bron die beschreven wordt. Dit kan bijvoorbeeld de locatie zijn. Het object is dan de
waarde die het predikaat voor de aangegeven bron heeft.
RDFa31 of Resource Description Framework — in — attributes is een uitbreiding op XHTML
om uitgebreide metadata aan webdocumenten toe te voegen. Er wordt ook gewerkt aan een
versie die werkt in standaard HTML.
2.5.3 Open Graph Protocol
Het Open Graph Protocol32 is ontwikkeld door Facebook en gebaseerd op RDFa. Het is een
mooi voorbeeld van een gedeelde webgraaf. Je kan via het protocol informatie opvragen over
mensen die beschikbaar is op Facebook. Het stelt ontwikkelaars in staat om hun pagina’s
objecten van de sociale graaf te maken. Zo krijgen pagina’s met het OGP dezelfde functionaliteit
als “Facebook Pages”33. Met behulp van het Open Graph Protocol kan je dus geografische
coordinaten toevoegen aan een web pagina. Zowel in een door de mens leesbare vorm, als in
lengte- en breedteligging. In praktijk kan dit eenvoudig door de juiste meta-elementen toe te
voegen in de header van een HTML pagina. De elementen die relevant zijn worden getoond in
het volgende stukje code:
<html xmlns:og="http://ogp.me/ns#">
<head>
...
[REQUIRED TAGS]
<meta property="og:latitude" content="37.416343" />
<meta property="og:longitude" content="-122.153013" />
30http://www.w3.org/TR/REC-rdf-syntax31http://en.wikipedia.org/wiki/RDFa32http://www.ogp.me/33http://developers.facebook.com/docs/opengraph/

2.5 Semantisch Web 22
<meta property="og:street-address" content="1601 S California Ave" />
<meta property="og:locality" content="Palo Alto" />
<meta property="og:region" content="CA" />
<meta property="og:postal-code" content="94304" />
<meta property="og:country-name" content="USA" />
...
</head>
Deze techniek zorgt voor een gedeelde invulling van het semantische web, maar dan vooral
gefocust op het sociale deel van het web. Er wordt natuurlijk gepoogd om hier zoveel mogelijk
zaken bij te betrekken zodat de graaf kan blijven groeien. Een locatie kan bijvoorbeeld op
verschillende manieren in de graaf terecht komen: het kan de woonplaats of werkplaats van een
aantal gebruikers zijn, of ook een populaire vakantiebestemming. Culturele zaken; zoals films,
boeken of optredens hebben verbanden met mensen. Ook wetenschap staat tenslotte in verband
met mensen, en zo kan je in feite verwachten dat op termijn alle data binnen de sociale graaf
zal passen. Het grootste nadeel van het Open Grpah Protocol is dat het volledig eigendom is
van Facebook.
2.5.4 DBpedia
DBpedia34 is een inspanning van de online gemeenschap om gestructureerde informatie te ex-
traheren uit Wikipedia en die online beschikbaar te stellen. Zo is het mogelijk om via DBpedia
specifieke zoekopdrachten te doen naar data uit Wikipedia. Hiermee kan je vragen stellen zoals:
Geef de rivieren die in de Rijn uitmonden en meer dan 50 kilometer lang zijn? Het is duidelijk
dat dit niet zomaar mogelijk zou zijn met de gewone encyclopedie. Om dit te kunnen realiseren
worden de gegevens die geextraheerd zijn uit Wikipedia bijgehouden in RDF triplets.
Tevens is het mogelijk om lijsten met bepaalde karakteristieken te downloaden, wat natuur-
lijk interessant is voor onderzoek. Zo kunnen we eenvoudig deelverzamelingen van Wikipedia
downloaden om zo een lijst te bekomen met alle artikels waarvan geografische coordinaten voor-
handen zijn.
34http://dbpedia.org/About

2.6 Verwant onderzoek 23
2.6 Verwant onderzoek
2.6.1 Geografisch bereik van een pagina
Een groot deel van het gerelateerd onderzoek bevindt zich in het domein van de contextbepaling
voor zoekmachines. Voor deze contextbepaling wordt de taak meestal opgedeeld in drie deel-
taken. Een eerste stap bestaat uit Geoparsing, waarbij de geografische namen aanwezig in het
document verzameld en geclassificeerd worden volgens type. Vervolgens wordt met geocoding de
specifieke geografische plaats van deze entiteiten bepaald. Tenslotte wordt het juiste geografisch
bereik van de pagina bepaald, dit noemt men Geofocus [6, 7]. In [7] werden toch 70% van de
webpagina’s binnen de juiste stad geplaatst. Hierbij werd het Open Directory Project corpus35
gebruikt dat meer dan 1 miljoen pagina’s aanbiedt met hun geografisch bereik.
In de eerste plaats wordt bij het Geoparsen een gazetteer gebruikt. De termen uit de gazetteer
worden gezocht in de pagina’s. Een van de grootste problemen die overblijven is de ambiguıteit
van de verkregen termen. Er zijn twee verschillende types van ambiguıteit mogelijk, namelijk
Geo/Geo ambiguıteit en Geo/Non-Geo ambiguıteit [6, 7]. Geo/Geo ambiguıteit komt voor
wanneer twee of meer plaatsen dezelfde naam hebben. De Geo/Non-Geo ambiguıteit komt voor
wannneer een plaatsnaam overeenkomt met een gewoon (veelgebruikt) woord uit de natuurlijke
taal.
Na het oplossen van de ambiguıteit worden in Web-a-Where [6] de gevonden plaatsen ge-
controleerd op een dusdanige manier dat alleen de belangrijke plaatsen overblijven voor de
Geocoding stap. Wanneer dit gebeurd is wordt de focus van het artikel bepaald.
Silva et al. [8] gebruiken deels een vergelijkbare techniek, maar ze gebruiken in hun algoritme
ook semantische verbanden tussen entiteiten die voorheen nog onbekend waren. Als een aantal
entiteiten altijd samen voorkomen met een onbekende entiteit kan je meestal ook het bereik van
die andere entiteit proberen bepalen. Daarnaast wordt ook de linkstructuur tussen de documen-
ten gebruikt, hiervoor wordt gesteund op de aanname van onderwerplocaliteit: onderwerpen die
verband houden met elkaar zullen vaak ook op geografisch vlak bij elkaar in de buurt liggen.
Het NetGeo project [9] hield zich ook bezig met de bepaling van geografische locaties op het
web. Ze probeerden niet het bereik van pagina’s te bepalen maar wel een lengte -en breedteligging
voor bepaalde IP adressen. Dit deden ze met behulp van whois queries en textuele analyse van
de top level hostname.
35http://www.dmoz.org

2.6 Verwant onderzoek 24
2.6.2 Identificatie van locaties in Wikipedia
In [10] werden in grote mate Wikipedia pagina’s met allerhande inhoud geannoteerd met de
gepaste locatie en tijd. Er werd een hierarchie opgesteld van geografische concepten. Landen
worden in de juiste continenten geplaatst, steden worden verbonden met die landen, en ook die
steden worden waar mogelijk nog verder ontleed. Deze hierarchische boom is opgesteld door
middel van de uitgaande links in de Wikipedia pagina’s. Deze manier van verbanden zoeken is
interessant omdat er vaak een geografisch of tijdsgebonden verband is tussen pagina’s die naar
elkaar linken. Door rekening te houden met de links van geografisch geannoteerde pagina’s kon
men hier voor andere pagina’s bepalen over welk land of welke stad die gaan. In deze paper
worden enkel artikels binnen het juiste land of de juiste stad geplaatst en wordt niet geprobeerd
de juiste lengte -en breedteligging te bepalen zoals we in de masterproef wel gaan doen. De
distributie van het resultaat van de gegeotagde artikels kwam overeen met de distributie uit
ander onderzoek [11] waarbij meer dan 30 miljoen foto’s op een kaart geplaatst werden. Een
groot deel van de artikels beschrijven plaatsen in Noord-Amerika en Europa. Daartegenover
staan dan Zuid-Amerika en Afrika waar veel minder artikels over bestaan.
Voor de bouw van de geografische boom werd zoals in ons onderzoek vertrokken van een door
DBpedia36 gegeneerde deelverzameling van Wikipedia met geografische coordinaten. Verder
werd gebruik gemaakt van de infoboxes uit de Wikipedia pagina’s die aangeven of een bepaalde
pagina een land of een ander geografisch concept beschrijft.
Overell en Ruger [12] hebben een onderzoek uitgevoerd dat het dichtst in de buurt komt
van wat in deze masterproef behandeld wordt: het bepalen van locaties in teksten en deze
vervolgens proberen linken aan de juiste plaats uit de TGN (zie 2.4.2). Tevens gebruiken ze
Wikipedia artikels om hun techniek — een regelgebaseerd systeem om de juiste plaatsnaam
te vinden — mee te testen. Ze hebben hiervoor ook handmatig een verzameling gegenereerd
waarbij de koppeling correct gemaakt is.
Het regelgebaseerde systeem dient dus voornamelijk om de namen te koppelen aan de juiste
locatie in de TGN. De regels die hierbij over het algemeen het meest gebruikt worden zijn de
volgende:
• Unique match Er is maar 1 plaats
• Defaults Kies op basis van een eenvoudige heuristische regel zoals: De belangrijkste plaats
36http://dbpedia.org/About

2.6 Verwant onderzoek 25
• Referents Gebruik plaatsen die in de buurt (typisch 2-5 woorden) van de plaats voorko-
men om een beslissing te nemen.
• Minimum Bounding Box Probeer een veelhoek te passen rond de plaats waarover beslist
moet worden, en de andere plaatsen reeds aanwezig in de tekst. De kleinste veelhoek die
gevormd kan worden bepaalt de plaats.
• Polygonal Overlay Leg rond elke plaats in de buurt een vlak op de kaart. De plaats
die het meest aantal overlappende lagen heeft geniet de voorkeur. Indien er meerdere een
gelijk (maximaal) aantal lagen hebben kiezen we degene die het dichtsbij ligt.
Deze regels kunnen natuurlijk in varierende volgorde en met verschillende parameters toe-
gepast worden. Ze kunnen tevens ook samen gebruikt worden of je kan ze elk afzonderlijk hun
resultaat laten bepalen. Op basis van resultaten met deze “basisregels” werd een gecombineerde
methode op basis van de “Minimum Bounding Box” en “Most Important place” methoden
gemaakt.
Met hun combinatiemethode konden Overell en Ruger een 80% van de pagina’s correct als
plaats identificeren. Hiervan konden ze 80% aan de juiste TGN plaats koppelen.
Het onderzoek van Buscaldi en Rossi [13] heeft vervolgens deze methode vergeleken met
een op WordNet37 gebaseerde methode, die geografisch gerelateerde woorden gebruikt. Tevens
hebben ze ook een multinomiale Naive Bayes classifier getraint op een deel van Ludovic Denoyer’s
Wikipedia XML corpus [14]. Dit zijn een aantal collecties van XML-bestanden, in verschillende
talen, gebaseerd op artikels uit Wikipedia. Deze collecties werden oorspronkelijk ontwikkeld
voor gestructureerde gevensbevraging en de verwerking van natuurlijke taal.
De Geografische termen werden uit de WordNet synsets gehaald met behulp van de holoniem
(deel van) relatie en zijn inverse, het meroniem (omvat). Vertrekkende van de Noordelijke en
Zuidelijke hemisfeer werden iteratief via meroniem relaties alle geographische synsets opgehaald.
De woorden die in die synsets en in de beschrijving daarvan zaten zijn dan, op uitzondering
van stopwoorden, toegevoegd aan de verzameling van sleutelwoorden. Via de Dice en cosinus
similariteitsmaat werd vervolgens de afstand tussen de verzameling woorden uit WordNet en de
Wikipedia pagina bepaald. Hierbij presteerde de cosinus formule beter dan de Dice formule.
Voor de Multinomiale Naive Bayes methode werden 40.380 willekeurige artikels gekozen uit
de Wikipedia XML corpus. Daarvan waren er 17.728 aangeduid als plaatsen en 22,652 als
37http://wordnet.princeton.edu/

2.6 Verwant onderzoek 26
organisaties en personen. Van de 44.180 features die origineel aanwezig waren blijven er, na het
toepassen van de “Transition Point” [15] techniek, slechts 2.903 over. De Wordnet methode kan
de multinomiale Naive Bayes methode verslaan wanneer gebruikt gemaakt wordt van de cosinus
similariteitsmaat. De methodes besproken door Buscaldi en Rossi halen geen betere resultaten
dan die van Overell. De conclusie in [13] is dat de informatie die aanwezig is in de metadata
sowieso waardevoller is dan het artikel zelf.
2.6.3 Wikipedia als bron voor classificatie
Ook bij sommige van de voorgaande onderzoeken werd de inhoud van Wikipedia reeds gebruikt
om andere pagina’s te classificeren. In [16] wordt Wikipedia echter letterlijk als bron gebruikt ter
classificatie van andere webpagina’s. In dit artikel poogt men om de informatie die verschenen
is op verschillende nieuwssites, verspreid over Brazilie, te classificeren.
Deze techniek gaat niet op zoek naar directe referenties in de tekst, zoals bij het opzoeken van
data uit een of andere gazetteer. De locatiebepaling gebeurt door het koppelen van termen die
verband houden met Wikipedia artikels van bepaalde op voorhand uitgekozen locaties. Om de
plaatsgerelateerde termen uit Wikipedia te halen werden binnenkomende en uitgaande links van
de Wikipedia artikels, over de plaatsen die gekozen werden, geanalyseerd. Elke term krijgt ook
een onderscheidbaarheidsindex, die bepaalt hoe specifiek die term is voor een bepaald artikel.
Dit betekent hoeveel informatie het voorkomen van die term ons geeft voor het identificeren van
de plaats waarover het in dit artikel gaat. Dit gebeurt op basis van het aantal voorkomens van
de gevonden termen en of deze al dan niet in binnenkomende of in uitgaande links gevonden
werden. Ook voor ons werk is dit laatste idee mogelijk bruikbaar. De resultaten die in het
onderzoek behaald zijn, zijn met 84% vrij hoog, maar de vraag is of deze behouden blijven bij
het gebruik van grotere en meer willekeurig gekozen datasets.

TAALMODELLEN VOOR HET GEOREFERENCEN VAN WIKIPEDIA PAGINA’S 27
Hoofdstuk 3
Taalmodellen voor het georeferencen
van Wikipedia pagina’s
In deze masterproef gaan we een methode bepalen die automatisch coordinaten aan een Wiki-
pedia artikel kan koppelen. De methode is gebaseerd op taalmodellen die reeds gegenereerd
werden in voorgaand onderzoek [2]. Eerst volgt een korte bespreking van hoe deze taalmodellen
bekomen werden, waarna de classificatiemethode verduidelijkt zal worden.
3.1 Flickr taalmodellen
De taalmodellen die gebruikt worden in dit onderzoek zijn oorspronkelijk opgebouwd door het
analyseren van Flickr foto’s en de daaraan toegevoegde tags. Er werd hiervoor vertrokken van een
deel van de foto’s gepubliceerd op Flickr die met geografische coordinaten geannoteerd werden.
Voor alle foto’s werden vervolgens via de Flickr API de corresponderende tags en coordinaten
gedownload. Met behulp van de coordinaten konden die foto’s vervolgens geclusterd worden. De
clustering werd uitgevoerd met behulp van het k-medoids clusteringsalgoritme. Deze methode
is verwant aan het k-means algoritme maar kan beter overweg met uitschieters.
Van de clusters die hieruit ontstaan worden de foto’s bijgehouden en de locatie van de meest
centraal in de cluster gelegen foto. Deze foto’s zijn op zichzelf niet nuttig voor de tekstclassifi-
catie die we in dit onderzoek willen uitvoeren. Bij foto’s wordt op Flickr echter de mogelijkheid
gegeven om er textuele tags aan toe te voegen, en deze zijn wel nuttig. Een tag is namelijk
woord of een concatenatie van woorden die de foto beschrijven. Dit kan de plaats zijn waar
deze genomen is, de gebouwen die er op staan of andere eigenschappen die de foto kenmerken.

3.1 Flickr taalmodellen 28
Vervolgens werden de tags van de foto’s opgehaald en samengevoegd tot een lijst van de aanwe-
zige tags en het aantal foto’s waarbij die voorkwamen in deze cluster. Daarnaast werd uiteraard
ook nog steeds het centrum van de locatie van de cluster bijgehouden. Dit resulteert in een
lijst van clusters met hun tags. De voorstelling van een cluster begint met een clusternummer,
de geografische coordinaten daarvan en het aantal foto’s die in die cluster zaten. Vervolgens
komen dan telkens de tags die de cluster typeren met het aantal keer die voorkwamen, zoals het
volgende voorbeeld illustreert.
570 48.20254 16.3688 8872
franzschubert 1
flamantrose 1
pfarrkirche 2
dracula 1
stmichael 1
flagelldha 1
fusgnger 1
jet 4
koerper 1
wolfgruber 1
margaretengrtel 3
innerstadt 14
berlinerballen 1
mitsubishi 1
smashing 3
richardstansich 7
brcken 2
tullnanderdonau 15
chairs 12
bankimoon 1

3.2 Termselectie 29
3.2 Termselectie
3.2.1 Algemeen
Aangezien het taggen een persoonlijke aangelegenheid is, zullen er tags zijn die slechts door
een bepaalde gebruiker gehanteerd worden. De meeste gebruikers komen echter slechts op een
beperkt aantal plaatsen die meestal redelijk sterk geografisch gegroepeerd liggen. Daardoor zou
het kunnen lijken dat een bepaalde tag die die gebruiker veel gebruikt indicatief is voor die regio
terwijl het gewoon een stopwoord is van deze gebruiker. Om te voorkomen dat dergelijke tags
ons resultaat in de classificatiefase zouden verstoren worden tags weggelaten die slechts door
enkele gebruikers gebruikt worden.
Het is niet alleen belangrijk om ongewenste effecten van onbeduidende termen op de classifica-
tie zelf te vermijden. Daarnaast zorgt het voor een snelheidswinst bij het classificatie algoritme.
Alle tags die overblijven bij de clusters zullen namelijk gebruikt worden in het algoritme, en
door niet-indicatieve tags te verwijderen kan het algoritme dus sneller werken.
Natuurlijk komen bij dergelijke tags niet enkel geografisch interessante woorden voor. Bij-
voorbeeld woorden zoals “straat” en “struik” of “boom” geven ons weinig tot geen informatie
omtrent de plaats waar de foto genomen is en dus ook niet over de cluster waarbinnen hij gelo-
kaliseerd is. Tevens heb je ook tags die voor een bepaalde streek wel heel belangrijk en specifiek
zijn terwijl ze dat voor een andere streek helemaal niet zijn. Er is dus een andere oplossing no-
dig om waardevolle data uit de tags te destilleren. Aangezien tags geen structuur of verbanden
bevatten die hun belangrijkheid aangeeft, zullen we hiervoor gebruik maken van een statistische
techniek: feature selection.
3.2.2 χ2 feature selection
In [17] werd gevonden dat χ2 feature selection in dit geval goede resultaten levert om tags
te verwijderen die een klein discriminerend vermogen hebben voor een bepaalde cluster. Met
andere woorden, tags die willekeurig in veel (uiteenliggende) clusters voorkomen en dus weinig
informatie opleveren over een bepaalde plaats worden verwijderd. Als A de verzameling van
gebieden/clusters is die overblijft na het clusteringsproces, dan wordt de χ2 statistiek voor elk
gebied a ∈ A en elke tag t die voorkomt bij foto’s in dat gebied als volgt berekend:
χ2(a, t) =(Ota − Eta)2
Eta+
(Ota − Eta)2
Eta+
(Ota − Eta)2
Eta
+(Ota − Eta)2
Eta
(3.1)

3.3 Naive Bayes met Laplace smoothing 30
Hierbij is Ota het aantal foto’s in gebied a waar tag t voorkomt, Ota het aantal foto’s buiten
gebied a waar de tag voorkomt, Ota het aantal foto’s in a waar de tag niet voorkomt en Ota het
aantal foto’s buiten a waar de tag niet voorkomt.
Verder is Eta het aantal voorkomens van tag t in foto’s van gebied a dat verwacht zou
kunnen worden als het voorkomen van tag t onafhankelijk zou zijn van de locatie van cluster
a, dit geeft Eta = N.P (a).P (t) met N het totaal aantal foto’s, P (t) het percentage foto’s die
getagd zijn met tag t en P (a) het percentage foto’s die in cluster a gemaakt/geplaatst zijn.
Op dezelfde manier vinden we voor Eta = N.P (t).(1 − P (a)), Eta = N.(1 − P (t)).P (a) en
Eta = N.(1− P (t)).(1− P (a)).
3.3 Naive Bayes met Laplace smoothing
Neem A de verzameling van disjuncte gebieden, en voor elk gebied a ∈ A is Xa de verzameling
van tags die dat gebied typeren en het aantal keer die voorkwamen. Nu wordt een multinomiale
Naive Bayes classifier gebruikt om de Wikipedia pagina’s te classificeren binnen de juiste cluster.
De multinomiale Naive Bayes classifier heeft als voordeel dat hij vrij eenvoudig, efficient en
krachtig is.
Met de regel van Bayes vinden we dat de probabiliteit P (a|x) dat een Wikipedia pagina x
over een bepaald gebied a gaat gegeven is door:
P (a|x) =P (a)× P (x|a)
P (x)(3.2)
Aangezien P (x), het beschouwen van de tags in de Wikipedia pagina zelf constant blijft voor
alle clusters kunnen we Vergelijking 3.2 vereenvoudigen tot:
P (a|x) ∝ P (a).P (x|a) (3.3)
Een Naive Bayes classifier wordt gekarakteriseerd door het feit dat alle termen onafhankelijk
zijn. Voor ons betekent dit dat de aanwezigheid van een bepaalde tag in de tekst geen invloed
heeft op de mogelijke aan- of afwezigheid van andere tags. Als we de waarschijnlijkheid van het
voorkomen van een tag t in een cluster a schrijven als P (t|a) vinden we vervolgens:
P (a|x) ∝ P (a).∏t∈x
P (t|a) (3.4)

3.4 Jelinek-Mercer en Bayesian smoothing 31
Als we van een multinomiaal taalmodel met Laplace smoothing gebruik maken kunnen we
de probabiliteit van P (t|a) als volgt schatten:
P (t|a) =Nt + 1
(∑
y∈Xa|y|) + |V |
(3.5)
Hierbij is Nt het aantal voorkomens van een bepaalde tag t in een cluster a,∑
y∈Xa|y| is
dan weer het totaal aantal tag voorkomens in gebied a, V blijft nog steeds de verzameling van
alle tags die voorkomen na feature selection.
Dan rest ons enkel nog de bepaling van de waarschijnlijkheid P(a) voor gebied a. Hiervoor
kan de Maximum Likelihood1 schatting gebruikt worden:
P (a) =|Xa|∑b∈A |Xb|
(3.6)
Door de classificatie zal typisch de meest waarschijnlijke cluster gekozen worden. Om nume-
rieke underflow te vermijden verplaatsten we ons resultaat naar het logaritmisch domein. Dit
brengt ons ten slotte bij de volgende formule:
a∗ = argmax(logP (a) +∑t∈x
logP (t|a)) (3.7)
3.4 Jelinek-Mercer en Bayesian smoothing
In eerste instantie hebben we gewerkt met een Naive Bayes classifier met “Laplace smoothing”.
Als A de verzameling van clusters is en V is de totale tagverzameling die overgebleven is na
de feature selection, dan is occ(t, a) het aantal van voorkomens van een tag t in een cluster a.
3.4.1 Jelinek-Mercer smoothing
Een eerste variant op Laplace smoothing is Jelinek-Mercer smoothing. Hierbij wordt de interpo-
latie bepaald tussen twee delen die samen de waarde voor die tag in dat gebied aangeven. Het
eerste deel is de kans dat als er een tag voorgekomen is in cluster a, dat dit dan tag t is. Deze
kans kan eenvoudig bepaald worden door het aantal voorkomens van tag t in cluster a te delen
door het totaal aantal voorkomens van alle tags in cluster a. Deze kans wordt dan geınterpoleerd
met de kans dat als er een tag voorkomt in om het even welke cluster dat dit dan tag t is. Deze
wordt analoog bepaald door het aantal voorkomens van tag t over alle clusters te delen door
1http://en.wikipedia.org/wiki/Maximum likelihood

3.5 Aanpassingen specifiek voor Wikipedia 32
het totaal aantal tagvoorkomens over alle clusters. Het gewicht dat elk van beide leden krijgen
wordt in Formule 3.8 bepaald door parameter λ die mag varieren in het bereik ]0, 1[.
P (t|a) = λ.occ(t, a)∑
t′∈V occ(t′, a)
+ (1− λ).
∑a′∈A occ(t, a
′)∑a′∈A
∑t′∈V occ(t
′, a′)(3.8)
Deze formule vervangt Formule 3.5 in de multinomiale Naive Bayes techniek om onze Jelinek-
Mercer variant te vormen.
3.4.2 Bayesian smoothing met Dirichlet Priors
Bayesian smoothing is vergelijkbaar met Laplace smoothing maar wordt over het algemeen
beschouwd als een beter alternatief bij het verwerken van natuurlijke taal. De elementen
die gebruikt worden om de smoothing te realiseren zijn dezelfde als bij de Jelinek-Mercer
smoothing. Jelinek-Mercer smoothing is echter een interpolerende smoothing techniek, waar
Bayesian smoothing een additieve smoothing techniek is. Bij het aantal voorkomens van tag
t in cluster a wordt µ keer de algemene kans op tag t opgeteld. Dit is hetzelfde quotient als
het tweede lid in de Jelinek-Mercer formule (3.8). Vervolgens wordt dit resultaat bij Bayesian
smoothing in Formule 3.9 gedeeld door het totaal aantal tag voorkomens in cluster a waarbij
parameter µ nog eens wordt opgeteld.
P (t|a) =occ(t, a) + µ(
∑a′∈A occ(t,a′)∑
a′∈A
∑t′∈V occ(t′,a′))
(∑
t′∈V occ(t′, a)) + µ
(3.9)
In deze formule kan parameter µ gekozen in het bereik ]0,+∞[. Het vinden van de juiste
waarde voor de parameters kan het resultaat sterk beınvloeden. Deze Bayesian smoothing
wordt toegepast door in de Naive Bayes classifier Formule 3.5 hiermee te vervangen. Wanneer
Formule 3.5 met Formule 3.9 vergeleken wordt, wordt direct duidelijk dat Nt = occ(t, a) en
dat∑
y∈Xa|y| =
∑t′∈V occ(t
′, a). Hierbij wordt dan in plaats van de 1 in de teller bij Laplace
smoothing, µ keer de algemene kans op tag t toegevoegd aan de teller. Bij de noemer wordt in
plaats het aantal tags die overbleven na de feature selection, gewoon µ toegevoegd.
3.5 Aanpassingen specifiek voor Wikipedia
3.5.1 Tekst vs Tags
Artikels verschillen structureel van de verzamelingen van tags die we kunnen vinden bij Flickr
foto’s. Aangezien spaties niet toegelaten zijn, zijn tags vaak een samentrekking van 2 of meerdere

3.5 Aanpassingen specifiek voor Wikipedia 33
woorden. Wanneer de woorden van een artikel met Flickr tags doorzocht worden zullen veel
waardevolle tags daardoor niet gevonden worden. Daarom is het belangrijk om ook de combinatie
van opeenvolgende woorden te bekijken als mogelijke tag.
3.5.2 Efficientie algoritme
Een belangrijke opmerking die gemaakt kan worden om de efficientie van de methode sterk te
verbeteren is dat het zoeken naar tags in Wikipedia pagina’s volledig kan losgekoppeld worden
van de classificatiestap. Voor deze scanfase dienen eerst alle tags die van belang zijn verzameld te
worden. Vervolgens kan elk artikel gewoon doorzocht worden met behulp van die lijst van tags.
Eens dit gebeurd is kan dit resultaat, dat we in bestanden op de lokale schijf kunnen opslaan,
behouden blijven voor alle classificaties waarbij eenzelfde tagverzameling gebruikt werd. Typisch
blijft deze tagverzameling gelijk zolang er met hetzelfde taalmodel gewerkt wordt.
3.5.3 Gebruik Wikipediastructuur
In eerste instantie wordt de classificatie uitgevoerd op bestanden die gegenereerd zijn door het
Wikipedia artikel integraal te doorzoeken op Flickr tags. Om betere resultaten te bekomen kan
de tekst van het artikel, die gebruikt wordt bij het zoeken naar Flickr tags, worden aangepast.
Hiervoor worden in deze masterproef een aantal mogelijkheden beschouwd:
A Titels: Enkel de titels (< h1 >,< h2 >, ...) worden doorzocht naar tags.
B Abstract : We behouden het eerste deel van de Wikipedia tekst en doorzoeken enkel dit
deel naar Flickr tags. Dit definieren we tot het moment waarop de eerstvolgende titel
(< h1 >,< h2 >, ...) in de Wikipedia pagina voorkomt.
C Sleutelwoorden: Hierbij gaan we niet enkel de titels behouden, maar ook de andere sleutel-
woorden zoals de linktekst (< a >), en de vet gemarkeerde items (< b > en < strong >).
D Binnenkomende links: Met de binnenkomende links bedoelen we de links die vanuit an-
dere Wikipedia pagina’s gemaakt zijn naar de beschouwde Wikipedia pagina. Van deze
verwante pagina’s gaan we dan de tekst doorzoeken naar Flickr tags. Hierbij kan eventueel
ook een van de aangepaste zoekmethodes gebruikt worden zoals abstract of sleutelwoorden.
Hierbij worden enkel Wikipedia pagina’s gebruikt die ook geevalueerd worden.
E Uitgaande links: De uitgaande links zijn de links die in de Wikipedia pagina zelf staan
naar andere Wikipedia pagina’s. Net zoals bij de binnenkomende links kan vervolgens de

3.5 Aanpassingen specifiek voor Wikipedia 34
artikeltekst of een deel daarvan doorzocht worden naar tags. Ook hier beperkten we ons
in dit onderzoek tot de links van pagina’s die reeds doorzocht werden.
In deze opsomming wordt direct duidelijk dat er twee verschillende types van uitbreidingen
beschouwd worden. Enerzijds hebben we een aantal technieken die de doorzoekbare tekst van
de Wikipedia pagina gaan reduceren tot een mogelijk meer interessant deel daarvan. Daarnaast
hebben we met de laatste twee voorbeelden een volledig andere benadering: hierbij wordt de
doorzoekbare tekst uitgebreid met informatie uit verwante pagina’s. Natuurlijk is het mogelijk
om, indien de reducerende technieken voor betere resultaten zorgen, deze ook in te schakelen bij
de aanpassingen in methode D en E.
Dat methodes A en C de meer interessante informatie uit de Wikipedia pagina selecteren
en dat dit betere resultaten zou kunnen opleveren lijkt realistisch. Bij methode B wordt echter
niet de belangrijke informatie in het volledige artikel gezocht. Het idee is hier dat het eerste
deel van de pagina meestal het best beschrijft waarover het artikel gaat. Bij lange pagina’s is
de inhoud verder in de pagina telkens minder nauw verwant met het onderwerp. Hier kunnen
bijvoorbeeld uitweidingen staan over de architect of de bouwperiode van een gebouw.
Waarom methoden D en E waarbij verwante Wikipedia pagina’s gebruikt worden, het resul-
taat positief zouden kunnen beınvloeden is misschien niet direct duidelijk. Wikipedia is echter
een gigantische graaf van artikels en voor elke plaats zijn de daaraan gelinkte plaatsen dus waar-
schijnlijk indicatief voor de locatie van de eerste plaats. Verschillende locaties in dezelfde stad
of buurt zullen namelijk vaak links hebben naar elkaar en de pagina over de stad of wijk waar
een monument staat zal bij dat monument naar alle waarschijnlijkheid ook vermeld zijn.
3.5.4 Combinatie van methodes
Na het bepalen van de resultaten met de methodes uit Sectie 3.5.3 kan in een volgende stap
dan eventueel de interpolatie berekend worden tussen het resultaat met het volledige artikel
en de gereduceerde/uitgebreide versies. Hierbij zal een parameter ξ geıntroduceerd worden
waarmee we het ideale gewicht van beide delen kunnen bepalen. Dit kan interessant zijn omdat
voor sommige pagina’s het gereduceerde model een beter resultaat kan opleveren terwijl dit het
resultaat voor andere pagina’s de prestatie sterk verslechtert. Dit zou bijvoorbeeld het geval
kunnen zijn voor pagina’s die op zich al erg klein zijn. In dit geval zou het niet gewenst zijn
om de tekst nog verder te reduceren. Het omgekeerde geldt dan weer voor heel grote pagina’s
waar waarschijnlijk al voldoende informatie in aanwezig is zodat ze niet meer uitgebreid hoeven

3.5 Aanpassingen specifiek voor Wikipedia 35
te worden met verwante pagina’s. In Vergelijking 3.10 staat de formule waarmee deze techniek
geımplementeerd kan worden.
P ∗(t|a) = ξ.P1(t|a) + (1− ξ).P2(t|a) (3.10)
Hierin wordt dus met behulp van parameter ξ de interpolatie berekend tussen P1(t|a) en
P2(t|a). P1(t|a) stelt de kans voor dat de tag in het gebied voorkomt met behulp van het artikel
zelf. P2(t|a) bepaald dezelfde kans maar maakt hiervoor gebruik van de gereduceerde/uitgebreide
pagina. Beide kansen kunnen berekend worden met behulp van de methodes die eerder besproken
zijn, zoals met Formule 3.8 en Formule 3.9.
3.5.5 Tag smoothing
Daar waar er bij de Flickr tags χ2 feature selection is toegepast om de tags met te klein discri-
minerend vermogen te verwijderen, zijn al de voorkomens in de Wikipedia pagina daarvan wel
behouden. Wikipedia pagina’s en Flickr tags zijn echter heel verschillende bronnen van infor-
matie. Bepaalde tags die voor een Flickr foto relevante informatie omtrent een bepaalde cluster
geven doen dit niet noodzakelijk voor een Wikipedia artikel. Voor een cluster die gaat over de
plaats waar het hoofdkwartier van Wikipedia gevestigd is zou bijvoorbeeld Wikipedia en tags
die dit bevatten heel belangrijk kunnen zijn, maar dit woord komt in elke Wikipedia pagina voor
en is dus helemaal niet discriminerend voor de pagina. Het is duidelijk dat dit tot een verkeerde
classificatie zou kunnen leiden. Daarom lijkt het relevant om ook op de gevonden tags in de
Wikipedia pagina’s smoothing toe te passen. Daarom gaan we proberen om tag smoothing te
introduceren, hierbij gaan we P (t|a) uitbreiden als een interpolatie tussen Formule 3.5 en onze
tag smoothing namelijk het aantal voorkomens van de tag in de Wikipedia pagina (occ(t|w))
gedeeld door het totaal aantal voorkomens in alle Wikipedia pagina’s (∑
w∈W occ(t, w)). Hierbij
is W de verzameling van alle Wikipedia pagina’s die in het onderzoek doorzocht worden. In
Vergelijking 3.11 wordt de formule getoond voor deze tag smoothing techniek. Hierbij kan voor
de berekening van P (t|a) een van de bovenstaande formules gebruikt worden.
P ∗(t|a) = σ.P (t|a) + (1− σ).occ(t, w)∑
w∈W occ(t, w)(3.11)

EVALUATIE 36
Hoofdstuk 4
Evaluatie
4.1 Dataset
Op DBpedia (Zie Sectie 2.5.4) kunnen lijsten met verwijzingen naar Wikipedia-artikels, met
bepaalde eigenschappen, gedownload worden. In dit onderzoek wordt de testverzameling op-
gebouwd vanuit de deelverzameling van Wikipedia-artikels waarvan geografische coordinaten
beschikbaar zijn. Deze lijst van DBpedia bevat een triplet met de coordinaten, de link naar de
informatie over die plaats in de DBpedia databank zelf en een link naar het Wikipedia-artikel.
Wij zullen vooral de link naar de Wikipedia-artikel gebruiken om de tekst af te halen en de
coordinaten zullen dienen als vergelijkingspunt voor onze techniek. De op DBpedia beschikbare
datasets worden op regelmatige basis geupdatet zodat de recentste wijzigingen op Wikipedia
ook zoveel mogelijk in de DBpedia deelverzamelingen te vinden zijn. In deze masterproef werd
gebruik gemaakt van de Engelstalige DBpedia versie 3.6, die werd gegenereerd uit Wikipedia op
10 november 2010.
Op Wikipedia kan men aan alle artikels coordinaten koppelen. Het geografisch bereik van
een artikel kan echter op verschillende manieren geınterpreteerd worden. Een artikel dat over
een persoon gaat, kan bijvoorbeeld geographisch gerelateerd zijn aan de plaats waar die persoon
heeft geleefd, maar ook aan de plaatsen waar deze persoon zijn werk invloeden heeft gehad
(bijvoorbeeld: plaatsen waar een topvoetballer gespeeld heeft). Daarom werd deze verzameling
verfijnd door er een filter, gebaseerd op Geonames, op toe te passen. Deze filtering gebeurt
door de titels van de artikels te doorzoeken naar plaatsnamen die in Geonames tot de categorie
“spot” behoren, waardoor enkel plaatsgebonden artikels overblijven. Zo worden ook artikels
over landen en andere grote gebieden verwijderd. Natuurlijk zijn er dubbelzinnige namen die

4.2 Evaluatiemethode 37
naar verschillende plaatsen kunnen verwijzen waardoor er nog een aantal ongewenste artikels
kunnen overblijven. Dit zal echter maar een erg kleine fractie zijn van de artikels die in onze
testset overblijvem. Na deze filtering blijft er een verzameling van 7537 artikels over, die zal
gebruikt worden om onze voorgestelde techniek op te testen.
4.2 Evaluatiemethode
4.2.1 Accuraatheid en Mean Reciprocal Rank
Aangezien de juiste coordinaten van elke artikel gekend zijn kan eenvoudig bepaald worden welke
cluster effectief het dichtst bij het artikel ligt. Dit kan door tussen de locatie van het artikel
en de medoıde van elke cluster de afstand te bepalen. De cluster die het dichtst bij het artikel
ligt wordt dan beschouwd als de beste cluster. Het procentueel aantal keer dat de beste cluster
gevonden wordt zullen we de accuraatheid noemen.
Door gebruik te maken van taalmodellen wordt er voor elke cluster een probabiliteit bepaald
die aangeeft hoe waarschijnlijk het is dat de cluster de locatie van het artikel bevat. Zo kan er
dus voor elk artikel een volgorde gemaakt worden tussen de verschillende clusters. Als de eerste
cluster niet de ideale cluster was resulteert dit in een accuraatheid van 0. Een rangschikking
waaarbij de correcte cluster als tweede voorkomt is intuıtief echter beter dan een rangschikking
waarbij de cluster op een verdere positie voorkomt. Daarom zal ook een uitbreiding op de
accuraatheid beschouwd worden om de resultaten te evalueren.
De Reciprocal Rank van een artikel lost deze tekortkoming van de accuraatheid op. De
Reciprocal Rank wordt bepaald door 1 te delen door de positie van de correcte cluster in de lijst.
De waarde van de Reciprocal Rank is dus 1 als de correcte cluster gevonden werd en bijvoorbeeld
1/2 als de correcte cluster als tweede cluster in de lijst voorkomt. De Mean Reciprocal Rank1 kan
dan bepaald worden door het gemiddelde van de Reciprocal Ranks van de verschillende artikels
te bepalen (zie Vergelijking 4.1).
MRR =1
|Q|
|Q|∑i=1
1
ranki(4.1)
Om te zien of een methode beter is dan een andere, moet er nog gekeken worden of ze de
MRR op een statistisch significante manier verbetert. Omdat er gemiddelden vergeleken worden
1http://en.wikipedia.org/wiki/Mean reciprocal rank

4.3 Baseline: Yahoo! Placemaker 38
controleren we die statistische significantie met behulp van de Wilcoxon2 test.
4.2.2 Afstand ten opzichte van de gevonden locatie
De afstand tussen twee locaties op de Aarde zal bepaald worden door gebruik te maken van de
Haversine formule3. Deze formule is belangrijk omdat ze de afstand tussen twee punten op een
bol kan bepalen uit hun lengte -en breedteligging. Het volgende codefragment implementeert de
Haversine formule:
private static double Radius = 6,371km
public double CalculationByDistance(Coordinate StartP, Coordinate EndP) {
double lat1 = StartP.getLatitudeE6()/1E6;
double lat2 = EndP.getLatitudeE6()/1E6;
double lon1 = StartP.getLongitudeE6()/1E6;
double lon2 = EndP.getLongitudeE6()/1E6;
double dLat = Math.toRadians(lat2-lat1);
double dLon = Math.toRadians(lon2-lon1);
double a = Math.sin(dLat/2) * Math.sin(dLat/2) +
Math.cos(Math.toRadians(lat1)) * Math.cos(Math.toRadians(lat2)) *
Math.sin(dLon/2) * Math.sin(dLon/2);
double c = 2 * Math.asin(Math.sqrt(a));
return Radius * c;
}
4.3 Baseline: Yahoo! Placemaker
Met de hierboven besproken technieken kunnen de verschillende resultaten onderling wel verge-
leken worden, en kan dus ook bepaald worden welke techniek het beste is. Het zou natuurlijk
interessant zijn om onze methode ook te vergelijken met een bestaande techniek die in staat is
om documenten te geoparsen. Zo kan de techniek die in deze masterproef voorgesteld wordt op
een objectieve manier vergeleken worden met de huidige state-of-the-art.
2http://www.or.vcu.edu/help/SPSS/SPSS.WilcoxonTests.pdf3http://en.wikipedia.org/wiki/Haversine formula

4.3 Baseline: Yahoo! Placemaker 39
4.3.1 Algemeen
De Yahoo! Placemaker4 is een gratis toegangkelijke webservice die Geoparsing (zie 2.3.3) kan
uitvoeren op volledige documenten of webpagina’s. De Placemaker API is gepubliceerd om ont-
wikkelaars in staat te stellen om hun webapplicaties locatiegebaseerd te maken. De Placemaker
is in staat om alle vormen van tekst te verwerken: status updates, webpagina’s of gewoon een
stuk tekst. De Placemaker haalt er dan alle plaatsen uit en zal proberen beslissen welke plaats
het best de gegeven data beschrijft.
De Placemaker probeert dus hetzelfde als wij, namelijk de locatie van een bepaalde tekst,
een artikel zo goed mogelijk bepalen. Dit lijkt dan ook de ideale benchmark om ons systeem
mee te vergelijken. Een verschil met onze methode is dat de Placemaker alle locaties die in
een document teruggevonden worden, in zijn antwoord gaat meegeven. De Placemaker zorgt
natuurlijk ook voor de disambiguering tussen die verschillende plaatsen en geeft aan wat volgens
hem de beste locatie is voor het document. Als zou blijken dat de disambiguering door de
Placemaker niet optimaal is kan deze taak in een eigen methode overgedaan worden. Naast
alle locaties die gevonden zijn wordt er tenslotte ook een WOEID teruggegeven, deze “Where
On Earth Identifier” zorgt voor de binding tussen alle locatiegebaseerde diensten van Yahoo!.
Zo kan er via de GeoPlanet API een hierarchie en beschrijving van de door hen geındexeerde
plaatsen opgevraagd worden.
4.3.2 Werkwijze
In een eerste fase gaat de Placemaker alle locaties die gekend zijn in de Yahoo! GeoPlanet
databank uit de tekst halen. Vervolgens worden niet vrijgegeven regels gebruikt om het bereik
van het document te bepalen. Er worden twee verschillende bereiken bepaald: het geografisch
bereik en het administratief bereik. Het geografisch bereik is de plaats die het best het document
beschrijft en kan om het even welk type zijn. Het administratief bereik is de plaats van een
administratief plaatsttype die het best de plaats beschrijft. De adminstratieve plaatstypes zijn:
“Country”, “State”, “County”, “Local Administrative Area” en “Town”.
4http://developer.yahoo.com/geo/placemaker/

4.4 Resultaten 40
4.4 Resultaten
4.4.1 Verschillende vormen van smoothing
In dit onderzoek zijn we vertrokken van de Naive Bayes classifier met Laplace smoothing (Zie
Sectie 3.3), de resultaten hiervan zullen een eerste indicatie geven over wat verwacht kan worden
van een dergelijke methode. Tabel 4.1 toont dat er 508 plaatsen binnen de kilometer juist
gevonden worden en 3446 binnen een straal van 100 kilometer. Aangezien de accuraatheid nog
maar 35,89% bedraagt is er nog ruimte voor verbetering.
Tabel 4.1: Resultaten bij Laplace smoothing
1 km 5km 10km 50km 100km 500km Acc MRR
508 1211 1558 2669 3446 5372 35,89 0,46
In een volgende stap werd de Laplace smoothing techniek vervangen door meer geavanceer-
dere varianten. Voor de resultaten met Jelinek-Mercer Smoothing (Zie Sectie 3.4.1) en Bayesian
smoothing met Dirichlet Priors (Zie Sectie 3.4.2) moeten respectievelijk een parameter λ en µ
gebruikt worden.
De parameter λ bij Jelinek-Mercer smoothing kan varieren in het bereik ]0,1[. De ideale
waarde voor parameter λ blijkt, zoals te zien in Tabel 4.2, op 0,3 te liggen. We merken in
ieder geval al een significante verbetering ten opzichte van het resultaat dat behaald werd met
de Laplace smoothingtechniek. Zo zijn de plaatsen die binnen een straal van 1 kilometer juist
geplaatst worden met 38% gestegen en die binnen de 100 kilometer zelfs met 43%.
Tabel 4.2: Ideale waarde voor parameter λ bepalen bij Jelinek-Mercer smoothing.
λ 1 km 5km 10km 50km 100km 500km Acc MRR
0,1 687 1580 2084 3861 4941 6570 63,70 0,73
0,3 704 1591 2099 3883 4947 6635 63,06 0,72
0,5 697 1591 2087 3883 4914 6613 61,75 0,71
0,7 695 1565 2045 3793 4814 6547 59,55 0,69
0,9 667 1508 1936 3570 4548 6328 55,18 0,64
Bij de Bayesian smoothing met Dirichlet Priors, dient de parameter µ groter dan 0 te zijn.
Hier ligt de ideale waarde rond het totaal aantal tagvoorkomens in alle clusters. Aangezien dit
aantal rond 27 miljoen ligt en bij heel kleine waarden voor parameter µ de resultaten tegenvielen,

4.4 Resultaten 41
werd er dan ook vooral in die regio gezocht naar de beste waarde voor parameter µ. Tabel 4.3
toont dat we met parameter µ rond 70 miljoen, de beste resultaten halen. In de praktijk blijkt
de exacte waarde van µ niet erg belangrijk, als de waarde maar hoog genoeg gekozen wordt. We
merken voornamelijk op dat het verschil tussen Jelinek-Mercer smoothing en Bayesian smoothing
met Dirichlet Priors erg klein is wanneer de parameters λ en µ optimaal gekozen worden. Ook
de accuraatheid van beide methoden ligt rond de 63% tegenover slechts 35,89% bij Laplace
smoothing.
Tabel 4.3: Ideale waarde voor parameter µ bepalen bij Bayesian smoothing met Dirichlet Priors.
µ 1 km 5km 10km 50km 100km 500km Acc MRR
10M 663 1557 2030 3545 4486 6115 57,33 0,65
30M 676 1602 2111 3827 4865 6597 61,74 0,70
50M 679 1606 2122 3880 4922 6660 62,35 0,71
70M 679 1607 2127 3909 4961 6690 62,79 0,72
90M 679 1606 2124 3915 4967 6695 62,70 0,72
In Figuur 4.1 hebben we de afwijking qua afstand voor alle artikels in beeld gebracht. Hier-
voor hebben we de bekomen afstanden tot de echte locatie gesorteerd en op de grafiek uitgezet.
De x-as geeft het aantal beschouwde artikels weer en op de y-as kan de afstand gelezen worden
waarbinnen er een bepaald aantal artikels geschat zijn. Zo krijgen we dus een continue represen-
tatie van het aantal artikels die binnen een bepaalde afstand geschat zijn. De drie verschillende
smoothing technieken die hierboven besproken werden kunnen hierin duidelijk vergeleken wor-
den. Hierin valt op dat de Jelinek-Mercer en Bayesian smoothing technieken beide een serieuze
verbetering brengen tegenover het resultaat met Laplace smoothing. De verschillen die we hier
halen tussen Jelinek-Mercer smoothing en Bayesian smoothing zijn verwaarloosbaar. Enkel de
500 slechtste resultaten zijn nog iets slechter bij Bayesian smoothing dan bij Jelinek-Mercer
smoothing, maar dit maakt niet veel uit want deze liggen bij al onze methodes voorlopig op
meer dan 5000 kilometer van de werkelijke plaats, wat sowieso slecht is.
4.4.2 Variatie in aantal clusters
Tot nu toe is telkens hetzelfde taalmodel met 2000 clusters gebruikt. Door de clustering fijner
of ruwer uit te voeren konden verschillende taalmodellen gegenereerd worden. De hierboven
geteste technieken kunnen mogelijks een beter resultaat opleveren indien we meer of minder

4.4 Resultaten 42
Figuur 4.1: Afwijking qua afstand met drie verschillende smoothing technieken: Laplace
smoothing, Jelinek-Mercer smoothing (λ = 0, 3) en Bayesian smoothing met Dirichlet Priors
(µ = 70M)

4.4 Resultaten 43
clusters gaan gebruiken om de classificatie uit te voeren.
In Tabel 4.4 staan de resultaten van de experimenten met verschillende clustergroottes uit-
gevoerd met behulp van de Jelinek-Mercer smoothing techniek met parameter λ gelijk aan 0,3.
Hier kan in de eerste plaats opgemerkt worden dat bij een klein aantal clusters het aantal plaat-
sen dat heel goed gelokaliseerd is erg klein is. Dit is logisch want als er maar 50 mogelijkheden
zijn, zal de gemiddelde fout al snel oplopen tot honderden kilometers. Als het aantal gebruikte
clusters omhoog gaat worden, zoals verwacht, de artikels als maar nauwkeuriger gematcht met
de juiste cluster. Hier geldt wel een tradeoff: waar er voor meer resultaten een zeer goede locatie
kan gevonden worden, kunnen er minder binnen een iets ruimer domein geplaatst worden. Een
mogelijkheid om de resultaten nog te verbeteren zou hier kunnen zijn om een adaptieve methode
te ontwikkelen die, voor artikels waar het waarschijnlijk is dat een goed resultaat gevonden wordt
een groter aantal clusters gebruikt, dan voor artikels waar maar een ruwe schatting mogelijk ge-
acht wordt. Om deze inschatting te maken zou bijvoorbeeld rekening kunnen gehouden worden
met de lengte van het Wikipedia-artikel, of andere eigenschappen die de kwaliteit van het artikel
kunnen aantonen.
Tabel 4.4: Resultaten van Jelinek-Mercer smoothing (λ = 0,3) met varierende clustergrootte
Clustergrootte 1 km 5km 10km 50km 100km 500km Acc MRR
50 20 159 269 762 1499 4890 79,43 0,85
500 340 1077 1423 3146 4355 6646 73,30 0,81
2000 704 1591 2099 3883 4947 6635 63,06 0,72
2500 774 1703 2230 4155 5163 6638 61,65 71,44
5000 943 1956 2496 4366 5291 6569 55,46 0,65
7500 1019 2032 2593 4493 5331 6435 52,04 0,62
10000 1067 2119 2716 4595 5343 6404 47,79 0,57
12500 1114 2171 2747 4620 5358 6339 47,95 0,58
15000 1141 2187 2801 4645 5306 6290 46,58 0,30
17500 1180 2243 2846 4692 5326 6307 45,65 0,30
20000 1184 2260 2874 4673 5281 6288 44,56 0,30

4.4 Resultaten 44
4.4.3 Tag Smoothing
Op de tags die overbleven na de clustering van de Flickr foto’s werd feature selection toegepast
om de tags die onvoldoende discriminerend waren voor een bepaalde cluster te verwijderen. Een
bepaalde tag kan natuurlijk in de Flickr tags zeer zelden voorkomen en daarbij voor een bepaalde
cluster heel belangrijk zijn, terwijl die in heel veel Wikipedia-artikels voorkomt. Dit zou ervoor
kunnen zorgen dat bepaalde clusters onrechtmatig bevoordeeld worden. Daarom hebben we een
methode bedacht die “Tag smoothing” (Zie Sectie 3.5.5) implementeert om dit tegen te gaan.
Tabel 4.5: Resultaten van de Tag smoothing techniek met basisfunctie Jelinek-Mercer (λ = 0,3)
en 2000 clusters
σ 1 km 5km 10km 50km 100km 500km Acc MRR
0,5 304 842 1043 1525 1880 3596 12,06 0,21
0,7 327 885 1095 1570 1930 3519 13,55 0,23
0,9 370 960 1211 1780 2191 3705 17,73 0,28
0,999 495 1232 1609 2802 3662 5147 39,87 0,52
1 704 1591 2099 3883 4947 6635 63,06 0,72
In Tabel 4.5 kan je zien dat de resultaten met behulp van deze “Tag smoothing” techniek
niet verbeterd kunnen worden. Onderaan de tabel is het resultaat van de basismethode die hier
gebruikt is geplaatst, en we merken dat het resultaat met elke parameter voor σ het resultaat
verslechtert. Een andere mogelijkheid die getest zou kunnen worden is het toepassen van feature
selection op de gevonden tags uit de Wikipedia-artikels. Op die manier kunnen tags die in te veel
artikels voorkomen en het resultaat neigen te verstoren helemaal verwijderd worden, alvorens
de eigenlijke classificatie aangevat wordt.
4.4.4 Gebruik Wikipediastructuur
In de voorgaande testen werd telkens met het volledige Wikipedia-artikel gewerkt om de re-
sultaten te bepalen. In voorgaand onderzoek [12] werd echter besloten dat vooral de tekst op
belangrijke plaatsen geografisch relevante informatie bevat. Daarom lijkt het zeer interessant
om de tekst van het artikel waarin gezocht wordt aan te passen tot belangrijkere delen van de
tekst zoals beschreven in Sectie 3.5.3.
De resultaten van de toepassing van de Bayesian smoothing techniek met Dirichlet Priors
toegepast op een aangepast deel van de tekst met een taalmodel van 2000 clusters zijn te vinden

4.4 Resultaten 45
in Tabel 4.6. De belangrijkste opmerking die gemaakt kan worden uit deze resultaten is dat
het gebruik van enkel de sleutelwoorden van een bepaald artikel een beter resultaat oplevert
dan wanneer het volledige artikel gebruikt wordt. In Sectie 4.4.5 zal dit resultaat teruggekop-
peld worden naar de voorgaande technieken waardoor we mogelijks het eindresultaat van onze
methode nog kunnen verbeteren. Daarnaast is het opvallend dat voor het grootste deel van de
artikels het verschil tussen het gebruik van het volledige artikel en het abstract daarvan erg klein
is. Dit is een heel interessante opmerking, want indien het niet nodig zou zijn om het volledige
artikel te gebruiken, dan kan een veel grotere efficientie bekomen worden. Daarnaast kunnen
dan alternatieve combinaties geprobeerd worden om de resultaten te verbeteren.
Met de methoden op basis van een gereduceerde artikeltekst boeken we dus goede resultaten.
Maar ook met methoden die als uitbreidend beschreven kunnen worden, worden interessante
resultaten behaald. Momenteel kan er eigenlijk niet van uitbreidend gesproken worden, omdat
daarvoor ook de tekst van het artikel zelf in rekening dient gebracht te worden. Toch worden,
zeker bij gebruik van de informatie uit de uitgaande links van de Wikipedia-artikels, de artikels
nog redelijk goed gekoppeld aan de juiste cluster. Hieruit kan duidelijk afgeleid worden dat
de gegevens in de gelinkte artikels geografisch verwant zijn met die uit de artikels zelf. Dat
de inkomende links minder goed presteren dan de uitgaande is duidelijk, maar dit resultaat
geeft mogelijk een vertekend beeld aangezien niet alle binnenkomende links onderzocht zijn. We
waren namelijk niet in staat om volledig Wikipedia af te zoeken naar links en hebben ons daarom
beperkt tot links vanuit pagina’s in onze testset. In ieder geval kunnen de binnenkomende links
zeker nut hebben voor artikels die op zich zeer klein zijn. Er is dan namelijk te weinig informatie
in het artikel zelf en bijgevolg zullen er ook weinig sleutelwoorden en uitgaande links te vinden
zijn.
Aangezien de resultaten waarbij enkel in de sleutelwoorden van een artikel naar tags gezocht
werd beter zijn dan wanneer het volledige artikel doorzocht werd, hebben we ook voor inkomende
links en uitgaande links beiden uitgetest. Bij inkomende links 1 en uitgaande links 1 wordt de
volledige artikeltekst van de verwante artikels gebruikt om de locatie te bepalen. Bij inkomende
links 2 en uitgaande links 2 worden enkel de sleutelwoorden van de verwante artikels gebruikt. In
Tabel 4.6 kan opgemerkt worden dat ook bij het gebruik van de verwante artikels het reduceren
van de artikeltekst tot sleutelwoorden het resultaat verbetert.
In Figuur 4.2 wordt de afwijking qua afstand van de Bayesian smoothing techniek met
Dirichlet Priors op verschillende gereduceerde versies van het artikel duidelijk in beeld gebracht.

4.4 Resultaten 46
Figuur 4.2: Afwijking qua afstand met de gereduceerde en uitgebreide modellen voor de artikel-
tekst zoals besproken in Sectie 3.5.3. De gebruikte smoothing techniek is Bayesian smoothing
met Dirichlet Priors (µ = 27M).

4.4 Resultaten 47
Tabel 4.6: Resultaten bij Bayesian smoothing met aangepaste tekst
type 1 km 5km 10km 50km 100km 500km Acc MRR
abstract 641 1498 1944 3323 4210 5777 53 0,60
sleutelwoorden 682 1630 2138 3874 4909 6645 60 0,69
inkomende links 1 264 584 755 1339 1800 2653 21 0,26
inkomende links 2 293 621 772 1373 1871 2798 22 0,28
uitgaande links 1 447 1053 1387 2723 3659 5178 41 0,51
uitgaande links 2 530 1201 1593 3157 4229 5998 48 0,58
artikel 654 1573 2064 3704 4705 6391 60 0,69
Ook het resultaat met het volledige artikel is in de grafiek opgenomen zodanig dat dit als
referentiepunt kan dienen.
4.4.5 Terugkoppeling resultaten en vergelijking met Yahoo! Placemaker
In de vorige subsectie is besproken dat door de sleutelwoorden te gebruiken in plaats van de
volledige tekst betere resultaten geboekt kunnen worden. Dit resultaat is echter enkel bekomen
met behulp van de Bayesian smoothing met Dirichlet Priors techniek (µ = 27M) toegepast op
een taalmodel van 2000 clusters. Daarom lijkt het relevant om te kijken hoe het gebruik van de
sleutelwoorden de prestaties van de andere technieken beınvloedt.
De clustergrootte verbeterde de resultaten in Sectie 4.4.2 en daarom is het relevant om ook de
verschillende clustergroottes nog eens uit te testen met behulp van deze verbeterde techniek. In
Figuur 4.3 worden de resultaten van de experimenten met taalmodellen met verschillend aantal
clusters getoond. Het is duidelijk dat de resultaten met fijnere clustering de Yahoo! Placemaker
overtreffen tot bij ongeveer de 7000 best gelokaliseerde artikels. Indien we de resultaten ook
voor de andere artikels beter wensen te krijgen zou eventueel gebruik kunnen gemaakt worden
van een adaptieve methode, die een grovere clustering gebruikt wanneer geen goede lokalisering
verwacht wordt.
In Tabel 4.7 staan de resultaten die met de Yahoo! Placemaker bekomen zijn naast de
beste resultaten die we in deze masterproef behaald hebben. Hier hebben we de methode met
Jelinek-Mercer smoothing (λ=0,3) op de belangrijkste modellen met gereduceerde tekst bepaald
bij ons grootste clusteraantal (20000). De methode die enkel tags zoekt in de sleutelwoorden
presteert dus duidelijk beter dan de Yahoo! Placemaker. Met onze methode worden er 16,48%

4.4 Resultaten 48
van de artikels binnen een straal van 1km geplaatst tegenover 4,14% met Yahoo! Placemaker.
Daarnaast worden er 76,50% (Yahoo! Placemaker: 67,08%) van de artikels binnen een straal
van 100km geplaatst.
Figuur 4.3: Afwijking qua afstand bij Jelinek-Mercer smoothing op het gereduceerde model met
enkel de sleutelwoorden bij verschillende taalmodellen en vergelijking met Yahoo! Placemaker.
Tabel 4.7: Vergelijking van het effect met de gereduceerde tekst van het Wikipedia-artikel dat
gescand wordt naar tagvoorkomens bij 20000 clusters met Jelinek-Mercer (λ=0,3) en vergelijking
met Yahoo! Placemaker (P.M.).
type 1 km 5km 10km 50km 100km 500km Acc MRR
artikel 1184 2260 2874 4673 5281 6288 44,56 0,30
abstract 1246 2256 2820 4555 5151 6161 43,79 0,29
sleutelwoorden 1242 2452 3128 5098 5766 6771 47,33 0,31
P.M. 313 1583 2395 4257 5056 6677 - -

CONCLUSIES 49
Hoofdstuk 5
Conclusies
Het geografisch bereik van webbronnen wordt als maar belangrijker voor de relevantie ervan
te bepalen op een bepaalde plaats. Dit wordt bevestigd door de populariteit van locatiegeba-
seerde diensten op mobiele toestellen. Bij het uploaden van foto’s naar Flickr kunnen gebruikers
bijvoorbeeld de locatie waar hij genomen is toevoegen. Op een gelijkaardige manier kunnen
gebruikers van Facebook hun huidige locatie toevoegen wanneer ze hun status updaten. Hoewel
ze als maar belangrijker worden zijn er voor veel bronnen op het Internet nog geen geografische
coordinaten beschikbaar. In deze masterproef hebben we een methode bepaald die in staat is
om de locatie van Wikipedia pagina’s te bepalen met behulp van taalmodellen.
Aangezien Wikipedia een encyclopedie is, die over elk onderwerp slechts een artikel heeft en
de geografische coordinaten dus ofwel toegevoegd zijn, ofwel nog toegevoegd dienen te worden,
zal het niet mogelijk zijn om taalmodellen hiervoor te trainen met behulp van de encyclopedie
zelf. In eerder onderzoek [2] werden echter succesvol taalmodellen getraind met Flickr data
waarmee de locatie van andere Flickr foto’s kon bepaald worden. Zoals gebleken is kunnen deze
taalmodellen dus ook gebruikt worden om de locatie van Wikipedia-artikels te bepalen.
Het geografisch bereik van een Wikipedia-artikel kan op verschillende manieren worden
geınterpreteerd. Een artikel over een persoon kan bijvoorbeeld geografisch gerelateerd zijn aan
de plaats waar die geleefd heeft, maar misschien ook aan de plaatsen waar het werk van die per-
soon invloed op heeft gehad (bijvoorbeeld de locaties van gebouwen die een architect ontworpen
heeft). Daarom hebben we in deze masterproef enkel artikels gebruikt die over een specifieke
plaats gaan zoals een gebouw of een stad. Om dit te bereiken hebben we de Wikipedia pagina’s
waarop de classifiers werden toegepast met behulp van gazetteers gefilterd.
Met behulp van een Naive Bayes classifier met verschillende smoothing technieken werd

CONCLUSIES 50
geprobeerd de juiste locatie van een Wikipedia pagina te bepalen. Voor optimale waarden van
respectievelijk parameter λ en µ haalden Jelinek-Mercer smoothing en Bayesian smoothing met
Dirichlet Priors de beste resultaten.
De taalmodellen die gebruikt werden in deze masterproef kunnen natuurlijk met verschillende
granulariteit bepaald worden. Er werden dan ook experimenten opgezet met modellen die een
verschillend aantal clusters bevatten. Hierbij bleek dat een groter aantal clusters de prestaties
in elk geval verbeterde. Hiermee werd voor de resultaten binnen de kilometer het resultaat met
Jelinek-Mercer op 2000 clusters met 57% verbeterd. Het resultaat voor plaatsen die binnen 100
kilometer van hun echte locatie geplaatst werden verbeterde echter maar met 6% meer. Dit is
echter te wijten aan het feit dat er overfitting optreed wanneer we meer clusters gaan gebruiken.
Om het resultaat nog te verbeteren hebben we vervolgens enkele aanpassingen voor de me-
thode bedacht. Door de nadruk te leggen op de belangrijkste delen van het artikel of door gebruik
te maken van verwante pagina’s zou het resultaat verbeterd kunnen worden. De Wikipedia pa-
gina’s hebben een uniforme structuur en door gebruik te maken van de HTML elementen konden
we het beste resultaat boeken, zoals ook in [13] gesteld werd. Door enkel gebruik te maken van
het abstract van het artikel konden ook de eerder behaalde resultaten benaderd worden. Ook
dit is interessant aangezien we dus kunnen bevestigen dat het grootste deel van de relevante
geografische informatie in het eerste deel van het artikel te vinden is. Daarnaast is er ook een
duidelijk verband aan te wijzen tussen de verwante pagina’s van een artikel en het artikel zelf.
Om de geschetste methode te vergelijken hebben we de artikels die wij gelokaliseerd hebben
ook laten geoparsen door Yahoo! Placemaker. De Placemaker is een gratis beschikbare state-
of-the-art webservice die in staat is om de locatie te bepalen voor documenten en webpagina’s.
Hiervoor maakt hij gebruik van gazetteers en ongedocumenteerde technieken om de verschillende
gevonden plaatsen te disambigueren. De methode die opgesteld werd in deze masterproef maakt
daarentegen slechts gebruik van ongestructureerde data verkregen uit Web 2.0 bronnen. Met
onze methode kunnen we het resultaat van Yahoo! Placemaker over de hele lijn overtreffen en
de resultaten die binnen 1 kilometer geplaatst worden verbeteren we zelfs met 250%.
Tot slot wensen we te benadrukken dat we in deze masterproef, bij ons weten voor het eerst,
georeferencing voor webpagina’s hebben toegepast zonder gebruik te maken van gazetteers of
andere vormen van gestructureerde informatie. De technieken gebruikt in deze masterproef blij-
ken erg effectief om dit probleem op te lossen en het is dus aangewezen om verder onderzoek
te doen met dergelijke modellen. Om de resultaten te verbeteren zou de combinatiemethode

CONCLUSIES 51
beschreven in Sectie 3.10 kunnen uitgewerkt worden of zou een adaptieve aanpak met verschil-
lende clusteringniveau’s kunnen gebruikt worden al naargelang verwacht wordt dat een bepaalde
pagina beter zou kunnen gelokaliseerd worden dan een andere. We hebben echter in deze master-
proef ook gekeken of er een verband is tussen artikellengte en de kwaliteit van de pagina op het
resultaat van de georeferencing methode maar hier konden geen verbanden gevonden worden.

BIBLIOGRAFIE 52
Bibliografie
[1] Mark Sanderson and Janet Kohler. Analyzing geographic queries. In Proceedings of the 1st
SIGIR Workshop on Geographic Information Retrieval, 2004.
[2] Olivier Van Laere, Steven Schockaert, and Bart Dhoedt. Towards automated georeferencing
of flickr photos. In Proceedings of the 6th Workshop on Geographic Information Retrieval,
pages 1–7, 2010.
[3] Gaihua Fu, Christopher B. Jones, and Alia I. Abdelmoty. Building a geographical ontology
for intelligent spatial search on the web. In Proceedings of IASTED International Conference
on Databases and Applications, pages 167–172, 2005.
[4] Christopher B. Jones, R. Purves, A. Ruas, M. Sester, M. Van Kreveld, and R. Weibel.
Spatial information retrieval and geographical ontologies an overview of the spirit project.
In Proceedings of the 25th Annual International ACM SIGIR Conference on Research and
Development in Information Retrieval, pages 387–388, 2002.
[5] Davide Buscaldi, Paolo Rosso, and Piedachu Peris Garca. Inferring geographic ontologies
from multiple resources for geographic information retrieval. In Proceedings of the SIGIR
Workshop on Geographic Information Retrieval, pages 52–55, 2006.
[6] Einat Amitay, Nadav Har’El, Ron Sivan, and Aya Soffer. Web-a-where: geotagging web
content. In Proceedings of the 27th annual international ACM SIGIR conference on Re-
search and development in information retrieval, pages 273–280, 2004.
[7] Alvaro Zubizarreta, Pablo de la Fuente, Jose M. Cantera, Mario Arias, Jorge Cabrero,
Guido Garcıa, Cesar Llamas, and Jesus Vegas. A georeferencing multistage method for
locating geographic context in web search. In Proceeding of the 17th ACM conference on
Information and knowledge management, pages 1485–1486, 2008.

BIBLIOGRAFIE 53
[8] Mario J. Silva, Bruno Martins, Marcirio Chaves, Ana Paula Afonso, and Nuno Cardoso.
Adding geographic scopes to web resources. Computers, Environment and Urban Systems,
30:378 – 399, 2006.
[9] D. Moore, R. Periakaruppan, and J. Donohoe. Where in the world is netgeo.caida.org? In
Proceedings of INET-2000, The 10th Annual Internet Society Conference, 2000.
[10] Adrian Popescu and Gregory Grefenstette. Spatiotemporal mapping of wikipedia concepts.
In Proceedings of the 10th annual joint conference on Digital libraries, pages 129–138, 2010.
[11] David J. Crandall, Lars Backstrom, Daniel Huttenlocher, and Jon Kleinberg. Mapping the
world’s photos. In Proceedings of the 18th international conference on World wide web,
pages 761–770, 2009.
[12] Simon E Overell and Stefan Ruger. Identifying and grounding descriptions of places. In
Proceedings of the SIGIR Workshop on Geographic Information Retrieval, pages 2–4, 2006.
[13] Davide Buscaldi and Paolo Rosso. A comparison of methods for the automatic identifica-
tion of locations in wikipedia. In Proceedings of the 4th ACM workshop on Geographical
information retrieval, pages 89–92, 2007.
[14] Ludovic Denoyer and Patrick Gallinari. The wikipedia XML corpus. SIGIR Forum, 40:64–
69, 2006.
[15] David Pinto, Hector Jimenez-salazar, Paolo Rosso, and Emilio Sanchis. TPIRS: A sys-
tem for document indexing reduction on webCLEF, extended abstract in working notes of
CLEF’05, 2005.
[16] Rafael Odon de Alencar, Clodoveu Augusto Davis, Jr., and Marcos Andre Goncalves. Ge-
ographical classification of documents using evidence from wikipedia. In Proceedings of the
6th Workshop on Geographic Information Retrieval, pages 1–8, 2010.
[17] Koen Michiels, Olivier Van Laere, Steven Schockaert, and Bart Dhoedt. Geografisch
geınformeerde zoeksystemen voor foto’s. Ghent University, 2009.