
Adlib gebruikersgroep - voorjaarsbijeenkomst 2014 - Hans Zonnevijlle - Copy Cataloguing
35
Copy cataloging met behulp van BookWhere door Hans Zonnevijlle, voormalig bibliothecaris van het Nederlands Fotomuseum. Voor vragen over onderstaande procedures, kunt U mij bereiken via: hanzonnev(apestaartje)knoware.nl mei 2014 1. Nut en noodzaak van copy cataloging = kopie catalogiseren 2. Geschiedenis 3. De praktijk bij het Nederlands fotomuseum Ervaringsfeit: door gebruik te maken van andermans catalogus records verveelvoudigd de output van je titelbeschrijvingswerk! Catalogiseren is voor velen niet het meest uitdagende werk in een bibliotheek. En de mankracht in een bibliotheek is beperkt. Daarnaast: we catalogiseren volgens de regels. Door gebruik te maken van de uitstekende catalogiseerders van Universiteiten en andere grote instellingen is de kwaliteit van je titelbeschrijving van een hoge orde. Kopie catalogiseren kan gedaan worden door minder gekwalificeerd personeel. Zolang je zorgt voor controle aan het eind van het titelbeschrijven, blijft de kwaliteit ge- waarborgd. Kopie catalogiseren is mogelijk door een aantal factoren: a. standaardisatie in de bibliotheekwereld b. digitale communicatie De geschiedenis van kopie catalogiseren beslaat al vele decennia. Ik heb nog gewerkt in bibliotheken die werkten met algemeen verkrijgbare doorslag fiches van titelbeschrijvingen die in separate bakjes op alfabet moesten worden weggezet. Eentje op auteursnaam in het auteursnamen bakje, en eentje op titel in het titelbakje. In 1965 verschijnt het eerste digitale uitwisselingsformat: MARC = Machine Readable Cataloging. Wikipedia weet hierover het volgende te melden: “Het programma maakt gebruik van codes om aan te geven welke gegevens ingevoerd moeten worden. Het nummer voor de titel is bijvoorbeeld 245, waardoor het in alle biblio- theken ter wereld gebruikt kan worden. MARC is een erg uitgebreid systeem dat de mogelijkheid biedt om alle mogelijke gege- vens in te voeren. Maar die uitgebreidheid is ook een nadeel. Het programma is theore- tisch op alles voorzien, maar in de praktijk niet erg handig.” meer lezen: http://www.loc.gov/marc/
-
Upload
adlibgebruikersgroep -
Category
Presentations & Public Speaking
-
view
167 -
download
0
Transcript of Adlib gebruikersgroep - voorjaarsbijeenkomst 2014 - Hans Zonnevijlle - Copy Cataloguing

Copy cataloging met behulp van BookWhere
door Hans Zonnevijlle, voormalig bibliothecaris van het Nederlands Fotomuseum.Voor vragen over onderstaande procedures, kunt U mij bereiken via:hanzonnev(apestaartje)knoware.nlmei 2014
1. Nut en noodzaak van copy cataloging = kopie catalogiseren
2. Geschiedenis
3. De praktijk bij het Nederlands fotomuseum
Ervaringsfeit: door gebruik te maken van andermans catalogus records verveelvoudigd de output van je titelbeschrijvingswerk! Catalogiseren is voor velen niet het meest uitdagende werk in een bibliotheek. En de mankracht in een bibliotheek is beperkt.
Daarnaast: we catalogiseren volgens de regels.Door gebruik te maken van de uitstekende catalogiseerders van Universiteiten en andere grote instellingen is de kwaliteit van je titelbeschrijving van een hoge orde.
Kopie catalogiseren kan gedaan worden door minder gekwalificeerd personeel. Zolang je zorgt voor controle aan het eind van het titelbeschrijven, blijft de kwaliteit ge-waarborgd.
Kopie catalogiseren is mogelijk door een aantal factoren:
a. standaardisatie in de bibliotheekwereldb. digitale communicatie
De geschiedenis van kopie catalogiseren beslaat al vele decennia. Ik heb nog gewerkt in bibliotheken die werkten met algemeen verkrijgbare doorslag fiches van titelbeschrijvingendie in separate bakjes op alfabet moesten worden weggezet. Eentje op auteursnaam in het auteursnamen bakje, en eentje op titel in het titelbakje.
In 1965 verschijnt het eerste digitale uitwisselingsformat: MARC = Machine Readable Cataloging.
Wikipedia weet hierover het volgende te melden:“Het programma maakt gebruik van codes om aan te geven welke gegevens ingevoerd moeten worden. Het nummer voor de titel is bijvoorbeeld 245, waardoor het in alle biblio-theken ter wereld gebruikt kan worden.MARC is een erg uitgebreid systeem dat de mogelijkheid biedt om alle mogelijke gege-vens in te voeren. Maar die uitgebreidheid is ook een nadeel. Het programma is theore-tisch op alles voorzien, maar in de praktijk niet erg handig.”meer lezen: http://www.loc.gov/marc/

Het MARC format hangt samen de communicatie via een client-server netwerkprotocol, Z39.50 om toegang te krijgen tot databases die in MARC-format kunnen exporteren.
Verder moet er een afstemming bestaan wat betreft de gebruikte codering van letters en tekens (=characters).
De verspreiding van PC bibliotheek-systemen heeft pas eind jaren 1980 begin 1990 plaatsgevonden. Ook Adlib is ooit gestart als een mini-computer software leverancier met systemen die toen meer dan een ton guldens kostten. In de 1990-er jaren herschreef Adlibde programmatuur voor de PC. Met zoveel als mogelijk, de functionaliteiten van de mini-computer. En daar zat in ieder geval de omgang met het MARC-format ingebakken. He-laas hebben ze niet teveel propaganda gemaakt voor de mogelijkheden van het kopie titel-beschrijven. Pas in 2007 (?) bouwden ze een kopie catalogiseer faciliteit in voor de KB en de Duitse GBV. Daarbij is de ontlening aan de KB bibliotheek noodzakelijkerwijs nogal ma-ger, maar is die bij de GBV van een zeer hoog niveau. Overigens is deze Adlib kopie cata-logiseer faciliteit gebaseerd op nieuwere internet-standaarden en uitwisselings protocollen,namelijk SRU (in feite de opvolger van Z39.50) en de XML-standaardisatie.
Helaas is deze faciliteit voor ons museum niet bruikbaar, omdat we niet concorderen met de huidige Adlib bibliotheek applicatie. Een lullig voorbeeldje: al vanaf het jaar nul gebrui-ken we de tag ti voor titel. De noodzakelijke omschrijving „title“ is in onderkast. Adlib is sinds ??? is overgegaan op „Title“ (of juist omgekeerd?). In de nieuwe constellatie werkt daarmee de automatische import van Adlib niet. Als gebruiker kun je ook helemaal niks veranderen aan de gateway om ze wel bruikbaar te maken. Daarnaast zouden we nogal wat moeten herprogrammeren om weer alles min of meer in overeenstemming te krijgen met Adlibs eigen nomenclatuur. We hebben hier de boot gemist. Maar we hebben geleerd van de nood een deugd te maken.
De aanleiding tot experimenteren met copier catalogiseren: de onvolprezen voormalig bi-bliothecaresse Saskia Scheltjens van het Rijksmuseum mompelde zo'n 10 jaar geleden “Ze zouden BookWhere standaard hebben moeten inbouwen in Adlib”. Wij dus op zoek naar dat programmaatje: BookWhere. En over dit programma gaan we het verder hebben.
BookWhere is een Z39.50 zoekmachine, gebaseerd op YAZ (Yet Another Z39.50 tool). YAZ is Open Source, en wordt vanaf 1995 onderhouden door Index Data in DenemarkenMeer lezen: http://www.indexdata.com/yaz
Hoe werkt dit „tooltje“?
Via BookWhere maak je contact met een voor jou bruikbare leverancier van MARC data. Je zoekt via bijvoorbeeld ISBN nummertje of ze de titel beschrijving hebben. Je download de titelbeschrijving in MARC format.Je importeert vervolgens deze MARC beschrijving via Adlibs MARC-import functie.Daarna fatsoeneer je de titelbeschrijving naar eigen goeddunken.Klaar.Nou ja bijna. Naast een correcte titelbeschrijving moeten er een aantal administratieve za-ken verwerkt worden, en wellicht moet het record nog verrijkt worden met een om-slag-scan of nuttige en noodzakelijke samenvattingen en/of commentaren in het samen-vattingsveld. Wellicht is het toevoegen van een serie trefwoorden ook nodig. Etc.Maar het „vuile“ tikwerk (en het denkwerk horend bij titelbeschrijven) wordt je voor een groot deel uit handen genomen. Het zoeken naar titelbeschrijvingen in de diverse MARC-repositories kan door niet-bibliotheek mensen heel goed gedaan worden.

Wel is het nodig om een goede workflow te organiseren.In onze bibliotheek hebben we een A4-tje waarin wordt bijgehouden wat er allemaal ge-daan is, en wat nog gedaan moet worden met het boek. Vooral als je met meer mensen werkt aan boeken is dit een must. Als bijlage beschikbaaronze „Checklist Gang van dit boek“.
De praktijk
Voor onze bibliotheek blijken een aantal bibliotheken zeer bruikbaar om titelbeschrijvingen te vinden, en die tevens een publiek toegankelijke Z39.50 service onderhouden.
We noemen:
PICARTA - de Nederlandse Centrale Catalogus; eigenlijk moet je voor het gebruik hiervan een behoorlijk bedrag betalen aan PICA/OCLC, maar met een truukje lukt het ook zonder al teveel geld.LIBIS - de Belgische Centrale Catalogus; ook hiervoor zou je moeten betalen, maar er zijn blijkbaar uitzonderingen.GBV - Gemeinsamer Bibliotheksverbund; een soort van Duitse centrale catalogus, die haar titelbeschrijvingen publiek beschikbaar heeft gemaakt.BNF - Bibliothèque nationale de France; beschikt eveneens over een publiek toegankelijk Z39.50 server.
Daarnaast zijn er nog veel meer europese nationale bibliotheken die een Z39.50 service leveren: een Oostenrijkse, een Spaanse, een Zweedse, een Noorse. Soms een uitkomst voor boeken uit die regio’s.
Voor het Engelstalige gebied zijn de volgende bibliotheken van belang - vooral omdat en-kele gespecialiseerd zijn in kunst(historisch) materiaal:
Victoria en Albert Museum, ook bekend als National Art Library (Londen)Getty Research Library (Los Angeles, California)
en de grote algemene leverancier van (Engelse) titelbeschrijvingen:
Library of Congres (Washington)
Alle genoemde instellingen en hun bibliotheken beschikken over een vrij toegankelijke Z39.50 server.
Bij elkaar, meer dan de gateways die Adlib aanbiedt.
De problemen
We bespreken hier de problemen die zich voordoen bij het gebruik van de Z39.50 servi-ces.
Weliswaar is MARC een algemene bibliotheek standaard, maar er zijn nogal wat variantenin omloop. Algemeen in gebruik is het MARC21 format. Veel Z39.50 services zijn in staat op aan-vraag een MARC21 aan te bieden.

De BNF in Parijs levert aan in Unimarc variant.De hierboven genoemde Oostenrijkse en Spaanse bibliotheken leveren in een eigen ver-sie van MARC aan.
Naast problemen met het format, zijn er essentiële problemen met de character set waar-van gebruik gemaakt wordt. Ons tooltje BookWhere laat er 4 zien: ANSI, Latin-1, ISO 6937/2 en UTF8. UTF8 is inmiddels een standaard, en stemt overeen met Unicode. Op het internet is het daardoor mogelijk om bijvoorbeeld in het Georgisch of Chinees te wer-ken.
Hands-on
Installeren en testen van BookWhere
We beginnen met het installeren van het programma „BookWhere voor Windows“ vanaf Windows XP. En het eerste probleem meldt zich. Je hebt voor installatie en gebruik van het programma „administrator“ rechten nodig. Op zoek naar de systeembeheerder!Is dit eenmaal gelukt, dan starten we BookWhere op. Het volgende wat we doen is een netwerk controle. Om contact te leggen met andere bibli-otheken, moet je vanuit je PC het internet op. En per Z39.50 service leverancier dienen een aantal poorten in de internet firewall naar buiten „open gezet“.
Onder Options, Network TestIn ons geval worden de volgende poorten getest: 210, 7090,2200, 2100, 5666, en 9909.Het programma geeft aan wanneer e.e.a. naar wens is ingesteld.
We starten New SessionEen enorme waslijst van beschikbare Z39.50 services wordt getoond.Die kun je bijvoorbeeld sorteren op Name.(of desgewenst naar land etc.)
Laten we beginnen met de GBV
We zoeken in de lijst naar de Gemeinsamer Verbundkatalog.We klikken op de regel met de rechtermuis knop, en een menu opent zich, waar we de Database Properties uit kiezen.De firma BookWhere heeft hier de hen bekende instellingen al ingegeven.naam: Gemeinsamer VerbundkatalogHost name: z3950.gbv.dePort: 20010DB Name: GVK (de database naam)Location-Country: GermanyLibrary Type: AcademicRecord Format: MARC21Character Encoding: Latin 1Website: http://www.gbv.deevent. database descriptionaan te vinken is:Use Z39.50 Version 2het aantal records dat per keer gedownload wordten dan een aantal belangrijke zaken die in het blauw staan.
Allereerst dient een erkende login code opgegeven zijn.

In het geval van de GBV zijn dat:UserID = 999Password: abc
Een aantal instellingen wordt gecontroleerd door op „test database“ te klikken.Een uitgebreid test rapport verschijnt, met aangevinkt waartoe de Z39.50 server in staat is.Voor ons van belang: Search, Present en Scan moeten afgevinkt zijn.Het rapport eindigt hopelijk met SUCCESS
Daarna is het noodzakelijk om op het blauwe „search fields...“ klikken. Na een tijd zijn alle beschikbare zoek mogelijkheden getest en aangevinkt.
Dan is het nodig de algemene „Login credentials“ in te vullen:UserID en Password. Zie boven,
We kunnen vervolgens al deze data opslaan.
Goed, de toegang tot de GBV Z39.50 server is nu geïnstalleerd.
Hoe werkt het verder?
We vinken deze GBV af, (aanvinken vakje vooraan de regel) waardoor de database be-schikbaar komt om te zoeken.
Het menu „Search Query“ opent. Standaard staan daar een viertal zoekvelden: ISBN, Tit-le, Author, en Any.We zijn erachter gekomen dat we “Author” moeten vervangen door het veld „Author-name personal“- dat is in te stellen via het „Settings menu“ (F7 doet het ook), tabblad Queries.We kunnen ook per keer gebruik maken van een extra zoekveld onder „More search fields“. Als je daarop klikt verschijnt een tientallen lange lijst met beschikbare zoekvelden (die BookWhere eerder via test search fields heeft uitgedokterd)
Als eerste zoekvoorbeeld: titel BlechtrommelAls je lang genoeg wacht krijg je een dikke 350 hitsIn de linker onderkant van het scherm zijn de hits verdeeld over diverse categorieën:Rating, Media Type en Database.Wij zijn geïnteresseerd in boeken en zetten een vinkje voor het icoontje voor boekenIn het bovenste gedeelte van het scherm een overzicht op Author, Title, Date, Database, Rating en Score. Allemaal elementen waarop gesorteerd kan worden!We vinden de laatste editie van Günter Grass, Die Blechtrommel uit 2009.
BookWhere heeft hier haast zijn diensten geleverd. We moeten alleen nog het programmade opdracht geven om een MARC-format record te downloaden op een van te voren vast-gelegde plaats, zodat we Adlib straks opdracht kunnen geven om dit MARC-record te im-porteren. We maken gebruik van een map „import“ die we eerder aangemaakt hebben in de Adlib-directory en we laten BookWhere het MARC-record daar te plaatsen onder de naam van “gbv”. Dat doen we door bovenin de menulijst op Actions te klikken, en te kiezenvoor Export Record(s). Een menuutje verschijnt waarin we kunnen invullen waar we het MARC record willen plaatsen met welke naam. Als we meer titels willen halen uit de GBV dan kunnen we de MARC-records ook achter elkaar in één file laten plaatsen. Dan moet jeaanvinken: „Append Records“.We klikken vervolgens op Save.

Tot zover het éénmalig gebruik van de GBV.Hoe het met de andere Z39.50 bibliotheken services moet, vertellen we later.
We willen nu laten zien hoe je een gedownload MARC-record kunt inlezen in de eigenlijke Adlib database. We gebruiken daarvoor het geëigende Adlib tootlje: de Import manager, die verborgen zit in Adlib Designer.
MARC Import via Adlib Designer
We laten BookWhere verder gewoon op de achtergrond open staan en openen Adlib De-signer.
Onder menu-kopje Beeld, vinden we
Import Taak beheer
Voor het importeren van externe data, moeten we voor alle seriematige acties een stan-daard import job aanmaken.
we kiezen onder Beheer, Nieuwe importjob aanmaken
een import-taak definitie menu wordt geopend.
In de eerste tab moeten we invullen:Naam van de taak: gbv in ons gevalwe kunnen in Beschrijving melden dat dit MARC-records betreft van de GBVde soort bronbestand: in ons geval MARC (algemeen ISO 2709)bronbestand: we klikken op de puntjes rechts om naar ons GBV-MARC-record te navige-ren in de import-directory. De gbv file wordt gevonden, en in het bronbestand ingevuld.Dan de vraag aan welke database/dataset het toegevoegd moet worden.We kiezen de plaats waar de data van de Adlib database staan.Voor ons de map: G:\Adlib\datade database is: CATALOen de speciale dataset: BESTEL
Deze dataset binnen de Adlib database hadden we eens aangemaakt om in ieder geval het dubbel bestellen van boeken tegen te gaan. Een Bestel subset, waarbij gezorgd is dat binnen deze dataset de velden NIET meteen gevalideerd moeten worden (zie verderop hoe dit is in te stellen in Adlib). Bij het intikken van bestellingen zal al snel een foutje in de auteurs-naam of uitgever optreden. Vandaar. Voor onze copy cataloging is zo een subset een uitkomst. We hebben geen idee wat we precies binnenkrigen via onze MARC experi-menten. Dus een tussenopslag in de subset BESTEL is een uitkomst. Op termijn kunnen we de validaties uitvoeren, en de titels verdelen over de diverse subsets die we hanteren. Terug naar de Import Job: de Dataset= BESTEL
De meest bewerkelijke tab van de import betreft de Mapping. Gelukkig een éénmalige ex-cercitie!Als eerste moeten we een Charachterset invoeren.In ons geval ANSI met als bestemmingsveld <CHARSET>vervolgens wandelen we een hele serie MARC velden af.

BookWhere zelf heeft ook de mogelijkheid om te laten zien welk MARC veld, waarvoor is gebruikt. Terug naar BookWhere dus. Het gedownloade record staat nog voor! Als we rechts klikken op de data van dit record, kunnen we kiezen voor MARC-aanzicht (MARC Display) van de data. Marc veld 245 blijkt te corresponderen met titelveld en bijvoorbeeld veld 260 $c met het jaar van uitgave.Dit „mappen“ is het meest bewerkelijke deel.
Ik zal een aantal screenshots plaatsen waar je kunt zien hoe we de MARC-velden „ge-mapt“ hebben naar de oldskool velden van onze Adlib applicatie.Helaas, zo weten we nu, verschilt dat per gebruiker en per applicatie (?)
Tabblad Opties van de Import Job Manager
In ieder geval vinken we UIT „Koppelingen verwerken“en vinken AAN: Forceren altijd toegestaanen Priref negerenVoortgangsteller zetten we voorzichtigheidshalve op 1That’s it
Tabblad Geavanceerd
hier wijzigen we nietsofwel:Grootte invoerbuffer 32000Standaardwoordomloop breedte = 0Importeer het databasebestand aangevinktHerindex automatisch UITgevinkt (?)Tekenset Codering: ANSI (Iso-Latin)
Tabblad Uitvoeren
Eerst klikken we linksboven op het floppy-symbool: importjob opslaan!Dan klikken we op het groene wieltjes - dan gaat het rode wieltje aan - wat later gaat het groene wieltje weer aan. We zien dat we 1 record hebben geïmporteerd.
Tijd om te zien wat ervan terecht is gekomen
We openen Adlib
We gaan naar de subset Bestel, en zoeken op recordnummer
Om bij het nieuwste (laatst ingevoerde) record te komen tikken we CTRL-F5
We kunnen nu de „mapping“ controleren door terug te gaan naar BookWhere.Als alles goed is, staat nog steeds het zoekresultaat voor Blechtrommel open.Het record dat we kiezen kunnen we ook als MARC record zichtbaar maken.Als we rechts klikken in het resultaten venster kunnen we kiezen voor: MARC Display i.p.v. Text Display.
Onjuistheden in onze mapping kunnen we nu destillerenOok een incomplete mapping kunnen we zo vinden.We voeren alle nodige instel activiteiten uit.

We verwijderen het record uit BESTEL. En laten Adlib opnieuw de import uitvoeren. Een laatste correctie.
Daarna valideren we alle noodzakelijke velden, Voor ons zijn dat Auteur, Uitgever, en Plaats van Uitgave.We openen het record en lopen langs alle gelinkte velden:alle namen etc. die niet bekend zijn bij onze Adlib database melden we aan via SHIFT-F4Ook laten we Adlib de ISBN controleren.
Opschonen.
We hebben veel data gedownload uit de GBV database, die niks voorstellen. Helaas wis-selt dat per titelbeschrijving. En zoals we later zullen zien ook per Z39.50 leverancier.Eventueel vervangen we hier de Duitse terminologie door Nederlandse.We verwijderen het overtollig materiaal voornamelijk met het knopje: Delete Occurrence.Als laatste stap moet het record overgeheveld worden naar de juiste subset. Inmiddels is de BESTEL subset een „friendly database“ voor vrijwel alle subsets (zie ver-der hoe dat te doen)
Als we nu de titel markeren en opslaan (CTRL-C) in het tijdelijk geheugen van Windows, kunnen we vervolgens vanuit bijvoorbeeld de subset Monografieën het zojuist gedownloa-de record ophalen uit de Bestel-subset. Hoe? In het menu onder het knopje Record, verwijst de allerlaatste keuze naar de mogelijkheid om te „ontlenen aan friendly databases“, in ons geval dus de BESTEL-subset. Soms levert de GVB een aantal URL-verwijzingen mee:via een website is dan bijvoorbeeld een PDF van de inhoudsopgave beschikbaarof de aanprijzings- tekst van de uitgever voor dit boek, een tekst die ook wel op de achter-kant van het boek staat.Onze praktijk is om daar gebruik van te maken:we laten de URL-verwijzingen staan, maar knippen en plakken uit de via de browser geo-pende PDF de Inhoudsopgave en de aanprijzings- tekst. Meestal ontbreekt het in de bibli-otheek aan mogelijkheden om een adequate samenvatting te schrijven. En dan is „iets“ beter dan niets, om duidelijk te maken waar een boek over gaat. Met dit soort verrijkingen wordt de catalogus niet alleen een tool om te zien òf we een boek hebben en waar het danstaat, maar dient hij tevens als zoekmachine, waarbij vooral de samenvattingen bruikbaar tekstmateriaal is.
OK. We hebben een import job gemaakt voor de GVB.
PICARTA
Nu maken we ook een importjob voor de Picarta database.De mogelijkheid om via een Z39.50 service bibliografische data te ontlenen (in bulk zeg maar) aan de PICA databases prijzig. Via een truukje kunnen we toch MARC records downloaden vanuit de NCC/OCLC databases.Daarvoor maken we gebruik van één van de minst bekende lidmaatschappen van de groteuniversiteits-bibliotheken: een IBL lenerspasje (IBL=InterBibliothecair Leenverkeer) à € 50 of zoiets. Normaal gesproken kun je met de gegevens van dit pasje thuis de PICA databa-ses doorzoeken, en met een druk op de knop via bijvoorbeeld Endnote een bibliografischeverwijzing genereren voor je artikel. Ook is het mogelijk een copie artikel op je bureau te laten belanden. Uiteraard tegen vergoeding.Het blijkt dat de data van dit pasje ook toegang geven tot de Z39.50 serivice van PICA.

Aan het werk.
De gegevens over de Z39.50 inlog kunnen we halen uit publiek toegankelijke teksten van PICA/OCLC. We zoeken naar het zgn. OCLC PICA Z39.50 Target Profile.We vinden daar de volgende gegevens:System name: TOLK Z39.50 Serveraddress: tolk.pica.nl:210en de available databases staan ook vermeld. Voor ons van belang is de PICARTA of de NCC-IBL database.De uitvoer is mogelijk naar allerlei MARC dialecten: Unimarc, USMARC/MARC21.Diverse Character Encodings zijn mogelijk. We kiezen voor de stanfdaard UTF8 (Unicode).
En natuurlijk meldden ze dat je een id en password nodig hebt; en dat je moet betalen.
We openen BookWhere en maken een nieuwe database aan: PICA.Daarvoor klikken we rechts in de waslijst van servers, en kiezen de mogelijkheid: New Database.We tikken bovenstaande gegevens in bij het database properties menu.Vervolgens testen we of bovenstaande werkt, door op de tekst „test database“ te drukken. En jawel, dat werkt.We laten BookWhere ook uitzoeken welke velden afzoekbaar zijn: test “search fields”.We moeten nu éénmalig de juiste gegevens intikken bij de „login info“.De User ID =- de nummertjes op je pasjePassword = het password dat jouw bibliotheek aan jou heeft gegeven voor dit pasje.We vinken aan dat we deze database willen gebruiken (vinkje links aan het begin van de regel).
We hebben nu de mogelijkheid om Pica MARC records te downloaden.
Tot onze tevredenheid merken we dat de MARC data op eenzelfde manier zijn gerang-schikt als bij de GVB (ze werken met dezelfde Pica tolk gate). We kunnen voor de import van zo een MARC record, dus gebruik maken van onze eerdere moeizame constructie van een GVB-import job in Adlib Designer.
Om het leven te vereenvoudigen groeperen we de GVB en Pica database onder eenzelfdegroep in BookWhere.Alle MARC data die we via deze groep vinden en downloaden kunnen we via dezelfde im-port job „gbv“ importeren in onze BESTEL subset van Adlib.
Meer!
Als aanhangsel geef ik de gegevens over een serie MARC21 servers die we ook regelma-tig gebruiken, en die gebruik kunnen maken van een iets andere import job “loc” genaamd (loc is de afkorting voor Library of Congress).
We maken zo gebruik van 3 groepen in BookWhere:
Favorieten (alle loc, Engelstalige servers/bibliotheken)PICA (de door PICA gebouwde servers, dus ook de GBV)Unimarc (de vnl. Franse afdeling, die gebruik maken van een de zgn. Unimarc versie, en

die ook een eigen import job nodig hebben; die noemen we „unimarc“.)LIBIS (de Belgische variant, maar daarvan hebben we pas sinds kort een werkende inlog gevonden). Inmiddels blijkt dit een “gewone” MARC21 service te zijn, en is toegevoegd aan de loc-groep.
Tot slot.
Workflow
Van belang is om een goede workflow te creëren.Daarvoor hebben we een Checklist gemaakt, die de gang van het boek door de biblio-theek wat betreft het titelbeschrijven en de administratie vastlegt.Zo krijgt ieder nieuw te catalogiseren boek een eigen checklist.Zie een voorbeeld als bijlage.
Wat getallen
We catalogiseren samen met twee andere instellingen in dezelfde database, gehost door Adlib, Uit de praktijk blijkt dat we ca. 40 % dezelfde boeken aanschaffen resp. krijgen.Bij het werk aan een boek is dit dus de eerste actie: kijken of een andere club de titel al gecatalogiseerd heeft. Zo ja, dan zijn we snel klaar.Voor de resterende 80 % proberen we eerst gebruik te maken van de copy cataloging faci-liteit van BookWhere. Ik heb niet direct gegevens, maar ik schat dat we meer dan 75 % van de nieuwe boeken wel vinden via BookWhere. Dan houden we wellicht 20 % aan titels over die we zelf hand-matig moeten beschrijven.Voor de liefhebbers: de aanwas op jaarbasis is ca. 1000 titels.Vooral voor retro catalogiseren werkt zoiets als BookWhere perfect. Je kunt een aantal ti-tels zoeken, en bij mekaar op slaan, om, ze later te importeren.Echt bulk catalogiseren dus.
De Kosten
Wat kost dat nou allemaal?
Allereerst de aanschaf van BookWhere: ik denk dat ik er 500 US$ voor heb betaald.
Daarnaast kost het nogal wat tijd, zeker in het begin, om e.e.a. te installeren en aan de praat te krijgen.
Maar daarna heb je ook wat!
Links over BookWhere:
Een bespreking uit 2010 over het gebruik van BookWhere - geschat aantal gebruikers we-reldwijd tussen de 6000-8000:http://www.librarytechnology.org/ltg-displaytext.pl?RC=16111 (2010)
De verkoop site van BookWhere, een product van WebClarity:http://www.webclarity.info/products/bookwhere/

ze verkopen daar BookWhere single user license voor US$ 567 (= ca. € 405)
Een beetje zoeken op het internet levert een deal voor US$ 497 (=ca.€ 386)bij: http://www.mlasolutions.com/pricingen bij:http://www.infocrofters.com/BookWhere.html
Friendly databases of datasets.
Hoe stel je via Adlib Designer voor een subset een “friendly” database in.We hebben deze faciliteit nodig om records uit de BESTEL subset over te hevelen naar deuiteindelijke subset – zeg maar boeken of AVM materiaal.
In Adlib Designer openen we de Applicatie browser, onder het kopje Gereedschappen.
Als pad kiezen we eerst de map waar alle catalogus zaken worden geregeld, dus niet de Data map.
Onze catalogus heet “Fotografiebibliotheek” met een serie subsets.
De BESTEL subset moet maar voor een beperkt aantal subsets vastgelegd worden als “friendly database”. In ons geval voor de Monografieën, Anthologieën, en de Boeken afde-ling. (We maken onderscheid tussen de beeldbanden en de vnl. tekstboeken).In Adlib Designer klikken we op een subset waarvoor we een friendly database willen vast-leggen. In de “boom” die hoort bij een subset, met o.a. Methodes, Schermen, Uitvoertakenen als laatste: Ontleenbare databases. Als je klikt op deze term krijg je een menu waarin jekunt kiezen voor Nieuw.We maken een nieuwe friendly (Ontleenbare) database aan, namelijk in ons geval De da-tabase BESTEL Je moet designer vertellen waar deze BESTEL database te vinden is, je moet een (standaard) zoekscherm invullen (bijv. qbfcata) en een zoekresultatenscherm (brief bijv.) en eern zoomscherm (bijv. qbflink).Je hebt hier ook de mogelijkheid om het record dat je hebt overgehaald uit de Bestel da-tasdet, in de Besteldataset te deleten. Vink daarvoor aan “verwijder origineel record na ontlenen).
Deze actie voer je uit voor alle andere datasets waarvoor je copy cataloging wilt toepas-sen.
Voor de volledigheid vermelden we hier dat Adlib, vanaf versie 6.5.0, een 3-tal gateways beschikbaar stelt, naar de KB, Library of Congress en de Gemeinsamer Verbundkatalog. Gateways die voor onze applicatie helaas niet bruikbaar zijn. De Adlib-gateways staan dusook onder “ontleenbare databases”. We moeten deze gateways wel voor elke subset apartaanmaken!

Bijlagen
1. Diverse Z39.50 servers:
Victoria and Albert Museum = National Art LibraryDomain: catalogue.nal.vam.ac.ukPort: 210Use Z39.50 Version 2
NCC-IBLDomain: tolk.pica.nlPort: 210Version 2Search 1 database at a time
National Gallery of CanadaDomain: bibcat.gallery.caPort: 210Databasename: INNOPACMarc21ALA
Library of CongressDomain: z3950.loc.govPort: 7090
Getty Research LibraryDomain: library.getty.eduPort: 7090
Gemeinsamer VerbundkatalogDomain: z3950.gbv.dePort: 20010Login:999abcSeach 1 database at a timeURL: www.gbv.de
Bibliotheque Nationale de France (UNIMARC-UTF8)Domain: z39.50.bnf.frPort: 2211Login:Z3950Z3950_BNFURL: www.bnf.fr
Austrian Union CatalogueDomain: z3950.obvsg.atPort: 9991Version 2Seach 1 database at a time

LIBISDomain: opac.libis.bePort: 9991Database naam: opac01Marc21UTF8login:ZMEDmeds
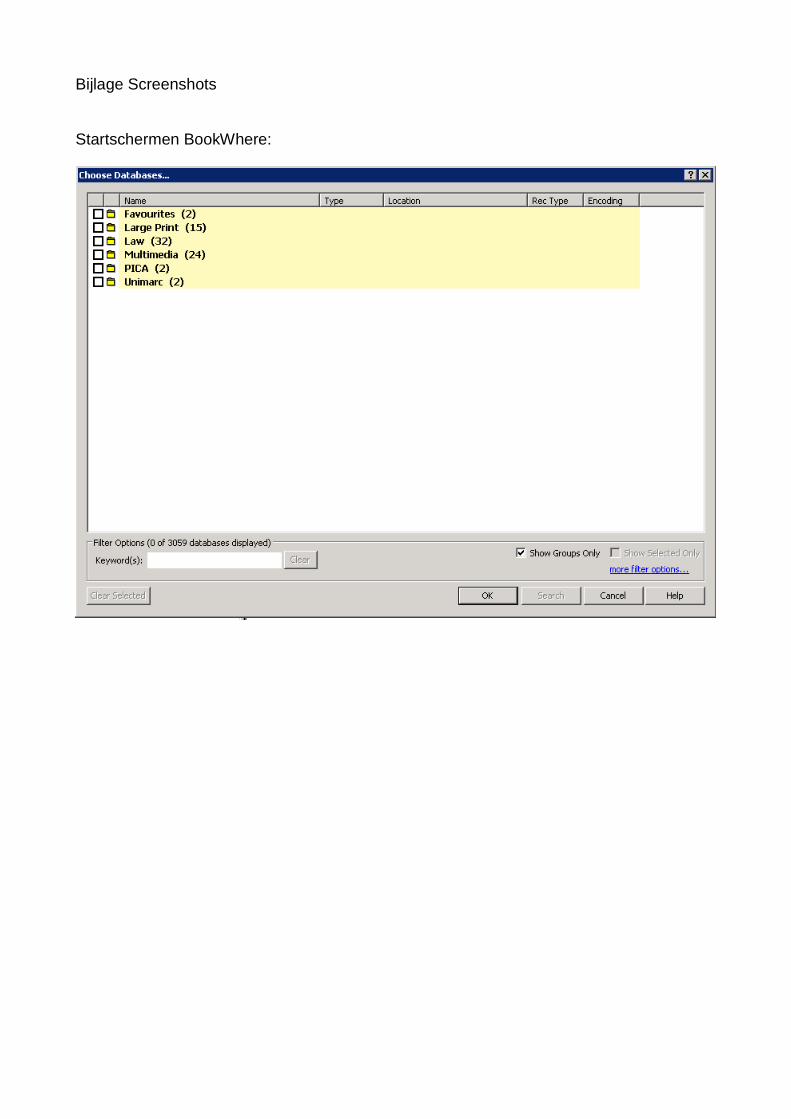
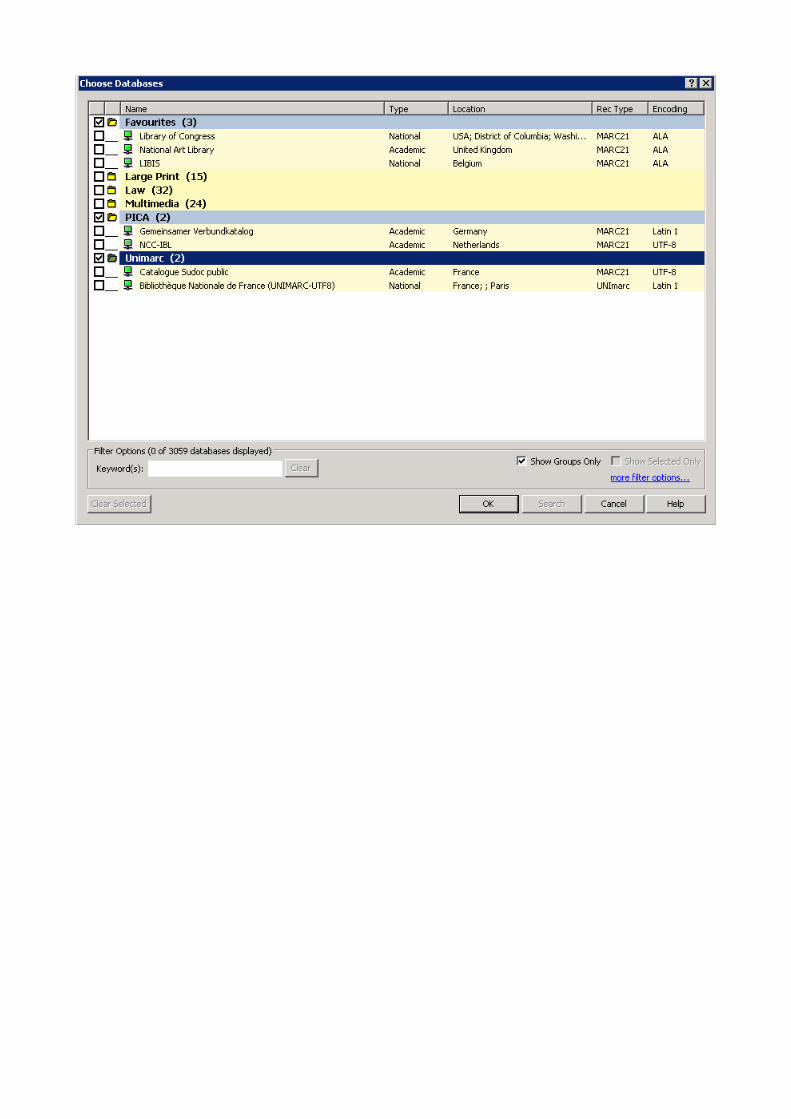
Bijlage Screenshots
Startschermen BookWhere:
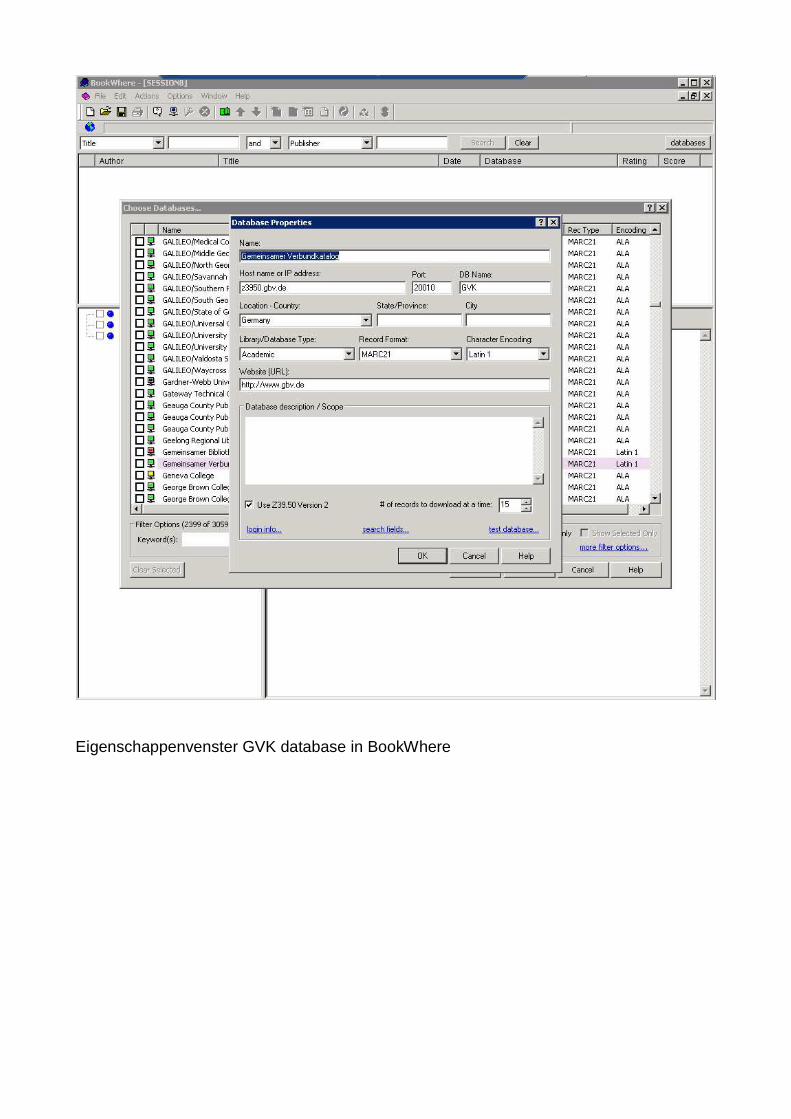
Eigenschappenvenster GVK database in BookWhere
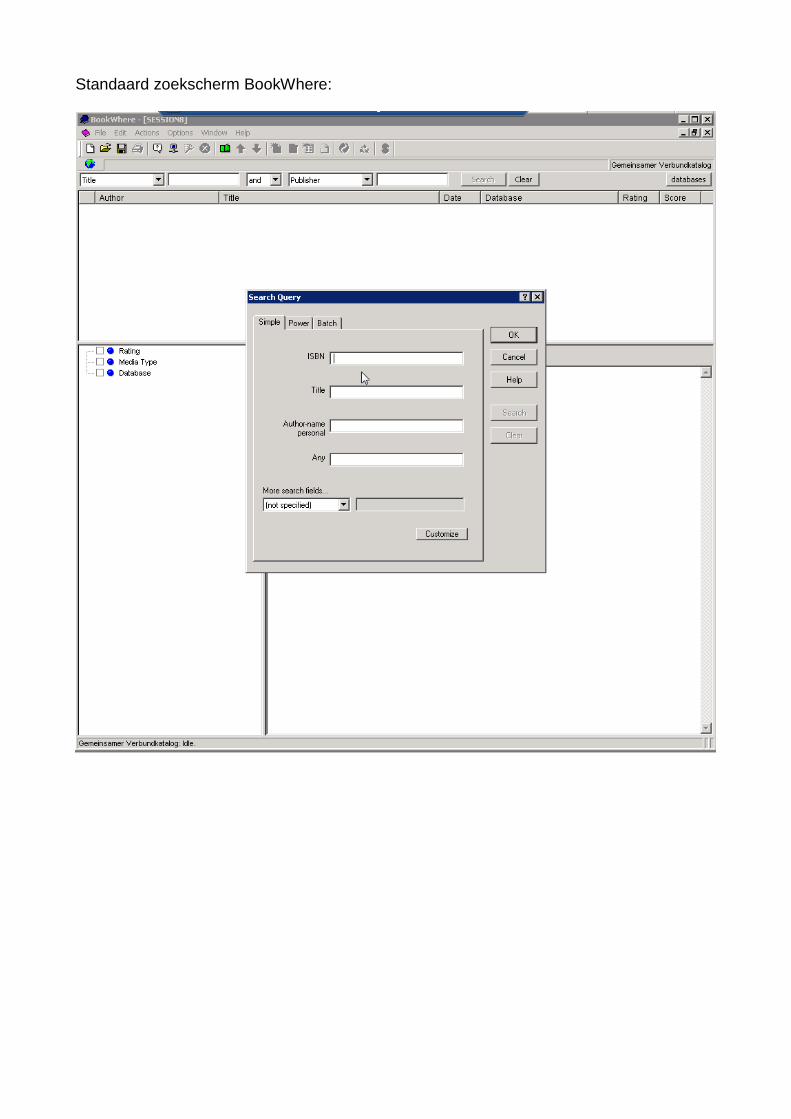
Standaard zoekscherm BookWhere:
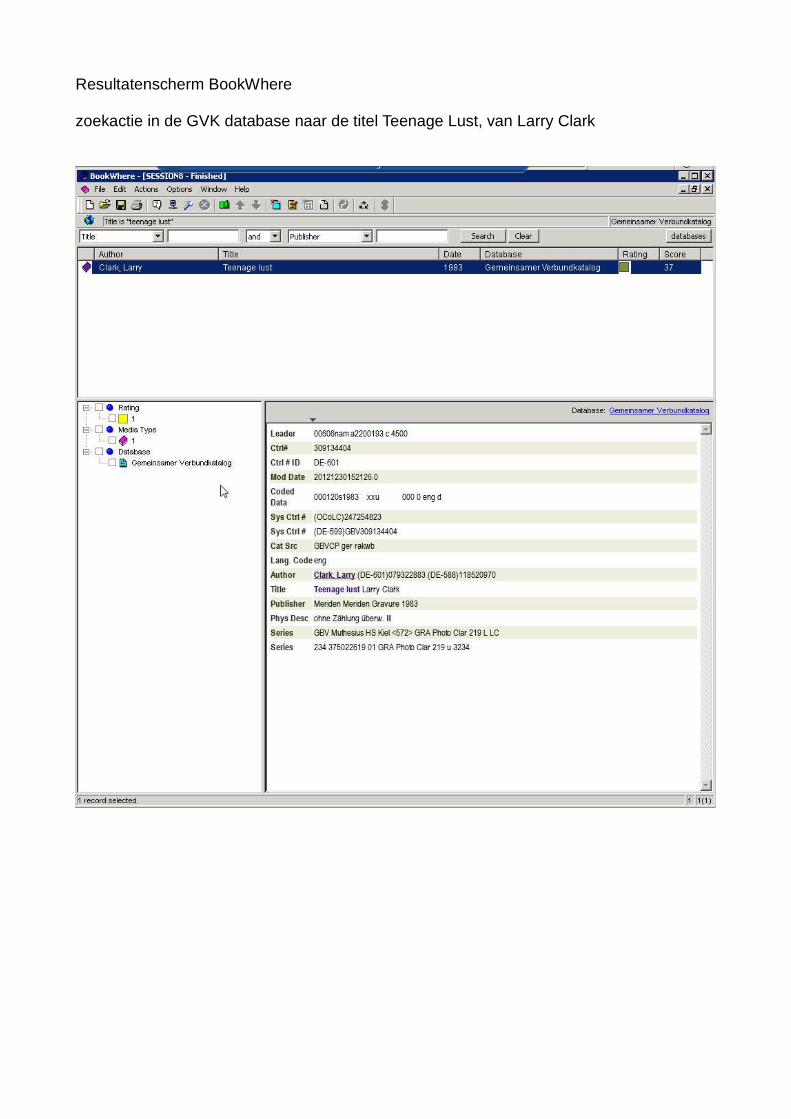
Resultatenscherm BookWhere
zoekactie in de GVK database naar de titel Teenage Lust, van Larry Clark
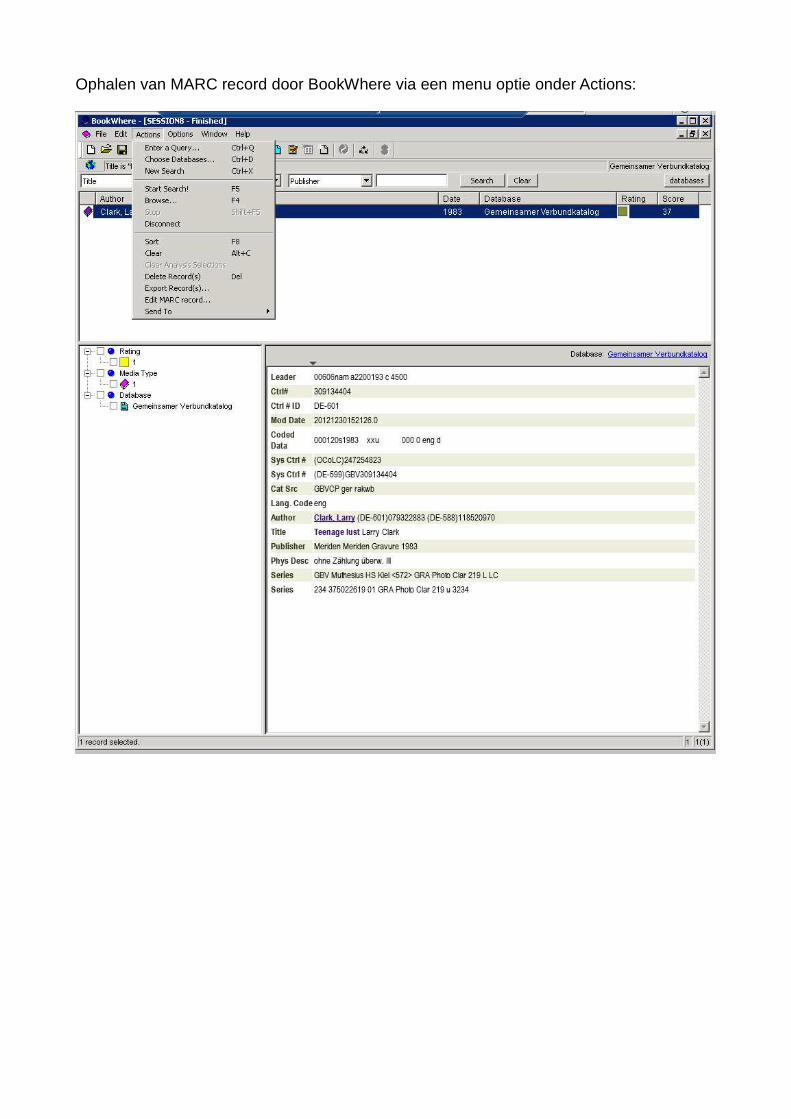
Ophalen van MARC record door BookWhere via een menu optie onder Actions:
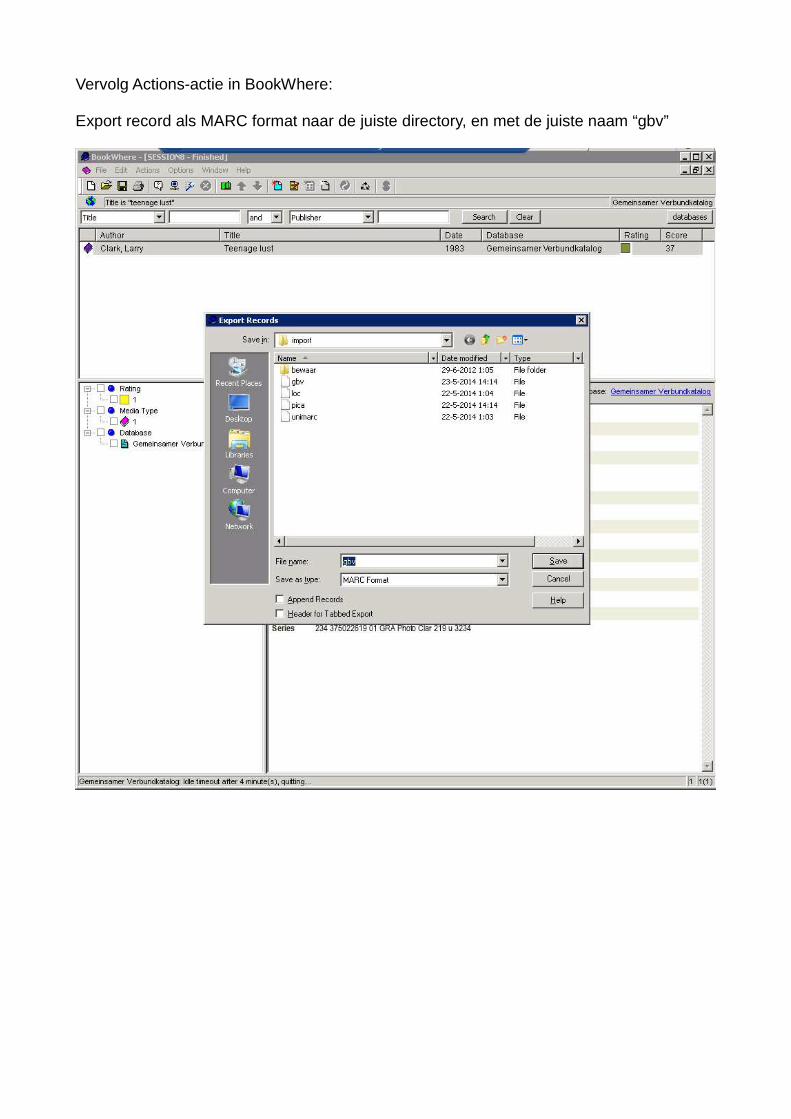
Vervolg Actions-actie in BookWhere:
Export record als MARC format naar de juiste directory, en met de juiste naam “gbv”
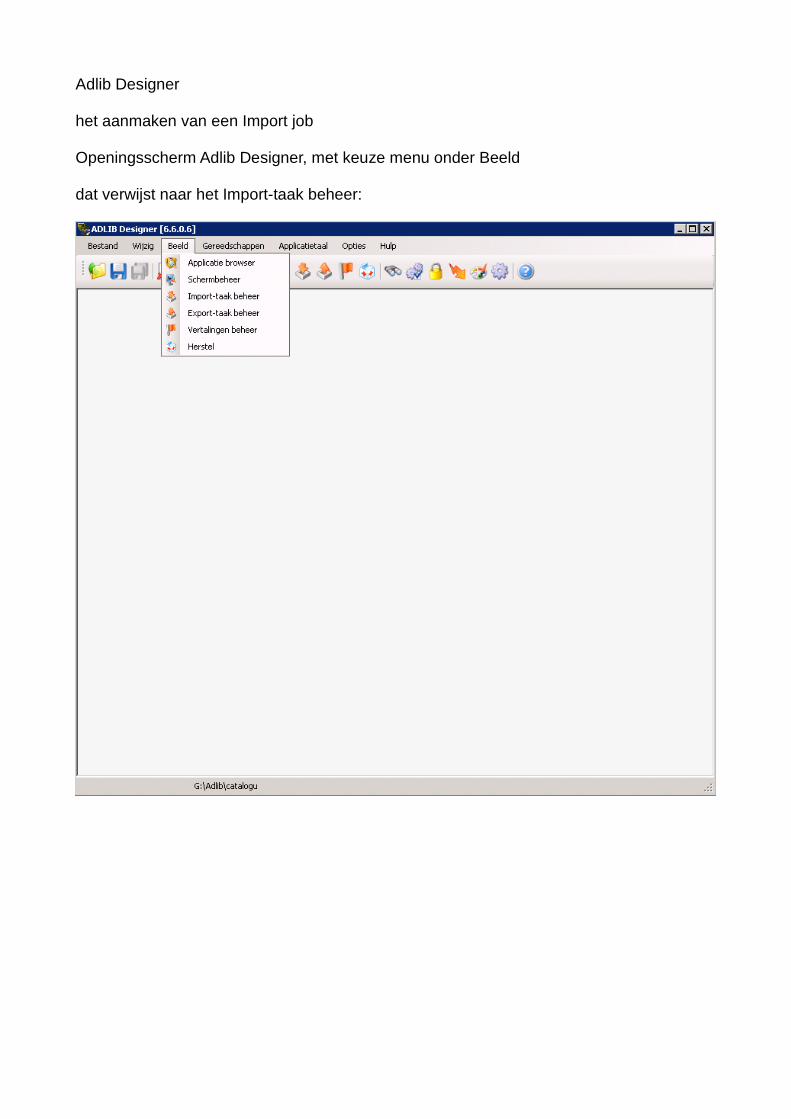
Adlib Designer
het aanmaken van een Import job
Openingsscherm Adlib Designer, met keuze menu onder Beeld
dat verwijst naar het Import-taak beheer:
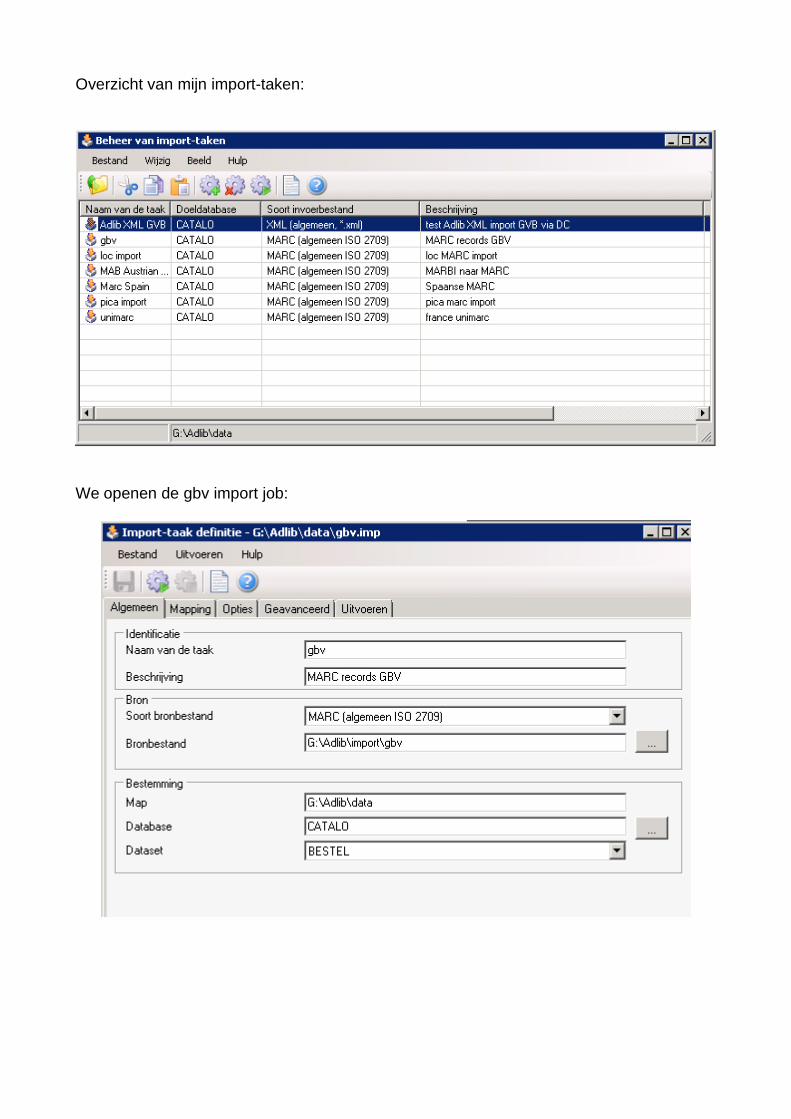
Overzicht van mijn import-taken:
We openen de gbv import job:
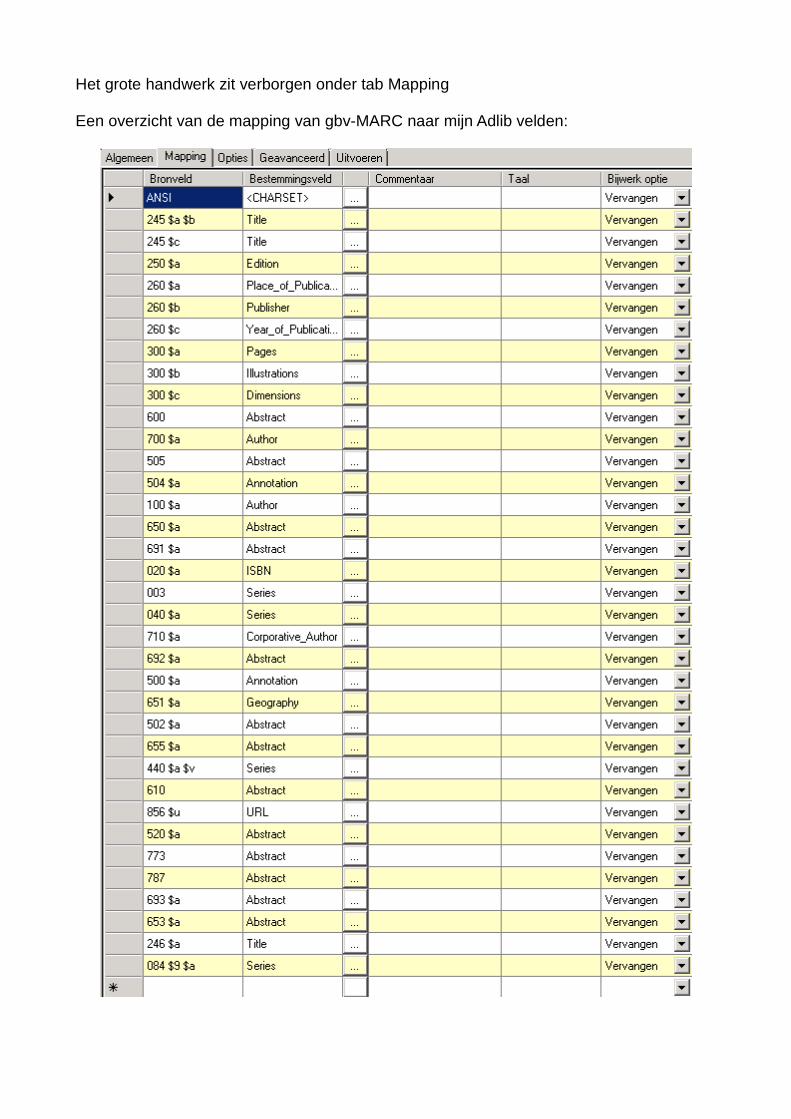
Het grote handwerk zit verborgen onder tab Mapping
Een overzicht van de mapping van gbv-MARC naar mijn Adlib velden:
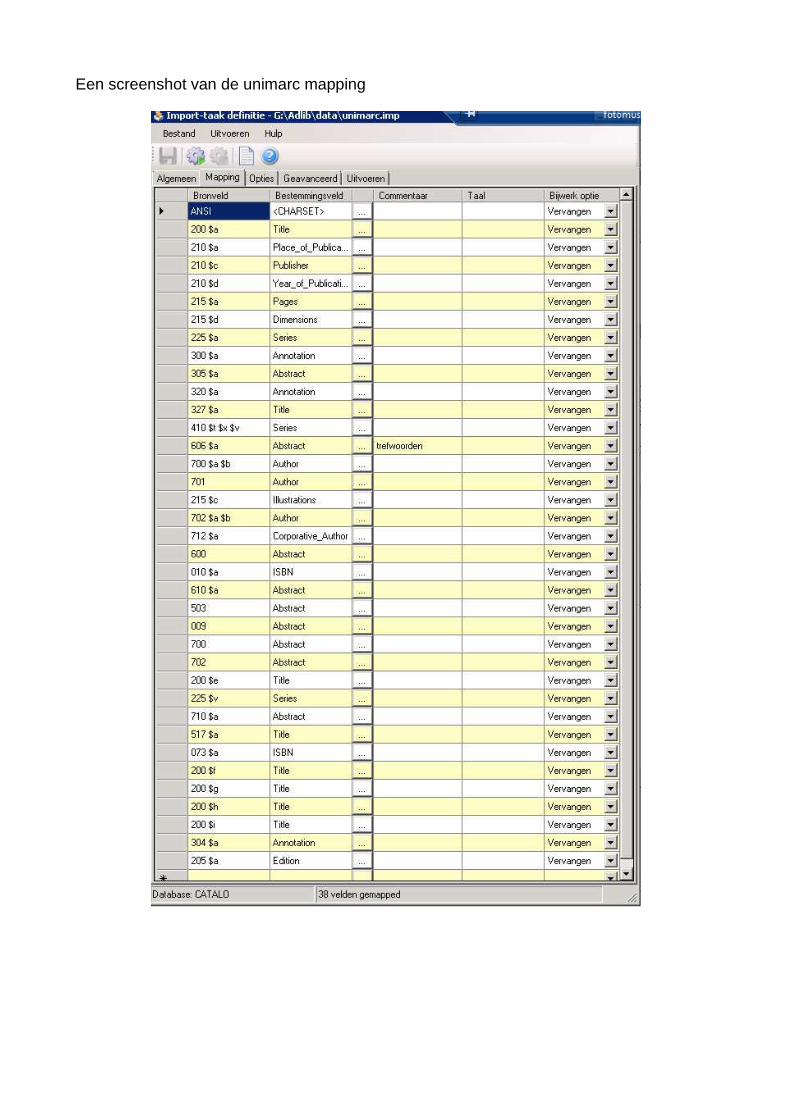
Een screenshot van de unimarc mapping
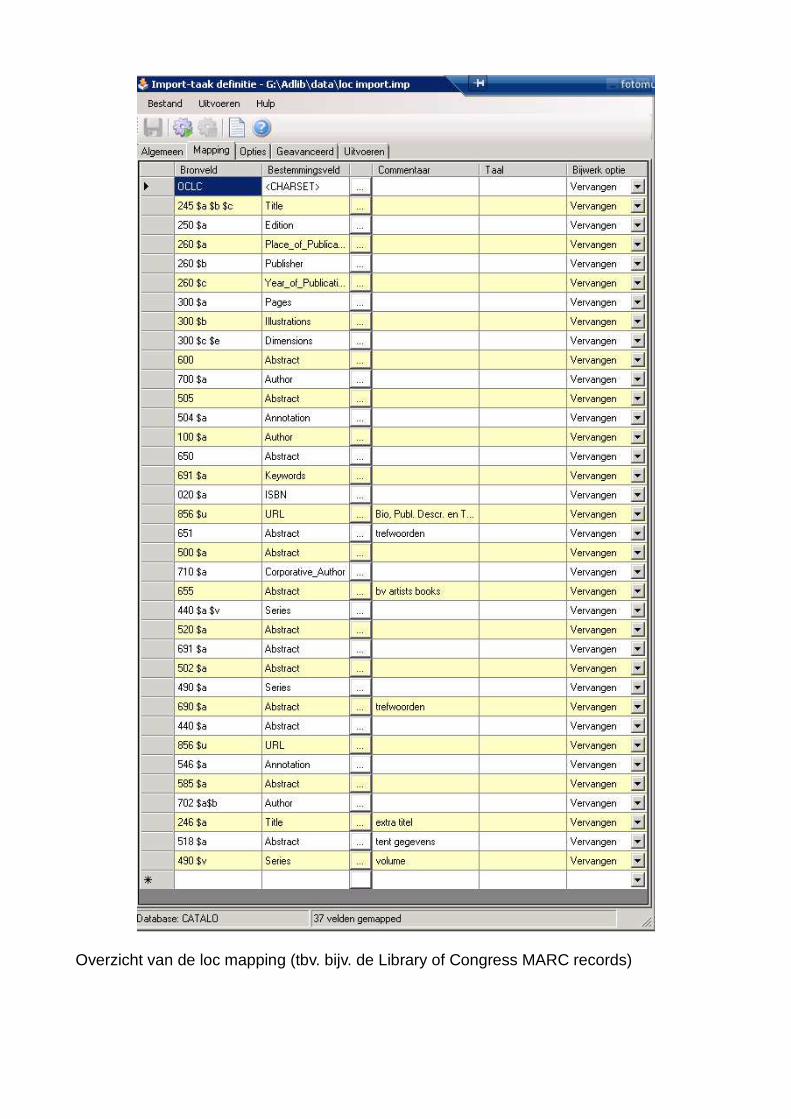
Overzicht van de loc mapping (tbv. bijv. de Library of Congress MARC records)
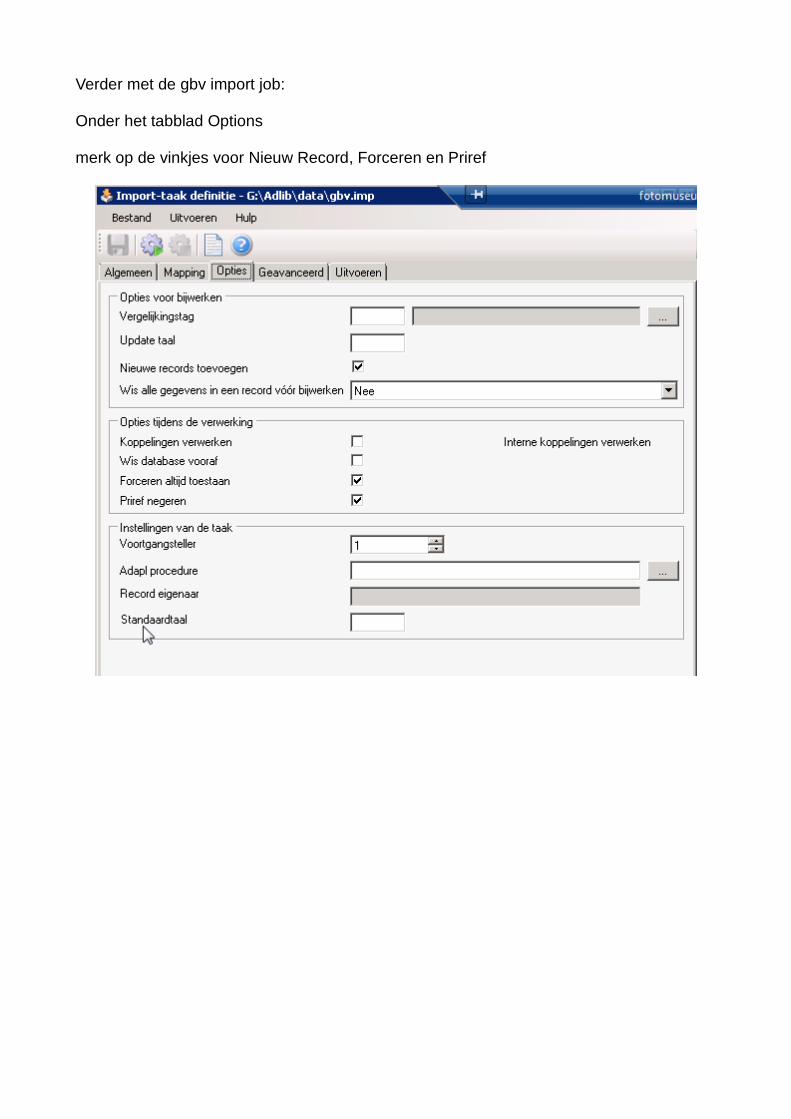
Verder met de gbv import job:
Onder het tabblad Options
merk op de vinkjes voor Nieuw Record, Forceren en Priref
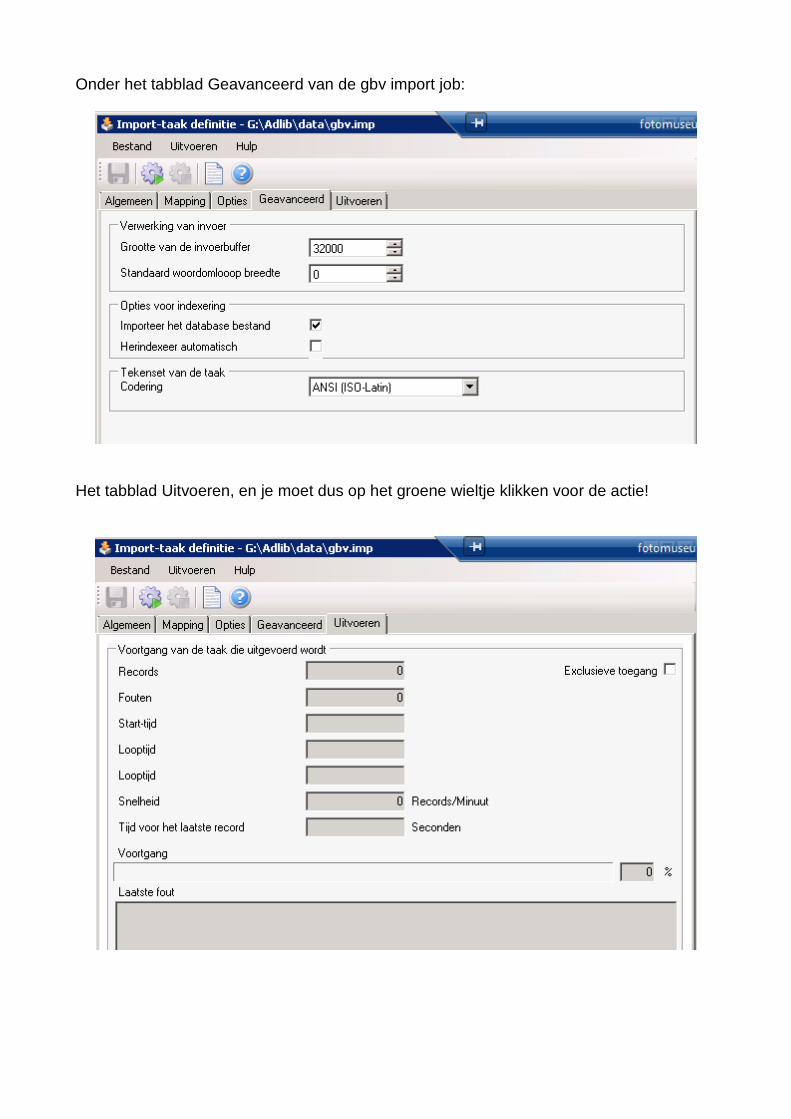
Onder het tabblad Geavanceerd van de gbv import job:
Het tabblad Uitvoeren, en je moet dus op het groene wieltje klikken voor de actie!
Adlib applicatie Ned. Fotomuseum, met de Bestel subset zichtbaar:
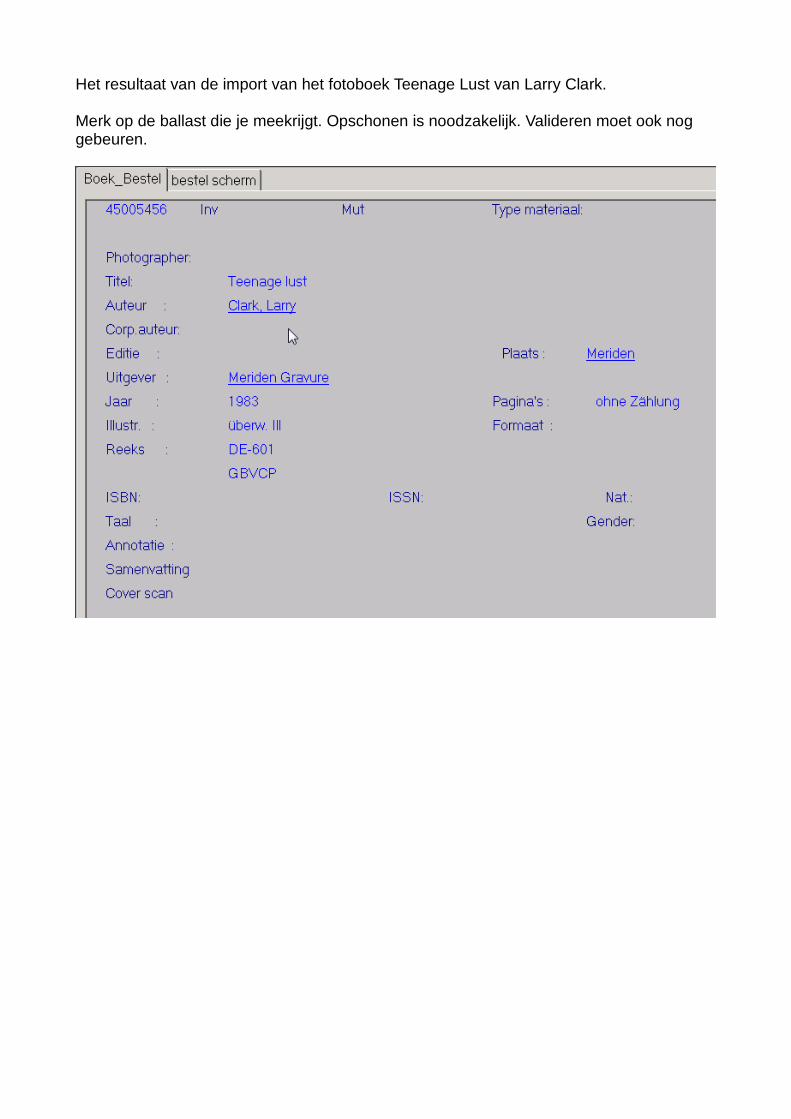
Het resultaat van de import van het fotoboek Teenage Lust van Larry Clark.
Merk op de ballast die je meekrijgt. Opschonen is noodzakelijk. Valideren moet ook nog gebeuren.
Instellen van “friendly” databases via Adlib Designer:
Openingsscherm Adlib Designer, menu onder Beeld
Keuze voor Applicatie browser:
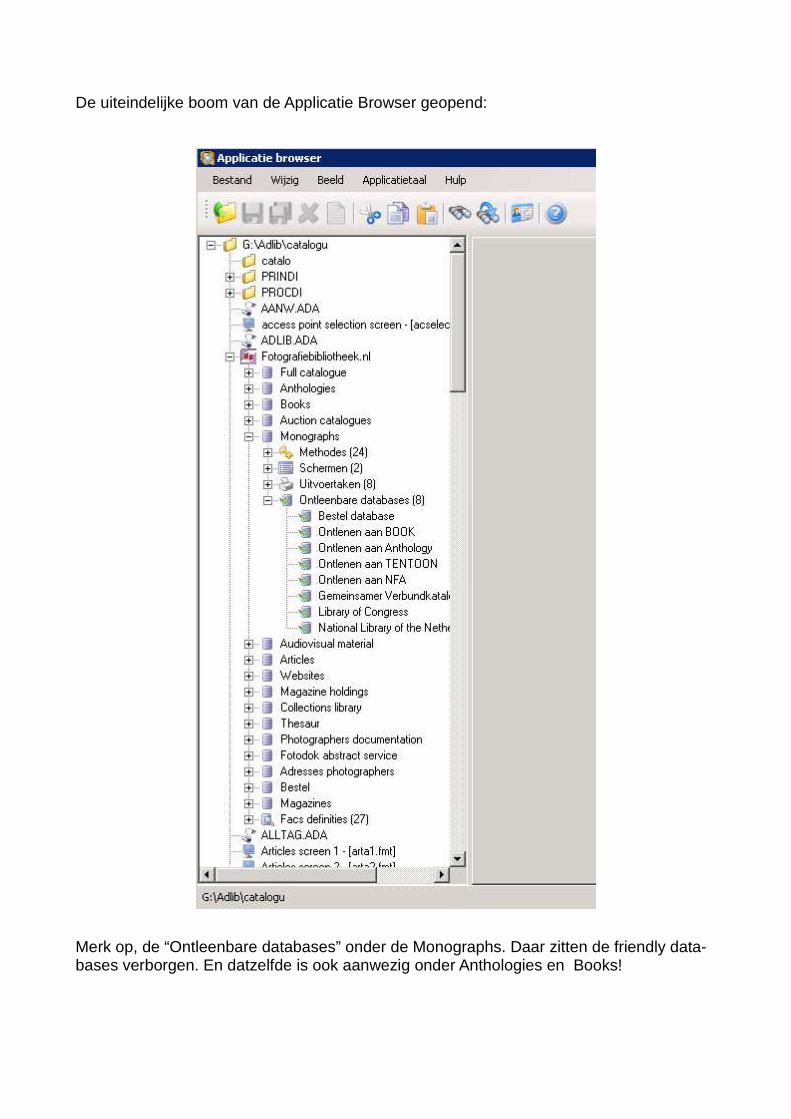
De uiteindelijke boom van de Applicatie Browser geopend:
Merk op, de “Ontleenbare databases” onder de Monographs. Daar zitten de friendly data-bases verborgen. En datzelfde is ook aanwezig onder Anthologies en Books!
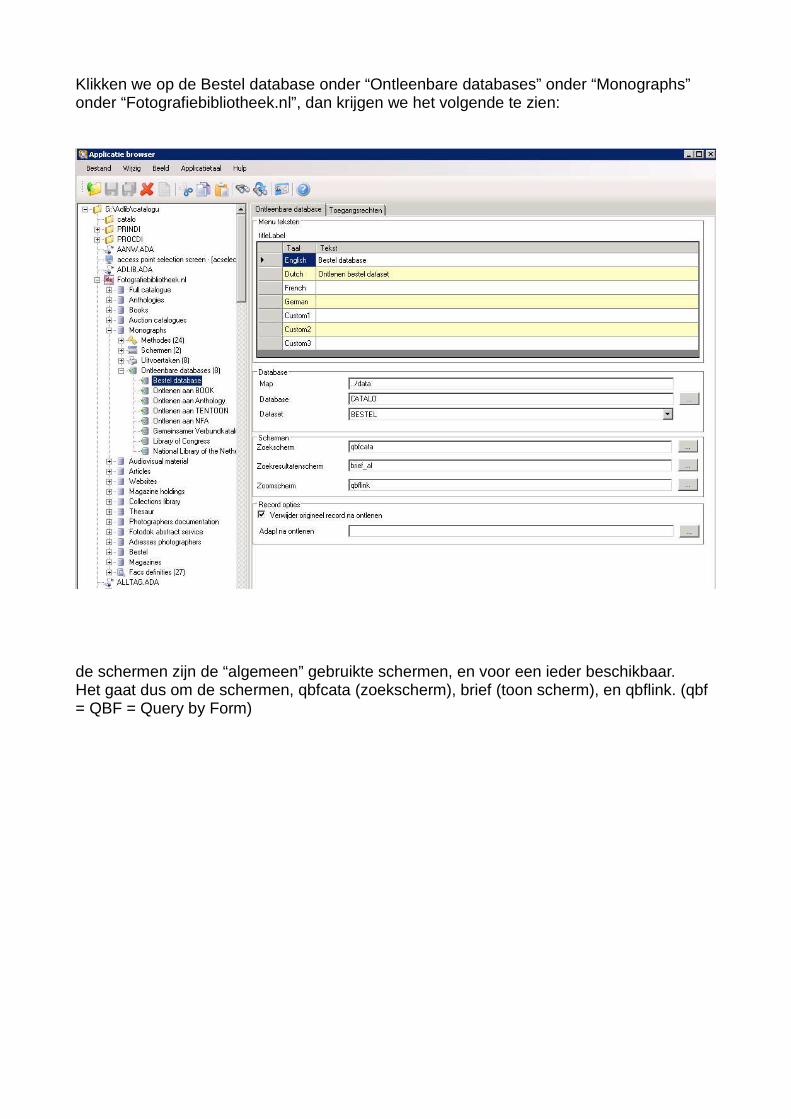
Klikken we op de Bestel database onder “Ontleenbare databases” onder “Monographs” onder “Fotografiebibliotheek.nl”, dan krijgen we het volgende te zien:
de schermen zijn de “algemeen” gebruikte schermen, en voor een ieder beschikbaar.Het gaat dus om de schermen, qbfcata (zoekscherm), brief (toon scherm), en qbflink. (qbf = QBF = Query by Form)
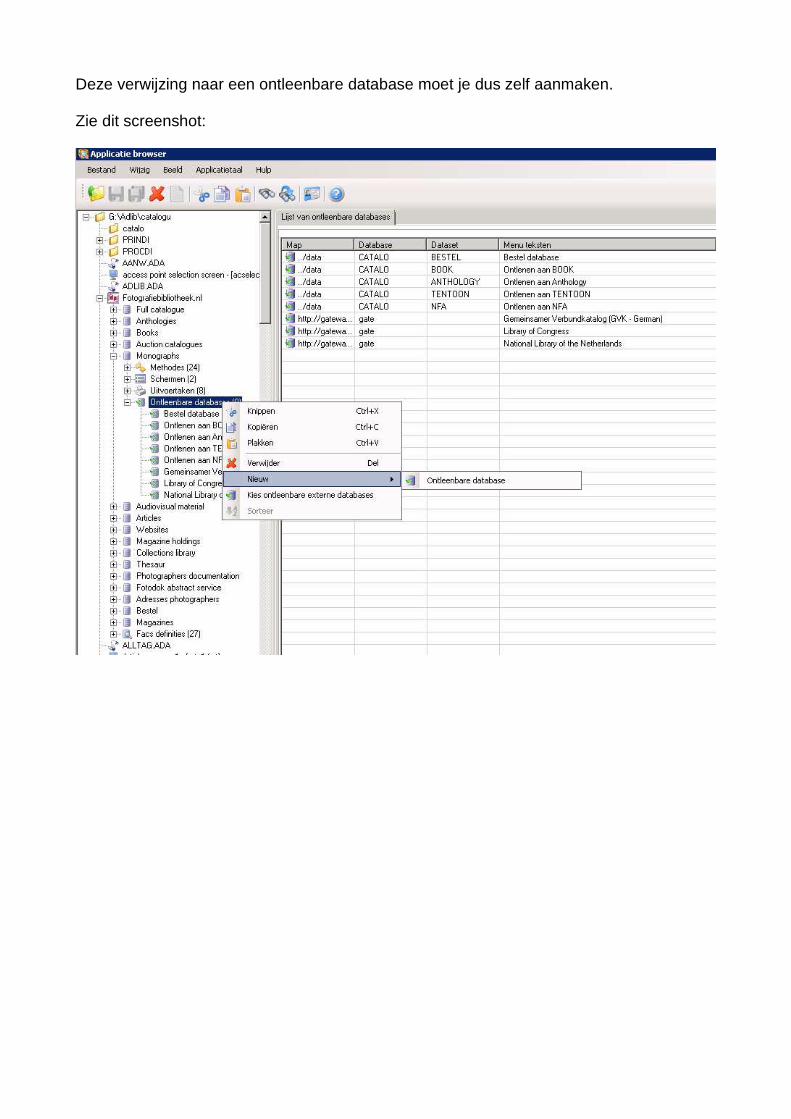
Deze verwijzing naar een ontleenbare database moet je dus zelf aanmaken.
Zie dit screenshot:
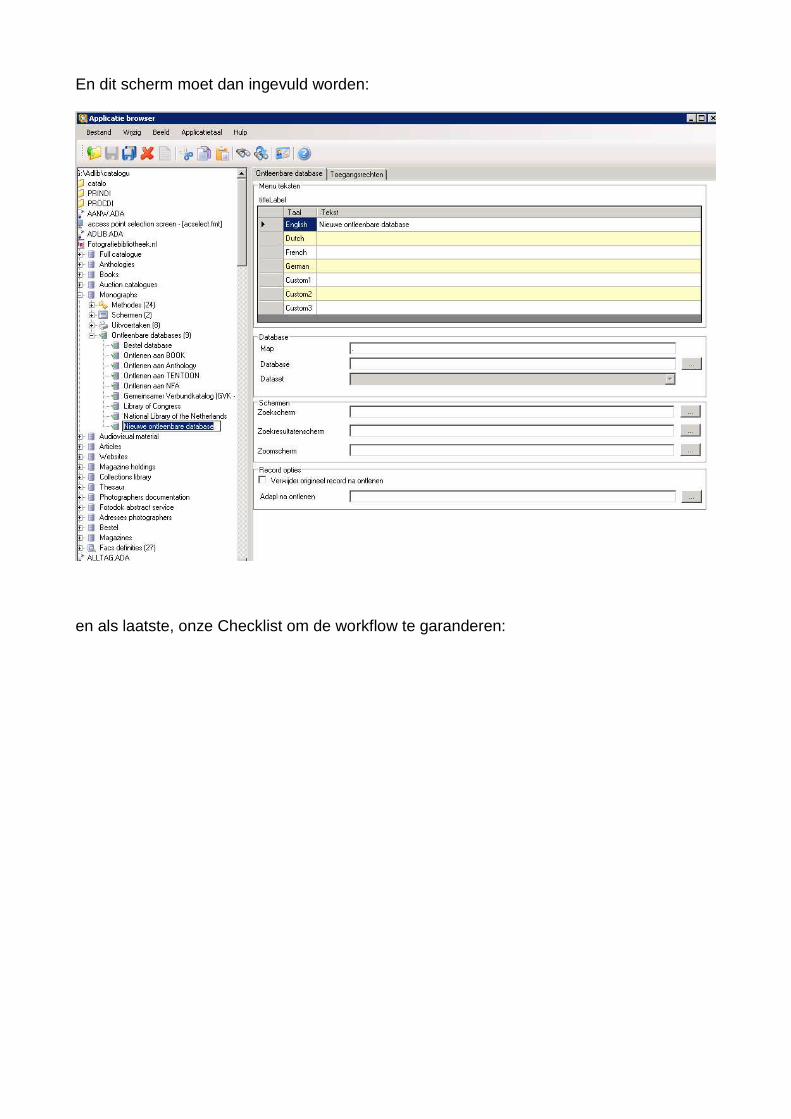
En dit scherm moet dan ingevuld worden:
en als laatste, onze Checklist om de workflow te garanderen:

CHECKLIST GANG VAN DIT BOEK
EXEMPLAAR NUMMER 0……….. DATUM: …. / …. / 20.……
NAAR STAPEL “ TE CATALOGISEREN ”
CHECKEN OF TITEL AL IN ADLIB ZIT (IN BESTEL OF ERGE NS ANDERS).AL IN ADLIB DAN METEEN EXEMPLAARNUMMER TOEVOEGEN IN ADLIBEN MOGELIJK HET RECORD IN BESTEL DELETEN
ZIT IN ADLIB, EN GECATALOGISEERDLABEL WORDT: …… …… …… ……. …… …..VERDER NAAR STAPEL “ LABEL MAKEN ”LABEL GEMAAKTNAAR STAPEL “OMSLAG SCANNEN”OMSLAG GESCAND – EVENTUEEL OMSLAG VERWIJDEREN EN WEGLEGGEN, EN MET GELE MARKER BEIDEN MARKERENBOEK NAAR DE STAPEL “ WEGZETTEN” EN DIT PAPIER OP STAPEL “ KLAAR ”
ZIT NIET IN ADLIBNAAR STAPEL “ OPZOEKEN VIA BOOKWHERE ”
GEVONDEN IN BOOKWHERE DOOR ……..NAAR STAPEL “ GEVONDEN IN BOOKWHERE ” EEN PAAR DAGEN WACHTEN EN DANRECORD TOEVOEGEN IN ADLIB IN MONO-, ANTHO OF BOOK D OOR ONTLENEN AANBESTEL EN INDIEN MONOGRAPH, DAN OOK FOTOGRAAF INVUL LEN RESP. MAKENGECATALOGISEERD DOOR ………LABEL WORDT: …. ….. …… ……. ……. ……. ……. …….VERDER NAAR STAPEL “ LABEL MAKEN ”LABEL GEMAAKTNAAR STAPEL “ OMSLAG SCANNEN ”OMSLAG GESCAND – EVENTUEEL OMSLAG VERWIJDEREN EN WEGLEGGEN, EN MET GELE MARKER BEIDEN MARKERENBOEK NAAR DE STAPEL “ WEGZETTEN” EN DIT PAPIER OP STAPEL “ KLAAR ”
NIET GEVONDEN IN BOOKWHERENAAR STAPEL “ NIET GEVONDEN IN BOOKWHERE ”DE STAPEL “ NIET GEVONDEN IN BOOKWHERE ”WORDT VERDEELD IN BOEKEN MET EEN HOGE OF LAGE PRIORITEIT. DE STAPEL MET HOGE PRIORIT EIT WORDT ORIGINEEL GECA-TALOGISEERD EN DE LAGE PRIORITEIT VERHUIST NAAR HET DEPOT.
LAGE PRIORITEITBIJ LAGE PRIORITEIT DIT BOEK METEEN AFLEGGEN NAAR D EPOT AFDELING “ NIET GE-VONDEN IN BOOKWHERE ” EN DIT PAPIER IN DE ORDNER ” KLAAR ”
HOGE PRIORITEITBIJ HOGE PRIORITEIT, BOEK ORIGINEEL CATALOGISERENBOEK NAAR STAPEL “ TE CATALOGISEREN ”GECATALOGISEERDLABEL WORDT: ……. ……….. ………….. …………….NAAR STAPEL “LABEL MAKEN”LABEL GEMAAKTNAAR STAPEL “OMSLAGEN SCANNEN”GESCANDNAAR STAPEL “WEGZETTEN” EN DIT PAPIER NAAR STAPEL “ KLAAR”


















