
Crypto Museum · 2014. 9. 9. · Created Date: 1/19/1998 4:12:35 PM

Jeroen Van Cleemput
crypto-analyseVerdedigingsmechanismen tegen micro-architecturale
Academiejaar 2008-2009Faculteit IngenieurswetenschappenVoorzitter: prof. dr. ir. Jan Van CampenhoutVakgroep Elektronica en informatiesystemen
Master in de ingenieurswetenschappen: computerwetenschappen Masterproef ingediend tot het behalen van de academische graad van
Begeleider: Bart CoppensPromotoren: prof. dr. ir. Koen De Bosschere, prof. dr. ir. Bjorn De Sutter

Voorwoord
Ik wil graag van de gelegenheid gebruik maken om mijn promotor, Prof. Dr. Ir. B. De Sutter,
en begeleider, Lic. B. Coppens, te bedanken voor de goede samenwerking. Ik kon steeds bij
hen terecht met vragen en voor feedback. Daarnaast had ik ook graag mijn promotor bedankt
voor het nalezen van mijn scriptie en het verschaffen van deskundig advies. Mijn ouders bedank
ik vervolgens voor de kans die ze me gaven om Computerwetenschappen te studeren, alsook
voor hun onvoorwaardelijke steun gedurende het schrijven van deze scriptie. Bovendien wil ik
iedereen, al dan niet expliciet vermeld, bedanken voor de steun gedurende mijn studies.
Jeroen Van Cleemput, mei 2009

Toelating tot bruikleen
“De auteur geeft de toelating deze scriptie voor consultatie beschikbaar te stellen en delen van
de scriptie te kopieren voor persoonlijk gebruik.
Elk ander gebruik valt onder de beperkingen van het auteursrecht, in het bijzonder met betrek-
king tot de verplichting de bron uitdrukkelijk te vermelden bij het aanhalen van resultaten uit
deze scriptie.”
Jeroen Van Cleemput, mei 2009

Verdedigingsmechanismen tegen
micro-architecturale crypto-analysedoor
Jeroen Van Cleemput
Scriptie ingediend tot het behalen van de academische graad vanburgerlijk ingenieur in de computerwetenschappen
Academiejaar 2008–2009
Promotor(s): Prof. Dr. Ir. B. DE SUTTER, Prof. Dr. Ir. K. DE BOSSCHEREScriptiebegeleider: Lic. B. COPPENS
Faculteit Toegepaste WetenschappenUniversiteit Gent
Vakgroep Elektronica en InformatiesystemenVoorzitter: Prof. Dr. Ir. J. VAN CAMPENHOUT
Samenvatting
Variabele uitvoeringstijd van programma’s is een bekend nevenkanaal voor micro-architecturalecrypto-analyse. Deze paper bespreekt drie compilertransformaties die de variatie in uitvoerings-tijd van enkele x86 instructies reduceren of elimineren.
Trefwoorden
crypto-analyse, compilertransformaties

Defense Mechanisms Against Micro-ArchitecturalCryptanalysis
Jeroen Van Cleemput
Supervisor(s): Bjorn De Sutter, Koen De Bosschere, Bart Coppens
Abstract—Variable program execution time is a well known side channelfor micro-architectural cryptanalysis. In addition to exi sting transforma-tions based on if-conversion this extended abstract suggests three additionaltransformations in the compiler backend that reduce or solve the variableexecution time of certain instructions for the x86 architecture. For the in-teger division instruction we suggest a transformation to remove variationin execution time due to early exit that is significantly faster than existingtechniques. Variable execution time due to load bypassing in the pipeline ismitigated by adding an artificial delay between a store and load instruction,this way load bypassing does not take place. Finally, an improved methodfor allocating dummy memory locations for load and store instructions inif-converted code is explained.
Keywords—micro-architectural cryptanalysis, compiler transformations
I. I NTRODUCTION
MICRO-ARCHITECTURAL cryptanalysis, unlike conven-tional cryptanalysis, is not about theoretical analysis of
cryptographic algorithms. Instead it uses extra information thatis not available in mathematical models. It observes the behav-ior of architectural components, signals and other properties likeexecution time. These side channels will show different proper-ties depending on the state a program is in. This knowledgecan be used to obtain more information about the current stateof the program. Because the state of the program at a certaintime depends on the input these side channels can effectivelybe used to obtain the original input or secret keys of encryptionalgorithms[5].
Coppens et al [1] have already proposed methods to eliminateall dependencies on secret keys from the control flow of a pro-gram, and in this paper we will propose new techniques to elim-inate timing-related dependencies from the data flow. Each ar-chitecture implements hardware components in a different way,therefor mitigation techniques against micro-architectural at-tacks can be very architecture specific. In this paper the focuslies on the x86 architecture, and more specific the Intel Core2platform. I will suggest three improvements focused on closingthe execution time of a program as a side channel.
II. VARIABLE LATENCY INTEGERDIVISION INSTRUCTIONS
. Integer division instructions on the Intel Core2 platformmakeuse of “early exit”[2]. The division has a variable execution timedepending on its operands. The necessary processor cycles arecomputed in advance and the division exits when this numberof cycles is reached. This can cause variable program executiontime if the divisions are dependant on program input.
. One possible solution is to make sure the variable latency ofthe division instruction does not affect the overall program ex-ecution time. For this we execute dummy code with a fixedexecution time in parallel with the integer division. Then guard
code is added to force the dummy code and the original divi-sion to run in parallel and to make sure the instructions after thedivision depend on both the dummy code and the original divi-sion. This way the following instructions will always have towait for the longest execution time, which will be the dummycode. If the dummy code uses one of the division operands asinput there is no need for guard code before the division. Andifthe result of the dummy code is 1, a simple multiplication withthe result of the original division can serve as guard code afterthe division. See fig. 1. This technique still allows a resource
Fig. 1. Dummy code is executed in parallel with the original division. Thenumber of multiplications in the dummy code needs to be determined foreach variable latency instruction.
contention side-channel attack [1]. An attacker can calculate in-teger divisions in second thread. The variable execution time ofthe divisions in the first thread will influence the amount of di-visions per timespan that can be calculated in the second thread.
. The transformation was tested on a modular exponentiational-gorithm with four different input sets[1]. 8 multiplications needto be added to 32bit code and 14 to 64bit code to be confidentthat there is no variation in execution time for the different sets.A 109% increase in execution time was measured an 78% in-crease for 64 bit code.
III. T HE PIPELINE BEHAVIOR OF LOAD INSTRUCTIONS
. Variable execution time can occur when a store instructionisfollowed by a load. If the memory disambiguation predictor [3]detects no dependency between the two memory addresses used,the load does not have to wait until the store finishes. The loadcan bypass the store instruction to obtain faster executiontimes.
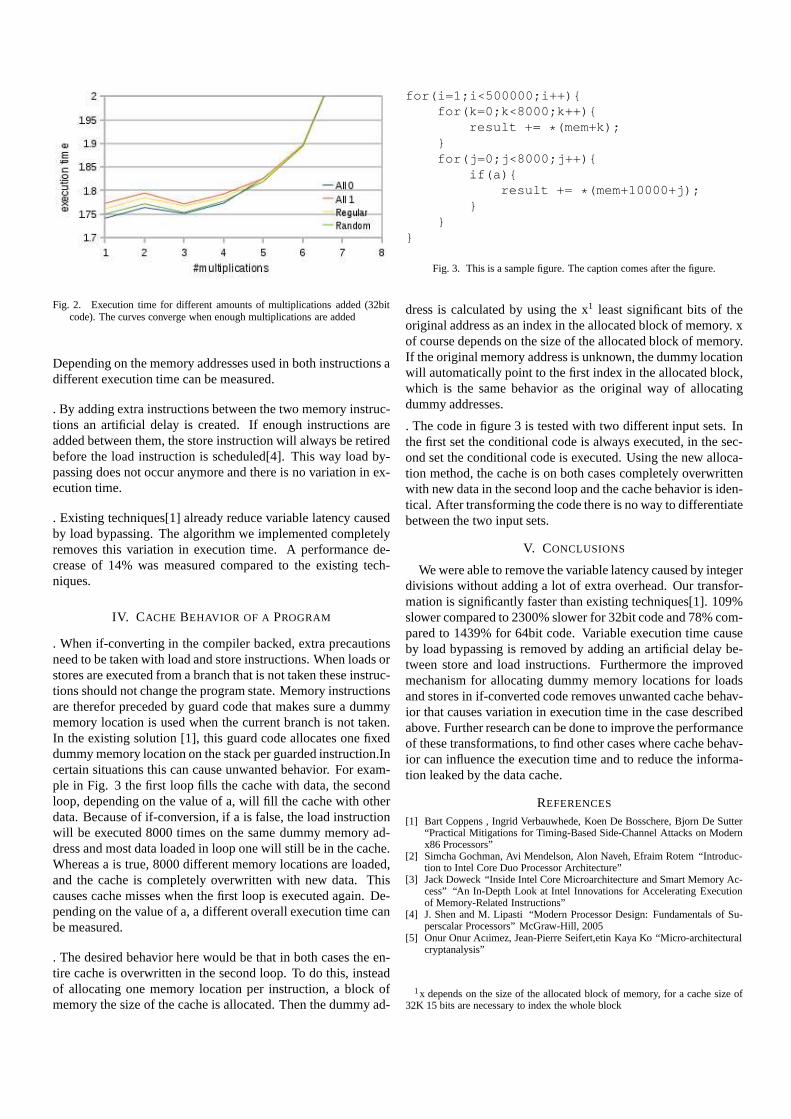
Fig. 2. Execution time for different amounts of multiplications added (32bitcode). The curves converge when enough multiplications areadded
Depending on the memory addresses used in both instructionsadifferent execution time can be measured.
. By adding extra instructions between the two memory instruc-tions an artificial delay is created. If enough instructionsareadded between them, the store instruction will always be retiredbefore the load instruction is scheduled[4]. This way load by-passing does not occur anymore and there is no variation in ex-ecution time.
. Existing techniques[1] already reduce variable latency causedby load bypassing. The algorithm we implemented completelyremoves this variation in execution time. A performance de-crease of 14% was measured compared to the existing tech-niques.
IV. CACHE BEHAVIOR OF A PROGRAM
. When if-converting in the compiler backed, extra precautionsneed to be taken with load and store instructions. When loadsorstores are executed from a branch that is not taken these instruc-tions should not change the program state. Memory instructionsare therefor preceded by guard code that makes sure a dummymemory location is used when the current branch is not taken.In the existing solution [1], this guard code allocates one fixeddummy memory location on the stack per guarded instruction.Incertain situations this can cause unwanted behavior. For exam-ple in Fig. 3 the first loop fills the cache with data, the secondloop, depending on the value of a, will fill the cache with otherdata. Because of if-conversion, if a is false, the load instructionwill be executed 8000 times on the same dummy memory ad-dress and most data loaded in loop one will still be in the cache.Whereas a is true, 8000 different memory locations are loaded,and the cache is completely overwritten with new data. Thiscauses cache misses when the first loop is executed again. De-pending on the value of a, a different overall execution timecanbe measured.
. The desired behavior here would be that in both cases the en-tire cache is overwritten in the second loop. To do this, insteadof allocating one memory location per instruction, a block ofmemory the size of the cache is allocated. Then the dummy ad-
for(i=1;i<500000;i++){for(k=0;k<8000;k++){
result += *(mem+k);}for(j=0;j<8000;j++){
if(a){result += *(mem+10000+j);
}}
}
Fig. 3. This is a sample figure. The caption comes after the figure.
dress is calculated by using the x1 least significant bits of theoriginal address as an index in the allocated block of memory. xof course depends on the size of the allocated block of memory.If the original memory address is unknown, the dummy locationwill automatically point to the first index in the allocated block,which is the same behavior as the original way of allocatingdummy addresses.
. The code in figure 3 is tested with two different input sets. Inthe first set the conditional code is always executed, in the sec-ond set the conditional code is executed. Using the new alloca-tion method, the cache is on both cases completely overwrittenwith new data in the second loop and the cache behavior is iden-tical. After transforming the code there is no way to differentiatebetween the two input sets.
V. CONCLUSIONS
We were able to remove the variable latency caused by integerdivisions without adding a lot of extra overhead. Our transfor-mation is significantly faster than existing techniques[1]. 109%slower compared to 2300% slower for 32bit code and 78% com-pared to 1439% for 64bit code. Variable execution time causeby load bypassing is removed by adding an artificial delay be-tween store and load instructions. Furthermore the improvedmechanism for allocating dummy memory locations for loadsand stores in if-converted code removes unwanted cache behav-ior that causes variation in execution time in the case describedabove. Further research can be done to improve the performanceof these transformations, to find other cases where cache behav-ior can influence the execution time and to reduce the informa-tion leaked by the data cache.
REFERENCES
[1] Bart Coppens , Ingrid Verbauwhede, Koen De Bosschere, Bjorn De Sutter“Practical Mitigations for Timing-Based Side-Channel Attacks on Modernx86 Processors”
[2] Simcha Gochman, Avi Mendelson, Alon Naveh, Efraim Rotem“Introduc-tion to Intel Core Duo Processor Architecture”
[3] Jack Doweck “Inside Intel Core Microarchitecture and Smart Memory Ac-cess” “An In-Depth Look at Intel Innovations for Accelerating Executionof Memory-Related Instructions”
[4] J. Shen and M. Lipasti “Modern Processor Design: Fundamentals of Su-perscalar Processors” McGraw-Hill, 2005
[5] Onur Onur Acıimez, Jean-Pierre Seifert,etin Kaya Ko “Micro-architecturalcryptanalysis”
1x depends on the size of the allocated block of memory, for a cache size of32K 15 bits are necessary to index the whole block

INHOUDSOPGAVE i
Inhoudsopgave
1 Inleiding 1
1.1 Cryptografie en crypto-analyse . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1
1.2 Micro-architecturale crypto-analyse . . . . . . . . . . . . . . . . . . . . . . . . . . 2
1.3 Bestaande verdedigingstechnieken . . . . . . . . . . . . . . . . . . . . . . . . . . . 4
1.3.1 Blinding . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4
1.3.2 Hardware . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4
1.3.3 Broncode . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5
1.3.4 Compiler . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5
1.4 Probleemstelling . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6
1.5 Doel . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6
1.6 Overzicht thesis . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6
2 Onderzoekscontext thesis 8
2.1 Controleverloop van een programma . . . . . . . . . . . . . . . . . . . . . . . . . 8
2.2 If-conversie . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9
2.2.1 Lussen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 12
2.2.2 Geheugeninstructies . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 12
2.2.3 Functieoproepen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 12
2.2.4 x86 ISA . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
2.3 Architectuur . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
2.3.1 Low level virtual machine . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
2.4 Terkortkomingen van bestaande technieken . . . . . . . . . . . . . . . . . . . . . 15
2.5 Verloop thesis . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16

INHOUDSOPGAVE ii
3 Variabele uitvoeringstijd van delingsinstructies 17
3.1 Early Exit . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17
3.2 Verifieren van variabele uitvoeringstijd . . . . . . . . . . . . . . . . . . . . . . . . 18
3.3 Bestudeerde oplossingen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 20
3.3.1 Oplossing 1: Tijd van de deling constant maken . . . . . . . . . . . . . . . 20
3.3.2 Oplossing 2: Tijd van de deling geen rol laten spelen . . . . . . . . . . . . 21
3.4 Implementatie . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 25
3.5 Resultaten . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 25
4 Geheugenafhankelijkheden 30
4.1 Afhankelijkheden tussen geheugenadressen . . . . . . . . . . . . . . . . . . . . . . 30
4.1.1 Memory disambiguation en load bypassing . . . . . . . . . . . . . . . . . . 30
4.1.2 Verificatie van bestaande resultaten . . . . . . . . . . . . . . . . . . . . . 32
4.2 Bestudeerde oplossingen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 36
4.3 Implementatie . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 42
4.4 Resultaten . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 47
5 Cachegedrag 49
5.1 Cachegeheugen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 49
5.2 Invloed van cachegeheugen op uitvoeringstijd . . . . . . . . . . . . . . . . . . . . 49
5.3 Bestudeerde oplossingen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 51
5.4 Implementatie . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 53
5.5 Resultaten . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 53
6 Besluit en toekomstperspectieven 55
A Detailed information 57
A.1 CPU Details . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 57
A.2 Cache Details . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 59

INLEIDING 1
Hoofdstuk 1
Inleiding
1.1 Cryptografie en crypto-analyse
Crypto-analyse is een techniek in de cryptografie waarin men probeert geencrypteerde infor-
matie te ontcijferen, of de geheime sleutel van een algoritme te achterhalen. Crypto-analyse is
zeker geen recente ontwikkeling. Zo werden bijvoorbeeld tijdens de tweede wereldoorlog crypto-
analysetechnieken toegepast op de Enigma codeermachine. Deze gedecodeerde informatie had
een grote invloed op het verdere verloop van de oorlog. Omdat we evolueren naar een samen-
leving die meer en meer gebruik maakt van digitale technologieen is vandaag het belang van
cryptografie misschien nog veel groter. Grote hoeveelheden (persoonlijke) informatie worden
dagelijks over het internet verstuurd en steeds meer gegevens worden elektronisch opgeslaan.
De eigenaars van deze gegevens willen uiteraard dat deze informatie enkel kan bekeken worden
door bevoegde personen. Met andere woorden, de gebruikte encryptiemethodes moeten bestand
zijn tegen crypto-analysemethodes door derden. Crypto-analyse is ook niet beperkt tot enkel
encryptiealgoritmes, maar kan bijvoorbeeld ook toegepast worden op authenticatie- en authori-
satieprotocols. Zo kan een aanvaller zich voordoen als een van twee communicerende personen
zonder dat de andere dit door heeft. Crypto-analysten houden zich dus bezig met het zoeken van
zwakke punten in cryptografische algoritmes, en proberen aan de hand van deze zwakke punten
een aanval op te stellen. Het gaat dus om algemene theoretische en wiskundige analyses van
algoritmes. Bijvoorbeeld hoeveel tijd nodig is om een 1024 bit RSA modulus te factoriseren[14].

1.2 Micro-architecturale crypto-analyse 2
1.2 Micro-architecturale crypto-analyse
Conventionele crypto-analyse is gebaseerd op de theorie. Men gaat er van uit dat alle algoritmes
worden uitgevoerd op een abstracte Turing machine. In de praktijk is dit echter niet het geval.
De algoritmes worden uitgevoerd op een computer die beperkt is door de restricties van de
hardware waaruit hij is opgebouwd. Wanneer programma’s worden uitgevoerd laten ze een spoor
na in de verschillende signalen en componenten van de architectuur. Ook kan er een verschil
in waarneembaar gedrag worden gezien. De uitvoeringstijd bijvoorbeeld van een algoritme.
Deze sporen verschillen naargelang de invoer van het algoritme. Naargelang de invoer van het
programma zal een ander uitvoeringspad genomen worden in de code en zullen dus ook andere
instructies worden uitgevoerd. Dit wordt het controleverloop van het programma genoemd.
Als het algoritme bijvoorbeeld een waarde uit het geheugen nodig heeft wordt deze waarde
bijgehouden in het cachegeheugen van de architectuur, waardoor eventueel andere gegevens eerst
uit de cache moeten verwijderd worden om plaats te maken. Afhankelijk van de input van het
algoritme kan een andere waarde geladen worden, waardoor de cache zich in een verschillende
toestand zal bevinden. Een sprong in de code kan dan weer een wijziging veroorzaken in de
interne toestand van de sprongvoorspeller. De componenten, signalen en het waarneembare
gedrag waaruit informatie kan afgeleid worden over de interne toestand van een algoritme of
programma worden nevenkanalen genoemd. Door het observeren van de nevenkanalen kan men
dus extra informatie afleiden over de interne toestand van een algoritme dan wat in de theorie
mogelijk is. Micro-architecturale cryptanalyse gaat over de technieken om deze nevenkanalen te
observeren en zo meer informatie te verzamelen over de huidige toestand van het algoritme, de
sleutel en de invoer.
Micro-architecturale cryptanalyse werd eerst toegepast op relatief eenvoudige architecturen
zoals de smartcard. Door zijn klein rekenvermogen zijn variaties in uitvoeringstijd hier heel
duidelijk. Omdat de smartcard ook meestal fysisch in dezelfde ruimte aanwezig is als de aanvaller
kunnen nevenkanalen zoals elektromagnetische velden[16] en warmteontwikkeling ook gebruikt
worden. Meer recent werden ook technieken ontwikkeld die kunnen toegepast worden op huidige
algemeen toepasbare computerarchitecturen zoals de Intel processoren.
Hoe gaat een aanvaller nu juist te werk bij een micro-architecturale aanval[6]? De aanvallen
hier beschreven veronderstellen dat de aanvaller toegang heeft tot de machine waar de aan-
val wordt uitgevoerd (zowel fysiek als via secure shell), alhoewel hier ook uitzonderingen op

1.2 Micro-architecturale crypto-analyse 3
bestaan[15].
Een van de meer eenvoudige aanvallen is de datacache-aanval. Een cache is een buffer
tussen de processor en het hoofdgeheugen1. De toegangstijd tot de cache is veel sneller dan het
hoofdgeheugen. Wanneer de processor gegevens nodig heeft zal hij eerst controleren als ze niet
in de cache aanwezig zijn, voor het hoofdgeheugen aan te spreken. Encryptiealgoritmes zoals
AES (Advanced Encryption Standard) maken gebruik van een lookuptabel[14] die zich in het
geheugen bevindt. Wanneer gegevens uit deze lookuptabel worden gelezen worden die ook in
de datacache gekopieerd, zodat ze de volgende keer sneller toegankelijk zijn. De aanvaller zal
dan proberen gelijktijdig met de encryptiedraad een eigen draad op te starten. Wanneer een
aanvaller in een tweede draad gegevens uit een voldoende grote array leest zal de cache enkel
gegevens van de aanvaller bevatten. Als de tweede draad de processor weer vrijgeeft zal het
encryptiealgoritme weer delen van de cache overschrijven door gegevens uit de lookuptabel te
halen. Wanneer de controle weer wordt overgedragen naar de tweede draad, kan de aanvaller
door te meten hoe lang het duurt om elk gegeven uit de array te lezen als de gegevens zich
nog in de cache bevinden. Op deze manier kan de aanvaller weten welke gegevens in de cache
overschreven zijn door het encryptiealgoritme en dus welke gegevens uit de lookuptabel zijn
gebruikt. Als een aanvaller informatie kan verzamelen uit verschillende uitvoeringen van AES
met dezelfde sleutel, is het eenvoudig om hieruit de geheime sleutel af te leiden.
Een aanval op de instructiecache is gelijkaardig aan een datacache-aanval. De instructiecache
werkt zoals de datacache maar dan enkel voor instructies. Hier wordt echter informatie over het
controleverloop van het programma verzameld. Het controleverloop is het pad in de code die
wordt uitgevoerd (zie Figuur 2.1). Dit is afhankelijk van de invoer van het algoritme. Wanneer
informatie kan verzameld worden over het controleverloop levert dit dus ook informatie op
over de geheime sleutel. Een aanvaller zal in een tweede thread dummyinstructies uitvoeren.
Vervolgens wordt controle overgedragen aan het encryptiealgoritme. Wanneer de draad van de
aanvaller controle terug krijgt kan hij door te meten hoelang het duurt om elke instructie uit
te voeren informatie verzamelen over de instructies uitgevoerd in het encryptiealgoritme en dus
het controleverloop en uiteindelijk de geheime sleutel.
Een aanval op de sprongvoorspeller is al iets minder eenvoudig. Een van de krachtigste
aanvallen is de simple branch predition attack (SBPA)[17]. Deze aanval gebruikt de branch
target buffer (BTB)[18] om informatie te verzamelen. De BTB houdt voor elke spronginstructie1zie hoofdstuk 5 voor een gedetailleerde bespreking

1.3 Bestaande verdedigingstechnieken 4
informatie bij. Wanneer de data over een instructie niet aanwezig is in de BTB zal de sprongin-
tructie langer uitvoeren. Deze vertraging kan gemeten worden door een aanvaller. Hier kan een
aanvaller niet zoals in de vorige aanvallen zomaar dummycode uitvoeren of dummywaarden uit
het geheugen lezen. Een specifieke sequentie van intructies is nodig om misses te forceren in de
BTB.
1.3 Bestaande verdedigingstechnieken
Het doel van de verdedigingstechnieken is altijd dezelfde: Het afsluiten van de nevenkanalen.
Het is de bedoeling ervoor te zorgen dat er geen verschil meer kan gemeten worden op de
nevenkanalen wanneer een programma verschillende invoer verwerkt. Ongeacht de input moet
een nevenkanaal hetzelfde gedrag vertonen. Maar hoe worden programma’s nu beveiligd tegen
micro-architecturale crypto-analyse? Hier bestaan reeds een aantal technieken voor, deze kan je
opsplitsen in vier categorieen.
1.3.1 Blinding
Blinding[8] is een techniek die er voor zorgt dat het encryptiealgoritme nooit te maken heeft
met de echte input of output. Stel dat f() een encryptie functie is en we willen y = f(x)
berekenen. Eerst wordt een blinding functie E(x) toegepast op de invoer. Daarna wordt de
invoer geencrypteerd f(E(x). Tenslotte wordt de output van het algoritme gedecodeerd zodat
D(f(E(x))) = y 2. Het encryptiealgoritme wordt nooit uitgevoerd op de originele input. Een
aanvaller kan via nevenkanalen dan ook enkel informatie verzamelen over de geblindeerde invoer,
waar hij niet veel mee is. Uiteraard moet het blinding algoritme wel bestand zijn tegen micro-
architecturala crypto-analyse.
1.3.2 Hardware
Een manier om zich te verdedigen tegen micro-architecturale cryptanalyse is hardware zelf aan-
passen. De hardware wordt zodanig aangepast dat het niet meer mogelijk is om deze als een
nevenkanaal te gebruiken. Een relatief eenvoudig voorbeeld hiervan is de data cache uit schake-
len. Op deze manier zal elke geheugentoegang even lang duren en kan hieruit geen informatie
worden afgeleid. De entropie van de uitvoeringstijd is dan namelijk 0, en bevat volgens de2Bron: wikipedia

1.3 Bestaande verdedigingstechnieken 5
informatietheorie geen informatie. Op gespecialiseerde hardware voor cryptografische toepas-
singen worden de micro-architecturale componenten die op conventionele architecturen informa-
tie “lekken” anders geımplementeerd. Een voorbeeld hiervan is de AES (Advanced Encryption
Standard) instructieset van Intel [9]. Dit zijn zes instructies die volledige hardwareondersteuning
voor AES-encryptie ondersteunen. Waar conventionele encryptiealgoritmes een look-uptabel in
het geheugen raadplegen, worden hier gespecialiseerde instructies gebruikt. Vier voor encryptie
en decryptie en twee voor het sleuteluitbreidingsalgoritme. Deze instructies hebben een vaste
data-onafhankelijke uitvoeringstijd. Bovendien worden encryptie en decryptie volledig in hard-
ware uitgevoerd en zijn er geen geheugentoegangen nodig. Dit elimineert de data cache als
nevenkanaal. Dit is echter niet de focus van mijn thesis en ik zal mij daarom ook beperken tot
deze korte inleiding.
1.3.3 Broncode
Het is ook mogelijk om beveiligingen tegen micro-architecturale crypto-analyse rechtstreeks in
de broncode aan te brengen [7]. Zoals in sectie 1.2 al vermeld, wordt een verschillend pad in de
code gekozen naargelang de invoer. Deze technieken zijn voornamelijk gericht op het aanpassen
van het controleverloop van een programma in de broncode. Een voorbeeld hiervan is een
techniek voorgesteld in de paper “The program counter security model: Automatic detection
and removal of control-flow side channel attacks”[7]. Door het gebruiken van bitmasks kan
men alle controlestructuren uit de broncode verwijderen. Dit is echter ook niet de focus van
mijn thesis en voor een gedetailleerde uitleg van deze techniek verwijs ik naar [7]. Een van de
grootste nadelen van deze techniek is dat er een kans bestaat dat de uitgevoerde transformaties op
niveau van de broncode later worden weggeoptimaliseerd door de compiler. In het artikel wordt
vermeld dat de gegenereerde code nog moet geverifieerd worden om een sleutelonafhankelijk
controleverloop te garanderen. Meer nadelen van deze techniek staan beschreven in [2].
1.3.4 Compiler
De rest van mijn thesis zal handelen over compilertechnieken die gebruikt kunnen worden om te
verdedigen tegen crypto-analyseaanvallen. Aanpassen van een compiler heeft een aantal voorde-
len ten opzichte van de vorige technieken. Eerst en vooral is er geen nood aan nieuwe hardware.
Dit is zeer wenselijk omdat dan reeds bestaande architecturen kunnen gebruikt worden voor be-
veiligde cryptografische programma’s. Er moet dus geen gespecialiseerde hardware ontworpen

1.4 Probleemstelling 6
worden, wat de kosten van een project enorm kan drukken. Ook beschikt men over het volledig
gamma van optimalisaties van de compiler. Terwijl transformaties in de broncode kunnen teniet
gedaan worden door compileroptimalisaties, worden de transformaties hier pas uitgevoerd na-
dat de compiler de code heeft geoptimaliseerd. De transformties kunnen dus worden toegepast
zonder dat men zich zorgen moet maken dat deze weer weggeoptimaliseerd worden door de com-
piler. Dit kan er voor zorgen dat de prestatie iets hoger ligt dan bij broncodetransformatie, waar
men een aantal compileroptimalisaties zal moeten uitschakelen. Het is natuurlijk niet nodig om
de volledige code van een programma te transformeren. Enkel de code die afhankelijk is van
de input van het algoritme moet getransformeerd worden. De code voor de gebruikersinterface
heeft bijvoorbeeld totaal geen invloed op de prestatie van het encryptiealgoritme. In de praktijk
komt dit er op neer dat de programeur met behulp van annotaties zal aanduiden welke delen
van de code moeten getransformeerd worden.
1.4 Probleemstelling
Micro-architecturale crypto-analyse maakt het mogelijk om gemakkelijker geheime informatie
te achterhalen dan mogelijk is met conventionele crypto-analyse methodes. Zeker met de toe-
nemende digitalisering van de maatschappij is het belangrijk om cryptogragische algoritmes
hiertegen te beveiligen.
1.5 Doel
Het doel van mijn thesis is te kijken in hoeverre het mogelijk is om software aan te passen
om zich te verdedigen tegen micro-architecturale crypto-analyse. Er is reeds onderzoek gedaan
naar verdedigingstechnieken tegen micro-archtitecturale crypto-analyse. Zo is reeds een techniek
ontwikkelt die het controleverloop van een programma onafhankelijk maakt van de invoer[2].
Nadat het controleverloop onafhankelijk is kan naargelang de invoer nog steeds een ander gedrag
in de nevenkanalen worden waargenomen. Mijn thesis zal zich meer richten op het elimineren
van deze data-afhankelijkheden. Hierbij ga ik mij focussen op de x86 architectuur.
1.6 Overzicht thesis
In hoofdstuk 2 wordt een overzicht gegeven van de onderzoekscontext van mijn thesis. De reeds
behaalde resultaten binnen de vakgroep en mogelijke verbeteringen worden hier besproken. Ook

1.6 Overzicht thesis 7
wordt een korte introductie gegeven tot het compilerrraamwerk dat gebruikt wordt voor de
implementatie. In volgende hoofstukken worden de drie compilertransformaties besproken. Op
het einde komt er nog een samenvatting en mogelijke toekomstperspectieven.

ONDERZOEKSCONTEXT THESIS 8
Hoofdstuk 2
Onderzoekscontext thesis
In dit hoofstuk ga ik bespreken hoe compilertransformaties kunnen worden gebruikt om een
programma te verdedigen tegen micro-architecturale crypto-analyse. In de onderzoeksgroep
werd reeds onderzoek gedaan naar verdedigingstechnieken en ik zal beginnen met een overzicht
te geven van werk dat reeds verricht is. Daarop volgt wat uitleg over het compilerraamwerk dat
wordt gebruikt en een overzicht van mijn eigen onderzoek.
2.1 Controleverloop van een programma
De transformaties die uitgevoerd worden in de compiler hebben allemaal slechts een doel: Het
afsluiten van de nevenkanalen. Dit wil zeggen dat, onafhankelijk van de input, het programma
hetzelfde gedrag toont in de nevenkanalen. Een van de nevenkanalen waar het meeste aandacht
aan zal worden besteed is de uitvoeringstijd. Een programma bestaat uit een reeks van basic
blocks. Basic blocks zijn stukken code die altijd na elkaar worden uitgevoerd. Ze hebben dus
een ingangspunt en eindigen op een branch- of returninstructie. Daartussen bevinden zich ook
geen branch of return instructies, anders zou men de basic block moeten opsplitsen in twee
basic blocks. Naargelang de waarde van de branchinstructie wordt de controle overgedragen
naar een ander basic block van het programma. Een eenvoudig voorbeeld is te zien in Figuur
2.1. Hier wordt naargelang de sprongcondities in basic block A ofwel de code in basic block B
of C uitgevoerd, alvorens de controle wordt overgedragen naar basic block D. Het is duidelijk
dat de uitvoeringstijd van een programma afhankelijk is van het controleverloop. Niet alle in-
structies hebben even veel processorcyclussen nodig en niet alle basic blocks bevatten evenveel
instructies. Naargelang de sprongvoorwaarden zal het programma dus een verschillende uitvoe-

2.2 If-conversie 9
ringstijd hebben. Dit is zelfs nog duidelijker in Figuur 2.2 waar naargelang de sprongvoorwaarde
basic block B wordt uitgevoerd, of het doorvalpad wordt genomen naar basic block C. Als de
sprongvoorwaarde dan nog eens afhankelijk is van de input van het programma, kan men dus
een andere uitvoeringstijd meten naargelang de gegevens die men wil coderen.
Figuur 2.1: Eenvoudig voorbeeld van controleverloop in een programma met basic blocks. Af-
hankelijk van conditie c wordt ofwel blok B of C uitgevoerd.
2.2 If-conversie
Om het verschil in uitvoeringstijd door gevolg van het controleverloop van een programma
te elimineren wordt een techniek van if-conversie [10][11] gebruikt. If-conversie is een tech-
niek die in compilers wordt gebruikt om controleafhankelijkheden om te zetten naar data-
afhankelijkheden. Het komt er op neer dat in plaats van basic blocks conditioneel uit te voeren
naargelang de sprongvoorwaarden, de instructies zelf conditioneel worden uitgevoerd. Het pro-
gramma wordt dus omgezet van een aantal basic blocks waartussen controle wordt overgedragen
naar een enkele basic block, waarvan de instructies conditioneel worden uitgevoerd. Dit wordt
gedaan door predikaten toe te voegen aan de instructies, die aangeven of de instructie al dan
niet moet worden uitgevoerd. Een voorbeeld van if-converie is te zien in Listing 2.1 en 2.2.
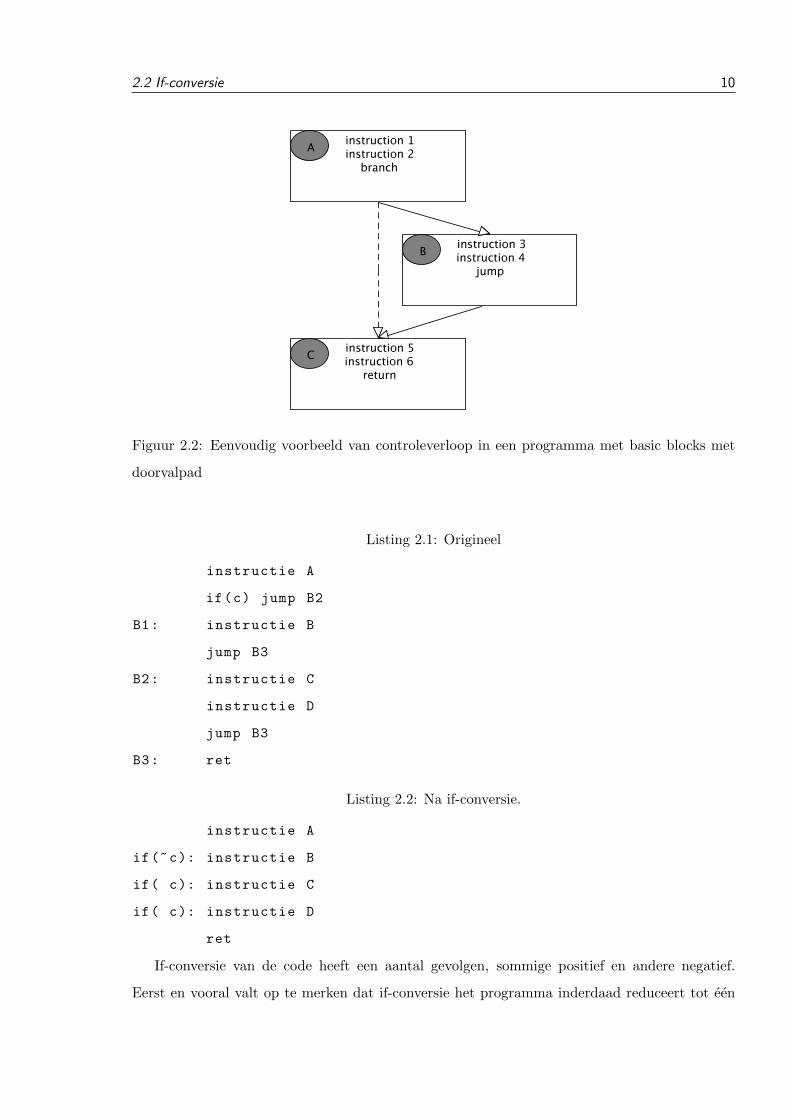
2.2 If-conversie 10
Figuur 2.2: Eenvoudig voorbeeld van controleverloop in een programma met basic blocks met
doorvalpad
Listing 2.1: Origineel
instructie A
if(c) jump B2
B1: instructie B
jump B3
B2: instructie C
instructie D
jump B3
B3: ret
Listing 2.2: Na if-conversie.
instructie A
if(~c): instructie B
if( c): instructie C
if( c): instructie D
ret
If-conversie van de code heeft een aantal gevolgen, sommige positief en andere negatief.
Eerst en vooral valt op te merken dat if-conversie het programma inderdaad reduceert tot een

2.2 If-conversie 11
Figuur 2.3: Controleverloop van het programma in Figuur 2.1 na if-conversie. Het programma
is gereduceerd tot een basic block waarin de instructies conditioneel worden uitgevoerd.
basisblok 2.3. Onafhankelijk van de input wordt dus altijd het volledige basisblok doorlopen
zonder dat de controle wordt overgedragen door spronginstructies. Er zijn dus geen sprongen
meer die afhankelijk zijn van de invoer (behalve voor lussen, maar dit wordt later besproken).
De sprongvoorspeller kan bij gevolg niet meer gebruikt worden als nevenkanaal. Zoals eerder
uitgelegd houdt de sprongvoorspeller voor elke spronginstructie een teller bij die aanduidt als
de sprong al dan niet wordt genomen. Als er geen sprongen meer voorkomen in de code kan de
sprongvoorspeller uiteraard ook geen informatie meer lekken over de interne toestand van het
programma. De gepredikeerde instructies verbruiken ook altijd evenveel processortijd, ongeacht
welke waarde hun predikaat heeft. De uitvoeringstijd van het basicblok zou dus constant moeten
zijn, en op een aantal instructies na is dit ook zo. De uitzonderingen hier zijn instructies met
variabele uitvoeringstijd, deze worden verder besproken. De reden waarom if-conversie niet altijd
wordt toegepast in compiler heeft te maken met het grootste nadeel, namelijk het prestatieverlies.
Het doel van een compiler is om het programma zo performant mogelijk te maken. If-conversie
doet eigenlijk juist het omgekeerde. In plaats van zo weinig mogelijk instructies zo snel mogelijk
uit te voeren, worden na if-conversie alle instructies uitgevoerd, zelfs als deze niet moeten worden
uitgevoerd. Dit heeft een enorme invloed op de prestatie van een programma.
If-conversie reduceert het verschil in uitvoeringstijd en sluit het gebruiken van de sprongvoor-
speller als nevenkanaal compleet af. Daartegenover staat natuurlijk het grote prestatieverlies.
If-conversie alleen lost enkel het probleem van variabele uitvoeringstijd op door gevolg van het
controleverloop van het programma. Er zijn een aantal codestructuren die na if-conversie nog
steeds voor variabele uitvoeringstijd zorgen. In de volgende secties worden deze codestructuren
verder besproken.

2.2 If-conversie 12
2.2.1 Lussen
Een basisblok kan een lust bevatten die afhankelijk van de input van een algoritme een variabel
aantal keer worden uitgevoerd. Het is ook mogelijk dat er op elk moment uit de lus wordt
gesprongen, bijvoorbeeld met een break in een C lus. Dit soort lussen worden niet-manifeste
lussen genoemd. Deze lussen zorgen ervoor dat, zelfs na if-conversie, het programma nog steeds
een variabele uitvoeringstijd heeft. Een mogelijke oplossing hiervoor is dat de gebruiker bij een
lus een vaste bovengrens aanduidt zodat de lus altijd een vast aantal keer wordt uitgevoerd.
Als de lus bijvoorbeeld drie keer moet worden doorlopen en de bovengrens tien is, dan worden
de laatste zeven iteraties uitgevoerd met de predikaten van de instructies op vals. Er moet
wel opgemerkt worden dat niet-manifeste lussen erg weinig voorkomen in encryptiealgoritmes.
De lussen zijn meestal afhankelijk van een constante waarde in het algoritme, bijvoorbeeld een
sleutellengte. Het is echter niet altijd gemakkelijk voor de compiler om te detecteren als een
lus manifest is. Daarom kan de programeur met behulp van annotaties aanduiden als een lus al
dan niet manifest is. Omdat de meeste lussen in encryptiealgoritmes reeds manifest zijn, is het
voldoende om de lussen te annoteren.
2.2.2 Geheugeninstructies
Extra voorzorgsmaatregelen moeten genomen worden bij instructies die naar het geheugen schrij-
ven of van het geheugen lezen. Er moet voor gezorgd worden dat deze instructies een dummy
geheugenadres gebruiken als ze zich in een tak bevinden die niet moet worden uitgevoerd. Ze
zouden anders de interne toestand van het programma kunnen wijzigen, of zelfs fouten veroor-
zaken als naar ongeldige adressen wordt geschreven. Dit wordt gedetailleerder beschreven in de
hoofdstukken over geheugengedrag.
2.2.3 Functieoproepen
Als in een basisblok een functieoproep staat, moet deze altijd worden opgeroepen. Zelfs als de tak
waarin de functie oproep staat niet wordt uitgevoerd, ander zou er een verschil in uitvoeringstijd
ontstaan. De lokale variabelen in de functie mogen echter niet naar de globale variabelen van
het programma gekopieerd worden als de functie is opgeroepen in een tak die niet mag worden
uitgevoerd. Hiervoor wordt een extra argument meegegeven met de functie. Een booleaanse
waarde die aangeeft als de functie effectief moet worden uitgevoerd. Als die waarde vals, is
worden de locale variabelen niet naar de globale gekopieerd en worden loads en stores op dummy

2.2 If-conversie 13
adressen uitgevoerd. Op deze manier kan de functie uitgevoerd worden zonder dat het iets aan
de toestand van het programma verandert.
2.2.4 x86 ISA
If-conversie is een techniek die ontwikkeld werd voor VLIW architecturen [12][11]. In de vorige
voorbeelden werd ervan uitgegaan dat alle instructie conditioneel kunnen worden uitgevoerd.
Dit is echter niet het geval voor de x86 ISA. De x86 ISA beschikt slechts over een instructie die
conditioneel kan worden uitgevoerd, de conditionele move (cmov). Dit wil niet niet zeggen dat
if-conversie niet kan toegepast worden op deze architectuur. In de paper “Practical Mitigations
for Timing-Based Side-Channel Attacks on Modern x86 Processors” [2] wordt een techniek
beschreven om if-conversie toe te passen op een x86 architectuur. Zie ook Listing 2.3.
1. Vooraleer een basisblok samen te voegen ervoor zorgen dat de instructies uit het basisblok
enkel op lokale (tijdelijke) variabelen werken.
2. Voeg safeguardcode toe aan instructies die de globale toestand van het programma kunnen
veranderen als ze worden uitgevoerd. Deze safeguardcode moet ervoor zorgen dat de
instructies kunnen worden uitgevoerd ook als hun predikaat op vals staat. Denk hierbij
aan loads, stores die voor neveneffecten kunnen zorgen als ze worden uitgevoerd in een niet
genomen tak. Er moet ook voorkomen worden dat delingen door 0 worden uitgevoerd, dit
zal excepties geven en het programma crashen.
3. Voeg aan het einde van het basisblok conditionele move-instructies toe die de lokale vari-
abelen naar globale variabelen kopieeren als het pad genomen is.
Op deze manier kan if-conversie ook toegepast worden op de x86 architectuur.
Listing 2.3: If-conversie voor x86 ISA. Dit is een voorbeeld genomen uit “Practical Mitigations
for Timing-Based Side-Channel Attacks on Modern x86 Processors” [2]
tmp_a = a;
if(~c) tmp_a = dummy_location;
*tmp_a = 10;
tmp_y = y;
if ( c ) tmp_y = 1;
tmp_d = x / tmp_y;

2.3 Architectuur 14
tmp_b = 10;
if(c) d = tmp_d;
if(~c) b = tmp_b;
2.3 Architectuur
De technieken die in het vervolg van mijn thesisboek beschreven worden, zijn architectuur
specifiek. Technieken die werken op een core2 platform kunnen bijvoorbeeld totaal geen in-
voed hebben op een pentium M platform. Het komt zelfs voor dat een bepaald probleem niet
voorkomt op een ander platform. Caches kunnen een verschillende grootte hebben, of anders
geımplementeerd zijn. Instructieselectie[18] kan op een andere manier gebeuren op verschillende
platformen en sprongvoorspellers kunnen ook een totaal ander ontwerp hebben. Een algeme-
ne oplossing in software voor het probleem van micro-architecturale crypto-analyse bestaat dus
(nog) niet. Daarom is het nuttig om platform per platform te zoeken naar mogelijke oplossingen.
Een architectuurspecifieke aanpak heeft ook voordelen ten opzichte van een architectuuronaf-
hankelijke benadering [2]. Programma’s die voor een specifieke architectuur zijn gecompileerd
zullen veel performanter zijn dan een programma die architectuuronafhankelijk is gecompileerd.
Enkel de transformaties die voor de specifieke doelarchtitectuur nodig zijn, zullen worden uitge-
voerd. Dit is vergelijkbaar met de manier waarop compilers zoals gcc ook architectuurspecifieke
optimalisaties kunnen uitvoeren. Het levert extra prestatiewinst op, maar de code is niet meer
overdraagbaar naar andere architecturen. Ik heb gekozen voor het intel core2 platform omdat
dit een veel gebruikt modern platform is. Het heeft een geavanceerde geheugenarchitectuur die
zeer geschikt is voor mijn experimenten en het verifieren van reeds bestaande resultaten. Om
de architectuurspecifieke aard aan te tonen heb ik ook een aantal experimenten uitgevoerd op
een Pentium M platform om resulaten te vergelijken. Verder werden de tests uitgevoerd op een
32bit linux besturingssysteem. Zie bijlage A voor meer details over de testsetup.
2.3.1 Low level virtual machine
Voor de implementatie van de tranformaties wordt gebruik gemaakt van de Low Level Virtual
Machine (LLVM) compiler infrastructuur. Via een C/C++ front-end wordt de C-code omgezet
naar een tussentijdse representatie van de code die eigen is aan LLVM. Dit wordt de inter-
mediate representation genoemd (IR). Op deze IR worden dan de optimalisatie transformaties

2.4 Terkortkomingen van bestaande technieken 15
Figuur 2.4: Schema van de llvm architectuur, gebaseerd op een figuur in “Introduction to the
LLVM Compiler Infrastructure” [4]
uitgevoerd. Daarna wordt deze IR vertaald naar architectuuronafhankelijke machinecode waar
transformaties op machine code niveau kunnen worden uitgevoerd. Ten laatste wordt de ma-
chineonafhankelijke code omgezet naar code voor een bepaalde doelarchitectuur, waar eventueel
nog architectuurspecifieke transformaties kunnen worden uitgevoerd. Met behulp van plugins
is het mogelijk om transformaties toe te voegen aan dit compilerraamwerk. Er is reeds een
plugin ontworpen binnen de vakgroep. Deze implementeert reeds het if-conversie algoritme en
alle codestructuren uit sectie 2.2 die nog voor variatie zorgen na if-conversie. In de rest van
de tekst zal ik gewoon over de balanceringsplugin spreken. Deze transformatie, ook wel pass
genoemd, wordt uitgevoerd op niveau van de mid-level optimizer in Figuur 2.4 en wordt dus
uitgevoerd op de IR. Voor mijn eigen experimenten zal ik deze plugin uitbreiden en aanpassin-
gen maken in de codegenerator. Deze uitbreidingen zullen per transformatie in detail besproken
worden in de volgende hoofdstukken. Zoals al eerder vermeld, moeten de transformaties niet op
alle code worden uitgevoerd. Het is mogelijk om annotaties mee te geven in de broncode. De
balanceringsplugin kan dan aan de hand van die annotaties beslissen als er transformaties op
een functie moeten worden uitgevoerd. Een voorbeeld van een annotatie voor C-code is te zien
in Listing 2.4. Dit is zeker geen overzicht van alle functionaliteit van LLVM, maar slechts de
functionaliteit waarvan ik gebruik heb gemaakt voor mijn onderzoek.
Listing 2.4: Een voorbeeld van annotaties in C.
int __attribute__ (( annotate("balance"))) myFunction(int* a, int* b);
2.4 Terkortkomingen van bestaande technieken
Terwijl if-conversie de variatie in uitvoeringstijd sterk doet verminderen en het gebruik van de
sprongvoorspeller als nevenkanaal uitsluit, zijn er toch nog enkele instructies die voor variatie
kunnen zorgen. In het vervolg van mijn thesis zal ik deze instructies verder onderzoeken en
enkele mogelijke verdedigingsmechanismen voorstellen. Een overzicht van de problemen die zich

2.5 Verloop thesis 16
nog stellen na if-conversie:
• Er doen zich wel nog data-afhankelijkheden voor, namelijk instructies met een variabele
uitvoeringstijd. Een eerste voorbeeld dat ik heb onderzocht, is de deling van gehele getal-
len. De gehele deling heeft een variabele uitvoeringstijd naargelang zijn operandi. Deze
wordt besproken in hoofdstuk 3.
• Vervolgens heb je instructies die lezen of schrijven naar het geheugen, zoals load- en store-
instructies. Instructies die naar het geheugen schrijven of uit het geheugen lezen, kunnen
op twee manieren de uitvoeringstijd beınvloeden. Ten eerste kan de processor afhankelijk-
heden detecteren tussen twee opeenvolgende instructies die het geheugen aanspreken. Als
deze instructies hetzelfde geheugenadres nodig hebben, kan het zijn dat de ene instructie
op de andere moet wachten tot dat de andere instructie klaar is. Als ze niet hetzelfde ge-
heugen adres nodig hebben kunnen deze instructies eventueel parallel uitgevoerd worden.
Deze afhankelijkheden worden besproken in hoofstuk 4.
• Ten laatste zijn er ook nog afhankelijkheden die veroorzaakt worden door het cachegedrag.
Om te voorkomen dat loads en stores de toestand van een programma veranderen wanneer
ze worden opgeroepen uit een niet genomen tak wordt voor deze instructies guardcode
toegevoegd. Deze guardcode zorgt ervoor dat de instructies op dummy geheugenadressen
worden uitgevoerd. Als de tak niet genomen is, zal een store-instructie schrijven naar
een dummy locatie en als de tak wel genomen is zal de store-instructie schrijven naar de
originele geheugenlocatie. Het schrijven naar de dummy locatie kan hier dan bijvoorbeeld
een cache-miss zijn, terwijl het schrijven naar de originele geheugenlocatie een cache-hit
is. Dit is een bijkomende bron van variabiliteit in de uitvoeringstijd. Dit wordt verder in
detail besproken in hoofdstuk 5.
2.5 Verloop thesis
De basis voor technieken in verband met controleverloop was reeds gelegd, zoals gepubliceerd in
[2]. Enkele ideen uit deze thesis werden reeds opgenomen in [2] tijdens revisie van dat artikel.
Ik zal telkens expliciet vermelden welke ideen ik zelf aangebracht heb, en welke niet.

VARIABELE UITVOERINGSTIJD VAN DELINGSINSTRUCTIES 17
Hoofdstuk 3
Variabele uitvoeringstijd van
delingsinstructies
In dit hoofdstuk wordt de gehele delingsinstructie in meer detail besproken. Afhankelijk van
zijn operandi heeft de deling een andere uitvoeringstijd. Dit biedt nog mogelijkheden om de uit-
voeringstijd van een programma als nevenkanaal te gebruiken. Zeker ook omdat cryptografische
algoritmes veel gebruik maken van gehele delingen, denk bijvoorbeeld aan modulo-bewerkingen
in modulaire exponentiatie. Er worden twee soorten oplossingen voorgesteld. In de eerste wordt
ervoor gezorgd dat de uitvoeringstijd van de deling constant is. De tweede oplossing zorgt er-
voor dat de variabele uitvoeringstijd geen invloed heeft op de totale uitvoeringstijd van een
programma.
3.1 Early Exit
De gehele delinginstructies op de Core2 duo hebben geen constante uitvoeringstijd [1]. Ze maken
gebruik van mogelijkheden tot ’early exit’. Het aantal cyclussen die nodig is om de deling te
berekenen wordt op voorhand bepaald en de deling wordt dan vervroegd afgerond als dit aantal
cyclussen is bereikt. Dit zorgt er niet voor dat de maximum uitvoeringstijd van de deling
vermindert, maar de gemiddelde uitvoeringstijd van een aantal random delingen zal wel dalen.
Omdat de uitvoeringstijd van de gehele deling afhankelijk is van zijn operandi en de operandi
mogelijks afhankelijk zijn van de programmainvoer kan de totale uitvoeringstijd nog altijd kan
varieren. Testen tonen aan dat op het pentium M platform geen early exit optreedt. Early exit
is dus specifiek voor het core2 duo platform.

3.2 Verifieren van variabele uitvoeringstijd 18
3.2 Verifieren van variabele uitvoeringstijd
Eerst en vooral ben ik begonnen met het verifieren of er wel degelijk een early exit optreedt
bij deling van gehele getallen op de Core2 Duo processor. Hiervoor heb ik een stukje C-code
geschreven zoals in Listing 3.1. De resultaten van de code voor gehele getallen (sdiv) voor
verschillende delers en deeltallen is te zien op Figuur 3.1 1. Op het eerste zicht treedt een early
exit op wanneer het deeltal kleiner is dan de deler. Meer specifiek kan dat verklaard worden
door te kijken naar de binaire representatie van deler en deeltal.
Figuur 3.1: Early Exit bij delingen van gehele getallen. Deze figuur stelt een 100x99 matrix voor
van uitvoeringstijden van gehele delingen. Horizontaal staan de deeltallen, vertikaal de delers.
Delingen in het rode oppervlak gebruiken geen early exit, delingen in het groene oppervlak wel.
Als het deeltal dus voldoende groter is dan de deler, treedt er een early exit op. Een uitzondering
hierop is de deling door 1, die altijd early exit gebruikt.
Door Figuur 3.1 te bestuderen kan een patroon afgeleid worden om te bepalen wanneer een
early exit zal optreden: Er wordt gekeken naar de meest significante 1 bit van deler en deeltal
van de deling. Als de meest significante 1 bit van het deeltal minder significant is dan de meest1Uitvoeringstijden voor positieve gehele getallen (natuurlijke getallen) zijn vergelijkbaar.

3.2 Verifieren van variabele uitvoeringstijd 19
significante van de deler, dan treedt er een early exit op. Als de deler dus voldoende groter is
dan het deeltal, zal er een early exit optreden.6396 → early exit6496 → geen early exit
Binaire representatie van de getallen:
96 : 1100000
64 : 1000000
63 : 0111111
Listing 3.1: C-code om early exit te testen.
unsigned int unsigned_division_test(unsigned int a,unsigned int b){
int i,j=0;
for(i=0;i <1000000000;i++){
j+= (a/b);
}
return j;
}
int signed_division_test(int a,int b){
int i,j=0;
for(i=0;i <100000000;i++){
j+= (a/b);
}
return j;
}

3.3 Bestudeerde oplossingen 20
3.3 Bestudeerde oplossingen
3.3.1 Oplossing 1: Tijd van de deling constant maken
Deling uitwerken in apparte functie
Een eerste optie die reeds bestaat, is de deling uit te werken door enkel gebruik te maken
van instructies met een vaste uitvoeringstijd [2] zoals bij een staartdeling. Deze code wordt
dan in een aparte functie geplaatst en alle delingsinstructies worden vervangen door een een
functieoproep.Dit zorgt ervoor dat de deling altijd een vaste uitvoeringstijd heeft. Omdat de
deling helemaal moet worden herschreven is het prestatieverlies wel enorm[2].
Deling herschrijven naar deling zonder early exit
Zoals in de vorige sectie reeds besproken, treedt er geen early exit op als het deeltal voldoende
groter is dan de deling. Het is mogelijk om met een paar eenvoudige wiskundige bewerkingen
de deling zo te herschrijven zodat dit het geval is. Op deze manier treedt er nooit een early exit
op.
A
B=
A + B −B
B(3.1)
=A + B
B− 1 (3.2)
=2(A + B)
2B− 1 (3.3)
We beginnen met ervoor te zorgen dat het deeltal altijd groter is dan de deler door het
deeltal te vervangen door de som van deler en deeltal en 1 van het totaal af te trekken zoals in
3.2. Omdat de deler mogelijk waarde 1 heeft en bij deling door 1 altijd een early exit optreedt,
worden de deler en deeltal nog eens vermenigvuldigd met 2 om dit probleem op te lossen (3.3).
De deling op deze manier herschrijven zorgt ervoor dat er nooit een early exit optreedt. Ook
presteert deze code niet veel slechter dan een normaal geval waar geen early exit optreedt. Het
aantal cyclussen nodig voor een gehele deling is namelijk veel groter dan de cyclussen nodig voor
het optellen en aftrekken van gehele getallen.
De formule 3.3 heeft echter problemen met afrondingen. Door het deeltal te vervangen door
de som van het deeltal en twee keer de deler zoals in 3.6 bekomen we een formule die exact
dezelfde resultaten geeft als de originele deling en die niet veel slechter presteert dan een deling

3.3 Bestudeerde oplossingen 21
zonder early exit.
A
B=
A + 2B − 2B
B(3.4)
=A + 2B
B− 2 (3.5)
=2(A + 2B)
2B− 2 (3.6)
Een groot nadeel van deze methode is dat de programeur niet meer beschikt over het volledige
bereik van gehele getallen. Het deeltal 2(A + 2B) zal namelijk zorgen voor een integeroverflow
bij grote waarden van A en B. De programeur moet dus rekening houden met het feit dat
de code deze transformatie zal ondergaan. De transformatie is niet zomaar toepasbaar op alle
broncode. Deze formule op zich biedt ook enkel een oplossing voor gehele delingen zonder teken.
De formule kan waarschijnlijk wel aangepast worden om te werken met gehele getallen met teken,
maar omdat deze aanpak in de praktijk niet erg nuttig is door gevolg van overflow, ben ik hier
niet verder op in gegaan. Deze twee nadelen zorgen ervoor dat deze methode in de praktijk
onbruikbaar is.
3.3.2 Oplossing 2: Tijd van de deling geen rol laten spelen
Een andere mogelijke oplossing is om ervoor de zorgen dat variabele uitvoeringstijd van de
deling geen invloed heeft op de globale uitvoeringstijd van het programma. Dit kan bekomen
worden door extra instructies toe te voegen aan de code en de processor te proberen forceren
om deze code parallel uit te voeren met de deling. Deze extra instructie moeten een vaste
uitvoeringstijd hebben, en tesamen langer duren dan de originele deling (Figuur 3.2). Daarna
moeten nog twee afhankelijkheden worden gecreerd om ervoor te zorgen dat de processor de
twee stukjes code parallel uitvoert. Eerst moet ervoor worden gezorgt dat zowel de deling als de
dummyinstructies afhankelijk zijn van eenzelfde waarde, zodat ze ongeveer gelijktijdig uitgevoerd
worden. Vervolgens moet ervoor gezorgd worden dat de code volgend op de deling afhankelijk
is van zowel de resultaten van de deling als de resultaten van de dummycode. Op deze manier
maakt het niet uit hoe lang de deling duurt. De volgende intructies moeten wachten tot het
resultaat van de dummycode is berekend. De instructies die de afhankelijkheden creeren zullen
in de rest van de tekst guardcode worden genoemd. Door het toevoegen van dummycode en
guardcode hebben de effecten van early exit geen invloed meer op de globale uitvoeringstijd van
het programma.
Een probleem bij deze aanpak is het vinden van geschikte guardcode. Een processor heeft

3.3 Bestudeerde oplossingen 22
Figuur 3.2: Parallel uitvoeren van code met vaste uitvoeringstijd.
verschillende rekeneenheden voor de verschillende soorten instructies. Een scheduler zorgt er-
voor dat de instructies in de correcte rekeneenheid worden geplaatst. Dit wordt schematisch
voorgesteld in Figuur 3.3. Om de code parallel te kunnen uitvoeren moet dus gekozen worden
voor instructies die op een andere rekeneenheid terecht komen. Dit kan getest worden door
een deling in parallel uit te voeren die nooit een early exit geeft. Er wordt dan nog altijd een
variabele uitvoeringstijd gemeten. Dit klopt met de veronderstelling, de twee delingen worden
gescheduled op dezelfde rekeneenheid, waardoor ze dus niet in parallel kunnen worden uitge-
voerd. Meetresultaten tonen aan dat de uitvoeringstijd van de extra deling gewoon bij de totale
uitvoeringstijd wordt opgeteld. Omdat de gehele deling een instructie is die een groot aantal
processorcyclussen nodig heeft om te berekenen, is het vinden van dummycode om parallel uit
te voeren niet triviaal. Load- en Store-instructies hebben ook een groot aantal processorcyclus-
sen nodig omdat deze moeten wachten op de tragere cache of het geheugen. Omdat loads en
stores zelf een variabele uitvoeringstijd hebben (zie verder), zijn dit dus geen geschikte kandida-
ten. Een andere mogelijkheid is het gebruiken van een aantal instructies die een kleiner aantal
processorcyclussen nodig hebben, zoals add, sub en mul.
Ook het vinden van geschikte guardcode is niet triviaal. Om ervoor te zorgen dat de code
die op de deling volgt zowel afhankelijk is van de deling als de dummycode die in parallel wordt

3.3 Bestudeerde oplossingen 23
Figuur 3.3: Een scheduler zend instructies naar de correcte rekeneenheden. Dit is een figuur
gebaseerd op [3].
uitgevoerd, moet de guardcode de resultaten van beide berekeningen op een of andere manier
combineren. Het gecombineerde resultaat moet dan ook door de daaropvolgende instructies
gebruikt worden. Wordt dit resultaat niet verder gebruikt, dan zal de dummycode en guard-
code hoogstwaarschijnlijk weggeoptimaliseerd worden door een van de volgende stappen in de
compiler. Het resultaat van de combinatie van de twee delingen moet dus hetzelfde zijn als het
resultaat van de originele deling. Als ervoor gezorgd wordt dat de resultaten van de dummycode
die in parallel wordt uitgevoerd altijd 1 is, kunnen in de guardcode gewoon de twee resultaten
met elkaar vermenigvuldigd worden. Dit resultaat kan dan door de volgende instructies gebruikt
worden in plaats van het resultaat van de originele deling.
Een volgend probleem is het zoeken van guardcode en dummy berekeningen die niet worden
weggeoptimaliseerd in volgende optimalisatiestappen. Gebruiken van constanten is niet aan te
raden. De compiler zal dan tijdens de compilatie al kunnen berekenen dat de uitkomst van de
dummycode 1 is en dat de originele deling met 1 wordt vermenigvuldigd. Dit heeft als gevolg
dat alle dummycode wordt weggeoptimaliseerd. Zelfs minder eenvoudige berekeningen zonder
constanten zoals een register Xor’en met zichzelf en er 1 bij optellen, of logische shift van 32
posities en erna 1 bij optellen worden door de compiler weggeoptimaliseerd.
Het volgende stuk code zoals in Figuur 3.4 wordt getoond, wordt niet weggeoptimaliseerd
door de compiler. Op een van de operandi van de originele deling wordt een rekenkundige ver-
schuiving naar rechts (SAR, shift arithmetic right) van 31 posities uitgevoerd. Een rekenkundige
verschuiving behoudt de meest linkse tekenbit van een getal in two’s complementrepresentatie.
Het resultaat van de verschuiving is dus 0 of -1. Hierna wordt er een een OR met 1 uitgevoerd
op het vorige resultaat. Er zijn weer twee mogelijke resultaten: -1 en 1. Daarna wordt dit
resultaat een aantal keer met zichzelf vermenigvuldigd tot de gewenste vaste uitvoeringstijd is
bereikt. Het resultaat van de dummy berekening is uiteraard 1, zodat de afhankelijkheid met

3.3 Bestudeerde oplossingen 24
een eenvoudige vermenigvuldiging kan worden opgelost.
Het is natuurlijk mogelijk om pas in een latere fase, nadat alle optimalisaties zijn uitgevoerd,
deze transformaties te doen. Dan moet er geen rekening gehouden worden met code die wordt
weggeoptimaliseerd. Omdat er in de vakgroep reeds een plugin geımplementeerd is die een aantal
transformaties uitvoert, heb ik besloten om deze te proberen uitbreiden in plaats van een nieuwe
plugin te implementeren die later in het compileerproces wordt uitgevoerd.
Figuur 3.4: Een voorbeeld van dummycode die reeds in IR kan worden geımplementeerd. De
dummycode die in parallel wordt uitgevoerd, bestaat uit een shift met behoud van teken van
een van de operandi van de originele deling. Daarna wordt de laatste bit van dit resultaat op
1 gezet zodat enkel +1 of −1 als resultaat kan worden bekomen. Dan wordt dit resultaat een
aantal keer met zichzelf vermenigvuldigd om een voldoende lange uitvoeringstijd te bekomen.
Omdat het resultaat van de dummycode altijd 1 is, volstaat een eenvoudige vermenigvuldiging
met het resultaat van de originele deling om een afhankelijkheid te creeren in de guardcode.
Een nadeel van deze methode ten opzichte van de methode die de deling in een aparte fucntie
uitrekent[2] is dat het nog steeds mogelijk is om door middel van een ander soort aanval toch
nog informatie te verzamelen, namelijk resource contention. De gehele delingsinstructie is niet
gepijplijnd. Dit wil zeggen dat deze instructies moeten wachten tot de vorige delingsinstructie
afgerond is om te uitgevoerd te worden. Ook worden delingsinstructies op eenzelfde rekeneen-

3.4 Implementatie 25
heid uitgevoerd[13]. Als een aanvaller in een tweede draad constant gehele delingsinstrucies
uitvoert en meet hoeveel hij er in een bepaald tijdsinterval kan uitvoeren, kan hij ook informatie
verzamelen over het algoritme dat in de eerste draad loopt. Als in de eerste draad een algoritme
wordt uitgevoerd met enkel early exit delingen zal de aanvaller meer delingen kunnen uitvoeren
dan wanneer de delingen in de eerste draad geen early exit gebruiken. De variatie in uitvoe-
ringstijd wordt nu gemeten op het programma van de aanvaller in plaats van op het beveiligde
programma. Deze aanval kan niet gebruikt worden op de twee andere methodes die hierboven
zijn beschreven. Deze gebruiken immers geen delingen met variabele uitvoeringstijd meer.
3.4 Implementatie
Om deze transformatie te implementeren heb ik de bestaande balanceringsplugin uitgebreid.
De bestaande plugin is een ModulePass, wat er op neer komt dat deze pass optimalisaties kan
uitvoeren op alle broncode van het programma. Een ander voorbeeld van een pass is bijvoorbeeld
een FunctionPass, deze is dan beperkt tot de code van een enkele functie. De modulepass voert
optimalisaties uit op de IR-representatie van LLVM. Als de pass een gehele delingsinstructie
tegenkomt, wordt een functie opgeroepen die de hierboven beschreven transformaties uitvoert.
3.5 Resultaten
Het algoritme die de deling parallel uitvoert met een aantal multiplicaties wordt getest met
behulp van een modulair exponentiatie algoritme (Listing 3.2). Om resultaten te kunnen ver-
gelijken is hetzelfde modulair exponentiatie algoritme gebruikt als in “Practical Mitigations
for Timing-Based Side-Channel Attacks on Modern x86 Processors” [2]. Het algoritme wordt
uitgevoerd met vier verschillende invoer sets:
• Enkel 0 set, bijna alle bits van de exponent zijn nul, enkel de twee meest significante bits
zijn een. Dit zorgt ervoor dat het de variabele result niet constant blijft. Alle andere
bits op nul zorgt ervoor dat de conditionele code in Listing 3.2 maar twee keer wordt
uitgevoerd. Dit pattroon geeft accurate sprongvoorspellingen door de processor.
• Enkel 1 set, alle bits uit de exponent zijn een. Dit zorgt ervoor dat de conditionele code
in Listing 3.2 elke iteratie wordt uitgevoerd. Dit pattroon geeft ook accurate sprongvoor-
spellingen door de processor.

3.5 Resultaten 26
• Regulier, de helft van de bits is een en de andere helft is nul, volgens een constant patroon.
De conditionele code wordt in de helft van de iteraties uitgevoerd en de sprongvoorspelling
is accuraat.
• Random, de helft van de bits is een en de andere helft is nul, maar deze keer is de volgorde
bepaald door een pseudo-randomgenerator. De conditionele code wordt in de helft van de
gevallen uitgevoerd maar de sprongvoorspelling is veel minder accuraat dan bij de reguliere
set.
Listing 3.2: C-code die modulaire exponentiatie implementeert. Dit stuk code wordt gebruikt
om de tranformatie te testen.
result = 1;
do{
result = (result*result) % n;
if (( exponent >>i) & 1)
result = (result*a) % n;
i--;
} while (i >=0);
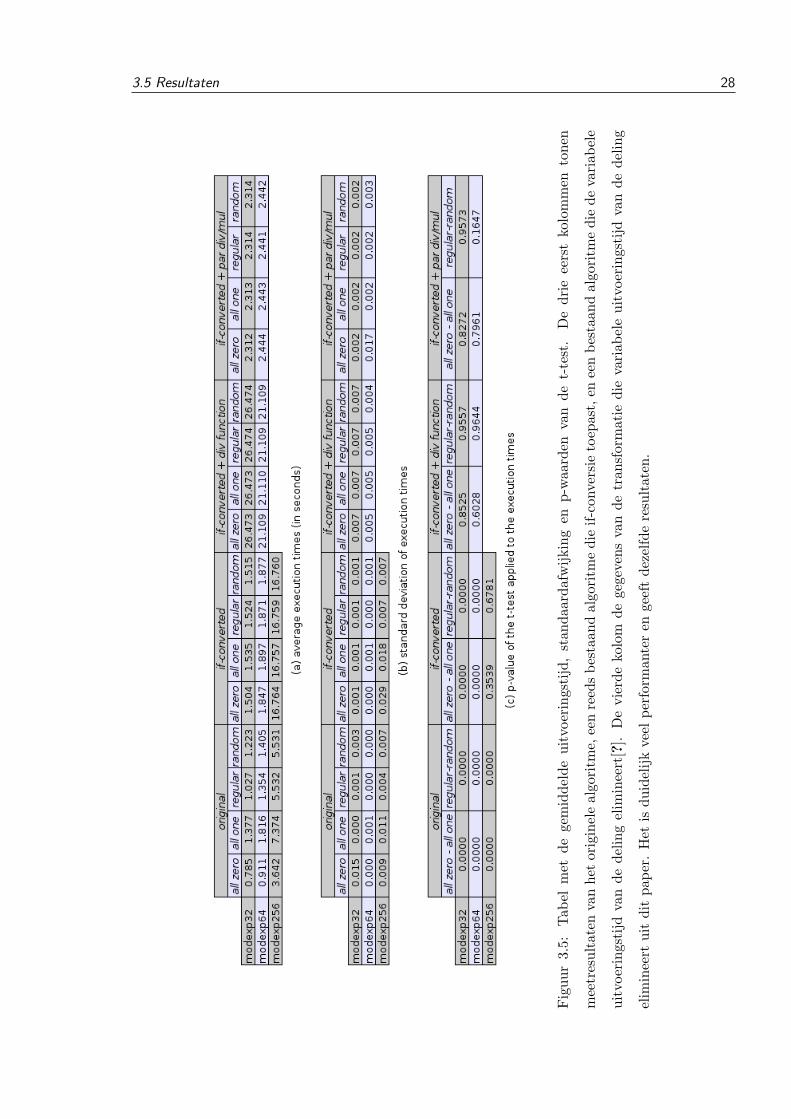
Figuur 3.5 toont de resultaten van de originele balanceringsplugin[2], de balanceringsplugin
die de deling in een andere functie uitwerkt en de versie die extra vermenigvuldigingen parallel
uitvoert. Het modulair exponentiatie algoritme wordt uitgevoerd op zowel 32, 64 als 256 bit
getallen. Voor de 256 bit versie is de invloed van de delingsinstructie verwaarloosbaar en geeft
de originele balanceringsplugin al goede resultaten.
In de twee meest rechtse kolommen staan de gegevens van de twee transformaties die de
variabele uitvoeringstijd van de deling elimineren. 3.5.a) Toont de gemiddelde uitvoeringstijd
over twintig uitvoeringen. Figuur 3.5.b) toont de standaardafwijking. Het is duidelijk dat de
transformatie die code parallel uitvoert veel performanter is dan de transformatie die de deling
in een aparte functie uitwerkt: 109% trager dan de originele code ten opzichte van 2300% trager
voor 32 bit code en 78% trager ten opzichte van 1439% trager voor 64 bit code.
In Figuur 3.5.c) worden de p-waarden van de t-test gegeven. P-waarden tonen aan hoe
gelijkaardig twee samples zijn. Lage p-waarden wil zeggen dat twee samples niet door eenzelfde
bron zijn gegenereerd. Hoge p-waarden tonen aan dat er geen verschil kan opgemerkt worden
tussen twee samples. De p-waarden in de tabel tonen aan dat if-conversie alleen niet voldoende

3.5 Resultaten 27
is voor de 32 en 64 bit versies van het modulair exponentiatie algoritme. Na het elimineren van
variabele uitvoeringstijd van de deling kan wel met voldoende zekerheid besloten worden dat er
geen verschil meer meetbaar is tussen de verschillende invoer sets.
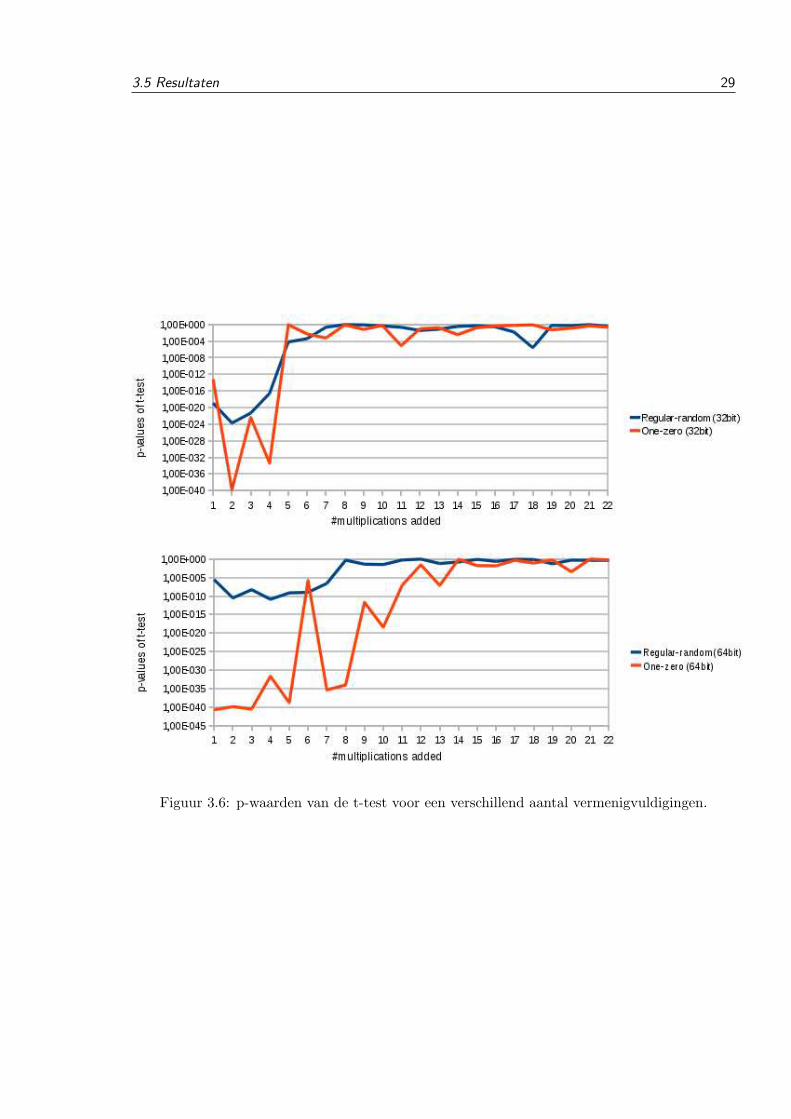
Het aantal vermenigvuldigingen die moet worden toegevoegd is afhankelijk van het aantal bits
dat gebruikt wordt om de getallen voor te stellen. Figuur 3.6 toont de p-waarden van de t-test
in functie van het aantal vermenigvuldigingen die in parallel wordt uitgevoert. Voor het 32bit
modulair exponentiatie algoritme kan er vanaf acht vermenigvuldigingen voldoende vertrouwen
gezegd worden dat de uitvoeringstijden gelijk zijn. Omdat de gemiddelde uitvoeringstijd van
de 64bit deling hoger is moeten er meer vermenigvuldigingen worden toegevoegd om evenhoge
p-waarden te krijgen.
De transformatie die vermenigvuldigingen parallel uitvoert is dus een veel performanter
alternatief voor de transformatie die de deling in een apparte functie berekent. De p-waarden
tonen aan dat er met voldoende zekerheid kan beslist worden dat de uitvoeringstijden voor de
verschillende sets gelijk zijn. Het enig nadeel is dat de techniek geen bescherming biedt tegen
een resource contention aanval.
3.5 Resultaten 28
Fig
uur
3.5:
Tab
elm
etde
gem
idde
lde
uitv
oeri
ngst
ijd,
stan
daar
dafw
ijkin
gen
p-w
aard
enva
nde
t-te
st.
De
drie
eers
tko
lom
men
tone
n
mee
tres
ulta
ten
van
het
orig
inel
eal
gori
tme,
een
reed
sbe
staa
ndal
gori
tme
die
if-co
nver
sie
toep
ast,
enee
nbe
staa
ndal
gori
tme
die
deva
riab
ele
uitv
oeri
ngst
ijdva
nde
delin
gel
imin
eert
[?].
De
vier
deko
lom
dege
geve
nsva
nde
tran
sfor
mat
iedi
eva
riab
ele
uitv
oeri
ngst
ijdva
nde
delin
g
elim
inee
rtui
tdi
tpa
per.
Het
isdu
idel
ijkve
elpe
rfor
man
ter
enge
eft
deze
lfde
resu
ltat
en.
3.5 Resultaten 29
Figuur 3.6: p-waarden van de t-test voor een verschillend aantal vermenigvuldigingen.

GEHEUGENAFHANKELIJKHEDEN 30
Hoofdstuk 4
Geheugenafhankelijkheden
Zoals eerder vermeld hebben load- en store-instructie ook een variabele uitvoeringstijd. Dit is
het gevolg van twee factoren. Ten eerste het pijplijngedrag van de loadinstructie en ten tweede
het cache gedrag van geheugeninstructies. In dit hoofdstuk wordt het pijplijngedrag van de
loadinstructie in meer detail bekeken. Ook wordt er een oplossing voorgesteld om variatie in
uitvoeringstijd ten gevolge van dit gedrag te vermijden.
4.1 Afhankelijkheden tussen geheugenadressen
4.1.1 Memory disambiguation en load bypassing
Intel processors maken gebruik van een out-of-orde geheugeneenheid (Inside Intel Core Micro-
architecture and Smart Memory Acces[3]). Dit wil zeggen dat de processor in staat is om
onafhankelijke geheugeninstructies in elke volgorde uit te voeren. Wanneer een store en een
loadinstructie na elkaar moeten worden uitgevoerd zal de memory disambiguation predictor
controleren als er een afhankelijkheid is tussen de twee geheugenadressen. Indien er geen af-
hankelijkheid wordt gedetecteerd, de voorspeller beslist dus dat de geheugeninstructies niet het
zelfde adres gebruiken, kan de loadinstructie voor de store-instructie worden uitgevoerd. Loadin-
structies voor store-instructies in de pijplijn plaatsen wordt load bypassing genoemd. Als er wel
een afhankelijkheid wordt gedetecteerd en de twee instructies (mogelijk) hetzelfde geheugenadres
gebruiken, moet de loadinstructie wachten tot de waarde in het geheugen beschikbaar is. Load
bypassing kan hier niet worden toegepast.
Sinds de core2 architectuur maakt Intel gebruik van meer geavanceerde technieken voor out-
of-order geheugentoegangen [3]. Waar in oudere Intel architecturen een load nooit voor een store

4.1 Afhankelijkheden tussen geheugenadressen 31
naar een ongekend adres wordt geplaats, kan dit nu wel. Indien later een conflict gedetecteerd
wordt, wordt de pijplijn gecleared. Voor elke loadinstructie wordt er een gesatureerde teller bij-
gehouden die aangeeft als de load voor een store in de pijnlijn mag worden geplaatst. Indien een
conflict wordt gedetecteerd, wordt deze teller op nul gezet zodat de volgende keer de instructie
wordt uitgevoerd, er geen bypassing meer optreedt.
Als niet naar het volledige geheugenadres wordt gekeken bij het controleren van afhankelijk-
heden tussen twee geheugeninstructies spreekt men van pessimistic load bypassing. In dit geval
kan het dus gebeuren dat er geen bypassing gebeurt, zelfs wanneer er geen afhankelijkheid is
tussen de twee instructies. De reden waarom niet het volledige geheugenadres wordt gebruikt
kan performantie zijn, of het gebruik van eenvoudigere hardware.
Load bypassing zorgt dus voor variatie in de uitvoeringstijd naargelang het geheugenadres
waar naartoe wordt geschreven. In de praktijk kan dit bijvoorbeeld voorkomen wanneer in een
lus achtereenvolgens naar een vaste locatie wordt geschreven en uit een willekeurige positie in een
array wordt gelezen. Het is gemakkelijk in te zien dat door disambiguation niet altijd eenzelfde
uitvoeringstijd zal gemeten worden.
In de testcode voor modulaire exponentiatie komt geen variatie in uitvoeringstijd voor ten
gevolge van load bypassing. Dit wil natuurlijk niet zeggen dat die niet voorkomt in ande-
re cryptografische algoritmes. Daarom wordt in dit hoofdstuk gebruik gemaakt van een stuk
C-code die speciaal gemaakt is om variatie in uitvoeringstijd door load bypassing te meten
(Listing 4.1). In een lus wordt na elkaar een waarde 2 naar geheugenplaats a geschreven
en dan de waarde uit geheugenplaats b gelezen. In de experimenten die volgen zal deze co-
de dan uitgevoerd worden met a en b die wijzen naar verschillende plaatsen in een array.

4.1 Afhankelijkheden tussen geheugenadressen 32
Listing 4.1: C-code die pessimistic load bypassing aantoont. Eerst wordt de constante waarde
2 naar de geheugenlocatie b geschreven, daarna wordt de waarde op geheugenlocatie a opgeteld
bij result. Verschillende offsets tussen a en b geven een verschillende uitvoeringstijd.
int mem3(int* a, int* b){
int result;
int j;
for(j=0;j<LOOPS;j++){
*b= 2;
result += *a;
}
return result;
}
Het is belanrijk om op te merken dat het verschil in uitvoeringstijd niets te maken heeft
met het feit dat er een cache-miss zou kunnen optreden. Het stukje code gebruikt slechts
twee geheugenadressen die wijzen naar gehele getallen van 4 byte groot. Dit past uiteraard in
het cache geheugen zodat er geen cache-misses voorkomen. Ook wordt de lus een voldoende
groot aantal keer uitgevoerd. Hierdoor zijn de sprongvoorspeller en de memory disambiguation
voorspeller “opgewarmd”. De tellers in deze componenten die beslissen of een sprong moet
genomen worden of een load voor een store mag uitgevoerd worden, zullen snel verzadigd zijn
en alle voorspellingen zullen correct gebeuren. De effecten van een verkeerde voorspelling in de
eerste iteraties zijn door het grote aantal iteraties verwaarloosbaar.
4.1.2 Verificatie van bestaande resultaten
Er is binnen de vakgroep reeds onderzoek gedaan naar de gevolgen van load bypassing [2]. Zij
kwamen tot het besluit dat enkel naar bit 2 tot 5 wordt gekeken om te controleren als er een
afhankelijkheid bestaat tussen twee geheugeninstructies. Dit komt er dus op neer dat wanneer
de offset tussen een store en een load modulo 64 gelijk is aan 0 of 4. Of in formulevorm:
(a− b)%64 = 0
(a− b)%64 = 4
Om dit te verifieren heb ik een test geschreven die het stukje code uit Listing 4.1 een aantal
keer uitvoert. Er wordt een array van gehele getallen van vier byte groot in het geheugen

4.1 Afhankelijkheden tussen geheugenadressen 33
geınitialiseerd en de pointers met a en b wijzen bij elke uitvoering naar een verschillende plaats
in de array. Zie Figuur 4.1. Initieel wijzen beide pointers naar dezelfde locatie. Bij elke
volgende uitvoering wordt a een plaats (4 bytes) opgeschoven in de array. Er wordt dus telkens
een verschillende offset tussen de twee geheugenadressen gebruikt. De uitvoeringstijden voor de
verschillende offsets zijn te zien in Figuur 4.2. Deze resultaten zijn inderdaad identiek aan de
resultaten die reeds gepubliceerd zijn[2].
Figuur 4.1: Pointers a en b wijzen naar verschillende plaatsen in een array, zodat verschillende
offsets tussen geheugenadressen worden getest.
Bij een tweede test wordt pointer b elke iteratie een plaats opgeschoven in plaats van a,
zoals aangetoond in Figuur 4.3. De grootte van de offset tussen de twee geheugeninstructies
is dus dezelfde als in de vorige test. Je zou dus verwachten dat ook op dezelfde plaatsen
afhankelijkheden worden gedetecteerd. Dit is echter niet het geval. Resultaten van de tweede
test zijn te zien op Figuur 4.4. Hier zijn er ook afhankelijkheden tussen de twee geheugenadressen
gedetecteerd wanneer de offset modulo 64 gelijk is aan 8 en 12. Hieruit kan besloten worden
dat ook de richting van de offset een rol speelt bij het bepalen van afhankelijkheden tussen twee
geheugeninstructies. Bij een positieve offset, zoals het eerste geval, worden afhankelijkheden
gedetecteerd bij modulo64 gelijk aan 0 en 4, bij een negatieve offset worden afhankelijkheden
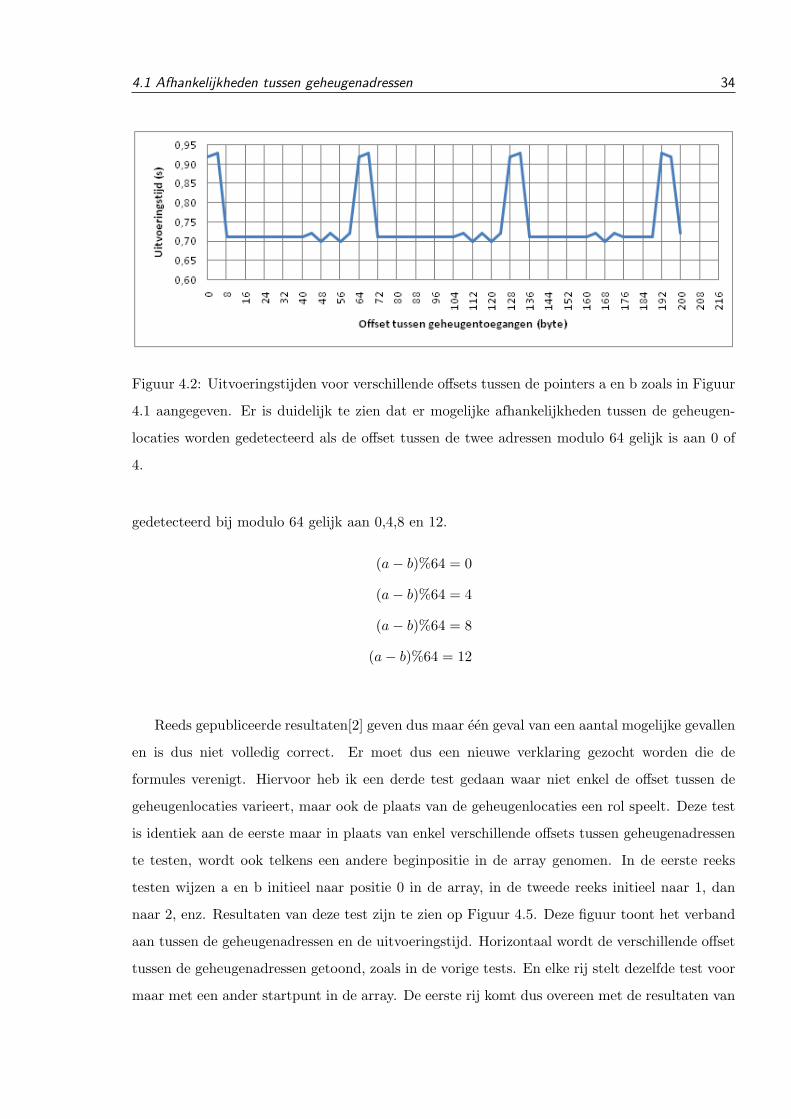
4.1 Afhankelijkheden tussen geheugenadressen 34
Figuur 4.2: Uitvoeringstijden voor verschillende offsets tussen de pointers a en b zoals in Figuur
4.1 aangegeven. Er is duidelijk te zien dat er mogelijke afhankelijkheden tussen de geheugen-
locaties worden gedetecteerd als de offset tussen de twee adressen modulo 64 gelijk is aan 0 of
4.
gedetecteerd bij modulo 64 gelijk aan 0,4,8 en 12.
(a− b)%64 = 0
(a− b)%64 = 4
(a− b)%64 = 8
(a− b)%64 = 12
Reeds gepubliceerde resultaten[2] geven dus maar een geval van een aantal mogelijke gevallen
en is dus niet volledig correct. Er moet dus een nieuwe verklaring gezocht worden die de
formules verenigt. Hiervoor heb ik een derde test gedaan waar niet enkel de offset tussen de
geheugenlocaties varieert, maar ook de plaats van de geheugenlocaties een rol speelt. Deze test
is identiek aan de eerste maar in plaats van enkel verschillende offsets tussen geheugenadressen
te testen, wordt ook telkens een andere beginpositie in de array genomen. In de eerste reeks
testen wijzen a en b initieel naar positie 0 in de array, in de tweede reeks initieel naar 1, dan
naar 2, enz. Resultaten van deze test zijn te zien op Figuur 4.5. Deze figuur toont het verband
aan tussen de geheugenadressen en de uitvoeringstijd. Horizontaal wordt de verschillende offset
tussen de geheugenadressen getoond, zoals in de vorige tests. En elke rij stelt dezelfde test voor
maar met een ander startpunt in de array. De eerste rij komt dus overeen met de resultaten van

4.1 Afhankelijkheden tussen geheugenadressen 35
Figuur 4.3: Pointers a en b wijzen naar verschillende plaatsen in een array, zodat verschillende
offsets tussen geheugenadressen worden getest. In tegenstelling tot 4.1 wijst hier pointer a elke
test naar het zelfde geheugenadres
de eerste test. In het rooster worden telkens de laatste 6 bits van de tweede geheugentoegang
gegeven. Het geheugenadres van de eerst geheugen toegang wordt gegeven in de kolom waar de
offset nul is. De rode vakjes duiden aan dat er een afhankelijkheid is gemeten. Bij groene vakjes
is geen afhankelijkheid gemeten. Er is duidelijk een ander gedrag wanneer andere beginposities
in de array worden gebruikt.
Dit gedrag herhaalt zich voor offsets groter dan 60 en shifts groter dan 15 (dit komt ook neer
op een shift van 60 bytes). Bijgevolg kan besloten worden dat enkel de laatste 6 bits gebruikt
worden om afhankelijkheden te bepalen. De minst significante bit heeft nummer 0, de meest
significante 5. Omdat integers vier bytes groot zijn, zijn bits 0 en 1 altijd 0 in deze test en
dus irrelevant. Bij de eerste test worden ook afhankelijkheden gemeten als de offset modulo
64 gelijk is aan 4. Dit kan als oorzaak hebben dat bit 3 ook genegeerd wordt bij controle van
afhankelijkheden. Dit blijkt ook het geval te zijn bij deze test. Dan blijven er enkel nog bit
3 tot 5 over. Als deze 3 bits worden geınterpreteerd als een binair getal, x1 voor de eerste
geheugentoegang en x2 voor de tweede geheugentoegang. Dan wordt er een afhankelijkheid
gedetecteerd als x2 gelijk is, of een lager dan x1. Omdat dit gedrag zich modulo 64 herhaalt,
is het voldoende om te controleren of dit klopt voor de gevallen in Figuur 4.5, alle andere
geheugenadressen zijn identiek aan een geval in Figuur 4.5.
Het is niet duidelijk waarom geheugenafhankelijkheden op deze manier worden berekend.
Slechts enkele bits van twee geheugenadressen vergelijken vereist duidelijk minder complexe
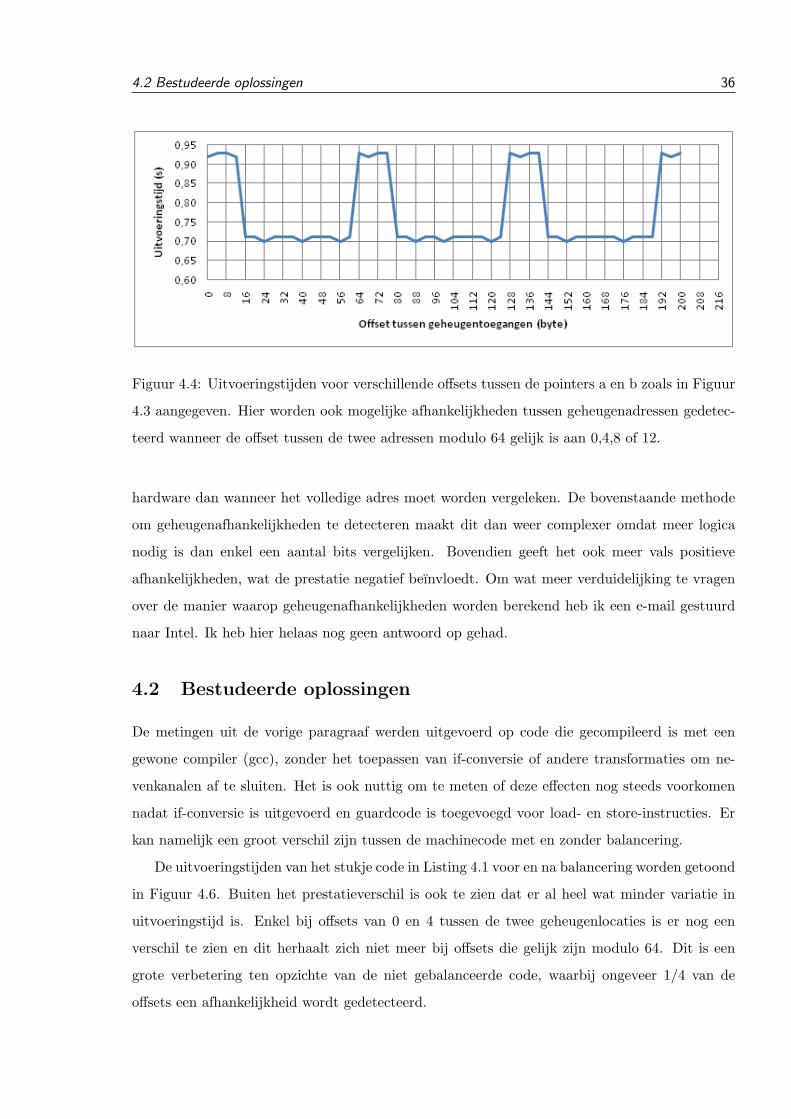
4.2 Bestudeerde oplossingen 36
Figuur 4.4: Uitvoeringstijden voor verschillende offsets tussen de pointers a en b zoals in Figuur
4.3 aangegeven. Hier worden ook mogelijke afhankelijkheden tussen geheugenadressen gedetec-
teerd wanneer de offset tussen de twee adressen modulo 64 gelijk is aan 0,4,8 of 12.
hardware dan wanneer het volledige adres moet worden vergeleken. De bovenstaande methode
om geheugenafhankelijkheden te detecteren maakt dit dan weer complexer omdat meer logica
nodig is dan enkel een aantal bits vergelijken. Bovendien geeft het ook meer vals positieve
afhankelijkheden, wat de prestatie negatief beınvloedt. Om wat meer verduidelijking te vragen
over de manier waarop geheugenafhankelijkheden worden berekend heb ik een e-mail gestuurd
naar Intel. Ik heb hier helaas nog geen antwoord op gehad.
4.2 Bestudeerde oplossingen
De metingen uit de vorige paragraaf werden uitgevoerd op code die gecompileerd is met een
gewone compiler (gcc), zonder het toepassen van if-conversie of andere transformaties om ne-
venkanalen af te sluiten. Het is ook nuttig om te meten of deze effecten nog steeds voorkomen
nadat if-conversie is uitgevoerd en guardcode is toegevoegd voor load- en store-instructies. Er
kan namelijk een groot verschil zijn tussen de machinecode met en zonder balancering.
De uitvoeringstijden van het stukje code in Listing 4.1 voor en na balancering worden getoond
in Figuur 4.6. Buiten het prestatieverschil is ook te zien dat er al heel wat minder variatie in
uitvoeringstijd is. Enkel bij offsets van 0 en 4 tussen de twee geheugenlocaties is er nog een
verschil te zien en dit herhaalt zich niet meer bij offsets die gelijk zijn modulo 64. Dit is een
grote verbetering ten opzichte van de niet gebalanceerde code, waarbij ongeveer 1/4 van de
offsets een afhankelijkheid wordt gedetecteerd.

4.2 Bestudeerde oplossingen 37
Fig
uur
4.5:
Uit
voer
ings
tijd
enva
nhe
tst
ukje
code
inL
isti
ng4.
1.B
ijro
devl
akke
nw
ordt
een
afha
nkel
ijkhe
idge
dete
ctee
rd,
bij
groe
neni
et.
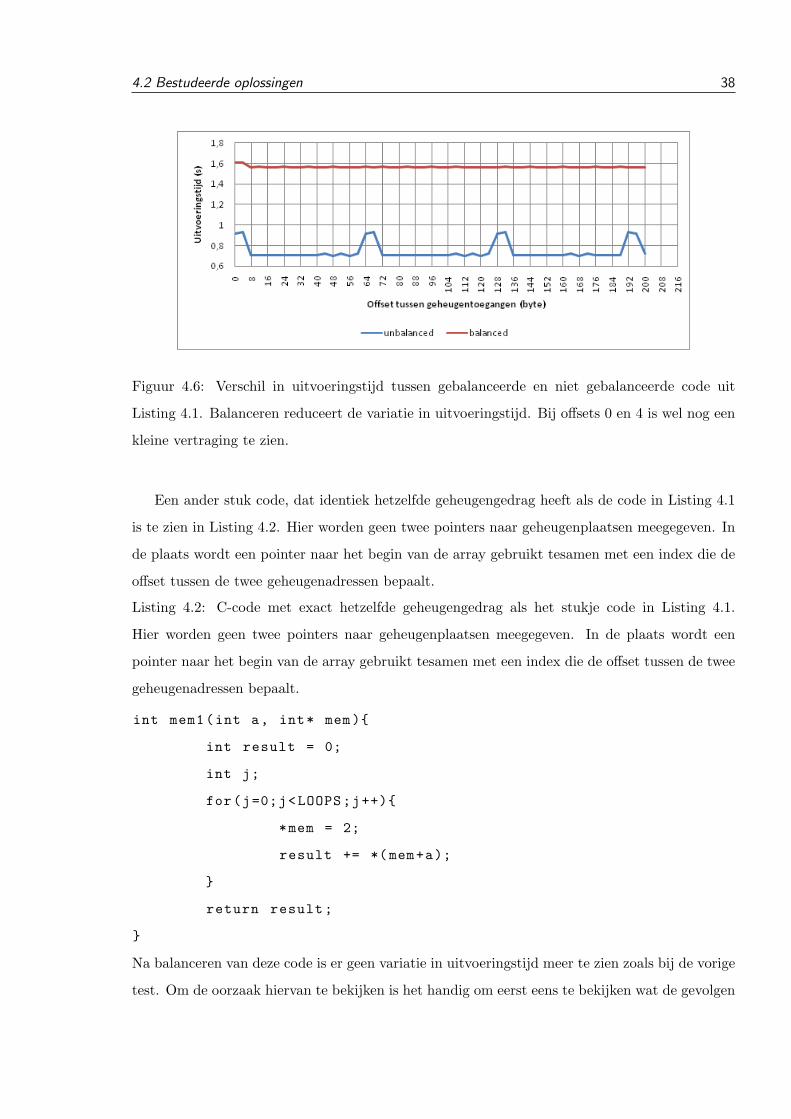
4.2 Bestudeerde oplossingen 38
Figuur 4.6: Verschil in uitvoeringstijd tussen gebalanceerde en niet gebalanceerde code uit
Listing 4.1. Balanceren reduceert de variatie in uitvoeringstijd. Bij offsets 0 en 4 is wel nog een
kleine vertraging te zien.
Een ander stuk code, dat identiek hetzelfde geheugengedrag heeft als de code in Listing 4.1
is te zien in Listing 4.2. Hier worden geen twee pointers naar geheugenplaatsen meegegeven. In
de plaats wordt een pointer naar het begin van de array gebruikt tesamen met een index die de
offset tussen de twee geheugenadressen bepaalt.
Listing 4.2: C-code met exact hetzelfde geheugengedrag als het stukje code in Listing 4.1.
Hier worden geen twee pointers naar geheugenplaatsen meegegeven. In de plaats wordt een
pointer naar het begin van de array gebruikt tesamen met een index die de offset tussen de twee
geheugenadressen bepaalt.
int mem1(int a, int* mem){
int result = 0;
int j;
for(j=0;j<LOOPS;j++){
*mem = 2;
result += *(mem+a);
}
return result;
}
Na balanceren van deze code is er geen variatie in uitvoeringstijd meer te zien zoals bij de vorige
test. Om de oorzaak hiervan te bekijken is het handig om eerst eens te bekijken wat de gevolgen

4.2 Bestudeerde oplossingen 39
zijn van het toevoegen van safeguardcode op niveau van assembler code. Zoals eerder vermeld
worden loads en stores uitgevoerd op dummy adressen als de tak waar de instructie zich in be-
vindt niet wordt uitgevoerd. Dit wordt in assembler code geimplementeerd met een conditionele
move instructie. De safeguardcode zorgt er dus voor dat er meer assemblerinstructies staan tus-
sen twee opeenvolgende geheugeninstructies waardoor deze ook minder invloed op elkaar hebben.
Listing 4.3: Assembly voor mem3 balanced. Dit stuk code kopieert de waarde 2 naar het
geheugen en telt een waarde uit het geheugen op bij het register edi. De cmov instructies zijn de
safeguardcode die naargelang de tak genomen is ofwel het originele of het dummygeheugenadres
selecteren.
cmovl %ecx ,%ebx
movl $0x2 ,(% ebx)
lea (%esp),%ebx
cmovl %edx ,%ebx
add (%ebx),%edi
Listing 4.4: Assembly voor mem1 balanced. Omdat het geheugen hier via een index wordt
geraadpleegd is er een extra lea (load effective address) instructie nodig om de exacte geheugen-
plaats te berekenen. Dit zorgt voor extra intructies tussen de twee geheugeninstructies.
cmovl %ecx ,%ebx
movl $0x2 ,(% ebx)
lea (%ecx ,%edx ,4),%ebx
lea (%esp),%ebp
cmovl %ebx ,%ebp
add 0x0(%ebp),%edi
Listing 4.3 toont een stuk van de machine-instructies voor de code in Listing 4.1. Deze code heeft
nog steeds een variabele uitvoeringstijd. Listing 4.4 bevat de machine-instructies gegenereerd
uit Listing 4.2 waar geen variatie meer voorkomt in de uitvoeringstijd. Een meer gedetailleerde
uitleg bij de code vindt u in het bijschrift. Omdat de het tweede stuk code (4.2) een geındexeerde
toegang maakt tot de array in tegenstelling tot een rechtstreekse wijzer naar een geheugenplaats,
is er een extra lea(load effective addres) instructie nodig om het effectieve geheugenadres te be-
rekenen. In het tweede geval(4.4) worden er dus meer machine-instructies uitgevoerd tussen de
twee geheugeninstructies als in het eerste geval (4.3). Het zou dus kunnen dat het toevoegen
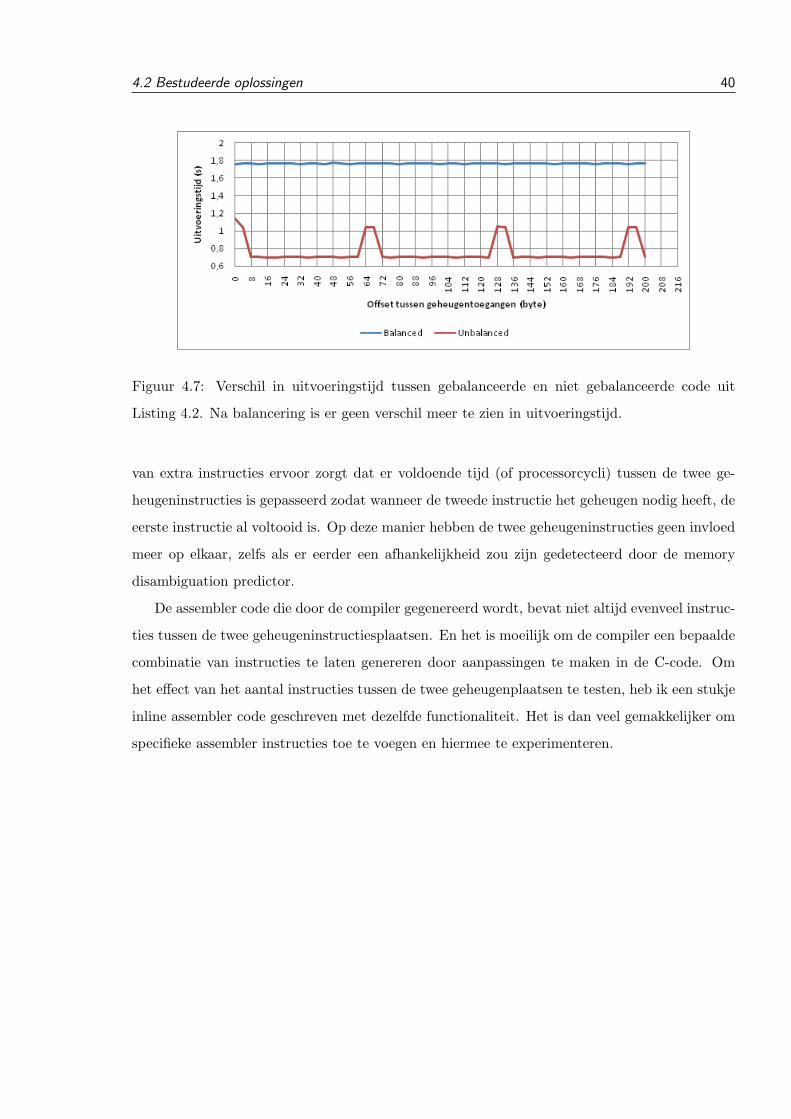
4.2 Bestudeerde oplossingen 40
Figuur 4.7: Verschil in uitvoeringstijd tussen gebalanceerde en niet gebalanceerde code uit
Listing 4.2. Na balancering is er geen verschil meer te zien in uitvoeringstijd.
van extra instructies ervoor zorgt dat er voldoende tijd (of processorcycli) tussen de twee ge-
heugeninstructies is gepasseerd zodat wanneer de tweede instructie het geheugen nodig heeft, de
eerste instructie al voltooid is. Op deze manier hebben de twee geheugeninstructies geen invloed
meer op elkaar, zelfs als er eerder een afhankelijkheid zou zijn gedetecteerd door de memory
disambiguation predictor.
De assembler code die door de compiler gegenereerd wordt, bevat niet altijd evenveel instruc-
ties tussen de twee geheugeninstructiesplaatsen. En het is moeilijk om de compiler een bepaalde
combinatie van instructies te laten genereren door aanpassingen te maken in de C-code. Om
het effect van het aantal instructies tussen de twee geheugenplaatsen te testen, heb ik een stukje
inline assembler code geschreven met dezelfde functionaliteit. Het is dan veel gemakkelijker om
specifieke assembler instructies toe te voegen en hiermee te experimenteren.

4.2 Bestudeerde oplossingen 41
Listing 4.5: Inline assemblercode om te experimenteren met verschillend aantal instructies tussen
de twee geheugeninstructies. Esi wordt hier als telregister gebruikt en ebx en ecx bevatten
pointers naar de twee geheugenlocaties. Zoals in de vorige stukjes C-code wordt hier ook een
lus uitgevoerd die achtereenvolgens naar het geheugen schrijft en uit het geheugen leest.
asm ( "movl $0 , %%esi;" //esi teller
"movl $0, %%eax;"
"movl %0, %%ebx;" //a in ebx
"movl %1, %%ecx;" //b in ecx
"jmp overloop ;"
"loop:"
"movl $2, (%%ebx);"
"addl (%%ecx),%%eax;"
"incl %%esi;"
"overloop :"
"cmpl $1000000000 ,%%esi;"
"jl loop;"
:
: "r" (ap), "r" (bp)
: "%esi","%ebx","%eax","%ecx");
Het doel is het toevoegen van instructies na een geheugeninstructie zodat er voldoende pro-
cessorcycli verlopen tussen twee geheugen instructies zodat de eerste instructie altijd al voltooid
is als de tweede instructie het geheugen nodig heeft. De assembler code gegenereerd uit de func-
tie mem1 heeft zo’n gedrag. Het is dus wenselijk dat de compiler altijd machinecode genereert
zoals in 4.4. Maar welke instructies zijn het meest geschikt om toe te voegen?
Figuur 4.8 en 4.9 tonen de verschillende uitvoeringstijden bij het toevoegen van extra instruc-
ties. Eerst heb ik conditionele move (cmov) instructies proberen toe te voegen 1. Als dezelfde
bron en doel operandi worden gebruikt, verandert dit niets aan de toestand van het programma.
Dit blijkt echter niet altijd te werken. Wanneer de conditionele move in een van zijn operandi een
register gebruikt die afhankelijk is van de geheugeninstructie, moet de conditionele move wach-
ten tot deze instructie gedaan is, waardoor de uitvoeringstijd van de conditionele move gewoon1Er is geen speciale reden waarom ik deze instructie eerst heb geprobeerd, dit was gewoon de eerste instructie
die in mij opkwam.

4.3 Implementatie 42
bij het totaal wordt opgeteld en er nog evenveel variatie is. Bijvoorbeeld als in 4.5 het register
ebx gebruikt wordt als een van de operandi. Dit is duidelijk te zien in Figuur 4.8. Er moet
dus gezocht worden naar instructies die niet moeten wachten tot de geheugeninstructie voltooid
is. We kunnen de operandi van de conditionele move veranderen zodat ze niet meer afhankelijk
zijn van de geheugeninstructies. Bijvoorbeeld edx gebruiken als bron- en doeloperand voor de
conditionele move, dan bekomen we de resultaten in Figuur 4.9. Hier is de uitvoeringstijd bij
het toevoegen van conditionele move instructies constant.
De NOP-instructie is een instructie die geen effect heeft op de toestand van het programma
en wordt onder andere gebruikt als padding tussen stukken gealigneerde code. Het voordeel van
deze instructie is dat ze geen operandi heeft. Er kunnen dus geen extra data-afhankelijkheden
ontstaan door het toevoegen van deze instructies. Dit is een groot voordeel ten opzichte van
de conditionele move. Een bijkomend voordeel is dat deze instructie ook weinig processorcycli
gebruikt. Zo kan er veel fijner bepaald worden hoeveel extra cycli er moeten worden toegevoegd
en kan het prestatieverlies zo laag mogelijk gehouden worden. Dit is te zien op zowel Figuur 4.8
als 4.9. Het toevoegen van een NOP-instructie is niet voldoende om de variatie weg te werken.
Het toevoegen van twee of meerdere NOP-instructies na de geheugentoegang werkt het verschil
in uitvoeringstijd volledig weg. Omdat bij het toevoegen van twee NOP-instructies soms nog
wat variatie in uitvoeringstijd kan voorkomen, is het toch beter om altijd drie NOP-instructies
toe te voegen.
Er kan dus besloten worden dat het toevoegen van extra instructies tussen geheugeninstruc-
ties ervoor zorgt dat de tweede instructie nooit meer moet wachten tot de eerst voltooid is. Wat
ervoor zorgt dat de variatie in uitvoeringstijd door afhankelijkheden tussen geheugenadressen
wordt geelimineerd. Er wordt eigenlijk voor gezorgd dat de tweede instructie gewoon altijd moet
wachten door een artificiele wachtijd in te voegen na de eerste instructie. De ideale instructie om
toe te voegen blijkt de NOP-instructie te zijn omdat deze instructie nooit extra data afhankelijk-
heden kan introduceren. Er is ook een minimaal verlies aan prestatie. Omdat de NOP-instructie
weinig cycli gebruikt, kan de artificiele wachttijd min of meer gelijk gekozen worden als de tijd
die de tweede instructie normaal zou moeten wachten als er een afhankelijkheid is gedetecteerd.
4.3 Implementatie
Het is niet mogelijk om de bestaande balanceringsplugin uit te breiden om deze transformatie
uit te voeren. De bestaande plugin werkt op het niveau van de IR (intermediate representati-

4.3 Implementatie 43
Figuur 4.8: Uitvoeringstijden van code in Listing 4.5 bij het toevoegen van instructies na elke ge-
heugeninstructie. Er worden een twee of drie NOP-instructies toegevoegd, dit zijn no-operation
instructies die verder geen invloed hebben op het programma. En een of twee conditionele move
instructies. Hier zijn de operandi van de conditionele move instructie verkeerd gekozen (cmov
%%ebx,%%ebx) zodat ze moeten wachten op de vorige geheugeninstructie. Hierdoor is nog een
vertraging te zien bij offsets 0 en 4. Het kiezen van de toe te voegen instructies mag dus niet
lukraak gebeuren. Bij NOP-instructies komt dit probleem niet voor omdat ze geen argumenten
hebben.
on). Hier worden machineonafhankelijke transformaties uitgevoerd op de code. Het is dus niet
mogelijk om in deze fase transformaties toe te voegen die werken op machine-instructies. Pas
nadat de IR uiteindelijk vertaald is naar machinespecifieke assembler kunnen extra instructies
worden toegevoegd. Er moet dus een pass geschreven worden voor de codegenerator.
Een llvm pass die hiervoor geschikt is, is de MachineFunctionPass. Dit is een pass die
per functie optimalisaties of transformaties kan uitvoeren op niveau van machine-instructies.
De versie van llvm die gebruikt wordt voor de balanceringsplugin is een oudere versie die niet
over dezelfde functionaliteit beschikt als de meest recente uitgave. Het is met deze versie niet
mogelijk om een plugin te implementeren voor een machinefunctionpass. De codegenerator (llc:
llvm system compiler) van de gebruikte llvm versie ondersteunt het laden van passes als plugin
nog niet. Dit heeft vooral te maken met het feit dat het niet eenvoudig via de commandline aan
te duiden is wanneer de pass moet worden uitgevoerd. Er worden namelijk een aantal passes
uitgevoerd tijdens codegeneratie, zoals bijvoorbeeld registerallocatie die heel wat instructies zal
herschrijven om de code te mappen op een eindig aantal registers. Afhankelijk van de volgorde
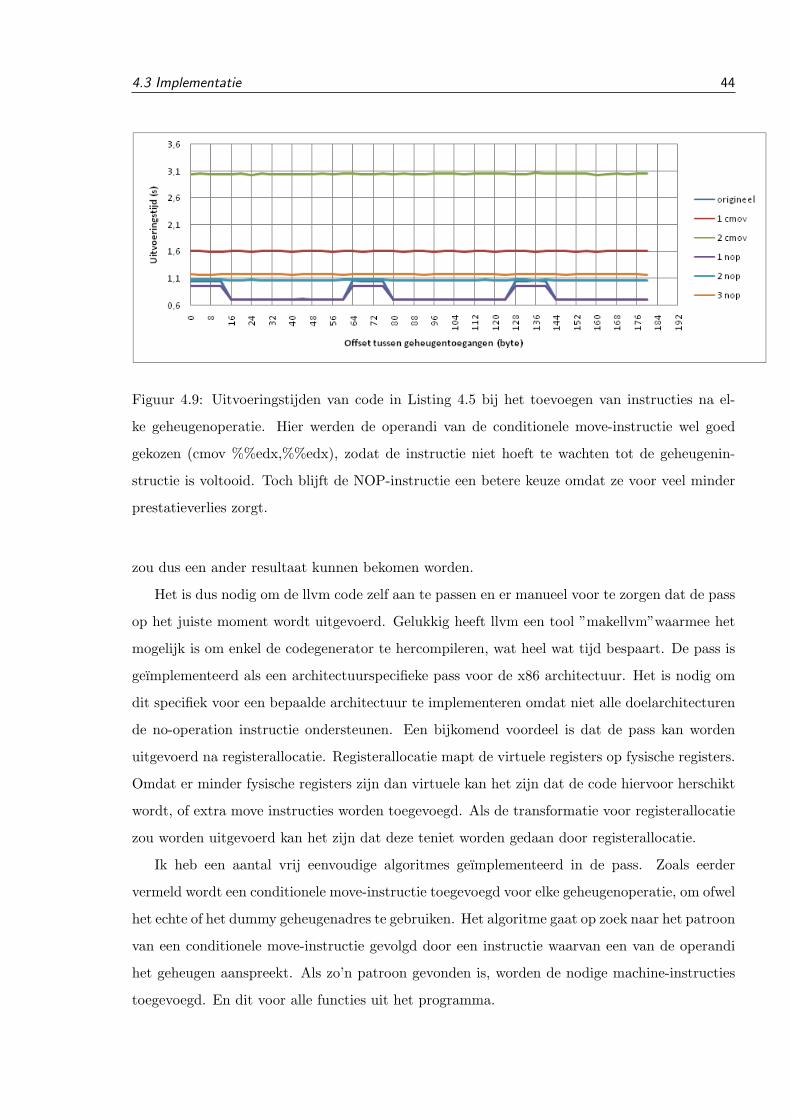
4.3 Implementatie 44
Figuur 4.9: Uitvoeringstijden van code in Listing 4.5 bij het toevoegen van instructies na el-
ke geheugenoperatie. Hier werden de operandi van de conditionele move-instructie wel goed
gekozen (cmov %%edx,%%edx), zodat de instructie niet hoeft te wachten tot de geheugenin-
structie is voltooid. Toch blijft de NOP-instructie een betere keuze omdat ze voor veel minder
prestatieverlies zorgt.
zou dus een ander resultaat kunnen bekomen worden.
Het is dus nodig om de llvm code zelf aan te passen en er manueel voor te zorgen dat de pass
op het juiste moment wordt uitgevoerd. Gelukkig heeft llvm een tool ”makellvm”waarmee het
mogelijk is om enkel de codegenerator te hercompileren, wat heel wat tijd bespaart. De pass is
geımplementeerd als een architectuurspecifieke pass voor de x86 architectuur. Het is nodig om
dit specifiek voor een bepaalde architectuur te implementeren omdat niet alle doelarchitecturen
de no-operation instructie ondersteunen. Een bijkomend voordeel is dat de pass kan worden
uitgevoerd na registerallocatie. Registerallocatie mapt de virtuele registers op fysische registers.
Omdat er minder fysische registers zijn dan virtuele kan het zijn dat de code hiervoor herschikt
wordt, of extra move instructies worden toegevoegd. Als de transformatie voor registerallocatie
zou worden uitgevoerd kan het zijn dat deze teniet worden gedaan door registerallocatie.
Ik heb een aantal vrij eenvoudige algoritmes geımplementeerd in de pass. Zoals eerder
vermeld wordt een conditionele move-instructie toegevoegd voor elke geheugenoperatie, om ofwel
het echte of het dummy geheugenadres te gebruiken. Het algoritme gaat op zoek naar het patroon
van een conditionele move-instructie gevolgd door een instructie waarvan een van de operandi
het geheugen aanspreekt. Als zo’n patroon gevonden is, worden de nodige machine-instructies
toegevoegd. En dit voor alle functies uit het programma.

4.3 Implementatie 45
Het is nu natuurlijk mogelijk dat er een aantal vals positieve matches gebeuren. Dit heeft
wel geen invloed op de correctheid van het programma, maar eventueel wel op de prestatie van
de code. Bij encryptietools of programma’s is de meest rekenintensieve code het encryptiealgo-
ritme zelf. Deze code wordt normaalgezien altijd gebalanceerd. Het toevoegen van enkele extra
instructies buiten deze code, dus in code die niet gebalanceerd moet worden, zal weinig invloed
hebben op de totale prestatie van het programma. Het is mogelijk om de annotaties van de
functie te controleren. Dit is echter niet geımplementeerd.
Invoegen van NOP-instructies is ook niet ideaal. Omdat deze instructie geen operandi heeft
kan de scheduler deze instructie plaatsen waar hij wil. Het is dus niet zeker dat de toegevoegde
NOP-instructies worden uitgevoerd op de plaats waar ze in de code staan. Dit kan het random
gedrag verklaren van de uitvoeringstijd bij het toevoegen van NOP-instructies. Bijvoorbeeld het
toevoegen van x NOP-instructies geeft een constante uitvoeringstijd voor een gegeven stuk code,
maar het toevoegen van x+1 instructies dan weer niet. Toch is het zoeken van het juiste aantal
instructies per geval eenvoudiger dan het zoeken van gepaste registers voor unaire of binaire
instructies.
algoritme 1
Mijn eerste poging om te automatiseren is een zeer eenvoudig en naıef algoritme. De machine-
instructies van alle functies worden overlopen tot een conditionele move-instructie is gevonden.
Daarna wordt gecontroleerd als de daaropvolgende instructie een geheugenoperand heeft. In-
dien dit zo is wordt na deze instructie een aantal NOP-instructies ingevoegd. Dit is geen goede
aanpak omdat in de gegenereerde code niet altijd evenveel instructies tussen twee geheugenin-
structies staan. Drie NOP instucties toevoegen bij het ene stuk code zal bijvoorbeeld dan niet
meer werken bij een ander stuk code. Ook is het niet altijd nodig om na elke geheugeninstructie
NOP-instructies toe te voegen omdat deze niet altijd worden gevolgd door een andere geheugen-
instructie. Dit is aangetoond in Figuur 4.10. Een vast aantal NOP-instructies toevoegen werkt
dus nooit in alle gevallen.
algoritme 2
Een betere aanpak is om ervoor te zorgen dat er altijd een minimum aantal instructies tussen
twee geheugeninstructies worden uitgevoerd. Het algoritme telt hoeveel instructies er tussen
twee geheugeninstructies liggen en beslist op basis daarvan hoeveel extra instructies er moeten

4.3 Implementatie 46
Figuur 4.10: Algoritme 1. Uitvoeringstijden na het toevoegen van een constant aantal NOP-
instructies na het balanceren van de code in Listing 4.1 (mem3) en in 4.2 (mem1). Het toevoegen
van een constant aantal NOP-instructies is duidelijk geen goede aanpak.
worden toegevoegd. Een bijkomend voordeel van dit algoritme is de prestatiewinst omdat niet na
elke geheugeninstructie extra NOP-instructies worden toegevoegd. Figuren 4.11 en 4.12 tonen
de resultaten van dit algoritme.
Minimum drie of vier instructies tussen twee geheugeninstructies werkt niet in beide gevallen.
Minimum vijf instructies werkt wel in beide gevallen. Het verschil tussen de twee gevallen kan
verklaard worden door het feit dat NOP-instructies geen afhankelijkheden hebben en in het ene
geval waarschijnlijk in een andere volgorde worden gescheduled. Vijf instructies werkt wel in
beide gevallen, maar het prestatieverlies is bijna niet meer toelaatbaar, vooral omdat maar een
kleine variatie in uitvoeringstijd wordt weggewerkt.
algoritme 3
Dit algoritme is een aangepaste versie van algoritme 2. Het zorgt in beide gevallen voor de laagste
constante uitvoeringstijd. Bij twee geheugeninstructies waar minder dan drie andere instructies
tussen staan wordt het aantal instructies ertussen aangevuld tot 4. Met andere woorden als er
reeds drie of meer instructies tussen twee geheugeninstructies staan wordt er niets aangepast.
Anders wordt ervoor gezorgd dat er minimum vier instructies tussen staan. Dit combineert de
beste resultaten van de twee gevallen uit het vorige algoritme. Uitvoeringstijden van de stukjes
code zijn te zien op Figuur 4.13.
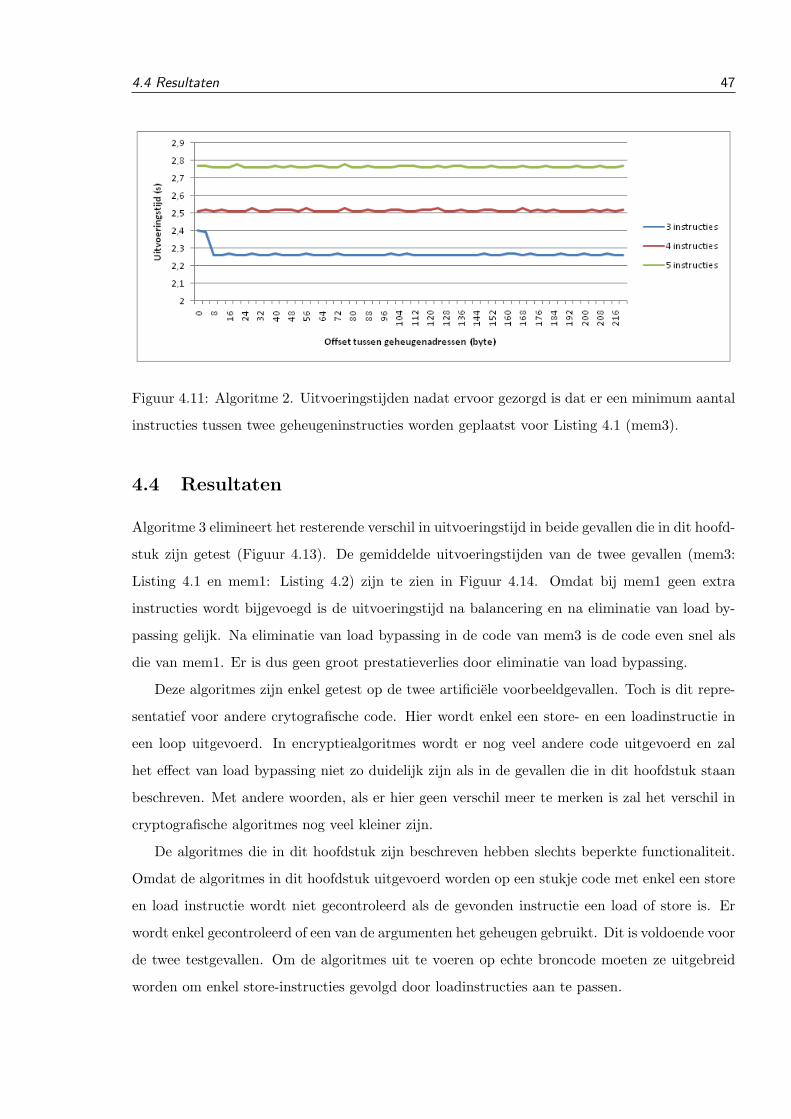
4.4 Resultaten 47
Figuur 4.11: Algoritme 2. Uitvoeringstijden nadat ervoor gezorgd is dat er een minimum aantal
instructies tussen twee geheugeninstructies worden geplaatst voor Listing 4.1 (mem3).
4.4 Resultaten
Algoritme 3 elimineert het resterende verschil in uitvoeringstijd in beide gevallen die in dit hoofd-
stuk zijn getest (Figuur 4.13). De gemiddelde uitvoeringstijden van de twee gevallen (mem3:
Listing 4.1 en mem1: Listing 4.2) zijn te zien in Figuur 4.14. Omdat bij mem1 geen extra
instructies wordt bijgevoegd is de uitvoeringstijd na balancering en na eliminatie van load by-
passing gelijk. Na eliminatie van load bypassing in de code van mem3 is de code even snel als
die van mem1. Er is dus geen groot prestatieverlies door eliminatie van load bypassing.
Deze algoritmes zijn enkel getest op de twee artificiele voorbeeldgevallen. Toch is dit repre-
sentatief voor andere crytografische code. Hier wordt enkel een store- en een loadinstructie in
een loop uitgevoerd. In encryptiealgoritmes wordt er nog veel andere code uitgevoerd en zal
het effect van load bypassing niet zo duidelijk zijn als in de gevallen die in dit hoofdstuk staan
beschreven. Met andere woorden, als er hier geen verschil meer te merken is zal het verschil in
cryptografische algoritmes nog veel kleiner zijn.
De algoritmes die in dit hoofdstuk zijn beschreven hebben slechts beperkte functionaliteit.
Omdat de algoritmes in dit hoofdstuk uitgevoerd worden op een stukje code met enkel een store
en load instructie wordt niet gecontroleerd als de gevonden instructie een load of store is. Er
wordt enkel gecontroleerd of een van de argumenten het geheugen gebruikt. Dit is voldoende voor
de twee testgevallen. Om de algoritmes uit te voeren op echte broncode moeten ze uitgebreid
worden om enkel store-instructies gevolgd door loadinstructies aan te passen.
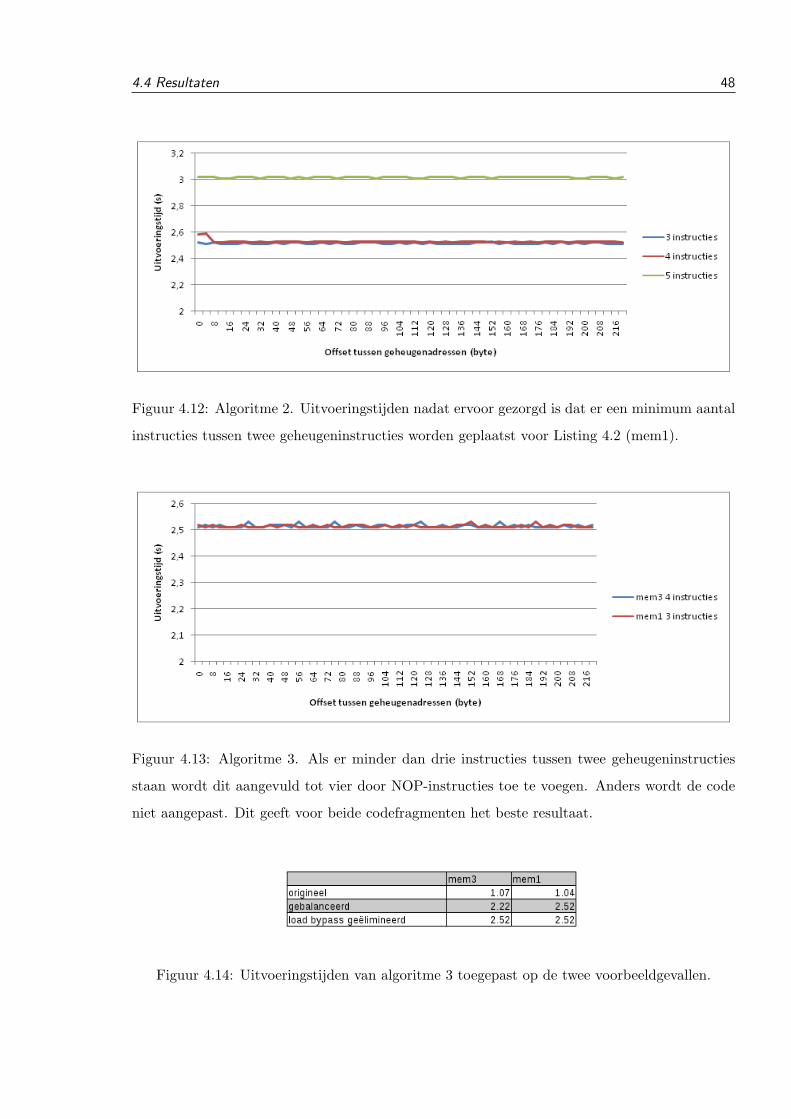
4.4 Resultaten 48
Figuur 4.12: Algoritme 2. Uitvoeringstijden nadat ervoor gezorgd is dat er een minimum aantal
instructies tussen twee geheugeninstructies worden geplaatst voor Listing 4.2 (mem1).
Figuur 4.13: Algoritme 3. Als er minder dan drie instructies tussen twee geheugeninstructies
staan wordt dit aangevuld tot vier door NOP-instructies toe te voegen. Anders wordt de code
niet aangepast. Dit geeft voor beide codefragmenten het beste resultaat.
Figuur 4.14: Uitvoeringstijden van algoritme 3 toegepast op de twee voorbeeldgevallen.

CACHEGEDRAG 49
Hoofdstuk 5
Cachegedrag
In dit hoofdstuk wordt de invloed van de cache op de uitvoeringstijd bestudeerd. Eerst worden
de gevolgen van if-conversie op het cachegedrag besproken. Daarna wordt een specifiek geval
bestudeerd en een mogelijke oplossing voorgesteld.
5.1 Cachegeheugen
Een cache is een buffer tussen de processor en het hoofdgeheugen. Het houdt de meest gebruikte
data bij zodat niet telkens het hoofdgeheugen moet geraadpleegd worden. Cachegeheugen is veel
sneller dan het hoofdgeheugen. Op moderne architecturen wordt een hierarchische cachestruc-
tuur gebruikt. Dit wil zeggen dat er verschillende niveaus van cachegeheugens aanwezig zijn met
telkens een grotere toegangstijd. Op Figuur 5.1 worden de verschillende cachegeheugens en hun
toegangstijden schematisch voorgesteld. Als een programma gegevens uit het geheugen nodig
heeft, zal eerst worden gecontroleerd als de data aanwezig is in het eerste cacheniveau. Indien
niet (cache-miss) zal een van de volgende niveaus en uiteindelijk het hoofdgeheugen worden
aangesproken. Naargelang de gevraagde data aanwezig is in het cachegeheugen zal een load of
store-instructie dus een andere uitvoeringstijd hebben.
5.2 Invloed van cachegeheugen op uitvoeringstijd
Zoals in de inleiding en het vorige hoofdstuk reeds vermeld is, worden load- en store-instructies
uitgevoerd op dummy geheugenadressen als ze worden opgeroepen in een tak die niet wordt
uitgevoerd. Afhankelijk van de invoer van het programma kan dus ofwel het originele geheuge-
nadres ofwel het dummy geheugenadres worden gebruikt. Dit kan voor een ander cachegedrag

5.2 Invloed van cachegeheugen op uitvoeringstijd 50
Figuur 5.1: Cachelayout van een Intel Core2 Duo processor. Het RAM geheugen is geen deel
van de processor en wordt via de Northbridge aangesproken.
zorgen. De gegevens op het originele geheugenadres kunnen zich reeds in de cache bevinden en
de gegevens op het dummy geheuegenadres niet. Als de instructie wordt uitgevoerd in een tak
die niet genomen is, zal een cache-miss optreden. Bijgevolg moet het volgende cacheniveau ge-
raadpleegd worden, wat voor een extra vertraging zorgt. Op deze manier kan het cachegedrag de
totale uitvoeringstijd van een programma beınvloeden. If-conversie introduceert dus een nieuwe
data-afhankelijkheid.
Er kunnen twee hoofdgevallen onderscheiden worden. Deze worden getoond op figuren 5.2
en 5.4. In het eerste geval (Figuur 5.2) is het geheugenadres altijd gekend. In dit geval is het
mogelijk om een dummy geheugenadres te berekenen aan de hand van het gekende adres. Als
a een geldig adres is, is het zelfs mogelijk om de load instructies het originele geheugenadres te
laten gebruiken.
In het tweede geval (Figuur 5.4) is het adres niet gekend wanneer de tak niet wordt genomen.
A is dan een nullpointer en het is niet mogelijk om aan de hand hiervan een dummy adres te
berekenen.
Figuur 5.2: Geval waar het originele geheugenadres gekend is. Het is mogelijk om het dummy
geheugenadres te kiezen als functie van het originele.
Er moet dus gezocht worden naar een manier om de dummy geheugenadressen zo te kie-
zen dat de variatie in uitvoeringstijd van een programma ten gevolge van het cachegedrag zo

5.3 Bestudeerde oplossingen 51
Figuur 5.3: Geval waar het originele geheugenadres niet gekend is. Er moet een andere manier
gezocht worden om een geschikt dummy geheugenadres te kiezen.
klein mogelijk is. We zeggen zo klein mogelijk omdat het bijna onmogelijk is om het originele
geheugenadres en het dummy geheugenadres in dezelfde toestand te hebben (Ofwel beide in de
cache ofwel alletwee enkel in geheugen). De cache wordt beınvloed door externe factoren zoals
andere draden waarover we geen controle hebben. Het is dan ook niet triviaal om een algeme-
ne oplossing te vinden die direct alle variatie ten gevolge van cache gedrag uit een programma
haalt. Het is echter wel nuttig om te kijken als een oplossing kan gevonden worden voor bepaalde
codeconstructies die voor variatie in uitvoeringstijd zorgen ten gevolge van het cache gedrag.
5.3 Bestudeerde oplossingen
Het stukje code in Listing 5.1 is een voorbeeld van een codeconstructie die ervoor kan zorgen dat
het cachegedrag extra variatie toevoegt aan de totale uitvoeringstijd van het programma. De
code bestaat uit een lus met daarin twee andere lussen. De eerste lus leest 8000 gehele getallen
uit een array. De Intel Core2 Duo processor heeft 32KByte L1 cache geheugen, de cache wordt
dus volledig overschreven met gegevens van de eerste loop. Daarna worden afhankelijk van de
waarde van a, 8000 andere getallen uit het geheugen gelezen. Als a waar is wordt de cache
overschreven met gegevens uit de tweede loop en zullen in de volgende iteratie cache-misses
optreden in de eerste loop. Als a vals is worden er geen gegevens uit het geheugen gelezen en
zullen de gegevens van de eerste loop voor het grootste deel nog in de cache zitten.

5.3 Bestudeerde oplossingen 52
Listing 5.1: C-code die variatie in uitvoeringstijd ten gevolge van cache gedrag aantoont.
for(i=1;i <500000;i++){
for(k=0;k <8000;k++){
result += *(mem+k);
}
for(j=0;j <8000;j++){
if(a){
result += *(mem +10000+j);
}
}
}
Na balancering verandert er niet veel aan dit gedrag. Zoals if-conversie nu is geımplementeerd,
wordt per geheugeninstructie een dummy geheugenlocatie gealloceerd op de stack. Als a vals is
zal dus 8000 keer hetzelfde geheugenadres worden opgevraagd. Ook nu zullen de meeste gegevens
uit de eerste lus nog in de cache aanwezig zijn. Afhankelijk van de waarde van a treden dus meer
cache-misses op in de eerste loop en dit zou kunnen bijdragen tot variatie in de uitvoeringstijd
van het programma.
Dit kan opgelost worden door in plaats van per geheugeninstructie een dummy geheugen-
locatie op de stack te alloceren een blok geheugen te alloceren voor het hele programma. Het
dummy geheugenadres kan dan berekend worden door de laatste x bits van het originele ge-
heugenadres te gebruiken als index binnen het gealloceerde blok geheugen. Op deze manier
wordt bij een instructie die naar een constant origineel adres schrijft ook naar een constant
dummyadres geschreven. Als de instructie uit een array leest zal dan ook telkens uit een ander
dummy geheugenlocatie worden gelezen. In de voorbeeldcode zal loop twee nu altijd de cache
overschrijven met zijn gegevens, zelfs als a vals is.
De grootte van het gealloceerde blok is gelijk aan de grootte van de cache. Een blok kleiner
dan de cache zal de variatie in uitvoeringstijd wel verkleinen, maar het zal niet mogelijk zijn
om in de tweede loop de volledige cache te overschrijven. Het aantal bits x moet exact gelijk
zijn aan het binair logaritme van het gealloceerde blok geheugen. Als het kleiner is zal niet het
volledige geheugenblok gebruikt worden. Als het groter is kan buiten het geheugenblok worden
geschreven wat een segmentation fault kan geven.
Er is ook geen probleem wanneer het adres niet gekend is of als het om een nullpointer gaat.

5.4 Implementatie 53
De laaste bits van het originele adres zijn dan 0 of een arbitraire waarde. In het geval dat de
bits 0 zijn, zal het dummyadres wijzen naar het begin van het gealloceerde blok geheugen. Dit is
gelijk aan de manier waarop in de huidige plugin een waarde wordt gealloceerd. Een arbitraire
waarde zal eveneens naar een random index binnen het geheugenblok wijzen.
5.4 Implementatie
Deze transformatie is geımplementeerd als een uitbreiding op de bestaande balanceringsplugin.
De code die dummy geheugenadressen alloceert heb ik vervangen door het algoritme dat in de
vorige sectie beschreven is. Het gebruiken van het originele adres als index in een gealloceerd blok
geheugen is zeer eenvoudig. Eerst wordt een logische and uitgevoerd van het originele adres en
een bitmasker die de meest significante bits op nul zet. Enkel voldoende bit worden behouden om
het gealloceerde blok geheugen te indexeren. Dit resultaat wordt dan opgeteld bij het beginadres
van het blok geheugen. In formulevorm: DummyAdres = ADD(GeheugenBlokAdresPointer ,
AND(OrigineelAdres, 1 . . . 11).
5.5 Resultaten
Het stuk C-code in Listing 5.1 wordt uitgevoerd met twee invoersets. In de eerste set is a
constant vals en wordt de conditionele code nooit uitgevoerd. In de tweede set is a constant
waar en wordt de conditionele code altijd uitgevoerd. Figuur 5.4 toont de resultaten van de testen
uitgemiddeld over 40 uitvoeringen. Bij de originele manier van geheugenadressen alloceren is er
een duidelijk verschil tussen de gemiddelde uitvoeringstijden. De p-waarden van de t-test zijn
dus ook erg laag, wat er op duidt dat er een duidelijk verschil is tussen de twee samples van
uitvoeringstijden. Bij de nieuwe methode liggen de gemiddelde uitvoeringstijden veel dichter
bij elkaar. Uit de hoge p-waarde kan afgeleid worden dat er geen merkbaar verschil meer is
tussen de uitvoeringstijden van de twee invoersets. De laatse rij toont het aantal cache-misses
per geval voor de oude en nieuwe manier van alloceren. Waar er bij de oude manier een duidelijk
verschil was zijn er nu in beide gevallen evenveel cachemisses. Omdat er code wordt toegevoegd
die voor elke geheugeninstructie het correcte dummy geheugenadres moet berekenen, is er een
prestatieverlies van 14,5%.

5.5 Resultaten 54
Figuur 5.4: TODO.

BESLUIT EN TOEKOMSTPERSPECTIEVEN 55
Hoofdstuk 6
Besluit en toekomstperspectieven
Binnen de vakgroep zijn reeds compilertransformaties ontworpen die het controleverloop onaf-
hankelijk maakt van de invoer van het programma. Mijn thesis vult dit onderzoek aan met een
aantal tranformaties die data-afhankelijkheden elimineren.
In de eerste plaats wordt een alternatieve oplossing voorgesteld om de variabele uitvoerings-
tijd van de gehele deling te elimineren. Door het parallel uitvoeren van instructies met een
langere vaste uitvoeringstijd met de originele deling kan de globale uitvoeringstijd onafhankelijk
gemaakt worden van de uitvoeringstijd van de deling. Deze transformatie is veel performanter
dan de reeds bestaande transformatie[2] bij het uitvoeren van een modulair exponentiatie algo-
ritme: 109% en 78% trager voor respectievelijk 32- en 64bit code. Reeds bestaande technieken
zijn 2300% en 1439% trager voor respectievelijk 32- en 64bit code. Dit is een enorme snelheids-
winst. Een nadeel ten opzichte van de bestaande techniek is dat de code nog steeds kwetsbaar
is voor een resource contention aanval.
Vervolgens werd het pijplijngedrag van load- en store-instructies onderzocht. Naargelang
er afhankelijkheden worden gedetecteerd tussen een opeenvolgende store en loadinstructie kan
load bypassing optreden. Dit kan zorgen voor variabele uitvoeringstijd van een programma.
Na balancering is de meeste variatie reeds geelimineerd. In deze paper wordt een oplossing
voorgesteld die de resterende variatie elimineert. Er wordt een artificiele vertraging toegevoegd
tussen load- en store-instructies door het toevoegen van NOP-instructies. Op deze manier wordt
er geen load bypassing meer uitgevoerd. Op de geteste gevallen geeft het elimineren van load
bypassing een prestatieverlies van 0% en 14% afhankelijk van de broncode.
Ten laatste werd nog een geval onderzocht waar het cachegedrag invloed heeft op de uitvoe-
ringstijd van een programma. Door het implementeren van een nieuwe manier van alloceren van

BESLUIT EN TOEKOMSTPERSPECTIEVEN 56
dummy geheugenadressen bij if-conversie wordt deze variatie weggewerkt.
Combinatie van reeds bestaande technieken gecombineerd met de oplossingen hier voorge-
steld zorgen ervoor dat nevenkanalen zoals sprongvoorspeller en instructiecache volledig zijn
afgesloten. De variatie in uitvoeringstijd wordt door de transformaties in deze paper nog verder
gereduceerd, waardoor hier veel minder informatie uit kan gehaald worden. Reeds bestaande
transformaties gebaseerd op if-conversie tesamen met de tranformaties beschreven in deze paper
zullen het een aanvaller aanzienlijk lastiger maken om geheime informatie te achterhalen door
middel van micro-architecturale crypto-analyse.
Verder onderzoek kan nog gebeuren om de performantie van de transformaties te optimalise-
ren en andere gevallen te analyseren waar de cache nog invloed kan hebben op de uitvoeringstijd.
Het is ook nuttig om mogelijkheden te onderzoeken om de data-cache als nevenkanaal af te slui-
ten.

DETAILED INFORMATION 57
Bijlage A
Detailed information
A.1 CPU Details
processor : 0
vendor_id : GenuineIntel
cpu family : 6
model : 23
model name : Intel(R) Core(TM)2 Duo CPU T6400 @ 2.00GHz
stepping : 10
cpu MHz : 1200.000
cache size : 2048 KB
physical id : 0
siblings : 2
core id : 0
cpu cores : 2
apicid : 0
initial apicid : 0
fdiv_bug : no
hlt_bug : no
f00f_bug : no
coma_bug : no
fpu : yes
fpu_exception : yes

A.1 CPU Details 58
cpuid level : 13
wp : yes
flags : fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat
pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe nx lm
constant_tsc arch_perfmon pebs bts pni monitor ds_cpl est tm2 ssse3
cx16 xtpr sse4_1 lahf_lm
bogomips : 3989.96
clflush size : 64
power management:
processor : 1
vendor_id : GenuineIntel
cpu family : 6
model : 23
model name : Intel(R) Core(TM)2 Duo CPU T6400 @ 2.00GHz
stepping : 10
cpu MHz : 1200.000
cache size : 2048 KB
physical id : 0
siblings : 2
core id : 1
cpu cores : 2
apicid : 1
initial apicid : 1
fdiv_bug : no
hlt_bug : no
f00f_bug : no
coma_bug : no
fpu : yes
fpu_exception : yes
cpuid level : 13
wp : yes
flags : fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat

A.2 Cache Details 59
pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe nx lm
constant_tsc arch_perfmon pebs bts pni monitor ds_cpl est tm2 ssse3
cx16 xtpr sse4_1 lahf_lm
bogomips : 3989.96
clflush size : 64
power management:
A.2 Cache Details
/sys/devices/system/cpu/cpu1/cache/index0
Level: 1
Type: Data
Size: 32K
Number of sets: 64
/sys/devices/system/cpu/cpu1/cache/index1
Level: 1
Type: Instruction
Size: 32K
Number of sets: 64
/sys/devices/system/cpu/cpu1/cache/index2
Level: 2
Type: Unified
Size: 2048K
Number of sets: 4096

BIBLIOGRAFIE 60
Bibliografie
[1] Simcha Gochman, Avi Mendelson, Alon Naveh, Efraim Rotem “Introduction to Intel Core
Duo Processor Architecture”
[2] Bart Coppens , Ingrid Verbauwhede, Koen De Bosschere, Bjorn De Sutter “Practical
Mitigations for Timing-Based Side-Channel Attacks on Modern x86 Processors”
[3] Jack Doweck “Inside Intel Core Microarchitecture and Smart Memory Access” “An In-
Depth Look at Intel Innovations for Accelerating Execution of Memory-Related Instruc-
tions”
[4] Chris Lattner “Introduction to the LLVM Compiler Infrastructure”
[5] The LLVM Compiler Infrastructure http://llvm.org/
[6] Onur Onur Acıimez, Jean-Pierre Seifert,etin Kaya Ko “Micro-architectural cryptanalysis”
[7] D. Molnar, M. Piotrowski, D. Schultz, and D. Wagner, The program counter security
model: Automatic detection and removal of control-flow side channel attacks, pp. 156168,
2005.
[8] Paul C. Kocher; “Timing Attacks on Implementations of Diffie-Hellman, RSA, DSS, and
Other Systems”
[9] Shay Gueron, “Advanced encryption standard (AES) Instruction set”
[10] Fisher, J.A. and Faraboschi, P. and Young, C., “Embedded Computing, A VLIW Approach
to Architecture, Compilers and Tools”
[11] by Joseph A. Fisher, Paolo Faraboschi, Cliff Young, “Embedded Computing: A VLIW
Approach to Architecture, Compilers and Tools”

BIBLIOGRAFIE 61
[12] David I. August and John W. Sias and Jean-Michel Puiatti and Scott A. Mahlke and
Daniel A. Connors and Kevin M. Crozier and Wen-mei W. Hwu, “The program decision
logic approach to predicated execution”
[13] J. Coke, H. Balig, N. Cooray, E. Gamsaragan, P. Smith, K. Yoon, J. Abel, and A. Valles,
“Improvements in the Intel Core 2 processor family architecture and microarchitecture”,
Intel Technology Journal, vol. 12, no. 03, pp. 179-192, 2008.
[14] William Stallings “Cryptography and Network Security, Principles and Practices”
[15] D. Brumley, D. Bonch, “Remote Timing Attacks are Practical.”
[16] K. Gandolfi, C Mourtel, F. Olivier, “Electromagnetic Analysis: Concrete Results.”
[17] Onur Aciicmez, Cetin Kaya Koc, Jean-Pierre Seifert, “On the power of simple branch
prediction analysis.”
[18] J. Shen and M. Lipasti “Modern Processor Design: Fundamentals of Superscalar Proces-
sors” McGraw-Hill, 2005









![Bijzonder resistente micro-organismen (BRMO) BRMO [VWK].pdfBRMO (Bijzonder resistente micro-organismen): (pathogene) micro-organismen die ongevoelig zijn voor de meest geëigende (dus](https://static.fdocuments.nl/doc/165x107/5e39447f80bcc1091f3c578e/bijzonder-resistente-micro-organismen-brmo-brmo-vwkpdf-brmo-bijzonder-resistente.jpg)









