NVIDIA Hardware
33
Karl Hillesland - NVIDIA Hardware - 11/2 - Slide 1 NVIDIA Hardware NVIDIA Hardware Karl Hillesland Karl Hillesland November 2, 2000 November 2, 2000
description
NVIDIA Hardware. Karl Hillesland November 2, 2000. Major release in fall, improvement in spring NV10: GeForce 256 (Fall 1999) NV15: GeForce2 GTS (Spring 2000) NV11: GeForce2 MX (Summer 2000) NV16: GeForce2 Ultra (Fall 2000) NV20: ??? (Anandtech: Dec 2000 - April 2001) - PowerPoint PPT Presentation
Transcript of NVIDIA Hardware

Karl Hillesland - NVIDIA Hardware - 11/2 - Slide 1
NVIDIA HardwareNVIDIA Hardware
Karl HilleslandKarl Hillesland
November 2, 2000November 2, 2000

Karl Hillesland - NVIDIA Hardware - 11/2 - Slide 2
Cards discussedCards discussed
• Major release in fall, improvement in springMajor release in fall, improvement in spring• NV10: GeForce 256 (Fall 1999)NV10: GeForce 256 (Fall 1999)• NV15: GeForce2 GTS (Spring 2000) NV15: GeForce2 GTS (Spring 2000) • NV11: GeForce2 MX (Summer 2000)NV11: GeForce2 MX (Summer 2000)• NV16: GeForce2 Ultra (Fall 2000)NV16: GeForce2 Ultra (Fall 2000)• NV20: ??? (Anandtech: Dec 2000 - April 2001)NV20: ??? (Anandtech: Dec 2000 - April 2001)• NV25?: X-Box (Fall 2001) NV25?: X-Box (Fall 2001)

Karl Hillesland - NVIDIA Hardware - 11/2 - Slide 3
GeForce 256GeForce 256
• 0.22um, 23 M transistors0.22um, 23 M transistors• 120 MHz core120 MHz core• 128 bit, 166 MHz SDR or 150 MHz DDR, up to 128 MB (64 128 bit, 166 MHz SDR or 150 MHz DDR, up to 128 MB (64
MB biggest I’ve ever heard of)MB biggest I’ve ever heard of)• AGP 4x with fast writesAGP 4x with fast writes• 350 MHz RAMDAC350 MHz RAMDAC• DVDDVD• TV-outTV-out

Karl Hillesland - NVIDIA Hardware - 11/2 - Slide 4
GeForce 256 TrianglesGeForce 256 Triangles
• 15 MTris/s (BenMark5 gives 13M. Have seen 15 MTris/s (BenMark5 gives 13M. Have seen other references to 14.5M) other references to 14.5M)
• Up to 6 triangles “in-flight” at a timeUp to 6 triangles “in-flight” at a time• 2 matrix Vertex skinning2 matrix Vertex skinning• Texture coordinate generation (+emboss, Texture coordinate generation (+emboss,
reflection, cube map)reflection, cube map)• 8 lights8 lights

Karl Hillesland - NVIDIA Hardware - 11/2 - Slide 5
BenMark5BenMark5NV10: 13 MTris/s, NV15: 24 MTris/sNV10: 13 MTris/s, NV15: 24 MTris/s

Karl Hillesland - NVIDIA Hardware - 11/2 - Slide 6
Transform Engine
LightingEngine
SetupEngine
RenderingEngine
Four Independent Pipelined EnginesFour Independent Pipelined Engines
Industry-leading 3D performance15-25M triangles/second
Sustained DMA, transform/clip/light, setup, rasterize and render rateExtremely efficient
>70% of the chip active at all timesUp to 6 triangles “in flight” at a time
Super-pipelined designVery low latency between engines
QuadEngineTM Architecture (from summer 99 notes)

Karl Hillesland - NVIDIA Hardware - 11/2 - Slide 7
GeForce 256 pixels/texelsGeForce 256 pixels/texels
• 4 pixel pipes, one texture each. Can do 2-texture multi-4 pixel pipes, one texture each. Can do 2-texture multi-texturing by coupling pipestexturing by coupling pipes
• 24/8 bit Z/stencil, 32 bit color (note: 4*(24+8+32)=256)24/8 bit Z/stencil, 32 bit color (note: 4*(24+8+32)=256)• Register CombinersRegister Combiners• Texture CompressionTexture Compression• 8-tap anisotropic filtering8-tap anisotropic filtering• range based fogrange based fog• anti-aliasing(?)anti-aliasing(?)

Karl Hillesland - NVIDIA Hardware - 11/2 - Slide 8
GeForce 256 -> GeForce2 GTSGeForce 256 -> GeForce2 GTS
• 2 textures per pipe2 textures per pipe• 25M Transistors 25M Transistors • 0.18 Micron technology0.18 Micron technology• 200 MHz core clock, 166 MHz DDR (“333” MHz)200 MHz core clock, 166 MHz DDR (“333” MHz)• 25M Tris/s (BenMark5 gives 24M Tris/s)25M Tris/s (BenMark5 gives 24M Tris/s)• Flat panelFlat panel

Karl Hillesland - NVIDIA Hardware - 11/2 - Slide 9
GeForce2 GTS GeForce2 GTS GeForce2 MX GeForce2 MX
• Remove two pixel pipes (left with 2, 2 textures each)Remove two pixel pipes (left with 2, 2 textures each)• Dual head supportDual head support• ““Digital Vibrance Control”Digital Vibrance Control”• Low power and heat Low power and heat • Slower Core Clock (175 MHz)Slower Core Clock (175 MHz)• Either 64 or 128 bit memory possibleEither 64 or 128 bit memory possible• Cheaper: (intended for ~ $100 range)Cheaper: (intended for ~ $100 range)

Karl Hillesland - NVIDIA Hardware - 11/2 - Slide 10
GeForce2 GTS GeForce2 GTS GeForce2 Ultra GeForce2 Ultra
• Faster core clock: 250 MHzFaster core clock: 250 MHz• Faster memory: 225 MHz DDR ( “450” MHz)Faster memory: 225 MHz DDR ( “450” MHz)• Expensive: ~ $500Expensive: ~ $500

Karl Hillesland - NVIDIA Hardware - 11/2 - Slide 11
GeForce GeForce Quadro Quadro
• Increased clock ratesIncreased clock rates• Acceleration of some common CAD-oriented Acceleration of some common CAD-oriented
features (.e.g, anti-aliased lines)features (.e.g, anti-aliased lines)

Karl Hillesland - NVIDIA Hardware - 11/2 - Slide 12
BandwidthsBandwidths
• AGP 4x : 1.2 GB/sAGP 4x : 1.2 GB/s• Video memory: 333 MHz * 128 bits = 5.3 GB/sVideo memory: 333 MHz * 128 bits = 5.3 GB/s• PCI: 132 MB/s PCI: 132 MB/s • Host: PC100 with SDRAM = 1.6 GB/sHost: PC100 with SDRAM = 1.6 GB/s

Karl Hillesland - NVIDIA Hardware - 11/2 - Slide 13
Vertex BandwidthVertex Bandwidth
• Q3 -> 18 bytes per vertexQ3 -> 18 bytes per vertex–position 2 * 3 = 6 bytesposition 2 * 3 = 6 bytes–texture coords, 2 textures: 2 * 2 * 2 = 8 bytestexture coords, 2 textures: 2 * 2 * 2 = 8 bytes–color: 4 bytescolor: 4 bytes
• The double eagle: 10/16 bytes per vertexThe double eagle: 10/16 bytes per vertex–position 2 * 3 = 6 bytesposition 2 * 3 = 6 bytes–color: 4 bytes color: 4 bytes

Karl Hillesland - NVIDIA Hardware - 11/2 - Slide 14
Vertex Bandwidth, Q3Vertex Bandwidth, Q3
• AGP 4x : 1.2 GB/s / 18 = 67 M Verts/sAGP 4x : 1.2 GB/s / 18 = 67 M Verts/s• Video memory: 5.3 GB/s / 18 = 294 M Verts/sVideo memory: 5.3 GB/s / 18 = 294 M Verts/s• PCI: 132 MB/s / 18 = 7.3 M Verts/sPCI: 132 MB/s / 18 = 7.3 M Verts/s• Host: PC100 with SDRAM: 1.6 GB/s / 18 = Host: PC100 with SDRAM: 1.6 GB/s / 18 =
88 M Verts/s88 M Verts/s

Karl Hillesland - NVIDIA Hardware - 11/2 - Slide 15
Add indicesAdd indices
• Assume “perfect strips” (one new vertex for each Assume “perfect strips” (one new vertex for each triangle)triangle)
• Each triangle -> 3 indices, 1 new vertexEach triangle -> 3 indices, 1 new vertex• 18 + 2 bytes/index * 3 indicies/tri = 20 bytes/tri18 + 2 bytes/index * 3 indicies/tri = 20 bytes/tri• indicies and verticies may come across different indicies and verticies may come across different
bussesbusses• Vertex cache can save some bandwidthVertex cache can save some bandwidth

Karl Hillesland - NVIDIA Hardware - 11/2 - Slide 16
Texture CompositingTexture Compositing
TextureEnvironment
0 TextureEnvironment
1
TextureFetching
SpecularColorSum Fog
Application
Tex0
Tex1
Fragment Color
Fog Color/Factor
Specular Color

Karl Hillesland - NVIDIA Hardware - 11/2 - Slide 17
Register CombinersRegister Combiners
• Replaces blending of fragment, texture, fog, and Replaces blending of fragment, texture, fog, and secondary colors.secondary colors.
• Provides configurable 8-bit, signed math per-pixel Provides configurable 8-bit, signed math per-pixel operationsoperations
• Cascading of register combiners for more Cascading of register combiners for more sophisticated computations (Hardware limit on sophisticated computations (Hardware limit on levels. Currently 2)levels. Currently 2)

Karl Hillesland - NVIDIA Hardware - 11/2 - Slide 18
Register CombinersRegister Combiners
Spare 0
Fragment Color
TextureFetching
GeneralCombiner
0
4 RGB Inputs
Texture 0
Texture 1
Fog Color/Factor
Reg
iste
r Set
6 RGB Inputs
Specular Color
4 Alpha Inputs
3 RGB Outputs
3 Alpha Outputs
GeneralCombiner
1
4 RGB Inputs
4 Alpha Inputs
3 RGB Outputs
3 Alpha Outputs
FinalCombiner
1 Alpha Input
Specular Color

Karl Hillesland - NVIDIA Hardware - 11/2 - Slide 19
Input/Output mappingsInput/Output mappings
• Input mappingsInput mappings– InvertInvert– NegateNegate– Bias by 1/2Bias by 1/2– Expand by 2Expand by 2
• Output mappings Output mappings – Bias by 1/2Bias by 1/2– Scale by 1/2, 2 or 4Scale by 1/2, 2 or 4

Karl Hillesland - NVIDIA Hardware - 11/2 - Slide 20
General Combiner, RGBGeneral Combiner, RGB
zero
primary color
secondary color
constant color 0
constant color 1
fog
spare 1
spare 0
texture 0
texture 1A B + C D
A B mux C D-or-
A B
A B-or-
C D
C D-or-
A B C D
inputmap
inputmap
inputmap
not writeable
RGB A RGB A
input registers
computations
output registers
scaleandbias
inputmap
not readable
zero
primary color
secondary color
constant color 0
constant color 1
fog
spare 1
spare 0
texture 0
texture 1

Karl Hillesland - NVIDIA Hardware - 11/2 - Slide 21
General Combiner, AlphaGeneral Combiner, Alpha
zero
primary color
secondary color
constant color 0
constant color 1
fog
spare 1
spare 0
texture 0
texture 1A B + C D
A B mux C D-or-
A B
C D
A B C D
inputmap
inputmap
inputmap
not writeable
RGB A RGB A
input registers output registers
scaleandbias
inputmap
not readable
zero
primary color
secondary color
constant color 0
constant color 1
fog
spare 1
spare 0
texture 0
texture 1

Karl Hillesland - NVIDIA Hardware - 11/2 - Slide 22
Final CombinerFinal Combiner
zero
primary color
secondary color
constant color 0
constant color 1
fog
spare 1
spare 0
texture 0
texture 1
A B C D
RGB A
input registers
A B + ( 1 - A) C + D
E F
E F
G
spare 0 +secondary color
inputmap
inputmap
inputmap
inputmap
inputmap
inputmap
inputmap
fragment RGB out
fragment Alpha outG

Karl Hillesland - NVIDIA Hardware - 11/2 - Slide 23
X-Box (Abrash on Dr. Dobbs)X-Box (Abrash on Dr. Dobbs)
• Intel PIII/733 with 238 KB cacheIntel PIII/733 with 238 KB cache• 250-300 MHz Core250-300 MHz Core• DVD, hard diskDVD, hard disk• custom sound with 64 3D-audio channelscustom sound with 64 3D-audio channels

Karl Hillesland - NVIDIA Hardware - 11/2 - Slide 24
X-Box Transform/lightingX-Box Transform/lighting
• 125 M Tris gouraud, transformed, shaded, two textures. 125 M Tris gouraud, transformed, shaded, two textures. • +one infinite light, 62.45 MTris/sec, +one infinite light, 62.45 MTris/sec, • 8 local lights 8 MTris/sec8 local lights 8 MTris/sec• 125 M particles/s (single color front-facing squares)125 M particles/s (single color front-facing squares)• Vertex ProgramsVertex Programs• Surface engine “works with CPU” for Catmull-Clark, Surface engine “works with CPU” for Catmull-Clark,
Bezier, Loop, and uniform B-splines at 50Mtris/secBezier, Loop, and uniform B-splines at 50Mtris/sec

Karl Hillesland - NVIDIA Hardware - 11/2 - Slide 25
Vertex ProgramsVertex Programs
• Replaces transformation and lightingReplaces transformation and lighting• Custom vertex lightingCustom vertex lighting• Custom skinning and blendingCustom skinning and blending• Custom texture coordinate generationCustom texture coordinate generation• Custom matrix operationsCustom matrix operations• Custom vertex computations of your choiceCustom vertex computations of your choice

Karl Hillesland - NVIDIA Hardware - 11/2 - Slide 26
Vertex ProgramsVertex Programs
• Input is untransformed, unlit vertexInput is untransformed, unlit vertex• Create a transformed vertexCreate a transformed vertex• Optionally computeOptionally compute
– lightinglighting– texture coordinatestexture coordinates– fog coordinatesfog coordinates– point sizespoint sizes

Karl Hillesland - NVIDIA Hardware - 11/2 - Slide 27
Vertex Programs cont.Vertex Programs cont.
• Does 4-vector fixed point mathDoes 4-vector fixed point math• 17 Instructions:17 Instructions:
–ARL, MOV, MUL, ADD, MAD, RCP, RSQ, ARL, MOV, MUL, ADD, MAD, RCP, RSQ, DP3, DP4, DST, MIN, MAX, SLT, SGE, EXP, DP3, DP4, DST, MIN, MAX, SLT, SGE, EXP, LOG, LITLOG, LIT

Karl Hillesland - NVIDIA Hardware - 11/2 - Slide 28
Vertex Program RegistersVertex Program Registers
16x4 Vertex Attribute Registers
Vertex Program
128 instructions
15x4 Vertex Result Registers
96x4 Program Parameters
(e.g, modelview projection matrix)
12x4 Temporary registers

Karl Hillesland - NVIDIA Hardware - 11/2 - Slide 29
Using Vertex Programs (OpenGL)Using Vertex Programs (OpenGL)
• Programs are arrays of GLubytes(“strings”)Programs are arrays of GLubytes(“strings”)• Created/managed similar to texture objectsCreated/managed similar to texture objects• No penalty for switching in and out of vertex No penalty for switching in and out of vertex
program modeprogram mode• execution time ~proportional to length of programexecution time ~proportional to length of program

Karl Hillesland - NVIDIA Hardware - 11/2 - Slide 30
X-Box memory bandwidthX-Box memory bandwidth
• UMA with GPU in controlUMA with GPU in control• 64 MB, 128 bit, 200 MHz DDR RAM64 MB, 128 bit, 200 MHz DDR RAM• 1 GPix/sec fill rate + “occlusion circuitry”1 GPix/sec fill rate + “occlusion circuitry”• ““automatic z compression”automatic z compression”

Karl Hillesland - NVIDIA Hardware - 11/2 - Slide 31
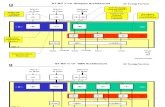
X-Box bandwidth diagramX-Box bandwidth diagram

Karl Hillesland - NVIDIA Hardware - 11/2 - Slide 32
X-Box TexturesX-Box Textures
• 4 textures per pixel (but takes two clocks for >2)4 textures per pixel (but takes two clocks for >2)• One texture can be used as lookup to next textureOne texture can be used as lookup to next texture• 8 general register combiners + final combiner8 general register combiners + final combiner• 3D Textures3D Textures• Cube maps, compression, etc.Cube maps, compression, etc.• 2 or 4 sample anti-aliasing2 or 4 sample anti-aliasing

Karl Hillesland - NVIDIA Hardware - 11/2 - Slide 33
Texture compression (OpenGL)Texture compression (OpenGL)
• DXTC/S3TC DXTC/S3TC –Pre-compressed (DDS file)Pre-compressed (DDS file)–Compressed by driverCompressed by driver
• DXT1/S3TC, DXT3, DXT5 (not DXT2, DXT4)DXT1/S3TC, DXT3, DXT5 (not DXT2, DXT4)• Ugly (be careful of trickery though)Ugly (be careful of trickery though)