FPGA-gebaseerde instructiesetuitbreiding voor...
73
Faculteit Ingenieurswetenschappen Vakgroep Elektronica en Informatiesystemen Voorzitter: prof. dr. ir. J. Van Campenhout FPGA-gebaseerde instructiesetuitbreiding voor blokgebaseerde wavelettransformatie door Jeroen Cosyn Promotor: prof. dr. ir. D. Stroobandt Thesisbegeleiders: dr. ir. M. Christiaens, ir. B. Schrauwen Scriptie ingediend tot het behalen van de academische graad van Burgerlijk Ingenieur Elektrotechniek Academiejaar 2005-2006
Transcript of FPGA-gebaseerde instructiesetuitbreiding voor...

Faculteit Ingenieurswetenschappen
Vakgroep Elektronica en Informatiesystemen
Voorzitter: prof. dr. ir. J. Van Campenhout
FPGA-gebaseerde
instructiesetuitbreiding voor
blokgebaseerde wavelettransformatiedoor
Jeroen Cosyn
Promotor: prof. dr. ir. D. Stroobandt
Thesisbegeleiders: dr. ir. M. Christiaens, ir. B. Schrauwen
Scriptie ingediend tot het behalen van
de academische graad van Burgerlijk Ingenieur Elektrotechniek
Academiejaar 2005-2006

Woord Vooraf
In de eerste plaats gaat mijn dank uit naar prof. Dirk Stroobandt. Hij heeft mij de
mogelijkheden gegeven tot het onderzoek van dit scriptieonderwerp.
De assistentie wens ik te bedanken voor hun hulp en begeleiding. Speciale dank
gaat uit naar mijn begeleiders Mark Christiaens en Benjamin Schrauwen, alsook
naar Harald Devos, Peter Bertels, Karel Bruneel, Philippe Faes, Hendrik Eeckhaut
en Michiel D’Haene.
In het bijzonder wens ik Harald te bedanken voor de nodige uitleg bij de wavelet-
transformaties en voor het nalezen van dit werk. Peter dank ik voor het verlenen van
zijn LaTeX template en voor de interesse die hij gedurende het ganse jaar toonde in
mijn scriptie. Bij problemen stonden Karel en Philippe altijd klaar om mij uit de
nood te helpen, waarvoor ook mijn oprechte dank.
Voor deze scriptie heb ik veel samengewerkt met Pieter-Paul. Ik wens hem dan ook
te danken voor alle hulp en voor het toffe gezelschap gedurende het hele jaar. Ook
Steven en Jabran zorgden voor de nodige ontspanning en de goede sfeer tijdens het
werken. De vele spelletjes Hangaroo zal ik niet snel vergeten. Wout en Carl wens ik
van harte te bedanken omdat ze zo’n fantastische vrienden zijn. Samen hebben we
er een onvergetelijk jaar van gemaakt.
Verder wil ik nog mijn familie bedanken voor alles wat ze voor mij doen en gedaan
hebben. Te veel om op te noemen ... Bedankt!
Jeroen

Toelating tot bruikleen
De auteur geeft de toelating deze scriptie voor consultatie beschikbaar te stellen en
delen van de scriptie te kopieren voor persoonlijk gebruik.
Elk ander gebruik valt onder de beperkingen van het auteursrecht, in het bijzon-
der met betrekking tot de verplichting de bron uitdrukkelijk te vermelden bij het
aanhalen van resultaten uit deze scriptie.
Jeroen Cosyn, 6 juni 2006

FPGA-gebaseerde instructiesetuitbreiding voorblokgebaseerde wavelettransformatie
door
Jeroen Cosyn
Scriptie ingediend tot het behalen van
de academische graad van Burgerlijk Ingenieur Elektrotechniek
Academiejaar 2005-2006
Universiteit Gent
Faculteit Ingenieurswetenschappen
Vakgroep Elektronica en Informatiesystemen
Voorzitter: prof. dr. ir. J. Van Campenhout
Promotor: prof. dr. ir. D. Stroobandt
Thesisbegeleiders: dr. ir. M. Christiaens, ir. B. Schrauwen
Samenvatting
De dag van vandaag zijn mobiele multimedia toepassingen niet meer uit de samen-
leving weg te denken. Om aan de noden van deze toepassingen te voldoen kan het
gebruik van herconfigureerbare hardware (FPGA’s) overwogen worden. FPGA’s
bieden een tussenoplossing tussen de rekenkracht van een hardware-implementatie
en de herconfigureerbaarheid van een software-implementatie. Een FPGA is uiter-
mate geschikt voor het uitvoeren van de parallelle onderdelen van een algoritme,
maar voor de implementatie van het controleverloop is hij minder geschikt. Een
oplossing hiervoor is het gebruik van een FPGA die een processor bevat. De Xilinx
Virtex-4 FX FPGA beschikt over een PowerPC en een APU controller die de com-
municatie tussen de FPGA en de processor verzorgt. De APU controller stelt ons
in staat de instructieset van de PowerPC uit te breiden met eigen instructies.
In deze thesis wordt de implementatie van een blokgebaseerde wavelettransformatie
op de Virtex-4 FX onderzocht. Deze wavelettransformatie maakt deel uit van een
schaalbare videocodec die binnen het RESUME project wordt ontwikkeld. De wer-
king en het gebruik van de hardware wordt bestudeerd en er wordt gekeken of deze
aan de verwachtingen voldoet. We komen tot het besluit dat zowel het gebruik van
de blokgebaseerde wavelettransformatie als van een FPGA die een PowerPC bevat
voordelen oplevert ten opzichte van andere mogelijkheden.
Trefwoorden: FPGA, instructiesetuitbreiding, hardware-implementatie, wavelet-
transformatie

FPGA-based instruction set extension forlocal wavelet transform
Jeroen Cosyn
Supervisor(s): prof. dr. ir. D. Stroobandt, dr. ir. M. Christiaens, dr. ir. B. Schrauwen
Abstract—Nowadays we can’t imagine a world without mobile multime-dia applications. To satisfy the needs of such applications, we can considerthe use of reconfigurable hardware (FPGA’s). FPGA’s offer a compromisebetween the calculation power of a hardware implementation and the re-configurability of a software implementation. However, for the executionof the parallel parts of an algorithm an FPGA is a good choice, but forthe implementation of the controlling parts it’s less suitable. The use of anFPGA with an embedded processor might be a good alternative. The XilinxVirtex-4 FX FPGA contains a PowerPC and an APU controller that takescare of the communication between the FPGA and the processor. The APUcontroller allows us to extend the instruction set of the PowerPC with cus-tom instructions. In this article we investigate the implementation of a localwavelet transform1 on the Virtex-4 FX. This wavelet transform is part of ascalable video codec that is being developed in the RESUME project. Weexplore the hardware and see if it comes up to one’s expectations. We arriveat the conclusion that both the use of the local wavelet transform and theuse of an FPGA with embedded PowerPC delivers advantages over otherpossibilities.
Keywords—FPGA, instruction set extension, hardware implementation,wavelet transform
I. I NTRODUCTION
IN The RESUME (Reconfigurable Embedded Systems forUse in scalable Multimedia Environments) project a scalable
wavelet based video codec is being developed. ”Scalable video”is encoded in such a way that it allows to easily change the Qual-ity of Service (QoS) i.e. the framerate, resolution, color depthand image quality of the decoded video, without having to de-code the whole video stream if only a part of it is required [1].The video encoder consists of three main parts: motion esti-mation, discrete wavelet transform and the wavelet entropy en-coder.
For the implementation of the video codec one can choosebetween different possibilities. A general purpose processor ischeap and easy to program, but might not have enough compu-tational power. An ASIC is fast, but is also difficult to design,expensive and not reconfigurable. A better option might be theuse of an FPGA. An FPGA combines performance with flexi-bility. An FPGA is very good at executing parallel tasks, butfor the controlling parts of the algorithm the FPGA is less suit-able. To solve this problem the use of an FPGA with embeddedprocessor can be a solution.
In this article the Virtex-4 FX FPGA will be explored. ThisFPGA contains a PowerPC and an APU controller that takescare of the data-transfer. The implementation of a local wavelettransform will be investigated and evaluated.
First a short explanation on wavelet transforms will be given(II), followed by the exploration of the hardware (III) and theimplementation of a local wavelet transform (IV). Finally theresults (V) and a conclusion (VI) are presented.
1also called block-based wavelet transform
II. WAVELET TRANSFORM
The discrete wavelet transform separates the low-pass andhigh-pass components of an image. The transformed image isdivided into four parts. The upper left part contains the low-passcomponents and is a low resolution version of the original im-age. Further transform of these components will result in lowerresolutions. The inverse wavelet transform can stop at an arbi-trary level, resulting in resolution scalability.
The wavelet transform of an image is done by filtering the ele-ments with the 9/7 filter pairs. To transform a row, two elementsare read with each filter operation and a low-pass and a high-pass component are calculated. When all rows are transformed,the result is used to transform the columns. To transform thenext level the same method can be used. This implementation iscalled a row-column wavelet transform (RCWT).
Another implementation that yields the same results is a lo-cal wavelet transform (LWT). In this case the image is read innon-overlapping blocks. For each block the production of thetransform advances for as many levels as possible. The mem-ory hierarchy of the LWT offers practical speed advantages inprogrammable platforms [2].
III. E XPLORING THE HARDWARE
With the Virtex-4 FX FPGA we can use Fabric Co-processorModules (FCM’s) implemented in the FPGA fabric as user-defined configurable hardware accelerators. These modules areconnected to the embedded PowerPC through the APU con-troller interface. This way we are able to extend the instructionset of the PowerPC with custom instructions that are executedby the FCM. In this article we discuss the use of User-DefinedInstructions (UDI’s).
Fig. 1. System overview of a framework for the use of UDI’s
To implement an FCM that executes a UDI we can make useof the framework shown in figure 1. A Fabric Co-processor Bus(FCB) is used between the FCM and the APU controller. ThisFCB enables us to use more than one FCM. The FCM consistsof an fcmudi and a userfunc module. The fcmudi module

takes care of the communication with the APU controller andcan be used for all FCM’s. The userfunc module does the realcalculations and needs to be modified for each FCM.
The APU controller also needs to be enabled in software. Thiscan be done in this way:
mtmsr(mfmsr() | XREG_MSR_APU_AVAILABLE);
The following function executes a UDI on the FPGA:
UDI<n>FCM_GPR_GPR_GPR(a, b, c);
The number of the UDI that has to be executed is indicated by<n> (n between 0 and 7). Arguments b and c are two operand32 bit General Purpose Registers (GPR’s), a is a target GPR.
IV. H ARDWARE IMPLEMENTATION OF A LOCAL WAVELET
TRANSFORM
The filters that are used to transform an image are very suit-able for execution on the FPGA because of their parallelism. Sowe diceded to let the FPGA do the filtering, while the PowerPCwill be used for controlling the filtering and the data-transfers tothe DDR SDRAM. When using an LWT there is a need for over-lap memory, so the Block RAM on the FPGA is used for savingthe values of the flip-flops. When performing a filter operationthe right values are loaded from the Block RAM to calculate theresult. This way the PowerPC only needs to pass the addressof the Block RAM together with two elements to perform a fil-ter operation. It makes no difference when the filtering jumpsbetween rows and columns on different levels, like in an LWT.Figure 2 shows how it works. Making use of the frameworkpresented above, we implemented this functionality in an FCM.
Fig. 2. Filter implementation on the FPGA with the use of Block RAM
We use the UDI0FCMGPRGRPGPR(a, b, c) function forexecuting the UDI for filtering. Arguments b and c contain theinput elements and the Block RAM address, respectively, a re-turns the two calculated wavelet coefficients.
Both an RCWT and a simplified LWT with four decompo-sition levels have been implemented on the Virtex-4 FX. Thesimplified LWT implementation is a bit different from the origi-nal one, but should give some idea of how well the local wavelettransform performs.
V. RESULTS
When comparing the execution of a filter operation on theFPGA to the execution on the PowerPC, we learn that the FPGAproduces the results 7 times faster. So offloading these calcula-tions to the FPGA certainly is advantageous.
TABLE I
RCWT OF A CIF IMAGE ON THE V IRTEX-4 FX
time per frames time per framesl frame (ms) per second frame (ms) per second
no cache no cache with cache with cache1 128,7 7,8 64,5 15,52 158,7 6,3 78,0 12,83 157,3 6,3 79,3 12,64 159,3 6,3 79,3 12,6
TABLE II
LWT OF A CIF IMAGE ON THE V IRTEX-4 FX
time per frames time per framesl frame (ms) per second frame (ms) per second
no cache no cache with cache with cache1 405,3 2,5 74,5 13,42 148,7 6,7 22,1 45,13 134,7 7,4 15,2 65,94 128,7 7,8 11,5 86,9
TABLE III
RCWT OF A CIF IMAGE ON THE AMD PROCESSOR
l time per frame (ms) frames per second1 7,0 143,22 8,7 114,93 9,1 110,14 9,2 108,9
Tables I, II and III show the results of the RCWT and theLWT of a CIF (352×288 pixels) image on the Virtex-4 FX andof the RCWT on an AMD processor2 (l = #levels).
VI. CONCLUSIONS
When using the cache the LWT clearly performs better thanthe RCWT for multilevel decomposition. Using an AMDprocessor is faster, but the differences with the LWT becomesmaller with the increasing number of decomposition levels. Wecan conclude that the use of an FPGA with embedded processorcertainly has got a lot to offer. The FPGA and the PowerPC bothcan be used for executing the tasks they’re most capable of.
ACKNOWLEDGMENTS
I would like to thank my supervisors prof. Dirk Stroobandt,Mark Christiaens and Benjamin Schrauwen and all other peoplewho helped me with my research.
REFERENCES
[1] H. Eeckhaut, D. Stroobandt, H. Devos and M. Christiaens,Improving thehardware friendliness of a wavelet based scalable video codec, WSEASTransactions on Systems, 4(5):625-634, 2005.
[2] Y. Andreopoulos, N. Zervas, G. Lafruit, P. Schelkens, T. Stouraitis, C.Goutis and J. Cornelis,A local wavelet transform implementation versus anoptimal row-column algorithm for the 2D multilevel decomposition, IEEEInternational Conference on Image Processing, 1:330-333, 2001.
2AMD Athlon XP 3000+, 2,17 GHz, 512 MiB RAM, Windows XP

Inhoudsopgave
1 Inleiding 1
1.1 Probleemstelling . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1
1.2 Videocodec . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2
1.3 Doelstelling . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4
1.4 Structuur . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6
2 Hardware platform 7
2.1 Xilinx ML403 Evaluation Platform . . . . . . . . . . . . . . . . . . . 7
2.2 Virtex-4 FX . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
2.2.1 FPGA . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8
2.2.2 PowerPC . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8
2.2.3 APU controller . . . . . . . . . . . . . . . . . . . . . . . . . . 9
2.3 Softwarepakketten . . . . . . . . . . . . . . . . . . . . . . . . . . . . 10
2.3.1 Xilinx ISE . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 10
2.3.2 Xilinx EDK . . . . . . . . . . . . . . . . . . . . . . . . . . . . 10
2.3.3 ModelSim . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11
3 Wavelettransformatie 12
3.1 Discrete wavelettransformatie . . . . . . . . . . . . . . . . . . . . . . 13
3.2 Tweedimensionale wavelettransformatie . . . . . . . . . . . . . . . . . 15
3.3 Soorten wavelettransformaties . . . . . . . . . . . . . . . . . . . . . . 17
3.3.1 Rij-kolomgebaseerd . . . . . . . . . . . . . . . . . . . . . . . . 18
3.3.2 Rijgebaseerd . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19
i

3.3.3 Blokgebaseerd . . . . . . . . . . . . . . . . . . . . . . . . . . . 20
3.4 Voordelen van blokgebaseerde wavelettransformatie . . . . . . . . . . 24
4 Verkenning van de hardware 25
4.1 De APU controller verder toegelicht . . . . . . . . . . . . . . . . . . . 25
4.1.1 Instructiecategorieen . . . . . . . . . . . . . . . . . . . . . . . 26
4.1.2 Instructie indeling . . . . . . . . . . . . . . . . . . . . . . . . . 27
4.1.3 Instructie decoderen . . . . . . . . . . . . . . . . . . . . . . . 27
4.2 Pre-Defined Instruction . . . . . . . . . . . . . . . . . . . . . . . . . . 28
4.2.1 FCM Register Load/Store . . . . . . . . . . . . . . . . . . . . 28
4.3 User-Defined Instruction . . . . . . . . . . . . . . . . . . . . . . . . . 32
4.3.1 Module op de FPGA . . . . . . . . . . . . . . . . . . . . . . . 32
4.3.2 Software . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 35
4.3.3 Een basissysteem bouwen . . . . . . . . . . . . . . . . . . . . 37
4.4 Problemen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 39
5 Hardware-implementatie van een wavelettransformatie 41
5.1 Module op de FPGA voor een blokgebaseerde wavelettransformatie . 41
5.1.1 Schuifregisters voor de filterbewerkingen . . . . . . . . . . . . 41
5.1.2 Filtering als UDI . . . . . . . . . . . . . . . . . . . . . . . . . 42
5.1.3 Gebruik van Block RAM op de FPGA . . . . . . . . . . . . . 45
5.2 De PowerPC programmeren . . . . . . . . . . . . . . . . . . . . . . . 48
5.2.1 Regeling van de filterbewerkingen . . . . . . . . . . . . . . . . 48
5.2.2 DDR SDRAM en instructie- & data cache . . . . . . . . . . . 48
5.2.3 Wavelettransformaties op de PowerPC . . . . . . . . . . . . . 49
5.3 Resultaten . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 49
5.4 Mogelijke verbeteringen . . . . . . . . . . . . . . . . . . . . . . . . . 53
6 Besluit 55
A 9/7 filtercoefficienten 56
ii

B Inhoud van CD-ROM 58
Bibliografie 60
iii

Lijst van afkortingen
APU Auxiliary Processor Unit
CIF Beeldformaat, 352 bij 288 pixels
FCB Fabric Co-processor Bus
FCM Fabric Co-processor Module
FIR Finite Impulse Response
FPGA Field Programmable Gate Array
GPR General Purpose Register
RAM Random Access Memory
RESUME Reconfigurable Embedded Systems for Use in scalable
Multimedia Environments
QCIF Quarter CIF, 176 bij 144 pixels
UDI User-Defined Instruction
VHDL Very high speed integrated circuit
Hardware Description Language
iv

Hoofdstuk 1
Inleiding
1.1 Probleemstelling
Binnen het RESUME (Reconfigurable Embedded Systems for Use in scalable Mul-
timedia Environments) project wordt een schaalbare wavelet-gebaseerde videocodec
ontwikkeld. Dit project is een samenwerking tussen verschillende universiteiten.
Binnen het RESUME project wordt zowel gewerkt aan het optimaliseren van de al-
goritmes van de videocodec, als aan de hardware-implementatie van deze videocodec
voor gebruik in herconfigureerbare ingebedde systemen.
Men kan overwegen om de videocodec volledig te implementeren op herconfigureer-
bare hardware (FPGA’s). Dit is echter niet zo evident, gezien het complexe con-
troleverloop van sommige onderdelen van deze videocodec. Een FPGA kan vele
voordelen opleveren doordat hij zeer geschikt is om bewerkingen uit te voeren die
een sterk parallellisme vertonen. Voor de implementatie van het controleverloop is
een FPGA echter niet de beste oplossing.
Om aan dit probleem tegemoet te komen kunnen we gebruik maken van een FPGA
die een processor ter beschikking heeft. Hiervoor doen we een beroep op de Virtex-4
FX FPGA van Xilinx. Deze maakt gebruik van een APU (Auxiliary Processor Unit)
controller voor de data-transfer tussen modules op de FPGA en de geıntegreerde
PowerPC. De FPGA kan dan gebruikt worden voor de parallelle onderdelen van het
algoritme uit te voeren, terwijl de PowerPC de onderdelen met complex controlever-
loop voor zijn rekening neemt. De APU controller stelt ons in staat de instructieset
van de PowerPC uit te breiden met eigen instructies.
1

1.2 Videocodec
De binnen het RESUME project ontwikkelde schaalbare wavelet-gebaseerde video-
codec wordt in deze sectie uit de doeken gedaan (gebaseerd op [11] en [6]).
Het principe van een schaalbare videcodec komt erop neer dat een video slechts een
keer hoeft gecodeerd te worden en daarna gedecodeerd kan worden naargelang de
gewenste kwaliteit van de gebruiker. Men kan dan kiezen om de video te bekijken
zonder kwaliteitsverlies, of met een lagere beeldfrequentie, resolutie of beeldkwaliteit.
Op deze manier kan een gecodeerde video voldoen aan de eisen van alle gebruikers.
Indien een versie van lagere kwaliteit gewenst is volstaat het van slechts een deel
van de gecodeerde video te decoderen, waardoor minder rekenkracht en geheugen
vereist is. Bijvoorbeeld bij draagbare toestellen kan op deze manier de processor en
de batterij gespaard worden. Indien in een netwerk de bandbreedte beperkt is kan
er overgegaan worden op lagere kwaliteit om zo de hoeveelheid verzonden data te
verminderen.
Figuur 1.1 toont de verschillende stappen die bij het coderen van een video overlopen
worden. Deze stappen worden nu verder toegelicht.
Figuur 1.1: Schaalbare wavelet-gebaseerde videoencoder
BewegingsSchatting (BS) In een video verschillen opeenvolgende beelden over
het algemeen niet veel van mekaar. Bij bewegingsschatting wordt deze eigenschap
van temporele redundantie gebruikt om een beeld uit een video om te zetten naar
een verzameling bewegingsvectoren en een foutbeeld. Een beeld kan geschat worden
uit twee referentiebeelden door het op te delen in blokken en deze te vergelijken met
blokken uit de referentiebeelden. Hieruit kunnen bewegingsvectoren afgeleid worden
die de relatieve posities van deze blokken ten opzichte van die in de referentiebeelden
bijhouden. Omdat een beeld meestal niet volledig kan gereconstrueerd worden door
referentiebeelden en bewegingsvectoren alleen wordt ook een foutbeeld aangemaakt.
Dit foutbeeld is het verschil tussen het geschatte en het originele beeld. Foutbeelden
bevatten minder informatie en zullen na codering compacter kunnen voorgesteld
worden.
2

Door de beelden op een hierarchische manier te schatten bekomen we schaalbaarheid
in beeldfrequentie. Dit is weergegeven in figuur 1.2. Er wordt telkens gewerkt
met een Group of Pictures (GOP) die bestaat uit zestien beelden, waarvan een
referentiebeeld. De pijlen op de figuur geven aan welke beelden uit welke beelden
geschat worden. De framerate kan bepaald worden door de gecodeerde beelden tot
op het gewenste niveau te decoderen.
De BewegingsVectorCodering (BVC) staat in voor het coderen van de bewegingsvec-
toren. De foutbeelden worden samen met de referentiebeelden doorgestuurd. Merk
op dat de foutbeelden in tegenstelling tot de referentiebeelden negatieve waarden
kunnen bevatten.
Meer uitleg over de bewegingsschatting is te vinden in [6] en [8].
Figuur 1.2: Schaalbaarheid in framerate: bewegingsschatting
Discrete WaveletTransformatie (DWT) Referentiebeelden en foutbeelden on-
dergaan een discrete wavelettransformatie om de laag- en hoogdoorlaatcomponenten
van mekaar te scheiden. Na transformatie is het beeld opgedeeld in vier kwad-
ranten met links boven de laagdoorlaatcomponenten. Deze zijn een lage resolutie
voorstelling van het originele beeld. Door deze componenten verder te transformeren
kunnen we het originele beeld verder schalen naar lagere resoluties. Dit is voorgesteld
in figuur 1.3. Door bij het decoderen te stoppen op het gewenste niveau kunnen we
een bepaalde resolutie verkrijgen. We bekomen dus schaalbaarheid in resolutie.
Door het feit dat de laag- en hoogdoorlaatcomponenten van een beeld gescheiden
worden zal de meeste informatie geconcentreerd zitten in een kleine fractie van
het getransformeerde beeld. Hierdoor zal men bij codering een sterkere compressie
kunnen bekomen.
3

Meer uitleg over de discrete wavelettransformatie is te vinden in [10] en in hoofdstuk
3 van dit werk.
Figuur 1.3: Schaalbaarheid in resolutie: discrete wavelettransformatie
Wavelet Entropie Decoder (QT + EC) De getransformeerde beelden worden
gecomprimeerd door middel van een wavelet entropie codering. Deze codering kan
opgesplitst worden in twee delen, nl. de quadtree en de arithmetische codering.
Door de beelden op te splitsen in bitvlakken, gaande van meest beduidende naar
minst beduidende, en deze afzonderlijk te coderen, bekomen we schaalbaarheid in
beeldkwaliteit. Dit staat afgebeeld in figuur 1.4. Hoe meer bitvlakken er gedecodeerd
worden, hoe nauwkeuriger de resultaten en hoe beter de uiteindelijke beeldkwaliteit.
Meer uitleg over de quadtree en entropiecodering is te vinden in [9].
In een laatse stap worden alle gecodeerde onderdelen van de video verpakt in een
bitstroom (P).
Bij het decoderen worden de verschillende stappen in omgekeerde volgorde over-
lopen. Eerst gebeurt een QuadTree en EntropieDecodering (QT + ED), dan volgt
een Inverse Discrete WaveletTransformatie (IDWT), en tenslotte een BewegingVec-
torDecodering (BVD) en BewegingsCompensatie (BC).
1.3 Doelstelling
Het doel van deze thesis is het implementeren van een blokgebaseerde wavelettrans-
formatie op de Virtex-4 FX FPGA. Hiervoor dient de werking en het gebruik van
deze FPGA met geıntegreerde PowerPC onderzocht te worden. Er wordt gebruik
4

Figuur 1.4: Schaalbaarheid in beeldkwaliteit: quadtree en entropiecodering
gemaakt van de APU controller om de instructieset van de PowerPC uit te breiden
met instructies die zullen uitgevoerd worden op de FPGA. Er zal dus vooral op zoek
gegaan worden naar de parallelle onderdelen van het algoritme, om deze dan op een
efficiente manier via modules op de FPGA uit te voeren.
Het onderzoek naar de werking en het gebruik van de APU controller vormt een
essentieel onderdeel van deze thesis. Deze APU controller verzorgt de communicatie
tussen de FPGA en de PowerPC. De bedoeling is dan ook om na te gaan of het
gebruik van deze APU controller voordelen oplevert. Er zal onderzocht worden of
de mogelijkheid tot het aanvullen van de instructieset van de PowerPC met eigen
instructies voor uitvoering op de FPGA aan de verwachtingen voldoet. Met andere
woorden, is het gebruik van de Virtex-4 FX FPGA een goede keuze ten opzichte
van andere mogelijkheden voor het implementeren van een schaalbare videocodec?
De onderdelen van het algoritme die op de FPGA worden uitgevoerd worden geım-
plementeerd in VHDL. De software voor de PowerPC die gebruik maakt van deze
onderdelen wordt geschreven in C.
Deze thesis loopt voor een groot stuk samen met de thesis van Pieter-Paul De Clercq
[8]. Beide thesissen maken gebruik van de Virtex-4 FX FPGA, maar behandelen een
verschillend onderdeel van de videocodec. In de thesis van Pieter-Paul wordt de be-
5

wegingsschatting behandeld, in deze thesis de blokgebaseerde wavelettransformatie.
Er wordt onderzocht hoe deze blokgebaseerde wavelettransformatie op de Virtex-4
FX FPGA kan geımplementeerd worden en de resultaten zullen worden geevalueerd.
1.4 Structuur
In hoofdstuk 2 wordt wat meer uitleg gegeven bij de hardware en de bijhorende
softwarepaketten.
Hoofstuk 3 behandelt de wavelettransformatie. Eerst wordt de discrete wavelet-
transformatie besproken. Verder worden de tweedimensionale transformatie en de
verschillende mogelijke algoritmes toegelicht. De voordelen van de blokgebaseerde
wavelettransformatie komen hier ook kort aan de beurt.
In hoofdstuk 4 komt de verkenning van de hardware aan bod. Vooral de APU
controller krijgt hier de nodige aandacht. Aan de hand van een paar voorbeelden
wordt het uitvoeren van instructies op de FPGA vanuit de PowerPC verduidelijkt.
De hardware-implementatie van een wavelettransformatie wordt in hoofdstuk 5 uit
de doeken gedaan. Zowel de hardware als de software worden besproken. Ook de
resultaten zijn hier terug te vinden.
Tot slot wordt in hoofdstuk 6 een kort besluit geformuleerd.
6

Hoofdstuk 2
Hardware platform
Dit hoofstuk geeft wat meer uitleg bij het hardware platform waarvan gebruik
gemaakt wordt in deze thesis. Eerst wordt er dieper ingegaan op het ontwikkel-
bord en de Virtex-4 FX chip. Van deze chip worden de verschillende onderdelen
afzonderlijk besproken. Verder worden ook de gebruikte softwarepakketten kort
toegelicht.
2.1 Xilinx ML403 Evaluation Platform
Voor de realisatie van deze thesis wordt gebruik gemaakt van de Xilinx Virtex-4 FX
FPGA. Het ontwikkelen van een ontwerp voor deze FPGA gebeurt op het Xilinx
ML403 Evaluation Platform (figuur 2.1). Dit bord heeft de nodige randapparaten,
connectoren en interfaces aan boord voor een grote waaier aan toepassingen. Figuur
2.2 toont een schema van de verschillende onderdelen [15].
2.2 Virtex-4 FX
De Virtex-4 FX is een FPGA die ontwikkeld is door Xilinx en gebruik maakt van
het 90nm CMOS proces. In deze thesis wordt de XC4VFX12 versie gebruikt. Deze
FPGA bevat een IBM PowerPC 405 RISC processor die is uitgerust met een APU,
een snelle interface tussen de PowerPC en co-processoren op de FPGA. De verschil-
lende onderdelen van de Virtex-4 FX worden nu wat verder toegelicht [19].
7

Figuur 2.1: Xilinx ML403 Evaluation Platform
2.2.1 FPGA
Een Field Programmable Gate Array (FPGA) is een chip die geherconfigureerd kan
worden aan de hand van een Hardware Description Language (HDL). In deze thesis
wordt VHDL gebruikt voor de beschrijving van het gedrag en de structuur van het
ontwerp. De XC4VFX12 FPGA beschikt over 12312 logische cellen, 32 XtremeDSP
blokken, 36 blokken van 18 Kb Block RAM en een PowerPC processor.
2.2.2 PowerPC
De XC4VFX12 FPGA bevat een IBM PowerPC 405 RISC processor. Dit is een 32 bit
implementatie van de PowerPC embedded-environment architectuur die is afgeleid
van de PowerPC architectuur. De processor bevat een pijplijn met vijf trappen,
tweeendertig 32 bit general purpose registers (GPRs), afzonderlijke instructie en
data caches en een JTAG interface. Verder heeft hij toegang tot de Processor Local
Bus (PLB) en On-Chip Memory (OCM) en beschikt hij over een APU controller.
Meer uitleg over de PowerPC 405 processor is te vinden in [18].
8

Figuur 2.2: Xilinx ML403 Evaluation Platform blokschema
2.2.3 APU controller
De PowerPC processor kan berekeningen laten uitvoeren door modules op de FPGA.
Zo een module wordt een Fabric Co-processor Module (FCM) genoemd. De Aux-
iliary Processor Unit (APU) controller1 is een co-processor interface die de data-
transfer regelt tussen de modules op de FPGA en de geıntegreerde processor, zoals
te zien is op figuur 2.3 [5].
De APU controller laat toe de instructieset van de PowerPC processor uit te breiden
met eigen instructies. Bovendien zorgt de APU voor de synchronisatie tussen de
snelle klok van de PowerPC en de trage FCM interface klok. Op deze manier bekomt
men een veel efficientere integratie tussen een applicatie-specifieke functie en de
pijplijn van de processor. Dit maakt de APU implementatie beter dan het gebruik
van een bus. Figuur 2.4 toont het pijplijn schema van de PowerPC processor, de
APU controller en de FCM [18, 13].
Er zijn twee soorten instructies die kunnen uitgevoerd worden door een FCM, nl.
Pre-Defined Instructions en User-Defined Instructions (UDI’s). Bij een Pre-Defined
Instruction is het formaat gedefinieerd door de PowerPC instructieset. Een User-
Defined Instruction heeft een configureerbaar formaat en is een echte uitbreiding
1De APU controller zal in dit werk vaak kortweg de APU genoemd worden.
9

van de PowerPC instructieset.
Indien we slechts een FCM implementeren kunnen we gebruik maken van een directe
verbinding tussen de APU en de FCM. Bij een systeem met meerdere FCMs wordt
er gebruik gemaakt van een Fabric Co-processor Bus (FCB).
Figuur 2.3: Processor blok op de FPGA met PowerPC en APU controller
2.3 Softwarepakketten
2.3.1 Xilinx ISE
Voor het implementeren van een logisch ontwerp voor een FPGA wordt gebruik
gemaakt van de Xilinx Integrated Software Environment (ISE). ISE wordt onder
andere gebruikt voor het compileren, analyseren en synthetiseren van het ontwerp.
Voor het invoeren van dit ontwerp wordt in deze thesis VHDL gebruikt.
Aan de hand van ISE komen we meer informatie te weten over het hardware ontwerp,
zoals de maximale klokfrequentie, het aantal logische cellen die gebruikt worden,
het aantal Block RAM en DSP blokken, enz. Verder levert ISE een schema van
het ontwerp waarop alle verschillende onderdelen en verbindingen weergegeven zijn.
Deze informatie kan gebruikt worden om het ontwerp verder te optimaliseren.
2.3.2 Xilinx EDK
De Xilinx Embedded Development Kit (EDK) is een serie van software tools voor het
ontwerp van complete ingebedde processor systemen op programmeerbare hardware.
10

Figuur 2.4: Pijplijn schema
In het geval van de Virtex-4 FX is dit een FPGA met geıntegreerde IBM PowerPC
processor [14].
Xilinx Platform Studio (XPS) is de grafische user interface technologie die alle
processen integreert, van de declaratie tot de verificatie van het ontwerp. Vanuit
XPS kunnen alle systeem tools gebruikt worden die nodig zijn om hardware en
software systeem componenten te verwerken [17].
Samen met EDK moet ook ISE geınstalleerd worden. EDK hangt af van ISE com-
ponenten voor het synthetiseren van het hardware ontwerp, het naar een FPGA te
mappen en het genereren en downloaden van de bitstream.
2.3.3 ModelSim
ModelSim SE van Mentor Graphics is de omgeving die in deze thesis gebruikt wordt
voor het simuleren van een ontwerp. Vanuit ISE of EDK kunnen de bestanden
die nodig zijn voor een simulatie aangemaakt worden. ModelSim geeft dan een
tijdsanalyse van het gedrag van het systeem. Hieruit kan dan informatie gehaald
worden om zo tot een correcte of betere werking te komen.
11

Hoofdstuk 3
Wavelettransformatie
Het gebruik van wavelets is een zeer efficiente en flexibele methode voor de trans-
formatie van signalen. Vooral in het gebied van beeldverwerking is reeds aange-
toond dat de wavelettransformatie tot goede resultaten leidt. Door een beeld voor
het gecomprimeerd wordt te transformeren, kan men een veel efficientere codering
bekomen. Het beeld wordt getransformeerd naar een domein verschillend van het in-
tensiteitsdomein van het oorspronkelijke beeld. De bedoeling is de correlatie tussen
de intensiteiten van de beeldelementen te verlagen, waardoor redundante informatie
niet steeds opnieuw moet gecodeerd worden. Tevens zorgt een transformatie ervoor
dat de meeste informatie geconcentreerd zit in een kleine fractie van de getrans-
formeerde elementen. Door van deze eigenschap gebruik te maken kan men bij
codering zeer sterke compressie bekomen, terwijl er toch weinig aan kwaliteit moet
ingeleverd worden.
De wavelettransformatie maakt gebruik van basisfuncties met een varierende schaal,
zogenaamde wavelets. Hierdoor zullen traag varierende eigenschappen (lage fre-
quenties) van een signaal over een langere tijdspanne bestudeerd worden dan snel
varierende eigenschappen (hoge frequenties). Dit levert voordelen op ten opzichte
van het gebruik van Fourier basisfuncties, die met een vaste schaal werken.
Ondanks het feit dat wavelets reeds geruime tijd bekend zijn, is het pas sinds kort,
met de introductie van wavelets in de multimedia compressie standaarden MPEG-4
en JPEG-2000, dat er uitgebreid onderzoek verricht wordt naar het verbeteren van
de implementatieaspecten van de transformatie.
Dit hoofdstuk bevat verschillende passages die gebaseerd zijn op [10] en [7]. In deze
werken is ook verdere informatie terug te vinden over wavelettransformaties.
12

3.1 Discrete wavelettransformatie
De discrete wavelettransformatie gaat de laag- en hoogdoorlaatcomponenten van
een signaal van mekaar scheiden. Hiertoe maakt de transformatie gebruik van twee
FIR-filters, nl. een laagdoorlaat filter (h) en een hoogdoorlaat filter (g). Sturen we
het signaal door het laagdoorlaat filter, dan bekomen we na onderbemonstering een
signaal dat een lagere resolutie is van het origineel. Het hoogdoorlaat filter zorgt
voor een detailsignaal dat alle informatie bevat dat niet in het lage resolutie signaal
zit.
De videocodec die gebruikt wordt binnen het RESUME project maakt gebruik van
de 9/7 filters1. De filteroperaties die nodig zijn voor de voorwaartse wavelettrans-
formatie zien er dan als volgt uit:
LD(n) =8∑
k=0
h(k)x(n− k) (3.1)
HD(n) =6∑
l=0
g(l)x(n− l) (3.2)
Hierbij staat x(n) voor het n-de element van het signaal, LD voor laagdoorlaat en
HD voor hoogdoorlaat. De waarden van de filtercoefficienten voor de voorwaartse
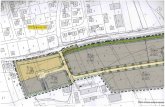
wavelettransformatie zijn terug te vinden in tabel A.1. Er valt op te merken dat
deze filters symmetrisch zijn. Op figuur 3.1 zijn de filters afgebeeld in het frequen-
tiedomein.
De inverse wavelettransformatie gebeurt op analoge wijze. Hierbij worden de laag-
en hoogdoorlaatcomponenten terug omgezet naar de originele elementen. De fil-
tercoefficienten die in dit geval gebruikt worden kan men aanschouwen in tabel A.2.
Ook deze filters zijn symmetrisch.
Doordat we bij de discrete wavelettransformatie het te transformeren signaal door
twee FIR-filters sturen, zal elk element afgebeeld worden op twee nieuwe elementen,
nl. een laagdoorlaat en een hoogdoorlaat element. Hierdoor treedt er redundantie op.
Het getransformeerde signaal is tweemaal zo lang als het originele en zal dus gedeci-
meerd moeten worden met een factor 2. Figuur 3.2 geeft aan hoe de transformatie in
zijn werk gaat. Zowel de voorwaartse als de inverse transformatie staan afgebeeld.
Bij de inverse transformatie worden nullen ingevoegd bij de upsampling. Door de
bekomen laagdoorlaatcomponenten nog eens te transformeren komen we tot een
transformatie over twee niveau’s. De signalen a, b en c zijn de waveletcoefficienten
19/7 staat voor het aantal coefficienten van de filters. 5/3 filters worden ook frequent gebruikt.
13
van het signaal. Op figuur 3.3 zien we de opdeling van het spectrum na deze trans-
formaties.
Figuur 3.1: Filters in het frequentiedomein
Figuur 3.2: Implementatie van de voorwaartse en inverse wavelettransformatie over tweeniveau’s
Figuur 3.3: Opdeling van het spectrum na transformatie over twee niveau’s
14

We kunnen de bekomen laagdoorlaatcomponenten steeds verder transformeren zo-
lang de lengte van het signaal dat toelaat. Aangezien de laagdoorlaatcomponenten
eigenlijk een lage resolutie voorstelling van het originele signaal zijn kan men op
deze manier het oorspronkelijke signaal verder schalen naar een lagere resolutie.
Aangezien bij de discrete wavelettransformatie van een signaal de helft van de
bekomen laag- en hoogdoorlaatcomponenten overbodig is, hoeft men enkel die fil-
teroperaties te doen die leiden tot nuttige resultaten. Het is dus niet nodig om
per element twee filterbewerkingen uit te voeren, maar men kan de filters telkens
verschuiven over twee posities en per twee nieuwe elementen van het signaal een
laagdoorlaat- (LD) en een hoogdoorlaatelement (HD) berekenen. Elke verschuiving
levert dus twee getransformeerde elementen op. Deze procedure is afgebeeld op
figuur 3.4. Door aan de uiteinden van het signaal een aantal elementen te spiege-
len zorgt men ervoor dat het getransformeerde signaal (laagdoorlaat- en hoogdoor-
laatelementen) even lang is als het originele signaal.
3.2 Tweedimensionale wavelettransformatie
De discrete wavelettransformatie wordt vooral toegepast in het gebied van de beeld-
verwerking. Om een tweedimensionaal beeld te transformeren zal men tweemaal
een eendimensionale discrete wavelettransformatie toepassen, eenmaal op de rijen
en eenmaal op de kolommen van het resultaat. Op figuur 3.5 is afgebeeld hoe dit
in zijn werk gaat. Eerst worden alle rijen getransformeerd, daarna alle kolommen.
Op de figuur staat L voor de bekomen laagdoorlaatcomponenten, terwijl H staat
voor de bekomen hoogdoorlaatcomponenten. Men merkt op dat de discrete wave-
lettransformatie een volledig beeld in een keer trasformeert. Dit in tegenstelling tot
bijvoorbeeld de discrete cosinustransformatie, die het beeld opdeelt in blokken en
deze afzonderlijk gaat transformeren.
De transformatie over een niveau resulteert in een beeld dat is opgedeeld in vier
gebieden. Linksboven bevinden zich de laagdoorlaatcomponenten van zowel de rij-
als de kolomtransformaties. Dit resulteert in een lage resolutie voorstelling van het
originele beeld. Men bekomt dus een beeld dat vier keer kleiner is. De andere
drie kwadranten bevatten de details die nodig zijn om uit het lage resolutiebeeld
het originele te reconstrueren. Hiervoor zal de inverse discrete wavelettransformatie
over twee dimensies gebruikt worden.
Men kan de discrete wavelettransforamatie ook over meer dan een niveau toepassen.
Door het kwadrant met de laagdoorlaatcomponenten verder te transformeren over de
rijen en de kolommen wordt dit verder opgedeeld in vier kleinere gebieden. Opnieuw
zal in de linker bovenhoek een geschaalde versie van het originele beeld verschijnen.
15
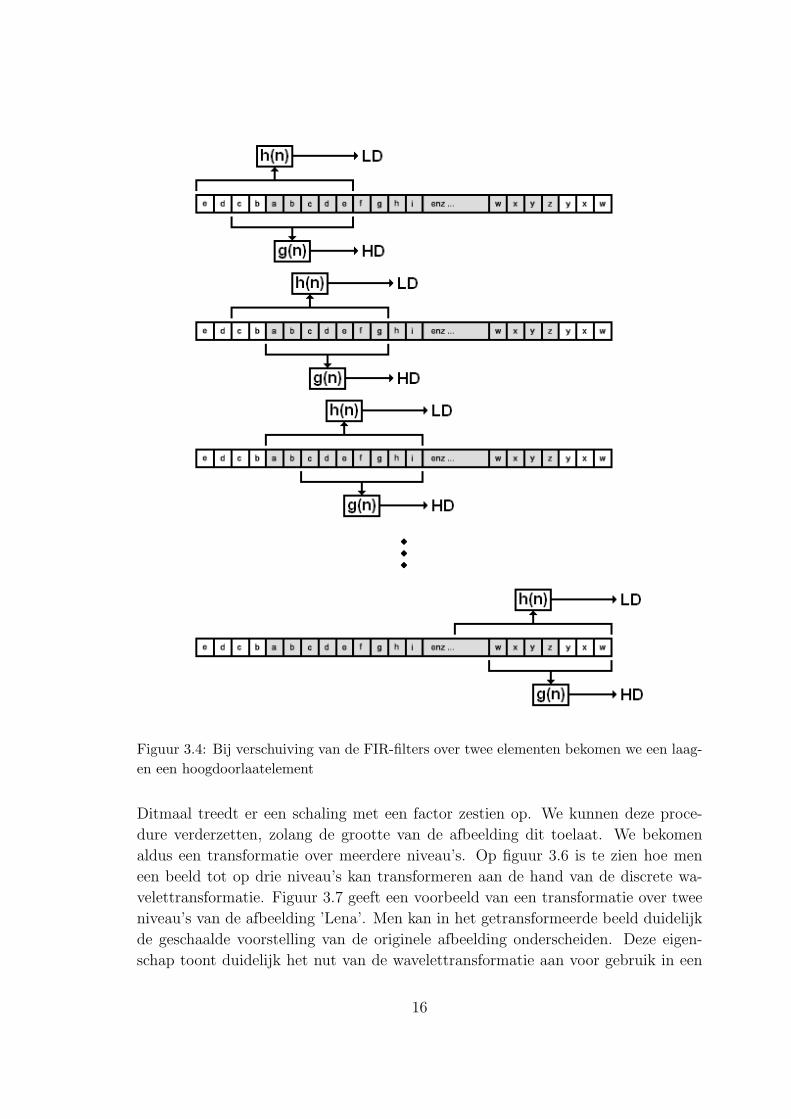
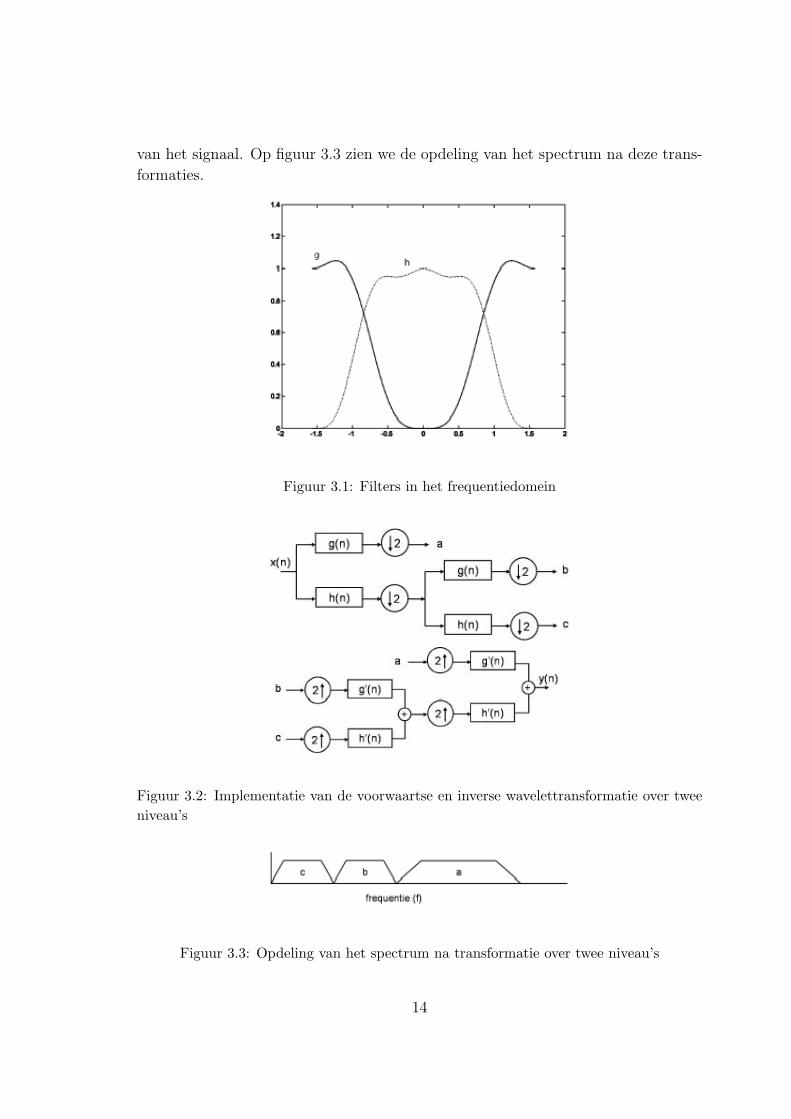
Figuur 3.4: Bij verschuiving van de FIR-filters over twee elementen bekomen we een laag-en een hoogdoorlaatelement
Ditmaal treedt er een schaling met een factor zestien op. We kunnen deze proce-
dure verderzetten, zolang de grootte van de afbeelding dit toelaat. We bekomen
aldus een transformatie over meerdere niveau’s. Op figuur 3.6 is te zien hoe men
een beeld tot op drie niveau’s kan transformeren aan de hand van de discrete wa-
velettransformatie. Figuur 3.7 geeft een voorbeeld van een transformatie over twee
niveau’s van de afbeelding ’Lena’. Men kan in het getransformeerde beeld duidelijk
de geschaalde voorstelling van de originele afbeelding onderscheiden. Deze eigen-
schap toont duidelijk het nut van de wavelettransformatie aan voor gebruik in een
16

schaalbare videocodec. Indien men een beeld wenst met een lagere resolutie dan het
origineel hoeft men enkel de inverse discrete wavelettransformatie toe te passen tot
op het niveau met de gewenste resolutie. De overige gebieden met hoogdoorlaat-
componenten bevatten dan enkel overbodige informatie.
Figuur 3.5: Wavelettransformatie over een niveau
Figuur 3.6: Wavelettransformatie over meerdere niveau’s
3.3 Soorten wavelettransformaties
De discrete wavelettransformatie van een afbeelding kan op verschillende manieren
gebeuren. De algoritmes die gebruikt worden om de waveletcoefficienten te bereke-
nen kunnen opgedeeld worden in twee categorieen [2, 1].
Bij de eerste categorie worden de elementen van de afbeelding op die manier over-
lopen dat men een strikte breedte-eerst productie van de waveletcoefficienten bekomt.
Hieraan wordt meestal gerefereerd als de rij-kolomgebaseerde wavelettransforma-
tie. In dit geval zal de afbeelding niveau per niveau getransformeerd worden. Dit
wil zeggen dat men pas een niveau verder kan transformeren als het vorige niveau
volledig getransformeerd is.
17

Figuur 3.7: Wavelettransformatie van ’Lena’ over twee niveau’s
De tweede categorie leidt tot een ruwe diepte-eerst productie van de waveletcoeffi-
cienten. De twee technieken die het meeste voorkomen zijn de rijgebaseerde2 en de
blokgebaseerde3 wavelettransformatie. Bij deze werkwijze worden de waveletcoeffi-
cienten rechtstreeks tot op het hoogste niveau geproduceerd.
3.3.1 Rij-kolomgebaseerd
Bij de rij-kolomgebaseerde wavelettransformatie worden per niveau eerst alle rijen
en daarna alle kolommen getransformeerd. Deze procedure staat afgebeeld op figuur
3.8 [1]. Om te beginnen wordt het beeld gefilterd en gedecimeerd over alle rijen.
Dit komt neer op het verschuiven van de FIR-filters over twee posities, om zo een
laag- en een hoogdoorlaatcomponent te bekomen, en dit voor elke rij van het beeld
(figuur 3.4). Het getransformeerde beeld (rechts boven) wordt nu over alle kolommen
gefilterd en gedecimeerd. Een tussentijds resultaat van de filtering van de kolommen
is links beneden op de figuur te zien. Rechts beneden staat het resultaat van een
volledige rij-kolomgebaseerde transformatie over een niveau afgebeeld.
Om het beeld een niveau verder te transformeren past men dezelfde werkwijze toe
op de geproduceerde laagdoorlaat waveletcoefficienten. Deze procedure kan men
verderzetten tot men het gewenste aantal niveau’s heeft bereikt.
2Er bestaat ook een algoritme van een rijgebaseerde wavelettransformatie die niveau per niveaugebeurt. Hier wordt in deze scriptie niet verder op ingegaan.
3De blokgebaseerde wavelettransformatie wordt ook wel de lokale wavelettransformatie (localwavelet transform) genoemd.
18
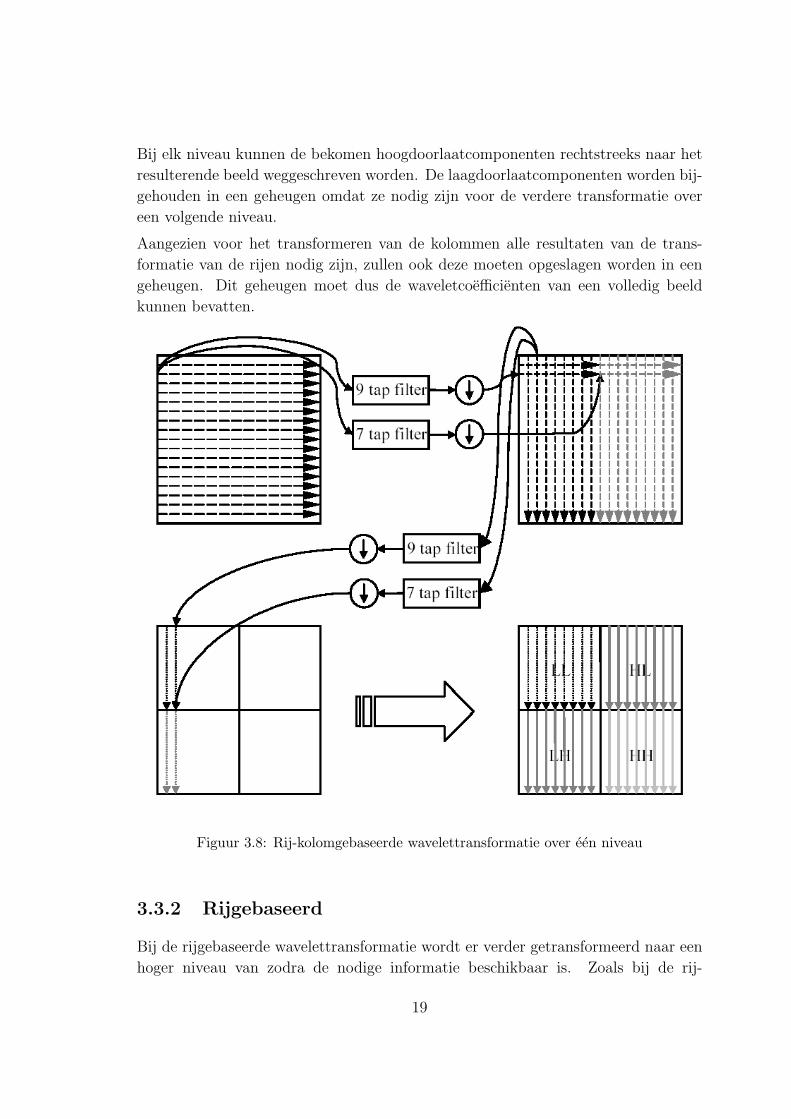
Bij elk niveau kunnen de bekomen hoogdoorlaatcomponenten rechtstreeks naar het
resulterende beeld weggeschreven worden. De laagdoorlaatcomponenten worden bij-
gehouden in een geheugen omdat ze nodig zijn voor de verdere transformatie over
een volgende niveau.
Aangezien voor het transformeren van de kolommen alle resultaten van de trans-
formatie van de rijen nodig zijn, zullen ook deze moeten opgeslagen worden in een
geheugen. Dit geheugen moet dus de waveletcoefficienten van een volledig beeld
kunnen bevatten.
Figuur 3.8: Rij-kolomgebaseerde wavelettransformatie over een niveau
3.3.2 Rijgebaseerd
Bij de rijgebaseerde wavelettransformatie wordt er verder getransformeerd naar een
hoger niveau van zodra de nodige informatie beschikbaar is. Zoals bij de rij-
19

kolomgebaseerde wavelettransformatie wordt er begonnen met het transformeren
van de rijen van het beeld. In dit geval zal men echter niet wachten met het trans-
formeren van de kolommen tot wanneer alle rijen van het beeld getransformeerd zijn.
Van het moment dat er voldoende rijen omgezet zijn om een eerste filteroperatie op
de kolommen toe te passen, zal men overgaan op de transformatie van de kolom-
men om zo de eerste waveletcoefficienten van het eerste niveau te bekomen. De
bekomen laagdoorlaat waveletcoefficienten kunnen dan een eerste rijtransformatie
ondergaan. Telkens wanneer er twee nieuwe rijen van het originele beeld getrans-
formeerd zijn kunnen er weer kolomtransformaties gebeuren en kunnen de bekomen
laagdoorlaat waveletcoefficienten van het eerste niveau opnieuw een rijtransformatie
ondergaan. Wanneer er voldoende rijen getransformeerd zijn om een eerste filter-
operatie op de kolommen van het eerste niveau toe te passen, zal men in staat zijn
waveletcoefficienten van het tweede niveau te berekenen. Op deze manier kunnen
we doorgaan tot op het gewenste niveau.
In tegenstelling tot de rij-kolomgebaseerde wavelettransformatie worden de wavelet-
coefficienten hier niet niveau per niveau berekend, maar wordt er rechtstreeks door-
gerekend tot het op hoogste niveau. Door deze manier van werken is het aantal
geheugentoegangen minimaal. Het originele beeld wordt eenmaal ingelezen en het
resultaat wordt eenmaal weggeschreven. Wel is er in dit geval nood aan een ge-
heugen voor de transformatie van de kolommen. De rijen worden altijd in een keer
getransformeerd. Bij de kolommen daarentegen komen er per twee rijtransformaties
twee nieuwe elementen bij en moeten de vorige elementen die nodig zijn voor filter-
ing dus bijgehouden worden. Het geheugen dat hiervoor gebruikt wordt noemt men
het overlapgeheugen.
3.3.3 Blokgebaseerd
De blokgebaseerde wavelettransformatie werkt zoals de rijgebaseerde wavelettrans-
formatie niet niveau per niveau. Het beeld wordt opgedeeld in niet-overlappende
blokken die net groot genoeg zijn om juist een laagdoorlaatwaveletcoefficient van het
hoogste niveau te produceren. De opdeling van een beeld gebeurt zoals aangegeven
op figuur 3.9. De pijlen geven aan hoe de blokken overlopen worden. Om tot een
transformatie van L niveau’s te komen zijn er blokken nodig van 2L bij 2L elementen.
Dit komt door het feit dat wanneer we een niveau hoger gaan de laagdoorlaatcompo-
nenten per rij en per kolom gehalveerd worden. Om identieke resultaten te bekomen
als de rij-kolomgebaseerde wavelettransformatie vereisen de randen van het beeld een
andere initialisatie. De blokgrootte wordt dan bepaald door αL, waarbij αL gegeven
20

wordt door [10]4:
α1 = 5 (3.3)
αL = 2L+2 − 3 (3.4)
Bij tranformatie over een niveau (L=1) zijn vijf elementen voldoende voor een eerste
laagdoorlaat waveletcoefficient te bekomen. Zoals te zien is op figuur 3.4 worden de
elementen aan de rand van een rij of kolom gespiegeld en bekomen we dus negen
elementen voor transformatie. Dit is juist voldoende voor een filteroperatie. Bij
meerdere niveau’s (L>1) bekomen we een recursieve formule.
De blokken op het einde van een rij of kolom worden opgevuld met de resterende
elementen.
Figuur 3.9: Indeling van een beeld in blokken
We nemen nu een voorbeeld van een transformatie over twee niveau’s. Hiervoor is
een blokgrootte van vier bij vier elementen nodig. Figuur 3.10 toont aan hoe dit
4Deze formules zijn enkel geldig indien de 9/7 FIR-filters gebruikt worden.
21

in zijn werk gaat. De zwarte bollen stellen laagdoorlaatelementen voor, de grijze
bollen staan voor hoogdoorlaatelementen. Eerst worden binnen het blok de rijen
getransformeerd. Daarna volgen de kolomtransformaties om tot een transformatie
over een niveau te komen. Dezelfde procedure gebeurt dan op de vier bekomen
laagdoorlaatelementen om tot een transformatie over twee niveau’s te komen. Bij
de filteroperaties zijn er elementen uit eerder getransformeerde blokken nodig. Deze
worden bijgehouden in een overlapgeheugen. De resulterende elementen van deze
bloktransformatie kunnen dan weggeschreven worden naar hun definitieve plaats in
het te berekenen beeld zoals afgebeeld op figuur 3.11.
Figuur 3.10: Transformatie van een blok over twee niveau’s
Figuur 3.11: Plaats in het beeld waar de geproduceerde waveletcoefficienten terechtkomenna transformatie van een blok over twee niveau’s
Voor de transformatie van een blok zijn er elementen nodig van eerder getrans-
formeerde blokken. Indien we gebruik maken van 9/7 FIR-filters zijn er negen
elementen nodig voor een filteroperatie. Dit betekent dat er zeven elementen dienen
opgeslagen te worden in een overlapgeheugen voor elke rij of kolom die binnen het
22

blok moet getransformeerd worden. De werkwijze van dit overlapgeheugen staat
afgebeeld op figuur 3.12 [2]. Wanneer elementen uit het overlapgeheugen gebruikt
zijn voor filteroperaties in een blok worden ze overschreven door nieuwe elementen
die gebruikt zullen worden voor filteroperaties in een ander blok.
Voor de rijtransformaties dienen enkel die elementen bijgehouden te worden die
nodig zijn voor de transformatie van een blok. Omdat we de blokken rij per rij
afgaan worden deze elementen toch weer overschreven bij het overgaan naar een
volgende blok binnen dezelfde rij. Bij de kolomtransformaties zijn er elementen
nodig uit alle blokken van de rij die als laatste volledig getransformeerd is. We
dienen dus alle elementen bij te houden die nodig zijn voor de kolomtransformaties
van alle blokken in een rij.
Er valt op te merken dat wanneer we een niveau hoger gaan er maar half zoveel
overlapgeheugen nodig is aangezien er maar half zoveel rij- en kolomtransformaties
gebeuren.
Figuur 3.12: Werkwijze van het overlapgeheugen bij blokgebaseerde wavelettransformatie
De rijgebaseerde wavelettransformatie kan gezien worden als het asymptotische geval
van de blokgebaseerde wavelettransformatie, wanneer de blokbreedte gelijk wordt
aan de breedte van de afbeelding [2]. In beide gevallen is het aantal geheugen-
toegangen minimaal. Het originele beeld wordt eenmaal ingelezen en het resultaat
wordt eenmaal weggeschreven. In het geval van rijgebaseerde wavelettransformatie
maakt men geen gebruik van overlapgeheugen voor de rijen.
23

3.4 Voordelen van blokgebaseerde wavelettrans-
formatie
Het grootste probleem bij het gebruik van de discrete wavelettransformatie is de
nood aan een groot geheugen en een grote geheugenbandbreedte voor de productie
van de waveletcoefficienten. De blokgebaseerde wavelettransformatie minimaliseert
het aantal toegangen tot het externe geheugen door berekende waarden zo vlug mo-
gelijk te hergebruiken voor verdere berekeningen en gebruik te maken van kleine
geheugen componenten. Op deze manier zal de uitvoeringstijd en de energie dissi-
patie zo goed als mogelijk beperkt worden.
De filteroperaties die nodig zijn voor transformatie gebeuren aan de hand van schuif-
operaties en zullen sneller kunnen gebeuren indien een ganse rij of kolom in een keer
kan gefilterd worden dan wanneer deze filtering onderbroken wordt. In het laat-
ste geval dient men bij verderzetting van de filteroperaties de vorige waarden eerst
terug in het schuifregsiter te schuiven, wat een zekere vertraging met zich meebrengt.
Dit is het geval bij de blokgebaseerde wavelettransformatie, die voor de filteroper-
aties het beeld opdeelt in blokken. Bij een discrete wavelettransformatie vormt
de rekentijd van de filtering echter veel minder een probleem dan het grote aantal
vereiste gehegentoegangen. Aangezien de blokgebaseerde wavelettransformatie leidt
tot een drastische vermindering van dit aantal geheugentoegangen en bijhorende
bandbreedte krijgt deze dus de voorkeur [4, 3, 12, 2].
24

Hoofdstuk 4
Verkenning van de hardware
Voor deze thesis wordt gebruik gemaakt van het ML403 ontwikkelbord van Xilinx.
Op dit bord bevindt zich een Virtex-4 FX FPGA met ingebedde PowerPC processor.
De bedoeling van dit werk is na te gaan welke de voor- en nadelen zijn van het gebruik
van herconfigureerbare hardware die een instructieset processor tot zijn beschikking
heeft. Om dit te bewerkstelligen is het van belang de hardware eerst wat beter te
leren kennen.
De Auxiliary Processor Unit (APU) controller is de interface die de data-transfer
regelt tussen de FPGA en de PowerPC. Deze interface laat toe de instructieset van
de PowerPC uit te breiden met eigen instructies. De APU is een nieuwe technologie
die zijn intrede deed in de Virtex-4 FPGAs en bijgevolg verliep het onderzoek naar
de werking ervan niet altijd zonder problemen. Omdat deze APU een belangrijk
onderdeel vormt van het gebruik van de Virtex-4 FX FPGA met PowerPC processor
was het een van de hoofddoelen te onderzoeken hoe men ermee kan omgaan.
Dit hoofdstuk geeft eerst wat extra informatie bij de APU controller. Ook wordt
het gebruik van Pre-Defined en User-Defined Instructions (UDI’s) besproken aan de
hand van voorbeelden. Verder volgt er nog een uitleg over hoe men een systeem
kan bouwen dat gebruik maakt van UDI’s. Het onderzoek naar het gebruik en de
werking van de hardware verliep niet altijd zoals gewenst. In een laatste sectie
worden enkele problemen die zijn opgetreden kort besproken.
4.1 De APU controller verder toegelicht
In hoofdstuk 2 werd het nut van de APU controller reeds uit de doeken gedaan. De
APU stelt de gebruiker in staat eigen instructies toe te voegen aan de instructieset
van de PowerPC processor om deze te laten uitvoeren door een Fabric Co-processor
25

Module (FCM) op de FPGA. In deze sectie wordt dieper ingegaan op de verschillende
soorten FCM instructies, hoe ze eruit zien en hoe ze gedecodeerd worden [18].
4.1.1 Instructiecategorieen
De interactie van de FCM instructies met de normale processor-pijplijn-uitvoering
kan verschillen. De instructies kunnen opgedeeld worden in autonome of niet-
autonome instructies. Bij niet-autonome instructies kan er nog een onderscheid
gemaakt worden tussen blokkerend en niet-blokkerend.
Autonome instructies
Bij het gebruik van een autonome instructie wordt de pijplijn van de processor niet
opgehouden. Nadat de instructie doorgestuurd is naar de FPGA kan de proces-
sor onmiddellijk doorgaan met het uitvoeren van het programma. Er wordt geen
toestand of data teruggestuurd naar de processor. Bij opeenvolgende autonome in-
structies kan het zijn dat de processor toch zal moeten wachten. Dit komt voor
indien de module op de FPGA nog niet klaar is met de uitvoering van de vorige
instructie.
Niet-autonome instructies
Wanneer een instructie ervoor zorgt dat de FPGA een toestand of data terugstuurt
naar de processor zal er gebruik gemaakt worden van een niet-autonome instruc-
tie. In dit geval zal de pijplijn van de processor opgehouden worden tot wanneer
de instructie uitgevoerd is. Niet-autonome instructies kunnen blokkerend of niet-
blokkerend zijn.
Blokkerende instructies Indien een niet-autonome instructie bij de uitvoering
niet mag onderbroken worden door de processor maakt men gebuik van een blok-
kerende instructie. Bij het afbreken van de instructie kunnen er fouten optreden
wanneer de instructie later weer verdergezet wordt.
Niet-blokkerende instructies Indien een niet-autonome instructie toelaat dat
de uitvoering ervan onderbroken wordt door de processor wordt gebruik gemaakt
van een niet-blokkerende instructie. De instructie kan probleemloos afgebroken en
later weer verdergezet worden.
26

4.1.2 Instructie indeling
FCM instructies zijn 32 bit groot en zijn ingedeeld zoals te zien is op figuur 4.1.
De processor gebruikt de opcodes om de mogelijke FCM instructies te identificeren.
Deze opcodes worden door de APU of door de FCM gedecodeerd om uit te maken
over welke specifieke FCM instructie het gaat. Bij Pre-Defined Instructions verwij-
zen de RA en RB velden naar operandregisters en verwijst het RT-veld naar het
doelregister. Bij User-Defined Instructions (UDI’s) hangt de interpretatie van deze
velden af van de FCM.
Figuur 4.1: Indeling van een FCM instructie
4.1.3 Instructie decoderen
FCM-instructies kunnen gedecodeerd worden door de APU of door de FCM, afhanke-
lijk van het type van de instructie.
Decodering door APU
De APU gaat na welke bronnen van de processor nodig zijn voor de uitvoering
van de instructie en zal deze informatie doorgeven aan de processor. De APU kan
Pre-Defined Instructions en acht User-Defined Instructions decoderen.
Pre-Defined Instruction De APU kan twee soorten van Pre-Defined Instruc-
tions decoderen, nl. Floating Point Instructions en FCM Load/Store Instructions.
User-Defined Instruction Er kunnen maximaal acht UDI’s gedecodeerd worden
door de APU. Na decodering stuurt de APU het signaal APUFCMDECUDI[0:2]
naar de FCM. Dit signaal geeft aan welke UDI de APU gedecodeerd heeft. Hierdoor
hoeft de FCM slechts 3 bits te decoderen in plaats van 32 om de instructie te
achterhalen.
27

Decodering door FCM
Decodering door de FCM gaat trager dan decodering door de APU omwille van
de lagere klokfrequentie van de FPGA ten opzichte van de PowerPC. We maken
het onderscheid tussen het decoderen van Pre-Defined Instructions en User-Defined
Instructions.
Pre-Defined Instruction De FCM kan gebruikt worden voor het decoderen van
Integer Divide Instructions. Er dient echter ook vermeld te worden dat Floating
Point Instructions en FCM Load/Store Instructions, die door de APU gedecodeerd
worden, ook door de FCM moeten gedecodeerd worden. De APU kan de instructie
doorsturen, maar kan niet aangeven welke instructie hij gedecodeerd heeft. De
FCM zal voor de uitvoering de instructie dus moeten decoderen om op die manier
een aantal gegevens te achterhalen.
User-Defined Instruction UDI’s die niet door de APU gedecodeerd worden
zullen doorgegeven worden naar de FCM voor decodering. Hierdoor kunnen er
meer dan acht UDI’s gedefinieerd worden. Decodering door de FCM is trager en
dus minder efficient.
4.2 Pre-Defined Instruction
In deze sectie wordt de uitvoering van Pre-Defined Instructions op de Virtex-4 FX
FPGA besproken aan de hand van een FCM Register Load/Store voorbeeld. Hier-
voor werd gebruik gemaakt van application note xapp717 van Xilinx [13].
4.2.1 FCM Register Load/Store
Een FCM Load instructie transfereert data vanuit het geheugen1 via de processor
en de APU naar registers op de FPGA. Een FCM Store instructie doet net het
omgekeerde. De decodering van de instructies gebeurt door de APU.
Bij de application note is C code geleverd voor de software die op de processor
uitgevoerd wordt. Voor de implementatie van de FCM is er een Verilog bestand
beschikbaar. Aangezien voor deze thesis gebruik gemaakt wordt van VHDL diende
eerst en vooral de Verilog code vertaald te worden naar werkende VHDL code.
1D-Cache of DSPLB/DSOCM adresseerbaar geheugen.
28

Systeem overzicht
Op figuur 4.2 is een overzicht van het systeem te zien. De APU en FCM zijn
rechtstreeks met elkaar verbonden, zonder tussenkomst van een Fabric Co-processor
Bus (FCB). De FCM bestaat uit een automaat, een decoder en een registerbestand.
De automaat regelt de bewerkingen op de FPGA en zorgt voor de communicatie
met de APU. De decoder gaat na of de instructie die door de APU doorgegeven
is aan de FCM geldig is en haalt er de nodige informatie uit. Het registerbestand
wordt gebruikt om de data die met het geheugen uitgewisseld wordt op te slaan.
Figuur 4.2: FCM Register Load/Store systeem overzicht
Gebruikte poorten tussen APU en FCM
De poorten van de APU worden door de FCM gebruikt om instructies en data
te transfereren tussen de processor, de APU en de FPGA. De FCM Load/Store
instructies maken slechts gebruik van een deel van deze poorten. In tabel 4.1 zijn
de outputpoorten van de FCM weergegeven. De inputpoorten van de FCM staan
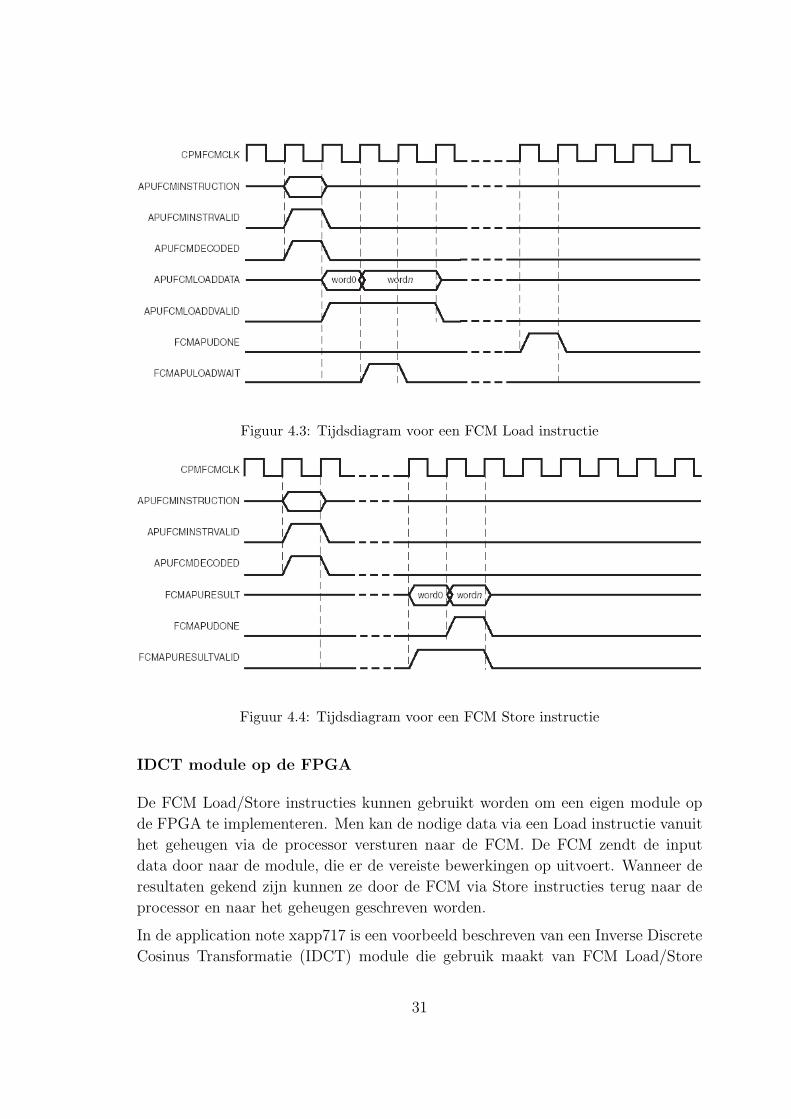
in tabel 4.2. Figuren 4.3 en 4.4 tonen de tijdsdiagrammen van respectievelijk een
FCM Load en een FCM Store instructie voor een dubbel woord (2 x 32 bit).
Ondanks het feit dat FCM Load/Store instructies door de APU gedecodeerd wor-
den zal ook de FCM deze instructies nog moeten decoderen. De FCM gaat het
APUFCMINSTRUCTION[0:31] signaal gebruiken om er uit af te leiden of het om
een Load of Store instructie gaat, hoeveel bits er dienen getransfereerd te worden
en welke processorregisters er gebruikt worden. Er wordt ook nagekeken of het om
een geldige instructie gaat.
29

Tabel 4.1: FCM Register Load/Store outputpoorten
Signaal Functie
FCMAPURESULT[0:31] Het resultaat van de uitvoering van de
instructie door de FCM.
FCMAPURESULTVALID Geeft aan of de waarde van
FCMAPURESULT[0:31] geldig is.
FCMAPUDONE Wijst de APU erop dat de uitvoering
van de instructie door de FCM voltooid
is.
FCMAPULOADWAIT De FCM is niet klaar om de volgende
load data van de APU te ontvangen.
Zolang dit signaal hoog staat zal de
APU dezelfde data blijven aanbieden.
Tabel 4.2: FCM Register Load/Store inputpoorten
Signaal Functie
APUFCMINSTRUCTION[0:31] De instructie die doorgegeven wordt
aan de FCM. Dit signaal is geldig
zolang APUFCMINSTRVALID hoog
staat.
APUFCMINSTRVALID Geeft aan wanneer een geldige APU in-
structie gedecodeerd is door de APU of
wanneer een niet-gedecodeerde instruc-
tie doorgegeven wordt aan de FCM
voor decodering.
APUFCMDECODED Wijst erop dat de APU de instructie
heeft gedecodeerd alvorens ze naar de
FCM door te sturen.
APUFCMLOADDATA[0:31] Data die geladen wordt van het geheu-
gen naar het APU registerbestand.
APUFCMLOADDVALID Zolang dit signaal hoog staat is de data
op de APUFCMLOADDATA[0:31]
poort geldig.
30
Figuur 4.3: Tijdsdiagram voor een FCM Load instructie
Figuur 4.4: Tijdsdiagram voor een FCM Store instructie
IDCT module op de FPGA
De FCM Load/Store instructies kunnen gebruikt worden om een eigen module op
de FPGA te implementeren. Men kan de nodige data via een Load instructie vanuit
het geheugen via de processor versturen naar de FCM. De FCM zendt de input
data door naar de module, die er de vereiste bewerkingen op uitvoert. Wanneer de
resultaten gekend zijn kunnen ze door de FCM via Store instructies terug naar de
processor en naar het geheugen geschreven worden.
In de application note xapp717 is een voorbeeld beschreven van een Inverse Discrete
Cosinus Transformatie (IDCT) module die gebruik maakt van FCM Load/Store
31

instructies [13]. Via Load instructies wordt een blok van 8 x 8 bytes naar de IDCT
module gestuurd. Na uitvoering wordt het blok terug naar het geheugen geschreven.
Er wordt niet verder ingegaan op dit voorbeeld dat gebruik maakt van Pre-Defined
Instructions. In het verdere verloop van dit werk zal de aandacht gaan naar User-
Defined Instructions. Deze bieden meer mogelijkheden en zijn dan ook een interes-
sant onderzoeksgebied.
4.3 User-Defined Instruction
Het gebruik van User-Defined Instructions als uitbreiding van de instructieset van de
PowerPC processor wordt in deze sectie behandeld. Aan de hand van een eenvoudige
som instructie wordt aangetoond hoe men UDI’s kan aanwenden om eigen instructies
te laten uitvoeren door een FCM op de FPGA. De implementatie van deze som
instructie is afkomstig van de PPC405 APU and FPU Labs van Xilinx2. Door
van het raamwerk van deze UDI gebruik te maken kan men overgaan op het zelf
implementeren van UDI’s voor een systeem.
De hier behandelde UDI’s worden door de APU gedecodeerd. Het geval waarbij de
FCM de UDI’s decodeert wordt hier niet besproken.
4.3.1 Module op de FPGA
De module die hier besproken wordt voert een som instructie uit op de FPGA.
Deze FCM is representatief voor elke andere module die gebruikt wordt om een
UDI uit te voeren. Op figuur 4.5 is een raamwerk afgebeeld van hoe een FCM kan
geımplementeerd worden. Er wordt gebruik gemaakt van een Fabric Co-processor
Bus (FCB) om de APU en de FCM te verbinden. Deze bus kan aangewend worden
om meerdere FCMs met de APU te connecteren.
De FCM bestaat uit twee aparte modules, nl. een automaat (fcm udi) en een module
voor de uitvoering van de instructie (user func). De automaat is een interface module
van de FCM die zorgt voor de communicatie tussen de FCM en de APU en die
de nodige signalen doorgeeft aan de user func module. Deze fcm udi module is
algemeen en hoeft niet aangepast te worden bij het implementeren van andere UDI’s.
De module voor de uitvoering van de instructie is de co-processing eenheid van de
FCM en zorgt ervoor dat de FCM de vereiste functionaliteit heeft. De code van deze
2Deze PPC405 APU and FPU Labs zijn op aanvraag ter beschikking gesteld door Xilinx. Zebevatten ook meer uitleg bij hoe men de Floating Point Unit kan integreren in een systeem.
32

Figuur 4.5: Systeem overzicht van een raamwerk voor het gebruik van UDIs
user func module dient aangepast te worden wanneer men een andere UDI wenst te
implementeren.
Voor de communicatie tussen de APU en de FCM is de fcm udi module verbonden
met alle poorten die de APU ter beschikking stelt. De poorten die hier van belang
zijn staan in tabel 4.3 voor de outputs van de FCM en in tabel 4.4 voor de inputs.
De FCM zal het APUFCMINSTRUCTION[0:31] signaal niet opnieuw decoderen
omdat dit reeds gebeurd is in de APU. Het APUFCMDECUDI[0:2] signaal vertelt
de FCM over welke UDI het gaat.
Tabel 4.3: FCM UDI outputpoorten
Signaal Functie
FCMAPURESULT[0:31] Het resultaat van de uitvoering van de
instructie door de FCM.
FCMAPURESULTVALID Geeft aan of de waarde van
FCMAPURESULT[0:31] geldig is.
FCMAPUDONE Wijst de APU erop dat de uitvoering
van de instructie door de FCM voltooid
is.
FCMAPUSLEEPNOTREADY Dit signaal staat hoog zolang de FCM
bezig is met de uitvoering van de in-
structie.
33
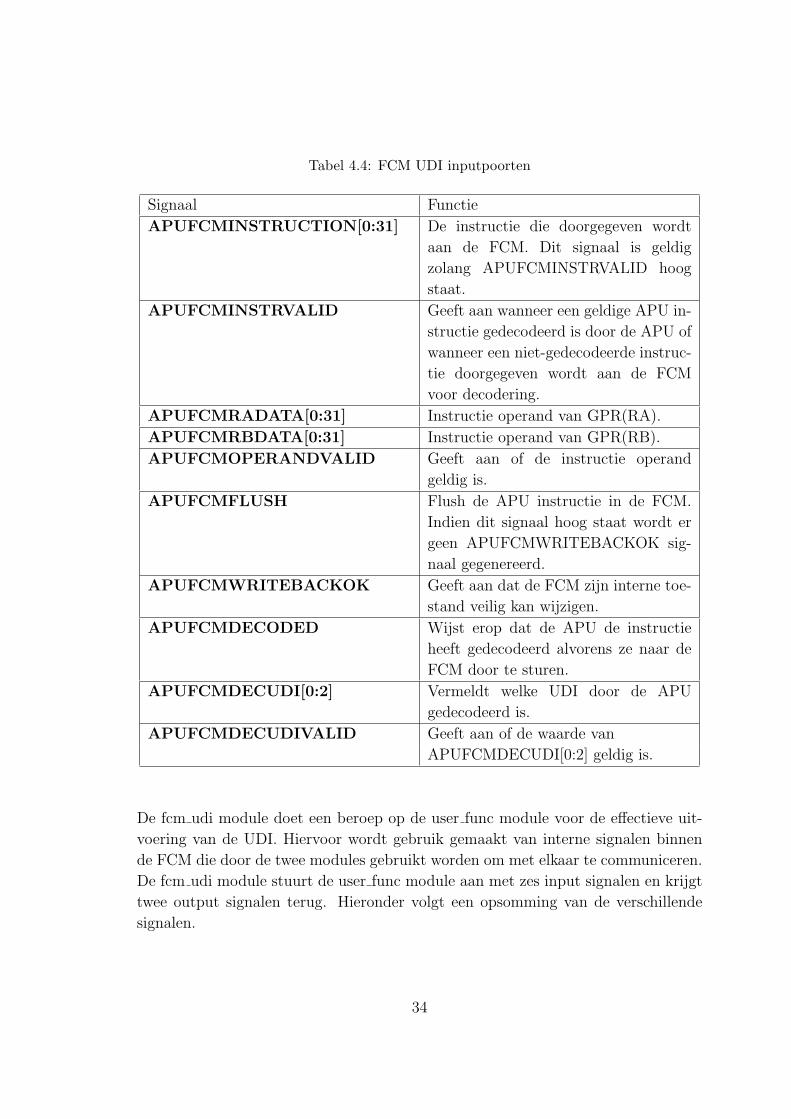
Tabel 4.4: FCM UDI inputpoorten
Signaal Functie
APUFCMINSTRUCTION[0:31] De instructie die doorgegeven wordt
aan de FCM. Dit signaal is geldig
zolang APUFCMINSTRVALID hoog
staat.
APUFCMINSTRVALID Geeft aan wanneer een geldige APU in-
structie gedecodeerd is door de APU of
wanneer een niet-gedecodeerde instruc-
tie doorgegeven wordt aan de FCM
voor decodering.
APUFCMRADATA[0:31] Instructie operand van GPR(RA).
APUFCMRBDATA[0:31] Instructie operand van GPR(RB).
APUFCMOPERANDVALID Geeft aan of de instructie operand
geldig is.
APUFCMFLUSH Flush de APU instructie in de FCM.
Indien dit signaal hoog staat wordt er
geen APUFCMWRITEBACKOK sig-
naal gegenereerd.
APUFCMWRITEBACKOK Geeft aan dat de FCM zijn interne toe-
stand veilig kan wijzigen.
APUFCMDECODED Wijst erop dat de APU de instructie
heeft gedecodeerd alvorens ze naar de
FCM door te sturen.
APUFCMDECUDI[0:2] Vermeldt welke UDI door de APU
gedecodeerd is.
APUFCMDECUDIVALID Geeft aan of de waarde van
APUFCMDECUDI[0:2] geldig is.
De fcm udi module doet een beroep op de user func module voor de effectieve uit-
voering van de UDI. Hiervoor wordt gebruik gemaakt van interne signalen binnen
de FCM die door de twee modules gebruikt worden om met elkaar te communiceren.
De fcm udi module stuurt de user func module aan met zes input signalen en krijgt
twee output signalen terug. Hieronder volgt een opsomming van de verschillende
signalen.
34

Inputs:
• p: Doorverbonden met APUFCMRADATA[0:31].
• q: Doorverbonden met APUFCMRBDATA[0:31].
• calc start: Signaal dat aangeeft wanneer de user func module
mag beginnen met het uitvoeren van de nodige bewerkingen.
• calc abort: Doorverbonden met APUFCMFLUSH.
• clock: Doorverbonden met het FCM klok signaal.
• reset: Doorverbonden met het FCM reset signaal.
Outputs:
• n: Doorverbonden met FCMAPURESULT[0:31].
• calc complete: Doorverbonden met FCMAPUDONE en
FCMAPURESULTVALID.
Door gebruik te maken van de udi fcm en user func modules zijn we in staat een
systeem te maken dat een beroep kan doen op UDI’s. De udi fcm module kun-
nen we onveranderd laten. In de user func module kunnen de nodige bewerkingen
geımplementeerd worden.
4.3.2 Software
Om een UDI te kunnen uitvoeren moet deze in de software opgeroepen worden.
De PowerPC processor kan geprogrammeerd worden in C. Figuur 4.6 geeft een af-
geslankte versie van de ’sum.c’ code die is meegeleverd met de PPC405 APU and
FPU Labs. Enkel die code is overgebleven die nodig is om een som instructie te
laten uitvoeren door de FPGA vanuit de processor.
Bij uitvoering van de software krijgen we de volgende output:
1 + 2 = 3
Via het commando XApu EnableApu() wordt de APU geactiveerd. Dit commando
roept de volgende functie op die gedefinieerd is in ’xapu.h’:
35

#include "xapu.h"
#include "xutil.h"
#include "xpseudo_asm.h"
int main(void) {
int x=1, y=2, z=0;
XApu_EnableApu();
xil_printf("1 + 2 = ");
UDI0FCM_GPR_GPR_GPR(z, x, y);
xil_printf("%x\r\n", z);
return 0;
}
Figuur 4.6: C code om een som uit te voeren op de FPGA
mtmsr(mfmsr() | XREG_MSR_APU_AVAILABLE);
Hierdoor wordt in het PowerPC Machine-State Register (MSR) de zesde bit op ’1’
gebracht3. Dit zorgt ervoor dat de processor ervan op de hoogte is dat de APU
aanwezig is.
Om een UDI uit te voeren gebruikt men het volgende commando:
UDI<n>FCM_GPR_GPR_GPR(a, b, c);
Hierbij staat <n> voor de UDI die moet uitgevoerd worden (n kan waarden aan-
nemen van 0 tot 7). Er worden drie 32 bit argumenten meegegeven met de instruc-
tie: twee GPR’s die data naar de FPGA sturen (b en c) en een GPR die data van
de FPGA ontvangt (a). Voor het uitprinten van gegevens wordt het commando
xil printf() gebruikt. Meer informatie is te vinden in [16].
3XREG MSR APU AVAILABLE = 0x02000000, gedefinieerd in ’xreg405.h’.
36

4.3.3 Een basissysteem bouwen
Voor het bouwen van een systeem voor het ML403 ontwikkelbord wordt gebruik
gemaakt van Xilinx Platform Studio (XPS). Zoals beschreven in hoofdstuk 2 is dit
de grafische user interface technologie van de Embedded Development Kit (EDK).
Hieronder worden de belangrijkste stappen besproken om een systeem te bouwen
dat een FCM en de nodige software integreert. Hiervoor is gebruik gemaakt van
EDK 8.1.
In een eerste stap wordt de Base System Builder wizard gebruikt om de nodige rand-
apparaten te selecteren en de processor te configureren. In het systeem dat voor deze
scriptie gemaakt is wordt enkel gebruik gemaakt van de RS232 Uart seriele poort
en van het DDR SDRAM 64M×32 geheugen. De referentie en de bus klokfrequen-
tie worden ingesteld op 100 MHz, de processor klokfrequentie op 300 MHz. Ook
het gebruik van het cache geheugen dient hier aangevinkt te worden. Voor de rest
worden de basisinstellingen gebruikt.
De FCM die we wensen te integreren in het systeem dient in de pcores map van
het project terecht te komen. Op de CD-ROM die bij deze scriptie hoort is een
fcm udi v1 00 a map terug te vinden voor zowel Verilog als VHDL code. Deze FCM
voert een eenvoudige som instructie uit en is afkomstig uit de PPC405 APU and
FPU Labs. Men dient deze map in de pcores map te plaatsen en de user func
module aan te passen aan de gewenste UDI, zoals eerder beschreven. Onder Project
kan men dan Rescan User Repositories aanklikken om de FCM op te sporen. In de
IP Catalog tab dient men vervolgens de Project Repository → fcm udi module bij
het systeem te voegen. Ook de Bus → fcb v10 FCB wordt hier toegevoegd. Door
gebruik te maken van de Bus Interface filter in de System Assembly View stellen
we de PPC405 in als master op de FCB (vierkantje naast MFCB aanklikken) en de
FCM als slave (bolletje naast SFCB aanklikken).
Nog onder de Bus Interface filter gaan we de parameters van de PowerPC instellen
om APU instructie decodering aan te zetten. Hiervoor vullen we de volgende waar-
den in bij de eigenschappen van ppc405 04 (zie [18] voor meer uitleg):
APU Controller Configuration Register Initial Value = 0x0001 (FCM aan)
UDI Configuration Register 1 Initial Value = 0xC07701 (blokkerende UDI)
UDI Configuration Register 2-8 Initial Values = 0x000000 (geen UDI)
Voor de FCM laten we de parameters ongewijzigd (bij eigenschappen van fcm udi 0):
4Deze configuratie kan ook dynamisch gebeuren via het Device Control Register (DCR) insoftware. Hier wordt niet verder op ingegaan.
37

C_UDI_REG_NUM = 0b000 (nummer van de UDI)
C_NONBLOCKING = 0 (niet-autonome blokkerende instructie)
In de volgende stap gaan we de klok- en resetsignalen aanleggen aan de FCM en de
FCB. Hiervoor maken we gebruik van de Ports filter. Voor de FCB wordt dit (onder
fcb v10 0):
FCB_CLK -> sys_clk_s
SYS_RST -> sys_bus_reset
Voor de FCM leggen we hetvolgende kloksignaal aan (onder fcm udi 0):
clock -> sys_clk_s
Nu gaan we dit ontwerp in hardware implementeren via Hardware, Generate Bit-
stream. Als resultaat krijgen we een .bit bestand dat vanuit XPS op de FPGA kan
geladen worden.
Verder dient ook de software in het systeem geıntegreerd te worden. Hiervoor maken
we een software project aan via Add Software Application Project onder de Appli-
cations tab en importeren we de gewenste source en header bestanden. We zorgen
ervoor dat Mark to Initialize BRAMs enkel bij dit project aangevinkt staat. Dan
volgt nog Generate Linker Script en Build Project. We bekomen nu een .elf bestand,
dit is de software executable.
Voor het downloaden en uitvoeren van het programma op het ML403 bord wordt
een verbinding met de processor gemaakt via de Xilinx Microprocessor Debugger
(XMD). Hiervoor gebruiken we de volgende commando’s:
XMD% connect ppc hw
XMD% rst
XMD% dow executable.elf (juiste locatie van de executable invullen)
XMD% run
Voor de communicatie met het ontwikkelbord wordt Hyperterminal gebruikt. Hierbij
gelden de volgende instellingen:
38

Baud rate: 9600
Data: 8 bit
Parity: none
Stop: 1 bit
Flow control: none
4.4 Problemen
De verkenning van de hardware verliep natuurlijk niet altijd zonder problemen. Deze
problemen zijn vaak de zaken waar men het meeste tijd mee verliest. Een aantal
van deze struikelblokken worden hier kort toegelicht.
Het FCM Register Load/Store voorbeeld en de PPC405 APU and FPU Labs die
door Xilinx ter beschikking gesteld worden bevatten Verilog code. Voor deze scriptie
wordt gebruik gemaakt van VHDL. De Verilog code moest dus vertaald worden.
Aangezien Verilog onbekend terrein voor mij was liep dit niet altijd van een leien
dakje.
Bij de PPC405 APU and FPU Labs wordt aangegeven dat het kloksignaal van
de FCB (FCB CLK) aan sys clk en het resetsignaal (SYS RST) aan sys rst moet
toegekend worden. Hiervoor werd in XPS gebruik gemaakt van de signalen sys clk s
en sys rst s. Het systeem weigerde echter te werken. Na veel zoekwerk ben ik er
met de hulp van iemand van Xilinx achter gekomen dat de signalen sys clk s en
sys bus reset dienen gebruikt te worden.
Voor een eerste eigen FCM die een UDI uitvoert te testen heb ik een schuifregister
geımplementeerd dat dienst doet als FIR-filter. Hiervoor heb ik in de user func
module de nodige aanpassingen aangebracht. De resultaten van de filterbewerkingen
waren echter niet wat ze moesten zijn. Uit simulaties bleek dat er na elke UDI
een flush wordt uitgevoerd en APUFCMFLUSH dus even op ’1’ komt. Om de
waarden in de registers van het schuifregister te bewaren mogen deze dus niet gereset
worden in de user func module wanneer het calc abort signaal (doorverbonden met
APUFCMFLUSH) op ’1’ komt.
Soms kan het zijn dat de uitvoering van een systeem op het ML403 bord niet werkt.
Door een kleine aanpassing te maken in de software, zoals het toevoegen van een
xil printf(), zijn de problemen soms opgelost. De redenen voor dit vreemde ver-
schijnsel zijn mij onbekend.
Aan het begin van deze scriptie is er gewerkt met EDK 7.1. In deze versie was het
gebruik van de APU niet echt een lachertje. Later konden we verderwerken met
39

EDK 8.1, die een gemakkelijkere en overzichtelijkere integratie van FCM’s in een
systeem biedt. Jammer dat we niet vlugger van deze nieuwere en betere software
konden gebruik maken.
40

Hoofdstuk 5
Hardware-implementatie van een
wavelettransformatie
Om de beschikbare hardware te kunnen testen en evalueren wordt gebruik gemaakt
van een discrete wavelettransformatie. In de schaalbare videocodec die in de in-
leiding vermeld wordt doet men een beroep op de blokgebaseerde wavelettrans-
formatie. Het onderzoek naar hoe zo’n blokgebaseerde wavelettransformatie kan
geımplementeerd worden op de Virtex-4 FX FPGA vormt dan ook een belangrijk
onderdeel van deze thesis.
In dit hoofdstuk wordt eerst de module die op de FPGA geımplementeerd wordt
uit de doeken gedaan. Vervolgens komt de software die op de PowerPC draait
en de module op de FPGA zal aanspreken aan bod. Verder worden de resultaten
bekeken en geevalueerd. Om te besluiten worden een aantal mogelijke verbeteringen
besproken.
5.1 Module op de FPGA voor een blokgebaseerde
wavelettransformatie
5.1.1 Schuifregisters voor de filterbewerkingen
Zoals te lezen is in hoofdstuk 3 bestaat de discrete wavelettransformatie van een
afbeelding uit een opeenvolging van filteroperaties. De filtercoefficienten die ge-
bruikt worden voor het berekenen van de laag- en hoogdoorlaatcomponenten zijn
weergegeven in tabel A.1. In tabel A.2 staan de filtercoefficienten voor de inverse
transformatie afgebeeld. De symmetrie van deze FIR-filters kan gebruikt worden
41

bij het implementeren van de filterbewerkingen. Figuur 5.1 toont een mogelijke
implementatie [10].
Figuur 5.1: Rechtstreekse implementatie van de laagdoorlaat FIR-filter
Het nadeel van deze implementatie is dat ze geen hoge klokfrequentie aankan omwille
van de lengte van het langste pad, tenzij de filterbewerkingen over meerdere klokcycli
gespreid worden. Een betere oplossing is het gebruik van een schuifregister als FIR-
filter. Door het feit dat er bij elke filteroperatie twee elementen tegelijk verwerkt
worden kan men aan de hand van een schuifregister tot een zeer efficiente imple-
mentatie komen. Figuren 5.2 en 5.3 tonen hoe uit twee elementen een laag- en een
hoogdoorlaatcomponent kunnen berekend worden. Op figuren 5.4 en 5.5 staan de
inverse transformaties afgebeeld. Aangezien de FIR-filters symmetrisch zijn hoeven
een aantal vermenigvuldigingen slechts een keer te gebeuren. Door de duidelijke
aanwezigheid van parallellisme zullen deze implementaties van de filterbewerkingen
zich heel goed tot een hardware implementatie lenen.
5.1.2 Filtering als UDI
We gaan nu op zoek naar hoe we een FCM kunnen implementeren die zorgt voor een
hardware-versnelling van een blokgebaseerde wavelettransformatie. In hoofdstuk
4 werd het raamwerk voor een FCM die een UDI uitvoert besproken. Van dit
raamwerk wordt nu gebruik gemaakt om een UDI te definieren die een filteroperatie
uitvoert. De fcm udi module kunnen we ongewijzigd laten. De user func module
wordt aangepast zodat ze de eigenlijke filterbewerkingen zal uitvoeren op de FPGA.
Een automaat binnen deze module zorgt voor de juiste uitvoering van de FIR-filter.
42

Figuur 5.2: Schuifregister voor de berekening van een laagdoorlaatcomponent
Figuur 5.3: Schuifregister voor de berekening van een hoogdoorlaatcomponent
Figuur 5.4: Schuifregister voor de berekening van een oneven element
Voor de berekeningen binnen de FCM wordt gebruik gemaakt van de 2-complement-
voorstelling, aangezien er ook met negatieve getallen gewerkt wordt. De filtercoeffici-
enten bevatten zowel positieve als negatieve getallen en ook de beelden die getrans-
formeerd worden kunnen negatieve elementen bevatten (foutbeelden). Omdat de
filtercoefficienten van de FIR-filters kommagetallen zijn wordt verder ook gebruik
gemaakt van fixed point bewerkingen.
43

Figuur 5.5: Schuifregister voor de berekening van een even element
De keuze van het aantal bits en de indeling ervan wordt nu kort toegelicht.
• Originele elementen
9 bits → 1 tekenbit + 8 bits
De elementen van een referentiebeeld zijn 8 bits groot. Foutbeelden kunnen
ook negatieve waarden bevatten en vereisen dus een extra tekenbit.
• Getransformeerde elementen
16 bits → 1 tekenbit + 12 bits + 3 bits na de komma
Per niveau waarover er getransformeerd wordt zal het bereik verdubbelen. Er
is dus telkens 1 extra bit nodig. Aangezien we in deze thesis niet verder gaan
dan een transformatie over 4 niveau’s zullen 9 + 4 = 13 bits volstaan. Voor de
opslag van de waveletcoefficienten is het makkelijker om te kiezen voor een 16
bits notatie. We nemen nog 3 bits achter de komma voor de nauwkeurigheid
van de bewerkingen.
• Filtercoefficienten
18 bits → 1 tekenbit + 17 bits na de komma
Aangezien de FPGA beschikt over 18×18 bits vermenigvuldigers en de fil-
tercoefficienten intern gedeclareerd zijn zullen we de volle 18 bits benutten.
De filtercoefficienten nemen waarden aan tussen -1 en 1, waardoor buiten de
tekenbit geen extra bits voor de komma vereist zijn. De 17 bits achter de
komma zorgen voor een nauwkeurigheid tot op 5 cijfers na de komma. De
18 bits voorstellingen van de filtercoefficienten voor de voorwaartse en inverse
wavelettransformatie staan genoteerd in tabellen A.3 en A.4.
Nadat de VHDL code van de FCM geschreven is kan deze geıntegreerd worden in een
systeem. We zijn nu in staat om filteroperaties uit te voeren vanuit de PowerPC op
de FPGA via een UDI. De waarden van de twee GPR’s die via de APU aan de FCM
44

doorgegeven worden bevatten de twee elementen voor transformatie. Het register
waarnaar de FCM het resultaat terugschrijft bevat de twee 16 bits resultaten. In
tabel 5.1 staan de resultaten van de voorwaartse en inverse wavelettransformatie
van tien elementen, uitgevoerd door een FCM op de FPGA. Men kan zien dat de
elementen quasi perfect kunnen gereconstrueerd worden.
Tabel 5.1: Resultaten van een voorwaartse + inverse wavelettransformatie
originele na voorwaartse +
elementen inverse transformatie
56 55,875
-139 -139,125
-180 -180
244 243,875
-202 -202
9 8,75
-97 -97
126 125,875
253 252,875
-85 -85,125
5.1.3 Gebruik van Block RAM op de FPGA
Bij een blokgebaseerde wavelettransformatie moet de afbeelding eenmaal volledig uit
het hoofdgeheugen gelezen en eenmaal volledig naar het hoofdgeheugen geschreven
worden. Intern is er nood aan een geheugen dat het blok dat uit het hoofdgeheugen
geladen is bijhoudt en aan een overlapgeheugen dat elementen bijhoudt van andere
blokken voor de toepassing van de wavelettransformatie. Voor dit overlapgeheugen
maken we gebruik van Block RAM geheugen op de FPGA. De Virtex-4 FX waarover
we beschikken bevat 36 Block RAM blokken van 18 Kb.
Het Block RAM geheugen wordt gebruikt om de waarden van de flip-flops van de
schuifregisters op te slaan, zoals te zien is op figuur 5.6. Bij elke filteroperatie worden
de juiste waarden uit het Block RAM gelezen en gebruikt voor het berekenen van het
resultaat. Doordat de waarden van de flip-flops worden bijgehouden op een bepaald
adres in het Block RAM kan men op elk ogenblik de filteroperatie onderbreken om
het schuifregister te gebruiken voor een andere filteroperatie. Later kan men de
bewerking eenvoudig verderzetten door het juiste adres van het Block RAM aan te
45

geven. Het is dus niet nodig om alle waarden weer volledig in het schuifregister te
schuiven.
Figuur 5.6: Schuifregister met gebruik van Block RAM op de FPGA
Deze implementatie is zeer geschikt voor gebruik in een blokgebaseerde wavelettrans-
formatie. Doordat de filteroperaties hier in blokken georganiseerd zijn in plaats van
volgens rijen of kolommen worden ze vaak onderbroken en gaat het nut van de
schuifregisters wat verloren. Bij gebruik van het Block RAM maakt het geen ver-
schil of een filteroperatie al dan niet onderbroken wordt, de FCM moet enkel op de
hoogte zijn van het juiste Block RAM geheugenadres. Op deze manier is een nadeel
van blokgebaseerde wavelettransformaties ten opzichte van rij-kolomgebaseerde en
rijgebaseerde weggewerkt.
Voor de toepassing van een wavelettransformatie zijn twee filteroperaties nodig, een
met 9 en een met 7 taps. Hierbij zijn er respectievelijk 7 en 5 flip-flops waarvan de
waarde dient opgeslagen te worden in het Block RAM. Uit de overige 4 flip-flops
worden de uitgangen berekend. Er zijn dus 12 Block RAM geheugens nodig. Deze
kunnen allen terzelfder tijd gelezen of geschreven worden. Elk Block RAM heeft 18
Kb opslagruimte. We kiezen ervoor om 18 bits van de flip-flops in het Block RAM
op te slaan. Bijgevolg zijn we in staat om voor 1024 filterbewerkingen de nodige
waarden bij te houden. Dit is ruim voldoende voor de transformatie van CIF en
QCIF beelden.
De synthesizer zal de Block RAM geheugens automatisch gebruiken indien ze volgens
de juiste syntax beschreven zijn. Er dient dus in de VHDL code op gelet te worden
dat er geen verkeerde bewerkingen met het Block RAM gebeuren, zoals bv. een reset.
46

In het andere geval zal gebruik gemaakt worden van Distributed RAM. Dit maakt
gebruik van Look-Up Tables (LUT’s) en neemt veel meer plaats in op de FPGA.
Door het gebruik van Block RAM treedt er in de FCM extra vertraging op. Niet
zozeer de snelheid van het Block RAM is hierbij de beperkende factor, wel de lengte
van het langste pad. Voor elk van de 12 gebruikte Block RAM geheugens zijn 18
functieblokken nodig, een voor elke binnenkomende bit. Op de FPGA wensen we
een kloksnelheid van 100 MHz te bekomen. Aangezien deze niet gehaald wordt is
het nodig om bij de filteroperaties in de user func module de optellers en vermeni-
givuldigingers in een aparte klokcyclus te gebruiken. Door een klokcyclus op te
offeren kunnen we op deze manier het langste pad inkorten en wordt een maximale
kloksnelheid van 118 MHz mogelijk.
Hieronder staan de statistieken van welke onderdelen de FPGA gebruikt voor de
FCM. Men kan ook zien hoeveel van de FPGA bronnen hiervoor gebruikt worden.
Deze waarden zijn afkomstig van de FCM voor voorwaartse wavelettransformatie.
De FCM voor inverse transformatie levert gelijkaardige resultaten.
Macro Statistics
# FSMs : 1
# Block RAMs : 12
1024x18-bit single-port block RAM : 12
# Multipliers : 9
16x18-bit registered multiplier : 9
# Adders/Subtractors : 14
34-bit adder : 14
# Registers : 674
Flip-Flops : 674
Number of Slices: 651 out of 5472 11%
Number of Slice Flip Flops: 656 out of 10944 5%
Number of 4 input LUTs: 1203 out of 10944 10%
Number of FIFO16/RAMB16s: 12 out of 36 33%
Number used as RAMB16s: 12
Number of DSP48s: 4 out of 32 12%
47

5.2 De PowerPC programmeren
5.2.1 Regeling van de filterbewerkingen
Er is voor gekozen de FPGA enkel te gebruiken voor de toepassing van de filter-
operaties. Deze bewerkingen zijn vanwege hun parallellisme immers zeer geschikt
voor implementatie op herconfigureerbare hardware. Het overlapgeheugen zit mee
geıntegreerd op de FPGA in Block RAM geheugen. De aansturing van deze filter-
bewerkingen gebeurt vanop de PowerPC. We gaan de FPGA dus gebruiken voor
een hardware-versnelling van de FIR-filters en de complexe aansturing in software
laten. Het regelen van de geheugentransfers van en naar het hoofdgeheugen gebeurt
ook vanuit de PowerPC. Van het overlapgeheugen hoeft de processor zich echter niet
veel aan te trekken. Hij hoeft enkel het correcte Block RAM adres door te geven
aan de FCM.
De uitvoering van een filteroperatie op de FPGA vanuit de software gebeurt via het
UDI0FCM GPR GPR GPR(z, x, y) commando. De waarden van de 32 bit registers
die als argumenten meegegeven worden zien er als volgt uit:
• input x: 2 x 16 bits voor het doorgeven van 2 elementen voor transformatie.
• input y: 10 bit adres van het overlapgeheugen (Block RAM).
• output z: 2 x 16 bits voor het doorgeven van de 2 getransformeerde elementen.
De input elementen zijn 16 bits groot omdat na een eerste transformatie de wavelet-
coefficienten uit 16 bits bestaan en hiermee verdergerekend zal worden. Bij de 9 bit
input elementen van een afbeelding dienen achteraan 3 nullen ingevoegd te worden
om in overeenstemming te zijn met de fixed-point-notatie.
5.2.2 DDR SDRAM en instructie- & data cache
Voor het testen en evalueren van wavelettransformaties wordt gebruik gemaakt van
random gegenereerde CIF (352 bij 288 pixels) en QCIF (176 bij 144 pixels) af-
beeldingen1. Voor de elementen van deze beelden worden short integers (16 bits)
gebruikt.
1De Linux kernel die op het ML403 bord draait is niet in staat om om te gaan met de APU. Hetinlezen van afbeeldingen voor bewerkingen die gebruik maken van UDIs is dan ook niet mogelijk.Meer informatie over de Linux kernel is te vinden in [8].
48

Voor de transformatie van CIF en QCIF afbeeldingen wordt een beroep gedaan op
het DDR SDRAM geheugen (64 MiB) en op instructie en data cache. Om het RAM
geheugen en de cache te kunnen gebruiken dienen deze aangezet te worden bij het
bouwen van het systeem.
Bij het gebruik van het DDR SDRAM geheugen moet men erop letten dat rijen
buiten de main() functie gedeclareerd worden. Bij rijen met een groot aantal ele-
menten zullen er anders instructies overschreven worden en het systeem zal crashen.
De instructie en data cache moeten voor gebruik nog geactiveerd worden binnen de
main() functie. Dit kan op de volgende manier gedaan worden:
XCache_EnableICache(0x80000001);
XCache_EnableDCache(0x80000001);
5.2.3 Wavelettransformaties op de PowerPC
Uiteindelijk komen we dan tot het implementeren van een wavelettransformatie op de
Virtex-4 FX. Aangezien er hiervoor niet zoveel tijd meer over was heb ik mij beperkt
tot de implementatie van een rij-kolomgebaseerde wavelettransformatie tot op 4
niveau’s en een vereenvoudigde versie van een blokgebaseerde wavelettransformatie,
ook tot op 4 niveau’s. Beide maken gebruik van dezelfde FCM die eerder besproken
werd.
De vereenvoudigde versie van de blokgebaseerde wavelettransformatie deelt de af-
beelding op in blokken en gaat deze transformeren tot op het gewenste niveau. Er is
echter geen rekening gehouden met de initialisatie aan de randen van de afbeelding.
Ook worden bij het wegschrijven van het resultaat naar het DDR SDRAM geheu-
gen de blokken op dezelfde plaats in de afbeelding teruggeschreven. In werkelijkheid
komen de resultaten verspreid over de afbeelding terecht. De berekening van de
waveletcoefficienten van de blokken gebeurt wel op dezelfde manier. De organisatie
van de geheugentransfers en de regeling van de filterbewerkingen zal dus gelijkaardig
zijn. Deze implementatie van de blokgebaseerde wavelettransformatie zal een een
beeld vormen van de snelheid die haalbaar is op de Virtex-4 FX.
5.3 Resultaten
In eerste instantie is er getest hoeveel tijdswinst het oplevert wanneer de filterbe-
werkingen voor wavelettransformatie op de FPGA in plaats van op de PowerPC
uitgevoerd worden. We bekomen hierbij dat het gebruik van de FPGA 7 tot 7,5
49

keer sneller is. Bovendien ondervindt de uitvoering op de FPGA er geen hinder
van wanneer bij filtering van rij of kolom versprongen wordt. De overlapgeheugens
worden immers bijgehouden in het Block RAM en de juiste waarden worden wan-
neer nodig in de flip-flops van het schuifregister geschreven. Het gebruik van een
FPGA om bepaalde rekenintensieve opdrachten op zich te nemen levert dus duidelijk
voordelen op.
Voor het uitvoeren van een volledige wavelettransformatie van een beeld op de
Virtex-4 FX is zoals eerder vermeld gebruik gemaakt van een rij-kolomgebaseerde
en van een vereenvoudigde blokgebaseerde wavelettransformatie. In beide gevallen
is er een transformatie toegepast tot op vier niveau’s, zowel voor QCIF als voor CIF
afbeeldingen. Hierbij is opgemeten hoeveel tijd het transformeren van een beeld
in beslag neemt. Het corresponderende aantal beelden die per seconde kunnen ver-
werkt worden kan hieruit bepaald worden. De resultaten van de rij-kolomgebaseerde
versie staan in tabellen 5.2 en 5.3, voor de blokgebaseerde versie zijn de resultaten
terug te vinden in tabellen 5.4 en 5.5. Er is ook een onderscheid gemaakt tussen het
al dan niet gebruiken van een instructie- en datacache.
Ter vergelijking is er ook een rij-kolomgebaseerde wavelettransformatie uitgevoerd
op een pc met AMD processor2. Hiervoor is gebruik gemaakt van de C code die
hoort bij [2]. De transformatie is ook hier toegepast tot op vier niveau’s, eveneens
voor QCIF en voor CIF afbeeldingen. De resultaten staan in tabellen 5.6 en 5.73.
Tabel 5.2: Snelheid van een rij-kolomgebaseerde wavelettransformatie van een QCIF af-beelding op de Virtex-4 FX
tijd per beelden tijd per beelden
niveau’s beeld (ms) per seconde beeld (ms) per seconde
zonder cache zonder cache met cache met cache
1 33,3 30,0 4,7 214,3
2 41,3 24,2 6,0 166,7
3 44,0 22,7 6,2 162,2
4 43,7 22,9 6,2 162,2
Uit deze resultaten valt op te merken dat de rij-kolomgebaseerde wavelettransfor-
matie hier niet echt geschikt is voor real-time toepassing. Behalve in het geval van
2AMD Athlon XP 3000+, 2,17 GHz, 512 MiB RAM, Windows XP.3De C code die hier gebruikt wordt past de rij-kolomgebaseerde wavelettransformatie toe op
drie verschillende manieren. In dit geval is gebruik gemaakt van methode II. Deze geeft de besteresultaten.
50
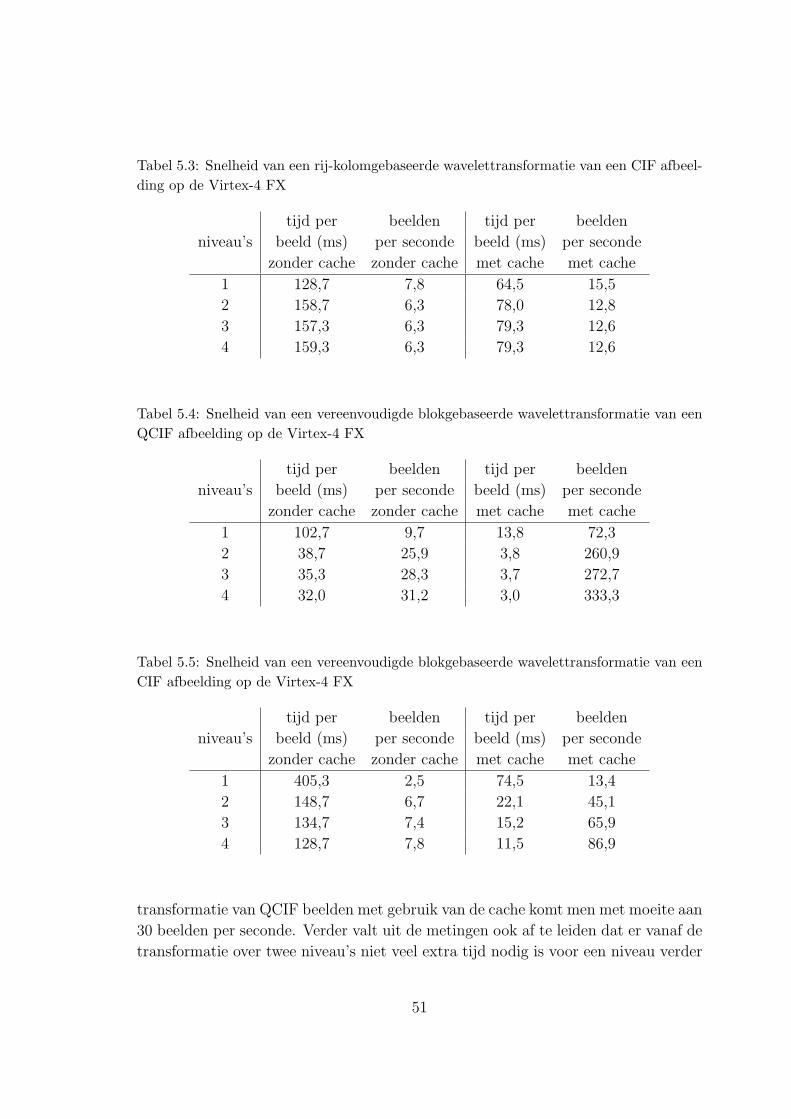
Tabel 5.3: Snelheid van een rij-kolomgebaseerde wavelettransformatie van een CIF afbeel-ding op de Virtex-4 FX
tijd per beelden tijd per beelden
niveau’s beeld (ms) per seconde beeld (ms) per seconde
zonder cache zonder cache met cache met cache
1 128,7 7,8 64,5 15,5
2 158,7 6,3 78,0 12,8
3 157,3 6,3 79,3 12,6
4 159,3 6,3 79,3 12,6
Tabel 5.4: Snelheid van een vereenvoudigde blokgebaseerde wavelettransformatie van eenQCIF afbeelding op de Virtex-4 FX
tijd per beelden tijd per beelden
niveau’s beeld (ms) per seconde beeld (ms) per seconde
zonder cache zonder cache met cache met cache
1 102,7 9,7 13,8 72,3
2 38,7 25,9 3,8 260,9
3 35,3 28,3 3,7 272,7
4 32,0 31,2 3,0 333,3
Tabel 5.5: Snelheid van een vereenvoudigde blokgebaseerde wavelettransformatie van eenCIF afbeelding op de Virtex-4 FX
tijd per beelden tijd per beelden
niveau’s beeld (ms) per seconde beeld (ms) per seconde
zonder cache zonder cache met cache met cache
1 405,3 2,5 74,5 13,4
2 148,7 6,7 22,1 45,1
3 134,7 7,4 15,2 65,9
4 128,7 7,8 11,5 86,9
transformatie van QCIF beelden met gebruik van de cache komt men met moeite aan
30 beelden per seconde. Verder valt uit de metingen ook af te leiden dat er vanaf de
transformatie over twee niveau’s niet veel extra tijd nodig is voor een niveau verder
51
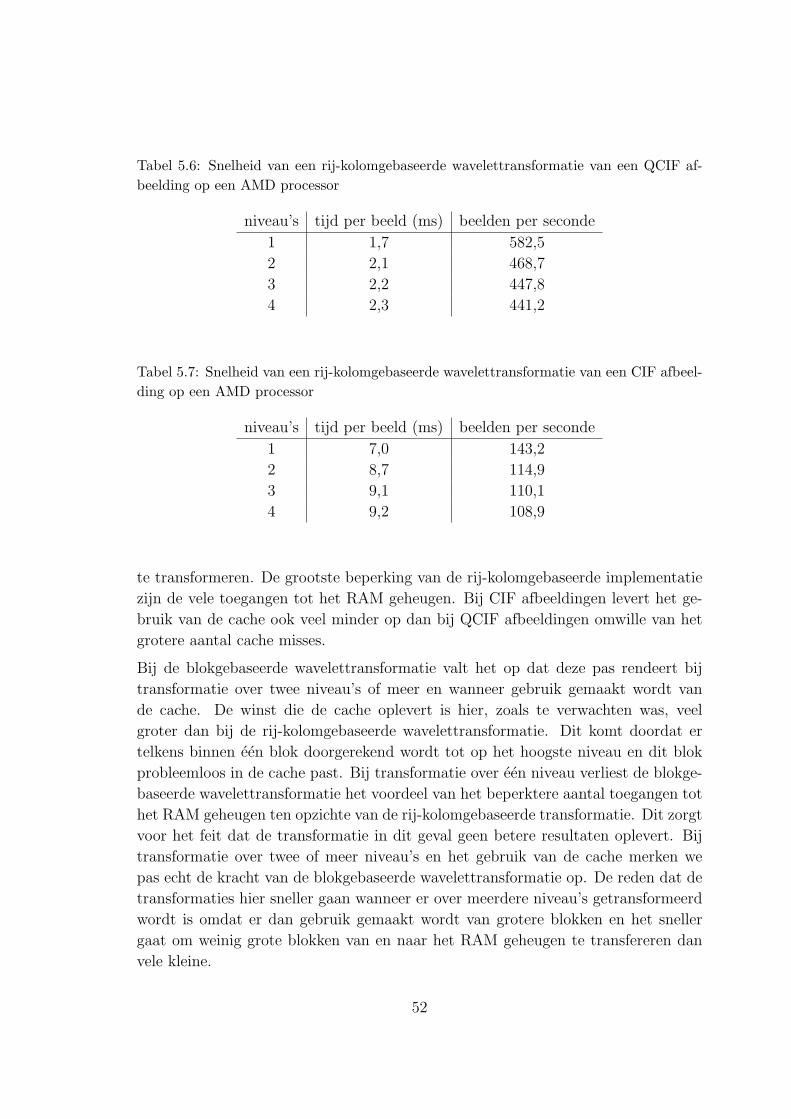
Tabel 5.6: Snelheid van een rij-kolomgebaseerde wavelettransformatie van een QCIF af-beelding op een AMD processor
niveau’s tijd per beeld (ms) beelden per seconde
1 1,7 582,5
2 2,1 468,7
3 2,2 447,8
4 2,3 441,2
Tabel 5.7: Snelheid van een rij-kolomgebaseerde wavelettransformatie van een CIF afbeel-ding op een AMD processor
niveau’s tijd per beeld (ms) beelden per seconde
1 7,0 143,2
2 8,7 114,9
3 9,1 110,1
4 9,2 108,9
te transformeren. De grootste beperking van de rij-kolomgebaseerde implementatie
zijn de vele toegangen tot het RAM geheugen. Bij CIF afbeeldingen levert het ge-
bruik van de cache ook veel minder op dan bij QCIF afbeeldingen omwille van het
grotere aantal cache misses.
Bij de blokgebaseerde wavelettransformatie valt het op dat deze pas rendeert bij
transformatie over twee niveau’s of meer en wanneer gebruik gemaakt wordt van
de cache. De winst die de cache oplevert is hier, zoals te verwachten was, veel
groter dan bij de rij-kolomgebaseerde wavelettransformatie. Dit komt doordat er
telkens binnen een blok doorgerekend wordt tot op het hoogste niveau en dit blok
probleemloos in de cache past. Bij transformatie over een niveau verliest de blokge-
baseerde wavelettransformatie het voordeel van het beperktere aantal toegangen tot
het RAM geheugen ten opzichte van de rij-kolomgebaseerde transformatie. Dit zorgt
voor het feit dat de transformatie in dit geval geen betere resultaten oplevert. Bij
transformatie over twee of meer niveau’s en het gebruik van de cache merken we
pas echt de kracht van de blokgebaseerde wavelettransformatie op. De reden dat de
transformaties hier sneller gaan wanneer er over meerdere niveau’s getransformeerd
wordt is omdat er dan gebruik gemaakt wordt van grotere blokken en het sneller
gaat om weinig grote blokken van en naar het RAM geheugen te transfereren dan
vele kleine.
52

Uit de resultaten van de rij-kolomgebaseerde wavelettransformatie die uitgevoerd
wordt op de AMD processor valt af te leiden dat deze de resultaten van de Virtex-
4 FX duidelijk achter zich laat. Voor transformatie over vier niveau’s begint de
blokgebaseerde wavelettransformatie met cache echter wel al aardig in de buurt te
komen.
Verder is er ook nog een vergelijking gemaakt tussen de uitvoering van een rij-
kolomgebaseerde wavelettransformatie die gebruik maakt van hardware-versnelling
en een die enkel gebruik maakt van de PowerPC. Hiervoor is een QCIF afbeelding
getransformeerd over een niveau. De uitvoering die gebruik maakt van de FPGA is
hier bijna drie keer sneller dan wanneer enkel de PowerPC gebruikt wordt. In dit
geval wordt de meeste tijd echter in beslag genomen door de vele toegangen tot het
RAM geheugen, die in beide situaties hetzelfde zijn. Verder onderzoek op dit gebied
is uit tijdsgebrek niet gebeurd.
5.4 Mogelijke verbeteringen
Voor het testen van de blokgebaseerde wavelettransformatie op de Virtex-4 FX is
gebruik gemaakt van een vereenvoudigde implementatie. De volgende stap zou zijn
van een volledige blokgebaseerde wavelettransformatie te implementeren, zowel voor
voorwaartse als inverse transformatie. Op die manier kan verder gezocht worden
naar wat de knelpunten zijn om deze dan verder te optimaliseren.
Verder kan ook overwogen worden om de blokken van de afbeelding volledig te
laten transformeren door de FPGA. Vanuit de software hoeven dan enkel de RAM
geheugenadressen van de elementen uit zo’n blok doorgegeven te worden. Op deze
manier is er echter niet veel verschil meer met een volledige implementatie op een
FPGA, zonder gebruik te maken van een processor. Bovendien is het minder evident
om het controleverloop te implementeren op een FPGA dan in software.
Een tussenoplossing kan zijn om het transformeren van de blokken aan de randen
van de afbeelding te laten verlopen in software omdat deze een vrij complex con-
troleverloop hebben. De transformatie van alle andere blokken gebeurt op telkens
dezelfde manier en kan dan op de FPGA gebeuren.
Uit de profileringsinformatie van de videocodec4 blijkt dat bij het decoderen van
de foreman CIF-sequentie minder dan 8 procent van de tijd gespendeerd wordt aan
de inverse wavelettransformatie. Bij het encoderen is de tijd die de voorwaartse
wavelettransformatie in beslag neemt bijna verwaarloosbaar ten opzichte van de
rest. Hier wordt gebruik gemaakt van de rij-kolomgebaseerde wavelettransformatie.
4Deze profileringsinformatie is opgesteld door Pieter-Paul. Meer hierover is te vinden in [8].
53

Het is dus duidelijk dat indien we een snellere implementatie van de videocodec
wensen te bekomen het optimaliseren van de wavelettransformatie slechts een zeer
beperkte winst zal opleveren.
54

Hoofdstuk 6
Besluit
We kunnen besluiten dat het gebruik van een FPGA die een PowerPC bevat zeker
voordelen oplevert ten opzichte van een afzonderlijke FPGA of een afzonderlijke
processor. Men kan de FPGA gebruiken voor datgene waar hij goed in is, nl. voor
het uitvoeren van de onderdelen die een sterk parallellisme vertonen. De controle kan
overgelaten worden aan de PowerPC. Doordat het soms complexe controleverloop
niet meer op de FPGA hoeft geımplementeerd te worden is het implementeren van
een ontwerp in hardware hierdoor een stuk eenvoudiger geworden. Dit is een grote
troef van de Virtex-4 FX.
Er is zowel een rij-kolomgebaseerde als een vereenvoudigde blokgebaseerde wavelet-
transformatie geımplementeerd op de Virtex-4 FX. De rij-kolomgebaseerde imple-
mentatie is in staat om 162 QCIF of 12 CIF beelden per seconde te transformeren
over vier niveau’s. De blokgebaseerde implementatie transformeert 333 QCIF of
86 CIF beelden per seconde, eveneens over vier niveau’s. Hieruit kunnen we op-
maken dat de blokgebaseerde wavelettransformatie wel degelijk voordelen oplevert
ten opzichte van de rij-kolomgebaseerde wavelettransformatie. Vooral bij de trans-
formatie van CIF beelden is er een groot verschil. Deze snelheidswinst is het gevolg
van het minimale aantal toegangen tot het RAM geheugen en het efficienter gebruik
van het cache geheugen.
Wanneer we nu de prestaties van de Virtex-4 FX vergelijken met deze van een pc
met AMD processor (2,17 GHz, 512 MiB RAM), kunnen we concluderen dat de
Virtex-4 FX minder presteert, maar dat het verschil niet zeer groot is. De AMD
processor transformeert 441 QCIF of 108 CIF beelden per seconde over vier niveau’s
aan de hand van de rij-kolomgebaseerde wavelettransformatie. Mits verdere optima-
lisatie van de hardware-implementatie kunnen met de Virtex-4 FX dus zeker mooie
resultaten behaald worden. Bovendien heeft de Virtex-4 FX een veel lager vermo-
genverbruik, wat hem veel geschikter maakt voor gebruik in mobiele toepassingen.
55

Bijlage A
9/7 filtercoefficienten
Tabel A.1: Filtercoefficienten voor de voorwaartse wavelettransformatie
h(0) = 0.03782845550726 g(0) = -0.06453888262870
h(1) = -0.02384946501956 g(1) = 0.04068941760916
h(2) = -0.11062440441844 g(2) = 0.41809227322162
h(3) = 0.37740285561283 g(3) = -0.78848561640558
h(4) = 0.85269867900889 g(4) = 0.41809227322162
h(5) = 0.37740285561283 g(5) = 0.04068941760916
h(6) = -0.11062440441844 g(6) = -0.06453888262870
h(7) = -0.02384946501956
h(8) = 0.03782845550726
56

Tabel A.2: Filtercoefficienten voor de inverse wavelettransformatie
h(0) = -0.06453888262870 g(0) = -0.03782845550726
h(1) = -0.04068941760916 g(1) = -0.02384946501956
h(2) = 0.41809227322162 g(2) = 0.11062440441844
h(3) = 0.78848561640558 g(3) = 0.37740285561283
h(4) = 0.41809227322162 g(4) = -0.85269867900889
h(5) = -0.04068941760916 g(5) = 0.37740285561283
h(6) = -0.06453888262870 g(6) = 0.11062440441844
g(7) = -0.02384946501956
g(8) = -0.03782845550726
Tabel A.3: 18 bits voorstelling van de filtercoefficienten voor de voorwaartse wavelettrans-formatie
h(0) = 000001001101011110 g(0) = 111101111011110101
h(1) = 111111001111001010 g(1) = 000001010011010101
h(2) = 111100011101011100 g(2) = 001101011000010000
h(3) = 001100000100111011 g(3) = 100110110001001100
h(4) = 011011010010010101 g(4) = 001101011000010000
h(5) = 001100000100111011 g(5) = 000001010011010101
h(6) = 111100011101011100 g(6) = 111101111011110101
h(7) = 111111001111001010
h(8) = 000001001101011110
Tabel A.4: 18 bits voorstelling van de filtercoefficienten voor de inverse wavelettransfor-matie
h(0) = 111101111011110101 g(0) = 111110110010100010
h(1) = 111110101100101011 g(1) = 111111001111001010
h(2) = 001101011000010000 g(2) = 000011100010100100
h(3) = 011001001110110100 g(3) = 001100000100111011
h(4) = 001101011000010000 g(4) = 100100101101101011
h(5) = 111110101100101011 g(5) = 001100000100111011
h(6) = 111101111011110101 g(6) = 000011100010100100
g(7) = 111111001111001010
g(8) = 111110110010100010
57

Bijlage B
Inhoud van CD-ROM
Naast een pdf versie van dit scriptieverslag zijn op de bijhorende CD-ROM de vol-
gende mappen terug te vinden:
• Code Yiannis
C code die hoort bij [2].
• FCM loadstore
FCM Register Load/Store pcore, zowel voor Verilog als voor VHDL.
• FCM UDI DWT
Systeem voor het toepassen van een wavelettransformatie op het ML403 Eval-
uation Platform. Er wordt gebruik gemaakt van Block RAM op de FPGA en
van het DDR SDRAM geheugen en de instructie- en datacache. Het systeem
bevat twee software projecten, een voor een rij-kolomgebaseerde en een voor
een vereenvoudigde blokgebaseerde wavelettransformatie.
• FCM UDI filter schuifregister
Systeem voor het uitvoeren van de 9/7 FIR-filters als User-Defined Instruction.
• FCM UDI filter schuifregister inv
Systeem voor het uitvoeren van de inverse 9/7 FIR-filters als User-Defined
Instruction.
• FCM UDI sum
Som UDI pcore uit de PPC405 APU and FPU Labs, zowel voor Verilog als
voor VHDL.
• PPC405 APU and FPU Labs
• xapp717
58

Bibliografie
[1] Y. Andreopoulos, P. Schelkens en J. Cornelis. Analysis of wavelet transform
implementations for image and texture coding applications in programmable
platforms. IEEE Workshop on Signal Processing Systems, 1:273–284, 2001.
[2] Y. Andreopoulos, P. Schelkens, G. Lafruit, K. Masselos en J. Cornelis. High-
level cache modeling for 2-D discrete wavelet transform implementations. Jour-
nal of VLSI Signal Processing Systems, 34(3):209–226, juli 2003.
[3] Y. Andreopoulos, P. Schelkens, T. Stouraitis en J. Cornelis. Efficient imple-
mentations of wavelet transforms - a roadmap. IEEE International Workshop
on Systems, Signals and Image Processing (IWSSIP), 1:74–79, 2001.
[4] Y. Andreopoulos, N. Zervas, G. Lafruit, P. Schelkens, T. Stouraitis, C. Goutis
en J. Cornelis. A local wavelet transform implementation versus an optimal
row-column algorithm for the 2D multilevel decomposition. IEEE International
Conference on Image Processing, 1:330–333, 2001.
[5] A. Ansari, P. Ryser en D. Isaacs. Accelerated system performence with APU-
enhanced processing. Xcell Journal, 52:36–39, first quarter 2005.
[6] P. Bertels. Hardware-ontwerp van een bewegingsschatter voor videocompressie.
Afstudeerwerk, Universiteit Gent, 2004.
[7] A. Bicer. Motion compensated three dimensional wavelet transform based video
compression and coding. Afstudeerwerk, Middle East Technical University,
2005.
[8] P. De Clercq. FPGA-gebaseerde instructiesetuitbreiding voor videobewegings-
schatting. Afstudeerwerk, Universiteit Gent, 2006.
[9] M. D’Haene. Het ontwerpen van entropie-encodering op FPGA als onderdeel
van een wavelet-gebaseerde video-encoder. Afstudeerwerk, Universiteit Gent,
2004.
59

[10] I. Doms. Ontwerp van wavelettransformaties op FPGA. Afstudeerwerk, Uni-
versiteit Gent, 2004.
[11] H. Eeckhaut, D. Stroobandt, H. Devos en M. Christiaens. Improving the hard-
ware friendliness of a wavelet based scalable video codec. WSEAS Transactions
on Systems, 4(5):625–634, 2005.
[12] B. Vanhoof, L. Nachtergaele, G. Lafruit, M. Peon, B. Masschelein, F. Catthoor,
J. Bormans en I. Bolsens. A scalable MPEG-4 wavelet-based visual texture
compression system with optimized memory organization. IEEE Transactions
on Circuits and Systems for Video Technology, 13(4):348–357, april 2003.
[13] Xilinx. Accelerated System Performance with the APU Controller and
XtremeDSP Slices. http://www.xilinx.com/bvdocs/appnotes/xapp717.pdf.
[14] Xilinx. Embedded System Tools Reference Manual.
http://www.xilinx.com/ise/embedded/est rm.pdf.
[15] Xilinx. ML403 Virtex-4 FX Evaluation Platform.
http://www.xilinx.com/products/boards/ml401/docs/ML403.pdf.
[16] Xilinx. OS and Libraries Document Collection.
http://www.xilinx.com/ise/embedded/oslibs rm.pdf.
[17] Xilinx. Platform Studio User Guide.
http://www.xilinx.com/ise/embedded/ps ug.pdf.
[18] Xilinx. PowerPC 405 Processor Block Reference Guide.
http://www.xilinx.com/bvdocs/userguides/ug018.pdf.
[19] Xilinx. Virtex-4 Family Overview.
http://www.xilinx.com/bvdocs/publications/ds112.pdf.
60

Lijst van figuren
1.1 Schaalbare wavelet-gebaseerde videoencoder . . . . . . . . . . . . . . 2
1.2 Schaalbaarheid in framerate: bewegingsschatting . . . . . . . . . . . . 3
1.3 Schaalbaarheid in resolutie: discrete wavelettransformatie . . . . . . . 4
1.4 Schaalbaarheid in beeldkwaliteit: quadtree en entropiecodering . . . . 5
2.1 Xilinx ML403 Evaluation Platform . . . . . . . . . . . . . . . . . . . 8
2.2 Xilinx ML403 Evaluation Platform blokschema . . . . . . . . . . . . . 9
2.3 Processor blok op de FPGA met PowerPC en APU controller . . . . 10
2.4 Pijplijn schema . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11
3.1 Filters in het frequentiedomein . . . . . . . . . . . . . . . . . . . . . . 14
3.2 Implementatie van de voorwaartse en inverse wavelettransformatie
over twee niveau’s . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
3.3 Opdeling van het spectrum na transformatie over twee niveau’s . . . 14
3.4 Bij verschuiving van de FIR-filters over twee elementen bekomen we
een laag- en een hoogdoorlaatelement . . . . . . . . . . . . . . . . . . 16
3.5 Wavelettransformatie over een niveau . . . . . . . . . . . . . . . . . . 17
3.6 Wavelettransformatie over meerdere niveau’s . . . . . . . . . . . . . . 17
3.7 Wavelettransformatie van ’Lena’ over twee niveau’s . . . . . . . . . . 18
3.8 Rij-kolomgebaseerde wavelettransformatie over een niveau . . . . . . 19
3.9 Indeling van een beeld in blokken . . . . . . . . . . . . . . . . . . . . 21
3.10 Transformatie van een blok over twee niveau’s . . . . . . . . . . . . . 22
3.11 Plaats in het beeld waar de geproduceerde waveletcoefficienten terechtkomen
na transformatie van een blok over twee niveau’s . . . . . . . . . . . . 22
61

3.12 Werkwijze van het overlapgeheugen bij blokgebaseerde wavelettrans-
formatie . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 23
4.1 Indeling van een FCM instructie . . . . . . . . . . . . . . . . . . . . . 27
4.2 FCM Register Load/Store systeem overzicht . . . . . . . . . . . . . . 29
4.3 Tijdsdiagram voor een FCM Load instructie . . . . . . . . . . . . . . 31
4.4 Tijdsdiagram voor een FCM Store instructie . . . . . . . . . . . . . . 31
4.5 Systeem overzicht van een raamwerk voor het gebruik van UDIs . . . 33
4.6 C code om een som uit te voeren op de FPGA . . . . . . . . . . . . . 36
5.1 Rechtstreekse implementatie van de laagdoorlaat FIR-filter . . . . . . 42
5.2 Schuifregister voor de berekening van een laagdoorlaatcomponent . . 43
5.3 Schuifregister voor de berekening van een hoogdoorlaatcomponent . . 43
5.4 Schuifregister voor de berekening van een oneven element . . . . . . . 43
5.5 Schuifregister voor de berekening van een even element . . . . . . . . 44
5.6 Schuifregister met gebruik van Block RAM op de FPGA . . . . . . . 46
62

Lijst van tabellen
4.1 FCM Register Load/Store outputpoorten . . . . . . . . . . . . . . . . 30
4.2 FCM Register Load/Store inputpoorten . . . . . . . . . . . . . . . . 30
4.3 FCM UDI outputpoorten . . . . . . . . . . . . . . . . . . . . . . . . . 33
4.4 FCM UDI inputpoorten . . . . . . . . . . . . . . . . . . . . . . . . . 34
5.1 Resultaten van een voorwaartse + inverse wavelettransformatie . . . . 45
5.2 Snelheid van een rij-kolomgebaseerde wavelettransformatie van een
QCIF afbeelding op de Virtex-4 FX . . . . . . . . . . . . . . . . . . . 50
5.3 Snelheid van een rij-kolomgebaseerde wavelettransformatie van een
CIF afbeelding op de Virtex-4 FX . . . . . . . . . . . . . . . . . . . . 51
5.4 Snelheid van een vereenvoudigde blokgebaseerde wavelettransforma-
tie van een QCIF afbeelding op de Virtex-4 FX . . . . . . . . . . . . 51
5.5 Snelheid van een vereenvoudigde blokgebaseerde wavelettransforma-
tie van een CIF afbeelding op de Virtex-4 FX . . . . . . . . . . . . . 51
5.6 Snelheid van een rij-kolomgebaseerde wavelettransformatie van een
QCIF afbeelding op een AMD processor . . . . . . . . . . . . . . . . 52
5.7 Snelheid van een rij-kolomgebaseerde wavelettransformatie van een
CIF afbeelding op een AMD processor . . . . . . . . . . . . . . . . . 52
A.1 Filtercoefficienten voor de voorwaartse wavelettransformatie . . . . . 56
A.2 Filtercoefficienten voor de inverse wavelettransformatie . . . . . . . . 57
A.3 18 bits voorstelling van de filtercoefficienten voor de voorwaartse wa-
velettransformatie . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 57
A.4 18 bits voorstelling van de filtercoefficienten voor de inverse wavelet-
transformatie . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 57
63