
@spcl eth Tal Ben-Nun, Johannes de Fine Licht, Alexandros ... · Tal Ben-Nun, Johannes de Fine...
43
spcl.inf.ethz.ch @spcl_eth Tal Ben-Nun, Johannes de Fine Licht, Alexandros-Nikolaos Ziogas, Timo Schneider, Torsten Hoefler Stateful Dataflow Multigraphs: A Data-Centric Model for Performance Portability on Heterogeneous Architectures This project has received funding from the European Research Council (ERC) under grant agreement "DAPP (PI: T. Hoefler)".
Transcript of @spcl eth Tal Ben-Nun, Johannes de Fine Licht, Alexandros ... · Tal Ben-Nun, Johannes de Fine...

spcl.inf.ethz.ch
@spcl_eth
Tal Ben-Nun, Johannes de Fine Licht, Alexandros-Nikolaos Ziogas, Timo Schneider, Torsten Hoefler
Stateful Dataflow Multigraphs: A Data-Centric Model for Performance Portability on Heterogeneous Architectures
This project has received funding from the European Research Council (ERC) under grant agreement "DAPP (PI: T. Hoefler)".
spcl.inf.ethz.ch
@spcl_eth
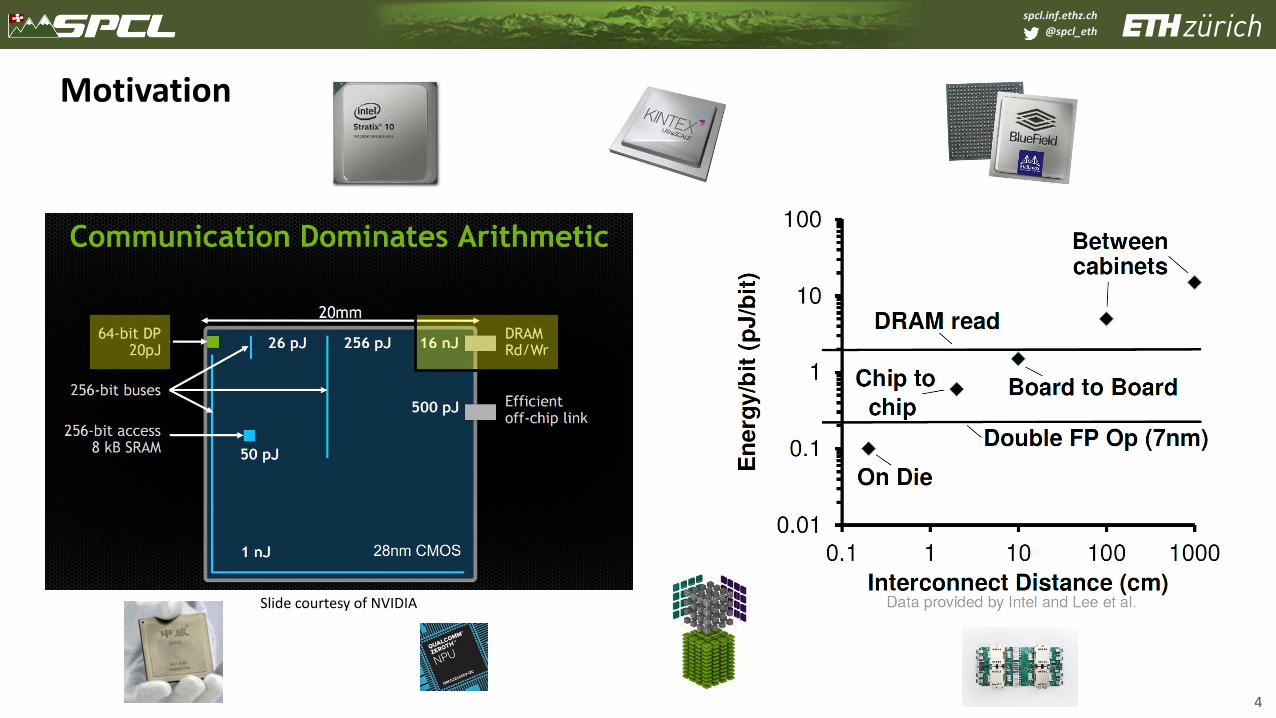
Motivation
4
Slide courtesy of NVIDIA

spcl.inf.ethz.ch
@spcl_eth
6
Source: US DoE
Computational Scientist

spcl.inf.ethz.ch
@spcl_eth
7
Domain Scientist Performance Engineer

spcl.inf.ethz.ch
@spcl_eth
Optimization Techniques
▪ Multi-core CPU▪ Tiling for complex cache hierarchies
▪ Register optimizations
▪ Vectorization
▪ Many-core GPU▪ Coalesced memory access
▪ Warp divergence minimization, register tiling
▪ Task fusion
▪ FPGA▪ Maximize resource utilization (logic units, DSPs)
▪ Streaming optimizations, pipelining
▪ Explicit buffering (FIFO) and wiring
8
spcl.inf.ethz.ch
@spcl_eth
9
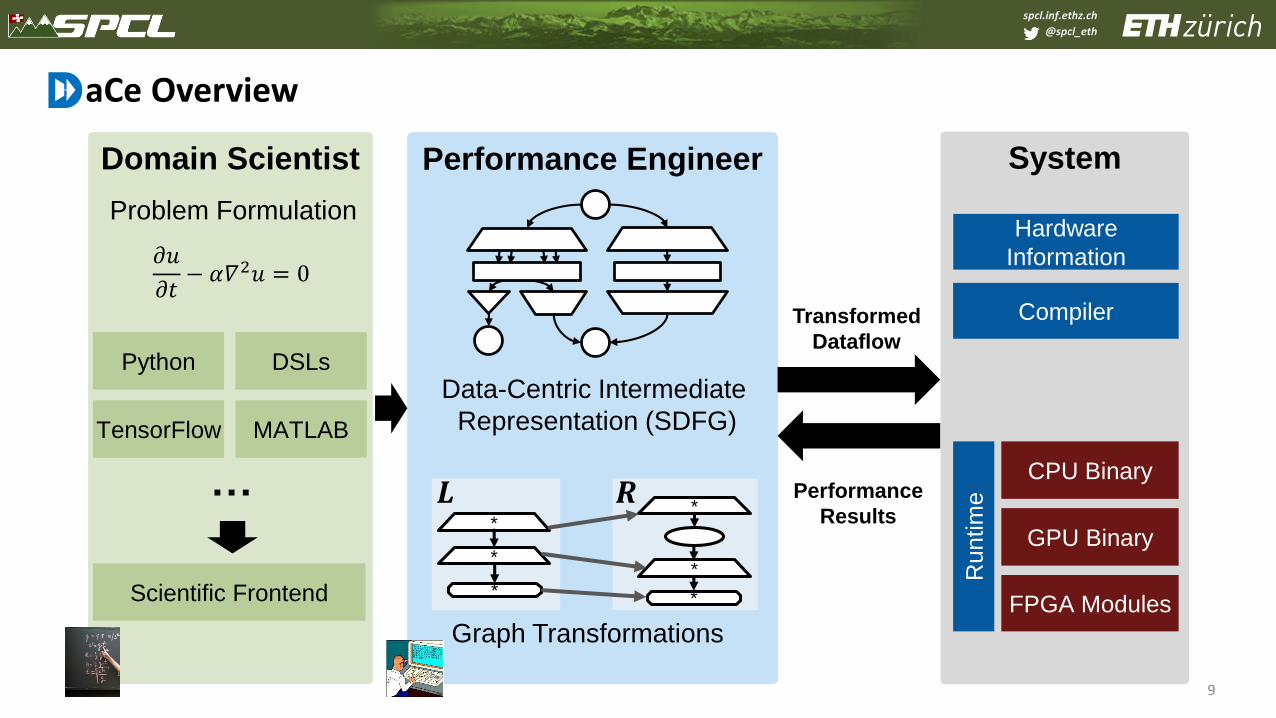
aCe Overview
SystemDomain Scientist Performance Engineer
Data-Centric Intermediate
Representation (SDFG)
𝜕𝑢
𝜕𝑡− 𝛼𝛻2𝑢 = 0
…
FPGA Modules
CPU Binary
Runtim
e
Hardware
Information
Graph Transformations
CompilerTransformed
Dataflow
Performance
ResultsGPU Binary
Python
𝑳 𝑹*
*
*
*
*
*
TensorFlow
DSLs
MATLAB
Scientific Frontend
Problem Formulation
spcl.inf.ethz.ch
@spcl_eth
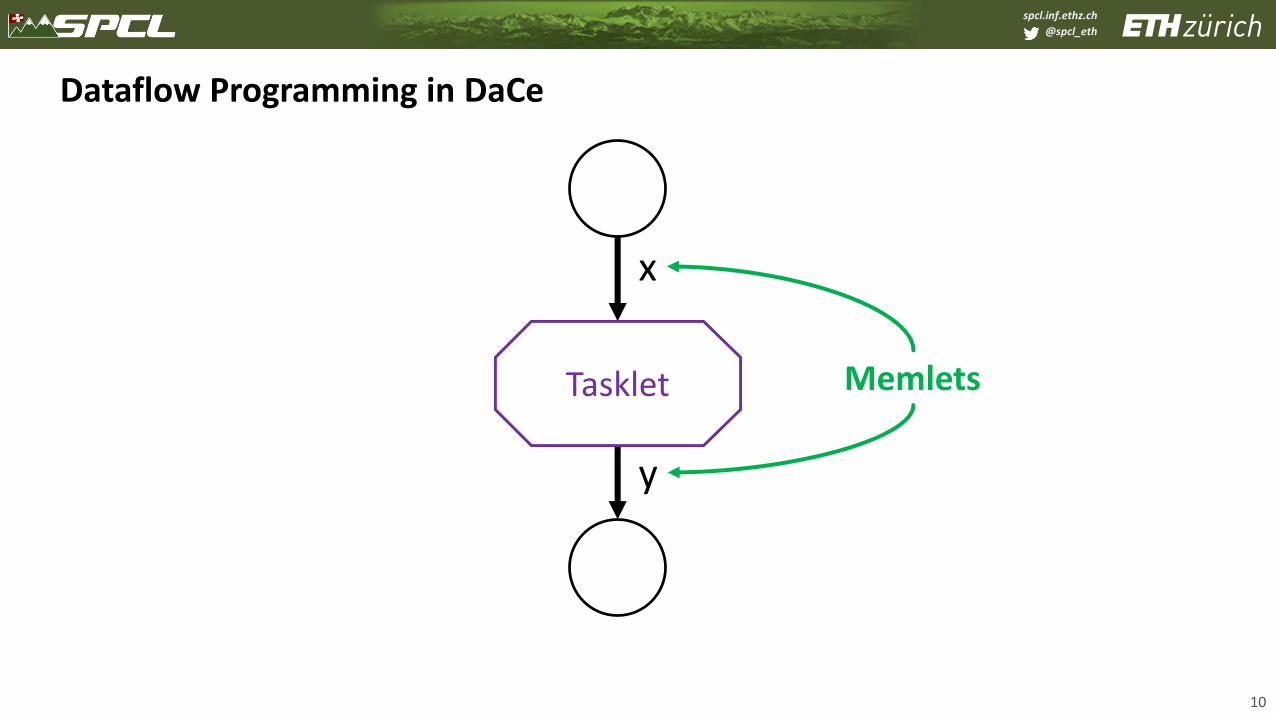
Dataflow Programming in DaCe
10
𝑦 = 𝑥2 + sin𝑥
𝜋
x
y
Tasklet Memlets
spcl.inf.ethz.ch
@spcl_eth
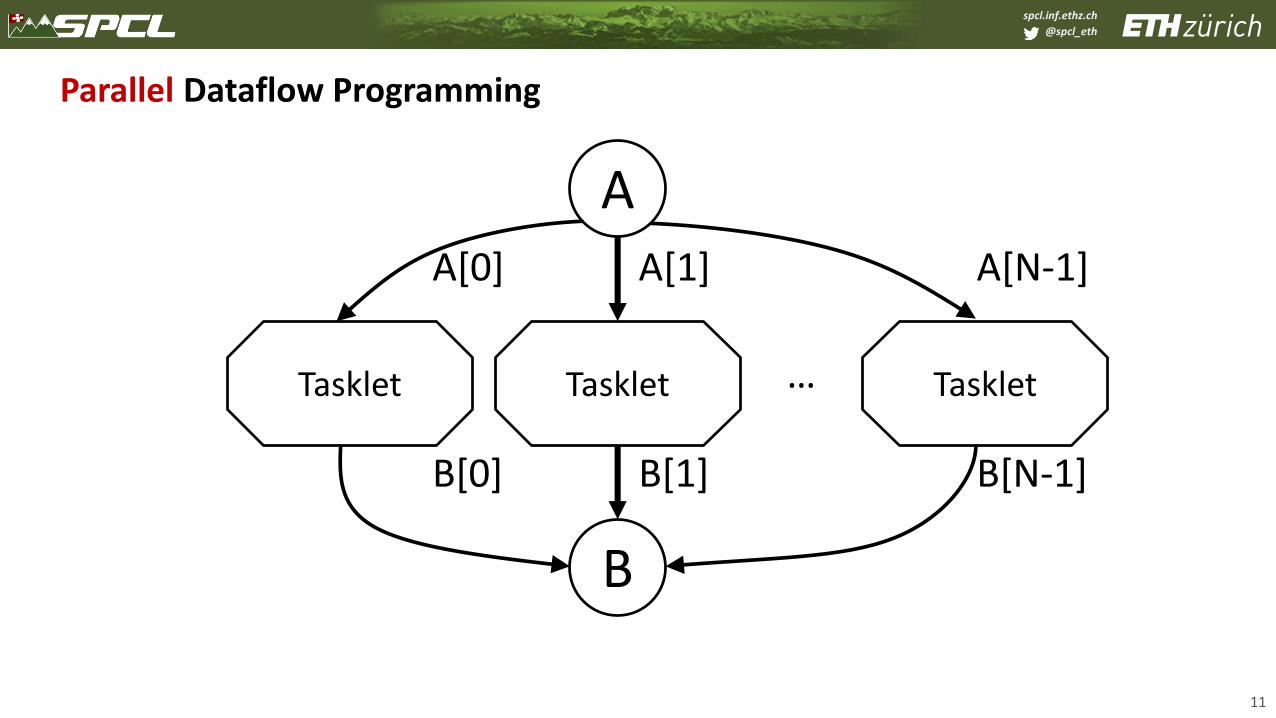
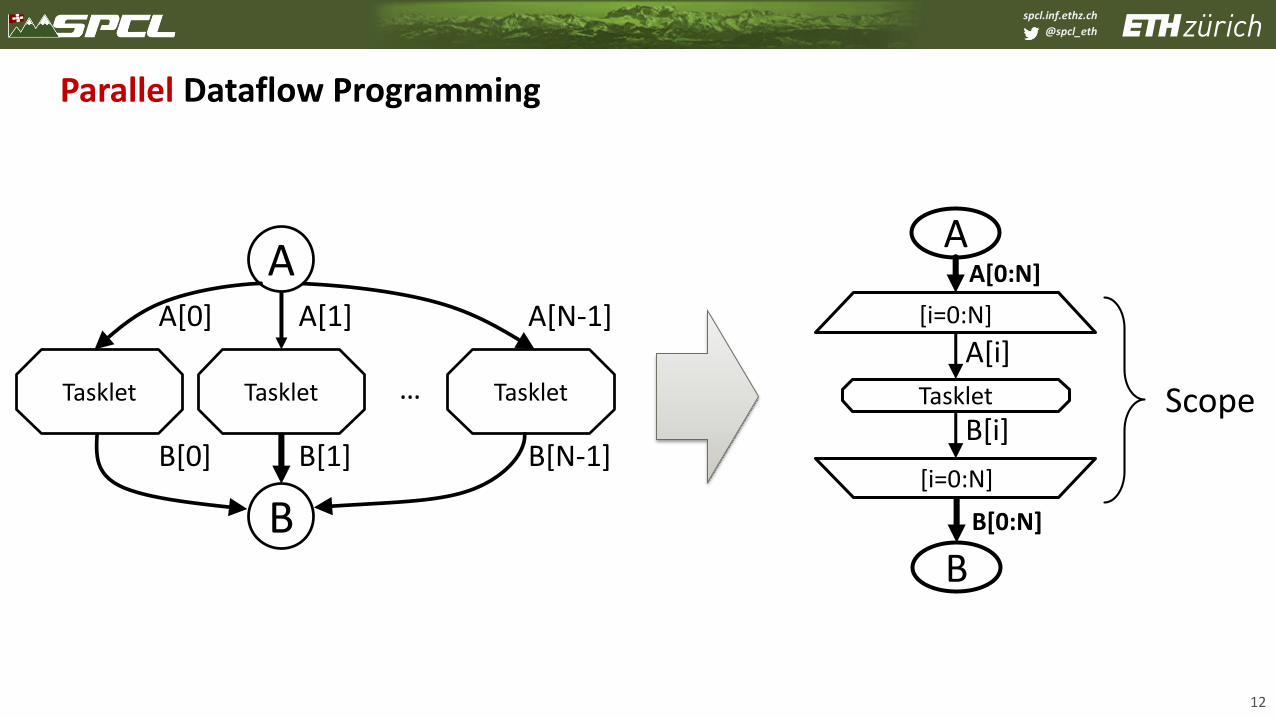
Parallel Dataflow Programming
11
…
B
Tasklet
A[1]
B[1]
A[0]
B[0]
A[N-1]
B[N-1]
A
Tasklet Tasklet
spcl.inf.ethz.ch
@spcl_eth
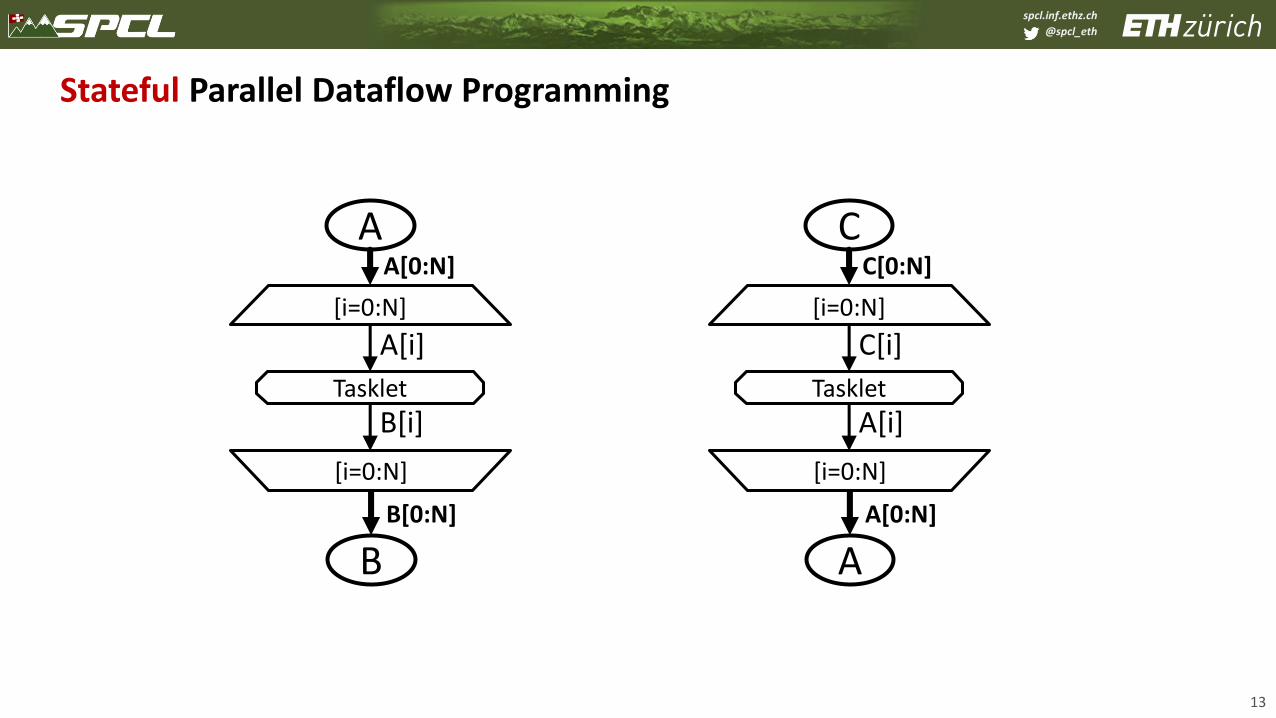
Parallel Dataflow Programming
12
A
B
[i=0:N]
Tasklet
A[i]
B[i]
[i=0:N]
A[0:N]
B[0:N]
…
B
TaskletTasklet Tasklet
A[1]
B[1]
A[0]
B[0]
A[N-1]
B[N-1]
A
Scope
spcl.inf.ethz.ch
@spcl_eth
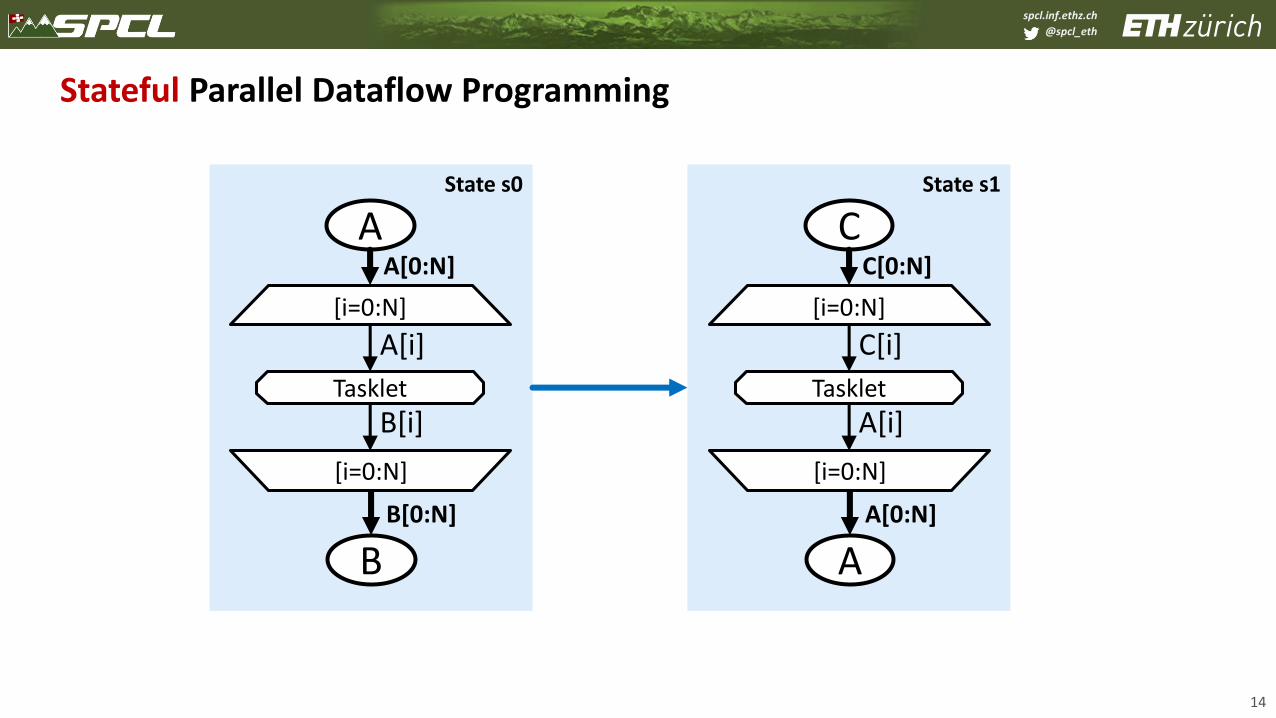
Stateful Parallel Dataflow Programming
13
A
B
[i=0:N]
Tasklet
A[i]
B[i]
[i=0:N]
A[0:N]
B[0:N]
C
A
[i=0:N]
Tasklet
C[i]
A[i]
[i=0:N]
C[0:N]
A[0:N]
spcl.inf.ethz.ch
@spcl_eth
State s1State s0
Stateful Parallel Dataflow Programming
14
A
B
[i=0:N]
Tasklet
A[i]
B[i]
[i=0:N]
A[0:N]
B[0:N]
C
A
[i=0:N]
Tasklet
C[i]
A[i]
[i=0:N]
C[0:N]
A[0:N]
spcl.inf.ethz.ch
@spcl_eth
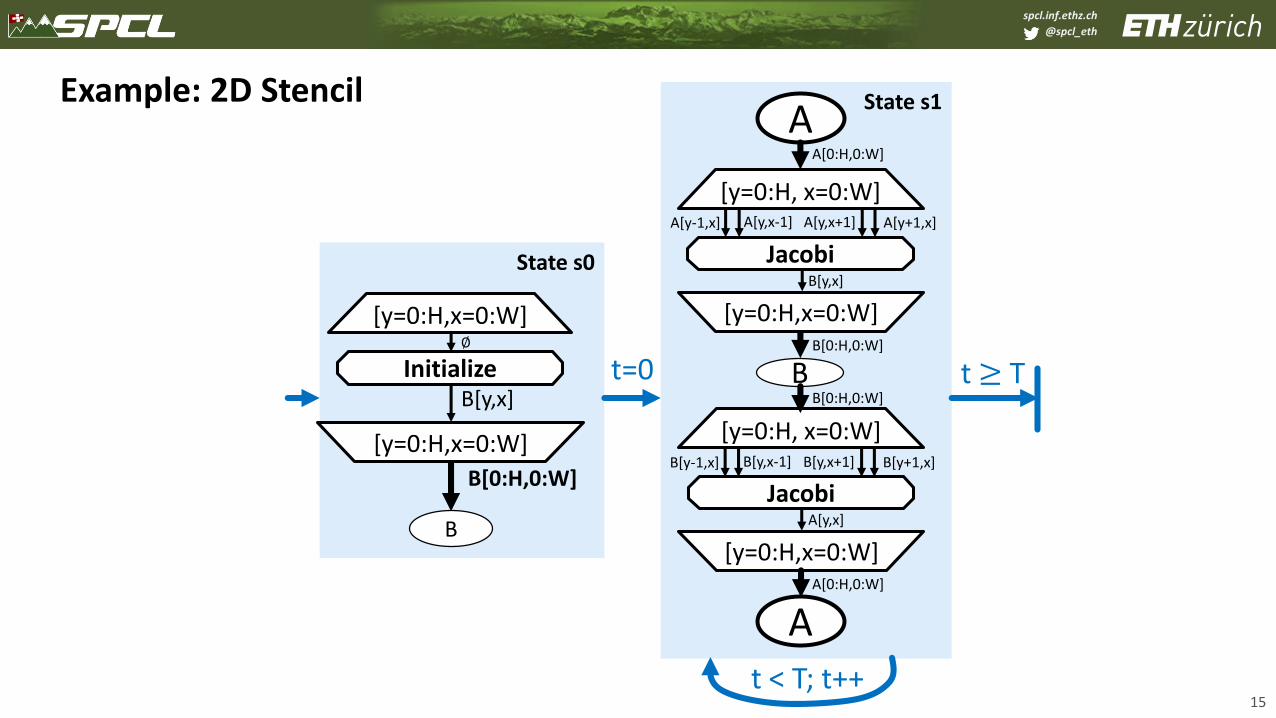
Example: 2D Stencil
15
State s1
State s0
[y=0:H,x=0:W]
InitializeB[y,x]
[y=0:H,x=0:W]
B[0:H,0:W]
Bt < T
t < T; t++
A
B
[y=0:H, x=0:W]
[y=0:H,x=0:W]
Jacobi
A
t ≥ Tt=0
A[y-1,x] A[y+1,x]A[y,x-1] A[y,x+1]
B[y,x]
[y=0:H, x=0:W]
[y=0:H,x=0:W]
Jacobi
A[y,x]
B[y-1,x] B[y+1,x]B[y,x-1] B[y,x+1]
∅
A[0:H,0:W]
B[0:H,0:W]
B[0:H,0:W]
A[0:H,0:W]
spcl.inf.ethz.ch
@spcl_eth
Conflict Resolution
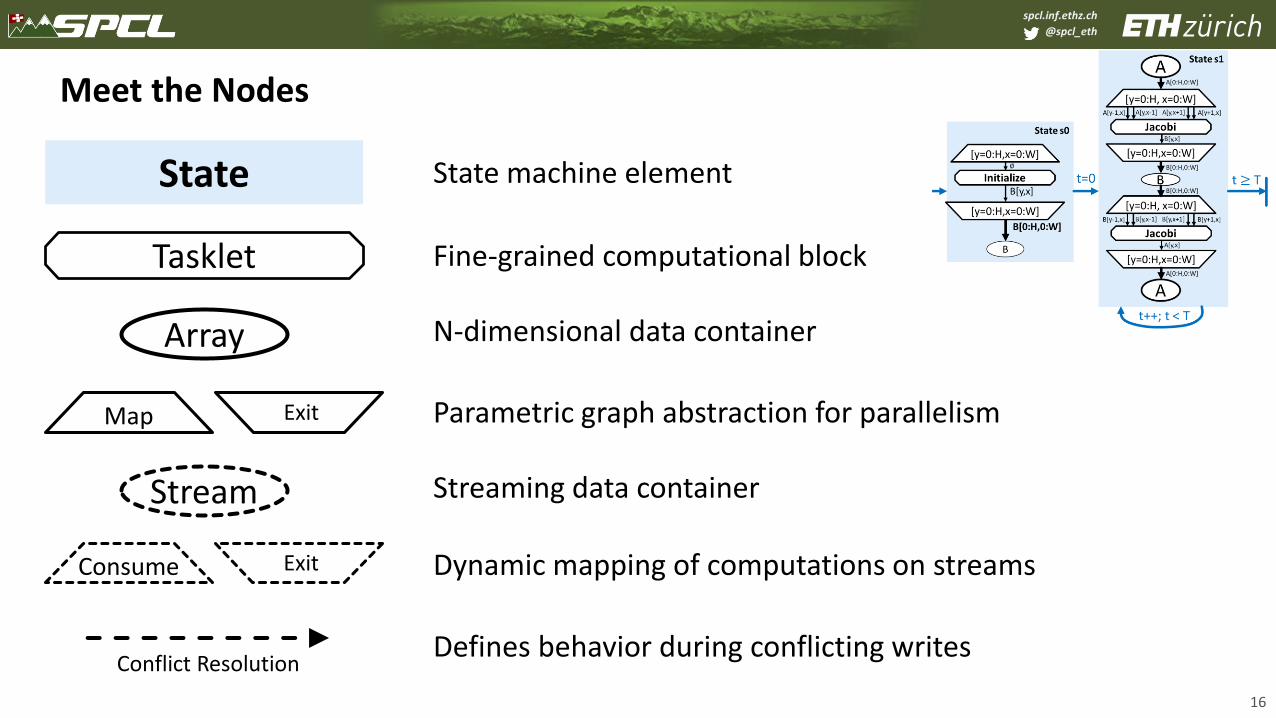
Meet the Nodes
16
State State machine element
Tasklet Fine-grained computational block
Array N-dimensional data container
Stream Streaming data container
Consume Exit Dynamic mapping of computations on streams
Defines behavior during conflicting writes
Map Exit Parametric graph abstraction for parallelism

spcl.inf.ethz.ch
@spcl_eth
Conflict Resolution
Meet the Nodes
17
State State machine element
Tasklet Fine-grained computational block
Array N-dimensional data container
Stream Streaming data container
Consume Exit Dynamic mapping of computations on streams
Defines behavior during conflicting writes
Map Exit Parametric graph abstraction for parallelism
State s0
[i=0:N]
Filter
B[0:N]
B
A[i]
Bsize
S
S
S
Bsize(+)
Bsize(+)
A
[i=0:N]
A[0:N]
spcl.inf.ethz.ch
@spcl_eth
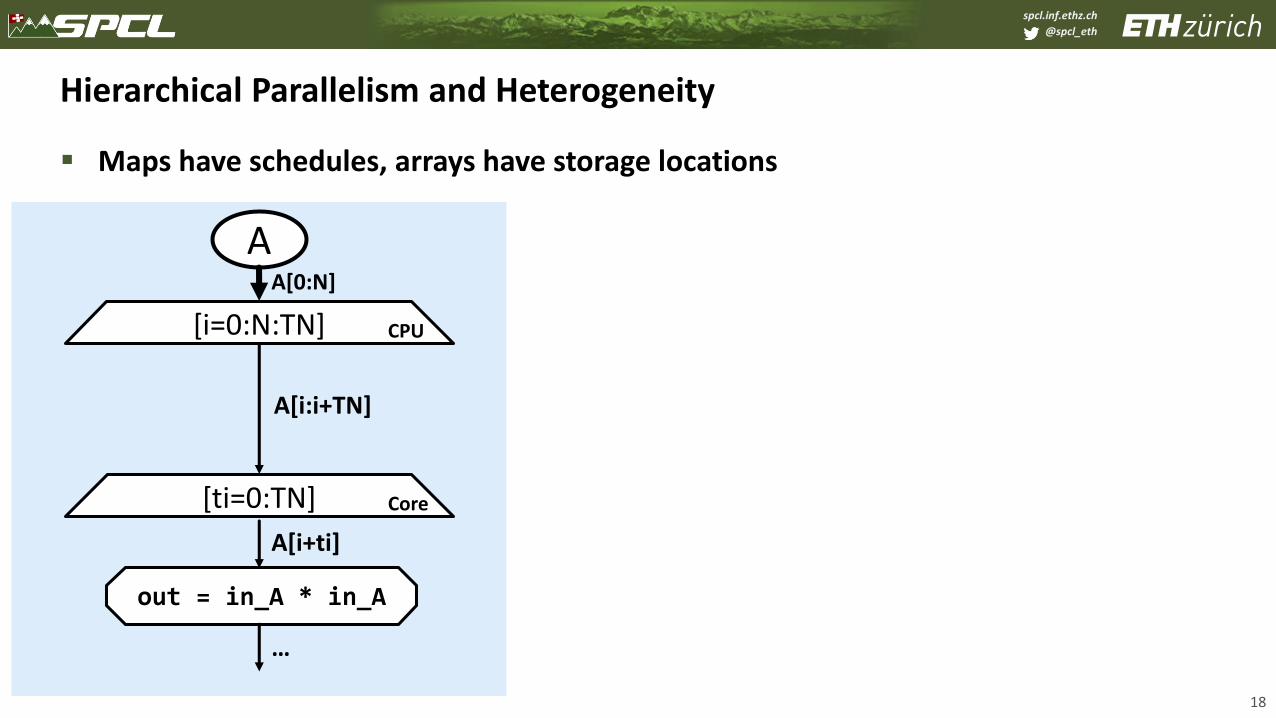
Hierarchical Parallelism and Heterogeneity
▪ Maps have schedules, arrays have storage locations
18
[i=0:N:TN]
A[i:i+TN]
AA[0:N]
CPU
[ti=0:TN] Core
out = in_A * in_A
A[i+ti]
…
spcl.inf.ethz.ch
@spcl_eth
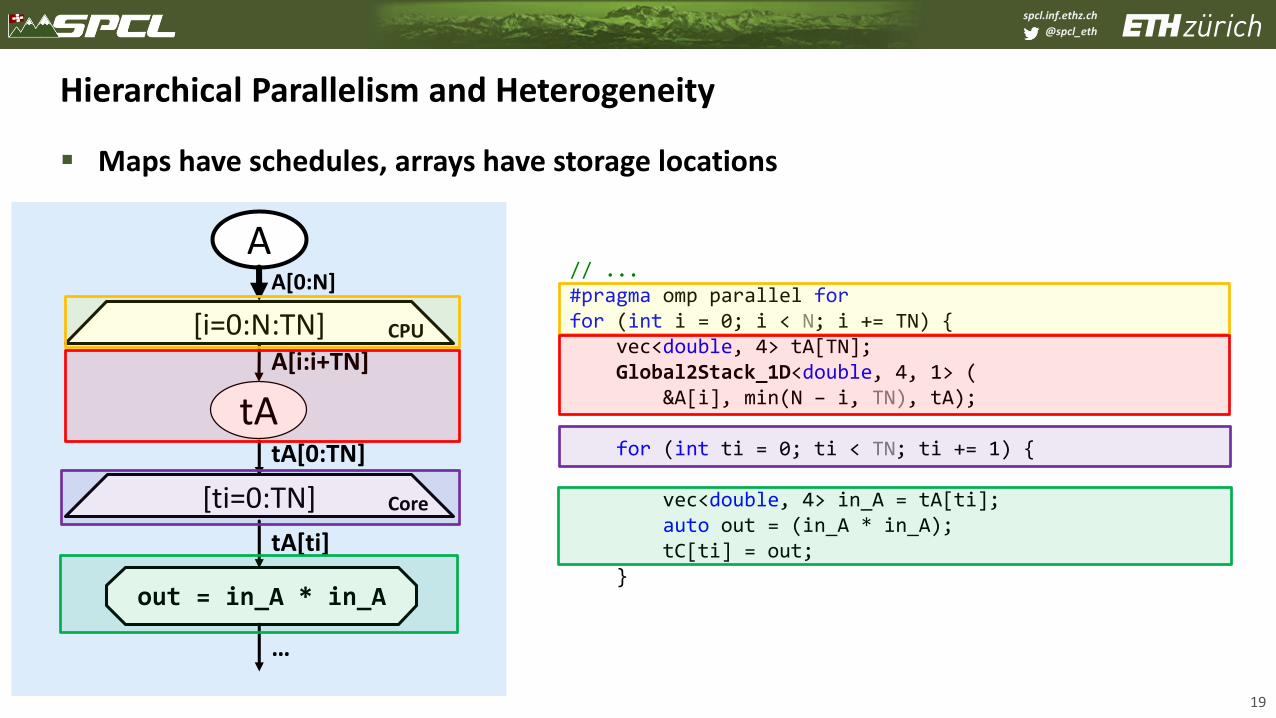
Hierarchical Parallelism and Heterogeneity
▪ Maps have schedules, arrays have storage locations
19
// ...#pragma omp parallel forfor (int i = 0; i < N; i += TN) {
vec<double, 4> tA[TN];Global2Stack_1D<double, 4, 1> (
&A[i], min(N – i, TN), tA);
for (int ti = 0; ti < TN; ti += 1) {
vec<double, 4> in_A = tA[ti];auto out = (in_A * in_A);tC[ti] = out;
}
[i=0:N:TN]A[i:i+TN]
tA
AA[0:N]
CPU
[ti=0:TN] Core
out = in_A * in_A
tA[0:TN]
tA[ti]
…
spcl.inf.ethz.ch
@spcl_eth
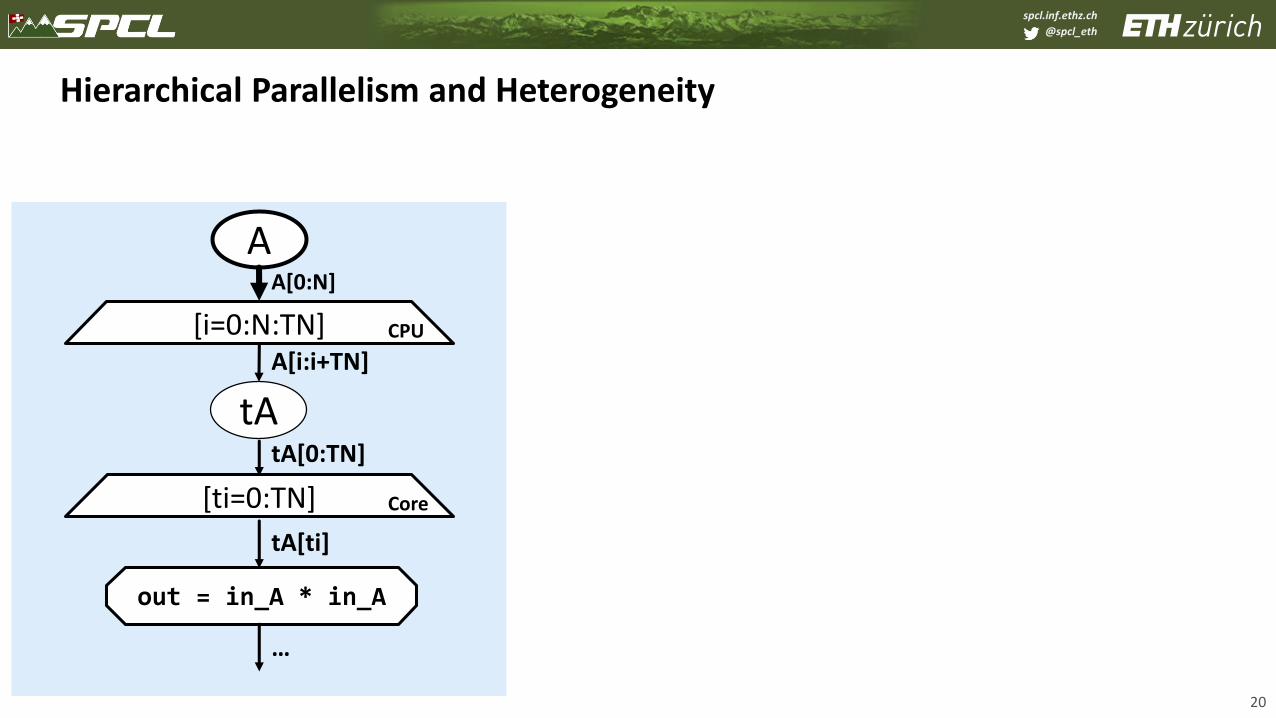
Hierarchical Parallelism and Heterogeneity
20
[i=0:N:TN]A[i:i+TN]
tA
AA[0:N]
CPU
[ti=0:TN] Core
out = in_A * in_A
tA[0:TN]
tA[ti]
…

spcl.inf.ethz.ch
@spcl_eth
Hierarchical Parallelism and Heterogeneity
21
__global__ void multiplication_1(...) { int i = blockIdx.x * TN; int ti = threadIdx.y + 0; if (i+ti >= N) return;
__shared__ vec<double, 2> tA[TN]; GlobalToShared1D<double, 2, TN, 1, 1, false>(gA, tA);
vec<double, 2> in_A = tA[ti];auto out = (in_A * in_A);tC[ti] = out;
}
[i=0:N:TN]gA[i:i+TN]
tA
gAgA[0:N]
GPUDevice
[ti=0:TN]GPUBlock
out = in_A * in_A
tA[0:TN]
tA[ti]
…
AA[0:N]
spcl.inf.ethz.ch
@spcl_eth
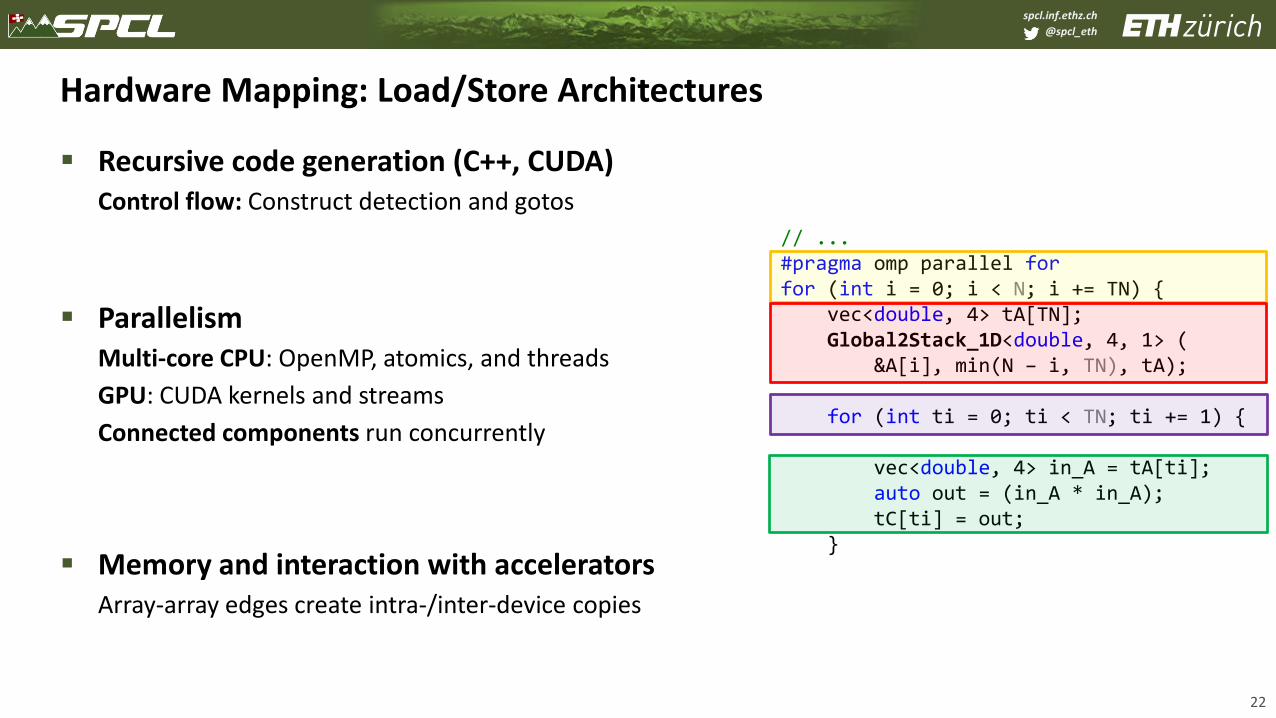
Hardware Mapping: Load/Store Architectures
▪ Recursive code generation (C++, CUDA)Control flow: Construct detection and gotos
▪ Parallelism Multi-core CPU: OpenMP, atomics, and threads
GPU: CUDA kernels and streams
Connected components run concurrently
▪ Memory and interaction with acceleratorsArray-array edges create intra-/inter-device copies
22
// ...#pragma omp parallel forfor (int i = 0; i < N; i += TN) {
vec<double, 4> tA[TN];Global2Stack_1D<double, 4, 1> (
&A[i], min(N – i, TN), tA);
for (int ti = 0; ti < TN; ti += 1) {
vec<double, 4> in_A = tA[ti];auto out = (in_A * in_A);tC[ti] = out;
}
spcl.inf.ethz.ch
@spcl_eth
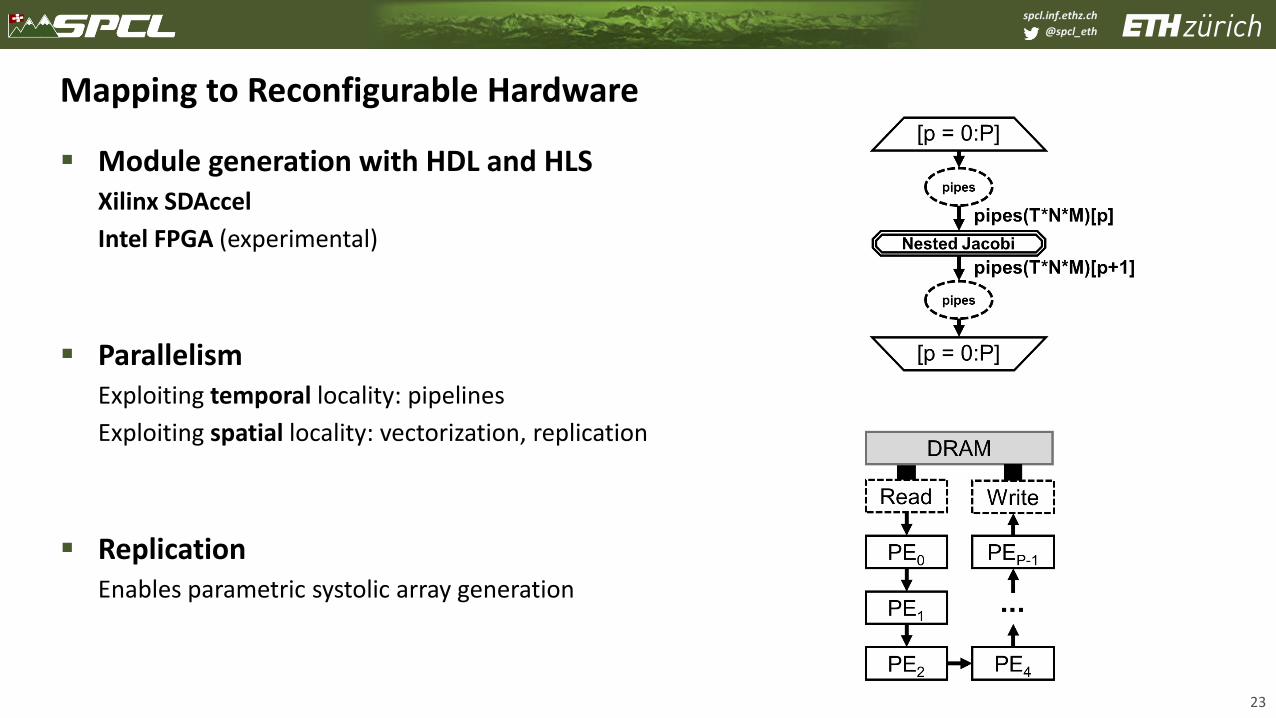
Mapping to Reconfigurable Hardware
▪ Module generation with HDL and HLSXilinx SDAccel
Intel FPGA (experimental)
▪ ParallelismExploiting temporal locality: pipelines
Exploiting spatial locality: vectorization, replication
▪ ReplicationEnables parametric systolic array generation
23
spcl.inf.ethz.ch
@spcl_eth
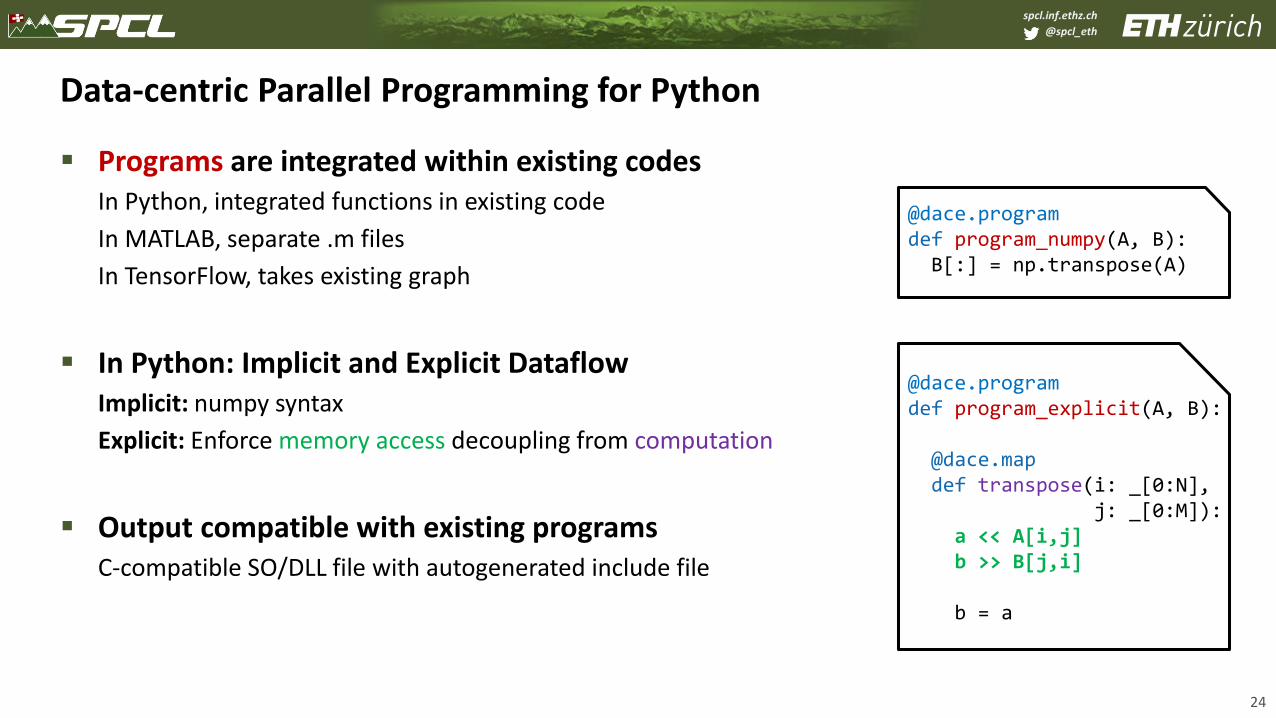
Data-centric Parallel Programming for Python
▪ Programs are integrated within existing codesIn Python, integrated functions in existing code
In MATLAB, separate .m files
In TensorFlow, takes existing graph
▪ In Python: Implicit and Explicit DataflowImplicit: numpy syntax
Explicit: Enforce memory access decoupling from computation
▪ Output compatible with existing programs C-compatible SO/DLL file with autogenerated include file
24
@dace.programdef program_explicit(A, B):
@dace.mapdef transpose(i: _[0:N],
j: _[0:M]):a << A[i,j]b >> B[j,i]
b = a
@dace.programdef program_numpy(A, B):B[:] = np.transpose(A)
spcl.inf.ethz.ch
@spcl_eth
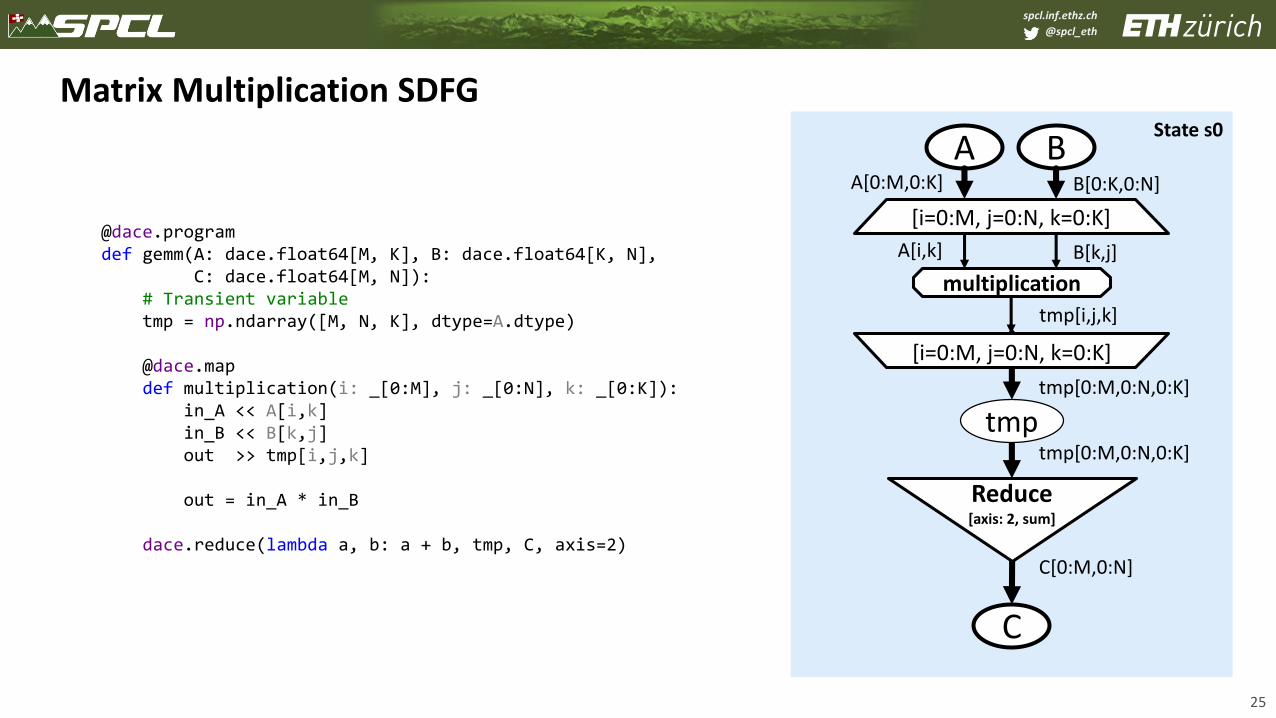
Matrix Multiplication SDFG
25
@dace.programdef gemm(A: dace.float64[M, K], B: dace.float64[K, N],
C: dace.float64[M, N]):# Transient variabletmp = np.ndarray([M, N, K], dtype=A.dtype)
@dace.mapdef multiplication(i: _[0:M], j: _[0:N], k: _[0:K]):
in_A << A[i,k]in_B << B[k,j]out >> tmp[i,j,k]
out = in_A * in_B
dace.reduce(lambda a, b: a + b, tmp, C, axis=2)
State s0A
[i=0:M, j=0:N, k=0:K]
multiplication
B[k,j]
[i=0:M, j=0:N, k=0:K]
A[0:M,0:K]
tmp[0:M,0:N,0:K]
BB[0:K,0:N]
A[i,k]
tmp[i,j,k]
C
tmptmp[0:M,0:N,0:K]
C[0:M,0:N]
Reduce[axis: 2, sum]

spcl.inf.ethz.ch
@spcl_eth
Matrix Multiplication SDFG
26
State s0A
[i=0:M, j=0:N, k=0:K]
multiplication
B[k,j]
[i=0:M, j=0:N, k=0:K]
A[0:M,0:K]
BB[0:K,0:N]
A[i,k]
C (+) [i,j]
C
C[0:M,0:N]
@dace.programdef gemm(A: dace.float64[M, K], B: dace.float64[K, N],
C: dace.float64[M, N]):# Transient variabletmp = np.ndarray([M, N, K], dtype=A.dtype)
@dace.mapdef multiplication(i: _[0:M], j: _[0:N], k: _[0:K]):
in_A << A[i,k]in_B << B[k,j]out >> tmp[i,j,k]
out = in_A * in_B
dace.reduce(lambda a, b: a + b, tmp, C, axis=2)
spcl.inf.ethz.ch
@spcl_eth
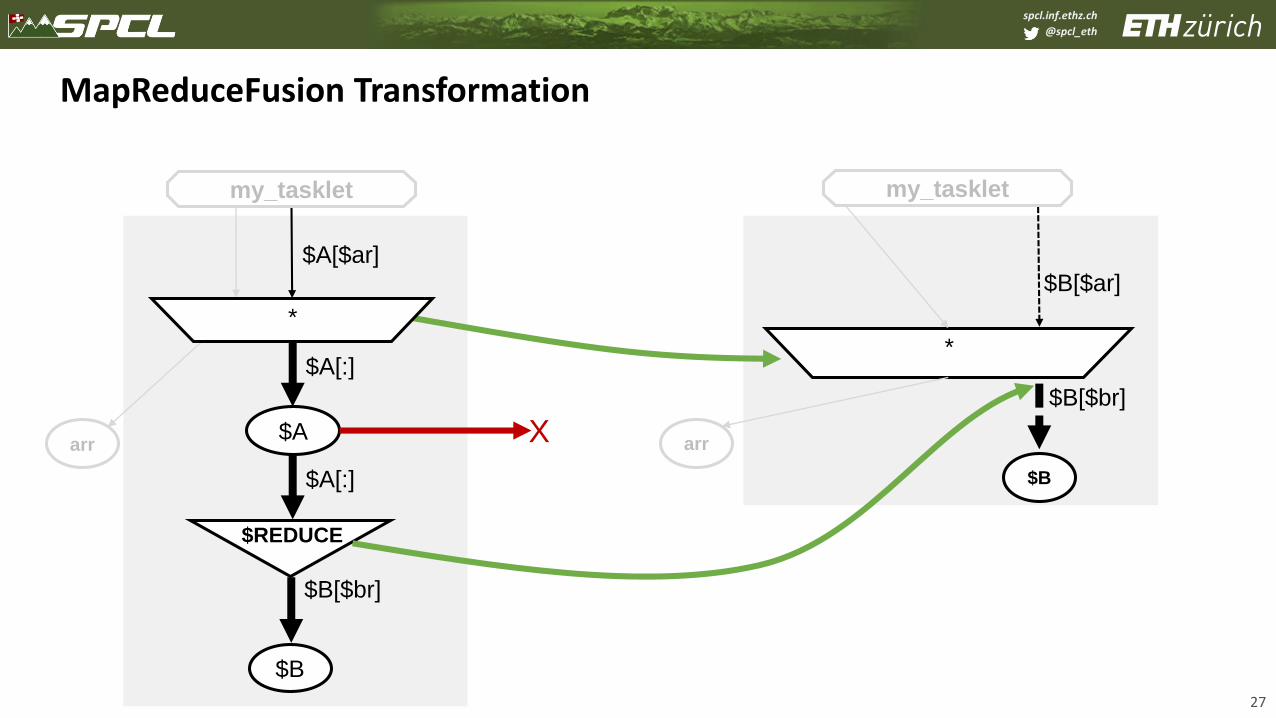
MapReduceFusion Transformation
27
$A
$A[:]
$A[:]
*
$REDUCE
$B[$br]
$A[$ar]
$B[$br]
$B[$ar]
$B
my_tasklet
arr
my_tasklet
$B
arr
*
X
spcl.inf.ethz.ch
@spcl_eth
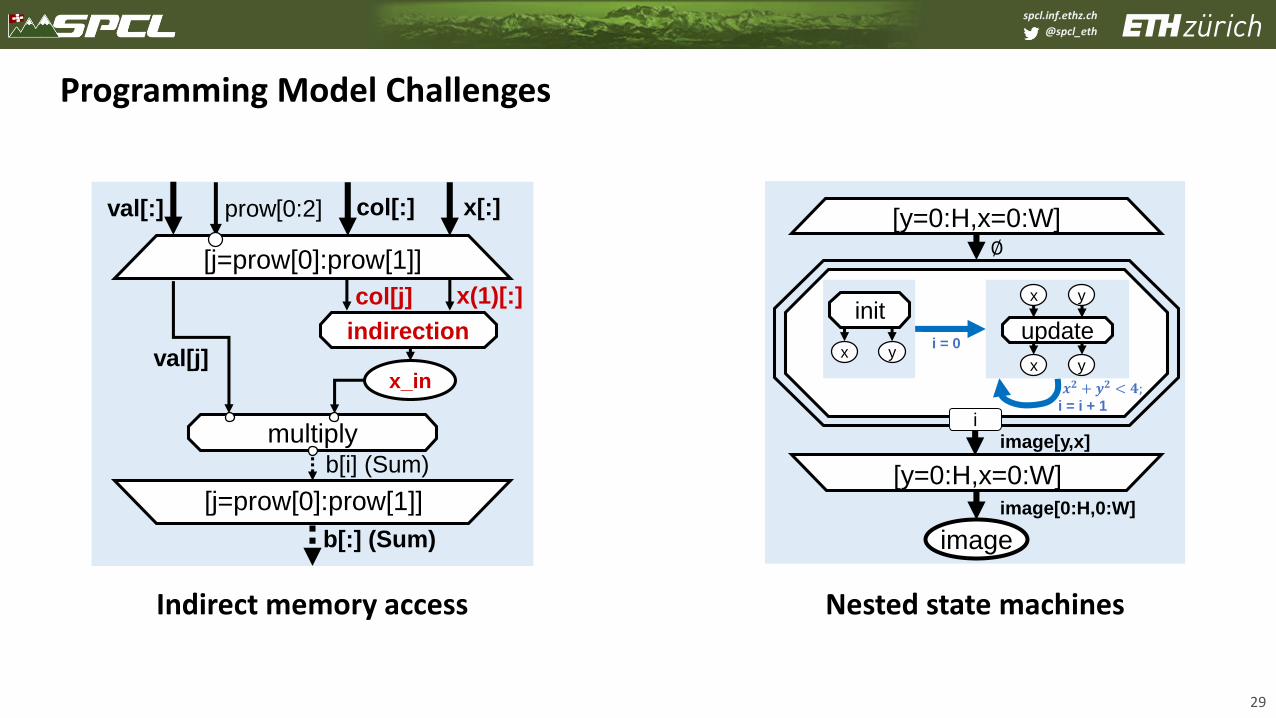
Programming Model Challenges
29
[j=prow[0]:prow[1]]
multiplyb[i] (Sum)
b[:] (Sum)
prow[0:2]val[:] col[:] x[:]
indirection
x_inval[j]
col[j] x(1)[:]
[j=prow[0]:prow[1]]
[y=0:H,x=0:W]
image[0:H,0:W]
[y=0:H,x=0:W]
image
∅
𝒙𝟐 + 𝒚𝟐 < 𝟒;i = i + 1
i
init
x yx y
image[y,x]
x y
updatei = 0
Indirect memory access Nested state machines
spcl.inf.ethz.ch
@spcl_eth
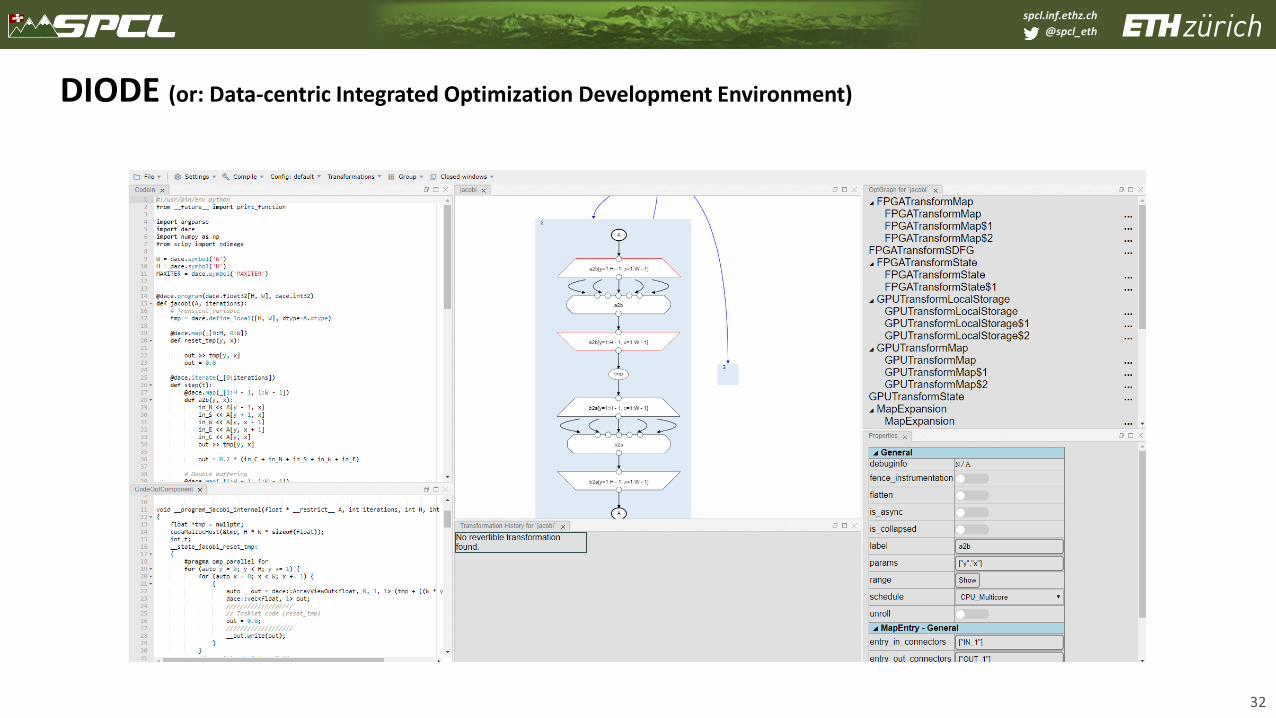
DIODE (or: Data-centric Integrated Optimization Development Environment)
32
spcl.inf.ethz.ch
@spcl_eth
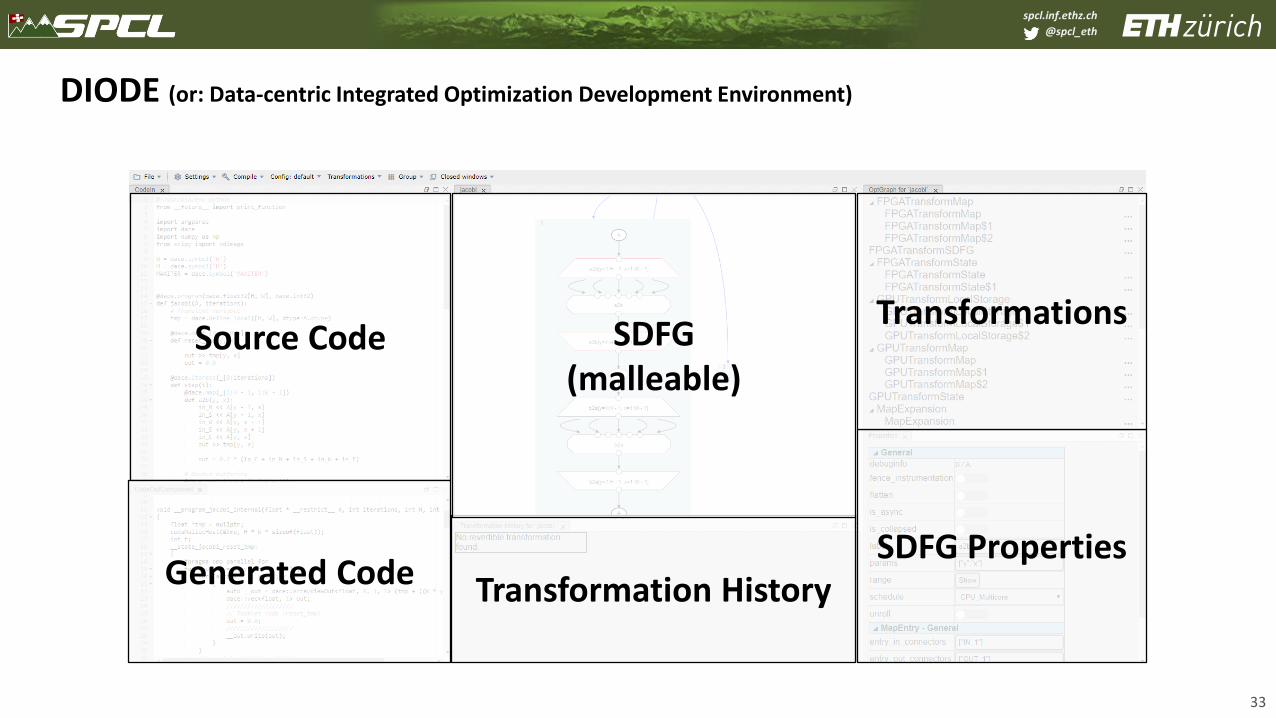
DIODE (or: Data-centric Integrated Optimization Development Environment)
33
Source Code
Transformation History
SDFG(malleable)
SDFG PropertiesGenerated Code
Transformations
spcl.inf.ethz.ch
@spcl_eth
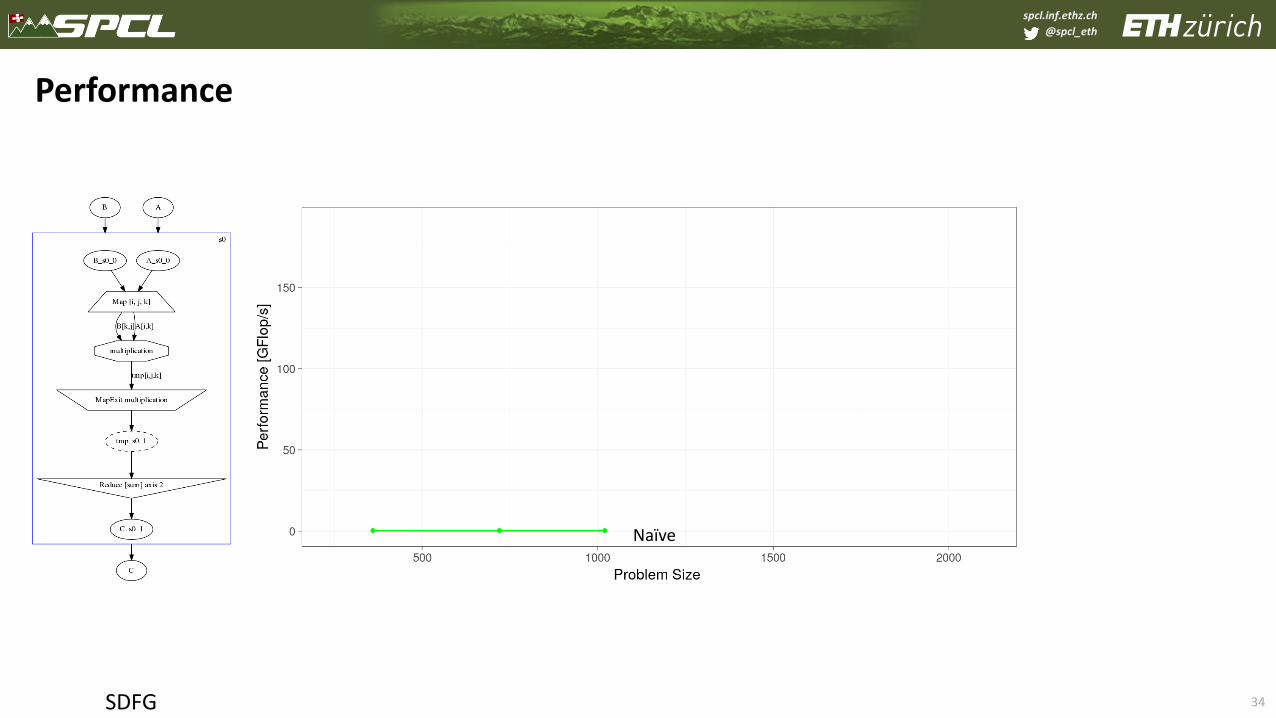
34
Performance
SDFG
Naïve
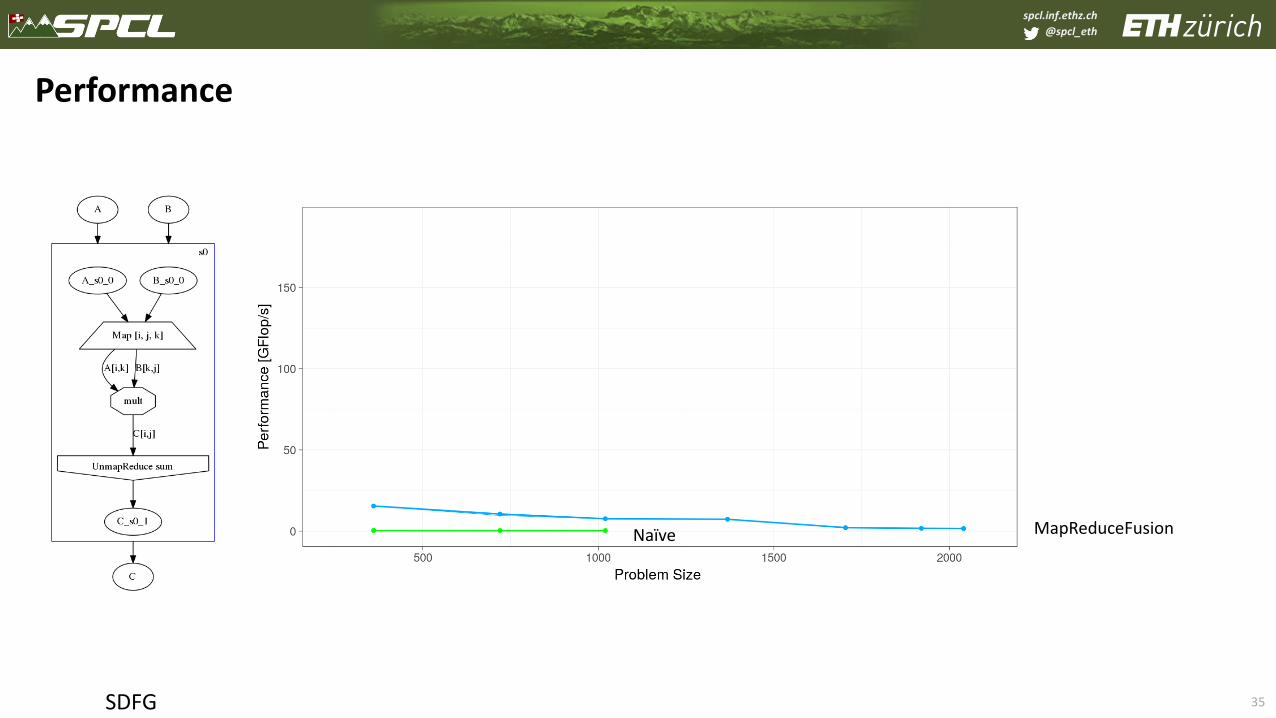
spcl.inf.ethz.ch
@spcl_eth
35
Performance
SDFG
MapReduceFusionNaïve
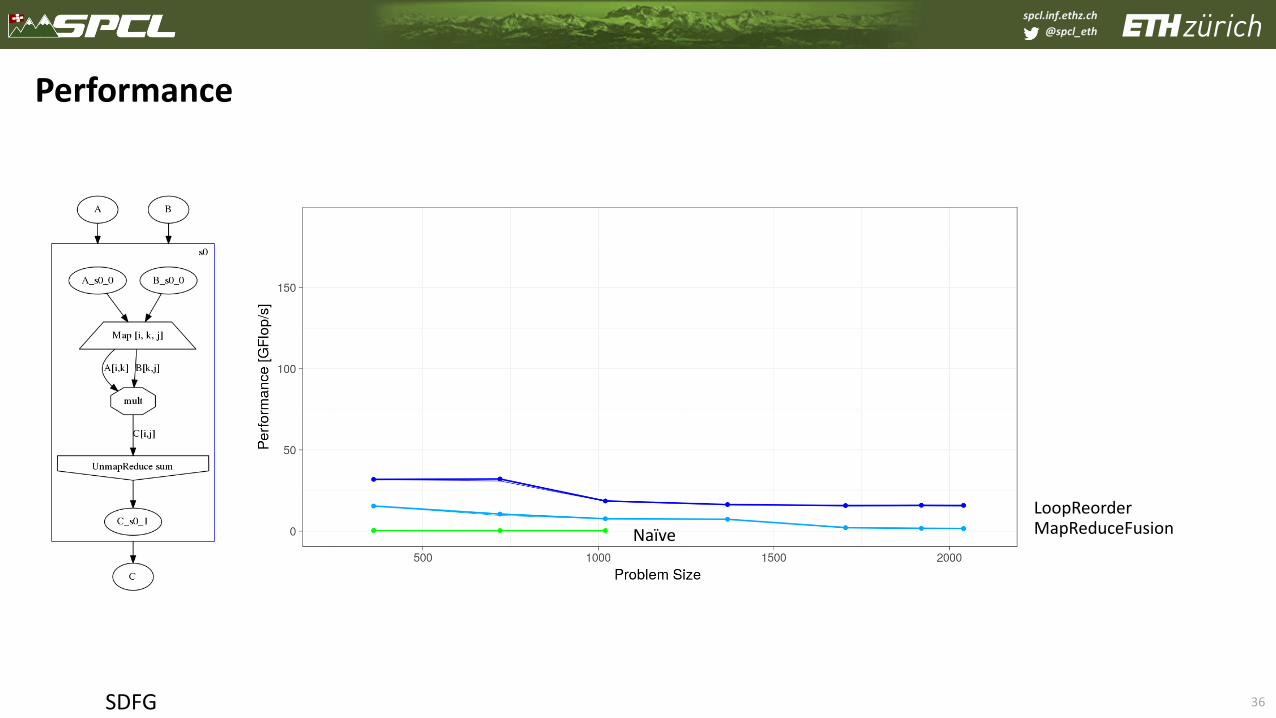
spcl.inf.ethz.ch
@spcl_eth
36
Performance
SDFG
LoopReorderMapReduceFusionNaïve
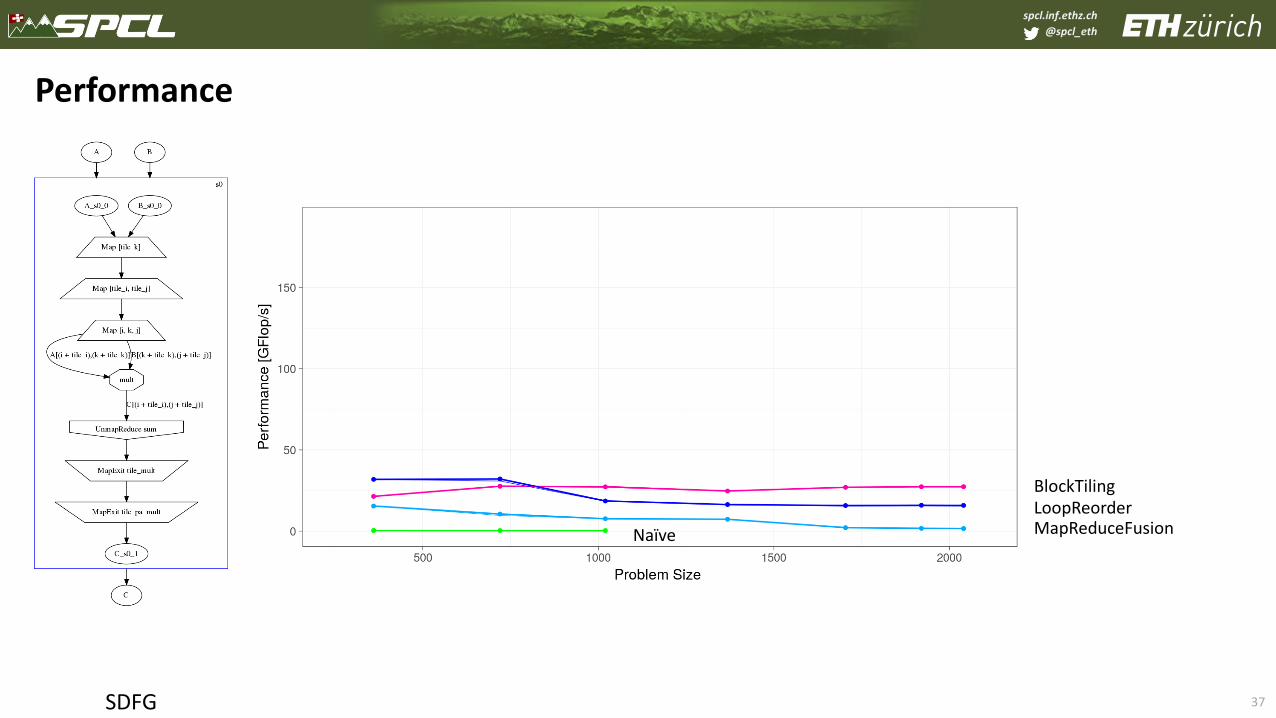
spcl.inf.ethz.ch
@spcl_eth
37
Performance
SDFG
BlockTilingLoopReorderMapReduceFusionNaïve
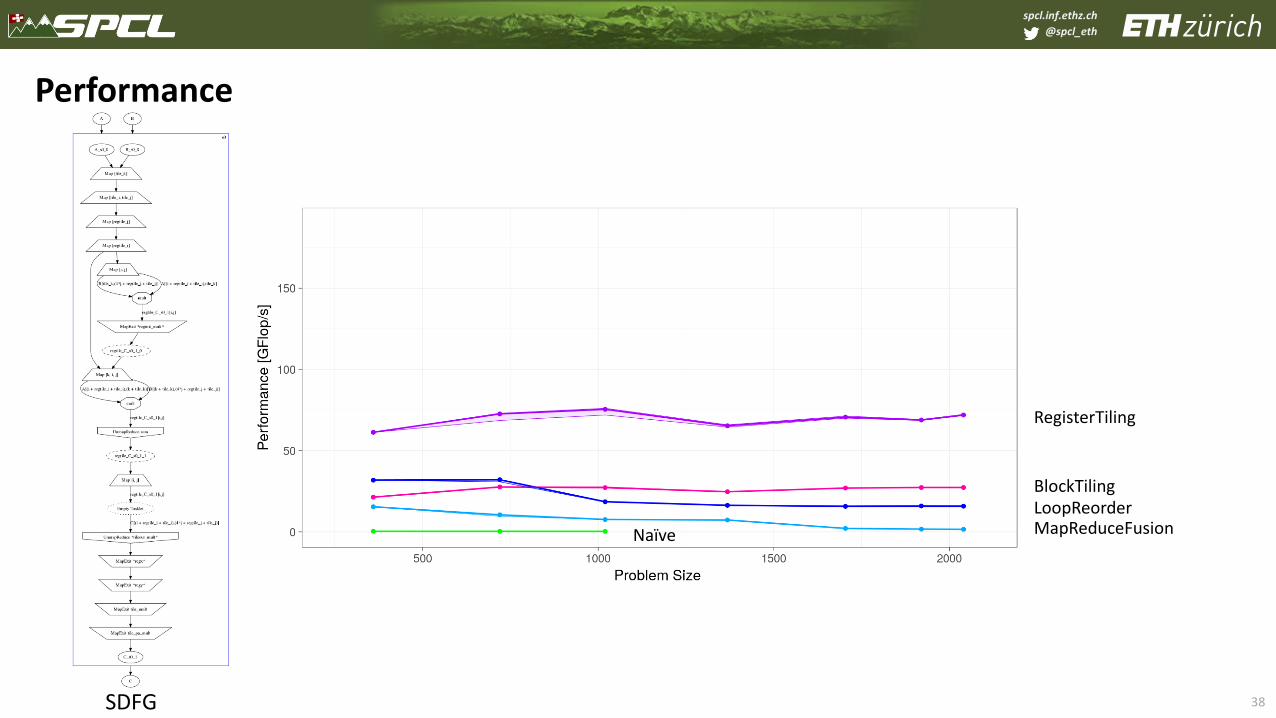
spcl.inf.ethz.ch
@spcl_eth
38
Performance
SDFG
RegisterTiling
BlockTilingLoopReorderMapReduceFusionNaïve
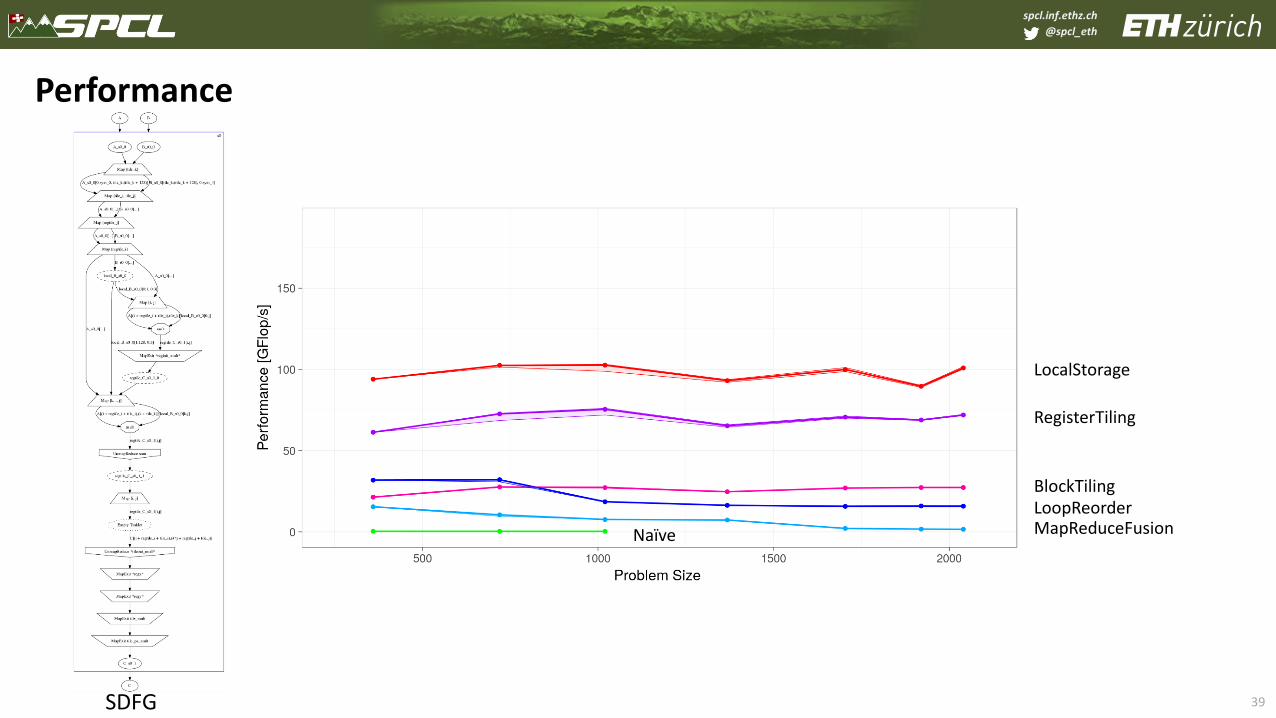
spcl.inf.ethz.ch
@spcl_eth
39
Performance
SDFG
LocalStorage
RegisterTiling
BlockTilingLoopReorderMapReduceFusionNaïve
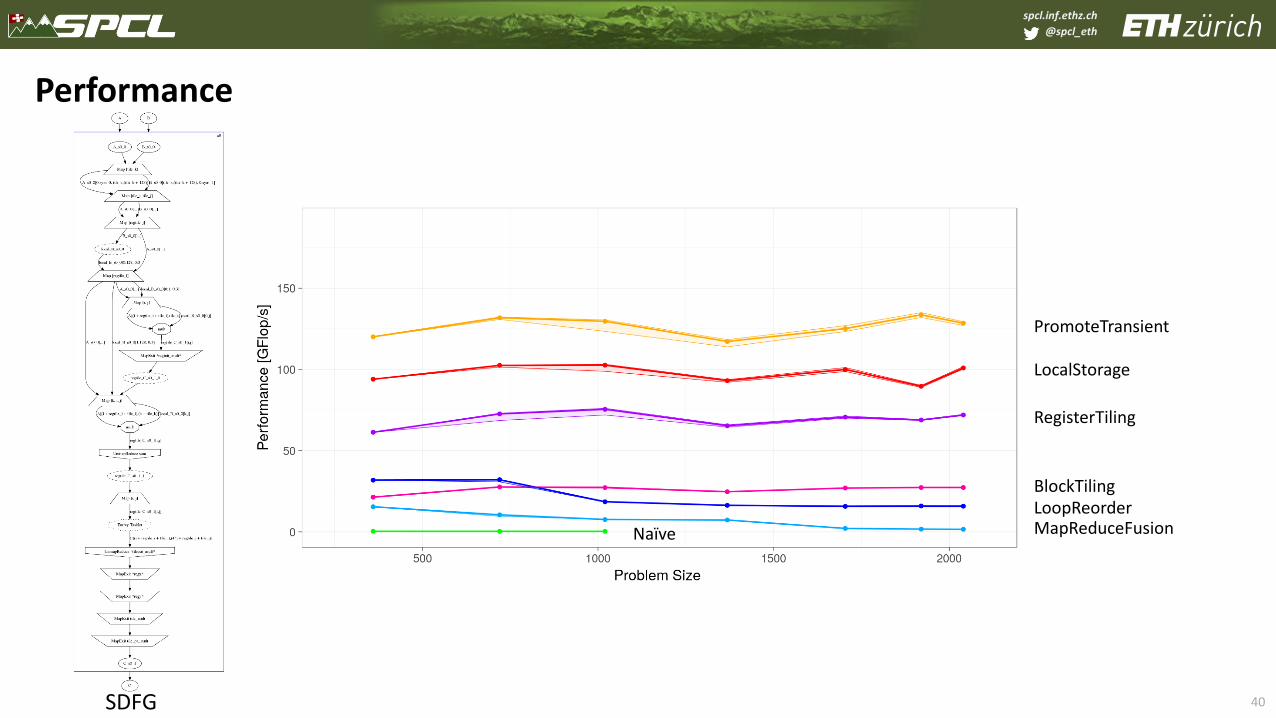
spcl.inf.ethz.ch
@spcl_eth
40
Performance
SDFG
PromoteTransient
LocalStorage
RegisterTiling
BlockTilingLoopReorderMapReduceFusionNaïve
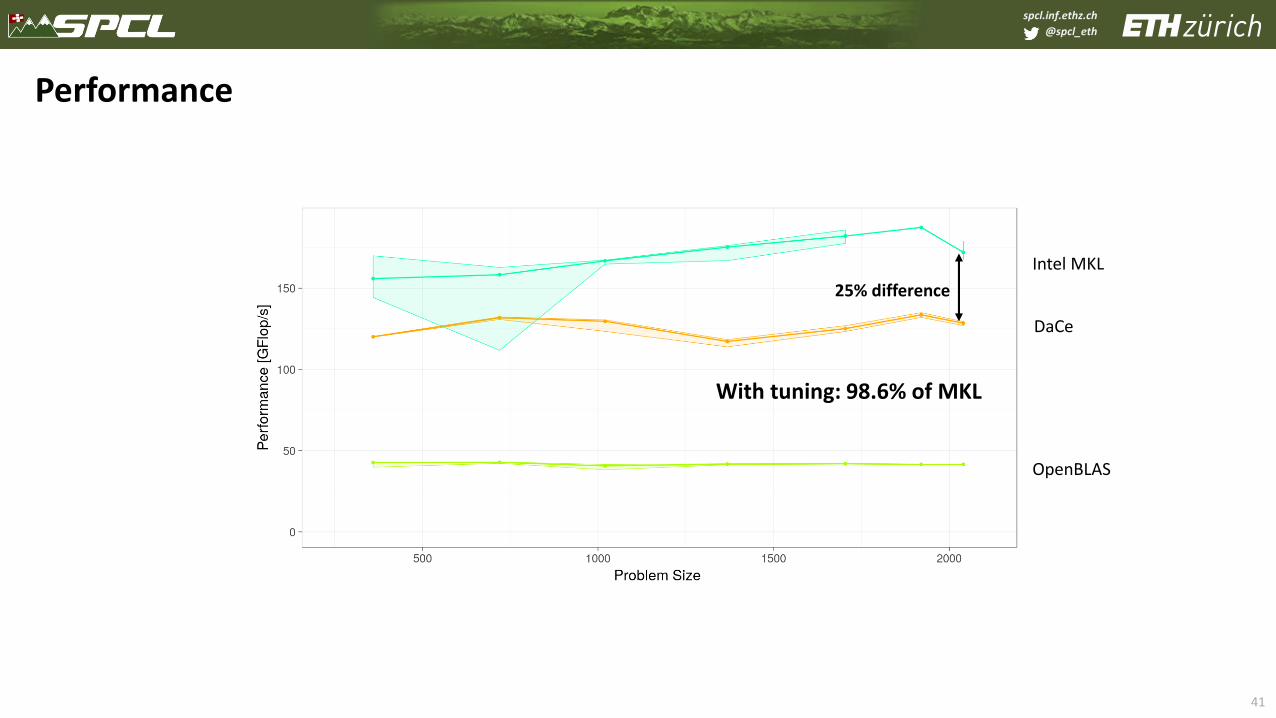
spcl.inf.ethz.ch
@spcl_eth
41
Performance
Intel MKL
OpenBLAS
25% difference
DaCe
With tuning: 98.6% of MKL
spcl.inf.ethz.ch
@spcl_eth
42
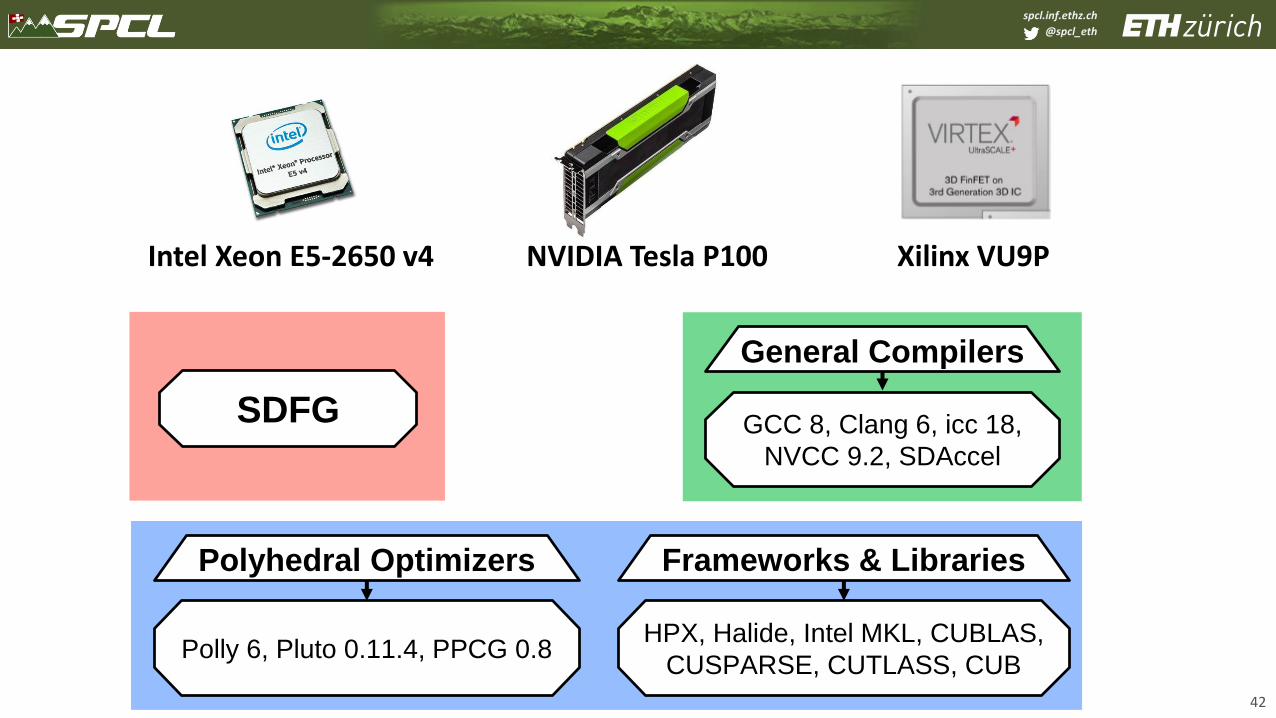
SDFG
General Compilers
GCC 8, Clang 6, icc 18,
NVCC 9.2, SDAccel
Polyhedral Optimizers
Polly 6, Pluto 0.11.4, PPCG 0.8HPX, Halide, Intel MKL, CUBLAS,
CUSPARSE, CUTLASS, CUB
Intel Xeon E5-2650 v4 NVIDIA Tesla P100 Xilinx VU9P
Frameworks & Libraries
spcl.inf.ethz.ch
@spcl_eth
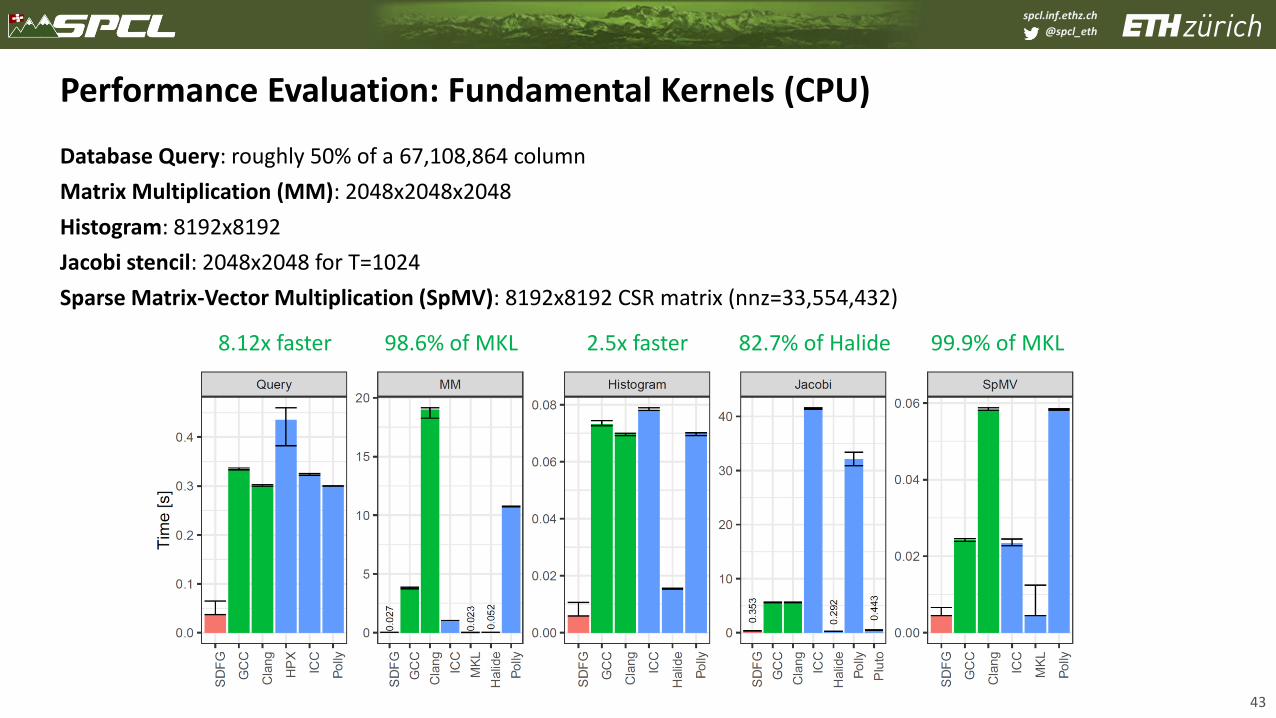
Performance Evaluation: Fundamental Kernels (CPU)
Database Query: roughly 50% of a 67,108,864 column
Matrix Multiplication (MM): 2048x2048x2048
Histogram: 8192x8192
Jacobi stencil: 2048x2048 for T=1024
Sparse Matrix-Vector Multiplication (SpMV): 8192x8192 CSR matrix (nnz=33,554,432)
43
99.9% of MKL8.12x faster 98.6% of MKL 2.5x faster 82.7% of Halide
spcl.inf.ethz.ch
@spcl_eth
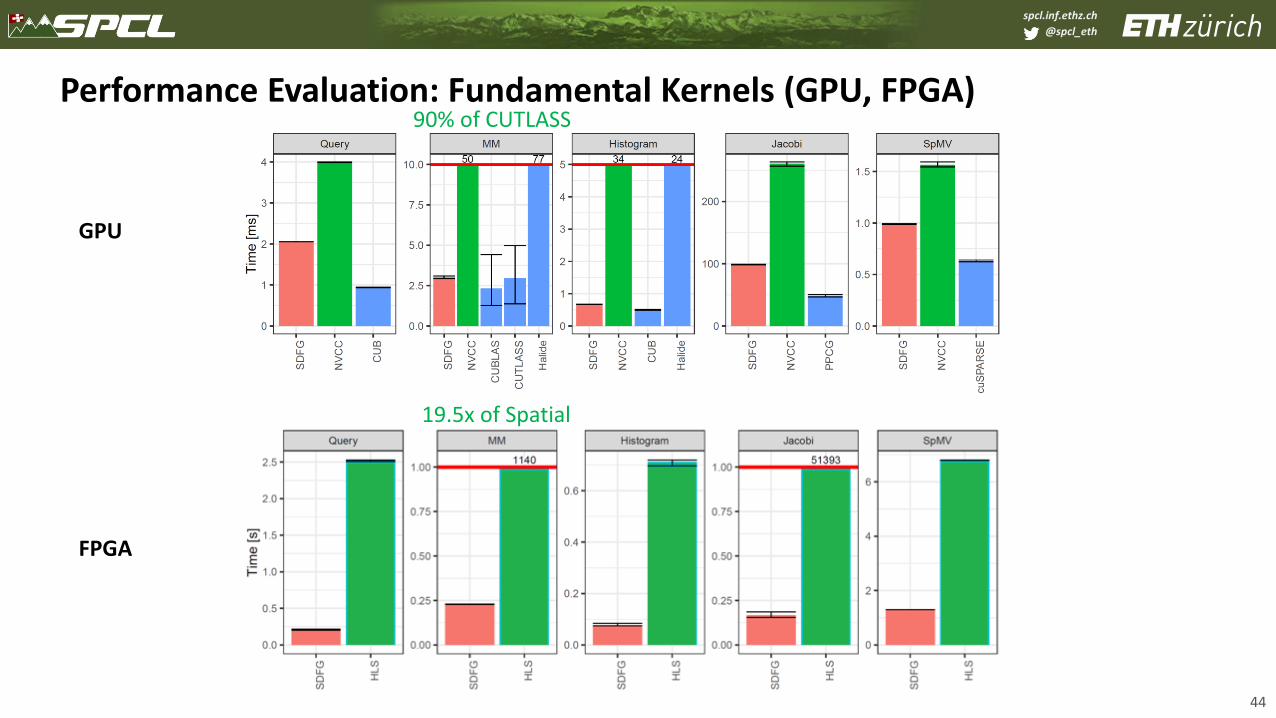
Performance Evaluation: Fundamental Kernels (GPU, FPGA)
44
GPU
FPGA
19.5x of Spatial
90% of CUTLASS
spcl.inf.ethz.ch
@spcl_eth
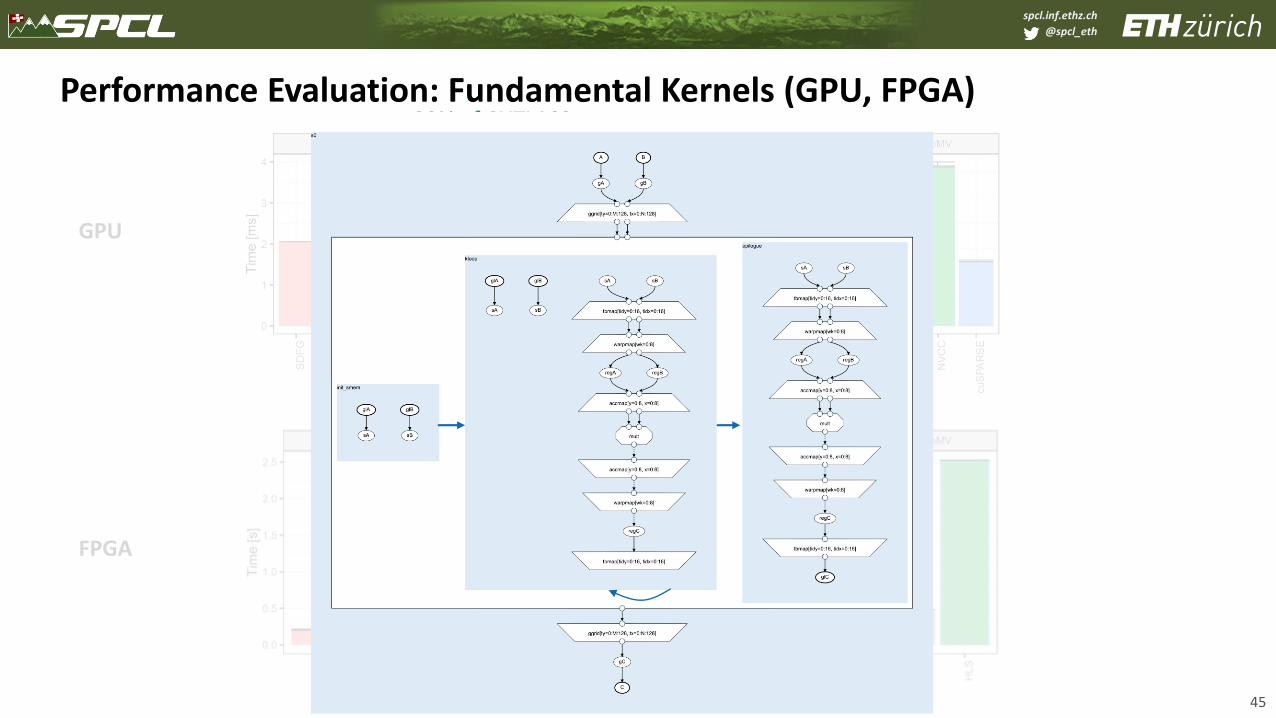
Performance Evaluation: Fundamental Kernels (GPU, FPGA)
45
GPU
FPGA
19.5x of Spatial
90% of CUTLASS
spcl.inf.ethz.ch
@spcl_eth
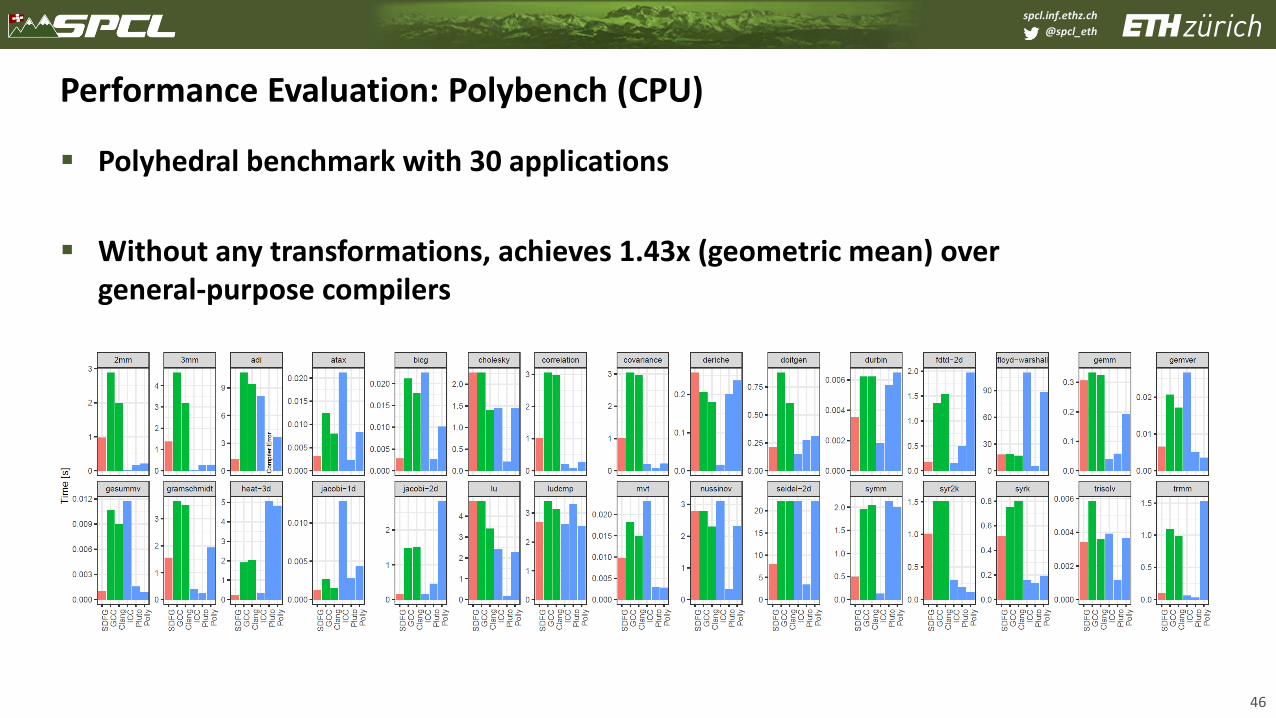
Performance Evaluation: Polybench (CPU)
▪ Polyhedral benchmark with 30 applications
▪ Without any transformations, achieves 1.43x (geometric mean) over general-purpose compilers
46
spcl.inf.ethz.ch
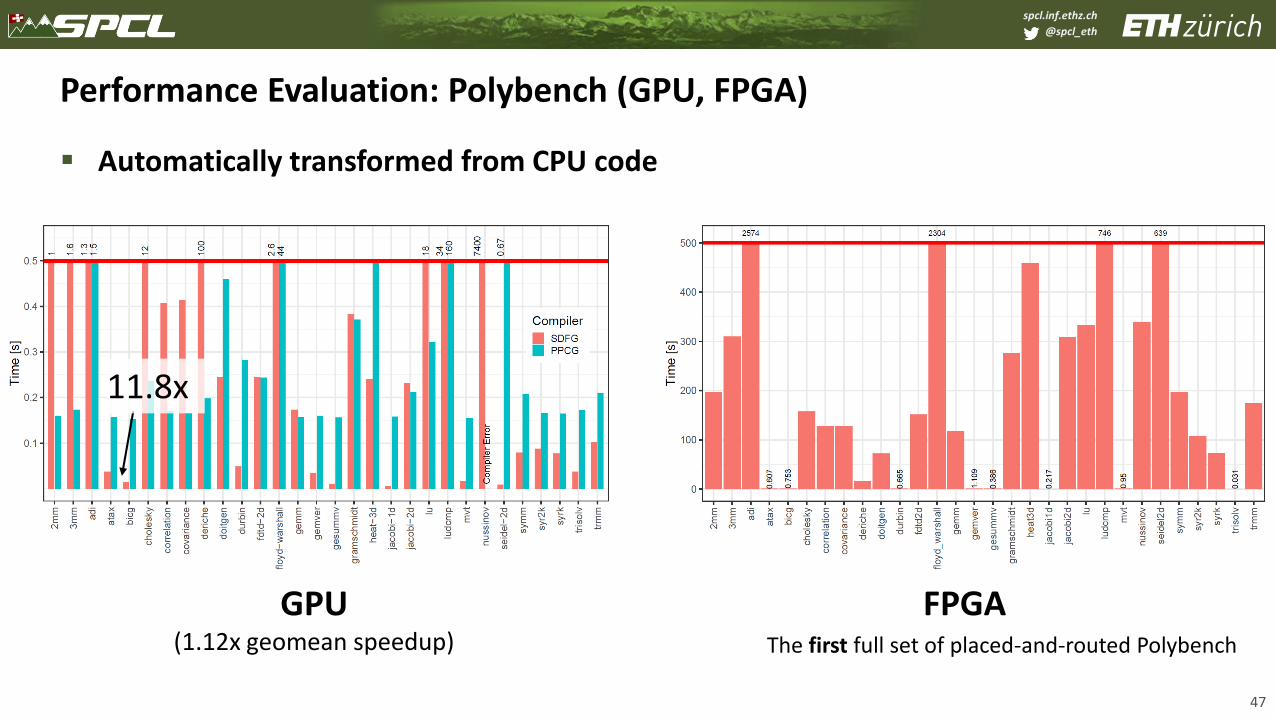
@spcl_eth
Performance Evaluation: Polybench (GPU, FPGA)
▪ Automatically transformed from CPU code
47
GPU(1.12x geomean speedup)
FPGAThe first full set of placed-and-routed Polybench
11.8x
spcl.inf.ethz.ch
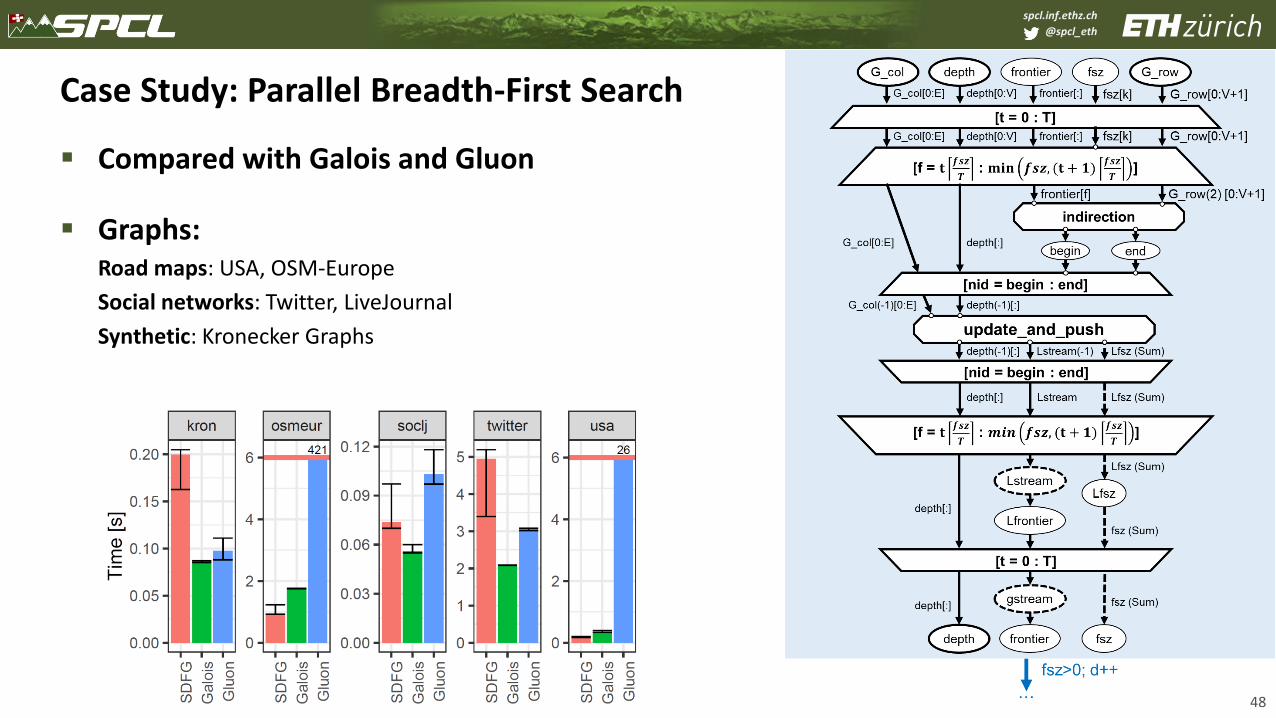
@spcl_eth
Case Study: Parallel Breadth-First Search
▪ Compared with Galois and Gluon
▪ Graphs:Road maps: USA, OSM-Europe
Social networks: Twitter, LiveJournal
Synthetic: Kronecker Graphs
48
spcl.inf.ethz.ch
@spcl_eth
Conclusions
49This project has received funding from the European Research Council (ERC) under grant agreement "DAPP (PI: T. Hoefler)".
@dapp.programdef program(A, B):
@dapp.map(_[0:N,0:M])def transpose(i, j):a << A[i,j]b >> B[j,i]
...
https://www.github.com/spcl/dace
pip install dace


















