
Ontwerp en evaluatie van open access algoritmen voor TDM ...
88
Timothy Huber TDM-PON's Ontwerp en evaluatie van open access algoritmen voor Academiejaar 2013-2014 Faculteit Ingenieurswetenschappen en Architectuur Voorzitter: prof. dr. ir. Daniël De Zutter Vakgroep Informatietechnologie Master of Science in de ingenieurswetenschappen: computerwetenschappen Masterproef ingediend tot het behalen van de academische graad van Begeleiders: dr. ir. Bart Lannoo, Abhishek Dixit Promotoren: prof. dr. ir. Mario Pickavet, prof. dr. ir. Didier Colle
Transcript of Ontwerp en evaluatie van open access algoritmen voor TDM ...

Timothy Huber
TDM-PON'sOntwerp en evaluatie van open access algoritmen voor
Academiejaar 2013-2014Faculteit Ingenieurswetenschappen en ArchitectuurVoorzitter: prof. dr. ir. Daniël De ZutterVakgroep Informatietechnologie
Master of Science in de ingenieurswetenschappen: computerwetenschappen Masterproef ingediend tot het behalen van de academische graad van
Begeleiders: dr. ir. Bart Lannoo, Abhishek DixitPromotoren: prof. dr. ir. Mario Pickavet, prof. dr. ir. Didier Colle


Voorwoord
Alvorens deze thesis aan te vangen, zou ik graag enkele mensen willen bedanken voor hun steun
en inzet. Zonder hen had ik deze masterproef nooit tot zo een goed einde gebracht.
Eerst en vooral wil ik mijn promotoren prof. Mario Pickavet en prof. Didier Colle bedanken
voor het uitschrijven van dit boeiend onderwerp, de kritische vragen op de evaluatiemomenten
en de hints en opmerkingen om de masterproef in een goede richting te sturen. Daarnaast wil
ik uiteraard ook mijn begeleiders Bart en Abhishek bedanken. Abhishek, I will write this in
English for you as the rest of my thesis will be in Dutch. I would like to thank you for your help
with the OPNET simulator, certainly if a simulation got stuck or an algorithm did not perform
as expected. Also thank you for your thoughtful remarks during our meetings at Zuiderpoort.
Ook Bart moet ik hiervoor bedanken, aangezien deze opmerkingen mij nieuwe inzichten opge-
leverd hebben. Daarenboven moet ik Bart ook nog bedanken voor het nalezen van mijn thesis,
waardoor ik dit mooi resultaat kan afleveren.
Vervolgens wil ik ook nog mijn vriendin Stephanie Van Goethem bedanken voor haar steun de
voorbije 6 jaar. Daarenboven heeft zij verschillende malen mijn thesis nagelezen op schrijffouten
en zinsconstructies om de tekst zo professioneel mogelijk te maken, zonder dat zij over enige
kennis van computernetwerken beschikt. Zelfs vanuit Canada was ze een luisterend oor en een
bron van inspiratie tijdens het schrijven van deze thesis!
Ten slotte wil ik ook mijn familie en vrienden bedanken die mij, door hun steun en motivatie,
stimuleerden om deze masterproef succesvol te beeindigen. Zij hebben er mede voor gezorgd dat
er voldoende ontspanning was het hele jaar door.
Timothy Huber, juni 2014


Toelating tot bruikleen
“De auteur geeft de toelating deze scriptie voor consultatie beschikbaar te stellen en delen van
de scriptie te kopieren voor persoonlijk gebruik.
Elk ander gebruik valt onder de beperkingen van het auteursrecht, in het bijzonder met betrek-
king tot de verplichting de bron uitdrukkelijk te vermelden bij het aanhalen van resultaten uit
deze scriptie.”
Timothy Huber, juni 2014


Ontwerp en evaluatie van open access
algoritmen voor TDM-PON’sdoor
Timothy HUBER
Scriptie ingediend tot het behalen van de academische graad van
Master in de ingenieurswetenschappen: computerwetenschappen
Academiejaar 2013–2014
Promotor: Prof. Dr. Ir. M. PICKAVET
Promotor: Prof. Dr. Ir. D. COLLE
Scriptiebegeleider: Dr. Ir. B. LANNOO
Scriptiebegeleider: Ir. A. DIXIT
Faculteit Ingenieurswetenschappen en Architectuur
Universiteit Gent
Vakgroep Informatietechnologie
Voorzitter: Prof. Dr. Ir. D. DE ZUTTER
Samenvatting
De huidige toegangsnetwerken hebben hun limiet bereikt en fiber biedt de ultieme oplossing
om de snelheden nog te verhogen. Het uitrollen van fiber brengt enorme financiele kosten met
zich mee waardoor open access in een Passive Optical Network (PON) een goede keuze is.
Om dit te realiseren werd een veelbelovend dual Service Level Agreement (SLA) scheduling
algoritme voorgesteld. In deze masterproef werd dit algoritme aangepast en vergeleken met
een reeds bestaand algoritme voor open access, namelijk Weighted Round Robin (WRR). Mits
de juiste configuraties werd ervoor gezorgd dat het dual SLA scheduling algoritme een betere
performantie heeft dan het WRR scheduling algoritme op gebied van vertraging en verdeling
van de beschikbare bandbreedte.
Trefwoorden
Open access, TDM-PON, dual Service Level Agreement (SLA), Fiber to the Home (FTTH)


Design and evaluation of open access algorithms forTDM-PONs
Timothy Huber
Supervisor(s): Mario Pickavet, Didier Colle, Bart Lannoo, Abhishek Dixit
Abstract— Current access networks reached their limits and fiber willbe the solution to further increase the speeds in access networks. The de-ployment of fiber is very expensive, that is why open access in a PassiveOptical Network (PON) will be a good choice to reduce the costs. To realiseopen access, a promising dual Service Level Agreement (SLA) schedulingalgorithm was proposed in literature. In this research the algorithm wasadjusted to enhance the performance and was compared with an existingscheduling algorithm, Weighted Round Robin (WRR). With the correctconfiguration, the dual SLA scheduling algorithm delivers a better perfor-mance than the WRR scheduling algorithm according to delay and band-width distribution.
Keywords— Open access, TDM-PON, dual Service Level Agreement(SLA), Fiber to the Home (FTTH)
I. INTRODUCTION
THE increasing demand for bandwidth in the access networkis caused by multiple factors such as: watching digital tele-
vision, streaming High Definition (HD) videos over the internet,sharing large data files, etc. Current architectures only use fiberup to the Local EXchange (LEX) or the street cabinet, whichis also known as Fiber To The Curb (FTTC). From the LEX orstreet cabinet to the customer, a copper technology is used tocreate a tree and branch topology (coax cable) or a star topology(twisted pair cable). Several Data Over Cable Service InterfaceSpecification (DOCSIS) and Digital Subscriber Line (DSL) ver-sions were designed for coax and twisted pair to maximize thespeeds from these links in the access networks. Unfortunatelythese specifications reached the physical limitations of the ca-bles and that is why another technology in the access network isnecessary.
Fiber is the most promising technology as it already showedits capabilities in the core network [1]. The only issue with usingfiber in the access network, is the cost to deploy this technology[2]. A first improvement is to use a Point-to-MultiPoint (P2MP)instead of a Point-to-Point (P2P) architecture. A big part of thefiber between the Optical Line Terminal (OLT), at the LEX, andthe Optical Network Units (ONUs), at the customers, is sharedto reduce the cost. The second cost reduction is achieved by us-ing a passive node in the street cabinet instead of an active nodeto perform the optical splitting and combining. The active nodeneeds power supply and higher maintenance costs, which couldbe easily avoided. The last possibilty to save money, is not onlysharing the fiber between the ONUs but also share it betweenthe network providers (NPs) and service providers (SPs) whichis referred to as open access [2, 3].
The cost reduction is useful and necessary but requires a goodalgorithm in the OLT provided by the NP to fairly distributethe bandwidth according to the Service Level Agreement (SLA)from the ONU and the SLA from the SP. Not only should the
bandwidth be distributed fairly, also the delay requires attention:priority traffic needs low and constant delays, ONUs with a highload may not have lower delays than ONUs with a low load, etc.
II. DUAL SLA SCHEDULING ALGORITHM
A first implementation of an open access algorithm is thedual SLA scheduling algorithm proposed by Banerjee et al. [4].This algorithm makes a fair bandwidth distribution between theONUs when the total demand exceeds the total capacity of thelink. The algorithm is based on the flowchart given in Fig. 1.The algorithm is based on two pre-defined SLAs: the SLA for anONU and the SLA for a SP. One of the SLAs will be the primarySLA and therefore will be the most important SLA, whereas thesecondary SLA is less important and might not be met in somecases.
The goal of the dual SLA scheduling algorithm is to minimizethe deficit for each ONU that requests more than its SLA, whichis depicted by step 4 in Fig. 1. If the demand exceeds the avail-able capacity, the algorithm will first try to meet the secondarySLA (step 2) and afterwards the primary SLA (step 3) whichmight lead to a different allocation according to the secondarySLA. If some ONUs do not use the capacity which is given bytheir SLA, this spare capacity will be fairly divided amongst theother ONUs that request more than their SLA.
36 IEEE JOURNAL ON SELECTED AREAS IN COMMUNICATIONS, VOL. 24, NO. 8, AUGUST 2006
Fig. 3. Invocation of the scheduling algorithm for time-slot computation.
which states that the sum of all bandwidths allocatedmust be less than or equal to the capacity available forthe maximum time cycle duration.
3) Scheduling time cycle constraint:
Tadv ≤ ∆ ≤ T (8)
which states that the scheduling time cycle must be lessthan the maximum scheduling time cycle and greaterthan the minimum time by which the scheduler mustadvance.
Objectives:The following objectives are in order of priority.
1) Meet the primary-SLA bandwidth requirement.2) Try to meet the secondary-SLA bandwidth requirement.
If it is not possible to meet all the secondary SLAs, thenthe deficit in meeting the secondary SLAs should be asuniform as possible.
3) Divide any surplus bandwidth after meeting SLAs fairlyacross the primary-SLA entities, and then correspond-ingly for each secondary-SLA entity.
IV. DUAL-SLA SCHEDULING ALGORITHM
We present the scheduling algorithm to implement ourmathematical model formulated in Section III. For describingthe algorithm, we choose an example in which the primarySLA is for the users, and the secondary SLA is for theSPs, although this may easily be reversed. The schedulingalgorithm is invoked at time t, and it considers the givenparameters as defined in the previous section. The algorithmis presented in the flowchart in Fig. 4. The following twocases arise.
Case I: Demand is less than capacity available in themaximum time cycle duration, i.e.,
ifi=M∑
i=1
j=N∑
j=1
qi,j,t ≤ C (9)
then the demand may be met entirely using the availablecapacity, and the allocated time-slots may be determined bythe following two equations:
gi,j,t,t+∆ = qi,j,t ∀ i ∈ 1, . . . ,M, j ∈ 1, . . . , N (10)
Case IIStep 1:Identify mandatory bandwidth assignments.
Step 2:Allocate bandwidth to meet Secondary SLA
Step 3:Allocate bandwidth to meet Primary SLA. If sufficient capacity is not available, then recover bandwidth assigned in Step 2 to meet deficit.
Step 4:Assign remaining time-slot fairly amongst users.
Isdemand < capacity of maximum timeslot ?
Case IAllocate bandwidth equal to demand
Yes No
Start
Fig. 4. Flowchart for Dual-SLA scheduling algorithm.
∆ = Max [Tadv,i=M∑
i=1
j=N∑
j=1
qi,j,t/R] (11)
The latter equation states that we would like to advancethe scheduler by the larger of Tadv and the actual time thatwas taken to transmit the packets in the queues. The aboveequation assumes no additional overhead in the system, asmentioned before.
Case II: Demand is greater than available capacity. This isthe interesting case where the role of fair scheduling comesin. The primary SLA is specified for either the users or theSPs, and depending on the choice of the primary SLA, thesecondary SLA is specified for the opposite entity. In thefollowing description of the algorithm, we assume that theprimary SLA is for users, and the secondary SLA is for SPs.
Step 1: Identify Mandatory Bandwidth Allocations. Theobjective is to identify the following two situations:
1) Users whose cumulative demand is less than the primarySLA requirement, i.e., users j, for which the followingequation is true:
i=M∑
i=1
qi,j,t < uMINj (12)
In such a case, the entire demand for that user must bemet.
2) Users who do not satisfy the above, but who are cur-rently subscribing to only a single SP. For such users,a grant equal to the primary SLA (uMIN
j ) must beassigned, because there is no alternate competing SP.
Steps 2, 3, and 4 use algorithm Allocate Max-Min FairBandwidth shown in Fig. 5. Given some available bandwidth,the objective is to ensure distribution of the bandwidth amonga set of entities (SPs/ users) to achieve max-min fairness. Afeasible allocation set [x1, x2, x3, . . . , xr] is said to be max-min fair [3] when it is impossible to increase the allocation
Authorized licensed use limited to: UNIVERSITY OF MELBOURNE. Downloaded on January 13, 2010 at 04:13 from IEEE Xplore. Restrictions apply.
Fig. 1. Flowchart dual SLA scheduling algorithm [4]
III. MODIFICATIONS
The dual SLA scheduling algorithm has some disadvantagesand shortcomings. First of all, when the demand is higherthan the capacity the bandwidth is fairly distributed amongst theONUs to reduce the deficit. ONUs that request a lot more thantheir SLA (e.g. demand of 150 Mbps and SLA of 60 Mbps),will receive the highest amount of bandwidth (e.g. 120 Mbps)whereas ONUs that request a little bit more than their SLA (e.g.demand of 75 Mbps and SLA of 60 Mbps) will only receive theirSLA (e.g. 60 Mbps). This means: if you are an ONU, increaseyour demand to receive the highest bandwidth. Therefore a firstmodification was made to this algorithm: divide the remainingbandwidth equal amongst the ONUs that request more than theirSLA. In the previous example the ONU that requested 75 Mbpswill get this 75 Mbps, and the ONU that requested 150 Mbpswill get 100 Mbps.
Start
QP < QMAXCase 1:GP = QP
Yes
GBE = WBE,P x GP
GBE = min(GBE , QMAX - GP)
Case 2:GP = QMAX
No
GBE = max(GBE , WBE,MIN x QMAX)
Fig. 2. Flowchart priority traffic with dual SLA
A second shortcoming of the dual SLA scheduling algorithmis the lack of supporting priority traffic, such as video or voice.A new approach was needed to retain the current bandwidth dis-tribution and to ensure a low and constant delay for priority traf-fic. Before the bandwidth is distributed amongst all ONUs, thetotal amount of priority traffic and best effort traffic is calcu-lated. According to the flowchart in Fig. 2 the total grants forpriority traffic and best effort traffic are calculated. The totalgrant for best effort traffic has a maximum value, as it may notexceed the total capacity. To ensure that best effort traffic re-ceives enough bandwidth, there is also a minimum value to begranted for best effort traffic. To optimize the delay for prioritytraffic and meet the conditions for best effort traffic, the weightsWBE,P and WBE,MIN should be adjusted for each situation.WBE,MIN ensures the minimal bandwidth for best effort traffic,whereas WBE,P ensures a low delay for priority traffic. Afterthe total grants (for best effort and priority) are calculated, thegranted bandwidth is distributed amongst the users according tothe dual SLA scheduling algorithm (all the previous improve-ments included).
IV. WRR SCHEDULING ALGORITHM
In order to be able to compare the results of the (modified)dual SLA scheduling algorithm, a general scheduling algorithm,that can be used in the context of open access, was implemented.This implementation makes use of switches which contain theWeighted Round Robin (WRR) algorithm. In this implementa-tion a switch is placed at each ONU and assigned a Virtual LAN(VLAN). This VLAN makes a virtual connection between a SPand all its ONUs. The OLT contains one bigger switch to con-nect all the SPs with all the ONUs, and this switch assigns theVLAN tag for a packet according to the SP that has send thepacket.
V. ANALYSIS AND EVALUATION
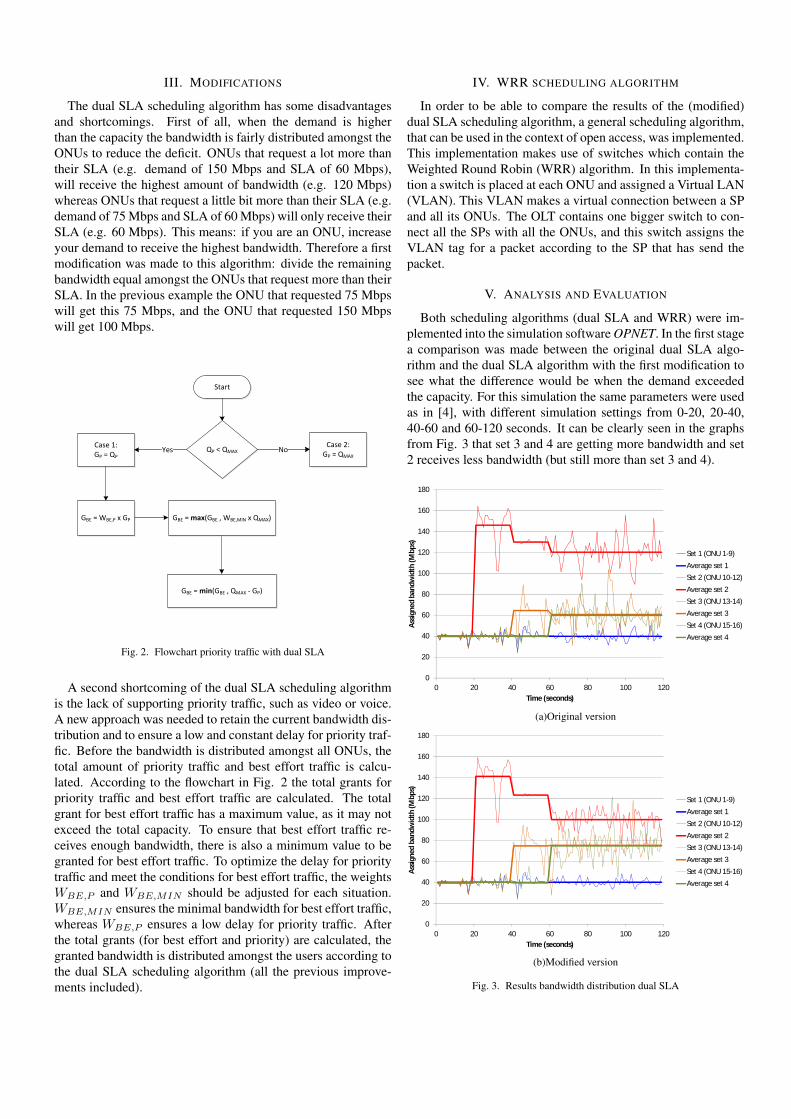
Both scheduling algorithms (dual SLA and WRR) were im-plemented into the simulation software OPNET. In the first stagea comparison was made between the original dual SLA algo-rithm and the dual SLA algorithm with the first modification tosee what the difference would be when the demand exceededthe capacity. For this simulation the same parameters were usedas in [4], with different simulation settings from 0-20, 20-40,40-60 and 60-120 seconds. It can be clearly seen in the graphsfrom Fig. 3 that set 3 and 4 are getting more bandwidth and set2 receives less bandwidth (but still more than set 3 and 4).
0
20
40
60
80
100
120
140
160
180
0 20 40 60 80 100 120
Assi
gned
ban
dwid
th (M
bps)
Time (seconds)
Set 1 (ONU 1-9)
Average set 1Set 2 (ONU 10-12)
Average set 2Set 3 (ONU 13-14)
Average set 3Set 4 (ONU 15-16)
Average set 4
(a)Original version
0
20
40
60
80
100
120
140
160
180
0 20 40 60 80 100 120
Assi
gned
ban
dwid
th (M
bps)
Time (seconds)
Set 1 (ONU 1-9)Average set 1
Set 2 (ONU 10-12)
Average set 2Set 3 (ONU 13-14)
Average set 3
Set 4 (ONU 15-16)Average set 4
(b)Modified version
Fig. 3. Results bandwidth distribution dual SLA
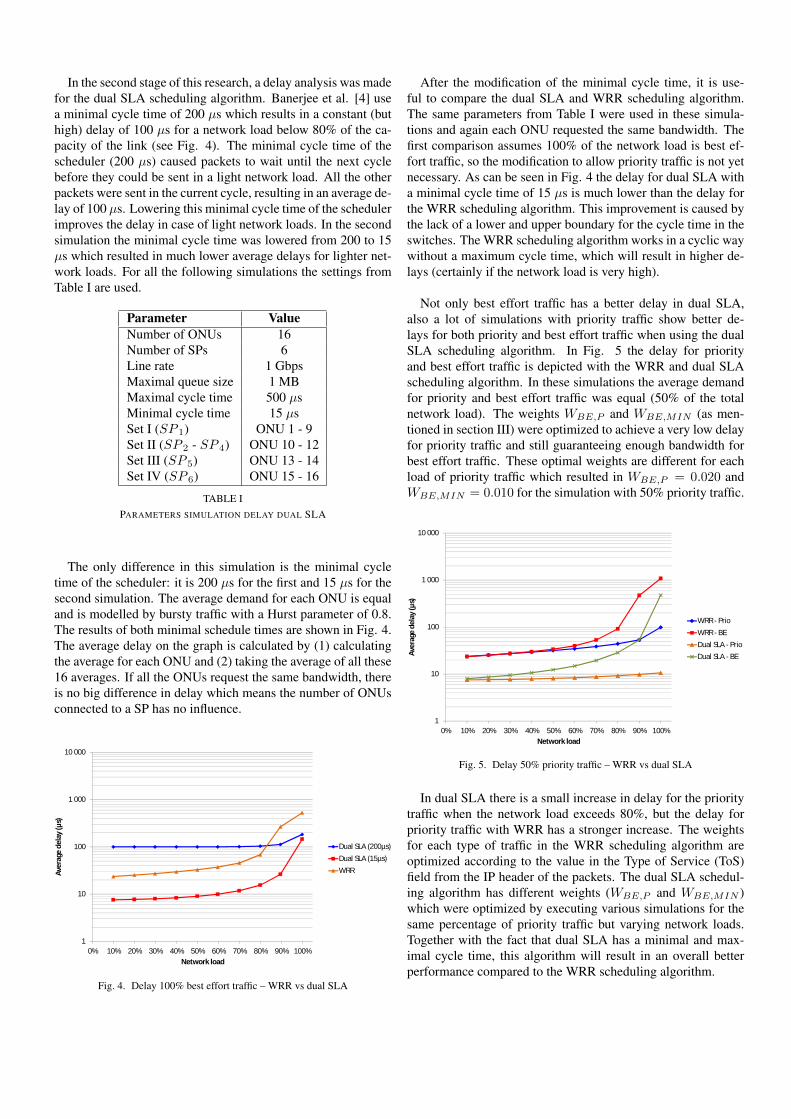
In the second stage of this research, a delay analysis was madefor the dual SLA scheduling algorithm. Banerjee et al. [4] usea minimal cycle time of 200 µs which results in a constant (buthigh) delay of 100 µs for a network load below 80% of the ca-pacity of the link (see Fig. 4). The minimal cycle time of thescheduler (200 µs) caused packets to wait until the next cyclebefore they could be sent in a light network load. All the otherpackets were sent in the current cycle, resulting in an average de-lay of 100 µs. Lowering this minimal cycle time of the schedulerimproves the delay in case of light network loads. In the secondsimulation the minimal cycle time was lowered from 200 to 15µs which resulted in much lower average delays for lighter net-work loads. For all the following simulations the settings fromTable I are used.
Parameter ValueNumber of ONUs 16Number of SPs 6Line rate 1 GbpsMaximal queue size 1 MBMaximal cycle time 500 µsMinimal cycle time 15 µsSet I (SP 1) ONU 1 - 9Set II (SP 2 - SP 4) ONU 10 - 12Set III (SP 5) ONU 13 - 14Set IV (SP 6) ONU 15 - 16
TABLE IPARAMETERS SIMULATION DELAY DUAL SLA
The only difference in this simulation is the minimal cycletime of the scheduler: it is 200 µs for the first and 15 µs for thesecond simulation. The average demand for each ONU is equaland is modelled by bursty traffic with a Hurst parameter of 0.8.The results of both minimal schedule times are shown in Fig. 4.The average delay on the graph is calculated by (1) calculatingthe average for each ONU and (2) taking the average of all these16 averages. If all the ONUs request the same bandwidth, thereis no big difference in delay which means the number of ONUsconnected to a SP has no influence.
1
10
100
1 000
10 000
0% 10% 20% 30% 40% 50% 60% 70% 80% 90% 100%
Aver
age
dela
y (µ
s)
Network load
Dual SLA (200µs)
Dual SLA (15µs)WRR
Fig. 4. Delay 100% best effort traffic – WRR vs dual SLA
After the modification of the minimal cycle time, it is use-ful to compare the dual SLA and WRR scheduling algorithm.The same parameters from Table I were used in these simula-tions and again each ONU requested the same bandwidth. Thefirst comparison assumes 100% of the network load is best ef-fort traffic, so the modification to allow priority traffic is not yetnecessary. As can be seen in Fig. 4 the delay for dual SLA witha minimal cycle time of 15 µs is much lower than the delay forthe WRR scheduling algorithm. This improvement is caused bythe lack of a lower and upper boundary for the cycle time in theswitches. The WRR scheduling algorithm works in a cyclic waywithout a maximum cycle time, which will result in higher de-lays (certainly if the network load is very high).
Not only best effort traffic has a better delay in dual SLA,also a lot of simulations with priority traffic show better de-lays for both priority and best effort traffic when using the dualSLA scheduling algorithm. In Fig. 5 the delay for priorityand best effort traffic is depicted with the WRR and dual SLAscheduling algorithm. In these simulations the average demandfor priority and best effort traffic was equal (50% of the totalnetwork load). The weights WBE,P and WBE,MIN (as men-tioned in section III) were optimized to achieve a very low delayfor priority traffic and still guaranteeing enough bandwidth forbest effort traffic. These optimal weights are different for eachload of priority traffic which resulted in WBE,P = 0.020 andWBE,MIN = 0.010 for the simulation with 50% priority traffic.
1
10
100
1 000
10 000
0% 10% 20% 30% 40% 50% 60% 70% 80% 90% 100%
Aver
age
dela
y (µ
s)
Network load
WRR - Prio
WRR - BE
Dual SLA - PrioDual SLA - BE
Fig. 5. Delay 50% priority traffic – WRR vs dual SLA
In dual SLA there is a small increase in delay for the prioritytraffic when the network load exceeds 80%, but the delay forpriority traffic with WRR has a stronger increase. The weightsfor each type of traffic in the WRR scheduling algorithm areoptimized according to the value in the Type of Service (ToS)field from the IP header of the packets. The dual SLA schedul-ing algorithm has different weights (WBE,P and WBE,MIN )which were optimized by executing various simulations for thesame percentage of priority traffic but varying network loads.Together with the fact that dual SLA has a minimal and max-imal cycle time, this algorithm will result in an overall betterperformance compared to the WRR scheduling algorithm.

VI. CONCLUSION
This paper focuses on open access and compares two dif-ferent scheduling algorithms. The simulations showed that theoriginal dual SLA scheduling algorithm had some issues whichneeded to be modified. After this modification an improvementwas noticable in bandwidth distribution and in queuing delay.Comparing the queuing delay from the dual SLA with the WRRscheduling algorithm, it is straightforward to conclude that dualSLA has a better performance. The possibility to change theweights and minimal cycle times according to the load, will im-prove the average delay for each ONU.
REFERENCES
[1] T. Koonen, ”Fiber to the Home/Fiber to the Premises: What, Where, andWhen?”, Proceedings of the IEEE, vol. 94, no. 5, pp. 911–934, May 2006.
[2] A. Dixit, M. Van der Wee, B. Lannoo, D. Colle, S. Verbrugge, M. Pick-avet, and P. Demeester, ”Planning Open Access in Next-Generation PassiveOptical Networks”, Ghent University-iMinds
[3] A. Banerjee and M. Sirbu, ”Towards Technologically and CompetitivelyNeutral Fiber to the Home (FTTH) Infrastructure”, in Broadband Services:Business Models and Technologies for Community Networks. Jonh Wiley,September 2003.
[4] A. Banerjee, G. Kramer, and B. Mukherjee, ”Fair Sharing Using DualService-Level Agreements to Achieve Open Access in a Passive OpticalNetwork”, IEEE Journal on Selected Areas in Communications, vol. 24,no. 8, pp. 32–44, August 2006.

Inhoudsopgave
Lijst van afkortingen en symbolen v
1 Inleiding 1
2 State of the art 3
2.1 Fiber to the Home . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3
2.1.1 Van koper naar fiber . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3
2.1.2 P2P archictectuur . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8
2.1.3 Actieve optische netwerken . . . . . . . . . . . . . . . . . . . . . . . . . . 10
2.1.4 Passieve optische netwerken . . . . . . . . . . . . . . . . . . . . . . . . . . 10
2.1.4.1 TDM . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11
2.1.4.2 WDM . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11
2.1.4.3 TWDM . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
2.2 Dynamic Bandwidth Allocation . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
2.2.1 Algemeen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
2.2.2 Aangepaste versie . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
2.3 Open access . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15
2.3.1 Inleiding . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15
2.3.2 Service Level Agreements . . . . . . . . . . . . . . . . . . . . . . . . . . . 16
2.3.3 Open access door dual SLA scheduling algoritme . . . . . . . . . . . . . . 18
2.3.4 Open access door WRR scheduling algoritme . . . . . . . . . . . . . . . . 19
3 Ontwerp en implementatie 21
3.1 Gebruikte algoritmen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21
3.1.1 Dual SLA scheduling algoritme . . . . . . . . . . . . . . . . . . . . . . . . 21
3.1.1.1 Inleiding . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21
i

ii INHOUDSOPGAVE
3.1.1.2 Werking . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21
3.1.1.3 Voorbeeld . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 22
3.1.2 Aangepast dual SLA scheduling algoritme (versie 1) . . . . . . . . . . . . 24
3.1.2.1 Inleiding . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 24
3.1.2.2 Werking . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 24
3.1.2.3 Voorbeeld . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 25
3.1.3 Aangepast dual SLA scheduling algoritme (versie 2) . . . . . . . . . . . . 26
3.1.3.1 Inleiding . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 26
3.1.3.2 Werking . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 27
3.1.3.3 Voorbeeld . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 28
3.2 Implementatie aangepast dual SLA scheduling algoritme . . . . . . . . . . . . . . 29
3.2.1 Algemeen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 29
3.2.2 OLT . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 29
3.2.2.1 Algemeen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 29
3.2.2.2 Scheduler . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 30
3.2.3 ONU . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31
3.3 Implementatie WRR scheduling algoritme . . . . . . . . . . . . . . . . . . . . . . 32
3.3.1 Algemeen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 32
3.3.2 Werking WRR scheduling algoritme . . . . . . . . . . . . . . . . . . . . . 32
3.4 Self-similar trafiek . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 34
4 Simulaties en resultaten 35
4.1 Analyse verdeling bandbreedte dual SLA . . . . . . . . . . . . . . . . . . . . . . . 35
4.1.1 Testopstelling . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 35
4.1.2 Resultaten . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 36
4.2 Analyse vertraging in dual SLA open access . . . . . . . . . . . . . . . . . . . . . 39
4.2.1 Vergelijking van origineel en aangepast algoritme . . . . . . . . . . . . . . 39
4.2.1.1 Testopstelling . . . . . . . . . . . . . . . . . . . . . . . . . . . . 39
4.2.1.2 Resultaten . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 40
4.2.2 Elke ONU vraagt dezelfde bandbreedte . . . . . . . . . . . . . . . . . . . 41
4.2.2.1 Testopstelling . . . . . . . . . . . . . . . . . . . . . . . . . . . . 41
4.2.2.2 Resultaten . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 42
4.2.3 De ONU’s vragen verschillende bandbreedtes . . . . . . . . . . . . . . . . 42

INHOUDSOPGAVE iii
4.2.3.1 Testopstelling . . . . . . . . . . . . . . . . . . . . . . . . . . . . 42
4.2.3.2 Resultaten . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 44
4.3 Vergelijking vertraging dual SLA en WRR . . . . . . . . . . . . . . . . . . . . . . 45
4.3.1 Alleen best effort trafiek . . . . . . . . . . . . . . . . . . . . . . . . . . . . 45
4.3.1.1 Testopstelling . . . . . . . . . . . . . . . . . . . . . . . . . . . . 45
4.3.1.2 Resultaten . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 45
4.3.2 Bepaling gewichten . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 46
4.3.2.1 Testopstelling . . . . . . . . . . . . . . . . . . . . . . . . . . . . 46
4.3.2.2 Resultaten . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 47
4.3.3 25% prioriteitstrafiek . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 52
4.3.3.1 Testopstelling . . . . . . . . . . . . . . . . . . . . . . . . . . . . 52
4.3.3.2 Resultaten . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 53
4.3.4 50% prioriteitstrafiek . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 54
4.3.4.1 Testopstelling . . . . . . . . . . . . . . . . . . . . . . . . . . . . 54
4.3.4.2 Resultaten . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 54
4.3.5 75% prioriteitstrafiek . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 55
4.3.5.1 Testopstelling . . . . . . . . . . . . . . . . . . . . . . . . . . . . 55
4.3.5.2 Resultaten . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 56
5 Conclusie en toekomstperspectieven 57
5.1 Conclusie . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 57
5.2 Toekomstperspectieven . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 58
Bibliografie 59
Lijst van figuren 63
Lijst van tabellen 65
Bijlagen 67

iv INHOUDSOPGAVE

Lijst van afkortingen en symbolen
ADSL Asymmetric Digital Subscriber Line.
AES Advanced Encryption System.
CBR Constante Bit Rate.
CMTS Cable Modem Termination System.
DBA Dynamic Bandwidth Allocation.
DOCSIS Data Over Cable Service Interface Specification.
DSL Digital Subscriber Line.
DSLAM Digital Subscriber Line Access Multiplexer.
FTTB Fiber to the Building.
FTTC Fiber to the Curb.
FTTH Fiber to the Home.
FTTN Fiber to the Node.
FTTP Fiber to the Premises.
HD High Definition.
HFC Hybrid Fiber Coax.
IP Internet Protocol.
IPACT Interleaved Polling with Adaptive Cycle Time.
v

vi LIJST VAN AFKORTINGEN EN SYMBOLEN
LAN Local Area Network.
LEX Local EXchange.
MAC Media-Access Control.
MP2P MultiPoint-to-Point.
OFDMA Orthogonal Frequency Division Multiple Access.
OLT Optical Line Terminal.
ONU Optical Network Unit.
P2MP Point-to-MultiPoint.
P2P Point-to-Point.
PON Passive Optical Network.
QoS Quality of Service.
RR Round Robin.
SDSL Symmetric Digital Subscriber Line.
SLA Service Level Agreement.
TDM Time Division Multiplexing.
ToS Type of Service.
TWDM Time and Wavelength Division Multiplexing.
VBR Variabele Bit Rate.
VDSL Very high speed Digital Subscriber Line.
VLAN Virtual Local Area Network.
VoD Video on Demand.
WDM Wavelength Division Multiplexing.
WRR Weighted Round Robin.

Hoofdstuk 1
Inleiding
Sinds enkele jaren is de hoeveelheid internettrafiek in de toegangsnetwerken enorm gestegen, wat
verschillende oorzaken heeft. De opkomst van digitale televisie heeft ertoe geleid dat gebruikers
naar zenders in High Definition (HD) kunnen kijken maar ook gebruik kunnen maken van Video
on Demand (VoD) enz. Daarnaast willen deze gebruikers ook steeds een snellere internetcon-
nectie om gemakkelijk bestanden te kunnen delen, video’s online te kunnen bekijken (YouTube)
en videogesprekken van hoge kwaliteit te voeren (Skype).
De core netwerken zijn reeds geruime tijd voorzien van fiber om deze stijging aan te kunnen,
maar het merendeel van aansluitingen in Belgie zijn nog steeds via de traditionele toegangsnet-
werken: coax en twisted pair. Er zijn al verschillende technieken toegepast om het maximale van
deze twee kopertechnologieen te bereiken. Helaas is de fysische limiet van deze kabels bereikt,
waardoor een alternatie nodig is in de toegangsnetwerken: fiber!
Fiber to the Home (FTTH) of Fiber to the Building (FTTB) is de meest onderzochte technologie
om de verhoogde trafiek van dataverkeer in toegangsnetwerken op te vangen. Helaas is hieraan
een groot nadeel verbonden: het uitrollen van fiber in de toegangsnetwerken brengt een enorme
financiele kost met zich mee. Om te vermijden dat elke netwerk provider deze kost moet maken,
kan het concept van een Passive Optical Network (PON) met open access toegepast worden. De
fiber in de toegangsnetwerken wordt in dit geval gedeeld door alle netwerk en service providers
zodanig dat de uitrol van fiber slechts eenmalig moet uitgevoerd worden.
1

2 HOOFDSTUK 1: INLEIDING
Open access brengt een kostenbesparing met zich mee, maar zorgt ook voor enkele aandachts-
punten. Zo moet elke netwerk provider ervoor zorgen dat de bandbreedte fair verdeeld wordt
onder de gebruikers afhankelijk van hun Service Level Agreement (SLA). Ook moet de vertra-
ging voor prioritaire trafiek voldoende laag zijn om goede beeld- en geluidskwaliteit te kunnen
aanbieden. Ook mag de infrastructuur geen onderscheid maken tussen de netwerk providers met
een gelijke SLA.
Het delen van de fiber is enkel realiseerbaar indien een multiplexing techniek wordt voorzien, zo-
als Time Division Multiplexing (TDM) of Wavelength Division Multiplexing (WDM). Bij TDM
is er een algoritme nodig om de tijdssloten gelijk te verdelen onder de service providers en de
gebruikers. Het algoritme heeft een rechtstreekse invloed op het verdelen van de bandbreedte
alsook op de vertraging die elke gebruiker of service provider ondervindt.
Het doel van deze thesis is om een TDM-PON te ontwerpen waarbij een open access algoritme
is geımplementeerd. Hierbij worden er verschillende parameters aangepast aan het systeem om
te kijken hoe bepaalde algoritmen hierop reageren. Hierbij wordt zowel de verdeling van de
beschikbare bandbreedte en de vertraging van de pakketten geanalyseerd om zo een goede ver-
gelijking te kunnen maken tussen verschillende algoritmen.
Deze thesis is als volgt gestructureerd. In hoofdstuk 2 wordt vertrokken vanuit de oorsprong
van toegangsnetwerken om zo tot FTTH komen. Na het bespreken van de architecturen en de
multiplexing technieken, wordt het concept van open access toegelicht. In hoofdstuk 3 worden
de algoritmen nader toegelicht met enkele voorbeelden, gevolgd door de implementatie van deze
algoritmen in de simulatiesoftware OPNET. Vervolgens worden in hoofdstuk 4 de algoritmen
onderworpen aan verscheidene testopstellingen. Hierdoor kunnen de algoritmen onderling ver-
geleken worden door de sterktes en zwaktes aan te geven. Er wordt afgesloten in hoofdstuk 5
met enkele conclusies, ideeen en werk voor de toekomst in dit onderzoeksdomein.

Hoofdstuk 2
State of the art
2.1 Fiber to the Home
2.1.1 Van koper naar fiber
Deze thesis situeert zich in het domein van de toegangsnetwerken. Een toegangsnetwerk is het
deel van het netwerk dat klanten toegang verleent tot de diensten van een service provider.
Anno 2014 bestaat het merendeel van de toegangsnetwerken voor particulieren nog steeds uit
een kopertechnologie. De twee gebruikte kopertechnologieen zijn coax en twisted pair. Coax
werd oorspronkelijk gebruikt om analoge televisie te verspreiden via een kabel in plaats van het
draadloos verspreiden via de antenne. Twisted pair werd gekozen om een telefonienetwerk uit te
rollen zodat personen in staat waren met elkaar te communiceren over een lange afstand. Over
een coax kabel werd dezelfde informatie gestuurd naar elke gebruiker (alle televisiekanalen),
waardoor iedereen gebruik maakt van dezelfde (gedeelde) kabel. Het telefoonnetwerk daarente-
gen moest voorzien dat de informatie gesplitst werd per gebruiker, waardoor iedereen zijn eigen
kabel had. Dit zorgt voor twee verschillende topologieen: de tree and branch topologie voor het
televisienetwerk (zie figuur 2.1a) en de star topologie voor het telefonienetwerk (zie figuur 2.1b).
Bij de opkomst van het internet, hebben verschillende bedrijven de bestaande kopertechnologieen
aangepast om iedereen toegang tot het internet te kunnen aanbieden. Het verschil in fysische
eigenschappen van de kabel en het verschil in topologie heeft ervoor gezorgd dat de ontwikkelde
standaarden voor beide topologieen ook verschillen.
3

4 HOOFDSTUK 2: STATE OF THE ART
(a) Tree and branch topologie
(b) Star topologie
Figuur 2.1: Topologie van de gebruikte kopertechnologieen in Belgie
Coax Hiervoor werd in Amerika de Data Over Cable Service Interface Specification (DOCSIS)
standaard ontwikkeld. Euro-DOCSIS is dezelfde standaard, maar aangepast naar de fysische ei-
genschappen van het Europese coax-netwerk [1]. Er zijn reeds verschillende versies van DOCSIS
ontwikkeld waarbij een nieuwe versie enkele verbeteringen aanbrengt ten opzichte van de vorige
[1].
• (Euro-)DOCSIS 1.0: de eerste versie van DOCSIS die bestond uit een best effort data
service.
• (Euro-)DOCSIS 1.1: Quality of Service (QoS) en beveiliging (authenticatie) werden toe-
gevoegd.
• (Euro-)DOCSIS 2.0: de specificatie van de fysische laag werd aangepast om symmetrische
bandbreedtes te verkrijgen.

2.1 Fiber to the Home 5
• (Euro-)DOCSIS 3.0: channel bonding om hogere snelheden te bekomen, ondersteuning van
IPv6, toevoegen van Advanced Encryption System (AES), ...
• (Euro-)DOCSIS 3.1: momenteel de laatste versie waarbij Orthogonal Frequency Division
Multiple Access (OFDMA) wordt toegepast om snelheden van 10 Gbps in de downstream
en 1-2 Gbps in de upstream te kunnen realiseren.
Aangezien de kabel gedeeld wordt, is de maximale bandbreedte niet altijd gegarandeerd. De the-
oretisch haalbare maximale snelheden, weergegeven in tabel 2.1, kunnen enkel behaald worden
op voorwaarde dat niemand anders het netwerk gebruikt.
Versie DOCSIS Downstream Upstream
DOCSIS 1.x 55.62 Mbps 10.24 Mbps
DOCSIS 2.0 55.62 Mbps 30.72 Mbps
DOCSIS 3.0 444.96 Mbps 122.88 Mbps
Tabel 2.1: Downstream en upstream snelheden DOCSIS [1]
Twisted pair Om naast de telefoongesprekken ook nog data te kunnen versturen over een twi-
sted pair kabel, zijn verschillende Digital Subscriber Line (DSL) standaarden ontwikkeld. Deze
standaarden worden meestal samengevat als de xDSL standaard, waarbij de ‘x’ kan vervangen
worden door alle mogelijke DSL technologieen. Er zijn verschillende soorten DSL, waarbij de
volledige groep in twee categorieen kan opgedeeld worden: de symmetrische DSL standaarden
en de asymmetrische DSL standaarden. Bij Symmetric Digital Subscriber Line (SDSL) is de
bandbreedte van de downstream even groot als de bandbreedte van de upstream. Daarentegen
is de bandbreedte van de downstream groter dan de upstream in het geval van Asymmetric
Digital Subscriber Line (ADSL). Al de standaarden die in Belgie gebruikt werden, zijn asymme-
trisch (op uitzondering van VDSL2 waar ook symmetrisch mogelijk is1). De theoretisch haalbare
maximale snelheden zijn weergegeven in tabel 2.2.
1De som van de snelheden bij VDSL2 is maximaal 200 Mbps. De bandbreedte kan hierbij zowel asymmetrisch
als symmetrisch verdeeld worden. Hierbij is het ook mogelijk dat de upstream meer toegewezen krijgt dan de
downstream, wat bij ADSL, ADSL2, ADSL2+ en Very high speed Digital Subscriber Line (VDSL) niet mogelijk
is.
6 HOOFDSTUK 2: STATE OF THE ART
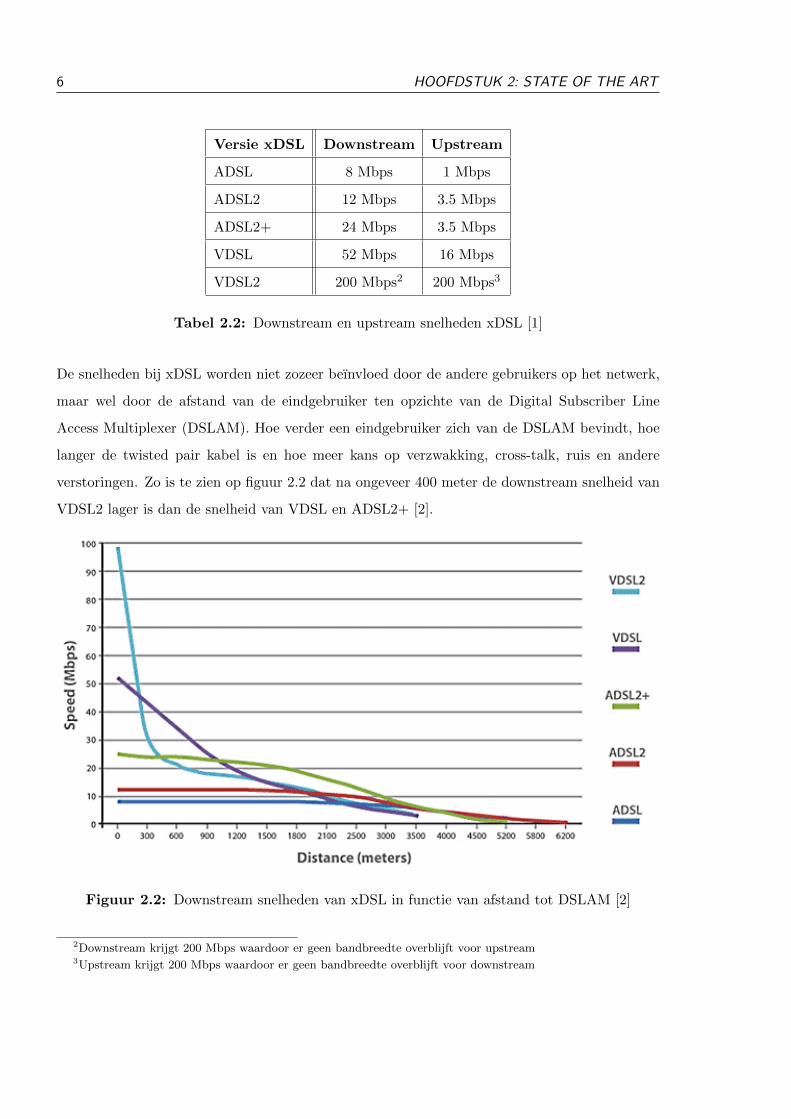
Versie xDSL Downstream Upstream
ADSL 8 Mbps 1 Mbps
ADSL2 12 Mbps 3.5 Mbps
ADSL2+ 24 Mbps 3.5 Mbps
VDSL 52 Mbps 16 Mbps
VDSL2 200 Mbps2 200 Mbps3
Tabel 2.2: Downstream en upstream snelheden xDSL [1]
De snelheden bij xDSL worden niet zozeer beınvloed door de andere gebruikers op het netwerk,
maar wel door de afstand van de eindgebruiker ten opzichte van de Digital Subscriber Line
Access Multiplexer (DSLAM). Hoe verder een eindgebruiker zich van de DSLAM bevindt, hoe
langer de twisted pair kabel is en hoe meer kans op verzwakking, cross-talk, ruis en andere
verstoringen. Zo is te zien op figuur 2.2 dat na ongeveer 400 meter de downstream snelheid van
VDSL2 lager is dan de snelheid van VDSL en ADSL2+ [2].
Figuur 2.2: Downstream snelheden van xDSL in functie van afstand tot DSLAM [2]
2Downstream krijgt 200 Mbps waardoor er geen bandbreedte overblijft voor upstream3Upstream krijgt 200 Mbps waardoor er geen bandbreedte overblijft voor downstream

2.1 Fiber to the Home 7
Triple play Service providers bieden nu niet enkel televisie of telefonie aan, maar kunnen
triple play aan de klanten leveren. Triple play is een combinatie van telefonie, internet en (di-
gitale) televisie en wordt in een pakket aangeboden aan de klant. De jaarlijkse stijging van
de wereldwijde internettrafiek en het groeiende aanbod aan televisiezenders in High Definition
(HD), zorgt ervoor dat de toegangsnetwerken steeds hogere snelheden te verwerken krijgen [3].
Zoals in de vorige paragrafen vermeld staat, zijn er technieken toegepast om de snelheden bij
zowel coax als twisted pair te verhogen met als doel triple play te kunnen ondersteunen. Helaas
zijn de fysische limieten van de kopertechnologieen zo goed als bereikt, waardoor er moet gezocht
worden naar alternatieven.
Fiber Glasvezel of fiber is een van de meest veelbelovende technieken om de verhoogde tra-
fiek in de toegangsnetwerken op te vangen. In de huidige toegangsnetwerken bevindt zich al
fiber en wordt in het algemeen gesproken over Fiber to the Curb (FTTC) of Fiber to the Node
(FTTN) (bij coax wordt dit ook meestal Hybrid Fiber Coax (HFC) genoemd). Hierbij wordt
fiber enkel tot een lokale cabine (de Local EXchange (LEX)) gebracht en blijft het laatste stuk
tot aan het huis van de particulier uit een kopertechnologie bestaan. Dit wil zeggen dat de
connectie vanuit het core netwerk tot de DSLAM (de LEX voor twisted pair) of de Cable Mo-
dem Termination System (CMTS) (de LEX voor coax) in fiber wordt uitgevoerd (zie figuur 2.3).
Maar om de snelheden nog te verhogen, kan de fiber volledig tot aan de woning van de klant gaan
en is er sprake van een volledig optisch netwerk. Dit is beter bekend als Fiber to the Premises
(FTTP), wat meestal opgesplitst wordt in Fiber to the Home (FTTH) en Fiber to the Building
(FTTB) [4]. Het onderscheid tussen beide types wordt gemaakt op basis van het aantal klanten
die verbonden zijn: bij FTTB zijn er meerdere klanten verbonden via de fiber (bijvoorbeeld in een
flatgebouw) tegenover FTTH waar er slechts een klant verbonden is. Het eindpunt van de fiber in
het gebouw is de Optical Network Unit (ONU) en is verantwoordelijk voor de omzetting tussen
het optisch en het elektrisch signaal. De ONU’s zijn, langs de optische zijde, verbonden met de
Optical Line Terminal (OLT). De OLT stelt de LEX in een optisch netwerk voor en verbindt het
toegangsnetwerk met het core netwerk. De wijze waarop de ONU’s verbonden zijn met de OLT,
hangt af van de gekozen architectuur. Er zijn drie mogelijke architecturen in optische netwerken:
Point-to-Point (P2P), een actieve ster of een passieve ster [4]. Beide ster-architecturen kunnen
gebundeld worden onder Point-to-MultiPoint (P2MP). Deze drie architecturen zijn terug te
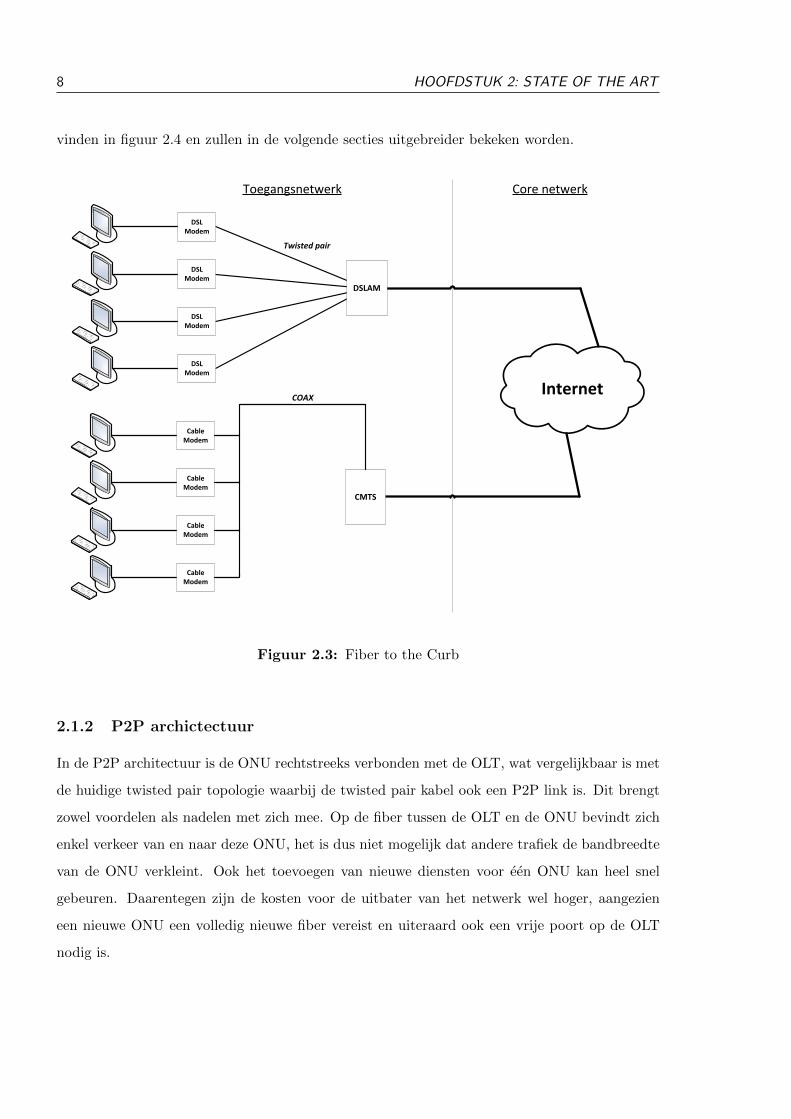
8 HOOFDSTUK 2: STATE OF THE ART
vinden in figuur 2.4 en zullen in de volgende secties uitgebreider bekeken worden.
Twisted pair
DSLAM
DSLModem
DSLModem
DSLModem
DSLModem
Toegangsnetwerk Core netwerk
CMTS
CableModem
CableModem
CableModem
CableModem
COAXInternet
Figuur 2.3: Fiber to the Curb
2.1.2 P2P archictectuur
In de P2P architectuur is de ONU rechtstreeks verbonden met de OLT, wat vergelijkbaar is met
de huidige twisted pair topologie waarbij de twisted pair kabel ook een P2P link is. Dit brengt
zowel voordelen als nadelen met zich mee. Op de fiber tussen de OLT en de ONU bevindt zich
enkel verkeer van en naar deze ONU, het is dus niet mogelijk dat andere trafiek de bandbreedte
van de ONU verkleint. Ook het toevoegen van nieuwe diensten voor een ONU kan heel snel
gebeuren. Daarentegen zijn de kosten voor de uitbater van het netwerk wel hoger, aangezien
een nieuwe ONU een volledig nieuwe fiber vereist en uiteraard ook een vrije poort op de OLT
nodig is.
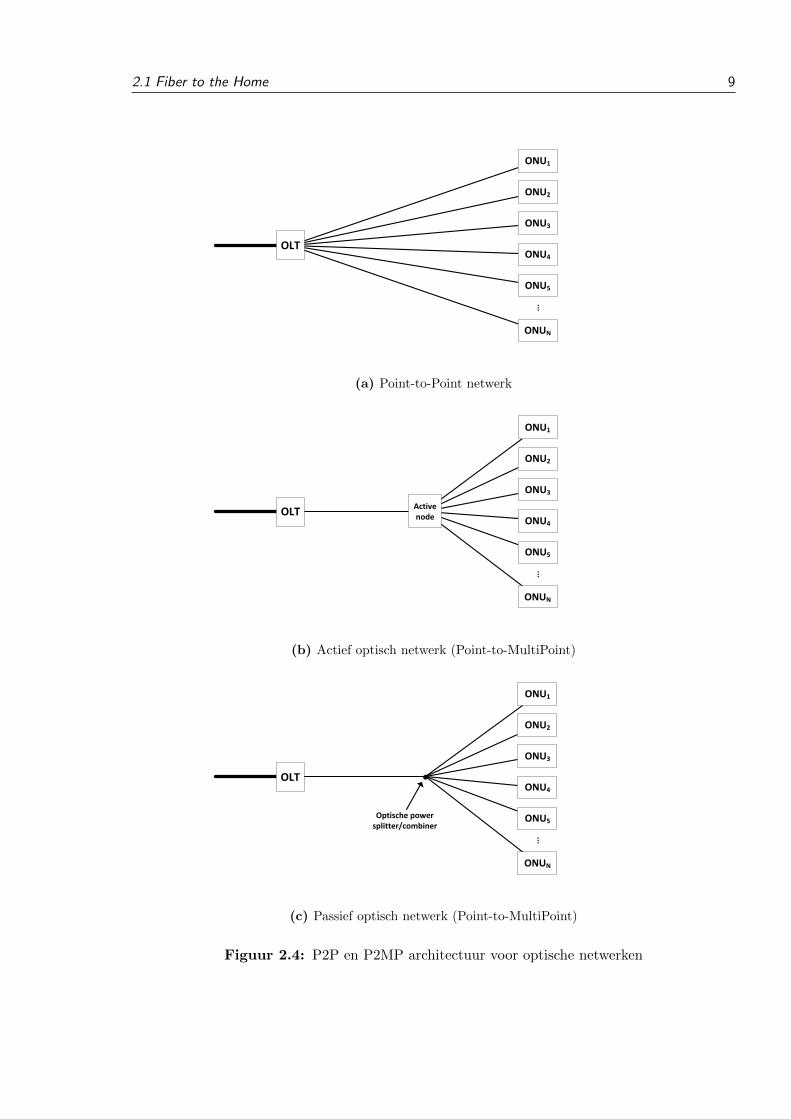
2.1 Fiber to the Home 9
ONU1
ONU2
ONU3
ONU4
ONU5
ONUN
...OLT
(a) Point-to-Point netwerk
OLT
ONU1
ONU2
ONU3
ONU4
ONU5
ONUN
...
Active node
(b) Actief optisch netwerk (Point-to-MultiPoint)
Optische powersplitter/combiner
OLT
ONU1
ONU2
ONU3
ONU4
ONU5
ONUN
...
(c) Passief optisch netwerk (Point-to-MultiPoint)
Figuur 2.4: P2P en P2MP architectuur voor optische netwerken

10 HOOFDSTUK 2: STATE OF THE ART
2.1.3 Actieve optische netwerken
Bij een actieve ster is er een fiber die rechtstreeks van de OLT naar een actieve node, die dicht bij
de ONU’s geplaatst is, gaat. Alle ONU’s zijn op hun beurt aan de hand van een fiber verbonden
met de actieve node. De topologie die hier gebruikt wordt, is de tree and branch topologie.
Hierbij zijn de takken van de actieve node naar de ONU’s meestal veel korter in verhouding
met de link tussen de OLT en de actieve node. Deze architectuur heeft als voordeel dat een
nieuwe ONU enkel een nieuwe fiber vereist van de actieve node naar de ONU. Deze fiber is in
verhouding met een P2P architectuur veel korter en dus goedkoper. Het grote nadeel van dit
systeem is de actieve node: deze component heeft ook energievoorziening en onderhoud nodig,
wat het totale systeem weer duurder maakt.
2.1.4 Passieve optische netwerken
Deze architectuur is gelijkaardig aan de actieve ster, met het verschil dat de actieve node nu
vervangen wordt door een passieve optische power splitter/combiner. Dit zorgt ervoor dat de
nadelen van de actieve node (energie en onderhoud) geelimineerd worden en de voordelen be-
houden blijven. Hierdoor is deze architectuur heel populair voor het gebruiken van fiber in
toegangsnetwerken. Het gebruiken van een passieve node in het toegangsnetwerk is wereldwijd
gekend als een Passive Optical Network (PON). Door de voordelen en de populariteit van de
technologie, zal deze architectuur als vertrekpunt beschouwd worden in deze thesis.
De werking van de passieve node verschilt van deze van de actieve node door het ontbreken
van een energievoorziening. De passieve node zal de inkomende signalen van de OLT splitsen
en vervolgens over alle takken naar de ONU’s sturen. De ontvanger in de ONU zal op zijn
beurt de juiste trafiek doorlaten naar de gebruiker en alle overige trafiek negeren. In upstream
richting (van de ONU naar de OLT) zal de passieve node de inkomende trafiek combineren om
gezamenlijk trafiek over de link van de passieve node naar de OLT te sturen. Het combineren
van trafiek, beter gekend als multiplexing, kan op verschillende manieren gebeuren. De meest
voor de hand liggende technieken zullen hier besproken worden.

2.1 Fiber to the Home 11
2.1.4.1 TDM
Een eerste mogelijkheid om signalen te combineren is Time Division Multiplexing (TDM) [4].
Hierbij wordt de fiber in tijdssloten verdeeld en krijgt een ONU tijdssloten toegewezen, zoals
in figuur 2.5a wordt weergegeven. Er zijn twee mogelijkheden om tijdssloten toe te kennen aan
ONU’s:
1. Statische toekenning: elke ONU krijgt een vast aantal tijdssloten toegewezen en heeft
steeds recht op dezelfde tijdssloten. Dit zorgt ervoor dat de upstream bandbreedte van
elke ONU steeds gegarandeerd is, maar heeft ook als gevolg dat er veel tijdssloten onbenut
kunnen blijven indien ONU’s geen upstream trafiek moeten sturen.
2. Dynamische toekenning: elke ONU krijgt een aantal tijdssloten toegewezen, afhankelijk
van bepaalde parameters zoals: prioriteit van de trafiek, hoeveelheid van de trafiek, wat
de resterende capaciteit van de link is, enz. Hierbij moet de OLT op de hoogte zijn van al
deze parameters van elke ONU, wat op twee mogelijkheden gerealiseerd kan worden:
(a) De ONU stuurt een REPORT bericht nadat de OLT hierom gevraagd heeft (beter
bekend als polling).
(b) De ONU stuurt een REPORT bericht op het einde van het laatste toegekende tijds-
slot.
Deze REPORT berichten bevatten de vulgraden van de buffers bij de ONU, welke prioriteit
aan deze buffers is toegekend, over welke ONU het gaat, enz. Aan de hand van deze
berichten kan de OLT ervoor zorgen dat de tijdssloten correct en fair worden toegekend.
De OLT zal vervolgens GRANT berichten sturen naar de ONU’s om aan te geven welke
ONU welke tijdssloten heeft gekregen en welke trafiek in deze tijdssloten is toegelaten. Het
dynamisch toekennen van tijdssloten, in de literatuur beter gekend als Dynamic Bandwidth
Allocation (DBA), vereist enige logica bij de OLT en wordt uitgebreider besproken in sectie
2.2.
Dynamische toekenning van tijdssloten heeft een duidelijke meerwaarde ten opzichte van stati-
sche toekenning, waardoor dit als vertrekpunt zal gekozen worden in deze thesis.
2.1.4.2 WDM
Een tweede techniek die regelmatig gebruikt wordt, is Wavelength Division Multiplexing (WDM)
[4, 5]. Hier worden de verschillende ONU’s geen tijdssloten toegewezen, maar krijgt elke ONU
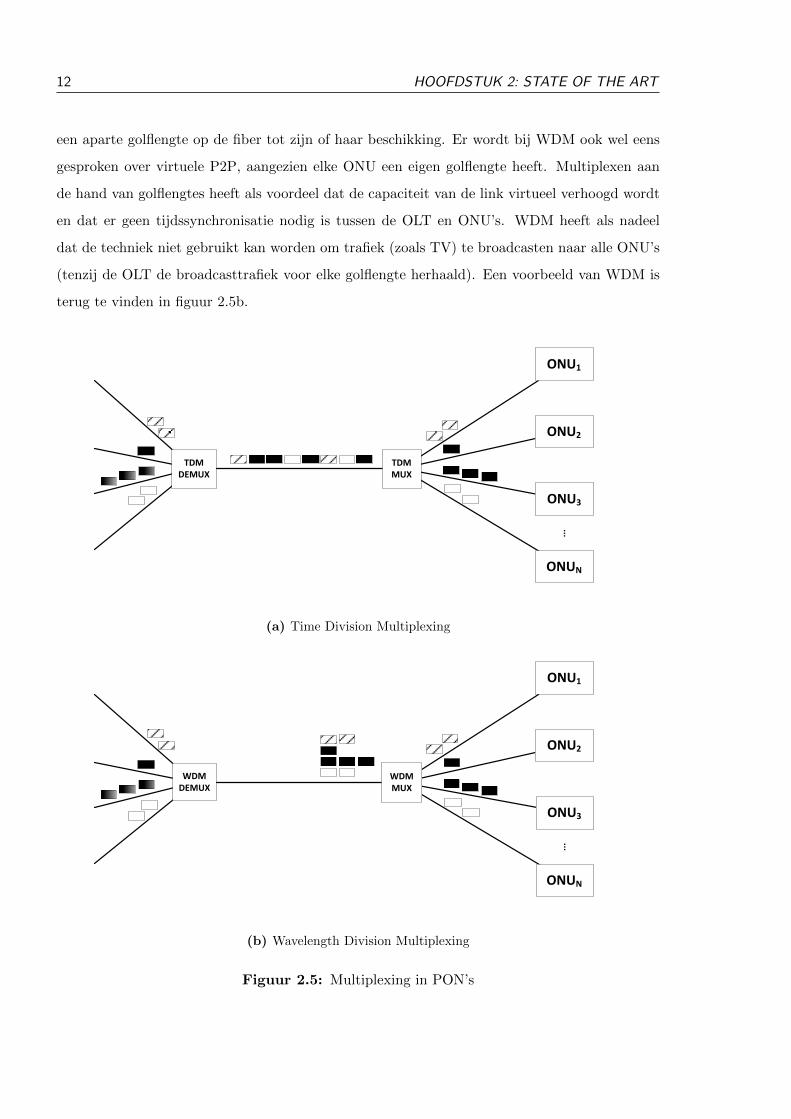
12 HOOFDSTUK 2: STATE OF THE ART
een aparte golflengte op de fiber tot zijn of haar beschikking. Er wordt bij WDM ook wel eens
gesproken over virtuele P2P, aangezien elke ONU een eigen golflengte heeft. Multiplexen aan
de hand van golflengtes heeft als voordeel dat de capaciteit van de link virtueel verhoogd wordt
en dat er geen tijdssynchronisatie nodig is tussen de OLT en ONU’s. WDM heeft als nadeel
dat de techniek niet gebruikt kan worden om trafiek (zoals TV) te broadcasten naar alle ONU’s
(tenzij de OLT de broadcasttrafiek voor elke golflengte herhaald). Een voorbeeld van WDM is
terug te vinden in figuur 2.5b.
ONU1
ONU2
ONU3
ONUN
...
TDM DEMUX
TDMMUX
(a) Time Division Multiplexing
ONU1
ONU2
ONU3
ONUN
...
WDM DEMUX
WDMMUX
(b) Wavelength Division Multiplexing
Figuur 2.5: Multiplexing in PON’s

2.2 Dynamic Bandwidth Allocation 13
2.1.4.3 TWDM
Time and Wavelength Division Multiplexing (TWDM) is een techniek waarbij er zowel gemul-
tiplext wordt op gebied van tijdssloten als van golflengtes [5]. Hierdoor kan de gemiddelde
vertraging per ONU naar beneden gaan ten opzichte van TDM en tegelijk kan er meer trafiek
gemultiplext worden ten opzichte van WDM, welke beperkt is in het aantal golflengtes. De voor-
delen van beide technieken worden gecombineerd, maar zorgen er wel voor dat de multiplexer
en demultiplexer veel complexer zullen zijn dan bij de vorige technieken.
2.2 Dynamic Bandwidth Allocation
2.2.1 Algemeen
Zoals in sectie 2.1.1 reeds vermeld werd, valt een passief optisch toegangsnetwerk onder de
P2MP netwerktopologie. Dit is het geval als het netwerk bekeken wordt vanuit de OLT, ofwel in
downstream richting. Wordt het netwerk bekeken vanuit de ONU’s (upstream), dan is dit een
MultiPoint-to-Point (MP2P) netwerktopologie [6]. Beide topologieen zijn hetzelfde, enkel hun
standpunt in het netwerk verschilt. Downstream is er geen probleem met de trafiek, aangezien
alle pakketten gebroadcasted worden naar de ONU’s. Upstream vormt er zich wel een probleem,
aangezien er pakketten van verschillende ONU’s tegelijk op de link kunnen verschijnen. De
passieve optische combiner heeft geen logica, dus kan niet garanderen dat dit proces foutloos
verloopt.
Om dit probleem in de upstream richting op te lossen, wordt de techniek van DBA toegepast.
Hierbij wordt bandbreedte dynamisch toegekend aan elke ONU, afhankelijk van wat de ONU’s
aan bandbreedte gevraagd hebben. Het toekennen van bandbreedte gebeurt aan de hand van het
verdelen van tijdssloten tussen de ONU’s. In een toegewezen tijdsslot kan een ONU pakketten
versturen met de zekerheid dat de link vrij is. Deze tijdssloten worden dynamisch toegekend en
zijn afhankelijk van het aantal pakketten dat zich in de buffers van de ONU’s bevindt.
Het proces om deze tijdssloten toe te kennen, werkt als volgt:
1. Stel dat de OLT de vulgraad van de buffers van elke ONU kent (deze vulgraden worden
bijgehouden in een polling tabel).

14 HOOFDSTUK 2: STATE OF THE ART
2. De OLT stuurt een GRANT bericht naar de eerste ONU voor een bepaald aantal tijdsslo-
ten.
3. De ONU stuurt de pakketten die mogelijk zijn binnen de toegekende tijdssloten. Na al
deze pakketten stuurt de ONU ook nog een REQUEST bericht, dat de huidige vulgraad
van de buffer bevat.
4. De OLT kan nu zijn polling tabel updaten voor deze ONU.
5. Op het moment dat de eerste ONU zijn pakketten aan het zenden is, berekent de OLT
welke tijdssloten de tweede ONU krijgt toegewezen. Hierdoor kan de tweede ONU direct
beginnen zenden nadat de tijdssloten van de eerste zijn verlopen.
6. Dit proces loopt op dezelfde manier tot alle ONU’s een grant gekregen hebben, waarna
het volledige proces zich herhaalt.
Bovenstaand proces is beter bekend onder de naam Interleaved Polling with Adaptive Cycle
Time (IPACT) [6].
2.2.2 Aangepaste versie
De basisvorm van IPACT heeft nog enige tekortkomingen op volgende gebieden:
• Er wordt geen onderscheid gemaakt tussen verschillende soorten trafiek (spraak, video en
internet).
• De bandbreedte wordt niet altijd fair verdeeld over de ONU’s, aangezien een hogere vul-
graad altijd meer tijdssloten oplevert (ten koste van andere ONU’s).
• Er is ook geen ondersteuning voor meerdere service providers die geconnecteerd zijn aan
de OLT.
Om deze tekortkomingen op te lossen zijn er verschillende aanpassingen gerealiseerd [7, 8, 9].
In [10] wordt er gebruik gemaakt van een globale prioriteit: elke ONU heeft hetzelfde aantal
buffers (een per soort trafiek), onafhankelijk van het aantal service providers dat er aan de OLT
geconnecteerd is. De OLT kan nu tijdssloten toekennen aan de ONU’s op basis van de globale
prioriteit van de trafiek.

2.3 Open access 15
Er wordt niet alleen rekening gehouden met de globale prioriteit, maar ook met het fair verdelen
van de capaciteit. Zo worden er eerst tijdssloten toegekend aan de buffers met een lage vulgraad,
zodat deze een minimale bandbreedte krijgen. Vervolgens wordt er gekeken naar de buffers met
een hoge vulgraad, waar de globale prioriteit op toegepast wordt. Dit principe is gelijklopend
met dual Service Level Agreement (SLA) dat terug te vinden is in sectie 2.3.2.
2.3 Open access
2.3.1 Inleiding
Het implementeren van een PON is goedkoper dan het implementeren van een actief optisch
netwerk, aangezien de passieve node geen energievoorziening en minder (of zelfs geen) onderhoud
vereist. Helaas is de totale kost voor het uitrollen van fiber in de toegangsnetwerken zeer hoog
[5, 11], waardoor het goedkoper is om de infrastructuur te delen. Indien de infrastructuur gedeeld
wordt, is het noodzakelijk om volgend onderscheid te maken [12]:
1. Infrastructuur provider: de provider die verantwoordelijk is voor het uitrollen en on-
derhouden van de infrastructuur. Deze provider kan eventueel nog als volgt worden opge-
splitst:
(a) De passieve infrastructuur provider is verantwoordelijk voor het passieve deel van het
netwerk, wat zich beperkt tot de fiber en de passieve node.
(b) De netwerk provider is verantwoordelijk voor alle actieve componenten in het netwerk,
namelijk de OLT’s en ONU’s.
2. Service provider: de provider die verantwoordelijk is voor het aanbieden van diensten
(internet, telefonie, digitale televisie) aan de eindgebruikers.
In de huidige toegangsnetwerken (twisted pair en coax) is de infrastructuur provider ook een
service provider, zoals Belgacom en Telenet in Belgie. Er is sprake van een traditioneel toe-
gangsnetwerk indien er slechts een service provider op de infrastructuur aanwezig is (zie figuur
2.6a). Sinds enkele jaren echter zijn Belgacom en Telenet verplicht hun netwerk open te stel-
len voor concurrenten, waardoor er mogelijk meerdere service providers hetzelfde netwerk delen.
Hier onstaat een ingewikkelde situatie waarbij een service provider, die tevens een infrastructuur
provider is, zijn netwerk moet delen met andere service providers.

16 HOOFDSTUK 2: STATE OF THE ART
Om de mogelijkheid tot belangenvermenging te vermijden, moet een onafhankelijke derde partij
als infrastructuur provider gekozen worden. Hierbij maakt deze derde partij geen onderscheid
tussen de verschillende service providers die gebruik willen maken van het netwerk. Deze si-
tuatie is beter bekend als open access en is weergegeven in figuur 2.6b. Het is ook mogelijk
dat de infrastructuur provider bestaat uit twee bedrijven, zoals in Stockholm: daar is Stokab
(eigendom van de stad Stockholm) de passieve infrastructuur provider en zijn er verschillende
netwerk providers [12, 13]. Bij open access is het essentieel voor de netwerk provider dat de
bandbreedte niet alleen op een faire manier verdeeld wordt over de service providers, maar ook
op een faire manier verdeeld wordt over de eindgebruikers. Naast de bandbreedte moet ook de
vertraging gelijkaardig zijn voor hetzelfde type van trafiek (video, data, ...), onafhankelijk van
de service provider die de trafiek aanbiedt.
2.3.2 Service Level Agreements
In de traditionele toegangsnetwerken (zonder open access), waarbij de infrastructuur beheerd
wordt door de service provider zelf, heeft de eindgebruiker enkel een SLA met de service provider.
Een SLA is een contract tussen een leverancier van diensten en een klant, waarin beschreven staat
welke diensten er geleverd zullen worden en wat de kwaliteit van deze diensten is. Daarnaast
wordt er in dit document ook vermeld wat de rechten en plichten van de eindgebruiker en de
leverancier zijn, opdat het kwaliteitsniveau van de diensten kan gegarandeerd worden [14, 15].
Enkele onderdelen die meestal vermeld worden in een SLA met een service provider:
• De bandbreedte van het internet (maximaal, gemiddeld of minimaal),
• Hoeveel van deze bandbreedte naar upload gaat en hoeveel naar download gaat,
• Het aantal videokanalen dat de gebruiker (al dan niet gelijktijdig) kan bekijken,
• Het aantal storingen dat er mogen plaatsvinden per jaar (zonder dat de service provider
een terugbetaling hoeft te doen),
• Wat de tussenkomst van de service provider bij een grote onderbreking is,
• Wie er aansprakelijk is voor bepaalde fouten, enz.

2.3 Open access 17
Optische powersplitter/combiner
OLTSP
ONU1
ONU2
ONU3
ONU4
ONU5
ONUN
...
(a) Traditioneel toegangsnetwerk
Optische powersplitter/combiner
OLT
SP1
SP2
SP3
SPM
ONU1
ONU2
ONU3
ONU4
ONU5
ONUN
...
...
(b) Open access in een PON
Figuur 2.6: Soorten toegangsnetwerken
Dual SLA Als de open access architectuur bekeken wordt, zijn er drie partijen te onderschei-
den: de eindgebruikers, de service providers en de infrastructuur provider. De service provider
is nu niet meer verantwoordelijk voor het beheer van de infrastructuur, wat in traditionele toe-
gangsnetwerken wel het geval is. Doordat er nu sprake is van drie partijen, is het noodzakelijk
dat er met dual SLA gewerkt wordt [16]. Bij een dual SLA zijn er twee types van SLA’s:
1. De eerste SLA is tussen de netwerk provider en de service providers. In dit contract wordt
alles beschreven omtrent de infrastructuur die ter beschikking wordt gesteld aan de service

18 HOOFDSTUK 2: STATE OF THE ART
providers. Enkele voorwaarden die in het contract kunnen staan: hoeveel bandbreedte
krijgt een service provider, wat zijn de gemiddelde vertragingen, enz.
2. De tweede SLA is tussen de netwerk provider en de eindgebruikers. Dit contract is gelijk-
aardig aan het eerste type SLA, met het verschil dat het nu niet de service providers maar
de eindgebruikers zijn. De beschreven voorwaarden voor een eindgebruiker (op gebied van
infrastructuur) zijn onafhankelijk van de gekozen service provider.
De netwerk provider heeft de taak om de bandbreedte fair te verdelen zonder dat de voorwaar-
den van de SLA’s geschonden worden. Er mag dus geen discriminatie optreden, noch naar de
eindgebruikers noch naar service providers toe. Er zijn verschillende oplossingen om een open
access netwerk te beheren. In de volgende secties zullen twee technieken besproken worden die
beide behoren tot de categorie bit stream open access [13, 17]. Hierbij wordt gekeken naar de
stroom van bits (of pakketten) om te bepalen hoe de bandbreedte verdeeld wordt.
2.3.3 Open access door dual SLA scheduling algoritme
Een eerste mogelijkheid om open access te implementeren, is door middel van een dual SLA
scheduling algoritme op niveau van de Media-Access Control (MAC) laag [16]. Deze implemen-
tatie maakt een onderscheid tussen de primaire en secundaire SLA. Wanneer er veel trafiek is, is
het mogelijk dat er niet aan beide SLA’s tegelijk kan voldaan worden. Dan wordt er gekozen om
eerst aan de primaire SLA te voldoen en vervolgens te kijken in hoeverre er aan de secundaire
SLA kan voldaan worden. Vanuit rationeel standpunt is er gekozen om de SLA van de eindge-
bruikers als primaire SLA te kiezen en de SLA van de service providers als secundaire, maar dit
kan eenvoudig omgewisseld worden.
De OLT bevat alle functionaliteit om de bandbreedte toe te kennen. Hierbij kijkt de OLT naar
de buffers in het systeem:
• Indien het downstream verkeer is, dan wordt de vulgraad van de buffers van de service
providers geanalyseerd.
• Indien het upstream verkeer is, dan wordt de vulgraad van de buffers van de ONU’s
geanalyseerd.

2.3 Open access 19
De vulgraad van een buffer is het totaal aantal bytes van alle pakketten die zich in de buffer
bevinden. De bandbreedte wordt toegekend afhankelijk van de vulgraad van deze buffers. Het
volgende tijdsstip dat de OLT de buffers controleert (schedule time), hangt ook af van de vul-
graad van de buffers op het huidige tijdsstip. Meer uitleg over de werking van dit algoritme is
terug te vinden in sectie 3.1.1.
2.3.4 Open access door WRR scheduling algoritme
Een andere mogelijkheid om open access te realiseren, is door gebruik te maken van bestaande
switches. Deze maken gebruik van het Weighted Round Robin (WRR) scheduling algoritme om
te bepalen welke pakketten op welk tijdsstip afgehandeld worden. De implementatie in praktijk
bestaat uit een switch bij de OLT en een switch per ONU. Voor elke service provider wordt een
Virtual Local Area Network (VLAN) aangemaakt, waarbij de eindgebruikers van deze service
provider worden toegekend aan VLAN.
Virtual LAN Om de service providers en de ONU’s toe te kennen aan een VLAN, moeten
alle switches geconfigureerd worden. Elke poort van de switch in de OLT krijgt een VLAN
toegewezen op basis van de service provider die via deze poort geconnecteerd is. Bij de switches
van de ONU’s wordt hetzelfde principe toegepast, waarbij enkel de trafiek van een bepaalde
VLAN wordt doorgelaten. Het toekennen van ONU’s en service providers aan een VLAN heeft
enkele voordelen:
• De broadcasts die verstuurd worden, beperken zich tot het VLAN. Dit komt de snelheid
en beschikbaarheid van de link ten goede.
• De eindgebruikers van een service provider vormen logisch gezien een gemeenschappelijk
Local Area Network (LAN) met de service provider, wat de netwerktopologie vereenvou-
digt.
• De eindgebruikers zijn logisch gegroepeerd per service provider, zonder dat ze op dezelfde
switch zitten (in tegenstelling tot een LAN).

20 HOOFDSTUK 2: STATE OF THE ART

Hoofdstuk 3
Ontwerp en implementatie
3.1 Gebruikte algoritmen
3.1.1 Dual SLA scheduling algoritme
3.1.1.1 Inleiding
Zoals in sectie 2.3.3 reeds werd aangehaald, werkt het dual SLA scheduling algoritme aan de
hand van een primaire en een secundaire SLA. In [16] is geopteerd om de SLA van de gebruikers
te kiezen als primaire SLA en de SLA van de service providers als secundaire SLA. Daarnaast is
er enkel sprake over downstream verkeer (van de service providers naar de ONU’s). Beide keuzes
uit deze publicatie werden overgenomen in deze thesis om de resultaten eenvoudig te kunnen
verifieren.
3.1.1.2 Werking
Voor het algoritme uitgevoerd wordt, moeten er enkele parameters vastgelegd worden zoals:
• Het aantal service providers,
• Het aantal ONU’s,
• De kanaalcapaciteit van het PON (bijvoorbeeld 1 Gbps),
• De primaire en secundaire SLA en
• De minimale en maximale cyclustijd in de scheduler.
Indien deze parameters ingesteld zijn, kan het algoritme gestart worden. Tijdens elke cyclus van
de scheduler, worden volgende parameters berekend:
21

22 HOOFDSTUK 3: ONTWERP EN IMPLEMENTATIE
• De bandbreedtes die worden toegekend (per service provider en per ONU) en
• De tijd die de huidige cyclus duurt. Dit is afhankelijk van de totale bandbreedte die is
toegekend en de maximaal beschikbare bandbreedte.
Om deze parameters te berekenen, wordt de flowchart uit figuur 3.1 gevolgd. In de eerste fase is
het belangrijk om te kijken of de totale vraag kleiner is dan de maximaal beschikbare capaciteit.
Indien dit het geval is, wordt elke vraag toegekend aangezien het allemaal binnen de capaciteit
past. De duur van de huidige cyclustijd is afhankelijk van de gebruikte capaciteit waardoor de
cyclustijd nu moet berekend worden.
Indien de vraag groter is dan de capaciteit, wordt het dual SLA scheduling algoritme uitgevoerd
om een zo fair mogelijke verdeling te maken van de bandbreedte. Na het toekennen van de
verplichte bandbreedtes (stap 1), wordt een toekenning gedaan aan de hand van het secundaire
SLA (stap 2). Vervolgens gebeurt er een toekenning aan de hand van de primaire SLA en wordt
er gekeken of deze overeenstemt met de toekenning op basis van de secundaire SLA. Indien
deze toekenningen niet gelijk zijn, wordt er bandbreedte hersteld van de secundaire SLA om
toch tegemoet te kunnen komen aan de primaire SLA (stap 3). Als laatste wordt de onbenutte
bandbreedte fairly verdeeld over de ONU’s die meer vragen dan hun SLA (stap 4). De duur van
de huidige cyclustijd is uiteraard de maximale cyclustijd aangezien de beschikbare capaciteit
volledig toegewezen is.
3.1.1.3 Voorbeeld
Om de werking van stap 4 in het algoritme duidelijk te maken, wordt volgend voorbeeld gegeven.
De parameters die voor dit voorbeeld gekozen werden, zijn terug te vinden in tabel 3.1.
Parameter Waarde
Kanaalcapaciteit 960 Mbps
Maximale cyclustijd 500 µs
Aantal service providers 3
SLA per service provider (secundair) 320 Mbps
Aantal ONU’s 16
SLA per ONU (primair) 60 Mbps
Tabel 3.1: Parameters dual SLA scheduling algoritme

3.1 Gebruikte algoritmen 2336 IEEE JOURNAL ON SELECTED AREAS IN COMMUNICATIONS, VOL. 24, NO. 8, AUGUST 2006
Fig. 3. Invocation of the scheduling algorithm for time-slot computation.
which states that the sum of all bandwidths allocatedmust be less than or equal to the capacity available forthe maximum time cycle duration.
3) Scheduling time cycle constraint:
Tadv ≤ ∆ ≤ T (8)
which states that the scheduling time cycle must be lessthan the maximum scheduling time cycle and greaterthan the minimum time by which the scheduler mustadvance.
Objectives:The following objectives are in order of priority.
1) Meet the primary-SLA bandwidth requirement.2) Try to meet the secondary-SLA bandwidth requirement.
If it is not possible to meet all the secondary SLAs, thenthe deficit in meeting the secondary SLAs should be asuniform as possible.
3) Divide any surplus bandwidth after meeting SLAs fairlyacross the primary-SLA entities, and then correspond-ingly for each secondary-SLA entity.
IV. DUAL-SLA SCHEDULING ALGORITHM
We present the scheduling algorithm to implement ourmathematical model formulated in Section III. For describingthe algorithm, we choose an example in which the primarySLA is for the users, and the secondary SLA is for theSPs, although this may easily be reversed. The schedulingalgorithm is invoked at time t, and it considers the givenparameters as defined in the previous section. The algorithmis presented in the flowchart in Fig. 4. The following twocases arise.
Case I: Demand is less than capacity available in themaximum time cycle duration, i.e.,
ifi=M∑
i=1
j=N∑
j=1
qi,j,t ≤ C (9)
then the demand may be met entirely using the availablecapacity, and the allocated time-slots may be determined bythe following two equations:
gi,j,t,t+∆ = qi,j,t ∀ i ∈ 1, . . . ,M, j ∈ 1, . . . , N (10)
Case IIStep 1:Identify mandatory bandwidth assignments.
Step 2:Allocate bandwidth to meet Secondary SLA
Step 3:Allocate bandwidth to meet Primary SLA. If sufficient capacity is not available, then recover bandwidth assigned in Step 2 to meet deficit.
Step 4:Assign remaining time-slot fairly amongst users.
Isdemand < capacity of maximum timeslot ?
Case IAllocate bandwidth equal to demand
Yes No
Start
Fig. 4. Flowchart for Dual-SLA scheduling algorithm.
∆ = Max [Tadv,i=M∑
i=1
j=N∑
j=1
qi,j,t/R] (11)
The latter equation states that we would like to advancethe scheduler by the larger of Tadv and the actual time thatwas taken to transmit the packets in the queues. The aboveequation assumes no additional overhead in the system, asmentioned before.
Case II: Demand is greater than available capacity. This isthe interesting case where the role of fair scheduling comesin. The primary SLA is specified for either the users or theSPs, and depending on the choice of the primary SLA, thesecondary SLA is specified for the opposite entity. In thefollowing description of the algorithm, we assume that theprimary SLA is for users, and the secondary SLA is for SPs.
Step 1: Identify Mandatory Bandwidth Allocations. Theobjective is to identify the following two situations:
1) Users whose cumulative demand is less than the primarySLA requirement, i.e., users j, for which the followingequation is true:
i=M∑
i=1
qi,j,t < uMINj (12)
In such a case, the entire demand for that user must bemet.
2) Users who do not satisfy the above, but who are cur-rently subscribing to only a single SP. For such users,a grant equal to the primary SLA (uMIN
j ) must beassigned, because there is no alternate competing SP.
Steps 2, 3, and 4 use algorithm Allocate Max-Min FairBandwidth shown in Fig. 5. Given some available bandwidth,the objective is to ensure distribution of the bandwidth amonga set of entities (SPs/ users) to achieve max-min fairness. Afeasible allocation set [x1, x2, x3, . . . , xr] is said to be max-min fair [3] when it is impossible to increase the allocation
Authorized licensed use limited to: UNIVERSITY OF MELBOURNE. Downloaded on January 13, 2010 at 04:13 from IEEE Xplore. Restrictions apply.
Figuur 3.1: Flowchart dual SLA scheduling algoritme [16]
Uit de maximale cyclustijd van de scheduler en de kanaalcapaciteit, kan de capaciteit in bytes
afgeleid worden: 960 Mbps × 500 µs = 480 kB. Ook de SLA’s worden op dezelfde manier
aangepast en bedragen nu 160 kB voor de secundaire en 30 kB voor de primaire SLA. De
ONU’s worden ingedeeld per service provider en hun buffers krijgen ook een gemiddelde vulgraad
toegewezen (zie tabel 3.2). In dit voorbeeld zijn er geen verplichte bandbreedtes die moeten
toegekend worden.
Set ONU’s Service provider Vulgraad
A 1 - 9 SP 1 20 kB
B 10 - 12 SP 2 75 kB
C 13 - 16 SP 3 37.5 kB
Tabel 3.2: Verdeling ONU’s dual SLA scheduling algoritme
De totale vraag is 555 kB (9 × 20 + 3 × 75 + 4 × 37.5) en is dus groter dan de capaciteit.

24 HOOFDSTUK 3: ONTWERP EN IMPLEMENTATIE
Eerst wordt de bandbreedte volgens de secundaire SLA toegekend, waarbij elke service provider
160 kB krijgt. Vervolgens wordt de primaire SLA toegekend, waarbij elke ONU 30 kB krijgt.
Beide SLA’s komen niet overeen waardoor er bandbreedte hersteld wordt. Als laatste wordt de
onbenutte capaciteit verdeeld over de ONU’s die meer vragen dan hun SLA. ONU 1 - 9 gebruiken
slechts 20 kB van de toegekende 30 kB, waardoor er 90 kB vrijkomt. Deze 90 kB wordt verdeeld
onder ONU’s 10 - 16 waarbij de fout (deficit) per user (het verschil tussen de gevraagde en
toegekende bandbreedte) zo laag mogelijk gehouden wordt. De toegekende bandbreedte (in kB)
in elke stap is terug te vinden in tabel 3.3.
SetSec. SLA Prim. SLA Final
SP ONU SP ONU SP ONU
A 160 17.78 270 30 180 20
B 160 53.33 90 30 180 60
C 160 40 120 30 120 30
Tabel 3.3: Toegekende bandbreedte per service provider en per ONU in het dual SLA schedu-
ling algoritme
3.1.2 Aangepast dual SLA scheduling algoritme (versie 1)
3.1.2.1 Inleiding
Het voorbeeld van het dual SLA scheduling algoritme in sectie 3.1.1.3 geeft al aan dat er enkele
problemen kunnen onstaan: zo krijgen de ONU’s die 37.5 kB vragen enkel hun SLA toegewezen
(30 kB). De ONU’s die daarentegen 75 kB vragen, wat veel hoger is dan hun SLA, krijgen 60
kB toegewezen om de gemiddelde fout per user zo laag mogelijk te houden. Hier wordt meteen
duidelijk dat ONU’s die veel meer vragen dan hun SLA ook veel bandbreedte zullen krijgen, ten
koste van andere ONU’s die misschien niet zo veel meer vragen dan hun SLA. Hierdoor werd
de vierde stap (zie figuur 3.1) aangepast om de onbenutte bandbreedte op een andere manier te
verdelen.
3.1.2.2 Werking
Het algoritme werkt op dezelfde manier zoals in sectie 3.1.1.2 beschreven staat, op uitzondering
van de vierde stap. Als eerste wordt een lijst gemaakt van alle ONU’s die meer vragen dan
hun SLA. Deze lijst wordt oplopend gesorteerd volgens de vraag van elke ONU. De onbenutte

3.1 Gebruikte algoritmen 25
capaciteit wordt nu gedeeld door het aantal ONU’s in de lijst en wordt bij de SLA van de ONU’s
in de lijst geteld. Dan wordt gekeken naar de eerste ONU in de lijst om te zien of deze meer
vraagt dan zijn (tijdelijk) nieuwe SLA. Indien hij hetzelfde of meer vraagt, wordt elke ONU uit
de lijst deze nieuwe SLA toegekend. Indien hij minder vraagt, wordt toegekend wat hij vraagt
en wordt de onbenutte bandbreedte van deze ONU opnieuw verdeeld (en dit blijft zich herhalen
tot de laatste ONU bereikt is).
3.1.2.3 Voorbeeld
Indien hetzelfde voorbeeld uit sectie 3.1.1.3 hernomen wordt, blijft het algoritme gelijkaardig
tot en met het toekennen van de primaire SLA. De onbenutte bandbreedte is opnieuw 90 kB
aangezien ONU 1 - 9 maar 20 kB vragen terwijl hun SLA 30 kB bedraagt. Nu wordt een lijst
gemaakt van alle ONU’s die meer vragen dan hun SLA en wordt deze lijst gesorteerd volgens
oplopende vraag. Dit resulteert in volgende ONU’s: 13, 14, 15, 16, 10, 11 en 12. ONU’s 13 - 16
vragen nog 7.5 kB meer dan hun SLA, ONU 10 - 12 vragen nog 45 kB meer dan hun SLA. De
onbenutte bandbreedte wordt gedeeld door het aantal ONU’s in de lijst, wat resulteert in 12.85
kB per ONU. Hierdoor wordt de (tijdelijk) nieuwe SLA voor elke ONU 42.85 kB (iteratie 1).
ONU’s 13 - 16 vragen slechts 37.5 kB, dus krijgen de gevraagde bandbreedte toegewezen en de
onbenutte bandbreedte wordt opnieuw verdeeld voor ONU 10 - 12 (iteratie 2).
SetOrigineel Iteratie 1 Iteratie 2
Vraag Grant SLA Grant SLA Grant
C 37.5 30 42.85 37.5 37.5 37.5
B 75 30 42.85 42.85 50 50
Tabel 3.4: Toekenning onbenutte bandbreedte per ONU in het aangepaste dual SLA scheduling
algoritme
Als tabel 3.4 (na iteratie 2) met tabel 3.3 vergeleken wordt, is de fout (deficit) voor ONU’s 10
- 12 hoger maar heeft elke ONU meer gekregen dan zijn SLA.
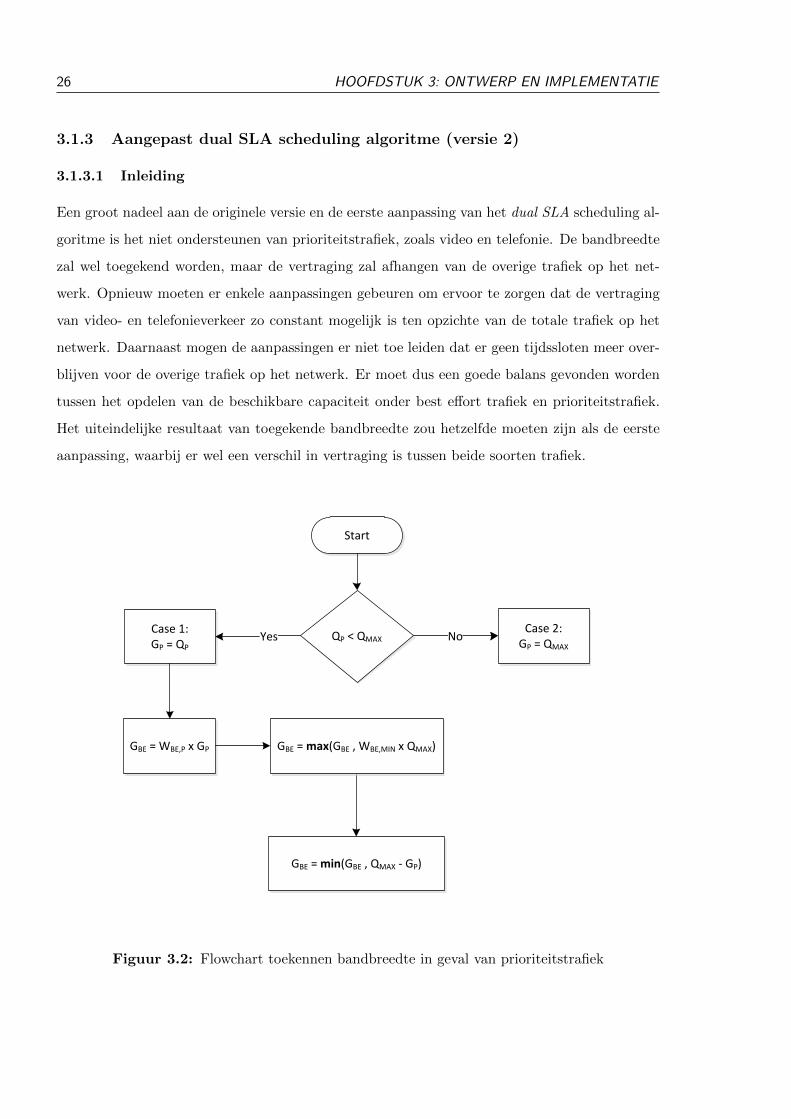
26 HOOFDSTUK 3: ONTWERP EN IMPLEMENTATIE
3.1.3 Aangepast dual SLA scheduling algoritme (versie 2)
3.1.3.1 Inleiding
Een groot nadeel aan de originele versie en de eerste aanpassing van het dual SLA scheduling al-
goritme is het niet ondersteunen van prioriteitstrafiek, zoals video en telefonie. De bandbreedte
zal wel toegekend worden, maar de vertraging zal afhangen van de overige trafiek op het net-
werk. Opnieuw moeten er enkele aanpassingen gebeuren om ervoor te zorgen dat de vertraging
van video- en telefonieverkeer zo constant mogelijk is ten opzichte van de totale trafiek op het
netwerk. Daarnaast mogen de aanpassingen er niet toe leiden dat er geen tijdssloten meer over-
blijven voor de overige trafiek op het netwerk. Er moet dus een goede balans gevonden worden
tussen het opdelen van de beschikbare capaciteit onder best effort trafiek en prioriteitstrafiek.
Het uiteindelijke resultaat van toegekende bandbreedte zou hetzelfde moeten zijn als de eerste
aanpassing, waarbij er wel een verschil in vertraging is tussen beide soorten trafiek.
Start
QP < QMAXCase 1:GP = QP
Yes
GBE = WBE,P x GP
GBE = min(GBE , QMAX - GP)
Case 2:GP = QMAX
No
GBE = max(GBE , WBE,MIN x QMAX)
Figuur 3.2: Flowchart toekennen bandbreedte in geval van prioriteitstrafiek

3.1 Gebruikte algoritmen 27
3.1.3.2 Werking
In vergelijking met de eerste aanpassing van het dual SLA scheduling algoritme, is de start van
het algoritme verschillend. Eerst wordt de som van alle vulgraden van de buffers met best effort
trafiek (QBE) en met prioriteitstrafiek (QP ) genomen. Vervolgens wordt een berekening ge-
maakt waarbij een capaciteit aan prioriteitstrafiek (GP ) en aan best effort trafiek (GBE) wordt
toegekend. Deze toekenningen (grants) worden bekomen via de flowchart uit figuur 3.2. Als
eerste wordt gekeken of de totale vraag van de prioriteitstrafiek (QP ) kan verzonden worden
binnen de maximale cyclustijd (QMAX). Wanneer dit niet het geval is (case 2), wordt de maxi-
male cyclustijd volledig toegekend aan prioriteitstrafiek en wordt er niets toegekend aan best
effort trafiek.
Indien de vraag van de prioriteitstrafiek lager is dan de maximale cyclustijd (case 1), wordt er
voldoende bandbreedte toegekend om deze vraag volledig te kunnen behandelen. Vervolgens
moet er ook bandbreedte toegekend worden aan de best effort trafiek aangezien de maximale
cyclustijd nog niet werd bereikt. Indien de volledige overschot van bandbreedte wordt toegekend
aan best effort trafiek, ontstaat het volgende probleem: bij weinig prioriteitstrafiek en veel best
effort trafiek zal de vertraging van de prioriteitstrafiek zeer hoog zijn. Stel dat de maximale
capaciteit van een cyclus 480 kB is, en dat prioriteitstrafiek en best effort trafiek respectievelijk
10 en 470 kB vragen, dan zal de prioriteitstrafiek een vertraging hebben van de helft van de
maximale cyclustijd aangezien best effort de volledige capaciteit opvult. Om dit te voorkomen,
wordt er een toekenning van bandbreedte aan best effort (GBE) gedaan in functie van de toeken-
ning van bandbreedte aan prioriteit (GP ). Hiervoor wordt het gewicht WBE,P gebruikt, zoals
in formule 3.1 is weergegeven.
GBE = WBE,P ×GP (3.1)
Het gewicht WBE,P wordt zodanig gekozen dat de vertraging van de prioriteitstrafiek zo laag
mogelijk is. Deze toekenning kan wel voor een probleem zorgen: indien er in een bepaalde cyclus
geen prioriteitstrafiek is (QP = 0), zal er geen toekenning zijn voor prioriteitstrafiek (GP = 0)
maar dus ook geen toekenning voor best effort trafiek (GBE = 0). Hierdoor moet een minimale
grens worden gesteld opdat er nog steeds een toekenning aan best effort trafiek plaatsvindt.
Er wordt gebruik gemaakt van een tweede gewicht (WBE,MIN ) om dit probleem op te lossen.
Hierbij wordt het maximum genomen van hetgeen reeds is toegekend via formule 3.1 en de

28 HOOFDSTUK 3: ONTWERP EN IMPLEMENTATIE
minimale bandbreedte die best effort trafiek moet verkrijgen (zie formule 3.2).
GBE = max(GBE ,WBE,MIN ×QMAX) (3.2)
De gewichten WBE,P en WBE,MIN moeten zodanig gekozen worden dat de vertraging van pri-
oriteitstrafiek zo laag mogelijk is en dat er tegelijk genoeg bandbreedte wordt toegekend aan
best effort trafiek. Als laatste moet er wel nog gecontroleerd worden of de toekenning van
bandbreedte aan best effort trafiek nog binnen de resterende capaciteit past van de scheduler.
In formule 3.3 wordt er het minimum genomen van de toegekende bandbreedte aan best effort
trafiek uit formule 3.2 en de capaciteit die nog overblijft na het toekennen van prioriteitstrafiek.
GBE = min(GBE , QMAX −GP ) (3.3)
Nu de toekenning van capaciteit voor prioriteitstrafiek en best effort trafiek is berekend, wordt
het dual SLA scheduling algoritme toegepast om de totale capaciteiten fair te verdelen onder de
ONU’s.
3.1.3.3 Voorbeeld
De werking van dit algoritme wordt vooral duidelijk indien er weinig prioriteitstrafiek en veel
best effort trafiek is. Veronderstel de parameters uit tabel 3.5 en het algoritme uit figuur 3.2. QP
is kleiner dan QMAX en zal volledig toegekend worden, waardoor er slecht 2 kB (WBE,P ×GP )
aan best effort trafiek wordt toegekend. Vervolgens wordt er gekeken of er niet meer toegekend
moet worden aan best effort trafiek, wat hier het geval blijkt te zijn. Best effort trafiek krijgt
namelijk een minimale capaciteit van 12 kB (WBE,MIN × QMAX) wat 6 keer meer is dan wat
oorspronkelijk toegekend was.
Parameter Waarde
QMAX 480 kB
QP 10 kB
QBE 400 kB
WBE,P 0.200
WBE,MIN 0.025
Tabel 3.5: Parameters voorbeeld dual SLA scheduling algoritme (versie 2)

3.2 Implementatie aangepast dual SLA scheduling algoritme 29
3.2 Implementatie aangepast dual SLA scheduling algoritme
3.2.1 Algemeen
Voor alle implementaties van bovenstaande algoritmen werd gebruik gemaakt van de netwerksi-
mulator van OPNET [18]. Een gedetailleerde beschrijving van de werking van OPNET is terug
te vinden in [19]. In figuur 3.3 is te zien dat er geopteerd is voor een busarchitectuur om een
TDM-PON systeem te simuleren. Deze busarchitectuur wordt gebruikt ter vervanging van een
optische splitter/combiner en verbindt de OLT met alle ONU’s. In deze simulatie is er gekozen
voor 16 ONU’s aangezien er meestal voor dit aantal wordt gekozen in het simuleren van een
PON [6, 16]. Er zijn twee bus-links: een bovenaan en een onderaan. Deze worden gebruikt om
downstream en upstream te scheiden. Dit is om het overzicht te bewaren en de resultaten van de
simulaties sneller te kunnen evalueren. In de volgende secties zullen de OLT en de ONU verder
besproken worden.
Figuur 3.3: Projectmodel in OPNET om het dual SLA scheduling algoritme in een TDM-PON
te simuleren
3.2.2 OLT
3.2.2.1 Algemeen
De OLT in dit simulatiemodel bevat niet enkel de functionaliteit van de OLT in de praktijk,
maar heeft ook enkele service providers en een queue voor deze service providers. In de praktijk
zijn de service providers fysisch gescheiden van de OLT, maar hier zijn ze samengevoegd voor de
eenvoud. Het node model van de OLT is terug te vinden in figuur 3.4. De trafiek die gegenereerd
wordt door de service providers, komt rechtstreeks in de queue van de OLT terecht. Deze queue
bestaat op zich uit 6 subqueues, een voor elke service provider. De scheduler zal dan tijdssloten
toekennen aan de service providers en stuurt de trafiek van de subqueues naar de bus-link.

30 HOOFDSTUK 3: ONTWERP EN IMPLEMENTATIE
Figuur 3.4: Node model van de OLT in een TDM PON
3.2.2.2 Scheduler
Het toekennen van tijdssloten is gebaseerd op het algoritme beschreven in sectie 3.1.2. Het
algoritme werkt als volgt:
1. De scheduler vraagt aan de queue wat de vulgraad is van alle subqueues (in aantal bytes)
2. De scheduler kijkt of de som van deze vulgraden kan verzonden worden binnen de maxi-
male cyclustijd van de scheduler. Indien dit mogelijk is, zal de scheduler elke subqueue
voldoende tijdssloten geven om alles te zenden. Indien het niet mogelijk is om alles binnen
de maximale cyclustijd te verzenden, worden volgende stappen toegepast:
(a) De scheduler sorteert alle vulgraden (per service provider en per ONU) van laag naar
hoog (oplopend)
(b) De scheduler deelt de capaciteit van de link door het aantal gebruikers. Indien de
vulgraad lager is dan deze limiet, wordt deze vulgraad automatisch toegekend en
wordt de resterende capaciteit gedeeld door het resterende aantal gebruikers. Indien
de vulgraad gelijk of hoger is, wordt voor elke vulgraad deze limiet toegekend. Een
voorbeeld hiervan is terug te vinden in sectie 3.1.2.3.
3. Afhankelijk van de totale vulgraad van de queue, wordt het volgende tijdsstip berekend
waarop de vulgraden van de subqueues opnieuw opgevraagd worden (stap 1). Dit is de som
van alle toegekende tijdssloten, tenzij dit lager is dan de minimale cyclustijd (de verklaring
hiervoor is terug te vinden na dit algoritme).
4. Nu gaat het algoritme terug naar stap 1

3.2 Implementatie aangepast dual SLA scheduling algoritme 31
Zoals in het algoritme beschreven staat, wordt er gewerkt met een minimale en maximale cy-
clustijd. Beide tijdslimieten hebben een bepaalde functionaliteit in het algoritme:
• De minimale cyclustijd heeft als doel de scheduler niet te frequent te laten controleren wat
de vulgraden van de subqueues zijn, indien er weinig trafiek in het netwerk is. Stel dat
alle subqueues zo goed als leeg zijn, dan zal de scheduler heel regelmatig vragen wat de
vulgraden zijn aangezien er weinig tijdssloten moeten toegekend worden. Dit zorgt ervoor
dat de scheduler sneller moet werken en hierdoor minder energie-efficient is. Daartegenover
staat wel het voordeel van een lage minimale cyclustijd: hoe lager deze minimale tijd, hoe
minder lang een pakket in de queue hoeft te wachten waardoor de vertragingen per pakket
veel lager zal zijn.
• De maximale cyclustijd heeft als doel om de scheduler niet te lang te laten wachten indien
er heel veel trafiek in het netwerk is. Als de vulgraad van de subqueues te hoog is, zou
de scheduler veel tijdssloten nodig hebben om alle trafiek te kunnen zenden. Dit heeft als
gevolg dat de cyclustijd van de scheduler zal verlengen. Daarenboven is het geen oplossing
om de grootte van de subqueues te verlagen, want dit kan volgende problemen opleveren:
– Als er een burst optreedt, moet deze (in de mate van het mogelijke) opgevangen
kunnen worden door de subqueue. Indien de grootte van de subqueue te laag is,
wordt een groot deel van deze burst verwijderd.
– Als er maar een gebruiker trafiek verstuurt op het netwerk (bijvoorbeeld ’s nachts),
mag hij/zij de volledige capaciteit gebruiken aangezien er niemand anders gebruik
maakt van het netwerk. Indien de subqueue te klein zou zijn, zou er ook hier veel
pakketten verloren kunnen gaan omdat de subqueue al volledig gevuld is.
Daarom is het van belang om de grootte van de subqueue voldoende groot te maken en
tegelijk de scheduler niet te lang te laten wachten indien er veel trafiek is.
3.2.3 ONU
De functionaliteit van de ONU is eerder beperkt. De ONU ontvangt alle pakketten die op de
bus geplaatst zijn en classificeert deze pakketten: alle pakketten die niet bestemd zijn voor deze
ONU worden direct verwijderd, alle andere pakketten worden doorgestuurd naar de processor.
De processor bepaalt aan de hand van de ontvangen pakketten hoeveel bandbreedte deze ONU
heeft gekregen.

32 HOOFDSTUK 3: ONTWERP EN IMPLEMENTATIE
3.3 Implementatie WRR scheduling algoritme
3.3.1 Algemeen
Zoals in sectie 2.3.4 aangehaald werd, is het mogelijk om open access te realiseren door een switch
te plaatsen bij de OLT en een switch te plaatsen bij elke ONU. Bij switches is het niet mogelijk
om gebruik te maken van een busarchitectuur, waardoor de optische splitter/combiner op een
andere manier moet vervangen worden. In plaats van een switch te plaatsen bij elke ONU (zoals
in de praktijk het geval is) is er een switch voor alle ONU’s, die de optische splitter/combiner
vervangt (zie figuur 3.5). Aangezien deze switch voor de ONU’s een actieve node is, zou deze
configuratie in praktijk een actief optisch netwerk zijn. De link tussen beide switches bepaalt
de kanaalcapaciteit van het optisch netwerk.
De switch bij de OLT bevat het WRR scheduling algoritme en een queue voor elke service
provider die aangesloten is. De pakketten die toekomen bij de switch krijgen een VLAN toege-
wezen afhankelijk van de service provider die de pakketten verzonden heeft. Hierna worden de
pakketten doorgestuurd naar de juiste queue en wachten ze tot het WRR scheduling algoritme
tijdssloten heeft toegekend om deze pakketten te versturen over de link. Indien de pakketten
aankomen bij de switch van de ONU’s, worden de pakketten direct doorgestuurd naar de ONU
waarvoor ze bestemd waren. Opnieuw zal de ONU bijhouden hoeveel pakketten hij ontvangen
heeft, opdat er gemakkelijk kan bepaald worden hoeveel bandbreedte de ONU kreeg.
3.3.2 Werking WRR scheduling algoritme
Het Weighted Round Robin (WRR) algoritme is gebaseerd op het Round Robin (RR) algoritme
en houdt rekening met de gewichten van elke queue. Het RR algoritme werkt op een cyclische
manier: het neemt het eerste pakket in de eerste queue, vervolgens het eerste pakket in de tweede
queue, enz. tot het eerste pakket van de laatste queue genomen is. Vervolgens gaat hij terug
naar de eerste queue en neemt daar opnieuw het eerste pakket, enz. Hierdoor is elke queue even
belangrijk, waardoor het niet kan zijn dat een queue met een lage vulgraad moet wachten op
een queue met een hoge vulgraad.

3.3 Implementatie WRR scheduling algoritme 33
Figuur 3.5: Projectmodel in OPNET om het WRR scheduling algoritme in een TDM-PON te
simuleren
Bij het WRR scheduling wordt dezelfde techniek toegepast, maar wordt er gekeken naar het
gewicht van een queue [20]. Aan de hand van dit gewicht wordt een berekening gemaakt hoeveel
pakketten van deze queue worden genomen. Maar in het geval van telefonietrafiek is er nog
steeds een probleem: de grootte van de pakketten in de queue van telefonietrafiek zal steeds
klein zijn in tegenstelling tot de grootte van de pakketten in de queue van best effort trafiek.
Dit probleem is opgelost indien ook de gemiddelde pakketgrootte in rekening wordt gebracht
bij het bepalen van het aantal pakketten dat mag verzonden worden. Voor elke queue i wordt
het aantal pakketten (NoP = Number of Packets) bepaald door het gewicht (W = Weight) te
delen door de gemiddelde pakketgrootte (APS = Average Packet Size) zoals in formule 3.4 is
weergegeven.
NoP (i) =W (i)
APS(i)(3.4)
Het gewicht W (i) dat hier gebruikt wordt, mag niet vergeleken worden met de gewichten WBE,P
en WBE,MIN die bij de aangepaste versie van dual SLA gebruikt worden. De gewichten worden
op een verschillende manier gebruikt om een prioriteitstrafiek toe te laten, waardoor er geen
verband is tussen de waarden van deze gewichten.

34 HOOFDSTUK 3: ONTWERP EN IMPLEMENTATIE
3.4 Self-similar trafiek
Alvorens over te gaan naar de resultaten van de simulaties, is het belangrijk te vermelden hoe
de trafiek gegenereerd wordt. In vele publicaties wordt best effort trafiek ook wel beschreven als
self-similar (of long-range dependent) [21, 22, 23]. Dit wil zeggen dat de trafiek steeds bursty
is, onafhankelijk van de tijd waarover de trafiek geanalyseerd wordt (enkele seconden, minuten,
uren of dagen). Ook nadat de trafiek door het netwerk is gegaan (en verschillende aggregaties
heeft ondergaan), behoudt de trafiek zijn bursty karakter. Bursty trafiek wordt gekenmerkt door
twee periodes: de ON en OFF periode waarbij er respectievelijk veel pakketten en geen (of heel
weinig) pakketten verstuurd worden.
Self-similar trafiek wordt meestal aangegeven met een Hurst-parameter (self-similarity parame-
ter) [24]. Deze parameter, H, moet zich tussen de 0.5 en 1 bevinden, maar om internettrafiek te
modelleren wordt meestal vastgelegd op 0.8 [22]. Soms wordt ook gewerkt met de parameters α
en B om de self-similar trafiek te modelleren. α bepaalt de dikte van het einde van de distributie
(shape-parameter) [24] en heeft een rechtstreeks verband met de Hurst-parameter. Aangezien
0.5 < H < 1 zorgt vergelijking 3.5 ervoor dat 1 < α < 2.
H =3− α
2(3.5)
B bepaalt de locatie van de burst en wordt daarom beschreven als de location-parameter. De
parameters α en B worden vervolgens in de Pareto-distributie toegepast om de trafiek te gene-
reren. De verwachtingswaarde van de Pareto-distributie is gedefinieerd volgens vergelijking 3.6
[25].
E[X] =α×Bα− 1
(3.6)
Deze verwachtingswaarde bepaalt de ON en OFF periode en bepaalt zo de internettrafiek.

Hoofdstuk 4
Simulaties en resultaten
4.1 Analyse verdeling bandbreedte dual SLA
4.1.1 Testopstelling
Om de correctheid van het projectmodel in OPNET te verifieren, wordt er gestart met het
controleren van de behaalde resultaten uit [16]. Hier wordt een simulatie uitgevoerd over 120
seconden, waarbij na 20, 40 en 60 seconden de gevraagde bandbreedte van bepaalde ONU’s
verhoogt. Hiervoor werden de parameters uit [16] overgenomen die in tabel 4.1, 4.2 en 4.3 terug
te vinden zijn.
Parameter Waarde
Aantal ONU’s in het PON model 16
Aantal service providers in het PON model 6
Kanaalcapaciteit van het PON model 1 Gbps
Maximale buffergrootte 1 MB
Maximale cyclustijd 500 µs
Minimale cyclustijd 200 µs
Set I ONU 1 - 9
Set II ONU 10 - 12
Set III ONU 13 - 14
Set IV ONU 15 - 16
Tabel 4.1: Algemene parameters die gebruikt worden tijdens de simulatie van de toekenning
van bandbreedte aan de hand van het dual SLA scheduling algoritme
35
36 HOOFDSTUK 4: SIMULATIES EN RESULTATEN
De trafiek die in tabel 4.3 weergegeven is, is enkel de gemiddelde waarde. De trafiek die in het
model gegenereerd wordt, is self-similar met 0.8 als Hurst-parameter (zie sectie 3.4 voor meer
uitleg).
Tijd SP1 SP2 SP3 SP4 SP5 SP6
0s - 20s I, II, III, IV Offline Offline Offline Offline Offline
20s - 40s I, II, III, IV II II II Offline Offline
40s - 60s I, II, III, IV II II II III Offline
60s - 120s I, II, III, IV II II II III IV
Tabel 4.2: Sets per service provider in functie van simulatietijd
Nadat het projectmodel voor dual SLA in OPNET dezelfde resultaten opleverde als in [16], werd
de scheduler aangepast naar de eerste aangepaste versie van het dual SLA scheduling algoritme.
Alle parameters in het simulatiemodel werden behouden om een duidelijke vergelijking te kun-
nen maken tussen de verdeling van het oorspronkelijke dual SLA scheduling algoritme en het
aangepaste dual SLA scheduling algoritme.
Tijd Set I Set II Set III Set IV
0s - 20s 40 Mbps 40 Mbps 40 Mbps 40 Mbps
20s - 40s 40 Mbps 150 Mbps 40 Mbps 40 Mbps
40s - 60s 40 Mbps 150 Mbps 75 Mbps 40 Mbps
60s - 120s 40 Mbps 150 Mbps 75 Mbps 75 Mbps
Tabel 4.3: Gemiddelde trafiek per ONU in functie van simulatietijd
4.1.2 Resultaten
De resultaten van het dual SLA scheduling algoritme uit [16], zoals beschreven in sectie 3.1.1.2,
zijn terug te vinden in figuur 4.1a. Daarna werd het algoritme in OPNET geımplementeerd om
de resultaten uit figuur 4.1a te controleren. De resultaten van de simulatie in OPNET van het
originele dual SLA scheduling algoritme met de parameters zoals in [16], zijn terug te vinden in
figuur 4.1b. Figuur 4.1a en 4.1b geven de toegekende bandbreedte per set van ONU’s weer in
functie van de simulatietijd.
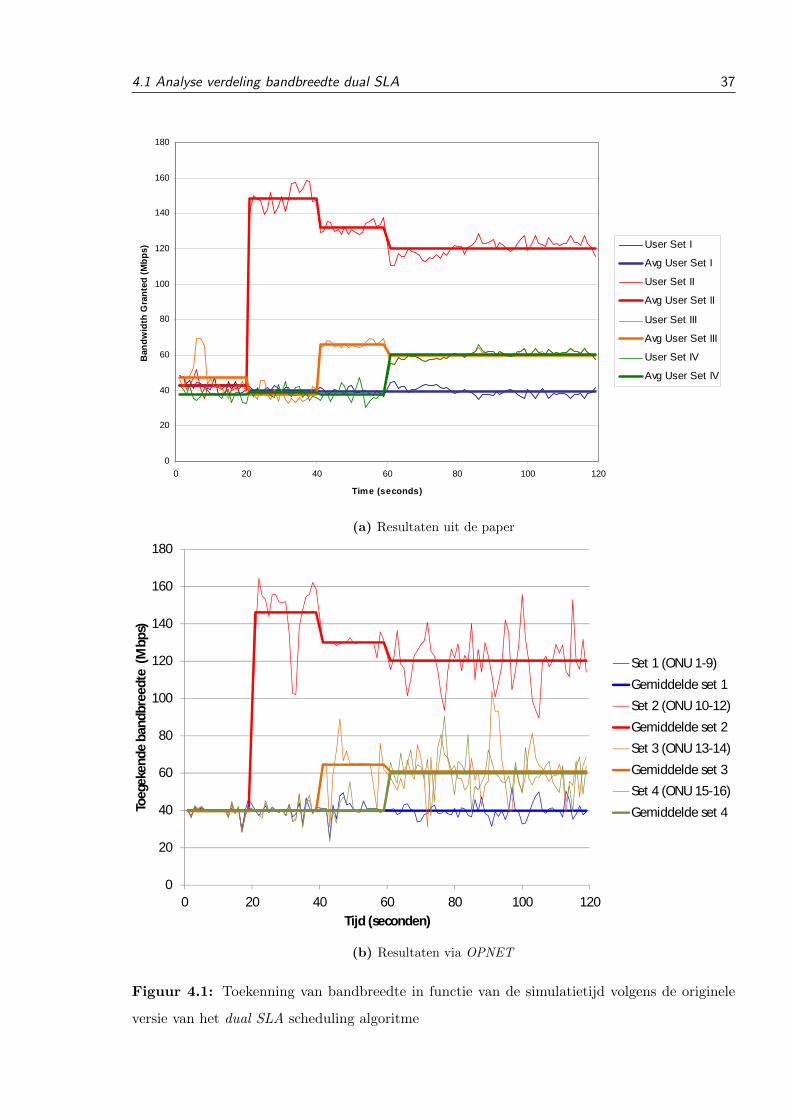
4.1 Analyse verdeling bandbreedte dual SLA 37
Chapter 3: Fair Sharing Using Dual SLAs to achieve Open Access 66
Throughput to SPs by the Dual-SLA Scheduling Algorithm
0
100
200
300
400
500
600
700
800
0 20 40 60 80 100 120
Time (seconds)
Ban
dwid
th G
rant
ed (M
bps)
SP 1
Avg SP 1
SP 2
Avg SP 2
SP 3
Avg SP 3
SP 4
Avg SP 4
SP 5
Avg Sp 5
SP 6
Avg SP 6
(a) SPs
Throughput to Users by the Dual-SLA Scheduling Algorithm
0
20
40
60
80
100
120
140
160
180
0 20 40 60 80 100 120
Time (seconds)
Ban
dwid
th G
rant
ed (M
bps) User Set I
Avg User Set I
User Set II
Avg User Set II
User Set III
Avg User Set III
User Set IV
Avg User Set IV
(b) Users
Figure 3.11: Throughput when using Dual-SLA based scheduler.
(a) Resultaten uit de paper
0
20
40
60
80
100
120
140
160
180
0 20 40 60 80 100 120
Toeg
eken
de b
andb
reed
te (
Mbp
s)
Tijd (seconden)
Set 1 (ONU 1-9)
Gemiddelde set 1Set 2 (ONU 10-12)
Gemiddelde set 2Set 3 (ONU 13-14)
Gemiddelde set 3Set 4 (ONU 15-16)
Gemiddelde set 4
(b) Resultaten via OPNET
Figuur 4.1: Toekenning van bandbreedte in functie van de simulatietijd volgens de originele
versie van het dual SLA scheduling algoritme

38 HOOFDSTUK 4: SIMULATIES EN RESULTATEN
In figuur 4.1 is te zien dat de gemiddelde toegekende bandbreedte van de implementatie in
OPNET (figuur 4.1b) overeenkomt met de resultaten uit [16] (figuur 4.1a). Enkel tijdens de
simulatie van 0 tot 20 seconden is de gemiddelde bandbreedte voor set 2 en 3 hoger in figuur
4.1a dan figuur 4.1b. Voor set 2 is dit duidelijk te wijten aan de hoge piek (burst tussen 5
en 10 seconden) die niet gecompenseerd wordt door een lage piek. Dit zorgt ervoor dat het
gemiddelde hoger zal liggen dan normaal. Ook bij set 3 is er een gelijkaardig scenario, maar is
de piek minder hoog waardoor het gemiddelde iets lager ligt dan het gemiddelde van set 2. De
simulatie in OPNET van 0 tot 20 seconden had geen extreme pieken waardoor het gemiddelde
gelijklopend is voor elke set.
Alhoewel dat de gemiddelde toegekende bandbreedte gelijklopend is, is er een duidelijk verschil
in de effectieve toegekende bandbreedte. Zo vertonen de resultaten in figuur 4.1a minder hoge
en lage pieken dan de resultaten in figuur 4.1b. Zelfs tussen de verschillende simulatieperiodes
in OPNET is er een groot verschil: zo heeft set 2 een zeer lage piek en enkele hoge pieken tussen
20 en 40 seconden, maar tussen 40 en 60 seconden zijn er bijna geen pieken. Deze pieken zijn
afkomstig van de bursts die worden gegenereerd om self similar trafiek te modelleren. De ver-
wachtingswaarde en gemiddelde grootte van de bursts worden bepaald door de Hurst-parameter
en de Pareto-distributie, maar de plaats en grootte van de effectieve bursts zijn eerder willekeu-
rig [21, 22]. Dit verklaart de grote verschillen in effectieve toegekende bandbreedte.
Aangezien de gemiddelde toekenning van bandbreedte per set ONU’s uit figuur 4.1a en 4.1b
gelijk is, wordt geconcludeerd dat de implementatie van het originele dual SLA scheduling algo-
ritme in OPNET correct is. Hierna werd het orginele algoritme vervangen door de aangepaste
versie uit sectie 3.1.2. De resultaten van de toekenning van bandbreedte aan de hand van dit
vernieuwde algoritme, zijn terug te vinden in figuur 4.2. Ook in deze figuur is de toegekende
bandbreedte per set van ONU’s in functie van de simulatietijd weergegeven.
Zoals bij de voorbeelden in secties 3.1.1.3 en 3.1.2.3 al werd aangegeven, is het verdelen van de
bandbreedte verschillend bij beide modellen indien de maximale capaciteit overschreden wordt.
Bij de originele versie wordt er gekeken om de fout per ONU zo laag mogelijk te houden, te-
genover de aangepaste versie waarbij de onbenutte bandbreedte gelijk verdeeld wordt onder de
ONU’s die meer vragen dan hun SLA. Na 40 seconden krijgen set III en IV meer bandbreedte
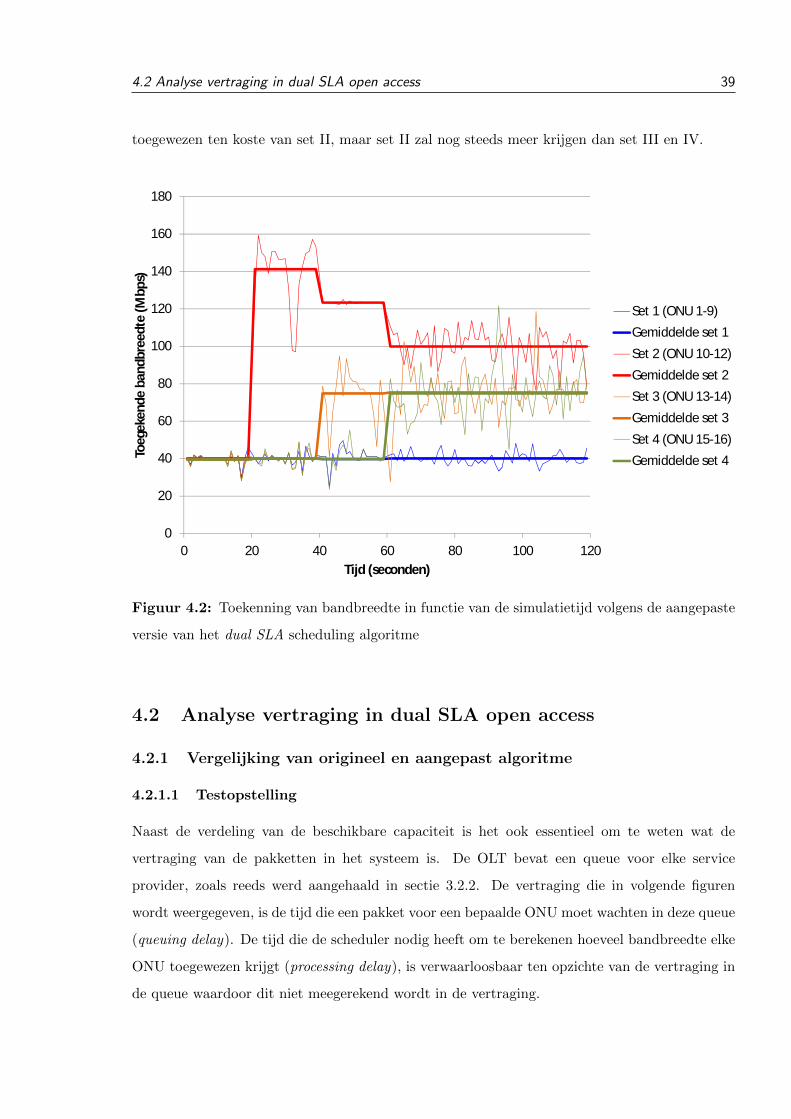
4.2 Analyse vertraging in dual SLA open access 39
toegewezen ten koste van set II, maar set II zal nog steeds meer krijgen dan set III en IV.
0
20
40
60
80
100
120
140
160
180
0 20 40 60 80 100 120
Toeg
eken
de b
andb
reed
te (M
bps)
Tijd (seconden)
Set 1 (ONU 1-9)Gemiddelde set 1
Set 2 (ONU 10-12)
Gemiddelde set 2Set 3 (ONU 13-14)
Gemiddelde set 3
Set 4 (ONU 15-16)Gemiddelde set 4
Figuur 4.2: Toekenning van bandbreedte in functie van de simulatietijd volgens de aangepaste
versie van het dual SLA scheduling algoritme
4.2 Analyse vertraging in dual SLA open access
4.2.1 Vergelijking van origineel en aangepast algoritme
4.2.1.1 Testopstelling
Naast de verdeling van de beschikbare capaciteit is het ook essentieel om te weten wat de
vertraging van de pakketten in het systeem is. De OLT bevat een queue voor elke service
provider, zoals reeds werd aangehaald in sectie 3.2.2. De vertraging die in volgende figuren
wordt weergegeven, is de tijd die een pakket voor een bepaalde ONU moet wachten in deze queue
(queuing delay). De tijd die de scheduler nodig heeft om te berekenen hoeveel bandbreedte elke
ONU toegewezen krijgt (processing delay), is verwaarloosbaar ten opzichte van de vertraging in
de queue waardoor dit niet meegerekend wordt in de vertraging.

40 HOOFDSTUK 4: SIMULATIES EN RESULTATEN
In deze simulaties wordt er gebruik gemaakt van de parameters die in tabel 4.1 terug te vinden
zijn, waarin ook is aangegeven welke service providers en welke ONU’s tot een bepaalde set be-
horen. De originele en aangepaste versie van het dual SLA scheduling algoritme vertonen geen
verschil in vertraging aangezien er enkel een verandering is in het verdelen van de bandbreedte
indien de netwerkbelasting te hoog is.
Opmerkelijk is wel dat de vertraging voor een netwerkbelasting van 10% tot 80% zo goed als
gelijk was, namelijk 100 µs. Dit is te wijten aan de minimale cyclustijd van de scheduler, die in
[16] gelijk is aan 200 µs (zie tabel 4.1). Indien er weinig trafiek op het netwerk is, worden de
pakketten die net voor de huidige cyclus toekomen direct in de huidige cyclus gestuurd en pak-
ketten die net daarna binnenkomen, moeten wachten op de volgende cyclus. Hierdoor moeten
de pakketten gemiddeld gezien een halve cyclustijd wachten, wat in dit geval 100 µs is.
Een eenvoudige oplossing om dit probleem te elimineren, is het verlagen van de minimale cy-
clustijd van de scheduler. In de tweede simulatie werd de minimale cyclustijd van de scheduler
verlaagd van 200 µs naar 15 µs, waardoor de vertraging bij een lage netwerkbelasting van 100
µs naar 7.5 µs zou moeten dalen. De simulaties zijn als volgt opgebouwd: er wordt gesimuleerd
voor 20 seconden waarbij de originele netwerkbelasting 10% is. Na elke 20 seconden wordt de
netwerkbelasting met 10% verhoogd en bij elke simulatie wordt de gemiddelde vertraging van
de pakketten uitgelezen. Deze simulaties worden uitgevoerd tot de totale netwerkbelasting van
100% bekomen wordt.
4.2.1.2 Resultaten
De opmerkelijke situatie waarbij de vertraging voor een netwerkbelasting tot 80% bijna overal
100 µs bedraagt, is duidelijk terug te vinden in de bovenste grafiek in figuur 4.3. Het verlagen
van de minimale cyclustijd heeft een enorme verlaging van de vertraging in deze zone teweeg ge-
bracht, zonder dat er hierbij schade werd toegebracht aan het fair verdelen van de bandbreedte.
Het aanpassen van deze parameter was dus noodzakelijk om een lagere vertraging te realiseren
op de trafiek. Sectie 4.2.2.2 gaat iets uitgebreider in op het bekomen van deze vertragingen uit
de resultaten van de simulaties.
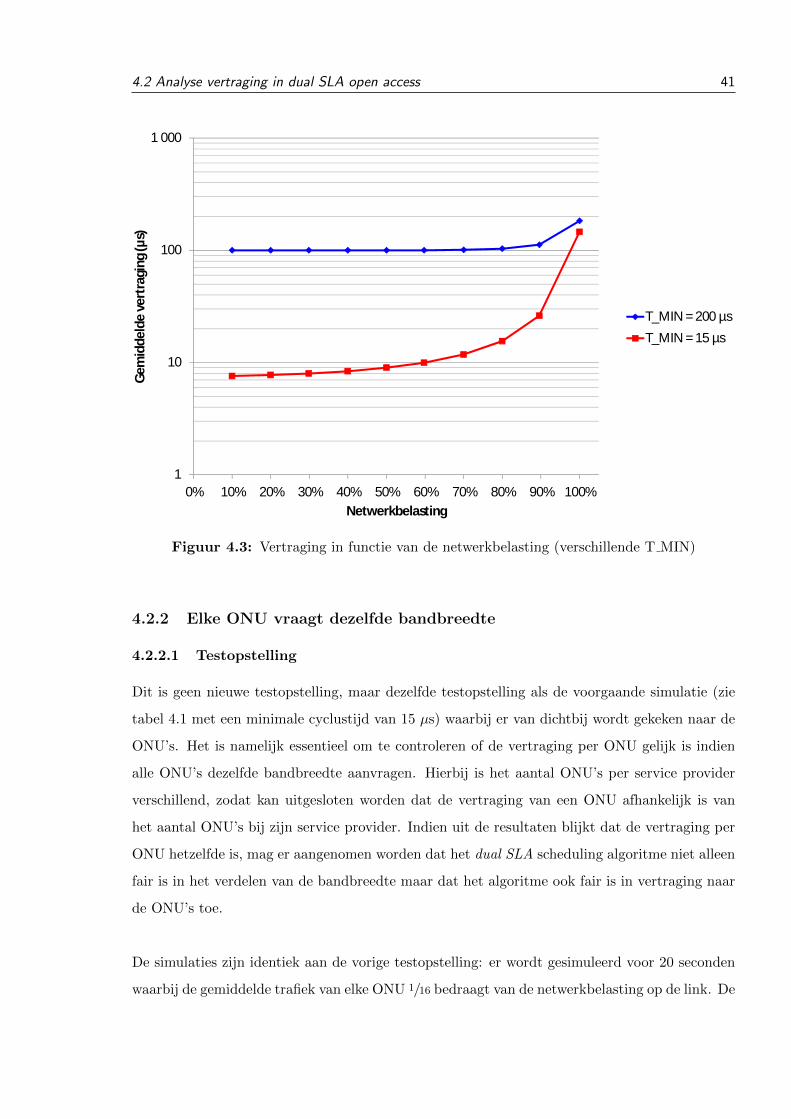
4.2 Analyse vertraging in dual SLA open access 41
1
10
100
1 000
0% 10% 20% 30% 40% 50% 60% 70% 80% 90% 100%
Gem
idde
lde
vert
ragi
ng (µ
s)
Netwerkbelasting
T_MIN = 200 µs
T_MIN = 15 µs
Figuur 4.3: Vertraging in functie van de netwerkbelasting (verschillende T MIN)
4.2.2 Elke ONU vraagt dezelfde bandbreedte
4.2.2.1 Testopstelling
Dit is geen nieuwe testopstelling, maar dezelfde testopstelling als de voorgaande simulatie (zie
tabel 4.1 met een minimale cyclustijd van 15 µs) waarbij er van dichtbij wordt gekeken naar de
ONU’s. Het is namelijk essentieel om te controleren of de vertraging per ONU gelijk is indien
alle ONU’s dezelfde bandbreedte aanvragen. Hierbij is het aantal ONU’s per service provider
verschillend, zodat kan uitgesloten worden dat de vertraging van een ONU afhankelijk is van
het aantal ONU’s bij zijn service provider. Indien uit de resultaten blijkt dat de vertraging per
ONU hetzelfde is, mag er aangenomen worden dat het dual SLA scheduling algoritme niet alleen
fair is in het verdelen van de bandbreedte maar dat het algoritme ook fair is in vertraging naar
de ONU’s toe.
De simulaties zijn identiek aan de vorige testopstelling: er wordt gesimuleerd voor 20 seconden
waarbij de gemiddelde trafiek van elke ONU 1/16 bedraagt van de netwerkbelasting op de link. De

42 HOOFDSTUK 4: SIMULATIES EN RESULTATEN
netwerkbelasting is het percentage van de capaciteit van de link dat gemiddeld gezien gebruikt
wordt en is bijvoorbeeld 32% indien elke ONU gemiddeld gezien 20 Mbps levert. Er werden
10 simulaties uitgevoerd waarbij de eerste simulatie een netwerkbelasting had van 10% en de
netwerkbelasting van elke daaropvolgende simulatie met 10% werd verhoogd.
4.2.2.2 Resultaten
Figuur 4.3 geeft de resultaten weer van de vertraging per set ONU’s in functie van de netwerk-
belasting. De markeringen van de vertragingen op de grafiek werden als volgt bekomen:
1. Eerst werd de vertraging van elk pakket voor een bepaalde ONU opgeteld en gedeeld
door het aantal ontvangen pakketten. Dit bepaalt de gemiddelde vertraging die een ONU
ondervindt. In het begin van de simulatie kunnen de vertragingen sterk verschillen, maar
na 20 seconden simuleren is deze waarde redelijk stabiel.
2. Vervolgens werden de gemiddelde vertragingen van alle ONU’s van een bepaalde set opge-
teld en gedeeld door het aantal ONU’s van deze set. Hierdoor werd de gemiddelde vertra-
ging van deze set bepaald en werd deze waarde toegevoegd aan de grafiek. De gemiddelde
vertragingen van alle ONU’s van de set waren zo goed als allemaal gelijk, waardoor er zich
geen probleem vormde bij het uitmiddelen van deze vertragingen.
De vertraging per ONU is gelijk indien elke ONU dezelfde bandbreedte aanvraagt. De vertra-
ging is ook onafhankelijk van het aantal ONU’s dat geconnecteerd is met een bepaalde service
provider, waardoor er kan gesteld worden dat het algoritme ook fair is op gebied van vertraging
per ONU.
4.2.3 De ONU’s vragen verschillende bandbreedtes
4.2.3.1 Testopstelling
Het algoritme blijkt fair te zijn op gebied van vertraging als de gemiddelde trafiek per ONU
gelijk is. Indien de trafiek per ONU verschilt, zou deze vertraging niet meer gelijk mogen lopen.
Dit is te wijten aan het bursty karakter van de trafiek, waardoor een hogere gemiddelde trafiek
voor grotere bursts zal zorgen. De pakketten uit een grotere burst kunnen mogelijks niet in
dezelfde cyclus verstuurd worden waardoor een deel van de pakketten van dezelfde burst zal
moeten wachten tot de volgende cyclus. De vertraging van een ONU met een lagere gemiddelde
trafiek zou nu niet meer dezelfde gemiddelde vertraging mogen hebben als de ONU met de

4.2 Analyse vertraging in dual SLA open access 43
hogere gemiddelde trafiek. Om deze stelling te kunnen verifieren, werden er andere simulaties
uitgevoerd. De ONU’s werden nu opgedeeld in twee sets, waarbij de gemiddelde trafiek van de
eerste set ONU’s steeds hetzelfde blijft terwijl de gemiddelde trafiek van de tweede set ONU’s
stijgt na elke simulatie. De ONU’s worden toegewezen aan verschillende service providers volgens
tabel 4.4.
Service provider ONU’s
SP 1 ONU 1 - 8
SP 2 - SP 3 ONU 9 - 10
SP 4 ONU 11 - 12
SP 5 ONU 13 - 14
SP 6 ONU 15 - 16
Tabel 4.4: Verdeling van de ONU’s onder de service providers in het geval dat ONU’s een
verschillende bandbreedte vragen
Simulatie Bandbreedte set 1 Bandbreedte set 2 Netwerkbelasting
1 30 Mbps 10 Mbps 32%
2 30 Mbps 20 Mbps 40%
3 30 Mbps 30 Mbps 48%
4 30 Mbps 40 Mbps 56%
5 30 Mbps 50 Mbps 64%
6 30 Mbps 60 Mbps 72%
7 30 Mbps 70 Mbps 80%
8 30 Mbps 80 Mbps 88%
9 30 Mbps 90 Mbps 96%
Tabel 4.5: De gemiddelde bandbreedte die per ONU gevraagd wordt en de netwerkbelasting
bij de verschillende simulaties
De vaste set (set 1) bevat ONU’s 9 tot en met 16, ofwel service provider 2 tot en met 6. Deze
ONU’s vragen bij elke simulatie dezelfde gemiddelde bandbreedte, namelijk 30 Mbps per ONU.
De variabele set (set 2) bevat ONU’s 1 tot en met 8 en bevat hierdoor enkel service provider 1.
De vraag per ONU is bij de eerste simulatie 10 Mbps en stijgt per simulatie met 10 Mbps per
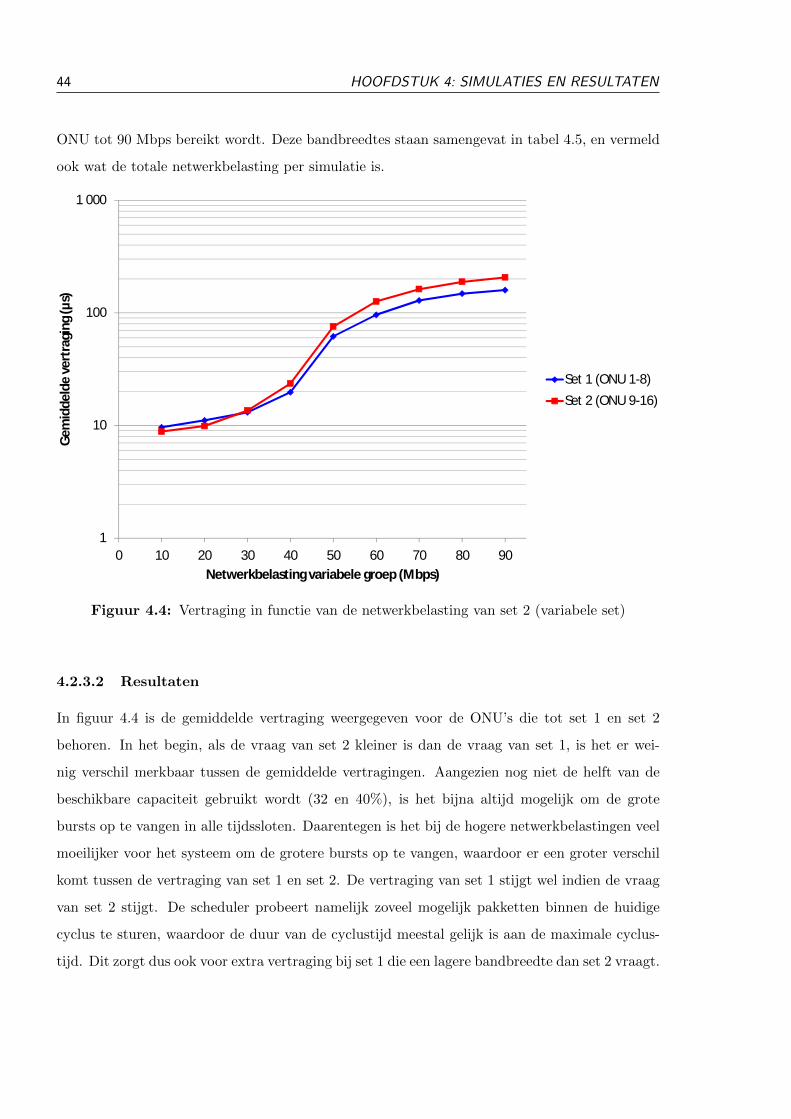
44 HOOFDSTUK 4: SIMULATIES EN RESULTATEN
ONU tot 90 Mbps bereikt wordt. Deze bandbreedtes staan samengevat in tabel 4.5, en vermeld
ook wat de totale netwerkbelasting per simulatie is.
1
10
100
1 000
0 10 20 30 40 50 60 70 80 90
Gem
idde
lde
vert
ragi
ng (µ
s)
Netwerkbelasting variabele groep (Mbps)
Set 1 (ONU 1-8)Set 2 (ONU 9-16)
Figuur 4.4: Vertraging in functie van de netwerkbelasting van set 2 (variabele set)
4.2.3.2 Resultaten
In figuur 4.4 is de gemiddelde vertraging weergegeven voor de ONU’s die tot set 1 en set 2
behoren. In het begin, als de vraag van set 2 kleiner is dan de vraag van set 1, is het er wei-
nig verschil merkbaar tussen de gemiddelde vertragingen. Aangezien nog niet de helft van de
beschikbare capaciteit gebruikt wordt (32 en 40%), is het bijna altijd mogelijk om de grote
bursts op te vangen in alle tijdssloten. Daarentegen is het bij de hogere netwerkbelastingen veel
moeilijker voor het systeem om de grotere bursts op te vangen, waardoor er een groter verschil
komt tussen de vertraging van set 1 en set 2. De vertraging van set 1 stijgt wel indien de vraag
van set 2 stijgt. De scheduler probeert namelijk zoveel mogelijk pakketten binnen de huidige
cyclus te sturen, waardoor de duur van de cyclustijd meestal gelijk is aan de maximale cyclus-
tijd. Dit zorgt dus ook voor extra vertraging bij set 1 die een lagere bandbreedte dan set 2 vraagt.

4.3 Vergelijking vertraging dual SLA en WRR 45
4.3 Vergelijking vertraging dual SLA en WRR
4.3.1 Alleen best effort trafiek
4.3.1.1 Testopstelling
Nu het algoritme zowel fair is in toekenning van bandbreedte als in vertraging van pakketten,
moet er ook gekeken worden of de behaalde vertraging niet te hoog is. Om te kunnen verifieren
of de resultaten van de vertraging goed of slecht zijn, is het noodzakelijk om deze resultaten
te vergelijken met een implementatie waarvan de resultaten reeds door OPNET gecontroleerd
werden. Hiervoor wordt gebruik gemaakt van de tweede methodologie om bit stream open access
te realiseren, namelijk aan de hand van switches die werken met het WRR scheduling algoritme.
Om eenvoudig te kunnen vergelijken, is er geopteerd om de gemiddelde trafiek per ONU terug
gelijk te maken zoals in sectie 4.2.2. Hierbij wordt opnieuw gewerkt met de aangepaste versie
van het dual SLA scheduling algoritme en worden de parameters uit tabel 4.1 met een minimale
cyclustijd van 15 µs toegepast. Opnieuw worden er simulaties uitgevoerd van 20 seconden
waarbij de gemiddelde trafiek van elke ONU 1/16 bedraagt van de netwerkbelasting op de link.
Nu beide modellen (aangepast dual SLA en WRR) dezelfde parameters krijgen, is het eenvoudig
om ze met elkaar te vergelijken.
4.3.1.2 Resultaten
In figuur 4.5 is de vertraging van de pakketten weergegeven in functie van de netwerkbelasting.
Er zijn twee curves op de grafiek te zien, namelijk een voor de vertraging bij het WRR schedu-
ling algoritme en een voor de vertraging bij het aangepast dual SLA scheduling algoritme. De
vertraging is weergegeven in een logaritmische schaal om het verschil toch duidelijk te kunnen
aangeven in het geval van een lage netwerkbelasting.
Uit figuur 4.5 is het duidelijk dat het aangepast dual SLA scheduling algoritme voor minder
vertraging zorgt dan het WRR scheduling algoritme van de switches. In het begin is het absolute
verschil niet zo veel: 7.5 µs voor dual SLA tegenover 23.6 µs voor WRR bij 10% netwerkbelasting.
Naar het einde toe wordt het absolute verschil wel groter: 145 µs voor dual SLA tegenover 528 µs
voor WRR bij 100% netwerkbelasting. Het dual SLA scheduling algoritme heeft een onder- en
bovengrens voor de cyclustijd (respectievelijk 15 en 500 µs), wat het WRR scheduling algoritme
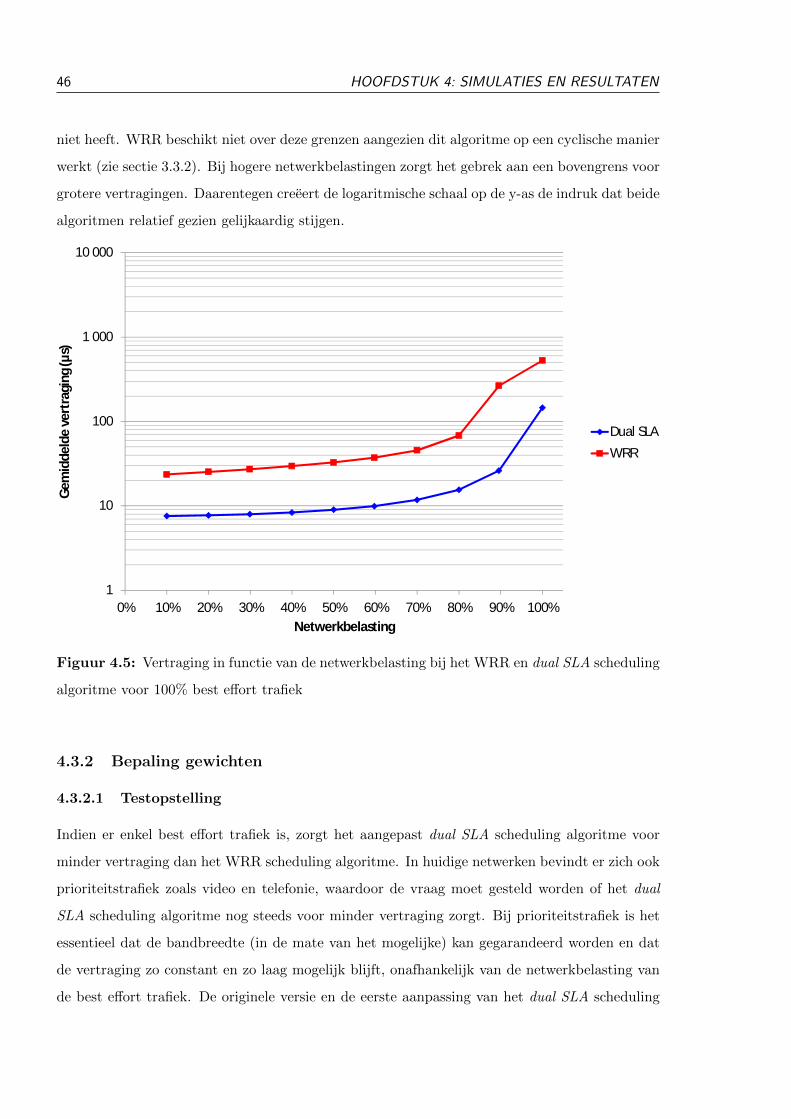
46 HOOFDSTUK 4: SIMULATIES EN RESULTATEN
niet heeft. WRR beschikt niet over deze grenzen aangezien dit algoritme op een cyclische manier
werkt (zie sectie 3.3.2). Bij hogere netwerkbelastingen zorgt het gebrek aan een bovengrens voor
grotere vertragingen. Daarentegen creeert de logaritmische schaal op de y-as de indruk dat beide
algoritmen relatief gezien gelijkaardig stijgen.
1
10
100
1 000
10 000
0% 10% 20% 30% 40% 50% 60% 70% 80% 90% 100%
Gem
idde
lde
vert
ragi
ng (µ
s)
Netwerkbelasting
Dual SLA
WRR
Figuur 4.5: Vertraging in functie van de netwerkbelasting bij het WRR en dual SLA scheduling
algoritme voor 100% best effort trafiek
4.3.2 Bepaling gewichten
4.3.2.1 Testopstelling
Indien er enkel best effort trafiek is, zorgt het aangepast dual SLA scheduling algoritme voor
minder vertraging dan het WRR scheduling algoritme. In huidige netwerken bevindt er zich ook
prioriteitstrafiek zoals video en telefonie, waardoor de vraag moet gesteld worden of het dual
SLA scheduling algoritme nog steeds voor minder vertraging zorgt. Bij prioriteitstrafiek is het
essentieel dat de bandbreedte (in de mate van het mogelijke) kan gegarandeerd worden en dat
de vertraging zo constant en zo laag mogelijk blijft, onafhankelijk van de netwerkbelasting van
de best effort trafiek. De originele versie en de eerste aanpassing van het dual SLA scheduling

4.3 Vergelijking vertraging dual SLA en WRR 47
algoritme bevatte nog geen functionaliteit om prioriteitstrafiek te ondersteunen, waardoor een
nieuwe aanpassing aan het algoritme werd uitgevoerd (zie sectie 3.1.3).
De tweede aanpassing van het dual SLA scheduling algoritme maakt gebruik van twee gewich-
ten: WBE,P en WBE,MIN . Elke hoeveelheid van prioriteitstrafiek heeft een optimale waarde voor
beide gewichten om de vertraging van de prioriteitstrafiek zo laag mogelijk te maken. Optimaal
wil ook zeggen dat de bandbreedte van best effort trafiek in de mate van het mogelijke gega-
randeerd moet worden. Anders zou de optimale oplossing zijn om best effort niet meer door te
laten en dan heeft prioriteitstrafiek de laagst mogelijke vertraging. Er werden enkele simulaties
uitgevoerd om voor 25%, 50% en 75% prioriteitstrafiek de optimale gewichten te bepalen (meer
informatie over de parameters, zie secties 4.3.3, 4.3.4 en 4.3.5). Hierbij werd telkens gewerkt met
een netwerkbelasting van 90% aangezien dit toch enig verschil geeft in vertraging, maar waarbij
de bandbreedte (gemiddeld gezien) kan gegarandeerd worden.
4.3.2.2 Resultaten
25% prioriteitstrafiek Als eerste werd de simulatie met 90% netwerkbelasting, waarvan 25%
prioriteitstrafiek, uitgevoerd. De resultaten hiervan zijn terug te vinden in figuur 4.6, waarbij
figuur 4.6a en 4.6b respectievelijk de vertraging van de prioriteitstrafiek en best effort trafiek
weergeven. Beide vertragingen worden in functie van verschillende waarden van WBE,P en
WBE,MIN weergegeven. Hierbij is duidelijk te zien dat er zo goed als geen verschil is tussen
WBE,P = 0.020 en WBE,P = 0.200. Nadat WBE,MIN lager gaat dan de waarde 0.013 (in het
geval van 90% netwerkbelasting) kan de bandbreedte voor best effort niet meer gegarandeerd
worden, wat de vertraging van best effort trafiek enorm laat stijgen (zie figuur 4.6b).
De reden dat de bandbreedte niet meer kan gegarandeerd worden als WBE,MIN < 0.013 is voor
de hand liggend: hoe lager WBE,MIN wordt ingesteld, hoe lager de minimale bandbreedte voor
best effort trafiek is. In dit geval was de best effort trafiek 75% van de totale netwerkbelasting,
waardoor WBE,MIN niet te laag mag zijn. WBE,MIN mag ook niet te hoog zijn (bvb. 0.040), om
dat dit een nefaste invloed heeft op de vertraging van de prioriteitstrafiek (zie figuur 4.6a). De
optimale waarden voor 25% prioriteitstrafiek situeren zich in volgende regio’s: WBE,P ≤ 0.200
en 0.013 ≤WBE,MIN ≤ 0.020.
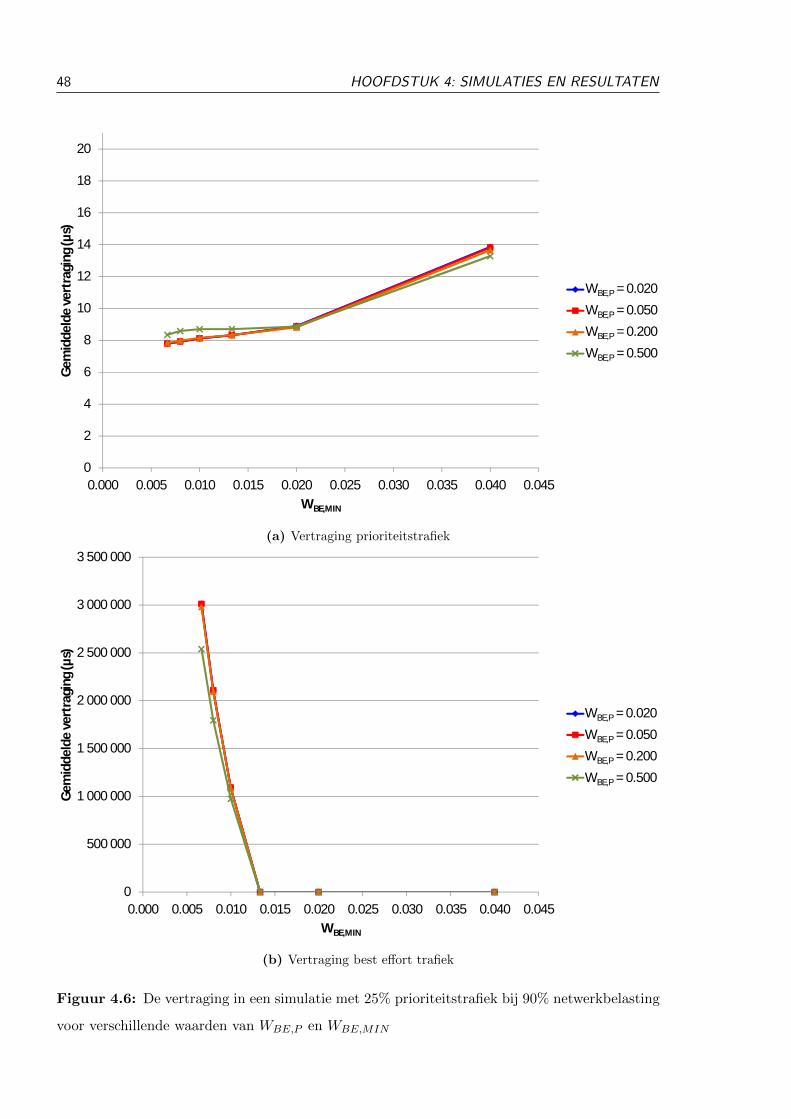
48 HOOFDSTUK 4: SIMULATIES EN RESULTATEN
0
2
4
6
8
10
12
14
16
18
20
0.000 0.005 0.010 0.015 0.020 0.025 0.030 0.035 0.040 0.045
Gem
idde
lde
vert
ragi
ng (µ
s)
WBE,MIN
WBE = 0,020
WBE = 0,050
WBE = 0,200WBE = 0,500
WBE,P = 0.020
WBE,P = 0.050
WBE,P = 0.200
WBE,P = 0.500
(a) Vertraging prioriteitstrafiek
0
500 000
1 000 000
1 500 000
2 000 000
2 500 000
3 000 000
3 500 000
0.000 0.005 0.010 0.015 0.020 0.025 0.030 0.035 0.040 0.045
Gem
idde
lde
vert
ragi
ng (µ
s)
WBE,MIN
WBE = 0,020
WBE = 0,050
WBE = 0,200WBE = 0,500
WBE,P = 0.020
WBE,P = 0.050
WBE,P = 0.200
WBE,P = 0.500
(b) Vertraging best effort trafiek
Figuur 4.6: De vertraging in een simulatie met 25% prioriteitstrafiek bij 90% netwerkbelasting
voor verschillende waarden van WBE,P en WBE,MIN
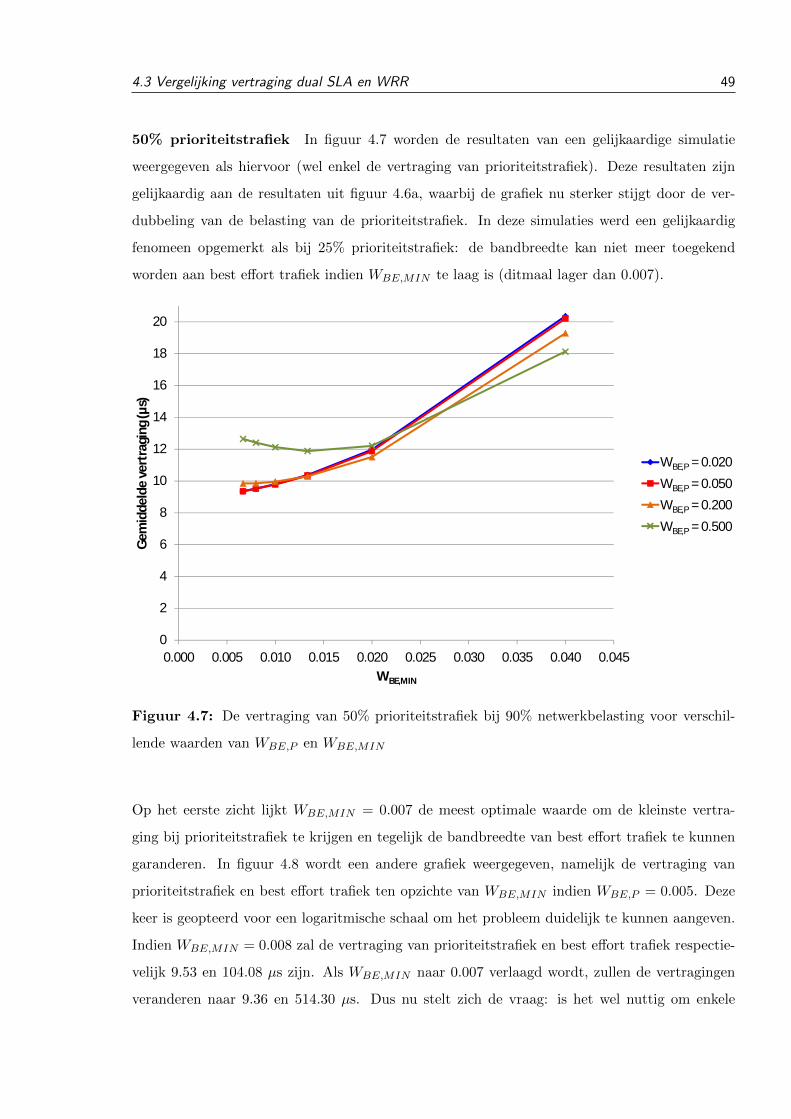
4.3 Vergelijking vertraging dual SLA en WRR 49
50% prioriteitstrafiek In figuur 4.7 worden de resultaten van een gelijkaardige simulatie
weergegeven als hiervoor (wel enkel de vertraging van prioriteitstrafiek). Deze resultaten zijn
gelijkaardig aan de resultaten uit figuur 4.6a, waarbij de grafiek nu sterker stijgt door de ver-
dubbeling van de belasting van de prioriteitstrafiek. In deze simulaties werd een gelijkaardig
fenomeen opgemerkt als bij 25% prioriteitstrafiek: de bandbreedte kan niet meer toegekend
worden aan best effort trafiek indien WBE,MIN te laag is (ditmaal lager dan 0.007).
0
2
4
6
8
10
12
14
16
18
20
0.000 0.005 0.010 0.015 0.020 0.025 0.030 0.035 0.040 0.045
Gem
idde
lde
vert
ragi
ng (µ
s)
WBE,MIN
WBE = 0,020
WBE = 0,050
WBE = 0,200WBE = 0,500
WBE,P = 0.020
WBE,P = 0.050
WBE,P = 0.200
WBE,P = 0.500
Figuur 4.7: De vertraging van 50% prioriteitstrafiek bij 90% netwerkbelasting voor verschil-
lende waarden van WBE,P en WBE,MIN
Op het eerste zicht lijkt WBE,MIN = 0.007 de meest optimale waarde om de kleinste vertra-
ging bij prioriteitstrafiek te krijgen en tegelijk de bandbreedte van best effort trafiek te kunnen
garanderen. In figuur 4.8 wordt een andere grafiek weergegeven, namelijk de vertraging van
prioriteitstrafiek en best effort trafiek ten opzichte van WBE,MIN indien WBE,P = 0.005. Deze
keer is geopteerd voor een logaritmische schaal om het probleem duidelijk te kunnen aangeven.
Indien WBE,MIN = 0.008 zal de vertraging van prioriteitstrafiek en best effort trafiek respectie-
velijk 9.53 en 104.08 µs zijn. Als WBE,MIN naar 0.007 verlaagd wordt, zullen de vertragingen
veranderen naar 9.36 en 514.30 µs. Dus nu stelt zich de vraag: is het wel nuttig om enkele
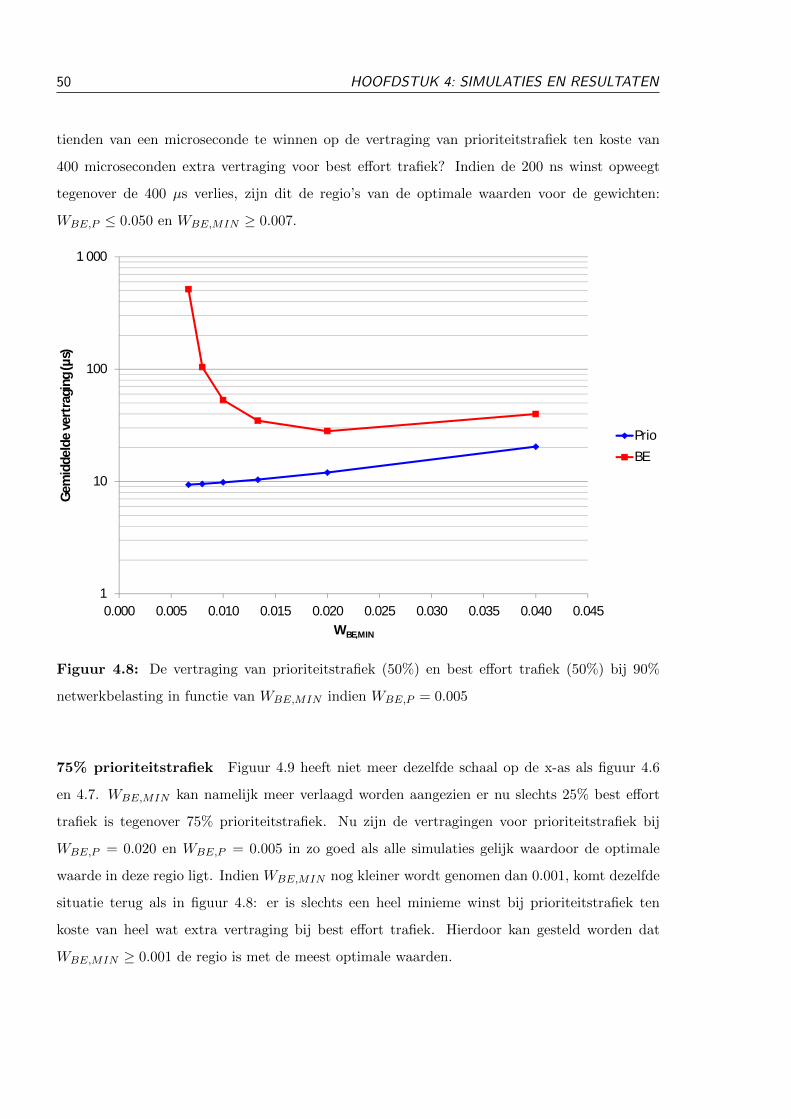
50 HOOFDSTUK 4: SIMULATIES EN RESULTATEN
tienden van een microseconde te winnen op de vertraging van prioriteitstrafiek ten koste van
400 microseconden extra vertraging voor best effort trafiek? Indien de 200 ns winst opweegt
tegenover de 400 µs verlies, zijn dit de regio’s van de optimale waarden voor de gewichten:
WBE,P ≤ 0.050 en WBE,MIN ≥ 0.007.
1
10
100
1 000
0.000 0.005 0.010 0.015 0.020 0.025 0.030 0.035 0.040 0.045
Gem
idde
lde
vert
ragi
ng (µ
s)
WBE,MIN
PrioBE
Figuur 4.8: De vertraging van prioriteitstrafiek (50%) en best effort trafiek (50%) bij 90%
netwerkbelasting in functie van WBE,MIN indien WBE,P = 0.005
75% prioriteitstrafiek Figuur 4.9 heeft niet meer dezelfde schaal op de x-as als figuur 4.6
en 4.7. WBE,MIN kan namelijk meer verlaagd worden aangezien er nu slechts 25% best effort
trafiek is tegenover 75% prioriteitstrafiek. Nu zijn de vertragingen voor prioriteitstrafiek bij
WBE,P = 0.020 en WBE,P = 0.005 in zo goed als alle simulaties gelijk waardoor de optimale
waarde in deze regio ligt. Indien WBE,MIN nog kleiner wordt genomen dan 0.001, komt dezelfde
situatie terug als in figuur 4.8: er is slechts een heel minieme winst bij prioriteitstrafiek ten
koste van heel wat extra vertraging bij best effort trafiek. Hierdoor kan gesteld worden dat
WBE,MIN ≥ 0.001 de regio is met de meest optimale waarden.
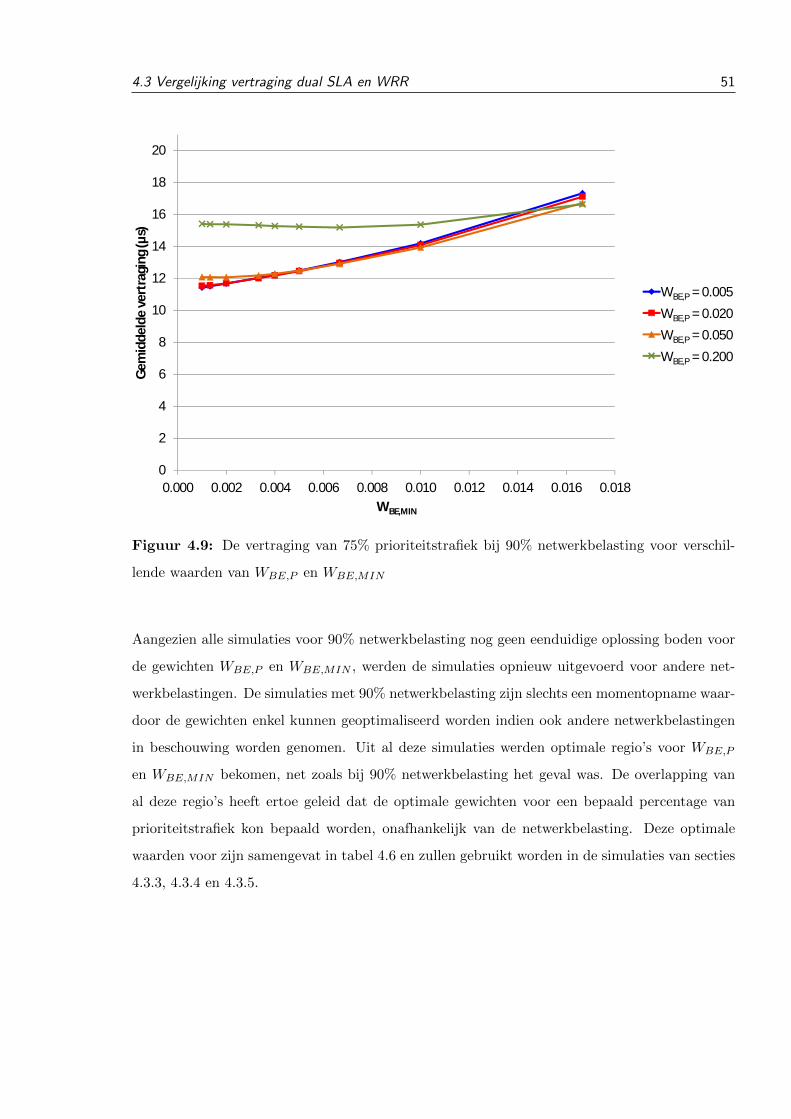
4.3 Vergelijking vertraging dual SLA en WRR 51
0
2
4
6
8
10
12
14
16
18
20
0.000 0.002 0.004 0.006 0.008 0.010 0.012 0.014 0.016 0.018
Gem
idde
lde
vert
ragi
ng (µ
s)
WBE,MIN
WBE = 0,005
WBE = 0,020
WBE = 0,050WBE = 0,200
WBE,P = 0.005
WBE,P = 0.020
WBE,P = 0.050
WBE,P = 0.200
Figuur 4.9: De vertraging van 75% prioriteitstrafiek bij 90% netwerkbelasting voor verschil-
lende waarden van WBE,P en WBE,MIN
Aangezien alle simulaties voor 90% netwerkbelasting nog geen eenduidige oplossing boden voor
de gewichten WBE,P en WBE,MIN , werden de simulaties opnieuw uitgevoerd voor andere net-
werkbelastingen. De simulaties met 90% netwerkbelasting zijn slechts een momentopname waar-
door de gewichten enkel kunnen geoptimaliseerd worden indien ook andere netwerkbelastingen
in beschouwing worden genomen. Uit al deze simulaties werden optimale regio’s voor WBE,P
en WBE,MIN bekomen, net zoals bij 90% netwerkbelasting het geval was. De overlapping van
al deze regio’s heeft ertoe geleid dat de optimale gewichten voor een bepaald percentage van
prioriteitstrafiek kon bepaald worden, onafhankelijk van de netwerkbelasting. Deze optimale
waarden voor zijn samengevat in tabel 4.6 en zullen gebruikt worden in de simulaties van secties
4.3.3, 4.3.4 en 4.3.5.

52 HOOFDSTUK 4: SIMULATIES EN RESULTATEN
Percentage prioriteitstrafiek WBE,P WBE,MIN
25% prio 0.050 0.0167
50% prio 0.020 0.0100
75% prio 0.005 0.0025
Tabel 4.6: Gewichten per percentage prioriteitstrafiek
4.3.3 25% prioriteitstrafiek
4.3.3.1 Testopstelling
Nu de optimale gewichten voor prioriteitstrafiek bepaald zijn, wordt opnieuw gesimuleerd voor
een varierende netwerkbelasting waarbij elke ONU dezelfde bandbreedte vraagt. De parameters
uit tabel 4.1 zijn hetzelfde gebleven, op uitzondering van de verdeling van ONU’s per set. De
verdelingen zijn zodanig gemaakt dat er gemakkelijk een of meerdere sets kunnen gekozen worden
om 25, 50 en 75% van de ONU’s samen te nemen.
Parameter Waarde
Aantal ONU’s in het PON model 16
Aantal service providers in het PON model 6
Kanaalcapaciteit van het PON model 1 Gbps
Maximale buffergrootte 1 MB
Maximale cyclustijd 500 µs
Minimale cyclustijd 15 µs
Set I (SP 1) ONU 1 - 8
Set II (SP 2 - SP 3) ONU 9 - 10
Set III (SP 4) ONU 11 - 12
Set IV (SP 5) ONU 13 - 14
Set V (SP 6) ONU 15 - 16
Tabel 4.7: Algemene parameters die gebruikt worden tijdens de simulatie van de vertraging
aan de hand van het WRR en dual SLA scheduling algoritme in het geval van prioriteitstrafiek
Alle parameters die nu gebruikt worden, zijn weergegeven in tabel 4.7. Opnieuw vraagt elke
ONU evenveel bandbreedte zodat de vertragingen tussen beide algoritmen eenduidig kunnen
vergeleken worden. In de eerste analysefase van prioriteitstrafiek is er gekozen om service pro-

4.3 Vergelijking vertraging dual SLA en WRR 53
vider 5 en 6 prioriteitstrafiek te laten genereren. Aangezien er in totaal 4 ONU’s geconnecteerd
zijn aan deze service providers, is 25% van de netwerkbelasting steeds prioriteitstrafiek.
Bij 25% prioriteitstrafiek werd ervoor gekozen om service provider 5 en 6 prioriteitstrafiek te
laten genereren, waardoor enkel ONU 13 tot en met 16 prioriteitstrafiek ontvangen. Uit de
simulaties is gebleken dat het niet uitmaakt of een ONU enkel prioriteitstrafiek of enkel best
effort trafiek of een combinatie van beide vraagt, de vertraging van een bepaald type trafiek zal
altijd afhangen van de totale gevraagde bandbreedte voor dit type trafiek.
De prioriteitstrafiek wordt gemodelleerd aan de hand van een exponentiele distributie in plaats
van een Pareto-distributie aangeziend video en voice meestal minder grote bursts bevatten in
vergelijking met best effort trafiek. Voice heeft eerder een Constante Bit Rate (CBR) en vi-
deo heeft een Variabele Bit Rate (VBR) (zonder extreme bursts), waardoor deze trafiek een
verschillend patroon vertoont dan best effort trafiek.
4.3.3.2 Resultaten
In figuur 4.10 worden er vier grafieken weergegeven: de gemiddelde vertraging voor best effort
trafiek en prioriteitstrafiek, zowel bij het WRR als bij dual SLA scheduling algoritme. De trend
bij vertragingen voor de best effort trafiek is gelijkaardig aan de trend indien er 100% best effort
trafiek is (zie figuur 4.5).
Opvallend in figuur 4.10 is het verschil tussen de vertragingen van prioriteitstrafiek bij WRR
en dual SLA. Zoals formule 3.4 aangeeft, wordt bij WRR per queue het aantal pakketten be-
rekend dat mag verzonden worden. De pakketten van prioriteitstrafiek en best effort trafiek
hebben een verschillende waarde in het Type of Service (ToS) veld (IP header) en worden in een
verschillende queue bijgehouden. De switch in OPNET past automatisch de gewichten van de
queues aan opdat de vertraging voor prioriteitstrafiek verlaagd wordt en nog steeds voldoende
bandbreedte aan best effort trafiek wordt toegekend.
De gewichten die gebruikt worden in dual SLA werden geoptimaliseerd, zoals in sectie 4.3.2
beschreven werd. Daarnaast beschikt dual SLA over een onder- en bovengrens, wat WRR niet
heeft, waardoor de combinatie van deze factoren zorgt dat de vertraging voor zowel prioriteits-
trafiek als best effort trafiek het kleinste is bij het dual SLA scheduling algoritme.
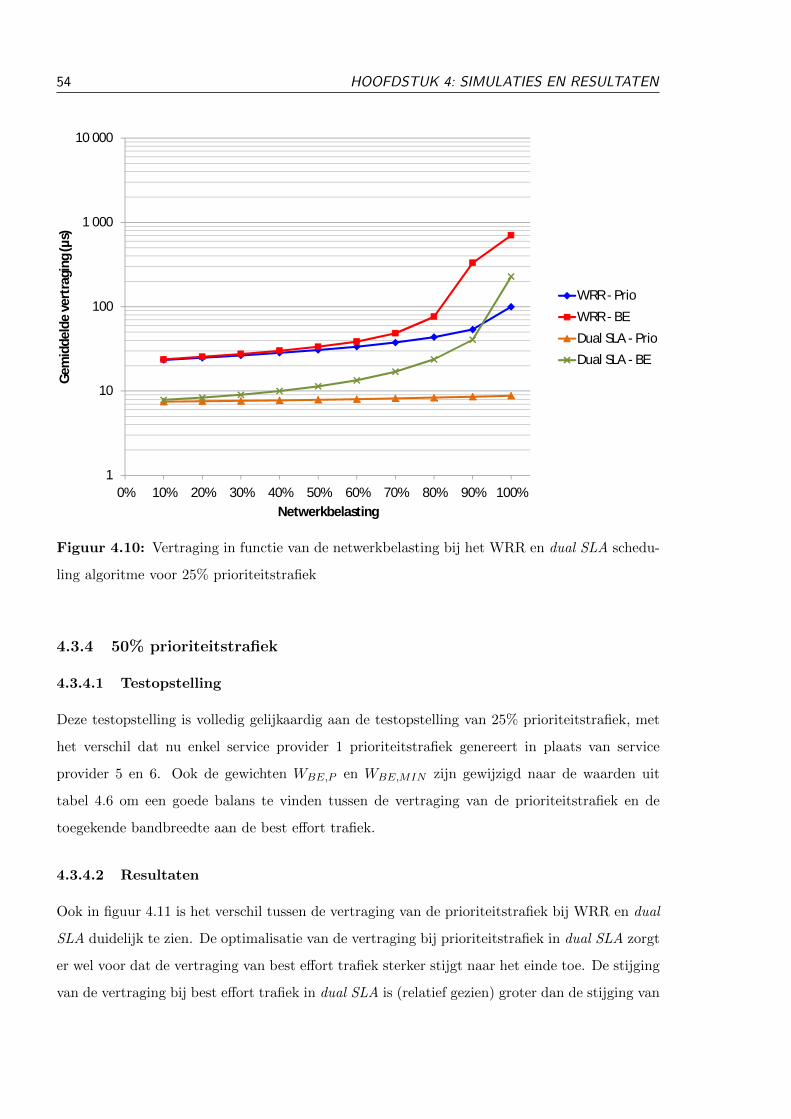
54 HOOFDSTUK 4: SIMULATIES EN RESULTATEN
1
10
100
1 000
10 000
0% 10% 20% 30% 40% 50% 60% 70% 80% 90% 100%
Gem
idde
lde
vert
ragi
ng (µ
s)
Netwerkbelasting
WRR - Prio
WRR - BE
Dual SLA - PrioDual SLA - BE
Figuur 4.10: Vertraging in functie van de netwerkbelasting bij het WRR en dual SLA schedu-
ling algoritme voor 25% prioriteitstrafiek
4.3.4 50% prioriteitstrafiek
4.3.4.1 Testopstelling
Deze testopstelling is volledig gelijkaardig aan de testopstelling van 25% prioriteitstrafiek, met
het verschil dat nu enkel service provider 1 prioriteitstrafiek genereert in plaats van service
provider 5 en 6. Ook de gewichten WBE,P en WBE,MIN zijn gewijzigd naar de waarden uit
tabel 4.6 om een goede balans te vinden tussen de vertraging van de prioriteitstrafiek en de
toegekende bandbreedte aan de best effort trafiek.
4.3.4.2 Resultaten
Ook in figuur 4.11 is het verschil tussen de vertraging van de prioriteitstrafiek bij WRR en dual
SLA duidelijk te zien. De optimalisatie van de vertraging bij prioriteitstrafiek in dual SLA zorgt
er wel voor dat de vertraging van best effort trafiek sterker stijgt naar het einde toe. De stijging
van de vertraging bij best effort trafiek in dual SLA is (relatief gezien) groter dan de stijging van
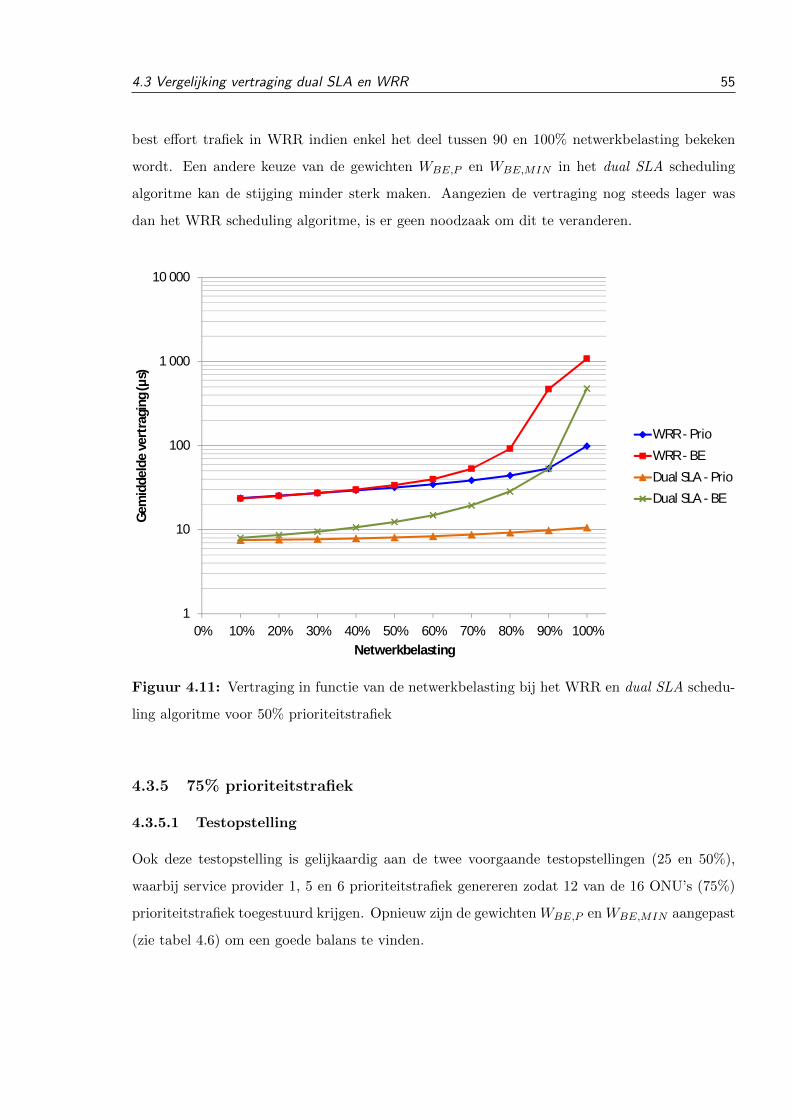
4.3 Vergelijking vertraging dual SLA en WRR 55
best effort trafiek in WRR indien enkel het deel tussen 90 en 100% netwerkbelasting bekeken
wordt. Een andere keuze van de gewichten WBE,P en WBE,MIN in het dual SLA scheduling
algoritme kan de stijging minder sterk maken. Aangezien de vertraging nog steeds lager was
dan het WRR scheduling algoritme, is er geen noodzaak om dit te veranderen.
1
10
100
1 000
10 000
0% 10% 20% 30% 40% 50% 60% 70% 80% 90% 100%
Gem
idde
lde
vert
ragi
ng (µ
s)
Netwerkbelasting
WRR - Prio
WRR - BE
Dual SLA - PrioDual SLA - BE
Figuur 4.11: Vertraging in functie van de netwerkbelasting bij het WRR en dual SLA schedu-
ling algoritme voor 50% prioriteitstrafiek
4.3.5 75% prioriteitstrafiek
4.3.5.1 Testopstelling
Ook deze testopstelling is gelijkaardig aan de twee voorgaande testopstellingen (25 en 50%),
waarbij service provider 1, 5 en 6 prioriteitstrafiek genereren zodat 12 van de 16 ONU’s (75%)
prioriteitstrafiek toegestuurd krijgen. Opnieuw zijn de gewichten WBE,P en WBE,MIN aangepast
(zie tabel 4.6) om een goede balans te vinden.
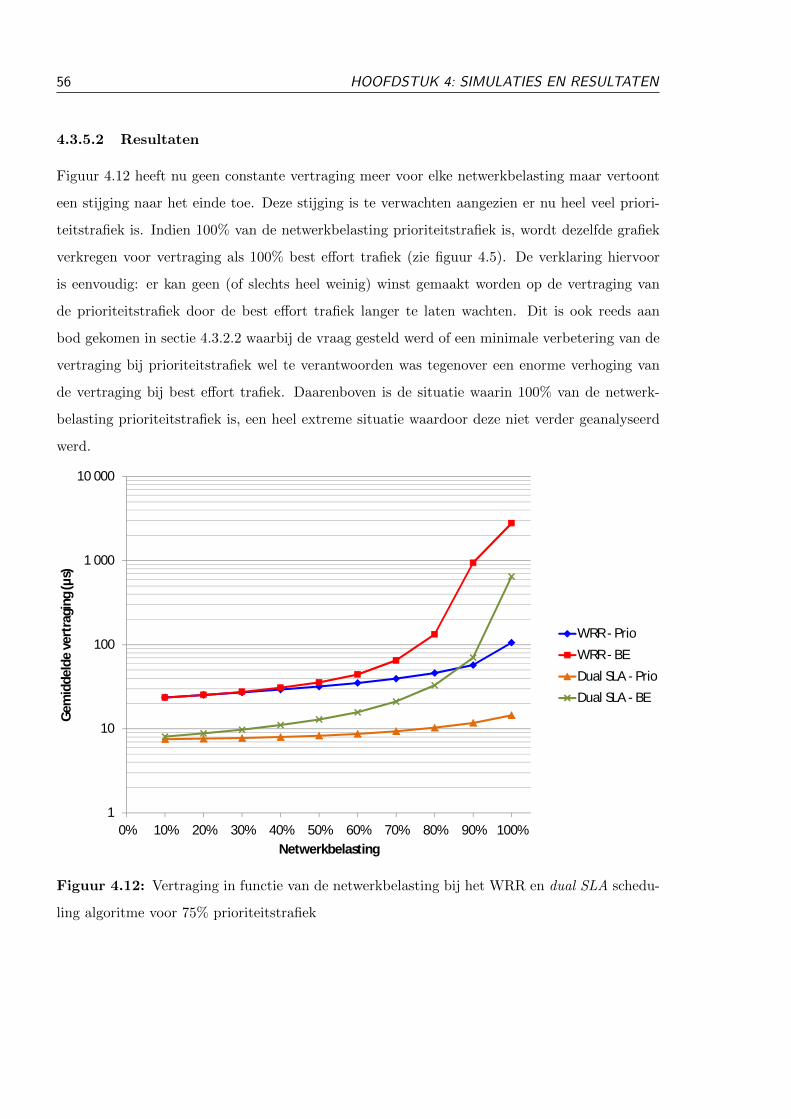
56 HOOFDSTUK 4: SIMULATIES EN RESULTATEN
4.3.5.2 Resultaten
Figuur 4.12 heeft nu geen constante vertraging meer voor elke netwerkbelasting maar vertoont
een stijging naar het einde toe. Deze stijging is te verwachten aangezien er nu heel veel priori-
teitstrafiek is. Indien 100% van de netwerkbelasting prioriteitstrafiek is, wordt dezelfde grafiek
verkregen voor vertraging als 100% best effort trafiek (zie figuur 4.5). De verklaring hiervoor
is eenvoudig: er kan geen (of slechts heel weinig) winst gemaakt worden op de vertraging van
de prioriteitstrafiek door de best effort trafiek langer te laten wachten. Dit is ook reeds aan
bod gekomen in sectie 4.3.2.2 waarbij de vraag gesteld werd of een minimale verbetering van de
vertraging bij prioriteitstrafiek wel te verantwoorden was tegenover een enorme verhoging van
de vertraging bij best effort trafiek. Daarenboven is de situatie waarin 100% van de netwerk-
belasting prioriteitstrafiek is, een heel extreme situatie waardoor deze niet verder geanalyseerd
werd.
1
10
100
1 000
10 000
0% 10% 20% 30% 40% 50% 60% 70% 80% 90% 100%
Gem
idde
lde
vert
ragi
ng (µ
s)
Netwerkbelasting
WRR - Prio
WRR - BE
Dual SLA - PrioDual SLA - BE
Figuur 4.12: Vertraging in functie van de netwerkbelasting bij het WRR en dual SLA schedu-
ling algoritme voor 75% prioriteitstrafiek

Hoofdstuk 5
Conclusie en toekomstperspectieven
5.1 Conclusie
In deze thesis werd onderzoek verricht naar het integreren van open access in een Passive Opti-
cal Network (PON) aan de hand van Time Division Multiplexing (TDM). Als eerste werd een
bestaand scheduling algoritme (dual SLA) geımplemteerd in OPNET om de resultaten uit voor-
gaand onderzoek te kunnen verifieren. Vervolgens werd ook een tweede implementatie gemaakt
in OPNET gebaseerd op switches die gebruiken maken van het WRR scheduling algoritme.
Na de verificatie van het dual SLA scheduling algoritme, werd er een eerste aanpassing gedaan
om de bandbreedte op een andere manier te verdelen bij een te hoge netwerkbelasting. Deze
aanpassing had een gelijkmatigere verdeling van de onbenutte bandbreedte tussen de ONU’s die
een hogere capaciteit dan hun SLA vroegen. Daarna werd er gekeken naar de queuing delay van
het algoritme, waarbij de minimale cyclustijd verlaagd werd met als doel de vertraging bij een
lage netwerkbelasting naar beneden te krijgen.
Uiteindelijk werd er een nog een tweede aanpassing gedaan aan het dual SLA scheduling al-
goritme, ditmaal om prioriteitstrafiek te kunnen ondersteunen. Na deze aanpassing werd er
een vergelijkende studie uitgevoerd tussen het WRR en dual SLA scheduling algoritme. Hierbij
werden verschillende scenario’s getest met variaties op gebied van de gevraagde capaciteit, het
type trafiek, het aantal ONU’s per service provider enz. Uit al deze resultaten blijkt dat de aan-
passingen aan het dual SLA scheduling algoritme hun doel bereikt hebben: de vertragingen en
verdeling van bandbreedte is geoptimaliseerd ten opzichte van het WRR scheduling algoritme.
57

58 HOOFDSTUK 5: CONCLUSIE EN TOEKOMSTPERSPECTIEVEN
5.2 Toekomstperspectieven
Aanpassingen huidig algoritme De laatste versie van het dual SLA scheduling algoritme
ondersteunt prioriteitstrafiek en zorgt ervoor dat de vertraging zo laag mogelijk is. Helaas zijn de
gebruikte gewichten geoptimaliseerd door beide waarden te laten varieren in simulaties waarbij
de gemiddelde trafiek steeds hetzelfde was. Er zou een verband moeten gezocht worden tussen
deze gewichten en de hoeveelheid prioriteitstrafiek dat wordt aangeboden. Aan de hand van de
hoeveelheid prioriteitstrafiek in het systeem kan de scheduler vervolgens bepalen welke gewichten
moeten toegepast worden om een optimale situatie te bekomen.
Upstream In alle uitgevoerde simulaties werd er enkel downstream trafiek in beschouwing
genomen. Indien het algoritme nu “omgedraaid” wordt, zou hetzelfde kunnen toegepast worden
op de upstream trafiek. Hierbij zijn er wel enkele onderdelen waar meer aandacht aan moet
besteed worden, waaronder het sturen van REPORT en GRANT berichten. Aangezien de
queues van de service providers zich momenteel in de OLT bevinden, is het niet nodig om deze
berichten te sturen.
TWDM Momenteel wordt er enkel gemultiplext in tijd, maar dit zou kunnen uitgebreid wor-
den naar Time and Wavelength Division Multiplexing (TWDM). Enkele mogelijkheden tot on-
derzoek zijn: hoeveel golflengtes worden er gebruikt, worden golflengtes aan service providers
of aan ONU’s toegekend, worden er golflengtes vrij gehouden voor prioriteitstrafiek enz. Dit
vereist ook enige aanpassingen in OPNET, aangezien de simulatie software zelf geen onderscheid
kan maken tussen de verschillende golflengtes. Hierbij geeft [19] voldoende informatie over het
implementeren van TWDM in OPNET.
Economisch aspect Deze thesis heeft aangetoond dat het dual SLA scheduling betere resul-
taten oplevert dan het WRR scheduling algoritme. Hierbij moet wel de vraag gesteld worden in
hoeverre dit economisch gezien haalbaar is om te implementeren. In het begin van deze studie
werd de hoge kost voor het uitrollen van fiber in de toegangsnetwerken al aangehaald, maar hier
werd nog geen rekening gehouden met kostprijs voor de hardware en software die nodig is voor
de implementatie van scheduling algoritme.

Bibliografie
[1] L. Martens, HFC toegangsnetwerken: case study. Ghent University, 2013.
[2] LineBroker, “FTTC Technology overview, Internet Connectivity Technologies,” http://
linebroker.co.uk/fttc-tech.php, datum van raadpleging: 02/06/2014.
[3] Cisco, Cisco Visual Networking Index: Forecast and Methodology, 2012–2017,
May 2013, http://www.cisco.com/c/en/us/solutions/collateral/service-provider/
ip-ngn-ip-next-generation-network/white paper c11-481360.pdf, datum van raadple-
ging: 02/06/2014.
[4] T. Koonen, “Fiber to the Home/Fiber to the Premises: What, Where, and When?” Pro-
ceedings of the IEEE, vol. 94, no. 5, pp. 911–934, May 2006.
[5] A. Dixit, M. Van der Wee, B. Lannoo, D. Colle, S. Verbrugge, M. Pickavet, and P. Demees-
ter, “Planning Open Access in Next-Generation Passive Optical Networks.”
[6] G. Kramer, B. Mukherjee, and G. Pesavento, “IPACT: a Dynamic Protocol for an Ethernet
PON (EPON),” IEEE Communications Magazine, vol. 40, no. 2, pp. 74–80, February 2002.
[7] J. Xie, S. Jiang, and Y. Jiang, “A Dynamic Bandwidth Allocation Scheme for Differentiated
Services in EPONs,” IEEE Communications Magazine, vol. 42, no. 8, pp. 32–39, August
2004.
[8] Y. Luo and N. Ansari, “Bandwidth allocation for multiservice access on EPONs,” IEEE
Communications Magazine, vol. 43, no. 2, pp. 16–21, February 2005.
[9] G. Kramer, A. Banerjee, N. K. Singhal, B. Mukherjee, S. Dixit, and Y. Ye, “Fair queueing
with service envelopes (FQSE): A cousin-fair hierarchical scheduler for subscriber access
networks,” IEEE Journal on Selected Areas in Communications, vol. 22, no. 8, pp. 1497–
1513, October 2004.
59

60 BIBLIOGRAFIE
[10] J. Chen, B. Chen, and L. Wosinska, “Joint Bandwidth Scheduling to Support Differentiated
Services and Multiple Service Providers in 1G and 10G EPONs,” IEEE/OSA Journal of
Optical Communications and Networking, vol. 1, no. 4, pp. 343–351, September 2009.
[11] A. Banerjee and M. Sirbu, “Towards Technologically and Competitively Neutral Fiber to
the Home (FTTH) Infrastructure,” in Broadband Services: Business Models and Technolo-
gies for Community Networks. John Wiley, September 2003.
[12] M. Van der Wee, C. Mattsson, A. Raju, O. Braet, A. Nucciarelli, B. Sadowski, S. Verbrugge,
and M. Pickavet, “Making a success of FTTH learning from case studies in Europe,” Journal
of the Institute of Telecommunications Professionals, vol. 5, no. 4, pp. 22–31, 2011.
[13] M. Forzati, C. Larsen, and C. Mattsson, “Open access networks, the Swedish experience,”
in 2010 12th International Conference on Transparent Optical Networks (ICTON), June
2010, pp. 1–4.
[14] Belgacom, “Algemene Voorwaarden,” http://www.belgacom.be/assets/content/pdf/
custom/general conditions/GTC One NL.pdf, datum van raadpleging: 13/05/2014.
[15] Telenet, “Algemene Voorwaarden,” http://klantenservice.telenet.be/attachment/
algemene-voorwaarden, datum van raadpleging: 13/05/2014.
[16] A. Banerjee, G. Kramer, and B. Mukherjee, “Fair Sharing Using Dual Service-Level Agree-
ments to Achieve Open Access in a Passive Optical Network,” IEEE Journal on Selected
Areas in Communications, vol. 24, no. 8, pp. 32–44, August 2006.
[17] P. Chanclou, S. Gosselin, J. F. Palacios, V. L. Alvarez, and E. Zouganeli, “Overview of
the optical broadband access evolution: a joint article by operators in the IST network
of excellence e-Photon/One,” IEEE Communications Magazine, vol. 44, no. 8, pp. 29–35,
August 2006.
[18] O. T. Inc., “OPNET Modeler 16A,” http://www.opnet.com/solutions/network rd/modeler.
html, datum van raadpleging: 02/06/2014.
[19] S. De Schoenmaeker, Ontwerp en evaluatie van toekomstige dynamische bandbreedte-
allocatie-protocollen voor hybride WDM/TDM PON netwerken. Ghent University, June
2011.

BIBLIOGRAFIE 61
[20] M. Katevenis, S. Sidiropoulos, and C. Courcoubetis, “Weighted round-robin cell multiplex-
ing in a general-purpose ATM switch chip,” IEEE Journal on Selected Areas in Communi-
cations, vol. 9, no. 8, pp. 1265–1279, October 1991.
[21] K. Park and W. Willinger, Self-Similar Network Traffic: An Overview. John Wiley &
Sons, Inc., 2002, pp. 1–38.
[22] W. Willinger, M. S. Taqqu, R. Sherman, and D. V. Wilson, “Self-similarity Through High-
variability: Statistical Analysis of Ethernet LAN Traffic at the Source Level,” ACM SIG-
COMM Computer Communication Review, vol. 25, no. 4, pp. 100–113, October 1995.
[23] M. S. Taqqu, W. Willinger, and R. Sherman, “Proof of a fundamental result in self-similar
traffic modeling,” ACM SIGCOMM Computer Communication Review, vol. 27, no. 2, pp.
5–23, April 1997.
[24] W. E. Leland, W. Willinger, M. S. Taqqu, and D. V. Wilson, “On the Self-Similar Nature
of Ethernet Traffic,” ACM SIGCOMM Computer Communication Review, vol. 25, no. 1,
pp. 202–213, January 1995.
[25] B. C. Arnold, Pareto distribution. Wiley Online Library, 1985.

62 BIBLIOGRAFIE

Lijst van figuren
2.1 Topologie van de gebruikte kopertechnologieen in Belgie . . . . . . . . . . . . . . 4
2.2 Downstream snelheden van xDSL in functie van afstand tot DSLAM [2] . . . . . 6
2.3 Fiber to the Curb . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8
2.4 P2P en P2MP architectuur voor optische netwerken . . . . . . . . . . . . . . . . 9
2.5 Multiplexing in PON’s . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 12
2.6 Soorten toegangsnetwerken . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17
3.1 Flowchart dual SLA scheduling algoritme [16] . . . . . . . . . . . . . . . . . . . . 23
3.2 Flowchart toekennen bandbreedte in geval van prioriteitstrafiek . . . . . . . . . . 26
3.3 Projectmodel voor de simulatie van dual SLA . . . . . . . . . . . . . . . . . . . . 29
3.4 Node model van de OLT in een TDM PON . . . . . . . . . . . . . . . . . . . . . 30
3.5 Projectmodel voor de simulatie van WRR . . . . . . . . . . . . . . . . . . . . . . 33
4.1 Toekenning bandbreedte originele versie dual SLA . . . . . . . . . . . . . . . . . 37
4.2 Toekenning bandbreedte aangepaste versie dual SLA . . . . . . . . . . . . . . . . 39
4.3 Vertraging bij verschillende T MIN . . . . . . . . . . . . . . . . . . . . . . . . . . 41
4.4 Vertraging bij verschillende vraag van ONU’s . . . . . . . . . . . . . . . . . . . . 44
4.5 Vertraging bij best effort trafiek . . . . . . . . . . . . . . . . . . . . . . . . . . . . 46
4.6 Gewichten bij 25% prioriteitstrafiek . . . . . . . . . . . . . . . . . . . . . . . . . . 48
4.7 Gewichten bij 50% prioriteitstrafiek . . . . . . . . . . . . . . . . . . . . . . . . . . 49
4.8 Vertraging bij 50% prioriteitstrafiek en WBE,P = 0.005 . . . . . . . . . . . . . . . 50
4.9 Gewichten bij 75% prioriteitstrafiek . . . . . . . . . . . . . . . . . . . . . . . . . . 51
4.10 Vertraging bij 25% prioriteitstrafiek . . . . . . . . . . . . . . . . . . . . . . . . . 54
4.11 Vertraging bij 50% prioriteitstrafiek . . . . . . . . . . . . . . . . . . . . . . . . . 55
4.12 Vertraging bij 75% prioriteitstrafiek . . . . . . . . . . . . . . . . . . . . . . . . . 56
63

64 LIJST VAN FIGUREN

Lijst van tabellen
2.1 Downstream en upstream snelheden DOCSIS [1] . . . . . . . . . . . . . . . . . . 5
2.2 Downstream en upstream snelheden xDSL [1] . . . . . . . . . . . . . . . . . . . . 6
3.1 Parameters dual SLA scheduling algoritme . . . . . . . . . . . . . . . . . . . . . . 22
3.2 Verdeling ONU’s dual SLA scheduling algoritme . . . . . . . . . . . . . . . . . . 23
3.3 Toegekende bandbreedte dual SLA scheduling algoritme . . . . . . . . . . . . . . 24
3.4 Toekenning onbenutte bandbreedte aangepast dual SLA scheduling algoritme . . 25
3.5 Parameters voorbeeld dual SLA scheduling algoritme (versie 2) . . . . . . . . . . 28
4.1 Parameters simulatie bandbreedte dual SLA . . . . . . . . . . . . . . . . . . . . . 35
4.2 Sets per service provider . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 36
4.3 Gemiddelde trafiek per ONU . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 36
4.4 Toekenning ONU’s aan service providers bij verschillende vraag . . . . . . . . . . 43
4.5 Simulaties vertraging bij verschillende vraag ONU’s . . . . . . . . . . . . . . . . . 43
4.6 Gewichten per percentage prioriteitstrafiek . . . . . . . . . . . . . . . . . . . . . . 52
4.7 Parameters simulatie vertraging prioriteitstrafiek . . . . . . . . . . . . . . . . . . 52
65

66 LIJST VAN TABELLEN

Bijlagen
67


Bijlage I: Inhoud CD-ROM
De bijgeleverde CD-ROM bevat vier mappen:
1. 01 – Boek: deze map bevat het volledige boek (inclusief extended abstract)
2. 02 – Referenties: deze map bevat alle referenties die gebruikt werden in deze thesis
3. 03 – OPNET models: deze map bevat alle code voor de 2 projecten die in OPNET
geımplementeerd werden
4. 04 – Resultaten: deze map bevat alle resultaten en grafieken die ook in deze thesis
vermeld werden
69

70


















