







Talen
Pages
Wettelijk


8/3/2019 07 - XML - DOM
http://slidepdf.com/reader/full/07-xml-dom 1/53
eXtensible Markup Language
Document Object Model 1.0
<?xml version=“1.0”><course startdate=“February 06, 2006”>
<title> eXtensible Markup Language </title>
<lecturer>Phan Vo Minh Thang</lecturer></course>

8/3/2019 07 - XML - DOM
http://slidepdf.com/reader/full/07-xml-dom 2/53
<? xml version=“1.0”> <material> XML Lectures Notes <section id=“ 07 ”> Document Object Model </section> </material>
A Piece of XML
<seq id="my_seq" name="NUCLEAR RIBONUCLEOPROTEIN">
<dbxref>
<database>SWISS-PROT</database>
<unique_id>P09651</unique_id>
</dbxref>
<residues type="aa">
SKSESPKEPEQLRKLFIGGLSFETTDESLRSHFEQWGTLTDCVVMRDPNTKRS
RGFGFVTYATVEEVDAAMNARPHKVDGRVVEPKRAVSREDSQRPGAHLTVKKI
FVGGIKEDTEEHHLRDYFEQYGKIEVIEIMTDRGSGKKRGFAFVTFDDHDSVD
KIVIQKYHTVNGHNCEVRKALSKQEMASASSSQRGRSGSGNFGGGRGGGFGGN
DNFGRGGNFSGRGGFGGSRGGGGYGGSGDGYNGFGNDGGYGGGGPGYSGGSRG
YGSGGQGYGNQGSGYGGSGSYDSYNNGGGRGFGGGSGSNFGGGGSYNDFGNYN
NQSSNFGPMKGGNFGGRSSGPYGGGGQYFAKPRNQGGYGGSSSSSSYGSGRRF
</residues>
</seq>

8/3/2019 07 - XML - DOM
http://slidepdf.com/reader/full/07-xml-dom 3/53
<? xml version=“1.0”> <material> XML Lectures Notes <section id=“ 07 ”> Document Object Model </section> </material>
An XML DTD
<?xml version='1.0' encoding="US-ASCII"?>
<!DOCTYPE biosequence [
<!ELEMENT seq (dbxref*, residues?) >
<!ATTLIST seq id ID #REQUIRED
name CDATA #IMPLIED
length CDATA #IMPLIED >
<!ELEMENT residues (#PCDATA)>
<!ATTLIST residues type (dna | rna | aa) #REQUIRED>
]>

8/3/2019 07 - XML - DOM
http://slidepdf.com/reader/full/07-xml-dom 4/53
<? xml version=“1.0”> <material> XML Lectures Notes <section id=“ 07 ”> Document Object Model </section> </material>
Using a XML Parser
Three basic steps to using an XML parser
• Create a parser object
• Pass your XML document to the parser
• Process the results
Generally, writing out XML is outside scope of parsers(though some may implement proprietary mechanisms)

8/3/2019 07 - XML - DOM
http://slidepdf.com/reader/full/07-xml-dom 5/53
<? xml version=“1.0”> <material> XML Lectures Notes <section id=“ 07 ”> Document Object Model </section> </material>
Types of Parser
There are several different ways to categorise parsers:
• Validating versus non-validating parsers
• Parsers that support the Document Object Model (DOM)
• Parsers that support the Simple API for XML (SAX)
• Parsers written in a particular language (Java, C++, Perl, etc.)

8/3/2019 07 - XML - DOM
http://slidepdf.com/reader/full/07-xml-dom 6/53
<? xml version=“1.0”> <material> XML Lectures Notes <section id=“ 07 ”> Document Object Model </section> </material>
Non-validating Parsers
Speed and efficiency
• It takes a significant amount of effort for an XML parser to processa DTD and make sure that every element in an XML document
follows the rules of the DTD.
If only want to find tags and extract information - use non-validating
8/3/2019 07 - XML - DOM
http://slidepdf.com/reader/full/07-xml-dom 7/53
<? xml version=“1.0”> <material> XML Lectures Notes <section id=“ 07 ”> Document Object Model </section> </material>
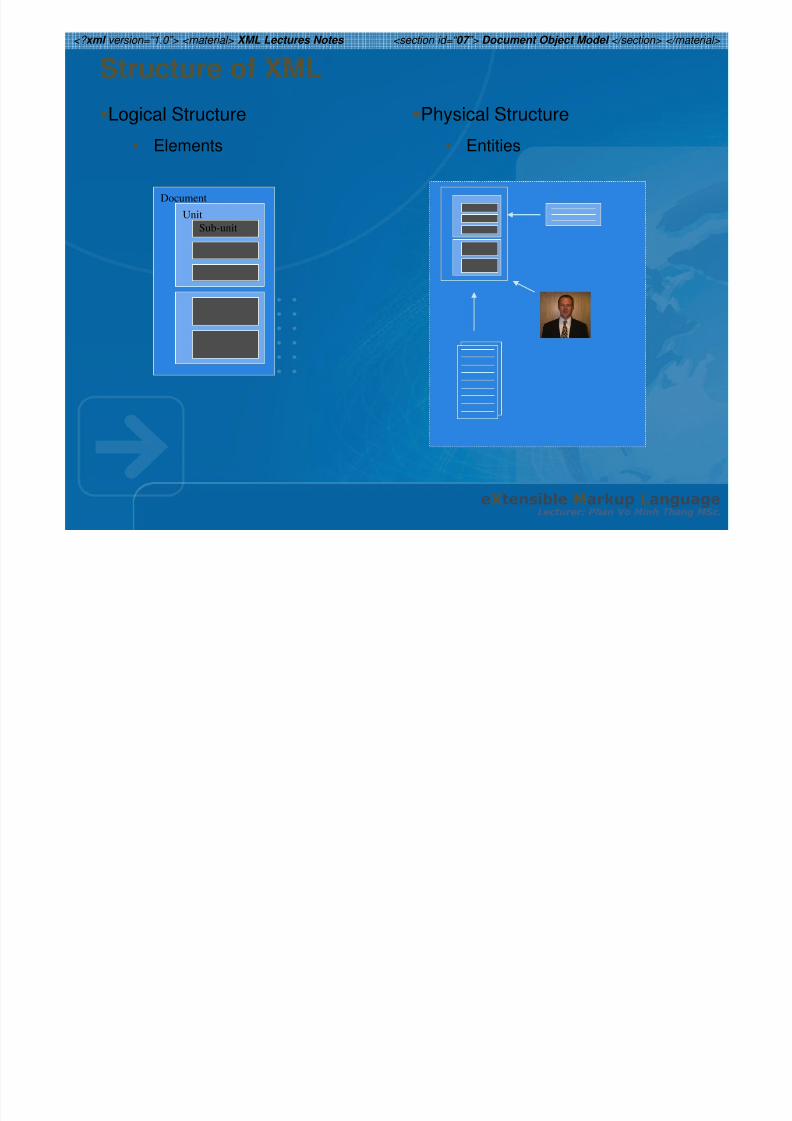
Structure of XML
Logical Structure
• Elements
Physical Structure
• Entities
DocumentUnit
Sub-unit

8/3/2019 07 - XML - DOM
http://slidepdf.com/reader/full/07-xml-dom 8/53
<? xml version=“1.0”> <material> XML Lectures Notes <section id=“ 07 ”> Document Object Model </section> </material>
XML Hierarchy
Document
Unit
Sub-unit
Document
Unit
Sub-unit
N.B. All elements must be nested
XML can be described in a
tree hierarchy
Parent
Child
Sibling

8/3/2019 07 - XML - DOM
http://slidepdf.com/reader/full/07-xml-dom 9/53
<? xml version=“1.0”> <material> XML Lectures Notes <section id=“ 07 ”> Document Object Model </section> </material>
Parsing XML
Two established API's
• SAX (Simple API for XML)
Define handlers containing methods as XML parsed
• DOM (Document Object Model)
Defines a logical tree representing the parsed XML
Apps that don't require complex manipulation can useSAX
Apps that need structural manipulations of many XML
tokens should use DOM

8/3/2019 07 - XML - DOM
http://slidepdf.com/reader/full/07-xml-dom 10/53
<? xml version=“1.0”> <material> XML Lectures Notes <section id=“ 07 ”> Document Object Model </section> </material>
DOM
Document Object Model
Set of interfaces for an application thatreads an XML file into memory and stores itas a tree structure
The abstract API allows for constructing,accessing and manipulating the structureand content of XML and HTML documents

8/3/2019 07 - XML - DOM
http://slidepdf.com/reader/full/07-xml-dom 11/53
<? xml version=“1.0”> <material> XML Lectures Notes <section id=“ 07 ”> Document Object Model </section> </material>
Advantages of DOM
When you parse an XML document
with a DOM parser, you get back atree structure that contains all of the
elements of your document
The DOM provides a variety offunctions you can use to examine the
contents and structure of thedocument

8/3/2019 07 - XML - DOM
http://slidepdf.com/reader/full/07-xml-dom 12/53
<? xml version=“1.0”> <material> XML Lectures Notes <section id=“ 07 ”> Document Object Model </section> </material>
Why use the DOM?
Task of writing parsers is reduced to coding against anAPI for the document structure
Domain-specific frameworks will be written on top of DOM
Tag data in XML - Code against DOM interfaces to access
application data

8/3/2019 07 - XML - DOM
http://slidepdf.com/reader/full/07-xml-dom 13/53
<? xml version=“1.0”> <material> XML Lectures Notes <section id=“ 07 ”> Document Object Model </section> </material>
DOM versus SAX
If your document is very large andyou only need a few elements -use SAX
If you need to process manyelements and perform operationson XML - use DOM
If you need to access the XML
many times - use DOM

8/3/2019 07 - XML - DOM
http://slidepdf.com/reader/full/07-xml-dom 14/53
<? xml version=“1.0”> <material> XML Lectures Notes <section id=“ 07 ”> Document Object Model </section> </material>
DOM Standard
DOM 1.0 standard from www.w3.org Assumes an object-oriented approach
Composed of number of interfaces
• org.w3c.dom.*
Central class is 'Document' (DOM tree)
Standard does not include
• Tree walking
• Writing out XML format

8/3/2019 07 - XML - DOM
http://slidepdf.com/reader/full/07-xml-dom 15/53
<? xml version=“1.0”> <material> XML Lectures Notes <section id=“ 07 ”> Document Object Model </section> </material>
Creating a DOM Tree
A DOM implementation will have a method to pass a XMLfile to a factory object that will return a Document objectthat represents root element of whole document
After this, may use DOM standard interface to interact withXML structure
DOM Parser DOM TreeXML File
A
P
I
Application

8/3/2019 07 - XML - DOM
http://slidepdf.com/reader/full/07-xml-dom 16/53
<? xml version=“1.0”> <material> XML Lectures Notes <section id=“ 07 ”> Document Object Model </section> </material>
Creating a DOM Tree (2)
import org.w3c.dom.*; //DOM interfaces
import com.sun.xml.tree.*; //Using Sun classes
import org.xml.sax.*; //Need SAX classes
public class myClass {…
Document myDoc; //Document object
try {
//if 'true' -> validate myDoc =
XmlDocument.createXmlDocument("file:/doc.xml", true);
} catch (IOException err) {…}
catch (SAXException err) {…}
catch (DOMException err) {…}
//If no exceptions, should have a 'Document' object

8/3/2019 07 - XML - DOM
http://slidepdf.com/reader/full/07-xml-dom 17/53
<? xml version=“1.0”> <material> XML Lectures Notes <section id=“ 07 ”> Document Object Model </section> </material>
DOM Interfaces and Classes
DocumentFragment
Document
CharacterData
Text
Comment
CDATASection
Attr
Element
DocumentType
Notation
EntityEntityReference
ProcessingInstruction
Node NodeList
NamedNodeMap
DocumentType

8/3/2019 07 - XML - DOM
http://slidepdf.com/reader/full/07-xml-dom 18/53
<? xml version=“1.0”> <material> XML Lectures Notes <section id=“ 07 ”> Document Object Model </section> </material>
DOM Interfaces
The DOM defines several Java interfaces• Node The base data type of the DOM
• ElementRepresents element
• Attr Represents an attribute of an element• Text The content of an element or attribute
• Document Represents the entire XML
document. A Document object isoften referred to as a DOM tree

8/3/2019 07 - XML - DOM
http://slidepdf.com/reader/full/07-xml-dom 19/53
<? xml version=“1.0”> <material> XML Lectures Notes <section id=“ 07 ”> Document Object Model </section> </material>
Node Interface
Basic object of DOM (single node in tree)
Nodes describe
Node collections
• NodeList, NamedNodeMap, DocumentFragment
Several nodes extend the Node interface
Elements
Attributes
Text
Comments
CDATA sections
Entity declarations
Entity references
Notation declarations
Entire documents
Processing instructions

8/3/2019 07 - XML - DOM
http://slidepdf.com/reader/full/07-xml-dom 20/53
<? xml version=“1.0”> <material> XML Lectures Notes <section id=“ 07 ”> Document Object Model </section> </material>
Node Methods
Three categories of methods• Node characteristics
name, type, value
• Contextual location and access to relativesparents, siblings, children, ancestors, descendants
• Node modification
Edit, delete, re-arrange child nodes

8/3/2019 07 - XML - DOM
http://slidepdf.com/reader/full/07-xml-dom 21/53
<? xml version=“1.0”> <material> XML Lectures Notes <section id=“ 07 ”> Document Object Model </section> </material>
Node Methods (2)
short getNodeType();
String getNodeName();
String getNodeValue() throws DOMException;
void setNodeValue(String value) throws DOMException;
boolean hasChildNodes();
NamedNodeMap getAttributes();
Document getOwnerDocument();

8/3/2019 07 - XML - DOM
http://slidepdf.com/reader/full/07-xml-dom 22/53
<? xml version=“1.0”> <material> XML Lectures Notes <section id=“ 07 ”> Document Object Model </section> </material>
Node Types - getNodeType()
ELEMENT_NODE = 1
ATTRIBUTE_NODE = 2
TEXT_NODE = 3
CDATA_SECTION_NODE = 4
ENTITY_REFERENCE_NODE = 5
ENTITY_NODE = 6
PROCESSING_INSTRUCTION_NODE = 7
COMMENT_NODE = 8
DOCUMENT_NODE = 9
DOCUMENT_TYPE_NODE = 10
DOCUMENT_FRAGMENT_NODE = 11
NOTATION_NODE = 12
if (myNode.getNodeType() == Node.ELEMENT_NODE) {
//process node
…
}

8/3/2019 07 - XML - DOM
http://slidepdf.com/reader/full/07-xml-dom 23/53
<? xml version=“1.0”> <material> XML Lectures Notes <section id=“ 07 ”> Document Object Model </section> </material>
Node Names and Values
Every node has a name and possibly a value
Name is not a unique identifier (only location)
Type Interface Name Name Value
ATTRIBUTE_NODE Attr Attribute name Attribute value
DOCUMENT_NODE Document #document NULL
DOCUMENT_FRAGMENT_NODE DocumentFragment #document-fragment NULL
DOCUMENT_TYPE_NODE DocumentType DOCTYPE name NULL
CDATA_SECTION_NODE CDATASection #cdata-section CDATA content
COMMENT_NODE Comment Entity name Content string
ELEMENT_NODE Element Tag name NULL
ENTITY_NODE Entity Entity name NULL
ENTITY_REFERENCE_NODE EntityReference Entity name NULL
NOTATION_NODE Notation Notation name NULL
PROCESSING_INSTRUCTION_
NODE
ProcessingInstruction Target string Content string
TEXT_NODE Text #text Text string
Table as from “The XML Companion” - Neil Bradley

8/3/2019 07 - XML - DOM
http://slidepdf.com/reader/full/07-xml-dom 24/53
<? xml version=“1.0”> <material> XML Lectures Notes <section id=“ 07 ”> Document Object Model </section> </material>
Child Nodes
Most Nodes cannot have children, except
• Document, DocumentFragment, Element
Can check for presence of children
• if (myNode.hasChildNodes()) {
//process children of myNode
…
}

8/3/2019 07 - XML - DOM
http://slidepdf.com/reader/full/07-xml-dom 25/53
<? xml version=“1.0”> <material> XML Lectures Notes <section id=“ 07 ”> Document Object Model </section> </material>
Node Navigation
Every node has a specific location in tree
Node interface specifies methods to find surroundingnodes
• Node getFirstChild();
• Node getLastChild();
• Node get NextSibling();
• Node getPreviousSibling();
• Node getParent Node();
• NodeList getChild Nodes();

8/3/2019 07 - XML - DOM
http://slidepdf.com/reader/full/07-xml-dom 26/53
<? xml version=“1.0”> <material> XML Lectures Notes <section id=“ 07 ”> Document Object Model </section> </material>
Node Navigation (2)
getFirstChild()
getPreviousSibling()
getChildNodes()
getNextSibling()
getLastChild()
getParentNode()
Node parent = myNode.getParentNode();
if (myNode.hasChildren()) {
NodeList children = myNode.getChildNodes();
}
Figure as from “The XML Companion” - Neil Bradley

8/3/2019 07 - XML - DOM
http://slidepdf.com/reader/full/07-xml-dom 27/53
<? xml version=“1.0”> <material> XML Lectures Notes <section id=“ 07 ”> Document Object Model </section> </material>
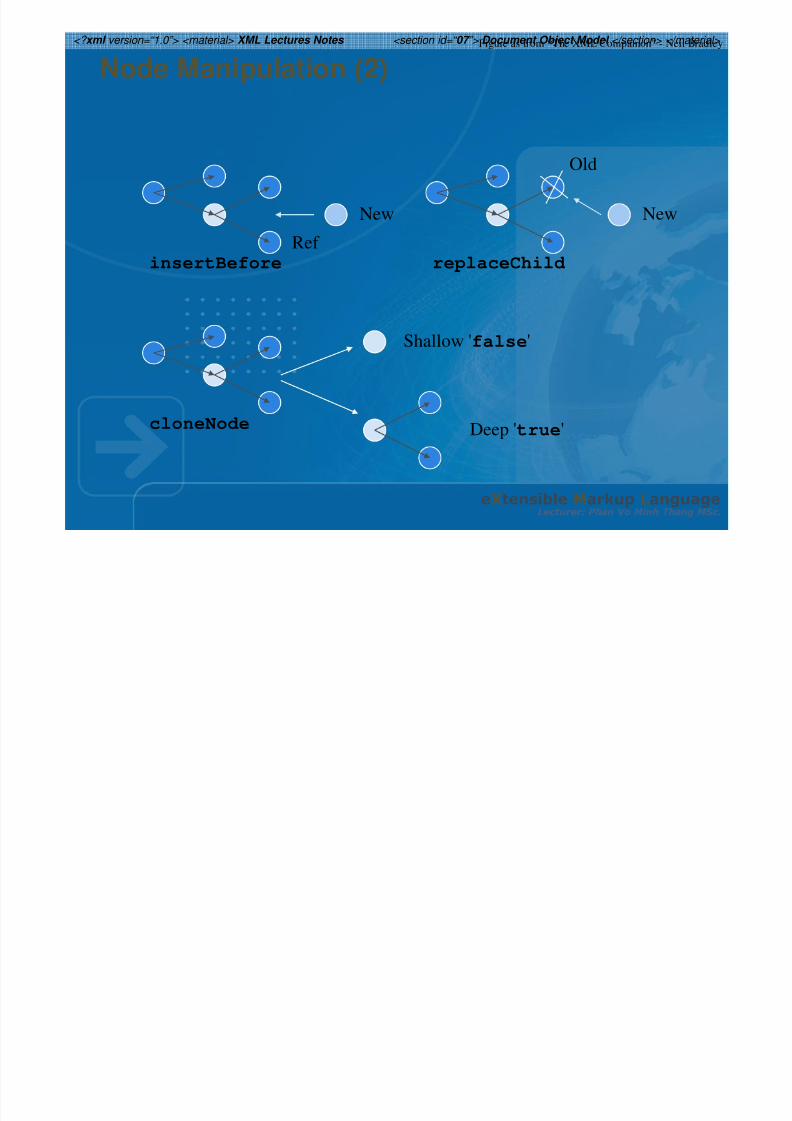
Node Manipulation
Children of a node in a DOM tree can be manipulated -added, edited, deleted, moved, copied, etc.
Node removeChild(Node old) throws DOMException;
Node insertBefore(Node new, Node ref) throws DOMException;
Node appendChild(Node new) throws DOMException;
Node replaceChild(Node new, Node old) throws DOMException;
Node clone Node(boolean deep);
? l i “1 0” t i l XML L t N t ti id “07” D t Obj t M d l / ti / t i l
8/3/2019 07 - XML - DOM
http://slidepdf.com/reader/full/07-xml-dom 28/53
<? xml version=“1.0”> <material> XML Lectures Notes <section id=“ 07 ”> Document Object Model </section> </material>
Node Manipulation (2)
Ref
New
insertBefore
Old
New
replaceChild
cloneNode
Shallow 'false'
Deep 'true'
Figure as from “The XML Companion” - Neil Bradley
?xml version “1 0” material XML Lectures Notes section id “07” Document Object Model /section /material

8/3/2019 07 - XML - DOM
http://slidepdf.com/reader/full/07-xml-dom 29/53
<? xml version=“1.0”> <material> XML Lectures Notes <section id=“ 07 ”> Document Object Model </section> </material>
Document::Node Interface
Represents entire XML document (tree root)
Methods
//Information from DOCTYPE - See 'DocumentType'
DocumentType getDocumentType();
//Information about capabilities of DOM implementation
DOMImplementation getImplementation();
//Returns reference to root node element
Element getDocumentElement();
//Searches for all occurrences of 'tagName' in nodes
NodeList getElementsByName(String tagName);
<?xml version “1 0”> <material> XML Lectures Notes <section id “07”> Document Object Model </section> </material>

8/3/2019 07 - XML - DOM
http://slidepdf.com/reader/full/07-xml-dom 30/53
<? xml version= 1.0 > <material> XML Lectures Notes <section id= 07 > Document Object Model </section> </material>
Document::Node Interface (2)
Factory methods for node creationElement createElement(String tagName) throws DOMException;
DocumentFragment createDocumentFragment();
Text createTextNode(String data);
Comment createComment(String data);
CDATASection createCDATASection(String data) throws
DOMException;ProcessingInstruction createProcessingInstruction(
String target, String data) throws DOMException;
Attr createAttribute(String name) throws DOMException;
EntityReference createEntityReference(String name)throws DOMException;
<?xml version=“1 0”> <material> XML Lectures Notes <section id=“07”> Document Object Model </section> </material>

8/3/2019 07 - XML - DOM
http://slidepdf.com/reader/full/07-xml-dom 31/53
<? xml version= 1.0 > <material> XML Lectures Notes <section id= 07 > Document Object Model </section> </material>
DocumentType::Node Interface
Information about document encapsulated in DTDrepresentation
DOM 1.0 doesn’t allow editing of this node
//Returns name of document
String getName();
//Returns general entities declared in DTD
NamedNodeList getEntities();
//Returns notations declared in DTD
NamedNodeList getNotations();
<?xml version=“1 0”> <material> XML Lectures Notes <section id=“07”> Document Object Model </section> </material>

8/3/2019 07 - XML - DOM
http://slidepdf.com/reader/full/07-xml-dom 32/53
<? xml version 1.0 > <material> XML Lectures Notes <section id 07 > Document Object Model </section> </material>
Element::Node Interface
Two categories of methods
• General element methods
• Attribute management methods
String getTagName();
NodeList getElementsByTagName();
void normalize();
String getAttribute(String name);void setAttribute(String name, String value)
throws DOMException;
void removeAttribute(String name)
throws DOMException;
Attr getAttributeNode(String name);void setAttributeNode(Attr new)
throws DOMException;
void removeAttributeNode(Attr old)
throws DOMException;
<? xml version=“1.0”> <material> XML Lectures Notes <section id=“ 07 ”> Document Object Model </section> </material>

8/3/2019 07 - XML - DOM
http://slidepdf.com/reader/full/07-xml-dom 33/53
e s o 0 ate a ectu es otes sect o d 0 ocu e t Object ode sect o ate a
Element::Node Interface (2)
Only Element objects have attributes but attributemethods of Element are simple
• Need name of attribute
• Cannot distinguish between default value specified in DTDand given in XML file
• Cannot determine attribute type [String]
Instead use getAttributes() method of Node
• Returns Attr objects in a NamedNodeMap
<? xml version=“1.0”> <material> XML Lectures Notes <section id=“ 07 ”> Document Object Model </section> </material>

8/3/2019 07 - XML - DOM
http://slidepdf.com/reader/full/07-xml-dom 34/53
j
Attr::Node Interface
Interface to objects holding attribute data
Entity ref's are children of attribute's
//Get name of attribute
String getName();
//Get value of attributeString getValue();
//Change value of attribute
void setValue(String value);
//if 'true' - attribute defined in element, else in DTD
boolean getSpecified();
<? xml version=“1.0”> <material> XML Lectures Notes <section id=“ 07 ”> Document Object Model </section> </material>

8/3/2019 07 - XML - DOM
http://slidepdf.com/reader/full/07-xml-dom 35/53
Attr::Node Interface (2)
Attributes not considered part of DOM• parentNode, previousSibling and nextSibling have
null value for Attr object
Create attribute objects using factory method ofDocument
//Create the empty Attribute node
Attr newAttr = myDoc.createAttribute("status");
//Set the value of the attributenewAttr.setValue("secret");
//Attach the attribute to an element
myElement.setAttributeNode(newAttr);
<? xml version=“1.0”> <material> XML Lectures Notes <section id=“ 07 ”> Document Object Model </section> </material>

8/3/2019 07 - XML - DOM
http://slidepdf.com/reader/full/07-xml-dom 36/53
CharacterData::Node Interface
Useful general methods for dealing with text
Not used directly
• sub-classed to Text and Comment Node types
String getData() throws DOMException;
void setData(String data) throws DOMException;
int getLength();
void appendData(String data) throws DOMException;
String substringData(int offset, int length)
throws DOMException;
void insertData(int offset, String data)
throws DOMException;
void deleteData(int offser, int length)
throws DOMException;
void replaceData(int offset, int length, String data)
throws DOMException;
<? xml version=“1.0”> <material> XML Lectures Notes <section id=“ 07 ”> Document Object Model </section> </material>

8/3/2019 07 - XML - DOM
http://slidepdf.com/reader/full/07-xml-dom 37/53
Text::Node Interface
Represents textual content of Element or Attr
• Usually children of these nodes
Always leaf nodes
Single method added to CharacterData
• Text splitText(int offset) throws DOMException
Factory method in Document for creation
Calling normalize() on an Element merges its Text
objects
<? xml version=“1.0”> <material> XML Lectures Notes <section id=“ 07 ”> Document Object Model </section> </material>

8/3/2019 07 - XML - DOM
http://slidepdf.com/reader/full/07-xml-dom 38/53
CDATASection::Text Interface
Represents CDATA that is not to be interpreted asmarkup (only delimiter recognised is the "]]>" string
that ends the CDATA section)
The DOMString attribute of the Text node holds the
text of the CDATA section
No methods added to CharacterData
Factory method in Document for creation
• CDATASection newCDATA =
myDoc.createDATASection("press <<<ENTER>>>");
<? xml version=“1.0”> <material> XML Lectures Notes <section id=“ 07 ”> Document Object Model </section> </material>

8/3/2019 07 - XML - DOM
http://slidepdf.com/reader/full/07-xml-dom 39/53
Comment::Text Interface
Represents comments
all the characters between starting '<!--' and ending '-->'
No methods added to CharacterData
Factory method in Document for creation
• Comment newComment = myDoc.createComment(" my comment "); //Note spaces
<? xml version=“1.0”> <material> XML Lectures Notes <section id=“ 07 ”> Document Object Model </section> </material>

8/3/2019 07 - XML - DOM
http://slidepdf.com/reader/full/07-xml-dom 40/53
ProcessingInstruction::Node Interface
Represent processing instruction declarations
• Name of node is target application name
• Value of node is target application command
Factory method in Document for creation
• ProcessingInstruction newPI =
myDoc.createProcessingInstruction("ACME","page-break");
//Get the content of the processing instruction
String getData()
//Set the content of the processing instruction
void setData(String data)
//The target of this processing instructionString getTarget();
<? xml version=“1.0”> <material> XML Lectures Notes <section id=“ 07 ”> Document Object Model </section> </material>

8/3/2019 07 - XML - DOM
http://slidepdf.com/reader/full/07-xml-dom 41/53
EntityReference::Node Interface
DOM includes interfaces for handling notations, entitiesand entity references
• If the entities have not been replaced by the parser
Element Text
Text
EntityReference Text
An
value
xml
eXtensible
Markup
Language
<!ENTITY xml "eXtensible Markup Language">
<para>An &xml; value</para>
valuename
<? xml version=“1.0”> <material> XML Lectures Notes <section id=“ 07 ”> Document Object Model </section> </material>

8/3/2019 07 - XML - DOM
http://slidepdf.com/reader/full/07-xml-dom 42/53
Entity::Node Interface
Represents an entity, either parsed or unparsed, in anXML document
• Parser may replace entity references, or createEntityReference nodes
Must retain Entity for non-parsable data
Extends Node interface and adds methods
For non-parsable entities - can get notation name
String getPublicId();
String getSystemId();
String getNotationName();
<? xml version=“1.0”> <material> XML Lectures Notes <section id=“ 07 ”> Document Object Model </section> </material>
E i N d I f (2)

8/3/2019 07 - XML - DOM
http://slidepdf.com/reader/full/07-xml-dom 43/53
Entity::Node Interface (2)
A parsable Entity may have children that represent
the replacement value of the entity
All entities of a Document accessed with getEntities()method in DocumentType
Entity Text
TextEntityReference
xml
eXtensible
Markup
Languagename
xml
eXtensible
Markup
Language
<!ENTITY MyBoat PUBLIC "BOAT" SYSTEM "boat.gif" NDATA GIF>
String publicId = ent.getPublicId(); //BOAT
String systemId = ent.getSystemId(); //boat.gif
String notation = ent.getNotationName(); //GIF
<? xml version=“1.0”> <material> XML Lectures Notes <section id=“ 07 ”> Document Object Model </section> </material>
N t ti N d I t f

8/3/2019 07 - XML - DOM
http://slidepdf.com/reader/full/07-xml-dom 44/53
Notation::Node Interface
Each notation declaration in DTD represented by a Notation node
Methods added to Node interface
All notations of a Document accessed withgetNotations() method in DocumentType object
//Returns content of PUBLIC identifier
String getPublicId();
//Returns content of SYSTEM identifier
String getSystemId();
<? xml version=“1.0”> <material> XML Lectures Notes <section id=“ 07 ”> Document Object Model </section> </material>
N d Li t I t f

8/3/2019 07 - XML - DOM
http://slidepdf.com/reader/full/07-xml-dom 45/53
NodeList Interface
Holds collection of ordered Node objects
Two methods
//Find number of Nodes in NodeListint getLength();
//Return the i-th Node
Node item(int index);
------------------------------------------------- Node child;
NodeList children = element.getChildNodes()'
for (int i = 0; i < children.getLength(); i++) {
child = children.item(i);
if (child.getNodeType() == Node.ELEMENT_NODE) {System.out.println(child.getNodeName());
}
}
<? xml version=“1.0”> <material> XML Lectures Notes <section id=“ 07 ”> Document Object Model </section> </material>
N dN d M I t f

8/3/2019 07 - XML - DOM
http://slidepdf.com/reader/full/07-xml-dom 46/53
NamedNodeMap Interface
Holds collection of unordered Node objects
• E.g. Attribute, Entity and Notation
Unique names are essential as nodes are accessed byname
NamedNodeMap myAttributes = myElement.getAttributes();
NamedNodeMap myEntities = myDocument.getEntities(); NamedNodeMap myNotations = myDocument.getNotations();
------------------------------------------------------
int getLength();
Node item(int index);
Node getNamedItem(String name); Node setNamedItem(Node node) throws DOMException;//Node!
Node removeNamedItem(String name) throws DOMException;
<? xml version=“1.0”> <material> XML Lectures Notes <section id=“ 07 ”> Document Object Model </section> </material>
DocumentFragment::Node Interface

8/3/2019 07 - XML - DOM
http://slidepdf.com/reader/full/07-xml-dom 47/53
DocumentFragment::Node Interface
Fragment of Document can be temporarily stored inDocumentFragment node
• Lightweight object, e.g. for 'cut-n-paste'
When attached to another Node - destroys itself (very
useful for adding siblings to tree)
DocumentFragment
DOM tree
New DOM tree
<? xml version=“1.0”> <material> XML Lectures Notes <section id=“ 07 ”> Document Object Model </section> </material>
DOMImplementation Interface

8/3/2019 07 - XML - DOM
http://slidepdf.com/reader/full/07-xml-dom 48/53
DOMImplementation Interface
Interface to determine level of support in DOM parser• hasFeature(String feature, String version);
• if (theParser.hasFeature("XML", "1.0") {
//XML is supported…
}
<? xml version=“1.0”> <material> XML Lectures Notes <section id=“ 07 ”> Document Object Model </section> </material>
DOM Objects

8/3/2019 07 - XML - DOM
http://slidepdf.com/reader/full/07-xml-dom 49/53
DOM Objects
DOM object⇔ compiled XML
Can save time and effort if send and receive DOM objectsinstead of XML source
• Saves having to parse XML files into DOM at sender and receiver
• But, DOM object may be larger than XML source
<? xml version=“1.0”> <material> XML Lectures Notes <section id=“ 07 ”> Document Object Model </section> </material>
DOM versus XSL

8/3/2019 07 - XML - DOM
http://slidepdf.com/reader/full/07-xml-dom 50/53
DOM versus XSL
If you want to do complicated sorting orrestructuring that's beyond the realm of XSL,use DOM
In this method, you parse the XMLdocument, then write Java code to
manipulate the DOM tree in whatever wayyou wish. Your code has complete access tothe DOM and all of its methods, so you're notbound by the limitations or design decisionsof XSL
<? xml version=“1.0”> <material> XML Lectures Notes <section id=“ 07 ”> Document Object Model </section> </material>
DOM and XSL

8/3/2019 07 - XML - DOM
http://slidepdf.com/reader/full/07-xml-dom 51/53
DOM and XSL
An XSL processor can transform an input XML documentto an XML or HTML output document based on rules in asecond XML document
• A DOM implementation of XSL/XSLT such as LotusXSL processoris useful here

8/3/2019 07 - XML - DOM
http://slidepdf.com/reader/full/07-xml-dom 52/53
<? xml version=“1.0”> <material> XML Lectures Notes <section id=“ 07 ”> Document Object Model </section> </material>
Info

8/3/2019 07 - XML - DOM
http://slidepdf.com/reader/full/07-xml-dom 53/53
Info
Course name:
Special Selected Topic in
Information System
Section: Document Object Model 1.0
Number of slides: 53
Updated date: 12/02/2006
Contact: Mr.Phan Vo Minh Thang
Top Related