Performantieanalyse van Iteratieve Reconstructiealgoritmes ...
70
Joachim Buyse reconstructiealgoritmes voor microCT Performantieanalyse van iteratieve Academiejaar 2011-2012 Faculteit Ingenieurswetenschappen en Architectuur Voorzitter: prof. dr. ir. Jan Van Campenhout Vakgroep Elektronica en Informatiesystemen Master in de ingenieurswetenschappen: computerwetenschappen Masterproef ingediend tot het behalen van de academische graad van Begeleider: Bert Vandeghinste Promotoren: prof. Christian Vanhove, prof. dr. Stefaan Vandenberghe
Transcript of Performantieanalyse van Iteratieve Reconstructiealgoritmes ...

Joachim Buyse
reconstructiealgoritmes voor microCTPerformantieanalyse van iteratieve
Academiejaar 2011-2012Faculteit Ingenieurswetenschappen en ArchitectuurVoorzitter: prof. dr. ir. Jan Van CampenhoutVakgroep Elektronica en Informatiesystemen
Master in de ingenieurswetenschappen: computerwetenschappen Masterproef ingediend tot het behalen van de academische graad van
Begeleider: Bert VandeghinstePromotoren: prof. Christian Vanhove, prof. dr. Stefaan Vandenberghe


Joachim Buyse
reconstructiealgoritmes voor microCTPerformantieanalyse van iteratieve
Academiejaar 2011-2012Faculteit Ingenieurswetenschappen en ArchitectuurVoorzitter: prof. dr. ir. Jan Van CampenhoutVakgroep Elektronica en Informatiesystemen
Master in de ingenieurswetenschappen: computerwetenschappen Masterproef ingediend tot het behalen van de academische graad van
Begeleider: Bert VandeghinstePromotoren: prof. Christian Vanhove, prof. dr. Stefaan Vandenberghe

De auteur en promotoren geven de toelating deze scriptie voor consultatie beschikbaar te stellen
en delen ervan te kopieren voor persoonlijk gebruik. Elk ander gebruik valt onder de beperkingen
van het auteursrecht, in het bijzonder met betrekking tot de verplichting uitdrukkelijk de bron
te vermelden bij het aanhalen van resultaten uit deze scriptie.
The author and promoters give the permission to use this thesis for consultation and to copy
parts of it for personal use. Every other use is subject to the copyright laws, more specifically
the source must be extensively specified when using from this thesis.
Gent, Juni 2012
De promotoren De begeleider De auteur
Prof. dr. C. Vanhove ir. Bert Vandeghinste Joachim Buyse
Prof. dr. S. Vandenberghe

Voorwoord
“Most of us, swimming against the tides of trouble the world knows nothing about,
need only a bit of praise or encouragement - and we will make the goal.”
Jerome Fleishman
Dit werk had nooit kunnen worden wat het is, zonder de hulp en steun van zo veel mensen. Ik
zou hierbij iedereen die op een of andere manier een bijdrage heeft geleverd van harte willen
bedanken.
In het bijzonder wil ik mijn dank uitdrukken aan mijn begeleider Bert Vandeghinste, die ondanks
zijn eigen doctoraat toch steeds de tijd vond om me te helpen wanneer ik een probleem had.
Ook wil ik mijn promotoren Stefaan Vandenberghe en Christian Vanhove bedanken om dit
thesisonderwerp speciaal voor mij op te stellen. Zonder jullie was dit werk er niet geweest.
Ik wil ook mijn ouders en zus bedanken voor de enorme steun en vertrouwen die ze mij gegeven
hebben. Jullie hielpen me steeds de moed te vinden om voort te gaan. Tot slot wil ik ook nog
mijn vrienden bedanken om altijd klaar te staan voor de broodnodige ontspanning en plezier,
wanneer ik er even tussenuit moest.
Aan iedereen, bedankt!
Joachim Buyse
v

Performantieanalyse van IteratieveReconstructiealgoritmes voor microCT
door
Joachim Buyse
Masterproef ingediend tot het behalen van de academische graad van
Master in de ingenieurswetenschappen: Computerwetenschappen
Academiejaar 2011-2012
Promotoren: prof. dr. Christian Vanhove, prof. dr. Stefaan Vandenberghe
Begeleider: ir. Bert Vandeghinste
Faculteit Ingenieurswetenschappen en Architectuur
Universiteit Gent
Vakgroep Elektronica en Informatiesystemen
Voorzitter: prof. dr. ir. Jan Van Campenhout
Samenvatting
In dit werk wordt de implementatie van 5 iteratieve reconstructiealgoritmes – SART, OS-
SART, OS-EM, OS-ISRA en OS-MLTR – voor microCT op GPU vergeleken met analytische
reconstructie. De algoritmes worden aan de hand van een water, een laag contrast en een
draadfantoom beoordeeld op ruisbestendigheid, contrast, spatiale resolutie en uitvoeringstijd.
Het blijkt dat OS-MLTR superieure resultaten levert op gebied van ruisbestendigheid en
contrast, wanneer als startbeeld een iteratie op een lagere resolutie uitgevoerd wordt. OS-
ISRA presteert onafhankelijk van het startbeeld het beste op spatiale resolutie, maar door
de lage ruisbestendigheid van het algoritme zijn de resultaten van analytische reconstructie,
OS-SART en OS-MLTR aantrekkelijker. Analytische reconstructie blijft nog steeds minstens
dubbel zo snel als de iteratieve algoritmes, maar hun uitvoeringstijden, die voor OS-ISRA en
OS-MLTR zelfs onder de 20 minuten liggen, zijn niet langer onpraktisch. Verder onderzoek
naar het versnellen van backprojecties kan deze tijden nog gevoelig verbeteren.
Trefwoorden: Performantie, Iteratieve Reconstructie, microCT

Performantieanalyse van IteratieveReconstructiealgoritmes voor microCT
Joachim BuyseSupervisors: Bert Vandeghinste, Christian Vanhove, Stefaan Vandenberghe
Abstract—In recent years, iterative reconstruction for microCThas become increasingly popular. With the introduction of generalpurpose GPUs, iterative techniques could become a valuablealternative for analytical reconstruction. In this work, severaliterative reconstruction algorithms implemented on GPU werecompared to FBP analytical reconstruction. Based on a water, alow contrast and a wire phantom, we compared the performanceof the different algorithms based on noise, contrast, spatialresolution and execution time. For each of these parameters wealso examined the influence of the start image. We found thatOS-MLTR and OS-SART in combination with a multiresolutionalstart image have the best noise resistance and contrast. Amongthe iterative algorithms, OS-ISRA has the best spatial resolution,yet because of its low noise resistance, analytical reconstruction,OS-MLTR and OS-SART create more visually pleasing images.Analytical reconstruction remains fastest, yet more research onfaster backprojection could speed up iterative algorithms to thesame level.
Index Terms—microCT, iterative, reconstruction, GPU, perfor-mance
I. INTRODUCTION
ANALYTICAL reconstruction has been the de facto stan-dard in CT for the past 40 years. It is the fastest way to
reconstruct an image, but has some distinct drawbacks. It isimpossible to incorporate accurate noise models or a prioriinformation about the image in the reconstruction process,and the mathematics become very difficult for non-standardgeometries. When considering microCT, the imaging scale getsmuch smaller and accurate noise modelling becomes moreimportant. Iterative techniques on the other hand do allowfor incorporating more accurate models, but due to the largedata sets and the fact that multiple reconstruction iterations areneeded, they can take days to converge to a solution. Due torecent improvements of general purpose Graphical ProcessingUnits (GPUs) however, it has become feasible to implementiterative algorithms on the GPU, effectively speeding them updue to parallelization. Hereafter we will introduce five iterativereconstruction algorithms for microCT, each one implementedon the GPU. We compared them to analytical reconstructionbased on noise, contrast, spatial resolution and reconstructiontimes. We also examined the influence of the start image onthese respective parameters.
II. METHODS
A. Hardware
All algorithms were implemented in NVidia R©CUDATM
, anAPI that allows general purpose programming for GPU. Tests
were performed on a NVidia TeslaTM
M2070-Q card. Thisis one of NVidias recent high-end GPUs, containing 448cores with 6GiB of onboard RAM memory. The host PC ranon an Intel R©Xeon R©E5620 quadcore processor and contained16GiB of RAM memory. Scans were made on a GM-I R©FLEXTriumph
TMscanner. This is a pre-clinical tri-modal scanner,
containing microCT, PET and SPECT subsystems.
B. Algorithms
The algorithms that were implemented are SART[1],OS-SART[2], OS-EM[3], OS-ISRA[4] and OS-MLTR[5]. Wechose to use the ordered subset extension of the algorithms,due to the limitations we faced concerning available memory.The full set of projections takes approximately 5GiB ofspace, which consumes most of the available memory on theGPU. Dividing the projections in subsets reduces this amountsignificantly, since only the projections in a subset need tobe loaded into the memory. Table I contains the number ofsubsets for each algorithm. We compared the normalized root-mean-square error (NRMSE) between subsequent iterationsfor different subset sizes. The lower the NRMSE betweeniterations, the further the algorithm has converged. For eachalgorithm we chose the number of subsets that let it convergefastest.
TABLE INUMBER OF SUBSETS PER ALGORITHM
SART OS-SART OS-EM OS-ISRA OS-MLTR
nr. subsets 1024 256 512 256 256
Equations 1-4 show the expressions for the differentalgorithms that were implemented – OS-SART and SARTshare the same equation since SART is a special case ofOS-SART. In the equations, the aij represent the coefficientsin the projection/backprojection matrix, xj the calculatedattenuation values, bi the log-adjusted measurements and yithe unadjusted measurements.
xn+1j = xnj +
1∑
i′∈Sn
ai′j
∑
i∈Sn
aij
bi −∑k
aikxnk
∑k
aik(1)
xn+1j =
xnj∑i′∈Sn
ai′j
∑
i∈Sn
aijbi∑
k
aikxnj(2)

2
xn+1j = xnj
∑i∈Sn
aijbi
∑i∈Sn
aij∑k
aikxnj(3)
xn+1j = xnj − 1
Dln
∑i∈Sn
aijyi
∑i∈Sn
aij yi
(4)
yi = bie−∑
k
aikxnk
The analytical reconstructions that were used as referencereconstruction, were reconstructed using the COBRA (ExximComputing Corporation, Pleasanton, Ca, USA) software pack-age, which implements a Feldkamp-type[6] analytical recon-struction algorithm for cone-beam geometries.
C. Phantoms
In order to be able to quantify the differences between thealgorithms, three phantoms were used. The first phantom isthe water phantom, consisting of a cylinder uniformly filledwith water, and is used to determine the noise propertiesof the algorithms. The second phantom we used was a lowcontrast phantom (QRM GmbH, Moehrendorf, Germany). Itis a cylindrical phantom with cylindrical inserts, which haveattenuation values that are 40 and 80 HU lower than theirsurroundings. It is used to determine the contrast resolutionof the different algorithms. The last phantom was a wirephantom (QRM GmbH, Moehrendorf, Germany). It is anairfilled, cylindrical phantom with two tungsten wires with10µm diameter, aligned parallel to the axial axis. One wire islocated in the center of the phantom, the other in the periphery,allowing the evaluation of the spatial resolution both in thecenter of the phantom and at the periphery.
D. Start Images
To evaluate the influence of the starting image, we discernedfour different starting images, of which three can be consideredlow-pass and one high-pass. The first start image is the moststraight-forward one. It is a uniform image, having only onesingle grey value (0 for the additive, 100 for multiplicativealgorithms). The second start image, the high-pass one, con-sists of random grey values (uniformly chosen in [0, 0.1[ forthe additive and in [1, 101[ for the multiplicative algorithms).As a third start image, we used the result of the analyticalreconstruction in an attempt to combine the benefits of bothanalytical and iterative reconstruction. The final start imagerepresents a similar attempt, however, instead of using theresult of an analytical reconstruction, we use the result of afast iterative reconstruction performed at a smaller resolution.
III. RESULTS
A. Noise
A random start image turns out to be a bad choice whennoise resistance is important. Using this start image, signal-to-noise ratios are only 30% of those obtained by using analytical
reconstruction. When using low-pass start images, OS-SARTand OS-MLTR introduce the least noise. Their signal-to-noise ratios are almost twice as high as those of SART, OS-EM and OS-ISRA reconstructions, and slightly higher thanthose of analytical reconstruction. When combined with themultiresolutional start image, OS-MLTR has a signal-to-noiseratio that is more than 50% higher than the signal-to-noiseratio of analytical reconstruction. The results of OS-MLTR incombination with this start image can be explained throughthe convergence speed of OS-MLTR. When determining theoptimal number of subsets, we saw that OS-MLTR convergesmuch slower than the other algorithms. Because of this, therewill be much less noise introduced after a first iteration. Sinceit is the first iteration that is upscaled and used as a start image,this results in a good signal-to-noise ratio.
B. Contrast
The results for optimal contrast are very much alike theresults of noise sensitivity. We didn’t consider the randomstart image when judging contrast, since the signal-to-noiseratios were so low that the cylindrical inserts couldn’t bediscerned on the scans. For the low-pass start images, themultiresolutional start image in combination with OS-MLTRagain produces the best results, with OS-SART as a closesecond. The contrast-to-noise ratio for this combination ismore than twice as high as the contrast-to-noise ratio ofanalytical reconstruction.
C. Spatial Resolution
For the spatial resolution, the starting image has less effecton the different results. Even for the random start image,similar results are obtained as for the other start images. Con-trary to the results for noise and contrast, the algorithms needmore time to achieve their best results for spatial resolution.This is normal, since the algorithms first reconstruct the low-pass part of the image, adding more detail as the number ofiterations rises. OS-ISRA has the highest spatial resolution.After 5 iterations the full width at half maximum (FWHM)of the center wire is about 0.16 mm, which is only slightlyhigher than analytical reconstruction, which has a FWHMof approximately 0.14 mm for the center wire. However,for the wire at the periphery, OS-ISRA has a FWHM ofapproximately 0.16 mm, opposed to 0.21 mm for analyticalreconstruction. OS-SART and OS-MLTR, the algorithms thatscored best at noise sensitivity and contrast resolution, havethe lowest spatial resolution, with a FWHM of 0.23 to 0.25mm for both wires. OS-ISRA however introduced significantlymore noise in its reconstruction than OS-SART, OS-MLTRand analytical reconstruction. So even though their spatialresolution is higher, the reconstructions produced by OS-SART, OS-MLTR and especially analytical reconstruction willbe visually better.
D. Execution Time
The two fastest algorithms of the five we tested, were OS-ISRA and OS-MLTR. Their execution times were several min-utes faster than those of the other algorithms, when iterating

3
for maximal noise resistance and contrast. The execution timesare however still a lot higher than those of analytical recon-struction – typically twice as high – but they aren’t unfeasibleanymore. The largest contributing factor to the execution timeis the backprojection step in the algorithms, taking up almost85% of the execution times. The implementations of bothOS-ISRA and OS-MLTR also have some more room for im-provement, since each iteration has two backprojections – thedirect consequence of doing the calculations in image space.Because we divided the projections in subsets, each subsethas to be backprojected. If more memory is available, or lessprojections are used, the backprojections can be precalculated,further reducing the execution times.
IV. CONCLUSION
We have been able to show that, especially for noiseand contrast, superior results can be obtained by iterativereconstruction, compared to analytical construction. Executingthe algorithms on GPU is still slower than analytical recon-struction, but the execution times are no longer unfeasiblyhigh. It can thus be concluded that, in the years to come, iter-ative reconstruction will be a viable alternative for analyticalreconstruction in pre-clinical practice.
REFERENCES
[1] A. H. Andersen and A. C. Kak, “Simultaneous algebraic reconstructiontechnique (SART): a superior implementation of the art algorithm,”Ultrasonic Imaging, vol. 6, no. 1, pp. 81–94, 1984.
[2] G. Wang and M. Jiang, “Ordered-Subset Simultaneous Algebraic Re-construction Techniques (OS-SART),” Journal of X-Ray Science andTechnology, vol. 12, no. 3, pp. 167–177, 2004.
[3] M. Hudson and R. Larkin, “Accelerated Image Reconstruction usingOrdered Subsets of Projection Data,” IEEE Trans. Med. Imag, vol. 13,pp. 601–609, 1994.
[4] M. E. Daube-Witherspoon and G. Muehllehner, “An Iterative ImageSpace Reconstruction Algorthm Suitable for Volume ECT,” IEEE Trans.Med. Imag, vol. 5, pp. 61–66, june 1986.
[5] J. Nuyts, B. De Man, P. Dupont, M. Defrise, P. Suetens, and L. Mortel-mans, “Iterative reconstruction for helical CT: a simulation study,”Physics in Medicine and Biology, vol. 43, no. 4, pp. 729–737, 1998.
[6] L. A. Feldkamp, L. C. Davis, and J. W. Kress, “Practical cone-beamalgorithm,” J. Opt. Soc. Am. A, vol. 1, pp. 612–619, June 1984.

Lijst van symbolen en afkortingen
ART Algebraic Reconstruction Technique
CNR Contrast-to-Noise Ratio
CT Computed Tomography
CUDA Compute Unified Device Architecture
EM Expectation Maximisation
FBP Filtered Backprojection
FWHM Full Width at Half Maximum
GPU Graphical Processing Unit
GPGPU General Purpose Graphical Processing Unit
HU Hounsfield Unit
ISRA Image Space Reconstruction Algorithm
ML-EM Maximum Likelihood Expectation Maximisation
MLTR Maximum Likelihood algorithm for Transmission tomography
NRMSE Normalised Root Mean Square Error
OS-EM Ordered Subset Expectation Maximisation
OS-SART Ordered Subset Simultaneous Algebraic Reconstruction Technique
PET Positron Emission Tomography
PSF Point Spread Function
SART Simultaneous Algebraic Reconstruction Technique
SNR Signal-to-Noise Ratio
SPECT Single Photon Emission Computed Tomography
x

Inhoudsopgave
Voorwoord v
Overzicht vi
Extended Abstract vii
Lijst van symbolen en afkortingen x
Inhoudsopgave xi
1 Inleiding 1
1.1 CT . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1
1.1.1 Achtergrond . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1
1.1.2 Acquisitie . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1
1.1.3 CT-beeld . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3
1.2 Micro-CT . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4
1.3 Reconstructie . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5
1.3.1 Analytische Reconstructie . . . . . . . . . . . . . . . . . . . . . . . . . . . 6
1.3.2 Iteratieve Reconstructie . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8
1.4 Doel van thesis . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 10
2 Methodieken 12
2.1 Opstelling . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 12
2.2 Algoritmes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 12
2.2.1 OS-SART en SART . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
2.2.2 OS-EM . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15
2.2.3 OS-ISRA . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16
2.2.4 OS-MLTR . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17
2.3 Fantomen en metrieken . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 18
2.3.1 Ruis en Contrast . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 18
2.3.2 Resolutie . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19
2.4 Invloed van het startbeeld . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19
2.5 Monte Carlo Simulatie . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 22
xi

Inhoudsopgave xii
3 Resultaten 23
3.1 Convergentie . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 23
3.2 Ruisgevoeligheid . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 25
3.3 Contrast . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 33
3.4 Resolutie . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 38
3.5 Snelheid . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 47
3.5.1 Vergelijking van de uitvoeringstijden . . . . . . . . . . . . . . . . . . . . . 47
3.5.2 Analyse van de uitvoeringstijden . . . . . . . . . . . . . . . . . . . . . . . 47
4 Conclusie 52
4.1 Bespreking van de algoritmes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 52
4.2 Eindbeschouwing . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 53
Bibliografie 55

Hoofdstuk 1
Inleiding
1.1 CT
CT – Computed Tomography – is een veelgebruikte niet-invasieve techniek in de medische beeld-
vorming. Deze wordt gebruikt voor het genereren van 3D beelden van de binnenkant van een
object. De techniek maakt gebruik van tomografie om, op basis van een groot aantal traditionele
rontgenfoto’s onder verschillende hoeken, een reeks axiale doorsneden van het object te creeren.
1.1.1 Achtergrond
De basis voor CT werd voor het eerst gelegd door Johann Radon in 1917 [1][2], toen hij bewees
dat het, gegeven genoeg lijnintegralen doorheen een oppervlak, mogelijk is om de verdeling van
deze waarden over datzelfde oppervlak te berekenen. De bevindingen van Radon werden echter
niet meteen opgepikt voor medische toepassingen. Het duurde tot de jaren 60 van vorige eeuw
voordat hierin verandering kwam. Aangezien traditionele radiografie inherent slechts beperkte
informatie kan weergeven, werd gezocht naar nieuwe alternatieven. Een rontgenfoto is immers
een superpositie van alle weefsels waar de x-stralen doorheen zijn gegaan, en dus is het zeer
moeilijk om diepte-informatie te verkrijgen. In de jaren 60 kwam men tot de conclusie dat
een rontgenfoto in principe zeer goed te vergelijken valt met een set lijnintegralen doorheen het
object. Het moest dus mogelijk zijn om met behulp van voldoende foto’s een accuraat beeld
te krijgen van de binnenkant van een object. Het duurde tenslotte nog tot de jaren 70 – en de
opkomst van de eerste relatief compacte computers – vooraleer een praktische implementatie
ontwikkeld werd door Hounsfield.
1.1.2 Acquisitie
CT maakt gebruik van rontgenfoto’s voor het afbeelden van de binnenkant van een object. Het
proces waarbij op basis van deze rontgenfoto’s een 3D beeld wordt gemaakt, heet reconstructie
(zie 1.3). Vooraleer met reconstructie kan begonnen worden, zijn er dus eerst rontgenfoto’s no-
dig. Rontgenstralen hebben de eigenschap dat ze, wanneer ze door een object gaan, geabsorbeerd
worden. Dit fenomeen wordt attenuatie genoemd. De mate waarin de rontgenstraal geattenu-
eerd wordt, hangt af van de attenuatiecoefficient en de dikte van het object waar ze doorheen
gaat. Als I0 de intensiteit is van de uitgezonden rontgenstraal, µ de attenuatiecoefficient en d
1

Hoofdstuk 1. Inleiding 2
de lengte van het pad van de straal doorheen het object, dan wordt de uiteindelijke intensiteit
I gegeven door 1.1. Wanneer het een heterogeen object betreft, kan deze formule eenvoudig
uitgebreid worden naar 1.2 wanneer de overgang tussen de verschillende materialen discreet is,
of naar 1.3 wanneer de overgang tussen de materialen continu is.
I = I0e−µd (1.1)
I = I0e−
∑iµidi
(1.2)
I = I0e−
∫L
µ(r)ds
(1.3)
De mate waarin de fotonen in de rontgenstraling geabsorbeerd worden door het weefsel, hangt
echter ook af van hun energie. Dit betekent dat formule 1.3, die enkel rekening houdt met de
positie r(x,y,z), nog aangepast moet worden om dit effect in rekening te brengen. Formule 1.4
geeft de correcte uitdrukking, waarbij eveneens rekening gehouden wordt met het energiespec-
trum. Deze formule wordt ook de wet van Beer-Lambert genoemd[3][4]. Wanneer geen rekening
gehouden wordt met het energiespectrum van de rontgenstralen, kunnen artefacten in het beeld
optreden.
Fotonen met een lage energie worden veel sneller geabsorbeerd door weefsel dan fotonen met
hoge energie[5][6], een effect dat beam-hardening wordt genoemd1. Dit vertaalt zich in een
beeld dat in het midden donkerder zal zijn dan aan de zijkanten. Het is dus belangrijk om de
rontgenstralen op voorhand reeds te filteren, zodat enkel de rontgenstralen met hogere energie
door het weefsel gaan. Alle lage-energie rontgenstralen die uitgestuurd en volledig geabsorbeerd
worden, leveren immers geen enkele informatie op voor de beeldvorming, maar zorgen er echter
wel voor dat de patient nodeloos een hogere dosis straling binnenkrijgt.
I =
∫I0(E)e
−∫L
µ(E,r)ds
dE (1.4)
Om een zinvolle reconstructie te kunnen uitvoeren, zijn er vele projecties nodig vanuit ver-
schillende hoeken. Doorgaans worden de stralingsbron en de detector aan weerszijden van een
roterende gantry gemonteerd, met het te scannen object in het middelpunt. Op die manier kan
het te scannen object – bv. een patient – stationair blijven, terwijl de bron en de detector er
omheen draaien.
Figuur 1.1 geeft een schematische voorstelling van een mogelijke opstelling, waarbij per rotatie
van de bron en detector, een enkele slice gescand wordt. Deze figuur is een voorbeeld van een
fan-beam systeem; de rontgenstralen hebben een waaiervorm en de detector is slechts 1 pixel
breed. In de x- en y-richting valt het object volledig binnen de stralenbundel, dus er is enkel
een axiale translatie nodig om een volledig object te kunnen scannen. Hierbij kan er ofwel een
1Een rontgenstraal met breed energiespectrum wordt uitgestuurd, maar enkel het hoog-energiegedeelte wordt
gedetecteerd; de straal is ‘harder’ geworden.

Hoofdstuk 1. Inleiding 3
continue ofwel sequentiele translatie gebruikt worden. Bij de eerste zal de bron een spiraalvormig
pad vormen rond het object, bij de tweede is er telkens een afwisseling van een volledige rotatie
en een kleine translatie.
Figuur 1.1: Schematische voorstelling van een CT-scanner
Een tweede soort systeem – hetwelke in dit werk gehanteerd zal worden – is een cone-beam
scanner. Hierbij heeft de bundel rontgenstralen de vorm van een kegel en is de detector een
vlakke rechthoek – hetgeen dus betekent dat slechts een piramidevormig gebied gedetecteerd
wordt. Door deze geometrie zal een groter deel van het object per rotatie gescand kunnen
worden, waardoor er minder rotaties nodig zijn. Bij micro-CT zal het volledige object zelfs
binnen de stralenbundel vallen, waardoor slechts een rotatie nodig is om het volledige object te
kunnen reconstrueren. Door gebruik te maken van een cone-beam wordt het reconstrueren wel
moeilijker, aangezien er nu 3D reconstructie nodig is, waar het bij fan-beam systemen voldoende
was om 2D reconstructies te doen.
1.1.3 CT-beeld
Een CT-beeld bestaat uit een hele reeks 2D beelden, die elk een axiale doorsnede van het
gescande object voorstellen. Aangezien elk van deze doorsneden een bepaalde dikte heeft, zullen
de pixels in deze 2D beelden in principe kleine volume-elementjes voorstellen. Omwille hiervan
wordt bij CT-beelden nooit de term pixel gebruikt, maar veeleer de term voxel – volume element.
Elke voxelwaarde is een maat voor de attenuatie van het volume-element dat de voxel voorstelt.
Aangezien de gemeten waarden echter ook afhankelijk zijn van de energie van de rontgenstralen,
zullen de voxelwaarden slechts een relatieve maat zijn voor de attenuatie. De voxelwaarden
voor een bepaald soort materiaal kunnen dus varieren over verschillende scans. Het is echter
wel zo dat de onderlinge verhoudingen van de voxelwaarden van verschillende materialen binnen
een scan dezelfde zullen zijn in andere scans. Het is dus mogelijk om de voxelwaarden te
normaliseren, zodat een kwantitatieve vergelijking van scans mogelijk is. Om voxelwaarden te

Hoofdstuk 1. Inleiding 4
normaliseren wordt gebruik gemaakt van formule 1.5. Deze formule toont hoe voxelwaarden
kunnen omgezet worden naar Hounsfield Units (HU). De Hounsfield schaal – genoemd naar Sir
Godfrey Newbold Hounsfield1 – neemt de attenuatiecoefficient van water als het referentiepunt
ten opzichte waarvan de voxelwaarden geschaald worden. Volgens deze formule zal water dus
een voxelwaarde van 0 krijgen. Aangezien de attenuatiecoefficient van water gebruikt wordt als
callibratiepunt, zal het dus nodig zijn om een waterfantoom te scannen, teneinde de voxelwaarden
van andere scans te kunnen schalen.
HU = 1000 ∗ µ(x, y, z)− µwaterµwater
(1.5)
1.2 Micro-CT
Terwijl CT beeldvorming al verscheidene decennia een veelgebruikte beeldvormingstechniek is,
heeft het toch relatief lang geduurd vooraleer deze ook ingang vond in laboratoriumomstandig-
heden en pre-klinische tests. De belangrijkste reden hiervoor is de beperkte spatiale resolutie
van een CT-scanner. In pre-klinische omstandigheden zijn knaagdieren nog steeds de de facto
standaard waar het het testen van geneesmiddelen en therapieen betreft. De grootte van een
voxel in een klinische CT scanner ligt ergens rond de 0.35 mm3, hetgeen voldoende detail weer-
geeft wanneer het om mensen gaat. Wanneer echter wordt overgegaan op knaagdieren, komt
deze 0.35 mm3 anatomisch gezien overeen met een voxelgrootte van ongeveer 17 µm3[7]. Hieruit
ontstond dus de nood voor micro-CT; CT-scanners met een spatiale resolutie die veel hoger ligt
dan deze die normaal bereikt kan worden met klinische CT scanners.
Er gingen verscheidene uitdagingen gepaard met het ontwerpen van de eerste micro-CT scanners.
Het is bijvoorbeeld veel moeilijker om een roterende gantry te stabiliseren voor een micro-
CT scanner, dan voor een klinische CT scanner, aangezien de schaal veel kleiner is[8]. De
eerste systemen die ontwikkeld werden waren dan ook de micro-CT scanners waarbij de bron en
detector stationair kunnen blijven. Dit heeft uiteraard als gevolg dat het specimen moet roteren.
Aangezien dit praktische problemen geeft voor in vivo micro-CT – waarbij het specimen nog in
leven is2 – worden dit soort systemen voornamelijk gebruikt bij in vitro beeldvorming. Pas later
werden dan de eerste systemen geıntroduceerd waarbij het specimen stationair kon blijven en
de rontgenbron en detector roteren. Dit zijn dan effectief schaalmodellen van de klinische CT
scanners.
Verder zal ook de ruis een groot probleem vormen bij microCT. Formule 1.6 3 geeft de vari-
antie van de lineaire attenuatie coefficient – en dus een maat voor de ruis – in functie van een
aantal parameters. σ2sys is een term die staat voor alle ruis die geproduceerd wordt door foton-
onafhankelijke bronnen4. Verder staat ∆x voor de voxelgrootte in de reconstructie afbeelding,
nang voor het aantal projecties dat gebruikt wordt om deze afbeelding te bekomen en N voor het
1Als eerbetoon voor het maken van de eerste praktische CT-scanner.2Door een levend specimen te laten roteren wordt de beeldvorming beınvloed; ingewanden zullen zich verplaat-
sen tijdens het roteren, waardoor artefacten zullen ontstaan.3Formule overgenomen uit [9]4e.g. ruis die geıntroduceerd wordt door de detector

Hoofdstuk 1. Inleiding 5
aantal fotonen per geprojecteerde lijnintegraal. Ruis is dus omgekeerd evenredig met de voxel-
grootte, hetgeen betekent dat de grotere spatiale resolutie van microCT extra ruis introduceert
ten opzichte van klinische CT. Het aantal voxels, L in formule 1.7, is dan weer evenredig met
de ruis. Meer voxels zullen dus ook meer ruis introduceren. Voorts staat ook N in de noemer
van formule 1.6, met andere woorden, hoe minder fotonen ontvangen worden, hoe meer ruis de
gereconstrueerde afbeelding zal bevatten. Het aantal fotonen dat ontvangen wordt, is, zoals for-
mule 1.7 aangeeft, afhankelijk van een aantal parameters. Enerszijds is er het aantal fotonen dat
vertrekt uit de bron. Dit wordt bepaald door de hoeveelheid fotonen geproduceerd per eenheid
van stroomsterkte (φ), de stroomsterkte van de bron (I) en de duur van de blootstelling (∆t).
Hoe meer fotonen vertrekken vanuit de bron, hoe meer er ook kunnen aankomen. Voorts speelt
ook de grootte (W en H), het aantal (n) en de efficientie (η) van de detector-elementen een rol.
Grotere detector-elementen kunnen meer fotonen ontvangen en deze zullen dan ook minder ruis
introduceren. Bij microCT zijn de detector-elementen echter een heel stuk kleiner dan bij CT
het geval is, aangezien op een kleinere schaal gewerkt wordt. Dit zal er dus opnieuw voor zorgen
dat microCT beelden ruiziger zijn dan CT beelden.
σ2µ =π2
12∆x2nangN+ σ2sys (1.6)
N =φI∆tnWHηe−µd
L(1.7)
Tenslotte zorgt ook de dosis rontgenstraling die gebruikt kan worden voor in vivo acquisitie
voor problemen. De hoeveelheid straling die een mens kan verdragen zonder negatieve effecten
te ondervinden, is vele malen groter dan deze die de proefdieren die in pre-klinische testen
gebruikt worden kunnen verdragen. In het bijzonder wanneer het over studies gaat waarbij
eenzelfde dier vele malen gescand dient te worden, moet de dosis zeer laag gehouden worden[9].
De dosis laag houden betekent de energie van de fotonen verhogen, waardoor er minder fotonen
geabsorbeerd zullen worden. Dit zal er eveneens voor zorgen dat er meer fotonen gedetecteerd
zullen worden (e−µd in 1.7) en er dus minder ruis aanwezig zal zijn. Wanneer er echter minder
fotonen geabsorbeerd worden, zal de beeldvorming verstoord worden. Het is immers net de
absorptie van fotonen die voor een beeld zorgt. Er zal dus nauwkeurig een dosis gekozen moeten
worden die te verdragen is door de proefdieren, maar toch nog een kwalitatief beeld geeft.
1.3 Reconstructie
Het omzetten van projecties naar de eigenlijke 3D beelden kan op verschillende manieren ge-
beuren. Deze reconstructietechnieken kunnen in twee grote categorieen onderverdeeld worden,
afhankelijk van de manier waarop de reconstructie gedaan wordt. Enerzijds zijn er de analyti-
sche reconstructietechnieken, die traditioneel het meest gebruikt worden voor het reconstrueren
van CT-beelden en anderzijds zijn er de iteratieve technieken, die vooral bij SPECT en PET
gangbaar zijn, maar de laatste jaren ook hun opmars maken bij de reconstructie van CT-beelden.
In wat volgt zullen beide categorieen aan bod komen, met elk hun voor en nadelen.

Hoofdstuk 1. Inleiding 6
1.3.1 Analytische Reconstructie
Principe1
Zoals in 1.1.1 reeds kort vermeld werd, kan de waarde die een detector meet wanneer er een
rontgenstraal op invalt, vergeleken worden met het nemen van een lijnintegraal over de attenu-
atiewaarden langs het pad van deze rontgenstraal. Radon bewees reeds in 1917[1] dat het op
basis van voldoende lijnintegralen onder verschillende hoeken, het mogelijk is om het geprojec-
teerde object te reconstrueren. Hoe dit in zijn werk gaat kan het eenvoudigst begrepen worden
wanneer overgegaan wordt op een systeem waarbij de acquisitie gebeurt via een reeks parallelle
rontgenstralen die door een 2D object gaan. Een projectie van een CT-scanner onder de projec-
tiehoek θ kan dan vergeleken worden met het nemen van een reeks lijnintegralen over het object,
vooropgesteld dat er een kleine aanpassing wordt gedaan aan de projectiedata. Formule 1.4 in
1.1.2 gaf de uitdrukking voor de gemeten intensiteiten. Door abstractie te maken van de energie-
afhankelijkheid, kan deze uitdrukking omgevormd worden tot 1.8, hetgeen een lijnintegraal over
de attenuatiecoefficienten voorstelt.
ln
(I
I0
)=
∫
L
µ(r)ds (1.8)
x cosθ + y sinθ = t (1.9)
pθ(t) =
∫ ∫f(x, y) δ(x cosθ + y sinθ − t)dx dy (1.10)
Laat 1.9 de formule zijn voor een lijn onder een hoek θ door het punt (0, t), dan zal de Radon
transformatie van het object waarvan de attenuatiewaarden verdeeld zijn volgens f(x, y) gegeven
worden door 1.10. Het doel van analytische reconstructie is om op basis van deze projecties pθ(t)
het geprojecteerde object te reconstrueren. De eenvoudigste manier om van deze projecties terug
te gaan naar het geprojecteerde beeld, is door de projectieoperatie te inverteren. Formule 1.11
toont zo een backprojectie, waarbij de projectiewaarden uniform uitgesmeerd worden langs het
pad van de lijnintegraal. Door dit te doen voor alle projecties – zoals in 1.12 – kan dan een
gereconstrueerd beeld bekomen worden. Bemerk ook dat de grenzen van de integraal slechts
lopen van 0 tot π. Dit betekent dus dat het voldoende is om over een hoek van 180◦ projecties
te nemen om een volledig beeld te bekomen.
bθ(x, y) =
∞∫
−∞
pθ(t) δ(x cosθ + y sinθ − t)dt (1.11)
fb(x, y) =
π∫
0
bθ(x, y)dθ (1.12)
De backprojectie in 1.12 heeft echter een groot probleem. Aangezien er geen a priori informatie is
over de te reconstrueren afbeelding, werd ervoor gekozen om de projecties uniform uit te smeren
1Op basis van [10]

Hoofdstuk 1. Inleiding 7
over de projectielijn. Dit zorgt er weliswaar voor dat een punt met een hoge attenuatiewaarde
ook effectief een hoge voxelwaarde zal krijgen, maar dit zorgt er ook voor dat, juist door het
uitsmeren, de omgeving van dit punt ook een hogere waarde zal krijgen. Figuur 1.2 toont dit
fenomeen wanneer een puntbron eerst geprojecteerd en vervolgens teruggeprojecteerd wordt. Het
rechter gedeelte van de figuur illustreert het resultaat dat idealiter bekomen zou moeten worden
na de reconstructie; een wit punt met een scherpe aflijning ten opzichte van zijn omgeving.
Hetgeen echter bekomen wordt na een backprojectie is het linker deel van de figuur; een wit punt
dat uitgesmeerd is over zijn omgeving. Het spreekt voor zich dat hoe meer projecties gebruikt
zullen worden, hoe minder opvallend dit uitsmeren zal zijn. Een groot aantal projecties gebruiken
zal echter geen perfecte oplossing zijn, aangezien er steeds een wazige rand zal overblijven.
Figuur 1.2: Het verschil tussen het bekomen en het gewenste resultaat voor backprojectie
Een betere oplossing kan gevonden worden door figuur 1.2 nogmaals te bekijken. Het linker deel
stelt het resultaat voor van het projecteren en terugprojecteren van een puntbron. Dit deel van
de figuur kan dus beschouwd worden als het impulsantwoord van het systeem. Er kan aangetoond
worden dat dit impulsantwoord gegeven wordt door 1r , waardoor de backprojectie kan beschouwd
worden als het originele beeld geconvolueerd met dit impulsantwoord. De meest voor de hand
liggende oplossing is dan om de backprojectie te gaan Fourier-transformeren om deze factor te
verwijderen. Een 2D Fourier-transformatie is echter enorm traag, daar waar de backprojectie
zeer snel is. Het centrale sectie theorema stelt echter dat de 1D Fourier-transformatie van
de projectie van een 2D functie, equivalent is met de lijn die onder de projectiehoek door
het centrum van de 2D Fourier-transformatie van deze 2D functie gaat. Anders gezegd, een
trage 2D Fourier-transformatie kan omzeild worden door een snelle 1D Fourier-transformatie
van de projecties. Met 1.13 en 1.14 als de Fourier-transformatie en diens inverse, kan dus een
gefilterde vorm van de backprojectie1 opgesteld worden. Formule 1.15 toont hoe in FBP elke
projectie gecorrigeerd kan worden met een ramp filter – het Fourier-spectrum equivalent van het
impulsantwoord – alvorens de backprojectie uit te voeren. Deze correctie zal negatieve waarden
1FBP oftewel Filtered Backprojection

Hoofdstuk 1. Inleiding 8
introduceren, die er dan voor zullen zorgen dat het uitsmeren verdwijnt.
F1(pθ(t) =
∫pθ(t) e
−j2πρtdt (1.13)
pθ(t) =
∫F1(pθ(t)) e
j2πρtdρ (1.14)
f(x, y) =
π∫
0
∞∫
−∞
F1(pθ(t)) ej2πρt |ρ|dρ
δ(x cosθ + y sinθ − t)dθ (1.15)
Zoals al eerder werd vermeld, zal in dit werk echter gebruik gemaakt worden van een cone-beam
scanner. Formule 1.15 zal dus niet in deze vorm gebruikt worden, al zal hetzelfde principe
wel blijven gelden. In plaats van 1.15 zal het FDK [11] algoritme voor cone-beam geometrieen
gebruikt worden, in combinatie met Parker Weighting[12].
Nadelen
Filtered Backprojectie mag dan al zeer snel zijn – de voornaamste reden voor zijn populariteit
– het heeft echter ook een aantal nadelen. Allereerst veronderstelt FBP exacte projectiedata.
Dit is echter een utopie, aangezien er uit 1.6 al bleek dat er redelijk wat ruis op de gemeten
data kan zitten. Voorts zal het filteren van de projectiedata met een ramp filter enkel werken
wanneer er een voldoende groot aantal projecties zal zijn. Indien dit niet het geval is, zullen er
streepartefacten ontstaan. Tot slot is het ook volkomen onmogelijk om enige a-priori informatie
over de ruis of over het te reconstrueren beeld te incorporeren in de reconstructie, hetgeen wel
perfect mogelijk zal zijn bij iteratieve reconstructie.
1.3.2 Iteratieve Reconstructie
Principe
Iteratieve reconstructie start vanuit een andere premisse dan analytische reconstructie. In plaats
van uit te gaan van een Radon model, wordt bij iteratieve reconstructie gekozen voor een alge-
mener lineair model. Op deze manier wordt het mogelijk om meer informatie over het acquisitie-
proces en de aard van het beeld te incorporeren in de reconstructie [13]. Dit heeft uiteraard als
gevolg dat het beeld dat bekomen wordt door iteratieve reconstructie een stuk nauwkeuriger zal
zijn dan datgene dat bekomen wordt door analytische reconstructie. Door een betere modellering
van de ruis zal deze bijvoorbeeld een stuk minder aanwezig zijn bij iteratieve reconstructies.
Iteratieve reconstructie algoritmes benaderen het probleem van de reconstructie steeds op de-
zelfde manier.
Gegeven een set gemeten projectiewaarden en extra informatie over de metingen, de
afbeelding en het gescande object, zoek de distributie van de attenuatiewaarden in
het object.
Dit komt overeen met een algemeen lineair inverse probleem. Uiteraard is het in het geval
van CT niet praktisch om in het continue domein te werken, dus wordt er in het discrete
domein gewerkt. De structuur van iteratieve algoritmes is over het algemeen vrij gelijkaardig,

Hoofdstuk 1. Inleiding 9
Figuur 1.3: Iteratieve reconstructie
op een paar kleine variaties na. Er zijn steeds vier duidelijke stappen te onderscheiden in elke
iteratie: een projectie, het berekenen van de fout, een terugprojectie en een update van de
reconstructie. Een algemeen schema is gegeven in Figuur 1.3. Er wordt gestart van een zeker
startbeeld1, hetgeen geprojecteerd wordt om een reeks projecties te bekomen. Deze projecties
worden dan vergeleken met de projecties die bekomen zijn via metingen. De fout die hieruit
bekomen wordt, wordt teruggeprojecteerd naar de afbeeldingsruimte, om vervolgens gebruikt te
worden in de update van het startbeeld. Dit nieuwe beeld wordt daarna gebruikt als startbeeld
van de volgende iteratie. Op deze manier zal het beeld stap voor stap dichter bij de oplossing
van het reconstructie-probleem komen. De exacte vorm van het schema in Figuur 1.3 hangt
voornamelijk af van de optimalisatiefunctie. Afhankelijk van de functie die bepaalt hoe dicht
een bepaald beeld komt bij het beoogde resultaat, zal het schema een andere implementatie
krijgen.
Iteratieve reconstructietechnieken werden tot nu toe voornamelijk gebruikt bij nucleaire beeld-
vormingstechnieken, zoals PET2 en SPECT3. Bij deze beeldvormingstechnieken is een Radon-
model een slechte benadering van de acquisitie, waardoor analytische reconstructie zeer moeilijk
is. Iteratieve reconstructietechnieken geven veruit de beste resultaten waardoor deze dan ook
al vele jaren in gebruik zijn. Het voordeel is dat de algoritmes die in PET en SPECT gebruikt
worden voor iteratieve reconstructie, op een paar wijzigingen na, ook gebruikt kunnen worden
voor CT reconstructie. Veel van de algoritmes die gebruikt worden voor iteratieve reconstructie
bij CT zijn dus al vele jaren in gebruik bij iteratieve reconstructie voor PET en SPECT.
Limitaties
De keuze tussen iteratieve en analytische reconstructie is er voornamelijk een tussen nauwkeu-
righeid en efficientie. Iteratieve reconstructie zal een nauwkeuriger beeld geven dan analytische
reconstructie, aangezien de werkelijkheid nauwkeuriger gemodelleerd kan worden. Aan de andere
1Meer informatie hieromtrent in 2.42Positron Emission Tomography3Single-Photon Emission Computed Tomography

Hoofdstuk 1. Inleiding 10
kant zal iteratieve reconstructie een stuk langer duren dan analytische. Dit is eenvoudig te zien
in Figuur 1.3. Waar bij analytische reconstructie enkel een terugwaartse projectie uitgevoerd
moet worden, moet bij iteratieve reconstructie bij elke iteratie zowel een voorwaartse als een
terugwaartse projectie uitgevoerd worden. Dit zorgt er uiteraard voor dat de uitvoeringstijden
bij iteratieve reconstructie een tot meerdere grootteorden hoger liggen dan bij analytische re-
constructie. Rekentijden die uren tot dagen aanslepen zijn niet ongewoon, en het behoeft weinig
illustratie dat dit een van de redenen is waarom het gebruik van iteratieve reconstructietechnie-
ken vooral beperkt blijft tot laboratorium-omstandigheden.
Een tweede beperking van iteratieve reconstructie is de hoeveelheid geheugen die nodig is voor
de reconstructie. Tabellen 1.1 en 1.2 geven een indicatie van de hoeveelheid geheugen die nodig
is om de projecties en de reconstructie bij te houden. Terwijl de grootte van de afbeelding
enigszins beperkt blijft, loopt de benodigde hoeveelheid geheugen voor de projecties al snel op
tot enkele gigabytes. Deze hoeveelheid wordt nog eens verdubbeld wanneer de fout met de
gemeten projecties berekend wordt, aangezien dan zowel de berekende als de gemeten projecties
in het geheugen moeten gehouden worden. Dit is nog een reden waarom iteratieve reconstructie
– tot voor enkele jaren – nooit echt ingang vond bij CT. Het is pas sinds eind twintigste,
begin eenentwintigste eeuw dat computers over voldoende werkgeheugen beschikken om deze
hoeveelheden data te kunnen bevatten.
#projecties 256 512 1024
Grootte (GiB) 1.26 2.53 5.06
Tabel 1.1: Benodigd geheugen voor pro-
jecties
#pixels 2563 5123
Grootte (MiB) 64 512
Tabel 1.2: Benodigd geheugen voor ge-
reconstrueerd beeld
1.4 Doel van thesis
In dit werk zal gepoogd worden om een oplossing te vinden voor de extreem hoge reconstructie-
tijden die bij iteratieve reconstructie gangbaar zijn. Zoals zal blijken in 2.2 zijn de algoritmes
die gebruikt worden voor iteratieve reconstructie voor een groot deel parallelliseerbaar. Dit
biedt dus een groot potentieel voor het verlagen van de uitvoeringstijd. In de voorbije jaren
werd het steeds interessanter om oplossingsmethoden te parallelliseren met behulp van de GPU1
[14][15]. Deze hardware is specifiek ontworpen om op zeer efficiente manier extreem parallelle
programma’s uit te voeren. Traditioneel zijn deze volledig geoptimaliseerd voor grafische toe-
passingen – vandaar ook de naam – aangezien deze bijna uitsluitend gebruikt werden door de
game-industrie. Meer recent echter zijn de API’s aangepast om meer algemene berekeningen te
kunnen ondersteunen, waardoor de GPU’s zijn geevolueerd naar GPGPU’s2. Onder meer de
NVidia® CUDA� API [16] biedt de mogelijkheid om NVidia’s grafische kaarten te gebruiken
voor meer algemene doeleinden.
1Graphical Processing Unit, de grafische kaart van de PC2General Purpose GPU

Hoofdstuk 1. Inleiding 11
Verderop zullen vijf algoritmes geıntroduceerd worden die in dit werk aan bod zullen komen. Elk
van deze algoritmes zal geımplementeerd worden voor GPU. Op deze manier zullen de extreem
lange uitvoeringstijden, die kenmerkend zijn voor iteratieve reconstructie, vermeden kunnen
worden. De algoritmes zullen onderling vergeleken worden op basis van een aantal metrieken1
en voor elke metriek zal ook telkens de vergelijking gemaakt worden met een beeld dat bekomen
werd via analytische reconstructie. Op deze manier zal het mogelijk zijn om de performantie
van elk algoritme te beoordelen in functie van de omgevingsparameters. Zo zal dan uiteindelijk
blijken of het mogelijk is om via iteratieve reconstructie resultaten te verkrijgen die beter zijn
dan deze bekomen via analytische reconstructie, in vergelijkbare uitvoeringstijden.
1zie hoofdstuk 2

Hoofdstuk 2
Methodieken
2.1 Opstelling
Alle testen werden uitgevoerd op de PC waarvan de specificaties weergegeven worden in tabellen
2.1 en 2.2. Het framework van de algoritmes bouwde voort op het framework dat eerder al
gecreeerd werd door Bert Vandeghinste, geschreven in C++. De algoritmes zelf werden voor
het grootste deel uitgevoerd op de GPU; de code hiervoor werd geschreven in CUDA�.
NVidia®Tesla�M2070-Q
Aantal CUDA�cores 448
Geheugen 6 GiB
Enkele-precisie 1030 GFLOP
Dubbele-precisie 515 GFLOP
API CUDA�
Tabel 2.1: Specificaties van de grafische
kaart
Host
CPU Intel®Xeon®E5620
Kloksnelheid 2.40GHz
#Cores 4 (8 Threads)
Geheugen 16 GiB
OS Fedora 13
Tabel 2.2: Specificaties van
de host PC
Voor het scannen van fantomen werd gebruikt gemaakt van een FLEX Triumph�(Gamma Me-
dica Ideas, Northridge, CA, USA) scanner. Dit is een pre-klinische, tri-modale scanner die over
zowel een micro-CT als een PET en SPECT scanner beschikt. In dit werk werd uiteraard enkel
de CT modaliteit gebruikt. Tenslotte werden de analytische reconstructies uitgevoerd met be-
hulp van het COBRA softwarepakket van Exxim Computing Corporation, dat, zoals eerder al
vermeld werd, een Feldkamp-type reconstructie implementeert.
2.2 Algoritmes
In dit werk zullen vijf algoritmes onderzocht worden: OS-SART, SART, ISRA, MLEM en MLTR.
Door de limitaties die in 1.3.2 en 1.4 aan bod gekomen zijn, zullen er echter enkele aanpassingen
moeten aangebracht worden aan deze algoritmes. Algoritmes zoals ISRA, MLEM en MLTR heb-
ben immers meer geheugen nodig dan er beschikbaar is op de GPU, aangezien zij alle projecties
in het geheugen houden. Deze beperking kan eenvoudig omzeild worden door voor elk van deze
algoritmes een ordered subset[17] versie te maken. Dit houdt in dat de projecties in een aantal
12

Hoofdstuk 2. Methodieken 13
groepen – subsets – opgedeeld worden. Tijdens een iteratie worden vanaf nu alle projecties
per subset doorlopen, waarbij voor elke subset het reconstructieschema van Figuur 1.3 gevolgd
wordt – een soort verdeel en heers strategie dus. Op deze manier moeten er slechts even veel
projecties in het geheugen gehouden worden als er hoeken in de subset zijn. Deze ingreep lijkt
op het eerste zicht de uitvoeringstijd te verhogen, maar wanneer de subsets mutueel exclusief
gekozen zijn, blijft de uitvoeringstijd grofweg dezelfde. Meer nog, het gebruik van subsets zorgt
voor een significante stijging van de convergentiesnelheid, waardoor er minder iteraties nodig
zijn en de uitvoeringstijd drastisch verlaagd wordt.
Een van de enige nadelen van het verdelen in subsets van de projecties, is dat hierdoor de
oplossingsruimte ook in verschillende stukken verdeeld wordt. In elke pass wordt in een andere
oplossingsruimte gezocht, die normaal gezien telkens overlapt met de overige oplossingsruimten.
Wanneer al deze oplossingsruimten exact een gemeenschappelijk gebied hebben, kan op deze
manier uiteraard zeer snel naar een correcte oplossing geconvergeerd worden. In de aanwezigheid
van ruis kan dit echter leiden tot een situatie waarbij er geen gemeenschappelijk stuk meer is,
waardoor de convergentie niet meer gegarandeerd is. Een tweede nadeel van het opdelen in
subsets is dat er sneller ruis geıntroduceerd wordt in de afbeeldingen naarmate de projecties in
meer subsets opgedeeld worden. Het zal dus nog belangrijker worden om het itereren op tijd te
stoppen.
Aangezien de invloed van de manier waarop de projecties verdeeld worden over de verschillende
subsets geen specifiek onderzoeksdoel is van deze thesis, worden deze gewoon sequentieel toege-
wezen aan de verschillende subsets1. Dit is een van de eenvoudigste manieren om de projecties
over de subsets te verdelen. Complexere methoden voor het onderverdelen van projecties in
subsets kunnen onder andere gevonden worden in [17] en [18].
2.2.1 OS-SART en SART
OS-SART[19] en SART[20] – Simultaneous Algebraic Reconstruction Technique – zijn beide
uitbreidingen van het ART algoritme voorgesteld in [21]. Deze categorie algoritmes zien het
reconstructie-probleem als het vinden van een afbeelding die voldoet aan de beperkingen die
opgelegd zijn door de gemeten2 data en de veronderstellingen die gemaakt worden over de
afbeelding en de data.
ART is gebaseerd op de Kaczmarz methode [22] voor het oplossen van stelsels lineaire vergelij-
kingen van de vorm Ax = b. In deze uitdrukking stellen de xi de onbekenden voor waarnaar de
vergelijkingen moeten opgelost worden. A is de coefficientenmatrix waarin de Aij de coefficienten
van de onbekenden zijn in de vergelijkingen. Tot slot stellen de bi de uitkomsten van de vergelij-
kingen voor. De Kaczmarz methode beschouwt elk van de vergelijkingen waaraan de onbekenden
moeten voldoen als een hypervlak. In de afwezigheid van ruis zullen al deze vlakken een uniek
snijpunt hebben, de oplossing van het stelsel. Er wordt gestart vanaf een willekeurig punt in
de oplossingsruimte, dat in een eerste stap geprojecteerd3 wordt op een van de hypervlakken,
1i.e. projectie 1 in subset 1, projectie 2 in subset 2 enz.2Tenzij anders aangegeven gaat dit over de data na correctie!3Projectie in de zin van lineaire algebra!

Hoofdstuk 2. Methodieken 14
gedefinieerd door een van de vergelijkingen. Het punt dat hierdoor bekomen wordt, wordt ver-
volgens geprojecteerd op een van de volgende hypervlakken. Dit proces herhaalt zich totdat
verdere projecties niets meer veranderen aan de positie van het punt.
Figuur 2.1: Illustratie van het ART algoritme
Figuur 2.1 geeft een grafisch voorbeeld van deze methode in een 2D geval. In de figuur is duidelijk
te zien dat de convergentiesnelheid enorm kan varieren afhankelijk van de vergelijkingen; hoe
orthogonaler de vergelijkingen zullen zijn, hoe sneller het algoritme zal convergeren. Voorts is
het belangrijk dat de hypervlakken ook effectief een snijpunt hebben. Als er ruis aanwezig is
in de acquisities, kan het zijn dat de doorsnede van de hypervlakken leeg is. In dit geval zal
het algoritme niet langer kunnen convergeren naar een unieke oplossing, maar blijven oscilleren
in de ruimte afgebakend door de verschillende hypervlakken. Indien de hoeveelheid ruis relatief
beperkt blijft, zal de oplossing die bekomen wordt door het algoritme gewoon stop te zetten
echter dicht genoeg liggen bij de unieke oplossing die in een ruisloos geval zou zijn bekomen.
Het belangrijkste nadeel van deze aanpak is dat het onmogelijk is om een statistisch model van
de data te incorporeren[13].
OS-SART en SART zijn uitbreidingen van ART in de zin dat, waar ART slechts 1 pixel van
een projectie gebruikt bij een update, zij de bijdragen van alle projecties gebruiken. Meer nog,

Hoofdstuk 2. Methodieken 15
OS-SART en SART updaten per iteratie alle voxels in de afbeelding, waar ART dit maar voor 1
voxel per keer doet1. In essentie verschillen OS-SART en SART slechts weinig van elkaar. Het
enige verschil zit in het aantal subsets dat gebruikt wordt bij de reconstructie. SART gebruikt
per definitie slechts 1 projectie per subset, waar dit bij OS-SART kan varieren. Dit maakt SART
dus een bijzonder geval van OS-SART.
Formule 2.1 geeft de algemene expressie voor (OS-)SART. Uit de formule blijkt dat OS-SART
en SART het schema van Figuur 1.3 vrij exact volgen. Het berekenen van de fout gebeurt door
het verschil te nemen van de gemeten projecties (bi) met de voorwaartse projectie van de vorige
iteratie (xnk). Vooraleer deze fout teruggeprojecteerd wordt, wordt ze eerst nog genormaliseerd.
Na de backprojectie is er opnieuw een normalisatie, alvorens de additieve update plaatsvindt.
xn+1j = xnj +
1∑i′∈Sn
ai′j
∑
i∈Sn
aij
bi −∑k
aikxnk
∑k
aik(2.1)
2.2.2 OS-EM
OS-EM[17] – Ordered Subset Expectation Maximisation – is de ordered subset uitbreiding
van het ML-EM2 algoritme[23][24] dat gebaseerd is op het Maximum Likelihood criterium van
Fisher[25]. In tegenstelling tot de op ART gebaseerde algoritmes is ML-EM een statistisch al-
goritme. ML-EM beschouwt de transmissiedata als een realisatie van een Poisson-distributie3,
aangezien Poisson-ruis de dominante bijdrage levert in de ruis van CT-beelden[26]. Het ML-EM
algoritme gaat steeds dat beeld reconstrueren dat statistisch gezien de grootste kans heeft om
tot de gemeten projecties te leiden. Hierbij heeft het de eigenschap dat het een asymptotisch
efficient algoritme is, waardoor het minder vatbaar voor ruis zou moeten zijn. CT beelden zijn
echter inherent vrij ruizig, waardoor het beeld met de grootste kans om de gemeten projecties
te veroorzaken eveneens vrij ruizig zal zijn. Hierdoor is het belangrijk om het itereren op tijd
te stoppen, alvorens het algoritme convergeert naar een te ruizig resultaat.
L (Φ) = ln g(y|Φ) (2.2)
Q(Φ′|Φ
)= E
[ln f(s|Φ′)|y,Φ
](2.3)
Zoals blijkt uit de naam bestaat ML-EM uit twee delen; ML, wat staat voor Maximum Likeli-
hood, en EM, wat staat voor Expectation Maximisation. Wat ML-EM dus concreet wil bereiken,
is het maximaliseren van een aannemelijkheidsfunctie door middel van het maximaliseren van
een overeenstemmende verwachtingswaarde. Formules 2.2 en 2.3 zijn cruciaal om dit te berei-
ken. Er wordt verondersteld dat de projecties, de vector y, de incomplete data vormen, terwijl
gezocht wordt naar de complete data, vector s. De complete data zal zowel de incomplete als
de ontbrekende data, zoals het geprojecteerde object, bevatten. Op basis hiervan kan dan de
1Vandaar ook de benaming Simultaneous ART2Maximum Likelihood Expectation Maximisation3Deze redenering klopt echter niet helemaal, aangezien ML-EM werkt met de gecorrigeerde gemeten projecties.
Hierdoor zal de ruiskarakterisatie bij ML-EM niet helemaal juist zijn. Bij MLTR zal op dit vlak wel de juiste
redenering gemaakt worden.

Hoofdstuk 2. Methodieken 16
log-aannemelijkheidsfunctie L (Φ) opgesteld worden, die een maat geeft voor de aannemelijk-
heid dat een bepaalde set projecties y het resultaat is van de projectie van een object Φ. Door
formule 2.2 te maximaliseren, zal uiteindelijk een set waarden voor Φ bekomen worden, die
het beeld zullen schetsen dat statistisch de grootste kans heeft om tot de gemeten projecties te
komen. Er zijn verschillende mogelijkheden om L te maximaliseren, waarvan EM degene is die
bij ML-EM gebruikt zal worden. EM is een iteratieve methode waarbij elke iteratie gebeurt in
twee stappen. In een eerste stap wordt op basis van formule 2.3 Q(Φ|Φn) berekend, hetgeen
overeenkomt met het berekenen van het gemiddelde1 van de log-aannemelijkheidsfunctie van de
complete data, gegeven de schatting voor het object uit de vorige iteratie. In de tweede stap,
de maximalisatiestap, wordt dit gemiddelde gemaximaliseerd door die waarde voor Φ te zoeken
die Q(Φ|Φn) maximaliseert. Deze waarde wordt dan de Φn+1 die in de volgende iteratie zal
gebruikt worden. Het kan aangetoond worden[23] dat deze procedure L (Φ) in elke iteratie zal
laten toenemen.
OS-EM mag dan wel een veralgemening zijn van het ML-EM algoritme, het is echter geen echt
EM algoritme. Meer nog, convergentie van het OS-EM is nog steeds niet bewezen, al geeft het in
de meeste gevallen wel een gelijkaardig resultaat als ML-EM. Een bijkomend nadeel is, dat het
opdelen in subsets van de projecties zorgt voor extra ruis en ervoor kan zorgen dat het algoritme
begint te oscilleren rond een oplossing[13].
xn+1j =
xnj∑i′∈Sn
ai′j
∑
i∈Sn
aijbi∑
k
aikxnj
(2.4)
Formule 2.4 geeft de algemene expressie voor OS-EM. Ook OS-EM volgt het schema van figuur
1.3 vrij nauwkeurig. De fout wordt hier berekend door de gemeten projecties te delen door
de berekende projecties. In tegenstelling tot 2.1 voor (OS-)SART is er geen normalisatie van
de fout, deze is er wel na diens backprojectie. De update bij OS-EM is multiplicatief, hetgeen
betekent dat OS-EM een inherente positiviteitsbeperking bevat.
2.2.3 OS-ISRA
OS-ISRA is de ordered subset uitbreiding van ISRA[27][28][29] – Image Space Reconstruction
Algorithm. ISRA is eveneens gebaseerd op het ML criterium van Fisher en is daardoor ge-
lijkaardig aan het ML-EM algoritme. Het is ontstaan met de opkomst van PET en SPECT
scanners met een steeds kleinere axiale resolutie. Hierdoor moest overgeschakeld worden op
3D reconstructie en dreigden de datasets te groot te worden. Om dit te omzeilen creeerden
Daube-Witherspoon en Muehllehner ISRA. Het grote verschil tussen ISRA en ML-EM is het
verschillend iteratie-schema. Bij ISRA zijn de ‘Compare’ en ‘Backproject’ stappen omgewisseld,
met andere woorden de fout wordt niet langer in de projectieruimte berekend, maar in de beeld-
ruimte2. Dit heeft als gevolg dat er veel minder bewerkingen uitgevoerd moeten worden om
1Aangezien de complete data niet gekend is – indien dit wel zo was zou het probleem triviaal op te lossen
zijn – kan de log-aannemelijkheidsfunctie zelf niet berekend worden, dus moet genoegen genomen worden met het
gemiddelde ervan, dat wel berekend kan worden.2Vandaar de naam Image Space Reconstruction Algorithm

Hoofdstuk 2. Methodieken 17
de fout te berekenen. De backprojectie van de gemeten projecties kan eenvoudig op voorhand
berekend worden. Deze aanpassing zorgt er echter wel voor dat ISRA geen echt ML algoritme
meer is, ondanks de gelijkenissen. De convergentie is echter wel nog steeds gegarandeerd[29].
Formule 2.5 geeft de algemene uitdrukking voor de ordered subset uitbreiding van ISRA1. Het
is duidelijk dat het net als OS-EM om een multiplicatief algoritme gaat, waardoor het even-
eens een positiviteitsbeperking bevat. In tegenstelling tot OS-SART en OS-EM vindt er echter
geen normalisatie plaats. De afbeelding wordt rechtstreeks geupdatet met de in de beeldruimte
berekende fout.
xn+1j = xnj
∑i∈Sn
aijbi
∑i∈Sn
aij∑k
aikxnj
(2.5)
Door met subsets te werken ontstaat er nog een extra moeilijkheid wat betreft het op voorhand
berekenen van de backprojectie van de gemeten data. In plaats van slechts een enkele backpro-
jectie moet er voor elke subset een backprojectie berekend worden. Hierdoor kan de hoeveelheid
geheugen die nodig is om deze bij te houden zeer snel oplopen naargelang het aantal subsets
stijgt. Het is dus vooral bij kleine subsets voordeliger om deze backprojectie per iteratie te
berekenen.
2.2.4 OS-MLTR
MLTR[30] – Maximum Likelihood algorithm for Transmission tomography – is net als ML-
EM en ISRA gebaseerd op het ML criterium van Fisher. In tegenstelling tot de voorgaande
algoritmes, werkt MLTR echter niet op de gecorrigeerde gemeten data, maar rechtstreeks op de
ruwe gemeten data. Dit zorgt voor een veel nauwkeurigere ruismodellering dan bij ML-EM het
geval is. ML-EM vertrekt immers van de foute veronderstelling dat de logaritme van de data
een realisatie is van een Poisson-distributie, terwijl dit niet het geval is. Het is immers de ruwe
gemeten data die Poisson gedistribueerd is.
Uitbreidingen van MLTR blijken bijzonder goed te zijn in het verwijderen van beam-hardening2
artefacten en artefacten ten gevolge van metalen implantaten[32][33]. Het verbeterde acquisitie-
model van MLTR blijkt dus zeer beloftevol te zijn[32].
yi = bie−
∑kaikx
nk
xn+1j = xnj −
1
Dln
∑i∈Sn
aijyi
∑i∈Sn
aij yi
(2.6)
Formule 2.6 geeft de algemene uitdrukking voor de ordered subset uitbreiding van MLTR3. Deze
formule is enigszins verschillend van deze gebruikt in [30], [32] en [33], maar is wel volkomen
1Vanaf hier zal ISRA verwijzen naar de ordered subset uitbreiding, tenzij anders aangegeven.2Wanneer rontgenstralen doorheen een object gaan, worden stralen met lagere energie gemakkelijker geabsor-
beerd, waardoor de straling achter het object gemiddeld een hogere energie heeft. Dit kan leiden tot artefacten
in de reconstructie.[31]3Vanaf hier zal MLTR verwijzen naar de ordered subset uitbreiding, tenzij anders aangegeven.

Hoofdstuk 2. Methodieken 18
equivalent. MLTR in de vorm van 2.6 reduceert echter het aantal projecties en backprojecties
die per iteratie gemaakt moeten worden. Dit zorgt voor een snellere uitvoering en is daarom te
verkiezen boven de andere formuleringen. In 2.6 stelt yi de ruwe gemeten projectiedata voor, yi
de berekende projecties en bi de gemeten waarde zonder object. D is een normalisatiefactor.
2.3 Fantomen en metrieken
Om een performantieanalyse te kunnen uitvoeren zoals beschreven in 1.4 zijn er verschillende
metrieken en fantomen nodig. In dit werk werden een drietal fantomen gebruikt om een aantal
eigenschappen zoals ruisgevoeligheid, contrast en spatiale resolutie te kunnen opmeten. Van elk
fantoom werden 1024 projecties gemaakt voor reconstructie. In wat volgt zullen elk van deze
fantomen besproken worden met voor elk fantoom de metrieken waarop het betrekking heeft.
2.3.1 Ruis en Contrast
Voor het bepalen van de ruisgevoeligheid van de verschillende algoritmes werd een waterfantoom
gebruikt. Dit fantoom bestaat uit een cilinder die uniform gevuld wordt met water. Op deze
manier kan er een scan gemaakt worden van een volkomen homogeen ‘object’. Bij een volledig
ruisloze acquisitie, zou bij reconstructie het watervolume in theorie overal een constante waarde
moeten hebben. Wanneer er echter ruis aanwezig is bij de acquisitie, dan zal dit zich ook verta-
len naar het gereconstrueerde beeld. Aangezien het deel van de reconstructieafbeelding dat het
watervolume voorstelt normaal overal dezelfde waarde moet hebben, zal de standaardafwijking
van de waarden in dit deel gelijk zijn aan de standaardafwijking van de ruis. Deze standaard-
afwijking zal dan voor elke reconstructie gebruikt kunnen worden om met behulp van 2.7 de
signaal-ruisverhouding te berekenen.
SNR =µbeeldσwater
(2.7)
Het bepalen van het contrast gebeurt door het scannen van een fantoom met laag contrast.
Dit houdt in dat het fantoom op zijn minst twee aan elkaar grenzende volumes heeft met een
dichtheid die slechts minimaal verschilt. In dit werk werd gebruik gemaakt van een QRM M32-
LC-18 fantoom[34]. Dit is een cilindrisch fantoom uit hars waarin vier smalle cilinders zitten.
Twee van deze cilinders hebben een diameter van 2.5 mm, de andere twee een diameter van
1 mm. De vier cilinders zijn twee aan twee uit een ander materiaal gemaakt: de ene soort
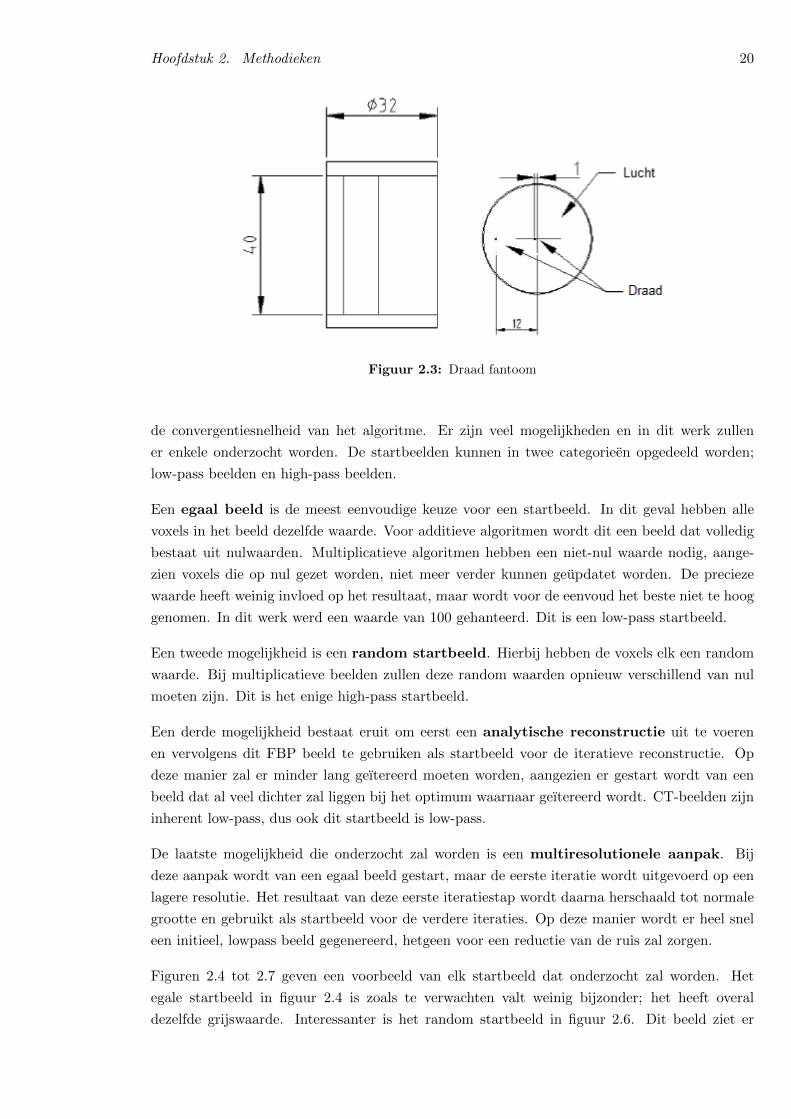
heeft een verschil van ∼40HU met de achtergrond, de andere soort verschilt ∼80HU van de
achtergrond. Figuur 2.3 geeft een schematische voorstelling van het fantoom en formule 2.8
geeft de uitdrukking waarmee de contrast-ruisverhouding berekend kan worden. Hierin stelt SA
het signaal voor van een cilinder en SB het signaal van de hars die de cilinders omhult.
CNR =|SA − SB|σwater
(2.8)
Signaal-ruisverhouding en contrast-ruisverhouding zijn nauw aan elkaar verwant; hoe beter de
signaal-ruisverhouding is, hoe beter ook de contrast-ruisverhouding zal zijn. Er is echter een
ondergrens voor de SNR vanaf waar het voor het menselijk oog niet langer mogelijk is om

Hoofdstuk 2. Methodieken 19
met 100 % zekerheid objecten van elkaar te onderscheiden. Rose kwam reeds in 1948 tot de
vaststelling dat deze ongeveer op een SNR van 5 ligt[35]. Het zal dus weinig zinvol zijn om
contrast te bekijken op beelden waar de SNR lager ligt dan deze ondergrens.
Figuur 2.2: Laag contrast fantoom
2.3.2 Resolutie
Voor het beoordelen van de resolutie wordt gebruikt gemaakt van een draadfantoom. Dit is een
fantoom waarin zich een dunne draad bevindt in lucht of een of andere vloeistof. Hier werd een
QRM M32-Wire fantoom[34][36] gebruikt. Bij dit fantoom zijn er twee wolfraam draden met
een diameter van 10 µm gespannen in lucht. Dit zorgt ervoor dat er een groot contrast is tussen
de draden en hun omgeving, waardoor er betere metingen gedaan kunnen worden. De eerste van
de twee draden bevindt zich dicht bij het centrum van het fantoom, het andere ligt in de buurt
van de rand. Op die manier kunnen er zowel resolutiemetingen in het midden, als meer naar
buiten toe gedaan worden. Dit is belangrijk aangezien de resolutie van een CT-beeld normaal
gezien beter is in het centrum dan erbuiten. Figuur 2.3 geeft een schematische voorstelling van
het fantoom.
Om uitspraken te kunnen doen over de resolutie, wordt gebruik gemaakt van de PSF1. Aan
de PSF van beide draden wordt een Gaussiaan gefit. Van deze Gaussiaan wordt dan telkens
de FWHM2 berekend. Hoe kleiner de FWHM is, hoe nauwkeuriger het algoritme zal zijn. De
FWHM zal steeds in twee richtingen gemeten worden; in radiale en in tangentiale richting.
2.4 Invloed van het startbeeld
Zoals Figuur 1.3 al aangaf, heeft een iteratief algoritme steeds een startbeeld nodig voor de
reconstructie. De keuze van een bepaald startbeeld kan een significante invloed hebben op
1Point Spread Function: het signaal dat bekomen wordt wanneer een puntbron aangelegd wordt aan het
systeem, hetgeen hier overeenkomt met het scannen van een zeer dunne draad.2Full Width at Half Max: de breedte van de Gaussiaan op het punt waar de piek de helft van zijn maximale
hoogte bereikt.
Hoofdstuk 2. Methodieken 20
Figuur 2.3: Draad fantoom
de convergentiesnelheid van het algoritme. Er zijn veel mogelijkheden en in dit werk zullen
er enkele onderzocht worden. De startbeelden kunnen in twee categorieen opgedeeld worden;
low-pass beelden en high-pass beelden.
Een egaal beeld is de meest eenvoudige keuze voor een startbeeld. In dit geval hebben alle
voxels in het beeld dezelfde waarde. Voor additieve algoritmen wordt dit een beeld dat volledig
bestaat uit nulwaarden. Multiplicatieve algoritmen hebben een niet-nul waarde nodig, aange-
zien voxels die op nul gezet worden, niet meer verder kunnen geupdatet worden. De precieze
waarde heeft weinig invloed op het resultaat, maar wordt voor de eenvoud het beste niet te hoog
genomen. In dit werk werd een waarde van 100 gehanteerd. Dit is een low-pass startbeeld.
Een tweede mogelijkheid is een random startbeeld. Hierbij hebben de voxels elk een random
waarde. Bij multiplicatieve beelden zullen deze random waarden opnieuw verschillend van nul
moeten zijn. Dit is het enige high-pass startbeeld.
Een derde mogelijkheid bestaat eruit om eerst een analytische reconstructie uit te voeren
en vervolgens dit FBP beeld te gebruiken als startbeeld voor de iteratieve reconstructie. Op
deze manier zal er minder lang geıtereerd moeten worden, aangezien er gestart wordt van een
beeld dat al veel dichter zal liggen bij het optimum waarnaar geıtereerd wordt. CT-beelden zijn
inherent low-pass, dus ook dit startbeeld is low-pass.
De laatste mogelijkheid die onderzocht zal worden is een multiresolutionele aanpak. Bij
deze aanpak wordt van een egaal beeld gestart, maar de eerste iteratie wordt uitgevoerd op een
lagere resolutie. Het resultaat van deze eerste iteratiestap wordt daarna herschaald tot normale
grootte en gebruikt als startbeeld voor de verdere iteraties. Op deze manier wordt er heel snel
een initieel, lowpass beeld gegenereerd, hetgeen voor een reductie van de ruis zal zorgen.
Figuren 2.4 tot 2.7 geven een voorbeeld van elk startbeeld dat onderzocht zal worden. Het
egale startbeeld in figuur 2.4 is zoals te verwachten valt weinig bijzonder; het heeft overal
dezelfde grijswaarde. Interessanter is het random startbeeld in figuur 2.6. Dit beeld ziet er

Hoofdstuk 2. Methodieken 21
Figuur 2.4: Egaal startbeeld
Figuur 2.5: FBP startbeeld
Figuur 2.6: Random startbeeld
Figuur 2.7: Multiresolutioneel startbeeld
eigenlijk gewoon uit zoals een egaal beeld, waar extreem veel ruis op zit. Een egaal startbeeld
daarentegen, kan beschouwd worden als een startbeeld waar helemaal geen ruis op zit. Het
verschil in ruis op het startbeeld zal uiteraard gevolgen hebben voor de hoeveelheid ruis die
effectief in de reconstructie aanwezig zal zijn, zoals zal blijken in 3.5. Figuur 2.5 en 2.7 zijn
dan weer vrij gelijkaardig, al is het multiresolutioneel startbeeld iets waziger dan het FBP
startbeeld. Het wazige van het multiresolutioneel startbeeld wordt veroorzaakt door het schalen
van het beeld. Hierbij wordt nearest neighbour interpolatie gebruikt omwille van de relatief
goede snelheid van deze interpolatiemethode. Het schalen zorgt er echter voor dat de scherpe
details uitgevlakt worden. Dit is echter positief, aangezien hierdoor de ruis, die bij het FBP
startbeeld licht aanwezig is, enigszins uitgevlakt wordt.
In hoofdstuk 3 zal de invloed van het startbeeld niet apart besproken worden, maar als onderdeel
van de overige parameters die onderzocht worden. Op die manier kan voor elke parameter
gekeken worden hoeveel invloed het startbeeld heeft op de prestatie van elk algoritme voor die

Hoofdstuk 2. Methodieken 22
bepaalde parameter.
2.5 Monte Carlo Simulatie
Initieel was het de bedoeling om ook Monte Carlo-technieken te onderzoeken. Deze zouden
kunnen gebruikt worden om een betere modellering van de projectie te bekomen. Met behulp van
Monte Carlo-technieken is het immers mogelijk om de rontgenstralen te modelleren, waardoor er
nauwkeurigere projecties kunnen berekend worden. Initiele testen met de software die hiervoor
ter beschikking stond gaven echter aan dat een enkele projectie over 1024 hoeken al een aantal
uur in beslag neemt. Aangezien er echter honderden projecties nodig zijn per iteratie zou dit
proces dus veel te veel tijd in beslag nemen. In samenspraak met de begeleider is er toen
afgesproken om deze piste niet verder te onderzoeken.

Hoofdstuk 3
Resultaten
3.1 Convergentie
Aangezien vier van de vijf algoritmes die zullen onderzocht worden, ordered subset varianten
zijn, moet er dus bepaald worden in hoeveel subsets de projectiedata zal worden opgedeeld.
Aangezien snelheid een belangrijke factor is, is het voordelig als er minder iteraties nodig zijn
om het gewenste resultaat te bereiken. Het aantal subsets dat er voor zorgt dat het algoritme
het snelst naar een oplossing convergeert, zal dus een goede keuze zijn. Om de convergentie te
kunnen testen, wordt elk algoritme verschillende malen uitgevoerd, telkens met een verschillend
aantal subsets. Elk algoritme voert acht iteraties uit alvorens het wordt stopgezet. Zoals zal
blijken uit de resultaten is acht iteraties ruim voldoende om een duidelijk beeld te krijgen van
de convergentie. Meer nog, voor het optimale aantal subsets zal na vijf iteraties het beeld niet
drastisch meer veranderen.
De metriek die werd gebruikt om de mate van convergentie te testen, is de NRMSE1 tussen
de opeenvolgende iteraties. NRMSE is een maat voor het verschil tussen twee verschillende
afbeeldingen. Formule 3.1 geeft de uitdrukking die toelaat om de NRMSE tussen twee opeen-
volgende iteraties te berekenen. In deze formule stellen de x1,i de grijswaarden van de pixels
van de eerste afbeelding en x2,i de grijswaarden van de pixels van de tweede afbeelding voor.
xmax en xmin zijn de maximale respectievelijk minimale grijswaarde die in beide afbeeldingen
voorkomt. Naarmate het algoritme convergeert zal de NRMSE tussen opeenvolgende iteraties
steeds kleiner worden. Het aantal subsets waarvoor de NRMSE het snelste daalt, is dus het
aantal subsets dat het algoritme het snelst laat convergeren.
NRMSE =1
xmax − xmin
√√√√√n∑i=1
(x1,i − x2,i)2
n(3.1)
Figuren 3.1, 3.2, 3.3 en 3.4 tonen de NRMSE tussen opeenvolgende iteraties van de verschillende
algoritmes voor verschillende aantallen subsets. Zoals blijkt uit de figuren, zal het aantal subsets
voornamelijk invloed hebben in de eerste iteraties van de algoritmes. Hoe groter het aantal
iteraties, hoe minder invloed het aantal subsets zal hebben op de convergentiesnelheid.
1Normalized Root Mean Square Error
23
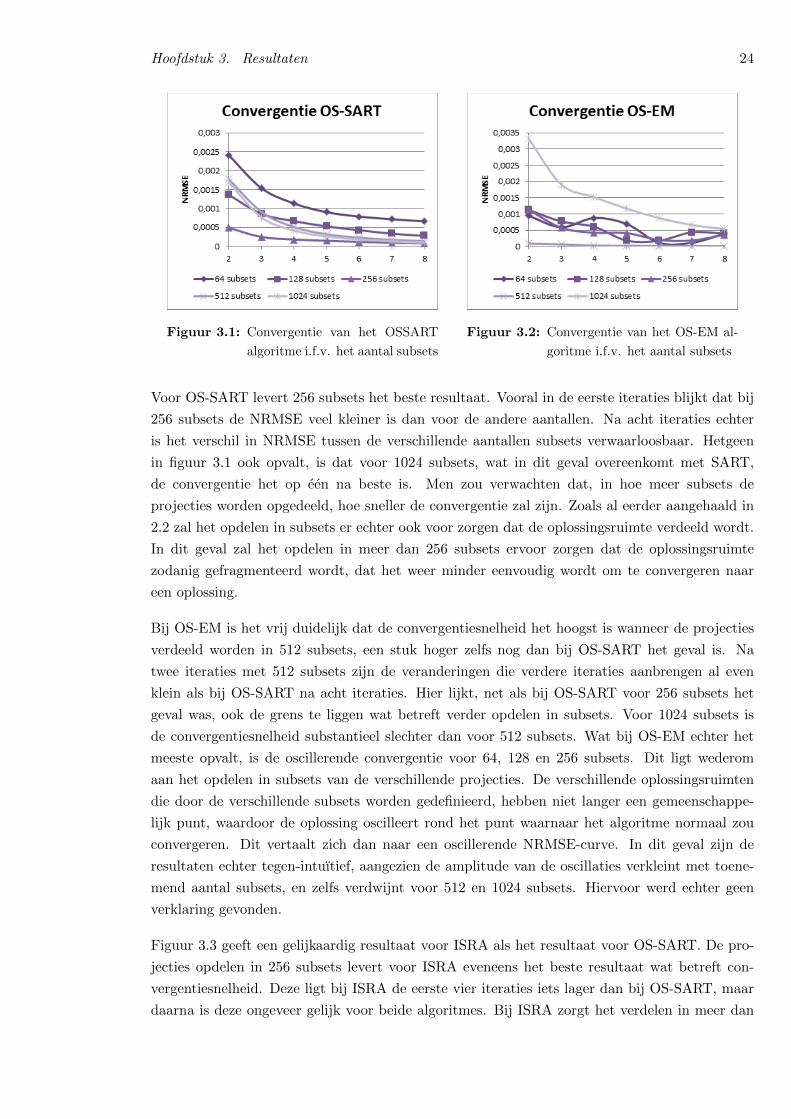
Hoofdstuk 3. Resultaten 24
Figuur 3.1: Convergentie van het OSSART
algoritme i.f.v. het aantal subsets
Figuur 3.2: Convergentie van het OS-EM al-
goritme i.f.v. het aantal subsets
Voor OS-SART levert 256 subsets het beste resultaat. Vooral in de eerste iteraties blijkt dat bij
256 subsets de NRMSE veel kleiner is dan voor de andere aantallen. Na acht iteraties echter
is het verschil in NRMSE tussen de verschillende aantallen subsets verwaarloosbaar. Hetgeen
in figuur 3.1 ook opvalt, is dat voor 1024 subsets, wat in dit geval overeenkomt met SART,
de convergentie het op een na beste is. Men zou verwachten dat, in hoe meer subsets de
projecties worden opgedeeld, hoe sneller de convergentie zal zijn. Zoals al eerder aangehaald in
2.2 zal het opdelen in subsets er echter ook voor zorgen dat de oplossingsruimte verdeeld wordt.
In dit geval zal het opdelen in meer dan 256 subsets ervoor zorgen dat de oplossingsruimte
zodanig gefragmenteerd wordt, dat het weer minder eenvoudig wordt om te convergeren naar
een oplossing.
Bij OS-EM is het vrij duidelijk dat de convergentiesnelheid het hoogst is wanneer de projecties
verdeeld worden in 512 subsets, een stuk hoger zelfs nog dan bij OS-SART het geval is. Na
twee iteraties met 512 subsets zijn de veranderingen die verdere iteraties aanbrengen al even
klein als bij OS-SART na acht iteraties. Hier lijkt, net als bij OS-SART voor 256 subsets het
geval was, ook de grens te liggen wat betreft verder opdelen in subsets. Voor 1024 subsets is
de convergentiesnelheid substantieel slechter dan voor 512 subsets. Wat bij OS-EM echter het
meeste opvalt, is de oscillerende convergentie voor 64, 128 en 256 subsets. Dit ligt wederom
aan het opdelen in subsets van de verschillende projecties. De verschillende oplossingsruimten
die door de verschillende subsets worden gedefinieerd, hebben niet langer een gemeenschappe-
lijk punt, waardoor de oplossing oscilleert rond het punt waarnaar het algoritme normaal zou
convergeren. Dit vertaalt zich dan naar een oscillerende NRMSE-curve. In dit geval zijn de
resultaten echter tegen-intuıtief, aangezien de amplitude van de oscillaties verkleint met toene-
mend aantal subsets, en zelfs verdwijnt voor 512 en 1024 subsets. Hiervoor werd echter geen
verklaring gevonden.
Figuur 3.3 geeft een gelijkaardig resultaat voor ISRA als het resultaat voor OS-SART. De pro-
jecties opdelen in 256 subsets levert voor ISRA eveneens het beste resultaat wat betreft con-
vergentiesnelheid. Deze ligt bij ISRA de eerste vier iteraties iets lager dan bij OS-SART, maar
daarna is deze ongeveer gelijk voor beide algoritmes. Bij ISRA zorgt het verdelen in meer dan
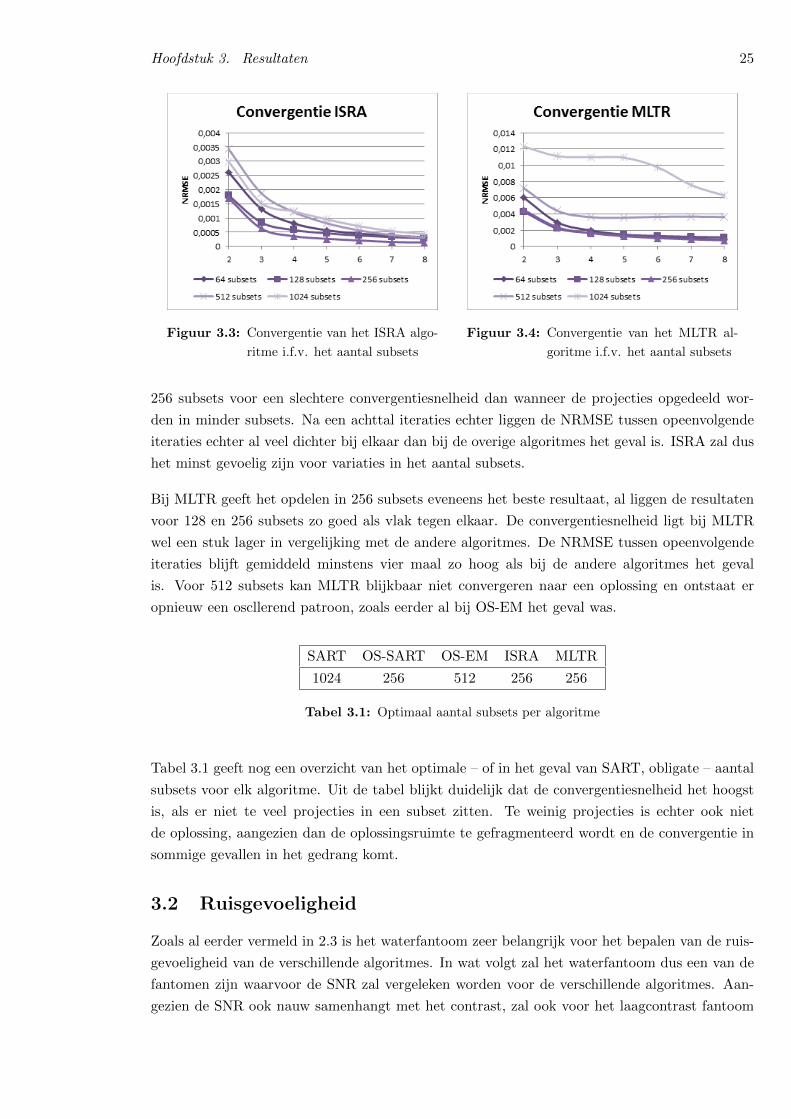
Hoofdstuk 3. Resultaten 25
Figuur 3.3: Convergentie van het ISRA algo-
ritme i.f.v. het aantal subsets
Figuur 3.4: Convergentie van het MLTR al-
goritme i.f.v. het aantal subsets
256 subsets voor een slechtere convergentiesnelheid dan wanneer de projecties opgedeeld wor-
den in minder subsets. Na een achttal iteraties echter liggen de NRMSE tussen opeenvolgende
iteraties echter al veel dichter bij elkaar dan bij de overige algoritmes het geval is. ISRA zal dus
het minst gevoelig zijn voor variaties in het aantal subsets.
Bij MLTR geeft het opdelen in 256 subsets eveneens het beste resultaat, al liggen de resultaten
voor 128 en 256 subsets zo goed als vlak tegen elkaar. De convergentiesnelheid ligt bij MLTR
wel een stuk lager in vergelijking met de andere algoritmes. De NRMSE tussen opeenvolgende
iteraties blijft gemiddeld minstens vier maal zo hoog als bij de andere algoritmes het geval
is. Voor 512 subsets kan MLTR blijkbaar niet convergeren naar een oplossing en ontstaat er
opnieuw een oscllerend patroon, zoals eerder al bij OS-EM het geval was.
SART OS-SART OS-EM ISRA MLTR
1024 256 512 256 256
Tabel 3.1: Optimaal aantal subsets per algoritme
Tabel 3.1 geeft nog een overzicht van het optimale – of in het geval van SART, obligate – aantal
subsets voor elk algoritme. Uit de tabel blijkt duidelijk dat de convergentiesnelheid het hoogst
is, als er niet te veel projecties in een subset zitten. Te weinig projecties is echter ook niet
de oplossing, aangezien dan de oplossingsruimte te gefragmenteerd wordt en de convergentie in
sommige gevallen in het gedrang komt.
3.2 Ruisgevoeligheid
Zoals al eerder vermeld in 2.3 is het waterfantoom zeer belangrijk voor het bepalen van de ruis-
gevoeligheid van de verschillende algoritmes. In wat volgt zal het waterfantoom dus een van de
fantomen zijn waarvoor de SNR zal vergeleken worden voor de verschillende algoritmes. Aan-
gezien de SNR ook nauw samenhangt met het contrast, zal ook voor het laagcontrast fantoom

Hoofdstuk 3. Resultaten 26
de SNR vergeleken worden. Op basis hiervan zal dan verder beslist kunnen worden voor welke
algoritmes/startbeelden het nuttig zal zijn om contrast te berekenen. Elk algoritme werd na vijf
iteraties gestopt, aangezien hierboven in 3.1 al bleek dat, wanneer het optimale aantal subsets
genomen wordt, na een vijftal iteraties de beelden niet veel meer veranderen.
OS-SART
Figuur 3.5 toont voor OS-SART de SNR van het water en laagcontrast fantoom voor verschil-
lende startbeelden. Wat onmiddellijk opvalt is dat de SNR enorm laag is wanneer vertrokken
wordt van een random startbeeld. Dit startbeeld komt immers overeen met een high-pass beeld
dat zuiver uit ruis bestaat. Aangezien CT-beelden echter inherent low-pass zijn, moet er dus
veel meer aangepast worden aan het startbeeld dan bij een low-pass1 startbeeld het geval is. Dit
blijkt ook duidelijk uit de SNR van de opeenvolgende iteraties; waar de SNR daalt met stijgend
aantal iteraties voor de low-pass startbeelden, stijgt deze voor het random startbeeld. De SNR
lijkt op basis van de resultaten te convergeren naar een SNR die rond de 3 a 4 ligt.
In vergelijking met analytische reconstructie geven OS-SART met een egaal startbeeld en OS-
SART met FBP startbeeld ongeveer gelijke – voor het laagcontrast fantoom – tot een stuk betere
resultaten – voor het waterfantoom – tijdens de eerste iteraties. Voor de multiresolutionele
aanpak liggen de resultaten nog iets beter, met voor het waterfantoom een veel hogere SNR
dan voor analytische reconstructie het geval is. Het is opvallend dat wanneer gestart wordt van
de multiresolutionele aanpak of van een FBP als startbeeld, er slechts weinig verbetering is ten
opzichte van een egaal startbeeld. Enkel in de eerste iteratie ligt de SNR iets hoger dan bij
een egaal startbeeld het geval is. Dit betekent dus dat, wanneer van een low-pass startbeeld
vertrokken wordt, OS-SART zeer snel het effect van een verschillend startbeeld teniet doet2.
Om een reconstructie te bekomen met een goede SNR zal het dus voldoende zijn om een low-
pass startbeeld te gebruiken en het itereren na een of twee iteraties stop te zetten. Verdere
analyse van de spatiale resolutie en uitvoeringstijd zal uitwijzen of het voor OS-SART effectief
voordeliger is om een gesofisticeerder startbeeld dan een gewoon egaal startbeeld te gebruiken.
SART
Figuur 3.6 toont de SNR voor de verschillende startbeelden en fantomen voor het SART algo-
ritme. De verschillende SNR liggen hier een stuk dichter bij elkaar dan bij OS-SART het geval
was, maar met minder hoge uitschieters. Ook hier convergeert de SNR na enkele iteraties, dit
keer naar een SNR van 2 a 3. Het random startbeeld geeft opnieuw het minst goede resultaat, al
ligt de SNR toch een stuk hoger dan bij OS-SART het geval was. SART kan dus duidelijk beter
om met een high-pass startbeeld dan OS-SART. De low-pass startbeelden geven bijna identieke
resultaten op gebied van SNR. In het bijzonder in de eerste iteraties geven deze een significant
beter resultaat dan voor een random startbeeld het geval is, maar de resultaten liggen toch nog
een heel stuk lager dan voor analytische reconstructie het geval is. Waar er bij OS-SART wat
1Egaal, multiresolutioneel of FBP startbeeld2i.e. waar het SNR betreft.
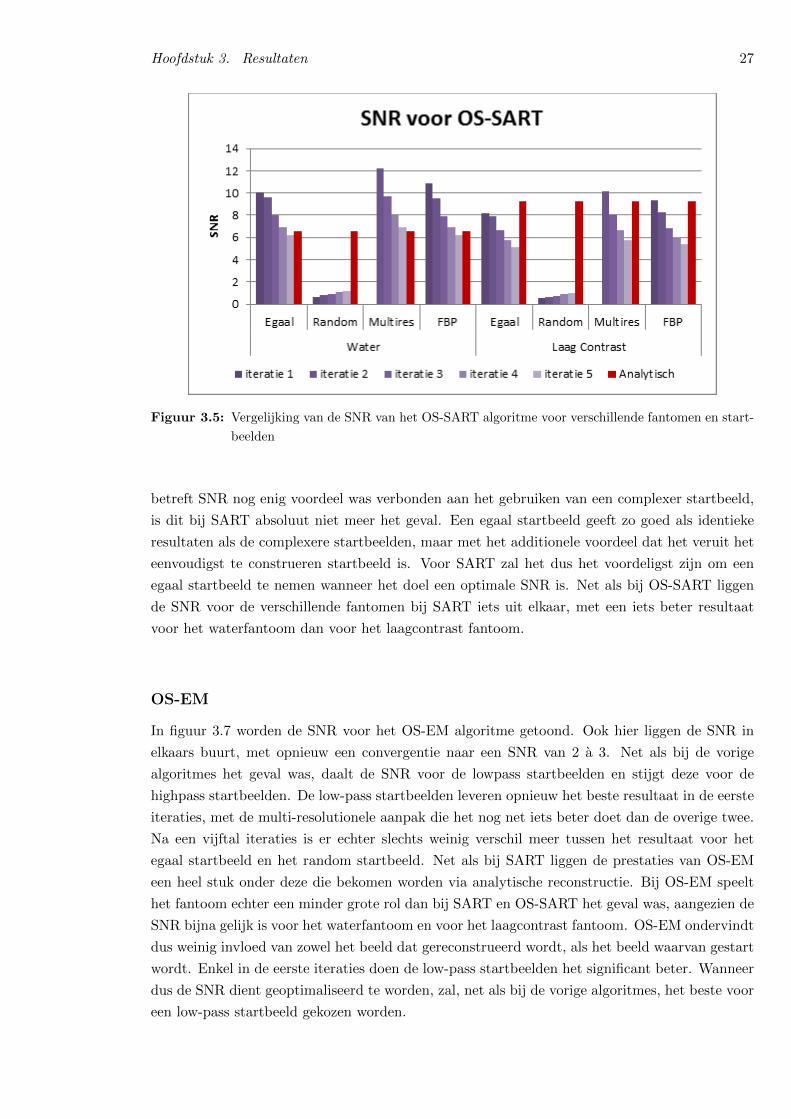
Hoofdstuk 3. Resultaten 27
Figuur 3.5: Vergelijking van de SNR van het OS-SART algoritme voor verschillende fantomen en start-
beelden
betreft SNR nog enig voordeel was verbonden aan het gebruiken van een complexer startbeeld,
is dit bij SART absoluut niet meer het geval. Een egaal startbeeld geeft zo goed als identieke
resultaten als de complexere startbeelden, maar met het additionele voordeel dat het veruit het
eenvoudigst te construeren startbeeld is. Voor SART zal het dus het voordeligst zijn om een
egaal startbeeld te nemen wanneer het doel een optimale SNR is. Net als bij OS-SART liggen
de SNR voor de verschillende fantomen bij SART iets uit elkaar, met een iets beter resultaat
voor het waterfantoom dan voor het laagcontrast fantoom.
OS-EM
In figuur 3.7 worden de SNR voor het OS-EM algoritme getoond. Ook hier liggen de SNR in
elkaars buurt, met opnieuw een convergentie naar een SNR van 2 a 3. Net als bij de vorige
algoritmes het geval was, daalt de SNR voor de lowpass startbeelden en stijgt deze voor de
highpass startbeelden. De low-pass startbeelden leveren opnieuw het beste resultaat in de eerste
iteraties, met de multi-resolutionele aanpak die het nog net iets beter doet dan de overige twee.
Na een vijftal iteraties is er echter slechts weinig verschil meer tussen het resultaat voor het
egaal startbeeld en het random startbeeld. Net als bij SART liggen de prestaties van OS-EM
een heel stuk onder deze die bekomen worden via analytische reconstructie. Bij OS-EM speelt
het fantoom echter een minder grote rol dan bij SART en OS-SART het geval was, aangezien de
SNR bijna gelijk is voor het waterfantoom en voor het laagcontrast fantoom. OS-EM ondervindt
dus weinig invloed van zowel het beeld dat gereconstrueerd wordt, als het beeld waarvan gestart
wordt. Enkel in de eerste iteraties doen de low-pass startbeelden het significant beter. Wanneer
dus de SNR dient geoptimaliseerd te worden, zal, net als bij de vorige algoritmes, het beste voor
een low-pass startbeeld gekozen worden.
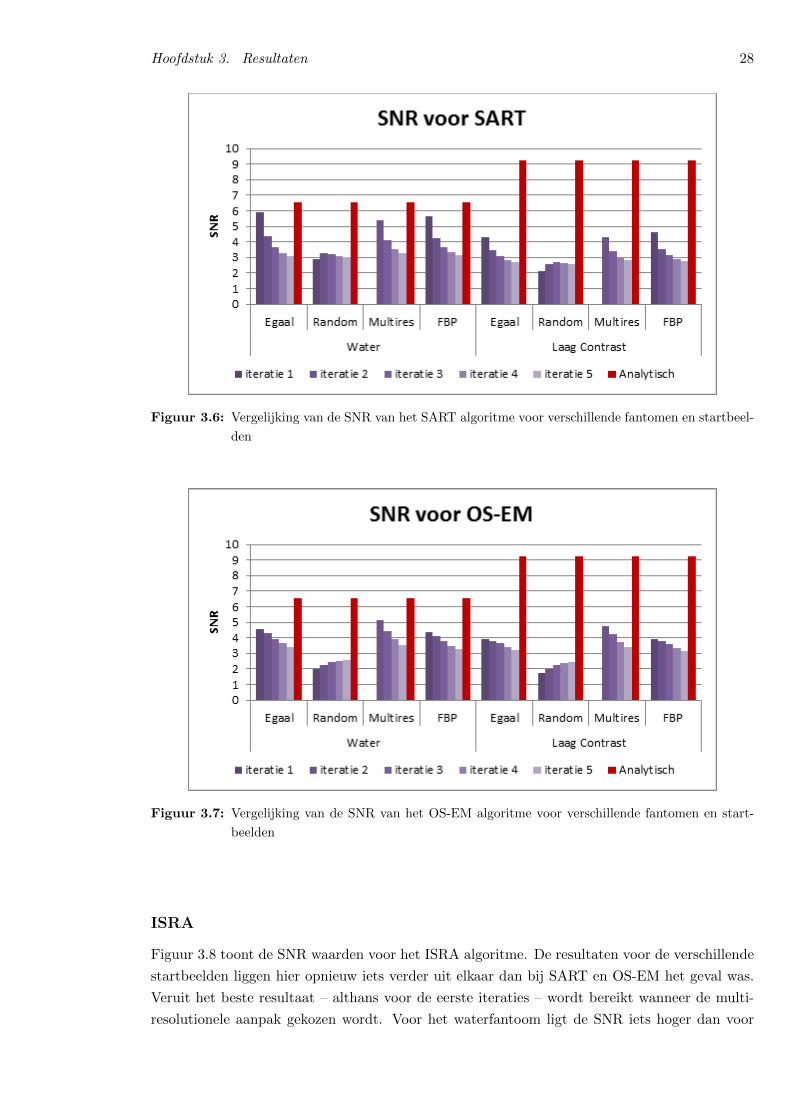
Hoofdstuk 3. Resultaten 28
Figuur 3.6: Vergelijking van de SNR van het SART algoritme voor verschillende fantomen en startbeel-
den
Figuur 3.7: Vergelijking van de SNR van het OS-EM algoritme voor verschillende fantomen en start-
beelden
ISRA
Figuur 3.8 toont de SNR waarden voor het ISRA algoritme. De resultaten voor de verschillende
startbeelden liggen hier opnieuw iets verder uit elkaar dan bij SART en OS-EM het geval was.
Veruit het beste resultaat – althans voor de eerste iteraties – wordt bereikt wanneer de multi-
resolutionele aanpak gekozen wordt. Voor het waterfantoom ligt de SNR iets hoger dan voor
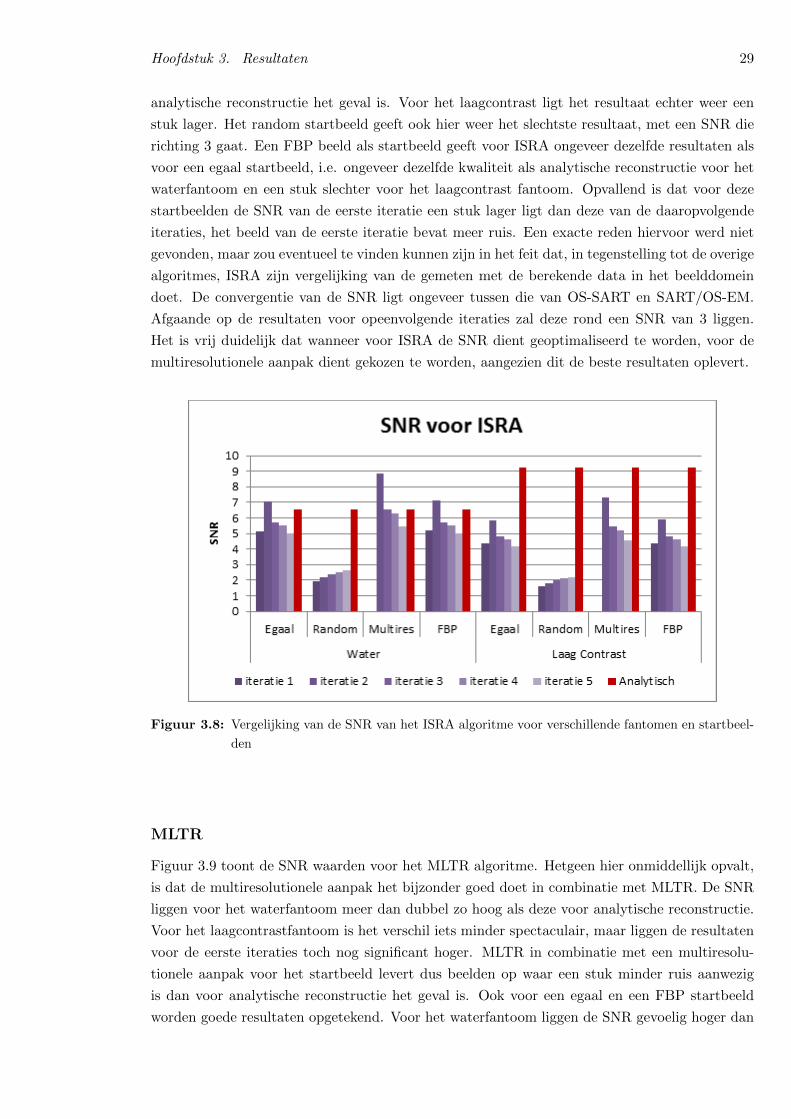
Hoofdstuk 3. Resultaten 29
analytische reconstructie het geval is. Voor het laagcontrast ligt het resultaat echter weer een
stuk lager. Het random startbeeld geeft ook hier weer het slechtste resultaat, met een SNR die
richting 3 gaat. Een FBP beeld als startbeeld geeft voor ISRA ongeveer dezelfde resultaten als
voor een egaal startbeeld, i.e. ongeveer dezelfde kwaliteit als analytische reconstructie voor het
waterfantoom en een stuk slechter voor het laagcontrast fantoom. Opvallend is dat voor deze
startbeelden de SNR van de eerste iteratie een stuk lager ligt dan deze van de daaropvolgende
iteraties, het beeld van de eerste iteratie bevat meer ruis. Een exacte reden hiervoor werd niet
gevonden, maar zou eventueel te vinden kunnen zijn in het feit dat, in tegenstelling tot de overige
algoritmes, ISRA zijn vergelijking van de gemeten met de berekende data in het beelddomein
doet. De convergentie van de SNR ligt ongeveer tussen die van OS-SART en SART/OS-EM.
Afgaande op de resultaten voor opeenvolgende iteraties zal deze rond een SNR van 3 liggen.
Het is vrij duidelijk dat wanneer voor ISRA de SNR dient geoptimaliseerd te worden, voor de
multiresolutionele aanpak dient gekozen te worden, aangezien dit de beste resultaten oplevert.
Figuur 3.8: Vergelijking van de SNR van het ISRA algoritme voor verschillende fantomen en startbeel-
den
MLTR
Figuur 3.9 toont de SNR waarden voor het MLTR algoritme. Hetgeen hier onmiddellijk opvalt,
is dat de multiresolutionele aanpak het bijzonder goed doet in combinatie met MLTR. De SNR
liggen voor het waterfantoom meer dan dubbel zo hoog als deze voor analytische reconstructie.
Voor het laagcontrastfantoom is het verschil iets minder spectaculair, maar liggen de resultaten
voor de eerste iteraties toch nog significant hoger. MLTR in combinatie met een multiresolu-
tionele aanpak voor het startbeeld levert dus beelden op waar een stuk minder ruis aanwezig
is dan voor analytische reconstructie het geval is. Ook voor een egaal en een FBP startbeeld
worden goede resultaten opgetekend. Voor het waterfantoom liggen de SNR gevoelig hoger dan
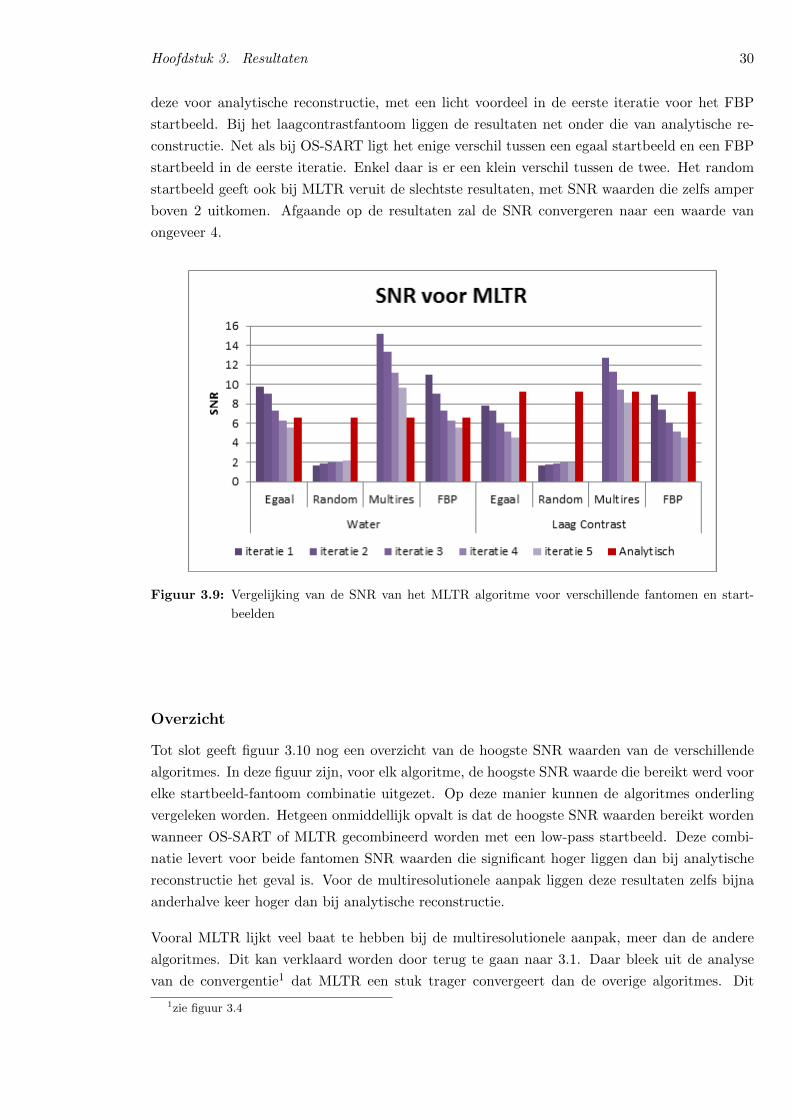
Hoofdstuk 3. Resultaten 30
deze voor analytische reconstructie, met een licht voordeel in de eerste iteratie voor het FBP
startbeeld. Bij het laagcontrastfantoom liggen de resultaten net onder die van analytische re-
constructie. Net als bij OS-SART ligt het enige verschil tussen een egaal startbeeld en een FBP
startbeeld in de eerste iteratie. Enkel daar is er een klein verschil tussen de twee. Het random
startbeeld geeft ook bij MLTR veruit de slechtste resultaten, met SNR waarden die zelfs amper
boven 2 uitkomen. Afgaande op de resultaten zal de SNR convergeren naar een waarde van
ongeveer 4.
Figuur 3.9: Vergelijking van de SNR van het MLTR algoritme voor verschillende fantomen en start-
beelden
Overzicht
Tot slot geeft figuur 3.10 nog een overzicht van de hoogste SNR waarden van de verschillende
algoritmes. In deze figuur zijn, voor elk algoritme, de hoogste SNR waarde die bereikt werd voor
elke startbeeld-fantoom combinatie uitgezet. Op deze manier kunnen de algoritmes onderling
vergeleken worden. Hetgeen onmiddellijk opvalt is dat de hoogste SNR waarden bereikt worden
wanneer OS-SART of MLTR gecombineerd worden met een low-pass startbeeld. Deze combi-
natie levert voor beide fantomen SNR waarden die significant hoger liggen dan bij analytische
reconstructie het geval is. Voor de multiresolutionele aanpak liggen deze resultaten zelfs bijna
anderhalve keer hoger dan bij analytische reconstructie.
Vooral MLTR lijkt veel baat te hebben bij de multiresolutionele aanpak, meer dan de andere
algoritmes. Dit kan verklaard worden door terug te gaan naar 3.1. Daar bleek uit de analyse
van de convergentie1 dat MLTR een stuk trager convergeert dan de overige algoritmes. Dit
1zie figuur 3.4

Hoofdstuk 3. Resultaten 31
Figuur 3.10: Vergelijking van de hoogste SNR waarden van de verschillende algoritmes voor de ver-
schillende startbeelden en fantomen.
houdt echter ook in dat MLTR veel minder snel ruis zal beginnen introduceren dan de overige
algoritmes. Dit effect wordt nog versterkt door het toepassen van de multiresolutionele aanpak,
waardoor de beelden die MLTR produceert veel meer low-pass zijn dan de beelden die de overige
algoritmes produceren. Dit zorgt er dan ook voor dat de SNR waarden hoger zullen liggen.
SART en OS-EM geven de minst goede resultaten over de verschillende fantomen en startbeelden
bekeken. Enkel voor het random startbeeld geven zij de beste resultaten, maar het verschil met
de andere algoritmes is bijna verwaarloosbaar. Voor al de overige combinaties van startbeeld met
fantoom zijn de SNR waarden slechts de helft van deze die OS-SART en MLTR opleveren. ISRA
geeft voor de low-pass startbeelden ongeveer dezelfde resultaten als analytische reconstructie.
Dit is dus net iets minder goed dan OS-SART en MLTR, maar toch aanvaardbaar wat betreft
ruis.
Uit figuur 3.10 blijkt ook dat er geen enkel algoritme is dat het echt goed doet voor een random
startbeeld. De maximale SNR waarden die voor een random startbeeld bereikt kunnen worden
bedragen slechts een derde tot, in het slechtste geval, een vijfde van de maximale waarden die
met de overige startbeelden kunnen bekomen worden. Er kan dus veilig besloten worden dat,
wanneer een goede SNR belangrijk is, een random startbeeld geen goede keuze zal zijn. De
beste keuze voor een goede SNR is OS-SART of MLTR in combinatie met de multiresolutionele
aanpak voor het startbeeld.
De afbeeldingen 3.11 tot 3.14 bevestigen deze resultaten visueel. Het is duidelijk dat zelfs
het beste resultaat voor een random startbeeld – afbeelding 3.13 – nog steeds veel meer ruis
bevat dan de analytische reconstructie – afbeelding 3.11. Aan de andere kant zijn OS-SART –
afbeelding 3.14 – en vooral MLTR – afbeelding 3.12 – met multiresolutioneel startbeeld een stuk
minder ruizig dan analytische reconstructie. MLTR geeft een bijna perfect egaal watervolume,
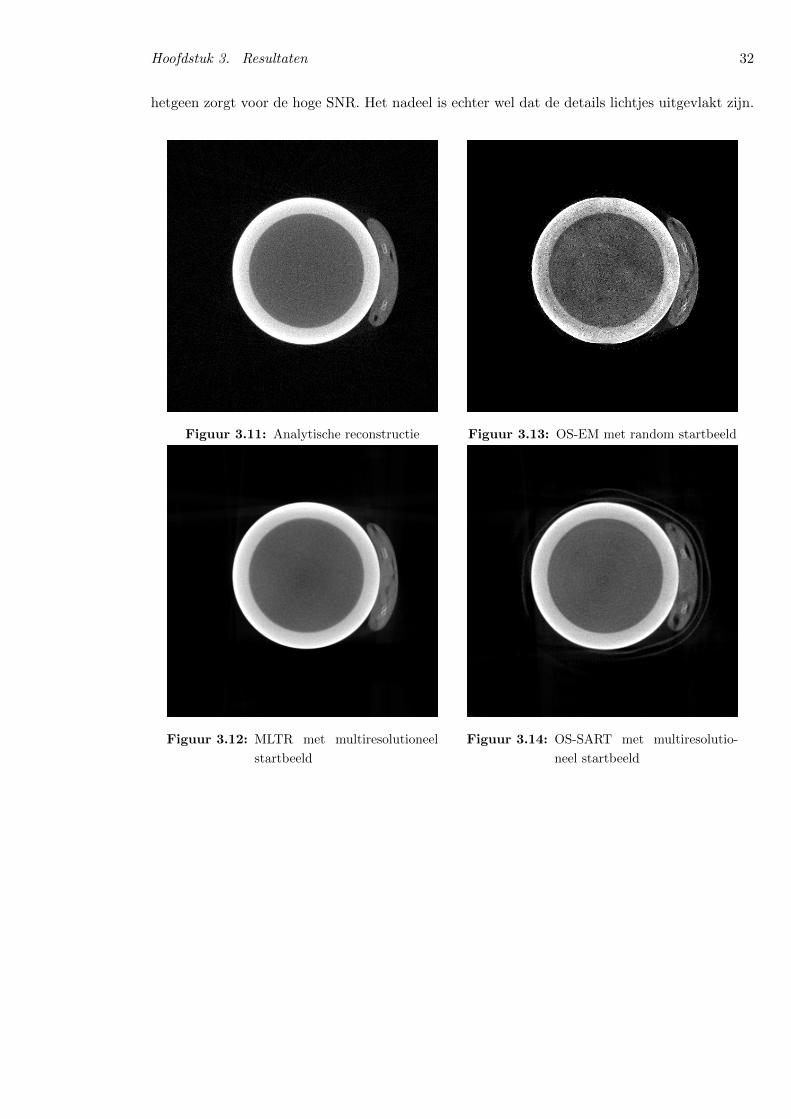
Hoofdstuk 3. Resultaten 32
hetgeen zorgt voor de hoge SNR. Het nadeel is echter wel dat de details lichtjes uitgevlakt zijn.
Figuur 3.11: Analytische reconstructie
Figuur 3.12: MLTR met multiresolutioneel
startbeeld
Figuur 3.13: OS-EM met random startbeeld
Figuur 3.14: OS-SART met multiresolutio-
neel startbeeld
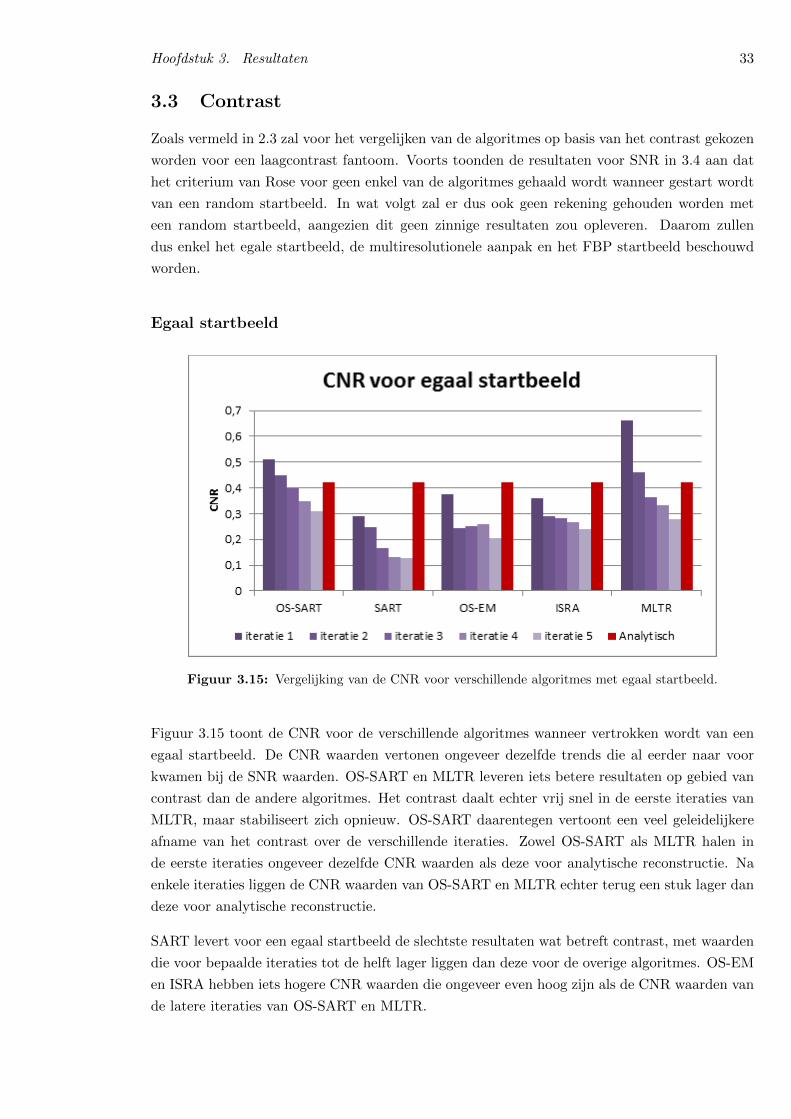
Hoofdstuk 3. Resultaten 33
3.3 Contrast
Zoals vermeld in 2.3 zal voor het vergelijken van de algoritmes op basis van het contrast gekozen
worden voor een laagcontrast fantoom. Voorts toonden de resultaten voor SNR in 3.4 aan dat
het criterium van Rose voor geen enkel van de algoritmes gehaald wordt wanneer gestart wordt
van een random startbeeld. In wat volgt zal er dus ook geen rekening gehouden worden met
een random startbeeld, aangezien dit geen zinnige resultaten zou opleveren. Daarom zullen
dus enkel het egale startbeeld, de multiresolutionele aanpak en het FBP startbeeld beschouwd
worden.
Egaal startbeeld
Figuur 3.15: Vergelijking van de CNR voor verschillende algoritmes met egaal startbeeld.
Figuur 3.15 toont de CNR voor de verschillende algoritmes wanneer vertrokken wordt van een
egaal startbeeld. De CNR waarden vertonen ongeveer dezelfde trends die al eerder naar voor
kwamen bij de SNR waarden. OS-SART en MLTR leveren iets betere resultaten op gebied van
contrast dan de andere algoritmes. Het contrast daalt echter vrij snel in de eerste iteraties van
MLTR, maar stabiliseert zich opnieuw. OS-SART daarentegen vertoont een veel geleidelijkere
afname van het contrast over de verschillende iteraties. Zowel OS-SART als MLTR halen in
de eerste iteraties ongeveer dezelfde CNR waarden als deze voor analytische reconstructie. Na
enkele iteraties liggen de CNR waarden van OS-SART en MLTR echter terug een stuk lager dan
deze voor analytische reconstructie.
SART levert voor een egaal startbeeld de slechtste resultaten wat betreft contrast, met waarden
die voor bepaalde iteraties tot de helft lager liggen dan deze voor de overige algoritmes. OS-EM
en ISRA hebben iets hogere CNR waarden die ongeveer even hoog zijn als de CNR waarden van
de latere iteraties van OS-SART en MLTR.
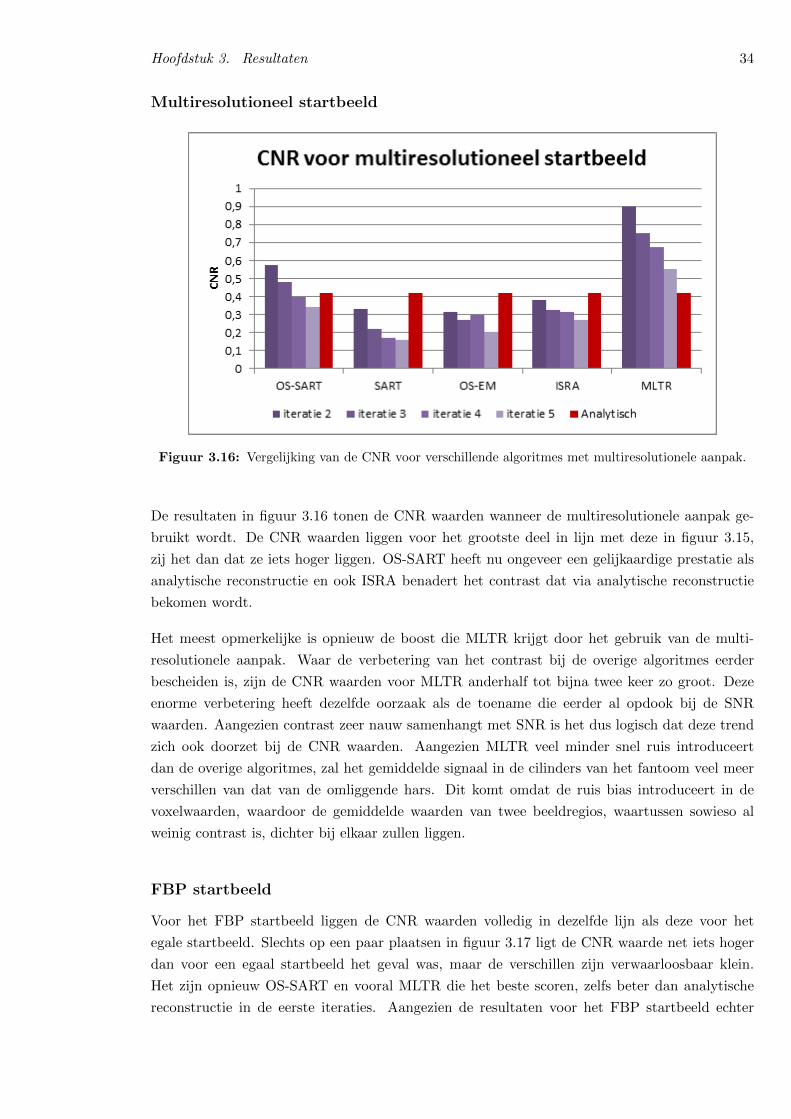
Hoofdstuk 3. Resultaten 34
Multiresolutioneel startbeeld
Figuur 3.16: Vergelijking van de CNR voor verschillende algoritmes met multiresolutionele aanpak.
De resultaten in figuur 3.16 tonen de CNR waarden wanneer de multiresolutionele aanpak ge-
bruikt wordt. De CNR waarden liggen voor het grootste deel in lijn met deze in figuur 3.15,
zij het dan dat ze iets hoger liggen. OS-SART heeft nu ongeveer een gelijkaardige prestatie als
analytische reconstructie en ook ISRA benadert het contrast dat via analytische reconstructie
bekomen wordt.
Het meest opmerkelijke is opnieuw de boost die MLTR krijgt door het gebruik van de multi-
resolutionele aanpak. Waar de verbetering van het contrast bij de overige algoritmes eerder
bescheiden is, zijn de CNR waarden voor MLTR anderhalf tot bijna twee keer zo groot. Deze
enorme verbetering heeft dezelfde oorzaak als de toename die eerder al opdook bij de SNR
waarden. Aangezien contrast zeer nauw samenhangt met SNR is het dus logisch dat deze trend
zich ook doorzet bij de CNR waarden. Aangezien MLTR veel minder snel ruis introduceert
dan de overige algoritmes, zal het gemiddelde signaal in de cilinders van het fantoom veel meer
verschillen van dat van de omliggende hars. Dit komt omdat de ruis bias introduceert in de
voxelwaarden, waardoor de gemiddelde waarden van twee beeldregios, waartussen sowieso al
weinig contrast is, dichter bij elkaar zullen liggen.
FBP startbeeld
Voor het FBP startbeeld liggen de CNR waarden volledig in dezelfde lijn als deze voor het
egale startbeeld. Slechts op een paar plaatsen in figuur 3.17 ligt de CNR waarde net iets hoger
dan voor een egaal startbeeld het geval was, maar de verschillen zijn verwaarloosbaar klein.
Het zijn opnieuw OS-SART en vooral MLTR die het beste scoren, zelfs beter dan analytische
reconstructie in de eerste iteraties. Aangezien de resultaten voor het FBP startbeeld echter
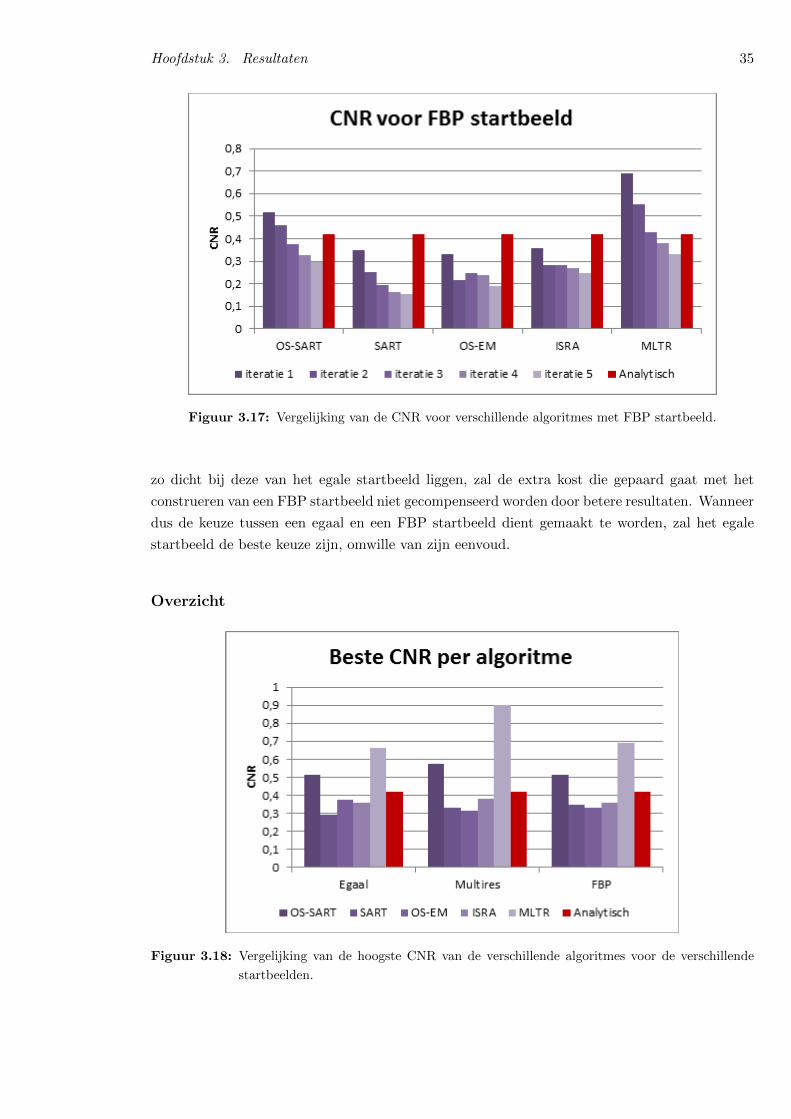
Hoofdstuk 3. Resultaten 35
Figuur 3.17: Vergelijking van de CNR voor verschillende algoritmes met FBP startbeeld.
zo dicht bij deze van het egale startbeeld liggen, zal de extra kost die gepaard gaat met het
construeren van een FBP startbeeld niet gecompenseerd worden door betere resultaten. Wanneer
dus de keuze tussen een egaal en een FBP startbeeld dient gemaakt te worden, zal het egale
startbeeld de beste keuze zijn, omwille van zijn eenvoud.
Overzicht
Figuur 3.18: Vergelijking van de hoogste CNR van de verschillende algoritmes voor de verschillende
startbeelden.

Hoofdstuk 3. Resultaten 36
Figuur 3.18 geeft tot slot een vergelijking van de beste CNR die elk algoritme weet te bereiken
voor elk startbeeld. Het valt niet te betwisten dat OS-SART en MLTR veruit de beste resul-
taten geven waar het contrast betreft. Beide presteren voor alle drie de startbeelden beter dan
analytische reconstructie. Het allerbeste resultaat wordt bekomen wanneer MLTR gecombineerd
wordt met de multiresolutionele aanpak. Deze combinatie presteert op gebied van contrast dub-
bel zo goed als analytische reconstructie. Het minst goede resultaat wordt geleverd door SART,
OS-EM en ISRA. Het beste resultaat voor deze algoritmes ligt iets onder dat voor analytische
reconstructie, ongeacht het startbeeld waarvan vertrokken wordt.
De afbeeldingen 3.19 tot 3.22 geven een visuele representatie van de resultaten. Afbeelding
3.21 die de reconstructie met SART voorsteld, is gevoelig ruiziger dan de overige afbeeldingen.
De cilinder op basis waarvan het contrast gemeten wordt, is nog amper te onderscheiden op
de reconstructie. Er is dus zo goed als geen contrast. Bij MLTR en OS-SART daarentegen,
zijn de cilinders vrij duidelijk te onderscheiden. Ook hier is de afbeelding voor MLTR lichtjes
uitgevlakt, al valt het minder op dan bij het water fantoom. Aan de andere kant is er wel weer
minder ruis aanwezig dan voor analytische reconstructie het geval is. De afbeeldingen bevestigen
dus de resultaten die hierboven bekomen werden.
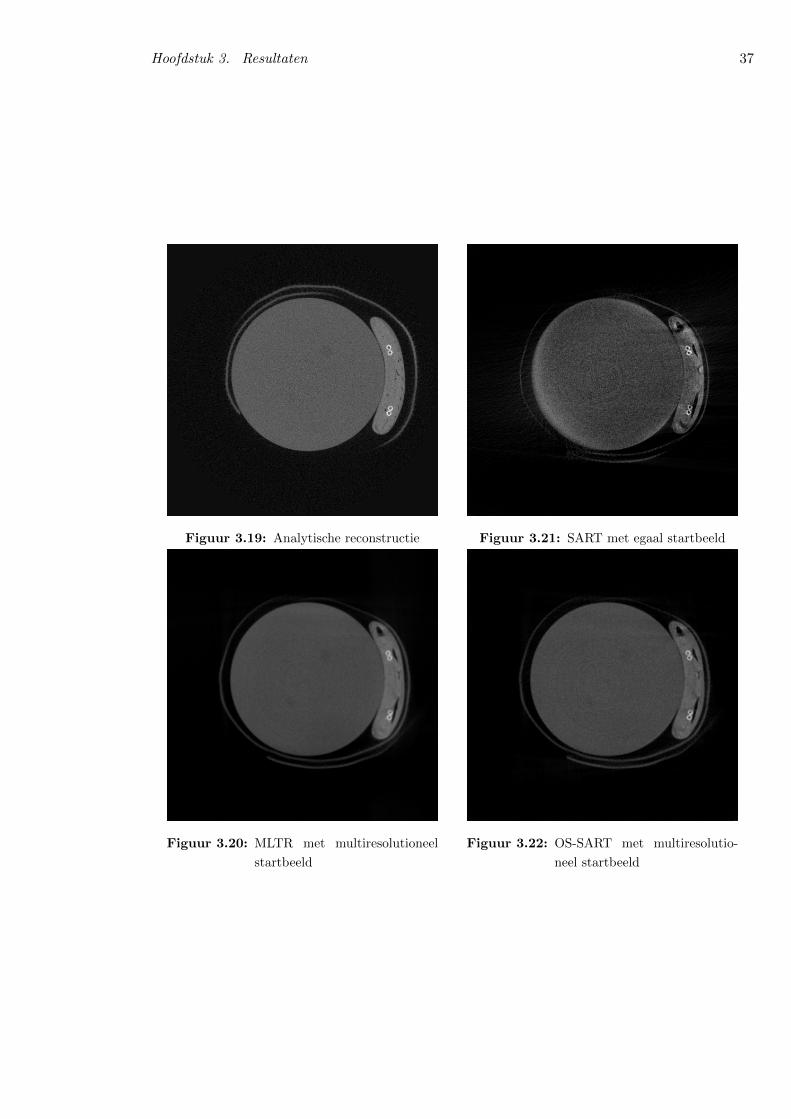
Hoofdstuk 3. Resultaten 37
Figuur 3.19: Analytische reconstructie
Figuur 3.20: MLTR met multiresolutioneel
startbeeld
Figuur 3.21: SART met egaal startbeeld
Figuur 3.22: OS-SART met multiresolutio-
neel startbeeld
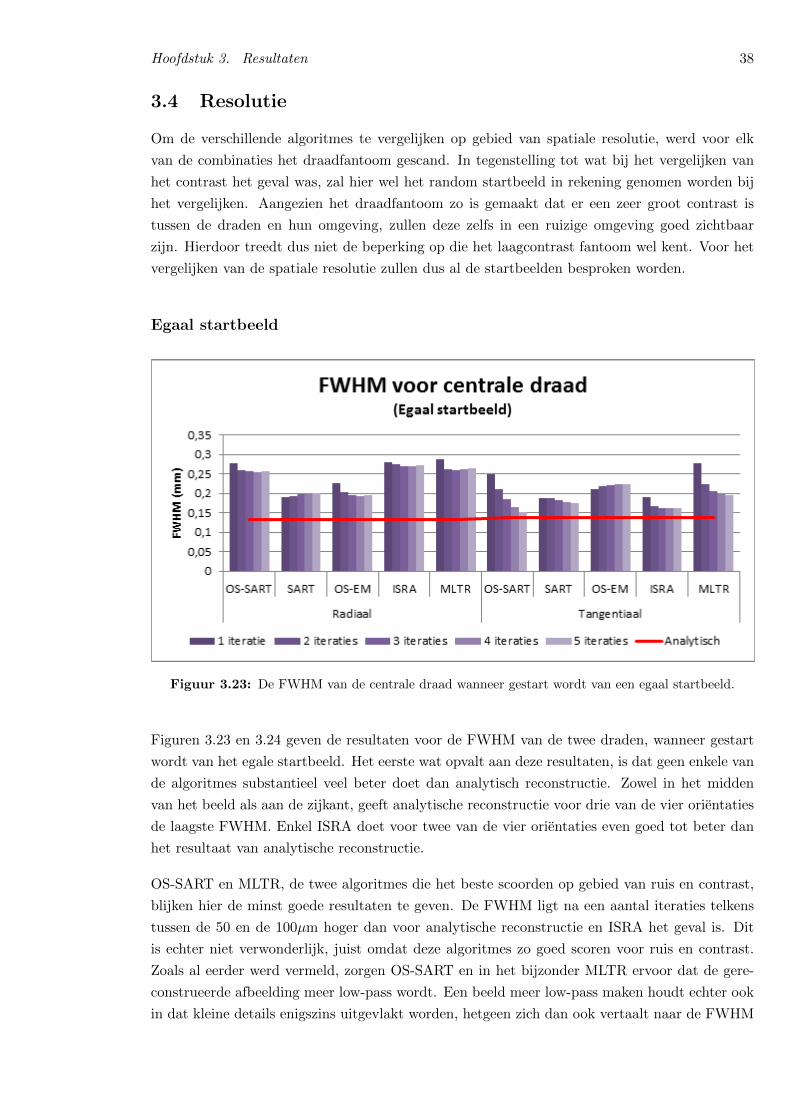
Hoofdstuk 3. Resultaten 38
3.4 Resolutie
Om de verschillende algoritmes te vergelijken op gebied van spatiale resolutie, werd voor elk
van de combinaties het draadfantoom gescand. In tegenstelling tot wat bij het vergelijken van
het contrast het geval was, zal hier wel het random startbeeld in rekening genomen worden bij
het vergelijken. Aangezien het draadfantoom zo is gemaakt dat er een zeer groot contrast is
tussen de draden en hun omgeving, zullen deze zelfs in een ruizige omgeving goed zichtbaar
zijn. Hierdoor treedt dus niet de beperking op die het laagcontrast fantoom wel kent. Voor het
vergelijken van de spatiale resolutie zullen dus al de startbeelden besproken worden.
Egaal startbeeld
Figuur 3.23: De FWHM van de centrale draad wanneer gestart wordt van een egaal startbeeld.
Figuren 3.23 en 3.24 geven de resultaten voor de FWHM van de twee draden, wanneer gestart
wordt van het egale startbeeld. Het eerste wat opvalt aan deze resultaten, is dat geen enkele van
de algoritmes substantieel veel beter doet dan analytisch reconstructie. Zowel in het midden
van het beeld als aan de zijkant, geeft analytische reconstructie voor drie van de vier orientaties
de laagste FWHM. Enkel ISRA doet voor twee van de vier orientaties even goed tot beter dan
het resultaat van analytische reconstructie.
OS-SART en MLTR, de twee algoritmes die het beste scoorden op gebied van ruis en contrast,
blijken hier de minst goede resultaten te geven. De FWHM ligt na een aantal iteraties telkens
tussen de 50 en de 100µm hoger dan voor analytische reconstructie en ISRA het geval is. Dit
is echter niet verwonderlijk, juist omdat deze algoritmes zo goed scoren voor ruis en contrast.
Zoals al eerder werd vermeld, zorgen OS-SART en in het bijzonder MLTR ervoor dat de gere-
construeerde afbeelding meer low-pass wordt. Een beeld meer low-pass maken houdt echter ook
in dat kleine details enigszins uitgevlakt worden, hetgeen zich dan ook vertaalt naar de FWHM
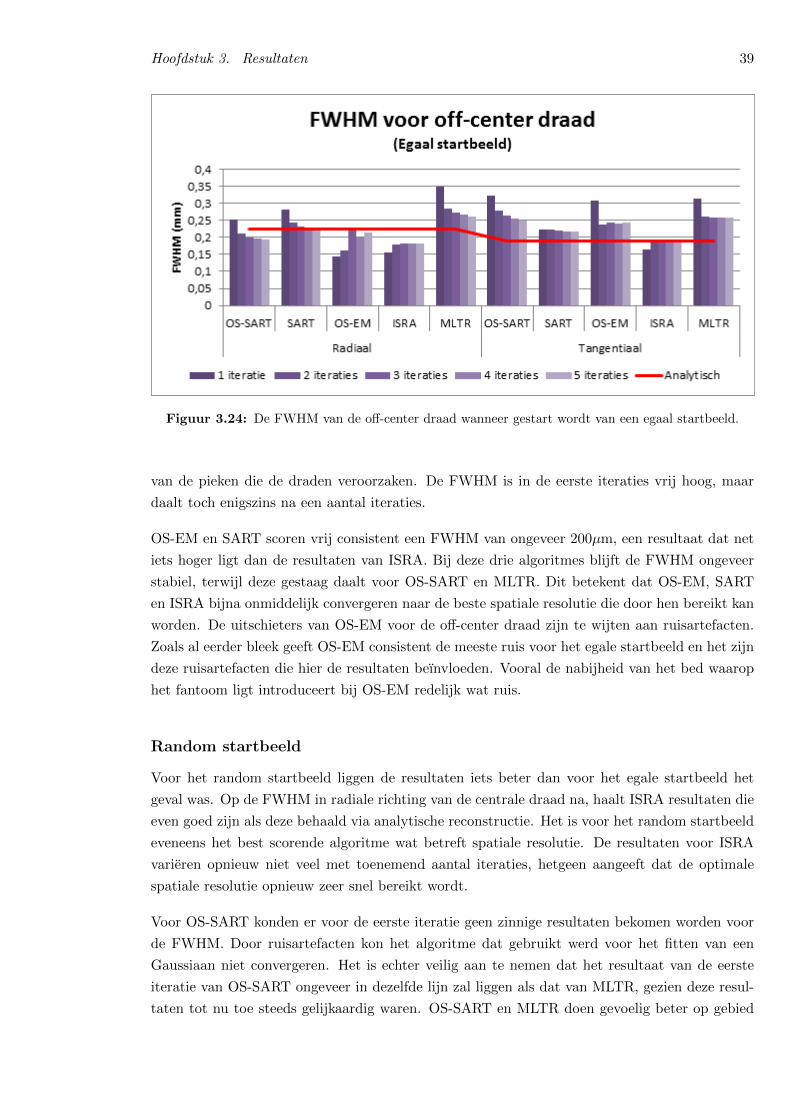
Hoofdstuk 3. Resultaten 39
Figuur 3.24: De FWHM van de off-center draad wanneer gestart wordt van een egaal startbeeld.
van de pieken die de draden veroorzaken. De FWHM is in de eerste iteraties vrij hoog, maar
daalt toch enigszins na een aantal iteraties.
OS-EM en SART scoren vrij consistent een FWHM van ongeveer 200µm, een resultaat dat net
iets hoger ligt dan de resultaten van ISRA. Bij deze drie algoritmes blijft de FWHM ongeveer
stabiel, terwijl deze gestaag daalt voor OS-SART en MLTR. Dit betekent dat OS-EM, SART
en ISRA bijna onmiddelijk convergeren naar de beste spatiale resolutie die door hen bereikt kan
worden. De uitschieters van OS-EM voor de off-center draad zijn te wijten aan ruisartefacten.
Zoals al eerder bleek geeft OS-EM consistent de meeste ruis voor het egale startbeeld en het zijn
deze ruisartefacten die hier de resultaten beınvloeden. Vooral de nabijheid van het bed waarop
het fantoom ligt introduceert bij OS-EM redelijk wat ruis.
Random startbeeld
Voor het random startbeeld liggen de resultaten iets beter dan voor het egale startbeeld het
geval was. Op de FWHM in radiale richting van de centrale draad na, haalt ISRA resultaten die
even goed zijn als deze behaald via analytische reconstructie. Het is voor het random startbeeld
eveneens het best scorende algoritme wat betreft spatiale resolutie. De resultaten voor ISRA
varieren opnieuw niet veel met toenemend aantal iteraties, hetgeen aangeeft dat de optimale
spatiale resolutie opnieuw zeer snel bereikt wordt.
Voor OS-SART konden er voor de eerste iteratie geen zinnige resultaten bekomen worden voor
de FWHM. Door ruisartefacten kon het algoritme dat gebruikt werd voor het fitten van een
Gaussiaan niet convergeren. Het is echter veilig aan te nemen dat het resultaat van de eerste
iteratie van OS-SART ongeveer in dezelfde lijn zal liggen als dat van MLTR, gezien deze resul-
taten tot nu toe steeds gelijkaardig waren. OS-SART en MLTR doen gevoelig beter op gebied
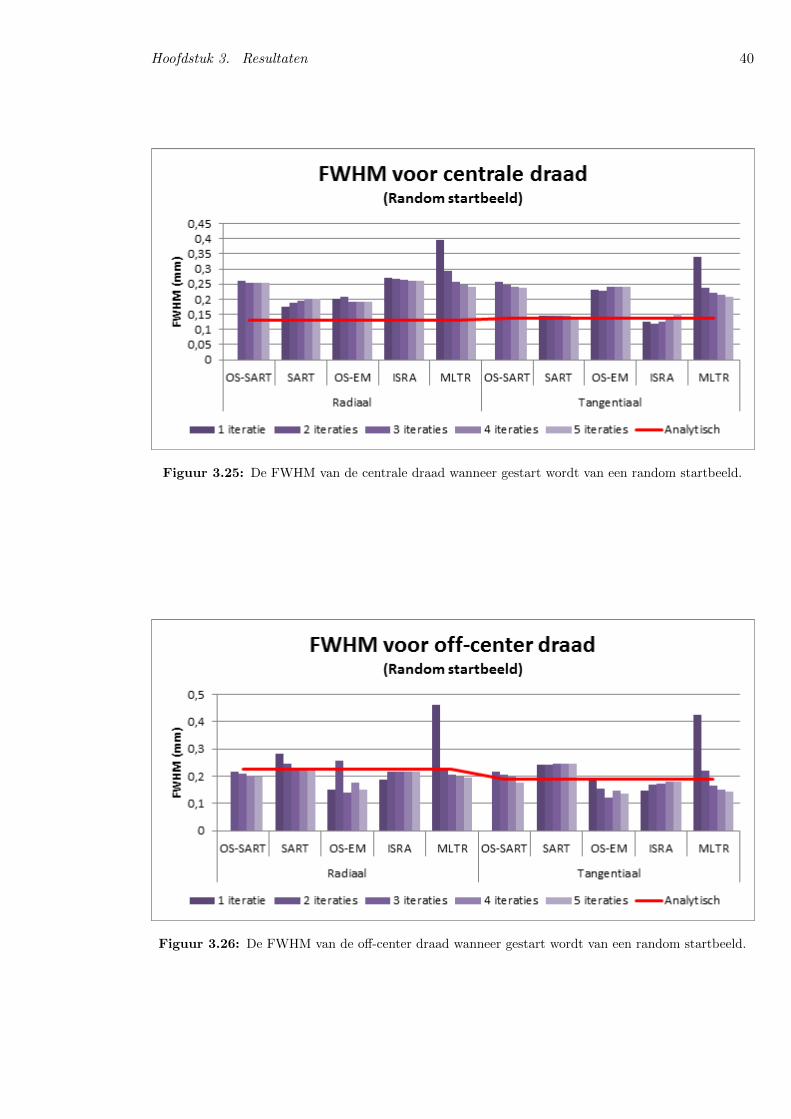
Hoofdstuk 3. Resultaten 40
Figuur 3.25: De FWHM van de centrale draad wanneer gestart wordt van een random startbeeld.
Figuur 3.26: De FWHM van de off-center draad wanneer gestart wordt van een random startbeeld.

Hoofdstuk 3. Resultaten 41
van spatiale resolutie wanneer gekozen wordt voor een random startbeeld, dan wanneer voor het
egale gekozen wordt. Na een tweetal iteraties liggen de resultaten aan de rand zelfs in dezelfde
lijn als de resultaten die via ISRA bekomen worden. Aangezien een random startbeeld high-pass
is, zal het in dit geval eenvoudiger zijn voor OS-SART en MLTR om de high-pass pieken van de
twee draden in het fantoom te genereren.
SART scoort voor een random startbeeld in het midden van de afbeelding gevoelig beter dan
aan de zijkanten. In het centrum heeft SART een gelijkaardige spatiale resolutie als analytische
reconstructie en in de radiale richting scoort het zelfs beter dan ISRA. Bij OS-EM doet zich
de omgekeerde trend voor; hier is het beeld centraal net iets minder goed dan aan de rand.
De oorzaak hiervoor kan echter opnieuw gevonden worden wanneer de ruis in rekening gebracht
wordt. De resultaten voor de off-center draad bij OS-EM varieren net als bij het egale startbeeld
redelijk veel aangezien het beeld aan de rand vrij ruizig is, door de nabijheid van het bed.
Multiresolutionele aanpak
Figuur 3.27: De FWHM van de centrale draad wanneer gebruik gemaakt wordt van de multiresolutio-
nele aanpak.
De multiresolutionele aanpak bleek eerder al bijzonder effectief om een goede SNR en CNR
te verkrijgen door de beelden lichtjes uit te vlakken. Het is dus logisch dat figuren 3.27 en
3.28 een FWHM tonen die overal lichtjes hoger liggen dan bij een random of egaal startbeeld
het geval was. SART, OS-EM en vooral ISRA zijn opnieuw de best scorende algoritmes wat
betreft spatiale resolutie, terwijl ook OS-SART het voor de off-center draad niet slecht doet. De
FWHM van deze algoritmes ligt boven dat van analytische reconstructie voor de centrale draad
en ongeveer gelijk, tot zelfs iets lager voor ISRA en OS-EM, voor de off-center draad.
OS-SART en MLTR, de algoritmes die opnieuw iets slechter scoren, hebben opnieuw duidelijk
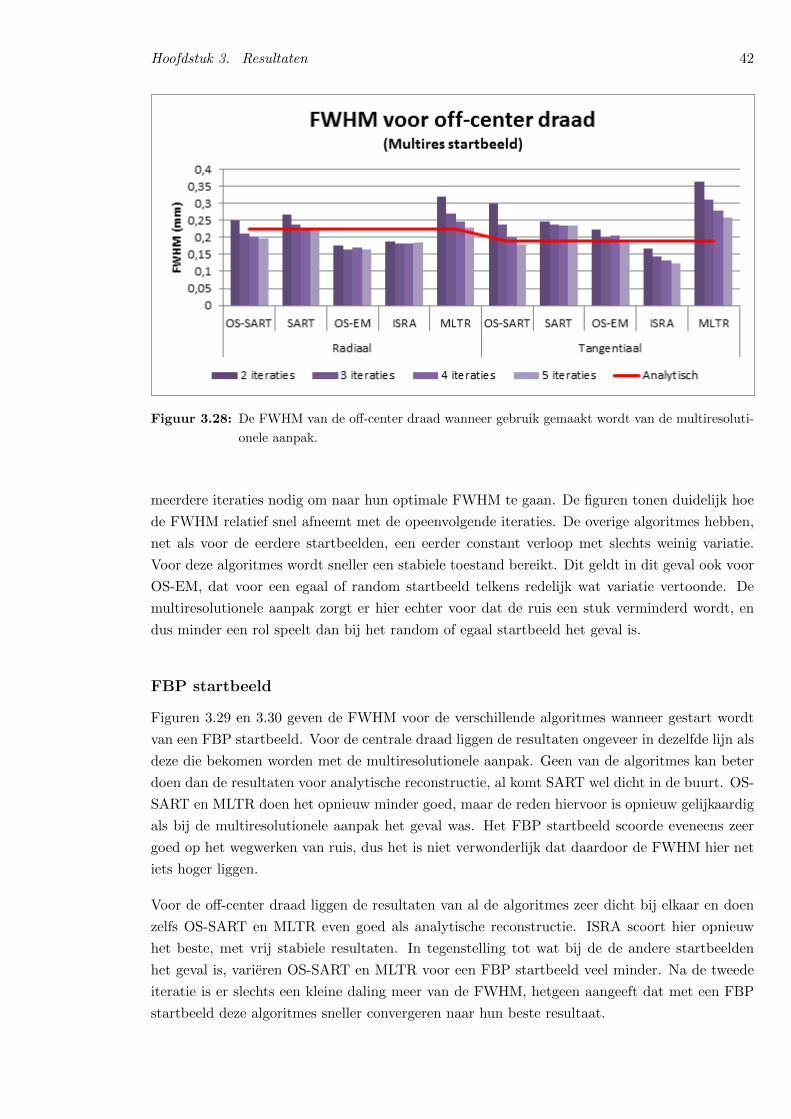
Hoofdstuk 3. Resultaten 42
Figuur 3.28: De FWHM van de off-center draad wanneer gebruik gemaakt wordt van de multiresoluti-
onele aanpak.
meerdere iteraties nodig om naar hun optimale FWHM te gaan. De figuren tonen duidelijk hoe
de FWHM relatief snel afneemt met de opeenvolgende iteraties. De overige algoritmes hebben,
net als voor de eerdere startbeelden, een eerder constant verloop met slechts weinig variatie.
Voor deze algoritmes wordt sneller een stabiele toestand bereikt. Dit geldt in dit geval ook voor
OS-EM, dat voor een egaal of random startbeeld telkens redelijk wat variatie vertoonde. De
multiresolutionele aanpak zorgt er hier echter voor dat de ruis een stuk verminderd wordt, en
dus minder een rol speelt dan bij het random of egaal startbeeld het geval is.
FBP startbeeld
Figuren 3.29 en 3.30 geven de FWHM voor de verschillende algoritmes wanneer gestart wordt
van een FBP startbeeld. Voor de centrale draad liggen de resultaten ongeveer in dezelfde lijn als
deze die bekomen worden met de multiresolutionele aanpak. Geen van de algoritmes kan beter
doen dan de resultaten voor analytische reconstructie, al komt SART wel dicht in de buurt. OS-
SART en MLTR doen het opnieuw minder goed, maar de reden hiervoor is opnieuw gelijkaardig
als bij de multiresolutionele aanpak het geval was. Het FBP startbeeld scoorde eveneens zeer
goed op het wegwerken van ruis, dus het is niet verwonderlijk dat daardoor de FWHM hier net
iets hoger liggen.
Voor de off-center draad liggen de resultaten van al de algoritmes zeer dicht bij elkaar en doen
zelfs OS-SART en MLTR even goed als analytische reconstructie. ISRA scoort hier opnieuw
het beste, met vrij stabiele resultaten. In tegenstelling tot wat bij de de andere startbeelden
het geval is, varieren OS-SART en MLTR voor een FBP startbeeld veel minder. Na de tweede
iteratie is er slechts een kleine daling meer van de FWHM, hetgeen aangeeft dat met een FBP
startbeeld deze algoritmes sneller convergeren naar hun beste resultaat.
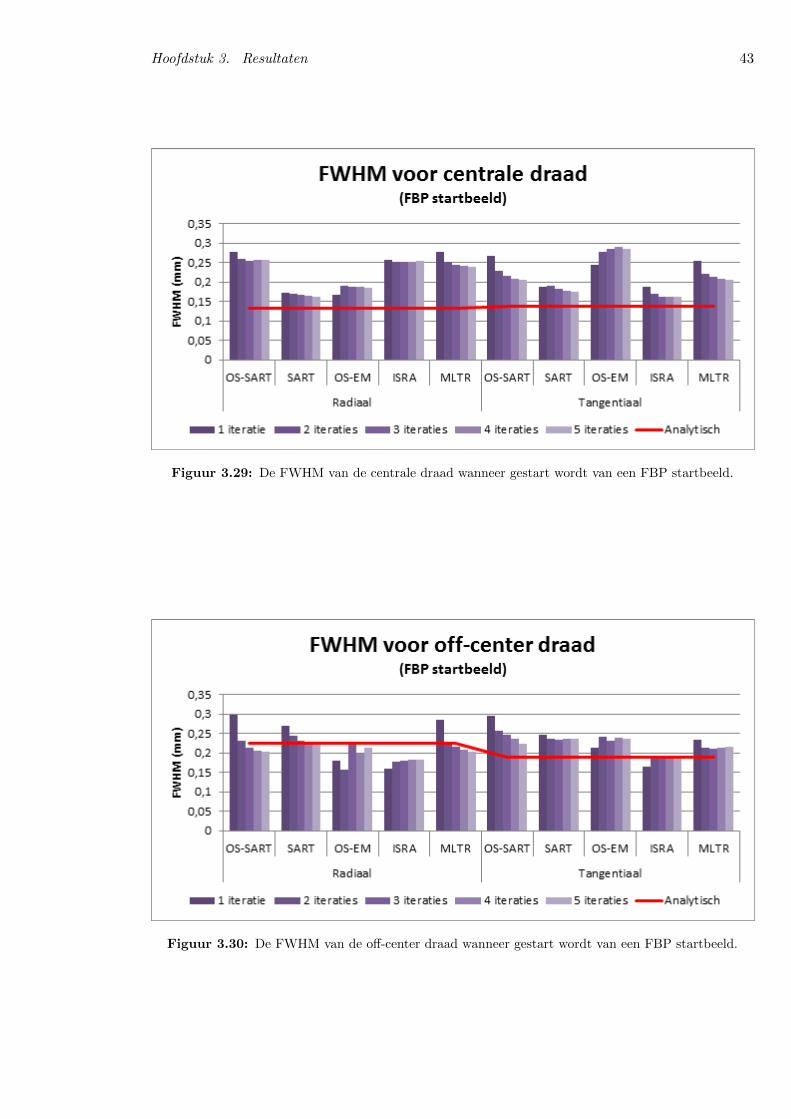
Hoofdstuk 3. Resultaten 43
Figuur 3.29: De FWHM van de centrale draad wanneer gestart wordt van een FBP startbeeld.
Figuur 3.30: De FWHM van de off-center draad wanneer gestart wordt van een FBP startbeeld.

Hoofdstuk 3. Resultaten 44
Overzicht
Tot slot geven figuren 3.31 en 3.32 de beste FWHM die door de verschillende algoritmes gehaald
worden voor de verschillende startbeelden. Op de radiale richting van de centrale draad na,
geeft ISRA het beste resultaat voor de spatiale resolutie, met resultaten die voor de centrale
draad in de buurt liggen van analytische reconstructie en voor de off-center draad zelfs een stuk
beter zijn. SART geeft voor de centrale draad de beste resultaten, even goed als deze van ISRA.
Voor de off-center draad liggen de resultaten voor SART echter iets minder goed en meer in de
lijn van de resultaten die OS-SART en MLTR leveren. Ook OS-EM scoort op bepaalde plaatsen
vrij goed, maar heeft door z’n hoge ruisgehalte vrij veel variatie in zijn resultaten. De beste
scores van OS-SART en MLTR zijn vrij stabiel over de verschillende orientaties, maar liggen
gemiddeld toch een kleine 50 a 100 µm hoger dan de resultaten bekomen met ISRA. Dit lijkt
veel te zijn, maar als er in acht genomen wordt dat de voxelgrootte 120 µm bedraagt, zal het
visuele verschil slechts zeer beperkt zijn.
De afbeeldingen 3.33 tot 3.36 geven de visuele representatie van enkele resultaten. Voor het
eerst kan hier een discrepantie opgemerkt worden tussen de analytische resultaten en de visuele
representatie. Hoewel zowel ISRA als OS-EM redelijk goed scoren wat betreft FWHM, zijn hun
respectievelijke afbeeldingen – 3.35 en 3.36 – toch niet overdreven duidelijk. De draden zijn dan
wel ongeveer even scherp als bij de analytische reconstructie op afbeelding 3.33, de rest van de
afbeelding is echter een heel stuk ruiziger. Dit komt doordat het aantal iteraties dat nodig is om
de optimale spatiale resolutie te verkrijgen, overeenstemmen met iteraties die een redelijk lage
SNR hadden. Hierdoor is de afbeelding die na 5 iteraties via MLTR bekomen wordt – afbeelding
3.34 – een heel stuk duidelijker, ondanks het feit dat de FWHM aan de hoge kant is. De stippen
op de afbeelding die overeen komen met de tungsten draden in het fantoom, zijn net iets breder
dan voor analytische reconstructie het geval is, maar dit valt amper op te maken uit de figuur.
ISRA mag dus dan wel de theoretisch beste resultaten geven, de ruis speelt echter een dusdanig
grote rol, dat de details verloren gaan.
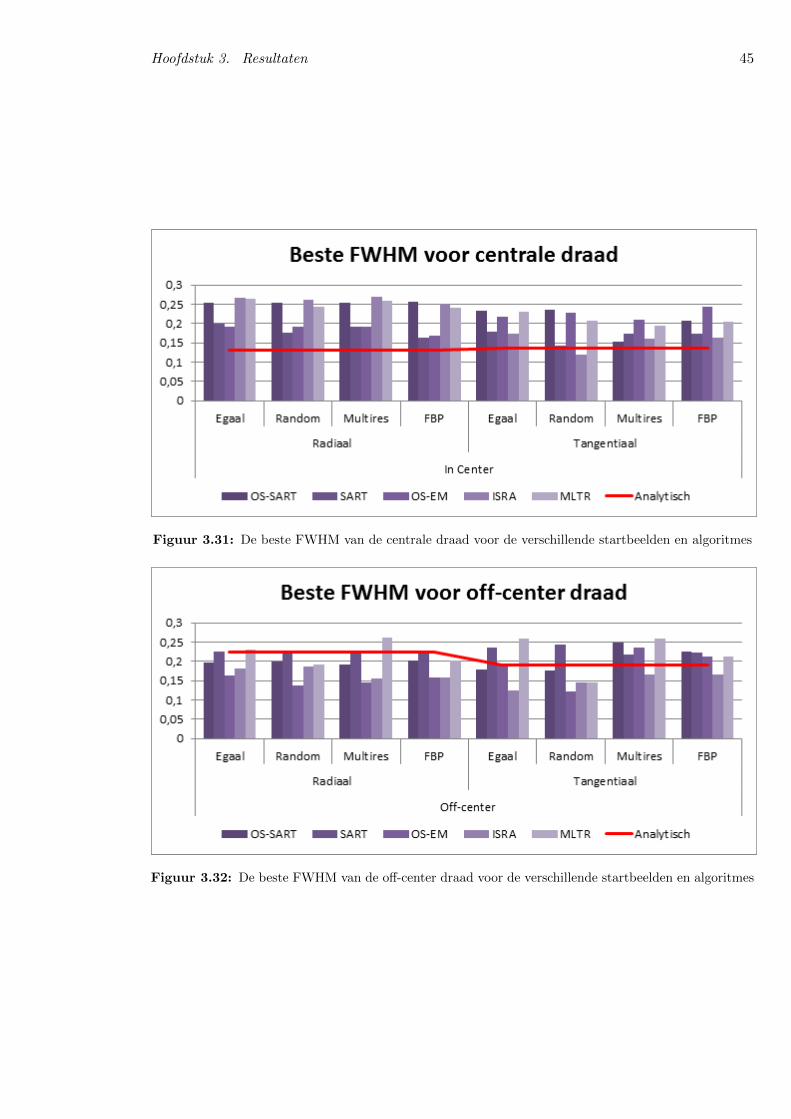
Hoofdstuk 3. Resultaten 45
Figuur 3.31: De beste FWHM van de centrale draad voor de verschillende startbeelden en algoritmes
Figuur 3.32: De beste FWHM van de off-center draad voor de verschillende startbeelden en algoritmes
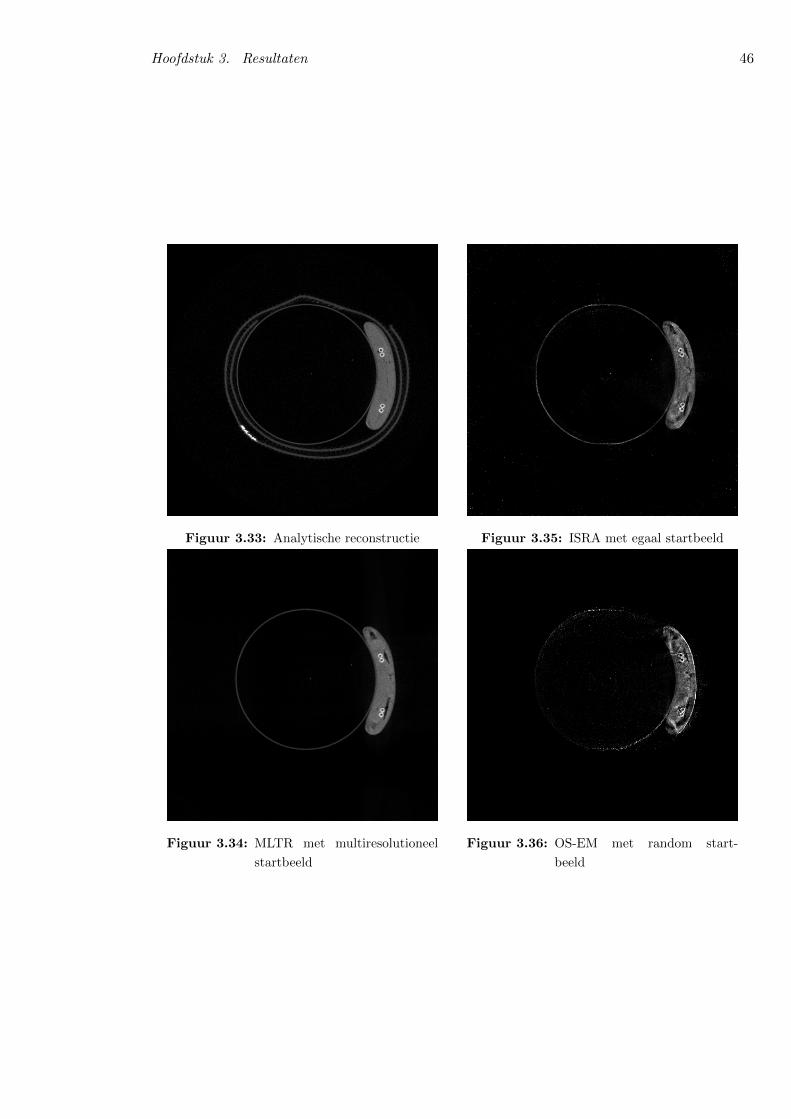
Hoofdstuk 3. Resultaten 46
Figuur 3.33: Analytische reconstructie
Figuur 3.34: MLTR met multiresolutioneel
startbeeld
Figuur 3.35: ISRA met egaal startbeeld
Figuur 3.36: OS-EM met random start-
beeld
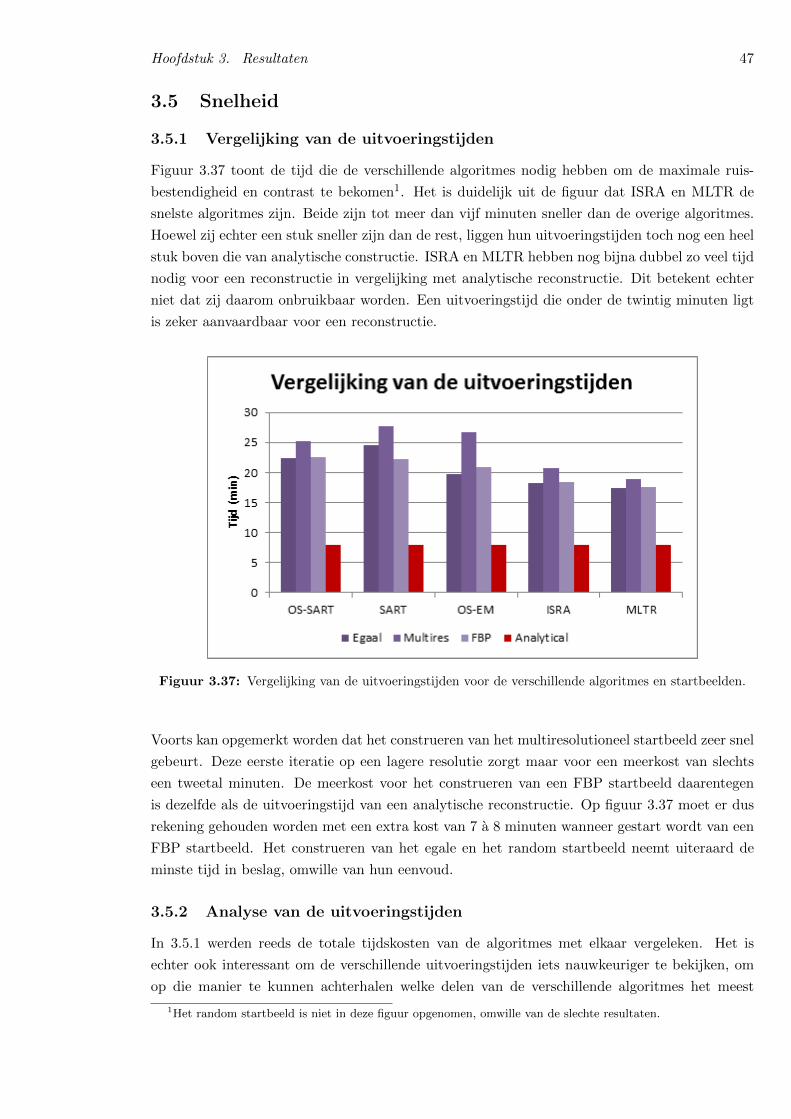
Hoofdstuk 3. Resultaten 47
3.5 Snelheid
3.5.1 Vergelijking van de uitvoeringstijden
Figuur 3.37 toont de tijd die de verschillende algoritmes nodig hebben om de maximale ruis-
bestendigheid en contrast te bekomen1. Het is duidelijk uit de figuur dat ISRA en MLTR de
snelste algoritmes zijn. Beide zijn tot meer dan vijf minuten sneller dan de overige algoritmes.
Hoewel zij echter een stuk sneller zijn dan de rest, liggen hun uitvoeringstijden toch nog een heel
stuk boven die van analytische constructie. ISRA en MLTR hebben nog bijna dubbel zo veel tijd
nodig voor een reconstructie in vergelijking met analytische reconstructie. Dit betekent echter
niet dat zij daarom onbruikbaar worden. Een uitvoeringstijd die onder de twintig minuten ligt
is zeker aanvaardbaar voor een reconstructie.
Figuur 3.37: Vergelijking van de uitvoeringstijden voor de verschillende algoritmes en startbeelden.
Voorts kan opgemerkt worden dat het construeren van het multiresolutioneel startbeeld zeer snel
gebeurt. Deze eerste iteratie op een lagere resolutie zorgt maar voor een meerkost van slechts
een tweetal minuten. De meerkost voor het construeren van een FBP startbeeld daarentegen
is dezelfde als de uitvoeringstijd van een analytische reconstructie. Op figuur 3.37 moet er dus
rekening gehouden worden met een extra kost van 7 a 8 minuten wanneer gestart wordt van een
FBP startbeeld. Het construeren van het egale en het random startbeeld neemt uiteraard de
minste tijd in beslag, omwille van hun eenvoud.
3.5.2 Analyse van de uitvoeringstijden
In 3.5.1 werden reeds de totale tijdskosten van de algoritmes met elkaar vergeleken. Het is
echter ook interessant om de verschillende uitvoeringstijden iets nauwkeuriger te bekijken, om
op die manier te kunnen achterhalen welke delen van de verschillende algoritmes het meest
1Het random startbeeld is niet in deze figuur opgenomen, omwille van de slechte resultaten.
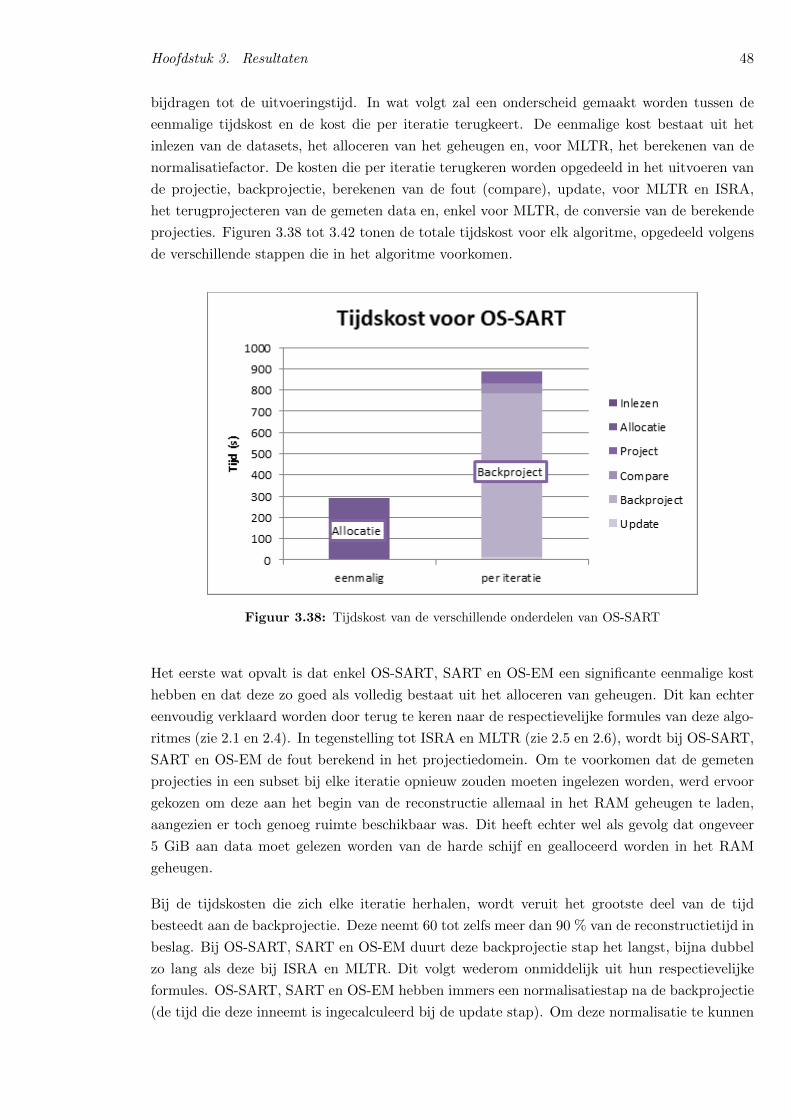
Hoofdstuk 3. Resultaten 48
bijdragen tot de uitvoeringstijd. In wat volgt zal een onderscheid gemaakt worden tussen de
eenmalige tijdskost en de kost die per iteratie terugkeert. De eenmalige kost bestaat uit het
inlezen van de datasets, het alloceren van het geheugen en, voor MLTR, het berekenen van de
normalisatiefactor. De kosten die per iteratie terugkeren worden opgedeeld in het uitvoeren van
de projectie, backprojectie, berekenen van de fout (compare), update, voor MLTR en ISRA,
het terugprojecteren van de gemeten data en, enkel voor MLTR, de conversie van de berekende
projecties. Figuren 3.38 tot 3.42 tonen de totale tijdskost voor elk algoritme, opgedeeld volgens
de verschillende stappen die in het algoritme voorkomen.
Figuur 3.38: Tijdskost van de verschillende onderdelen van OS-SART
Het eerste wat opvalt is dat enkel OS-SART, SART en OS-EM een significante eenmalige kost
hebben en dat deze zo goed als volledig bestaat uit het alloceren van geheugen. Dit kan echter
eenvoudig verklaard worden door terug te keren naar de respectievelijke formules van deze algo-
ritmes (zie 2.1 en 2.4). In tegenstelling tot ISRA en MLTR (zie 2.5 en 2.6), wordt bij OS-SART,
SART en OS-EM de fout berekend in het projectiedomein. Om te voorkomen dat de gemeten
projecties in een subset bij elke iteratie opnieuw zouden moeten ingelezen worden, werd ervoor
gekozen om deze aan het begin van de reconstructie allemaal in het RAM geheugen te laden,
aangezien er toch genoeg ruimte beschikbaar was. Dit heeft echter wel als gevolg dat ongeveer
5 GiB aan data moet gelezen worden van de harde schijf en gealloceerd worden in het RAM
geheugen.
Bij de tijdskosten die zich elke iteratie herhalen, wordt veruit het grootste deel van de tijd
besteedt aan de backprojectie. Deze neemt 60 tot zelfs meer dan 90 % van de reconstructietijd in
beslag. Bij OS-SART, SART en OS-EM duurt deze backprojectie stap het langst, bijna dubbel
zo lang als deze bij ISRA en MLTR. Dit volgt wederom onmiddelijk uit hun respectievelijke
formules. OS-SART, SART en OS-EM hebben immers een normalisatiestap na de backprojectie
(de tijd die deze inneemt is ingecalculeerd bij de update stap). Om deze normalisatie te kunnen
Hoofdstuk 3. Resultaten 49
Figuur 3.39: Tijdskost van de verschillende onderdelen van SART
Figuur 3.40: Tijdskost van de verschillende onderdelen van OS-EM
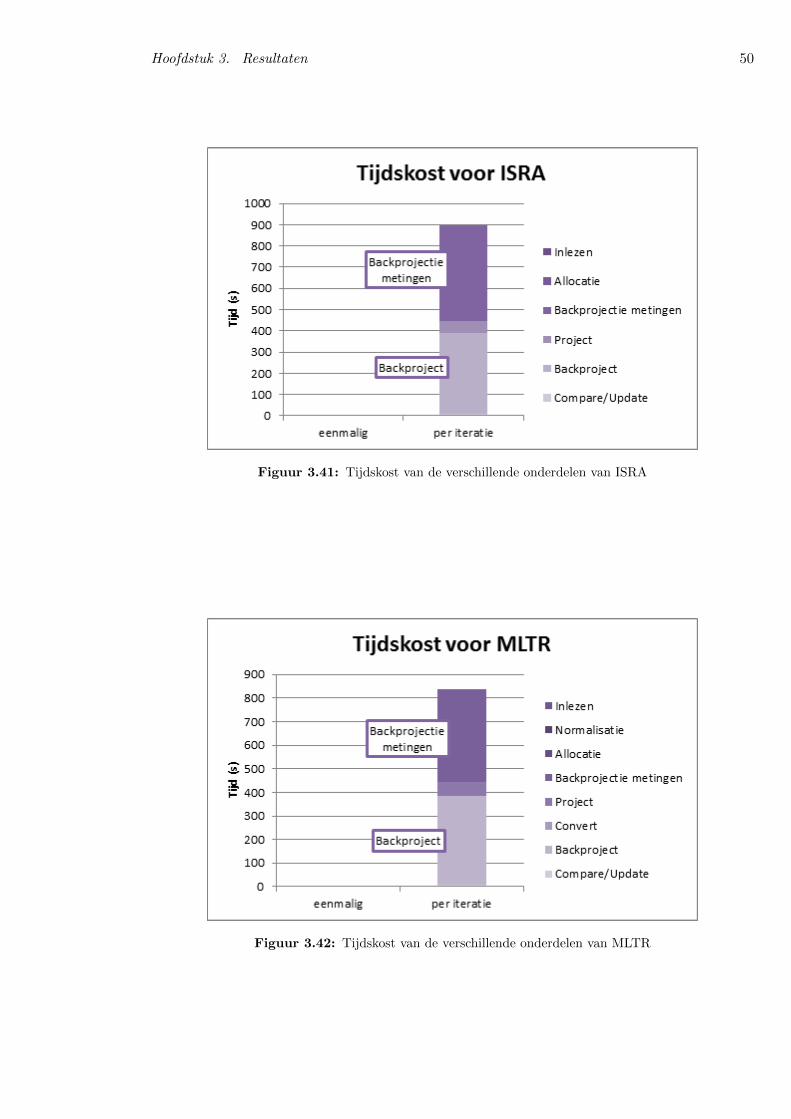
Hoofdstuk 3. Resultaten 50
Figuur 3.41: Tijdskost van de verschillende onderdelen van ISRA
Figuur 3.42: Tijdskost van de verschillende onderdelen van MLTR

Hoofdstuk 3. Resultaten 51
uitvoeren, moet echter tijdens de backprojectie ook al deze normalisatiecoefficienten berekend
worden. Het is het berekenen van deze coefficienten dat verantwoordelijk is voor het verschil
in tijd. Dit verschil wordt echter gecompenseerd doordat zowel MLTR als ISRA twee maal
een backprojectie moeten uitvoeren; een keer op de gemeten data en een keer op de berekende
data. In principe zou de backprojectie van de gemeten data op voorhand kunnen berekend
worden. Echter, zoals eerder al vermeld werd in 1.3.2, neemt een afbeelding ongeveer 512 MiB
in beslag. Aangezien zo’n afbeelding moet berekend worden per subset en er gewerkt wordt
met 256 subsets, zouden al deze afbeeldingen 128 GiB in beslag nemen. Dit is onhandelbaar
veel data, vandaar de keuze om de backprojectie van elke subset telkens te gaan herberekenen.
Wanneer echter gewerkt zou worden met 1 enkele subset die alle projecties bevat, is het wel
doenbaar om de backprojectie op voorhand te berekenen. Mits gebruik van een grafische kaart
met nog net iets meer on-board geheugen1, zou het zelfs mogelijk zijn om MLTR en ISRA
volledig te laten draaien op de GPU.
Er kan dus geconcludeerd worden dat de backprojectie nog het meeste ruimte heeft voor op-
timalisatie. Deze stap neemt veruit het meeste tijd in beslag en het optimaliseren ervan zal
dan ook de grootste impact hebben op de uitvoeringstijd. Voorts kunnen ISRA en MLTR nog
enorm versneld worden, door de terugkerende kost van het berekenen van de backprojectie van
de gemeten data te veranderen in een eenmalige kost.
1Een andere mogelijkheid zou zijn om het aantal projecties iets te verlagen, aangezien dan geheugen vrijkomt
dat gebruikt wordt voor het berekenen van de projecties.

Hoofdstuk 4
Conclusie
4.1 Bespreking van de algoritmes
OS-SART
OS-SART is een van de algoritmes die zeer goed presteert op het gebied van ruis en con-
trast. Voor beide parameters geeft het de op een na beste resultaten –beter dan analytische
reconstructie– gesteld dat vertrokken wordt van een low-pass startbeeld. Wanneer gestart wordt
van een random startbeeld daarentegen, liggen de resultaten een heel stuk lager. Op gebied van
spatiale resolutie is OS-SART een van de algoritmes die het het slechtste doen. Ongeacht het
startbeeld waarvan vertrokken wordt, levert OS-SART consequent een van de hoogste FWHM.
Ook qua snelheid behoort OS-SART niet tot de beste algoritmes, met voor zowat elk startbeeld
een uitvoeringstijd die toch enkele minuten verschilt met deze van het snelste algoritme.
SART
SART doet het een stuk minder goed dan OS-SART waar het ruis en contrast betreft. Enkel voor
het random startbeeld geeft SART het beste resultaat voor ruisbestendigheid, maar aangezien
de SNR voor dit startbeeld sowieso al een heel stuk onder deze van de overige startbeelden ligt,
is dit amper een overwinning te noemen. Op gebied van spatiale resolutie doet SART het iets
beter, met de beste FWHM voor de centrale draad van het fantoom. Voor de off-center draad
behoort het algoritme echter weer tot de minder goede resultaten en ook zijn uitvoeringstijd is
verscheidene minuten trager dan deze van de snellere algoritmes.
OS-EM
OS-EM kan zowat beschouwd worden als het minst goede algoritme dat in dit werk aan bod
kwam. Het scoort op geen enkele parameter echt goed en levert vaak zelfs de slechtste resultaten.
Enkel de spatiale resolutie geeft voor een paar combinaties goede resultaten, maar dit wordt
grotendeels teniet gedaan door de hoge ruis. Qua tijd is OS-EM ongeveer even snel als OS-
SART, dus ook enkele minuten trager dan het snelste algoritme.
52

Hoofdstuk 4. Conclusie 53
ISRA
ISRA scoort vrij goed all-round, met vooral uitstekende resultaten voor spatiale resolutie. Het
is het enige algoritme dat voor deze parameter ongeveer dezelfde resultaten kan opleveren als
analytische reconstructie voor de centrale draad en significant betere resultaten voor de off-
center draad. Het contrast en de ruisgevoeligheid van ISRA zijn zeker niet de beste, maar
liggen toch ongeveer in de lijn van de analytische reconstructie. Wanneer gestart wordt van
een multiresolutioneel startbeeld zijn de resultaten voor ruis en contrast zelfs net iets beter dan
analytische reconstructie. Ook qua uitvoeringstijd doet ISRA het lang niet slecht met voor elk
startbeeld de op een na beste tijd. Hier komt nog eens bij dat ISRA nog redelijk wat marge
heeft voor optimalisatie van de uitvoeringstijd.
MLTR
MLTR is met voorsprong het beste algoritme voor ruis en contrast. In het bijzonder in combi-
natie met een multiresolutioneel startbeeld haalt MLTR resultaten die dubbel zo hoog liggen als
deze van analytische reconstructie en nog een derde hoger dan deze van OS-SART. MLTR heeft
ook de snelste uitvoeringstijd met, net als ISRA, nog redelijk wat marge voor optimalisatie.
Enkel bij de spatiale resolutie scoort MLTR minder goed, met resultaten die gemiddeld toch een
50-tal µm hoger liggen dan het beste resultaat.
4.2 Eindbeschouwing
Uit dit werk kunnen een aantal duidelijke trends afgeleid worden. Allereerst kan gesteld worden
dat low-pass startbeelden ruim te verkiezen zijn boven high-pass startbeelden, in het bijzonder
in het geval van ruis en contrast. Het FBP startbeeld en zeker het multiresolutioneel startbeeld
geven de algoritmes een redelijke verbetering voor ruis en contrast. Als er echter tussen die twee
gekozen dient te worden, gaat de voorkeur uiteraard uit naar het multi-resolutionele startbeeld,
aangezien dit een heel stuk sneller te genereren valt dan een FBP startbeeld. Voor spatiale
resolutie hebben de startbeelden blijkbaar veel minder invloed op de resultaten.
Bij de algoritmes zijn er twee die beter presteren dan de rest: ISRA en MLTR. Beide zijn
ongeveer even snel en hebben elk hun specialisatie. Wanneer ruisbestendigheid en contrast van
belang zijn, zal MLTR in combinatie met het multiresolutionele startbeeld veruit de beste keuze
zijn, met resultaten die analytische reconstructie ver achter zich laten. ISRA presteert dan weer
goed op gebied van spatiale resolutie. Centraal in de reconstructie is de spatiale resolutie van
ISRA ongeveer even goed als deze van analytische reconstructie en aan de rand is ze net iets
beter. De goede spatiale resolutie wordt echter overschaduwd door de slechte ruisbestendigheid.
Tijdens het aantal iteraties dat nodig is voor een goede spatiale resolutie wordt zodanig veel
ruis geıntroduceerd dat MLTR, dat een minder goede spatiale resolutie heeft, visueel een stuk
beter oogt.
De uitvoeringstijden liggen nog steeds dubbel zo hoog als bij analytische reconstructie het geval
is, maar ze zijn niet meer onhandelbaar groot. Een 15 a 20 minuten voor een reconstructie van
ISRA en MLTR is zeker aanvaardbaar. In het bijzonder wanneer er rekening mee gehouden wordt

Hoofdstuk 4. Conclusie 54
dat de performantie van beide algoritmes nog ruimte heeft voor verbetering. In het bijzonder de
backprojecties, die afhankelijk van het algoritme 60 tot 90% van de reconstructietijd in beslag
nemen, kunnen nog verbeterd worden. Desondanks kunnen iteratieve reconstructietechnieken
in de toekomst zeker als valabel alternatief beschouwd worden voor analytische reconstructie.

Bibliografie
[1] J. Radon, “Uber die Bestimmung von Funktionen durch ihre Integralwerte langs gewisser
Mannigfaltigkeiten,” Berichte uber die Verhandlungen der Sachsische Akademie der Wis-
senschaften, vol. 69, pp. 262 – 277, 1917.
[2] J. Radon, “On the determination of functions from their integral values along certain ma-
nifolds,” IEEE Trans. Med. Imag, vol. 5, pp. 170 –176, dec. 1986.
[3] A. Beer, “Bestimmung der Absorption des rothen Lichts in farbigen Flussigkeiten,” Annalen
der Physik und Chemie, vol. 86, pp. 78–88, 1852.
[4] J. Lambert, Photometria sive de mensura et gradibus luminis, colorum et umbrae. 1760.
[5] R. A. Brooks and G. D. Chiro, “Beam hardening in x-ray reconstructive tomography,”
Physics in Medicine and Biology, vol. 21, no. 3, p. 390, 1976.
[6] K. Ramakrishna, K. Muralidhar, and P. Munshi, “Beam-hardening in simulated x-ray to-
mography,” NDT E International, vol. 39, no. 6, pp. 449–457, 2006.
[7] D. W. Holdsworth and M. M. Thornton, “Micro-CT in small animal and specimen imaging,”
Trends in biotechnology, vol. 20, no. 8, pp. S34–S39, 2002.
[8] C. T. Badea, M. Drangova, D. W. Holdsworth, and G. A. Johnson, “In Vivo Small Animal
Imaging using Micro-CT and Digital Subtraction Angiography,” Physics in Medicine and
biology, vol. 53, no. 19, pp. R319–, 2008.
[9] N. L. Ford, M. M. Thornton, and D. W. Holdsworth, “Fundamental Image Quality Limits
for Microcomputed Tomography in Small Animals.,” Med Phys, vol. 30, no. 11, pp. 2869–77,
2003.
[10] S. Vandenberghe, H. Hallez, R. Declerck, and J. Cornelis, Biomedical Signals and Images.
2009.
[11] L. A. Feldkamp, L. C. Davis, and J. W. Kress, “Practical cone-beam algorithm,” J. Opt.
Soc. Am. A, vol. 1, pp. 612–619, June 1984.
[12] D. Parker, “Optimal short scan convolution reconstruction for fan beam CT,” Med Phys,
vol. 9, pp. 254–257, 1982.
[13] M. N. Wernick and J. N. Aarsvold, Emission Tomography, The Fundamentals of PET and
SPECT. Elsevier, 2004.
55

Bibliografie 56
[14] Q. Huang, Z. Huang, P. Werstein, and M. Purvis, “GPU as a General Purpose Computing
Resource,” in Parallel and Distributed Computing, Applications and Technologies, 2008.
PDCAT 2008. Ninth International Conference on, pp. 151–158, 2008.
[15] J. D. Owens, M. Houston, D. Luebke, S. Green, J. E. Stone, and J. C. Phillips, “GPU
Computing,” Proceedings of the IEEE, vol. 96, pp. 879–899, May 2008.
[16] NVIDIA, NVIDIA CUDA Programming Guide 2.0. 2008.
[17] M. Hudson and R. Larkin, “Accelerated Image Reconstruction using Ordered Subsets of
Projection Data,” IEEE Trans. Med. Imag, vol. 13, pp. 601–609, 1994.
[18] J.-X. Pan, T. Zhou, Y. Han, and M. Jiang, “Variable Weighted Ordered Subset Image
Reconstruction Algorithm,” Int. J. Biomedical Imaging, vol. 2006, pp. 1–7, 2006.
[19] G. Wang and M. Jiang, “Ordered-Subset Simultaneous Algebraic Reconstruction Techni-
ques (OS-SART),” Journal of X-Ray Science and Technology, vol. 12, no. 3, pp. 167–177,
2004.
[20] A. H. Andersen and A. C. Kak, “Simultaneous algebraic reconstruction technique (SART): a
superior implementation of the art algorithm,” Ultrasonic Imaging, vol. 6, no. 1, pp. 81–94,
1984.
[21] R. Gordon, R. Bender, and G. T. Herman, “Algebraic reconstruction techniques (ART)
for three-dimensional electron microscopy and x-ray photography,” Journal of Theoretical
Biology, vol. 29, no. 3, pp. 471–481, 1970.
[22] S. Kaczmarz, “Angenaherte Auflosung von Systemen linearer Gleichungen,” Bulletin Inter-
national de l’Academie Polonaise des Sciences et des Lettres, vol. 35, pp. 355–357, 1937.
[23] A. P. Dempster, N. M. Laird, and D. B. Rubin, “Maximum Likelihood from Incomplete Data
via the EM Algorithm,” Journal of the Royal Statistical Society. Series B (Methodological),
vol. 39, no. 1, pp. 1–38, 1977.
[24] L. A. Shepp and Y. Vardi, “Maximum Likelihood Reconstruction for Emission Tomo-
graphy,” IEEE Trans. Med. Imag, vol. 1, no. 2, pp. 113–122, 1982.
[25] R. A. Fisher, “On the probable error of a coefficient of correlation deduced from a small
sample,” Metron, vol. 1, pp. 3–32, 1921.
[26] H. Guan and R. Gordon, “Computed tomography using algebraic reconstruction techni-
ques (ARTs) with different projection access schemes: a comparison study under practical
situations,” Physics in Medicine and Biology, vol. 41, pp. 1727–1743, 1996.
[27] M. E. Daube-Witherspoon and G. Muehllehner, “An Iterative Image Space Reconstruction
Algorthm Suitable for Volume ECT,” IEEE Trans. Med. Imag, vol. 5, pp. 61–66, june 1986.
[28] D. M. Titterington, “On the Iterative Image Space Reconstruction Algorithm for ECT,”
IEEE Trans. Med. Imag, vol. 6, pp. 52–56, march 1987.

Bibliografie 57
[29] J. Han, L. Han, M. Neumann, and U. Prasad, “On the Rate of Convergence of the Image
Space Reconstruction Algorithm,” Operators and Matrices, vol. 3, no. 1, pp. 41–58, 2009.
[30] J. Nuyts, B. De Man, P. Dupont, M. Defrise, P. Suetens, and L. Mortelmans, “Iterative
reconstruction for helical CT: a simulation study,” Physics in Medicine and Biology, vol. 43,
no. 4, pp. 729–737, 1998.
[31] J. M. Meagher, C. D. Mote, and H. B. Skinner, “CT Image Correction for Beam Hardening
Using Simulated Projection Data,” IEEE Trans. Nucl. Sci, pp. 1520–1524, august.
[32] B. De Man, J. Nuyts, P. Dupont, G. Marchal, and P. Suetens, “An Iterative Maximum-
Likelihood Polychromatic Algorithm for CT,” IEEE Trans. Med. Imag, vol. 20, no. 10,
pp. 999–1008, 2001.
[33] C. Lemmens, D. Faul, and J. Nuyts, “Suppression of Metal Artifacts in CT Using a Recon-
struction Procedure That Combines MAP and Projection Completion,” IEEE Trans. Med.
Imag, vol. 28, no. 2, pp. 250–260, 2009.
[34] W. Kalender, O. Durkee, B. andLangner, E. Stepina, and M. Karolczak
[35] A. Rose, “The Sensitivity Performance of the Human Eye on an Absolute Scale,” J. Opt.
Soc. Am., vol. 38, pp. 196–208, Feb. 1948.
[36] O. Fuchs, J. Krause, and W. Kalender, “Measurement of 3D Spatial Resolution in Multis-
clice Spiral Computed Tomography,” Physica Medica, no. 17, pp. 129–134, 2001.