

От Java Threads к лямбдамjug.ua/wp-content/uploads/2014/07/FromThreadsToLambda_Epam.pdf+...
109
От Java Threads к лямбдам Андрей Родионов @AndriiRodionov http://jug.ua/
Transcript of От Java Threads к лямбдамjug.ua/wp-content/uploads/2014/07/FromThreadsToLambda_Epam.pdf+...

javaday.org.ua

?

The Star7 PDA • SPARC based, handheld wireless PDA • with a 5" color LCD with touchscreen input • a new 16 bit color hardware double buffered NTSC framebuffer • 900MHz wireless networking • multi-media audio codec
• a new power supply/battery interface • a version of Unix (SolarisOs) that runs in under a megabyte including drivers for PCMCIA • radio networking • flash RAM file system
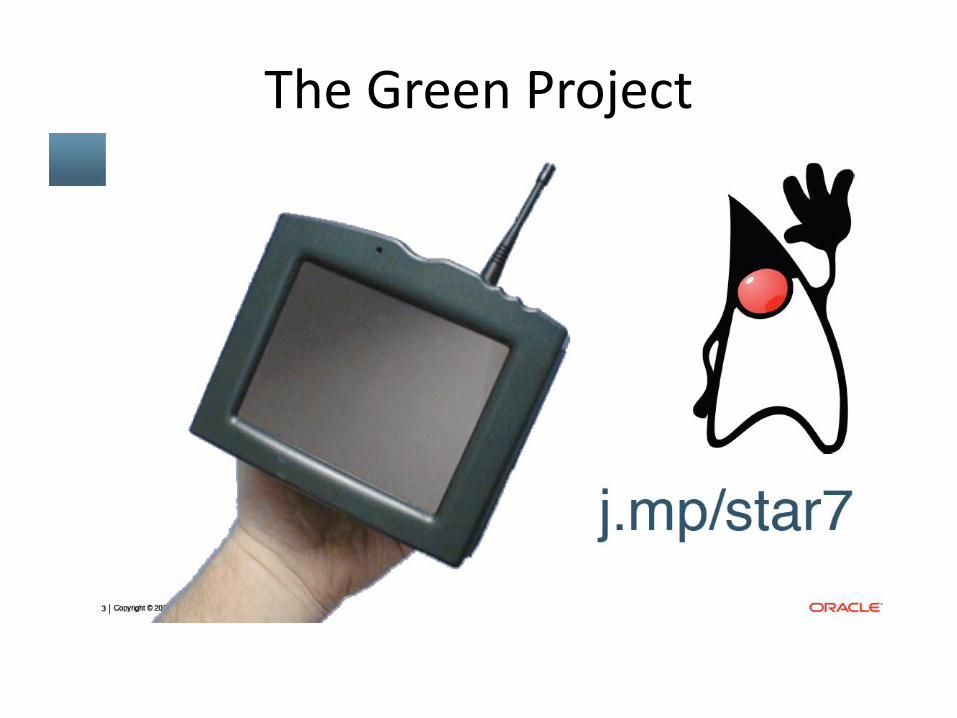
The Green Project

+ Оак • a new small, safe, secure, distributed, robust,
interpreted, garbage collected, multi-threaded, architecture neutral, high performance, dynamic programming language
• a set of classes that implement a spatial user interface metaphor, a user interface methodology which uses animation, audio, spatial cues, gestures
• All of this, in 1992!

Зачем это все?
• Если Oak предназначался для подобных устройств, когда еще было не особо много многопроцессорных машин (и тем более никто не мечтала о телефоне с 4 ядрами), то зачем он изначально содержал поддержку потоков???

Green Threads package
• The Green Threads package totally manages its own threads
• Green-threads Java runtimes don't require the underlying operating systems to support threads -- the runtime handles scheduling, preemption, and all other thread-related tasks all by itself

Напишем реализации одной и той же задачи с использованием
• Sequential algorithm
• Java Threads
• java.util.concurrent (Thread pool)
• Fork/Join
• Java 8 Stream API (Lambda)

А так же …
• Сравним производительность каждого из подходов

MicroBenchmarking?!

Вы занимаетесь микробенчмаркингом? Тогда мы идем к Вам!
(The Art Of) (Java) Benchmarking http://shipilev.net/

http://openjdk.java.net/projects/code-tools/jmh/ JMH is a Java harness for building, running, and analysing nano/micro/milli/macro benchmarks written in Java and other languages targetting the JVM.
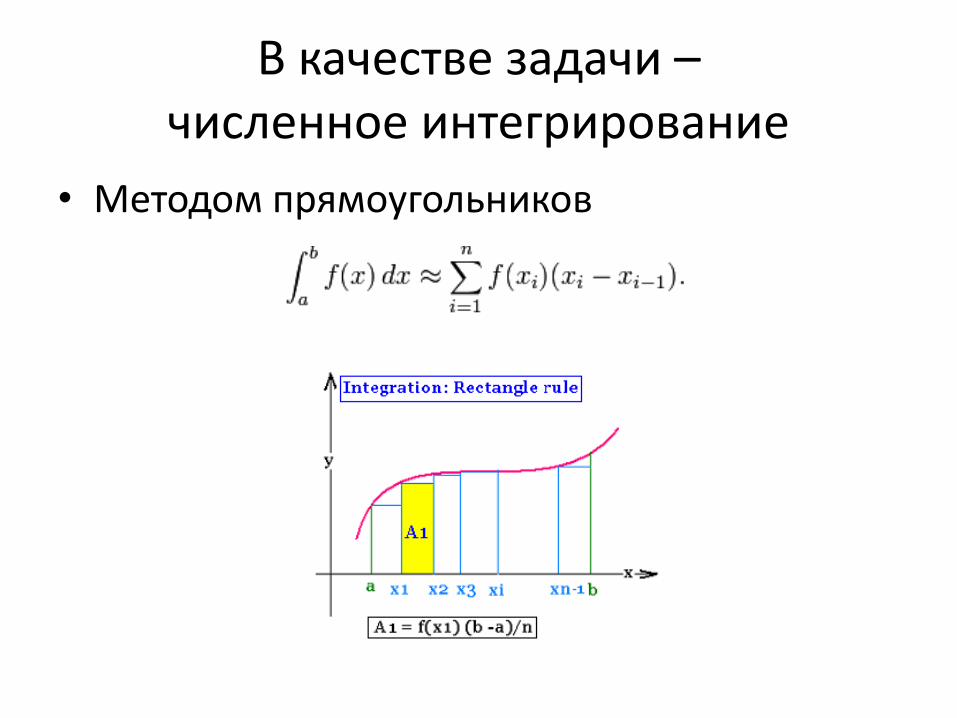
В качестве задачи – численное интегрирование
• Методом прямоугольников
Sequential algorithm

Sequential v.1
public class SequentialCalculate {
public double calculate(double start, double end, double step) {
double result = 0.0;
double x = start;
while (x < end) {
result += step * (sin(x) * sin(x) + cos(x) * cos(x));
x += step;
}
return result;
}
}

Sequential v.1
public class SequentialCalculate {
public double calculate(double start, double end, double step) {
double result = 0.0;
double x = start;
while (x < end) {
result += step * (sin(x) * sin(x) + cos(x) * cos(x));
x += step;
}
return result;
}
}

Sequential v.2 With Functional interface
public interface Function<T, R> {
R apply(T t);
}

Sequential v.2 With Functional interface
public interface Function<T, R> {
R apply(T t);
}
public class SequentialCalculate {
private final Function<Double, Double> func;
public SequentialCalculate (Function<Double, Double> func) {
this.func = func;
}
public double calculate(double start, double end, double step) {
double result = 0.0;
double x = start;
while (x < end) {
result += step * func.apply(x);
x += step;
}
return result;
}
}

Sequential v.2 With Functional interface
SequentialCalculate sc = new SequentialCalculate (
new Function<Double, Double>() {
public Double apply(Double x) {
return sin(x) * sin(x) + cos(x) * cos(x);
}
} );
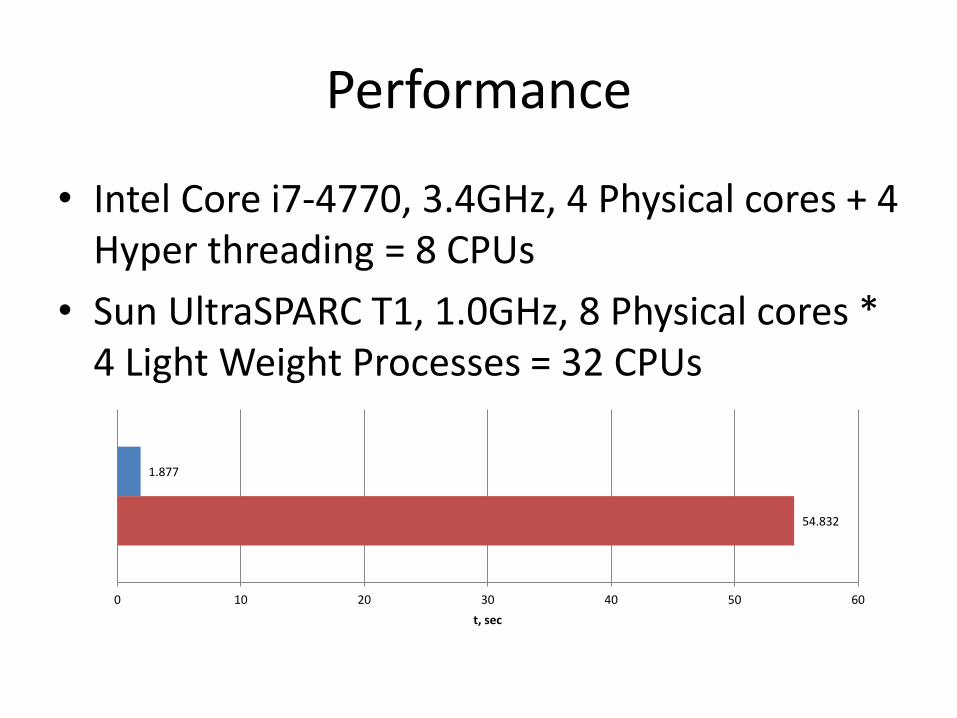
Performance
• Intel Core i7-4770, 3.4GHz, 4 Physical cores + 4 Hyper threading = 8 CPUs
• Sun UltraSPARC T1, 1.0GHz, 8 Physical cores * 4 Light Weight Processes = 32 CPUs
54.832
1.877
0 10 20 30 40 50 60
t, sec
Java Threads
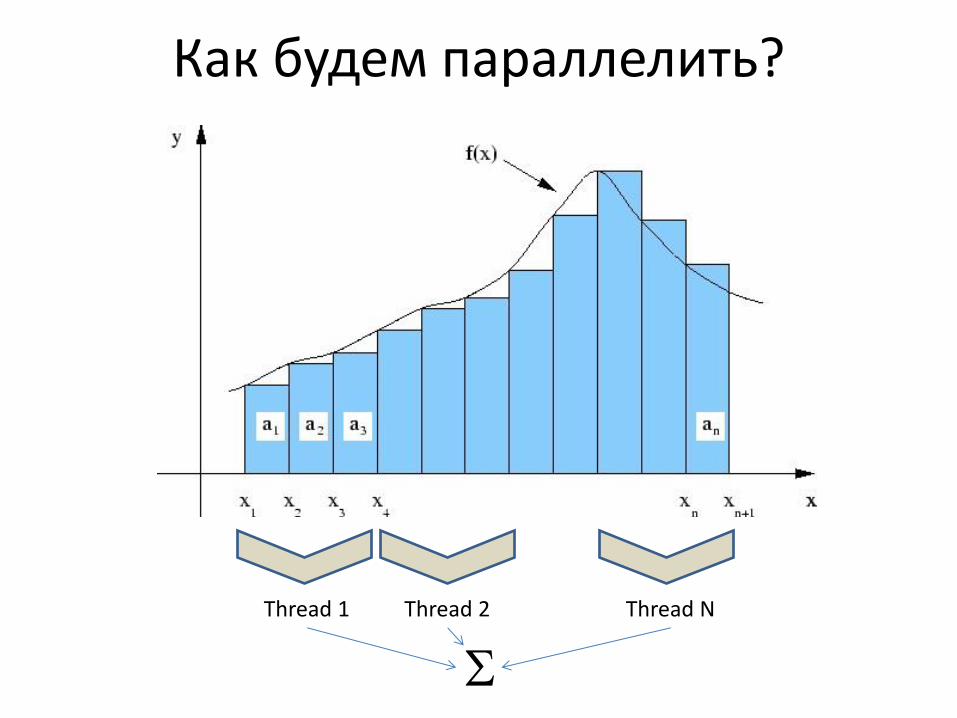
Как будем параллелить?
Thread 1 Thread 2 Thread N

class CalcThread extends Thread {
private final double start;
private final double end;
private final double step;
private double partialResult;
public CalcThread(double start, double end, double step) {
this.start = start;
this.end = end;
this.step = step;
}
@Override
public void run() {
double x = start;
while (x < end) {
partialResult += step * func.apply(x);
x += step;
}
}
}

public double calculate(double start, double end, double step,
int chunks) {
CalcThread[] calcThreads = new CalcThread[chunks];
double interval = (end - start) / chunks;
double st = start;
for (int i = 0; i < chunks; i++) {
calcThreads[i] = new CalcThread(st, st + interval, step);
calcThreads[i].start();
st += interval;
}
double result = 0.0;
for (CalcThread cs : calcThreads) {
cs.join();
result += cs.partialResult;
}
return result;
}
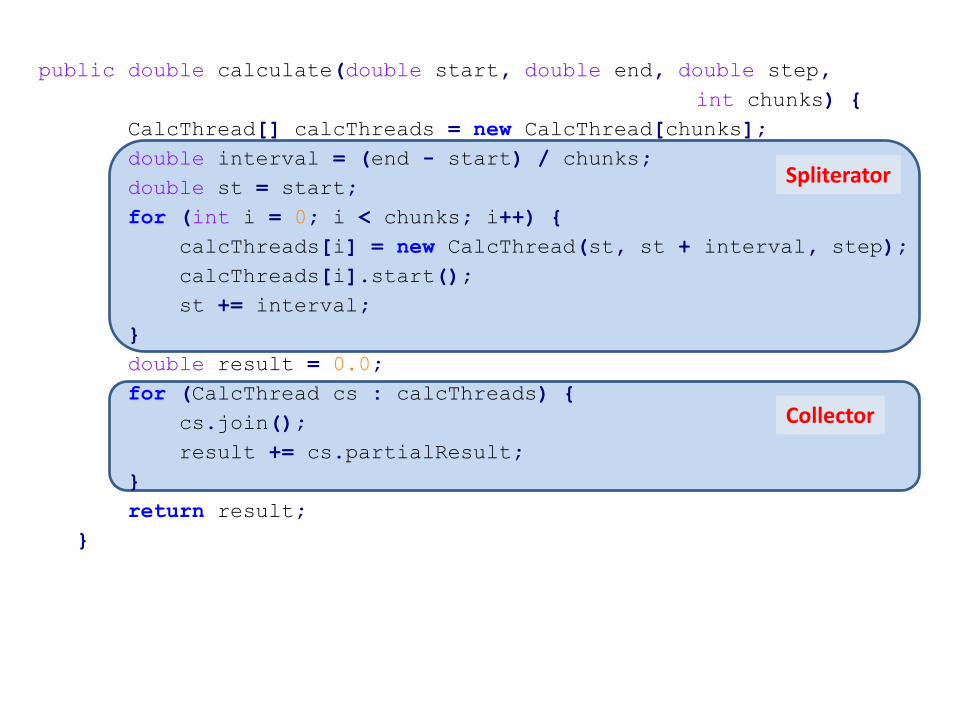
Spliterator
Collector
public double calculate(double start, double end, double step,
int chunks) {
CalcThread[] calcThreads = new CalcThread[chunks];
double interval = (end - start) / chunks;
double st = start;
for (int i = 0; i < chunks; i++) {
calcThreads[i] = new CalcThread(st, st + interval, step);
calcThreads[i].start();
st += interval;
}
double result = 0.0;
for (CalcThread cs : calcThreads) {
cs.join();
result += cs.partialResult;
}
return result;
}
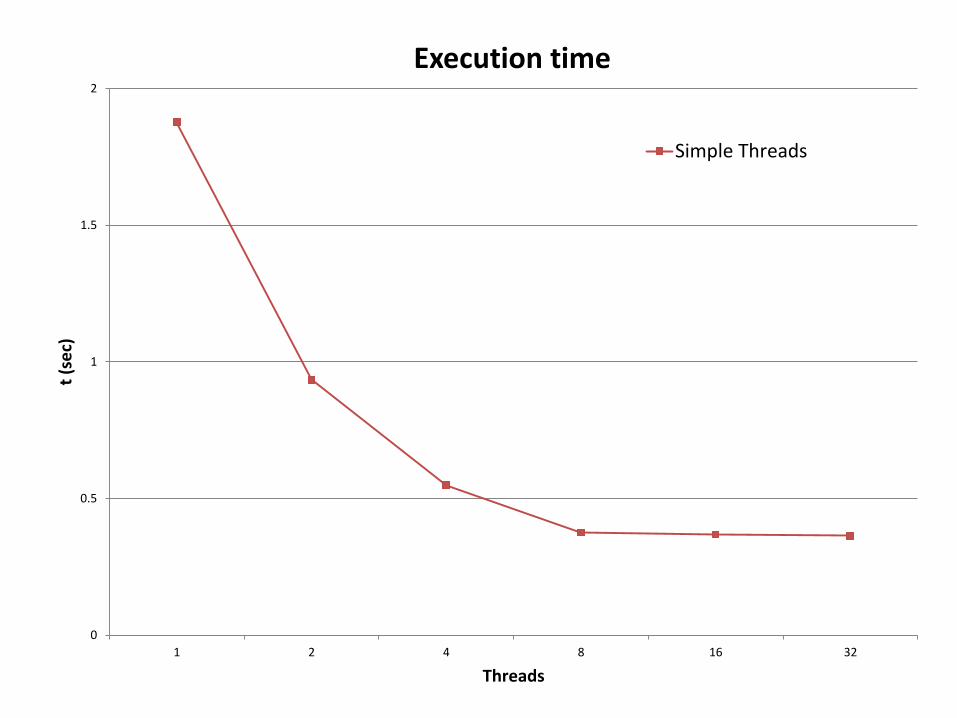
0
0.5
1
1.5
2
1 2 4 8 16 32
t (s
ec)
Threads
Execution time
Simple Threads
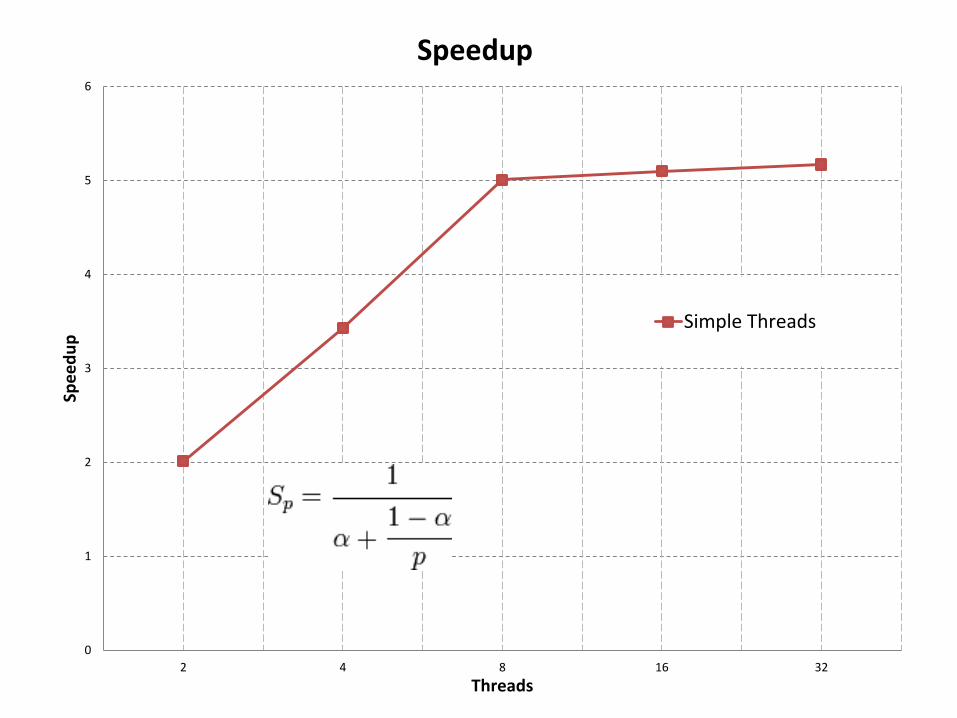
0
1
2
3
4
5
6
2 4 8 16 32
Spe
ed
up
Threads
Speedup
Simple Threads

Ограничения классического подхода
• "поток-на-задачу" хорошо работает с небольшим количеством долгосрочных задач
• слияние низкоуровневого кода, отвечающего за многопоточное исполнение, и высокоуровневого кода, отвечающего за основную функциональность приложения приводит к т.н. «спагетти-коду»
• трудности связанные с управлением потоками • поток занимает относительно много места в памяти
~ 1 Mb • для выполнения новой задачи потребуется
запустить новый поток – это одна из самых требовательных к ресурсам операций

java.util.concurrent

How not to manage tasks
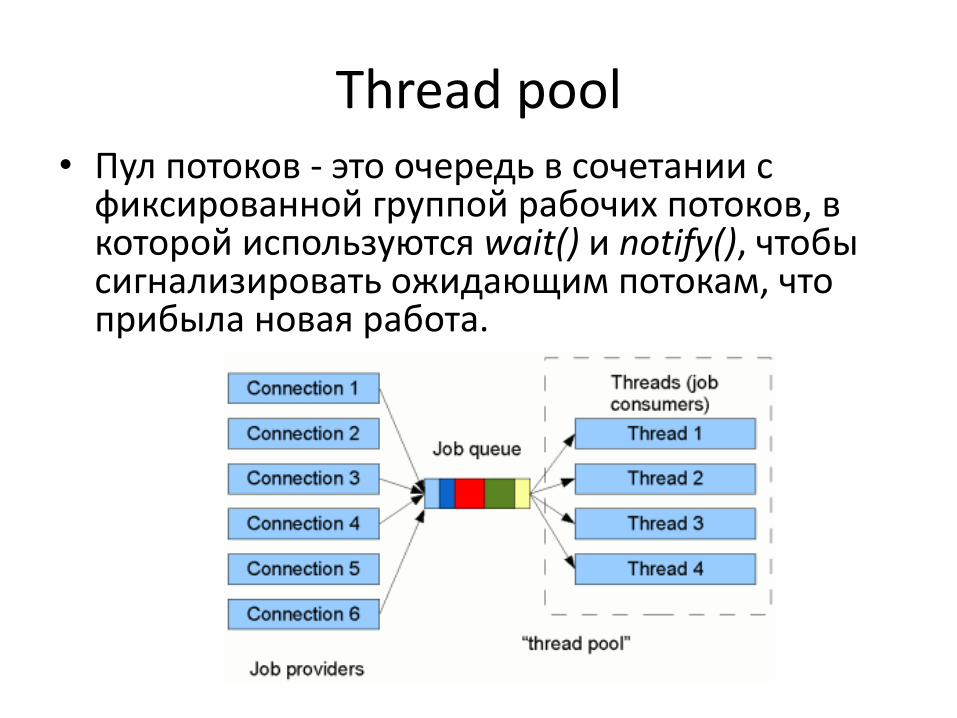
Thread pool • Пул потоков - это очередь в сочетании с
фиксированной группой рабочих потоков, в которой используются wait() и notify(), чтобы сигнализировать ожидающим потокам, что прибыла новая работа.

Thread Pool Example
Executes the given task at some time in the future. The task may execute in a new thread, in a pooled thread, or in the calling thread
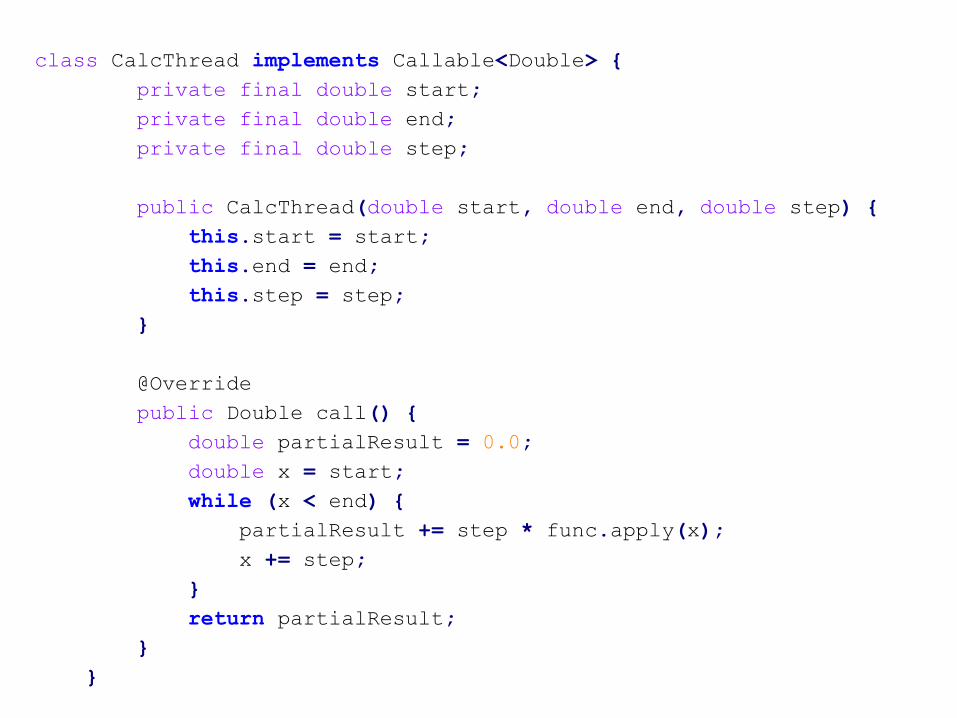
class CalcThread implements Callable<Double> {
private final double start;
private final double end;
private final double step;
public CalcThread(double start, double end, double step) {
this.start = start;
this.end = end;
this.step = step;
}
@Override
public Double call() {
double partialResult = 0.0;
double x = start;
while (x < end) {
partialResult += step * func.apply(x);
x += step;
}
return partialResult;
}
}

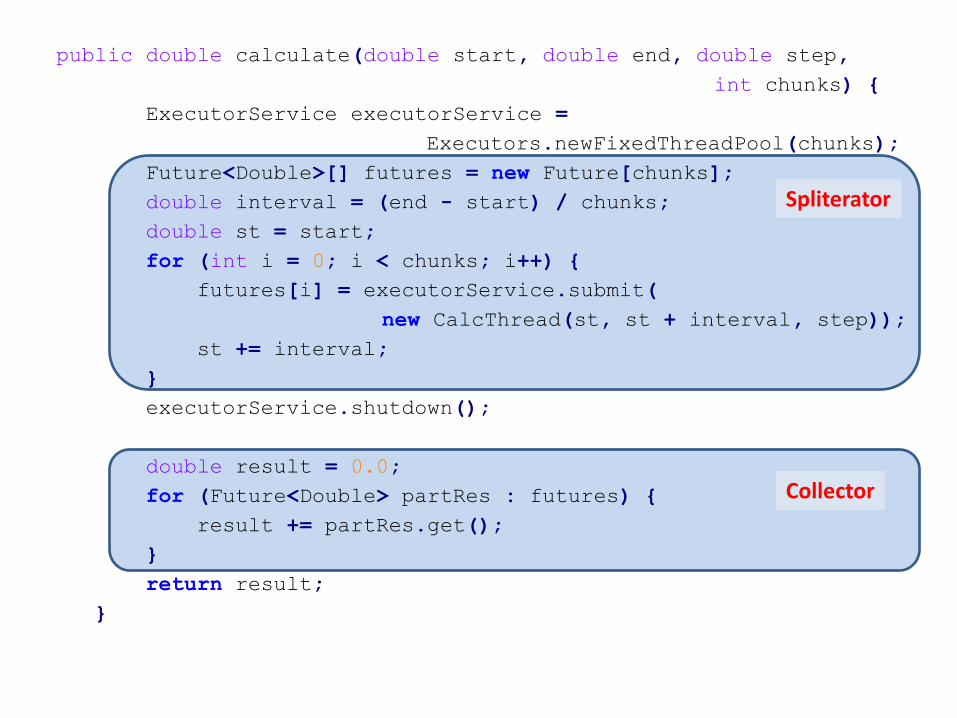
public double calculate(double start, double end, double step,
int chunks) {
ExecutorService executorService =
Executors.newFixedThreadPool(chunks);
Future<Double>[] futures = new Future[chunks];
double interval = (end - start) / chunks;
double st = start;
for (int i = 0; i < chunks; i++) {
futures[i] = executorService.submit(
new CalcThread(st, st + interval, step));
st += interval;
}
executorService.shutdown();
double result = 0.0;
for (Future<Double> partRes : futures) {
result += partRes.get();
}
return result;
}
public double calculate(double start, double end, double step,
int chunks) {
ExecutorService executorService =
Executors.newFixedThreadPool(chunks);
Future<Double>[] futures = new Future[chunks];
double interval = (end - start) / chunks;
double st = start;
for (int i = 0; i < chunks; i++) {
futures[i] = executorService.submit(
new CalcThread(st, st + interval, step));
st += interval;
}
executorService.shutdown();
double result = 0.0;
for (Future<Double> partRes : futures) {
result += partRes.get();
}
return result;
}
Spliterator
Collector
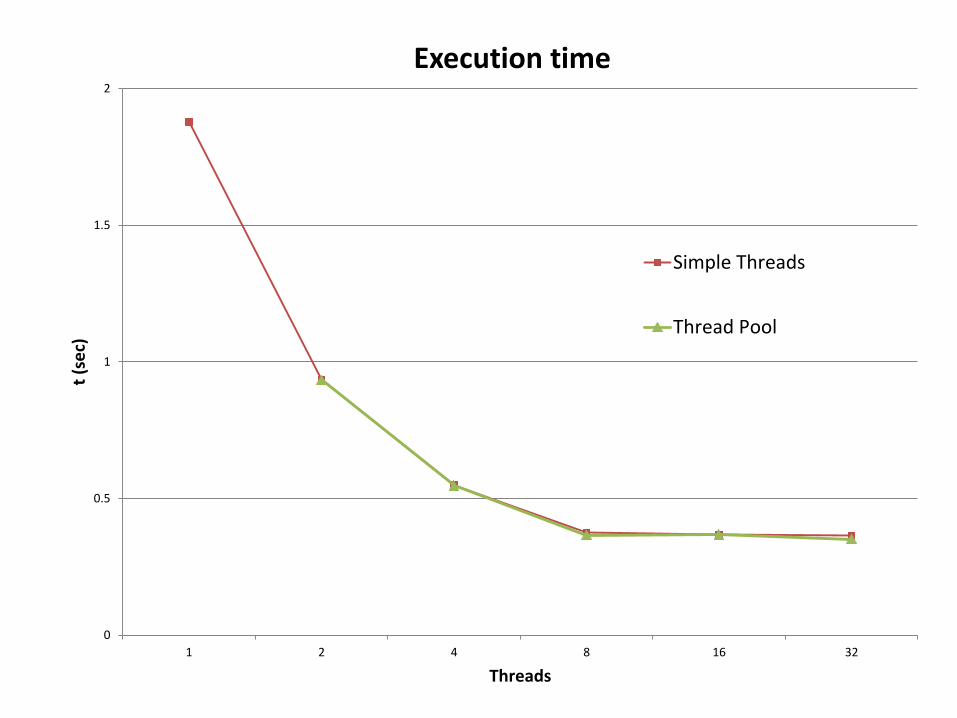
0
0.5
1
1.5
2
1 2 4 8 16 32
t (s
ec)
Threads
Execution time
Simple Threads
Thread Pool
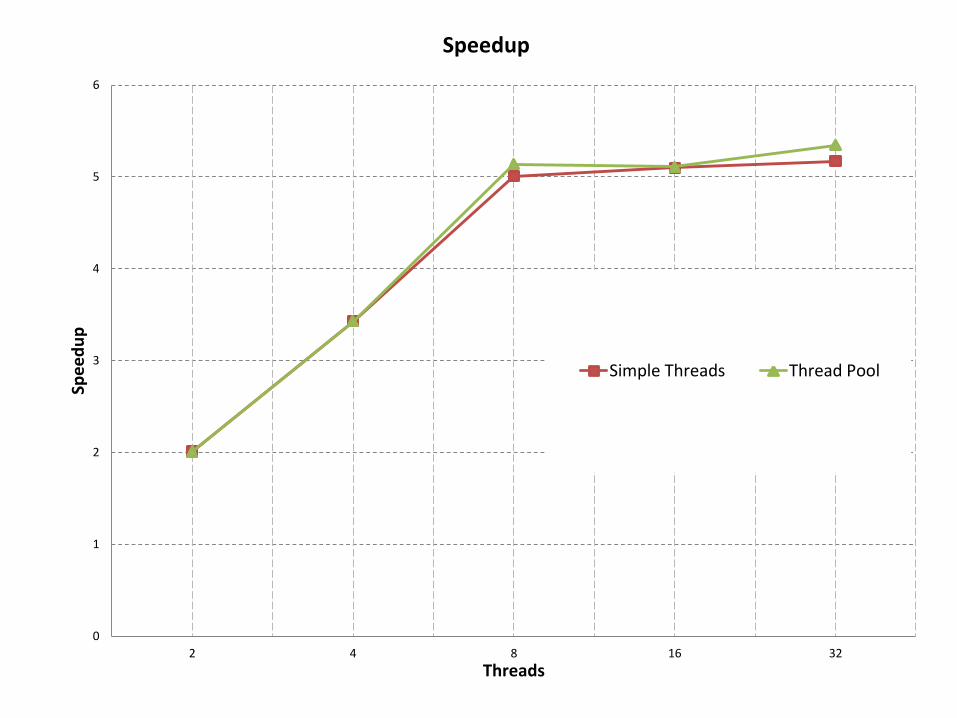
0
1
2
3
4
5
6
2 4 8 16 32
Spe
ed
up
Threads
Speedup
Simple Threads Thread Pool

Fork/Join

«Бытие определяет сознание» Доминирующие в текущий момент аппаратные
платформы формируют подход к созданию языков, библиотек и систем
• С самого момента зарождения языка в Java была поддержка потоков и параллелизма (Thread, synchronized, volatile, …)
• Однако примитивы параллелизма, введенные в 1995 году, отражали реальность аппаратного обеспечения того времени: большинство доступных коммерческих систем вообще не предоставляли возможностей использования параллелизма, и даже наиболее дорогостоящие системы предоставляли такие возможности лишь в ограниченных масштабах
• В те дни потоки использовались в основном, для выражения asynchrony, а не concurrency, и в результате, эти механизмы в целом отвечали требованиям времени
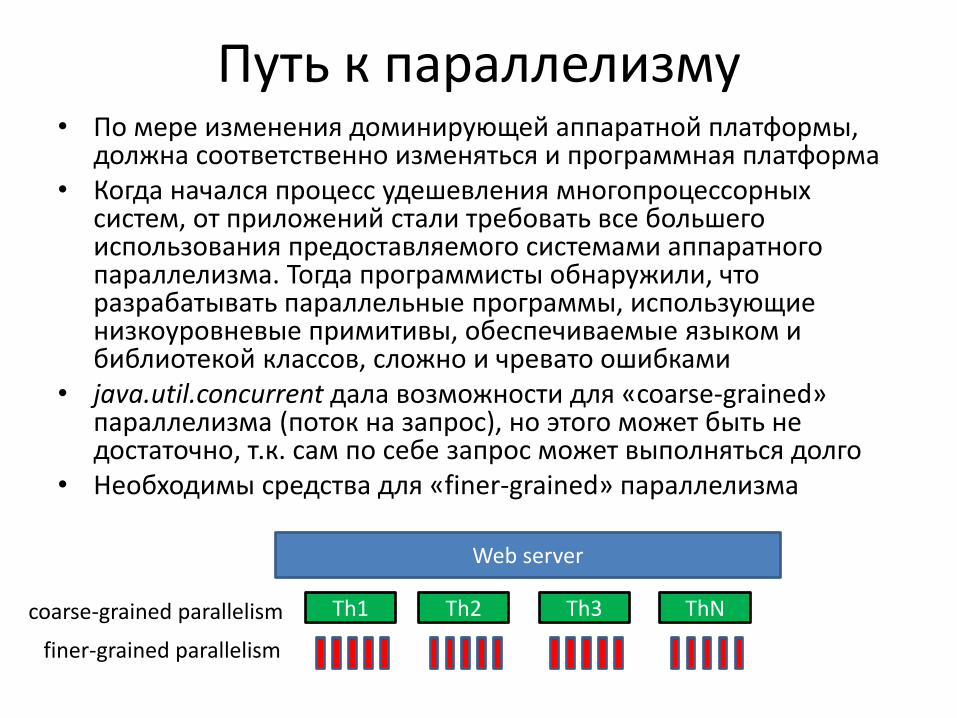
Путь к параллелизму • По мере изменения доминирующей аппаратной платформы,
должна соответственно изменяться и программная платформа • Когда начался процесс удешевления многопроцессорных
систем, от приложений стали требовать все большего использования предоставляемого системами аппаратного параллелизма. Тогда программисты обнаружили, что разрабатывать параллельные программы, использующие низкоуровневые примитивы, обеспечиваемые языком и библиотекой классов, сложно и чревато ошибками
• java.util.concurrent дала возможности для «coarse-grained» параллелизма (поток на запрос), но этого может быть не достаточно, т.к. сам по себе запрос может выполняться долго
• Необходимы средства для «finer-grained» параллелизма
Web server
Th1 Th2 Th3 ThN coarse-grained parallelism
finer-grained parallelism
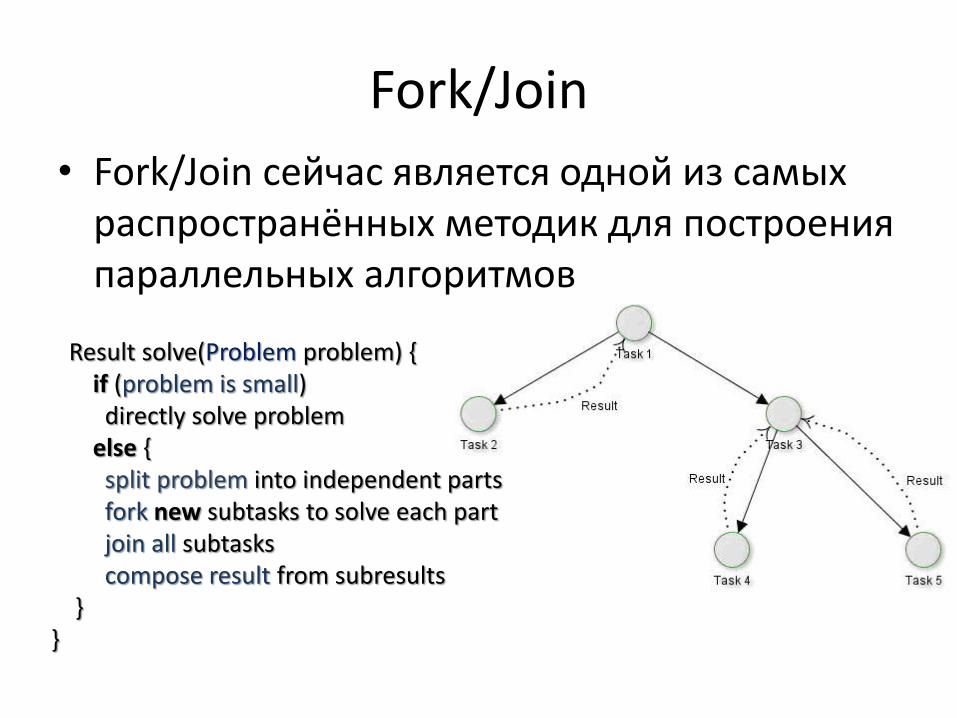
Fork/Join
• Fork/Join сейчас является одной из самых распространённых методик для построения параллельных алгоритмов
Result solve(Problem problem) { if (problem is small) directly solve problem else { split problem into independent parts fork new subtasks to solve each part join all subtasks compose result from subresults } }

ForkJoinExecutor
• ForkJoinExecutor подобен Executor, так как он предназначен для запуска задач, однако он в большей степени предназначен для требующих интенсивных расчетов задач, которые не блокируются
• ForkJoinPool, может в небольшом количестве потоков выполнить существенно большее число задач
• Это достигается путём так называемого work-stealing'а (планировщики на основе захвата работы ), когда спящая задача на самом деле не спит, а выполняет другие задачи
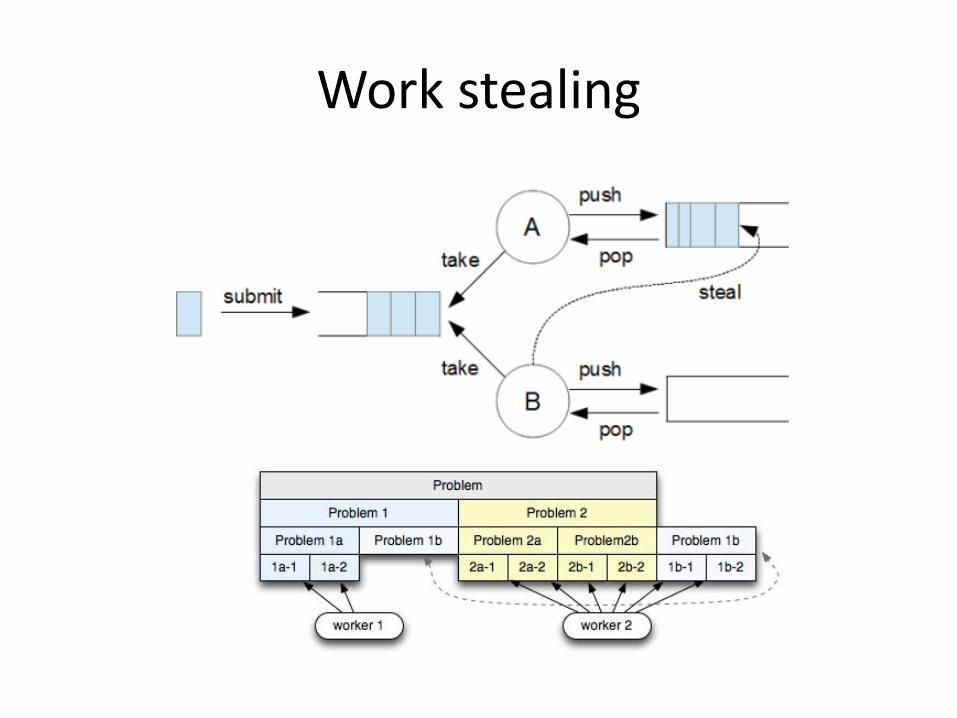
Work stealing

Work stealing • Планировщики на основе захвата работы (work
stealing) "автоматически" балансируют нагрузку за счёт того, что потоки, оказавшиеся без задач, самостоятельно обнаруживают и забирают "свободные" задачи у других потоков. Находится ли поток-"жертва" в активном или пассивном состоянии, неважно.
• Основными преимуществами перед планировщиком с общим пулом задач: – отсутствие общего пула :), то есть точки глобальной
синхронизации – лучшая локальность данных, потому что в большинстве
случаев поток самостоятельно выполняет порождённые им задачи

Fork/Join effectiveness
• It is important to note that local task queues and work stealing are only utilised (and therefore only produce benefits) when worker threads actually schedule new tasks in their own queues. If this doesn't occur, the ForkJoinPool is just a ThreadPoolExecutor with an extra overhead.
• If input tasks are already split (or are splittable) into tasks of approximately equal computing load, then the additional overhead of ForkJoinPool's splitting and work stealing make it less efficient than just using a ThreadPoolExecutor directly. But if tasks have variable computing load and can be split into subtasks, then ForkJoinPool's in-built load balancing is likely to make it more efficient than using a ThreadPoolExecutor.
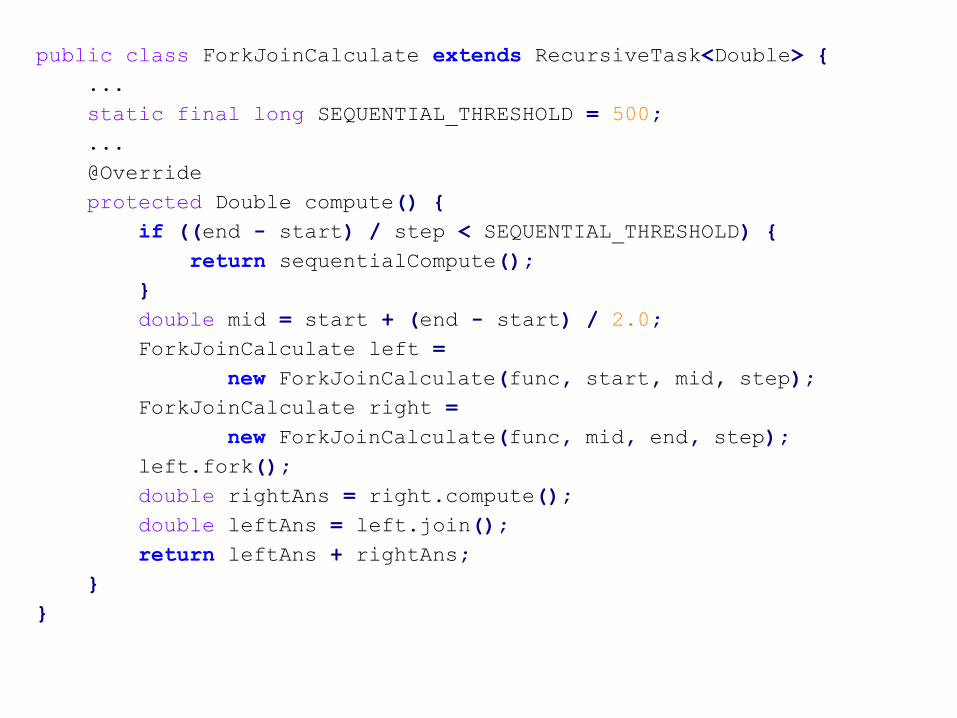
public class ForkJoinCalculate extends RecursiveTask<Double> {
...
static final long SEQUENTIAL_THRESHOLD = 500;
...
@Override
protected Double compute() {
if ((end - start) / step < SEQUENTIAL_THRESHOLD) {
return sequentialCompute();
}
double mid = start + (end - start) / 2.0;
ForkJoinCalculate left =
new ForkJoinCalculate(func, start, mid, step);
ForkJoinCalculate right =
new ForkJoinCalculate(func, mid, end, step);
left.fork();
double rightAns = right.compute();
double leftAns = left.join();
return leftAns + rightAns;
}
}

protected double sequentialCompute() {
double x = start;
double result = 0.0;
while (x < end) {
result += step * func.apply(x);
x += step;
}
return result;
}
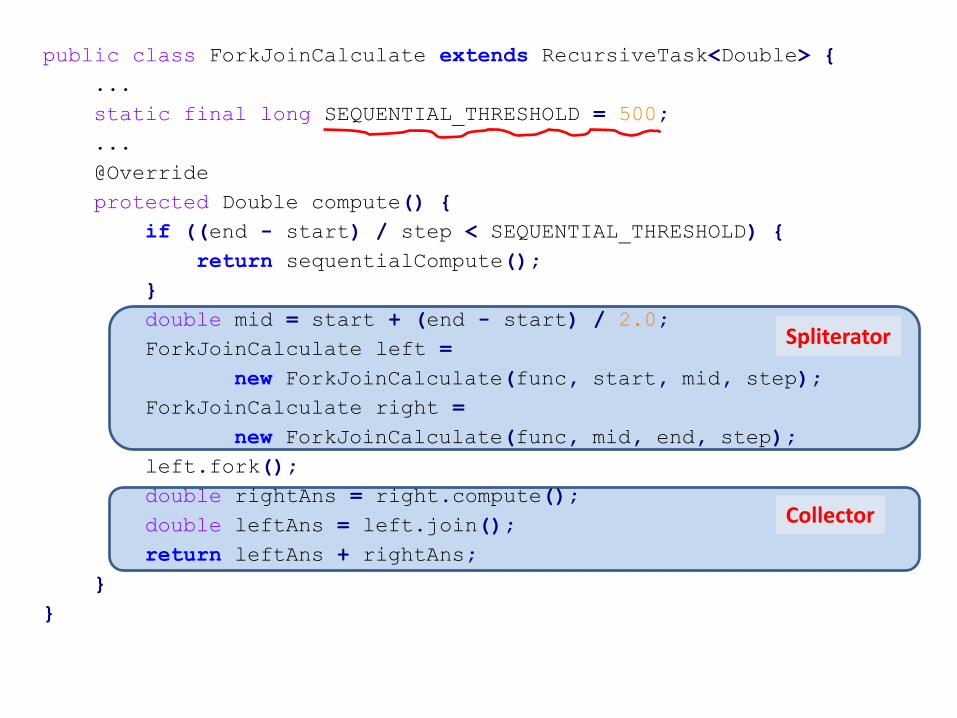
Spliterator
public class ForkJoinCalculate extends RecursiveTask<Double> {
...
static final long SEQUENTIAL_THRESHOLD = 500;
...
@Override
protected Double compute() {
if ((end - start) / step < SEQUENTIAL_THRESHOLD) {
return sequentialCompute();
}
double mid = start + (end - start) / 2.0;
ForkJoinCalculate left =
new ForkJoinCalculate(func, start, mid, step);
ForkJoinCalculate right =
new ForkJoinCalculate(func, mid, end, step);
left.fork();
double rightAns = right.compute();
double leftAns = left.join();
return leftAns + rightAns;
}
}
Collector
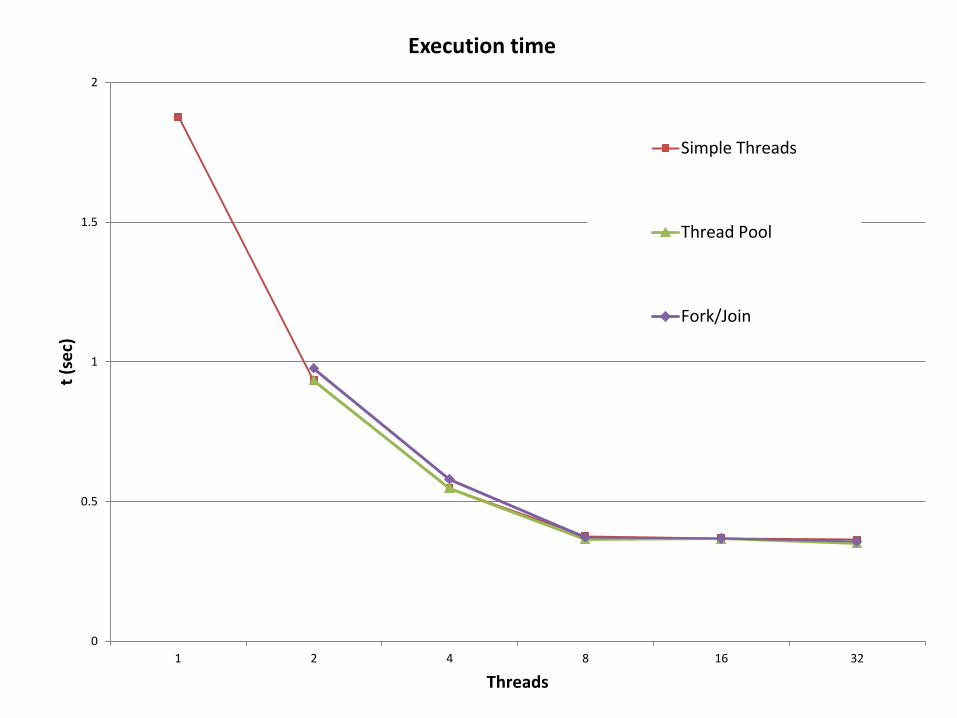
0
0.5
1
1.5
2
1 2 4 8 16 32
t (s
ec)
Threads
Execution time
Simple Threads
Thread Pool
Fork/Join
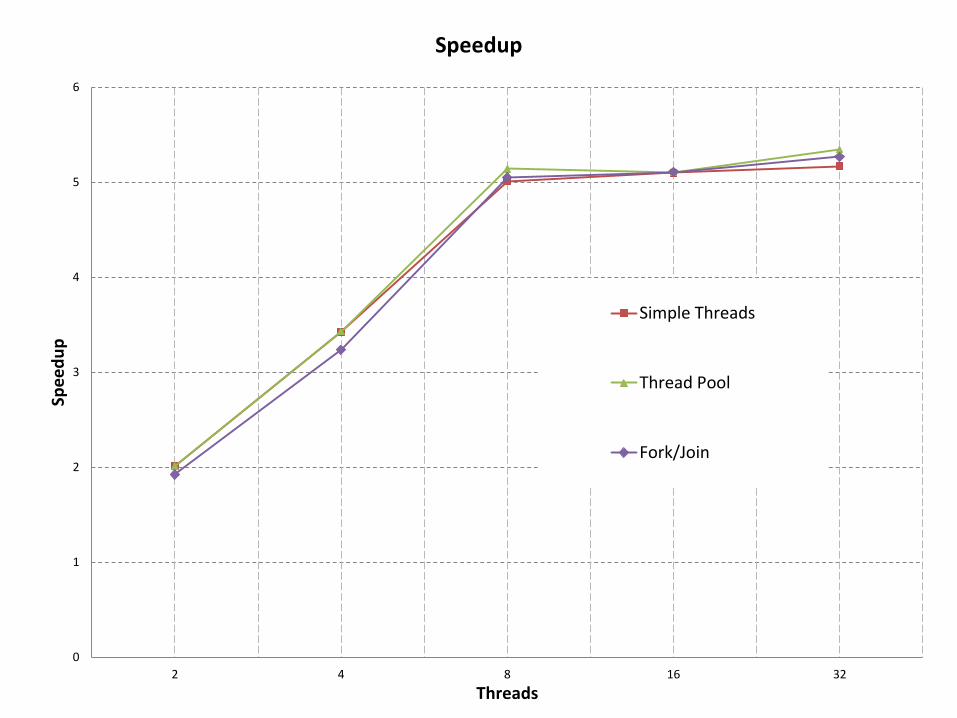
0
1
2
3
4
5
6
2 4 8 16 32
Spe
ed
up
Threads
Speedup
Simple Threads
Thread Pool
Fork/Join

The F/J framework Criticism • exceedingly complex
– The code looks more like an old C language program that was segmented into classes than an O-O structure
• a design failure – It’s primary uses are for fully-strict, compute-only, recursively
decomposing processing of large aggregate data structures. It is for compute intensive tasks only
• lacking in industry professional attributes – no monitoring, no alerting or logging, no availability for general
application usage
• misusing parallelization – recursive decomposition has narrower performance window. An
academic exercise
• inadequate in scope – you must be able to express things in terms of apply, reduce, filter,
map, cumulate, sort, uniquify, paired mappings, and so on — no general purpose application programming here
• special purpose

F/J source code
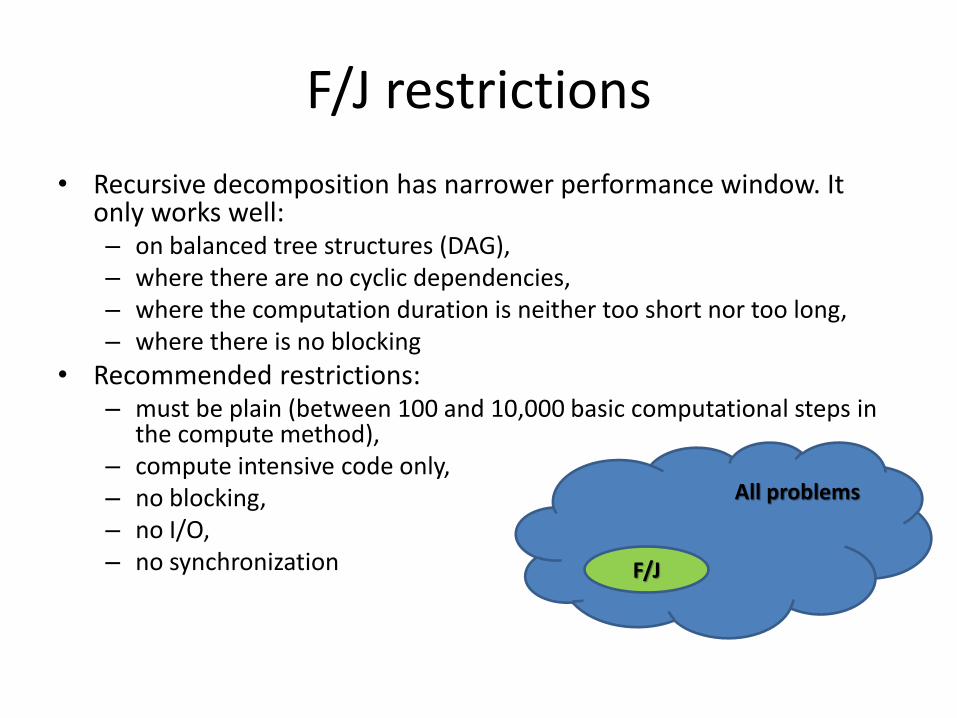
F/J restrictions
• Recursive decomposition has narrower performance window. It only works well: – on balanced tree structures (DAG), – where there are no cyclic dependencies, – where the computation duration is neither too short nor too long, – where there is no blocking
• Recommended restrictions: – must be plain (between 100 and 10,000 basic computational steps in
the compute method), – compute intensive code only, – no blocking, – no I/O, – no synchronization
F/J
All problems

Lambda


1994
“He (Bill Joy) would often go on at length about how great Oak would be if he could only add closures and continuations and parameterized types”
Patrick Naughton, one of the creators of the Java

1994
“He (Bill Joy) would often go on at length about how great Oak would be if he could only add closures and continuations and parameterized types”
“While we all agreed these were very cool language features, we were all kind of hoping to finish this language in our lifetimes and get on to creating cool applications with it”
Patrick Naughton, one of the creators of the Java

1994
“He (Bill Joy) would often go on at length about how great Oak would be if he could only add closures and continuations and parameterized types” “While we all agreed these were very cool language features, we were all kind of hoping to finish this language in our lifetimes and get on to creating cool applications with it” “It is also interesting that Bill was absolutely right about what Java needs long term. When I go look at the list of things he wanted to add back then, I want them all. He was right, he usually is”
Patrick Naughton, one of the creators of the Java

Ingredients of lambda expression
• A lambda expression has three ingredients: – A block of code
– Parameters
– Values for the free variables; that is, the variables that are not parameters and not defined inside the code

Ingredients of lambda expression
• A lambda expression has three ingredients: – A block of code
– Parameters
– Values for the free variables; that is, the variables that are not parameters and not defined inside the code
while (x < end) {
result += step * (sin(x) * sin(x) + cos(x) * cos(x));
x += step;
}

Ingredients of lambda expression
• A lambda expression has three ingredients: – A block of code
– Parameters
– Values for the free variables; that is, the variables that are not parameters and not defined inside the code
while (x < end) {
result += step * (sin(x) * sin(x) + cos(x) * cos(x));
x += step;
}
step * (sin(x) * sin(x) + cos(x) * cos(x));

Ingredients of lambda expression
• A lambda expression has three ingredients: – A block of code
– Parameters
– Values for the free variables; that is, the variables that are not parameters and not defined inside the code
while (x < end) {
result += step * (sin(x) * sin(x) + cos(x) * cos(x));
x += step;
}
step * (sin(x) * sin(x) + cos(x) * cos(x));
A block of code

Ingredients of lambda expression
• A lambda expression has three ingredients: – A block of code
– Parameters
– Values for the free variables; that is, the variables that are not parameters and not defined inside the code
while (x < end) {
result += step * (sin(x) * sin(x) + cos(x) * cos(x));
x += step;
}
step * (sin(x) * sin(x) + cos(x) * cos(x));
A block of code
Parameter(s)

Ingredients of lambda expression
• A lambda expression has three ingredients: – A block of code
– Parameters
– Values for the free variables; that is, the variables that are not parameters and not defined inside the code
while (x < end) {
result += step * (sin(x) * sin(x) + cos(x) * cos(x));
x += step;
}
step * (sin(x) * sin(x) + cos(x) * cos(x));
A block of code
Parameter(s) Free variable

Lambda expression
step * (sin(x) * sin(x) + cos(x) * cos(x));

Lambda expression
step * (sin(x) * sin(x) + cos(x) * cos(x));
x -> step * (sin(x) * sin(x) + cos(x) * cos(x));

Lambda expression
step * (sin(x) * sin(x) + cos(x) * cos(x));
x -> step * (sin(x) * sin(x) + cos(x) * cos(x));
Function<Double, Double> func =
x -> step * (sin(x) * sin(x) + cos(x) * cos(x));

Lambda expression
step * (sin(x) * sin(x) + cos(x) * cos(x));
x -> step * (sin(x) * sin(x) + cos(x) * cos(x));
Function<Double, Double> func =
x -> step * (sin(x) * sin(x) + cos(x) * cos(x));

Lambda expression
step * (sin(x) * sin(x) + cos(x) * cos(x));
x -> step * (sin(x) * sin(x) + cos(x) * cos(x));
Function<Double, Double> func =
x -> step * (sin(x) * sin(x) + cos(x) * cos(x));
Function<Double, Double> func =
x -> sin(x) * sin(x) + cos(x) * cos(x);
Function<Double, Double> calcFunc =
x -> step * x;
Function<Double, Double> sqFunc =
func.andThen(calcFunc);

SequentialCalculate sc = new SequentialCalculate (
new Function<Double, Double>() {
public Double apply(Double x) {
return sin(x) * sin(x) + cos(x) * cos(x);
}
} );

SequentialCalculate sc = new SequentialCalculate (
new Function<Double, Double>() {
public Double apply(Double x) {
return sin(x) * sin(x) + cos(x) * cos(x);
}
} );
SequentialCalculate sc =
new SequentialCalculate(x -> sin(x) * sin(x) + cos(x) * cos(x));

SequentialCalculate sc = new SequentialCalculate (
new Function<Double, Double>() {
public Double apply(Double x) {
return sin(x) * sin(x) + cos(x) * cos(x);
}
} );
SequentialCalculate sc =
new SequentialCalculate(x -> sin(x) * sin(x) + cos(x) * cos(x));
Function<Double, Double> func =
x -> sin(x) * sin(x) + cos(x) * cos(x);
SequentialCalculate sc = new SequentialCalculate(func);
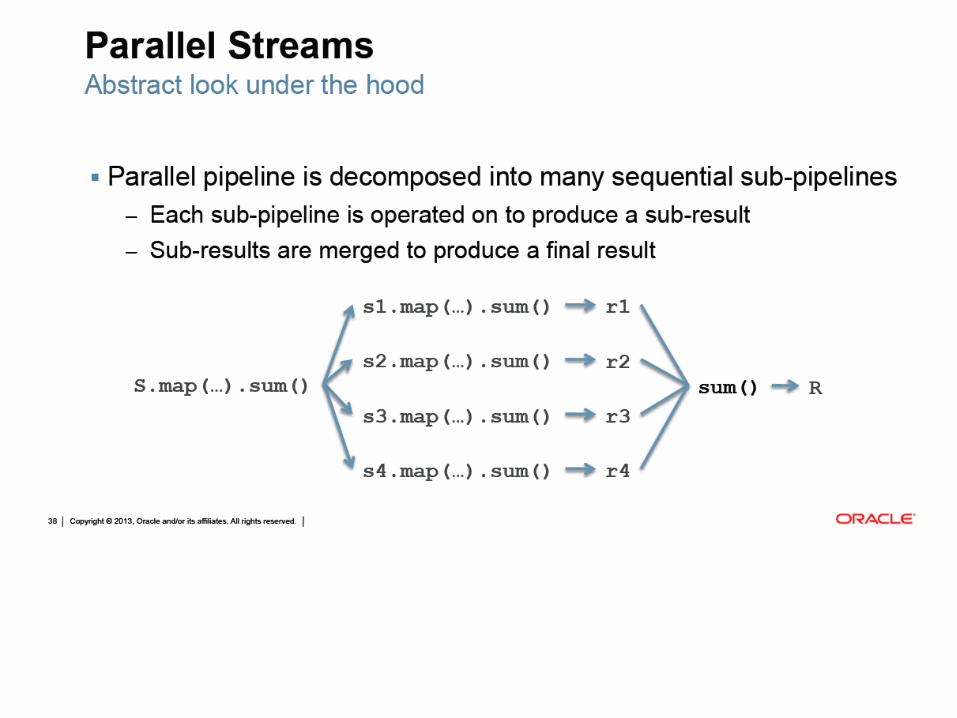
Stream API

Integral calculation double step = 0.001;
double start = 0.0;
double end = 10_000.0;
Function<Double, Double> func =
x -> sin(x) * sin(x) + cos(x) * cos(x);
Function<Double, Double> calcFunc = x -> step * x;
Function<Double, Double> sqFunc = func.andThen(calcFunc);
double sum = ...

Integral calculation double step = 0.001;
double start = 0.0;
double end = 10_000.0;
Function<Double, Double> func =
x -> sin(x) * sin(x) + cos(x) * cos(x);
Function<Double, Double> calcFunc = x -> step * x;
Function<Double, Double> sqFunc = func.andThen(calcFunc);
double sum = Stream.
iterate(0.0, s -> s + step).

Integral calculation double step = 0.001;
double start = 0.0;
double end = 10_000.0;
Function<Double, Double> func =
x -> sin(x) * sin(x) + cos(x) * cos(x);
Function<Double, Double> calcFunc = x -> step * x;
Function<Double, Double> sqFunc = func.andThen(calcFunc);
double sum = Stream.
iterate(0.0, s -> s + step).
limit((long) ((end - start) / step)).

Integral calculation double step = 0.001;
double start = 0.0;
double end = 10_000.0;
Function<Double, Double> func =
x -> sin(x) * sin(x) + cos(x) * cos(x);
Function<Double, Double> calcFunc = x -> step * x;
Function<Double, Double> sqFunc = func.andThen(calcFunc);
double sum = Stream.
iterate(0.0, s -> s + step).
limit((long) ((end - start) / step)).
map(sqFunc).

Integral calculation double step = 0.001;
double start = 0.0;
double end = 10_000.0;
Function<Double, Double> func =
x -> sin(x) * sin(x) + cos(x) * cos(x);
Function<Double, Double> calcFunc = x -> step * x;
Function<Double, Double> sqFunc = func.andThen(calcFunc);
double sum = Stream.
iterate(0.0, s -> s + step).
limit((long) ((end - start) / step)).
map(sqFunc).
reduce(0.0, Double::sum);

DoubleStream public interface DoubleUnaryOperator {
double applyAsDouble(double x);
}

DoubleStream
DoubleUnaryOperator funcD =
x -> sin(x) * sin(x) + cos(x) * cos(x);
DoubleUnaryOperator calcFuncD = x -> step * x;
DoubleUnaryOperator sqFuncDouble = funcD.andThen(calcFuncD);
double sum = ...
public interface DoubleUnaryOperator {
double applyAsDouble(double x);
}

DoubleStream
DoubleUnaryOperator funcD =
x -> sin(x) * sin(x) + cos(x) * cos(x);
DoubleUnaryOperator calcFuncD = x -> step * x;
DoubleUnaryOperator sqFuncDouble = funcD.andThen(calcFuncD);
double sum = DoubleStream.
iterate(0.0, s -> s + step).
limit((long) ((end - start) / step)).
map(sqFuncDouble).
sum();
public interface DoubleUnaryOperator {
double applyAsDouble(double x);
}
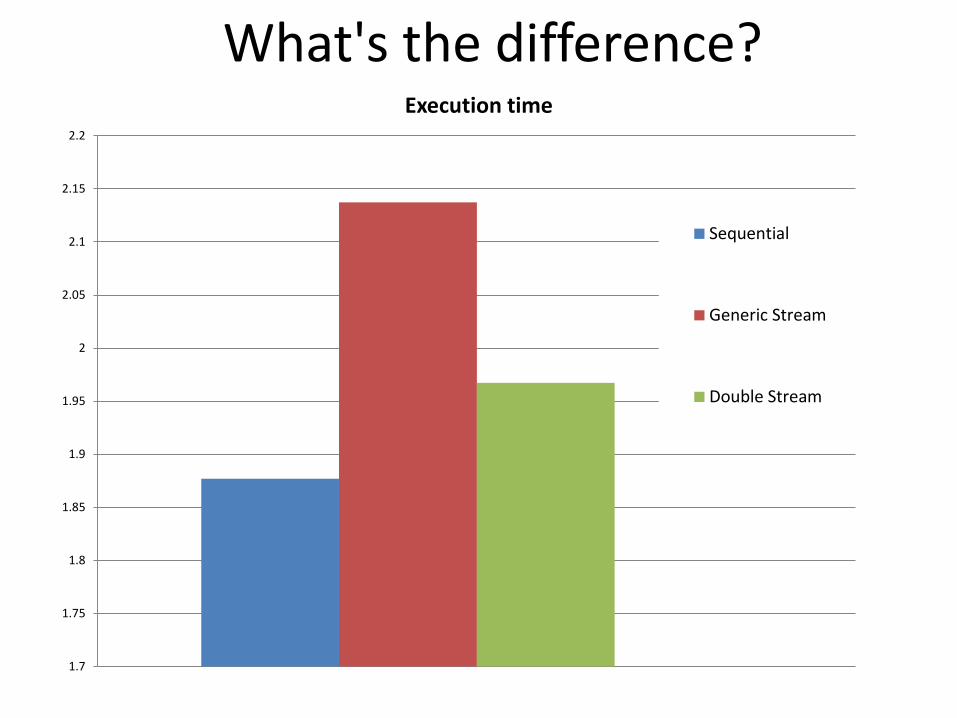
What's the difference?
1.7
1.75
1.8
1.85
1.9
1.95
2
2.05
2.1
2.15
2.2
Execution time
Sequential
Generic Stream
Double Stream

Stream parallel
double sum = DoubleStream.
iterate(0.0, s -> s + step).
limit((long) ((end - start) / step)).
parallel().
map(sqFuncDouble).
sum();

and …

flatMap
double sum = DoubleStream.
iterate(0.0, s -> s + (end - start) / chunks).
limit(chunks).
parallel().

flatMap
double sum = DoubleStream.
iterate(0.0, s -> s + (end - start) / chunks).
limit(chunks).
parallel().
flatMap(
c -> DoubleStream.
iterate(c, s -> s + step).
limit((long) ((end - start) / (chunks * step)))).
map(sqFuncDouble).
sum();

Stream parallel v.2 double sum = LongStream.
range(0, (long) ((end - start) / step)).
parallel().
mapToDouble(i -> start + step * i).
map(sqFuncDouble).
sum();

Spliterator
Collector
Spliterator
Collector
Streams parallel double sum = LongStream.
range(0, (long) ((end - start) / step)).
parallel().
mapToDouble(i -> start + step * i).
map(sqFuncDouble).
sum();
double sum = DoubleStream.
iterate(0.0, s -> s + (end - start) / chunks).
limit(chunks).
parallel().
flatMap(
c -> DoubleStream.
iterate(c, s -> s + step).
limit((long) ((end - start) / (chunks * step)))).
map(sqFuncDouble).
sum();
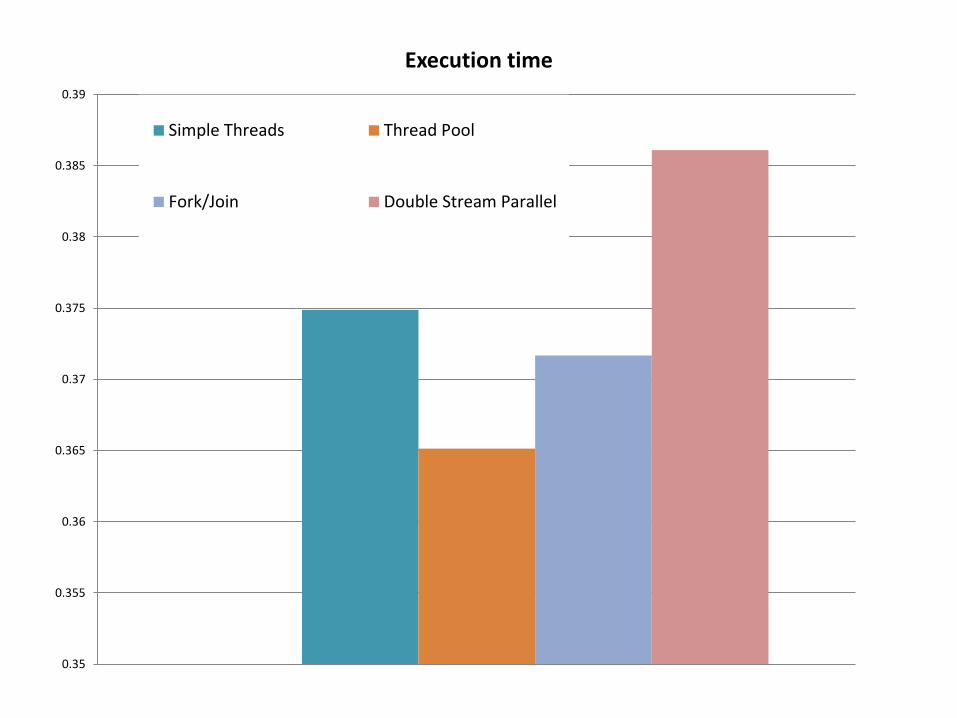
0.35
0.355
0.36
0.365
0.37
0.375
0.38
0.385
0.39
Execution time
Simple Threads Thread Pool
Fork/Join Double Stream Parallel
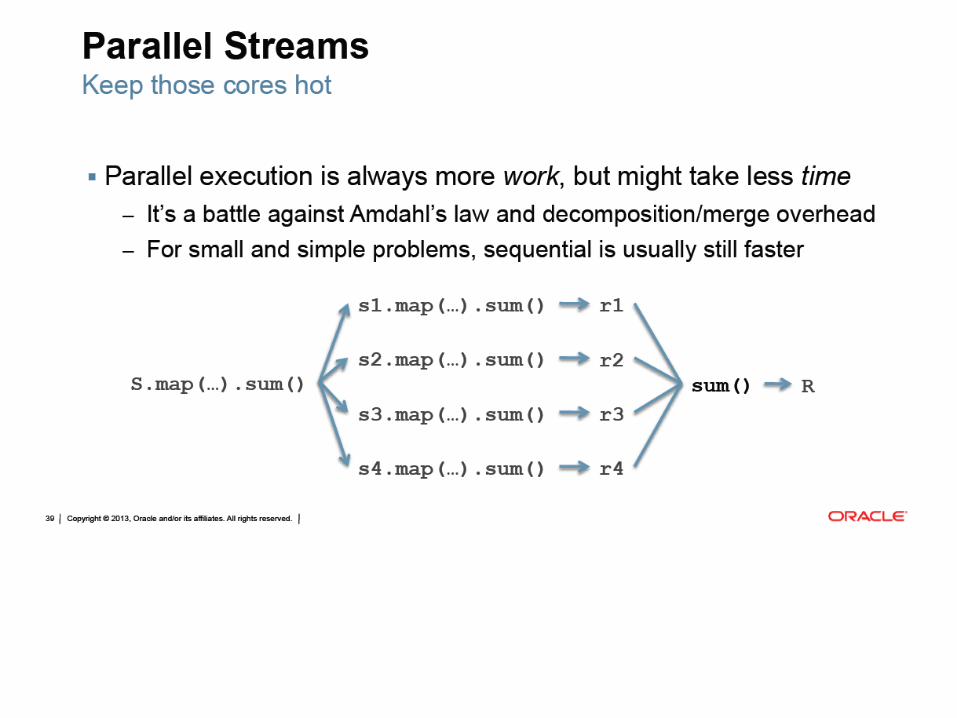
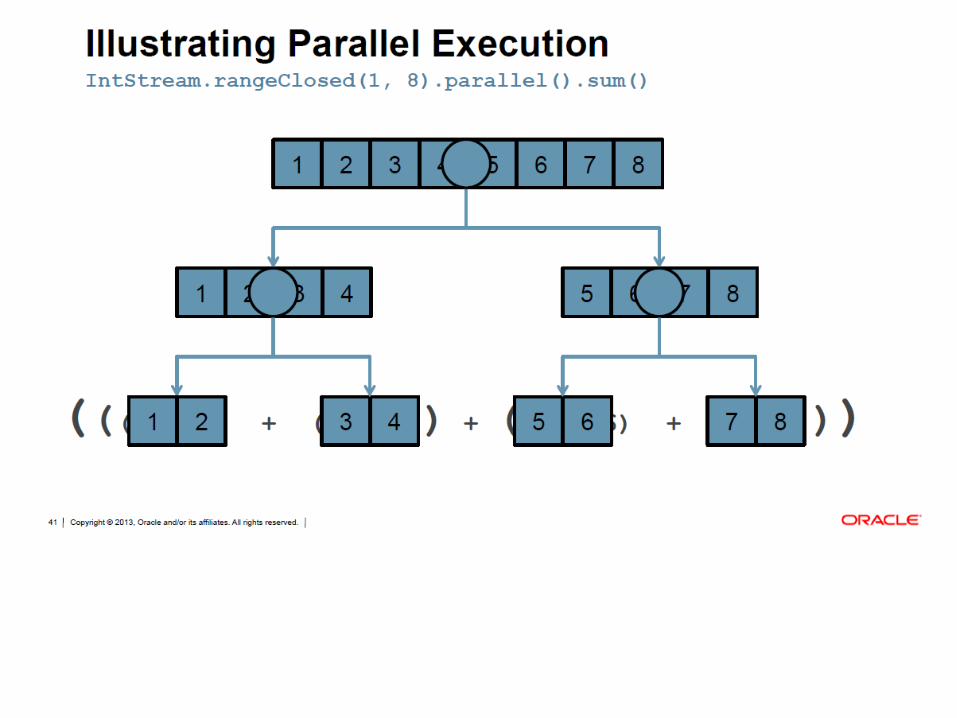
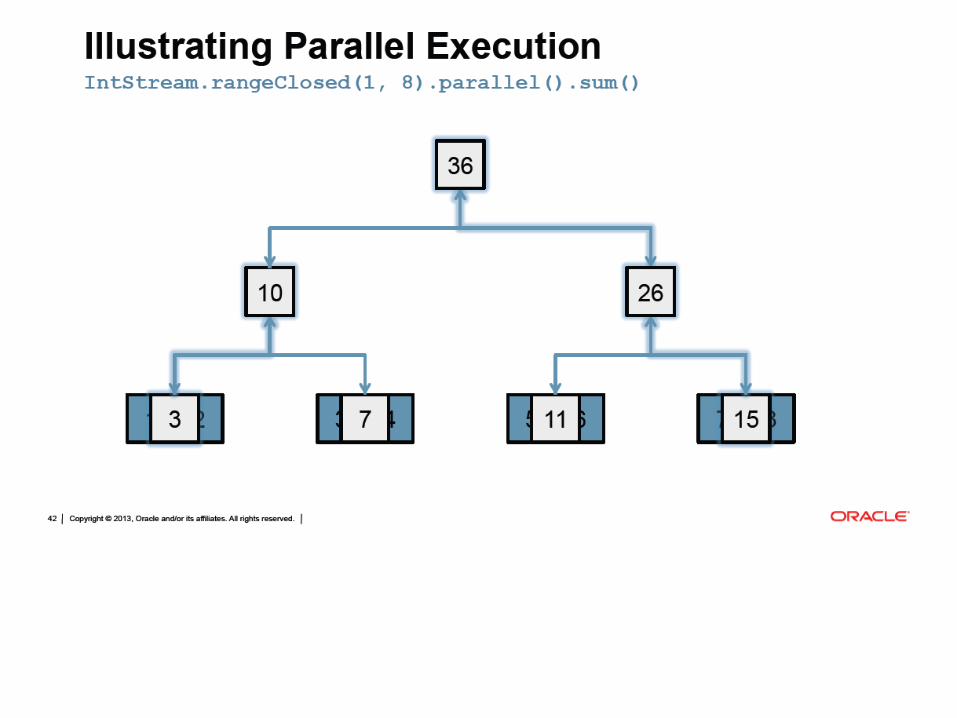
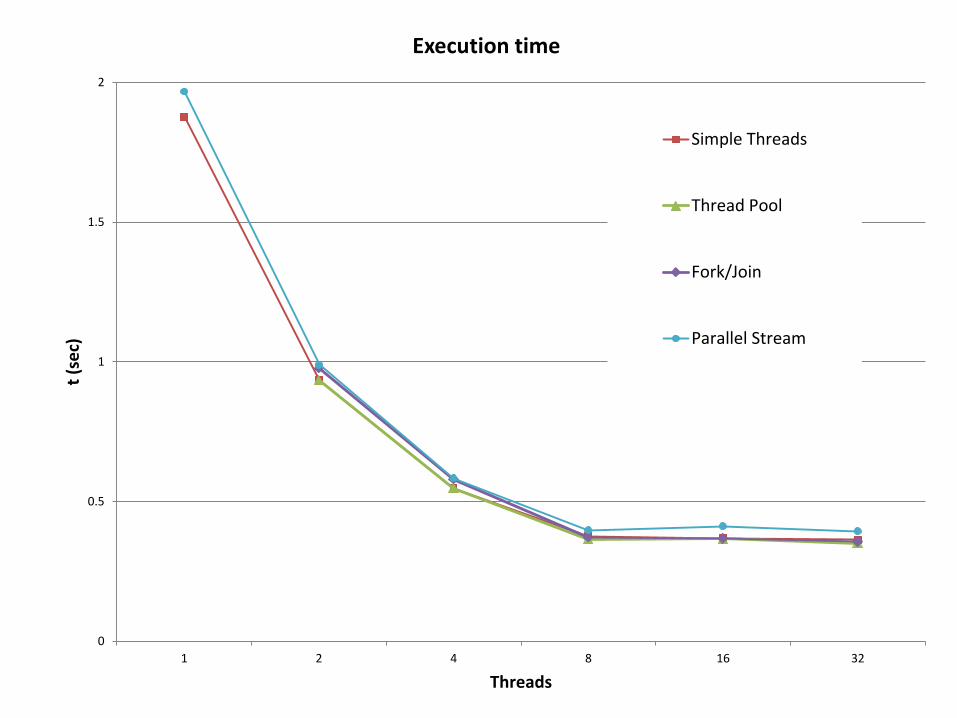
0
0.5
1
1.5
2
1 2 4 8 16 32
t (s
ec)
Threads
Execution time
Simple Threads
Thread Pool
Fork/Join
Parallel Stream
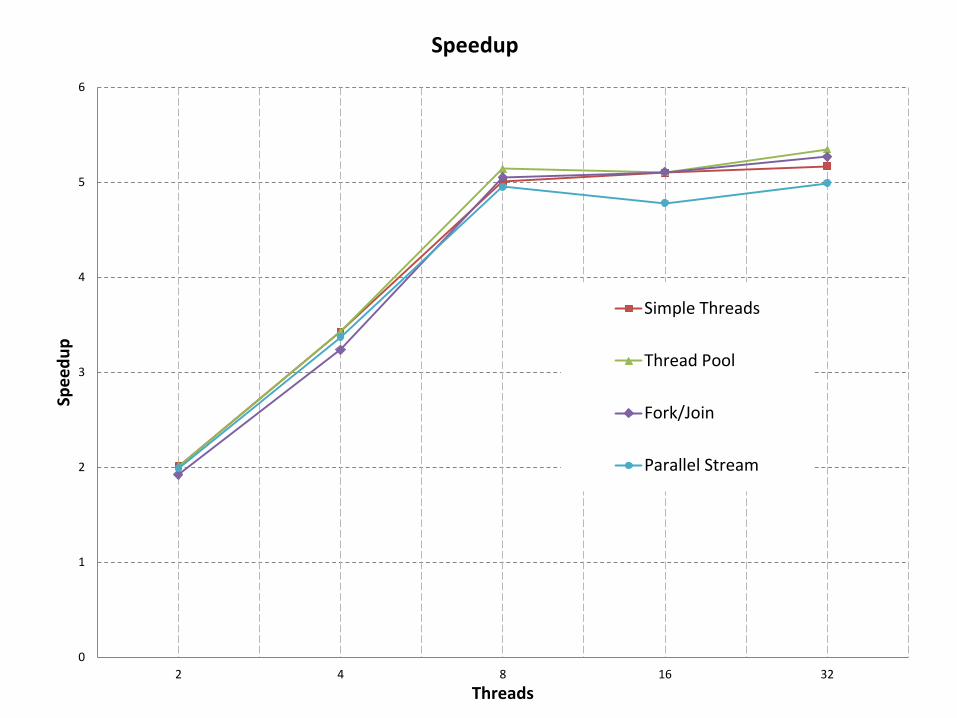
0
1
2
3
4
5
6
2 4 8 16 32
Spe
ed
up
Threads
Speedup
Simple Threads
Thread Pool
Fork/Join
Parallel Stream
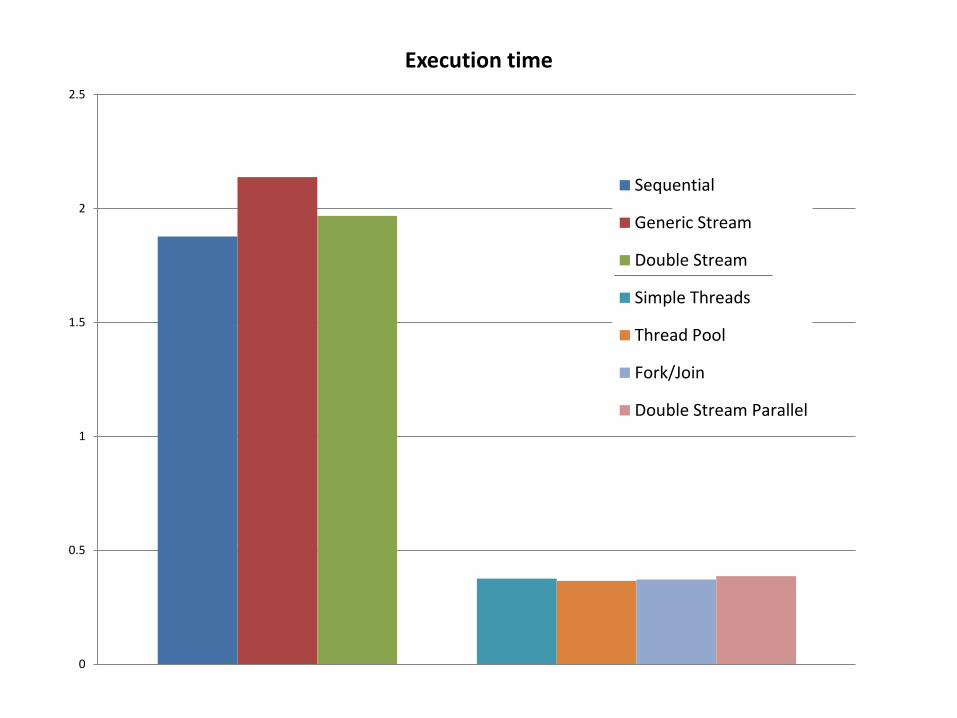
0
0.5
1
1.5
2
2.5
Execution time
Sequential
Generic Stream
Double Stream
Simple Threads
Thread Pool
Fork/Join
Double Stream Parallel

http://stackoverflow.com/questions/20375176/should-i-always-use-a-parallel-stream-when-possible?rq=1
http://stackoverflow.com/questions/20375176/should-i-always-use-a-parallel-stream-when-possible?rq=1
http://stackoverflow.com/questions/20375176/should-i-always-use-a-parallel-stream-when-possible?rq=1
http://stackoverflow.com/questions/20375176/should-i-always-use-a-parallel-stream-when-possible?rq=1
http://stackoverflow.com/questions/20375176/should-i-always-use-a-parallel-stream-when-possible?rq=1
http://stackoverflow.com/questions/20375176/should-i-always-use-a-parallel-stream-when-possible?rq=1
http://stackoverflow.com/questions/20375176/should-i-always-use-a-parallel-stream-when-possible?rq=1
http://stackoverflow.com/questions/20375176/should-i-always-use-a-parallel-stream-when-possible?rq=1
http://stackoverflow.com/questions/20375176/should-i-always-use-a-parallel-stream-when-possible?rq=1
http://stackoverflow.com/questions/20375176/should-i-always-use-a-parallel-stream-when-possible?rq=1
http://stackoverflow.com/questions/20375176/should-i-always-use-a-parallel-stream-when-possible?rq=1
http://stackoverflow.com/questions/20375176/should-i-always-use-a-parallel-stream-when-possible?rq=1
http://stackoverflow.com/questions/20375176/should-i-always-use-a-parallel-stream-when-possible?rq=1
http://stackoverflow.com/questions/20375176/should-i-always-use-a-parallel-stream-when-possible?rq=1
http://stackoverflow.com/questions/20375176/should-i-always-use-a-parallel-stream-when-possible?rq=1
http://stackoverflow.com/questions/20375176/should-i-always-use-a-parallel-stream-when-possible?rq=1
http://stackoverflow.com/questions/20375176/should-i-always-use-a-parallel-stream-when-possible?rq=1
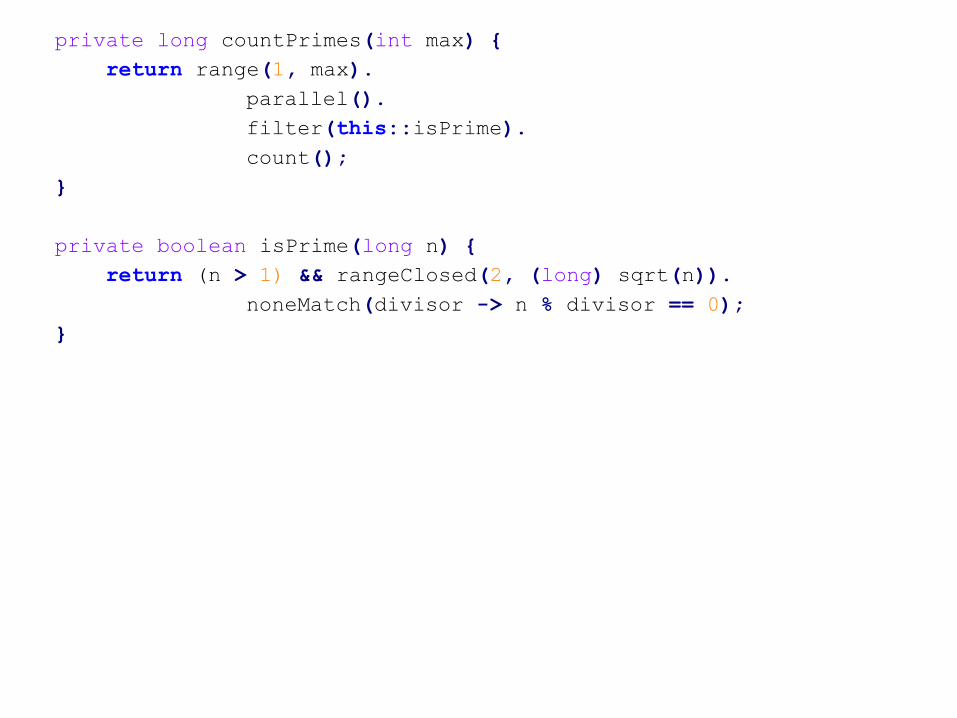
private long countPrimes(int max) {
return range(1, max).
parallel().
filter(this::isPrime).
count();
}
private boolean isPrime(long n) {
return (n > 1) && rangeClosed(2, (long) sqrt(n)).
noneMatch(divisor -> n % divisor == 0);
}

Parallel stream problem https://bugs.openjdk.java.net/browse/JDK-8032512
• The problem is that all parallel streams use common fork-join thread pool and if you submit a long-running task, you effectively block all threads in the pool.
• by default, all streams will use the same ForkJoinPool, configured to use as many threads as there are cores in the computer on which the program is running.
• So, for computation intensive stream evaluation, one should always use a specific ForkJoinPool in order not to block other streams.
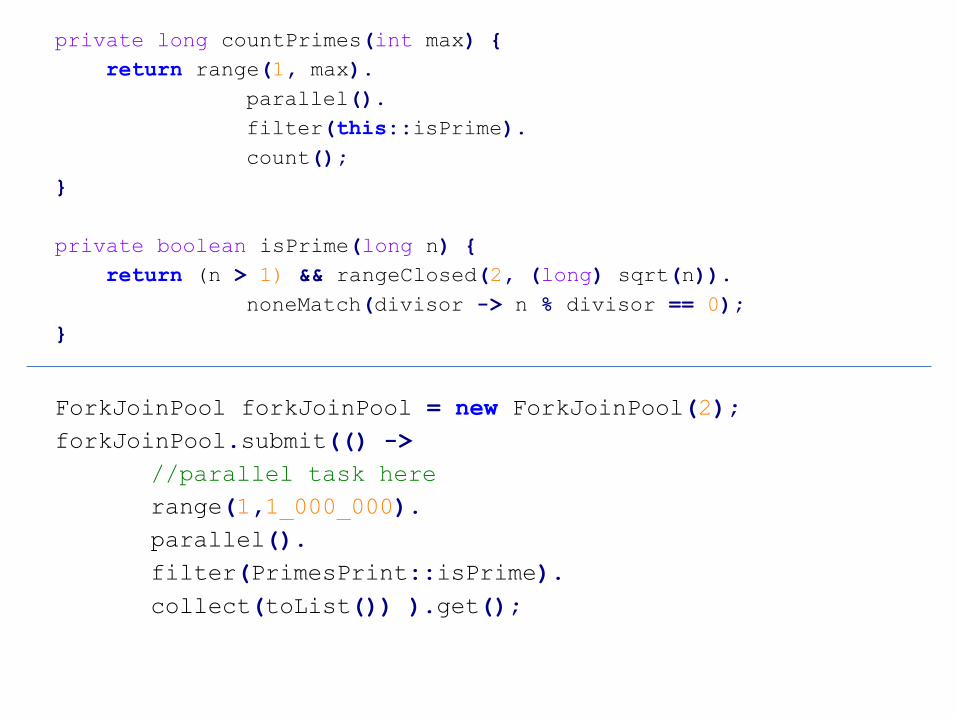
private long countPrimes(int max) {
return range(1, max).
parallel().
filter(this::isPrime).
count();
}
private boolean isPrime(long n) {
return (n > 1) && rangeClosed(2, (long) sqrt(n)).
noneMatch(divisor -> n % divisor == 0);
}
ForkJoinPool forkJoinPool = new ForkJoinPool(2);
forkJoinPool.submit(() ->
//parallel task here
range(1,1_000_000).
parallel().
filter(PrimesPrint::isPrime).
collect(toList()) ).get();

И на последок …
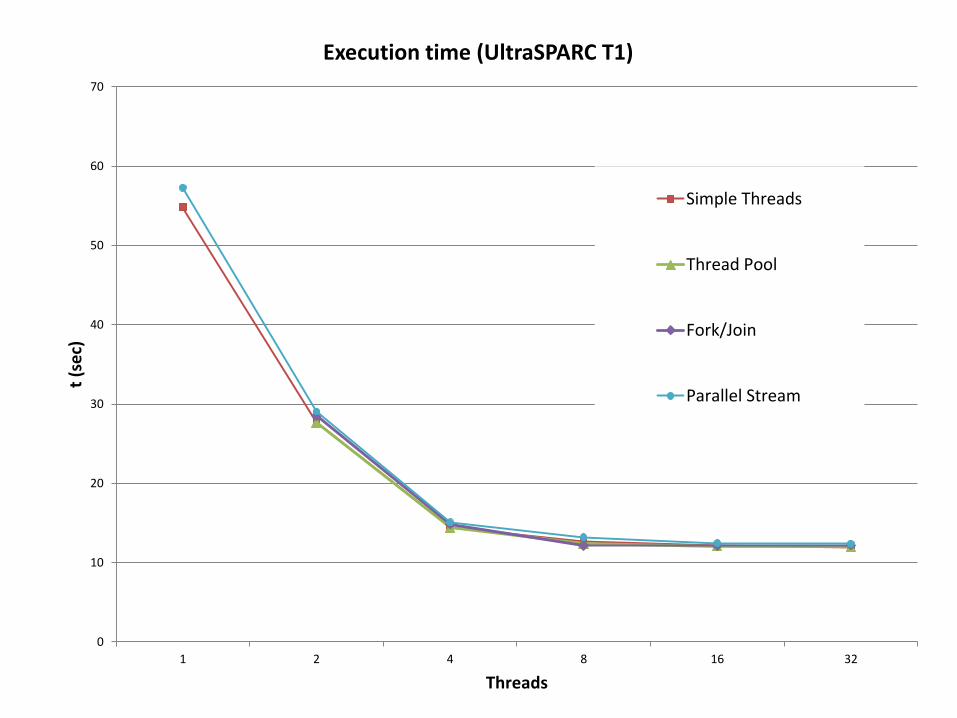
0
10
20
30
40
50
60
70
1 2 4 8 16 32
t (s
ec)
Threads
Execution time (UltraSPARC T1)
Simple Threads
Thread Pool
Fork/Join
Parallel Stream
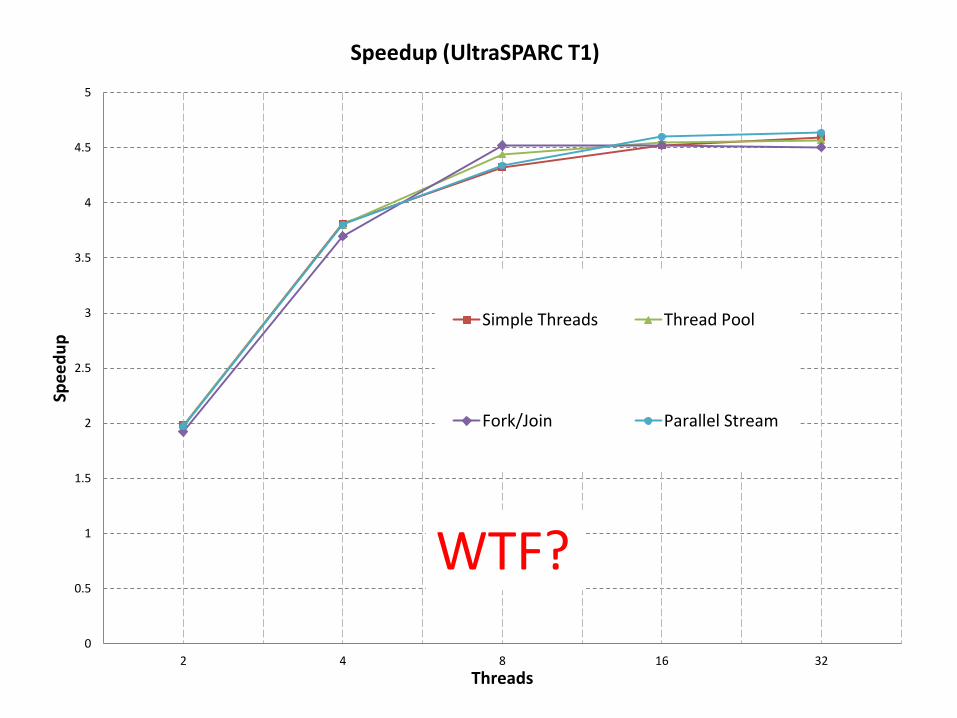
0
0.5
1
1.5
2
2.5
3
3.5
4
4.5
5
2 4 8 16 32
Spe
ed
up
Threads
Speedup (UltraSPARC T1)
Simple Threads Thread Pool
Fork/Join Parallel Stream
WTF?
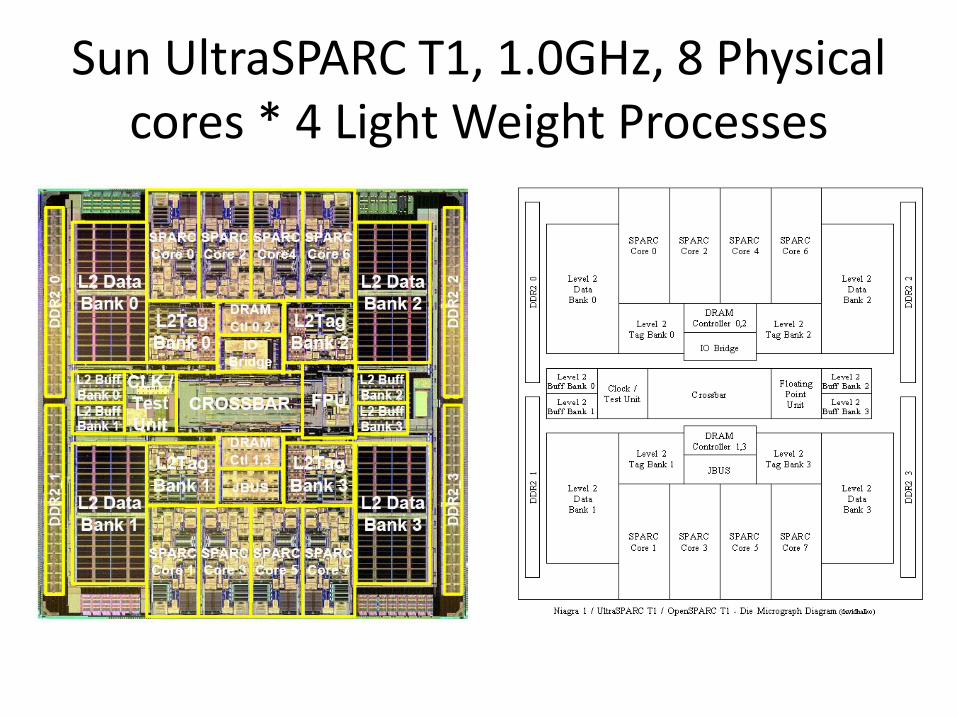
Sun UltraSPARC T1, 1.0GHz, 8 Physical cores * 4 Light Weight Processes

private long countPrimes(int max) {
return range(1, max).
parallel().
filter(this::isPrime).
count();
}
private boolean isPrime(long n) {
return (n > 1) && rangeClosed(2, (long) sqrt(n)).
noneMatch(divisor -> n % divisor == 0);
}
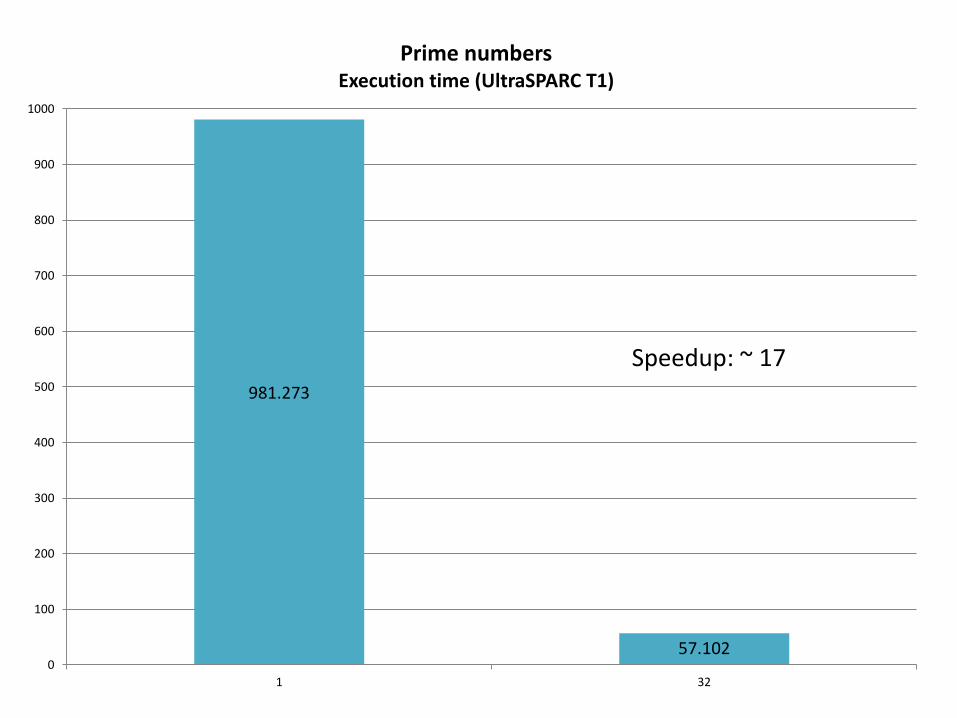
981.273
57.102 0
100
200
300
400
500
600
700
800
900
1000
1 32
Prime numbers Execution time (UltraSPARC T1)
Speedup: ~ 17

Thank you!


















