
ER1 Eduard Barbu - EXPERT Summer School - Malaga 2015
32
Collecting and Cleaning Multilingual Data Eduard Barbu Translated Malaga-26.06.2015
-
Upload
riilp -
Category
Data & Analytics
-
view
137 -
download
3
Transcript of ER1 Eduard Barbu - EXPERT Summer School - Malaga 2015

Collecting and Cleaning Multilingual Data
Eduard Barbu
Translated
Malaga-26.06.2015

Talk Summary
• Collecting Multilingual Data
– Automated generation of translation memories. – Estimating Data in Common Crawl. – Benchmarking crawlers.
• Cleaning Multilingual Data
– Data Estimation in Common Crawl – Crawler Testing – Strategy Implementation

Collecting Multilingual Data Team
• Team – Achim Ruopp – TAUS
– Christian Buck – PhD. Student
– Eduard Barbu – ER1
• Wiki and code – https://github.com/ModernMT/DataCollection
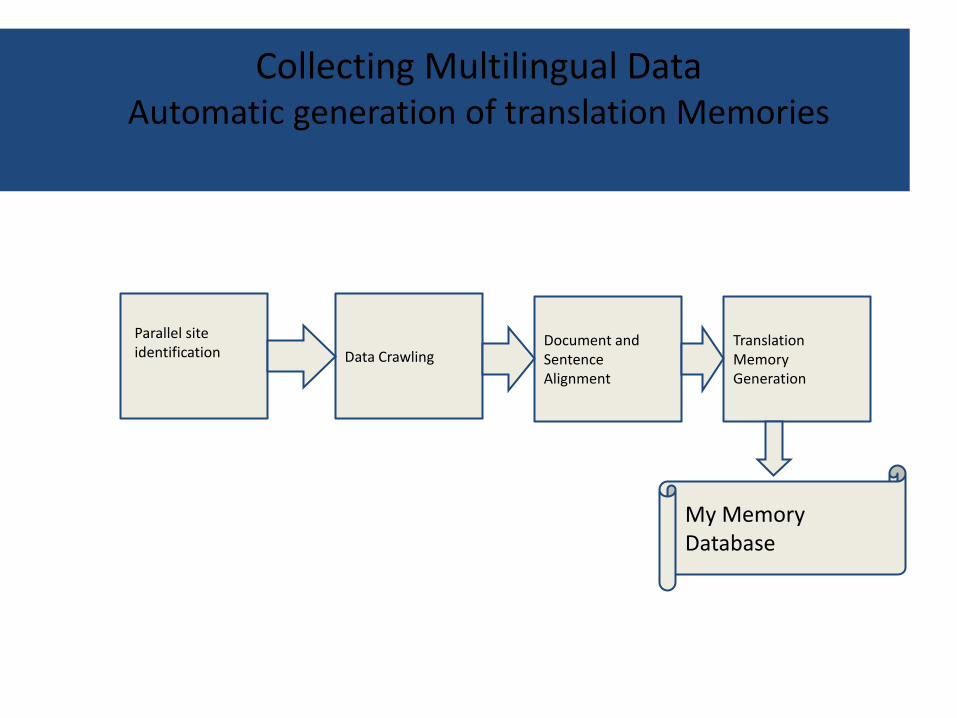
Collecting Multilingual Data
Automatic generation of translation Memories
Data Crawling Document and Sentence Alignment
Translation Memory Generation
Parallel site identification
My Memory Database

Parallel site identification
1. We know them beforehand 2. Use big collection of crawled documents (e.g
Common Crawl) that we know contain parallel documents
3. Apply the STRAND methodology to identify web sites. Use searching engines and name matching heuristics.

From Web to Translation Memories
• Data Crawling
• Document Alignment
• Paragraph and Sentence Alignment

Document Alignment
1. Guess the corresponding document from the URL (directory or language)
2. In general the problem seems to be the low recall.
3. Use features like: text length and various measures of document similarity to compute the corresponding documents. a. Vectors of punctuation, name entities, numbers b. Possibility of alignment of sentences in the document c. More sophisticated techniques ( e.g Eurovoc require some
training)

Paragraph and Sentence Alignment
1. Length Based alignment Algorithms (e.g. Church Gale)
2. Alignment algorithms that take into account the structure of the web page.
3. Available bilingual dictionaries might improve the precision of alignment.
4. Software that can be used (Hungalign, Gargantua etc...)

Data In Common Crawl
• Common Crawl is a nonprofit organization that crawls the web and makes the data available for free
• The data is stored on Amazon Servers
• It is hard to estimate how many pages are in Common Crawl (15-20 billions pages)

Estimation of amount of Parallel Data in Common Crawl
• Draw randomly web pages from Common Crawl indexes.
• Go to the site and find if it has a parallel page.
– Lang identifier in URL – Long Text – Content Translation – Number of words on page

Estimation of amount of Parallel Data in Common Crawl
• 350 pages (6.5 percent have translation) – At a Confidence Level of 80% and a Margin of
error 2% ------ 1024 pages
• We estimate that the Common Crawl has 17 billions pages then we find we have ~ 1 billion parallel pages and 170 billions words.

Testing Crawlers
• Test three crawlers : – ILSP Focused Crawler –public crawler – Bi-Textor –public crawler – TAUS Data Web Spider – in-house web spider. – Take positive and negative example of sites.
• Take positive and negative example of 14 sites (2 negatives) for English, French and Italian.

Testing Crawlers
• Spreadsheet with results.
• Normalize the results to allow the crawler comparison
• Estimate precision and recall using human evaluators.

Conclusions
• In Common Crawl there is a significant quantity of parallel data.
• The existing crawlers have low recall
• We implemented the strategy from the paper “Dirt Cheap Web-Scale Parallel Text from the Common Crawl ” – Extracted around 1 billion words for English-French.
• We prepared bilingual dictionaries (e.g. English-Italian dictionary has 2 millions entries.)

Cleaning Multilingual Data
• Find an automatic method to clean Translation Memories
• Clean : find that those bi-segments that are not true translations.
• Idea: it would be trivial if we knew the true translation of the source segment.

Typology of Errors
• Random Text : Instead of translating the users paste random text.
• Chat: Instead of translating the users chat. – How are you? –Bene. (Well)
• Language Error: The users mistake the language of the segments. – Non ho capito! – I did not understand – non ho capito bene - I do not speak English
• Partial Translations : The users provide partial translations of the segments. – Early 1980’s. Muirfield C.C.- Primi anni 1980.

Data
• Languages:
– English – Italian
• The sets to choose the training and test sets from
: – Mainly Positive Examples : Extracted from MATECAT
(26.813)- MATECAT Set – Mainly Negative Examples (in theory) : Segments
canceled from the web (25.760). Web Set

Examining Data
• Looking for a function that quantifies the length of the two strings. – The Best Results obtained for Church Gale.
• Two Plots : –Plot the distribution of Church Gale Score. – Inspect if this distribution is normal.
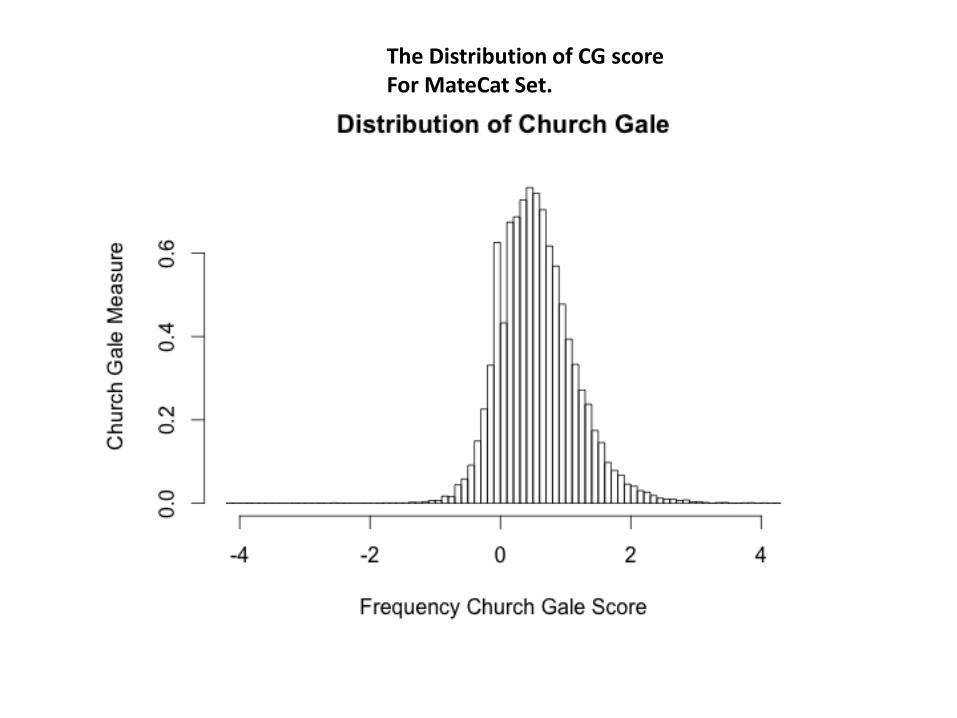
The Distribution of CG score For MateCat Set.
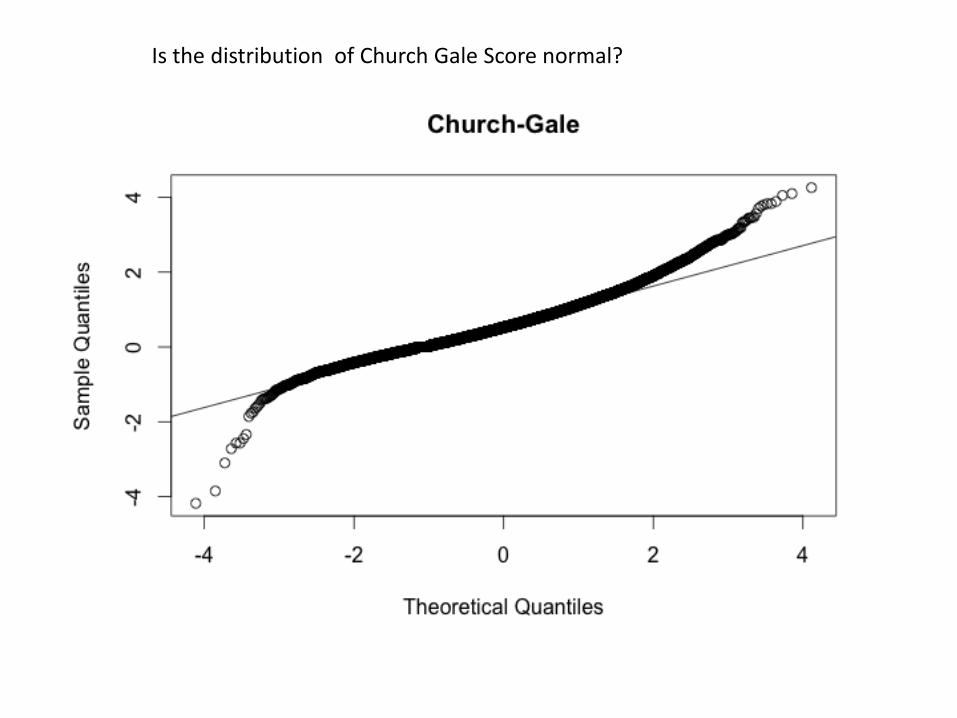
Is the distribution of Church Gale Score normal?
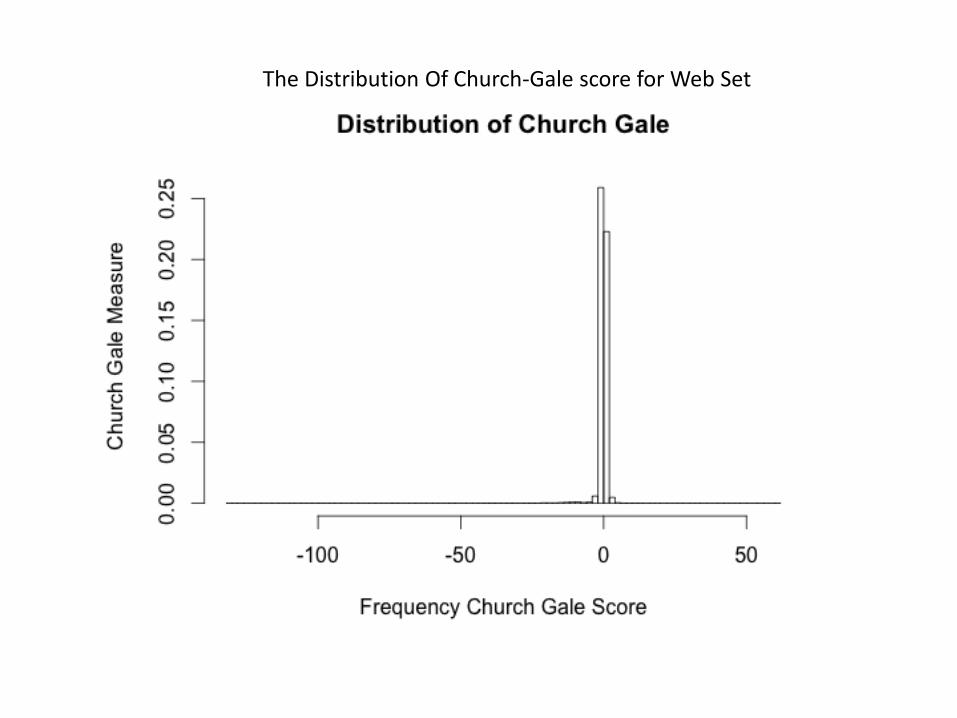
The Distribution Of Church-Gale score for Web Set
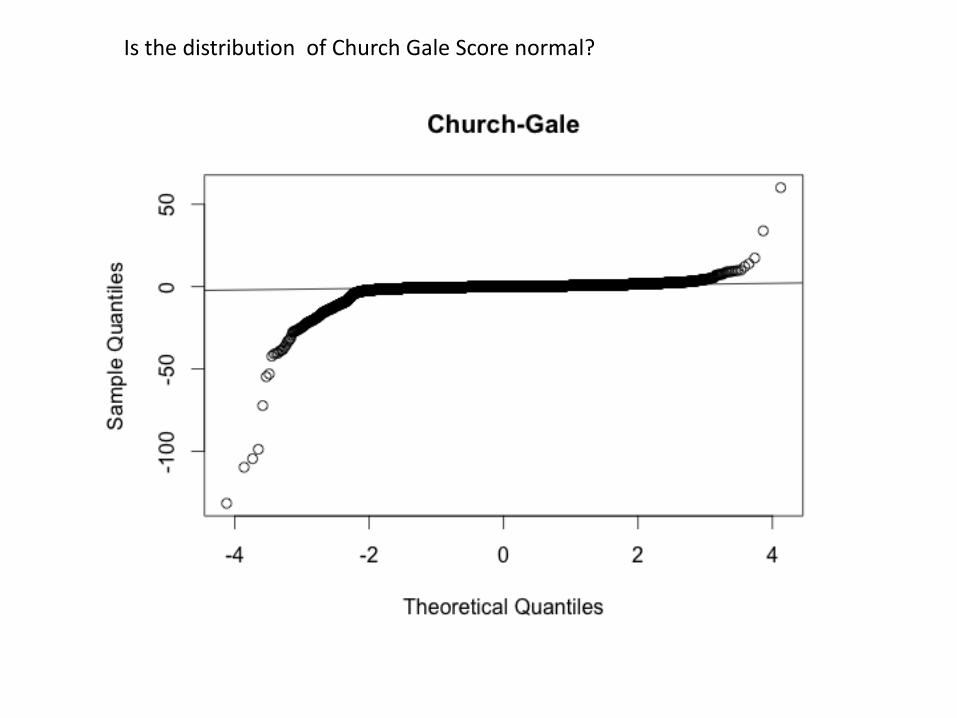
Is the distribution of Church Gale Score normal?

Problem Solution
• Machine Learning Solution • Binary Classification problem:
– Return yes if the source and destination segments in a bi-segment are true translations.
– Return no otherwise.
• Does not work well for partial translations

Training and Test Sets
• Manually chosen after substantial effort.
• Training Set – 1243 Translation Units/ 373 Negatives
• Test Set – 300 Translation Units (87 Negatives).

Features
• church-gale score • same : 1 if the segments are the same. • hasURL: 1 if the source and destination segment contain an
URL address. • hasTag : 1 if the source and destination segment contain a
tag. • hasEmail: 1 if the source and destination segment contain
an email address. • hasNumber : 1 if the source and destination segment
contain a number. • hasCapitalLetters : 1 if the source or target contain words
that have at least a capital letters • hasWordsCapitalLetters: 1 if the source and target contain
whole words in capital letters.

Features • punctsim : cosine similarity for defined punctuation between the
source and destination vectors (0<punctsim<1). • tagsim : cosine similarity between the source and destination tags
(0<tagsim<1) • emailsim : Like above. 0<emailsim<1 • urlsim : Like above. 0<urlsim<1 • numbersim : Like Above (0<numbersim<1) • query_similarity : cosine similarity between source translation and
source. • caplettersworddif: difference between the number of words that
have capital letters in source and destination divided by the total number of cap letter words(0<score<1)
• onlycaplettersdif : Like above with the difference that the score is with respect with only capital letter words(0<score<1)
• lang_dif -difference between the source and destination languages.

Evaluation I.
• Three-Fold Stratified Classification on the training set. – Three Fold- the data is split in three parts: two are
used for training and one for test. – Cross classification: 3 combinations. – Stratified classification : Preserves the percentage
of the positive and negative examples
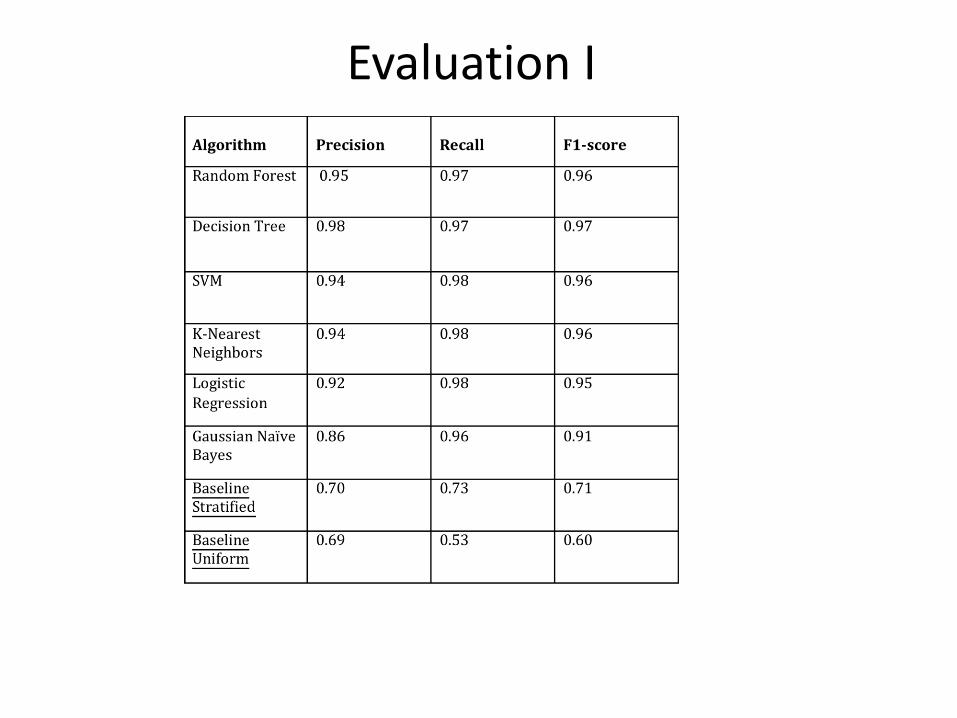
Evaluation I

Evaluation II
• Evaluation: Test Set • The Test randomly drawn from Web Set.
– 300 Translation Units (87 Negatives). – Annotated Manually .
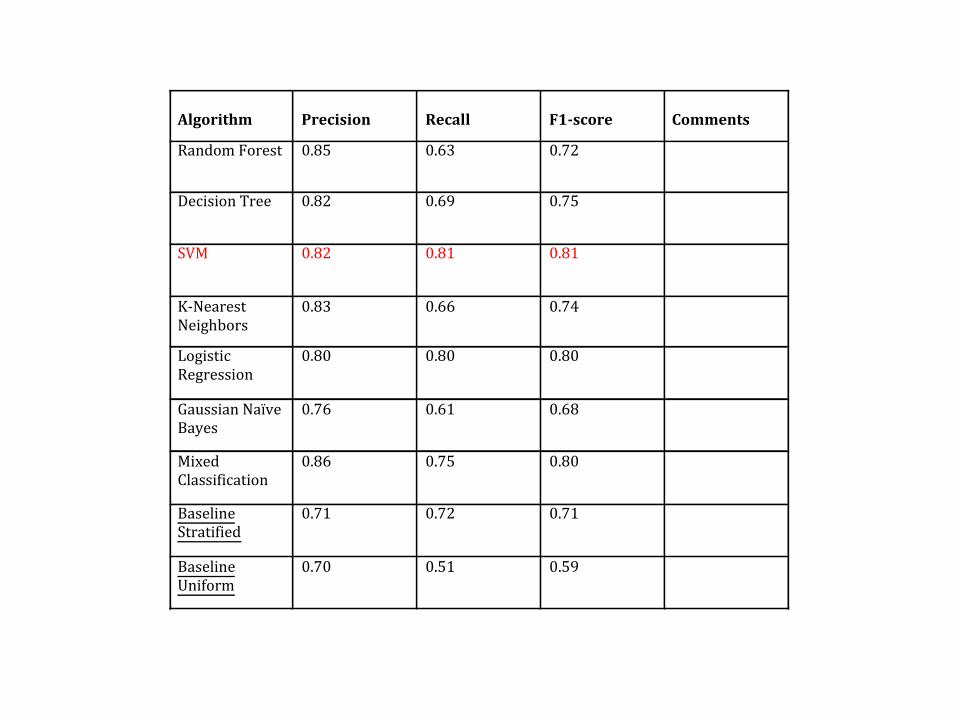
Algorithm
Precision
Recall
F1-score
Comments
RandomForest 0.85 0.63 0.72
DecisionTree 0.82 0.69 0.75
SVM 0.82 0.81 0.81
K-NearestNeighbors
0.83 0.66 0.74
LogisticRegression
0.80 0.80 0.80
GaussianNaïveBayes
0.76 0.61 0.68
MixedClassification
0.86 0.75 0.80
BaselineStratified
0.71 0.72 0.71
BaselineUniform
0.70 0.51 0.59

Conclusions
• The best result SVM. It marginally beats LR. • It might be that a Logistic Regression classifier
that outputs probabilities might be in fact better.
• Try finding better methods without machine learning.

»Thanks!


















