
Aula virtual apache_hadoop_v3 1
67
Centros de Competencia - BA Introducción a Apache Hadoop
-
Upload
moises-martinez-mateu -
Category
Software
-
view
393 -
download
0
Transcript of Aula virtual apache_hadoop_v3 1

Centros de Competencia - BA Introducción a Apache Hadoop

Introducción a Apache Spark
| 2
OBJETIVOS
Obtener una visión general de Apache Hadoop y su amplio y complejo ecosistema

Introducción a Apache Spark
| 3
AGENDA
Big Data Apache Hadoop Ecosistema de Hadoop Hadoop 2.0

Introducción a Apache Spark
| 4
CARACTERÍSTICAS - VOLUMEN
Capacidad de almacenar una gran cantidad de datos El volumen de datos se incrementa exponencialmente: (44x de 2009 a 2020)
Big Data

Introducción a Apache Spark
| 5
CARACTERÍSTICAS - VOLUMEN
Capacidad de almacenar una gran cantidad de datos El volumen de datos se incrementa exponencialmente: (44x de 2009 a 2020)
Big Data

Introducción a Apache Spark
| 6
CARACTERÍSTICAS - VARIEDAD
Capacidad de combinar datos en los diferentes formatos que se generan (textos, imágenes, vídeos, audios, logs, json, xml, pdf, bbdd, emails, etc.)
Big Data

Introducción a Apache Spark
| 7
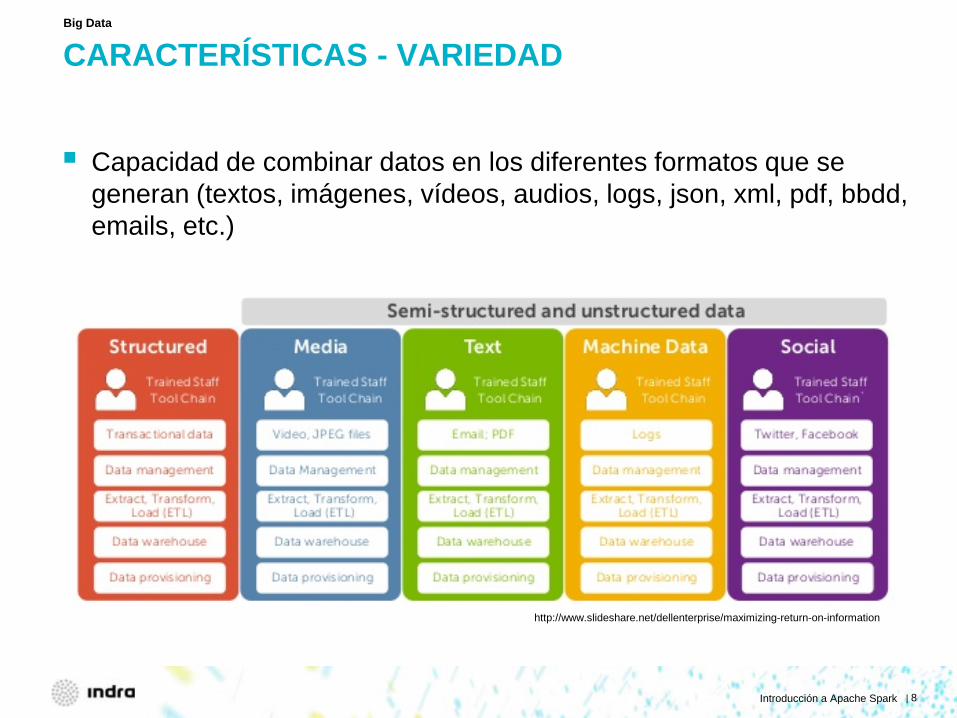
CARACTERÍSTICAS - VARIEDAD
Capacidad de combinar datos en los diferentes formatos que se generan (textos, imágenes, vídeos, audios, logs, json, xml, pdf, bbdd, emails, etc.)
Big Data
Introducción a Apache Spark
| 8
CARACTERÍSTICAS - VARIEDAD
Capacidad de combinar datos en los diferentes formatos que se generan (textos, imágenes, vídeos, audios, logs, json, xml, pdf, bbdd, emails, etc.)
Big Data
http://www.slideshare.net/dellenterprise/maximizing-return-on-information
Introducción a Apache Spark
| 9
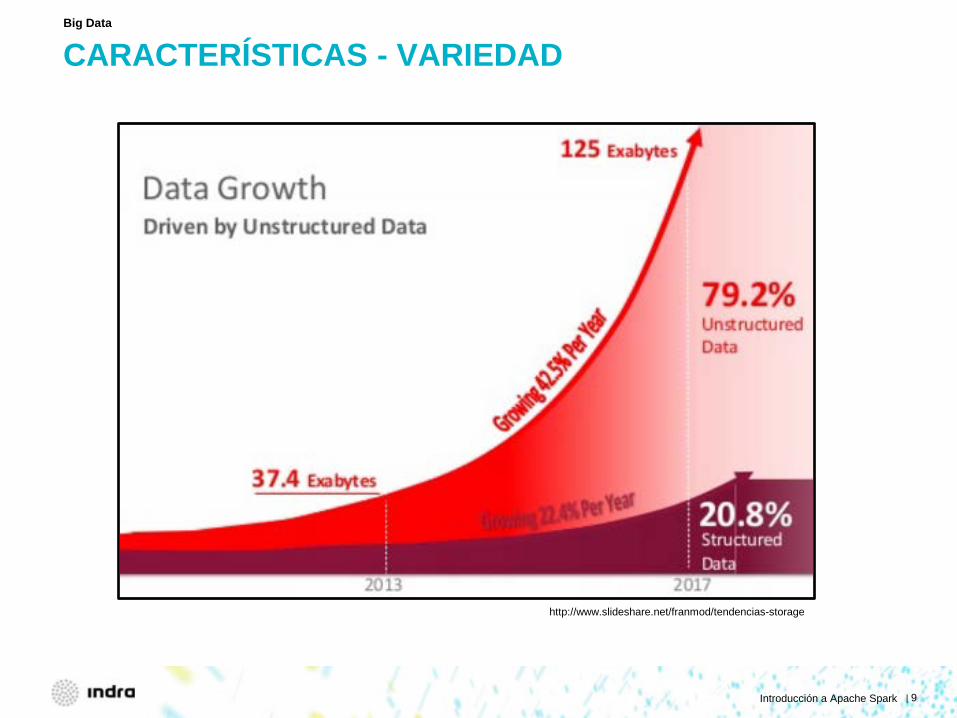
CARACTERÍSTICAS - VARIEDAD
Big Data
http://www.slideshare.net/franmod/tendencias-storage
Introducción a Apache Spark
| 10
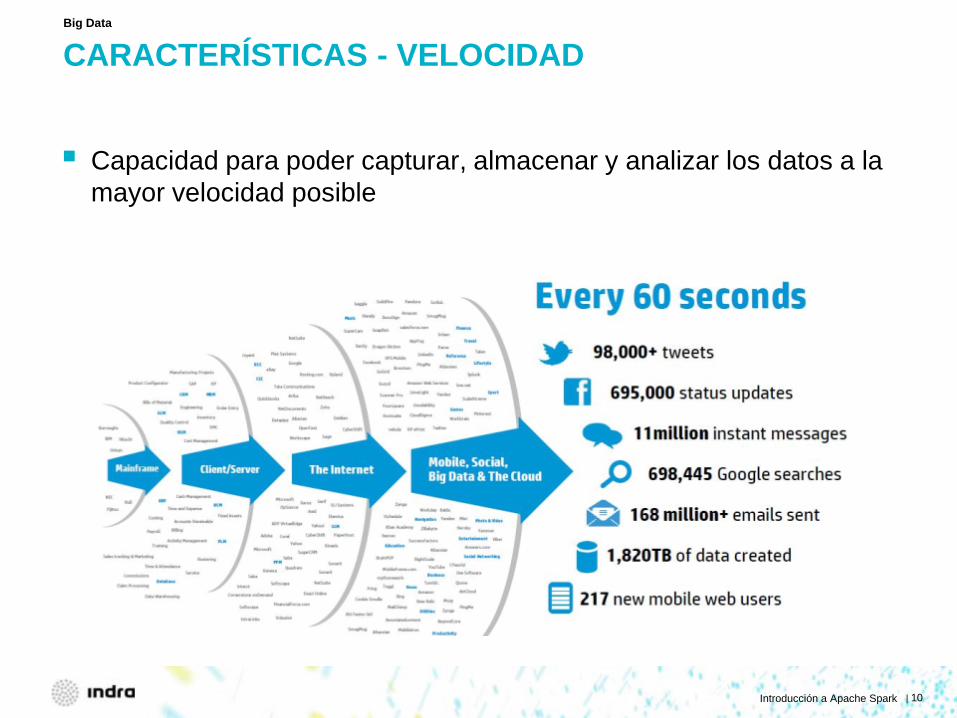
CARACTERÍSTICAS - VELOCIDAD
Capacidad para poder capturar, almacenar y analizar los datos a la mayor velocidad posible
Big Data
Introducción a Apache Spark
| 11
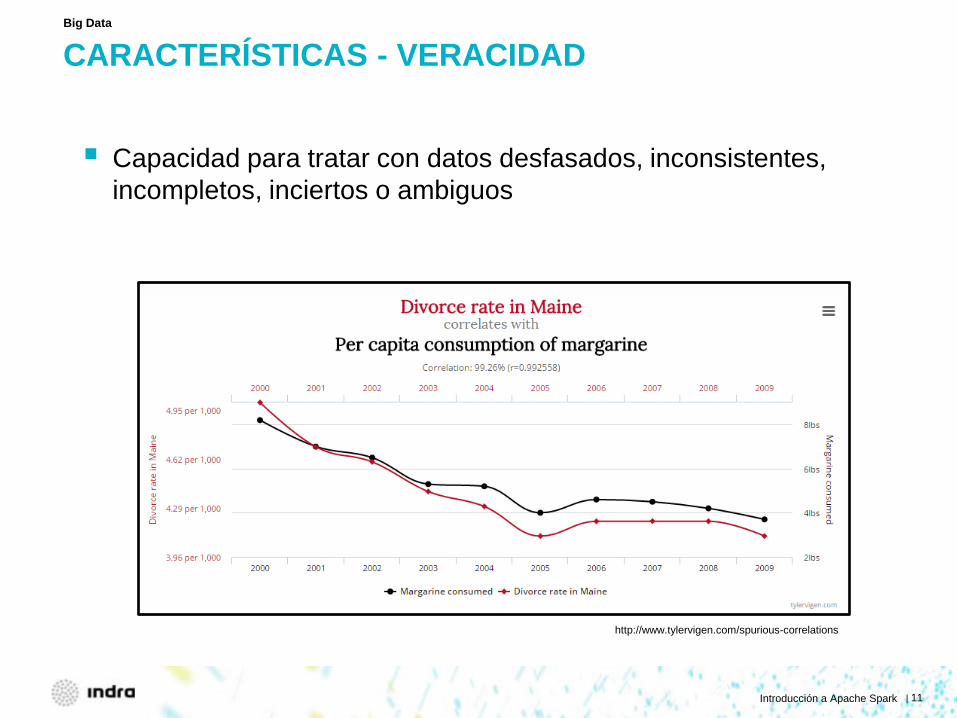
CARACTERÍSTICAS - VERACIDAD
Capacidad para tratar con datos desfasados, inconsistentes, incompletos, inciertos o ambiguos
Big Data
http://www.tylervigen.com/spurious-correlations
Introducción a Apache Spark
| 12
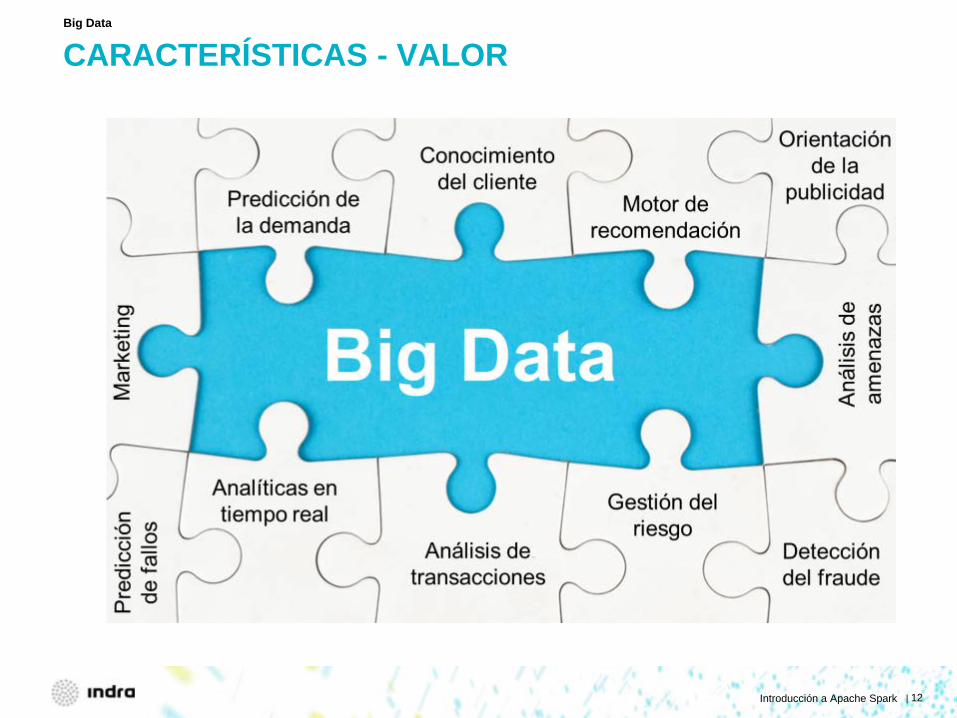
CARACTERÍSTICAS - VALOR
Big Data

Introducción a Apache Spark
| 13
Problema

Introducción a Apache Spark
| 14
SOLUCION TRADICIONAL La meta es tener una máquina cada vez más poderosa (memoria,
procesador, etc.)
Big Data

Introducción a Apache Spark
| 15
SOLUCION TRADICIONAL La meta es tener una máquina cada vez más poderosa (memoria,
procesador, etc.) Escalabilidad limitada Alto coste
Big Data
Introducción a Apache Spark
| 16
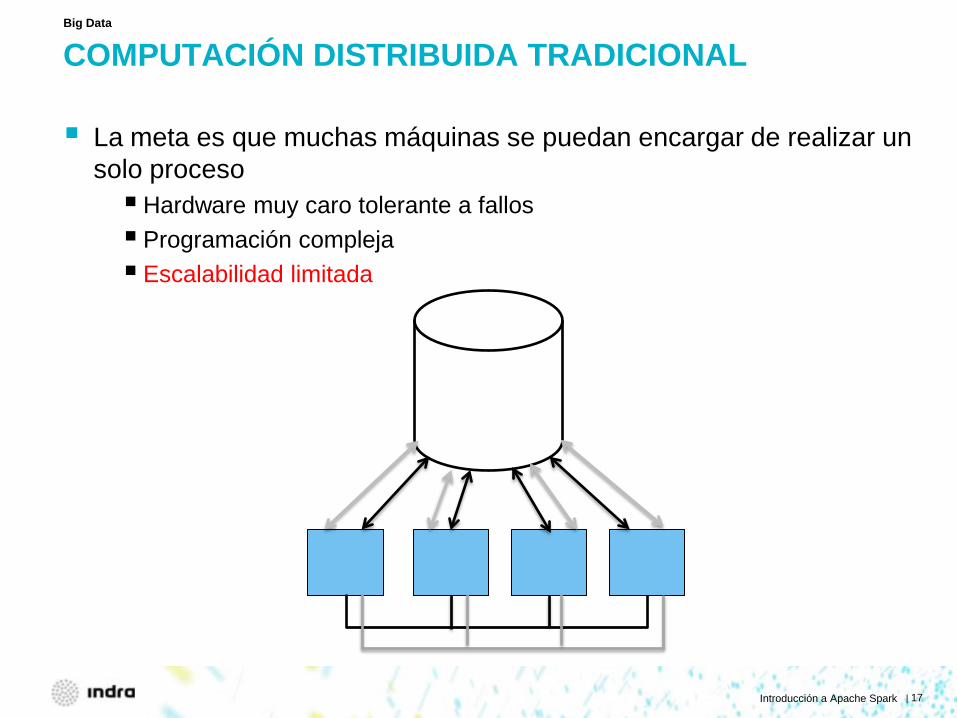
COMPUTACIÓN DISTRIBUIDA TRADICIONAL La meta es que muchas máquinas se puedan encargar de realizar un
solo proceso
Big Data
Introducción a Apache Spark
| 17
COMPUTACIÓN DISTRIBUIDA TRADICIONAL La meta es que muchas máquinas se puedan encargar de realizar un
solo proceso Hardware muy caro tolerante a fallos Programación compleja Escalabilidad limitada
Big Data

Introducción a Apache Spark
| 18
AGENDA
Big Data Apache Hadoop Ecosistema de Hadoop Hadoop 2.0
Introducción a Apache Spark
| 19
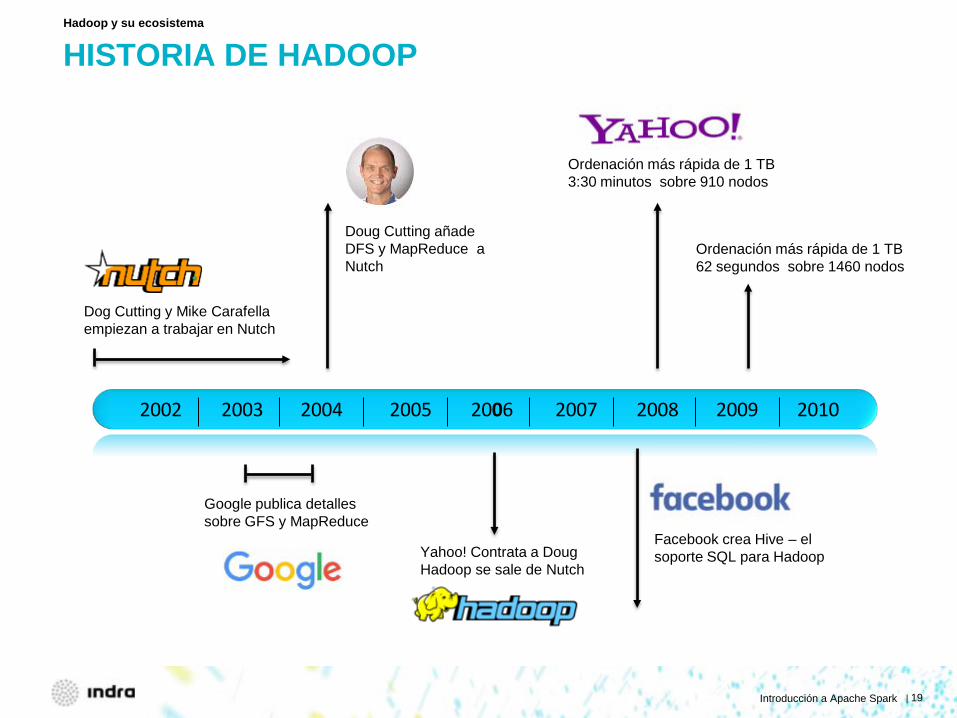
HISTORIA DE HADOOP
Hadoop y su ecosistema
2002 2003 2004 2005 2006 2007 2008 2009 2010
Dog Cutting y Mike Carafella empiezan a trabajar en Nutch
Google publica detalles sobre GFS y MapReduce
Doug Cutting añade DFS y MapReduce a Nutch
Yahoo! Contrata a Doug Hadoop se sale de Nutch
Facebook crea Hive – el soporte SQL para Hadoop
Ordenación más rápida de 1 TB 3:30 minutos sobre 910 nodos
Ordenación más rápida de 1 TB 62 segundos sobre 1460 nodos

Introducción a Apache Spark
| 20
¿QUÉ ES HADOOP?
Hadoop es un sistema para el almacenamiento y el procesamiento distribuido de datos a gran escala
Hadoop proporciona dos componentes:
Almacenamiento de datos: HDFS Procesamiento de datos: MapReduce
Hadoop y su ecosistema

Introducción a Apache Spark
| 21
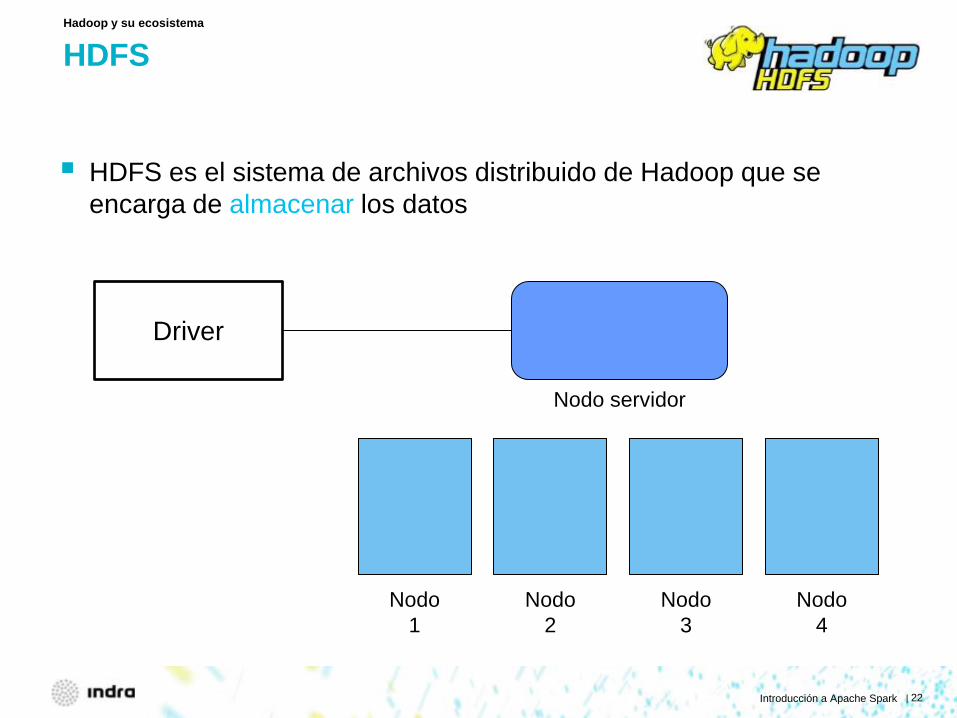
HDFS
HDFS es el sistema de archivos distribuido de Hadoop que se encarga de almacenar los datos
Hadoop y su ecosistema
Introducción a Apache Spark
| 22
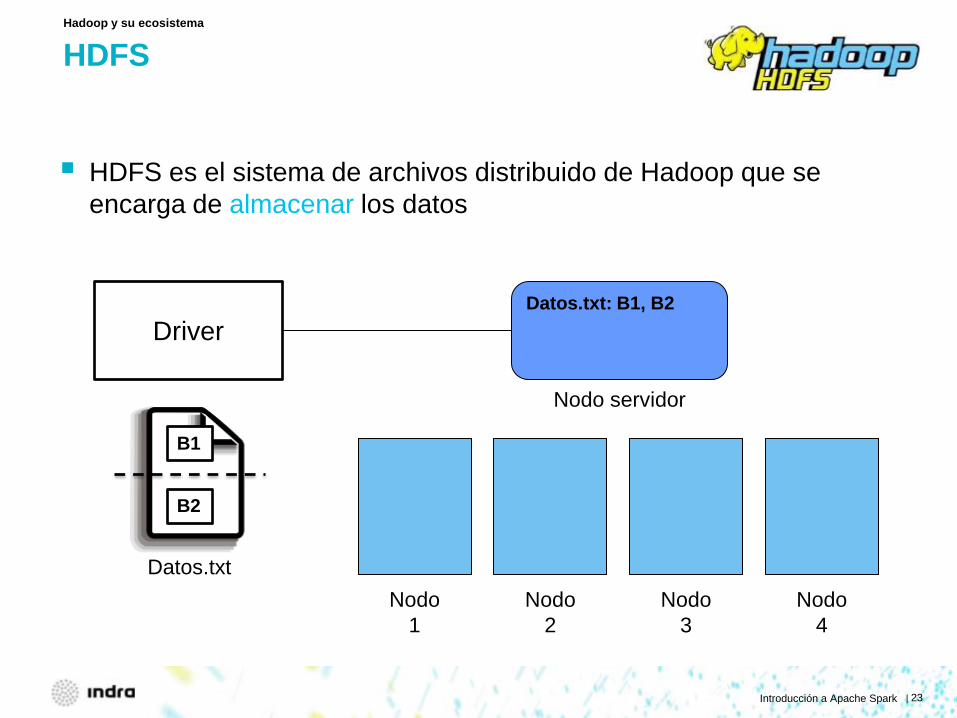
HDFS
HDFS es el sistema de archivos distribuido de Hadoop que se encarga de almacenar los datos
Hadoop y su ecosistema
Nodo 1
Nodo 2
Nodo 3
Nodo 4
Nodo servidor
Driver
Introducción a Apache Spark
| 23
HDFS
HDFS es el sistema de archivos distribuido de Hadoop que se encarga de almacenar los datos
Hadoop y su ecosistema
Nodo 1
Nodo 2
Nodo 3
Nodo 4
Datos.txt: B1, B2
Nodo servidor
Driver
Datos.txt
B1
B2
Introducción a Apache Spark
| 24
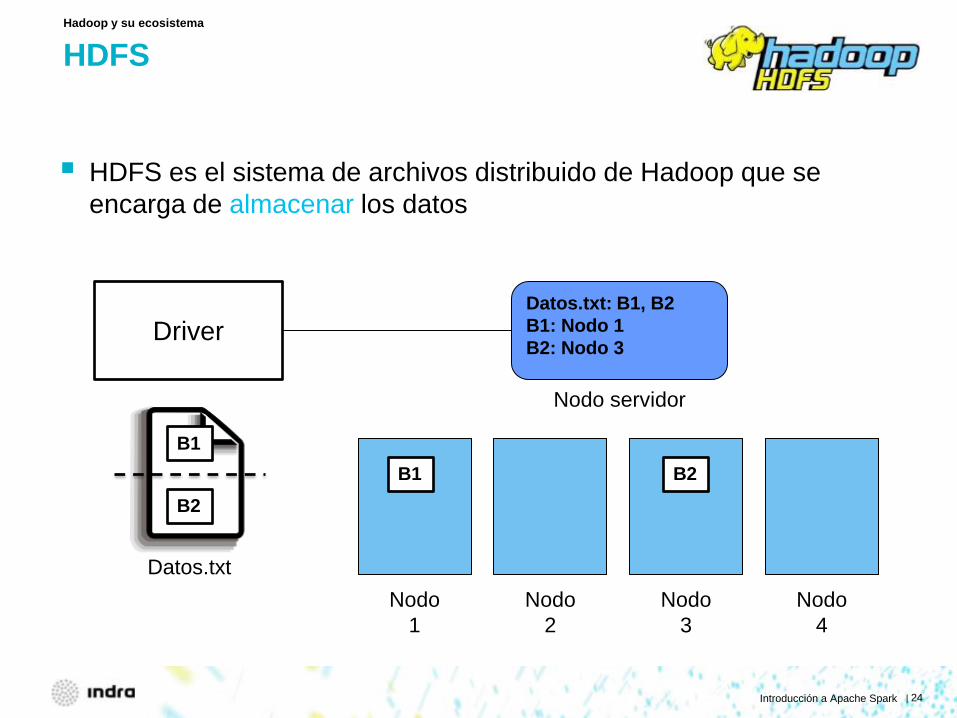
HDFS
HDFS es el sistema de archivos distribuido de Hadoop que se encarga de almacenar los datos
Hadoop y su ecosistema
Nodo 1
Nodo 2
Nodo 3
Nodo 4
Datos.txt: B1, B2 B1: Nodo 1 B2: Nodo 3
Nodo servidor
Driver
Datos.txt
B1
B2 B1 B2
Introducción a Apache Spark
| 25
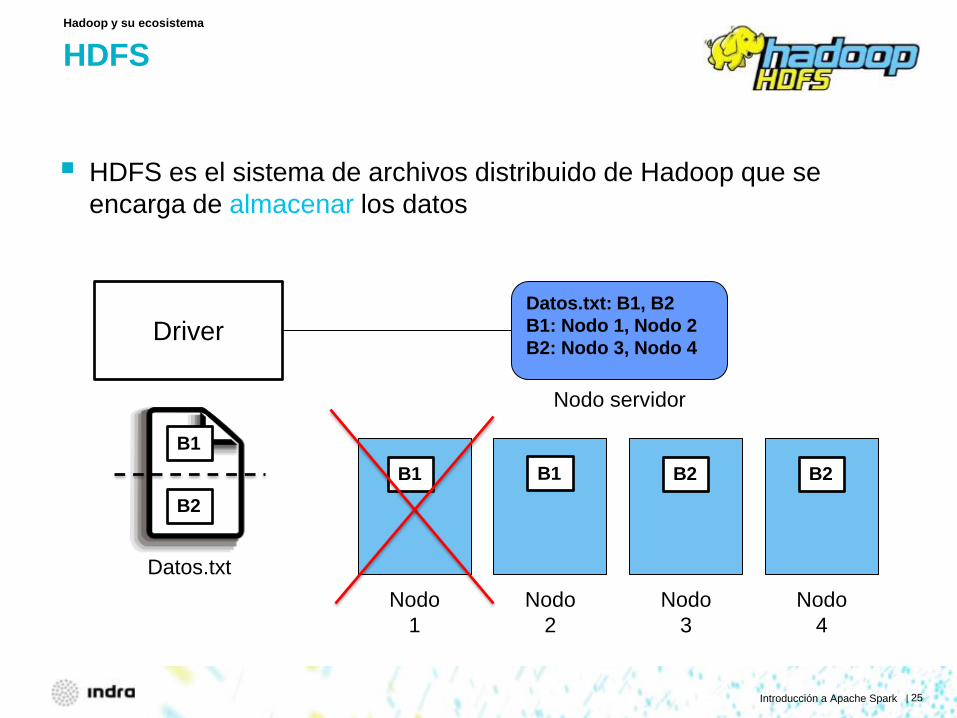
HDFS
HDFS es el sistema de archivos distribuido de Hadoop que se encarga de almacenar los datos
Hadoop y su ecosistema
Nodo 1
Nodo 2
Nodo 3
Nodo 4
Datos.txt: B1, B2 B1: Nodo 1, Nodo 2 B2: Nodo 3, Nodo 4
Nodo servidor
Driver
Datos.txt
B1
B2 B1 B2 B1 B2

Introducción a Apache Spark
| 26
MAPREDUCE
MapReduce es el sistema que utiliza Hadoop para procesar los datos en un clúster
Hadoop y su ecosistema

Introducción a Apache Spark
| 27
MAPREDUCE - EJEMPLO
¿Cómo cuento el número de ocurrencias de cada palabra en un documento?
Hadoop y su ecosistema
“Me llamo Lola Me llamo Claudia Me llamo Aimar Pilar me llamo Te gustan los perros?”
{Me: 4, llamo: 4, Lola: 1, Claudia: 1, Aimar: 1, Pilar: 1, …}

Introducción a Apache Spark
| 28
MAPREDUCE - EJEMPLO
Primera aproximación: Uso de una colección de claves / valores
Hadoop y su ecosistema
Colección Clave / Valor

Introducción a Apache Spark
| 29
MAPREDUCE - EJEMPLO
Primera aproximación: Uso de una colección de claves / valores
Hadoop y su ecosistema
“Me llamo Lola Me llamo Claudia Me llamo Aimar Pilar me llamo ¿Te gustan los perros?”
{}

Introducción a Apache Spark
| 30
MAPREDUCE - EJEMPLO
Primera aproximación: Uso de una colección de claves / valores
Hadoop y su ecosistema
“Me llamo Lola Me llamo Claudia Me llamo Aimar Pilar me llamo ¿Te gustan los perros?”
{Me: 1}

Introducción a Apache Spark
| 31
MAPREDUCE - EJEMPLO
Primera aproximación: Uso de una colección de claves / valores
Hadoop y su ecosistema
“Me llamo Lola Me llamo Claudia Me llamo Aimar Pilar me llamo ¿Te gustan los perros?”
{Me: 1, llamo: 1}

Introducción a Apache Spark
| 32
MAPREDUCE - EJEMPLO
Primera aproximación: Uso de una hashtable
Hadoop y su ecosistema
“Me llamo Lola Me llamo Claudia Me llamo Aimar Pilar me llamo ¿Te gustan los perros?”
{Me: 1, llamo: 1, Lola: 1}

Introducción a Apache Spark
| 33
MAPREDUCE - EJEMPLO
Primera aproximación: Uso de una hashtable
Hadoop y su ecosistema
“Me llamo Lola Me llamo Claudia Me llamo Aimar Pilar me llamo ¿Te gustan los perros?”
{Me: 2, llamo: 1, Lola: 1}
Introducción a Apache Spark
| 34
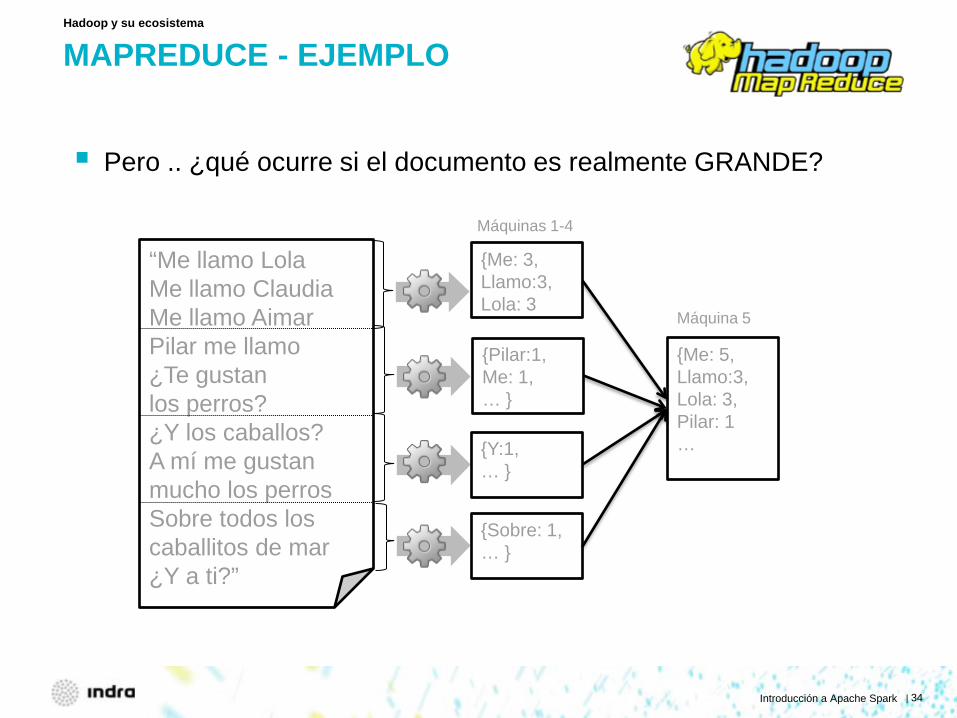
MAPREDUCE - EJEMPLO
Pero .. ¿qué ocurre si el documento es realmente GRANDE?
Hadoop y su ecosistema
“Me llamo Lola Me llamo Claudia Me llamo Aimar Pilar me llamo ¿Te gustan los perros? ¿Y los caballos? A mí me gustan mucho los perros Sobre todos los caballitos de mar ¿Y a ti?”
{Me: 3, Llamo:3, Lola: 3
{Pilar:1, Me: 1, … }
{Y:1, … }
{Sobre: 1, … }
{Me: 5, Llamo:3, Lola: 3, Pilar: 1 …
Máquinas 1-4
Máquina 5
Introducción a Apache Spark
| 35
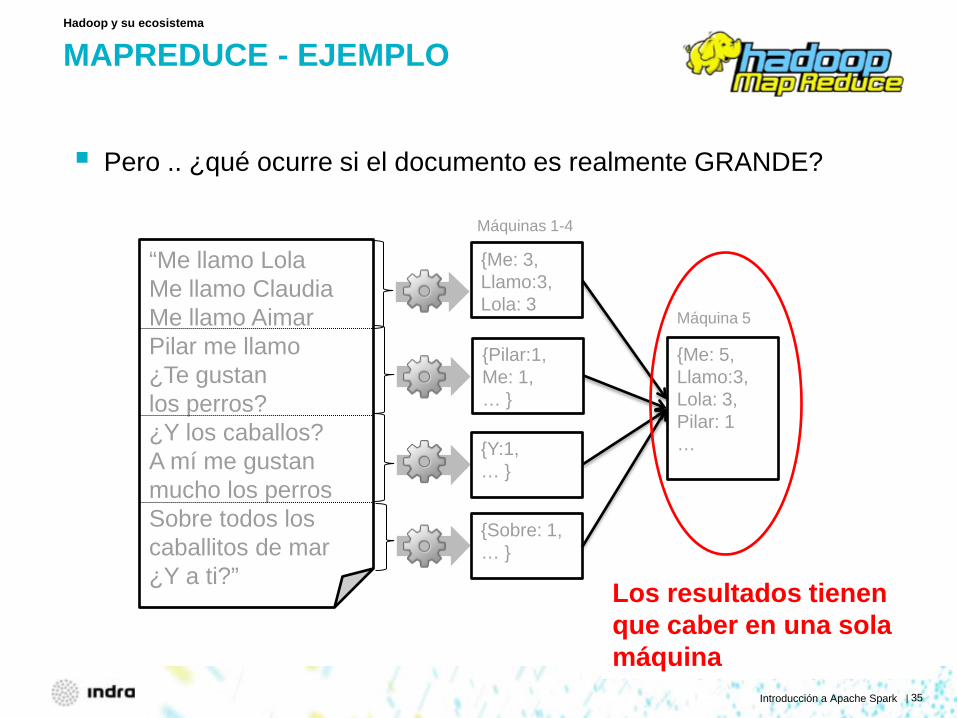
MAPREDUCE - EJEMPLO
Pero .. ¿qué ocurre si el documento es realmente GRANDE?
Hadoop y su ecosistema
“Me llamo Lola Me llamo Claudia Me llamo Aimar Pilar me llamo ¿Te gustan los perros? ¿Y los caballos? A mí me gustan mucho los perros Sobre todos los caballitos de mar ¿Y a ti?”
{Me: 3, Llamo:3, Lola: 3
{Pilar:1, Me: 1, … }
{Y:1, … }
{Sobre: 1, … }
{Me: 5, Llamo:3, Lola: 3, Pilar: 1 …
Máquinas 1-4
Máquina 5
Los resultados tienen que caber en una sola máquina
Introducción a Apache Spark
| 36
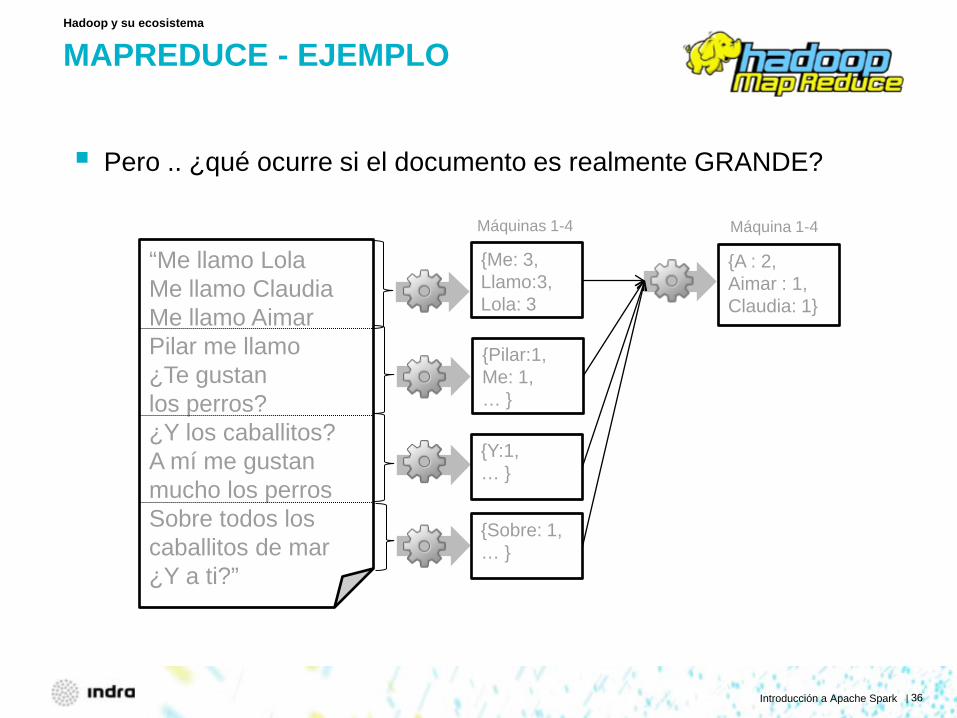
MAPREDUCE - EJEMPLO
Pero .. ¿qué ocurre si el documento es realmente GRANDE?
Hadoop y su ecosistema
“Me llamo Lola Me llamo Claudia Me llamo Aimar Pilar me llamo ¿Te gustan los perros? ¿Y los caballitos? A mí me gustan mucho los perros Sobre todos los caballitos de mar ¿Y a ti?”
{Me: 3, Llamo:3, Lola: 3
{Pilar:1, Me: 1, … }
{Y:1, … }
{Sobre: 1, … }
{A : 2, Aimar : 1, Claudia: 1}
Máquinas 1-4 Máquina 1-4
Introducción a Apache Spark
| 37
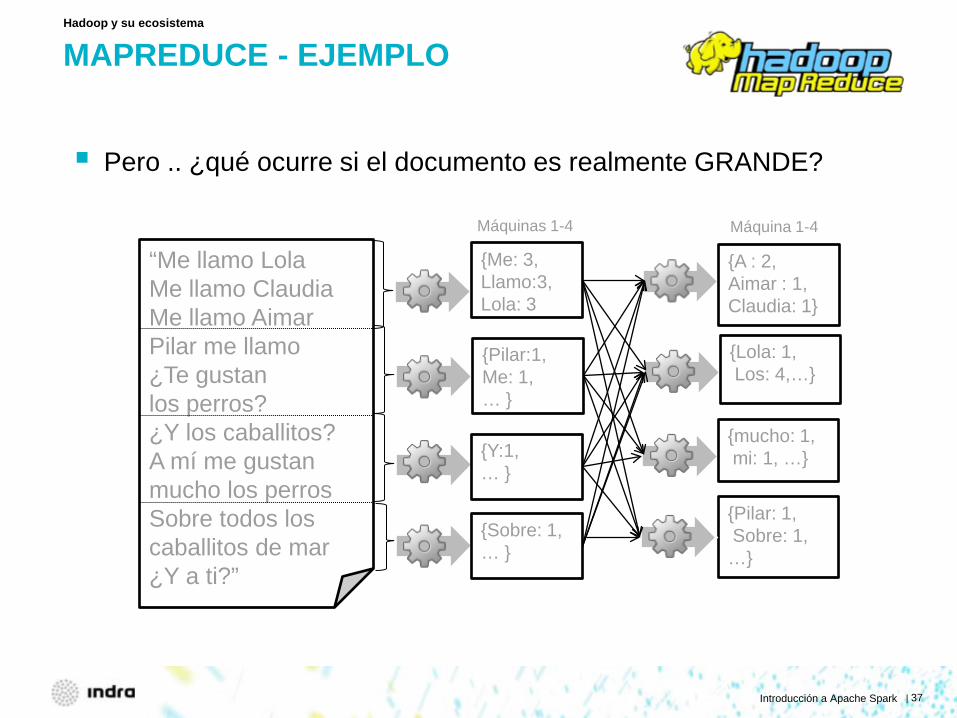
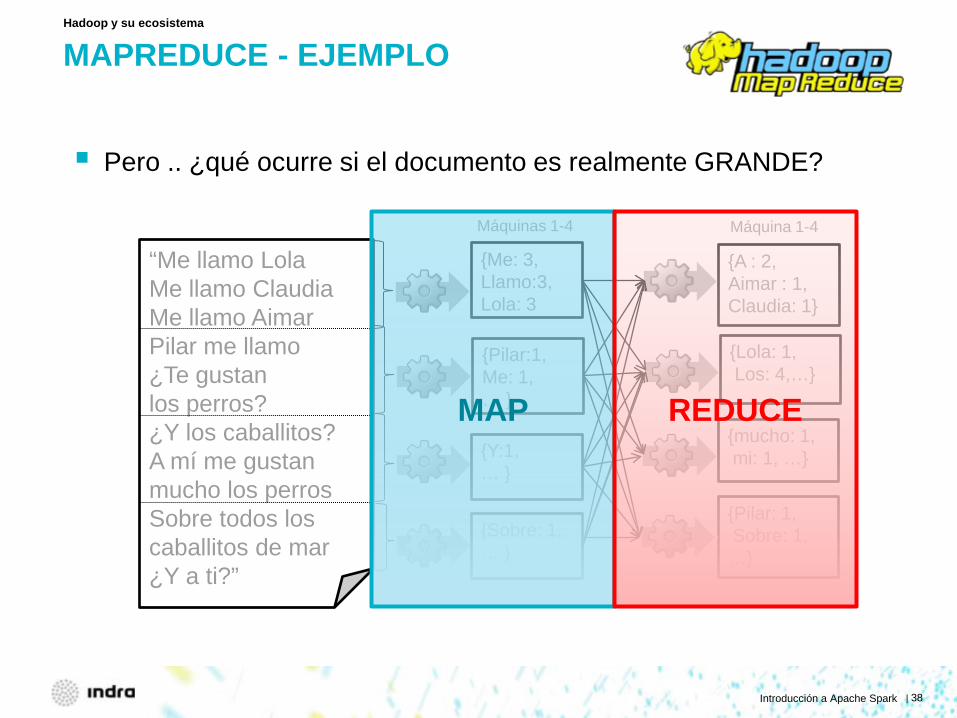
MAPREDUCE - EJEMPLO
Pero .. ¿qué ocurre si el documento es realmente GRANDE?
Hadoop y su ecosistema
“Me llamo Lola Me llamo Claudia Me llamo Aimar Pilar me llamo ¿Te gustan los perros? ¿Y los caballitos? A mí me gustan mucho los perros Sobre todos los caballitos de mar ¿Y a ti?”
{Me: 3, Llamo:3, Lola: 3
{Pilar:1, Me: 1, … }
{Y:1, … }
{Sobre: 1, … }
{A : 2, Aimar : 1, Claudia: 1}
{Pilar: 1, Sobre: 1, …}
{Lola: 1, Los: 4,…}
{mucho: 1, mi: 1, …}
Máquinas 1-4 Máquina 1-4
Introducción a Apache Spark
| 38
MAPREDUCE - EJEMPLO
Pero .. ¿qué ocurre si el documento es realmente GRANDE?
Hadoop y su ecosistema
“Me llamo Lola Me llamo Claudia Me llamo Aimar Pilar me llamo ¿Te gustan los perros? ¿Y los caballitos? A mí me gustan mucho los perros Sobre todos los caballitos de mar ¿Y a ti?”
{Me: 3, Llamo:3, Lola: 3
{Pilar:1, Me: 1, … }
{Y:1, … }
{Sobre: 1, … }
{A : 2, Aimar : 1, Claudia: 1}
{Pilar: 1, Sobre: 1, …}
{Lola: 1, Los: 4,…}
{mucho: 1, mi: 1, …}
Máquinas 1-4 Máquina 1-4
MAP REDUCE

Introducción a Apache Spark
| 39
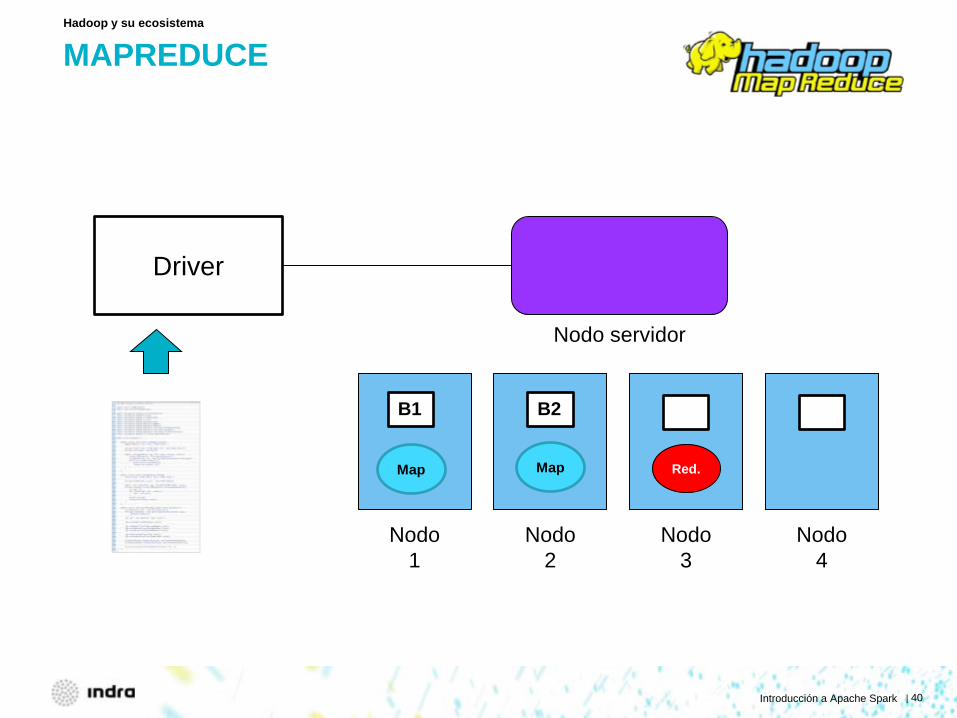
MAPREDUCE
Hadoop y su ecosistema
Introducción a Apache Spark
| 40
MAPREDUCE
Hadoop y su ecosistema
Nodo 1
Nodo 2
Nodo 3
Nodo 4
Nodo servidor
Driver
B1
Map
B2
Map Red.

Introducción a Apache Spark
| 41
CARACTERÍSTICAS
Hadoop y su ecosistema
Característica Descripción
Automático Un trabajo se realiza completamente sin que sea necesaria una intervención manual
Transparente Las tareas asignadas a un nodo que falla son retomadas por otras tareas
Grácil Los fallos sólo representan una perdida proporcional en la capacidad de proceso
Recuperable Esta capacidad se recupera cuando el componente es reemplazado más tarde
Consistente El fallo no produce corrupción o resultados inválidos
Introducción a Apache Spark
| 42
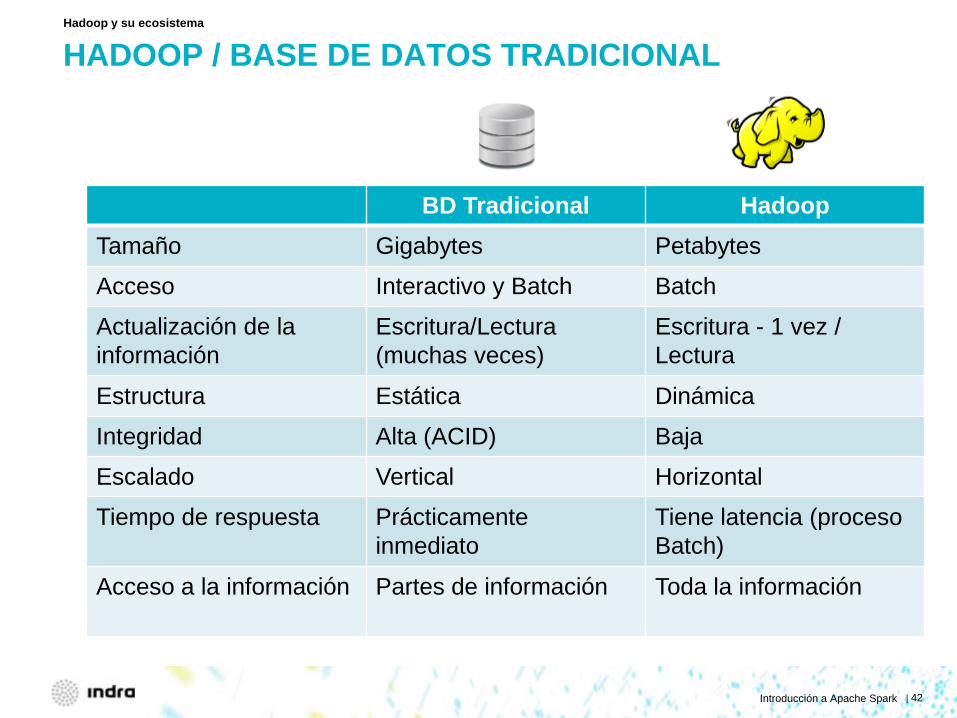
HADOOP / BASE DE DATOS TRADICIONAL
Hadoop y su ecosistema
BD Tradicional Hadoop Tamaño Gigabytes Petabytes
Acceso Interactivo y Batch Batch
Actualización de la información
Escritura/Lectura (muchas veces)
Escritura - 1 vez / Lectura
Estructura Estática Dinámica
Integridad Alta (ACID) Baja
Escalado Vertical Horizontal
Tiempo de respuesta Prácticamente inmediato
Tiene latencia (proceso Batch)
Acceso a la información Partes de información Toda la información

Introducción a Apache Spark
| 43
AGENDA
Big Data Apache Hadoop Ecosistema de Hadoop Evolución
Framework de procesamiento distribuido
Sistema de ficheros distribuido de Hadoop

Introducción a Apache Spark
| 44
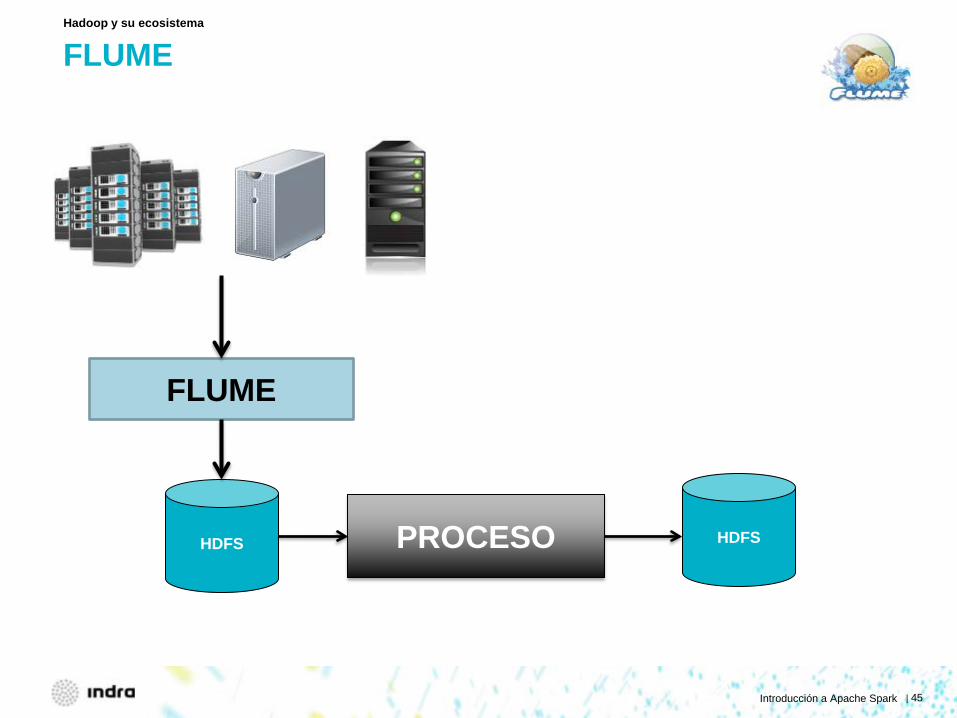
SQOOP
Hadoop y su ecosistema
PROCESO HDFS HDFS
SCOOP
DB
Introducción a Apache Spark
| 45
FLUME
Hadoop y su ecosistema
PROCESO HDFS HDFS
FLUME
Introducción a Apache Spark
| 46
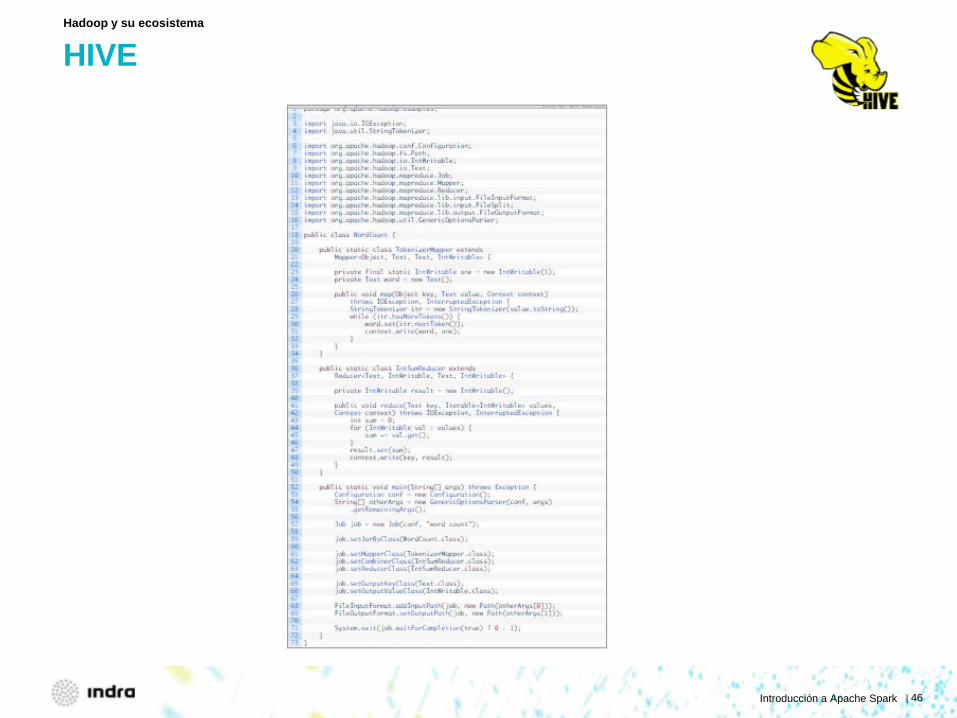
HIVE
Hadoop y su ecosistema

Introducción a Apache Spark
| 47
HIVE
Hadoop y su ecosistema
Introducción a Apache Spark
| 48
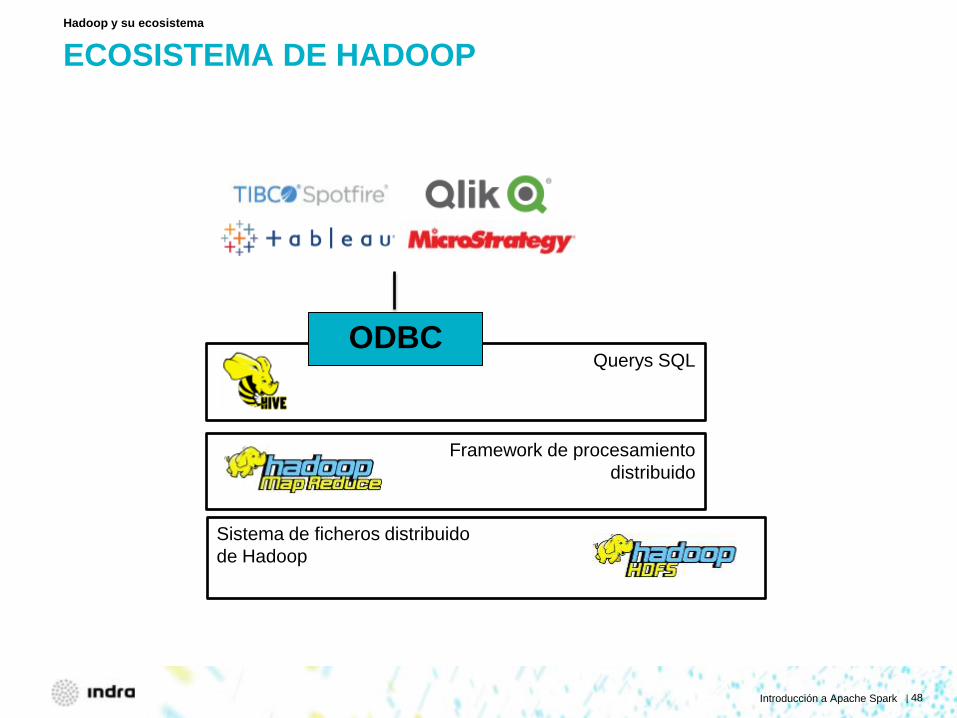
ECOSISTEMA DE HADOOP
Hadoop y su ecosistema
Framework de procesamiento distribuido
Sistema de ficheros distribuido de Hadoop
Querys SQL
ODBC
Introducción a Apache Spark
| 49
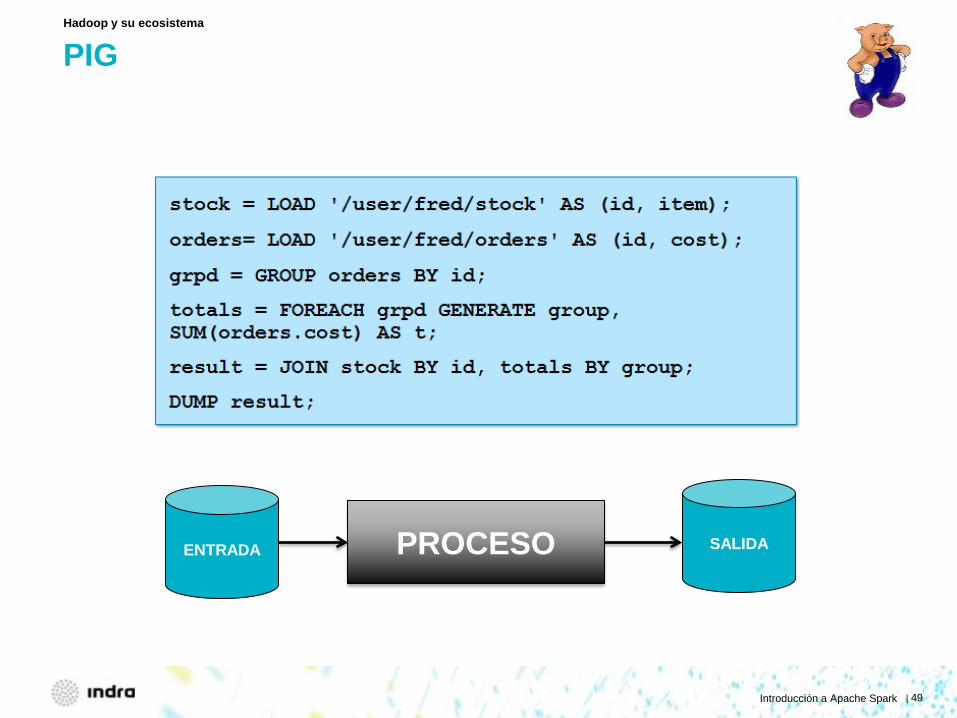
PIG
Hadoop y su ecosistema
PROCESO ENTRADA SALIDA
Introducción a Apache Spark
| 50
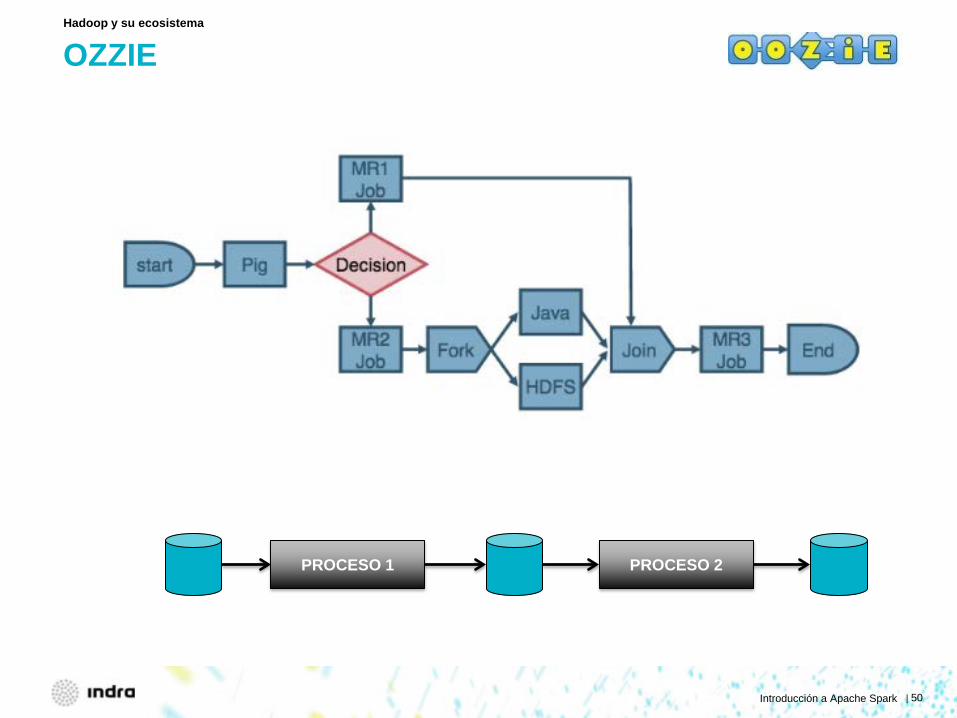
OZZIE
Hadoop y su ecosistema
PROCESO 1 PROCESO 2

Introducción a Apache Spark
| 51
MAHOUT
Hadoop y su ecosistema
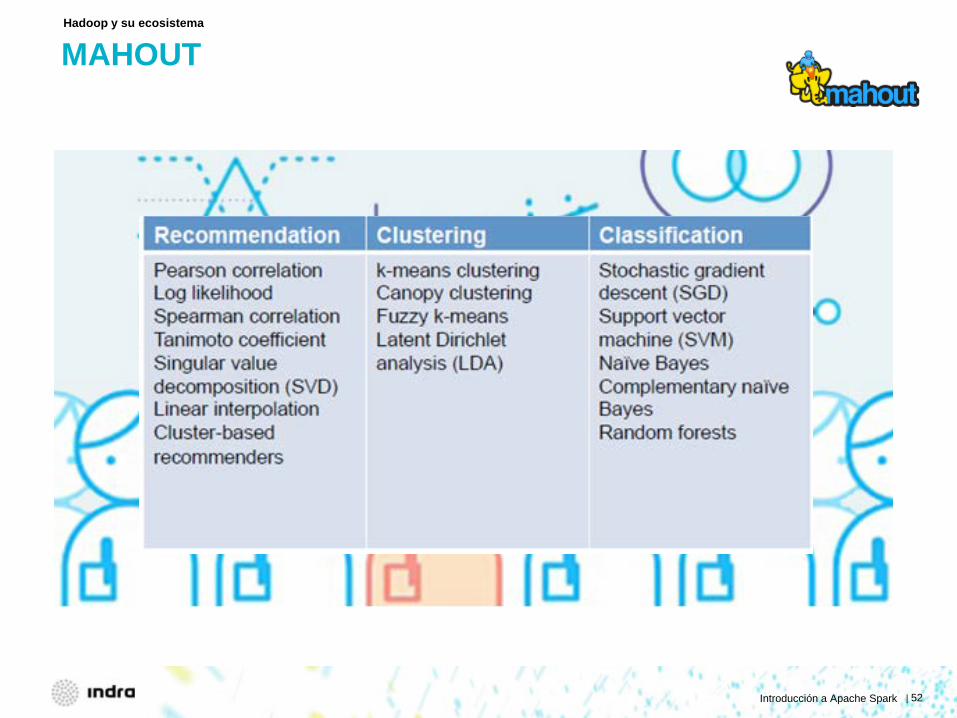
Introducción a Apache Spark
| 52
MAHOUT
Hadoop y su ecosistema

Introducción a Apache Spark
| 53
HBASE
Hadoop y su ecosistema
Framework de procesamiento distribuido
Sistema de ficheros distribuido de Hadoop

Introducción a Apache Spark
| 54
HBASE
Hadoop y su ecosistema
Framework de procesamiento distribuido
Sistema de ficheros distribuido de Hadoop
Base de datos NoSQL De tipo columnar
Introducción a Apache Spark
| 55
HUE
Hadoop y su ecosistema
Introducción a Apache Spark
| 56
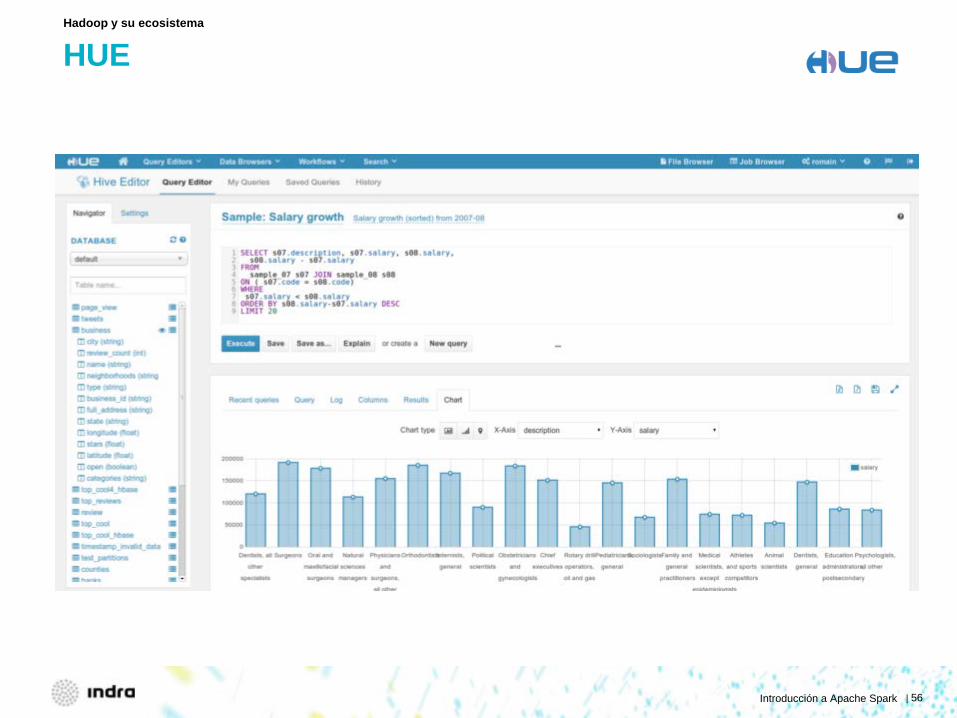
HUE
Hadoop y su ecosistema
Introducción a Apache Spark
| 57
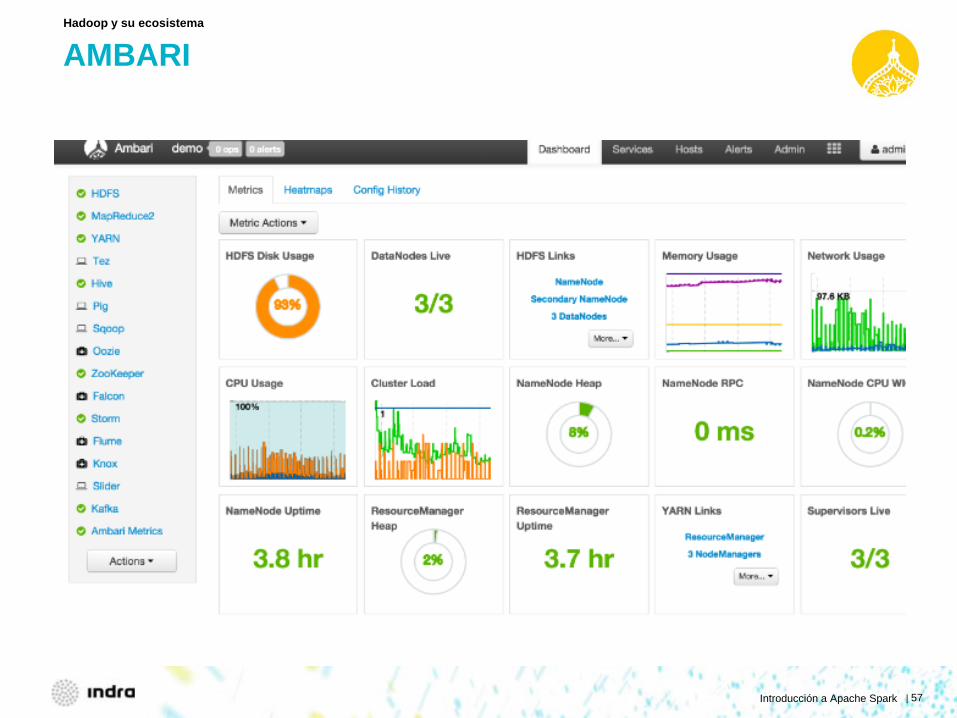
AMBARI
Hadoop y su ecosistema
Introducción a Apache Spark
| 58
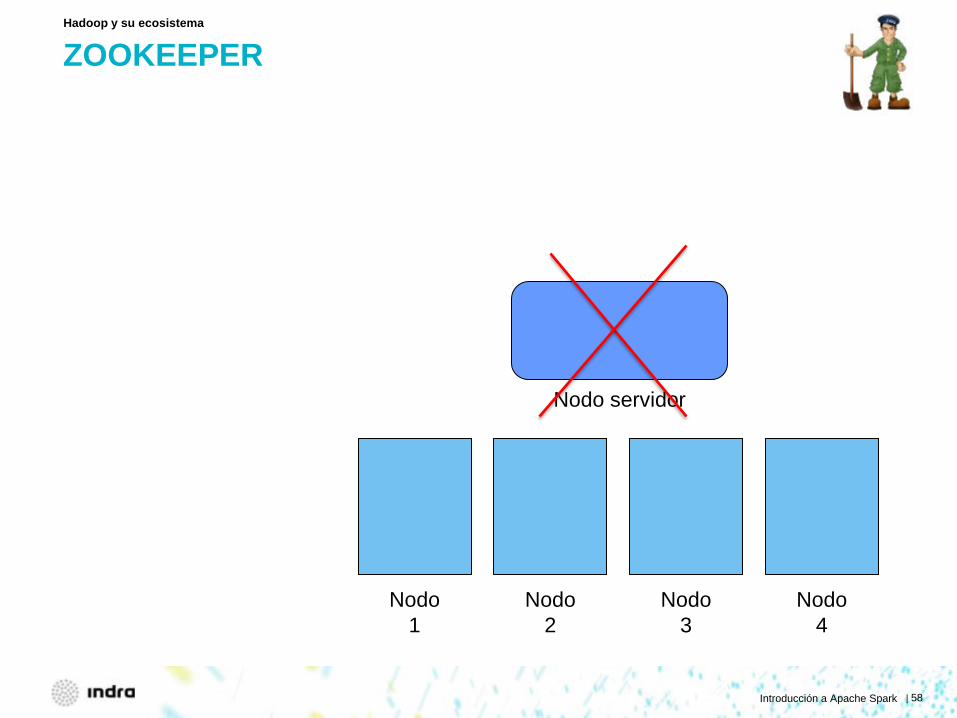
ZOOKEEPER
Hadoop y su ecosistema
Nodo 1
Nodo 2
Nodo 3
Nodo 4
Nodo servidor
Introducción a Apache Spark
| 59
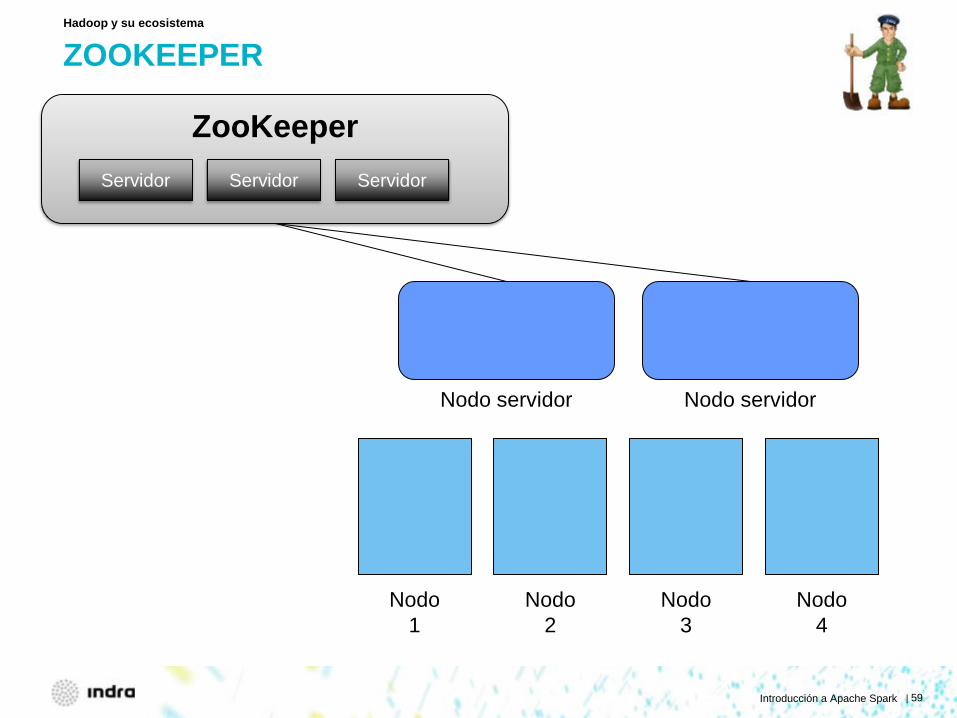
ZOOKEEPER
Hadoop y su ecosistema
Nodo 1
Nodo 2
Nodo 3
Nodo 4
Nodo servidor Nodo servidor
ZooKeeper Servidor Servidor Servidor
Introducción a Apache Spark
| 60
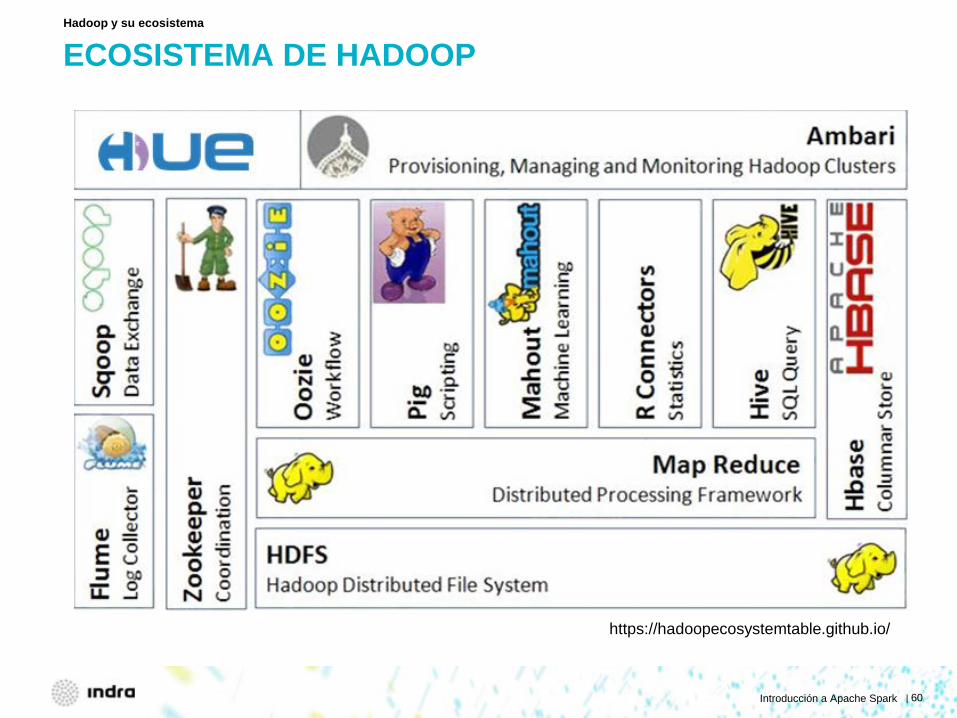
ECOSISTEMA DE HADOOP
Hadoop y su ecosistema
https://hadoopecosystemtable.github.io/

Introducción a Apache Spark
| 61
DISTRIBUCIONES DE HADOOP
Hadoop y su ecosistema

Introducción a Apache Spark
| 62
AGENDA
Big Data Apache Hadoop Ecosistema de Hadoop Hadoop 2.0
Introducción a Apache Spark
| 63
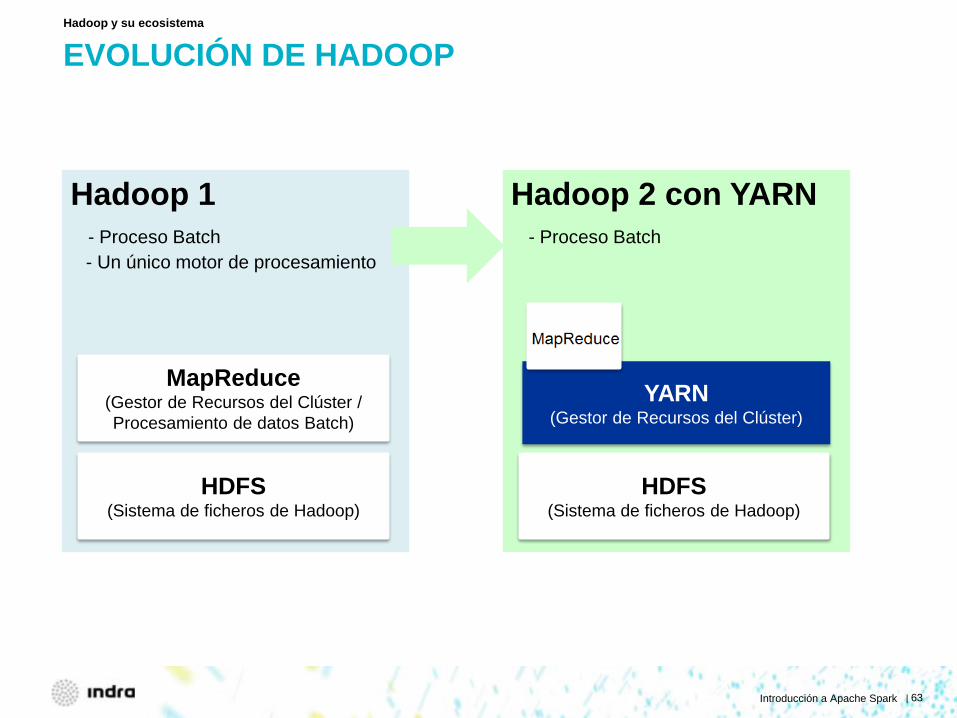
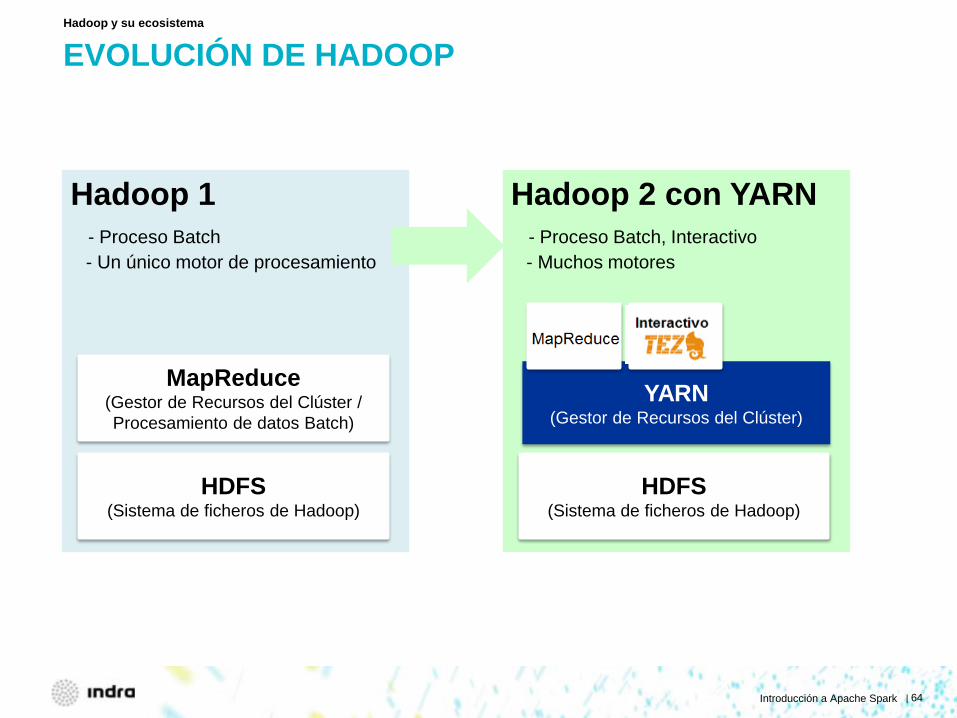
EVOLUCIÓN DE HADOOP Hadoop y su ecosistema
Hadoop 1 - Proceso Batch - Un único motor de procesamiento
HDFS (Sistema de ficheros de Hadoop)
MapReduce (Gestor de Recursos del Clúster / Procesamiento de datos Batch)
Hadoop 2 con YARN - Proceso Batch
HDFS (Sistema de ficheros de Hadoop)
YARN (Gestor de Recursos del Clúster)
Introducción a Apache Spark
| 64
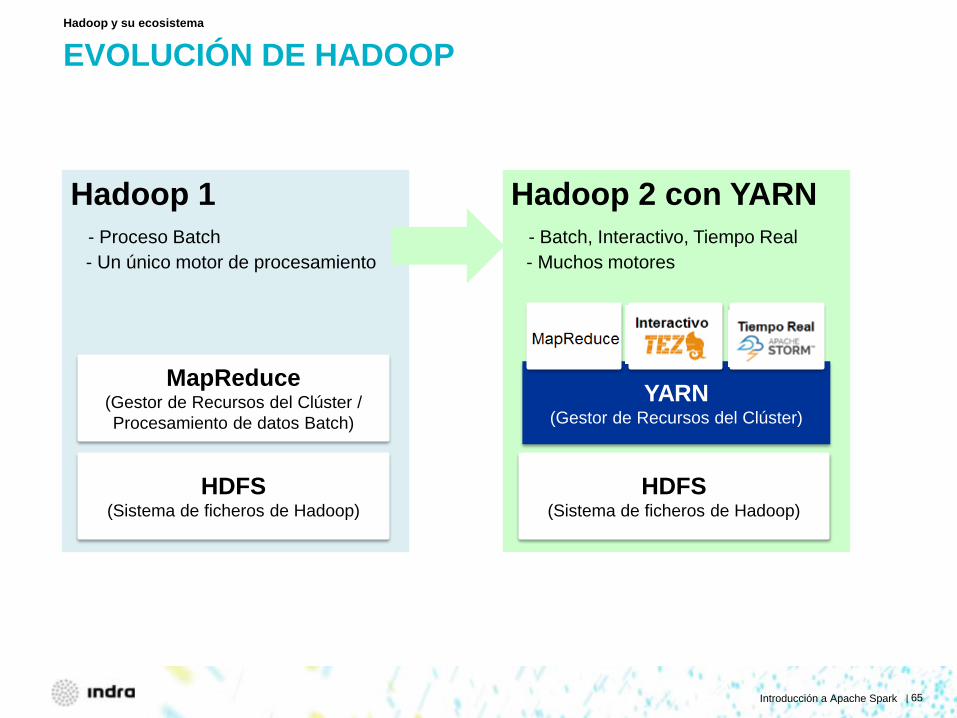
EVOLUCIÓN DE HADOOP Hadoop y su ecosistema
Hadoop 1 - Proceso Batch - Un único motor de procesamiento
HDFS (Sistema de ficheros de Hadoop)
MapReduce (Gestor de Recursos del Clúster / Procesamiento de datos Batch)
Hadoop 2 con YARN - Proceso Batch, Interactivo - Muchos motores
HDFS (Sistema de ficheros de Hadoop)
YARN (Gestor de Recursos del Clúster)
Introducción a Apache Spark
| 65
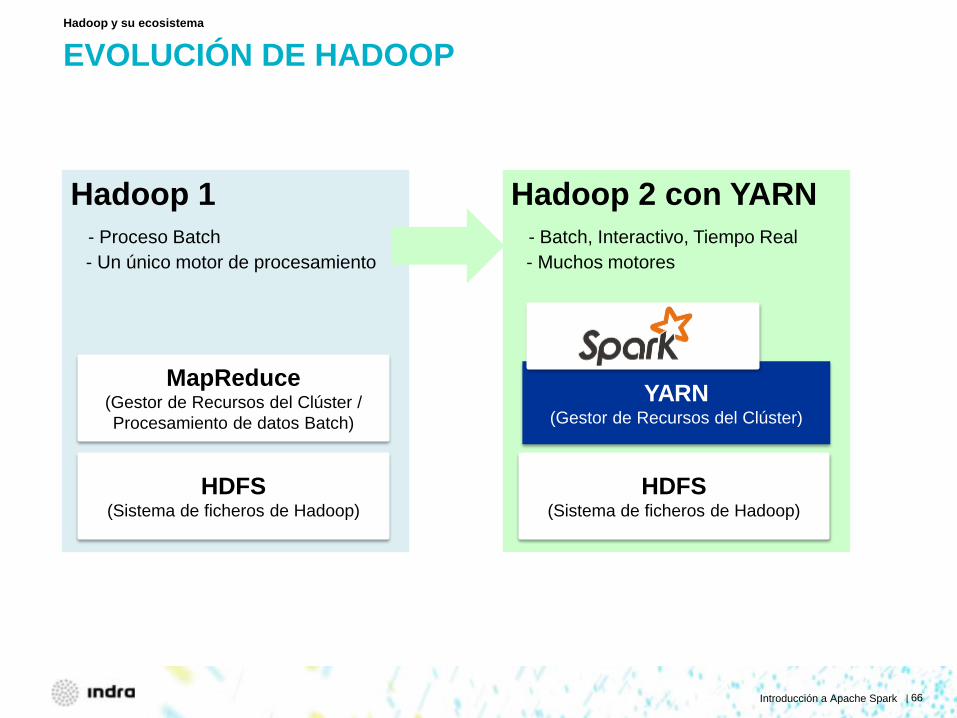
EVOLUCIÓN DE HADOOP Hadoop y su ecosistema
Hadoop 1 - Proceso Batch - Un único motor de procesamiento
HDFS (Sistema de ficheros de Hadoop)
MapReduce (Gestor de Recursos del Clúster / Procesamiento de datos Batch)
Hadoop 2 con YARN - Batch, Interactivo, Tiempo Real - Muchos motores
HDFS (Sistema de ficheros de Hadoop)
YARN (Gestor de Recursos del Clúster)
Introducción a Apache Spark
| 66
EVOLUCIÓN DE HADOOP Hadoop y su ecosistema
Hadoop 1 - Proceso Batch - Un único motor de procesamiento
HDFS (Sistema de ficheros de Hadoop)
MapReduce (Gestor de Recursos del Clúster / Procesamiento de datos Batch)
Hadoop 2 con YARN - Batch, Interactivo, Tiempo Real - Muchos motores
HDFS (Sistema de ficheros de Hadoop)
YARN (Gestor de Recursos del Clúster)

Muchas gracias
Centros de Competencia / Business Analytics Daniel Villanueva Jiménez [email protected] Avda. de Bruselas 35 28108 Alcobendas, Madrid España T +34 91 480 50 00 F +34 91 480 50 80 www.indracompany.com


















